Please answer these questions before submitting your issue. Thanks!
Leads to: SnowparkSQLException: (1304): 000904 (42000): SQL compilation error: error line 1 at position 214
invalid identifier 'A'
I expected both variants to work.
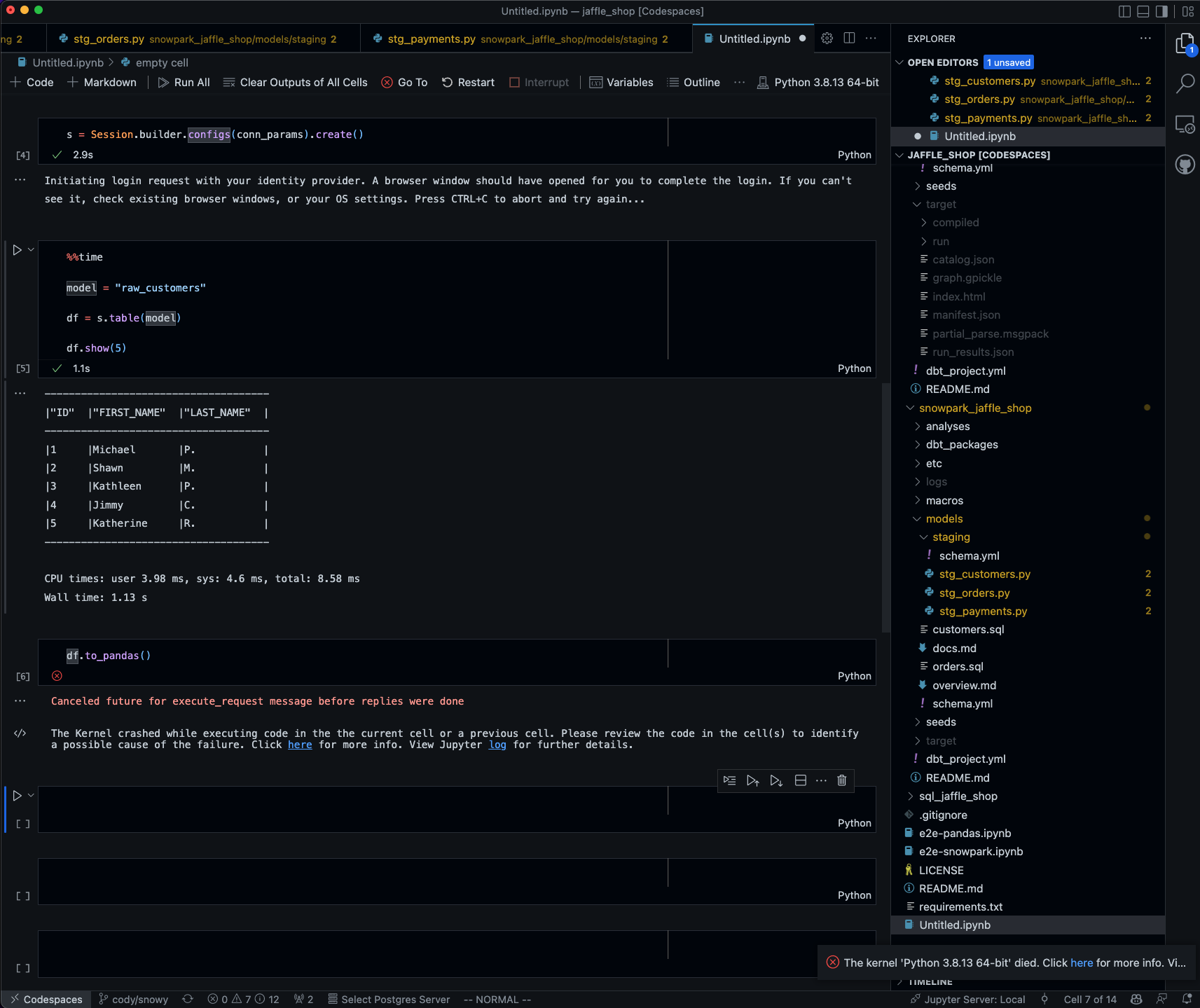
2022-10-31 09:43:34,998 - MainThread cursor.py:629 - execute() - DEBUG - executing SQL/command
2022-10-31 09:43:34,999 - MainThread cursor.py:714 - execute() - INFO - query: [SELECT * FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BIGINT AS "B1") WHERE ("B1" !=...]
