我是瓶子君,前端进阶博客:https://github.com/sisterAn/blog
作为一名前端,虽然在平常开发中很少写算法,但当我们需要深入前端框架、开发语言、开源库时,懂算法将大大提高我们看源码的能力。例如 :
- virtual-dom diff 算法做了一些约定,后将原先 O(n3) 的时间复杂度降到了O(n) ,核心原理就是一个树的深度优先搜索
- babel 这些就是一些编译原理的 parser 生成抽象语法树的知识,再将抽象语法树进行转换操作生成文件
- 浏览器的 history,底层可以使用栈来实现
- webpack 中利用 tree-shaking 优化
- v8 中的调用栈、消息队列等等
这些就大量使用了算法,看懂了就能更好的了解它们的性能,更高效的解决问题,提升我们的代码质量与思维视野,进阶到更高 Level,赚更多钱💰💰💰。
所以说,学算法是每个前端进阶必备!⛽️⛽️⛽️
所以,这里我整理了一份适用于前端的数据结构与算法系列,希望能帮助你从0到1构建完整的数据结构与算法体系(此处所有的题目均来自真实前端面试)。
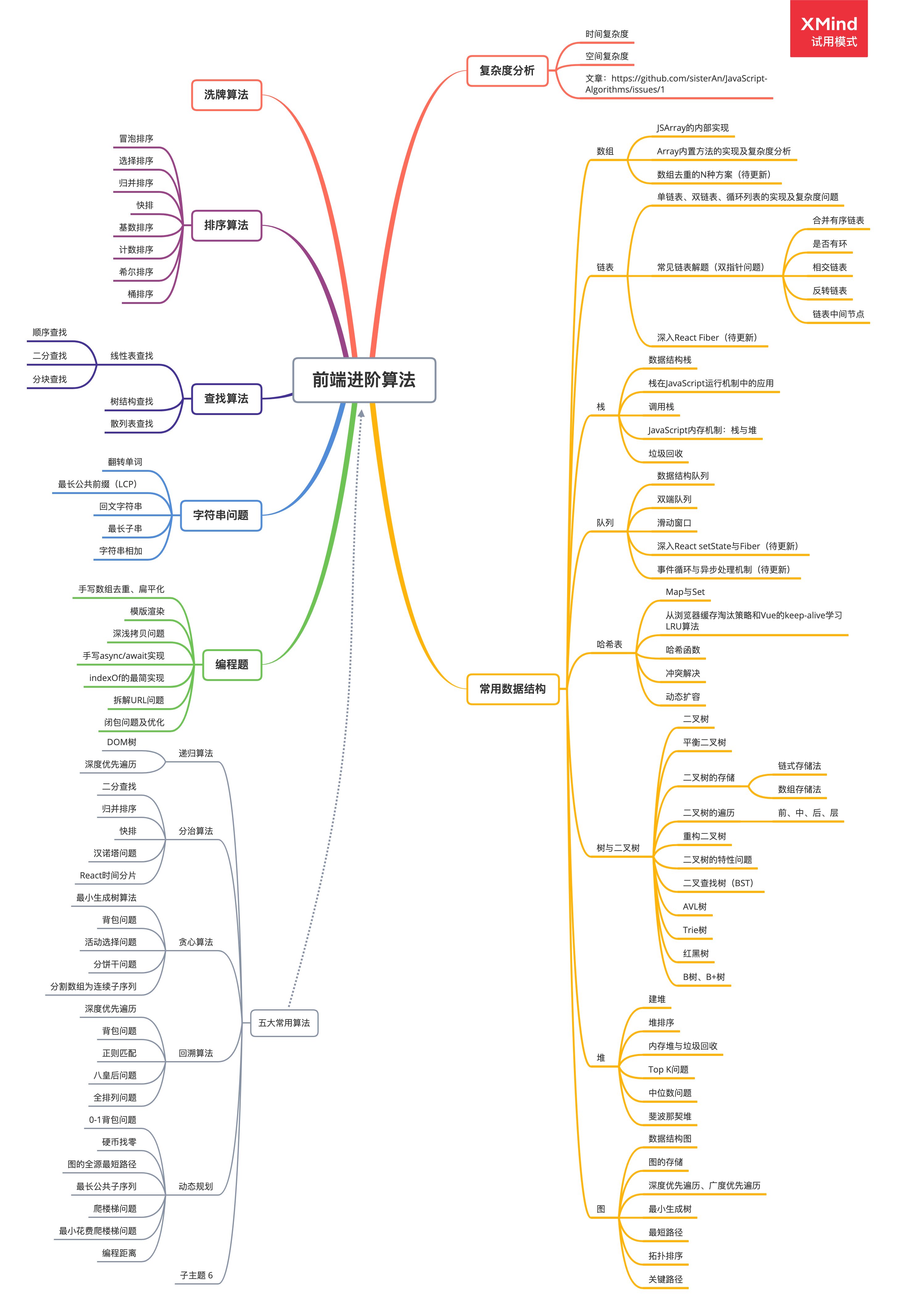
- 前端进阶算法1:如何分析、统计算法的执行效率和资源消耗?
