romeric / fastor Goto Github PK
View Code? Open in Web Editor NEWA lightweight high performance tensor algebra framework for modern C++
License: MIT License
A lightweight high performance tensor algebra framework for modern C++
License: MIT License




































































































































Tensor<double, 4, 4> Gt(const Tensor<double, 4>& a)
{
auto G = metric();
enum { i, j, k };
return G - einsum<Index<i>, Index<j>>(a, a) / dot(a, a);
}
Tensor<double,4,4,4,4,4,4,4,4> P4(const Tensor<double, 4>& a)
{
auto G = metric();
print(G);
std::cout << __LINE__ << std::endl;
enum { i, j, k, l, m, n, o, p };
auto g = G - einsum<Index<i>, Index<j>>(a, a) / dot(a, a);
auto gg = einsum<Index<m, i>, Index<n, j>>(g, g);
auto gggg = einsum<Index<m, i, n, j>, Index<o, k, p, l>>(gg, gg);
auto g_g_g_g_j = permutation<Index<m, i, n, j, o, l, p, k>>(gggg);
auto g_g_g_g_k = permutation<Index<m, i, n, k, o, j, p, l>>(gggg);
auto g_g_g_g_l = permutation<Index<m, i, n, k, o, l, p, j>>(gggg);
auto g_g_g_g_m = permutation<Index<m, i, n, l, o, j, p, k>>(gggg);
auto g_g_g_g_n = permutation<Index<m, i, n, l, o, k, p, j>>(gggg);
auto g_g_g_g_o = permutation<Index<m, j, n, i, o, k, p, l>>(gggg);
auto g_g_g_g_p = permutation<Index<m, j, n, i, o, l, p, k>>(gggg);
auto g_g_g_g_r = permutation<Index<m, j, n, k, o, i, p, l>>(gggg);
auto g_g_g_g_i0 = permutation<Index<m, j, n, k, o, l, p, i>>(gggg);
auto g_g_g_g_ii = permutation<Index<m, j, n, l, o, i, p, k>>(gggg);
auto g_g_g_g_ij = permutation<Index<m, j, n, l, o, k, p, i>>(gggg);
auto g_g_g_g_ik = permutation<Index<m, k, n, i, o, j, p, l>>(gggg);
auto g_g_g_g_il = permutation<Index<m, k, n, i, o, l, p, j>>(gggg);
auto g_g_g_g_im = permutation<Index<m, k, n, j, o, i, p, l>>(gggg);
auto g_g_g_g_in = permutation<Index<m, k, n, j, o, l, p, i>>(gggg);
auto g_g_g_g_io = permutation<Index<m, k, n, l, o, i, p, j>>(gggg);
auto g_g_g_g_ip = permutation<Index<m, k, n, l, o, j, p, i>>(gggg);
auto g_g_g_g_ir = permutation<Index<m, l, n, i, o, j, p, k>>(gggg);
auto g_g_g_g_j0 = permutation<Index<m, l, n, i, o, k, p, j>>(gggg);
auto g_g_g_g_ji = permutation<Index<m, l, n, j, o, i, p, k>>(gggg);
auto g_g_g_g_jj = permutation<Index<m, l, n, j, o, k, p, i>>(gggg);
auto g_g_g_g_jk = permutation<Index<m, l, n, k, o, i, p, j>>(gggg);
auto g_g_g_g_jl = permutation<Index<m, l, n, k, o, j, p, i>>(gggg);
auto get_gggg =
(1 / 24) *
(gggg + g_g_g_g_j + g_g_g_g_k + g_g_g_g_l + g_g_g_g_m + g_g_g_g_n +
g_g_g_g_o + g_g_g_g_p + g_g_g_g_r + g_g_g_g_i0 + g_g_g_g_ii +
g_g_g_g_ij + g_g_g_g_ik + g_g_g_g_il + g_g_g_g_im + g_g_g_g_in +
g_g_g_g_io + g_g_g_g_ip + g_g_g_g_ir + g_g_g_g_j0 + g_g_g_g_ji +
g_g_g_g_jj + g_g_g_g_jk + g_g_g_g_jl);
////////// 72 terms ///////////////////////////////////////////////
auto g_g_g_g_0 = permutation<Index<i, j, m, n, l, p, k, o>>(gggg);
auto g_g_g_g_1 = permutation<Index<i, j, m, n, l, o, k, p>>(gggg);
auto g_g_g_g_2 = permutation<Index<i, j, m, o, l, p, k, n>>(gggg);
auto g_g_g_g_3 = permutation<Index<i, j, m, o, l, n, k, p>>(gggg);
auto g_g_g_g_4 = permutation<Index<i, j, m, p, l, o, k, n>>(gggg);
auto g_g_g_g_5 = permutation<Index<i, j, m, p, l, n, k, o>>(gggg);
auto g_g_g_g_6 = permutation<Index<i, j, n, o, l, p, k, m>>(gggg);
auto g_g_g_g_7 = permutation<Index<i, j, n, o, l, m, k, p>>(gggg);
auto g_g_g_g_8 = permutation<Index<i, j, n, p, l, o, k, m>>(gggg);
auto g_g_g_g_9 = permutation<Index<i, j, n, p, l, m, k, o>>(gggg);
auto g_g_g_g_10 = permutation<Index<i, j, o, p, l, n, k, m>>(gggg);
auto g_g_g_g_11 = permutation<Index<i, j, o, p, l, m, k, n>>(gggg);
auto g_g_g_g_12 = permutation<Index<i, k, m, n, l, p, j, o>>(gggg);
auto g_g_g_g_13 = permutation<Index<i, k, m, n, l, o, j, p>>(gggg);
auto g_g_g_g_14 = permutation<Index<i, k, m, o, l, p, j, n>>(gggg);
auto g_g_g_g_15 = permutation<Index<i, k, m, o, l, n, j, p>>(gggg);
auto g_g_g_g_16 = permutation<Index<i, k, m, p, l, o, j, n>>(gggg);
auto g_g_g_g_17 = permutation<Index<i, k, m, p, l, n, j, o>>(gggg);
auto g_g_g_g_18 = permutation<Index<i, k, n, o, l, p, j, m>>(gggg);
auto g_g_g_g_19 = permutation<Index<i, k, n, o, l, m, j, p>>(gggg);
auto g_g_g_g_20 = permutation<Index<i, k, n, p, l, o, j, m>>(gggg);
auto g_g_g_g_21 = permutation<Index<i, k, n, p, l, m, j, o>>(gggg);
auto g_g_g_g_22 = permutation<Index<i, k, o, p, l, n, j, m>>(gggg);
auto g_g_g_g_23 = permutation<Index<i, k, o, p, l, m, j, n>>(gggg);
auto g_g_g_g_24 = permutation<Index<i, l, m, n, k, p, j, o>>(gggg);
auto g_g_g_g_25 = permutation<Index<i, l, m, n, k, o, j, p>>(gggg);
auto g_g_g_g_26 = permutation<Index<i, l, m, o, k, p, j, n>>(gggg);
auto g_g_g_g_27 = permutation<Index<i, l, m, o, k, n, j, p>>(gggg);
auto g_g_g_g_28 = permutation<Index<i, l, m, p, k, o, j, n>>(gggg);
auto g_g_g_g_29 = permutation<Index<i, l, m, p, k, n, j, o>>(gggg);
auto g_g_g_g_30 = permutation<Index<i, l, n, o, k, p, j, m>>(gggg);
auto g_g_g_g_31 = permutation<Index<i, l, n, o, k, m, j, p>>(gggg);
auto g_g_g_g_32 = permutation<Index<i, l, n, p, k, o, j, m>>(gggg);
auto g_g_g_g_33 = permutation<Index<i, l, n, p, k, m, j, o>>(gggg);
auto g_g_g_g_34 = permutation<Index<i, l, o, p, k, n, j, m>>(gggg);
auto g_g_g_g_35 = permutation<Index<i, l, o, p, k, m, j, n>>(gggg);
auto g_g_g_g_36 = permutation<Index<j, k, m, n, l, p, i, o>>(gggg);
auto g_g_g_g_37 = permutation<Index<j, k, m, n, l, o, i, p>>(gggg);
auto g_g_g_g_38 = permutation<Index<j, k, m, o, l, p, i, n>>(gggg);
auto g_g_g_g_39 = permutation<Index<j, k, m, o, l, n, i, p>>(gggg);
auto g_g_g_g_40 = permutation<Index<j, k, m, p, l, o, i, n>>(gggg);
auto g_g_g_g_41 = permutation<Index<j, k, m, p, l, n, i, o>>(gggg);
auto g_g_g_g_42 = permutation<Index<j, k, n, o, l, p, i, m>>(gggg);
auto g_g_g_g_43 = permutation<Index<j, k, n, o, l, m, i, p>>(gggg);
auto g_g_g_g_44 = permutation<Index<j, k, n, p, l, o, i, m>>(gggg);
auto g_g_g_g_45 = permutation<Index<j, k, n, p, l, m, i, o>>(gggg);
auto g_g_g_g_46 = permutation<Index<j, k, o, p, l, n, i, m>>(gggg);
auto g_g_g_g_47 = permutation<Index<j, k, o, p, l, m, i, n>>(gggg);
auto g_g_g_g_48 = permutation<Index<j, l, m, n, k, p, i, o>>(gggg);
auto g_g_g_g_49 = permutation<Index<j, l, m, n, k, o, i, p>>(gggg);
auto g_g_g_g_50 = permutation<Index<j, l, m, o, k, p, i, n>>(gggg);
auto g_g_g_g_51 = permutation<Index<j, l, m, o, k, n, i, p>>(gggg);
auto g_g_g_g_52 = permutation<Index<j, l, m, p, k, o, i, n>>(gggg);
auto g_g_g_g_53 = permutation<Index<j, l, m, p, k, n, i, o>>(gggg);
auto g_g_g_g_54 = permutation<Index<j, l, n, o, k, p, i, m>>(gggg);
