shhdgit / blogs Goto Github PK
View Code? Open in Web Editor NEWMy blogs
My blogs



前两天重构vue-easy-slider时发现原本10kb左右的源码经过打包压缩之后变成了40kb,惊了个呆,满脑WTF。翻了翻dist出来的文件也没有把vue打包进去,小小的懵逼了一下。
后面想起来webpack cli的配置里好像有各种options可以设置,包括打包时显示进程,打包完成后显示打了哪些bundle,module,chunk等等。遂打开webpack文档,找到--display-modules就是我想要的配置,然后发现多打的20多kb的内容是babel的async/await,generator,promise等模块。
以前写项目几乎都没关注babel多打的几十k的文件,我做过的web app需求方上了cdn后都没差那几十k的加载时间,也真都忘了。以前看大牛说过在es2015落地前用babel,落地后把babel拿掉,可是现在都2017年了,es2015还是不敢拿掉,而且还加上了es2016,es2017...嗯,前端开发之痛,向下兼容。
发现是babel的锅了,那么去掉这些模块,把代码中所有的回调改回callback模式,改完打包压缩16kb,一个组件的大小,还可以接受。
以后开发插件、库还是只写es5吧,免得这些小玩意儿变大。项目开发的话,对于有点规模量的项目,只要不是移动端并且有极端加载速度要求的项目,我觉得都应该上babel,stage状态的特性也可以上。开发起来真的顺畅了不止一点,简单明了的代码也更易于维护,学习新语法要几个钱?是吧(对比框架学习)。
我回忆了一下,没有任何博客或者视频的作者在Go中以self或this作为方法的receiver,但是在stack overflow的很多问题下面就经常能看见有人以self或this作为方法的receiver。这让我感到疑惑,用self作为receiver名有什么问题吗?
好像曾经在哪里看到过有人说receiver并不完全是一个指向自身的指针,谁能解释一下这种说法吗。把self看做指向自身的指针有什么问题吗?
例子:
type MyStruct struct {
Name string
}那种方式比较合适呢,还是两种都ok?
func (m *MyStruct) MyMethod() error {
// do something useful
}or
func (self *MyStruct) MyMethod() error {
// do something useful
}其他的人都说的很好了,我再补充几点重要的:
在Go里,不但可以通过receiver的方式调用一个方法,还可以像一个普通的函数一样调用。在type的名称后跟上相应方法的名称并将receiver作为第一个参数传入(这种使用方式叫做使用method expression)。
demo:
package main
import "fmt"
type Foo int
func (f Foo) Bar() {
fmt.Printf("My receiver is %v\n", f)
}
func main() {
a := Foo(46)
a.Bar()
b := Foo(51)
Foo.Bar(b)
}运行结果:
My receiver is 46
My receiver is 51可以看出来,你手动调用并赋予了执行的上下文环境,使得self失去了他的语义,与面向对象编程中广泛引用的一句话“调用一个对象的方法就是给这个对象传递信息”的概念没有一点联系。
总的来说,在Go里方法其实就是将函数语义化地绑定在指定type上,并接受一个叫做receiver的参数,不管你以哪种方式调用方法,调用过程其实都是一样的。与大多数主流语言不同,Go并没有将方法调用的细节隐藏起来。
在上面的demo中可以看到我定义了一个Bar()方法,他的receiver并不是一个指针类型,如果试着在方法内部为receiver赋值就会发现赋值是可以赋值,但是并不会影响到方法的调用者,因为receiver的值(Go中所有的值都一样)是按值传递的(所以这里的receiver只是调用者的一份拷贝)。
为了能在方法里改变receiver能影响到方法调用者,你需要定义一个指针类型的receiver:
func (f *Foo) Bar() {
// here you can mutate the value via *f, like
*f = 73
}例子中的方法接收了一个确定类型的值,可以看出使用self表示“自身”已经毫无意义了。这与传统面向对象语言默认将对象按引用传递不同,在Go里你可以在任何东西“里”定义方法(包括在方法上定义方法,net/http标准库就是这么做的),“对象里的方法”这种概念已经不复存在了。
在Go里,方法可以非常方便用与组织特定类型的各种功能。在代码执行期间,同样的值可以拥有有不一样的方法,结合Go提供的接口,鸭子类型的编码风格,使得这种(动态织入方法)编码方式非常流行。我们经常能看到编码时会定义一个“Support”类型,在其中放很多为其他不同类型提供的方法。
标准库sort就是一个很好的例子:在sort包里提供一种IntSlice类型,这种类型允许你对整数类型的slice([]int)进行排序。只要将slice转换为IntSlice之后就拥有了各种对slice进行排序的方法,并且排序时原来的slice值并不会被改变(因为IntSlice就是type IntSlice []int)。很难去说IntSlice里的所有方法的receive带有self这层含义,因为这里所有的方法都是提供给其他类型使用的。从哲♂学的角度上看,这些工具类型并不存在“self”的概念。
所以,不要给自己的思维加上太多枷锁,并不一定要使用语义化的方式去解释Go所提供的清晰明了的编码哲学。我自己对Go语言的学习理解来看,Go语言首要的编码风格应该是实用(与务虚相反)。所以每当你“感觉”某些概念很不自然,你就可以试着去弄清楚为什么这些东西在Go里要这样设计,大多数情况你最后会发现这种设计真是精妙。(我觉得熟悉C语言对于理解Go语言里methods设计有很大的帮助,更有助于理解这个问题。)
在讲依赖注入之前,先聊聊控制反转。
控制反转里的控制指什么?
谁控制谁?反转什么?
为什么需要反转?
解决什么问题?
