tweag / nickel Goto Github PK
View Code? Open in Web Editor NEWBetter configuration for less
Home Page: https://nickel-lang.org/
License: MIT License
Better configuration for less
Home Page: https://nickel-lang.org/
License: MIT License





![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")








![github-actions[bot] avatar](https://avatars.githubusercontent.com/in/15368?v=4 "github-actions[bot]")
















































































































































Is your feature request related to a problem? Please describe.
Given the stated goals, it seems like having an openapi2nickel tool would be rather valuable.
If this tool existed, and assuming the OpenAPI specs are... of good quality, it is fun to imagine being able to auto-generate Nickel modules for things like Kubernetes resources, Azure IaaS resources, etc.
Describe the solution you'd like
Someone to create an openapi2nickel tool.
Describe alternatives you've considered
Hm, I'm not sure what an alternative would be, this is kind of a specific idea.
Additional context
Related-ish work?
I realize this is a big feature request and might make better sense as a standalone tool, but I figured I might open this anyway for discussion?
Is your feature request related to a problem? Please describe.
Currently, we just have a List type for heterogeneous lists. A parametrized list type List t is more expressive, as it make the old List type representable as List Dyn, but it also makes it possible to represent lists which hold items of one fixed type, which is a common thing to use.
Describe the solution you'd like
Have a parametrized list type List t, where t is a type.
In Nix, one can define records fields piecewise, in the following sense:
{
a.b.c.d = "foo";
a.b.c = {e="bar"};
}
{
a.b.c.d = "foo";
a.b.c.e = "bar";
}
Both gives the same result:
{a={b={c={d="foo";e="bar";};};};}
We propose to add this feature in Nickel. To do so, we can rely on merge (#74) : the multiple definitions of a field are just merged together.
{
a={b={c=1;};};};
a={b={d=1;};};};
}
/* a={b={c=1;d=1;};} */
{
a={b={
/* Can also be used with enriched values, although one probably wants
* to centralize all the information at one place */
{
field = Contract(Str);
/* ... */
field = Docstring("Some doc", "Some string");
}
/* {field=Docstring("Some doc", Assume(Str, "Some string"));} */
If {f1=v1;...;fn=vn;} is a record declaration with potential duplicate fields, it is taken to mean f1': merge vf1_1 ... vf1_n1; ...; fm': merge vfm_1 ... vfm_m2; } where:
f1',...,fm' with m <= n is the subsequence obtained from f1,...,fn by removing all duplicates, keeping only the first occurrence of each distinct field name.fi', vfi_1, ... vfi_ni are the values corresponding to each occurrence of this field.merge v1 ... vn is v1 if n=1, or merge (merge v1 v2) v3 ... vn otherwisea.b.c.d = foo for a={b={c={d=foo;};};}; is convenient both in record declarations as well as for destructuring, but it is a separate concern.{a=1;a=2;} or wrap a record inside a computation as in {a=(x: {b=x}) 1;a={};}, this raises an "attribute already defined" error, whereas {a={b=1;};b={};} is accepted. In the current proposal there is no such restriction. If a field is defined with two conflicting concrete values, as in the first example, it either raises an error, or only the second value is kept, depending on the corresponding behavior of merge.The Makam parser generator takes too much memory. This started as an issue for Circle, but is now an issue for local building as well.
Even if some quick fixes could help, I think the ideal solution would be to generate it on Rust (or even JS) and do some interop. It's also nice to only mantain one grammar.
I'd need to:
We are approaching the state of an MVP. Before shipping, we must think first about the adoption story. In particular:
Nix is the best candidate, since Nickel started as a Nix expressions spin-off and always had it in mind as one of the main applications. As it tries to overcome many of the limitations of Nix, this is where it should add the most value.
As of now, a couple of propositions have been sketched to integrate Nickel in Nix:
Other natural candidates are the remaining use cases which originally motivated Nickel. The story would be simpler as Nickel could in principle just generate JSON in place of the native language and tooling. On the other hand, the benefits of switching to yet another language may be harder to substantiate than for Nix, and to overcome the adoption barrier.
A third possibility is to start a new cloud project (Nixops/Terraform like) from scratch, which would use Nickel as a native language. However this is a whole new project on its own, and is not a realistic first adoption plan.
Describe the bug
When reporting a type error, Nickel uses the position of the evaluated faulty expression instead of the original expression. This approach have the following problems:
To Reproduce
Here is a screenshot illustrating a bunch of non helpful error messages:

Expected behavior
let x = "a" ++ "b" in
x + 2
we would like the interpreter to point at the x in the x + 2 expression. Also pointing to the definition of x or reporting that it evaluates to "ab" could be a bonus.
let rec = {a = "string"} in
let f = fun x => x + rec.a in
let list = map f [1, 2, 3] in
head list
we would like the interpreter to point at the rec.a in the x + rec.a expression. A bonus would be to also show the definition of a or the value "string".
let x = "a" ++ "b" in
let y = 0 in
if x then y else y
we would like the interpreter to point at the x in the if x then y else y expression. As before, showing either the value or the definition site of x is a bonus.
Describe the bug
Evaluating a thunk with an enriched value inside can change its semantics in future usages.
To Reproduce
If we store a record with a default value in a variable, and merge it with a record with a value for the same field, then the value is selected and everything works as expected:
$nickel <<< 'let x = {a=Default(1)} in (merge x {a=2}).a'
Typechecked: Ok(Types(Dyn))
Done: Num(2.0)
However, if in the meantime we force the evaluation of a=Default(1), its thunk will be updated with 1, causing the merge to fail:
$nickel <<< 'let x = {a=Default(1)} in seq (x.a) ((merge x {a=2}).a)'
Typechecked: Ok(Types(Dyn))
error: Non mergeable terms
┌─ <stdin>:1:20
│
1 │ let x = {a=Default(1)} in seq (x.a) ((merge x {a=2}).a)
│ ^ ^ with this expression
│ │
│ cannot merge this expression
Expected behavior
We expect the second merge to succeed and produce the value 2, as the first one.
In general, we expect that the value of an expression does not depend on whether something has been evaluated or not. In this case, evaluating x.a should not change its status from an enriched value to a simple value.
Additional context
Laziness and enriched values interact in an unexpected way. When the interpreter sees a Default(t) (or a Docstring(doc,t)) in strict mode for enriched values (which is the evaluation mode most of the time), Default(t) is converted to t and the evaluation continues. This is done to select a default value when a field without value is requested, such as in {a = Default(1) }.a, which must evaluate to 1. But if a is in a thunk, then the thunk which initially contains Default(1) will be updated with 1, changing its semantics, as illustrated in the example above. We clearly don't want the semantics of an expression to depend on whether it has been evaluated before or not.
Currently, the builtin contracts for row types are not implemented yet (#157), but hopefully they will be soon.
Questions about the expressivity of such contracts have been discussed in #45. This is to be understood in the context of a function taking a record as an argument, where contracts act on two dual aspects:
{ a: Num } -> Num, the caller is responsible to provide me a record with a field a. The record contract can be open or closed: in the previous example, it is closed, as the argument must not have extra fields other than a. In a function forall a. {foo: Num | a} -> Num, it is open, since the argument must have at least foo, but can also have other extra fields.forall a. {foo: Num | a} -> {foo: Num} should not try to access any other field than foo on its argument. A function could have open usage, with a specification meaning "I need at least field foo, but I may access dynamically other field as well". This can't be expressed in the current type system.Reusing the table of @teofr, we can already fill part of it with the current type system:
| record contracts | closed fields | open fields |
|---|---|---|
| closed usage | closed record type: { a: Num } -> .. |
polymorphism: forall a. {foo: Num | a} -> .. |
| open usage | N/A (absurd) | ? |
One option to fill the blank would be to add a dynamic row type, as presented for example in this paper.