auto g_g_g_g_55 = permutation<Index<j, l, n, o, k, m, i, p>>(gggg);
auto g_g_g_g_56 = permutation<Index<j, l, n, p, k, o, i, m>>(gggg);
auto g_g_g_g_57 = permutation<Index<j, l, n, p, k, m, i, o>>(gggg);
auto g_g_g_g_58 = permutation<Index<j, l, o, p, k, n, i, m>>(gggg);
auto g_g_g_g_59 = permutation<Index<j, l, o, p, k, m, i, n>>(gggg);
auto g_g_g_g_60 = permutation<Index<k, l, m, n, j, p, i, o>>(gggg);
auto g_g_g_g_61 = permutation<Index<k, l, m, n, j, o, i, p>>(gggg);
auto g_g_g_g_62 = permutation<Index<k, l, m, o, j, p, i, n>>(gggg);
auto g_g_g_g_63 = permutation<Index<k, l, m, o, j, n, i, p>>(gggg);
auto g_g_g_g_64 = permutation<Index<k, l, m, p, j, o, i, n>>(gggg);
auto g_g_g_g_65 = permutation<Index<k, l, m, p, j, n, i, o>>(gggg);
auto g_g_g_g_66 = permutation<Index<k, l, n, o, j, p, i, m>>(gggg);
auto g_g_g_g_67 = permutation<Index<k, l, n, o, j, m, i, p>>(gggg);
auto g_g_g_g_68 = permutation<Index<k, l, n, p, j, o, i, m>>(gggg);
auto g_g_g_g_69 = permutation<Index<k, l, n, p, j, m, i, o>>(gggg);
auto g_g_g_g_70 = permutation<Index<k, l, o, p, j, n, i, m>>(gggg);
auto g_g_g_g_71 = permutation<Index<k, l, o, p, j, m, i, n>>(gggg);
auto get_g_g_g_g =
(1 / 84) *
(g_g_g_g_0 + g_g_g_g_1 + g_g_g_g_2 + g_g_g_g_3 + g_g_g_g_4 + g_g_g_g_5 +
g_g_g_g_6 + g_g_g_g_7 + g_g_g_g_8 + g_g_g_g_9 + g_g_g_g_10 +
g_g_g_g_11 + g_g_g_g_12 + g_g_g_g_13 + g_g_g_g_14 + g_g_g_g_15 +
g_g_g_g_16 + g_g_g_g_17 + g_g_g_g_18 + g_g_g_g_19 + g_g_g_g_20 +
g_g_g_g_21 + g_g_g_g_22 + g_g_g_g_23 + g_g_g_g_24 + g_g_g_g_25 +
g_g_g_g_26 + g_g_g_g_27 + g_g_g_g_28 + g_g_g_g_29 + g_g_g_g_30 +
g_g_g_g_31 + g_g_g_g_32 + g_g_g_g_33 + g_g_g_g_34 + g_g_g_g_35 +
g_g_g_g_36 + g_g_g_g_37 + g_g_g_g_38 + g_g_g_g_39 + g_g_g_g_40 +
g_g_g_g_41 + g_g_g_g_42 + g_g_g_g_43 + g_g_g_g_44 + g_g_g_g_45 +
g_g_g_g_46 + g_g_g_g_47 + g_g_g_g_48 + g_g_g_g_49 + g_g_g_g_50 +
g_g_g_g_51 + g_g_g_g_52 + g_g_g_g_53 + g_g_g_g_54 + g_g_g_g_55 +
g_g_g_g_56 + g_g_g_g_57 + g_g_g_g_58 + g_g_g_g_59 + g_g_g_g_60 +
g_g_g_g_61 + g_g_g_g_62 + g_g_g_g_63 + g_g_g_g_64 + g_g_g_g_65 +
g_g_g_g_66 + g_g_g_g_67 + g_g_g_g_68 + g_g_g_g_69 + g_g_g_g_70 +
g_g_g_g_71);
enum { mu, nu, lamda, sigma };
auto g_g = einsum<Index<mu, nu>, Index<lamda, sigma>>(g, g);
auto g_g1 = einsum<Index<i, j>, Index<k, l>>(g, g);
return get_gggg - get_g_g_g_g;
// (1 / 105) *
// (g_g + permutation<Index<mu, lamda, nu, sigma>>(g_g) +
// permutation<Index<mu, sigma, nu, lamda>>(g_g)) *
// (g_g1 + permutation<Index<i, k, j, l>>(g_g1) +
// permutation<Index<i, l, j, k>>(g_g1))
}
int main(){
Tensor<double, 4> Psi = {40, 0, 0, 3686};
// auto p4 = P4(Kp1);
}There is a mistake in the tensor.h implementation of product. this will always become 0.
FASTOR_INLINE T product() const {
if ((Size==0) || (Size==1)) return _data[0];
using V = SIMDVector<T,DEFAULT_ABI>;
constexpr int unroll_upto = V::unroll_size(Size);
constexpr int stride = V::Size;
int i = 0;
V vec =static_cast<T>(1);
for (; i< unroll_upto; i+=stride) {
vec *= V(_data+i);
}
T scalar = static_cast<T>(0); // this should be: T scalar = static_cast<T>(1);
for (; i< Size; ++i) {
scalar *= _data[i];
}
return vec.product()*scalar;
}
When trying to compile the following snippet with g++ 7.2.0, I receive the error:
error: ambiguous template instantiation for struct Fastor::tensor_type_finder<Fastor::Tensor<double, 3> >
snippet:
#include "Fastor.h"
using namespace Fastor;
int main(int argc, char *argv[]) {
constexpr std::size_t N = 3;
Tensor<double,N> vec1 = 0;
Tensor<double,N> vec2 = 0;
enum {a,b};
Tensor<double,N,N> tensor_prod = einsum<Index<a>,Index<b>>(vec1,vec2);
return 0;
}Compiling the same snippet with the same compiler, but chosing std=c++14 gives no error.
The operator() for tensors could be overloaded to provide a similar functionality to seq, fseq and iseq, like so
operator()(std::initializer_list<int> _s1, std::initializer_list<int> _s2);The tensor could then be indexed like
Tensor<double,4,4> A;
A({0,3},{1,3,2}) = 42.;This would be pretty easy to achieve by just providing a std::initializer_list constructor to seq. Note that std::initializer_list constructors themselves are constexpr.
This should however, be investigated, as at the moment Tensor class also has std::initializer_list constructor and the above syntax already works but gives incorrect results and also this syntax seems more appropriate for TensorRandomViews than TensorViews. In the sense, that it alludes to slicing a tensor with two vectors rather than with sequentially ascending ranges.
We lack SIMD based binary comparison operators. At the moment binary_cmp_ops have a pretty decent speed. Compilers are very good at generating binary comparison operators using SSE/AVX/AVX2 from scalar code though.
The following AVX code is slightly/marginally faster than our current implementation but still nearly twice slower than a plain scalar based implementation (that the compiler can optimise)
template<>
FASTOR_INLINE SIMDVector<bool,SIMDVector<double,256>::Size*sizeof(bool)*8>
operator>(const SIMDVector<double,256> &a, const SIMDVector<double,256> &b) {
constexpr FASTOR_INDEX Size = SIMDVector<double,256>::Size;
__m256d cmp = _mm256_cmp_pd(a.value,b.value,_CMP_GT_OQ);
int bitmask = _mm256_movemask_pd(cmp);
SIMDVector<bool,Size*sizeof(bool)*8> out;
bool FASTOR_ALIGN val_out[Size];
out.store(val_out);
for (FASTOR_INDEX i=0; i<Size; ++i) {
val_out[i] = (bitmask & (1<<i)) != 0;
}
out.load(val_out);
return out;
}
SIMDVector<T,DEFAULT_ABI> does not fall back to true scalar implementation for 32bit types or for any "sized" type other than 64bit which is a big limitation. This is of course only true for scalar implementations. In the presence of SSE...AVX512 there is no issue.
FASTOR_INLINE bool is_symmetric() {
if (is_uniform()) {
bool bb = true;
size_t M = dimension(0);
size_t N = dimension(1);
for (size_t i=0; i<M; ++i)
for (size_t j=0; j<N; ++j)
if (std::fabs(_data[i*N+j] - _data[j*N+i])<PRECI_TOL) {
bb = false;
}
return bb;
}
else {
return false;
}
}
should it not be:
FASTOR_INLINE bool is_symmetric() {
if (is_uniform()) {
bool bb = true;
size_t M = dimension(0);
size_t N = dimension(1);
for (size_t i=0; i<M; ++i)
for (size_t j=0; j<N; ++j)
if (std::fabs(_data[i*N+j] - _data[j*N+i]) **>** PRECI_TOL) {
bb = false;
}
return bb;
}
else {
return false;
}
}
For large tensor contractions meta functions of nprod specifially product function suffers from narrowing conversion as the data type is int. This should be Int64
It looks an awesome work.
Do you know mshadow?
It support CPU/GPU together through
Tensor<cpu, 2> ts1;
Tensor<gpu, 2> ts1;
This document also may be helpful.