- 前端进阶算法2:从Chrome V8源码看JavaScript数组(附赠腾讯面试题)
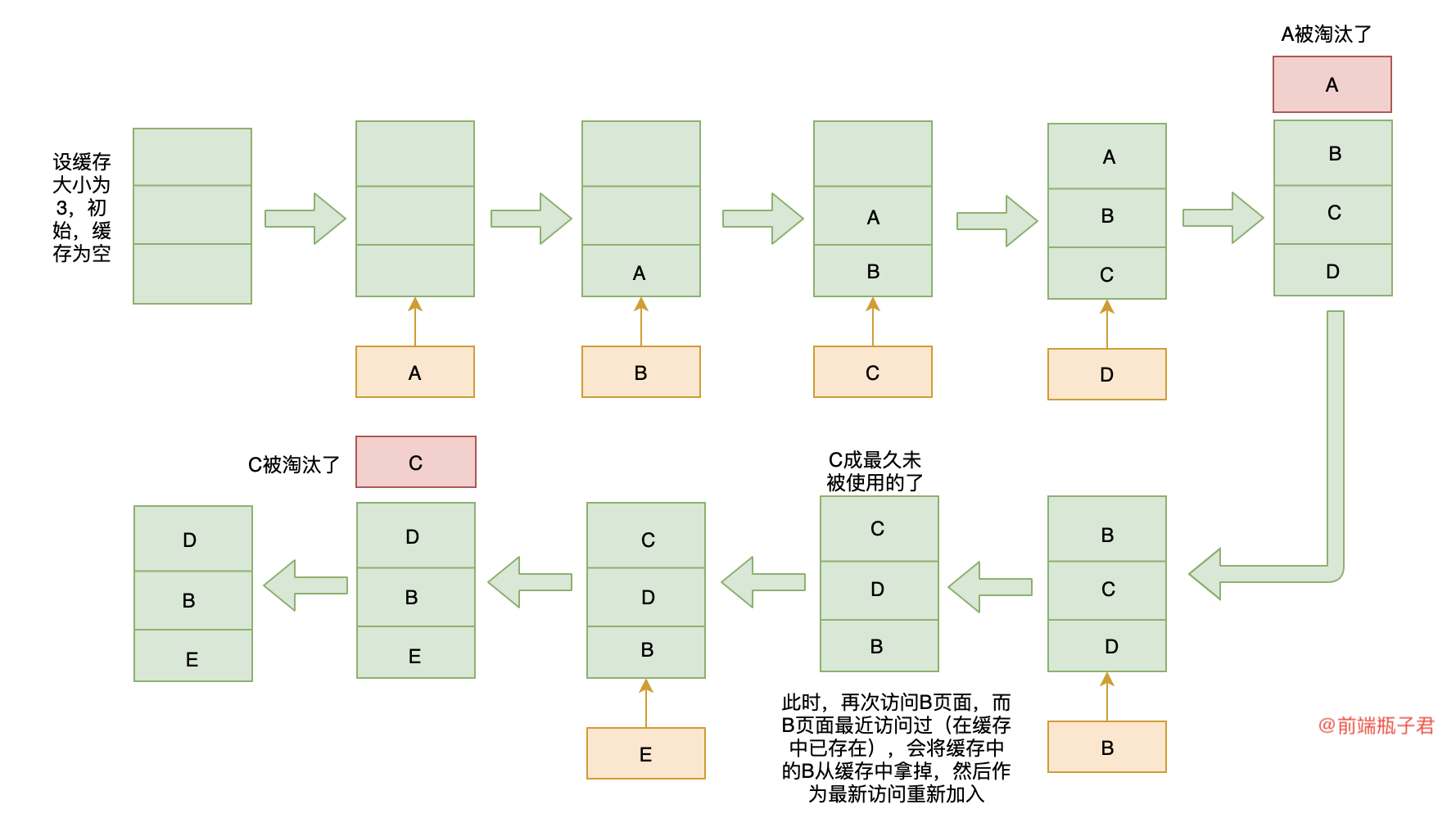
- 前端进阶算法3:从浏览器缓存淘汰策略和Vue的keep-alive学习LRU算法
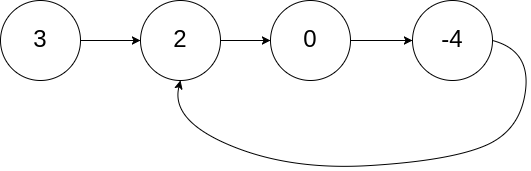
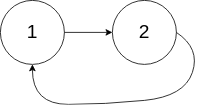
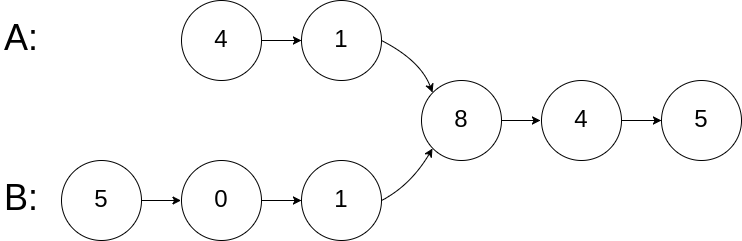
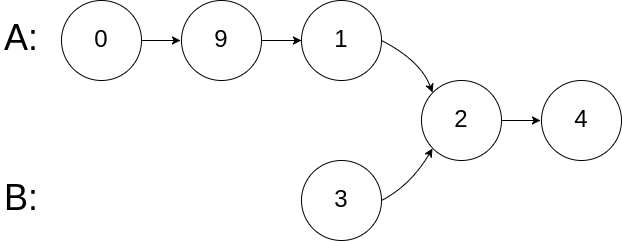
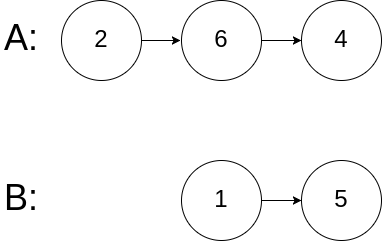
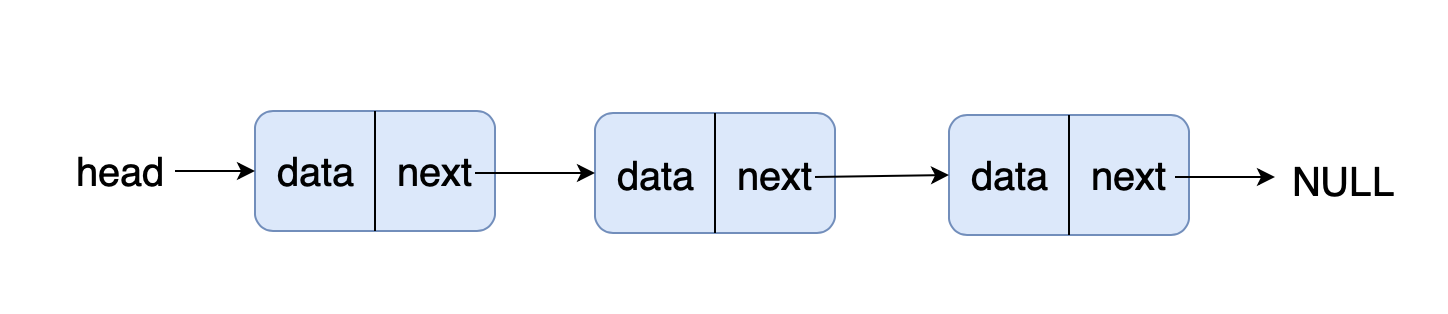
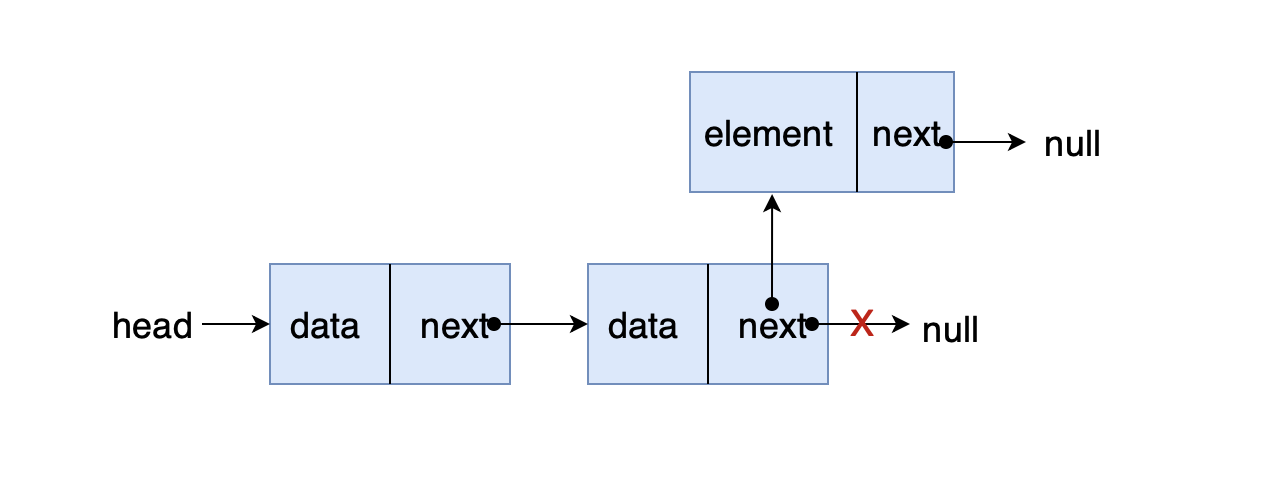
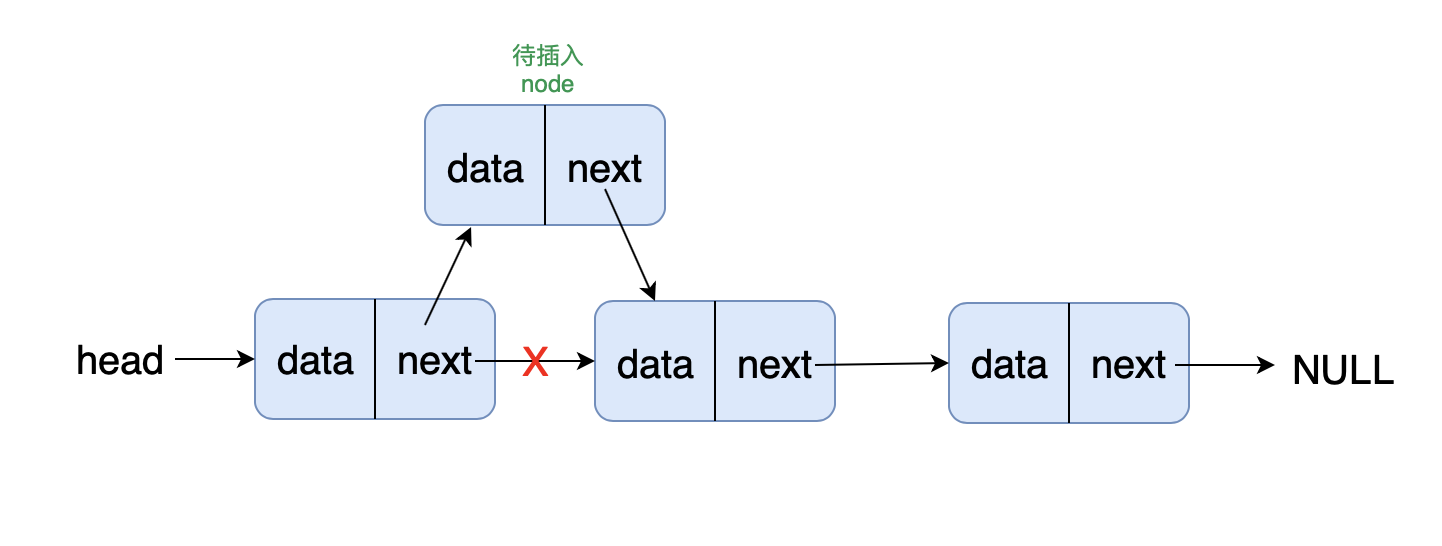
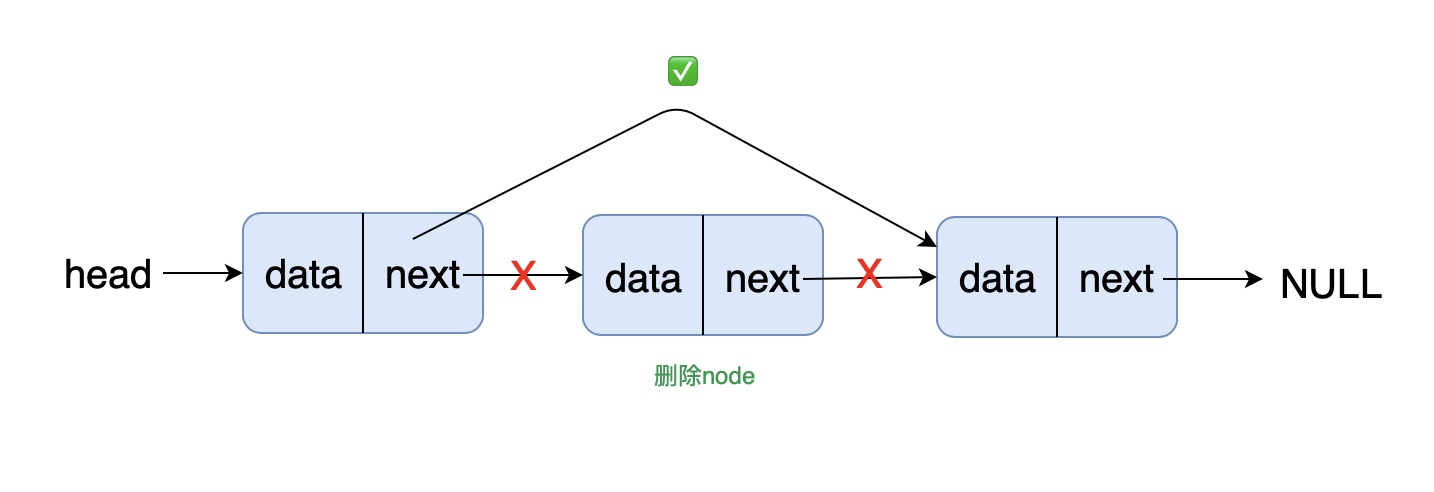
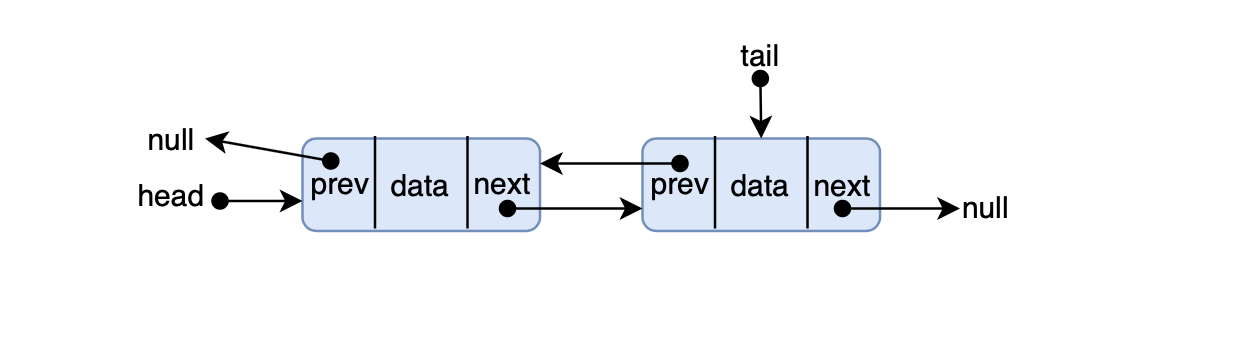
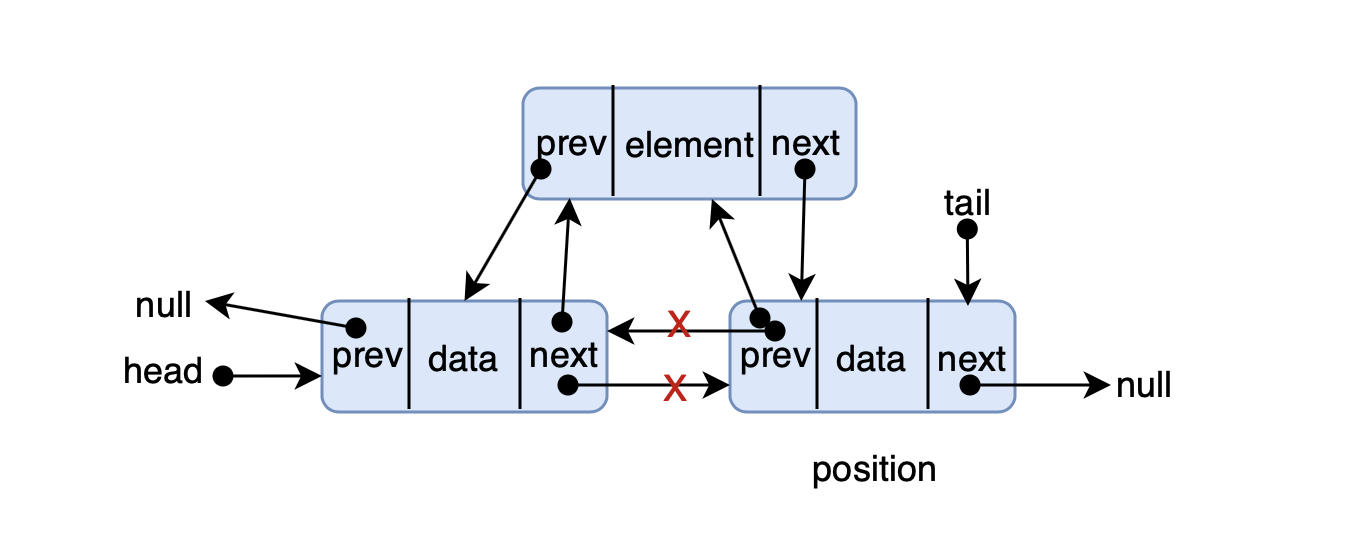
