rico-c / rico-blog Goto Github PK
View Code? Open in Web Editor NEW🕵Note & Translate & Source Code
🕵Note & Translate & Source Code



































问题:
马尔可夫链
马尔可夫链是一组具有马尔可夫性质的离散随机变量的集合,具备“无记忆”的性质:下一状态的概率分布只能由当前状态决定
隐马尔可夫模型
隐马尔可夫模型是关于时序的概率模型,描述由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程。







其中:
概率计算问题:给定模型
连续三天,做的事情分别是:walk,shop,clean。根据模型,计算产生这些行为的概率是多少。
学习问题:已知观测序列$O = (0_1,0_2, ...,O_T)$,估计模型$λ = (A,B,π)$的参数,使该模型下观测序列概率$P(O|λ)$最大。
同样是三天这三件事,而其他什么信息我都没有。建立一个模型,晴雨转换概率,第一天天气情况的概率分布,根据天气情况选择做某事的概率分布。
解码问题:已知模型$λ = (A,B,π)$和观测序列$O = (0_1,0_2, ...,O_T)$,求在指定观测序列下最有可能的状态序列。
同样是三天这三件事,这三天的天气是怎么样的。这三天怎么样的天气才最有可能让她做这样的事情。
给定模型 λ=(A,B,π)和观测序列 O=(01,02,...,OT),计算在该模型下观测序列 O出现的概率 P(O|λ)。
把每一种天气情况下产生这些行为遍历并计算概率的求和。
其中:
(1) 计算初值
$$α_1(1)=π_1b_1(o_1)=0.60.1=0.06$$
$$α_1(2)=π_2b_2(o_1)=0.40.6=0.24$$
(2) 递推计算
注:由上一阶段的不同状态跳转到状态1的概率和状态1对$o_2$的观测概率
$$a_2(1)=
\begin{bmatrix} \sum_{i=1}^2α_1(i)a_{i1}\end{bmatrix}b_1(o_2)=(0.060.7+0.240.4)0.4$$
$$α_2(2)=
\begin{bmatrix} \sum_{i=1}^2α_1(i)a_{i2}\end{bmatrix}b_2(o_2)=(0.060.3+0.24*0.6)*0.3$$
$$α_3(1)=
\begin{bmatrix} \sum_{i=1}^2α_1(i)a_{i2}\end{bmatrix}b_1(o_3)=...$$
$$α_3(2)=
\begin{bmatrix} \sum_{i=1}^2α_1(i)a_{i3}\end{bmatrix}b_2(o_3)=...$$
(3) 求和
$$P(O|λ)= α_3(1) + α_3(2)$$
复杂度$O(N^2T)阶$
已知模型$λ = (A,B,π)$和观测序列$O = (0_1,0_2, ...,O_T)$,求在指定观测序列下最有可能的状态序列。
在每个时刻$t$选择在该时刻最有可能出现的状态$i_t$,从而得到一个状态序列$I$,将它作为预测的结果。
只能保证当前时刻最优,不能保证全局最优
从时刻t=1开始,递推地计算在时刻t,状态为i的各条路径的最大概率,直到得到t=T状态为i的各条路径的最大概率。
定义在时刻t状态为i的所有单个路径(i1,i2,...it)中概率最大的值为:
递推可得
(1) 初始化,求t=1时的$δ_1(i)=π_ib_i(o_1)$:
$$δ_1(1)=π_1b_1(o_1)=0.60.1=0.06$$
$$δ_1(2)=π_2b_2(o_1)=0.40.6=0.24$$
(2)递推计算t=2和t=3下各状态的最大概率:
$$δ_2(1)=max{0.060.7,0.240.4}0.4=0.0384$$
$$ψ_2(1)=2$$
$$δ_2(2)=max{0.060.3,0.240.6}0.3=0.0432$$
$$ψ_2(2)=2$$
$$δ_3(1)=max{0.03840.7,0.04320.4}0.5= 0.0134$$
$$ψ_3(1)=1$$
$$δ_3(2)=max{0.03840.3,0.04320.6}0.1=0.0025$$
$$ψ_3(2)=2$$
(3) 最优路径的概率
$$P = 0.0134$$
最优终点是
$i_3^ =1$
逆推:
$i_2^=ψ_3(1)=1$
$i_1^*=ψ_2(1)=2$
同样是三天这三件事,而其他什么信息我都没有。建立一个模型,晴雨转换概率,第一天天气情况的概率分布,根据天气情况选择做某事的概率分布。
EM算法:
首先选取参数的初值,然后通过:
直到收敛为止。
# 切词 cut方法 ,默认使用HMM隐马尔可夫模型
# 例子:sentence: 我来到北京清华大学,今天天气不错,good day!
# 输出:我/来到/北京/清华大学/,/今天天气/不错/,/good/ /day/!
def cut(self, sentence, cut_all=False, HMM=True):
'''
The main function that segments an entire sentence that contains
Chinese characters into separated words.
Parameter:
- sentence: The str(unicode) to be segmented.
- cut_all: Model type. True for full pattern, False for accurate pattern.
- HMM: Whether to use the Hidden Markov Model.
'''
sentence = strdecode(sentence)
if cut_all:
re_han = re_han_cut_all
re_skip = re_skip_cut_all
else:
re_han = re_han_default
re_skip = re_skip_default
if cut_all:
cut_block = self.__cut_all
elif HMM:
cut_block = self.__cut_DAG
else:
cut_block = self.__cut_DAG_NO_HMM
# 按正则先把成块的文本切开
# blocks: ['', '我来到北京清华大学', ',', '今天天气不错', ',', 'good', ' ', 'day', '!']
blocks = re_han.split(sentence)
for blk in blocks:
if not blk:
continue
if re_han.match(blk):
# 对文本块使用__cut_DAG进一步切词
for word in cut_block(blk):
yield word
else:
tmp = re_skip.split(blk)
for x in tmp:
if re_skip.match(x):
yield x
elif not cut_all:
for xx in x:
yield xx
else:
yield x
# HMM下使用的切词
def __cut_DAG(self, sentence):
# sentence:我来到北京清华大学
# 输出对应的DAG图数据
DAG = self.get_DAG(sentence)
# {0: [0], 1: [1, 2], 2: [2], 3: [3, 4], 4: [4], 5: [5, 6, 8], 6: [6, 7], 7: [7, 8], 8: [8]}
# DAG[5]=[5,6,8]的意思就是,以’清‘开头的话,分别以5、6、8结束时,可以是一个词语,即’清‘、’清华‘、’清华大学‘
route = {}
# 维特比算法计算route
self.calc(sentence, DAG, route)
# route:
# {9: (0, 0), 8: (-8.142626068614787, 8), 7: (-8.006816355818659, 8), 6: (-17.53722513662092, 6), 5: (-11.085007904198626, 8), 4: (-20.20431518448597, 4), 3: (-18.548194315526874, 4), 2: (-24.22732015246924, 2), 1: (-27.379629658355885, 2), 0: (-32.587853155857076, 0)}
x = 0
buf = ''
N = len(sentence)
while x < N:
y = route[x][1] + 1
l_word = sentence[x:y]
# 无法形成词的buf,交由HMM进行标注
if y - x == 1:
buf += l_word
else:
if buf:
if len(buf) == 1:
yield buf
buf = ''
else:
if not self.FREQ.get(buf):
# 当遇到一些dict.txt中没出现的词的时候,会进入这个函数
# 使用HMM的方法,对这些未识别成功的词进行标注
recognized = finalseg.cut(buf)
for t in recognized:
yield t
else:
for elem in buf:
yield elem
buf = ''
yield l_word
x = y
# 动态规划 计算最优路径
def calc(self, sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0)
logtotal = log(self.total)
# 从后往前遍历句子
for idx in xrange(N - 1, -1, -1):
# 对每个字计算最有可能的词组
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx])
# 维特比算法
def viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] # 状态概率矩阵
path = {}
for y in states: # 初始化状态概率
# 求第一个字的状态概率
V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT)
path[y] = [y] # 记录路径
for t in xrange(1, len(obs)):
V.append({})
newpath = {}
for y in states:
# 在y状态下为第t个字的概率
em_p = emit_p[y].get(obs[t], MIN_FLOAT)
# t时刻状态为y的最大概率(从t-1时刻中选择到达时刻t且状态为y的状态y0)
(prob, state) = max(
[(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]])
# 第t个字,状态为y的概率
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
# 求出最后一个字哪一种状态的对应概率最大,最后一个字只可能是两种情况:E(结尾)和S(独立词)
(prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES')
return (prob, path[state])
# HMM标注切词
def __cut(sentence):
global emit_P
prob, pos_list = viterbi(sentence, 'BMES', start_P, trans_P, emit_P)
# 输出 pos_list: ['B', 'M', 'E', 'B', 'M', 'E', 'S', 'S']格式用于切词
begin, nexti = 0, 0
# print pos_list, sentence
for i, char in enumerate(sentence):
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
yield sentence[begin:i + 1]
nexti = i + 1
elif pos == 'S':
yield char
nexti = i + 1
if nexti < len(sentence):
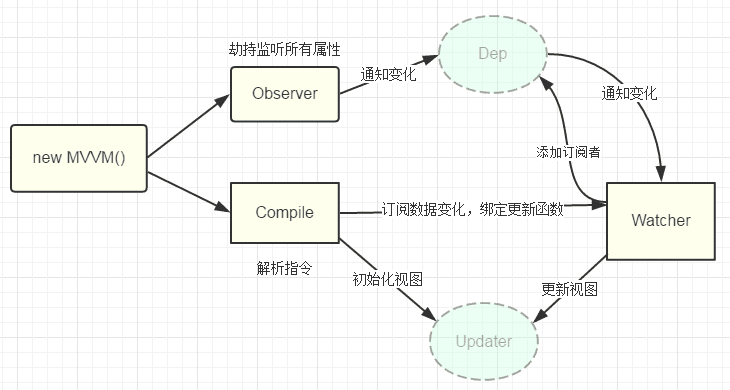
yield sentence[nexti:]根据Vue官方文档图片,Vue的双向绑定原理如下:
首先是HTML代码
<div id="app">
<div>
<input type="text" v-model="testData">
<p>{{ testData }}</p>
</div>
</div>下面是Vue.js的实现:
var app = new Vue({
el: '#app',
data: {
testData:
}
})
function Vue(options = {}) {
this.$options = options;
this.$el = document.querySelector(options.el); // 获取DOM
this._data = options.data; // 获取data
this._watcherTpl = {}; // watcher池
this._observer(this._data); // 重写data的set和get以双向绑定
this._compile(this.$el); // 传入dom,编译模板
};
// 重写data的get和set
Vue.prototype._observer = function (obj) {
var _this = this;
Object.keys(obj).forEach(key => {
_this._watcherTpl[key] = { // 每个数据的订阅池()
_directives: []
};
var value = obj[key];
var watcherTpl = _this._watcherTpl[key];
Object.defineProperty(_this._data, key, { // 重写数据的set get
configurable: true, // 可以删除
enumerable: true, // 可以遍历
get() {
return value; // 获取值的时候,直接返回
},
set(newVal) { // 改变值的时候 触发set
if (value !== newVal) {
value = newVal;
watcherTpl._directives.forEach((item) => { // 遍历订阅池
item.update();
// 遍历所有订阅的地方(v-model+v-bind+{{}}) 触发this._compile()中发布的订阅Watcher 更新视图
});
}
}
})
});
}
// 模板编译
Vue.prototype._compile = function (el) {
var _this = this, nodes = el.children; // 获取app的dom
for (var i = 0, len = nodes.length; i < len; i++) { // 遍历dom节点
var node = nodes[i];
if (node.children.length) {
_this._compile(node); // 递归深度遍历dom树
}
// 如果有v-model属性,并且元素是INPUT或者TEXTAREA,我们监听它的input事件
if (node.hasAttribute('v-model') && (node.tagName = 'INPUT' || node.tagName == 'TEXTAREA')) {
node.addEventListener('input', (function (key) {
var attVal = node.getAttribute('v-model'); // 获取v-model绑定的值
_this._watcherTpl[attVal]._directives.push(new Watcher( // 将dom替换成属性的数据并发布订阅 在set的时候更新数据
node,
_this,
attVal,
'value'
));
return function () {
_this._data[attVal] = nodes[key].value; // input值改变的时候 将新值赋给数据 触发set=>set触发watch 更新视图
}
})(i));
}
var reg = /\{\{\s*([^}]+\S)\s*\}\}/g, txt = node.textContent; // 正则匹配{{}}
if (reg.test(txt)) {
node.textContent = txt.replace(reg, (matched, placeholder) => {
// matched匹配的文本节点包括{{}}, placeholder 是{{}}中间的属性名
var getName = _this._watcherTpl; // 所有绑定watch的数据
getName = getName[placeholder]; // 获取对应watch 数据的值
if (!getName._directives) { // 没有事件池 创建事件池
getName._directives = [];
}
getName._directives.push(new Watcher( // 将dom替换成属性的数据并发布订阅 在set的时候更新数据
node,
_this,
placeholder,
'innerHTML'
));
return placeholder.split('.').reduce((val, key) => {
return _this._data[key]; // 获取数据的值 触发get 返回当前值
}, _this.$el);
});
}
}
}
// new Watcher() 为this._compile()发布订阅+ 在this._observer()中set(赋值)的时候更新视图
function Watcher(el, vm, val, attr) {
this.el = el; // 指令对应的DOM元素
this.vm = vm; // myVue实例
this.val = val; // 指令对应的值
this.attr = attr; // dom获取值,如value获取input的值 / innerHTML获取dom的值
this.update(); // 更新视图
}
Watcher.prototype.update = function () {
this.el[this.attr] = this.vm._data[this.val]; // 获取data的最新值 赋值给dom 更新视图
}执行 weex run android 后报错Environment variable $ANDROID_HOME not found
解决:
open .bash_profile打开.bash_profile文件,将Android Home 项换为复制的地址source ~/.bash_profiledone
原文地址:https://js.tensorflow.org/#getting-started
翻译:RicardoCao
有两种在JavaScript项目中使用TensorFlow.js的途径:使用script标签引入或在Webpack、Parcel、Roolup项目中使用NPM包引入。
在HTML文件中加入如下代码:
<html>
<head>
<!-- 加载TensorFlow.js -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/[email protected]/dist/tf.min.js"> </script>
<!-- 将你的代码写在这里 -->
<script>
// 定义一个线性回归模型.
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [1]}));
// 准备训练模型: 指定loss和optimizer.
model.compile({loss: 'meanSquaredError', optimizer: 'sgd'});
// 造一些假数据用于训练
const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]);
const ys = tf.tensor2d([1, 3, 5, 7], [4, 1]);
// 使用数据训练模型
model.fit(xs, ys, {epochs: 10}).then(() => {
// 使用模型去推测一个之前没有出现过的数据的结果:
// 打开浏览器devtools以查看输出
model.predict(tf.tensor2d([5], [1, 1])).print();
});
</script>
</head>
<body>
</body>
</html>将上面的HTML在浏览器中打开,以便查看结果。
可以通过使用NPM或YARN将TensorFlow.js添加至你的项目中。注意:本例使用ES2017语法(例如import),这里我们假定你已经在项目中使用打包工具。
yarn add @tensorflow/tfjs
npm install @tensorflow/tfjs
在main.js中如下配置:
import * as tf from '@tensorflow/tfjs';
// 定义一个线性回归模型.
const model = tf.sequential();
model.add(tf.layers.dense({units: 1, inputShape: [1]}));
// 准备训练模型: 指定loss和optimizer.
model.compile({loss: 'meanSquaredError', optimizer: 'sgd'});
// 造一些假数据用于训练
const xs = tf.tensor2d([1, 2, 3, 4], [4, 1]);
const ys = tf.tensor2d([1, 3, 5, 7], [4, 1]);
// 使用数据训练模型
model.fit(xs, ys, {epochs: 10}).then(() => {
// 使用模型去推测一个之前没有出现过的数据的结果:
model.predict(tf.tensor2d([5], [1, 1])).print();
});安装Node.js绑定以实现TensorFlow的强大能量。
yarn add @tensorflow/tfjs-node
npm install @tensorflow/tfjs-node
如果你的系统使用了带有CUDA compute support的英伟达GPU,可以使用GPU库来提升更高的性能(仅限Linux系统):
yarn add @tensorflow/tfjs-node-gpu
npm install @tensorflow/tfjs-node-gpu
Node.js应用例子:
const tf = require('@tensorflow/tfjs');
// 加载 binding:
require('@tensorflow/tfjs-node'); // Use '@tensorflow/tfjs-node-gpu' if running with GPU.
// 训练模型:
const model = tf.sequential();
model.add(tf.layers.dense({units: 100, activation: 'relu', inputShape: [10]}));
model.add(tf.layers.dense({units: 1, activation: 'linear'}));
model.compile({optimizer: 'sgd', loss: 'meanSquaredError'});
const xs = tf.randomNormal([100, 10]);
const ys = tf.randomNormal([100, 1]);
model.fit(xs, ys, {
epochs: 100,
callbacks: {
onEpochEnd: async (epoch, log) => {
console.log(`Epoch ${epoch}: loss = ${log.loss}`);
}
}
});Vue:支持纯ES5语法开发,在不使用脚手架的情况下兼容性也得到保证。
React:需要使用ES6语法进行开发,必须使用babel等工具对代码进行转码来保证兼容性。
Vue:JavaScript与HTML分离,可以更清晰、简单明了的处理逻辑和渲染,需要在HTML中引入v-if/v-for/{{}}等用于支持数据的响应式渲染。
React:使用JSX,JavaScript有能力更直接的处理渲染逻辑,尤其是复杂渲染逻辑。
Vue:双向数据绑定,直接修改data可以自动触发渲染。
React:单向数据绑定,state不可直接修改而是要依靠setState。
Vue:需要注意在data更新后,DOM上的数据变化要在$nexTick中才能操作,否则数据还没有自动更新。
React:需要注意优化在shouldComponentUpdate中避免使用setState以防止进入无限渲染循环。
Vue:Vue的组件是高度封装的函数,写Vue组件不是在写函数,而是在写函数的参数。
React:React组件是函数,写一个接收 props 作为参数,并对改props进行各种处理的函数。
Vue:
React:
Vue:
React:

Vue:可以直接使用style标签,通过scoped属性控制css的作用域。
React:可以直接在标签中使用style对象;也可以将style对象分离,在标签中引用;也可以使用引入的css文件。
Vue:使用阿里开源Weex实现对原生App的支持,使用mpvue等实现对小程序的支持。
React:FB开源React-Native实现对原生App的支持,京东开源Taro可以实现同时对小程序和原生的支持。
<meta name="viewport" content="width=devidce-width",user-scalable=no,initial-scale=1.0,maximum-scale=1.0,minimun-scale=1.0">
| 属性 | 可选值 | 描述 |
|---|---|---|
| width | device-width/指定数字 | 设置viewport宽度 |
| height | device-height/指定数字 | 设置viewport高度 |
| initial-scale | 指定数字 | 设置viewport初始缩放比例 |
| minimum-scale | 指定数字 | 设置viewport最小缩放比例 |
| maximum-scale | 指定数字 | 设置viewport最大缩放比例 |
| user-scalable | yes/no/1/0 | 设置viewport是否允许用户缩放 |
<video src="movie.ogg" width="320" height="240" controls="controls">
Your browser does not support the video tag.
