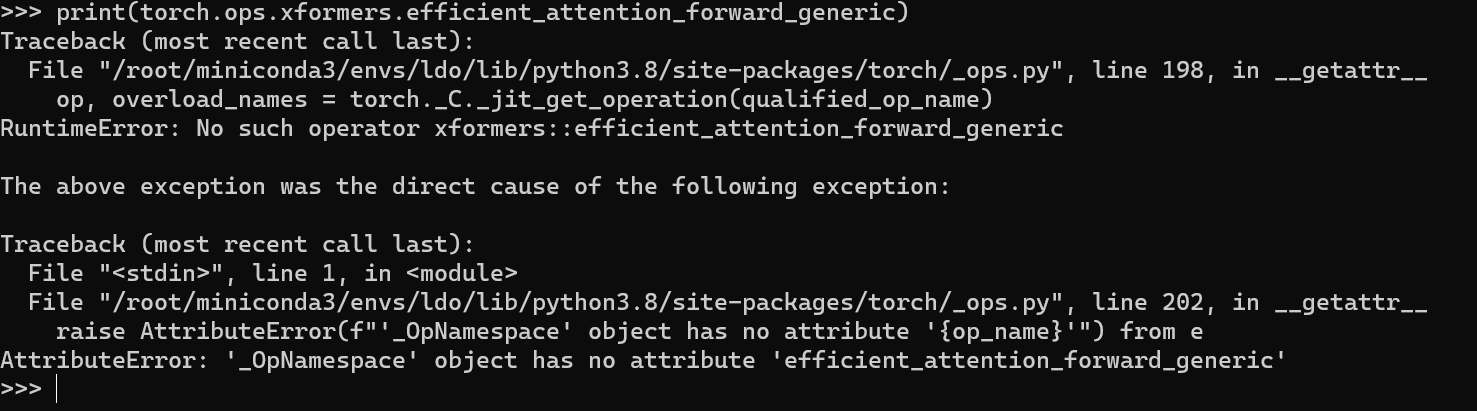
When I excuted training cell of dreambooth after installing all requirements, I got the error below. My GPU was Tesla T4.
/usr/local/lib/python3.7/dist-packages/bitsandbytes/cuda_setup/paths.py:99: UserWarning: /usr/lib64-nvidia did not contain libcudart.so as expected! Searching further paths...
f'{candidate_env_vars["LD_LIBRARY_PATH"]} did not contain '
/usr/local/lib/python3.7/dist-packages/bitsandbytes/cuda_setup/paths.py:21: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('"/usr/local/bin/dap_multiplexer","enableLsp"'), PosixPath('{"kernelManagerProxyPort"'), PosixPath('true}'), PosixPath('"172.28.0.3","jupyterArgs"'), PosixPath('6000,"kernelManagerProxyHost"'), PosixPath('["--ip=172.28.0.2"],"debugAdapterMultiplexerPath"')}
"WARNING: The following directories listed in your path were found to "
/usr/local/lib/python3.7/dist-packages/bitsandbytes/cuda_setup/paths.py:21: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('module'), PosixPath('//ipykernel.pylab.backend_inline')}
"WARNING: The following directories listed in your path were found to "
/usr/local/lib/python3.7/dist-packages/bitsandbytes/cuda_setup/paths.py:21: UserWarning: WARNING: The following directories listed in your path were found to be non-existent: {PosixPath('/env/python')}
"WARNING: The following directories listed in your path were found to "
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching /usr/local/cuda/lib64...
CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 7.5
CUDA SETUP: Detected CUDA version 111
CUDA SETUP: Loading binary /usr/local/lib/python3.7/dist-packages/bitsandbytes/libbitsandbytes_cuda111.so...
Steps: 0% 0/2500 [00:00<?, ?it/s]Traceback (most recent call last):
File "/content/diffusers/examples/dreambooth/train_dreambooth.py", line 606, in
main()
File "/content/diffusers/examples/dreambooth/train_dreambooth.py", line 550, in main
noise_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/accelerate/utils/operations.py", line 507, in call
return convert_to_fp32(self.model_forward(*args, **kwargs))
File "/usr/local/lib/python3.7/dist-packages/torch/amp/autocast_mode.py", line 12, in decorate_autocast
return func(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/diffusers/models/unet_2d_condition.py", line 254, in forward
encoder_hidden_states=encoder_hidden_states,
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/diffusers/models/unet_blocks.py", line 565, in forward
hidden_states = attn(hidden_states, context=encoder_hidden_states)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/diffusers/models/attention.py", line 167, in forward
hidden_states = block(hidden_states, context=context)
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/diffusers/models/attention.py", line 217, in forward
hidden_states = self.attn1(self.norm1(hidden_states)) + hidden_states
File "/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/diffusers/models/attention.py", line 287, in forward
out = xformers.ops.memory_efficient_attention(q, k, v, attn_bias=None, op=self.attention_op)
File "/usr/local/lib/python3.7/dist-packages/xformers/ops.py", line 626, in memory_efficient_attention
return op.apply(query, key, value, attn_bias, p)
File "/usr/local/lib/python3.7/dist-packages/xformers/ops.py", line 264, in forward
causal=causal,
File "/usr/local/lib/python3.7/dist-packages/torch/_ops.py", line 143, in call
return self._op(*args, **kwargs or {})
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Steps: 0% 0/2500 [00:10<?, ?it/s]
Traceback (most recent call last):
File "/usr/local/bin/accelerate", line 8, in
sys.exit(main())
File "/usr/local/lib/python3.7/dist-packages/accelerate/commands/accelerate_cli.py", line 43, in main
args.func(args)
File "/usr/local/lib/python3.7/dist-packages/accelerate/commands/launch.py", line 837, in launch_command
simple_launcher(args)
File "/usr/local/lib/python3.7/dist-packages/accelerate/commands/launch.py", line 354, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
subprocess.CalledProcessError: Command '['/usr/bin/python3', '/content/diffusers/examples/dreambooth/train_dreambooth.py', '--pretrained_model_name_or_path=/content/gdrive/MyDrive/stable-diffusion-v1-4', '--instance_data_dir=/content/data/sksBJ', '--output_dir=/content/models/sksBJ', '--instance_prompt=sksBJ man', '--seed=12345', '--resolution=512', '--mixed_precision=fp16', '--train_batch_size=1', '--gradient_accumulation_steps=1', '--use_8bit_adam', '--learning_rate=5e-6', '--lr_scheduler=constant', '--lr_warmup_steps=0', '--max_train_steps=2500']' returned non-zero exit status 1.