By Aritra Roy Gosthipaty and Sayak Paul (equal contribution)
In this repository, we provide tools to probe into the representations learned by different families of Vision Transformers (supervised pre-training with ImageNet-21k, ImageNet-1k, distillation, self-supervised pre-training):
- Original ViT [1]
- DeiT [2]
- DINO [3]
We hope these tools will prove to be useful for the community. Please follow along with this post on keras.io for a better navigation through the repository.
Updates
- June 3, 2022: The project got the Google OSS Expert Prize.
- May 10, 2022: The project got a mention from Yannic Kilcher in ML News. Thanks, Yannic!
- May 4, 2022: We're glad to receive the #TFCommunitySpotlight award for this project.
| Original Image | Attention Maps | Attention Maps Overlayed |
|---|---|---|
 |
 |
 |
output-dino.mp4
output-dog.mp4
In the DINO blog post, the authors show a video with the following caption:
The original video is shown on the left. In the middle is a segmentation example generated by a supervised model, and on the right is one generated by DINO.
A screenshot of the video is as follows:

We obtain the attention maps generated with the supervised pre-trained model and find that they are not that salient w.r.t the DINO model. We observe a similar behaviour in our experiments as well. The figure below shows the attention heatmaps extracted with a ViT-B16 model pre-trained (supervised) using ImageNet-1k:
| Dinosaur | Dog |
|---|---|
 |
 |
We used this Colab Notebook to conduct this experiment.
You can now probe into the ViTs with your own input images.
| Attention Heat Maps | Attention Rollout |
|---|---|

We don't propose any novel methods of probing the representations of neural networks. Instead we take the existing works and implement them in TensorFlow.
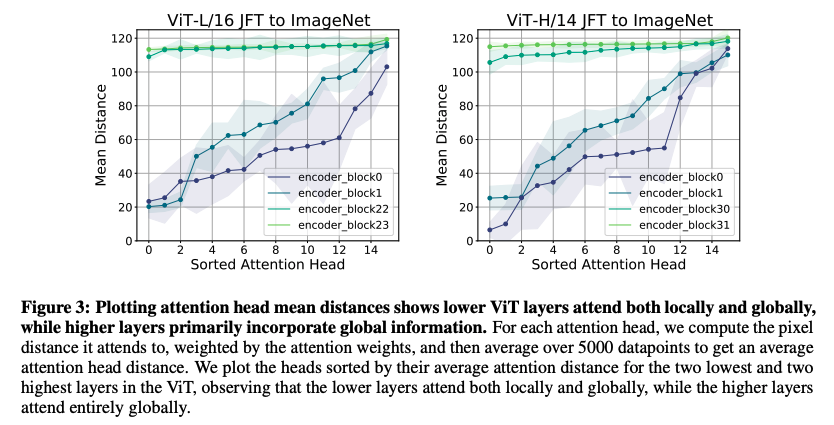
- Mean attention distance [1, 4]
- Attention Rollout [5]
- Visualization of the learned projection filters [1]
- Visualization of the learned positioanl embeddings
- Attention maps from individual attention heads [3]
- Generation of attention heatmaps from videos [3]
Another interesting repository that also visualizes ViTs in PyTorch: https://github.com/jacobgil/vit-explain.
We first implemented the above-mentioned architectures in TensorFlow and then we populated the pre-trained parameters into them using the official codebases. In order to validate this, we evaluated the implementations on the ImageNet-1k validation set and ensured that the reported top-1 accuracies matched.
We value the spirit of open-source. So, if you spot any bugs in the code or see a scope for improvement don't hesitate to open up an issue or contribute a PR. We'd very much appreciate it.
Our ViT implementations are in vit. We provide utility notebooks in the notebooks directory which contains the following:
dino-attention-maps-video.ipynbshows how to generate attention heatmaps from a video. (Visually,) best results were obtained with DINO.dino-attention-maps.ipynbshows how to generate attention maps from individual attention heads from the final transformer block. (Visually,) best results were obtained with DINO.load-dino-weights-vitb16.ipynbshows how to populate the pre-trained DINO parameters into our implementation (only for ViT B-16 but can easily be extended to others).load-jax-weights-vitb16.ipynbshows how to populate the pre-trained ViT parameters into our implementation (only for ViT B-16 but can easily be extended to others).mean-attention-distance-1k.ipynbshows how to plot mean attention distances of different transformer blocks of different ViTs computed over 1000 images.single-instance-probing.ipynbshows how to compute mean attention distance, attention-rollout map for a single prediction instance.visualizing-linear-projections.ipynbshows visualizations of the linear projection filters learned by ViTs.visualizing-positional-embeddings.ipynbshows visualizations of the similarities of the positional embeddings learned by ViTs.
DeiT-related code has its separate repository: https://github.com/sayakpaul/deit-tf.
Here are the links to the models where the pre-trained parameters were populated:
- Original ViT model (pretrained on ImageNet-21k and fine-tuned on ImageNet-1k)
- Original ViT model (pretrained on ImageNet-1k)
- DINO model (pretrained on ImageNet-1k)
- DeiT models (pretrained on ImageNet-1k including distilled and non-distilled ones)
Coming soon!
[1] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929
[2] DeiT: https://arxiv.org/abs/2012.12877
[3] DINO: https://arxiv.org/abs/2104.14294
[4] Do Vision Transformers See Like Convolutional Neural Networks?: https://arxiv.org/abs/2108.08810
[5] Quantifying Attention Flow in Transformers: https://arxiv.org/abs/2005.00928