日常使用:
大型系统容易遇到的问题:
依赖关系复杂(这个技术上不解决,架构设计解决),大型项目分层之后不仅上层需要依赖底层,也会遇到底层依赖上层实现的情况。这时候可能是底层提供可编程切面,也可能是底层提供接口,让上层实现后进行注入。
参考实现:
进入2018年,大部分前端早已不再单纯使用类似 Vue, React 等视图库了,一般都是配合该技术方向各式的生态将其武装成“全家桶”的形式使用。相较于前两年人人爱折腾,现在大家更愿意使用社区提供的最佳实践方案。就连 webpack v4 都有了默认配置,也算是被 parcel 逼了一把。既然越来越多的人都愿意接受更好、更成熟、更工程化的方案,那我们是不是可以重新将关注的目光转移回曾经的王者,如今在“默默成长”的 Angular 呢。
为了让大家对 Angular 学习路线有个宏观的感受,我这里把 Angular 与相关重要技术的参考资料放在前面,详细的知识点放在后面。
文章翻译已征得原作者同意,原文链接:link
最近在 stackoverflow 上总看有人问 Angular 报 ExpressionChangedAfterItHasBeenCheckedError 错误的原因。大部分提问的人不太明白 Angular 的变化监测机制,不明白为什么需要这个报错信息。一些开发者甚至认为这个错误代表程序内有 bug ,但这个报错其实不代表程序有 bug 。
本篇文章将深入讲解报这个错误的原因,介绍这个错误是如何被监测到的,还会展示该错误经常出现的场景,并且给出几个可行的解决方案。在最后一节将会解释 Angular 为什么需要这个监测机制。
每个 Angular 应用都是以组件树的形态呈现的。在变化监测阶段会每个组件执行以下操作( Digest Cycle 1 ):
ngOnInit , ngOnChanges , ngDoCheck 生命周期函数ngAfterViewInit 生命周期还有一些其他的操作在变化监测阶段被执行,我在这篇文章中详细列出了这些流程:Everything you need to know about change detection in Angular
每一步操作后, Angular 会保存所有与这次操作有关的属性的值,这些值被存在组件 view 的 oldValues 属性中。(开发模式下)所有组件完成变化监测之后 Angular 会开始下一个变化监测流程,第二次监测流程并不会再次执行上面列出的变化监测流程,而会比较之前变化监测循环保存的值(存在 oldValues 中的)与当前监测流程的值是否一致( Digest Cycle 2 ):
注意:这些额外的检查( Digest Cycle 2 )只发生在开发模式下,我会在后面的章节中解释其中原因。
接下来我们来看一个例子。假设你有一个父组件 A 和一个子组件 B , A 组件中有两个属性:name 和 text, A 组件的模板中使用了 name 属性:
template: '<span>{{name}}</span>'
然后在模板中加入 B 组件,并且通过输入属性绑定给 B 组件输入 text 属性:
@Component({
selector: 'a-comp',
template: `
<span>{{name}}</span>
<b-comp [text]="text"></b-comp>
`
})
export class AComponent {
name = 'I am A component';
text = 'A message for the child component`;
那么 Angular 在开始变化监测后会发生什么呢?( Digest Cycle 1 )变化监测会从 A 组件开始检查,第一步将 text 表达式中的 A message for the child component 向下传递到 B 组件,并且将这个值存在 view 上:
view.oldValues[0] = 'A message for the child component';
然后到了变化监测列表里的第二步,调用相应的生命周期函数。
接下来执行第三步,将 {{name}} 表达式解析为 I am A component 文本。将解析好的值更新到 DOM 上,并且存入 oldValues:
view.oldValues[1] = 'I am A component';
最后 Angular 对 B 组件执行相同的操作( Digest Cycle 1 ),一旦 B 组件完成以上的操作,此次变化监测循环便完成了。
如果 Angular 在开发模式下运行,那么将会执行一个额外的监测流程( Digest Cycle 2 )。text 属性在传递给 B 组件时的值是 A message for the child component 并存入 oldValues ,现在想象一下 A 组件在此之后将 text 的值更新为 updated text。然后( Digest Cycle 2 )的第一步将会检查 text 属性是否被改变:
AComponentView.instance.text === view.oldValues[0]; // false
'updated text' === 'A message for the child component'; // false
这个时候 Angular 就该抛出这个错误了
ExpressionChangedAfterItHasBeenCheckedError 。
同理,如果更新已经被渲染在 DOM 中并且被存在 oldValues 中的 name 属性,也会抛出相同的错误
AComponentView.instance.name === view.oldValues[1]; // false
'updated name' === 'I am A component'; // false
现在你可能会有些疑惑,这些值怎么会被改变呢?我们接着往下看。
罪魁祸首一般都是子组件或指令,下面我们来看一个简单的案例。我会先用尽可能简单的例子来重现场景,稍后也会给出真实场景下的例子。大家都知道父组件能使用子组件或指令,这里给出一个父组件为 A ,子组件为 B ,并且 B 组件有一个绑定属性 text 。我们将在子组件的 ngOnInit (此时数据已绑定)生命周期钩子中更新 text 属性:
export class BComponent {
@Input() text;
constructor(private parent: AppComponent) {}
ngOnInit() {
this.parent.text = 'updated text';
}
}
我们看见了预期的错误:
Error: ExpressionChangedAfterItHasBeenCheckedError: Expression has changed after it was checked. Previous value: 'A message for the child component'. Current value: 'updated text'.
现在我们对被用于父组件模板的 name 属性做相同的操作:
ngOnInit() {
this.parent.name = 'updated name';
}
这时候程序并没有报错,为什么会这样呢?
如果你仔细看变化监测( Digest Cycle 1 )的执行顺序,你会发现子组件的 ngOnInit 将在父组件的 DOM 更新之前被调用(在记录 oldValues 前改变了数据),这就是为什么上面的例子中更改 name 属性却不会报错。我们需要一个在 DOM 中 values 更新之后的钩子来做实验, ngAfterViewInit 是一个不错的选择:
export class BComponent {
@Input() text;
constructor(private parent: AppComponent) {}
ngAfterViewInit() {
this.parent.name = 'updated name';
}
}
我们又一次得到了预期的错误:
AppComponent.ngfactory.js:8 ERROR Error: ExpressionChangedAfterItHasBeenCheckedError: Expression has changed after it was checked. Previous value: 'I am A component'. Current value: 'updated name'.
当然现实中遇到的情况会更加错综复杂,父组件中属性在二次监测之前被更新通常是使用的外部服务或 observabals 间接导致的。但是其本质原因是相同的。
现在我们来看一些真实案例。
例子:plunker。这个应用中父组件和子组件共用一个共享服务,子元素通过共享服务设置一个属性的值并反映到父元素上。这个模式下子元素改变父元素的值的方式并不像上面简单例子中那么显而易见,是间接更新了父元素的属性。
例子:plunker。这个应用中父元素监听一个子元素广播的事件,这个事件导致父元素的属性被更新,这个属性又被用于子元素的 Input 绑定。这同样间接更新了父元素的属性。
这种模式与之前两种模式略有不同,前两种模式都是 Digest Cycle 2 中的第一步检测抛出的错误,而这种模式是由DOM更新检测( Digest Cycle 2 第二步)抛出的错误。例子:plunker。这个应用中父组件在 ngAfterViewInit 生命周期中动态添加子组件,该生命周期发生在当前组件 DOM 初次更新之后,而添加子组件将会修改 DOM 结构,那么前后两次 DOM 中所使用的 values 值就不同了(前提是子组件带有新的 values 引用),所以抛出了错误。
如果你仔细看报错信息的最后一句:
Expression has changed after it was checked. Previous value:… Has it been created in a change detection hook ?