When compiling this code:
Tensor<T, I> a;
Tensor<T, J,I> b;
Tensor<T, J> c = einsum<Index<a,b>, Index<b>>(b,a);
I get a segmentation-fault. Is this not allowed? or am i overlooking something essential here?
I am currently trying to use your library on a skylake cpu. Here, when i compile this code:
0001: #include "PerfEvent.hpp"
0002: #include <Fastor.h>
0003: #include <iostream>
0004:
0005: enum{a,b,c,d,e,f,g,h,i,j,k,l,m,n,o,p,q,r,s,t,u,v,w,x,y,z};
0006:
0007: int testFastor(){
0008: Fastor::Tensor<int,3,4,3> A, B; A.randint(); B.randint();
0009: Fastor::Tensor<int,3, 4, 4, 3> C;
0010: PerfEvent ev;
0011: unsigned count = 1024;
0012: {
0013: PerfEventBlock bl(ev, count);
0014: ev.setParam("name", "Fastor Contraction");
0015: C = Fastor::einsum<Fastor::Index<a, b, c>,Fastor::Index<c, d, e>>(A,B);
0016: }
0017:
0018: // std::cout << A << std::endl;
0019: // std::cout << B << std::endl;
0020: // std::cout << C << std::endl;
0021:
0022:
0023: // Fastor::Tensor<int,4,4> AB; AB.fill(0);
0024: // std::cout << AB << std::endl;
0025:
0026: // Fastor::Tensor<int,2,3> A2; A2.arange(1);
0027: // Fastor::Tensor<int,3,4> B2; B2.arange(1);
0028: // Fastor::Tensor<int,4,1> C2; C2.arange(1);
0029: // Fastor::Tensor<int,1,4> D2; D2.arange(1);
0030:
0031: // auto E2 = Fastor::einsum<Fastor::Index<a,b>,Fastor::Index<b,c>,Fastor::Index<c,d>,Fastor::Index<d,e>>(A2,B2,C2,D2);
0032: // std::cout << E2 << std::endl;
0033:
0034: // std::cout << A2.dimension(A2.Dimension-1) << std::endl;
0035:
0036: return 0;
0037: }
0038:
i get this error:
g++ main.cpp -march=native -O3 -o main -fopenmp -I Fastor
In file included from Fastor/simd_vector/simd_vector_base.h:5,
from Fastor/simd_vector/SIMDVector.h:4,
from Fastor/Fastor.h:6,
from aFastor.hpp:2,
from main.cpp:2:
Fastor/extended_intrinsics/extintrin.h: In function ‘__m256i _mm256_mul_epi64x(__m256i, __m256i)’:
Fastor/extended_intrinsics/extintrin.h:660:19: error: ‘_mm_mul_epi64’ was not declared in this scope
__m128i low = _mm_mul_epi64(low_a,low_b);
^~~~~~~~~~~~~
Fastor/extended_intrinsics/extintrin.h:660:19: note: suggested alternative: ‘_mm_mullo_epi64’
__m128i low = _mm_mul_epi64(low_a,low_b);
^~~~~~~~~~~~~
_mm_mullo_epi64
In file included from Fastor/simd_vector/SIMDVector.h:8,
from Fastor/Fastor.h:6,
from aFastor.hpp:2,
from main.cpp:2:
Fastor/simd_vector/simd_vector_int64.h: In member function ‘void Fastor::SIMDVector<long long int, 128>::operator*=(Fastor::Int64)’:
Fastor/simd_vector/simd_vector_int64.h:299:17: error: ‘_mm_mul_epi64’ was not declared in this scope
value = _mm_mul_epi64(value,numb);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:299:17: note: suggested alternative: ‘_mm_mullo_epi64’
value = _mm_mul_epi64(value,numb);
^~~~~~~~~~~~~
_mm_mullo_epi64
Fastor/simd_vector/simd_vector_int64.h: In member function ‘void Fastor::SIMDVector<long long int, 128>::operator*=(__m128i)’:
Fastor/simd_vector/simd_vector_int64.h:302:17: error: ‘_mm_mul_epi64’ was not declared in this scope
value = _mm_mul_epi64(value,regi);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:302:17: note: suggested alternative: ‘_mm_mullo_epi64’
value = _mm_mul_epi64(value,regi);
^~~~~~~~~~~~~
_mm_mullo_epi64
Fastor/simd_vector/simd_vector_int64.h: In member function ‘void Fastor::SIMDVector<long long int, 128>::operator*=(const Fastor::SIMDVector<long long int, 128>&)’:
Fastor/simd_vector/simd_vector_int64.h:305:17: error: ‘_mm_mul_epi64’ was not declared in this scope
value = _mm_mul_epi64(value,a.value);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:305:17: note: suggested alternative: ‘_mm_mullo_epi64’
value = _mm_mul_epi64(value,a.value);
^~~~~~~~~~~~~
_mm_mullo_epi64
Fastor/simd_vector/simd_vector_int64.h: In function ‘Fastor::SIMDVector<long long int, 128> Fastor::operator*(const Fastor::SIMDVector<long long int, 128>&, const Fastor::SIMDVector<long long int, 128>&)’:
Fastor/simd_vector/simd_vector_int64.h:402:17: error: ‘_mm_mul_epi64’ was not declared in this scope
out.value = _mm_mul_epi64(a.value,b.value);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:402:17: note: suggested alternative: ‘_mm_mullo_epi64’
out.value = _mm_mul_epi64(a.value,b.value);
^~~~~~~~~~~~~
_mm_mullo_epi64
Fastor/simd_vector/simd_vector_int64.h: In function ‘Fastor::SIMDVector<long long int, 128> Fastor::operator*(const Fastor::SIMDVector<long long int, 128>&, Fastor::Int64)’:
Fastor/simd_vector/simd_vector_int64.h:408:17: error: ‘_mm_mul_epi64’ was not declared in this scope
out.value = _mm_mul_epi64(a.value,numb);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:408:17: note: suggested alternative: ‘_mm_mullo_epi64’
out.value = _mm_mul_epi64(a.value,numb);
^~~~~~~~~~~~~
_mm_mullo_epi64
Fastor/simd_vector/simd_vector_int64.h: In function ‘Fastor::SIMDVector<long long int, 128> Fastor::operator*(Fastor::Int64, const Fastor::SIMDVector<long long int, 128>&)’:
Fastor/simd_vector/simd_vector_int64.h:414:17: error: ‘_mm_mul_epi64’ was not declared in this scope
out.value = _mm_mul_epi64(numb,b.value);
^~~~~~~~~~~~~
Fastor/simd_vector/simd_vector_int64.h:414:17: note: suggested alternative: ‘_mm_mullo_epi64’
out.value = _mm_mul_epi64(numb,b.value);
^~~~~~~~~~~~~
_mm_mullo_epi64
make: *** [Makefile:7: main] Error 1
From a closer look at your code, it seems, that _mm_mul_epi64 is not declared, if the CPU has this __AVX512CD__ flag set. Do i have to changed something in my code, or can i fix this somehow?
These CPU-Flags are set:
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault cat_l3 cdp_l3 invpcid_single pti ssbd mba ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts flush_l1d
Tensor<double, 4, 4, 4, 4> leci_four()
{
Tensor<double, 4, 4, 4, 4> leci;
leci.zeros();
leci(0, 1, 2, 3) = 1.;
leci(0, 1, 3, 2) = -1.;
leci(0, 3, 1, 2) = 1.;
leci(3, 0, 1, 2) = -1.;
leci(3, 0, 2, 1) = 1.;
leci(0, 3, 2, 1) = -1.;
leci(0, 2, 3, 1) = 1.;
leci(0, 2, 1, 3) = -1.;
leci(2, 0, 1, 3) = 1.;
leci(2, 0, 3, 1) = -1.;
leci(2, 3, 0, 1) = 1.;
leci(3, 2, 0, 1) = -1.;
leci(3, 2, 1, 0) = 1.;
leci(2, 3, 1, 0) = -1.;
leci(2, 1, 3, 0) = 1.;
leci(2, 1, 0, 3) = -1.;
leci(1, 2, 0, 3) = 1.;
leci(1, 2, 3, 0) = -1.;
leci(1, 3, 2, 0) = 1.;
leci(3, 1, 2, 0) = -1.;
leci(3, 1, 0, 2) = 1.;
leci(1, 3, 0, 2) = -1.;
leci(1, 0, 3, 2) = 1.;
leci(1, 0, 2, 3) = -1.;
return leci;
}
int main()
{
Tensor<double, 4> Psi = {40, 0, 0, 3686};
Tensor<double, 4> Kp1 = {1, 1, 1, 1};
Tensor<double, 4> Km1 = {1, 2, 3, 4};
Tensor<double, 4> Kp2 = {1, 1, 1, 1};
Tensor<double, 4> Km2 = {1, 2, 3, 4};
Tensor<double, 4> Phi;
Tensor<double, 4> f0;
Phi = Kp1 + Km1;
f0 = Kp2 + Km2;
auto leci = leci_four();
enum{i,j,k,l};
auto result = einsum<Index<i,j,k,l>,Index<j>>(leci,Psi);
print(result);
}
/// it return
[0,:,:]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[1,:,:]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[2,:,:]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[3,:,:]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000, 0.000000000 ]i think the calculate can not return all 0 in logic
and i use python do same thing
import jax.numpy as np
import numpy as onp
leci = onp.zeros((4, 4, 4, 4))
leci[0, 1, 2, 3] = 1
leci[0, 1, 3, 2] = -1
leci[0, 3, 1, 2] = 1
leci[3, 0, 1, 2] = -1
leci[3, 0, 2, 1] = 1
leci[0, 3, 2, 1] = -1
leci[0, 2, 3, 1] = 1
leci[0, 2, 1, 3] = -1
leci[2, 0, 1, 3] = 1
leci[2, 0, 3, 1] = -1
leci[2, 3, 0, 1] = 1
leci[3, 2, 0, 1] = -1
leci[3, 2, 1, 0] = 1
leci[2, 3, 1, 0] = -1
leci[2, 1, 3, 0] = 1
leci[2, 1, 0, 3] = -1
leci[1, 2, 0, 3] = 1
leci[1, 2, 3, 0] = -1
leci[1, 3, 2, 0] = 1
leci[3, 1, 2, 0] = -1
leci[3, 1, 0, 2] = 1
leci[1, 3, 0, 2] = -1
leci[1, 0, 3, 2] = 1
leci[1, 0, 2, 3] = -1
_leci = np.asarray(leci)
psi2s = np.array([-40,0,0,3686])
#print(psi2s)
print(np.einsum('ijkl,j->ikl',_leci,psi2s))
# it return
[[[ 0. 0. 0. 0.]