Currently, the tail of a row can either be the empty row, or a type variable to indicate an open row. But a type variable must be quantified somewhere and must obey to parametric polymorphism: as it is already the case for an arrow type like forall a. a -> a, contracts should enforce that the values of type a can never be inspected, just passed around. In particular, that makes the record closed in usage. This, for example, must not be allowed:
// Deserve a blame !
let f = Assume(forall a. {foo: Num | a} -> Str, fun rec => rec.bar) {foo = 1; bar = "blah"}
Using the dynamic row type would allow a new value for the tail of a row, which is the dynamic type. This would mean that the tail of a record becomes subject to inspection:
// Ok
let f = Assume({foo: Num | Dyn} -> Str, fun rec => rec.bar) {foo = 1; bar = "blah"}
Which corresponds exactly to the missing case in the table. This has implications for the type static system, since it would probably fails in the current state with an "Illformed type" error if trying to unify a row type with a Dyn tail somewhere (even if not consistently). But it should be possible to accommodate: a complete type system with the dynamic row type, gradual types and polymorphism is precisely described in the aforementioned paper.
Current status: Intersection and Union types ended up being much more complex than anticipated, on standby for now. We are looking for a simpler way to encode Sum types, this issue presents a possible solution.
The idea would be to encode sums by using Pi and Sigma types: A+B would become Sigma b: Bool, if b then A else B, which could be constructed with Pi b: Bool, (if b then A else B) -> Sigma c: Bool, if c then A else B.
For this, we'd need to implement two new kind of contracts:
x: A -> \x. B, which allow the codomain contract to depend on the input, as a reference we have [1] Racket's functions contracts, [2] is also a good reference. There are two challenges/decisions:
{idx: Bool, val: if idx then A else B} would allow us to have Sigma types quite naturally, together with some more complex stuff.Ideas/problems around this:
Pi b: Bool, (if b then A else B) -> (Pi c: Bool, if c then Bool else if b then A else B), where c is the accessor for the pair (true == fst, false == snd).cc @aspiwack
[1] Racket's contracts, in particular ->i
[2] On Contract Satisfaction in a Higher-Order World, Dimoulas & Felleisen
[3] Contracts Made Manifest, Greenberg et. al.
[4] An Investigation of Contracts as Projections, Findler et. al.
Describe the bug
Nickel panic when an identifier is unbound, instead of reporting an error in the standard way.
To Reproduce
$nickel <<< 'id'
...
thread 'main' panicked at 'Unbound variable Ident("id")', src/eval.rs:170:40
...
Expected behavior
This should show an error message that takes advantage of the error reporting infrastructure, with nice colors and locations.
Is your feature request related to a problem? Please describe.
The current implementation of polymorphic equality #159 rewrites { a = expa1, b = expb1, ...} == { a' = expa2, b = expb2, ..} to list.all (fun x => x) [ expa1 == expa2, expb1 == expb2, ..], and then proceeds. We should avoid allocating too much stuff and making numerous functions calls (implicitly to fold, head, tail, etc.) when computing equality, which is a fundamental operation that should stay reasonably lightweight.
Describe the solution you'd like
Implement the logic of the previous term directly in Rust land, avoiding Nickel functions calls and allocations as much as possible. One solution would be to add a builtin operator of varying arity that would basically be a native version of list.all id.
Is your feature request related to a problem? Please describe.
Currently, default values cannot be merged, meaning that two default values for the same field in a record results in an error. In particular,
merge { a = Default(1); } { a = Default(1); }
is not accepted when it really should evaluate to Default(1). Similarly,
merge { a = Default({ x = ... ;}); } { a = Default({ y = ... ;}); };
is currently rejected, while it could be given the value { a = Default({x = ... ; y = ... }); }.
More generally, merge is defined in a recursive manner on almost every other cases, and it would be more consistent for it te behave similarly on Default.
Describe the solution you'd like
Merge should try to recursively merge default values, that is:
merge Default(t1) Default(t2) = Default(merge t1 t2)
This would restore idempotency on equal default values.
Additional context
This was initially raised in #106 (comment)
PRs #96, #97 and #98 aim to improve source mapping (conversion of offsets to line and column in a source file, as done e.g. in the rust compiler), and improve error reporting, as well as to decouple one from the other. However it requires some effort to write and maintain code for consistent, informative and pretty error messages and resolving positions from multiple sources: as @aspiwack suggested, it is worth to look if there isn't already a library that can achieve this for us.
We initially selected 4 candidates:
Language-reporting started as a fork of codespan, but its features have been backported and it seems to be now deprecated, so we exclude it from the test. All of them are based on or inspired by the rust compiler error reporting infrastructure and hence have similar models.
| Libraries → Stats ↴ |
Codespan | Codemap | Annotate-snippets |
|---|---|---|---|
| Downloads | 290K (~0,75K/day) | 27K (45/day) | 574K (2,5K/day) |
| Reverse deps | 28 | 7 | 12 |
| Used by | cargo-deny CXX gleam gluon nushell |
starlark (rust impl) | dhall (rust impl.) rustfmt rust jrsonnet |
| Contributors | 19 | 4 | 10 |
| Last updated | 19 days ago | 1 year ago | 11 days ago |
| Overall sustainability |
| Libraries → Features ↴ |
Codespan | Codemap | Annotate-snippets |
|---|---|---|---|
| Multiple source files management | |||
| Source mapping | |||
| Snippet annotation | |||
| Colors |
| Libraries | Codespan | Codemap | Annotate-snippets |
|---|---|---|---|
| Modularity | codespan-reporting defines a file trait for source mapping that is independent from codespan |
codemap-diagnostic is built on the types of codemap and depends on it |
N/A |
On these aspects, the three libraries are relatively similar: both on source mapping, where a dictionary of source files allows to manage multiple sources and map absolute offsets to line and columns, and on error reporting, where the user constructs a structured representation of an annotation with labels, spans, error code, severity, and so on. Each one gives reasonable freedom in the configuration of the output format, and produces messages that resemble to the ones produced by the rust compiler.
Annotate-snippets is a well established library, backed by the rust compiler itself, but it does not handle source mapping, which is also needed in Nickel. Codespan and codemap are quite similar, with respect to features as well as usage, but codespan seems more active, more used and more modular: accordingly, we recommend the usage of codespan.
use codespan_reporting::diagnostic::{Diagnostic, Label};
use codespan_reporting::files::SimpleFiles;
use codespan_reporting::term::termcolor::{ColorChoice, StandardStream};
// `files::SimpleFile` and `files::SimpleFiles` help you get up and running with
// `codespan-reporting` quickly! More complicated use cases can be supported
// by creating custom implementations of the `files::Files` trait.
let mut files = SimpleFiles::new();
let file_id = files.add(
"FizzBuzz.fun",
unindent::unindent(
r#"
module FizzBuzz where
fizz₁ : Nat → String
fizz₁ num = case (mod num 5) (mod num 3) of
0 0 => "FizzBuzz"
0 _ => "Fizz"
_ 0 => "Buzz"
_ _ => num
fizz₂ : Nat → String
fizz₂ num =
case (mod num 5) (mod num 3) of
0 0 => "FizzBuzz"
0 _ => "Fizz"
_ 0 => "Buzz"
_ _ => num
"#,
),
);
// We normally recommend creating a custom diagnostic data type for your
// application, and then converting that to `codespan-reporting`'s diagnostic
// type, but for the sake of this example we construct it directly.