</video>
<audio src="song.ogg" controls="controls">
Your browser does not support the audio tag.
</audio>
使用 getCurrentPosition()方法来获得用户的位置
localStorage
属性
localStorage 方法存储的数据没有时间限制
localStorage的使用遵循同源策略
每个域名容量5M
用法
- localStorage.setItem("name", "张三"); 在本地客户端存储一个字符串类型的数据
- var data = localStorage.getItem("name"); 读取已存储在本地的数据
- var data2 = localStorage.removeItem("name"); 从本地存储中移除键名为name的数据
- localStorage.clear() 移除本地存储所有数据
sessionStorage
属性
sessionStorage 方法针对一个 session 进行数据存储。当用户关闭浏览器窗口后,数据会被删除。
用法
sessionStorage的四个用法与localstorage一致。
Web 存储的使用优缺点
优点
- localStorage拓展了cookie的4K限制
缺点
- 浏览器的大小不统一,并且在IE8以上的IE版本才支持localStorage这个属性
- 所有的浏览器中都会把localStorage的值类型限定为string类型
- localStorage不能被爬虫抓取到
Web Socket
意义
HTTP 协议有一个缺陷:通信只能由客户端发起 ,websocket可以实现服务端主动推送。
属性
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(3)数据格式比较轻量,性能开销小,通信高效。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是
ws(如果加密,则为wss),服务器网址就是 URL。用法
//客户端与服务器进行连接 var ws = new WebSocket("wss://echo.websocket.org"); //指定连接成功后的回调函数 ws.onopen = function(evt) { console.log("Connection open ..."); ws.send("Hello WebSockets!"); }; //指定收到服务器数据后的回调函数 ws.onmessage = function(evt) { console.log( "Received Message: " + evt.data); ws.close(); }; //指定连接关闭后的回调函数 ws.onclose = function(evt) { console.log("Connection closed."); };缺点
对前端开发者,往往要具备数据驱动使用javascript的能力,且需要维持住ws连接(否则消息无法推送);对后端开发者而言,难度增大了很多,一是长连接需要后端处理业务的代码更稳定(不要随便把进程和框架都crash掉),二是推送消息相对复杂一些,三是成熟的http生态下有大量的组件可以复用,websocket则太新了一点。
canvas为标量图,svg为矢量图,canvas为html5新增。
<canvas id="canvas" height="200" width="350"></canvas>
let canvas=document.getElementById("canvas");
let ctx = canvas.getContext('2d');
//绘制表框
function drawBackground() {
ctx.save();
ctx.translate(r, r);
ctx.beginPath();//起始一条路径,或重置当前路径
ctx.lineWidth = 10 * rem; //以0,0为原点,r为半径,0为起始角,2*Math.PI为结束角,顺时针画圆
ctx.arc(0, 0, r - ctx.lineWidth / 2, 0, 2 * Math.PI, false); //画圆
ctx.stroke();//绘制已定义的路径
}
//绘制秒针
function drawSecond(second) {
ctx.save();
ctx.beginPath();
ctx.fillStyle = '#c14443';
ctx.rotate(2 * Math.PI / 60 * second);//旋转
ctx.moveTo(-2, 20 * rem);
ctx.lineTo(2, 20 * rem);
ctx.lineTo(1, -r + 18 * rem);
ctx.lineTo(-1, -r + 18 * rem);
ctx.fill();
ctx.restore();
ctx.drawImage(img,10,10);//向画布上绘制图像、画布或视频
}
function draw() {
ctx.clearRect(0, 0, width, height);//清除前一帧画面
var now = new Date();//获取此刻时间
var seconds = now.getSeconds();
drawBackground();
drawSecond(seconds);
}
setInterval(draw, 1000); Canvas 在高清屏下绘制图片变模糊
不管当前的devicePixelRatio的值是多少,统一将canvasDOM节点的width属性设置为其csswidth属性的两倍,同理将height属性也设置为cssheight属性的两倍,即:
<canvas width="320" height="180" style="width:160px;height:90px;"></canvas>
这样整个 canvas 的坐标系范围就扩大为两倍,但是在浏览器的显示大小没有变,canvas画图的时候,按照扩大化的坐系来显示,不清晰的问题就得以改善了
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。串行“\\”匹配“\”而“\(”则匹配“(”。 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“`(. |
使用:
if(!(正则表达式.test(xxxx)))
邮箱
/^([a-z0-9_\.-]+)@([0-9a-z\.-]+)\.([a-z]{2,6})$/
/^[a-z0-9_-]{6,16}$/
if(!(/^1[34578][0-9]{9}$/.test(phone)))
web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能。您可以继续做任何愿意做的事情:点击、选取内容等等,而此时 web worker 在后台运行。用于更耗费 CPU 资源的任务。
使用
- 创建 web worker 文件,并使用*postMessage()*方法向 HTML 页面传回一段消息。
- 创建一个新的 web worker 对象,然后运行 "demo_workers.js" 中的代码。
- 向 web worker 添加一个 "onmessage" 事件监听器。
- 如需终止 web worker,并释放浏览器/计算机资源,请使用 terminate() 方法。
<!DOCTYPE html> <html> <body> <p>Count numbers: <output id="result"></output></p> <button onclick="startWorker()">Start Worker</button> <button onclick="stopWorker()">Stop Worker</button> <br /><br /> <script> var w; function startWorker() { if(typeof(Worker)!=="undefined") { if(typeof(w)=="undefined") { w=new Worker("demo_workers.js"); } w.onmessage = function (event) { document.getElementById("result").innerHTML=event.data; }; } else { document.getElementById("result").innerHTML="Sorry, your browser does not support Web Workers..."; } } function stopWorker() { w.terminate(); } </script> </body> </html>
区别
1.从属关系区别
@import是 CSS 提供的语法规则,只有导入样式表的作用;link是HTML提供的标签,不仅可以加载 CSS 文件,还可以定义 RSS、rel 连接属性等。2.加载顺序区别
加载页面时,link标签引入的 CSS 被同时加载;@import引入的 CSS 将在页面加载完毕后被加载。3.兼容性区别
@import是 CSS2.1 才有的语法,故只可在 IE5+ 才能识别;link标签作为 HTML 元素,不存在兼容性问题。4.DOM可控性区别
可以通过 JS 操作 DOM ,插入link标签来改变样式;由于 DOM 方法是基于文档的,无法使用@import的方式插入样式。5.权重区别(该项有争议)
link引入的样式权重大于@import引入的样式。
content-box : width == 内容区宽度
border-box : width == 内容区宽度 + padding宽度 + border宽度
如何设置两种模型:
box-sizing: content-box 是W3C盒子模型
box-sizing: border-box 是IE盒子模型
box-sizing的默认属性是content-box
content-box W3C标准模型
父{position:relative}
子{
position:absolute;
top:0,left:0;right:0,bottom:0;
margin:auto;}
父{
display:flex;
content-justify:center;
align-items:center;}
父{position:relative}
子{
position:absolute;
left:50%;
top:50%
transform:translate(-50%,-50%)}
<a>、<strong>、<b>、<em>、<i>、<span>等
行内元素的特点:
(1)和相邻行内元素在一行上。
(2)高、宽无效,但水平方向的padding和margin可以设置,垂直方向的无效。
(3)默认宽度就是它本身内容的宽度。
(4)行内元素只能容纳文本或则其他行内元素。(a特殊 a里面可以放块级元素 )
<h1>~<h6>、<p>、<div>、<ul>、<ol>、<li>等
块级元素的特点:
(1)总是从新行开始
(2)高度,行高、外边距以及内边距都可以控制。
(3)宽度默认是容器的100%
(4)可以容纳内联元素和其他块元素。
在行内元素中有几个特殊的标签——<img />、<input />、<td>,
可以对它们设置宽高和对齐属性,有些资料可能会称它们为行内块元素。
行内块元素的特点:
(1)和相邻行内元素(行内块)在一行上,但是之间会有空白缝隙。
(2)默认宽度就是它本身内容的宽度。
(3)高度,行高、外边距以及内边距都可以控制。
left{
width:100xp;
float:left
}
right{margin-left:100px}
left{
position:absolute;
left:0;
width:100px}
right{
position:absolute;
left:100px;
width:calc(100% - 100px)}
parent{display:flex}
left{flex:0 0 100px}
right{flex:1}
.father {
display: flex;
height: 100%;
}
.left,
.right {
flex: 0 0 100px;
background-color: red;
}
.middle {
flex: 1;
}
<div class="box">
<div class="middle-wrap">
<div class="middle"></div>
</div>
<div class="left"></div>
<div class="right"></div>
</div>
.box {
position: relative;
}
.middle-wrap {
position: relative;
float: left;
width: 100%;
}
.middle-wrap .middle {
margin: 0 100px; /*留出距离*/
}
.left {
float: left;
width: 100px;
margin-left: -100%;
}
.right {
float: left;
width: 100px;
margin-left: -100px;
}
flex-direction属性
主轴的方向
row(默认值):主轴为水平方向,起点在左端。row-reverse:主轴为水平方向,起点在右端。column:主轴为垂直方向,起点在上沿。column-reverse:主轴为垂直方向,起点在下沿。justify-content属性
项目在主轴上的对齐方式
flex-start(默认值):左对齐flex-end:右对齐center: 居中space-between:两端对齐,项目之间的间隔都相等。space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。align-items属性
交叉轴上如何对齐
flex-start:交叉轴的起点对齐。flex-end:交叉轴的终点对齐。center:交叉轴的中点对齐。baseline: 项目的第一行文字的基线对齐。stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。flex属性
flex属性默认值为0 1 auto
flex:flex-grow, flex-shrink,flex-basis
flex-grow属性定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。 如果所有项目的flex-grow属性都为1,则它们将等分剩余空间(如果有的话)flex-shrink属性定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。flex-basis属性定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。它的默认值为auto,即项目的本来大小。另外:下面两个表达式相等:
.item {flex: 1;}
.item {
flex-grow: 1;
flex-shrink: 1;
flex-basis: 0%;
}
网格容器
将属性
display值设为grid或inline-grid就创建了一个网格容器,所有容器直接子结点自动成为网格项目。
- display: grid网格项目按行排列,网格项目占用整个容器的宽度。
- display: inline-grid网格项目按行排列,网格项目宽度由自身宽度决定。
显示网格
属性
grid-template-rows和grid-template-columns用于显示定义网格,分别用于定义行轨道和列轨道。
- 属性
grid-template-rows:50px 100px用于定义行的尺寸。- 属性
grid-template-columns:50px 100px用于定义列的尺寸。- 长度值可以是
auto,表示轨道尺寸可以根据内容大小进行伸长或收缩。用网格线编号定位项目
- 通过设置网格线编号直接定位单个子元素
grid-row-start: 2; grid-row-end: 3; grid-column-start: 2; grid-column-end: 3;
- 属性
grid-column是grid-column-start和grid-column-end的简写形式。grid-column: 3 / 4; //二者等价 grid-column-start:3; grid-column-end:4;
- 通过
grid-column-start和grid-column-end属性值的设置,使该网格项目跨越多列。行同理。网格项目的对齐方式
- 属性
justify-items以行轴为参照对齐项目(水平),属性align-items以列轴为参照对齐项目(垂直)。
1、选择器越具体,优先级越高
2、同样优先级,写在后面的覆盖前面的
3、!important > id > class >tag >通配符
可以的有 font-size font-family color
不可以的有 border padding margin background-color width height等
过渡属性transition可以在一定的事件内实现元素的状态过渡为最终状态,用于模拟一种过渡动画效果,但是功能有限,只能用于制作简单的动画效果;
动画属性animation可以制作类似Flash动画,通过关键帧控制动画的每一步,控制更为精确,从而可以制作更为复杂的动画。
transition
transition: property duration timing-function delay;
| 值 | 描述 |
|---|---|
| transition-property | 规定设置过渡效果的 CSS 属性的名称。 |
| transition-duration | 规定完成过渡效果需要多少秒或毫秒。 |
| transition-timing-function | 规定速度效果的速度曲线。 |
| transition-delay | 定义过渡效果何时开始 |
animation
animation: name duration timing-function delay iteration-count direction;
| 值 | 描述 |
|---|---|
| animation-name | 规定需要绑定到选择器的 keyframe 名称。。 |
| animation-duration | 规定完成动画所花费的时间,以秒或毫秒计。 |
| animation-timing-function | 规定动画的速度曲线。 |
| animation-delay | 规定在动画开始之前的延迟。 |
| animation-iteration-count | 规定动画应该播放的次数。 |
| animation-direction | 规定是否应该轮流反向播放动画。 |
特性
作用
overflow:hidden 清除浮动
overflow:hidden 取消父子margin合并(子设置margin,父也会有margin)
因为BFC内部的元素和外部的元素绝对不会互相影响,因此, 当BFC外部存在浮动时,它不应该影响BFC内部Box的布局,BFC会通过变窄,而不与浮动有重叠。同样的,当BFC内部有浮动时,为了不影响外部元素的布局,BFC计算高度时会包括浮动的高度。避免margin重叠也是这样的一个道理。
如何触发BFC
获取宽度
在JavaScript中我们可以直接通过以下window上的属性获取设备像素比
window.devicePixelRatio
响应式
利用@media进行断点,在每个断点中编写css
@media (max-width:1000px){
div{background:blue;}
}
@media (min-width:1000px) and (max-width:1150px){
div{background: yellow;}
}
@media only screen and (max-width:1150px){
div{border:solid 1px;}
}
优点:兼容性好,@media在ie9以上是支持的,PC和MOBILE是同一套代码的,不用分开。
缺点:要写得css相对另外两个多很多,而且各个断点都要做好。css样式会稍微大点,更麻烦。
REM
REM这个单位,会根据html的font-size大小进行转换
(function (doc, win) {
var docEl = doc.documentElement,
resizeEvt = 'orientationchange' in window ? 'orientationchange' : 'resize',
recalc = function () {
var clientWidth = docEl.clientWidth;
if (!clientWidth) return;
docEl.style.fontSize = 100 * (clientWidth / 750) + 'px';
};
if (!doc.addEventListener) return;
win.addEventListener(resizeEvt, recalc, false);
doc.addEventListener('DOMContentLoaded', recalc, false);
})(document, window);
优点:能维持能整体的布局效果,移动端兼容性好,不用写多个css代码,而且还可以利用@media进行优化。
缺点:开头要引入一段js代码,单位都要改成rem(font-size可以用px),计算rem比较麻烦(可以引用预处理器,但是增加了编译过程,相对麻烦了点)。pc和mobile要分开。
设置viewport中的width
这种方案,就是定死viewport中的width大小。
比如设计稿是750的,然后就在代码上写:
<met name='viewport' content='width=750' />
优点:和REM相同,而且不用写rem,直接使用px,更加快捷。
缺点:效果可能没rem的好,图片可能会相对模糊,而且无法使用@media进行断点,不同size的手机上显示,高度间距可能会相差很大。
1、浮动带来的副作用:
1)块状元素,会钻进浮动元素的下面,被浮动元素所覆盖
2)行内元素,例如文字, 则会环绕在浮动元素的周围,为浮动元素留出空间
3)浮动元素的父元素坍缩
2、清除浮动:
//解决浮动导致的高度塌陷问题
.clearfix:after{
content:".";
display:block;
height:0;
clear:both;
visibility:hidden;
}
为兼容IE6,IE7,因为ie6,ie7不能用after伪类。加上下面代码
.clearfix{zoom:1}
em 是一种相对单位,它相对于父元素的字体大小。
rem是一种相对单位,它相对于根元素 html 的字体大小,会根据html的font-size大小进行转换
vh/vw都是相对于视口的单位,浏览器视口的区域就是通过 window.innerWidth以及 window.innerHeigth 度量得到的范围。 浏览器会将整个视口的宽度或者高度划分为100等份,因此1vw或者1wh就是相对视口宽度或者高度的1%
margin在垂直方向上相邻的值相同时会发生叠加,水平方向上相邻的值会相加
只有垂直方向的 margin 才会折叠,也就是说,水平方向的 margin 不会发生折叠的现象。
如何使元素上下margin不折叠呢?
触发底部元素的BFC(overflow:hidden除外)
如何使父子margin不折叠呢?