2022-10-31 09:43:34,999 - MainThread connection.py:1309 - _next_sequence_counter() - DEBUG - sequence counter: 52
2022-10-31 09:43:35,000 - MainThread cursor.py:459 - _execute_helper() - DEBUG - Request id: 64861187-0363-41e3-9eb4-b82085281cb6
2022-10-31 09:43:35,000 - MainThread cursor.py:461 - _execute_helper() - DEBUG - running query [SELECT * FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BIGINT AS "B1") WHERE ("B1" !=...]
2022-10-31 09:43:35,001 - MainThread cursor.py:470 - _execute_helper() - DEBUG - is_file_transfer: False
2022-10-31 09:43:35,001 - MainThread connection.py:979 - cmd_query() - DEBUG - _cmd_query
2022-10-31 09:43:35,001 - MainThread connection.py:1002 - cmd_query() - DEBUG - sql=[SELECT * FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BIGINT AS "B1") WHERE ("B1" !=...], sequence_id=[52], is_file_transfer=[False]
2022-10-31 09:43:35,002 - MainThread network.py:1147 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 1/1 active sessions
2022-10-31 09:43:35,003 - MainThread network.py:827 - _request_exec_wrapper() - DEBUG - remaining request timeout: None, retry cnt: 1
2022-10-31 09:43:35,006 - MainThread network.py:808 - add_request_guid() - DEBUG - Request guid: a8863f98-b7ce-4819-a054-e7503a15af33
2022-10-31 09:43:35,007 - MainThread network.py:1006 - _request_exec() - DEBUG - socket timeout: 60
2022-10-31 09:43:35,261 - MainThread connectionpool.py:456 - _make_request() - DEBUG - [https://snowhouse.snowflakecomputing.com:443](https://snowhouse.snowflakecomputing.com/) "POST /queries/v1/query-request?requestId=64861187-0363-41e3-9eb4-b82085281cb6&request_guid=a8863f98-b7ce-4819-a054-e7503a15af33 HTTP/1.1" 200 1082
2022-10-31 09:43:35,262 - MainThread network.py:1032 - _request_exec() - DEBUG - SUCCESS
2022-10-31 09:43:35,262 - MainThread network.py:1152 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 0/1 active sessions
2022-10-31 09:43:35,263 - MainThread network.py:715 - _post_request() - DEBUG - ret[code] = None, after post request
2022-10-31 09:43:35,263 - MainThread network.py:739 - _post_request() - DEBUG - Query id: 01a7fe47-0605-0b3a-0001-dd14b94dd35f
2022-10-31 09:43:35,264 - MainThread cursor.py:736 - execute() - DEBUG - sfqid: 01a7fe47-0605-0b3a-0001-dd14b94dd35f
2022-10-31 09:43:35,264 - MainThread cursor.py:738 - execute() - INFO - query execution done
2022-10-31 09:43:35,264 - MainThread cursor.py:740 - execute() - DEBUG - SUCCESS
2022-10-31 09:43:35,265 - MainThread cursor.py:743 - execute() - DEBUG - PUT OR GET: None
2022-10-31 09:43:35,265 - MainThread cursor.py:840 - _init_result_and_meta() - DEBUG - Query result format: arrow
2022-10-31 09:43:35,266 - MainThread cursor.py:854 - _init_result_and_meta() - INFO - Number of results in first chunk: 0
2022-10-31 09:43:35,266 - MainThread cursor.py:629 - execute() - DEBUG - executing SQL/command
2022-10-31 09:43:35,267 - MainThread cursor.py:714 - execute() - INFO - query: [SELECT "A" AS "l_avoo_A", "B1" AS "B1" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...]
