This Zotero plugin adds the functionality to perform an OCR for the PDFs selected in Zotero. It can add a new PDF including the recognized text, a note with the recognized text only, and HTML (HOCR) file(s). Tesseract OCR is used for the text recognition itself.
- Tesseract OCR is installed
- for Windows see https://github.com/UB-Mannheim/tesseract/wiki
- for Linux, Mac see https://tesseract-ocr.github.io/tessdoc/Installation.html
pdftoppmfrom poppler library is downloaded and installed- some hints for the installation: https://github.com/UB-Mannheim/zotero-ocr/wiki/Install-pdftoppm
To install the extension:
- Download the XPI file of the latest release.
- In Zotero, go to Tools → Add-ons and drag the .xpi onto the Add-ons window.
- Possibly, adjust the path to Tesseract in the add-on options.
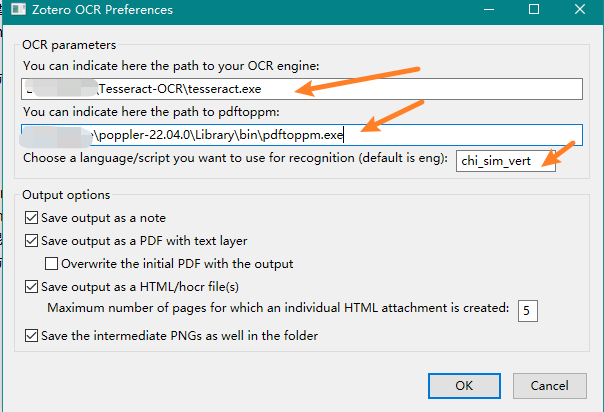
The configuration can be accessed under Tools → Zotero OCR Preferences (Zotero 6) or under Zotero → Settings (Zotero 7).
By default the fields for the paths to the OCR engine and pdftoppm are empty, which means, that the usual locations are looked at. If that does not work, then you should locate the tools on your local machine and enter the full paths including the name of the tools itself.
The default language/script to use with Tesseract, can only be one of the installed models. If you leave that field empty, then the English model (eng) will be used, which is always installed with Tesseract.

Moreover, these options are saved as Zotero preferences variables, which are also available through the Config Editor.
Run build.sh script, which creates a new .xpi file.
For a new release, run the script release.sh.
It runs the build.sh script, commits the code changes for the new release and adds a tag.
Push the updated local master branch and the tag to GitHub.
Then publish a new release on GitHub and attach the .xpi file there.
After any code changes one can build a new extension file by ./build.sh <version>.
Then in Zotero go to Tools, Add-ons, Install Add-on From File...
and choose there the newly created .xpi-file.
Zotero 6 will restart with the newly built add-on version.
Zotero 7 does not require a restart and will activate it immediately.
If any error occurs then you will see more details in the Help, Report Error...
dialog. For some debugging messages you can activate in Zotero the debugging
in the Help, Debug Output Logging.
Zotero OCR is free and Open Source software. The source code is released under GNU Affero General Public License v3.