[ 0. 0. 3686. 0.]
[ 0. -3686. 0. 0.]
[ 0. 0. 0. 0.]]
[[ 0. 0. -3686. 0.]
[ 0. 0. 0. 0.]
[ 3686. 0. 0. 40.]
[ 0. 0. -40. 0.]]
[[ 0. 3686. 0. 0.]
[-3686. 0. 0. -40.]
[ 0. 0. 0. 0.]
[ 0. 40. 0. 0.]]
[[ 0. 0. 0. 0.]
[ 0. 0. 40. 0.]
[ 0. -40. 0. 0.]
[ 0. 0. 0. 0.]]]This error was thrown, when i tried to compile this code:
Fastor::Tensor<T, h, 1> hidden = Fastor::einsum<Fastor::Index<a, b>, Fastor::Index<b, c>>(w_ih, inputs);
hidden += b_h;
hidden = (1) / (1 + exp((-1) * hidden));
The error:
In file included from lib/Fastor/Fastor.h:6,
from src/aFastor.hpp:4,
from src/main.cpp:5:
lib/Fastor/simd_vector/SIMDVector.h: In instantiation of ‘Fastor::SIMDVector<T, 512> Fastor::exp(const Fastor::SIMDVector<T, 512>&) [with T = float]’:
lib/Fastor/expressions/unary_ops/unary_math_ops.h:188:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnaryExpOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = float; Expr = Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:94:23: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; U = float; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:81:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = float; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:78:20: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; U = float; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:60:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = float; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/tensor/Tensor.h:167:37: required from ‘Fastor::Tensor<T, Rest>& Fastor::Tensor<T, Rest>::operator=(const Fastor::AbstractTensor<Derived, sizeof... (Rest)>&) [with Derived = Fastor::BinaryDivOp<int, Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>, 2>; T = float; long unsigned int ...Rest = {10, 1}]’
src/aFastor.hpp:168:20: required from ‘void fastorFF(cTensor<T>&, cTensor<T>&) [with T = float; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:178:25: required from ‘void FF() [with T = float; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:192:22: required from ‘void runFF() [with T = float]’
src/main.cpp:252:22: required from here
lib/Fastor/simd_vector/SIMDVector.h:17:15: error: incompatible types in assignment of ‘const float*’ to ‘float [16]’
out.value = internal_exp(a.value);
~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~
lib/Fastor/simd_vector/SIMDVector.h: In instantiation of ‘Fastor::SIMDVector<T, 512> Fastor::exp(const Fastor::SIMDVector<T, 512>&) [with T = double]’:
lib/Fastor/expressions/unary_ops/unary_math_ops.h:188:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnaryExpOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = double; Expr = Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:94:23: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; U = double; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:81:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = double; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:78:20: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; U = double; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:60:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = double; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/tensor/Tensor.h:167:37: required from ‘Fastor::Tensor<T, Rest>& Fastor::Tensor<T, Rest>::operator=(const Fastor::AbstractTensor<Derived, sizeof... (Rest)>&) [with Derived = Fastor::BinaryDivOp<int, Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>, 2>; T = double; long unsigned int ...Rest = {10, 1}]’
src/aFastor.hpp:168:20: required from ‘void fastorFF(cTensor<T>&, cTensor<T>&) [with T = double; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:178:25: required from ‘void FF() [with T = double; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:192:22: required from ‘void runFF() [with T = double]’
src/main.cpp:255:23: required from here
lib/Fastor/simd_vector/SIMDVector.h:17:15: error: incompatible types in assignment of ‘const double*’ to ‘double [8]’
In file included from lib/Fastor/simd_vector/simd_vector_base.h:6,
from lib/Fastor/simd_vector/SIMDVector.h:4,
from lib/Fastor/Fastor.h:6,
from src/aFastor.hpp:4,
from src/main.cpp:5:
lib/Fastor/math/internal_math.h: In instantiation of ‘T Fastor::internal_exp(T) [with T = const float*]’:
lib/Fastor/simd_vector/SIMDVector.h:17:29: required from ‘Fastor::SIMDVector<T, 512> Fastor::exp(const Fastor::SIMDVector<T, 512>&) [with T = float]’
lib/Fastor/expressions/unary_ops/unary_math_ops.h:188:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnaryExpOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = float; Expr = Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:94:23: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; U = float; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:81:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = float; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:78:20: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; U = float; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:60:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = float; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/tensor/Tensor.h:167:37: required from ‘Fastor::Tensor<T, Rest>& Fastor::Tensor<T, Rest>::operator=(const Fastor::AbstractTensor<Derived, sizeof... (Rest)>&) [with Derived = Fastor::BinaryDivOp<int, Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<float, 10, 1>, 2>, 2>, 2>, 2>; T = float; long unsigned int ...Rest = {10, 1}]’
src/aFastor.hpp:168:20: required from ‘void fastorFF(cTensor<T>&, cTensor<T>&) [with T = float; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:178:25: required from ‘void FF() [with T = float; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:192:22: required from ‘void runFF() [with T = float]’
src/main.cpp:252:22: required from here
lib/Fastor/math/internal_math.h:279:15: error: assignment of read-only location ‘*(out + ((sizetype)(i * 4)))’
out[i] = std::exp(a[i]);
~~~~~~~^~~~~~~~~~~~~~~~
lib/Fastor/math/internal_math.h: In instantiation of ‘T Fastor::internal_exp(T) [with T = const double*]’:
lib/Fastor/simd_vector/SIMDVector.h:17:29: required from ‘Fastor::SIMDVector<T, 512> Fastor::exp(const Fastor::SIMDVector<T, 512>&) [with T = double]’
lib/Fastor/expressions/unary_ops/unary_math_ops.h:188:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnaryExpOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = double; Expr = Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:94:23: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; U = double; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_add_op.h:81:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryAddOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = double; TLhs = int; TRhs = Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:78:20: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::helper(Fastor::FASTOR_INDEX) const [with LExpr = int; RExpr = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; U = double; typename std::enable_if<(std::is_arithmetic<U>::value && (! std::is_arithmetic<RExpr>::value)), bool>::type <anonymous> = 0; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/expressions/binary_ops/binary_div_op.h:60:35: required from ‘Fastor::SIMDVector<U, 512> Fastor::BinaryDivOp<TLhs, TRhs, DIM0>::eval(Fastor::FASTOR_INDEX) const [with U = double; TLhs = int; TRhs = Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>; long unsigned int DIM0 = 2; Fastor::FASTOR_INDEX = long unsigned int]’
lib/Fastor/tensor/Tensor.h:167:37: required from ‘Fastor::Tensor<T, Rest>& Fastor::Tensor<T, Rest>::operator=(const Fastor::AbstractTensor<Derived, sizeof... (Rest)>&) [with Derived = Fastor::BinaryDivOp<int, Fastor::BinaryAddOp<int, Fastor::UnaryExpOp<Fastor::BinaryMulOp<int, Fastor::Tensor<double, 10, 1>, 2>, 2>, 2>, 2>; T = double; long unsigned int ...Rest = {10, 1}]’
src/aFastor.hpp:168:20: required from ‘void fastorFF(cTensor<T>&, cTensor<T>&) [with T = double; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:178:25: required from ‘void FF() [with T = double; long int I = 10; long int h = 10; long int O = 10]’
src/main.cpp:192:22: required from ‘void runFF() [with T = double]’
src/main.cpp:255:23: required from here
lib/Fastor/math/internal_math.h:279:15: error: assignment of read-only location ‘*(out + ((sizetype)(i * 8)))’
make: *** [Makefile:15: main] Error 1
they have this dimensionality:
L,M,K and K,M,L with L= 17, M=77 and K=147. Is there a maximum size to Fastors capabilities?
Every dimensionality below that works, this is the code, where i apply it:
template<typename T, size_t L, size_t M, size_t K, size_t N, size_t O, std::enable_if_t<std::is_floating_point<T>::value, int> = 0>
void fastor3d(){
Fastor::Tensor<T,L,M,K> A; A.random();
Fastor::Tensor<T,K,N,O> B; B.random();
Fastor::Tensor<T,L,M,N,O> res;
PerfEvent ev;
{
PerfEventBlock bl(ev, countPE);
ev.setParam("name","Fastor3D");
res = Fastor::einsum<Fastor::Index<a,b,c>,Fastor::Index<c,d,e>>(A,B);
}
}
(N=M and O=L)
From Sebastian Moeckel: When I tried to compile Fastor with gcc6.2, I experienced the
following compilation error:
../commons/extended_algorithms.h: In function ‘std::array<int, N>
argsort(const std::array<_Tp, _Nm>&)’:
../commons/extended_algorithms.h:19:3: error: ‘iota’ is not a member of
‘std’
std::iota(idx.begin(),idx.end(),0);
Integer division is not implemented for SIMDVectors. Given that SIMD integer division does not exist, this should be implemented like trigonometric functions regardless of how slow it might be, as lack of this is a big limitation.