2022-10-31 09:43:35,267 - MainThread connection.py:1309 - _next_sequence_counter() - DEBUG - sequence counter: 53
2022-10-31 09:43:35,267 - MainThread cursor.py:459 - _execute_helper() - DEBUG - Request id: 0066d3c6-0df6-4129-a3fc-a5f384c194fd
2022-10-31 09:43:35,268 - MainThread cursor.py:461 - _execute_helper() - DEBUG - running query [SELECT "A" AS "l_avoo_A", "B1" AS "B1" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...]
2022-10-31 09:43:35,268 - MainThread cursor.py:470 - _execute_helper() - DEBUG - is_file_transfer: False
2022-10-31 09:43:35,268 - MainThread connection.py:979 - cmd_query() - DEBUG - _cmd_query
2022-10-31 09:43:35,269 - MainThread connection.py:1002 - cmd_query() - DEBUG - sql=[SELECT "A" AS "l_avoo_A", "B1" AS "B1" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...], sequence_id=[53], is_file_transfer=[False]
2022-10-31 09:43:35,270 - MainThread network.py:1147 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 1/1 active sessions
2022-10-31 09:43:35,270 - MainThread network.py:827 - _request_exec_wrapper() - DEBUG - remaining request timeout: None, retry cnt: 1
2022-10-31 09:43:35,271 - MainThread network.py:808 - add_request_guid() - DEBUG - Request guid: ba390adc-5e07-4f38-817a-03bdc5fd5d8e
2022-10-31 09:43:35,271 - MainThread network.py:1006 - _request_exec() - DEBUG - socket timeout: 60
2022-10-31 09:43:35,455 - MainThread connectionpool.py:456 - _make_request() - DEBUG - [https://snowhouse.snowflakecomputing.com:443](https://snowhouse.snowflakecomputing.com/) "POST /queries/v1/query-request?requestId=0066d3c6-0df6-4129-a3fc-a5f384c194fd&request_guid=ba390adc-5e07-4f38-817a-03bdc5fd5d8e HTTP/1.1" 200 1086
2022-10-31 09:43:35,456 - MainThread network.py:1032 - _request_exec() - DEBUG - SUCCESS
2022-10-31 09:43:35,456 - MainThread network.py:1152 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 0/1 active sessions
2022-10-31 09:43:35,457 - MainThread network.py:715 - _post_request() - DEBUG - ret[code] = None, after post request
2022-10-31 09:43:35,457 - MainThread network.py:739 - _post_request() - DEBUG - Query id: 01a7fe47-0605-0b44-0001-dd14b94e14fb
2022-10-31 09:43:35,457 - MainThread cursor.py:736 - execute() - DEBUG - sfqid: 01a7fe47-0605-0b44-0001-dd14b94e14fb
2022-10-31 09:43:35,458 - MainThread cursor.py:738 - execute() - INFO - query execution done
2022-10-31 09:43:35,458 - MainThread cursor.py:740 - execute() - DEBUG - SUCCESS
2022-10-31 09:43:35,458 - MainThread cursor.py:743 - execute() - DEBUG - PUT OR GET: None
2022-10-31 09:43:35,459 - MainThread cursor.py:840 - _init_result_and_meta() - DEBUG - Query result format: arrow
2022-10-31 09:43:35,459 - MainThread cursor.py:854 - _init_result_and_meta() - INFO - Number of results in first chunk: 0
2022-10-31 09:43:35,460 - MainThread cursor.py:629 - execute() - DEBUG - executing SQL/command
2022-10-31 09:43:35,460 - MainThread cursor.py:714 - execute() - INFO - query: [SELECT "A" AS "r_zqsj_A", "B2" AS "B2" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...]
2022-10-31 09:43:35,460 - MainThread connection.py:1309 - _next_sequence_counter() - DEBUG - sequence counter: 54
2022-10-31 09:43:35,461 - MainThread cursor.py:459 - _execute_helper() - DEBUG - Request id: bd78ee48-aa9d-4e74-864f-0a02b956d7db
2022-10-31 09:43:35,461 - MainThread cursor.py:461 - _execute_helper() - DEBUG - running query [SELECT "A" AS "r_zqsj_A", "B2" AS "B2" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...]