动态创建组件的情况下,解决这个问题最好的方案是改变创建组件时所处的生命周期钩子。比如之前章节中动态创建组件的流程就可以被移到 ngOnInit 中。即使文档中说明了 ViewChild 只能在 ngAfterViewInit 之后可用(完整、状态符合预期),但是创建组件时, view 就在插入子组件了,所以能提前获取 ViewChild 用于插入组件。
如果你 google 过这个错误,那么你应该看过一些回答推荐使用异步更新数据和手动调用一个变化监测两种方法来解决这个错误。虽然我在下面列出了这两种解决方案,但我更推荐重新设计应用的组织方式而不是使用这两种方法来解决这个问题,我会在最后一节给出理由。
你应该注意到一件事,不管是第一次变化监测还是第二次的验证监测都是同步执行的。这意味着如果我们在代码中异步更新属性的值,那么在第二次验证循环运行时这些属性是不会被改变的,那么也就不会报错了。让我们来试一下:
export class BComponent {
name = 'I am B component';
@Input() text;
constructor(private parent: AppComponent) {}
ngOnInit() {
setTimeout(() => {
this.parent.text = 'updated text';
});
}
ngAfterViewInit() {
setTimeout(() => {
this.parent.name = 'updated name';
});
}
}
确实没有错误抛出, setTimeout 将函数加入 macrotask 队列中,函数会在下一个 VM 周期里被调用。也可以通过使用 promise 里的 then 回调将函数加入当前 VM 周期其他同步代码被执行完之后:
Promise.resolve(null).then(() => this.parent.name = 'updated name');
Promise.then 并不会被放入 macrotask ,而是创建一个 microtask 。 microtask 队列将在当前周期中所有同步代码被执行完毕之后执行,因此属性的更新会发生在验证步骤之后。想学习更多关于 micro 和 macro task 在 Angular 中的应用可以看这篇文章:I reverse-engineered Zones (zone.js) and here is what I’ve found。
给 EventEmitter 传一个 true 能使事件的 emit 变为异步:
new EventEmitter(true);
另一个解决方案是在父组件 A 的第一和第二次验证之间强制加一个变化监测循环。触发强制变化监测的最佳位置是在 ngAfterViewInit 生命周期内,这时候所有的子组件的流程都已经执行完毕,所以随便在之前的哪个位置改变父组件的属性都无所谓:
export class AppComponent {
name = 'I am A component';
text = 'A message for the child component';
constructor(private cd: ChangeDetectorRef) {
}
ngAfterViewInit() {
this.cd.detectChanges();
}
嗯,一样没有报错,好像可以很开心的运行程序了。其实这里有个问题,当在父组件 A 中触发新添加的变化监测时, Anuglar 同样会为所有的子组件运行一次变化监测,那么父组件可能会被又一次更新。
Angular 强制使用至上而下的单向数据流,在父组件完成变化监测之后不允许内部子组件在第二次变化监测前改变父组件的属性。这能确保第一次变化监测后的组件树状态是确定的。如果在监测循环周期里有属性的改变导致依赖这些属性的使用者需要同步更新变化,那么这棵组件树状态就是不确定的。上面例子中子组件 B 依赖父组件的 text 属性,每当属性的值改变,在这些改变被传递到 B 组件之前这棵组件树都处于不确定的状态。这同样体现在 DOM 与属性之间的关系上, DOM 作为这些属性的使用者,然后将这些属性渲染到 UI 界面上。如果某些属性没有同步更新到界面上,用户将会看到错误的界面。
数据流的同步过程发生在文章开头列出的两堆操作中,所以如果你在数据同步过程完成之后再通过子组件修改父组件中的属性会发生什么呢?是的,你留下了一个不稳定的组件树,其中数据变更的顺序将无法预测。大部分时候这将会给用户呈现出一个有错误数据的页面,而且问题的排查将十分困难。
可能你会问了,那为什么不等到组件树稳定之后再进行变化监测呢?答案很简单,组件树可能永远不会稳定下来,一个子组件更新了父组件中的属性,父组件的属性又更新子组件的状态,子组件状态的更新又触发更新父组件的属性...这将是个无限循环。之前我展示了很多组件对属性直接更新或依赖的情况,但实际中的应用对属性的更新和依赖通常是间接,不易排查的。
有趣的是, AngularJS(Angular 1.x) 并没有使用单向数据流也能很大程度的保证组件树的稳定。但是我们经常会看到一个臭名昭著的错误 10 $digest() iterations reached. Aborting! 。随便去 google 一下就能找到大量关于这个错误的问题。
最后一个问题是,为什么第二次循环监测只在开发模式下运行?我猜想是因为不确定的数据并不会使框架崩溃或使程序无法使用,可能在下一次变化监测之后错误的数据会变为正确的数据。当然,毕竟这样不确定的情况并不符合开发者的预期,还是有可能会呈现出错误的数据,所有在开发时期将可能得错误解决总好过在上线后的应用中排查错误。
初次翻译略显生涩,如有错误欢迎指出。
Matrix router 被设计出来主要是为了满足以下两点需求:
Matrix URL 写法首次提出是在1996 提案中,提出者是 Web 的奠基人:Tim Berners-Lee。
虽然 Matrix 写法未曾进入过 HTML 标准,但它是合法的。而且在浏览器的路由系统中,它作为从父路由和子路由中单独隔离出参数的方式而广受欢迎。

matrix URL 是一种语义表达更加强大的 URL 协议,为复杂的路由能力提供设计语义上的可能性。
去中心化路由指的是 URL 与具体组件之间的映射关系是动态的,是由当前组件决定的,并非提前配置好的。组件本身带有路由配置信息,而不需要在一个集中的地方单独进行配置。
常见路由定义方式中 URL 与组件的映射关系是静态的,如:
export const routes: Route[] = [
{
path: '/user',
component: UserLayout,
children: [
{
path: ':id',
component: UserView,
},
],
},
];这么一个路由配置中,URL /user/:id 与 UserLayout 、 UserView 这么一组资源(组件)间的映射关系是静态的。
去中心化路由的定义方式:
// 定义一个 single route container
<template>
<some-layout>
<match>
<route path="/user/:id">
<user-view />
</route>
<route path="/_some_metadata">
<metadata-content />
</route>
</match>
</some-layout>
</template>
// 定义一个 multi route container
<template>
<some-layout>
<match>
<route path="/user/:id">
<user-view />
</route>
<route path="/_some_metadata">
<metadata-content />
</route>
</match>
<route namespace="sider" path="/_some_metadata">
<metadata-content />
</route>
</some-layout>
</template>去中心化的路由配置组件中,URL 与具体组件的映射关系是当前组件渲染时才知道的,这个规则层层递归,逐段consume,这样就可以做更多动态化的事情。比如递归的路由组件,能够根据 URL 动态递归地生成视图最终的结构。
常规前端路由主要流程:
本文基于 webpack4/5, vue-loader16
webpack
自从 redux 出来之后就风靡了整个前端圈,说目前前端方向所有状态管理方案设计都受到过 redux 的启发也不为过,但 redux 却又因其啰嗦冗长的模板代码为人诟病。今天这篇文章就先来聊聊我眼中的 redux。
redux 的一大问题是他没有给出明确的业务逻辑组织指导,但以 redux 的定位也不应该有这方面的指导,所以导致了对 redux 误会越来越多,甚至人人都要写一个“我最简单”改进版的地步。
最后的最后再说说前端工程化,我自己对于前端工程化的观点是:不需要人做的(重复)尽量自动化,需要人做的更加规范化。各种开发、构建、部署、规范链路上的方案与工具不过是工程化的手段罢了,不管手段再完善,自动化、规范化做得再好,最终写代码的还是人。只有最后写业务逻辑代码的人够专业,写出来的业务代码才做得到“可维护”,才更接近工程化的目标。所以如何引导人写出可维护的代码也是工程化的一大课题,大量框架都是这个方向的实践者。redux 在这方面其实已经很强大了,只是在规范化上差了点意思,ngrx 就做的很好,在保留 redux 强大能力的基础上在规范化上做了改进。
在编写代码时,数组遍历可以说是我们最常用的操作。今天就根据es5-shim中数组遍历部分的代码进行解读。先实现一个forEach函数。
// Monkey patch
Array.prototype.forEach = Array.prototype.forEach || forEach
function forEach (callback, thisArg) {
var object = new Object(this)
// 如果this是字符串则转换为数组
var self = isString(this) ? this.split('') : object
var i = -1
// robust检查
if (!self.length) throw new TypeError(self + 'isn\'t an array.')
