rdf-ext-archive / discussions Goto Github PK
View Code? Open in Web Editor NEWThis repo is for discussions all over the rdf-ext project
This repo is for discussions all over the rdf-ext project
With this commit I removed the command line tool from the rdf-ext package. The code uses the old interface and it was already planed to use a separate module for this tool.
From @bergos on June 24, 2014 22:13
Create a RDF-Ext Store implementation which caches graphs in memory or Web Storage and manually forwards changes to another RDF-Ext Store. Offline Web application features can be added very easy this way.
Copied from original issue: rdf-ext/rdf-ext#2
Should it return success == true when something has been deleted? or should report an error if something was not? (avoiding using success)
What is the plan for Microdata parsing in RDF-Ext? rdf-parser-microdata appears to be deprecated and no longer maintained.
I want to consume Schema.org data from a number of websites. While some of it is in JSON-LD a large portion of it is in Microdata.
From @elf-pavlik on November 26, 2014 15:16
I found email where @danbri mentions it back in 2007
http://lists.w3.org/Archives/Public/public-rdf-in-xhtml-tf/2007Aug/0170.html
I would find it super useful where I care mostly about providing JSON-LD but can also automatically serve RDFa for various crawlers
Also some existing python package: https://github.com/alexstolz/rdflib-rdfa-serializer
If this works out we could also try to make one for Microdata...
Copied from original issue: rdf-ext/rdf-ext#10
At the moment it's difficult to find all informations about RDF-Ext. A organization page could be used as landing page. The page should contain the following informations:
The package list should be maintained only on the organization page and removed from the readme.
We should write down a small guideline how to contribute to RDF-Ext. Here are my ideas and proposed directions:
We can't get there immediately. Till release 0.3.0 we should allow to break rules without further discussion.
From @betehess on January 25, 2015 23:32
Sorry, this is not exactly an issue but I didn't know where to ask those questions.
First, just know that I am mostly a n00b with Javascript. More exactly, that I don't have any experience with Node.js, nor with JS libraries relying on some Node.js toolchain.
First, I am not sure where to find the main rdf-ext.js library. I guess it's not that one? Do I need to build the library myself? How?
I have the same questions with the dependencies. For example, the README mentions N3.js. But I don't see it anywhere under lib. Do I need to pull manually that dependency? How do I know about which version is supported? What about the other files under lib?
About the documentation: I have seen http://bergos.github.io/rdf-ext-spec/ and I think I can read WebIDL. But in the example you added today, you used parseTurtle, which I don't find in the main specification. I guess it's somewhat related to DataParser? In any case, I am mostly interested in RDF parsers that can eagerly react on triples instead of the complete graph if that's available (we have our own Graph implementation in banana-rdf). Maybe it's the ProcessorCallback thing? I couldn't find its definition in the spec.
At this point, I would appreciate a few notes on how to get started with rdf-ext in the browser, with the examples you just added, and starting from a blank project. Thanks again for everything: I really want to use rdf-ext from banana-rdf :-) To get an idea of what I am doing, you can look at banana-rdf/banana-rdf#219 .
Copied from original issue: rdf-ext/rdf-ext#16
Just some ideas....
HOWTOs for implementatin provider:
HOWTOs for users:
What should have stream?
Everything that has a GraphCallback at least should have a stream method (store only),
discuss
I think having to pass null arguments as in
N3Parser.parse($("#data").text(), null, window.location.toString()).then(
is quite ugly. Wouldn't it be good to get rid of those as soon as possible?
If the context of a JSON-LD file contains prefixes add them to the prefixes of the store
for an older version:
// load prefixes of data elements
var context = data['@context'];
$.each(context, function(key, value) {
if (typeof value == "string" ) {
if(value.slice(-1)=='#' || value.slice(-1) == '/')
rdf.prefixes[key] = value;
}
});
From @bergos on August 21, 2015 23:31
We should define an parser/serializer API to stream Triples. The N3.js library would support that feature already.
Copied from original issue: rdf-ext/rdf-ext#43
#0.3.0
Version 0.3.0 contains many changes, but should require only minimal changes in the code to be 0.2.x compatible.
rdf objectrdf-ext returns the rdf object and longer a init functionVersion 1.0.0 will implement the interfaces defined by the RDFJS Representation Task Force.
This will require changes in libraries that use the low level interfaces such as parser, serializers, stores and object to graph mappers.