let diagnostic = Diagnostic::error()
.with_message("`case` clauses have incompatible types")
.with_code("E0308")
.with_labels(vec![
Label::primary(file_id, 328..331).with_message("expected `String`, found `Nat`"),
Label::secondary(file_id, 211..331).with_message("`case` clauses have incompatible types"),
Label::secondary(file_id, 258..268).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 284..290).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 306..312).with_message("this is found to be of type `String`"),
Label::secondary(file_id, 186..192).with_message("expected type `String` found here"),
])
.with_notes(vec![unindent::unindent(
"
expected type `String`
found type `Nat`
",
)]);
// We now set up the writer and configuration, and then finally render the
// diagnostic to standard error.
let writer = StandardStream::stderr(ColorChoice::Always);
let config = codespan_reporting::term::Config::default();
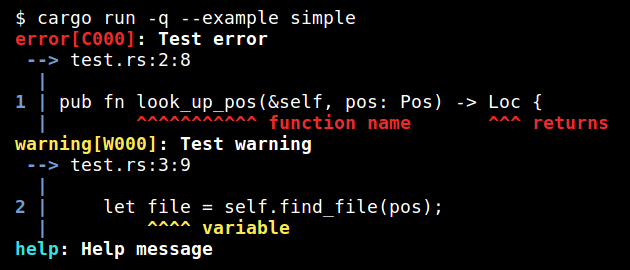
term::emit(&mut writer.lock(), &config, &files, &diagnostic)?;extern crate codemap_diagnostic;
extern crate codemap;
use codemap::{ CodeMap };
use codemap_diagnostic::{ Level, SpanLabel, SpanStyle, Diagnostic, ColorConfig, Emitter };
fn main() {
let file = r#"
pub fn look_up_pos(&self, pos: Pos) -> Loc {
let file = self.find_file(pos);
let position = file.find_line_col(pos);
Loc { file, position }
}
"#;
let mut codemap = CodeMap::new();
let file_span = codemap.add_file("test.rs".to_owned(), file.to_owned()).span;
let fn_span = file_span.subspan(8, 19);
let ret_span = file_span.subspan(40, 43);
let var_span = file_span.subspan(54, 58);
let sl = SpanLabel { span: fn_span, style: SpanStyle::Primary, label:Some("function name".to_owned()) };
let sl2 = SpanLabel { span: ret_span, style: SpanStyle::Primary, label:Some("returns".to_owned()) };
let d1 = Diagnostic { level:Level::Error, message:"Test error".to_owned(), code:Some("C000".to_owned()), spans: vec![sl, sl2] };
let sl3 = SpanLabel { span: var_span, style: SpanStyle::Primary, label:Some("variable".to_owned()) };
let d2 = Diagnostic { level:Level::Warning, message:"Test warning".to_owned(), code:Some("W000".to_owned()), spans: vec![sl3] };
let d3 = Diagnostic { level: Level::Help, message:"Help message".to_owned(), code: None, spans: vec![] };
let mut emitter = Emitter::stderr(ColorConfig::Auto, Some(&codemap));
emitter.emit(&[d1, d2, d3]);
}use annotate_snippets::{
display_list::{DisplayList, FormatOptions},
snippet::{Annotation, AnnotationType, Slice, Snippet, SourceAnnotation},
};
fn main() {
let snippet = Snippet {
title: Some(Annotation {
label: Some("expected type, found `22`"),
id: None,
annotation_type: AnnotationType::Error,
}),
footer: vec![],
slices: vec![Slice {
source: r#" annotations: vec![SourceAnnotation {
label: "expected struct `annotate_snippets::snippet::Slice`, found reference"
,
range: <22, 25>,"#,
line_start: 26,
origin: Some("examples/footer.rs"),
fold: true,
annotations: vec![
SourceAnnotation {
label: "",
annotation_type: AnnotationType::Error,
range: (205, 207),
},
SourceAnnotation {
label: "while parsing this struct",
annotation_type: AnnotationType::Info,
range: (34, 50),
},
],
}],
opt: FormatOptions {
color: true,
..Default::default()
},
};
let dl = DisplayList::from(snippet);
println!("{}", dl);
}
error[E0308]: mismatched types
--> src/format.rs:52:1
|
51 | ) -> Option<String> {
| -------------- expected `Option<String>` because of return type
52 | / for ann in annotations {
53 | | match (ann.range.0, ann.range.1) {
54 | | (None, None) => continue,
55 | | (Some(start), Some(end)) if start > end_index => continue,
... |
71 | | }
72 | | }
| |_____^ expected enum `std::option::Option`, found ()
Is your feature request related to a problem? Please describe.
The executable currently only read a program for the standard input, which is impractical.
Describe the solution you'd like
Allow to pass a file to read the program from as an argument. Nickel can still default to standard input if no argument is given.
Describe alternatives you've considered
One can currently do cat file | ./nickel.bin but this is verbose and annoying.
Describe the bug
When working on lists, it appears that some operations trigger an "Unbound identifier" error, while the identifier is actually bound. A minimal example seems to point at a thunk update problem, where maybe a thunk is updated but not its environment, or the environment is dropped when it should not. The problem does not seem to apply to records, so it is probably list-specific.
To Reproduce
nickel <<< 'let x = 1 in let y = [x] @ [] in elemAt y 0'
error: Unbound identifier
┌─ <stdin>:1:23
│
1 │ let x = 1 in let y = [x] @ [] in elemAt y 0
│ ^ this identifier is unbound
Note that if we turn y into a weak head normal form, henceforth avoiding a thunk update, the problem disappears:
nickel <<< 'let x = 1 in let y = [x] in elemAt y 0'
Done: Num(1.0)
Strangely, it also seems to be list-specific, as the equivalent with records does not trigger the error either:
nickel <<< 'let x = 1 in let y = merge {foo = x} {bar = 2} in y.foo'
Done: Num(1.0)
Expected behavior
We expect the first example above to evaluate normally and return 1.
Describe the bug
When merging records with a contract and a constant (say, a number), the environment of the contract is dropped, while it should not. This causes undue Unbound variable XXX errors, in particular for builtin contracts, which should always be available in the environment.
To Reproduce
Create two records with the same field a, one being assigned to a contract, and the other to a constant, and merge them. Then try to access a on the result:
let rec = merge {a = Contract(Num); } {a = 1; } in
rec.a
The whole environment of 1 is dropped as it is a constant. But the environment of Contract(Num) is also dropped, so the resulting field a has an empty environment, causing the following error:
'Unbound variable Ident("num")', src/eval.rs:170:40
It can't find the builtin contract num in the environment.
Expected behavior
The previous example should evaluate to 1 without any error.
Describe the bug
#135 introduced recursive records. The typechecking of such recursive records is incorrect: it accepts ill-typed programs. It does not correctly unify different representation of the same type.
Promise(Num, { a = 1 + b; b = a + 1 }.a)
Although this program loops, it is valid and well-typed. It illustrates the fact that before actually typechecking the body of each field a or b, the typechecker has to already have an entry in the typing environment for each field of the record (that can be a concrete type or a unification variable) for all the fields of the records before starting to actually typecheck each body (see also this comment).
The implementation of this mechanisms is wrong and the typechecker accepts ill-typed recursive records.
To Reproduce
The following program is accepted:
$nickel <<< 'Promise({ {| a : Num, b : Bool, |} }, { a = 1; b = Promise(Bool, a) } )'
...
It should not, since Promise(Bool, a) constrains a to be of type Bool, but the actual definition of a, together with the row type of the whole promise, constrain it to be a Num.
Expected behavior
This typechecker should reject this program. It should attempt to unify Bool and Num, and fail accordingly.
Describe the bug
If one uses variables inside an interpolated expression in the middle of a string, this causes an unexpected "unbound identifier" error. As often with these errors, an environment is probably getting dropped somewhere where it shouldn't.
To Reproduce
Use a variable as an interpolated expression somewhere in the middle of a string:
$nickel <<< '
let world = "world" in
"Hello, ${world}!"
'
error: Unbound identifier
┌─ <stdin>:3:11
│
3 │ "Hello, ${world}!"