Is there a way to make Fastor support std::complex<double> (or similar) as a data type?
It seems like vector_setter will have to be specialized to add support for complex numbers.
Tensor<double, 4, 4, 4, 4, 4, 4, 4, 4> _P4(const Tensor<double, 4>& a)
{
Tensor<double, 4, 4> G = metric();
std::cout << __LINE__ << std::endl;
enum { i, j, k, l, m, n, o, p };
Tensor<double, 4, 4> g = Gt(a);
auto gg = einsum<Index<m, i>, Index<n, j>>(g, g);
auto gggg = einsum<Index<m, i, n, j>, Index<o, k, p, l>>(gg, gg);
auto g_g_g_g_j = permutation<Index<m, i, n, j, o, l, p, k>>(gggg);
auto g_g_g_g_k = permutation<Index<m, i, n, k, o, j, p, l>>(gggg);
auto g_g_g_g_l = permutation<Index<m, i, n, k, o, l, p, j>>(gggg);
auto g_g_g_g_m = permutation<Index<m, i, n, l, o, j, p, k>>(gggg);
auto g_g_g_g_n = permutation<Index<m, i, n, l, o, k, p, j>>(gggg);
auto g_g_g_g_o = permutation<Index<m, j, n, i, o, k, p, l>>(gggg);
auto g_g_g_g_p = permutation<Index<m, j, n, i, o, l, p, k>>(gggg);
auto g_g_g_g_r = permutation<Index<m, j, n, k, o, i, p, l>>(gggg);
auto g_g_g_g_i0 = permutation<Index<m, j, n, k, o, l, p, i>>(gggg);
auto g_g_g_g_ii = permutation<Index<m, j, n, l, o, i, p, k>>(gggg);
auto g_g_g_g_ij = permutation<Index<m, j, n, l, o, k, p, i>>(gggg);
auto g_g_g_g_ik = permutation<Index<m, k, n, i, o, j, p, l>>(gggg);
auto g_g_g_g_il = permutation<Index<m, k, n, i, o, l, p, j>>(gggg);
auto g_g_g_g_im = permutation<Index<m, k, n, j, o, i, p, l>>(gggg);
auto g_g_g_g_in = permutation<Index<m, k, n, j, o, l, p, i>>(gggg);
auto g_g_g_g_io = permutation<Index<m, k, n, l, o, i, p, j>>(gggg);
auto g_g_g_g_ip = permutation<Index<m, k, n, l, o, j, p, i>>(gggg);
auto g_g_g_g_ir = permutation<Index<m, l, n, i, o, j, p, k>>(gggg);
auto g_g_g_g_j0 = permutation<Index<m, l, n, i, o, k, p, j>>(gggg);
auto g_g_g_g_ji = permutation<Index<m, l, n, j, o, i, p, k>>(gggg);
auto g_g_g_g_jj = permutation<Index<m, l, n, j, o, k, p, i>>(gggg);
auto g_g_g_g_jk = permutation<Index<m, l, n, k, o, i, p, j>>(gggg);
auto g_g_g_g_jl = permutation<Index<m, l, n, k, o, j, p, i>>(gggg);
Tensor<double, 4, 4, 4, 4, 4, 4, 4, 4> get_gggg =
(1 / 24) *
(gggg + g_g_g_g_j + g_g_g_g_k + g_g_g_g_l + g_g_g_g_m + g_g_g_g_n +
g_g_g_g_o + g_g_g_g_p + g_g_g_g_r + g_g_g_g_i0 + g_g_g_g_ii +
g_g_g_g_ij + g_g_g_g_ik + g_g_g_g_il + g_g_g_g_im + g_g_g_g_in +
g_g_g_g_io + g_g_g_g_ip + g_g_g_g_ir + g_g_g_g_j0 + g_g_g_g_ji +
g_g_g_g_jj + g_g_g_g_jk + g_g_g_g_jl);
////////// 72 terms ///////////////////////////////////////////////
auto g_g_g_g_0 = permutation<Index<i, j, m, n, l, p, k, o>>(gggg);
auto g_g_g_g_1 = permutation<Index<i, j, m, n, l, o, k, p>>(gggg);
auto g_g_g_g_2 = permutation<Index<i, j, m, o, l, p, k, n>>(gggg);
auto g_g_g_g_3 = permutation<Index<i, j, m, o, l, n, k, p>>(gggg);
auto g_g_g_g_4 = permutation<Index<i, j, m, p, l, o, k, n>>(gggg);
auto g_g_g_g_5 = permutation<Index<i, j, m, p, l, n, k, o>>(gggg);
auto g_g_g_g_6 = permutation<Index<i, j, n, o, l, p, k, m>>(gggg);
auto g_g_g_g_7 = permutation<Index<i, j, n, o, l, m, k, p>>(gggg);
auto g_g_g_g_8 = permutation<Index<i, j, n, p, l, o, k, m>>(gggg);
auto g_g_g_g_9 = permutation<Index<i, j, n, p, l, m, k, o>>(gggg);
auto g_g_g_g_10 = permutation<Index<i, j, o, p, l, n, k, m>>(gggg);
auto g_g_g_g_11 = permutation<Index<i, j, o, p, l, m, k, n>>(gggg);
auto g_g_g_g_12 = permutation<Index<i, k, m, n, l, p, j, o>>(gggg);
auto g_g_g_g_13 = permutation<Index<i, k, m, n, l, o, j, p>>(gggg);
auto g_g_g_g_14 = permutation<Index<i, k, m, o, l, p, j, n>>(gggg);
auto g_g_g_g_15 = permutation<Index<i, k, m, o, l, n, j, p>>(gggg);
auto g_g_g_g_16 = permutation<Index<i, k, m, p, l, o, j, n>>(gggg);
auto g_g_g_g_17 = permutation<Index<i, k, m, p, l, n, j, o>>(gggg);
auto g_g_g_g_18 = permutation<Index<i, k, n, o, l, p, j, m>>(gggg);
auto g_g_g_g_19 = permutation<Index<i, k, n, o, l, m, j, p>>(gggg);
auto g_g_g_g_20 = permutation<Index<i, k, n, p, l, o, j, m>>(gggg);
auto g_g_g_g_21 = permutation<Index<i, k, n, p, l, m, j, o>>(gggg);
auto g_g_g_g_22 = permutation<Index<i, k, o, p, l, n, j, m>>(gggg);
auto g_g_g_g_23 = permutation<Index<i, k, o, p, l, m, j, n>>(gggg);
auto g_g_g_g_24 = permutation<Index<i, l, m, n, k, p, j, o>>(gggg);
auto g_g_g_g_25 = permutation<Index<i, l, m, n, k, o, j, p>>(gggg);
auto g_g_g_g_26 = permutation<Index<i, l, m, o, k, p, j, n>>(gggg);
auto g_g_g_g_27 = permutation<Index<i, l, m, o, k, n, j, p>>(gggg);
auto g_g_g_g_28 = permutation<Index<i, l, m, p, k, o, j, n>>(gggg);
auto g_g_g_g_29 = permutation<Index<i, l, m, p, k, n, j, o>>(gggg);
auto g_g_g_g_30 = permutation<Index<i, l, n, o, k, p, j, m>>(gggg);
auto g_g_g_g_31 = permutation<Index<i, l, n, o, k, m, j, p>>(gggg);
auto g_g_g_g_32 = permutation<Index<i, l, n, p, k, o, j, m>>(gggg);
auto g_g_g_g_33 = permutation<Index<i, l, n, p, k, m, j, o>>(gggg);
auto g_g_g_g_34 = permutation<Index<i, l, o, p, k, n, j, m>>(gggg);
auto g_g_g_g_35 = permutation<Index<i, l, o, p, k, m, j, n>>(gggg);
auto g_g_g_g_36 = permutation<Index<j, k, m, n, l, p, i, o>>(gggg);
auto g_g_g_g_37 = permutation<Index<j, k, m, n, l, o, i, p>>(gggg);
auto g_g_g_g_38 = permutation<Index<j, k, m, o, l, p, i, n>>(gggg);
auto g_g_g_g_39 = permutation<Index<j, k, m, o, l, n, i, p>>(gggg);
auto g_g_g_g_40 = permutation<Index<j, k, m, p, l, o, i, n>>(gggg);
auto g_g_g_g_41 = permutation<Index<j, k, m, p, l, n, i, o>>(gggg);
auto g_g_g_g_42 = permutation<Index<j, k, n, o, l, p, i, m>>(gggg);
auto g_g_g_g_43 = permutation<Index<j, k, n, o, l, m, i, p>>(gggg);
auto g_g_g_g_44 = permutation<Index<j, k, n, p, l, o, i, m>>(gggg);
auto g_g_g_g_45 = permutation<Index<j, k, n, p, l, m, i, o>>(gggg);
auto g_g_g_g_46 = permutation<Index<j, k, o, p, l, n, i, m>>(gggg);
auto g_g_g_g_47 = permutation<Index<j, k, o, p, l, m, i, n>>(gggg);
auto g_g_g_g_48 = permutation<Index<j, l, m, n, k, p, i, o>>(gggg);
auto g_g_g_g_49 = permutation<Index<j, l, m, n, k, o, i, p>>(gggg);
auto g_g_g_g_50 = permutation<Index<j, l, m, o, k, p, i, n>>(gggg);
auto g_g_g_g_51 = permutation<Index<j, l, m, o, k, n, i, p>>(gggg);
auto g_g_g_g_52 = permutation<Index<j, l, m, p, k, o, i, n>>(gggg);
auto g_g_g_g_53 = permutation<Index<j, l, m, p, k, n, i, o>>(gggg);
auto g_g_g_g_54 = permutation<Index<j, l, n, o, k, p, i, m>>(gggg);
auto g_g_g_g_55 = permutation<Index<j, l, n, o, k, m, i, p>>(gggg);
auto g_g_g_g_56 = permutation<Index<j, l, n, p, k, o, i, m>>(gggg);
auto g_g_g_g_57 = permutation<Index<j, l, n, p, k, m, i, o>>(gggg);
auto g_g_g_g_58 = permutation<Index<j, l, o, p, k, n, i, m>>(gggg);