if (!isFn(callback)) throw new TypeError('Array.prototype.forEach callback must be a function')
while (++i < self.length) {
// 如果this的属性不为number或该index的属性不存在,则不遍历(确保为类数组遍历)
if (i in self) {
// 若存在thisArg,增加调用时回调函数this指向
if (thisArg) {
callback.call(thisArg, self[i], i, object)
} else {
callback(self[i], i, object)
}
}
}
}
function isString (str) {
return Object.prototype.toString.call(str) === '[object String]'
}
function isFn (fn) {
return Object.prototype.toString.call(str) === '[object Function]'
}function map (callback, thisArg) {
var object = new Object(this)
var self = isString(this) ? this.split('') : object
var i = -1
// 生成的新数组
var result = []
if (!self.length) throw new TypeError(self + 'isn\'t an array.')
if (!isFn(callback)) throw new TypeError('Array.prototype.forEach callback must be a function')
while (++i < self.length) {
if (i in self) {
if (thisArg) {
// 赋值
result[i] = callback.call(thisArg, self[i], i, object)
} else {
result[i] = callback(self[i], i, object)
}
}
}
// 返回新数组
return result
}前面说到map, every, some, filter与forEach的结构其实大同小异,主要是while内部的逻辑有所不同。其实这里实现的forEach, map等都属于内部迭代器,forEach函数内部定义了迭代规则,外部只需一次初始调用即可。同时,由于是内部迭代器,每需要一种不同的迭代功能,就得写一份类似的代码,较为复杂的迭代需求就不方便通过写好的迭代函数来实现了,大部分情况下我们会重新封装一个带for () {}语句的函数以复用。
这时候我们来看看外部迭代器能替我们解决什么问题。外部迭代器相当于将迭代的功能装在了数据结构上,增加了一些调用的复杂度,但相对也增强了迭代器的灵活性,减少了结构性的代码,基本写出来的都是需求的逻辑。
下面就是一个外部迭代器的实现,代码来自《JavaScript设计模式与开发实践》P105:
var Iterator = function (obj) {
var current = 0
var next = function () {
current += 1
}
var isDone = function () {
return current >= obj.length
}
var getCurrItem = function {
return obj[current]
}
return {
next: next,
isDone: isDone,
getCurrItem: getCurrItem,
}
}基于Class版:
class Iterator {
constructor (obj) {
this._current = 0
this._data = obj
}
next () {
this._current += 1
}
isDone () {
return this._current >= this._data.length
}
getCurrItem () {
return this._data[this._current]
}
}function compare (iterator1, iterator2) {
while (!iterator1.isDone() && !iterator2.isDone()) {
if (iterator1.getCurrItem() !== iterator2.getCurrItem()) {
throw new Error('iterator1和iterator2不相等')
}
iterator1.next()
iterator2.next()
}
alert('iterator1和iterator2相等')
}
var iterator1 = new Iterator([1, 2, 3])
var iterator2 = new Iterator([1, 2, 3])
compare(iterator1, iterator2) // 输出:iterator1和iterator2相等那么使用外部迭代器和直接使用循环语句写逻辑有什么不同呢,很大程度上,使用外部迭代器减少了循环的嵌套,使代码更清晰,这在多重迭代上体现的尤为明显。如果需求只有一层循环,那大可直接使用循环语句。
断断续续在好基友这工作也有一段时间了,本来是打算把主要精力放在公司自己的弹幕站项目上面的,奈何外包地狱,总是要先清理干净的。在这期间一共做了两个移动端的web应用开发,两个项目的技术栈选型全部用的webpack+vue全家桶+vux三件套。接下来一段时间的重心会转到弹幕站上面,选型的话应该还是webpack+vue,已经有了经验的积累,可以说这套技术栈等的就是今天了。ui组件方面应该能自己写的都会自己写了,不再直接套用第三方做修改了,因为需要根据设计来进行定制了。在弹幕站项目开始之前,还是先写篇文章总结自己对两个项目的收获。
项目一览:轻奢买手、纸飞机公益
首先说说我为什么选择webpack+vue吧。简单,就是简单。
webpack的话够黑盒,带来的优点是开箱即用,缺点嘛,太黑箱有时候会陷入莫名其妙报错-排bug循环。现在2.0的文档真的很完善了,而且中文文档也正在翻译中,想要解放劳动力同学们值得上手。这里推荐下自己的vue项目配置供学习参考,基本算是全功能吧,静态资源hash、css-module、dll-plugin、hot-reload、代码拆分 异步chunk、vue单文件组件开发、router、vuex、axios,有能完善的地方请多多指导。以前说webpack就是个打包工具,我体验下来webpack搭上npm script完全可以替代构建工具了,至少hold的住我现在的项目的级别了(潜台词:不需要搭配gulp使用)。
为什么选vue全家桶呢,概念易懂,上手轻松,性能强劲。本来选vue是为了做弹幕站的,弹幕站这种公司自身的项目肯定是要长期维护的,那么让新来的同事能快速上手就是个值得思考的点。我幻想了下整个workflow新人接班需要的时间,在不修改配置的前提下(webpack配置等)2-3天能够快速上手的框架,我觉得非vue莫属了。人性化的框架设计和文档,在搭好脚手架的情况下,vue的学习使用不比jQuery难。如果对近两年框架有所接触那么时间会更短,一天时间把vue的guide敲完是绰绰有余的。
