smartinmedia / net-core-docx-html-to-pdf-converter Goto Github PK
View Code? Open in Web Editor NEW.NET Core library to create custom reports based on Word docx or HTML documents and convert to PDF
License: MIT License
.NET Core library to create custom reports based on Word docx or HTML documents and convert to PDF
License: MIT License
















































































































Hi,
can anyone help regarding this bug. It seems the converter is accessing LibreOffice, but I get -1073740791 exit code.
thank you.
Hello everyone, I convert docx to pdf. It works when I run on VS 2022, but when I deploy to the server. It doesn't generate pdf file and doesn't return error.
Can anyone help me please. Many thanks

Everything works fine under IISExpress or Console application. When I try to run under IIS server, it doesn't work.
I am running under DefaultAppPool and I have given permission to DefaultAppPool to access LibreOffice directory but I am not able to get result.
Hey guys! I would like to make my simple but no less important contribution. I really believe in the potential of this library and I believe that it will still be very well known.
But I noticed that on the main page where it is being released (https://products.fileformat.com/word-processing/net/docx-to-pdf-converter/) the initial code, which is the gateway for developers who don't know the library, is incorrect.
Because the class instance code is missing. Because I believe that without it, it will not work:
var placeholders = new Placeholders();
It's missing here:
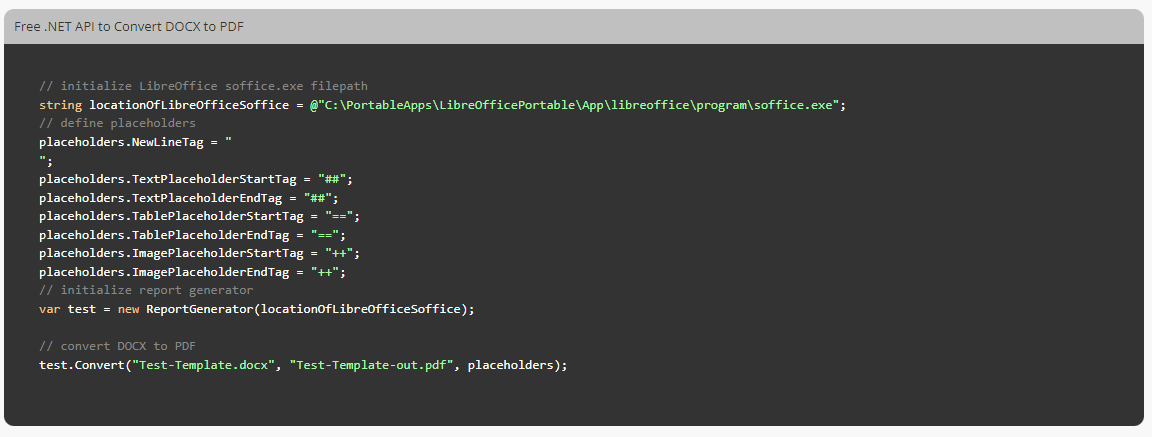
I know this may sound silly, but inattentive developers might not notice and give up on the library, thinking it's just another one that doesn't work!
Thanks in advance guys!
I am using DocXToPdfConverter NuGet Package in my application (C# .NET Core) to convert word documents to PDF format. Using this package and the example code given, I am able to successfully convert a word document to PDF file. However, the word document has an image which has a border (blue color) and that border is not displayed in the converted PDF file. I mean, the output PDF file contains the image without a border. Please let me know how to restore the formatting (such as borders, tables etc.,) in the output PDF file as they are in the input word document. Thank you.
Hi, everyone!
Please, help me
I can't find LibreOffice portable for linux(cetros 8). Can you get me link for downloading?
Describe the bug
I wanted to inquire if there had been any tests around multi threaded safety with using this library?
It is obviously starting a process for LibreOffice, but this begs to raise the question: what would happen if multiple Convert from DOCX to PDF operations had to happen in a server environment at the same time?