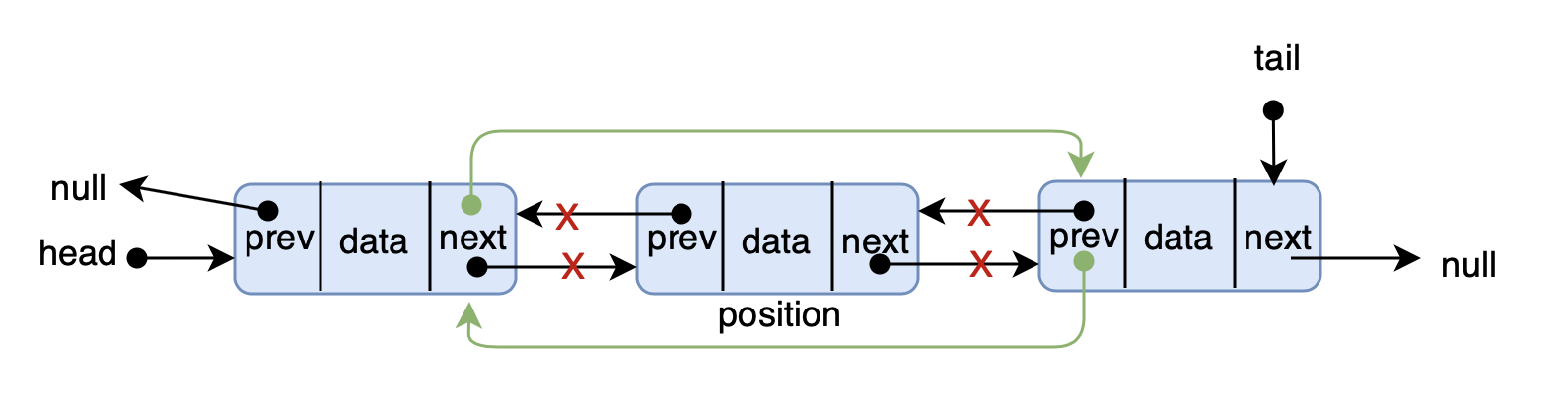
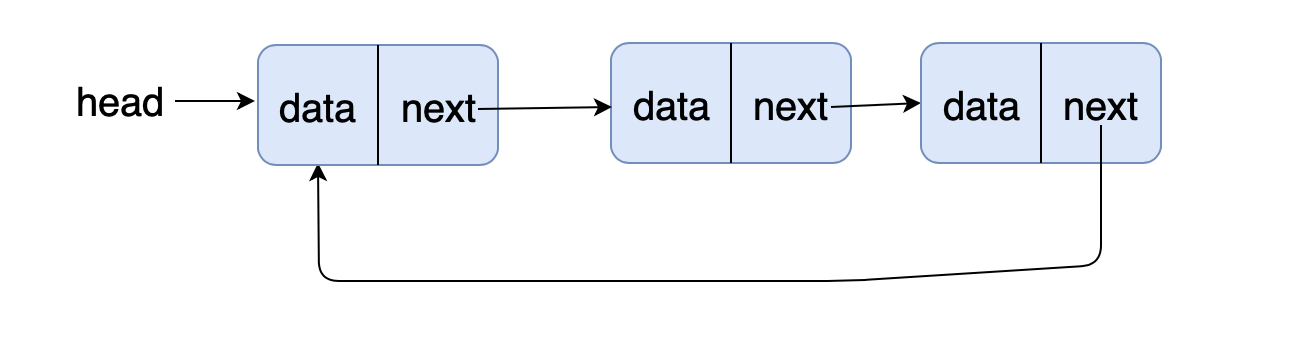
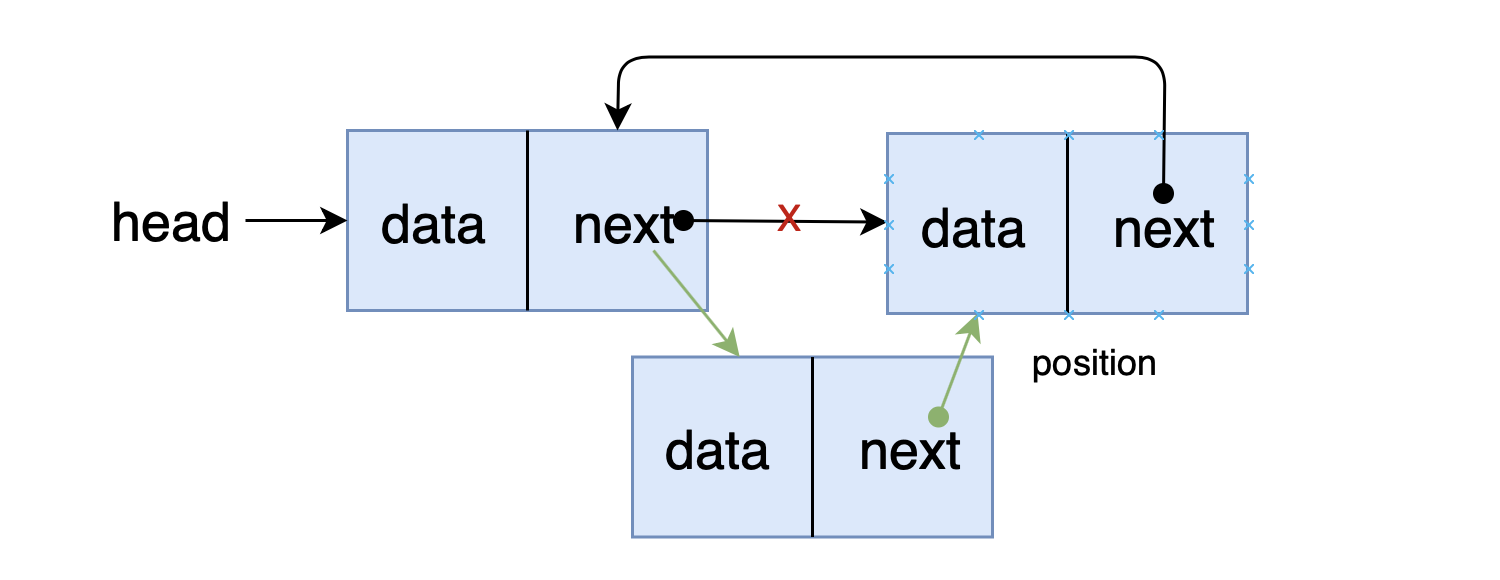
- 前端进阶算法4:链表原来如此简单(+leetcode刷题)
- 10 问 10 答,带你快速入门前端算法
- 视频面试超高频在线编程题,搞懂这些足以应对大部分公司
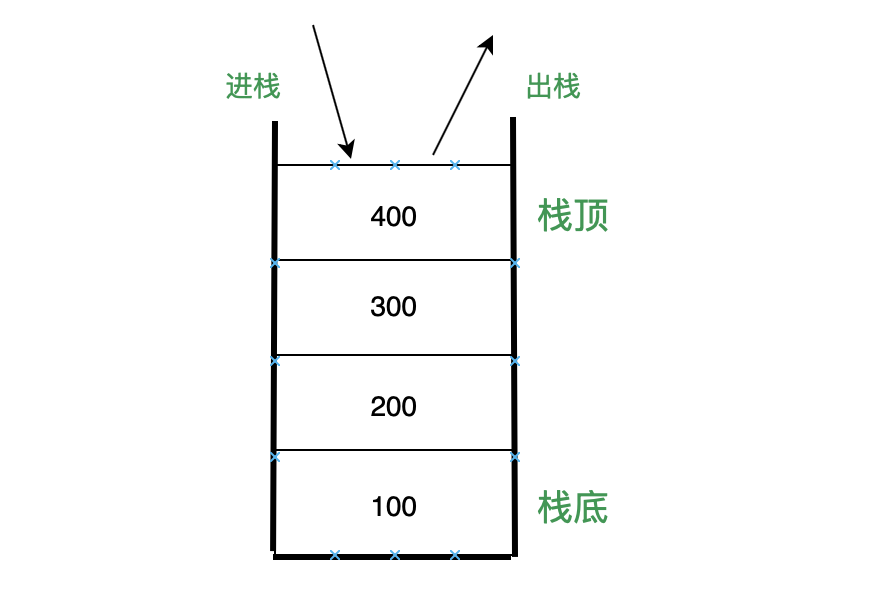
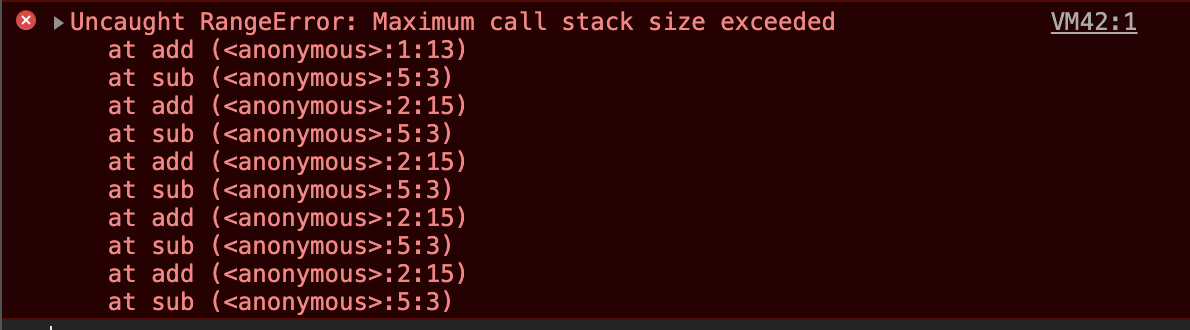
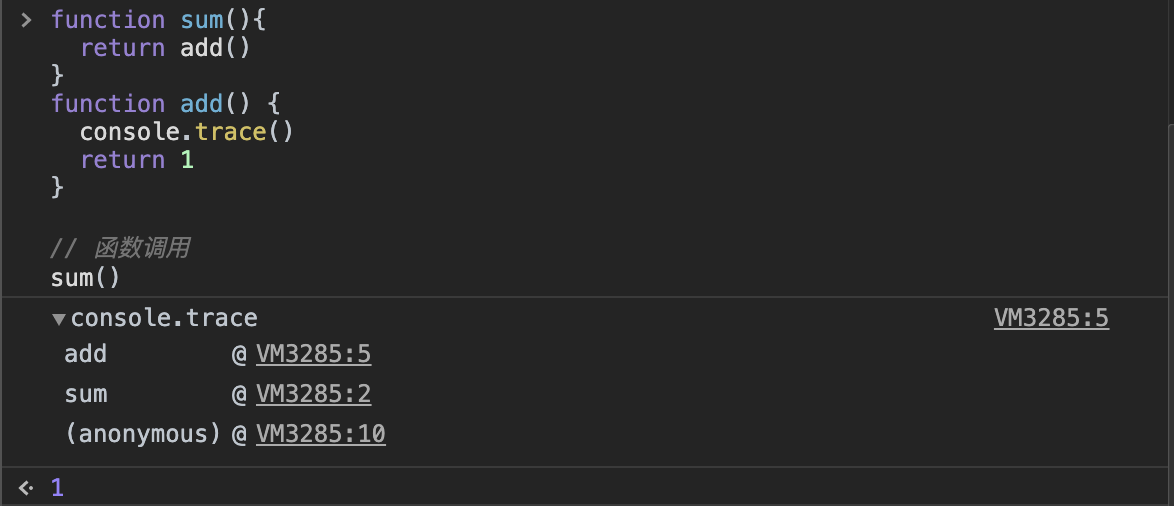
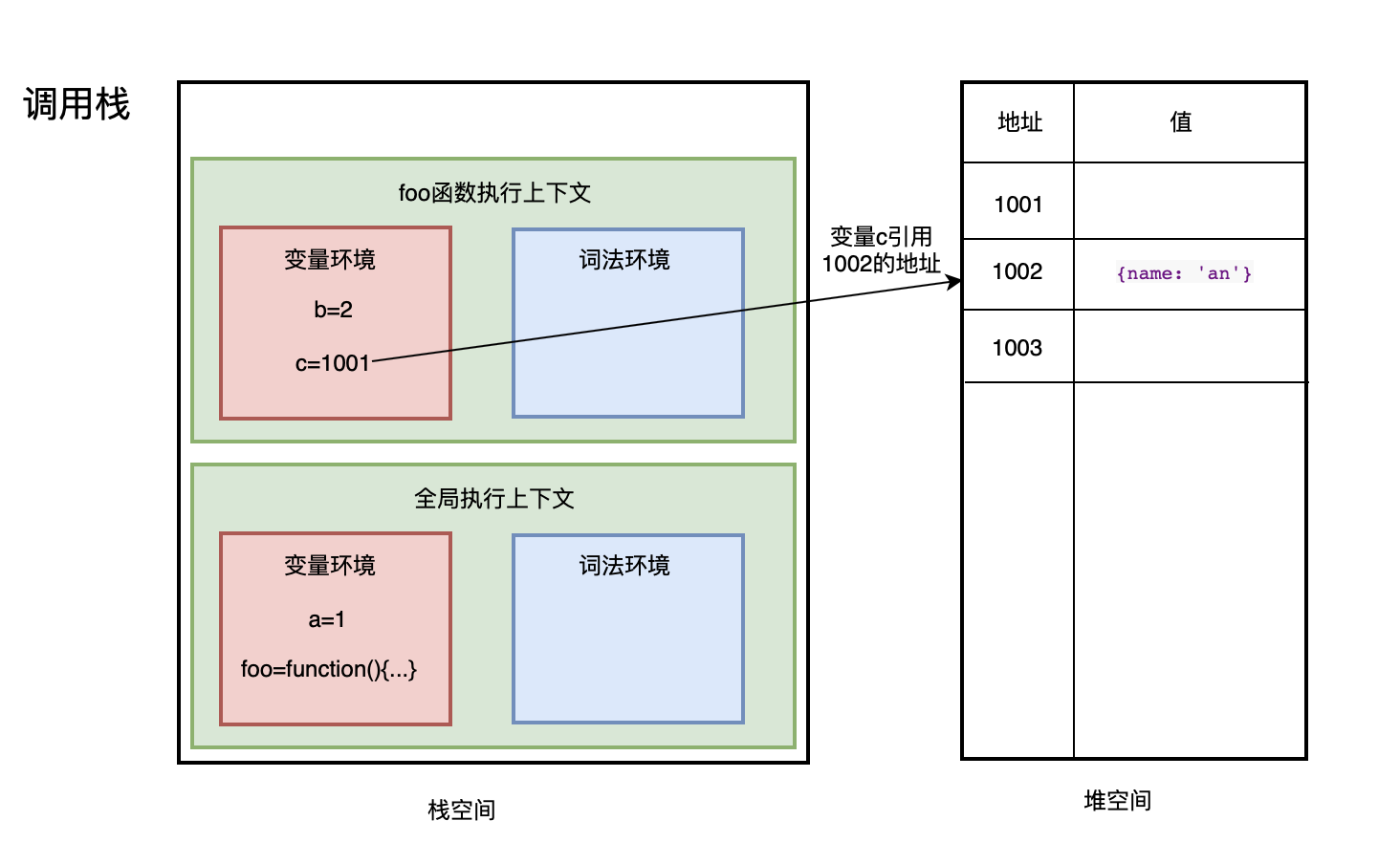
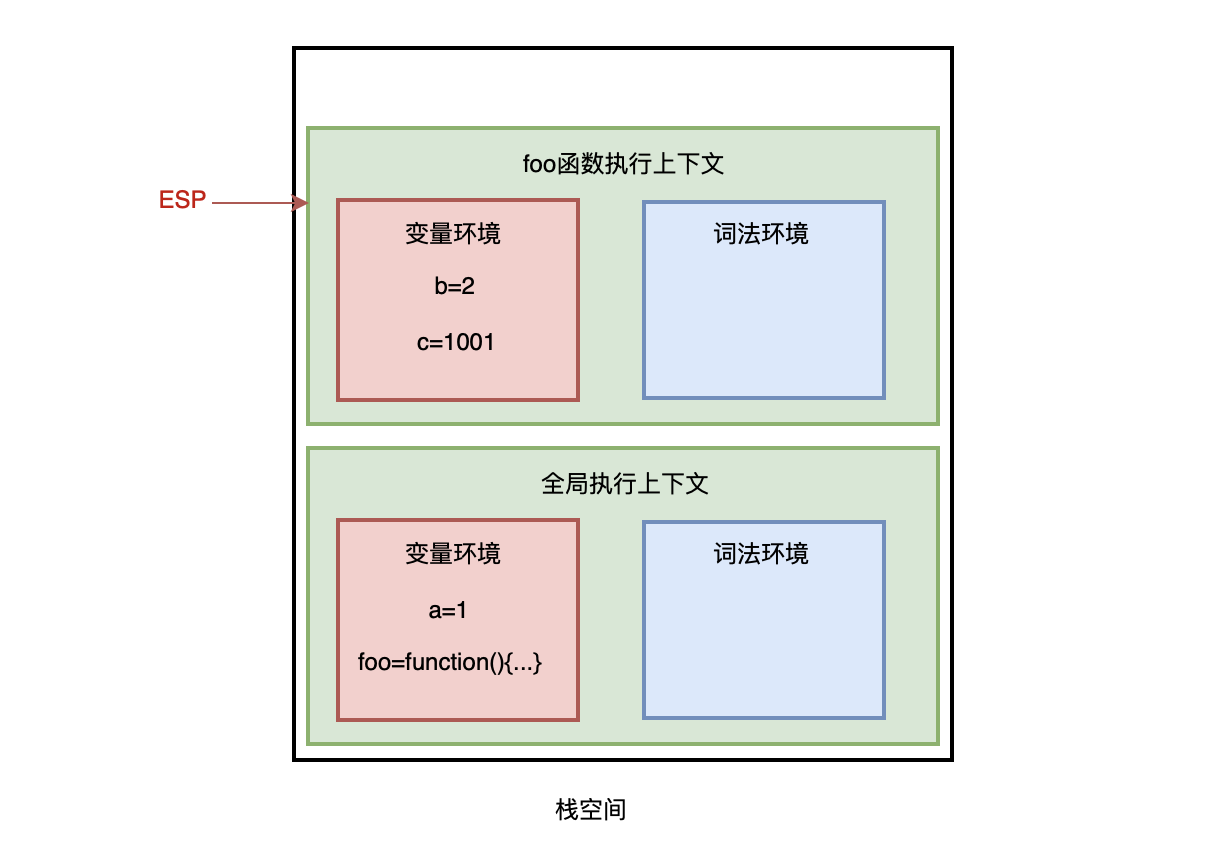
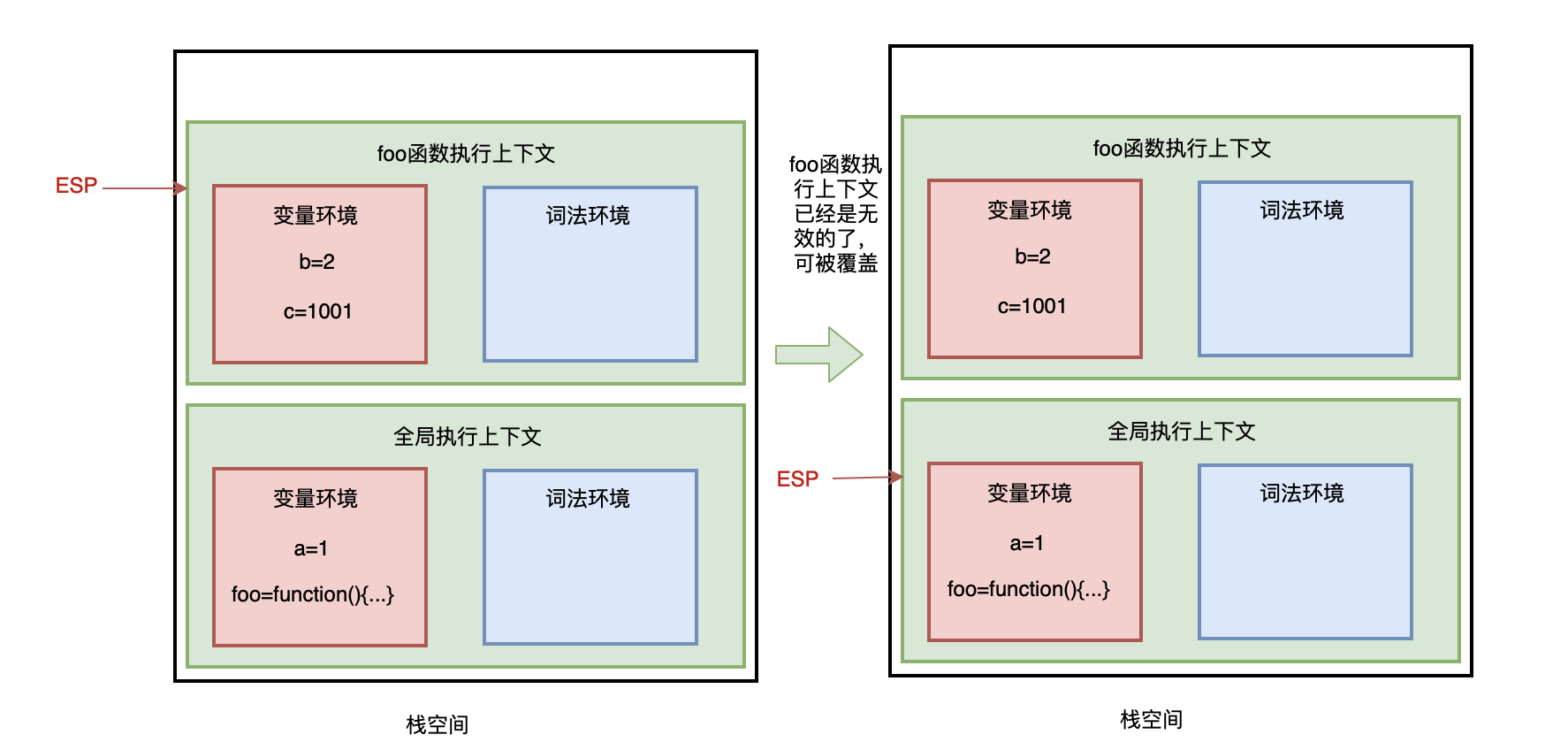
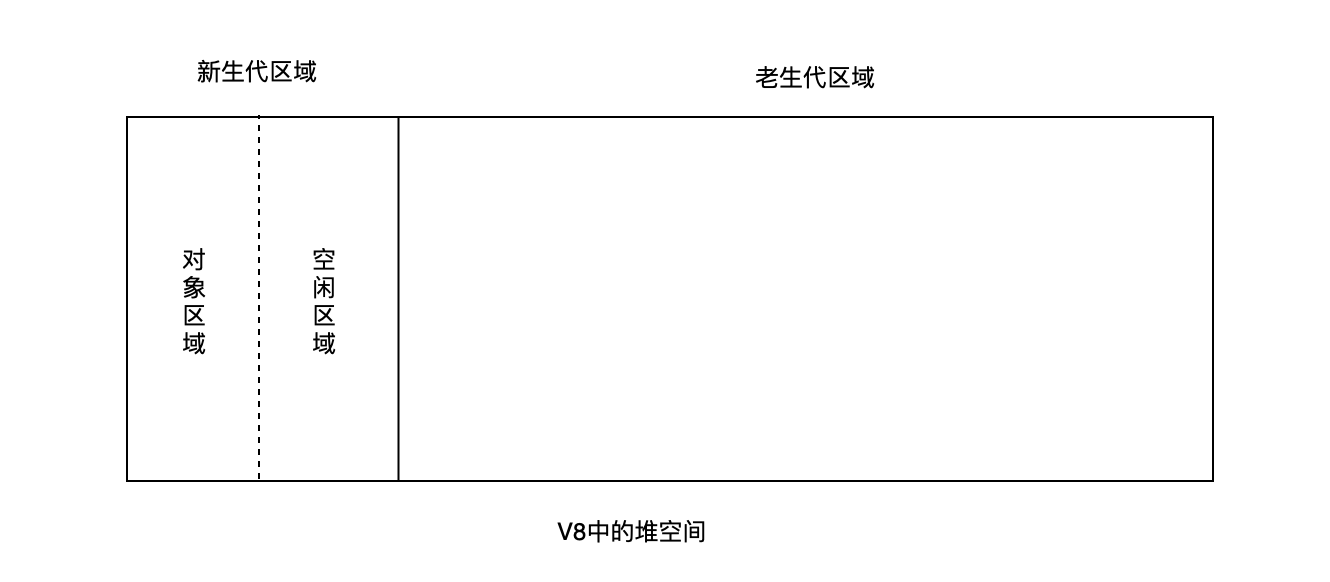
- 前端进阶算法5:全方位解读前端用到的栈结构(调用栈、堆、垃圾回收等)
- 前端进阶算法:常见算法题及完美题解