2022-10-31 09:43:35,461 - MainThread cursor.py:470 - _execute_helper() - DEBUG - is_file_transfer: False
2022-10-31 09:43:35,462 - MainThread connection.py:979 - cmd_query() - DEBUG - _cmd_query
2022-10-31 09:43:35,462 - MainThread connection.py:1002 - cmd_query() - DEBUG - sql=[SELECT "A" AS "r_zqsj_A", "B2" AS "B2" FROM ( SELECT 0 :: BIGINT AS "A", 0 :: BI...], sequence_id=[54], is_file_transfer=[False]
2022-10-31 09:43:35,463 - MainThread network.py:1147 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 1/1 active sessions
2022-10-31 09:43:35,463 - MainThread network.py:827 - _request_exec_wrapper() - DEBUG - remaining request timeout: None, retry cnt: 1
2022-10-31 09:43:35,464 - MainThread network.py:808 - add_request_guid() - DEBUG - Request guid: f185476b-0ebf-4db5-8e2c-4e89cd35bbd6
2022-10-31 09:43:35,464 - MainThread network.py:1006 - _request_exec() - DEBUG - socket timeout: 60
2022-10-31 09:43:35,650 - MainThread connectionpool.py:456 - _make_request() - DEBUG - [https://snowhouse.snowflakecomputing.com:443](https://snowhouse.snowflakecomputing.com/) "POST /queries/v1/query-request?requestId=bd78ee48-aa9d-4e74-864f-0a02b956d7db&request_guid=f185476b-0ebf-4db5-8e2c-4e89cd35bbd6 HTTP/1.1" 200 1083
2022-10-31 09:43:35,651 - MainThread network.py:1032 - _request_exec() - DEBUG - SUCCESS
2022-10-31 09:43:35,652 - MainThread network.py:1152 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 0/1 active sessions
2022-10-31 09:43:35,652 - MainThread network.py:715 - _post_request() - DEBUG - ret[code] = None, after post request