auto g_g_g_g_59 = permutation<Index<j, l, o, p, k, m, i, n>>(gggg);
auto g_g_g_g_60 = permutation<Index<k, l, m, n, j, p, i, o>>(gggg);
auto g_g_g_g_61 = permutation<Index<k, l, m, n, j, o, i, p>>(gggg);
auto g_g_g_g_62 = permutation<Index<k, l, m, o, j, p, i, n>>(gggg);
auto g_g_g_g_63 = permutation<Index<k, l, m, o, j, n, i, p>>(gggg);
auto g_g_g_g_64 = permutation<Index<k, l, m, p, j, o, i, n>>(gggg);
auto g_g_g_g_65 = permutation<Index<k, l, m, p, j, n, i, o>>(gggg);
auto g_g_g_g_66 = permutation<Index<k, l, n, o, j, p, i, m>>(gggg);
auto g_g_g_g_67 = permutation<Index<k, l, n, o, j, m, i, p>>(gggg);
auto g_g_g_g_68 = permutation<Index<k, l, n, p, j, o, i, m>>(gggg);
auto g_g_g_g_69 = permutation<Index<k, l, n, p, j, m, i, o>>(gggg);
auto g_g_g_g_70 = permutation<Index<k, l, o, p, j, n, i, m>>(gggg);
auto g_g_g_g_71 = permutation<Index<k, l, o, p, j, m, i, n>>(gggg);
return g_g_g_g_71;
}
Tensor<double, 4, 4> Gt(const Tensor<double, 4>& a)
{
Tensor<double, 4, 4> G = metric();
enum { i, j, k };
return G - einsum<Index<i>, Index<j>>(a, a) / dot(a, a);
}
int main()
{
Tensor<double, 4> Kp1 = {1, 1, 1, 8};
auto p4 = _P4(Kp1);
print(p4);
}The following gives incorrect result
Tensor<double,2,3> a;
a.iota();
Tensor<double,3> b = a(0,all);whereas this one gives the correct result
Tensor<double,2,3> a;
a.iota();
Tensor<double,1,3> b = a(0,all);when i use einsum example :
enum{i,j,k};
Tensor<double, 2, 2> a = {{1, 2}, {3, 4}};
Tensor<double, 2> w = {1, 1};
auto e3 = einsum<Index<i, j>, Index <i> >(a, w);
//it ruturn
[4.000]
[0.000]why?
As i am currently trying to understand and follow this framework, it would be really helpful for you to release a extensive documentation, listing all current features, things to expect, things to steer clear from and just related stuff. If i have missed this document somewhere, pardon me.
Reported by Sebastian Moeckel through email:
I obtain an error when trying to compile the following altered version
of the readme example:
#include <Fastor.h>
using namespace Fastor;
enum {I,J,K,L,M,N};
int main() {
// An example of Einstein summation
Tensor<double,5,5,5> A;
Tensor<double,5> B;
// fill A and B
A.random(); B.random();
auto C = einsum<Index<I,J,K>,Index<J>>(A,B);
return 0;
}The error (gcc 6.2) reads as follows:
In file included from
/home/don/.local/include/Fastor/tensor_algebra/einsum.h:6:0,
from /home/don/.local/include/Fastor/Fastor.h:11,
from FastorTest.cpp:1:
/home/don/.local/include/Fastor/meta/einsum_meta.h: In instantiation of
‘constexpr const int Fastor::general_stride_finder<Fastor::Index<0ul,
1ul, 2ul>, Fastor::Index<1ul>, Fastor::Tensor<double, 5ul, 5ul, 5ul>,
Fastor::Tensor<double, 5ul>, Fastor::std_ext::index_sequence<0ul> >::value’:
/home/don/.local/include/Fastor/tensor_algebra/strided_contraction.h:227:109:
required from ‘static typename Fastor::contraction_impl<Fastor::Index<I1
..., I2 ...>, Fastor::Tensor<T, Rest0 ..., Rest1 ...>, typename
Fastor::std_ext::make_index_sequence<(sizeof... (Rest0) + sizeof...
(Rest1))>::type>::type
Fastor::extractor_reducible_contract<Fastor::Index<I1 ...>,
Fastor::Index<I2 ...> >::contract_impl(const Fastor::Tensor<Int,
IterSizes ...>&, const Fastor::Tensor<T, Rest1 ...>&) [with T = double;
long unsigned int ...Rest0 = {5ul, 5ul, 5ul}; long unsigned int ...Rest1
= {5ul}; long unsigned int ...Idx0 = {0ul, 1ul, 2ul}; long unsigned int
...Idx1 = {1ul}; typename Fastor::contraction_impl<Fastor::Index<I1 ...,
I2 ...>, Fastor::Tensor<T, Rest0 ..., Rest1 ...>, typename
Fastor::std_ext::make_index_sequence<(sizeof... (Rest0) + sizeof...
(Rest1))>::type>::type = Fastor::Tensor<double, 5ul, 5ul>]’
/home/don/.local/include/Fastor/tensor_algebra/einsum.h:70:76:
required from ‘decltype (Fastor::extractor_contract_2<Index_I,
Index_J>::contract_impl(a, b)) Fastor::einsum(const Fastor::Tensor<T,
Rest0 ...>&, const Fastor::Tensor<T, Rest1 ...>&) [with Index_I =
Fastor::Index<0ul, 1ul, 2ul>; Index_J = Fastor::Index<1ul>; T = double;
long unsigned int ...Rest0 = {5ul, 5ul, 5ul}; long unsigned int ...Rest1
= {5ul}; typename std::enable_if<(! Fastor::is_reduction<Idx0,
Idx1>::value), bool>::type <anonymous> = 0u; decltype
(Fastor::extractor_contract_2<Index_I, Index_J>::contract_impl(a, b)) =
Fastor::Tensor<double, 5ul, 5ul>]’
FastorTest.cpp:11:47: required from here
/home/don/.local/include/Fastor/meta/einsum_meta.h:452:51: in
constexpr expansion of
‘Fastor::last_indices_prod<1ul>(Fastor::general_stride_finder<Fastor::Index<0ul,
1ul, 2ul>, Fastor::Index<1ul>, Fastor::Tensor<double, 5ul, 5ul, 5ul>,
Fastor::Tensor<double, 5ul>, Fastor::std_ext::index_sequence<0ul>
>::container_dim, 1)’
/home/don/.local/include/Fastor/meta/einsum_meta.h:433:59: in
constexpr expansion of ‘Fastor::last_indices_prod<1ul>(seq, (num + -1))’
/home/don/.local/include/Fastor/meta/einsum_meta.h:452:26: error: array
subscript value ‘-1’ is outside the bounds of array type ‘const int [1]’
static constexpr int value =
last_indices_prod(container_dim,sizeof...(Rest1));I obtain a similar error, when compiling with gcc 5.4.
Thanks for your support.
auto MMM(Tensor<double, 4>& a)
{
enum { i, j, k, l, m, n, o, p };
Tensor<double, 4> Kp1 = {1, 1, 1, 8};
auto x = einsum<Index<i>, Index<j>>(Kp1, Kp1);
auto result =
einsum<Index<i, j>, Index<k, l>>(x, x);
// einsum<Index<i, j>, Index<k, l>, Index<m, n>, Index<o, p>>(x, x, x, x);
// auto aaa = result* result;
Tensor<double,4,4> KK = {{1,2,3,4},{1,2,3,4},{1,2,3,4},{1,2,3,4}};
// print(KK);
auto aaa = KK * KK ;
return aaa;
}
int main()
{
Tensor<double, 4> Psi = {40, 0, 0, 3686};
auto mmm = MMM(Psi);
std::cout << __LINE__ << std::endl
print(mmm);
}
//it return
135
[ 0, 0, 0, 0]
[ 0, 0, 0, 0]
[ 0, inf, inf, inf]
[inf, inf, 0, 0]
//but when i change it with
auto MMM(Tensor<double, 4>& a)
{
enum { i, j, k, l, m, n, o, p };
Tensor<double, 4> Kp1 = {1, 1, 1, 8};
auto x = einsum<Index<i>, Index<j>>(Kp1, Kp1);
auto result =
einsum<Index<i, j>, Index<k, l>>(x, x);
// einsum<Index<i, j>, Index<k, l>, Index<m, n>, Index<o, p>>(x, x, x, x);
// auto aaa = result* result;
Tensor<double,4,4> KK = {{1,2,3,4},{1,2,3,4},{1,2,3,4},{1,2,3,4}};
print(KK);
auto aaa = KK * KK ;
return aaa;
}
// it return
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]
[1, 2, 3, 4]
135
[ 1, 4, 9, 16]
[ 1, 4, 9, 16]
[ 1, 4, 9, 16]
[ 1, 4, 9, 16]
Just opening for discussion. But implementing masked vectors for each vector type might give some performance advantage over the current implementation
Problems like in #34 should dispatch to specialised matmul.