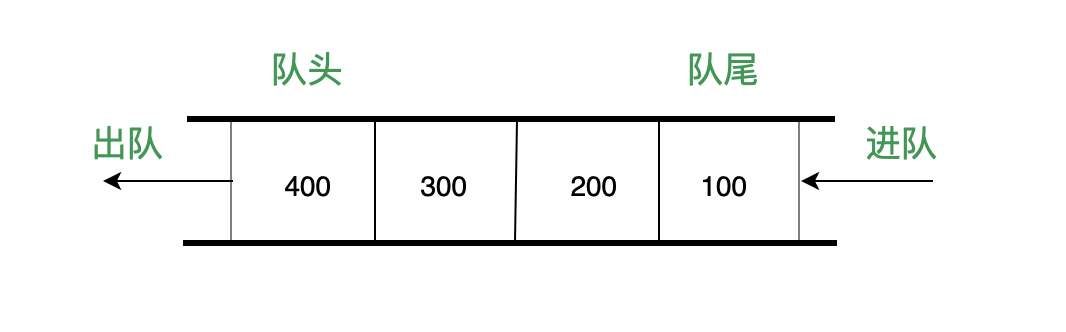
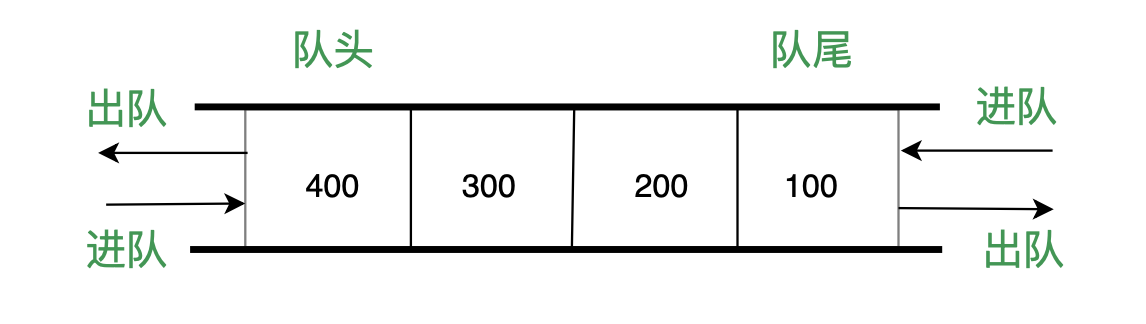
- 前端进阶算法6:一看就懂的队列及配套算法题
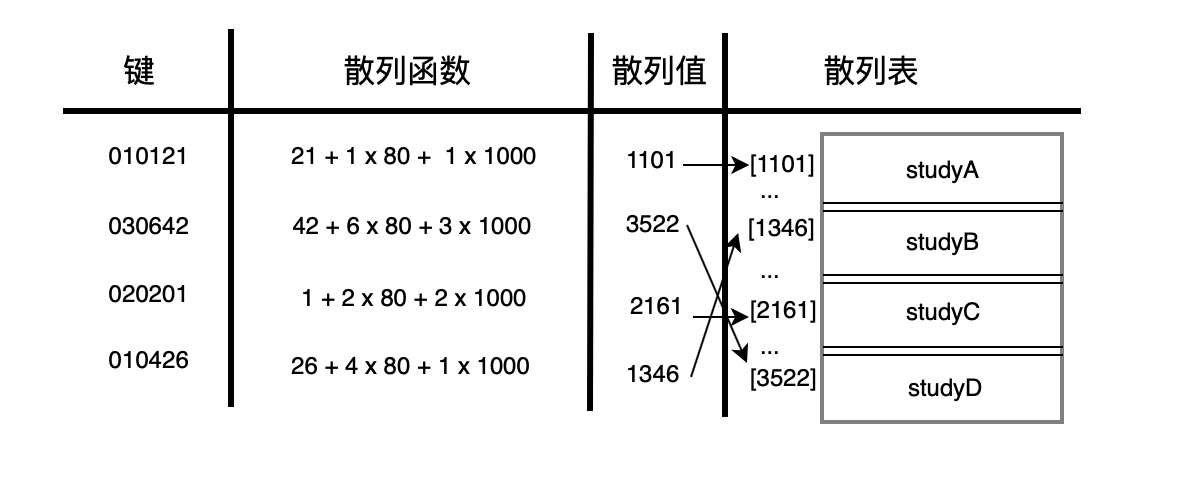
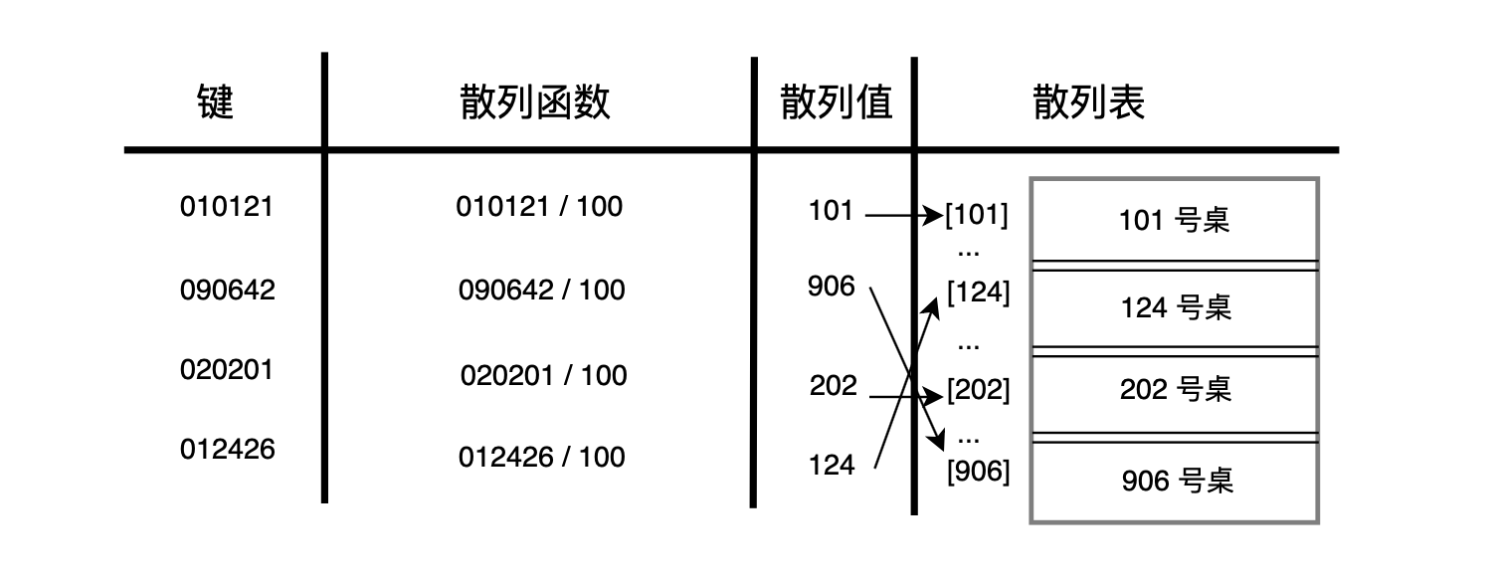
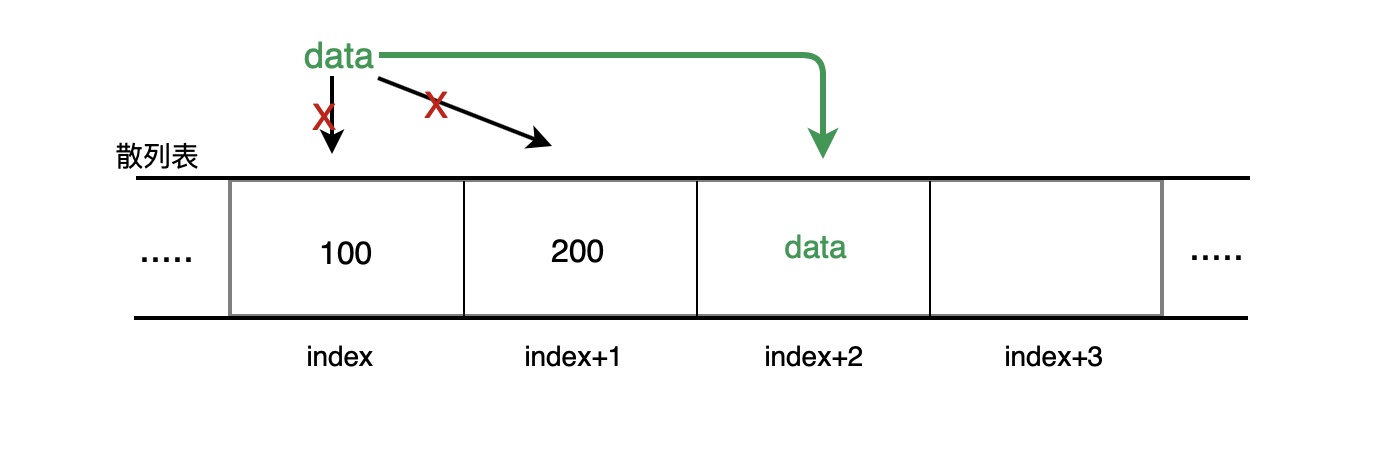
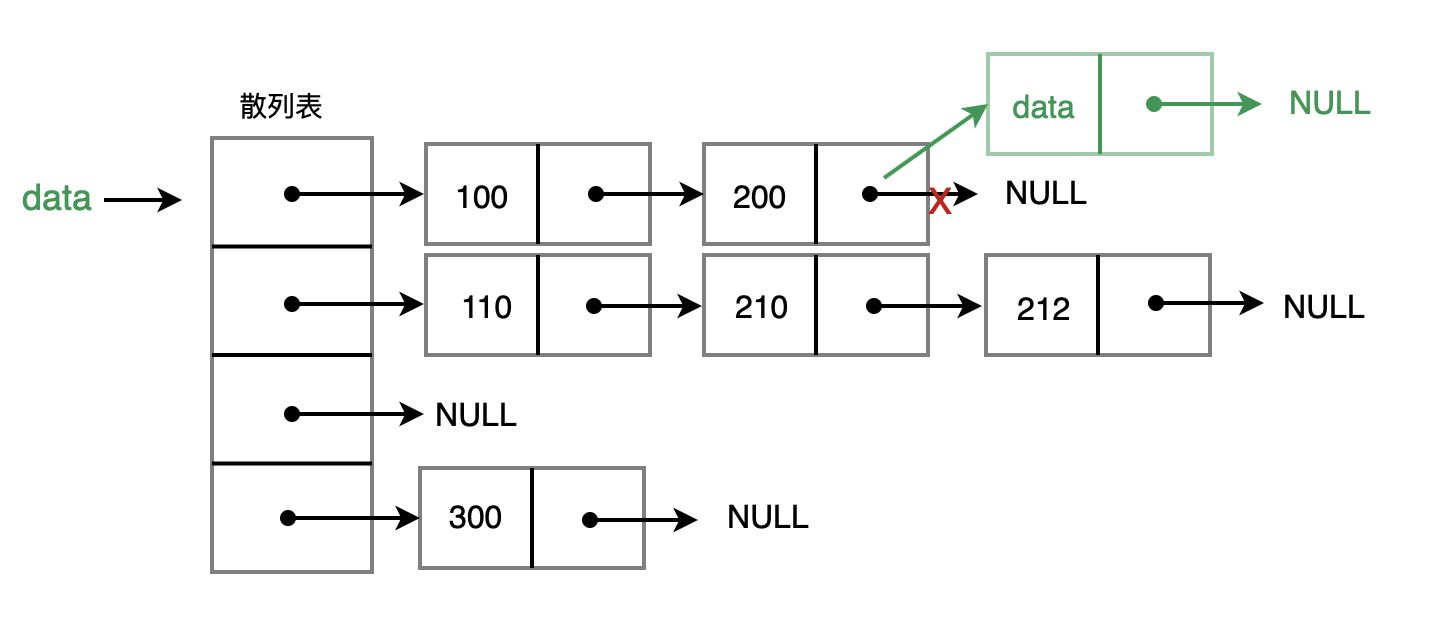
- 前端进阶算法7:头条正在面的哈希表问题
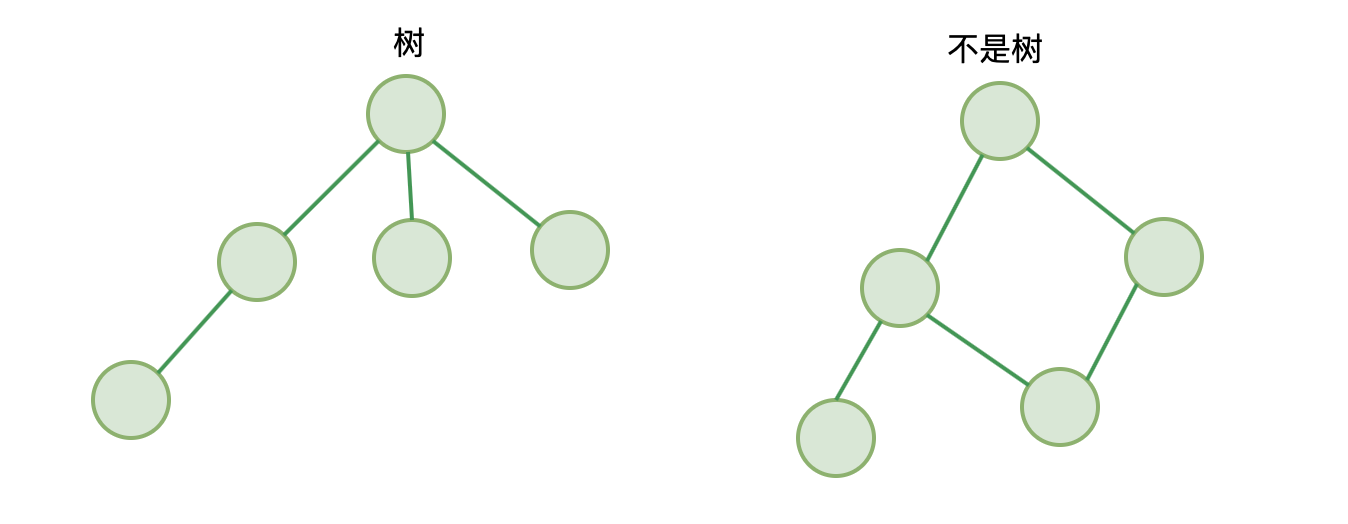
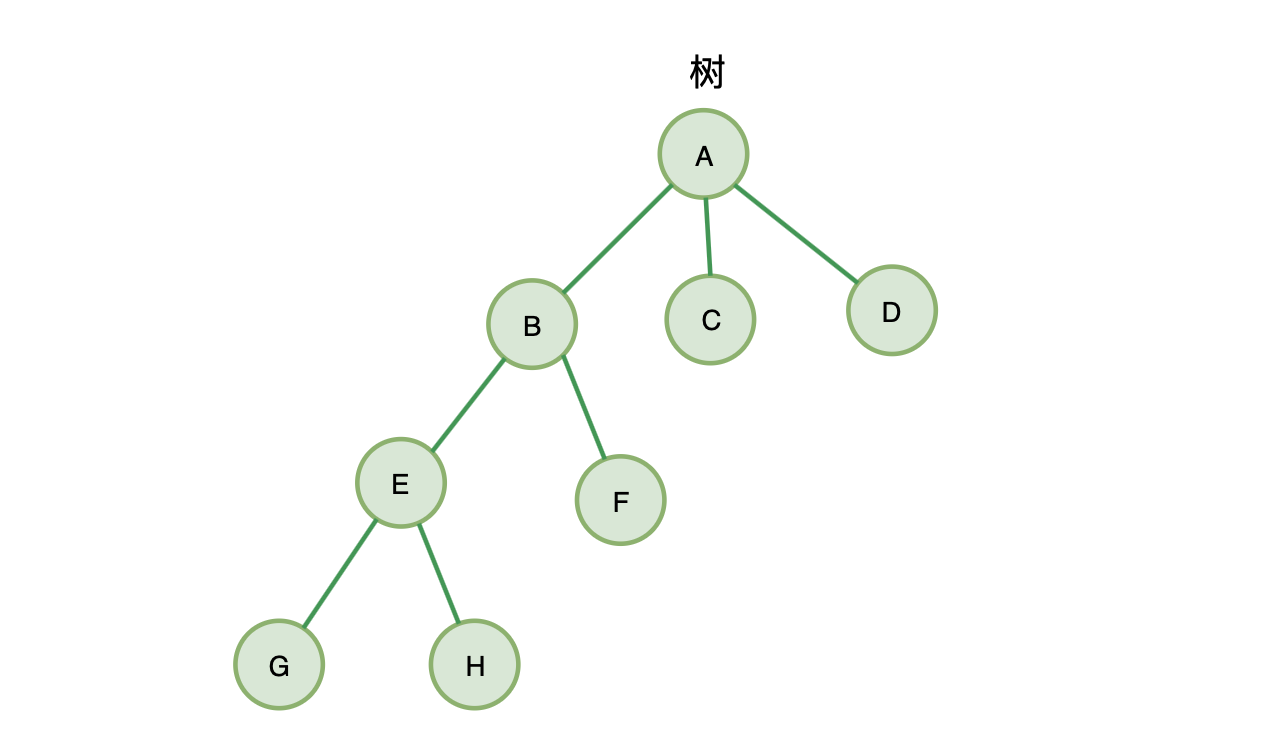
- 前端进阶算法8:小白都可以看懂的树与二叉树
- 前端进阶算法9:看完这篇,再也不怕堆排序、Top K、中位数问题面试了
- 前端进阶算法10:别再说你不懂topk问题了
- 前端进阶算法11:二叉查找树(BST树)
- 前端进阶算法12:数据结构与算法中的字符串
- 前端进阶算法13:一次搞定九大排序策略
- 前端进阶算法14:解读最常见的三大查找结构
- 前端进阶算法15:95% 的算法都是基于这 6 种算法**