2022-10-31 09:43:35,652 - MainThread network.py:739 - _post_request() - DEBUG - Query id: 01a7fe47-0605-0b3f-0001-dd14b94cf7c7
2022-10-31 09:43:35,652 - MainThread cursor.py:736 - execute() - DEBUG - sfqid: 01a7fe47-0605-0b3f-0001-dd14b94cf7c7
2022-10-31 09:43:35,653 - MainThread cursor.py:738 - execute() - INFO - query execution done
2022-10-31 09:43:35,653 - MainThread cursor.py:740 - execute() - DEBUG - SUCCESS
2022-10-31 09:43:35,654 - MainThread cursor.py:743 - execute() - DEBUG - PUT OR GET: None
2022-10-31 09:43:35,654 - MainThread cursor.py:840 - _init_result_and_meta() - DEBUG - Query result format: arrow
2022-10-31 09:43:35,655 - MainThread cursor.py:854 - _init_result_and_meta() - INFO - Number of results in first chunk: 0
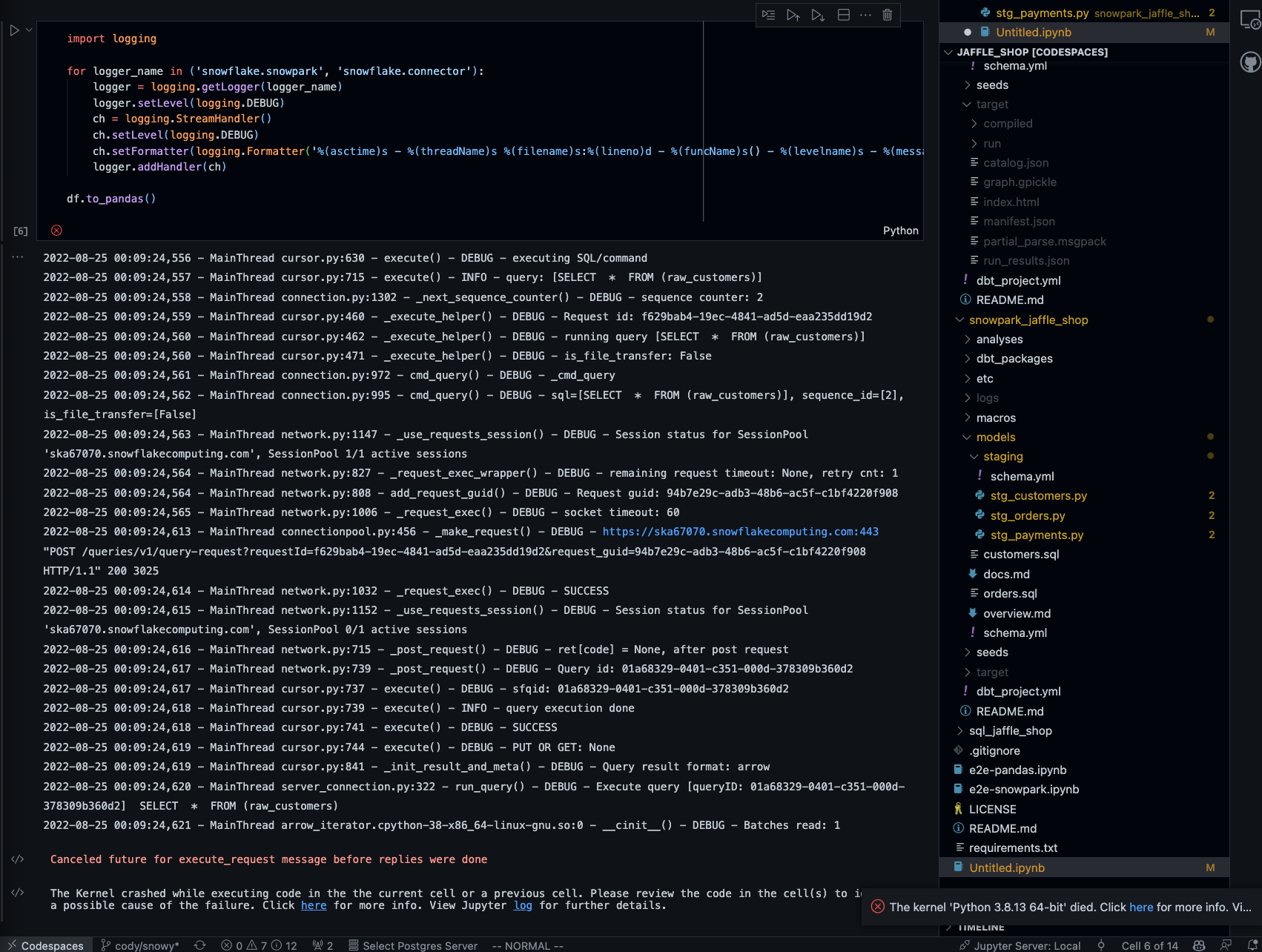
2022-10-31 09:43:35,655 - MainThread cursor.py:629 - execute() - DEBUG - executing SQL/command
2022-10-31 09:43:35,656 - MainThread cursor.py:714 - execute() - INFO - query: [SELECT * FROM (( SELECT 0 :: BIGINT AS "l_avoo_A", 0 :: BIGINT AS "B1") AS SNO...]
2022-10-31 09:43:35,656 - MainThread connection.py:1309 - _next_sequence_counter() - DEBUG - sequence counter: 55
2022-10-31 09:43:35,656 - MainThread cursor.py:459 - _execute_helper() - DEBUG - Request id: ec6e1d38-92a6-411d-9f91-b18f7b0f3035
2022-10-31 09:43:35,657 - MainThread cursor.py:461 - _execute_helper() - DEBUG - running query [SELECT * FROM (( SELECT 0 :: BIGINT AS "l_avoo_A", 0 :: BIGINT AS "B1") AS SNO...]