│ ^^^^^ this identifier is unbound
Note that the error is not triggered if the variable is alone in the string:
$nickel <<< 'let x = "a" in "${x}"'
Done: Str("a")
Expected behavior
Variables in scope should be accessible in interpolated string. The first example should succeed with result "Hello, world!".
In Nix, the rec keyword allows a field of a record to cross-reference the other fields of the same record. Jsonnet also provides this possibility via self. This is commonly used for sharing and reusing data as in (Nix syntax):
/* Share a single source of truth */
rec {
name="my-pkg";
version="1.1.2";
url="https://someurl/tarballs/my-pkg-${version}";
/* ... */
}
/* Code reuse */
rec {
/* Actual code from Nixpkg */
concatMap = /* ... */
flatten = x:
if isList x
then concatMap (y: flatten y) x
else [x];
}
}
We propose to add recursive records to Nickel.
Recursive records are a source of general recursion (although not the only one), as fields may reference themselves, directly or indirectly. This is exemplified in the definition of flatten above. Nickel is a configuration language, and most of its use cases should not require the use of general recursion. Several languages competing in the same domain are not Turing-complete, such as Dhall, CUE or Starlark. But recursion is hard to rule out in an untyped language with higher-order functions:
rec or mutually recursive top-level procedures may introduce direct or indirect recursionThe aforementioned languages sidestep these points because:
Moreover, even if rare, there are legitimate cases which require general recursion. Our intent is to offer great defaults, in particular for building and traversing data structures so that explicit recursion is almost never needed. But also to offer an escape hatch when there is no better solution. We propose to introduce recursion and recursive records, but in a way that makes accessing true recursion really explicit, or even a bit awkward.
Add a rec keyword which, when put before the definition a record, brings all the fields in scope.
Introduce a special variable which refers to the current record, self, to access other fields.
parent or super keyword for that, or to allow let bindings inside records to capture self in a local variable (both are done in Jsonet)as in OCaml, use an explicit let rec form for recursive bindings. A recursive record can be written as let rec r = {a=0; b=r.a+1} [1]
A simple solution to discourage recursion is to only rely on recursive records, without explicit recursive functions. This makes it accessible but awkward enough so that the user knows he is doing something non standard. Even more:
let rec to records.rec also at the (recursive) call site (as in Bosque), as in the fictitious let rec loop n = if n > 0 then rec loop (n - 1) else "done".If on the contrary, one wants to provide a direct syntax for recursive
functions:
It may be desirable for inheritance-like mechanisms to late bind self (or recursive fields in case 1.). In particular, when merging, self would be bound to the resulting record:
let r1 = {a="a" + self.b; b="b";} /* {a="ab";b="b;} in */
let r2 = {b="c";} in merge r1 r2 /* {a="ac";b="c";} in */
People simulates this capacity in Nix using fixpoints for overriding packages, and Jsonnet's self is late bound. This may also prove essential for incremental evaluation.
let rec is restricted in practice.The evaluator is mostly implemented, but doesn't compile. What's getting in the way is that all definitions use Box, when they should use naked pointers or a newtype thereof with the same semantics. These can eventually become a GC-managed pointer type.
What is the motivation behind this project? What will it allow to do that is currently not possible / hard with another language?
Describe the bug
The typechecker accepts invalid programs when using polymorphic row types. In particular, it can infer a row type with multiple conflicting types for the same field identifier, such as { {| a: Num, a: Str |} }.
To Reproduce
Here is an example of a bogus program being accepted:
$nickel <<< '
let extend = Assume(forall c. ({{| | c} }) -> ({ {| a: Str, | c } }), fun rec => rec$["a"="b"]) in
let bad = Promise(Str, (extend ({a = 1;})).a) in 0'
Typechecked: Ok(Types(Dyn))
Here, we have an extend function, which adds a field named a to a record and assigns it to a string. Then, this function is applied to the record {a = 1} which leads c to be unified with the type { {| a: Num |} }. Consequently, the return type of extend inside bad ends up being {| a: Str, a: Num |} (I checked by printing the type inferred by the typechecker) which is not a valid row type.
Expected behavior
The typechecker should constrain row unification variables introduced by foralls a to not contain fields already defined in the rows they appear in. Here, it should constrain the unification variable introduced by c to not contain the field a, and fail accordingly when we try to unify it with { {| a: Num |} }.
As the project codebase grows, more and more tests are accumulated. They are currently all mixed (unit, integration, regression, etc.), with sometimes hardcoded Nickel code, sometimes hand builded ASTs, and what not. This is not always easy to see what is actually covered and where. This is not the current priority until the MVP, but that could be nice to have a clean test suite and to detach generic language tests into separate nickel source files at some point.
Describe the bug
Trying to build Nickel using the instructions provided in README using nix doesn't work, running nix-shell gives the following error message:
error: --- UsageError ----------------------------------------------------------------- nix-shell
nix-shell requires a single derivation
Try 'nix-shell --help' for more information.
To Reproduce
nix-shell commandExpected behavior
A shell should spawn with all dependencies installed to build Nickel.
Environment
Is your feature request related to a problem? Please describe.
Parse errors could be more user-friendly. They currently include the location of the problem, but do not take advantage of the error reporting infrastructure which is capable of showing the incriminated snippet. Compare this:
$nickel <<< '%a" '
error: While parsing: Invalid token at 870
to a type error:
error: Type error
┌─ <stdin>:1:5
│
1 │ 1 + "a"
│ ^^^ This expression has type Str, but Num was expected
│
= +, 2nd argument
Describe the solution you'd like
Parse errors show the incriminated snippets, as do evaluation errors:
$nickel <<< '%a" '
error: Parse error
┌─ <stdin>:1:5
│
1 │ %a"
│ ^ Invalid token
Is your feature request related to a problem? Please describe.
The syntax of record and enum types is verbose. A few examples:
{ {| a: Num |} }
forall r. { {| a: Num, b: Str | r} }
< (| tag1 |) >
forall r. < (| tag1, tag2 | r) >
Describe the solution you'd like
Get rid of the unnecessary inner delimiters {| |} and (| |). Only use the pipe to separate fields from the polymorphic tail. This is for example the syntax of records in PureScript, although they use :: for typing, as in Haskell.
The examples would become:
{a: Num}
forall r. {a: Num, b: Str | r}
<tag1>
forall r. <tag1, tag2 | r>
Is your feature request related to a problem? Please describe.
The configuration language space is becoming very crowded. At this point, any newcomer will have to work extra hard to justify its existence. A baseline is probably Starlark: Python syntax, non-Turing complete, no type annotations, basic data types everyone expects (dictionaries and lists), no fancy semantics (like commutative merges etc). Every one else needs to explain clearly and concretely why departing from any one of these choices is necessary, and if so, for what use cases.
Describe the solution you'd like
Add a new section in the README, or in a new document accessible from the README, that motivates the need for Nickel relative to a select few canonical alternatives. In particular: CUE, Jsonnet, Starlark and Dhall.
Additional context
Existing comparisons to draw inspiration from: the "comparison" section of each "use case" page in CUE lang documentation.
The time has come to have a presentable syntax, if not sexy. The first target of this grand bikeshedding festival is typing annotations.
In Nickel, typing is controlled via two dual constructs: Promise(type, term) and Assume(type, term). They both have a static semantics, during the typechecking phase, and a dynamic semantics, during execution. Since the type system is gradual, the typechecker features two different modes:
The aforementioned constructs serve as annotations, but also toggle the typechecker mode.
Promise(type, term) delimits a term that must be statically checked. The typechecker enters in strict mode, and checks term against type.Assume(type, term), on the contrary, tells the typechecker "trust me on this one". The term is blindly accepted to have type type, and is not statically checked. The typechecker enters in non-strict mode.At run-time, both constructs evaluate to the same run-time check, that is that term indeed evaluates to a value of type type, but for slightly different reasons:
term indeed evaluates to a value of type type, without needing to check it again at run-time. While this is true for base types, there is an issue with higher-order types: a typed function can be called from untyped code. In particular, it can be passed arguments of the wrong type: the role of the run-time check is then to reject such calls by checking each argument, instead of raising a type mismatch error inside a seemingly well-typed function.Assume(type, term) is blindly trusted during typechecking, but term could very well be of the wrong type. To verify that term lives up to its expectations, a run-time check is inserted.Just to start the discussion.