- 前端进阶算法16:贪心算法套路问题
想要更多更快的学习本系列,可以关注公众号「前端瓶子君」😊😊😊
- 图解leetcode88:合并两个有序数组
- 字节&leetcode1:两数之和
- 腾讯&leetcode15:三数之和
- 字节:N数之和
- 腾讯:数组扁平化、去重、排序
- leetcode349:给定两个数组,编写一个函数来计算它们的交集
- 华为&leetcode146:设计和实现一个LRU(最近最少使用)缓存机制
- 阿里算法题:编写一个函数计算多个数组的交集
- leetcode21:合并两个有序链表
- 有赞&leetcode141:判断一个单链表是否有环
- 图解leetcode206:反转链表
- leetcode876:求链表的中间结点
- leetcode19:删除链表倒数第 n 个结点
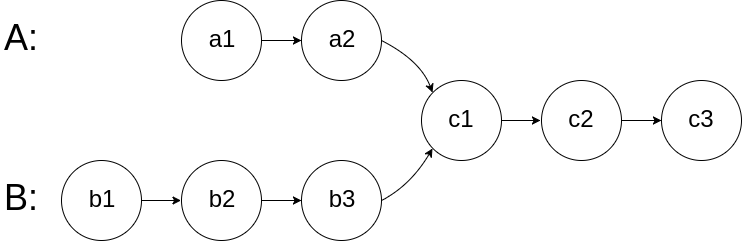
- 图解字节&leetcode160:编写一个程序,找到两个单链表相交的起始节点
- 腾讯&leetcode611:有效三角形的个数
- 快手算法:链表求和
- leetcode42:接雨水问题
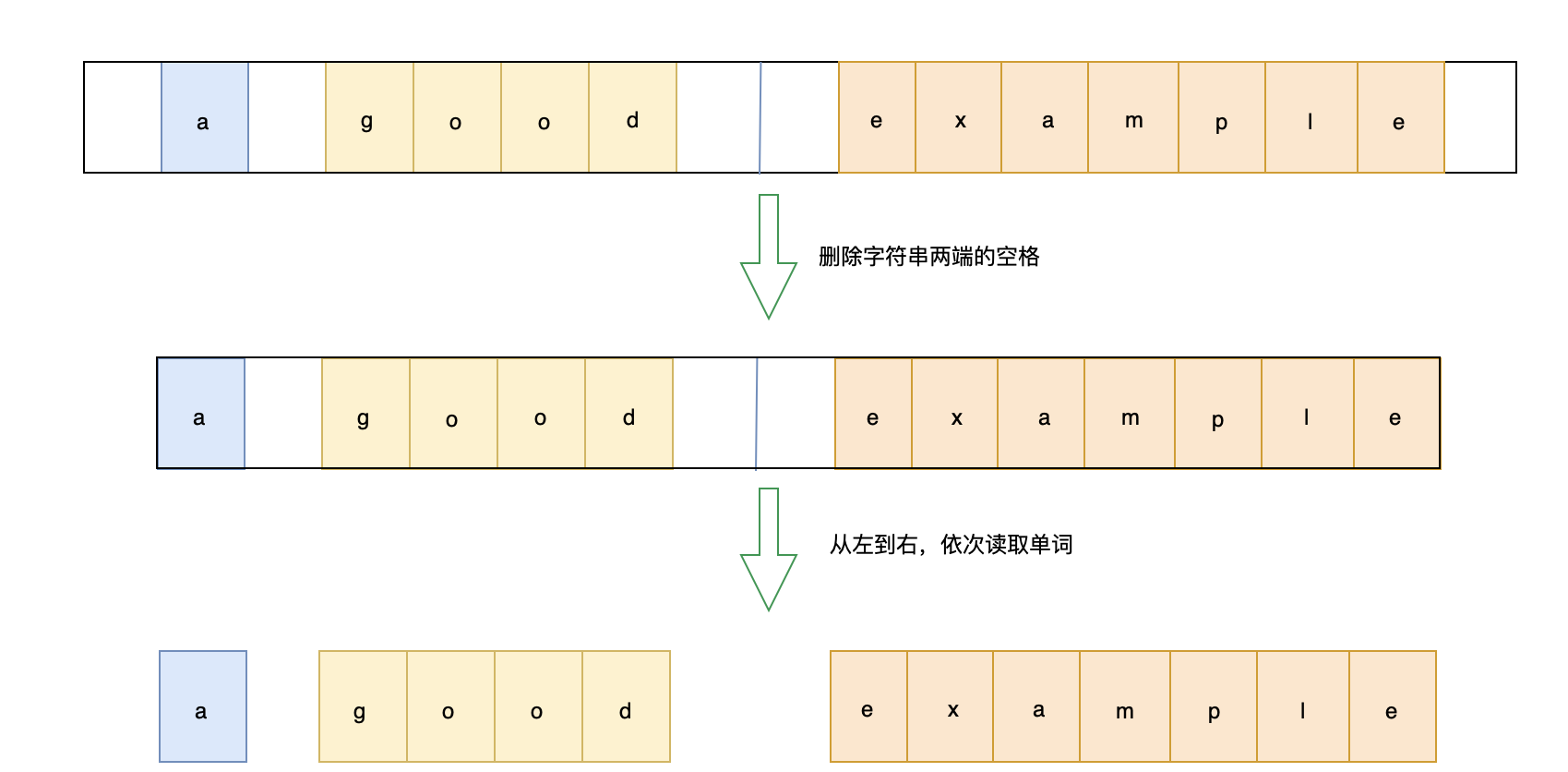