Vue从1.0升级到2.0的过程再对比Angular和React,让我想起《程序员修炼之道》中的种种忠告。比起Angular和React,我更信任Vue,更信任尤大。
脚手架准备好了(假装用我的webpack配置),yarn run dev走起,其余的精力专注业务代码就好了。开发完成推到我们自建的gitlab上,构建服务器自动拉取项目并构建,只需要在根目录下写deploy.sh的脚本就可以控制线上的构建的流程了。最后所有静态文件自动部署到cdn上,这么愉快的构建、部署流程,多亏了全栈好基友。我自己正在写的blog项目也用travis-ci为中介做了大致相同的部署流程。
监控方面,我们用的是sentry,这玩意儿真的好用,会把所有信息都汇总起来上报,如下图:
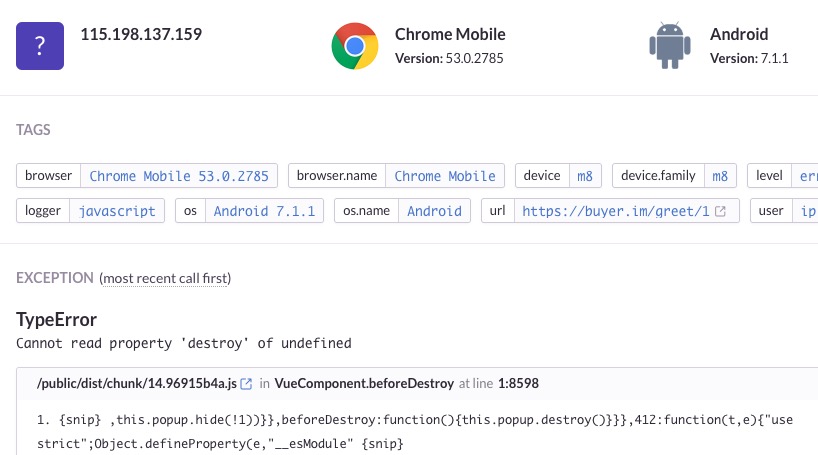
这是前端页面的线上监控,在页面引入一个raven-js再做一些配置即可,错误信息十分齐全,后端也是用的sentry做监控汇总。
测试方面,前端是真的没有做自动化测试,一是我的精力不够,二是ui组件大部分用的是第三方的,第三方做了大部分的测试,so,项目移交的时候对项目进行手工测试。
说起来,工程积累其实并不多,自动化主要是多用工具,在目录结构的合理性上我自觉有所提高。我个人认为的工程经验应该是大型项目,多人多团队合作的经验。这应该涉及到很多方面,如项目规划、代码规范、团队工具流、进度汇报、托管代码管理规范等等。下一个弹幕站项目吧,认真的规划一下,根据我们团队的大小考虑推动合理的工程化流程,也不能来的太猛...创业公司 且行且珍惜。
业务代码方面第二个项目全面上了async/await,我觉得用起来比promise甜了许多,学习成本也不高,并行的异步操作配合Promise.all()让代码简洁了一个数量级吧。Vue的实践上,使用了keep-alive的特性,keep-alive就是把组件缓存起来,下次再遇到这个组件就不是重新生成这个组件实例,而是从缓存中去取。要注意的就是created钩子只会在第一次生成该组件的时候触发了,后续从缓存里取组件的时候触发的是activated钩子。同理,不会再触发beforeDestroy,destroyed钩子,用deactivated钩子替换。
两个项目都是上了微信的,第一个项目多了一个微信支付接口。微信开发的话主要是微信开发者工具并没有跟真实的微信环境表现完全一致,很多时候开发者工具上跑通了微信上也不一定好使,还是得开启debug模式在微信真实环境下慢慢调试。其他也都是小问题,ios title hack,图片穿透,图片点击问题搜一搜都已经有人踩过坑了。
最后,两个项目下来自己想写文章了,想写给自己看,对自己负责,让自己满意的文章。路漫漫,坚持就会有所收获,加油。

这是我第一次认真组织blog,也是本系列的第一篇文章。既然这个系列是学习JavaScript,那么就从实现ES5的一些api开始吧,代码主要参考es5-shim,坚持下去的话下一步自然是实现ES6的api。写blog主要还是为了记录下自己的学习历程,不能总是看完文章、学完知识就丢到脑后,话不多说,坚持最重要。
大家都知道在JavaScript中的bind是用于绑定函数this指向的。bind方法会创建一个新函数,bind的第一个参数将作为新函数运行时的this,其余的参数将会在新函数后续被调用时位于其他实参前被传入。那么很明显,用bind函数可以很轻松的实现函数的curry化,这里就不展开介绍了,我们一起来看一看引擎盖下面是什么吧。
Function.prototype.bind = Function.prototype.bind || bindfunction bind () {
var target = this
return function () {
return target()
}
}function bind (that) {
var target = this
return function () {
return target.call(that)
}
}function bind (that) {
var target = this
var bindArgs = Array.prototype.slice.call(arguments, 1)
return function () {
var callArgs = Array.prototype.slice.call(arguments)
return target.apply(that, bindArgs.concat(callArgs))
}
}这里要绕过来的点在于bind调用时获取的是bind函数其余的参数bindArgs,新函数被调用时则获取到传入新函数的参数callArgs。两组参数组合后传入原函数,即bind的其余参数将在新函数被调用时位于其它实参前被传入。
this instanceof fn 这段代码判断某次调用是否通过new调用,如果是通过new调用的,那么this就是fn的实例。直接调用函数时的this指向global。知道了这点之后我们该如何改造我们的代码以达成目标呢:function bind (that) {
var target = this
var bindArgs = Array.prototype.slice.call(arguments, 1)
function bound () {
var callArgs = Array.prototype.slice.call(arguments)
if (this instanceof bound) {
return target.apply(this, callArgs.concat(bindArgs))
} else {
return target.apply(that, callArgs.concat(bindArgs))
}
}
// 实现继承,让bound函数生成的实例通过原型链能追溯到target函数
// 即 实例可以获取/调用target.prototype上的属性/方法
var Empty = function () {}
Empty.prototype = target.prototype
bound.prototype = new Empty() // 这里如果不加入Empty,直接bound.prototype = target.prototype的话
// 改变bound.prototype则会影响到target.prototype,原型继承基本都会加入这么一个中间对象做屏障
return bound
}至此我们实现了一个功能完整够用的bind函数,当然如果是写一个库,那就要应对各种奇怪的情况,考虑的需要更加严谨全面。更严谨的代码可以参考es5-shim的实现。
最近团队人数越来越多,为了让 code review 的体验更好,我们决定从 Git Workflow 切到 Forking Workflow。在网上看了一些文章之后,总结出一张 Forking Workflow 的流程图,更直观的让团队成员理解 Forking Workflow 的流程。

写这篇文章是因为 Vue, React, Angular 我都用过,想做点总结自己沉淀一下。然后又觉得好多源码分析文章不太容易看懂,大部分文章分析的时候会放上来一大堆源码,然后按照源码的每个模块进行分析。但框架实际调用这些模块的时机和顺序又不是按一个一个模块的静态代码里的顺序来的,是会穿插、组合着去使用这些模块。所以阅读这类源码分析文章的时候总是来回翻文章和代码示例,大脑得去模拟框架运行时的上下文从而理解文章内容,没法很友好地形成整体概念。这篇文章的目标是以尽量少的上下文切换讲明白前端视图层三大框架(库)数据驱动视图的原理和设计上的对比。如果看完还是觉得云里雾里说明文章写的还不够好,可以多多交流。我将持续改进这篇文章,以求成为一篇较好的原理入门文章。