触发父元素的BFC
display设置为inline-block时,li与li之间有看不见的空白间隔
造成「inline-block」元素空隙的本质是 HTML 中存在的空白符(whitespace)
行框的排列会受到中间空白(回车空格等等)的影响,这些空白也会被应用样式,占据空间,所以会有间隔
**解决1:**设置ul的font-size为0,缺陷是必须重新在li中去设置字体大小(副作用多)
解决2:使用如下写法
<ul
><li>1</li
><li>2</li
><li>3</li
></ul>
引起回流
1、添加或者删除可见的DOM元素;
2、元素位置改变;
3、元素尺寸改变——边距、填充、边框、宽度和高度
4、内容改变——比如文本改变或者图片大小改变而引起的计算值宽度和高度改变;
5、页面渲染初始化;
6、浏览器窗口尺寸改变——resize事件发生时;
string number boolean undefined null object symbol
typeof
// Numbers typeof 37 === 'number'; typeof 3.14 === 'number'; typeof Math.LN2 === 'number'; typeof Infinity === 'number'; typeof NaN === 'number'; // 尽管NaN是"Not-A-Number"的缩写 typeof Number(1) === 'number'; // 但不要使用这种形式! // Strings typeof "" === 'string'; typeof "bla" === 'string'; typeof (typeof 1) === 'string'; // typeof总是返回一个字符串 typeof String("abc") === 'string'; // 但不要使用这种形式! // Booleans typeof true === 'boolean'; typeof false === 'boolean'; typeof Boolean(true) === 'boolean'; // 但不要使用这种形式! // Symbols typeof Symbol() === 'symbol'; typeof Symbol('foo') === 'symbol'; typeof Symbol.iterator === 'symbol'; // Undefined typeof undefined === 'undefined'; typeof declaredButUndefinedVariable === 'undefined'; typeof undeclaredVariable === 'undefined'; // Objects typeof {a:1} === 'object'; // 使用Array.isArray 或者 Object.prototype.toString.call // 区分数组,普通对象 typeof [1, 2, 4] === 'object'; typeof new Date() === 'object'; // 下面的容易令人迷惑,不要使用! typeof new Boolean(true) === 'object'; typeof new Number(1) === 'object'; typeof new String("abc") === 'object'; // 函数 typeof function(){} === 'function'; typeof class C{} === 'function' typeof Math.sin === 'function'; typeof new Function() === 'function';instanceof
instanceof运算符用来检测constructor.prototype是否存在于参数object的原型链上。function Cat(){} Cat.prototype = {} function Dog(){} Dog.prototype ={} var dog1 = new Dog(); alert(dog1 instanceof Dog);//true alert(dog1 instanceof Object);//true Dog.prototype = Cat.prototype; alert(dog1 instanceof Dog);//false alert(dog1 instanceof Cat);//false alert(dog1 instanceof Object);//true; var dog2= new Dog(); alert(dog2 instanceof Dog);//true alert(dog2 instanceof Cat);//true alert(dog2 instanceof Object);//true Dog.prototype = null; var dog3 = new Dog(); alert(dog3 instanceof Cat);//false alert(dog3 instanceof Object);//true alert(dog3 instanceof Dog);//errorprototype
Object.prototype.toString.call(a) === '[object String]')console.log(Object.prototype.toString.call(123)) //"[object Number]" console.log(Object.prototype.toString.call('123')) //"[object String]" console.log(Object.prototype.toString.call(undefined)) //"[object Undefined]" console.log(Object.prototype.toString.call(true)) //"[object Boolean]" console.log(Object.prototype.toString.call(null)) //"[object Null]" console.log(Object.prototype.toString.call({})) //"[object Object]" console.log(Object.prototype.toString.call([])) //"[object Array]" console.log(Object.prototype.toString.call(function(){})) //"[object Function]"constructor
注意: constructor 在类继承时会出错
c.constructor === Array
var today=new Date()
var y=today.getFullYear()
var m=today.getMonth()
var d=today.getDate()
var h=today.getHours()
var m=today.getMinutes()
var s=today.getSeconds()
变量提升
函数提升
function functionName(){} //函数声明
var a = function(arg0,arg1){} //函数表达式
Array对象方法
length 数组中元素的数目
POP 删除最后一项
删除最后一项,并返回删除元素的值;如果数组为空则返回undefine
shift 删除第一项
删除原数组第一项,并返回删除元素的值;如果数组为空则返回undefine
push 增加到最后
并返回新数组长度;
unshift增加到最前
并返回新数组长度;
reverse 数组翻转
并返回翻转后的原数组,原数组翻转了
join数组转成字符串
并返回字符串,原数组木变
var a = [1,2,3,4,5]; var b=a.join('||');//b:"1||2||3||4||5" a:[1,2,3,4,5]indexOf数组元素索引
并返回元素索引,不存在返回-1,索引从0开始
var a = ['a','b','c','d','e']; a.indexOf('a');//0slice截取(切片)数组 得到截取的数组
返回从原数组中指定开始索引(包含)到结束索引(不包含)之间的项组成的新数组,原数组木变 ,索引从0开始
var a = ['a','b','c','d','e']; a.slice(1,3);//["b", "c"] a:['a','b','c','d','e']splice剪接数组 原数组变化 可以实现shift前删除,pop后删除,unshift前增加,同push后增加一样的效果
返回剪接的元素数组,原数组变化 ,索引从0开始
var a = ['a','b','c','d','e']; a.splice(0,0,88,99)//返回 [] 从第一个元素,截取长度0个 肯定是空 a:[88, 99, "a", "b", "c", "d", "e"] 同unshift前增加concat数组合并
返回合并后的新数组,原数组不变
var a = ['a','b','c','d','e']; a.concat([88,99]);//["a", "b", "c", "d", "e", 88, 99]filter 过滤
var arr = [ {"name":"apple", "count": 2}, {"name":"orange", "count": 5}, {"name":"pear", "count": 3}, {"name":"orange", "count": 16}, ]; var newArr = arr.filter(function(item){ return item.name === "orange"; }); console.log("Filter results:",newArr);reduce() 可以实现一个累加器的功能,将数组的每个值(从左到右)将其降低到一个值。
//统计一个数组中有多少个不重复的单词 var arr = ["apple","orange","apple","orange","pear","orange"]; function getWordCnt(){ return arr.reduce(function(prev,next){ prev[next] = (prev[next] + 1) || 1; return prev; },{}); } console.log(getWordCnt()); //reduce(callback, initialValue)会传入两个变量。回调函数(callback)和初始值(initialValue)**find()**方法返回数组中满足提供的测试函数的第一个元素的值。否则返回
undefined。var inventory = [ {name: 'apples', quantity: 2}, {name: 'bananas', quantity: 0}, {name: 'cherries', quantity: 5} ]; function findCherries(fruit) { return fruit.name === 'cherries'; } console.log(inventory.find(findCherries)); // { name: 'cherries', quantity: 5 }
String 对象方法
length 字符串的长度
charAt() 返回在指定位置的字符。
concat() 连接字符串。
indexOf() 检索字符串。
lastIndexOf() 从后向前搜索字符串。
match() 找到一个或多个正则表达式的匹配。
replace() 替换与正则表达式匹配的子串。
search() 检索与正则表达式相匹配的值。
slice() 提取字符串的片断,并在新的字符串中返回被提取的部分。
var str="Hello happy world!" document.write(str.slice(6,11)) //happysplit() 把字符串分割为字符串数组。
substring() 提取字符串中两个指定的索引号之间的字符。
var str="Hello world!" document.write(str.substring(3,7))// lo wtoLowerCase() 把字符串转换为小写。
toUpperCase() 把字符串转换为大写。
toString() 返回字符串。
- str.charAt()和str[]的区别
var s = "abc"; s[1]; // b s.charAt(1); // b s[5]; // undefined s.charAt(5); // ""
遍历对象
for in
主要用于遍历对象的可枚举属性,包括自有属性、继承自原型的属性
var obj = {"name":"Poly", "career":"it"} Object.defineProperty(obj, "age", {value:"forever 18", enumerable:false}); Object.prototype.protoPer1 = function(){console.log("proto");}; Object.prototype.protoPer2 = 2; console.log("For In : "); for(var a in obj) console.log(a);输出: name,carrer,protoPer1,protoPer2
Object.keys
返回一个数组,元素均为对象自有的可枚举属性
var obj = {"name":"Poly", "career":"it"} Object.defineProperty(obj, "age", {value:"forever 18", enumerable:false}); Object.prototype.protoPer1 = function(){console.log("proto");}; Object.prototype.protoPer2 = 2; console.log("Object.keys:") console.log(Object.keys(obj));输出:name,career
Object.getOwnProperty
用于返回对象的自有属性,包括可枚举和不可枚举的
var obj = {"name":"Poly", "career":"it"} Object.defineProperty(obj, "age", {value:"forever 18", enumerable:false}); Object.prototype.protoPer1 = function(){console.log("proto");}; Object.prototype.protoPer2 = 2; console.log("Object.getOwnPropertyNames: "); console.log(Object.getOwnPropertyNames(obj));输出:name,career,age
遍历数组
forEach
var arr=[1,2,3,4]; arr.forEach(function(val, index) { console.log(val, index); });for in
var arr=["张三","李四","王五","赵六"]; for (var i in arr){ console.log(i,":",arr[i]);
概念
Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。只有异步操作的结果,可以决定当前是哪一种状态,任何其他操作都无法改变这个状态。这也是Promise这个名字的由来,它的英语意思就是“承诺”,表示其他手段无法改变。
有了Promise对象,就可以将异步操作以同步操作的流程表达出来,避免了层层嵌套的回调函数。此外,Promise对象提供统一的接口,使得控制异步操作更加容易。
特点
Promise,一旦新建它就会立即执行,无法中途取消。Promise内部抛出的错误,不会反应到外部。pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。用法
基本用法:
const promise = new Promise(function(resolve, reject) {
// ... some code
if (/* 异步操作成功 */){
resolve(value);
} else {
reject(error);
}
});
then:
Promise 实例具有then方法,也就是说,then方法是定义在原型对象Promise.prototype上的。它的作用是为 Promise 实例添加状态改变时的回调函数。前面说过,then方法的第一个参数是resolved状态的回调函数,第二个参数(可选)是rejected状态的回调函数。
catch:
Promise.prototype.catch方法是.then(null, rejection)的别名,用于指定发生错误时的回调函数。
all:
Promise.all方法用于将多个 Promise 实例,包装成一个新的 Promise 实例。
const p = Promise.all([p1, p2, p3]);
p1、p2、p3的状态都变成fulfilled,p的状态才会变成fulfilled,此时p1、p2、p3的返回值组成一个数组,传递给p的回调函数。p1、p2、p3之中有一个被rejected,p的状态就变成rejected,此时第一个被reject的实例的返回值,会传递给p的回调函数。race:
Promise.race方法同样是将多个 Promise 实例,包装成一个新的 Promise 实例。
const p = Promise.race([p1, p2, p3]);
上面代码中,只要p1、p2、p3之中有一个实例率先改变状态,p的状态就跟着改变。那个率先改变的 Promise 实例的返回值,就传递给p的回调函数。
扩展运算符( spread )是三个点(...)。将一个数组转为用逗号分隔的参数序列。
console.log(...[1, 2, 3])
// 1 2 3
async函数返回一个 Promise 对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。//指定 50 毫秒以后,输出hello world。
function timeout(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms);
console.log(value);
}
asyncPrint('hello world', 50);
let xhr = new XMLHttpRequest()
xhr.open('GET','/xxxx')
xhr.onreadystatechange = function(){
if(xhr.readyState === 4 && xhr.status === 200){
console.log(xhr.responseText)
}
}
xhr.send('a=1&b=2')
POST:
//创建异步对象
var xhr = new XMLHttpRequest();
//设置请求的类型及url
//post请求一定要添加请求头才行不然会报错
xhr.setRequestHeader("Content-type","application/x-www-form-urlencoded");
xhr.open('post', '02.post.php' );
//发送请求
xhr.send('name=fox&age=18');
xhr.onreadystatechange = function () {
// 这步为判断服务器是否正确响应
if (xhr.readyState == 4 && xhr.status == 200) {
console.log(xhr.responseText);
}
};
JavaScript的单线程
JavaScript从诞生起就是单线程。原因大概是不想让浏览器变得太复杂,因为多线程需要共享资源、且有可能修改彼此的运行结果,对于一种网页脚本语言来说,这就太复杂了。后来就约定俗成,JavaScript为一种单线程语言。(Web Worker API可以实现多线程,但是JavaScript本身始终是单线程的。)
event loop事件循环
概念
在程序中设置两个线程:一个负责程序本身的运行,称为"主线程";另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为"Event Loop线程"
异步执行步骤
(1)所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
(2)主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
(3)一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
(4)主线程不断重复上面的第三步。
JS的异步编程方法
- callback回调函数
function fn1 () { console.log('Function 1') } function fn2 () { setTimeout(() => { console.log('Function 2') }, 500) } function fn3 () { console.log('Function 3') } //执行顺序 :F1 > F3 > F2function fn2 (f) { setTimeout(() => { console.log('Function 2') f() }, 500) } fn2(fn3) //可以通过callback使fn3在fn2后执行,达到F1 > F2 > F3的目的
- 事件发布/订阅
- Promise
function fn1 () { console.log('Function 1') } function fn2 () { return new Promise((resolve, reject) => { setTimeout(() => { console.log('Function 2') resolve() }, 500) }) } function fn3 () { console.log('Function 3') }fn1() fn2().then(() => { fn3() }) // output : Function 1 > Function 2 > Function 3
- async&await
function fn1 () { console.log('Function 1') } function fn2 () { return new Promise((resolve, reject) => { setTimeout(() => { console.log('Function 2') resolve() }, 500) }) } function fn3 () { console.log('Function 3') } async function asyncFunArr () { fn1() await fn2() fn3() } asyncFunArr() // output : Function 1 > Function 2 > Function 3
作用域
原则
ES5中没有块级作用域,只有函数作用域和全局作用域
每次定义一个函数,都会产生一个作用域链(scope chain)。当JavaScript寻找变量varible时(这个过程称为变量解析),总会优先在当前作用域链的第一个对象中查找属性varible ,如果找到,则直接使用这个属性;否则,继续查找下一个对象的是否存在这个属性。
闭包
概念
一个是可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
意义
局部变量无法共享和长久的保存,而全局变量可能造成变量污染,所以我们希望有一种机制既可以长久的保存变量又不会造成全局污染。
特点
占用更多内存,不容易被释放
使用
function createAdder(){ var n=0 return function(){ n += 1 console.log(n) } } let adder = createAdder() adder() //1 adder() //2 console.log(n) // n is not undefined
没有对象只有方法则指向全局对象
fn()的this是window
有对象调用方法就指向调用对象
a.fn()的this是a
new F()的this是新实例
箭头函数里的this是外部作用域的this
当我们使用add.call(),第一个参数是this需要绑定的对象,剩下的是add函数本来的参数
(function(){});
(function(){})()
立即执行函数是为了生成一个函数作用域,防止污染全局变量
浅拷贝
function copy(obj1) {
var obj2 = {};
for (var i in obj1) {
obj2[i] = obj1[i];
}
return obj2;
}
深拷贝
var a = {...}
var b = JSON.parse(JSON.stringify(a))
var china = {
nation : '**',
birthplaces:['北京','上海','广州'],
skincolr :'yellow',
friends:['sk','ls']
}
//深复制,要想达到深复制就需要用递归
function deepCopy(o,c){
var c = c || {}
for(var i in o){
if(typeof o[i] === 'object'){
//要考虑深复制问题了
if(o[i].constructor === Array){
//这是数组
c[i] =[]
}else{
//这是对象
c[i] = {}
}
//递归进入对象或数组中进行下一轮深层拷贝
deepCopy(o[i],c[i])
}else{
c[i] = o[i]
}
}
return c
}
var result = {name:'result'}
result = deepCopy(china,result)array.push(num)中push是沿着array.__proto__找到的,也就是Array.prototype.push
原型图
arr instanceof Array); // true instanceof 运算符用来测试一个对象是否是后者的实例。arr.constructor === Array ; // true Array.isArray([1, 2, 3]); // trueObject.prototype.toString.call(arr); //'[object Array]' 此种方法最准确Number:
isNaN 如果为true则不是Number类型
var foo = function() {}
编译后变量声明foo会“被提前”了,但是他的赋值(也就是FUNCTION_BODY)并不会被提前。
也就是,匿名函数只有在被调用时才被初始化。
function foo() {}
编译后函数声明和他的赋值都会被提前。
也就是说函数声明过程在整个程序执行之前的预处理就完成了,所以只要处于同一个作用域,就可以访问到,即使在定义之前调用它也可以。
1、匿名函数的事件不能解绑
2、匿名函数和普通函数最大的区别是在于,匿名函数可以作为一个具体的“值”赋予给变量或者对象属性,其次,由于匿名函数可以被定义在不同地方,使得他可以有效利用他所在的局域内的变量(或者说上下文中的变量)。
navigator.userAgent.indexOf('')
生成实例对象的传统方法是通过构造函数 ,
function Point(x, y) {
this.x = x;
this.y = y;
}
Point.prototype.toString = function () {
return '(' + this.x + ', ' + this.y + ')';
};
var p = new Point(1, 2);
上面的代码用 ES6 的class改写
//定义类
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
toString() {
return '(' + this.x + ', ' + this.y + ')';
}
}
function A(name){ this.name=name; } A.prototype.sayName=function(){ console.log(this.name); } function B(age){ this.age=age; }原型链继承
B.prototype=new A("mbj"); //被B的实例共享 var foo=new B(18); foo.age; //18,age是本身携带的属性 foo.name; //mbj,等价于foo.__proto__.name foo.sayName(); //mbj,等价于foo.__proto__.proto__.sayName() foo.toString(); //"[object Object]",等价于foo.__proto__.__proto__.__proto__.toString();
- 所有子类共享父类实例,如果某一个子类修改了父类,其他的子类在继承的时候,会造成意想不到的后果。
- 在构造子类实例的时候,不能给父类传递参数。
构造函数继承
function B(age,name){ this.age=age; A.call(this,name); } var foo=new B(18,"wmy"); foo.name; //wmy foo.age; //18 foo.sayName(); //undefined
- 父类的prototype中的函数不能复用
原型链+构造函数继承
function B(age,name){ this.age=age;A.call(this,name); } B.prototype=new A("mbj"); var foo=new B(18,"wmy"); foo.name; //wmy foo.age; //18 foo.sayName(); //wmyextends继承
class Point { } class ColorPoint extends Point { }
var arr = [
{"name":"apple", "count": 2},
{"name":"orange", "count": 5},
{"name":"pear", "count": 3},
{"name":"orange", "count": 16},
];
var newArr = arr.filter(function(item){
return item.name === "orange";
});
console.log("Filter results:",newArr);
//统计一个数组中有多少个不重复的单词
var arr = ["apple","orange","apple","orange","pear","orange"];
function getWordCnt(){
return arr.reduce(function(prev,next){
prev[next] = (prev[next] + 1) || 1;
return prev;
},{});
}
console.log(getWordCnt());
//reduce(callback, initialValue)会传入两个变量。回调函数(callback)和初始值(initialValue)
undefined。var inventory = [
{name: 'apples', quantity: 2},
{name: 'bananas', quantity: 0},
{name: 'cherries', quantity: 5}
];
function findCherries(fruit) {
return fruit.name === 'cherries';
}
console.log(inventory.find(findCherries)); // { name: 'cherries', quantity: 5 }
window.onload = function(){
var oUl = document.getElementById("ul1");
oUl.onclick = function(ev){
var ev = ev || window.event;
var target = ev.target || ev.srcElement;