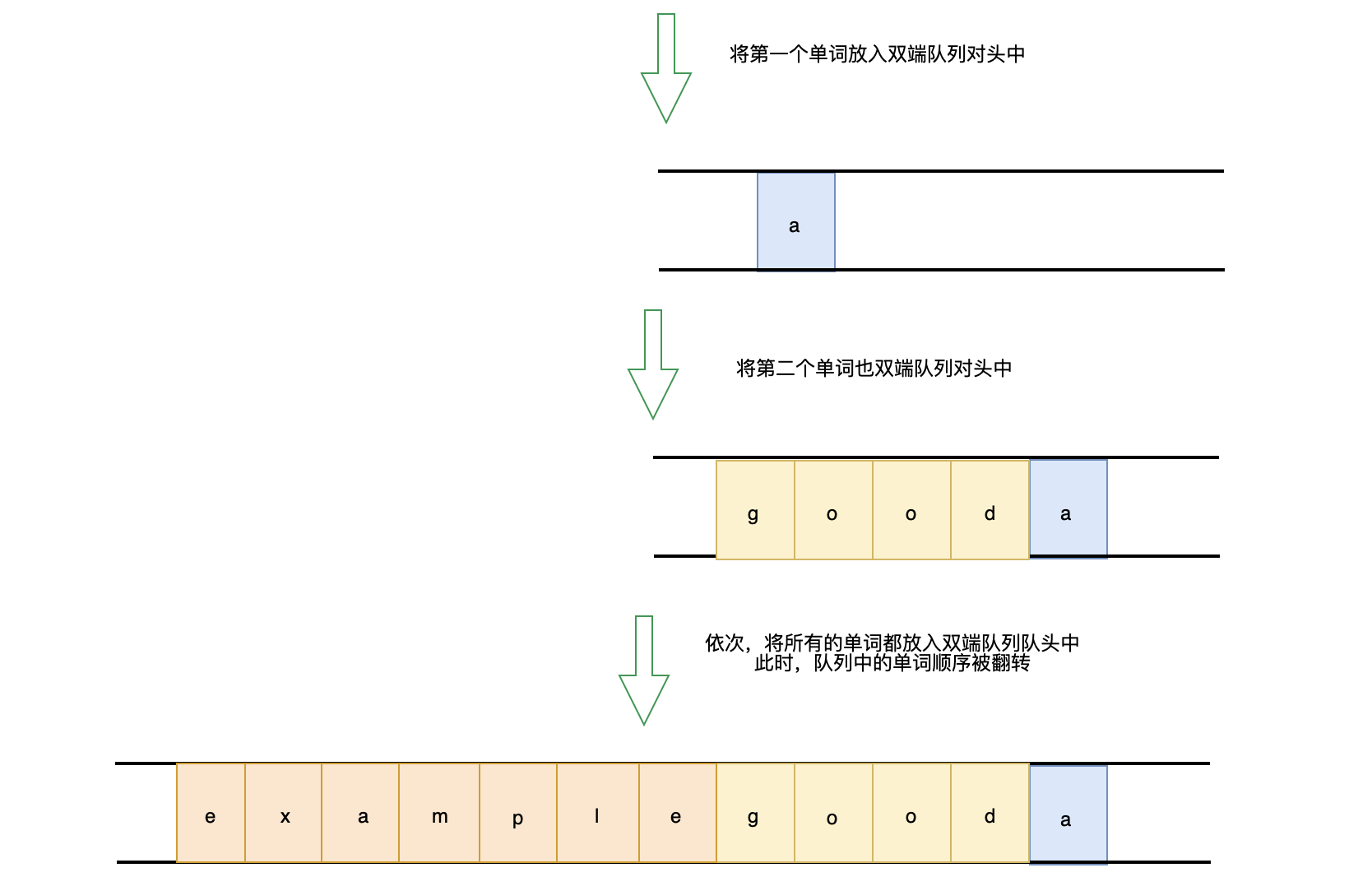
- 字节&leetcode151:翻转字符串里的单词
- 图解拼多多&leetcode14:最长公共前缀(LCP)
- 百度:实现一个函数,判断输入是不是回文字符串
- 字节&Leetcode3:无重复字符的最长子串
- Facebook&字节&leetcode415: 字符串相加
- 腾讯&leetcode43:字符串相乘
- 腾讯&剑指Offer:字符串转换整数 (atoi)
- 字节&leetcode155:最小栈(包含getMin函数的栈)
- 图解腾讯&哔哩哔哩&leetcode20:有效的括号
- leetcode1047:删除字符串中的所有相邻重复项
- leetcode1209:删除字符串中的所有相邻重复项 II
- 面试真题:删除字符串中出现次数 >= 2 次的相邻字符
- 腾讯&leetcode349:给定两个数组,编写一个函数来计算它们的交集
- 字节&leetcode1:两数之和
- 腾讯&leetcode15:三数之和
- leetcode380:常数时间插入、删除和获取随机元素
- 剑指Offer:第一个只出现一次的字符
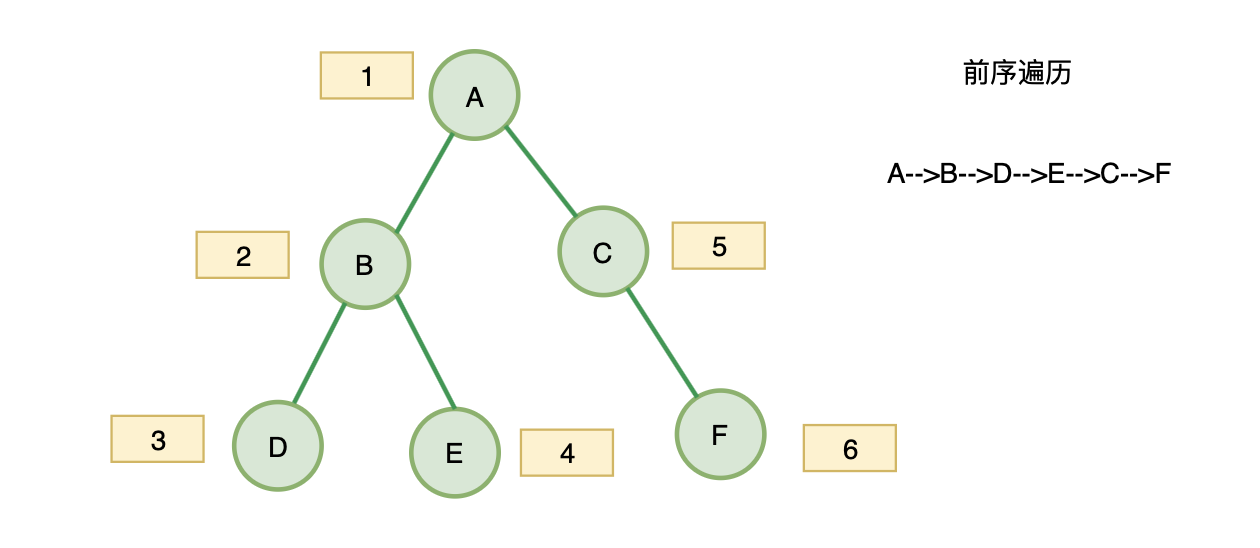