其实我觉得前端视图层框架没有什么 mvvm、mvc 之类的区别,把这些概念搬到前端对号入座只是人云亦云罢了。目前 Vue, React, Angular 在视图层这块都是 diff 一种类似 vnode 的数据结构(vnode, fiber, incremental dom),然后根据 diff 结果 mount/patch 相应的视图更新函数,都是 view model 驱动 view 的思路。Vue, React, Angular 之间真正的区别在于“如何做到数据驱动视图”,这仨分别选择了三种方式去做。
当然这里说的“真正的区别”只是指的技术实现上的区别,实际上三大框架所传递出来的理念和哲学也是完全不同的,这篇文章先不对框架背后设计做详细的分析,未来可以再起一篇文章聊聊这些。
聊 Vue 的响应式原理就离不开 Observer、Dep、Watcher ,我这里会将三者串联起来讲一讲 Vue 是如何实现依赖收集与响应式视图的,因为三者实际运行时其实是以很强耦合的方式组合起来使用的。
先聊一聊依赖收集,我们一起来看看下面三个问题:
首先,是开发者定义的 data、computed、watch 字段需要收集依赖,即数据需要收集依赖。因为我们的目标是数据驱动视图,其中的一种实现方式是在数据变动时,执行视图更新的回调函数。那么相应的,数据就需要一个容器(Dep)收集自身变动时需要执行的回调,这些需要执行的回调就是数据的依赖项(Watcher)。
了解了上面三点之后继续来讲数据是怎么做依赖收集的。Vue 实例初始化时会递归地将数据 observer 化,数据的 getter 会作为依赖收集的接口,setter 作为触发回调的接口。同时会在数据对象上挂一个 __ob__ 对象(Observer),这个 __ob__ 对象里会有用于收集依赖的容器 dep。我们先来看一下依赖收集接口的实现方式。
...
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter() {
....
dep.depend();
return value;
....
},
});
...
class Dep {
static target: Watcher | null = null;
subs: Array<Watcher>;
depend() {
if (Dep.target) {
this.subs.push(Dep.target);
}
}
...
}
class Watcher {
constructor (
private vm: Component,
key: string,
public cb: Function,
) {
// 这么做的时候才算是触发了依赖收集接口
Dep.target = this;
vm._data[key]; // goto reactiveGetter dep.depend();
Dep.target = null;
}
}这里 Vue 引入了一个中间变量 —— Dep.target 进行 watcher 传递(为什么要用 Dep.target 进行 watcher 的传递?因为依赖收集接口是数据的 getter,是隐式的,没法通过参数传递 watcher),Watcher 在实例化时会设置 Dep.target 为 watcher 实例自身(watcher 初始化时带有 vm、key 与 effect callback,且作为私有属性),然后会执行一次该 watcher 的 effect 函数(比如 render 函数),此时就会触发被包装过的数据的 getter,进行依赖收集。也就是说每当创建 Watcher 实例的时候就会进行依赖收集,那么啥时候会创建 Watcher 实例并进行依赖收集呢?主要是组件挂载、computed、watch 的时候:
// 初始化组件 - core/instance/lifecycle.js
function mountComponent (vm: Component, el: ?Element, hydrating?: boolean): Component {
...
// effect 函数为组件更新函数,可以想像成调用 render function,那么也会 touch 一遍 render 函数用到的数据,这些数据又会将当前这个 watcher 作为依赖项进行收集。
new Watcher(vm, updateComponent, noop, {
before () {
if (vm._isMounted && !vm._isDestroyed) {
callHook(vm, 'beforeUpdate');
}
}
}, true /* isRenderWatcher */);
...
}
// 初始化 computed - core/instance/state.js
function initComputed(vm: Component, computed: Object) {
...
for (const key in computed) {
const userDef = computed[key];
const getter = typeof userDef === 'function' ? userDef : userDef.get;
// effect 函数为开发者定义的 computed 函数,computed 函数会被函数内的数据作为依赖项收集,computed 字段本身又作为属性在 render 函数执行时被 touch,这里就出现了两条数据响应链路
watchers[key] = new Watcher(
vm,
getter || noop,
noop,
computedWatcherOptions,
);
}
...
}
// 初始化 watch - core/instance/state.js
Vue.prototype.$watch = function(expOrFn: string | Function, cb: any, options?: Object): Function {
...
const vm: Component = this
// effect 函数为开发者定义的 watch 函数,computed 函数会被函数内的数据作为依赖项收集
const watcher = new Watcher(vm, expOrFn, cb, options)
...
}讲完上面的依赖收集流程最后再讲一下数据变更最后是如何导致视图更新的。Vue 利用了 data setter,依然是隐式地触发依赖项回调方法的执行,在数据变更后会触发这个数据已收集在 __ob__.dep 里所有的 watcher 回调,其中就包含了视图模板初始化时收集的 render 相关函数。通过执行 render 函数生成新的 vnode 后,再经过一系列 vnode 的 diff 与 mount/patch 过程,最终触发相应平台(如 web dom)的更新,就做到了数据驱动视图。
...
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
set: function reactiveSetter(newVal) {
....
val = newVal;
dep.notify();
....