if(target.nodeName.toLowerCase() == 'li'){
alert(123);
alert(target.innerHTML);
}
}
}window.onload = function(){
var oBox = document.getElementById("box");
oBox.onclick = function (event) {
var event = event || window.event;
var target = event.target || event.srcElement;
if(target.nodeName.toLowerCase() == 'input'){
switch(target.id){
case 'add' :
alert('添加');
break;
case 'remove' :
alert('删除');
break;
case 'move' :
alert('移动');
break;
case 'select' :
alert('选择');
break;
}
}
}
}1)都是循环遍历数组中的每一项
2)forEach和map方法里每次执行匿名函数都支持3个参数,参数分别是item(当前每一项)、index(索引值)、arr(原数组)
3)匿名函数中的this都是指向window
4)只能遍历数组
区别在于map有返回值,而forEach没有返回值。
map方法返回一个新的数组
forEach()方法用于调用数组的每个元素,将元素传给回调函数。
性能上map稍落后于forEach
通过addEventListener((type, listener, useCapture)的useCapture来设定,useCapture=false代表着事件冒泡,useCapture=true代表着采用事件捕获。
事件绑定模型
<button onclick="func()">内联模型绑定</button>
同一个节点只能添加一次同类型事件,如果添加多次,最后一个生效。
通过DOM0绑定的事件,一旦绑定将无法取消。
.addEventListener("click",函数,true/false);
同一个节点,可以使用DOM2绑定多个同类型事件。
使用DOM2绑定的事件,可以有专门的函数进行取消。
事件流模型
触发一个节点的事件,会从当前节点开始,依次触发其祖先节点的同类型事件,直到DOM根节点。
所有事件绑定默认为事件冒泡
阻止冒泡:
e.stopPropagation();
触发一个节点的事件,会从DOM根节点开始,依次触发其祖先节点的同类型事件,直到当前节点自身。
使用addEventListener绑定事件,第三个参数传为true时表示事件捕获
监听父元素,看事件触发是哪个子元素
通过event.target识别具体是哪个子元素
<ul id="ul">
<li id="li-1">1</li>
<li id="li-2">2</li>
<li id="li-3">3</li>
<li id="li-4">4</li>
<li id="li-5">5</li>
</ul>
document.getElementById("ul").addEventListener("click",function(e) {
if(e.target && e.target.nodeName == "LI") {
console.log("List item ",e.target.id.replace("post-")," was clicked!");
}
})
创建新节点
createElement() //创建一个具体的元素
添加、移除、替换、插入
appendChild()
removeChild()
replaceChild()
insertBefore()
查找
getElementsByTagName()
getElementsByName()
getElementById()
getElementByClassName()
1XX信息性状态码(Informational)服务器正在处理请求
2XX成功状态码(Success)请求已正常处理完毕
200 OK 表示请求被服务器正常处理
204 No Content 表示请求已成功处理,但是没有内容返回(就应该没有内容返回的状况)
3XX重定向状态码(Redirection)需要进行额外操作以完成请求
301 Moved Permanently 永久重定向,表示请求的资源已经永久的搬到了其他位置
302 Found 临时重定向,表示请求的资源临时搬到了其他位置
303 See Other 表示请求资源存在另一个URI,应使用GET定向获取请求资源
304 Not Modified 使用缓存
4XX客户端错误状态码(Client Error)客户端原因导致服务器无法处理请求
400 Bad Request 表示请求报文存在语法错误或参数错误,服务器不理解
401 Unauthorized 表示发送的请求需要有HTTP认证信息或者是认证失败了
403 Forbidden 表示对请求资源的访问被服务器拒绝了
404 Not Found 表示服务器找不到你请求的资源
5XX服务器错误状态码(Server Error)服务器原因导致处理请求出错
500 Internal Server Error 表示服务器执行请求的时候出错了
503 Service Unavailable 表示服务器超负载或正停机维护,无法处理请求
意义
HTTP 协议有一个缺陷:通信只能由客户端发起 ,websocket可以实现服务端主动推送。
属性
(1)建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(3)数据格式比较轻量,性能开销小,通信高效。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。
用法
//客户端与服务器进行连接
var ws = new WebSocket("wss://echo.websocket.org");
//指定连接成功后的回调函数
ws.onopen = function(evt) {
console.log("Connection open ...");
ws.send("Hello WebSockets!");
};
//指定收到服务器数据后的回调函数
ws.onmessage = function(evt) {
console.log( "Received Message: " + evt.data);
ws.close();
};
//指定连接关闭后的回调函数
ws.onclose = function(evt) {
console.log("Connection closed.");
};
缺点
对前端开发者,往往要具备数据驱动使用javascript的能力,且需要维持住ws连接(否则消息无法推送);对后端开发者而言,难度增大了很多,一是长连接需要后端处理业务的代码更稳定(不要随便把进程和框架都crash掉),二是推送消息相对复杂一些,三是成熟的http生态下有大量的组件可以复用,websocket则太新了一点。
根据是否需要重新向服务器发起请求来分类,可以将其分为两大类(强制缓存,对比缓存),强制缓存如果生效,不需要再和服务器发生交互,而对比缓存不管是否生效,都需要与服务端发生交互。 两类缓存规则可以同时存在,强制缓存优先级高于对比缓存,也就是说,当执行强制缓存的规则时,如果缓存生效,直接使用缓存,不再执行对比缓存规则。
强制缓存
header中会有两个字段来标明失效规则Cache-Control,指的是当前资源的有效期
对比缓存
浏览器第一次请求数据时,服务器会将缓存标识与数据一起返回给客户端,客户端将二者备份至缓存数据库中。 再次请求数据时,客户端将备份的缓存标识发送给服务器,服务器根据缓存标识进行判断,判断成功后,返回304状态码,通知客户端比较成功,可以使用缓存数据。
在对比缓存生效时,状态码为304,并且报文大小和请求时间大大减少。
常见的请求头:
Accept: text/html,image/* #浏览器可以接收的类型
Accept-Charset: ISO-8859-1 #浏览器可以接收的编码类型
Accept-Encoding: gzip,compress #浏览器可以接收压缩编码类型
Accept-Language: en-us,zh-cn #浏览器可以接收的语言和国家类型
Host: www.lks.cn:80 #浏览器请求的主机和端口
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT #某个页面缓存时间
Referer: http://www.lks.cn/index.html #请求来自于哪个页面
User-Agent: Mozilla/4.0 compatible; MSIE 5.5; Windows NT 5.0 #浏览器相关信息
Cookie: #浏览器暂存服务器发送的信息
Connection: close1.0/Keep-Alive1.1 #HTTP请求的版本的特点
Date: Tue, 11 Jul 2000 18:23:51GMT #请求网站的时间
Allow:GET #请求的方法 GET 常见的还有POST
Keep-Alive:5 #连接的时间;5
Connection:keep-alive #是否是长连接
Cache-Control:max-age=300 #缓存的最长时间 300s
| 特性 | Cookie | Localstorage | sessionstorage |
|---|---|---|---|
| 生命周期 | 一般由服务器生成,可设置失效时间。如果在浏览器端生成Cookie,默认是关闭浏览器后失效。 | 除非被清除,否则永久保存 | 仅在当前会话下有效,关闭页面或浏览器后被清除 |
| 数据大小 | 4k | 5MB | |
| 与服务器端通信 | 每次都会携带在HTTP头中,如果使用cookie保存过多数据会带来性能问题 | 仅在客户端(即浏览器)中保存,不参与和服务器的通信 | |
| 用途 | 用于标识用户身份 | 用于浏览器端缓存数据 | |
| 易用性 | cookie需要自己封装setCookie,getCookie | 可以用源生接口,也可再次封装来对Object和Array有更好的支持 |
cookie
session
localstorage和cookie区别
浏览器端如何生成cookie?
document.cookie = "name=Jonh; ";
文件+文字同时上传
$("#upload-newtab-button").click(function(){
if(($("#uploadname").val())&&($("#uploadsinger").val())&&($("#uploadfile").val())){
var data = new FormData();
var fileobj = document.getElementById('uploadfile').files[0];
data.append("name",$("#uploadname").val());
data.append("singer",$("#uploadsinger").val());
data.append("file",fileobj);
$.ajax({
url: 'php/upload.php',
type: 'POST',
data: data,
dataType: 'text',
cache: false,
processData: false,
contentType: false,
success: function(feedbackdata){
$("#uploadresulutinfo").html(feedbackdata);
}
})
}else{
$("#uploadresulutinfo").html('请填写完整信息并上传指定格式的乐谱')
}
});
GET用来读数据,POST用来写数据
GET的参数有长度限制,一般是1024个字符,POST的参数没有长度限制,一般是4-10Mb
包:GET请求只需发一个包,POST请求需要发两个以上包(因为POST有消息体)
GET的参数放在URL的查询参数里,POST的参数放在请求消息体(数据)里
意义
同源策略主要用来防止CSRF攻击
属性
如果非同源,共有三种行为受到限制。
(1) Cookie、LocalStorage 和 IndexDB 无法读取。
(2) DOM 无法获得。
(3) AJAX 请求不能发送。
- js里发送ajax请求,如果请求的URL和当前的URL非同域,浏览器拒接提供接受的收据并报错。
- 解决办法:JSONP、CORS、代理服务器、POSTMESSAGE(主用于:页面和其打开的新窗口的数据传递)
- 相比JSONP只能发
GET请求,CORS允许任何类型的请求。代理服务器
例如www.123.com/index.html需要调用www.456.com/server.php,可以写一个接口www.123.com/server.php,由这个接口在后端去调用www.456.com/server.php并拿到返回值,然后再返回给index.html,这就是一个代理的模式。相当于绕过了浏览器端,自然就不存在跨域问题。
JSONP
实现
它的基本**是,网页通过添加一个
<script>元素,向服务器请求JSON数据,这种做法不受同源政策限制;服务器收到请求后,将数据放在一个指定名字的回调函数里传回来。function addScriptTag(src) { var script = document.createElement('script'); script.setAttribute("type","text/javascript"); script.src = src; document.body.appendChild(script); } window.onload = function () { addScriptTag('http://example.com/ip?callback=foo'); } function foo(data) { console.log('Your public IP address is: ' + data.ip); }; //服务器返回 foo({ "ip": "8.8.8.8" });缺点
JSONP只能发GET请求
CORS
意义
允许浏览器向跨源服务器,发出
XMLHttpRequest请求,从而克服了AJAX只能同源使用的限制性质
- 浏览器将CORS请求分成两类:简单请求(simple request)和非简单请求(not-so-simple request)。
- 简单请求请求方法是以下三种方法之一:HEAD/GET/POST
- 整个CORS通信过程,都是浏览器自动完成,不需要用户参与。对于开发者来说,CORS通信与同源的AJAX通信没有差别,代码完全一样。浏览器一旦发现AJAX请求跨源,就会自动添加一些附加的头信息。
使用
在头信息之中,增加一个
Origin字段 ,用来说明本次请求来自哪个源(协议 + 域名 + 端口)。服务器根据这个值,决定是否同意这次请求 .如果
Origin指定的源,不在许可范围内,服务器会返回一个正常的HTTP回应。浏览器发现,这个回应的头信息没有包含Access-Control-Allow-Origin字段(详见下文),就知道出错了,从而抛出一个错误,被XMLHttpRequest的onerror回调函数捕获。注意,这种错误无法通过状态码识别,因为HTTP回应的状态码有可能是200。如果
Origin指定的域名在许可范围内,服务器返回的响应,会多出几个头信息字段。//该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求 Access-Control-Allow-Origin: http://api.bob.com //该字段可选。表示是否允许发送Cookie。 Access-Control-Allow-Credentials: true Access-Control-Expose-Headers: FooBar Content-Type: text/html; charset=utf-8如果指定要发cookie,另一方面,开发者必须在AJAX请求中打开
withCredentials属性。 否则,即使服务器同意发送Cookie,浏览器也不会发送。var xhr = new XMLHttpRequest(); xhr.withCredentials = true;缺点
- 需要控制好允许访问的域名
- 浏览器兼容性稍弱
DNS查询
a. 浏览器缓存,浏览器会缓存DNS记录一段时间。
b.在hosts静态文件、DNS解析器缓存中查找某主机的ip地址
c.将前面的查询请求发给路由器,它一般会有自己的DNS缓存。
d. 每一个ISP(网络服务提供商)会有一个自己的本地域名服务器,他会在url第一次访问时缓存该域名的指向。下次再访问时,他会从缓存里把这个url曾经指向的IP调出来。
e.ISP的DNS服务器会从根域名开始进行递归查询
建立TCP连接,三次握手
发送HTTP请求
后台处理请求
发送HTTP相应
关闭TCP连接,四次挥手
解析HTML
下载CSS、并解析
下载JS、并解析
下载并解析图片
渲染DOM
渲染样式树
执行JS
Vue共有8个生命周期钩子函数,分别为:
父组件向子组件通信
使用props,父组件可以使用props向子组件传递数据。
//父组件
<template>
<child :msg="message"></child>
</template>
<script>
import child from './child.vue';
export default {
components: {
child
},
data () {
return {
message: 'father message';
}
}
}
</script>
//子组件
<template>
<div>{{msg}}</div>
</template>
<script>
export default {
props: {
msg: {
type: String,
required: true
}
}
}
</script>
子组件向父组件通信
使用vue事件,父组件向子组件传递事件方法,子组件通过$emit触发事件,回调给父组件。
//父组件
<template>
<child @msgFunc="func"></child>
</template>
<script>
import child from './child.vue';
export default {
components: {
child
},
methods: {
func (msg) {
console.log(msg);
}
}
}
</script>
//子组件
<template>
<button @click="handleClick">点我</button>
</template>
<script>
export default {
props: {
msg: {
type: String,
required: true
}
},
methods () {
handleClick () {
//........
this.$emit('msgFunc');
}
}
}
</script>
非父子组件、兄弟组件之间的数据传递
非父子组件通信,Vue官方推荐使用一个Vue实例作为**事件总线。 $on方法用来监听一个事件。
$emit用来触发一个事件。
/*新建一个Vue实例作为**事件总嫌*/
let event = new Vue();
/*监听事件*/
event.$on('eventName', (val) => {
//......do something
});
/*触发事件*/
event.$emit('eventName', 'this is a message.');
├── build --------------------------------- webpack相关配置文件
│ ├── build.js --------------------------webpack打包配置文件
│ ├── check-versions.js ------------------------------ 检查npm,nodejs版本
│ ├── dev-client.js ---------------------------------- 设置环境
│ ├── dev-server.js ---------------------------------- 创建express服务器,配置中间件,启动可热重载的服务器,用于开发项目
│ ├── utils.js --------------------------------------- 配置资源路径,配置css加载器
│ ├── vue-loader.conf.js ----------------------------- 配置css加载器等
│ ├── webpack.base.conf.js --------------------------- webpack基本配置
│ ├── webpack.dev.conf.js ---------------------------- 用于开发的webpack设置
│ ├── webpack.prod.conf.js --------------------------- 用于打包的webpack设置
├── config ---------------------------------- 配置文件
├── node_modules ---------------------------- 存放依赖的目录
├── src ------------------------------------- 源码
│ ├── assets ------------------------------ 静态文件
│ ├── components -------------------------- 组件
│ ├── main.js ----------------------------- 主js
│ ├── App.vue ----------------------------- 项目入口组件
│ ├── router ------------------------------ 路由
├── package.json ---------------------------- node配置文件
├── .babelrc--------------------------------- babel配置文件
├── .editorconfig---------------------------- 编辑器配置
├── .gitignore------------------------------- 配置git可忽略的文件
1)采用ES6的import ... from ...语法或CommonJS的require()方法引入组件
2)对组件进行注册,代码如下
// 注册
Vue.component('my-component', {
template: '<div>A custom component!</div>'
})
3)使用组件<my-component></my-component>
cpmputed/method
<p>Reversed message: "{{ reversedMessage() }}"</p>
// 在组件中
methods: {
reversedMessage: function () {
return this.message.split('').reverse().join('')
}
}
message 还没有发生改变,多次访问 reversedMessage 计算属性会立即返回之前的计算结果,而不必再次执行函数。watch
watch是监控一个对象,当变化时执行操作
<div id="watch-example">
<p>
Ask a yes/no question:
<input v-model="question">
</p>
<p>{{ answer }}</p>
</div>
var watchExampleVM = new Vue({
el: '#watch-example',
data: {
question: '',
answer: 'answer'
},
watch: {
// 如果 `question` 发生改变,这个函数就会运行
question: function (newQuestion, oldQuestion) {
this.answer = 'Waiting for you to stop typing...'
this.debouncedGetAnswer()
}
}
}
v-show 的元素始终会被渲染并保留在 DOM 中。v-show 只是简单地切换元素的 CSS 属性 display。v-if 是“真正”的条件渲染
v-if也是惰性的:如果在初始渲染时条件为假,则什么也不做——直到条件第一次变为真时,才会开始渲染条件块。相比之下,
v-show就简单得多——不管初始条件是什么,元素总是会被渲染,并且只是简单地基于 CSS 进行切换。一般来说,
v-if有更高的切换开销,而v-show有更高的初始渲染开销。因此,如果需要非常频繁地切换,则使用v-show较好;如果在运行时条件很少改变,则使用v-if较好。
Vue.js 为 v-on 提供了事件修饰符
<!-- 阻止单击事件继续传播 -->
<a v-on:click.stop="doThis"></a>
<!-- 提交事件不再重载页面 -->
<form v-on:submit.prevent="onSubmit"></form>
<!-- 修饰符可以串联 -->
<a v-on:click.stop.prevent="doThat"></a>
<!-- 只有修饰符 -->
<form v-on:submit.prevent></form>
<!-- 添加事件监听器时使用事件捕获模式 -->
<!-- 即元素自身触发的事件先在此处处理,然后才交由内部元素进行处理 -->
<div v-on:click.capture="doThis">...</div>
<!-- 只当在 event.target 是当前元素自身时触发处理函数 -->
<!-- 即事件不是从内部元素触发的 -->
<div v-on:click.self="doThat">...</div>
组件实例能够被在它们第一次被创建的时候缓存下来。为了解决这个问题,我们可以用一个 <keep-alive> 元素将其动态组件包裹起来。
<!-- 失活的组件将会被缓存!-->
<keep-alive>
<component></component>
</keep-alive>
<keep-alive>
<router-view></router-view>
</keep-alive>
一个“路径参数”使用冒号 : 标记。当匹配到一个路由时,参数值会被设置到 this.$route.params,可以在每个组件内使用
//HTML
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<script src="https://unpkg.com/vue-router/dist/vue-router.js"></script>
<div id="app">
<p>
<router-link to="/user/foo">/user/foo</router-link>
<router-link to="/user/bar">/user/bar</router-link>
</p>
<router-view></router-view>
</div>
//JS
const User = {
template: `<div>User {{ $route.params.id }}</div>`
}
const router = new VueRouter({
routes: [
{ path: '/user/:id', component: User }
]
})
const app = new Vue({ router }).$mount('#app')
//HTML
<script src="https://unpkg.com/vue/dist/vue.js"></script>
<script src="https://unpkg.com/vue-router/dist/vue-router.js"></script>
<div id="app">
<p>
<router-link to="/user/foo">/user/foo</router-link>
<router-link to="/user/foo/profile">/user/foo/profile</router-link>
<router-link to="/user/foo/posts">/user/foo/posts</router-link>
</p>
<router-view></router-view>
</div>
//JS
const User = {
template: `
<div class="user">
<h2>User {{ $route.params.id }}</h2>
<router-view></router-view>
</div>
`
}
const UserHome = { template: '<div>Home</div>' }
const UserProfile = { template: '<div>Profile</div>' }
const UserPosts = { template: '<div>Posts</div>' }
const router = new VueRouter({
routes: [
{ path: '/user/:id', component: User,
children: [
{ path: '', component: UserHome },
{ path: 'profile', component: UserProfile },
{ path: 'posts', component: UserPosts }
]
}
]
})
const app = new Vue({ router }).$mount('#app')
点击不同的li进行不同跳转并传参
<li v-for="article in articles" @click="getDescribe(article.id)">
方法一 通过动态路由的:值传参
getDescribe(id) {
// 直接调用$router.push 实现携带参数的跳转
this.$router.push({
path: `/describe/${id}`,
})
}
//路由配置
{
path: '/describe/:id',
name: 'Describe',
component: Describe
}
//取参数
$route.params.id
方法二 通过name确定路由,通过params来传递参数
this.$router.push({
name: 'Describe',
params: {
id: id
}
})
//路由配置
{
path: '/describe',
name: 'Describe',
component: Describe
}
//取参数
$route.params.id
方法三 使用query
this.$router.push({
path: '/describe',
query: {
id: id
}
})
//路由配置
{
path: '/describe',
name: 'Describe',
component: Describe
}
//取参数
$route.query.id
// 对象
router.push({ path: 'home' })
// 命名的路由
router.push({ name: 'user', params: { userId: 123 }})
// 带查询参数,变成 /register?plan=private
router.push({ path: 'register', query: { plan: 'private' }})
全局路由钩子:
router.beforeEach((to, from, next) => {
//会在任意路由跳转前执行,next一定要记着执行,不然路由不能跳转了
console.log('beforeEach')
console.log(to,from)
//
next()
})
//
router.afterEach((to, from) => {
//会在任意路由跳转后执行
console.log('afterEach')
})
单个路由钩子:
只有beforeEnter,在进入前执行,to参数就是当前路由
routes: [
{
path: '/foo',
component: Foo,
beforeEnter: (to, from, next) => {
// ...
