Some toy tasks/experiments to illustrate the concept of attention in machine learning, with heavy reference to Vaswani et al. (2017). In particular, we see how attention can be used in place of RNNs and CNNs for modeling sequences.
In the following scripts, no RNN or CNN is employed in the models.
Each task tries to illustrate a subconcept of attention, along with a tutorial/explanation accompanying every task.
This is still work-in-progress and feedback is appreciated!
Tasks/Experiments
- Counting Letters - Simple implementation of attention and tutorial on queries, keys and values
- Difference - Demonstration of self-attention and using it for modeling intra-sequence dependencies
- Signal - Demonstration of positional encodings
- Signal 2 - Demonstration of multihead-attention
- Translation - Demonstration of Transformer on translation
More details below.
In this task, we demonstrate a simplified form of attention and apply it to a counting task.
Consider a sequence, where each element is a randomly selected letter or null/blank. The task is to count how many times each letter appears in the sequence.
For example:
Input:
['A'], ['B'], [' '], ['B'], ['C']
Output:
[[1], [2], [1]]
The output is also a sequence, where each element corresponds to the count of a letter. In the above case, 'A', 'B' and 'C' appear 1, 2 and 1 times respectively.
We implement the Scaled Dot-Product Attention concept (described in Section 3.2.1 of Vaswani et al. (2017)) for this task and train without the use of recurrent or convolutional networks.
Here is a sample output from the script.
Input:
[[['A']
['A']
['C']
['C']
['B']
[' ']
['C']
['C']
['C']
['B']]]
Prediction:
[[2 2 5]]
Encoder-Decoder Attention:
Output step 0 attended mainly to Input steps: [0 1]
[0.232, 0.232, 0.061, 0.061, 0.064, 0.101, 0.061, 0.061, 0.061, 0.064]
Output step 1 attended mainly to Input steps: [4 9]
[0.066, 0.066, 0.06, 0.06, 0.232, 0.101, 0.06, 0.06, 0.06, 0.232]
Output step 2 attended mainly to Input steps: [2 3 6 7 8]
[0.044, 0.044, 0.152, 0.152, 0.043, 0.066, 0.152, 0.152, 0.152, 0.043]
For each output step, we see the learned attention being intuitively weighted on the relevant letters. In the above example, Output Step 0 counts the number of 'A's and attended mainly to Input Steps 0 and 1, which were the 'A's in the sequence.
Refer to the task's README for more details.
In this task, we demonstrate self-attention and see how it is useful for modeling inter-token/intra-sequence dependency.
Consider a sequence, where each element is a randomly selected letter or null/blank. The task has two parts:
- Count how many times each letter appears in the sequence
- Calculate the absolute difference between the first two counts
For example:
Input:
['A'], ['B'], [' '], ['B'], ['C']
Output:
[[1], [2], [1], [1]]
The output is also a sequence, where each element corresponds to the count of a letter and the last element corresponds to the difference between the first two elements. In the above case, 'A', 'B' and 'C' appear 1, 2 and 1 times respectively, while counts for 'A' and 'B' differ by 1.
As per Task 1, I implement the Scaled Dot-Product Attention (described in Section 3.2.1 of Vaswani et al. (2017)) for this task. I also demonstrate a simple case of self-attention.
There are two main models that can be trained with the script, with and without the --self_att flag, denoting whether to use self-attention.
Sample output from testing the model trained with --self_att:
Input:
[[['B']
['B']
['C']
[' ']
['A']
['C']
['A']
['A']
['C']
['C']]]
Prediction:
[[3 2 4 1]]
Encoder-Decoder Attention:
Output step 0 attended mainly to Input steps: [4 6 7]
[0.05, 0.05, 0.061, 0.075, 0.193, 0.061, 0.193, 0.193, 0.061, 0.061]
Output step 1 attended mainly to Input steps: [0 1]
[0.219, 0.219, 0.073, 0.089, 0.06, 0.073, 0.06, 0.06, 0.073, 0.073]
Output step 2 attended mainly to Input steps: [8 9]
[0.041, 0.041, 0.174, 0.093, 0.042, 0.174, 0.042, 0.042, 0.174, 0.174]
Output step 3 attended mainly to Input steps: [3]
[0.088, 0.088, 0.109, 0.116, 0.091, 0.109, 0.091, 0.091, 0.109, 0.109]
Self-Attention:
Attention of Output step 0:
[1.0, 0.0, 0.0, 0.0]
Attention of Output step 1:
[0.0, 1.0, 0.0, 0.0]
Attention of Output step 2:
[0.009, 0.006, 0.965, 0.021]
Attention of Output step 3:
[0.696, 0.06, 0.038, 0.205]
In the Self-Attention weights, notice that Output Steps 0, 1 and 2 are generally narcissistic and pay nearly 100% attention to themselves. This is because they are largely independent, just like the output in Task 1.
However, Output Step 3 pays far less attention to itself (20%) and instead pays a lot of attention on Output Step 0 (70%) and a tiny bit of attention to Output Step 1 (6%). Very intuitive, given that Output Step 3 is supposed to show the difference between Output Steps 0 and 1.