Promise would become a type annotation on a let-binding:
let x = Promise(type, term) in term
// becomes
let x : type = term in term
Assume can be thought of as a type coercion, or a type cast (the actual name in the gradual typing literature), in that it converts a term to an arbitrary type during typechecking. We can use the :> operator, used in OCaml for type coercions.
Assume(type, term)
// becomes
term :> type
: is used everywhere and usually relates to static typing.:> conveys the static semantics of Assume, which I find is emphasized by the asymmetry of the operator: the term is cast to a target type.Assume and Promise are not only annotations, they also delimit zones for typechecking, namely typed and untyped. Maybe we could use a syntax which makes this clearer (enclose the term between delimiters ?):> is specific to OCaml or comes from another language, but it is probably not that mainstream.Describe the bug
When merging two contracts, a contract corresponding to their composition is generated. However, there is currently no way to merge or combine labels. Nickel currently makes the arbitrary and unsound choice of using the label of the first contract for the composite in order to appease the rust compiler, but this leads to error messages pointing to a wrong location when such composed contract fails.
To Reproduce
$ nickel <<< '(merge (merge {a=Contract(Num);} {a=Contract(Str);}) {a=1;}).a'
[..]
error: Blame error: [Contract
str]. The blame is on the value (positive blame)
┌─ <stdin>:1:18
│
1 │ (merge (merge {a=Contract(Num);} {a=Contract(Str);}) {a=1;}).a
│ ^^^^^^^^^^^^^ bound here
Expected behavior
Have the error pointing to the actual failed contract if this is possible, or to another location (such as the whole merge) which may be less precise but is at least not wrong.
error: Blame error: [Contract
str]. The blame is on the value (positive blame)
┌─ <stdin>:1:18
│
1 │ (merge (merge {a=Contract(Num);} {a=Contract(Str);}) {a=1;}).a
│ ^^^^^^^^^^^^^ bound here
@edolstra noticed that since Nickel's type system is structural, we lose the information usually conveyed by type names in nominal type systems. If a package implements several different contracts, we would like to ask for the origin of some particular field, as in the following snippet (in an imaginary nominal Nickel):
contract Pkg1 {
from1 : Type
// ...
}
contract Pkg2 {
from2 : Type
// ...
}
let myPackage = { /* ... */} # Pkg1 # Pkg2
info myPackage.from1 //Origin: Pkg1
contracts myPackage //Pkg1, Pkg2
We do not suggest that the type system should be nominal, but that a mechanism providing the same feature would be a useful addition.
This is mainly intended as a discussion point on how to check records
Nix has some kind of checking on records, in particular argument set (pattern matching +/-), and some coding folklore built around these.
In particular you can pattern match on records on two different ways:
On the blame calculus we're developing, a contract has to check two different things, what the value looks like, and how it's used. Ideally we want to follow the above idea of two kinds of records, but came the moment to ask ourselves, how these two can be treated.
On the following table, each row states how a record can be used, while each column how it should be constructed. And on each cell we position a different contract
| record contracts | closed fields | open fields |
|---|---|---|
| closed usage | non-variadic | A |
| open usage | B | C |
It's pretty clear that a non-variadic argument set is closed in both axes, and it's pretty clear that B is useless. However, it's not so clear whether a variadic argument set goes on A or C.
Arguments in favor of A:
Arguments in favor of C:
Following @regnat's work on nix Section 3.3.2 it seems a good solution to allow a catch-all field on a record type, for instance, an A type would look like {a: Num, b: String, _ : Dyn} or even {a: Num, b: String, _ : Bool}. And a C type would look like {a: Num, b: String, _ : Void}.
If we were to add a special contract (type) to signal unexistent fields (Δ), we could write non-variadic records as {a: Num, b: String, _ : Δ} (we need this because otherwise the evaluation is not forced).
cc @aspiwack
TODO:
Is your feature request related to a problem? Please describe.
Basic error messages are not very informative (this example uses the updated syntax of #90 for record extension) :
$ nickel <<< '{a=1;}$[1=2]'
Evaluation didn't finished, found error:
Expected Num, got Str("a")
The actual problem is that the operator $[ exp1 = exp2 ] expects exp1 to be a string. But there is no location information in the error message and the problematic operation (dynamic extension of a record) is not specified either, which makes it rather unhelpful.
Moreover, error messages are currently locally defined in each case in the codebase, which may lead to several different phrasing for however similar errors.
Describe the solution you'd like
The core language of Nickel is pure, but its usage in practice requires side-effects, e.g. for retrieving information about the local environment. We propose to add effects to Nickel.
The effect system must be:
There are several possible directions to incorporate effects.
The first one is to provide effects inside the language through primitives, which are handled in a specific way by the interpreter. Primitives are akin to regular functions, as it is done in most general purpose languages, for example as in OCaml let availableMACs = map getInterfaceMAC (getNetworkInterfaces ()) in foo. Effects themselves would be implemented outside of the boundaries of the Nickel program, either directly by the interpreter or by an external handler. They may or may not be sequenced or tracked by the type system as in Haskell.
The point of requiring commutativity is to avoid undue sequentialization, which prevents parallel execution. Some effects may still need to be executed in a specific order, as in the previous example, but because they have a data dependency, not a temporal one. Requiring all effects to be linearly sequentialized from the toplevel, as the IO monad of Haskell, defeats the purpose of commutativity. One can still consider a monadic interface, but it must be tailored for commutativity, meaning it should be able to easily express independent computations. Since the core language is untyped, it makes less sense to track effects through types if these are not enforced nor visible in the signature of functions. Some form of effect tracking may be required later for incremental evaluation, though.
To sum up, with internal effects:
In the internal case effects may be hidden deep inside a program, stripping away the benefits of purity and hermeticity. A common approach to mitigate the side effects of side effects is to downright push the responsibility of executing them at the boundary of the program, and replace primitive calls with pure, top-level arguments. They can be then accessed like any other binding.
That is, our previous example becomes a top-level function fun availableMACs => foo. If there are other effects inside foo, they must also be hoisted as top-level arguments. Then, values can be directly passed on the command line as external variables in Jsonnet. In CUE, a dedicated external level, the scripting layer, is allowed to perform commands and pass the values to pure CUE code. Similarly, repository rules in Bazel are responsible for fetching environment specific data at the loading phase, while following operations are required to be hermetic.
To sum up, with external effects:
External effects entail a satisfying separation of concerns, as well as keeping the program itself pure. But the inability to compose effects is limiting. One of the motivating use cases for Nickel is a dynamic configuration problem (Terraform) where some information, say an IP address, is not available until another part of the configuration is executed, resulting in the deployment a machine. This cannot be expressed in the external setting.
The simplest choice is to make performing and interleaving effects implicit, à la ML. Indeed, the value of a monadic interface in presence of commutative effects and untyped code is not clear. In this setting, an effectful primitive is not much different from a regular function from the user's point of view. Performing an effect is similar to a system call in C: the program is paused, the handler for the primitive is executed, and the program is resumed with the result of the call. Extensibility is simple, as executing an external handler boils down to a remote procedure call.
Example:
/* ... */
let availableMACs = map getInterfaceMAC (getNetworkInterfaces ()) in
let home = getEnv "HOME" in
foo
perform someEffect someArg (see Eff).[EDITED from feature request to bug (see the comments below)]
Describe the bug
In a let binding let var = bound_exp in body, the variable var is given the type Dyn in body if it is not annotated (i.e. if it is not of the form Promise(...) or Assume(...)). In strict mode (inside a statically typed Promise block) however, the type of bound_exp is inferred: we should use this information and assign this type to var in body, rather than the unitype Dyn, which requires explicit an explicit type cast to be used.