}
}
]
路由组件钩子:
beforeRouteEnter (to, from, next) {
// 在渲染该组件的对应路由被 confirm 前调用
// 不!能!获取组件实例 `this`
// 因为当守卫执行前,组件实例还没被创建
},
beforeRouteUpdate (to, from, next) {
// 在当前路由改变,但是该组件被复用时调用
// 举例来说,对于一个带有动态参数的路径 /foo/:id,在 /foo/1 和 /foo/2 之间跳转的时候,
// 由于会渲染同样的 Foo 组件,因此组件实例会被复用。而这个钩子就会在这个情况下被调用。
// 可以访问组件实例 `this`
},
beforeRouteLeave (to, from, next) {
// 导航离开该组件的对应路由时调用
// 可以访问组件实例 `this`
}
从 store 实例中读取状态最简单的方法就是在计算属性中返回某个状态
//每当 store.state.count 变化的时候, 都会重新求取计算属性,并且触发更新相关联的 DOM。
const Counter = {
template: `<div>{{ count }}</div>`,
computed: {
count () {
return store.state.count
}
}
}
Vuex 允许我们在 store 中定义“getter”(可以认为是 store 的计算属性)。就像计算属性一样,getter 的返回值会根据它的依赖被缓存起来,且只有当它的依赖值发生了改变才会被重新计算。
const store = new Vuex.Store({
state: {
todos: [
{ id: 1, text: '...', done: true },
{ id: 2, text: '...', done: false }
]
},
getters: {
doneTodos: state => {
return state.todos.filter(todo => todo.done)
}
}
})
更改 Vuex 的 store 中的状态的唯一方法是提交 mutation
Mutation 必须是同步函数
const store = new Vuex.Store({
state: {
count: 1
},
mutations: {
increment (state) {
// 变更状态
state.count++
}
}
})
//通过commit来调用mutation中的方法
store.commit('increment')
const store = new Vuex.Store({
state: {
count: 0
},
mutations: {
increment (state) {
state.count++
}
},
actions: {
increment (context) {
context.commit('increment')
}
}
})
//Action 通过 store.dispatch 方法触发:
store.dispatch('increment')
Vuex 允许我们将 store 分割成模块(module)。每个模块拥有自己的 state、mutation、action、getter
vue.js 则是采用数据劫持结合发布者-订阅者模式的方式,通过Object.defineProperty()来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
要实现mvvm的双向绑定,就必须要实现以下几点:
那么将需要observe的数据对象进行递归遍历
给这个对象的某个值赋值,就会触发setter ,利用Obeject.defineProperty()来监听属性变动
建立订阅者集合的数组,在setter中写入方法遍历并执行通知方法给所有的订阅者
1、在自身实例化时往属性订阅器(dep)里面添加自己
2、自身必须有一个update()方法
3、待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
var examplearr=[8,94,15,88,55,76,21,39];
function sortarr(arr){
for(i=0;i<arr.length-1;i++){
for(j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
var temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
return arr;
}
sortarr(examplearr); function quickSort(arr){
//如果数组<=1,则直接返回
if(arr.length<=1){return arr;}
var pivotIndex=Math.floor(arr.length/2);
//找基准,并把基准从原数组删除
var pivot=arr.splice(pivotIndex,1)[0];
//定义左右数组
var left=[];
var right=[];
//比基准小的放在left,比基准大的放在right
for(var i=0;i<arr.length;i++){
if(arr[i]<=pivot){
left.push(arr[i]);
}
else{
right.push(arr[i]);
}
}
//递归
return quickSort(left).concat([pivot],quickSort(right));
} 返回-1或存在的数组下标。
//二分查找,递归实现。
function binarySearch(target,arr) {
var start= 0;
var end=arr.length-1;
var mid = parseInt(start+(end-start)/2);
if(target==arr[mid]){
return mid;
}else if(target>arr[mid]){
return binarySearch(target,arr,mid+1,end);
}else{
return binarySearch(target,arr,start,mid-1);
}
return -1;
}//不使用递归实现
function binarySearch(target,arr) {
var start = 0;
var end = arr.length-1;
while (start<=end){
var mid = parseInt(start+(end-start)/2);
if(target==arr[mid]){
return mid;
}else if(target>arr[mid]){
start= mid+1;
}else{
end= mid-1;
}
}
return -1;
}var arr = ['abc','abcd','sss','2','d','t','2','ss','f','22','d'];
var s = [];
for(var i = 0;i<arr.length;i++){
if(s.indexOf(arr[i]) == -1){ //判断在s数组中是否存在,不存在则push到s数组中
s.push(arr[i]);
}
}
console.log(s);var arr = [1,2,2,3,4] // 需要去重的数组
var set = new Set(arr) // {1,2,3,4}
var newArr = Array.from(set) // 再把set转变成array
console.log(newArr) // [1,2,3,4]function format(num){
num=num+'';//数字转字符串
var str="";//字符串累加
for(var i=num.length- 1,j=1;i>=0;i--,j++){
if(j%3==0 && i!=0){//每隔三位加逗号,过滤正好在第一个数字的情况
str+=num[i]+",";//加千分位逗号
continue;
}
str+=num[i];//倒着累加数字
}
return str.split('').reverse().join("");//字符串=>数组=>反转=>字符串
} const arr="abcdaabc";
let counter = {};
for (let i = 0, len = arr.length; i < len; i++ ) {
counter[arr[i]] ? counter[arr[i]]++ : counter[arr[i]] = 1;
}
console.log(counter);function getMaxPro(arr){
var minPrice=arr[0];
var maxProfit=0;
for (var i=0;i<arr.length;i++){
var currentPrice=arr[i];
minPrice=Math.min(minPrice,currentPrice);
var potentialProfit =currenrPrice-minPrice;
maxProfit=Math.max(maxProfit,potentialProfit);
}
return maxProfit;
}function random(n){
let str='abcdefghijkmnopqrstuvwxyz9876543210';
let tmp='',
i=0,
l=str.length;
for(i=0;i<n;i++){
tmp +=str.charAt(Math.floor(Math.random()*l))
}
return tmp;
}function reverseString(str){
var tmp = '';
for(var i=str.length-1; i>=0; i--)
tmp += str[i];
return tmp
}function reverseString(str){
var arr = str.split("");
var i = 0,j = arr.length-1;
while(i<j){
tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
i++;
j--;
}
return arr.join("");
}//非递归
function factorialize(num) {
var result = 1;
if(num < 0) return -1;
if(num == 0 || num == 1) return 1;
while(num>1) {
result *= num--;
}
return result;
}//递归
function factorialize(num) {
var result = 1;
if(num < 0) return -1;
if(num == 0 || num == 1) return 1;
if(num > 1) return num*factorialize(num-1);
}function findMaxDuplicateChar(str) {
if(str.length == 1) {
return str;
}
var charObj = {};
for(var i = 0; i < str.length; i++) {
if(!charObj[str.charAt(i)]) {
charObj[str.charAt(i)] = 1;
} else {
charObj[str.charAt(i)] += 1;
}
}
var maxChar = '',
maxValue = 1;
for(var k in charObj) {
if(charObj[k] >= maxValue) {
maxChar = k;
maxValue = charObj[k];
}
}
return maxChar + ':' + maxValue;
}function findLongestWord(str) {
//转化成数组
var astr=str.split( " " );
//对数组中每个元素的字符串长度进行比较,按照字符串长度由大至小排列数组顺序。
var bstr=astr.sort(function(a,b){
return b.length-a.length;
});
//取出数组中第一个元素(也就是最大长度的字符串)
var lenMax= bstr[0].length;
//返回长度值
return lenMax;
}
findLongestWord("The quick brown foxjumped over the lazy dog");
//结果:6function titleCase(str) {
var astr=str.toLowerCase().split(" ");
for(var i=0 ; i<astr.length; i++){
astr[i]=astr[i][0].toUpperCase()+astr[i].substring(1,astr[i].length);
}
var string=astr.join(" ");
return string;
}
titleCase("I'm a little teapot");
//结果:I'm A LittleTea Potvar a = 10;
var b = 12;
function swap (a,b) {
b = b - a;
a = a + b;
b = a - b;
return [a,b]
}
console.log(swap(a,b)); 发生了不在预期内执行的JS代码 ,达到获取本地的部分cookie信息等目的 。例如:网站form表单收集数据的时候,有的用户非法/恶意的把”html/css/js”代码内容给植入到form表单域中
- 攻击者对含有漏洞的服务器发起XSS攻击(注入JS代码)。
- 诱使受害者打开受到攻击的服务器URL。
- 受害者在Web浏览器中打开URL,恶意脚本执行。
XSS的分类
存储型XSS、反射型XSS、DOM-XSS
1、存储型XSS
数据库中存有的存在XSS攻击的数据,返回给客户端。若数据未经过任何转义。被浏览器渲染。就可能导致XSS攻击;
2、反射型XSS
将用户输入的存在XSS攻击的数据,发送给后台,后台并未对数据进行存储,也未经过任何过滤,直接返回给客户端。被浏览器渲染。就可能导致XSS攻击;
3、DOM-XSS
纯粹发生在客户端的XSS攻击
预防:从输入到输出都需要过滤、转义。
输入
- 在产品形态上,针对不同输入类型,对输入做变量类型限制。 如,
http://xss.qq.com?default=12,Default值强制限制为整形。- 字符串类型的数据,需要针对<、>、/、’、”、&五个字符进行实体化转义。
function(a){ return a.replace(/&/g, "&").replace(/</g, "<").replace(/>/g, ">").replace(/"/g, """).replace(/'/g, "'"); }输出
即使在客户端对用户的输入做了过滤、转义,攻击者一样可能,通过截包,转发等手段,修改你的请求包体。最终还是要在数据输出的时候做数据转义。
- 如果是字符串操作,保证字符串被引号包裹。
- 输出到页面上的数据必须使用相应方法转义,前端可以考虑寻找js插件处理。目前jquery-encoder,可用于前端json转义。使用方式与ESAPI类似,在需要渲染的时候进行转义。
过程
用户打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A;
在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;
用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B;
网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A;
浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户的Cookie信息以的权限处理该请求,导致来自网站B的恶意代码被执行。
避免:
验证 HTTP Referer 字段 : 在 HTTP 头中有一个字段叫 Referer,它记录了该 HTTP 请求的来源地址。在通常情况下,访问一个安全受限页面的请求来自于同一个网站。
CSRF Tokens
最终的解决办法是使用CSRF tokens。在请求地址中添加 token 并验证 ,CSRF tokens是如何工作的呢?
在后端生成表单的时候生成一串随机 token ,内置到表单里成为一个字段,同时,将此串 token 置入 session 中。每次表单提交到后端时都会检查这两个值是否一致,以此来判断此次表单提交是否是可信的。
攻击者需要通过某种手段获取你站点的CSRF token, 他们只能使用JavaScript来做。 所以,如果你的站点不支持CORS, 那么他们就没有办法来获取CSRF token, 降低了威胁。
确保CSRF token不能通过AJAX访问到! 不要创建一个/CSRF路由来获取一个token, 尤其不要在这个路由上支持CORS!
答案:
1)Loaders是用来告诉webpack如何转化处理某一类型的文件,并且引入到打包出的文件中
2)Plugin是用来自定义webpack打包过程的方式,一个插件是含有apply方法的一个对象,通过这个方法可以参与到整个webpack打包的各个流程(生命周期)。
html-webpack-plugin
extract-text-webpack-plugin
前段时间在做图片的WebP格式升级,WebP格式的图片在网络传输时可以节省流量,但是浏览器的兼容性并不好,这里收集整理了一些WebP图片兼容性处理的方案。
<picture>
<source srcset="img/pic.webp" type="image/webp">
<source srcset="img/pic.jpg" type="image/jpeg">
<img src="img/pic.jpg">
</picture>
该种方法要求在每个要请求webp图片的标签下都要通过picture标签来进行兼容性处理,
同时注意该标签在IE的兼容性并不是很好,不过已经比webp的兼容性好一些。
通过HTTP request header中是否存在Accept: image/webp来判断,
这种方法的缺点在于:很多时候我们的图片等静态资源都会放到CDN服务器上,在这个层面加上判断webp的逻辑会更麻烦一些
if(document.createElement('canvas').toDataURL('image/webp').indexOf('data:image/webp') == 0){
// 该浏览器支持WebP格式的图片
}
该种方法的原理为:
HTMLCanvasElement.toDataURL() 方法返回一个包含图片展示的 data URI 。可以使用 type 参数其类型,默认为 PNG 格式。
1.如果画布的高度或宽度是0,那么会返回字符串“data:,”。2.如果传入的类型非“image/png”,但是返回的值以“data:image/png”开头,那么该传入的类型是不支持的。3.Chrome支持“image/webp”类型。
stackoverflow上还有一种浏览器端检测是否支持webp的方法,这里也贴上:
var hasWebP = (function() {
var images = {
basic: "data:image/webp;base64,UklGRjIAAABXRUJQVlA4ICYAAACyAgCdASoCAAEALmk0mk0iIiIiIgBoSygABc6zbAAA/v56QAAAAA==",
lossless: "data:image/webp;base64,UklGRh4AAABXRUJQVlA4TBEAAAAvAQAAAAfQ//73v/+BiOh/AAA="
};
return function(feature) {
var deferred = $.Deferred();
$("<img>").on("load", function() {
if(this.width === 2 && this.height === 1) {
deferred.resolve();
} else {
deferred.reject();
}
}).on("error", function() {
deferred.reject();
}).attr("src", images[feature || "basic"]);
return deferred.promise();
}
})();
var add = function(msg) {
$("<p>").text(msg).appendTo("#x");
};
hasWebP().then(function() {
add("Basic WebP available");
}, function() {
add("Basic WebP *not* available");
});
hasWebP("lossless").then(function() {
add("Lossless WebP available");
}, function() {
add("Lossless WebP *not* available");
});
正常在需要做页面后退操作时,可以通过调用history对象的go方法和back方法来控制页面后退,
window.history.go(-1);
window.history.back();但是在部分移动端浏览器及webview中,页面实现了后退但是并没有刷新,而是使用了缓存。
这里总结了几种强制回退页面后刷新上一页的方法。
A页面打开B页面时,在B页面中document.referrer为A页面,通过主动跳转至document.referrer可以实现刷新上一页,但是副作用为会额外生成历史记录,导致再次点击后退时又回到当前页面。
window.location.href = document.referrer
A页面打开B页面时,在A页面监听pageshow事件,当由B页面退回至A页面时会触发pageshow事件。
window.addEventListener('pageshow', function(e) {
if (e.persisted) {
window.location.reload();
}
});
A页面打开B页面时,先替换当前历史记录点,然后再打开B页面。
var json={time:newDate().getTime()};
window.history.replaceState(json,"",window.location.href+"&t="+newDate().getTime());
window.location.href= url;
如果是在自家公司的APP中,可以通过与APP约定一个字段拼接在URL中,当APP检测到该字段时强制在APP层面触发刷新页面。
在Elasticsearch中存储数据的行为就叫做索引(indexing)
MySQL -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}| 名字 | 说明 |
|---|---|
| megacorp | 索引名(indces) |
| employee | 类型名(types) |
| 1 | 这个员工的ID(Documents) |
GET /megacorp/employee/1
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}GET /megacorp/employee/_search使用关键字_search来取代原来的文档ID, 默认情况下搜索会返回前10个结果
{
"took": 6,
"timed_out": false,
"_shards": { ... },
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "megacorp",
"_type": "employee",
"_id": "3",
"_score": 1,
"_source": {
"first_name": "Douglas",
"last_name": "Fir",
"age": 35,
"about": "I like to build cabinets",
"interests": [ "forestry" ]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_score": 1,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
},
{
"_index": "megacorp",
"_type": "employee",
"_id": "2",
"_score": 1,
"_source": {
"first_name": "Jane",
"last_name": "Smith",
"age": 32,
"about": "I like to collect rock albums",
"interests": [ "music" ]
}
}
]
}
}GET /megacorp/employee/_search?q=last_name:Smith到所有姓氏为Smith的结果
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}GET /megacorp/employee/_search
{
"query" : {
"filtered" : {
"filter" : {
"range" : {
"age" : { "gt" : 30 } <1>
}
},
"query" : {
"match" : {
"last_name" : "smith" <2>
}
}
}
}
}想要确切的匹配若干个单词或者短语(phrases)
例如我们想要查询同时包含"rock"和"climbing"(并且是相邻的)的员工记录。
要做到这个,我们只要将match查询变更为match_phrase查询即可:
高亮
GET /megacorp/employee/_search
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}{
...