2022-10-31 09:43:35,657 - MainThread cursor.py:470 - _execute_helper() - DEBUG - is_file_transfer: False
2022-10-31 09:43:35,658 - MainThread connection.py:979 - cmd_query() - DEBUG - _cmd_query
2022-10-31 09:43:35,658 - MainThread connection.py:1002 - cmd_query() - DEBUG - sql=[SELECT * FROM (( SELECT 0 :: BIGINT AS "l_avoo_A", 0 :: BIGINT AS "B1") AS SNO...], sequence_id=[55], is_file_transfer=[False]
2022-10-31 09:43:35,659 - MainThread network.py:1147 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 1/1 active sessions
2022-10-31 09:43:35,659 - MainThread network.py:827 - _request_exec_wrapper() - DEBUG - remaining request timeout: None, retry cnt: 1
2022-10-31 09:43:35,659 - MainThread network.py:808 - add_request_guid() - DEBUG - Request guid: d1d1e7fe-8d65-4fc0-8606-f8326fe383f2
2022-10-31 09:43:35,660 - MainThread network.py:1006 - _request_exec() - DEBUG - socket timeout: 60
2022-10-31 09:43:35,878 - MainThread connectionpool.py:456 - _make_request() - DEBUG - [https://snowhouse.snowflakecomputing.com:443](https://snowhouse.snowflakecomputing.com/) "POST /queries/v1/query-request?requestId=ec6e1d38-92a6-411d-9f91-b18f7b0f3035&request_guid=d1d1e7fe-8d65-4fc0-8606-f8326fe383f2 HTTP/1.1" 200 371
2022-10-31 09:43:35,878 - MainThread network.py:1032 - _request_exec() - DEBUG - SUCCESS
2022-10-31 09:43:35,879 - MainThread network.py:1152 - _use_requests_session() - DEBUG - Session status for SessionPool 'snowhouse.snowflakecomputing.com', SessionPool 0/1 active sessions
2022-10-31 09:43:35,879 - MainThread network.py:715 - _post_request() - DEBUG - ret[code] = 000904, after post request
2022-10-31 09:43:35,880 - MainThread network.py:739 - _post_request() - DEBUG - Query id: 01a7fe47-0605-0da9-0001-dd14b94e31c3
2022-10-31 09:43:35,880 - MainThread cursor.py:736 - execute() - DEBUG - sfqid: 01a7fe47-0605-0da9-0001-dd14b94e31c3
2022-10-31 09:43:35,881 - MainThread cursor.py:738 - execute() - INFO - query execution done
2022-10-31 09:43:35,881 - MainThread cursor.py:788 - execute() - DEBUG - {'data': {'internalError': False, 'errorCode': '000904', 'age': 0, 'sqlState': '42000', 'queryId': '01a7fe47-0605-0da9-0001-dd14b94e31c3', 'line': -1, 'pos': -1, 'type': 'COMPILATION'}, 'code': '000904', 'message': "SQL compilation error: error line 1 at position 214\ninvalid identifier 'A'", 'success': False, 'headers': None}
---------------------------------------------------------------------------
SnowparkSQLException Traceback (most recent call last)
Input In [61], in <cell line: 1>()
----> 1 joined_data = table_a.filter(
2 table_a.b1 != lit(4)
3 ).join(
4 table_b, (table_a['a'] == table_b['a'])
5 ).join(
6 table_c, (table_b['a'] == table_c['a'])
7 )
8 print(joined_data.queries)
9 joined_data.to_pandas()
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/telemetry.py:223, in df_api_usage.<locals>.wrap(*args, **kwargs)
221 @functools.wraps(func)
222 def wrap(*args, **kwargs):
--> 223 r = func(*args, **kwargs)
224 plan = r._select_statement or r._plan
225 # Some DataFrame APIs call other DataFrame APIs, so we need to remove the extra call
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/dataframe.py:2038, in DataFrame.join(self, right, on, how, lsuffix, rsuffix, **kwargs)
2033 elif not isinstance(using_columns, list):
2034 raise TypeError(
2035 f"Invalid input type for join column: {type(using_columns)}"
2036 )
-> 2038 return self._join_dataframes(
2039 right,
2040 using_columns,
2041 create_join_type(join_type or "inner"),
2042 lsuffix=lsuffix,
2043 rsuffix=rsuffix,
2044 )
2046 raise TypeError("Invalid type for join. Must be Dataframe")
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/dataframe.py:2246, in DataFrame._join_dataframes(self, right, using_columns, join_type, lsuffix, rsuffix)
2236 def _join_dataframes(
2237 self,
2238 right: "DataFrame",
(...)
