

![]()
Very powerful server agent for collecting & sending logs & metrics with an easy-to-use web console.
logkit-community Detail doc can be referred toWIKI
- File: read data in file, including csv file,kafka-rest log,nginx log.
- Elasticsearch: read data in ElasticSearch.
- MongoDB: read data in MongoDB.
- MySQL: read data in MySQL.
- MicroSoft SQL Server: read data in Microsoft SQL Server.
- Postgre SQL: read data in PostgreSQL.
- Kafka: read data in Kafka.
- Redis: read data in Redis.
- Socket: read data via tcp\udp\unixsocket protocol.
- Http: reveive data in post request as http server.
- Script: support script and read data from the result.
- Snmp: auto read data from Snmp service.
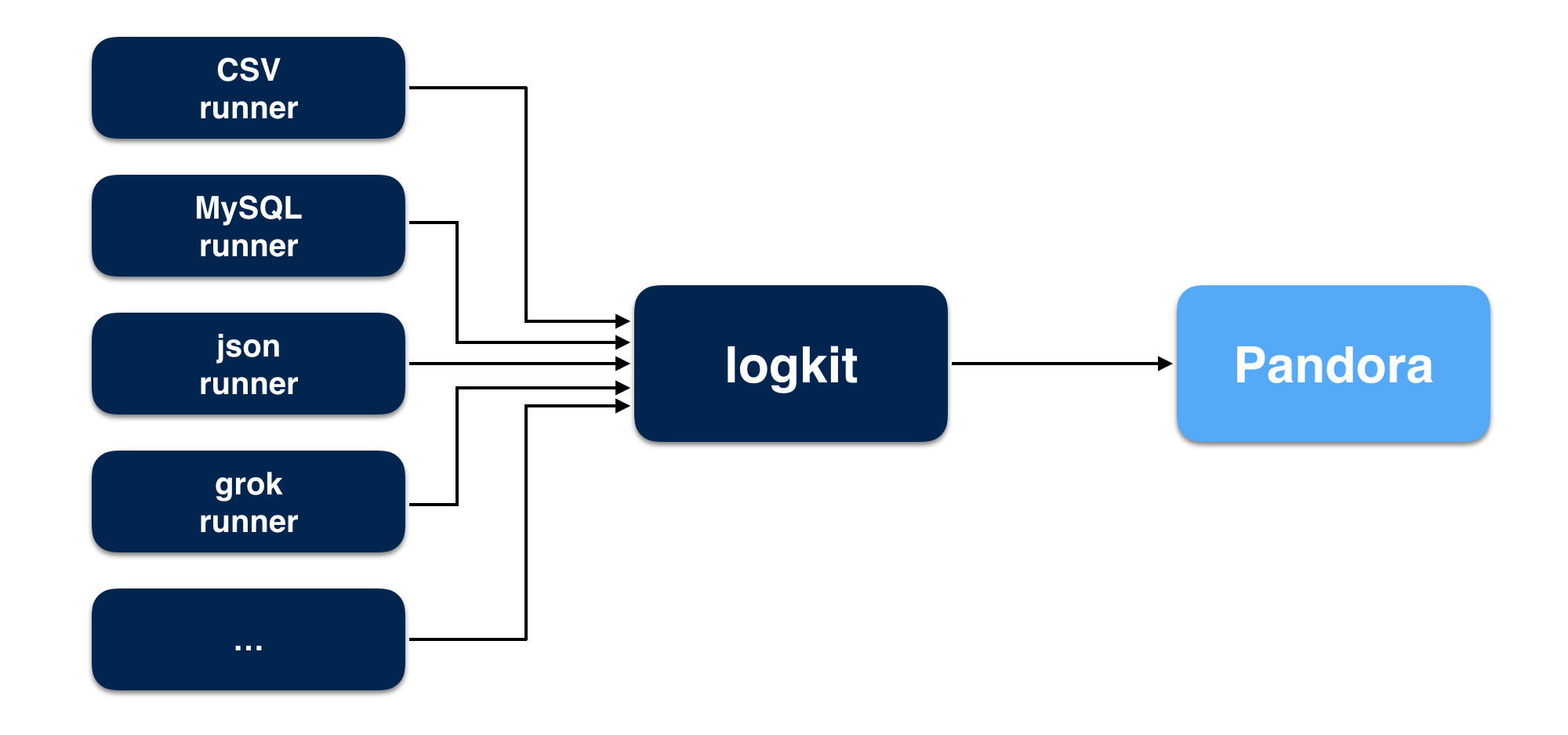
logkit-community support multiple sources and can send kinds of data to Pandora, every data source relevant to a logic runner,a runner's workaround as follows:
Weclome to contribute to logkit:
- fix or report bug
- pull issue improve wiki doc
- review code or create issues
- contribute code (contribute kinds of modules including reader、parser、sender and transformer)
lastest stable:Go to Download page
History:Go to Releases
Trial:construct lastest logkit trial version every 5:00am (only for Linux 64 and Docker), you can download it (note: not include update of frontend).
-
Docker image nightly:
docker pull wonderflow/logkit:nightly
- Linux
export LOGKIT_VERSION=<version number>
wget https://pandora-dl.qiniu.com/logkit_${LOGKIT_VERSION}.tar.gz && tar xvf logkit_${LOGKIT_VERSION}.tar.gz && rm logkit_${LOGKIT_VERSION}.tar.gz && cd _package_linux64/- MacOS
export LOGKIT_VERSION=<version number>
wget https://pandora-dl.qiniu.com/logkit_mac_${LOGKIT_VERSION}.tar.gz && tar xvf logkit_mac_${LOGKIT_VERSION}.tar.gz && rm logkit_mac_${LOGKIT_VERSION}.tar.gz && cd _package_mac/- Windows
please download https://pandora-dl.qiniu.com/logkit_windows_<LOGKIT_VERSION>.zip 并解压缩,go to directory
logkit.conf is logkit-community tool's configuration,mainly for specifing running resource and paths of runners.
Open logkit.conf, for example:
{
"max_procs": 8,
"debug_level": 1,
"clean_self_log":true,
"bind_host":"localhost:3000",
"static_root_path":"./public",
"confs_path": ["confs*"]
}For simply use, you can only focus on three options:
bind_hostport of logkit we。static_root_pathstatistic resource path of logkit page, recommand to use absolute path note:old version moved to "public-old" directory。confs_pathincluding add conf in web, logkit also support monitor directory to add runners. (if you only need to add logkit runner in web, you can ignore this option)
./logkit -f logkit.confthe web url is the value of bind_host configured in step 2
refer to README file:logkitweb/README.md
go build -o logkit logkit.go
./logkit -f logkit.confdocker pull wonderflow/logkit:<version>
docker run -d -p 3000:3000 -v /local/logkit/dataconf:/app/confs -v /local/log/path:/logs/path logkit:<version>get configs deploying in Kubernetes
curl -L -O https://raw.githubusercontent.com/qiniu/logkit/master/deploy/logkit_on_k8s.yamlenjoy it!







![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




















































































































































































