** Before running any of the files, please run "pip install -r requirements.txt" **
Please review the files in the following order:
~. utils.py - Just some utility functions commonly used in below files
- EDA.ipynb - Exploratory Data Analysis on original data and formatting/initial cleaning
- Data Cleaning.ipynb - Cleaning the data
- Baseline Model.ipynb - A baseline model with cosine similarity
- newsqa.py - Functions and classes for pre-processing the data and model training
- Advanced Modelling.ipynb - Data preparation and fine-tuining BERT and DistilBERT models
- main.py - FastAPI deployment
- front-end/newsqa.html - The front-end UI code
To run the code present in files 1 to 5 on a sample of the data, use "Demo Code.ipynb"
To test the API, run "uvicorn main:app --reload" and visit "http://127.0.0.1:8000/docs" or whatever port the app is running on your local machine. You need to have a trained model with path "data/bert_model.pt".
To view the front end, just open the file "front-end/newsqa.html" on a browser. You will have to change the url on line 68 and 88 of the file with your API's url.
News Articles are usually very long, and the highlights do not cover every important detail. If a person is interested in some detail of the news story, they have to go through the entire article, not just skim through it as they might miss details that they are looking for. This is sometimes inconvenient for a user as they might not have the time to go through it or they simply don’t like to read. A reading-comprehension based question answering model would help users to get details from a long news article by providing a question in natural language.
Microsoft’s NewsQA Dataset [1] contains nearly 120,000 question-answer pairs from 12,000 news articles on CNN. The news articles are not present in the dataset itself, but are referenced from another dataset, the DeepMind Q&A Dataset [2]. All the questions are written by humans who read just the article headline and highlights, which is exactly the use case for this project. The answers are in the form of character ranges from the news article or ‘None’ which means that the answer is not present in the article. There are multiple answers provided for each question, collected from different crowdworkers.
- The dataset contains a feature ("is_question_bad") that indicates the percentage of crowdworkes that thought that the question did not make any sense. All questions with the bad question ratio greater than 1 were removed.
- On exploring the answeres using character ranges, it was found that the character ranges sometimes would start or end in the middle of a word. So, the character ranges had to be expanded to include complete words. Sometimes, the character range would include one or two characters from the next paragraph, in which case the range had to be truncated.
- There are multiple answers for a single question in the dataset. A single answer needed to be selected.
- The dataset has a feature called validated answers where different crowdworkers vote the answer which they think is correct. So, the answer with the most votes is selected as the correct answer.
- However, only 56% of the question had validated answers available. So, for the other 44% of the questions, the frequency of each answer is calculated and the most frequent answer is selected.
- If all answers by different crowdworkers have the same frequency, a random answer is selected.
- F1 Score: For reading comprehension tasks, this metric is usually used. Overlap is calculated as the number of characters that overlap in the actual and predicted answer. F1 score is the harmonic mean of precision and recall.
- Accuracy: If the actual answer and the predicted answer overlaps by at least 1 token, it is considered correct. Accuracy is the percentage of answers that are correctly predicted. This metric was considered relavent because an overlap would mean that the model still did the job by redirecting the user towards where the answer is.
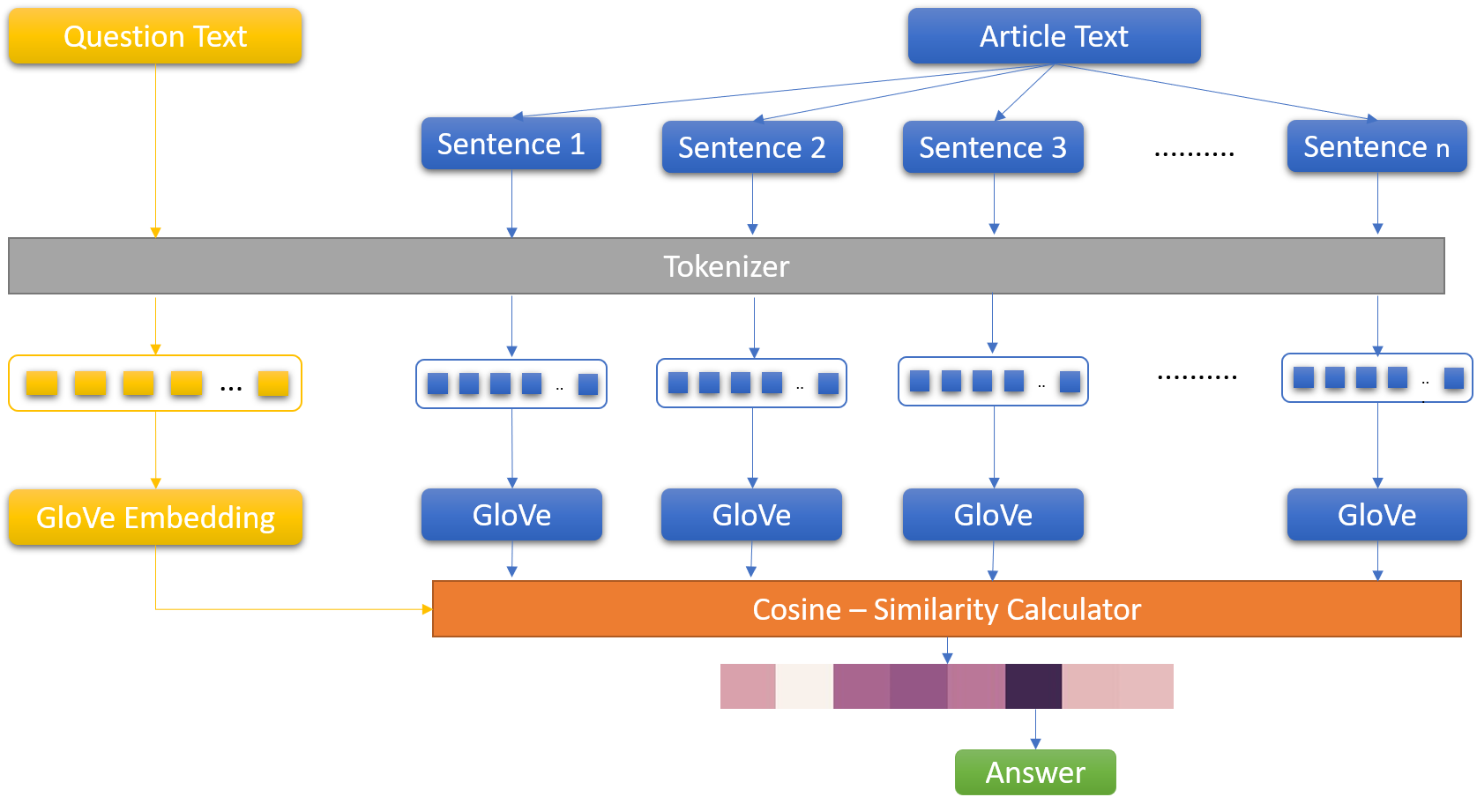
Before moving on to machine learning models, a baseline model was established using cosine similarity. First the article text is divided into sentences and the question & sentences are tokenized by removing stop words and URLs. Document-level embeddings are calculated by averaging the glove embeddings of each token in the sentence. Cosine similarity of the question with each sentence is calculated and the one with maximum similarity is chosen as the answer. F1 score was expected to be low, as this model predicts entire sentences and the actual answers are just 2-3 words long. F1 score of 0.0408 was obtained. But using the accuracy metric, it was found that this approach was able to predict the sentence which had the answer 12.6% of the time.
After establishing a baseline, I decided to move to transformer models as RNNs give equal importance to all tokens and because the articles are so long, RNNs would suffer from vanishing gradient problems. Because this problem requires to focus on just some part of the article, attention seems a good option. Buf before using these models, a lot of preprocessing needed to be done on the data.
- The dataset had character indices as answers but transformer models accept token indices. So a mapping from character index to word index and word index to token index needed to be maintained.
- Transformer models have input size restrictions and the article length usually exceed the maximum limit. To handle that a sliding window approach was used.
- For training and validation data where the answer is available, the sliding window is used to find a window where the answer is present. Again, a mapping between original token index and window token index has to be maintained.
- For test data where the answer is not available, the article is split into multiple windows of maximum input length and each question-window pair is considered as a seperate example. For this too, an index mapping between original token index and window token index has to be maintained.