2243 rsuffix: str = "",
2244 ) -> "DataFrame":
2245 if isinstance(using_columns, Column):
-> 2246 return self._join_dataframes_internal(
2247 right,
2248 join_type,
2249 join_exprs=using_columns,
2250 lsuffix=lsuffix,
2251 rsuffix=rsuffix,
2252 )
2254 if isinstance(join_type, (LeftSemi, LeftAnti)):
2255 # Create a Column with expression 'true AND <expr> AND <expr> .."
2256 join_cond = Column(Literal(True))
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/dataframe.py:2302, in DataFrame._join_dataframes_internal(self, right, join_type, join_exprs, lsuffix, rsuffix)
2293 def _join_dataframes_internal(
2294 self,
2295 right: "DataFrame",
(...)
2300 rsuffix: str = "",
2301 ) -> "DataFrame":
-> 2302 (lhs, rhs) = _disambiguate(
2303 self, right, join_type, [], lsuffix=lsuffix, rsuffix=rsuffix
2304 )
2305 expression = join_exprs._expression if join_exprs is not None else None
2306 join_logical_plan = Join(
2307 lhs._plan,
2308 rhs._plan,
2309 join_type,
2310 expression,
2311 )
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/dataframe.py:218, in _disambiguate(lhs, rhs, join_type, using_columns, lsuffix, rsuffix)
213 normalized_using_columns = {quote_name(c) for c in using_columns}
214 # Check if the LHS and RHS have columns in common. If they don't just return them as-is. If
215 # they do have columns in common, alias the common columns with randomly generated l_
216 # and r_ prefixes for the left and right sides respectively.
217 # We assume the column names from the schema are normalized and quoted.
--> 218 lhs_names = [attr.name for attr in lhs._output]
219 rhs_names = [attr.name for attr in rhs._output]
220 common_col_names = [
221 n
222 for n in lhs_names
223 if n in set(rhs_names) and n not in normalized_using_columns
224 ]
File ~/.pyenv/versions/3.8.15/lib/python3.8/functools.py:967, in cached_property.__get__(self, instance, owner)
965 val = cache.get(self.attrname, _NOT_FOUND)
966 if val is _NOT_FOUND:
--> 967 val = self.func(instance)
968 try:
969 cache[self.attrname] = val
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/dataframe.py:3435, in DataFrame._output(self)
3430 @cached_property
3431 def _output(self) -> List[Attribute]:
3432 return (
3433 self._select_statement.column_states.projection
3434 if self._select_statement
-> 3435 else self._plan.output
3436 )
File ~/.pyenv/versions/3.8.15/lib/python3.8/functools.py:967, in cached_property.__get__(self, instance, owner)
965 val = cache.get(self.attrname, _NOT_FOUND)
966 if val is _NOT_FOUND:
--> 967 val = self.func(instance)
968 try:
969 cache[self.attrname] = val
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/analyzer/snowflake_plan.py:215, in SnowflakePlan.output(self)
213 @cached_property
214 def output(self) -> List[Attribute]:
--> 215 return [Attribute(a.name, a.datatype, a.nullable) for a in self.attributes]
File ~/.pyenv/versions/3.8.15/lib/python3.8/functools.py:967, in cached_property.__get__(self, instance, owner)
965 val = cache.get(self.attrname, _NOT_FOUND)
966 if val is _NOT_FOUND:
--> 967 val = self.func(instance)
968 try:
969 cache[self.attrname] = val
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/analyzer/snowflake_plan.py:209, in SnowflakePlan.attributes(self)
207 @cached_property
208 def attributes(self) -> List[Attribute]:
--> 209 output = analyze_attributes(self.schema_query, self.session)
210 self.schema_query = schema_value_statement(output)
211 return output
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/analyzer/schema_utils.py:81, in analyze_attributes(sql, session)
78 session._run_query(sql)
79 return convert_result_meta_to_attribute(session._conn._cursor.description)
---> 81 return session._get_result_attributes(sql)
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/session.py:1048, in Session._get_result_attributes(self, query)
1047 def _get_result_attributes(self, query: str) -> List[Attribute]:
-> 1048 return self._conn.get_result_attributes(query)
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/analyzer/snowflake_plan.py:147, in SnowflakePlan.Decorator.wrap_exception.<locals>.wrap(*args, **kwargs)
143 else:
144 ne = SnowparkClientExceptionMessages.SQL_EXCEPTION_FROM_PROGRAMMING_ERROR(
145 e
146 )
--> 147 raise ne.with_traceback(tb) from None
148 else:
149 ne = SnowparkClientExceptionMessages.SQL_EXCEPTION_FROM_PROGRAMMING_ERROR(
150 e
151 )
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/analyzer/snowflake_plan.py:85, in SnowflakePlan.Decorator.wrap_exception.<locals>.wrap(*args, **kwargs)
83 def wrap(*args, **kwargs):
84 try:
---> 85 return func(*args, **kwargs)
86 except snowflake.connector.errors.ProgrammingError as e:
87 tb = sys.exc_info()[2]
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/snowpark/_internal/server_connection.py:209, in ServerConnection.get_result_attributes(self, query)
207 @SnowflakePlan.Decorator.wrap_exception
208 def get_result_attributes(self, query: str) -> List[Attribute]:
--> 209 return convert_result_meta_to_attribute(self._cursor.describe(query))
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/connector/cursor.py:825, in SnowflakeCursor.describe(self, *args, **kwargs)
816 """Obtain the schema of the result without executing the query.