To Reproduce
Use a let-binding without annotation inside a Promise block:
$nickel <<< 'Promise(Num,
let x = 2
in x + 2
)'
Typechecked: Err("The following types dont match Dyn -- Num")
$nickel <<< 'Promise(Str,
let f = fun s => "prefix" ++ s ++ "suffix" in
f " middle "
)'
Typechecked: Err("The following types dont match Dyn -- Arrow(Ptr(1), Ptr(2))")
Expected behavior
We expect the previous examples to work, with the typechecker correctly using the inferred types Num for x and Str -> Str for f in the rest of the Promise block.
Describe the bug
Currently, the lexer allows to use hyphens - in identifiers. This clashes with the use of, say, the dynamic field removing operator -$, or any binary operator starting with an hyphen.
To Reproduce
Using the field removing operator without spaces after an identifier causes an error:
nickel <<< 'let field = "a" in let rec = {a=1} in rec-$field'
error: Unexpected token
┌─ <stdin>:1:43
│
1 │ let field = "a" in let rec = {a=1} in rec-$field
│ ^
while adding a space makes parsing succeed:
nickel <<< 'let field = "a" in let rec = {a=1} in rec -$ field'
[...]
Expected behavior
Do not consider the hyphen - character as valid identifier character. This is not standard and clashes with potentially any binary operator starting with a -. Parsing exp binop exp should not be whitespace sensitive.
Records and arrays are the two ubiquitous and fundamental data structures of a configuration language, be it Nix expressions, Jsonnet, Cue, or Nickel. It is useful in practice to be able to easily extract a few specific fields from a record (which may be located deep inside), or a few elements at specific positions from a list. To this end, we propose to add destructuring to Nickel, a syntax that allows to directly extract sub-elements from records or lists by extending let-bindings to bind not only variables, but patterns.
There are good examples out there to take inspiration from, such as pattern matching (restricted to records and lists) in Haskell or OCaml, or the closest to the following proposal, destructuring in Javascript.
Nix expressions also offer destructuring facilities:
let inherit, which can be confused with its twin { inherit ...; }, and cannot specify default values for missing fieldsBoth cannot handle nested records nor bind a field to a variable with a different name. Lists cannot be destructured either. We intend to overcome these limitations in Nickel.
In the following, we provide a concrete proposal, as a starting point for discussion.
We would like to write this kind of expressions:
let {pname; src=srcSome; meta={description};} = somePkg in foo
/* bind pname to somePkg.pname,
* srcSome to somePkg.src,
* and description to somePkg.meta.description in foo */
let {foo ? "default"; bar;} = {bar=1;} in baz
/* bind foo to "default" and bar to 1 in baz */
let [fst, snd, {bar}] = [1, 2, {bar="bar";}, "rest", "is", "ignored"] in foo
/* bind fst to 1, snd to 2 and bar to "bar" in foo */
let [head, ...tail] = [1, 2, 3, 4] in foo
/* bind head to 1 and tail to [2, 3, 4] in foo */
let [_, _, third, fourth] = [1, 2, 3, 4] in foo
/* bind third to 3 and fourth to 4 in foo */
let {a; ...rest} = {a=1; b=2; c=3;} in foo
/* bind a to 1 and rest to {c=2; d=3;} in foo */
let f = fun {x; y; z;} => x + y + z in foo
/* bind x, y and z to the corresponding fields of the argument in the body of f */
We propose JavaScript-like destructuring, with the @ from Nix for capturing the whole match, featuring:
...foo@foo_ pattern in a list to ignore an elementlet-binding ::= let letpat = e in e
fun-pat ::= fun letpat1 ... letpatn => e
let-pat ::= pat | pat @ var
pat ::= var | { recpat1; ...; recpatn; rest } | [lstpat1, ..., lstpatn, rest]
rest ::= ε | ...var
recpat ::= fldpat | fldpat ? e
fldpat ::= field | field = pat
lstpat ::= pat | pat ? e | _
Here e is an arbitrary Nickel expression, field is a field identifier, var is a variable identifier, and ε means "empty" or "absent".
| Source expression | Rewrites to | Condition |
|---|---|---|
| let pat@var = e in e' | let var = e in let pat = var in e' | |
| let { field; Q } = e in e' | let { field = field; Q } = e in e' | |
| let { field ? default; Q } = e in e' | let { field = field ? default; Q } = e in e' | |
| let { field = pat; Q } = e in e' | let pat = e.field in let { Q } = e -$ "field" in e' | |
| let { field = pat ? default; Q } = e in e' | let pat = if hasField e field then e.field else default in let { Q } = e -$ "field" in e' |
|
| let { ...rest} = e in e' | let rest = e in e' | isRec e |
| let { } = e in e' | e' | isRec e |
| let [pat, Q] = l in e' | let pat = head l in let [Q] = tail l in e' | |
| let [pat ? e, Q] = l in e' | let pat = if isEmpty l then e else head l in let [Q] = tail l in e' |
|
| let [_, Q] = l in e' | let [Q] = tail l in e' | |
| let [...rest] = l in e' | let rest = l in e' | isList l |
| let [ ] = l in e' | l | isList l |
| fun pat1 ... patn => e | fun x1 ... xn => let pat1 = x1 in ... let patn = xn in e | x1, ..., xn fresh |
Q denotes the queue of a sequence of declarations, and can be empty. The -$ operator removes a field from a record.
We proposed a rich set of features, for completeness and consistency. Even if they do not cost much to add, some are of questionable value, and could be considered for removal or restriction. Notably:
...rest syntax is handy for popping a few values from a list and get back the queue in one match, but what it adds for records patterns is not clearIs your feature request related to a problem? Please describe.
At the typechecking phase, the typechecker maintains an environment mapping variables introduced by let expressions to types. Indeed, whether a variable was introduced in a statically typed Promise or outside, it can be used inside a Promise at some point and the typechecker must thus know about its type, or have at least an approximation.
The current rule to determine the type of a variable introduced outside of a Promise is:
let var = Assume(type, ...) in ... or let var = Promise(type, ...) in ..., then use the user-defined type.DynThis is an understandable rule in general as Nickel is untyped by default: outside of a statically checked Promise block, the typechecker shouldn't - and in general, can't - infer the type of an expression. But assigning the type Dyn to a variable forces the user to resort to explicit type casts (AKA Assumes) when using it inside a Promise:
$nickel <<< 'let magic_number = 2 in
Promise(Num -> Num,
fun x => x + magic_number
)'
Typechecked: Err("The following types dont match Num -- Dyn")
$nickel <<< 'let base_path = "/home/me/nickel/" in
let full_path = Promise(Str -> Str,
fun filename => base_path ++ filename ++ ".ncl"
) in
full_path "myfile"'
Typechecked: Err("The following types dont match Str -- Dyn")
Describe the solution you'd like
We could improve a bit the rule above, which determines the type associated to a variable, to accommodate simple common cases as long as the rule stays cheap and simple. For example:
let x = 1 in or let x = "str" in , deduce its type. This would make the previous examples to be accepted by the typechecker.let x = y, then use the type determined for y.The standard way of structuring options in Nix packages, and more generally in a lot of JSON-based configurations, is to represent categories - and potentially subcategories - as nested records. A declaration { cat.subcat.option="foo"; } is translated as { cat = {subcat = {option="foo";};};};}. This has a some disadvantages: in order to either access, or retrieve metadata (documentation, example, type, etc.), the evaluator needs to follow several levels of indirection, forcing along the way the evaluation of thunks containing each sub-record (although it will not evaluate the other fields, it still incurs overhead).
[EDIT]: The actual main motivation is to simplify package overriding: see Eelco's answer below
Unless one explicitly wants to access cat.subcat or cat as a whole in a separate record, it is both simpler, more efficient and sufficient to store an path a.b.c, not as a nested records, but just as a flat field named "a.b.c", which would be { "a.b.c": val } in JSON. In this case, both access and metadata query are direct.
