This implementation follows the step-by-step guide provided in Umar Jamil's YouTube video: Transformers from Scratch
This repository contains the implementation of a Transformer model in PyTorch, including scripts for training the model on bilingual datasets.
This implementation provides a modular and extensible structure for the Transformer model. Each component of the model is implemented as a separate class, making it easy to understand and modify individual parts of the architecture.
The Transformer model architecture is a complex structure best understood visually. Below is the diagram to help illustrate the concept:
For a detailed technical diagram of the Transformer architecture, please refer to this image:
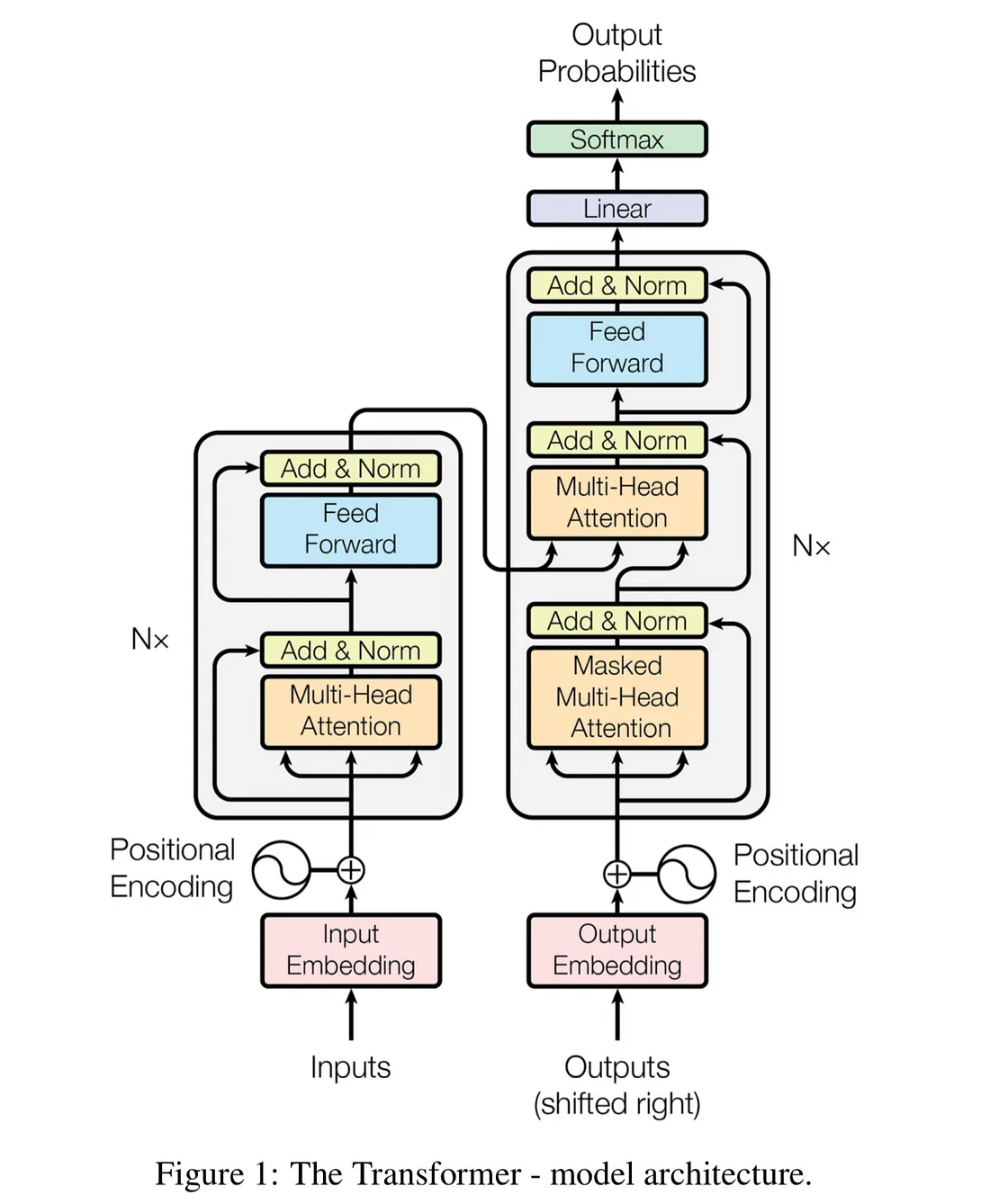
This diagram shows the intricate components of the Transformer model, including the encoder and decoder stacks, multi-head attention mechanisms, and feed-forward networks.
For a lighter take on "transformers", here's an image from the popular movie franchise:

While not technically related to our NLP model, this image serves as a fun reminder of the term "transformer" in popular culture!
Our implementation focuses on the technical architecture shown in the first image, not the movie characters. The model transforms input sequences into output sequences, hence the name "Transformer".
Contains the implementation of various components of the Transformer model such as:
- LayerNormalization
- FeedForwardBlock
- InputEmbeddings
- PositionalEncoding
- ResidualConnection
- MultiHeadAttentionBlock
- EncoderBlock
- Encoder
- DecoderBlock
- Decoder
- ProjectionLayer
- Transformer
Contains the implementation of:
- BilingualDataset: Handles the preparation of bilingual data for the Transformer model, including tokenization, padding, and masking.
- causal_mask: Creates a causal mask for the decoder to ensure that the model does not attend to future positions in the sequence.
Handles the training of the Transformer model. Includes functions such as:
greedy_decode: Performs greedy decoding to generate translations from the model.run_validation: Runs the validation process and calculates evaluation metrics.get_all_sentences: Yields all sentences in a dataset for a given language.get_or_build_tokenizer: Builds or loads a tokenizer.get_ds: Loads the dataset, builds tokenizers, and creates dataloaders.get_model: Builds the Transformer model.train_model: Orchestrates the training process.
To build and use the Transformer model, you need to follow these steps:
- Prepare the dataset: Ensure you have a bilingual dataset to train on.
- Configure the model: Set up the configuration parameters for the model and training process.
- Run the training script: Execute
train.pyto start the training process.
To train the model, execute the train.py script:
python train.py