- 字节&leetcode144:二叉树的前序遍历
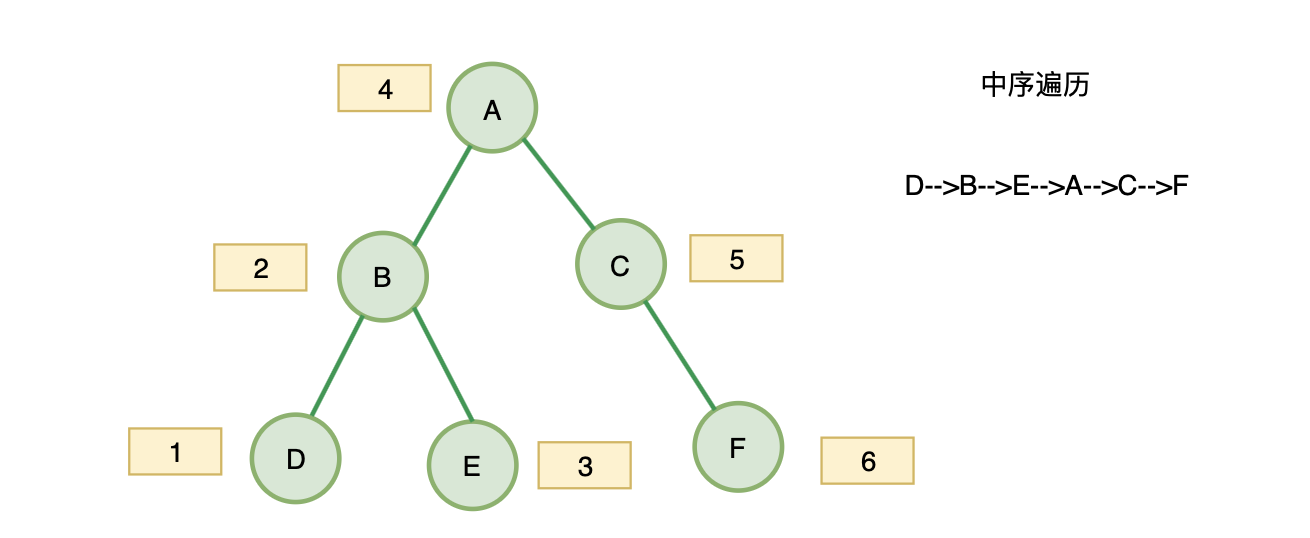
- 字节&leetcode94:二叉树的中序遍历
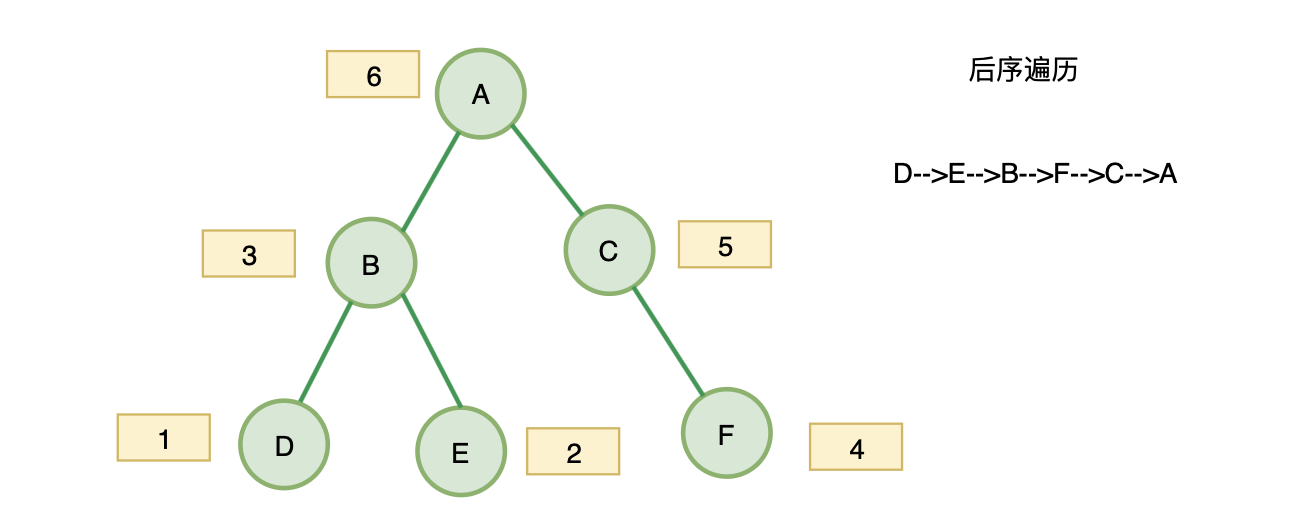
- 字节&leetcode145:二叉树的后序遍历
- leetcode102:二叉树的层序遍历
- 字节&leetcode107:二叉树的层次遍历
- 腾讯&leetcode104:二叉树的最大深度
- 字节&腾讯leetcode236:二叉树的最近公共祖先
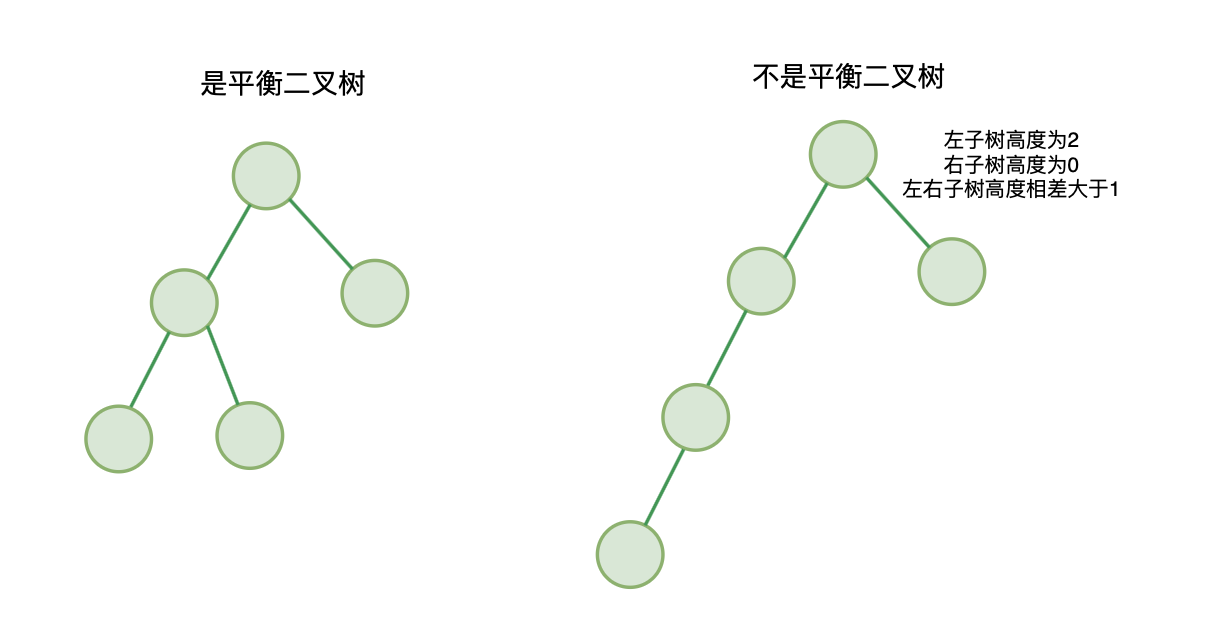
- 剑指Offer&leetcode110:平衡二叉树
- 字节&leetcode112:路径总和
- 剑指Offer&leetcode101:对称二叉树
- 字节一面:给定一个二叉树, 找到该树中两个指定节点间的最短距离
- 腾讯&leetcode230:二叉搜索树中第K小的元素
- 二叉树的左右子树交换
- 腾讯&字节:介绍一下快排原理以及时间复杂度,并实现一个快排
- 字节&阿里&网易&leetcode384:打乱数组(洗牌算法)
- 阿里五面:说下希尔排序的过程? 希尔排序的时间复杂度和空间复杂度又是多少?