On the other hand, we want to provide a uniform way of accessing such paths for the user, who should not have to know in which way the path is stored. This is not the case in e.g. JavaScript: accessing a path of nested records is done via record.a.b.c.d, while accessing a flat field is record["a.b.c"]. And for a good reason: without restrictions, using the same syntax for both is ambiguous. Indeed, what should the following evaluate to ?
let r = {
"a.b"="foo";
a={b="bar";};};
} in r.a.b
We can impose a natural condition to avoid ambiguity: for each field of a record r, whose name is f, then f ++ "." must not be the prefix of any other field of r.
We propose to make flat records the default, meaning that:
{a.b="foo";} has the expected meaning of a field "a.b" containing "foo". This is not the case currently in Nix.rec.a.b allows to access either the field "a.b" or the field "b" of the subrecord "a".Note that nested records are still definable via the syntax {a={b="foo";};}. #81 and #84 may need to be updated accordingly.
Currently, Nickel does not have lists nor arrays. We propose to add lists and a set of tools for manipulating them to the language, namely list operations and list comprehensions. The set of operations must be complete enough to allow users to avoid general recursion except for very few particular cases. This proposition, including syntax, is not final but rather a concrete basis for sparking discussion.
A list is an immutable sequence of comma-separated expressions. Each element is stored inside a thunk, such that it is only evaluated if needed, and at most once. Elements can have different types.
Example: ["a", 2, "/a/b/c", false, {a={b=2;};}]
| Operation | Syntax | Description | Example |
|---|---|---|---|
| concatenation | l ++ l' |
Concatenate two lists | ["a", 2] ++ ["3", {a=1;}] = ["a", 2, "3", {a=1;}] |
| access | elemAt l n |
Access the nth element of l | elemAt ["a", 2, "3] 1 = 2 |
| map | map f l |
Apply f to each element of l | map (fun x => x + 1) [1,2,3] = [2,3,4] |
| filter | filter f l |
Return a list consisting of the elements of l for which the function f returns true | filter (fun x => isNum x) [1, "2", 3, {a=4;}] = [1, 3] |
| flatten | flatten f l |
Concatenate a list of lists | flatten [[1, 2], [3, 4]] = [1, 2, 3, 4] |
| fold left | foldl f x l |
Iteratively apply (strictly) the binary operator f on elements of l, from left to right, starting with x | foldl (fun x y => x + y) 0 [1, 2, 3] = 6 |
| membership | elem x l |
Return true if x is an element of l, and false otherwise | elem 3 [1, 2, 3] = true |
| all | all p l |
Return true if the predicate p is true for all elements of l, and false otherwise | all (fun x => x % 2 == 0) [1, 2, 3] = false |
| any | any p l |
Return true if the predicate p is true for at least one element of l, and false otherwise | any (fun x => x % 2 == 0) [1, 2, 3] = true |
A syntax for easing the construction of lists. We basically propose Haskell list comprehensions.
[i*i | i <- [1,2,3]] = [1,4,9]
[[i,j] | i <- [1,2], j <- ["a","b"]] = [[1,"a"], [1,"b"], [2,"a"], [2,"b"]]
[i | i <- [1,2,3], i % 2 == 1] = [1,3]
A list comprehension is composed of a main expression, on the left of |, with free variables which will be bound to various values in order to generate the elements of the final list. The right of | is a list of comma separated qualifiers, which are either:
compr ::= [ e | qual1, ..., qualn]
qual ::= pat <- e | let bindings | e
e ::= any Nickel expression
pat may be taken to just be a variable for now, and can be extended later to be a pattern when we add pattern matching/destructuring. The last e in qual corresponds to guards.
[e | true] = [e]
[e | q] = [e | q, true]
[e | let binding, Q] = let binding in [e | Q]
[e | b, Q] = if b then [e | Q] else []
[e | p <- l, Q ] = let bind = fun p => [e | Q] in flatten (map bind l). This will have to be updated if p can be a more general pattern
[EDIT] I misunderstood something and jumped to conclusions. Polymorphic instantiation works (almost, see #88) fine
Describe the bug
Valid programs annotated with polymorphic types, that is with a Promise(ty, foo) where ty contains a forall, do not typecheck.
For example, executing (with some preparation first, see To reproduce) src/examples/forall.ncl containing
let f = Promise(forall a. (forall b. a -> b -> a), fun x => fun y => x) in
f
with nickel <src/examples/forall.ncl results in the error message:
Typechecked: Err("The following types dont match Arrow(Constant(1), Concrete(Arrow(Constant(2), Constant(1))))
-- Forall(Ident(\"a\"), Concrete(Forall(Ident(\"b\"), Concrete(Arrow(Concrete(Var(Ident(\"a\"))), Concrete(Arrow(Concrete(Var(Ident(\"b\"))), Concrete(Var(Ident(\"a\"))))))))))")
[...]
To Reproduce
This is not directly visible as there is a strict parameter, currently set to false when the typechecker starts, which basically disable typechecking if not set. It corresponds to "dynamic typing" mode, but it should still enforce the type of Promise: why it does not is a different matter. A quick way to isolate this issue is set it to true from the beginning, but then automatically included contracts do not typecheck anymore:
strict to true in typecheck.rsinclude_contracts to false in program.rscargo buildtarget/debug/nickel <src/examples/forall.nclExpected behavior
The program should be accepted by the typechecker:
Typechecked: Ok(Types(Arrow(Types(Dyn), Types(Arrow(Types(Dyn), Types(Dyn))))))
[...]
I've been thinking a bit about the problem of overriding à la Nixpkgs.
My thoughts is that it boils down to the semantics of merging recursive records. Or, a bit pedantically, merging codata.
Let me illustrate. Suppose we have a bunch of pkgs:
# nixpkgs.nix
rec {
packageA = …;
packageB = … packageA …;
}I want to override packageA so that packageB sees the new version. The current way that we think about this is that packageA will have some default values, and to make an override, we will do something like
let nipxkgs = import ./nixpkgs.nix; in
merge nixpkgs {
packageA = … some new stuff …;
}This returns a new nixpkgs where packageA has been changed (or, rather, made more definite, as per the merging model). The question, then, is: what version of packageA does packageB see?
So far, we've been thinking of it as if recursive records were data: unfold the record as a tree, and merge recursively. It's a simple model, it makes sense. And packageB sees the original version of packageA. But the fact is that, by virtue of the field being lazy, recursive records are, really codata. And maybe, thinking of them this way allows us to define a merging scheme where packageB will see the overriden packageA. Pretty much like in #83 (comment) . I haven't thought this through, so I don't know if we can carry this thought to a happy conclusion. But that would certainly be an elegant explanation for overriding.
Describe the bug
Since #134, builtins contracts are directly loaded in a global environment before the start of the Nickel abstract machine. However, they are not added to the typing environment at the typechecking phase. This means that using one in user-code results in an error, complaining that the identifier is unbound. While builtin contracts should not really be directly used (though it may be useful in user-defined contracts), this also affects the future standard library functions.
To Reproduce
Refer directly to a builtin contract:
$nickel <<< 'num "whatever" 1'
Typechecked: Err("Found an unbound var Ident(\"num\")")
Done: Num(1.0)
The program runs fine, but the typechecker complains that the identifier num is not defined.
Expected behavior
The typechecker should not raise an error. Builtin contracts and other potential standard library parts should be in the typing environment (or in a global typing environment, mimicking how the standard library is handled in the evaluator).
Following #183, the next aspect to debate is enriched values (this is a bad name that still need a replacement, but let's go with it for now).
Enriched values are fields meta-data for records. They can store a documentation, a default value, a type (seen as a contract) for now, and maybe even more in the future (example, merge strategy, etc.). They fill a similar purpose to the NixOS module system. Fields meta-data basically define schemas. Example:
let schema = {
host = Docstring("The host name of the server",
Contract(#url));
port = Docstring("The port to connect to",
Contract(#natural,
Default(4242)));
sshEnabled = Docstring("Connect via SSH instead of HTTPS",
Contract(Bool,
Default(false)));
} in ...