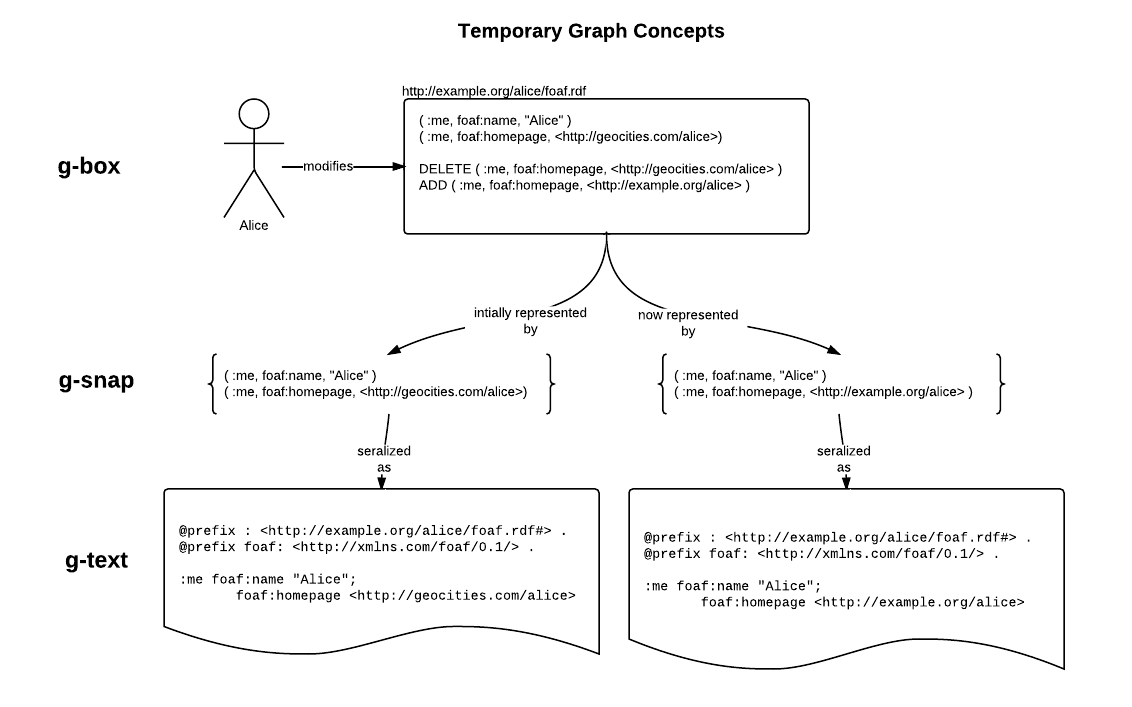
https://www.w3.org/2011/rdf-wg/wiki/Graph_Terminology#Visual_Diagram
so far i've seen LDF servers implementing Memento
https://github.com/LinkedDataFragments/Server.js/wiki/Configuring-Memento
The global rdf class should be the convenient main entry point of the API and allow access to the most commonly needed RDF specific functionality.
Some thoughts:
The JSON-LD parser module, based on AbstractParser, implements a new API. If we can agree on the new API I will create modules for all other parser, currently bundled with RDF-Ext.
Promise process (any toparse, optional ProcessorCallback callback, optional DOMString base, optional TripleFilter filter, optional SuccessCallback done)
.process returns now a Promise object. For asynchronous parsers the boolean value was useless anyway. Both, done and Promise.resolve, are called. done can be null. toparse can be a Stream. The parser detects if the toparse value is a Stream object. The rest works like defined in the RDF-Interfaces/RDF-Ext spec.
Promise parse (any toparse, optional ParserCallback? callback, optional DOMString base, optional TripleFilter filter, optional Graph graph)
Also .parse returns now a Promise object like .process. Both, callback and Promise.resolve, are called. callback can be null. toparse can be a Stream. The parser detects if the toparse value is a Stream object. The rest works like defined in the RDF-Interfaces/RDF-Ext spec.
ReadableStream stream (Stream inputStream, optional DOMString base, optional TripleFilter filter)
The .stream method is new. The data, end and error event is used. N3.js uses also a prefix event. This is currently not implemented. Do we need this? Everything else works as usual.
The mime type utils are only usefull when many parsers and serializers are registered. To remove the dependencies from the rdf-ext package, the code should get it's own package. Any proposals for a package name?
The distribution builder should use browserify to create browser distributions. It should include a command line and web interface.
It's already work in progress...
Can rdf-ext make distinction between a Dataset and a Graph?
https://github.com/rdf-ext/rdf-ext-spec/blob/gh-pages/API.md#graphoptional-arraygraph-other
Graph could represent a simple named or default graph and only contain Triples
Graph could provide simple access to it's name
Dataset could represent multiple graph and contain Quads
Currently Store seems very close to Dataset
https://github.com/rdf-ext/rdf-ext-spec/blob/gh-pages/API.md#store
But parsers like Trig, JSON-LD, N-Quads shouldn't return Store IMO
From @bergos on September 5, 2015 22:23
Copied from original issue: rdf-ext/rdf-ext#46
Hi,
I have written an RDF/XML serializer for rdf-ext. Please find it at http://github.com/kaefer3000/rdf-serializer-xml . I would be happy to transfer it to the organisation or have it included in rdf-formats-common.
Cheers,
Tobias
This would ensure every tagged version that passes the tests gets deployed and that only tagged versions are deployed.
Some stores may have a default graph, like the SPARQL store. Methods like .graph or .match require a IRI parameter for the named graph. What value should be used for the default graph? null is already used for any graph. true would allow to check if the value is set and it's not a string or RegExp object. Are there any reasons to not use true? Could it be handled in a different way?
We need support for filtering out literals which are not one of the preferred languages.
de > en > no language tag: often what you would display in the real world because a non-translated resource is better than no resourceIn both cases I would not get back more than one s-p-o triple back where there were multiple languages available.
I think I would like to have that on graph level so I can work with a graph in the UI which does not provide more than one literal to show for the same thing.
Optional:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.