},
});
...
class Dep {
subs: Array<Watcher>;
...
notify() {
const subs = this.subs.slice();
for (let i = 0, l = subs.length; i < l; i++) {
subs[i].cb();
}
}
}相比于 Vue 提供的隐式依赖收集与回调触发的接口,下面我来实现一个显式的接口来更明确的展示 Vue 依赖收集的逻辑,再对比一下显式接口与隐式接口的优缺点。
const targetMap = new WeakMap<any, Map<string, () => any>>();
function track(target: any, key: string, fn: Function) {
let depsMap = tagetMap.get(target);
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()));
}
let dep = depsMap.get(key);
if (!dep) {
depsMap.set(key, (dep = new Set()));
}
if (dep.has(fn)) {
return;
}
dep.add(fn);
}
function trigger(target: any, key: string) {
const depsMap = targetMap.get(target);
if (!depsMap) {
// never been tracked
return;
}
const effectsSet = depsMap.get(key);
effectsSet && effectsSet.forEach(effect => effect());
}相比而言显式的依赖收集接口更加清晰明了,而隐式的接口看似精巧实则概念间的耦合程度非常高。其实 Vue3 底层类似于上面的显式实现,得益于显式接口实现,Vue3 组合了大量的 reactivity api 暴露给开发者,甚至整个响应式系统可以独立拿出来脱离 Vue 体系使用。
其实有了依赖收集与回调触发的逻辑再搭配简单的模板编译就已经能够实现一个简单的 reactivity 式的视图开发库了,vnode 与 diff/mount/patch 在 Vue 的设计中更多是提供「最终 render 无关的抽象层」与「编译/运行时优化」的能力,并不是「数据驱动视图」的关键所在。
setState 时触发 render,render 是以一个组件为粒度递归向下级 vnode 触发
所以 react 必须优化 render 过程,引入了任务调度与 diff
对应 Scheduler(调度器),Reconciler(协调器),Renderer(渲染器)
...
每个组件都有一个数据变更监测实例,组件树能够形成一个数据变更监测树,组件可以控制依赖变更实例是否挂载到数据变更监测树上。angular 默认触发数据变更监测的方法是借助 zone.js 去做的。zone.js patch 了所有浏览器的异步接口,我们知道视图的更新只来自于视图初次渲染与异步回调之后(如 setTimeout、xhr、浏览器事件等)。那么通过 zone.js 统一在异步操作完成之后执行数据变更监测,这个流程内进行数据 diff 之后更新视图,diff 的策略组件也可以进行配置。其次数据也完全可以不使用 zone.js 来驱动视图,可以使用 rxjs 来玩。
...
之前在写组件(或指令)时,有些组件会与 Angular 的表单有交互,这时候我总得在外部传入一个 FormGroup ,然后在组件的内部写相应的逻辑对 Angular 表单进行操作。就这样用了一段时间后总感觉有些违和,要一次又一次的向组件内传递 FormGroup 对象(或者 FormControl ):
<form [formGroup]="anyForm"> // 第一次传form
<some-component [form]="anyForm"></some-component> // 又一次传form
<another-component [form]="anyForm"></another-component> // 又又一次传form
</form>这明显不合适。我能不能像原生表单一样去使用这些自定义组件?市面上的 UI 库好像都有一些组件能和原生表单一样使用 formControlName 这个属性,他们都用了啥黑科技?
<form [formGroup]="anyForm">
<input formControlName="cool"> // 原生表单组件
<input nz-input type="text" formControlName="coool"> // ng-zorro-antd 表单组件
</form>然后我就了解到了,这类组件应该叫做自定义表单。自定义表单组件实现 ControlValueAccessor 接口后就能够与外层包裹的 form 关联起来。其实 Angular 对原生表单的封装也是通过 directive (selector: 'input[type=...], textarea...')实现了 ControlValueAccessor 接口。
ControlValueAccessor 这个接口很简单,定义了四个方法:
writeValue(obj: any): voidregisterOnChange(fn: any): voidregisterOnTouched(fn: any): voidsetDisabledState(isDisabled: boolean)?: voidwriteValue:任何 FormControl 显式调用Api的 值 操作(如 patchValue() )都将调用自定义表单组件的 writeValue() 方法,并将新值作为参数传入。数据流向: form model -> component。
registerOnChange:注册�onChange事件, form 初始化时被调用,参数为事件触发函数。通常在 registerOnChange 中需要保存该事件触发函数,等到合适的时候(value change时)调用该函数以触发事件,事件函数的参数为 form model 要接收的 value 。数据流向: component -> form model。
registerOnTouched:注册onTouched事件,基本同 registerOnChange ,只是该函数用于通知表单组件已经处于 blur 状态(touched状态),改变绑定的 FormContorl 的内部状态。状态变更: component -> form。
setDisabledState:当调用 FormControl 变更状态的Api时得表单状态变为 DISABLED 时调用 setDisabledState() 方法,以通知自定义表单组件当前表单的读写状态。状态变更: form -> component。
说的天花乱坠,来实现一下吧:
@Component({
selector: 'image-form-item',
// 这里将组件注册为 Accessor
providers: [
{
provide: NG_VALUE_ACCESSOR,
useExisting: forwardRef(() => ImageFormItem),
multi: true,
}
],
template: `
<label for="img-input" (click)="onTouched()">
<i class="icon-plus" *ngIf="!src else briefImgTpl"></i>
<ng-template #briefImgTpl>
<img [src]="src">
</ng-template>
</label>
<input xxx-uploader id="img-input" type="file" style="display: none;" [disabled]="disabled" (change)="updateImage($event)">
`,
style: [`
...
`],
})
export class ImageFormItem implements ControlValueAccessor {
src: string
disabled: boolean
onChange: (value: string) => void = () => null
onTouched: () => void = () => null
updateImage(file: File) {
// 触发 onChange,component 内部的值同步到 form model
this.onChange(this.toBase64(file))
}
constructor() {}
// form model 的值同步到 component 内部
writeValue(value: string): void {
this.src = value
}
// 保存 onChange 事件函数
registerOnChange(fn: (value: string) => void): void {
this.onChange = fn
}
// 保存 onTouched 事件函数
registerOnTouched(fn: () => void): void {
this.onTouched = fn
}
// form model 的状态同步到 component 内部
setDisabledState(isDisabled: boolean): void {
this.disabled = isDisabled
}
private toBase64(file: File): string { ... }
}上面的代码就是一个简易的,伪·自定义图片表单组件了。
使用:
<form [formGroup]="anyForm">
<input formControlName="cool"> // 原生表单组件
<input nz-input type="text" formControlName="coool"> // ng-zorro-antd 表单组件
<image-form-item formControlName="cooool" /> // 我的自定义表单组件
</form>使用起来轻松又愉快,coooooool!
