
Welcome to AmazonMe, a web scraper designed to extract information from the Amazon website and store it in a MongoDB databse. This repository contains the code for the scraper, which utilizes the Requests and BeautifulSoup libraries to automate the scraping process. The scraper also leverages asyncio concurrency to efficiently extract thousands of data points from the website.
It's always a good practice to install a virtual environment before installing necessary requirements:
python.exe -m venv environmentname
environmentname/scripts/activateInstall necessary requirements:
pip install -r requirements.txt async def main():
base_url = ""
# Type True if you want to use proxy:
proxy = False
if proxy:
mongo_to_db = await export_to_mong(base_url, f"http://{rand_proxies()}")
else:
mongo_to_db = await export_to_mong(base_url, None)
# sheet_name = "Dinner Plates" # Please use the name of the collection in your MongoDB database to specify the name of the spreadsheet you intend to export.
# sheets = await mongo_to_sheet(sheet_name) # Uncomment this to export to excel database.
return mongo_to_db python main.pyDemo of the scraper scraping the content from Amazon
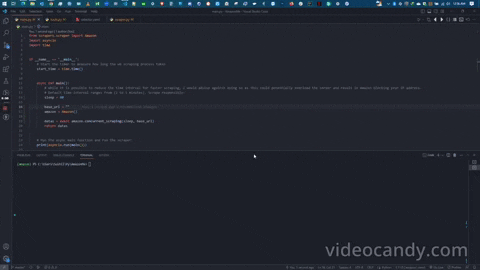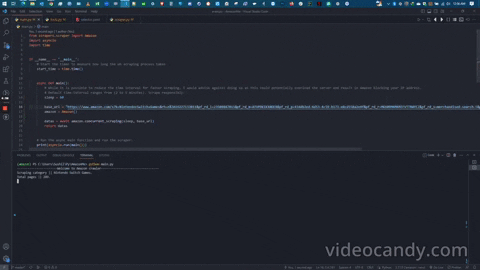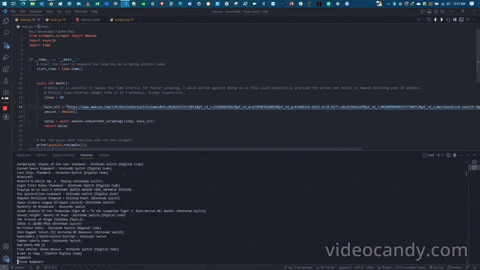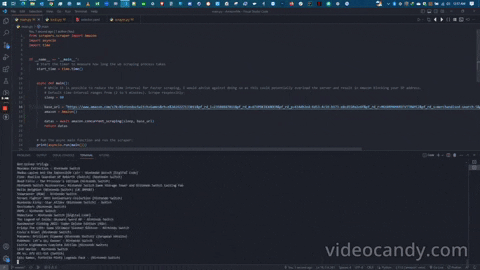
Upon executing the program, the scraper commences its operation by extracting the following fields and storing the required product information in Mongo databases.
- Product
- Asin
- Description
- Breakdown
- Price
- Deal Price
- You Saved
- Rating
- Rating count
- Availability
- Hyperlink
- Image url
- Image lists
- Store
- Store link
- ".com" (US)
- ".co.uk" (UK)
- ".com.mx" (Mexico)
- ".com.br" (Brazil)
- ".com.au" (Australia)
- ".com.jp" (Japan)
- ".com.be" (Belgium)
- ".in" (India)
- ".fr" (France)
- ".se" (Sweden)
- ".de" (Germany)
- ".it" (Italy)
Newly added to AmazonMe is the integration with MongoDB, allowing you to store the scraped data in a database for further analysis or usage. The scraper can now save the scraped data directly to a MongoDB database.
To enable MongoDB integration, you need to follow these steps:
- Make sure you have MongoDB installed and running on your machine or a remote server.
- Install the
pymongopackage by running the following command:python pip install pymongo - In the script or module where you handle the scraping and data extraction, import the
pymongoWith the MongoDB integration, you can easily query and retrieve the scraped data from the database, perform analytics, or use it for other purposes.
Please note that the script is designed to work with Amazon and may not work with other types of websites. Additionally, the script may be blocked by the website if it detects excessive scraping activity, so please use this tool responsibly and in compliance with Amazon's terms of service
If you have any issues or suggestions for improvements, please feel free to open an issue on the repository or submit a pull request.
This project is licensed under GPL-3.0 license. This scraper is provided as-is and for educational purposes only. The author is not repsonsible for any damages or legal issues that may result from its user. Use it at your own risk. Thank you for using the AmazonMe!