817
818 This function takes the same arguments as execute, please refer to that function
(...)
822 The schema of the result.
823 """
824 kwargs["_describe_only"] = kwargs["_is_internal"] = True
--> 825 self.execute(*args, **kwargs)
826 return self._description
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/connector/cursor.py:803, in SnowflakeCursor.execute(self, command, params, _bind_stage, timeout, _exec_async, _no_retry, _do_reset, _put_callback, _put_azure_callback, _put_callback_output_stream, _get_callback, _get_azure_callback, _get_callback_output_stream, _show_progress_bar, _statement_params, _is_internal, _describe_only, _no_results, _is_put_get, _raise_put_get_error, _force_put_overwrite, file_stream)
799 is_integrity_error = (
800 code == "100072"
801 ) # NULL result in a non-nullable column
802 error_class = IntegrityError if is_integrity_error else ProgrammingError
--> 803 Error.errorhandler_wrapper(self.connection, self, error_class, errvalue)
804 return self
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/connector/errors.py:275, in Error.errorhandler_wrapper(connection, cursor, error_class, error_value)
252 @staticmethod
253 def errorhandler_wrapper(
254 connection: SnowflakeConnection | None,
(...)
257 error_value: dict[str, str | bool | int],
258 ) -> None:
259 """Error handler wrapper that calls the errorhandler method.
260
261 Args:
(...)
272 exception to the first handler in that order.
273 """
--> 275 handed_over = Error.hand_to_other_handler(
276 connection,
277 cursor,
278 error_class,
279 error_value,
280 )
281 if not handed_over:
282 raise Error.errorhandler_make_exception(
283 error_class,
284 error_value,
285 )
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/connector/errors.py:330, in Error.hand_to_other_handler(connection, cursor, error_class, error_value)
328 if cursor is not None:
329 cursor.messages.append((error_class, error_value))
--> 330 cursor.errorhandler(connection, cursor, error_class, error_value)
331 return True
332 elif connection is not None:
File /media/psf/Home/vm_files/notebooks/venv/lib/python3.8/site-packages/snowflake/connector/errors.py:209, in Error.default_errorhandler(connection, cursor, error_class, error_value)
191 @staticmethod
192 def default_errorhandler(
193 connection: SnowflakeConnection,
(...)
196 error_value: dict[str, str],
197 ) -> None:
198 """Default error handler that raises an error.
199
200 Args:
(...)
207 A Snowflake error.
208 """
--> 209 raise error_class(
210 msg=error_value.get("msg"),
211 errno=error_value.get("errno"),
212 sqlstate=error_value.get("sqlstate"),
213 sfqid=error_value.get("sfqid"),
214 done_format_msg=error_value.get("done_format_msg"),
215 connection=connection,
216 cursor=cursor,
217 )
SnowparkSQLException: (1304): 01a7fe47-0605-0da9-0001-dd14b94e31c3: 000904 (42000): 01a7fe47-0605-0da9-0001-dd14b94e31c3: SQL compilation error: error line 1 at position 214
invalid identifier 'A'