See discussion in #42
when i write my code i meet a problem it puzzled me
the function is :
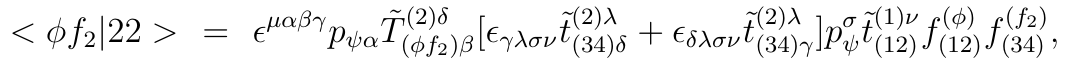
// definition of G_{mu,nu}
Tensor<double, 4, 4> metric()
{
Tensor<double, 4, 4> G = {{-1., 0., 0., 0.},
{0., -1., 0., 0.},
{0., 0., -1., 0.},
{0., 0., 0., 1.}};
return G;
}
Tensor<double, 4> phif222(const Tensor<double, 4>& psi2s,
const Tensor<double, 4>& phi,
const Tensor<double, 4>& f2,
const Tensor<double, 4>& kp,
const Tensor<double, 4>& km,
const Tensor<double, 4>& pip,
const Tensor<double, 4>& pim)
{
enum { mu, a, b, r, delta, sigma, nu, lamda };
Tensor<double, 4, 4, 4, 4> leci = leci_four();
Tensor<double, 4, 4> G = metric();
Tensor<double, 4, 4, 4, 4> leci_1 =
einsum<Index<mu, a, b, r>, Index<mu, nu>>(leci, G);
Tensor<double, 4, 4, 4, 4> leci_2 =
einsum<Index<mu, a, b, r>, Index<a, nu>>(leci_1, G);
Tensor<double, 4, 4, 4, 4> leci_3 =
einsum<Index<mu, a, b, r>, Index<b, nu>>(leci_2, G);
Tensor<double, 4, 4, 4, 4> leci_4 =
einsum<Index<mu, a, b, r>, Index<r, nu>>(leci_3, G);
////////////////////// T^{(2)}
Tensor<double, 4, 4> T2 = TT2(psi2s, phi, f2);
Tensor<double, 4, 4> T2_ = einsum<Index<mu, nu>, Index<nu, delta>>(T2, G);
////////////////////// t^{(2)}
Tensor<double, 4, 4> t2 = TT2(f2, pip, pim);
Tensor<double, 4, 4> t2_ = einsum<Index<mu, nu>, Index<nu, delta>>(t2, G);
////////////////////// t^{(1)}
Tensor<double, 4> t1 = TT1(phi, kp, km);
Tensor<double, 4> t1_ = einsum<Index<nu>, Index<nu, mu>>(t1, G);
////////////////////// p_{psi}_alph
Tensor<double, 4> psi2s_ = einsum<Index<mu>, Index<mu, nu>>(psi2s, G);
////////////////////////////////////////////////////////////////////
auto first_1 = einsum<Index<mu, a, b, r>, Index<a>>(leci_4, psi2s_);
auto first_2 = einsum<Index<mu, b, r>, Index<a, b>>(first_1, T2_);
auto second_1 =
einsum<Index<mu, delta, r>, Index<r, lamda, sigma, nu>>(first_1, leci);
auto second_2 = einsum<Index<mu, delta, r>, Index<delta, lamda, sigma, nu>>(
first_1, leci);
auto third_1 =
einsum<Index<mu, delta, lamda, sigma, nu>, Index<lamda, delta>>(
second_1, t2_);
auto third_2 =
einsum<Index<mu, r, lamda, sigma, nu>, Index<lamda, r>>(second_2, t2_);
Tensor<double, 4, 4, 4> add = third_1 + third_2;
print(add);
auto result = einsum<Index<mu, sigma, nu>, Index<sigma>>(add, psi2s);
auto result_ = einsum<Index<mu, nu>, Index<nu>>(result, t1_);
return result_;
}it is my code , i do not konw how to write the function use einsum , do i right in up code ?
can you help me , how to write so many term to einsum
When trying to compile the later code, gcc gets caught in an infinite loop and nearly crahses the system(mine atleast) when trying to compile the second outer-product of two vectors(I = 100, h= 50, O =10):
template<typename T, long I, long h, long O>
void fastorFF(cTensor<T> &In, cTensor<T> &tar){
T learnR = 0.05;
Fastor::Tensor<T, I, 1> inputs;
Fastor::Tensor<T, h, I> w_ih; w_ih.random();
Fastor::Tensor<T, O, h> w_ho; w_ho.random();
Fastor::Tensor<T, O, 1> target;
Fastor::Tensor<T, h, 1> b_h; b_h.random();
Fastor::Tensor<T, O, 1> b_o; b_o.random();
for(int i = 0; i < I; ++i){
inputs(i, 0) = In.get2({i});
}
for(int i = 0; i < O; ++i){
target(i, 0) = tar.get2({i});
}
{
Fastor::Tensor<T, h, 1> hidden = Fastor::einsum<Fastor::Index<a,b>, Fastor::Index<b,c>>(w_ih, inputs);
hidden += b_h;
hidden = (1)/(1 + exp((-1)*hidden));
Fastor::Tensor<T, O, 1> output = Fastor::einsum<Fastor::Index<a,b>, Fastor::Index<b,c>>(w_ho, hidden);
output += b_o;
hidden = (1)/(1 + exp((-1)*output));
Fastor::Tensor<T, O, 1> o_error = target - output;
Fastor::Tensor<T, O, 1> gradient = learnR * o_error * (output * (1 - output));
b_o += gradient;
===>w_ho += Fastor::einsum<Fastor::Index<a, b>, Fastor::Index<c, d>>(gradient, hidden);
Fastor::Tensor<T, h, 1> h_error = Fastor::einsum<Fastor::Index<b,a>, Fastor::Index<b,c>>(w_ho, o_error);
Fastor::Tensor<T, h, 1> h_gradient = learnR * h_error * (hidden * (1 - hidden));
b_h += h_gradient;
===>w_ih += Fastor::einsum<Fastor::Index<a,b>, Fastor::Index<c, d>>(h_gradient, inputs);
}
}
(every lower-case letter inside of Fastor::Index<> has been globally defined as an enum in ascending order)
Reported by @semoe
The following code does not return the expected results:
#include <Fastor.h>
using namespace Fastor;
enum {a,b,c,d,e,f,g,h,i,j,k,l};
int main() {
// An example of Einstein summation
Tensor<double,3,3> n_UU = 0;
Tensor<double,3,3,3> w_ddd = 0;
// fill n_UU
n_UU(0,0) = 1;
n_UU(1,1) = 1;
n_UU(2,2) = -1;
// fill w_ddd
w_ddd(0,0,0) = 1;
w_ddd(0,2,2) = 1;
w_ddd(1,0,1) = 1;
w_ddd(1,1,0) = -1;
w_ddd(2,0,2) = -1;
w_ddd(2,2,0) = 1;
print(w_ddd);
print(n_UU);
auto RTT = einsum<Index<a,c>,Index<f,g>,Index<c,f,b>,Index<g,d,a>>(n_UU, n_UU, w_ddd, w_ddd);
print();
print(RTT);
return 0;
}Output
[ -1.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, -1.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000 ]
expected output
[ -1.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000 ]
[ 0.000000000, 0.000000000, 0.000000000 ]
The fseq variant used to be much faster than the scalar code and now it is over 5 times slower
At the moment tensor views only work on class Tensor specifically. We should investigate providing tensor views for AbstractTensor in general.
Requested by Sebastian Moeckel:
Is there any plan to implement some implicit casting of Tensor<T> to T? i.e. writing
T C = einsum<Index<I>,Index<I>>(A,B);would be possible?
Hi Roman,
I am asking myself how to make use of the 0-optimization in Fastor (=speed up tensor operations by neglecting entries that are definitely 0).
Consider a class of the following form
class EOM<typename T, UInt N>
{
private:
Tensor<T,N,N> g_dd = 0;
Tensor<T,N,N> R_dd = 0;
public:
//some constructor, etc
void fill_g_dd(std::vector<T> coords)
{
// here only a small part of the components of g_dd are filled, the rest remains zero, i.e. is not touched, which components are filled is specified at compile time but depends on the runtime data coords, for instance
g_dd(0,0) = sin(coords[0]);
// etc......
}
void compute_R_dd()
{
// this now takes g_dd and computes R_dd, involving potentially many contractions, permutations, etc.
}
}How can I change the form of this class in order to make use of the zero-optimizations when computing R_dd from g_dd, which would really pay out since g_dd is sparse.
Is this even possible?
Thank you for your support.
Best regards,
Sebastian
Thanks a lot for the release, the code looks great. I've adapted my benchmark code to try your library. The code just does a bunch of inverse and mmuls to simulate a Kalman filter.
Fastor is ~2x faster than Eigen for small matrices (which is amazing), is as fast as Eigen for 64-size matrices, but roughly ~2x slower for 128-size matrices. This is -mavx on an i9-9700k with gcc 8. Do you have any idea why this might be the case?