"hits": {
"total": 1,
"max_score": 0.23013961,
"hits": [
{
...
"_score": 0.23013961,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [ "sports", "music" ]
},
"highlight": {
"about": [
"I love to go <em>rock</em> <em>climbing</em>" <1>
]
}
}
]
}
}想知道所有姓"Smith"的人最大的共同点(兴趣爱好)
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name": "smith"
}
},
"aggs": {
"all_interests": {
"terms": {
"field": "interests"
}
}
}
}...
"all_interests": {
"buckets": [
{
"key": "music",
"doc_count": 2
},
{
"key": "sports",
"doc_count": 1
}
]
}GET /megacorp/employee/_search
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。在接下来的《深入分片》一章,我们将详细说明分片的工作原理,但是现在我们只要知道分片就是一个Lucene实例,并且它本身就是一个完整的搜索引擎。我们的文档存
三个**复制分片(replica shards)**也已经被分配了——分别对应三个主分片,这意味着在丢失任意一个节点的情况下依旧可以保证数据的完整性。
文档的索引将首先被存储在主分片中,然后并发复制到对应的复制节点上。这可以确保我们的数据在主节点和复制节点上都可以被检索。
只要第二个节点与第一个节点有相同的cluster.name(请看./config/elasticsearch.yml文件),它就能自动发现并加入第一个节点所在的集群
_index |
文档存储的地方 |
|---|---|
_type |
文档代表的对象的类 |
_id |
文档的唯一标识 |
GET /website/blog/123?_source=title,text
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 1,
"exists" : true,
"_source" : {
"title": "My first blog entry" ,
"text": "Just trying this out..."
}
}HEAD方法来代替GET。HEAD请求不会返回响应体,只有HTTP头:index API 重建索引(reindex) 或者替换掉它。PUT /website/blog/123
{
"title": "My first blog entry",
"text": "I am starting to get the hang of this...",
"date": "2014/01/02"
}在响应中,我们可以看到Elasticsearch把_version增加了。
{
"_index" : "website",
"_type" : "blog",
"_id" : "123",
"_version" : 2,
"created": false <1>
}POST /website/blog/1/_update
{
"doc" : {
"tags" : [ "testing" ],
"views": 0
}
}POST /website/blog/1/_update
{
"script" : "ctx._source.tags+=new_tag",
"params" : {
"new_tag" : "search"
}
}第一种方法使用op_type查询参数:
PUT /website/blog/123?op_type=create
{ ... }或者第二种方法是在URL后加/_create做为端点:
PUT /website/blog/123/_create
{ ... }如果请求成功的创建了一个新文档,Elasticsearch将返回正常的元数据且响应状态码是201 Created。
另一方面,如果包含相同的_index、_type和_id的文档已经存在,Elasticsearch将返回409 Conflict响应状态码,错误信息类似如下:
{
"error" : "DocumentAlreadyExistsException[[website][4] [blog][123]:
document already exists]",
"status" : 409
}DELETE /website/blog/123
假设冲突不经常发生,也不区块化访问,然而,如果在读写过程中数据发生了变化,更新操作将失败。这时候由程序决定在失败后如何解决冲突。
上文我们提到index、get、delete请求时,我们指出每个文档都有一个_version号码,这个号码在文档被改变时加一。Elasticsearch使用这个_version保证所有修改都被正确排序。当一个旧版本出现在新版本之后,它会被简单的忽略。
version号码为10PUT /website/blog/2?version=10&version_type=external
{
"title": "My first external blog entry",
"text": "This is a piece of cake..."
}search API有两种表单:一种是“简易版”的查询字符串(query string)将所有参数通过查询字符串定义,另一种版本使用JSON完整的表示请求体(request body)
/_search
在所有索引的所有类型中搜索
/gb/_search
在索引gb的所有类型中搜索
/gb,us/_search
在索引gb和us的所有类型中搜索
/g*,u*/_search
在以g或u开头的索引的所有类型中搜索
/gb/user/_search
在索引gb的类型user中搜索
/gb,us/user,tweet/_search
在索引gb和us的类型为user和tweet中搜索
/_all/user,tweet/_search
在所有索引的user和tweet中搜索 search types user and tweet in all indices
Elasticsearch接受from和size参数:
size`: 结果数,默认`10
from`: 跳过开始的结果数,默认`0
GET /_search?size=5&from=10
Elasticsearch使用一种叫做**倒排索引(inverted index)**的结构来做快速的全文搜索
Elasticsearch支持以下简单字段类型:
| 类型 | 表示的数据类型 |
|---|---|
| String | string |
| Whole number | byte, short, integer, long |
| Floating point | float, double |
| Boolean | boolean |
| Date | date |
| JSON type | Field type |
|---|---|
Boolean: true or false |
"boolean" |
Whole number: 123 |
"long" |
Floating point: 123.45 |
"double" |
String, valid date: "2014-09-15" |
"date" |
String: "foo bar" |
"string" |
可以使用_mapping后缀来查看Elasticsearch中的映射
GET /gb/_mapping/tweet
{
"gb": {
"mappings": {
"tweet": {
"properties": {
"date": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"name": {
"type": "string"
},
"tweet": {
"type": "string"
},
"user_id": {
"type": "long"
}
}
}
}
}
}PUT /gb <1>
{
"mappings": {
"tweet" : {
"properties" : {
"tweet" : {
"type" : "string",
//指定为english分析器
"analyzer": "english"
},
"date" : {
"type" : "date"
},
"name" : {
"type" : "string"
},
"user_id" : {
"type" : "long"
}
}
}
}
}当然数组可以是空的。这等价于有零个值。事实上,Lucene没法存放null值,所以一个null值的字段被认为是空字段。
这四个字段将被识别为空字段而不被索引:
"empty_string": "",
"null_value": null,
"empty_array": [],
"array_with_null_value": [ null ]使用结构化查询,你需要传递query参数
合并多子句
查询的是邮件正文中含有“business opportunity”字样的星标邮件或收件箱中正文中含有“business opportunity”字样的非垃圾邮件
{
"bool": {
"must": { "match": { "email": "business opportunity" }},
"should": [
{ "match": { "starred": true }},
{ "bool": {
"must": { "folder": "inbox" }},
"must_not": { "spam": true }}
}}
],
"minimum_should_match": 1
}
}原则上来说,使用查询语句做全文本搜索或其他需要进行相关性评分的时候,剩下的全部用过滤语句
term主要用于精确匹配哪些值,比如数字,日期,布尔值或 not_analyzed的字符串(未经分析的文本数据类型):
{ "term": { "age": 26 }}
{ "term": { "date": "2014-09-01" }}
{ "term": { "public": true }}
{ "term": { "tag": "full_text" }}terms 过滤terms 跟 term 有点类似,但 terms 允许指定多个匹配条件。 如果某个字段指定了多个值,那么文档需要一起去做匹配:
{
"terms": {
"tag": [ "search", "full_text", "nosql" ]
}
}range 过滤range过滤允许我们按照指定范围查找一批数据:
{
"range": {
"age": {
"gte": 20,
"lt": 30
}
}
}范围操作符包含:
gt :: 大于
gte:: 大于等于
lt :: 小于
lte:: 小于等于
exists 和 missing 过滤exists 和 missing 过滤可以用于查找文档中是否包含指定字段或没有某个字段,类似于SQL语句中的IS_NULL条件
{
"exists": {
"field": "title"
}
}这两个过滤只是针对已经查出一批数据来,但是想区分出某个字段是否存在的时候使用。
bool 过滤bool 过滤可以用来合并多个过滤条件查询结果的布尔逻辑,它包含一下操作符:
must :: 多个查询条件的完全匹配,相当于 and。
must_not :: 多个查询条件的相反匹配,相当于 not。
should :: 至少有一个查询条件匹配, 相当于 or。
这些参数可以分别继承一个过滤条件或者一个过滤条件的数组:
{
"bool": {
"must": { "term": { "folder": "inbox" }},
"must_not": { "term": { "tag": "spam" }},
"should": [
{ "term": { "starred": true }},
{ "term": { "unread": true }}
]
}
}match_all 查询使用match_all 可以查询到所有文档,是没有查询条件下的默认语句。
{
"match_all": {}
}此查询常用于合并过滤条件。 比如说你需要检索所有的邮箱,所有的文档相关性都是相同的,所以得到的_score为1
match 查询match查询是一个标准查询,不管你需要全文本查询还是精确查询基本上都要用到它。
如果你使用 match 查询一个全文本字段,它会在真正查询之前用分析器先分析match一下查询字符:
{
"match": {
"tweet": "About Search"
}
}如果用match下指定了一个确切值,在遇到数字,日期,布尔值或者not_analyzed 的字符串时,它将为你搜索你给定的值:
{ "match": { "age": 26 }}
{ "match": { "date": "2014-09-01" }}
{ "match": { "public": true }}
{ "match": { "tag": "full_text" }}提示: 做精确匹配搜索时,你最好用过滤语句,因为过滤语句可以缓存数据。
不像我们在《简单搜索》中介绍的字符查询,match查询不可以用类似"+usid:2 +tweet:search"这样的语句。 它只能就指定某个确切字段某个确切的值进行搜索,而你要做的就是为它指定正确的字段名以避免语法错误。
multi_match 查询multi_match查询允许你做match查询的基础上同时搜索多个字段:
{
"multi_match": {
"query": "full text search",
"fields": [ "title", "body" ]
}
}bool 查询bool 查询与 bool 过滤相似,用于合并多个查询子句。不同的是,bool 过滤可以直接给出是否匹配成功, 而bool查询要计算每一个查询子句的 _score (相关性分值)。
must:: 查询指定文档一定要被包含。
must_not:: 查询指定文档一定不要被包含。
should:: 查询指定文档,有则可以为文档相关性加分。
以下查询将会找到 title 字段中包含 "how to make millions",并且 "tag" 字段没有被标为 spam。 如果有标识为 "starred" 或者发布日期为2014年之前,那么这些匹配的文档将比同类网站等级高:
{
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}GET /_search
{
"query": {
"filtered": {
"query": { "match": { "email": "business opportunity" }},
"filter": { "term": { "folder": "inbox" }}
}
}
}想知道语句非法的具体错误信息,需要加上 explain 参数:
GET /gb/tweet/_validate/query?explain <1>
{
"query": {
"tweet" : {
"match" : "really powerful"
}
}
}默认情况下,结果集会按照相关性进行排序 -- 相关性越高,排名越靠前
GET /_search
{
"query" : {
"filtered" : {
"filter" : { "term" : { "user_id" : 1 }}
}
},
"sort": { "date": { "order": "desc" }}
}PUT /my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "&=> and "]
}},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}}}对于准确值,你需要使用过滤器。过滤器的重要性在于它们非常的快。它们不计算相关性(避过所有计分阶段)而且很容易被缓存。
SELECT document
FROM products
WHERE price = 20
GET /my_store/products/_search
{
"query" : {
"filtered" : { <1>
"query" : {
"match_all" : {} <2>
},
"filter" : {
"term" : { <3>
"price" : 20
}
}
}
}
}match_all 用来匹配所有文档,这是默认行为
GET /my_store/products/_search
{
"query" : {
"filtered" : {
"filter" : {
"term" : {
"productID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
所有的字符都被转为了小写。 * 我们失去了连字符和 # 符号。 所以当我们用 XHDK-A-1293-#fJ3 来查找时,得不到任何结果,因为这个标记不在我们的倒排索引中。相反,那里有上面列出的四个标记。 显然,在处理唯一标识码,或其他枚举值时,这不是我们想要的结果。 为了避免这种情况发生,我们需要通过设置这个字段为 not_analyzed 来告诉 Elasticsearch 它包含一个准确值。
SELECT product
FROM products
WHERE (price = 20 OR productID = "XHDK-A-1293-#fJ3")
AND (price != 30)GET /my_store/products/_search
{
"query" : {
"filtered" : { <1>
"filter" : {
"bool" : {
"should" : [
{ "term" : {"price" : 20}}, <2>
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}} <2>
],
"must_not" : {
"term" : {"price" : 30}, <3>
// terms支持数组多项过滤
"terms" : {
"price" : [20, 30]
}
}
}
}
}
}
}日期范围
"range" : {
"timestamp" : {
"gt" : "2014-01-01 00:00:00",
"lt" : "2014-01-07 00:00:00"
}
}exists过滤器,可以返回Null值
GET /my_index/posts/_search
{
"query" : {
"filtered" : {
"filter" : {
"exists" : {
"field" : "tags"
}
}
}
}
} "hits" : [
{
"_id" : "1",
"_score" : 1.0,
"_source" : {
"tags" : ["search"]
}
},
{ "_id" : "5",
"_score" : 1.0,
"_source" : {
"tags" : ["search", null]
}
}
] git clone https://mirrors.tuna.tsinghua.edu.cn/git/CocoaPods/Specs.git首先,需要按照官方文档的步骤对app进行签名。
cd android进入安卓工程目录
./gradlew assembleRelease开始打包
这里可能会卡在:app:bundleReleaseJsAndAssets这个状态一直不动,这个时候直接control + c 放弃打包
首先我们在项目根目录下执行react-native bundle --platform android --dev false --entry-file index.android.js --bundle-output App/src/main/assets/index.android.bundle --assets-dest App/src/main/res/
注意:
处理好上面的步骤后,我们进入安卓的工程目录下,输入./gradlew assembleRelease -x bundleReleaseJsAndAssets尝试打包。
这时我们应该发现APP已经打包成功了,但是安装在手机上后发现代码没有更新,这是因为每次打包前都需要生成一个新的index.android.bundle文件,这时我们需要进入安卓工程目录,进到/src/main/assets下删除旧的index.android.bundle文件,在重复执行react-native bundle --platform android --dev false --entry-file index.android.js --bundle-output App/src/main/assets/index.android.bundle --assets-dest App/src/main/res/这个步骤,再尝试打包即可

厌倦了每次来一个活动写一次活动页,想要以自动化方式自动生成活动页?