ControlValueAccessor 背后的**是 Accessor/Visitor 模式。
对于 FormGroup, FormControl 而言,抹平了原生表单和自定义表单之间的区别。网上有一个比较好的比喻:对于银行柜台而言,今天来的客人和明天来的客人没有什么不同(原生表单和自定义表单),办储值和办提现的客人也没有什么区别(各种类型功能的表单),银行柜台都要接待他们,他们都是来银行柜台办业务的(FormGroup, FormControl提供的功能)。
从另一个角度看,对于访问者而言(原生表单和自定义表单),不用改变内部其他功能的实现,只需要实现相应的接口,就能获得新的功能。各个功能就被抽成了各个 Accessor 供访问者调用。不过也破坏了封装,但是在 Angular表单 这种情况下,就是为了故意解耦出 表单 这个概念和与之相关的各种 校验 操作。既然是故意的设计,那也就谈不上破坏封装了。
想想Angular团队每一个点的背后都藏着那么多的**与知识,真是可怕,也真是好玩。每天都在设计、应用、创新,将**展示给这个世界。
这个系列会做一些优秀开源项目的源码解析,一是为了沉淀和整理自己一年多来所学,二也是希望自己能坚持多做分享,多做开源。文章由初级工程师面向初级工程师,也请大神们多多指点。
小广告:一个vue slider组件
这次分享的是一个前端操作cookie的库(cookies.js),一共约80行代码,十分小巧简洁(由于功能&&80行的定位,我们不从工程角度分析这个库)。从第一个commit到现在不过十来天,就已经有将近2k的star了,这个库暴露出来的api非常简单,设计和实现的确有很多值得学习的地方。
var cookies = function (data, opt) {
// 一个合并对象属性的方法,和Object.assign有些类似
function defaults (obj, defs) {
obj = obj || {};
for (var key in defs) {
// 对象属性不存在时,进行浅拷贝
if (obj[key] === undefined) {
obj[key] = defs[key];
}
}
return obj;
}
这里cookies是外层的cookies
函数依然可以像对象一样去使用,见我的一篇回答
https://www.zhihu.com/question/44990793/answer/99612521
为函数对象添加属性是为了能通过下面这种简单的方式改变全局默认配置
(defaults函数在对象属性不存在时,才进行浅拷贝,对象属性存在则不做改动
所以提前赋值能起到改变全局默认配置的作用):
cookies.expires = 100 * 24 * 3600; // The time to expire in seconds
cookies.domain = false; // The domain for the cookie
cookies.path = '/'; // The path for the cookie
cookies.secure = https ? true : false; // Require the use of https
defaults(cookies, {
// cookie配置,详见 https://developer.mozilla.org/zh-CN/docs/Web/API/Document/cookie
// 这里不清楚作者为什么不使用Cache-Control,有大神能解答一下吗
expires: 365 * 24 * 3600,
path: '/',
secure: window.location.protocol === 'https:',
// Advanced,详见 https://github.com/franciscop/cookies.js#advanced-options
nulltoremove: true,
autojson: true,
autoencode: true,
encode: function (val) {
return encodeURIComponent(val);
},
decode: function (val) {
return decodeURIComponent(val);
}
});
// 设置某个cookie时单独改变配置
opt = defaults(opt, cookies);
// expires的值需要Date.toUTCString()格式的,即 Mon, 03 Jul 2006 21:44:38 GMT 这种格式
// 如果传入的expires值不是一个Data对象,则进行转换
function expires (time) {
var expires = time;
if (!(expires instanceof Date)) {
expires = new Date();
expires.setTime(expires.getTime() + (time * 1000));
}
return expires.toUTCString();
}
// 如果data为字串,则查询cookie
if (typeof data === 'string') {
// 分割document.cookie中的每个cookie
var value = document.cookie.split(/;\s*/)
// 如果autoencode为true,则数组中的每个cookie通过decode进行处理,否则直接返回
.map(opt.autoencode ? opt.decode : function (d) { return d; })
// 再将每个cookie分割成[ key, value ]的结构
.map(function (part) { return part.split('='); })
// 新建对象,将[ [ key1, value1 ], [ key2, value2 ] ]结构
// 转换为{ key1: value1, key2: value2 }结构
.reduce(function (parts, part) {
parts[part[0]] = part[1];
return parts;
}, {})[data]; // 获取指定cookie值,将值赋给value
// 是否将json字串转换为object输出
if (!opt.autojson) return value;
try {
return JSON.parse(value);
} catch (e) {
return value;
}
}
// data为object,则设置每个cookie
for (var key in data) {
// 当设置的值为undefined,或nulltoremove为true且设置的值为null时,将expired设为true
// 准备用于清除cookie值
var expired = data[key] === undefined || (opt.nulltoremove && data[key] === null);
// autojson为true时,将object转为json字串。若不转为字串,object将会以'[object Object]'存入cookie
var str = opt.autojson ? JSON.stringify(data[key]) : data[key];
// 是否对uri自动进行编码 https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/encodeURIComponent
var encoded = opt.autoencode ? opt.encode(str) : str;
// 如果expired为true,将cookie设空,以清除cookie
if (expired) encoded = '';
// 连接cookie的key,value以及各项设置
var res = opt.encode(key) + '=' + encoded +
(opt.expires ? (';expires=' + expires(expired ? -10000 : opt.expires)) : '') +
';path=' + opt.path +
(opt.domain ? (';domain=' + opt.domain) : '') +
(opt.secure ? ';secure' : '');
// 如果opt中有test方法,执行test方法
if (opt.test) opt.test(res);
// 种入cookie
document.cookie = res;
}
// 返回cookies,能做到如下串联调用
// cookies({ token: 42 })({ token: '42' })
// var token = cookies({ token: '42' })('token') token === '42'
return cookies;
};
该模块通过commonjs的module.exports暴露出去 或 通过AMD的define暴露出去 或 通过this['cookies'](global.cookies)暴露出去,具体看if条件。
webpack配置output中的libraryTarget设置为umd,就会在打包时自动添加这段代码
这样这个模块就可以通过多种方式引入(AMD, commonjs, global)
具体可查看(https://webpack.github.io/docs/configuration.html#output-librarytarget)
当然直接把这段代码加到模块末尾也是ok的。
(function webpackUniversalModuleDefinition (root) {
if (typeof exports === 'object' && typeof module === 'object') {
module.exports = cookies;
} else if (typeof define === 'function' && define.amd) {
define('cookies', [], cookies);
} else if (typeof exports === 'object') {
exports['cookies'] = cookies;
} else {
root['cookies'] = cookies;
}
})(this);

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.