Refer to the task's README for more details.
In this task, we demonstrate the importance of positional encodings.
Consider a sequence, where each element is a randomly selected letter. We call the first element the signal.
For example ('B' is the signal here):
Input:
['B'], ['B'], ['A'], ['B'], ['C']
Output:
[[2]]
The output is a sequence of one step, corresponding to the count of the letter specified by the signal (first input step).
In the above case, the first input step is 'B', which means that we have to count the number of 'B's in the following sequence. The output is hence 2, since there are 2 'B's in the sequence (not counting the signal).
In particular, all the 'B's, including the signal, are represented with the same vector when passed to the model. This means that the model must learn that the meaning of a 'B' changes, depending on whether it is the first letter or not.
There are two main models that can be trained with the script, with and without the --pos_enc flag, denoting whether to use positional encodings for the input.
Sample output from testing the model trained with --pos_enc:
Input:
[[['B']
['C']
['A']
['C']
['A']
['B']
['B']
['A']
['A']
['C']
['B']]]
Prediction:
[[3]]
Encoder-Decoder Attention:
Output step 0 attended mainly to Input steps: [0]
[0.41, 0.046, 0.063, 0.045, 0.063, 0.068, 0.067, 0.063, 0.063, 0.045, 0.067]
L2-Norm of Positional Encoding:
[0.816, 0.181, 0.183, 0.185, 0.186, 0.18, 0.185, 0.183, 0.185, 0.183, 0.178]
In the above output, despite Input Steps 0, 5, 6, 10 all being 'B's, the decoder pays extra attention (41%) to Input Step 0.
We can also check the L2-Norm for each vector in the positional encoding, where each vector represents the positional encoding for each step in the input sequence.
Here the L2-Norm of the positional vector is far larger for the first step (0.816) than for the rest of the input sequence (~0.18). This makes perfect sense, since the model should ideally modify the first step while leaving the rest of the sequence untouched.
Refer to the task's README for more details.
In this task, we show the advantages afforded by multihead-attention.
Consider a sequence, where each element is a randomly selected letter. We call the first three elements the signals.
For example ('C', 'B', 'B' are the signals here):
Input:
['C'], ['B'], ['B'], ['B'], ['A'], ['B'], ['C']
Output:
[[1], [2], [2]]
The output is a sequence of three steps, corresponding to the count of the letter specified by each signal (first three input steps).
In the above case, the first input step is 'C', which means that we have to count the number of 'C's in the following sequence. The output is hence 1, since there is 1 'C' in the sequence (not counting the signal).
Likewise, for the second and third signals. Also, note that signals can be repeated, like the repeated 'B' signals in the example above.
Sample output from testing the model trained with --multihead=True:
Input:
[[['B']
['C']
['C']
['C']
['B']
['A']
['A']
['B']
['A']
['C']
['C']
['C']
['A']]]
Prediction:
[[2 4 4]]
Encoder-Decoder Attention:
Attention of Output step 0 on Input steps
Head #0
[0.09, 0.091, 0.076, 0.065, 0.065, 0.088, 0.089, 0.065, 0.088, 0.065, 0.064, 0.064, 0.088]
Head #1
[0.459, 0.088, 0.095, 0.034, 0.052, 0.032, 0.029, 0.051, 0.03, 0.033, 0.033, 0.034, 0.03]
Head #2
[0.128, 0.003, 0.044, 0.003, 0.244, 0.084, 0.077, 0.239, 0.084, 0.003, 0.003, 0.003, 0.084]
Head #3
[0.023, 0.002, 0.062, 0.064, 0.029, 0.156, 0.149, 0.029, 0.15, 0.062, 0.062, 0.065, 0.149]
Attention of Output step 1 on Input steps
Head #0
[0.097, 0.189, 0.018, 0.076, 0.085, 0.057, 0.057, 0.085, 0.057, 0.074, 0.075, 0.074, 0.056]
Head #1
[0.023, 0.757, 0.001, 0.039, 0.016, 0.009, 0.01, 0.016, 0.01, 0.037, 0.038, 0.036, 0.009]
Head #2
[0.107, 0.037, 0.078, 0.035, 0.13, 0.095, 0.093, 0.129, 0.095, 0.035, 0.035, 0.035, 0.095]
Head #3
[0.055, 0.024, 0.076, 0.077, 0.06, 0.106, 0.104, 0.059, 0.105, 0.077, 0.076, 0.078, 0.104]
Attention of Output step 2 on Input steps
Head #0
[0.006, 0.001, 0.695, 0.009, 0.004, 0.063, 0.063, 0.004, 0.061, 0.01, 0.009, 0.009, 0.066]
Head #1
[0.023, 0.0, 0.782, 0.006, 0.018, 0.035, 0.031, 0.018, 0.033, 0.007, 0.006, 0.007, 0.034]
Head #2
[0.117, 0.0, 0.023, 0.0, 0.316, 0.061, 0.053, 0.305, 0.061, 0.0, 0.0, 0.0, 0.061]
Head #3
[0.008, 0.0, 0.042, 0.044, 0.012, 0.198, 0.184, 0.011, 0.187, 0.042, 0.042, 0.046, 0.184]
L2-Norm of Input Positional Encoding:
[1.47, 1.564, 1.911, 0.295, 0.287, 0.292, 0.299, 0.286, 0.291, 0.293, 0.289, 0.291, 0.29]
The output shows three sets of attention, one for each step of the output sequence. For each step, there are also four subsets of attention, each corresponding to a head.
