威尔逊得分(Wilson Score)排序算法 威尔逊得分(Wilson Score)排序算法:是对质量进行排序,评论中含有好评还有差评,综合考虑评论数与好评率,得分越高,质量越高。
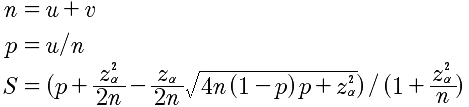
u表示正例数(好评),v表示负例数(差评),n表示实例总数(评论总数),p表示好评率,z是正态分布的分位数(参数),S表示最终的威尔逊得分。z一般取值2即可,即95%的置信度。
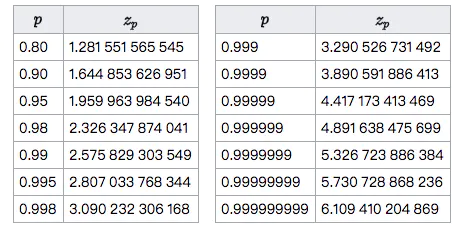
正太分布的分位数表:
算法性质:
性质:得分S的范围是[0,1),效果:已经归一化,适合排序 性质:当正例数u为0时,p为0,得分S为0;效果:没有好评,分数最低; 性质:当负例数v为0时,p为1,退化为1/(1 + z^2 / n),得分S永远小于1;效果:分数具有永久可比性; 性质:当p不变时,n越大,分子减少速度小于分母减少速度,得分S越多,反之亦然;效果:好评率p相同,实例总数n越多,得分S越多; 性质:当n趋于无穷大时,退化为p,得分S由p决定;效果:当评论总数n越多时,好评率p带给得分S的提升越明显; 性质:当分位数z越大时,总数n越重要,好评率p越不重要,反之亦然;效果:z越大,评论总数n越重要,区分度低;z越小,好评率p越重要; 威尔逊得分算法的分布图:
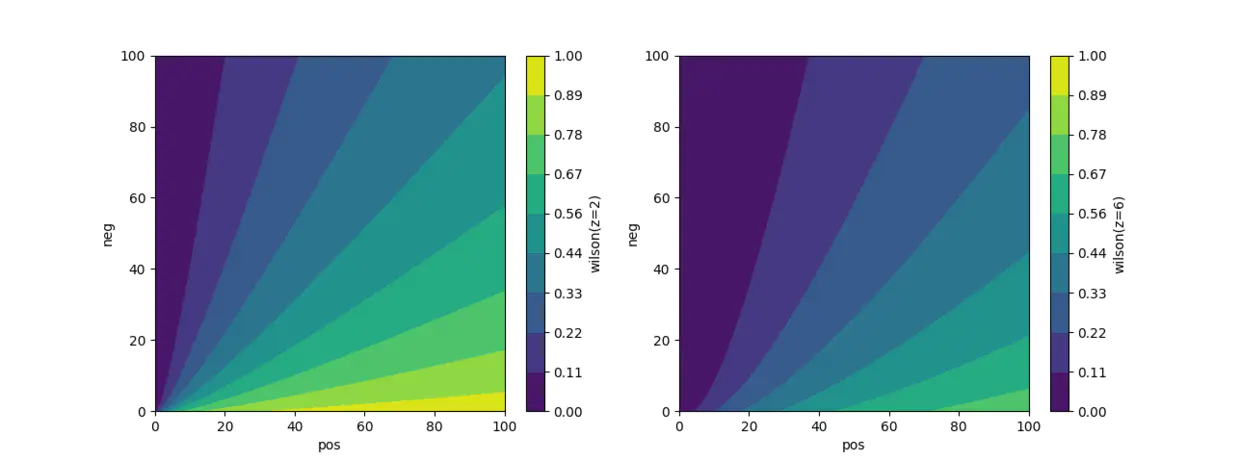
所以,zP一般是取值为2即可,即95%的置信度。