趁着公司需求实现了一个活动页的自动构建平台,因为还在编写代码中,这里就讲一下核心的思路:在Vue框架下,通过引入组件库的形式,自动化识别可使用的组件,并以拖拽加输入属性的形式形成一个完整的VNode结构,通过NodeJs模板引擎的处理,自动化生成活动页,同时开启webpack-dev-server,提供活动页搭建的实时预览。
画了个简单的草图,描述下大概的场景,我们可以在左侧的组件区拖动对应的组件到拖拽区,这时候检测到拖拽完成,就向Node端发送Ajax请求,Node端通过模板引擎重新更新代码,webpack-dev-server进行热更新,然后前端的实时演示区的页面得到更新。


UI组件库是活动页搭建的基础资源,这里的组件库的实现可以参考类似Mint-UI等基于Vue的UI库,目的是向Node端导出组件,向前端平台输出组件信息。为了前端更好的获取UI库信息(例如,该组件的各项Prop值都是用来做什么的,默认值是什么),我们需要对组件内部的props选项进行更丰富的配置,同时,为了前端在拿到组件信息的时候知道每个英文名字的组件名对应的中文功能是什么,还需要在组价内新增对组件的描述字段。
下面提供一个简单的示例:
<template>
<div class="btn" @click="jump">{{btnname}}</div>
</template>
<script>
export default {
name: "Button",
intro: "按钮", //这里写入组件的介绍用于前端展示
props: {
btnname: { type: String, default: "请输入按钮名称", desc: "按钮名称" },
jumpUrl: {
type: String, //这里可以决定前端在输入props值时的输入样式,例如,输入框/单选按钮等
default: "https://www.juejin.com", //prop的默认值
desc: "点击跳转链接" //该字段用于前端对该prop的描述,辅助用户更好理解该如何输入prop值来控制组件
}
},
methods: {
jump() {
location.href = this.jumpUrl;
}
}
};
</script>按上述配置好后,一个组件的基础信息就完善好了,接下来使用import导入组件,注册install方法,以使组件库能够被Vue.use()注册使用(具体UI组件库的实现可以参考其他组件库的实现,这里不再赘述)。
作为前端平台,有几个功能需要完成:
下面分开来讲一下如何实现:
在前端main.js中导入组件库,并遍历组件,并剔除install,余下为所有我们写好的组件。
然后分别读取每个组件的name、intro(中文介绍),同时提取每个prop对应的描述、类型,用于前端描述每个组件的详情。
import UI from 'UI/index.js';
Vue.prototype.UIData = Object.values(UI).filter(item => {
// 剔除install方法
return Object.prototype.toString.call(item) === "[object Object]"
}).map(item => {
let newPropObj = {};
let propDesc = [];
let propType = [];
for (let p in item.props) {
newPropObj[p] = item.props[p].default;
propDesc.push(item.props[p].desc);
propType.push(item.props[p].type.name);
}
return {
name: item.name,
intro: item.intro,
config: { props: newPropObj, propDesc: propDesc, propType: propType, style: {} },
coms: []
}
});现在,我们就可以通过访问this.UIData获取UI库中每个组件的信息及每个组件对应的prop的信息。
首先来实现拖拽形成组件,这里我们需要了解一下Vue的渲染函数官方文档点这里,在Node端我这里是使用了createElement函数,接受三个参数,分别是html标签,config参数和子元素的配置参数。
下面是该函数在Vue的官方文档介绍:
createElement(
// {String | Object | Function}
// 一个 HTML 标签字符串,组件选项对象,或者
// 解析上述任何一种的一个 async 异步函数。必需参数。
'div',
// {Object}
// 一个包含模板相关属性的数据对象
// 你可以在 template 中使用这些特性。可选参数。
{
// (详情见下一节)
},
// {String | Array}
// 子虚拟节点 (VNodes),由 `createElement()` 构建而成,
// 也可以使用字符串来生成“文本虚拟节点”。可选参数。
[
'先写一些文字',
createElement('h1', '一则头条'),
createElement(MyComponent, {
props: {
someProp: 'foobar'
}
})
]
)在前端进行拖拽操作后,我的目标是形成一个可被createElement函数使用的VNode参数,同时还应该允许将一个组件拖到另一个组件中形成层叠结构,也就是将一个组件的数据放在另一个组件数据createElement的第三个参数中。
为了实现拖拽功能,这里我们就需要使用一个第三方库,我这里使用的是SortableJS,这个库有一个Vue的封装版本叫Vue.Draggable,这个库的在线演示效果可以访问这里。
OK,进到演示页面翻到最下面可以看到有一个"Nested Sortables Example",也就是层叠拖拽,我这里就是使用了层叠的模式,来实现VNode数据的拼装。
组件区代码,用于向拖拽区拖出组件,这里有一点需要注意:
1)因为组件区的组件需要多次向拖拽区拖拽,默认模式下拖拽一次后,组件区的数据将被转移到拖拽区,这里需要设置为clone模式,以支持多次拖拽。
2)直接拖出去会被认为是组件的浅拷贝,当有多个相同的组件出现在拖拽区后会出现数据冲突的问题,这里需要将每一个拖出去的组件进行深拷贝处理,以保证每一个拖拽区的组件都有独立的数据。
<draggable v-model="UIData" :options="option" :clone="deepClone" :sort="false">
<el-menu-item
v-for="(element,index) in xzUIData"
:key="element.id"
>{{element.intro}} - {{element.name}}</el-menu-item>
</draggable>
option: {
group: { name: "optionname", pull: "clone", put: false }
}
deepClone(el) {
return JSON.parse(JSON.stringify(el));
}这时,我们从组件区拖拽向拖拽区后,就可以形成层叠的VNode结构,此时createElement函数的第一个和第三个参数就搞定了,然后要解决的第二个参数,也就是对应每个组件的配置。
我这里是通过写了一个组件,通过递归调用组件的方式达到修改每一层prop的目的。
<template>
<div >
<draggable
:element="'ul'"
:list="coms"
:options="{group:{ name:'optionname'},onEnd:handleDragEnd()}"
>
<li :key="index" v-for="(el,index) in coms" class="drag_li">
<span>{{el.name}}{{el.intro}}</span>
<div @click="set(index)" class="settingProp">设置参数</div>
<xzdrag v-if="el.coms" :coms="el.coms" @set="upSet()"></xzdrag>
</li>
</draggable>
</div>
</template>
<script>
import draggable from "vuedraggable";
export default {
name: "xzdrag",
components: {
draggable
}
}
</script> 这里v-for遍历的coms数据就是Vue.Draggable经过拖拽后生成的JSON数据,现在来遍历这个数据,同时,每当一个组件的coms数组(coms字段为我这里定义的createElement函数要用到的第三个参数,也就是子元素的数组)不为空时递归调用该组件,当点击对应组件的设置参数按钮后,就可以直接根据当前的层级数直接修改VNode数据中对应每个组件的prop参数。
现在,经过拖拽形成层叠的VNode数据,同时在递归的组件中设置prop,已经得到了一个完整的可用于createElement函数渲染页面的数据,现在这个数据已经可以准备传给Node服务用来拼装页面了。
在完成了构建页面的基本数据后,渲染一个活动页面当然还需要其他的数据,例如:活动名称、页面标签的标题、该页面是否允许分享、该页面是否允许浏览器打开、是否在加载时检验用户登录等全局功能,这些数据我们可以单独维护一个区域让用户输入相关参数,然后在模板文件中我们编写好代码,例如:
// handlebars模板语法
const isCheckLogin = {{isCheckLogin}};
//模板App.vue
mounted(){}
if(isCheckLogin){
// 实现代码
}
}在模板中写好相关代码并制定一个变量作为开关,当前端用户选择使用该功能时,isCheckLogin的代码就将被执行。
OK,所以现在,我们的前端要传给后端的数据已经全部准备好了,按照功能分类可以分成三块:
1)活动页基本信息
2)活动页全局功能的配置
3)活动页页面组件结构的VNode数据
VueDraggable库有拖拽完成后的事件钩子,每当拖拽完成后触发,同时,给VNode数据中的prop配置字段添加watch,当检测到prop数据有变时页需要手动触发拖拽完成的事件钩子,在拖拽事件钩子中,实现将当前的VNode数据和活动页的其他数据统一发送Ajax给Node服务端,由Node端做页面的拼装。
这里需要注意一件事,因为用户在使用时需要大量的进行参数修改和拖拽操作,所以在拖拽事件钩子上需要加一个防抖函数进行处理,我这里是加了500ms的防抖,防止发送过多的Ajax请求给Node端。
前端通过使用iframe,并在iframe中使用对应活动的实时预览url即可,这里需要使用Node回传的端口号进行url确认,下节会详细讲到。
我们肯定也希望在前端能够像控制浏览器一样的控制iframe,但事实上由于iframe与前端网页跨域的原因,很多操作都会被限制,这里讲几个我是如何实现几个关键操作的。
1)iframe手动刷新
在前端页面执行this.$refs.iframe.src=this.$refs.iframe.src即可刷新。
正常情况下,由于webpack-dev-server在开启热更新后,可以自动刷新iframe,所以大部分情况下是无需使用该项的。
2)清除活动页的localStorage等缓存
使用postMessage发送跨域通知,在活动页中注册window.addEventListener("message", receiveMessage, false) 监听,可以实现活动页的缓存清理。
3)二维码
用户使用时希望能在手机上实时看到该页面,这里我使用了qrcode第三方库,根据url生成二维码,可以提供用户扫描实时在真机上预览。
分开介绍一下:
用于处理前端Ajax请求并完成页面构建流程
本质上一个使用Vue-cli生成的Vue项目,然后将App.vue使用handleBars模板语法改写,使之能够接收前端传来的参数,根据参数形成不同的页面。
<script>
//App.vue
import Vue from "vue";
const mountedHook = JSON.parse(JSON.stringify({{{json mountedHook}}}));
const actInfo = JSON.parse(JSON.stringify({{{json info}}}));
const VNode = JSON.parse(JSON.stringify({{{json VNode}}}));
export default {
name: "App",
data(){
return {}
},
created(){
// 设置页面title
window.document.title = actInfo.actPageName?actInfo.actPageName:'default';
},
mounted() {
window.addEventListener("message", receiveMessage, false) ;
function receiveMessage(event) {
switch (event.data){
case 'clearStorage':
localStorage.clear()
break;
}
}
// 检查登录并跳转登录
if(mountedHook && mountedHook.checkLogin){
this.$checkLogin();
}
},
render: function(createElement) {
var create = function(a) {
if(a.length){
return a.map(item => {
return createElement(item.name, item.config, create(item.coms));
});
}else{}
};
return createElement(
VNode.name,
VNode.config,
VNode.coms.length?VNode.coms.map(item => {
return createElement(item.name, item.config, create(item.coms));
}):[]
);
}
};
</script>用于模板活动引用,在模板中引入组件库,如果前端传过来的VNode数据中有使用该组件,则该组件会被渲染出来。
每当新建一个活动页时,当使用前端传来的数据通过模板语法渲染后的活动代码的文件夹,会被复制到活动页目录中,作为活动页的文件夹。
首先我们要开两个核心的路由监听,其中一个是新建页面,一个是更新页面。
Node监听到新建页面请求后,首先将Handlebars模板语法使用一个初始化的空数据渲染后的页面的文件夹复制到活动页目录下,同时在该目录下开启webpack-dev-server,监听返回值,当监听到当前webpack的server的端口号后,发送response给前端,将当前活动页的devserver的端口号通知前端,同时前端将该端口号与域名拼接,注入到前端页面的iframe的src中,这时候,前端对活动页面的实时预览就完成了。
if (fs.existsSync(AppFilePath)) {
const content = fs.readFileSync(AppFilePath).toString();
const result = handlebars.compile(content)(componentsData);
fs.writeFileSync(AppFilePath, result);
var child = shell.exec(`webpack-dev-server --inline --config ${newActPath}/build/webpack.dev.conf.js`, { async: true });
var initBack = true;
child.stdout.on('data', function (data) {
if (data.indexOf('http://0.0.0.0') !== -1) {
console.log('devServer启动');
initBack && res.send(data);
initBack = false;
}
});
}当前端有拖拽的操作后,前端就会开始向后端发送带有VNode数据的Ajax请求,这时再次用Handlebars模板语法将App.vue的模板数据进行更新,这时webpack-dev-server会对比差异后进行热更新,前端通过iframe即可看到实时更新后的页面。
当页面构建完成后,可以使用数据将VNode等数据存储起来用于二次编辑,也可以直接执行webpack的build操作生成打包后文件,这时dist中的文件即可用于上线使用。
因为所有的活动都是基于同一个UI组件库,所以复用度非常高,同时每一个活动配一个node_modules文件夹确实太费空间,这里我们可以在创建活动的时候,过滤掉对node_modules文件夹的复制,同时创建一个向模板文件夹node_modules的软连接ln -s ${templatePath}/node_modules ${newActPath}/node_modules,这时node_modules包的占用体积就可以得到大幅度的节省,从一个新活动占用100+Mb到一个活动5Mb以下
当用户退出前端页面后,webpack-dev-server并不会随之自动关闭,如果不进行处理,将会占用大量内存,所以这里需要进行一下优化。
首先找到能够检测到的退出编辑节点,在前端页面的后退、跳转到其他页等离开活动编辑页的操作时发送Ajax通知Node当前页使用的webpack-dev-server端口号,然后Node根据端口号杀掉占用指定端口号的任务。但是有的用户直接退出浏览器或者其他情况,则可以在每开一个webpack-dev-server后确定当前的端口号后写一个定时器 ,在一定时间后,将该进程杀掉。
代码参考:kill -9 $(lsof -t -i:${port}
在Mac上调试时并没有遇到这种问题,但是当代搬到服务器上后,在Linux同时开一定量的devServer后,会遇到热更新失效的问题,这时需要手动修改Linux的inotify的最大监控值
echo 100000 | sudo tee /proc/sys/fs/inotify/max_user_watchesinotify是一个内核用于通知用户空间程序文件系统变化的机制,它的max_user_watches值在Linux上默认为8192,因为webpack的热更新需要使用到这里的相关配置,这里我手动改到了100000,还可以更高。
因为Node端接口拥有直接操作活动页的权限,所以需要接入校验机制,我这里是和用户的登录状态绑定在一起,当用户登陆后传递Http Header头中带有token信息,拿到token后再去登录的后端接口进行校验,并使用Redis进行缓存减少请求量。
到这里基本讲完了活动页自动构建的核心设计,最终活动页自动构建平台如果搭建完善的话,我个人的目标是前端工程师只需要不断的完善组件库,从而可以将搭建活动页面完全的放心交给产品经理来完成,当然如果要搭建完整的系统还会需要登录、活动审核等功能,因为整体实现还是不会很难这里就不再细说了,如果还有相关的问题的话,可以添加本人的微信ricardo_cy 讨论。
也欢迎大佬指出我的不足~
首先引用一下阿里iconfont官网的使用介绍:
unicode是字体在网页端最原始的应用方式,特点是:
- 兼容性最好,支持ie6+,及所有现代浏览器。
- 支持按字体的方式去动态调整图标大小,颜色等等。
- 但是因为是字体,所以不支持多色。只能使用平台里单色的图标,就算项目里有多色图标也会自动去色。
unicode使用步骤如下:
第一步:拷贝项目下面生成的font-face
@font-face {font-family: 'iconfont'; src: url('iconfont.eot'); src: url('iconfont.eot?#iefix') format('embedded-opentype'), url('iconfont.woff') format('woff'), url('iconfont.ttf') format('truetype'), url('iconfont.svg#iconfont') format('svg'); }第二步:定义使用iconfont的样式
.iconfont{ font-family:"iconfont" !important; font-size:16px;font-style:normal; -webkit-font-smoothing: antialiased; -webkit-text-stroke-width: 0.2px; -moz-osx-font-smoothing: grayscale;}第三步:挑选相应图标并获取字体编码,应用于页面
<i class="iconfont">3</i>
可以看到使用unicode方法iconfont需要主要操作
但是为什么引入了iconfont的字体后,在标签内直接输入一段编码就可以显示成图标呢?
这里我们可以看一个例子:
<p>Hello world</p>
p{
font-family: Helvetica Neue
} 这里world实际上是'world'的Unicode编码,当我们在HTML文件中直接写入Unicode编码后,并用浏览器打开后,可以看到浏览器将上面的p标签渲染成'Hello world'。
这是因为浏览器在解析HTML文件时,读到Hello,会先将该字符串转为对应的Unicode编码,随后向该标签所属的字体文件查询对应的Unicode编码的对应的字体,然后再在浏览器上渲染出来,如果是Unicode编码则直接向字体文件查询对应的字体,所以我们可以看到Unicode编码和直接输入字母或汉字渲染效果相同。
所以当我们引入了定义好的iconfont图标字体,只要通过在HTML中写入Unicode就可以渲染出对应的图标。
在如下代码中,如果我们直接使用VUE的花括号来动态加载UnicodeIconFont的话会发现并不能动态的渲染,只能在网页上渲染出Unicode的代码,而不能渲染出图标。
代码如下:

这是因为花括号和v-text相同,默认输出文本,而文本更新不会触发浏览器的HTML解析。
这时我们可以通过使用v-html来向标签动态的加载HTML元素,这是就会触发浏览器的HTML解析功能,图标就可以顺利的渲染出来了。

原文日期:2018.6.6
译者:RicardoCao
首先我们会发现箭头函数有非常多可以使用的句法,我们一起看看下面的例子:
在没有参数的情况下,可以直接在 =>前放置一个圆括号()
() => 42甚至连括号都不需要
_ => 42在单个参数情况下,圆括号是可选的:
x => 42 || (x) => 42在多个参数情况下,圆括号是必须的:
(x, y) => 42在箭头函数中,如果代码语句多于一条,就需要使用花括号包裹函数语句 ,而一旦你使用了花括号,你也需要在箭头函数中使用return返回对应的返回值。
这里有一个使用箭头函数的例子:
var feedTheCat = (cat) => {
if (cat === 'hungry') {
return 'Feed the cat';
} else {
return 'Do not feed the cat';
}
}如果想返回一个对象,则需要用圆括号将对象包裹起来,这可以强制编译器解析圆括号中的内容并返回,而不是将花括号内当做函数语句。
x =>({ y: x })我们需要注意到箭头函数是匿名的,这也意味着他们是没有函数名的,这也造成了一些问题:
当我们遇到BUG时,将不能根据函数名或发生异常的行数来定位异常函数的位置。
如果你需要在使用箭头函数中递归调用自身,那么你会发现这在箭头函数中是行不通的。
在ES6之前的函数this关键字指向会根据函数被调用的上下文环境决定。但是在箭头函数中,this在函数定义时绑定,这意味着箭头函数使用包裹箭头函数的外部代码中的this。
举个栗子,我们看下面的setTimeout方法:
// ES5
var obj = {
id: 42,
counter: function counter() {
setTimeout(function() {
console.log(this.id);
}.bind(this), 1000);
}
};在ES5的例子中,.bind(this)用来绑定this上下文,如果不使用bind的话,默认this将会是undefined。
// ES6
var obj = {
id: 42,
counter: function counter() {
setTimeout(() => {
console.log(this.id);
}, 1000);
}
};箭头函数无法绑定this关键字,所以它会自动向上一层作用域寻找this,并使用上一层的this。
在一下几个情景你也许应该避免使用箭头函数:
当你调用cat.jumps,lives的数量并不会减少,这是因为this没有被绑定在cat对象上,而是使用父作用域的this。
var cat = {
lives: 9,
jumps: () => {
this.lives--;
}
}运行结果:

如果是在动态上下文的回调中,箭头函数是不适用的,下面看一下栗子:
var button = document.getElementById('press');
button.addEventListener('click', () => {
this.classList.toggle('on');
});这时点击按钮,会报错TypeError,这是因为this没有被绑定到按钮上。
大量使用箭头函数,可能会对理解函数的含义造成障碍,这时可以考虑使用ES5函数增强可读性。
箭头函数不可以作为构造函数,不可以使用new命令,否则会抛出一个错误。
报错Error: Can't set headers after they are sent,需要找到res.send()后还在运行并有能力返回值的函数,发现在初始化创建页面时,绑定了一个监听npm run dev的事件,而在后续该事件依旧在继续触发,这里使用变量标识并禁止第二次以后的触发返回值。
var child = shell.exec('npm run dev', { async: true });
// 监听webpack运行成功后返回http服务端口及域名,回传至前端用于模拟器iframe
// Node.js不允许一次请求多次返回,使用变量标识,禁止第二次事件以后的数据返回
var initBack = true;
child.stdout.on('data', function (data) {
if (data.indexOf('http') !== -1) {
initBack && res.send(data);
initBack = false;
}
不要向div中注入domProps.innerHTML变量,会覆盖递归调用createElement
因为是浅拷贝,需要改为深拷贝
deepClone(el) {
return JSON.parse(JSON.stringify(el));
}
-bind_ip 0.0.0.0绑定到0.0.0.0以使外网访问/data/db文件夹并chmod给予写权限--fork --logpath=/data/db/log.log参数以守护进程的方式运行mongodbmongod -bind_ip 0.0.0.0 --fork --logpath=/data/db/log.log源码地址点这里:Vue-Cli源码地址
npm install -g @vue/cli在全局安装Vue-Cli后,可以使用vue create hello-world初始化项目,我们就从这里开始看源码。
下面为项目的package.json文件
{
"name": "@vue/cli",
"description": "Command line interface for rapid Vue.js development",
"bin": {
//注册vue命令
"vue": "bin/vue.js"
},
"author": "Evan You",
"license": "MIT",
"publishConfig": {
"access": "public"
},
"dependencies": {
"@vue/cli-shared-utils": "^3.2.2",
"@vue/cli-ui": "^3.2.3",
"@vue/cli-ui-addon-webpack": "^3.2.3",
"@vue/cli-ui-addon-widgets": "^3.2.3",
//给终端界面添加颜色
"chalk": "^2.4.1",
"cmd-shim": "^2.0.2",
//实现输入命令的响应
"commander": "^2.16.0",
"debug": "^4.1.0",
"deepmerge": "^3.0.0",
//从Git仓库下载并解析
"download-git-repo": "^1.0.2",
"ejs": "^2.6.1",
"envinfo": "^6.0.1",
"execa": "^1.0.0",
"fs-extra": "^7.0.1",
"globby": "^8.0.1",
"import-global": "^0.1.0",
//实现命令行的问答
"inquirer": "^6.0.0",
"isbinaryfile": "^3.0.2",
"javascript-stringify": "^1.6.0",
"js-yaml": "^3.12.0",
"lodash.clonedeep": "^4.5.0",
//命令行参数解析
"minimist": "^1.2.0",
"recast": "^0.15.2",
"request": "^2.87.0",
"request-promise-native": "^1.0.5",
"resolve": "^1.8.1",
//版本号解析工具
"semver": "^5.5.0",
"shortid": "^2.2.11",
//将windows风格的路径转为Unix风格的路径
"slash": "^2.0.0",
"validate-npm-package-name": "^3.0.0",
"yaml-front-matter": "^3.4.1"
},
"engines": {
"node": ">=8.9"
}
}首先,vue命令被注册在package.json的bin字段下,关于bin字段的使用可以参考npm官方文档介绍部分:
A lot of packages have one or more executable files that they’d like to install into the PATH. npm makes this pretty easy (in fact, it uses this feature to install the “npm” executable.)