Run on (8 X 4900 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x8)
L1 Instruction 32 KiB (x8)
L2 Unified 256 KiB (x8)
L3 Unified 12288 KiB (x1)
Load Average: 1.08, 0.79, 0.41
------------------------------------------------------------------------------------
Benchmark Time CPU Iterations
------------------------------------------------------------------------------------
CovarianceUpdateFastor<8> 241 ns 241 ns 2836716
CovarianceUpdateEigen<8>/8 393 ns 393 ns 1771414
CovarianceUpdateEigen<Eigen::Dynamic>/8 822 ns 822 ns 830852
CovarianceUpdateFastor<16> 1144 ns 1144 ns 610699
CovarianceUpdateEigen<16>/16 2117 ns 2117 ns 333241
CovarianceUpdateEigen<Eigen::Dynamic>/16 2352 ns 2352 ns 298774
CovarianceUpdateFastor<32> 7689 ns 7689 ns 90656
CovarianceUpdateEigen<32>/32 9936 ns 9936 ns 69588
CovarianceUpdateEigen<Eigen::Dynamic>/32 8752 ns 8752 ns 78695
CovarianceUpdateFastor<64> 44389 ns 44389 ns 15646
CovarianceUpdateEigen<64>/64 49503 ns 49503 ns 13345
CovarianceUpdateEigen<Eigen::Dynamic>/64 48440 ns 48440 ns 14342
CovarianceUpdateFastor<128> 449163 ns 449160 ns 1584
CovarianceUpdateEigen<128>/128 339488 ns 339446 ns 2104
CovarianceUpdateEigen<Eigen::Dynamic>/128 330540 ns 330537 ns 2167
To
FASTOR_BOUNDS_CHECK
FASTOR_SHAPE_CHECK
Reported by Jia-Wei via email:
This example while certainly dealing with very big tensors throws overflow error in opmin.h
#include <Fastor.h>
#include <ctime>
using namespace Fastor;
using namespace std;
enum {I,J,K,L,M,N};
int main() {
const int chi = 40;
Tensor<double,chi,chi,chi> A,B,C;
// fill A, B, C
A.random(); B.random(); C.random();
auto D = einsum<Index<I,N,M>,Index<J,L,N>,Index<K,M,L>>(A,B,C);
return 0;
}The root cause is overflow in the breadth-first cost model as reported by GCC
./meta/opmin_meta.h:25:26: error: overflow in constant expression [-fpermissive]
static constexpr int value = cost_tensor0*remaining_cost;
Note that this problem would persist even for small tensor networks which end up having a big cost.
Could I suggest to prefix Fastor definition with FASTOR_ to avoid conflicts with other libs? For example Zero or One defined in commons.h are pretty common. Moreover some of them are not used.
Thanks for this nice work !
Running your backend_benchmarks, causes this error.
Running customised matmul kernels for 3D numerical quadrature [Benchmarks SIMD vectorisation]
Matrices size (M, K, N) 3 4 3 Speed-up over scalar code [elapsed time] 2.32717 [saved CPU cycles] 9
free(): invalid next size (fast)
Makefile:45: recipe for target 'run' failed
make: *** [run] Aborted (core dumped)
I would like to know, what compilerflags i have to set if i want to ensure, that Fastor runs at its fullest potential. Right now, i have downloaded and linked it, but not really taken further precautions.
EDIT: -O3 and -march=native are being used
Is it possible to interface with raw data organized in column major layout?
The following code crashes
Tensor<double,4,4,40,41> a;
// Tensor<double,1,1,40,41> b = a(0,0,all,all) + 1 + a(0,0,all,all); // this one does not
Tensor<double,40,41,1,1> b = a(0,0,all,all);// + 1 + a(0,0,all,all); // this one doesthis is due to product_ and as arrays being multiplied and creating a much greater (out of bounds) index than necessary. The product_ array in both cases is {6560, 1640, 41, 1}
Using _mm512_permutevar_pd. Something like
// 0,1,2,
// 3,4,5,
// 6,7,8
__m512d trans07 = _mm512_loadu_pd(src);
const __m512i trans_mask = _mm512_setr_epi64(
0,3,6,
1,4,7,
2,5);
__m512d out = _mm512_permutevar_pd(trans07, trans_mask);
_mm512_storeu_pd(dst,out);
dst[8] = src[8];Load and store aside, this optimises to one cycle! Note that _mm512_permutevar_pd might not permute across 128/256 boundaries
when i print a double date, i only get 8 effective number . but i want 16 effective number
#include "../Fastor.h"
#include "base.h"
#include "func.h"
#include <cstdlib>
#include <fstream>
#include <iostream>
#include <vector>
using namespace Fastor;
template <typename T> void test()
{
Tensor<double, 4> Psi = {40, 0, 0, 3686};
Tensor<double, 4> Kp1 = {1, 1, 1, 1};
Tensor<double, 4> Km1 = {1, 2, 3, 4};
Tensor<double, 4> Kp2 = {1, 1, 1, 1};
Tensor<double, 4> Km2 = {1, 2, 3, 4};
Tensor<double, 4> Phi;
Tensor<double, 4> f0;
Phi = Kp1 + Km1;
f0 = Kp2 + Km2;
print(Phi);
print(f0);
}
int main()
{
test<double>();
return 0;
}
// i get
[ 2.000000000 ]
[ 3.000000000 ]
[ 4.000000000 ]
[ 5.000000000 ]
[ 2.000000000 ]
[ 3.000000000 ]
[ 4.000000000 ]
[ 5.000000000 ]
There is no reason why this shouldn't be. Opens the window for a lot of compile time optimisations. This already works fine. The only culprit at the moment is that fixed views do not support noalias() so while right now
A(all,all).noalias() = ...dispatches to TensorViews if all==fall then
A(all,all).noalias() = ...would dispatch to TensorFixedViews which don't have noalias() feature.
Consider
Tensor<T,4,4,4> a; a.iota(1);
Tensor<T,4,4> b; b.iota(1);
Tensor<T,4> c1 = einsum<Index<i,j,k>,Index<j,k> >(a,b);This a generalisation of #33 for high order tensors
make && make run && make clean
g++ -I../../ benchmark_finite_difference.cpp -o out_loops.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_LOOPS
g++ -I../../ benchmark_finite_difference.cpp -o out_seq_alias.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_SEQ_ALIAS
g++ -I../../ benchmark_finite_difference.cpp -o out_seq_noalias.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_SEQ_NOALIAS -DFASTOR_NO_ALIAS
g++ -I../../ benchmark_finite_difference.cpp -o out_iseq.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_ISEQ
g++ -I../../ benchmark_finite_difference.cpp -o out_fseq.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_FSEQ
g++ -I../../ benchmark_finite_difference.cpp -o out_seq_alias_vec.exe -std=c++14 -O3 -march=native -DNDEBUG -finline-limit=1000000 -ffp-contract=fast -mfma -DUSE_SEQ_ALIAS -DFASTOR_USE_VECTORISED_EXPR_ASSIGN
In file included from ../../Fastor.h:6,
from benchmark_finite_difference.cpp:1:
../../simd_vector/SIMDVector.h: In instantiation of ‘Fastor::SIMDVector<T, 512> Fastor::sin(const Fastor::SIMDVector<T, 512>&) [with T = double]’:
../../expressions/unary_ops/unary_math_ops.h:266:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnarySinOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = double; Expr = Fastor::Tensor<double, 100>; long unsigned int DIM0 = 1; Fastor::FASTOR_INDEX = long unsigned int]’
../../expressions/views/tensor_views_2d.h:618:22: required from ‘void Fastor::TensorViewExpr<Fastor::Tensor<T, M, N>, 2>::operator=(const Fastor::AbstractTensor<Derived, DIMS>&) [with Derived = Fastor::UnarySinOp<Fastor::Tensor<double, 100>, 1>; long unsigned int DIMS = 1; T = double; long unsigned int M = 100; long unsigned int N = 100]’
benchmark_finite_difference.cpp:137:14: required from ‘void run_finite_difference() [with T = double; long unsigned int num = 100]’
benchmark_finite_difference.cpp:195:51: required from here
../../simd_vector/SIMDVector.h:46:15: error: incompatible types in assignment of ‘const double*’ to ‘double [8]’
out.value = internal_sin(a.value);
~~~~~~~~~~^~~~~~~~~~~~~~~~~~~~~~~
In file included from ../../simd_vector/simd_vector_base.h:6,
from ../../simd_vector/SIMDVector.h:4,
from ../../Fastor.h:6,
from benchmark_finite_difference.cpp:1:
../../math/internal_math.h: In instantiation of ‘T Fastor::internal_sin(T) [with T = const double*]’:
../../simd_vector/SIMDVector.h:46:29: required from ‘Fastor::SIMDVector<T, 512> Fastor::sin(const Fastor::SIMDVector<T, 512>&) [with T = double]’
../../expressions/unary_ops/unary_math_ops.h:266:19: required from ‘Fastor::SIMDVector<U, 512> Fastor::UnarySinOp<Expr, DIMS>::eval(Fastor::FASTOR_INDEX) const [with U = double; Expr = Fastor::Tensor<double, 100>; long unsigned int DIM0 = 1; Fastor::FASTOR_INDEX = long unsigned int]’
../../expressions/views/tensor_views_2d.h:618:22: required from ‘void Fastor::TensorViewExpr<Fastor::Tensor<T, M, N>, 2>::operator=(const Fastor::AbstractTensor<Derived, DIMS>&) [with Derived = Fastor::UnarySinOp<Fastor::Tensor<double, 100>, 1>; long unsigned int DIMS = 1; T = double; long unsigned int M = 100; long unsigned int N = 100]’
benchmark_finite_difference.cpp:137:14: required from ‘void run_finite_difference() [with T = double; long unsigned int num = 100]’
benchmark_finite_difference.cpp:195:51: required from here
../../math/internal_math.h:297:15: error: assignment of read-only location ‘*(out + ((sizetype)(i * 8)))’
out[i] = std::sin(a[i]);
~~~~~~~^~~~~~~~~~~~~~~~
make: *** [Makefile:42: all] Error 1
I get this error, after trying to compile and run the benchmark on a AVX512-machine. Weirdly, this works just fine on my Ubuntu-machine at home.
Requested by Sebastian Moeckel:
Is there a way to use binary sub-operation in einsum, without splitting the einsum?
I.e. is it possible to write:
Tensor<double,5> A, B, C;
Tensor<double,5,5> D;
.... //some initialization
D = einsum<Index<I>,Index<J>>(A, B - C)instead of
D= einsum<Index<I>,Index<J>>(A, B) - einsum<Index<I>,Index<J>>(A,C);I mainly ask, since I have large BinarySubOp expressions (also defining
them into a separate variable did fail due to stack overflow).
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.