Refer to the task's README for more details.
In this task, we demonstrate the Transformer model on a translation task.
Here we implement the full Transformer model on the IWSLT 2016 de-en dataset, a much smaller than the WMT dataset used by Vawani et al., but sufficient to demonstrate the model's capabilities.
The training data and pretrained model is available here for testing.
Sample translation with --line=153
Input :
übrigens ist das zeug <UNK>
Truth :
this stuff is <UNK> as <UNK> by the way
Output:
by the way that's <UNK> stuff
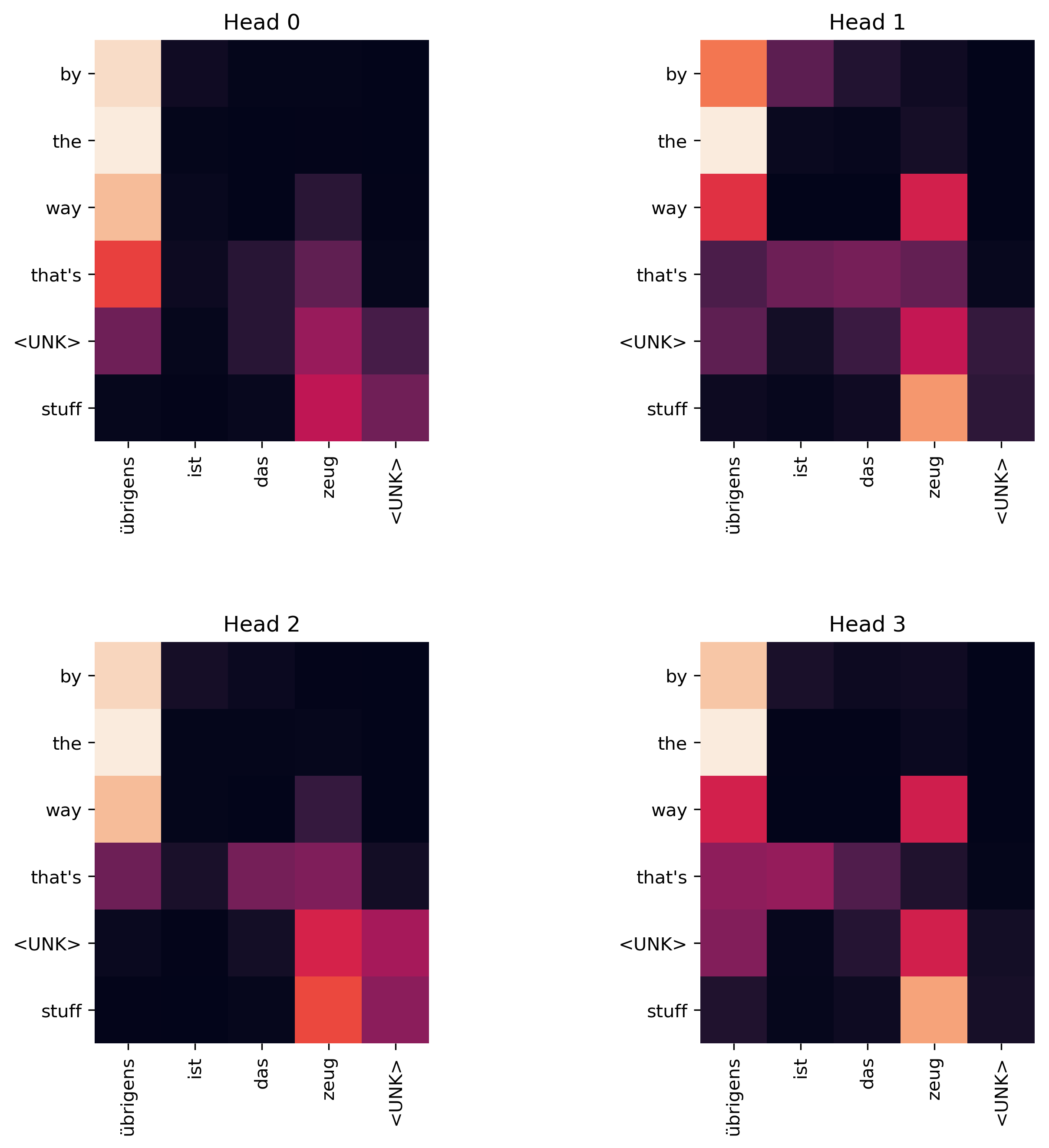
Here the tokens by the way all attend strongly to übrigens, which is the German parallel for the English phrase. In addition, we also see that the English translation <UNK> stuff correctly flips the order of the German tokens zeug <UNK> (where zeug means stuff).
Refer to the task's README for more details.