- BertForQuestionAnswering [3] from the huggingface transformers library is just a BERT model with a span classification head on top. The span classification head is basically a linear layer attached to the output of each token with two outputs. The outputs represent the probabilities of that token being the start and end of the answer respectively.
- Beause the BERT model is so big, it takes a very long time to fine-tune. So, the pretrained model which was trained on SQUAD dataset was used. Only the linear layer was fine-tuned because of computation and time limitations.
- After fine-tuning for 2 epochs the results were as follows:
| BERT | Loss | F1 Score | Accuracy |
|---|---|---|---|
| Before fine-tuning | 6.0508 | 0.2614 | 0.4329 |
| After fine-tuning | 3.3887 | 0.3313 | 0.5250 |

- Because the BERT model takes so much time to train, I decided to try out DistilBERT that is a light wieght model and is supposed to give a comparable performance to BERT.
- DistilBertForQuestionAnswering [4] from the higgingface transformers library was used. For this too, a pretrained model that was trained on SQUAD dataset was used.
- Only the last linear layer was fine-tuned for 5 epochs and these were the results:
| DistilBERT | Loss | F1 Score | Accuracy |
|---|---|---|---|
| Before fine-tuning | 6.4680 | 0.2837 | 0.4062 |
| After fine-tuning | 3.6821 | 0.3028 | 0.4342 |
BERT gave better results than DistilBERT, and so the BERT model was chosen to be used for deployment.
- Deployment included two stages: building a back-end API, and building a front-end UI.
- The API returns news articles from the dataset if needed and model predictions. It was build using FastAPI [5] and deployed on GCP.
- A simple UI was built using HTML and Bootstrap. The front-end UI makes jQuery AJAX calls to the API and highlights the answer in the text.

[1] Microsoft's NewsQA Dataset: https://www.microsoft.com/en-us/research/project/newsqa-dataset/
[2] DeepMind's Q&A Dataset: https://cs.nyu.edu/~kcho/DMQA/
[3] BertForQuestionAnswering: https://huggingface.co/transformers/model_doc/bert.html?highlight=bertforquestionanswering#transformers.BertForQuestionAnswering
[4] DistilBertForQuestionAnswering: https://huggingface.co/transformers/model_doc/distilbert.html#distilbertforquestionanswering
[5] FastAPI: https://fastapi.tiangolo.com/