To use this, supply a
binfield in your package.json which is a map of command name to local file name. On install, npm will symlink that file intoprefix/binfor global installs, or./node_modules/.bin/for local installs.
由bin字段注册的可执行文件vue.js为项目的入口,在经过全局安装后,vue命令被注册到全局的bin目录下,这时我们就可以直接全局使用vue.js可执行文件。
在vue.js顶部写入的#!/usr/bin/env node,可以保证默认使用node来运行该可执行文件,这样运行时就可以直接通过输入在bin中注册号的的执行名vue来运行vue.js。
执行vue命令后,首先检查node.js版本号:
//版本号对比工具
const semver = require('semver')
const requiredVersion = require('../package.json').engines.node
function checkNodeVersion (wanted, id) {
//process.version返回当前使用的Node.js版本号
if (!semver.satisfies(process.version, wanted)) {
console.log(chalk.red(
'You are using Node ' + process.version + ', but this version of ' + id +
' requires Node ' + wanted + '.\nPlease upgrade your Node version.'
))
//终止当前进程并返回1状态码
process.exit(1)
}
}
checkNodeVersion(requiredVersion, 'vue-cli')
if (semver.satisfies(process.version, '9.x')) {
//以红色字体渲染文本
console.log(chalk.red(
`You are using Node ${process.version}.\n` +
`Node.js 9.x has already reached end-of-life and will not be supported in future major releases.\n` +
`It's strongly recommended to use an active LTS version instead.`
))
}const program = require('commander')
const loadCommand = require('../lib/util/loadCommand')
program
.version(require('../package').version)
.usage('<command> [options]')Vue-Cli使用commander作为命令工具,详细关于commander的API可以查阅commander的github主页。
接着往下看,进入初始化项目的配置,下面是源码:
program
.command('create <app-name>')
.description('create a new project powered by vue-cli-service')
.option('-p, --preset <presetName>', 'Skip prompts and use saved or remote preset')
.option('-d, --default', 'Skip prompts and use default preset')
.option('-i, --inlinePreset <json>', 'Skip prompts and use inline JSON string as preset')
.option('-m, --packageManager <command>', 'Use specified npm client when installing dependencies')
.option('-r, --registry <url>', 'Use specified npm registry when installing dependencies (only for npm)')
.option('-g, --git [message]', 'Force git initialization with initial commit message')
.option('-n, --no-git', 'Skip git initialization')
.option('-f, --force', 'Overwrite target directory if it exists')
.option('-c, --clone', 'Use git clone when fetching remote preset')
.option('-x, --proxy', 'Use specified proxy when creating project')
.option('-b, --bare', 'Scaffold project without beginner instructions')
.action((name, cmd) => {
const options = cleanArgs(cmd)
// --git makes commander to default git to true
if (process.argv.includes('-g') || process.argv.includes('--git')) {
options.forceGit = true
}
require('../lib/create')(name, options)
}).command('create <app-name>')绑定了create命令,并保存了输入的项目名,.option('-d,--default','Skip prompts and use default preset')用于定义选项值,设置描述及选项快捷键,并将选项值保存到process.argv中。
在链式配置好选项值后,.action(()=>{})用于配置该命令的处理函数,将输入的项目名和配置的选项传入create.js中执行。
const fs = require('fs-extra')
const path = require('path')
const chalk = require('chalk')
const inquirer = require('inquirer')
const Creator = require('./Creator')
const { clearConsole } = require('./util/clearConsole')
const { getPromptModules } = require('./util/createTools')
const { error, stopSpinner, exit } = require('@vue/cli-shared-utils')
const validateProjectName = require('validate-npm-package-name')
async function create (projectName, options) {
if (options.proxy) {
//设置代理
process.env.HTTP_PROXY = options.proxy
}
const cwd = options.cwd || process.cwd()
const inCurrent = projectName === '.'
const name = inCurrent ? path.relative('../', cwd) : projectName
const targetDir = path.resolve(cwd, projectName || '.')
const result = validateProjectName(name)
if (!result.validForNewPackages) {
console.error(chalk.red(`Invalid project name: "${name}"`))
result.errors && result.errors.forEach(err => {
console.error(chalk.red.dim('Error: ' + err))
})
result.warnings && result.warnings.forEach(warn => {
console.error(chalk.red.dim('Warning: ' + warn))
})
exit(1)
}
if (fs.existsSync(targetDir)) {
if (options.force) {
await fs.remove(targetDir)
} else {
await clearConsole()
if (inCurrent) {
const { ok } = await inquirer.prompt([
{
name: 'ok',
type: 'confirm',
message: `Generate project in current directory?`
}
])
if (!ok) {
return
}
} else {
const { action } = await inquirer.prompt([
{
name: 'action',
type: 'list',
message: `Target directory ${chalk.cyan(targetDir)} already exists. Pick an action:`,
choices: [
{ name: 'Overwrite', value: 'overwrite' },
{ name: 'Merge', value: 'merge' },
{ name: 'Cancel', value: false }
]
}
])
if (!action) {
return
} else if (action === 'overwrite') {
console.log(`\nRemoving ${chalk.cyan(targetDir)}...`)
await fs.remove(targetDir)
}
}
}
}
const creator = new Creator(name, targetDir, getPromptModules())
await creator.create(options)
}
module.exports = (...args) => {
return create(...args).catch(err => {
stopSpinner(false) // do not persist
error(err)
if (!process.env.VUE_CLI_TEST) {
process.exit(1)
}
})
}header是h5的标签,尽量避免使用,换个名字即可。
最近在研究webpack,整理最近看过的一些资料结合项目中的webpack做了一些知识点整理。
可能有部分地方的代码有冲突,是因为为了展示更多情况直接填充进去导致的。
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin')
const UglifyPlugin = require('uglifyjs-webpack-plugin')
const ExtractTextPlugin = require('extract-text-webpack-plugin')
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
//静态资源的引用路径,默认是'/'
publicPath:'/'
},
//loader配置项写在module.rules中
module: {
rules: [
{
test: /\.jsx?/,
//匹配特定路径
include: [
//必须是绝对路径
path.resolve(__dirname, 'src')
],
//排除特定路径
exclude: [
path.resolve(__dirname, 'xxx')
],
use: 'babel-loader',
},
{
test: /\.less/,
//css文件需要多个loader进行处理
use: [
//处理css引用依赖
'style-loader',
{
loader: 'css-loader',
options: {
importLoaders: 1
},
},
{
//处理css内容
loader: 'less-loader',
options: {
noIeCompat: true
}, // 传递 loader 配置
},
],
},
{
test: /.*\.(gif|png|jpe?g|svg|webp)$/i,
use: [
{
//用file-loader处理不需要处理的文件,输出原文件
//url-loader 和 file-loader 的功能类似,但是在处理文件的时候,可以通过配置指定一个大小,当文件小于这个配置值时,url-loader 会将其转换为一个 base64 编码的 DataURL
loader: 'url-loader',
options: {
limit: 8192, // 单位是 Byte,当文件小于 8KB 时作为 DataURL 处理
}
},
{
//改loader用于压缩图片
loader: 'image-webpack-loader',
options: {
mozjpeg: { // 压缩 jpeg 的配置
progressive: true,
quality: 65
},
optipng: { // 使用 imagemin-optipng 压缩 png,enable: false 为关闭
enabled: false,
},
pngquant: { // 使用 imagemin-pngquant 压缩 png
quality: '65-90',
speed: 4
},
gifsicle: { // 压缩 gif 的配置
interlaced: false,
},
webp: { // 开启 webp,会把 jpg 和 png 图片压缩为 webp 格式
quality: 75
},
},
],
},
{
test: /\.css/,
include: [
path.resolve(__dirname, 'src'),
],
use: [
'style-loader',
{
loader: 'css-loader',
options: {
minimize: true, // 使用 css 的压缩功能
},
},
],
}
],
},
resolve: {
//该选项可以用来优化路径搜索速度
modules: [
"node_modules",
path.resolve(__dirname, 'src')
],
//当省略文件后缀时将按顺序依次进行匹配
extensions: [".wasm", ".mjs", ".js", ".json", ".jsx"],
//路径的代替,path.resolve 和 __dirname可以用来获取绝对路径
alias: {
utils: path.resolve(__dirname, 'src/utils')
}
},
devServer: {
historyApiFallback: true,
contentBase: "./",
quiet: false, //控制台中不输出打包的信息
hot: true, //开启热点
inline: true, //开启页面自动刷新
lazy: false, //不启动懒加载
progress: true, //显示打包的进度
port: '8080', //设置端口号
//将特定 URL 的请求代理到另外一台服务器上。
proxy: {
'/json': {
target: 'http://m.xiaozhu.com/',
pathRewrite: {'^/json' : ''},
changeOrigin: true
},
'/api': {
target: 'http://wirelesspub.xiaozhu.com/',
pathRewrite: {'^/api' : ''},
changeOrigin: true
},
'/mobile': {
target: 'http://mobile.xiaozhu.com/',
pathRewrite: {'^/mobile' : ''},
changeOrigin: true
}
}
},
//浏览器端可以支持未打包代码的展示和调试
devtool:"source-map",
//实现代码分离
optimization: {
splitChunks: {
chunks: "all", // 所有的 chunks 代码公共的部分分离出来成为一个单独的文件
},
},
//插件
plugins: [
//为我们创建一个 HTML 文件,其中会引用构建出来的 JS 文件
new HtmlWebpackPlugin({
filename: 'index.html', // 配置输出文件名和路径
template: 'assets/index.html', // 配置文件模板
}),
new UglifyPlugin(),
//css经过loader处理后会变成js文件,ExtractTextPlugin可以把CSS 文件分离出来,同时需要使用loader配置。可以更好的地利用缓存,尝试把一些公共资源单独分离开来,利用缓存加速,以避免重复的加载。
new ExtractTextPlugin('index.css'),
//在编译时可以配置的全局常量,在应用代码文件中,可以访问配置好的变量(webpack 内置的插件,可以直接使用)
new webpack.DefinePlugin({
PRODUCTION: JSON.stringify(true),
VERSION: JSON.stringify('5fa3b9'),
}),
//支持热替换,无需刷新网页完成更新
new webpack.HotModuleReplacementPlugin()
],
}const merge = require('webpack-merge')
module.exports = merge(baseWebpackConfig, {
//在webpack.development.js中引入base配置形成完整配置
}减少 resolve 的解析
尽可能快速地定位到需要的模块,不做额外的查询工作
减少 plugin 的消耗
适当地移除掉一些没有必要的 plugin
默认开启 uglifyjs-webpack-plugin 的 cache 和 parallel,即缓存和并行处理,这样能大大提高 production mode 下压缩代码的速度。
使用Github文档下的方式运行发现没有播放音乐成功。
尝试以下写法:
Sound.setCategory('Playback');
var whoosh = new Sound('http://42.81.26.4/mp3.9ku.com/hot/2012/05-14/467165.mp3', Sound.MAIN_BUNDLE, (error) => {
if (error) {
console.log('failed to load the sound', error);
return;
}
console.log('duration in seconds: ' + whoosh.getDuration() + 'number of channels: ' + whoosh.getNumberOfChannels());
whoosh.play((success) => {
if (success) {
console.log('successfully finished playing');
} else {
console.log('playback failed due to audio decoding errors');
// reset the player to its uninitialized state (android only)
// this is the only option to recover after an error occured and use the player again
whoosh.reset();
}
});
});
攻击者截取到正常请求,并重复请求,当该请求涉及到类如数据库插入等操作时,大量的请求会造成问题。
防止同一个请求被多次请求,保证每次请求的唯一性
因为一般攻击者从截取到发送请求会间隔超过60s,所以通过加入时间戳,服务器判断api的时间戳和服务器接到请求时间的时间戳差值是否大于60s,如果大于则判断为重放攻击
服务端第一次在接收到这个nonce的时候做下面行为:
nonce是由客户端根据足够随机的情况生成的,比如 md5(timestamp+rand(0, 1000)); 也可以使用UUID, 它就有一个要求,正常情况下,在短时间内(比如60s)连续生成两个相同nonce的情况几乎为0。
http://a.com/?uid=123×tamp=1480556543&nonce=43f34f33&sign=80b886d71449cb33355d017893720666
这个请求中的uid是我们真正需要传递的有意义的参数,timestamp,nonce,sign都是为了签名和防重放使用。
服务端接到这个请求:
需要将网址切换为:
http://localhost:8081/debugger-ui/
因为模拟器自动启动的网页打开的ip地址为局域网内地址,
要通过电脑调试,需要在chrome中打开lcoalhost的网页
android模拟器(simulator)把它自己作为了localhost,也就是说,代码中使用localhost或者127.0.0.1来访问,都是访问模拟器自己,这是不行的
如果你想在模拟器simulator上面访问你的电脑,那么就使用android内置的IP 10.0.2.2 吧, 10.0.2.2 是模拟器设置的特定ip,是你的电脑的别名alias记住,在模拟器上用10.0.2.2访问你的电脑本机.
在Chrome中打开开发者工具的Network标签卡,右键表头将Protocol选上即可查看,h2即为HTTP2.0。

HTTP 1.1于1997年1月发布,在HTTP 2.0发布前,一直被使用了15年,下面为HTTP 1.1 和1.0之间的主要差异:
在HTTP 0.9和1.0中,TCP连线在每一次请求/回应对之后关闭。在HTTP 1.1中,引入了保持连线的机制,一个连接可以重复在多个请求/回应使用。持续连线的方式可以大大减少等待时间,因为在发出第一个请求后,双方不需要重新运行TCP握手程序。
能够使不同域名配置在同一个IP地址的服务器上,web server上的多个虚拟站点可以共享同一个ip和端口。
HTTP 1.1还使改进了HTTP 1.0的带宽。 例如,HTTP 1.1引入了分块传输编码,以允许传递内容可以在持续连在线被流传输而不必使用到缓冲器。HTTP管道允许客户端在收到每个回应之前发送多个请求,进一步减少用户感受到的滞后时间。协议的另一个补充是字节服务,允许客户端请求资源的某一部分,服务器仅回应某资源的指明部分。
HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码。下面为HTTP2.0提供的新功能:
在 HTTP 1.x 协议中,浏览器客户端在同一时间,针对同一域名下的请求有一定数量限制,而在HTTP 2.0中实现了:
HTTP 1.x 与HTTP 2的网络请求差异如下图:


可以明确表达网络传输中中资源的优先级,网络中拥有多种资源类型,它们的依赖关系和权重各不相同,HTTP/2 协议还允许客户端随时更新这些优先级,进一步优化了浏览器性能。换句话说,我们可以根据用户互动和其他信号更改依赖关系和重新分配权重。
类似于”请先处理和传输响应 D,然后再处理和传输响应 C“
HTTP/2 打破了严格的请求-响应语义,支持一对多和服务器发起的推送工作流,服务器可以对一个客户端请求发送多个响应。 换句话说,除了对最初请求的响应外,服务器还可以向客户端推送额外资源,而无需客户端明确地请求。
在合适的时机,推送合适的资源,Push比No Push带来的网站时延提升是明显的。在网络带宽足够承载推送资源的前提下,我们预先推送浏览器后续请求需要的资源,网站的整体加载时间得到缩短。
每个 HTTP 传输都承载一组标头,这些标头说明了传输的资源及其属性。 在 HTTP/1.x 中,此元数据始终以纯文本形式,通常会给每个传输增加 500–800 字节的开销。如果使用 HTTP Cookie,增加的开销有时会达到上千字节。为了减少此开销和提升性能,HTTP/2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用两种简单但是强大的技术:
直接上图:

服务端
Node.js从 v8.4.0版本开始支持HTTP/2
npm i --save http2配置SSL证书
Node.js代码
引用官方文档的一个例子:
const http2 = require('http2');
const fs = require('fs');
const server = http2.createSecureServer({
key: fs.readFileSync('localhost-privkey.pem'),
cert: fs.readFileSync('localhost-cert.pem')
});
server.on('error', (err) => console.error(err));
server.on('stream', (stream, headers) => {
stream.respond({
'content-type': 'text/html',
':status': 200
});
stream.end('Hello World');
});
server.listen(8443);关于Node.js关于HTTP 2.0的更多API可以查看官方文档Node.js-HTTP/2官方文档
function Parent() {
this.a = 1;
this.b = [1, 2, this.a];
this.c = { demo: 8 };
this.show = function () {
console.log(this.a , this.b , this.c.demo );
}
}
function Child() {
this.a = 2;
this.change = function () {
this.b.push(this.a);
this.a = this.b.length;
this.c.demo = this.a;
}
}
Child.prototype = new Parent();
var parent = new Parent();
var child1 = new Child();
var child2 = new Child();
child1.a = 11;
child2.a = 12;
parent.show();//Q1
child1.show();//Q2
child2.show();//Q3
child1.change();
child2.change();
parent.show();//Q4
child1.show();//Q5
child2.show();//Q6下面分别模拟Q1-Q6的执行情况
直接调用 parent.show(),此时this指向parent,语句中的三条语句相当于分别在给window对象上赋值:
parent.a = 1;
parent.b = [1, 2, parent.a];
parent.c = { demo: 8 };此时,parent对象应为:
{
a:1,
b:[1,2,1],
c:{
demo:8
}
}在执行var child1 = new Child();语句时,child对象的a值为2,而因为后被手动赋值为11,所以child实例上的a被改为11,这时调用原型链上的show()方法,依次打印,
这里this.a根据原型链的查找规则,在实例上有a的赋值,所以直接使用实例上的值也就是11,其他值实例上没有,需要在原型上寻找,所以输出b为[1,2,this.a],
而这里的this.b因为是数组,为引用类型,在执行var parent = new Parent();时被定义在parent实例上,所有this.a的指针指向共同的引用地址,所以为1 ,
this.c因为也是引用类型,指针也被指向共同的引用对象地址。
实例上的a被重新赋值,所以this.a 的输出被改为12,其余执行步骤同Q2。
相当于再次调用parent实例上的show方法,因为数据没有发生变动,所以输出值同Q1。
因为在调用this.change时,this.a的值被赋值为this.b数组的长度,所有这里的a输出为4,this.b的值使用引用地址b数组,因为在下一步中又执行了一次对this.b数组的push,所以这里打印this.b是被push两次后的数组,而this.c也是被push两次后的数组的长度,注意因为this.a和this.c的数据类型不同,所以this.a是单独的内存,而this.c则是使用相同一块内存。
又对this.b数组执行了一次push,所以这次this.a的输出应为数组的当前长度也就是5,this.c的值也是数组长度也就是5。
在chrome控制台中运行代码得到结果如下:

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.