Don't mind url and natural, and imagine they are used-defined contracts (in practice they would probably be defined in an external or the standard library once for all). This is the current (and ugly) syntax [1]. The general structure is that we specify for each field a list of attributes among the possible ones (documentation, contract/type, and default value currently). This schema is then merged with a concrete configuration, which triggers the contract checking, set default values, decorate with the value with documentation, etc [2].
Let's start with the proposition of this gist, which is one of the original motivation behinid Nickel:
{
field | attr value
...
| attr value;
...
}
Where attr is one of doc/documentation, type/contract, and default. For contracts, type is terse but maybe contract emphasizes better that this about a run-time check.
The previous example becomes
{
host | doc "The host name of the server"
| type #url;
port | doc "The port to connect to"
| type #natural
| default 4242;
sshEnabled | doc "Connect via SSH instead of HTTPS"
| type Bool
| default false;
}
A possible variation is to have a colon ':' separating the attribute and the value: attr: value.
Is your feature request related to a problem? Please describe.
Error messages at the typechecking phase are unfathomable. They do not include positions, do not make a difference between the type that was expected and the one that was inferred, do not remember original type variable names: they just report basic unification clashes.
A few examples:
$nickel <<< 'let x = Promise(Num, 1) in
let y = x in
let res = Promise(Num, y + 1) in res'
Typechecked: Err("The following types dont match Num -- Dyn")
$nickel <<< 'let f = Promise(forall a. (forall b. a -> b -> b), fun x y => x) in f true false'
Typechecked: Err("Couldn\'t unify Constant(131) and Constant(130)")
$nickel <<< 'let f = Promise(Num -> Num, fun x => x + 1) in Promise(Num, f 1 2)'
Typechecked: Err("The following types dont match Arrow(Ptr(134), Concrete(Num)) -- Num")
Describe the solution you'd like
Proper typechecking errors. This is a vague and potentially large task. For the scope of this issue, it could be:
Then further improvements can be made step by step.
Describe the bug
Currently, the builtin contracts for row types are not implemented yet. This means that row types are unusable at runtime, since any term which is a Promise or Assume with a row type in the annotation leads to a panic if evaluated.
To Reproduce
Write an Assume or a Promise that is consumed during evaluation:
nickel <<< 'Assume({ {| a: Num |} }, {a = 1})'
thread 'main' panicked at 'TODO implement', src/types.rs:241:41
Expected behavior
We expect contracts to be implemented for enums and records, making the previous code to evaluate without errors.
Is your feature request related to a problem? Please describe.
In a configuration-oriented language, several fundamental operations may be elegantly subsumed by the use of a merge operator à la Cue: define both data and schemas in the same language, validate data against schemas, set default values and more generally have a form of inheritance for better code reuse.
Describe the solution you'd like
Enrich the language along two axis:
Additional context
This takes inspiration from the CUE programming language where types and values live in the same space, namely a bounded lattice (example of merging in CUE). Nickel allows more things (e.g general recursion and arbitrary terms as contracts) thus cannot have the same kind of strong properties, but we aim to still retain the spirit and the niceness of the feature.
The tests on Makam grew out of control, now the file is huge and slow to test.
Will reorganize them into one file per stage (parsing, typing, evaluation) and one testcase per functionality (functions, assume, records, enums, ...).
Describe the bug
A program which contains a let annotated (using either Promise or Assume) by a polymorphic type, itself located inside a Promise (which triggers the "strict" or "static" typechecking mode), is unduly rejected.
To Reproduce
let f =
Promise(forall a. a -> a, let g =
Promise(forall a. a -> a, fun x => x)
in g)
in f 2
which results in
Typechecked: Err("The following types dont match Arrow(Constant(119), Constant(119))
-- Forall(Ident(\"a\"), Concrete(Arrow(Concrete(Var(Ident(\"a\"))), Concrete(Var(Ident(\"a\"))))))")
Evaluation finished with result:
Num(2.0)
Expected behavior
Well-typed programs with polymorphic annotations inside a promise should typecheck. In particular, the previous example should result in the output:
Typechecked: Ok(Types(Dyn))
Evaluation finished with result:
Num(2.0)
The fate of a Nickel program is eventually to produce text in the form of configuration files. A fair amount of time is spent gathering and gluing together various pieces of strings in order to produce this configuration. Hence string interpolation, making text substitution easier, is a critical feature.
We propose to unashamedly reuse Nix string interpolation, which is well appreciated in the ecosystem and proved itself efficient for writing self-contained expressions, which mix strings containing shell commands, shell scripts, text descriptions, URLs, and so on. The syntax using $ is common (Shell, JavaScript, Perl, Scala, Kotlin, Julia, etc.) while the required additional { avoid clashing with the simple shell interpolation $var when embedding scripts or commands inside strings.
In the following, we provide a concrete proposal, as a starting point for discussion.
"here is a simple string"
/* indented multi-line string */
...
let script = ''
cd ~/.vim/
if [ -f "vimrc" ]; then
mv vimrc vimrc.bk
fi
touch vimrc
'' in foo
/* script =
"cd ~/.vim/
if [ -f "vimrc" ]; then
cp vimrc vimrc.bk
fi
touch vimrc" */
/* interpolation */
let gnu = "GNU" in "${gnu} = ${gnu}'s Not Unix"
/* "GNU = GNU's Not Unix" */
/* nested interpolation */
let cmdFlag = "foo" in
let optionsFlag = "-foo" in
let cmdDefault = "bar" in
let options = "-bar" in
"${if flag then "${cmdFlag} ${optionsFlag}" else "${cmdDefault}"} ${options} $out"
/* if flag is true, gives "foo -foo -bar $out"
* otherwise, "bar -bar $out"
*/
We propose two ways of defining strings:
"foo"''foo''The alternative delimiter '' is intended for enclosing strings that contain numerous ", such as shell commands, which would be then tiresome to escape. For indented strings enclosed by double single quotes, as the second example of the previous section, a number of spaces corresponding to the minimal indentation of the string as a whole is stripped from the beginning of each line. Also, the first line is removed if it is empty or contains only whitespaces. This makes it possible to write multi-line strings with the same level of indentation as the surrounding code without polluting the final string with unnecessary heading spaces.
Interpolation allows to embed a Nickel expression, which must evaluate to a string, inside another string using the ${expr} syntax. Such expressions can be arbitrary Nickel expressions and may contain themselves nested interpolated strings.
str ::= "strprts" | ''strprts''
strprts ::= ε | strprts STR | strprts ${e}
where e is any Nickel expression, STR is a sequence of string characters (without the special sequence ${, unless escaped), ε denotes an empty string and spaces between tokens denote concatenation.
Inside ", \ is used as usual to represent special sequences ("\n", "\t", and so on), to escape itself or to escape the interpolation sequence ${. On the other hand, it has no special meaning alone inside '', and must be prefixed with '' to recover it. For example, a tab is written ''''\t''.
| Sequence | Escape/" |
Escape/'' |
|---|---|---|
${ |
''${ |
\${ |
' |
''' |
' |
\ |
\ |
\\ |
| Source | Evaluation | Condition |
|---|---|---|
| ε | ||
| strprts STR | (eval strprts) STR | |
| strprts ${e} | (eval strprts) (eval e) | isStr e |
"strprts" |
"eval(strprts)" | |
''strprts'' |
''stripIndent (eval strprts)'' |
where stripIndent implements the behavior described above about smart indentation.
We may want to improve the behavior of Nix when substituting multi-line strings inside multi-line, indented strings (See #543 for Nix, or #200 for a similar discussion about Dhall).
Is your feature request related to a problem? Please describe.
The project has no README. Anyone stumbling upon this repository will find it hard to get answers to basic questions like, what does the code do and why does this project exists.
Describe the solution you'd like
Add a top-level README to the repository. You can use this template as a starting point. See also README driven development.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.