//Supposedly, only one instance of Libre Office can be run simultaneously
while (pname.Length > 0)
{
Thread.Sleep(5000);
}I think this needs to be properly semaphored if only one LibreOffice can run at a time.
I tried with the following modifications to the example provided:
using System.Collections.Generic;
using System.IO;
using System.Reflection;
using System.Threading.Tasks;
using DocXToPdfConverter;
using DocXToPdfConverter.DocXToPdfHandlers;
namespace ExampleApplication
{
class Program
{
private static readonly string locationOfLibreOfficeSoffice =
@"C:\temp\LibreOfficePortable\App\libreoffice\program\soffice.exe";
private static string executableLocation;
private static string htmlLocation;
private static string docxLocation;
static async Task Main(string[] args)
{
//This is only to get this example to work (find the word docx and the html file, which were
//shipped with this).
executableLocation = Path.GetDirectoryName(
Assembly.GetExecutingAssembly().Location);
//Here are the 2 test files as input. They contain placeholders
docxLocation = Path.Combine(executableLocation, "Test-Template.docx");
htmlLocation = Path.Combine(executableLocation, "Test-HTML-page.html");
List<Task> tasks = new List<Task>();
for (int i = 0; i < 100; i++)
{
tasks.Add(Task.Run(() => docxToHtml(i)));
}
await Task.WhenAll(tasks);
}
private static void docxToHtml(int number)
{
//Prepare texts, which you want to insert into the custom fields in the template (remember
//to use start and stop tags.
//NOTE that line breaks can be inserted as what you define them in ReplacementDictionaries.NewLineTag (here we use <br/>).
var placeholders = new Placeholders();
placeholders.NewLineTag = "<br/>";
placeholders.TextPlaceholderStartTag = "##";
placeholders.TextPlaceholderEndTag = "##";
placeholders.TablePlaceholderStartTag = "==";
placeholders.TablePlaceholderEndTag = "==";
placeholders.ImagePlaceholderStartTag = "++";
placeholders.ImagePlaceholderEndTag = "++";
//You should be able to also use other OpenXML tags in your strings
placeholders.TextPlaceholders = new Dictionary<string, string>
{
{"Name", "Mr. Miller" },
{"Street", "89 Brook St" },
{"City", "Brookline MA 02115<br/>USA" },
{"InvoiceNo", "5" },
{"Total", "U$ 4,500" },
{"Date", "28 Jul 2019" }
};
//Table ROW replacements are a little bit more complicated: With them you can
//fill out only one table row in a table and it will add as many rows as you
//need, depending on the string Array.
placeholders.TablePlaceholders = new List<Dictionary<string, string[]>>
{
new Dictionary<string, string[]>()
{
{"Name", new string[]{ "Homer Simpson", "Mr. Burns", "Mr. Smithers" }},
{"Department", new string[]{ "Power Plant", "Administration", "Administration" }},
{"Responsibility", new string[]{ "Oversight", "CEO", "Assistant" }},
{"Telephone number", new string[]{ "888-234-2353", "888-295-8383", "888-848-2803" }}
},
new Dictionary<string, string[]>()
{
{"Qty", new string[]{ "2", "5", "7" }},
{"Product", new string[]{ "Software development", "Customization", "Travel expenses" }},
{"Price", new string[]{ "U$ 2,000", "U$ 1,000", "U$ 1,500" }},
}
};
//You have to add the images as a memory stream to the Dictionary! Place a key (placeholder) into the docx template.
//There is a method to read files as memory streams (GetFileAsMemoryStream)
//We already did that with <+++>ProductImage<+++>
var productImage =
StreamHandler.GetFileAsMemoryStream(Path.Combine(executableLocation, "ProductImage.jpg"));
var qrImage =
StreamHandler.GetFileAsMemoryStream(Path.Combine(executableLocation, "QRCode.PNG"));
var productImageElement = new ImageElement() { Dpi = 96, memStream = productImage };
var qrImageElement = new ImageElement() { Dpi = 300, memStream = qrImage };
placeholders.ImagePlaceholders = new Dictionary<string, ImageElement>
{
{"QRCode", qrImageElement },
{"ProductImage", productImageElement }
};
/*
*
*
* Execution of conversion tests
*
*
*/
//Most important: give the full path to the soffice.exe file including soffice.exe.
//Don't know how that would be named on Linux...
var test = new ReportGenerator(locationOfLibreOfficeSoffice);
////Convert from HTML to HTML
//test.Convert(htmlLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), "Test-HTML-page-out.html"), placeholders);
////Convert from HTML to PDF
//test.Convert(htmlLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), "Test-HTML-page-out.pdf"), placeholders);
////Convert from HTML to DOCX
//test.Convert(htmlLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), "Test-HTML-page-out.docx"), placeholders);
////Convert from DOCX to DOCX
//test.Convert(docxLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), "Test-Template-out.docx"), placeholders);
////Convert from DOCX to HTML
//test.Convert(docxLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), "Test-Template-out.html"), placeholders);
//Convert from DOCX to PDF
test.Convert(docxLocation, Path.Combine(Path.GetDirectoryName(htmlLocation), $"Test-Template-out-{number}.pdf"), placeholders);
}
}
}This is really nice solution. But will it work with Azure? Where should I add soffice.exe on Azure?
I have Libreoffice installed and I can't find the ability to convert html to docx.
I used this library for some projects and I have success in my goals. So congratulations on this amazing build.
We need to update the core of our applications from .Net Core 2.1 to .Net Core 3.1. Do you know if this library works with .Net Core 3.1 version?
Describe the bug
It would make sense to include this package in a class library so that it can be referenced from other parts of the application. However when trying to install in a netstandard2.1 project, the following error is given:
Package DocXToPdfConverter 1.0.3 is not compatible with netstandard2.1 (.NETStandard,Version=v2.0). Package DocXToPdfConverter 1.0.3 supports: netcoreapp2.1
Expected behavior
Is there any reason why this library requires netcoreapp2.1 and cannot support netstandard2.1?
I have found that you can do the following:
TargetFramework to netstandard2.1. This requires no code changes.netcoreapp3.1And then everything will work. Your nuget package will then be a netstandard2.1 package to then be consumed in libraries.
The only reason for netstandard2.1 instead of the more generic netstandard2.0 is due to line 93 in ConvertWithLibreOffice.cs with ProcessStartInfo's ArgumentList. I'm sure there is away around this, but this was just a quick attempt to check compatibility.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.