- 腾讯&leetcode148:排序链表
- 字节算法题:扑克牌问题(反向推导题)
- 腾讯&leetcode611:有效三角形的个数
- 腾讯:简述二分查找算法与时间复杂度,并实现一个二分查找算法
- 腾讯&字节&leetcode34:在排序数组中查找元素的第一个和最后一个位置
- 腾讯&leetcode230:二叉搜索树中第K小的元素
- 腾讯&leetcode875:爱吃香蕉的珂珂
- 字节&leetcode70:爬楼梯问题
- 字节&leetcode746:使用最小花费爬楼梯
- 字节二面&leetcode53:最大子序和
- 腾讯&leetcode121:买卖股票的最佳时机
- 腾讯&leetcode647:回文子串
- 腾讯&leetcode5:最长回文子串
- 阿里&网易&leetcode64:最小路径和
- 携程&蘑菇街&bilibili:手写数组去重、扁平化函数
- 腾讯:不产生新数组,删除数组里的重复元素
- 蘑菇街:按照以下要求,写一个数组(包含对象等类型元素)去重函数
- 网易&美团:实现一个 findIndex 函数
- 字节:模拟实现 Array.prototype.splice
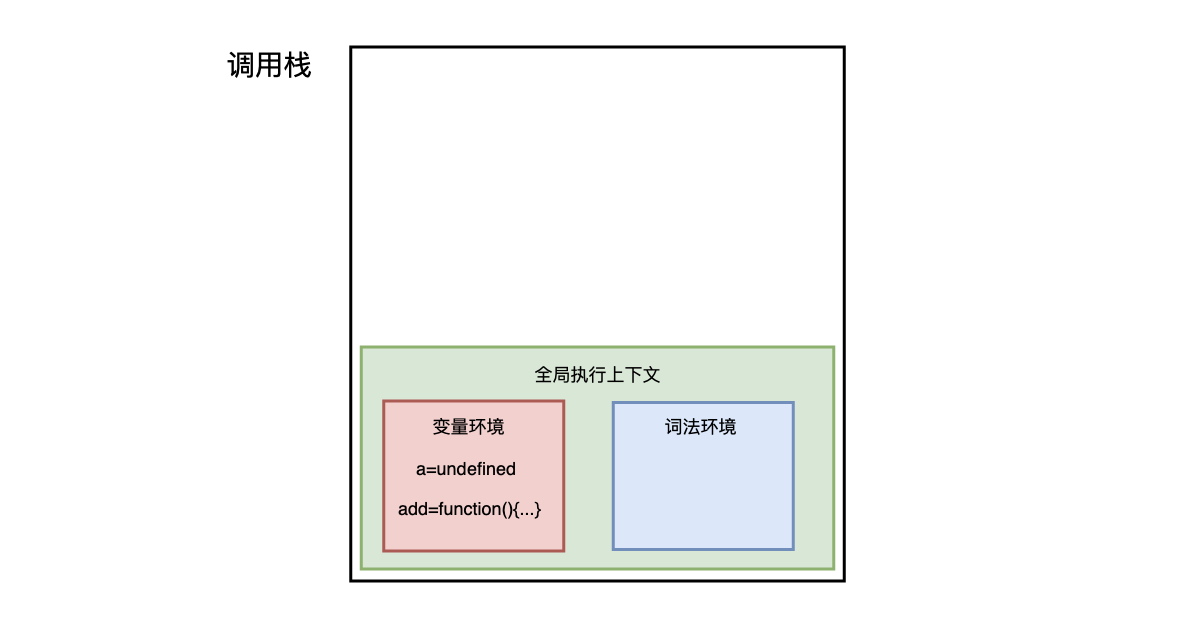
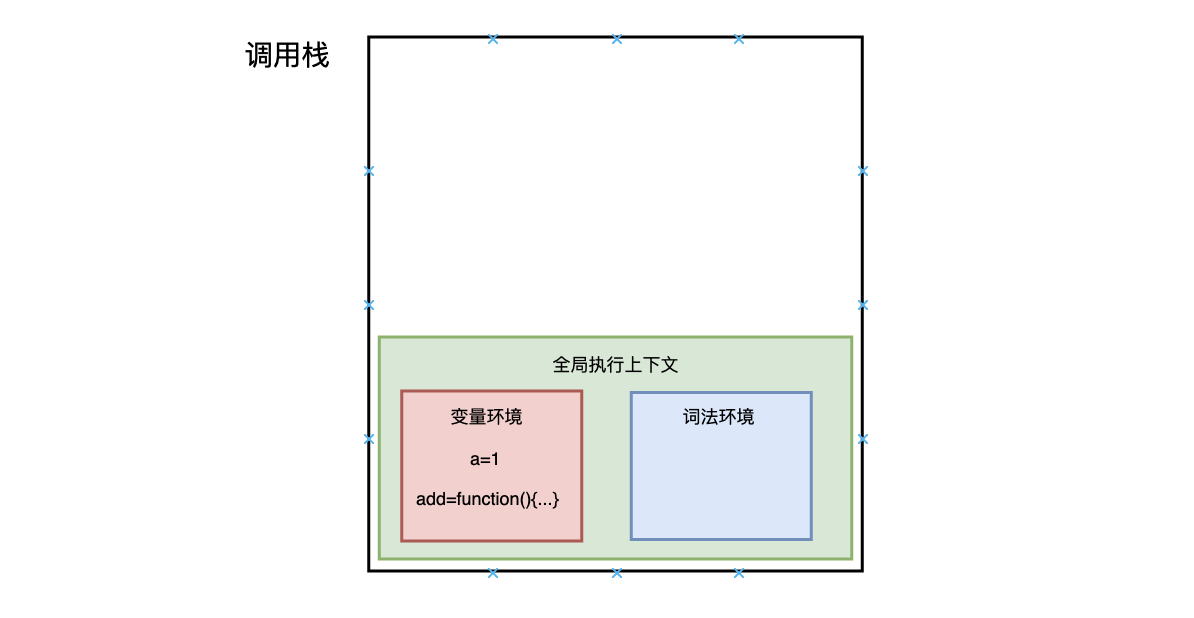
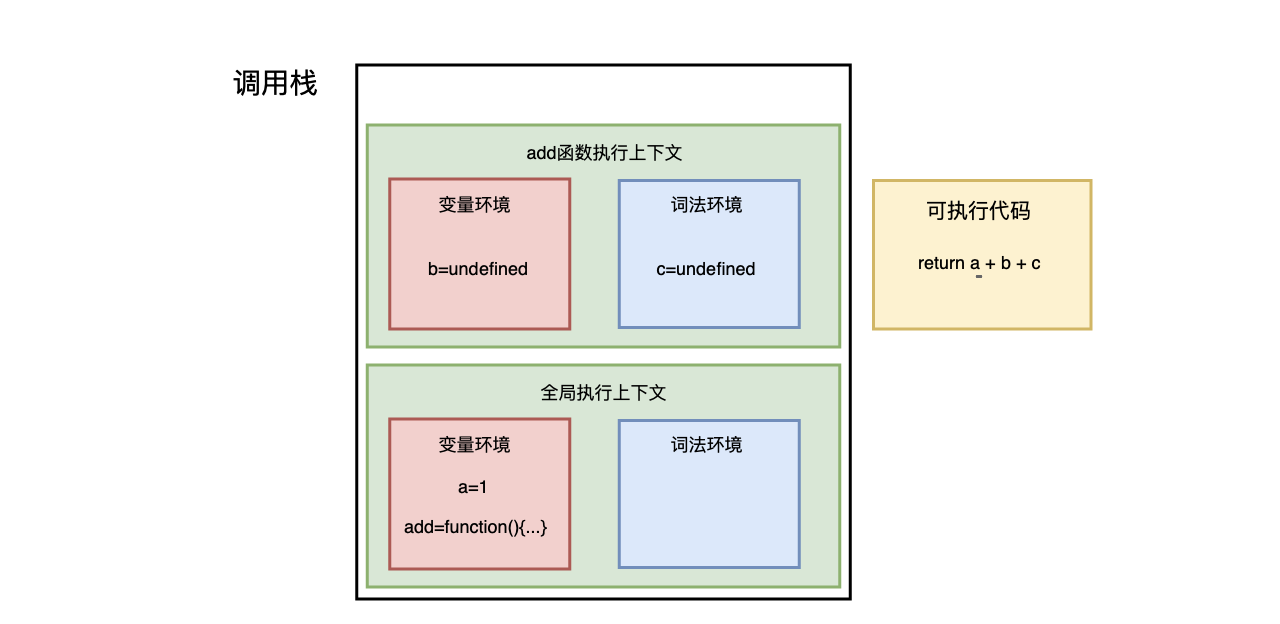
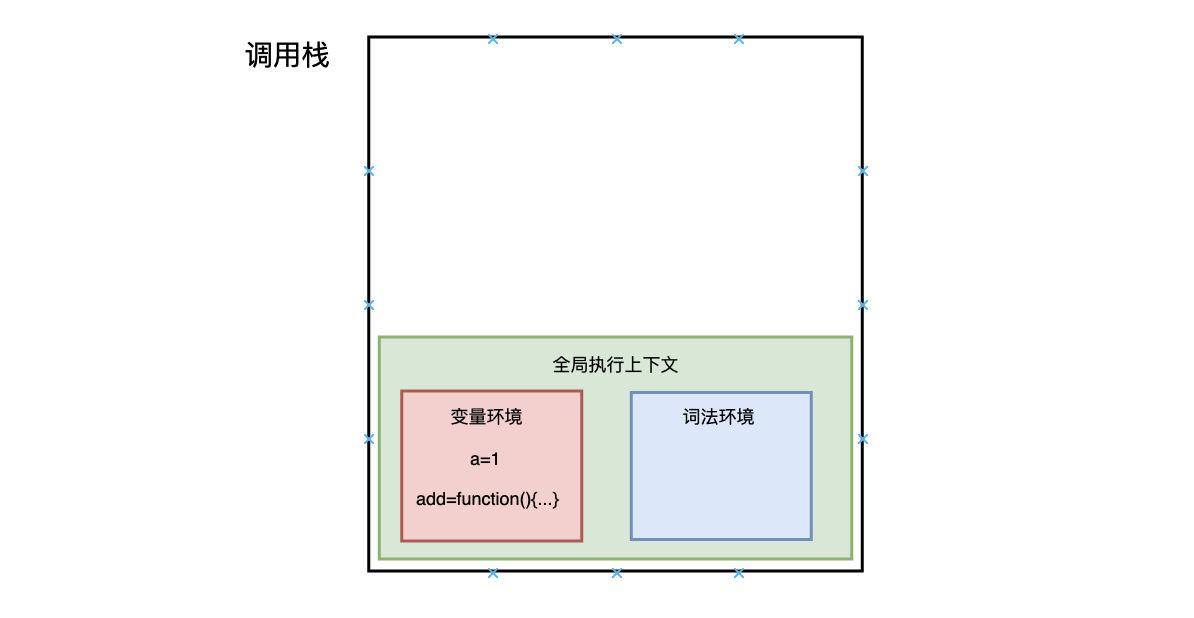
- 字节编程题:实现一个add方法
- 百度:模版渲染
- 百度:什么是浅拷贝和深拷贝?有什么区别?如何实现 Object 的深拷贝
- 阿里&字节:手写 async/await 的实现
- 编程题:用最简洁代码实现 indexOf 方法
- 阿里编程题:实现一个方法,拆解URL参数中queryString
- 字节:输出以下代码运行结果,为什么?如果希望每隔 1s 输出一个结果,应该如何改造?注意不可改动 square 方法
- 字节:修改以下 print 函数,使之输出 0 到 99,或者 99 到 0
- 阿里异步串行编程题:按照以下要求,实现 createFlow 函数
- 百度&阿里编程题:模拟实现一个 localStorage
- 美团编程题:编写一个算法解析以下符号,转换为json树的结构
- 阿里:如何判断两个变量相等
- 蘑菇街:找出字符串中连续出现最多的字符和个数
- 字节&剑指 Offer 29:顺时针打印矩阵
- 编程题:以下输出顺序多少 (setTimeout 与 promise 顺序)
- 腾讯算法题
- 腾讯:64匹马,8个赛道,找出跑最快的4匹马
- 华为:一个字符串里出现最多的字符是什么,以及出现次数
- 字节:N数之和
- 编程之美&百度&腾讯:黑球、白球各100,问最后剩下一个是黑球的概率
- 给你一个数组[2,1,2,4,3],你返回数组 [4,2,4,−1,−1]
- 腾讯:字符串的数字相加
- 找出一个字符串中的不匹配括号的位置,以json形式输出,位置index从0开始
- 基础题,直接写出答案
- 字节:模拟实现 new 操作符
- 解析 call/apply 原理,并手写 call/apply 实现
- 解析 bind 原理,并手写 bind 实现
- 手写 Promise 源码实现
- 百度:手写parseInt的实现,要求简单一些,把字符串型的数字转化为真正的数字即可,但不能使用JS原生的字符串转数字的API,比如Number()
- 百度:什么是浅拷贝和深拷贝?有什么区别?如何实现 Object 的深拷贝
- 高频:手写一个节流函数 throttle
- 高频:手写一个防抖函数 debounce
- 腾讯:介绍 setTimeout 实现机制与原理
- 阿里&字节:手写 async/await 的实现
- async await 和 promise 的关系
- 手写 axios 实现
- 手写一个发布-订阅模式
- 网易&美团:实现一个 findIndex 函数
- 字节:模拟实现 Array.prototype.splice
- 手写 useState 实现
- 字节:使用 CSS 画一个三角形
- 网易:请描述一下 cookies、 sessionStorage和localstorage区别
- 腾讯:HTTP 、 HTTPS 、 HTTP2 的区别?
- 字节&平安:CSS 实现文本的单行和多行溢出省略效
- 腾讯:简述一下用户访问网站的过程(缓存,DNS查询,建立链接,请求,响应,收到页面,解析DOM树,显示内容,首屏加载完成,可交互)
- 介绍一下浏览器缓存策略
- es6 及 es6+ 的能力集,你最常用的,这其中最有用的,都解决了什么问题
- react 与 vue 的技术栈对比,说下区别
- react16新增了哪些生命周期、有什么作用,为什么去掉某些15的生命周期
- 前端性能优化
- http 301 302 307之间的区别