upan / cheat-sheet Goto Github PK
View Code? Open in Web Editor NEW常用工具和开源项目链接收藏
常用工具和开源项目链接收藏






































这些新特性涉及的范围包括:字符集、语法、索引、JSON、从 MySQL 5.7 升级到 MySQL 8.0 需要注意的不兼容项、参数、Hint等。
默认字符集由 latin1 调整为 utf8mb4。
在 MySQL 8.0 中,utf8mb4 默认的校对集是 utf8mb4_0900_ai_ci,在 MySQL 5.7 中则是 utf8mb4_general_ci。
utf8mb4_0900_ai_ci 中的 0900 指的是 Unicode 9.0 规范,ai 是 accent insensitivity 的缩写,指的是不区分音调,ci 是 case insensitivity 的缩写,指的是不区分大小写。
CTE,简单来说,就是一个命名的临时结果集。
只需定义一次,即可多次使用。
使用 CTE 不仅让 SQL 语句变得简洁,同时也提升了 SQL 语句的可读性。
# 普通的公用表表达式
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;
# 递归公用表表达式
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;
窗口函数,也称为分析函数,可针对一组行进行计算,并为每行返回一个结果。
这一点与聚合函数不同。聚合函数只能为每个分组返回一个结果。
窗口函数中的 OVER 子句定义了所要计算行的行窗口。
看下面这个示例,都是为了实现行号,只不过在 MySQL 8.0 之前,需借助于自定义变量,而在 MySQL 8.0 中,可以直接使用 ROW_NUMBER()。
# MySQL 5.7
SET @row_number = 0;
SELECT dept_no, dept_name,
(@row_number:=@row_number + 1) AS row_num
FROM departments ORDER BY dept_no;
# MySQL 8.0
SELECT dept_no, dept_name,
ROW_NUMBER() OVER (ORDER BY dept_no) AS row_num
FROM departments;
下面是官方文档中的一个示例。
CREATE TABLE t1 (
# 文本默认值
i INT DEFAULT 0,
c VARCHAR(10) DEFAULT '',
# 表达式默认值
f FLOAT DEFAULT (RAND() * RAND()),
b BINARY(16) DEFAULT (UUID_TO_BIN(UUID())),
d DATE DEFAULT (CURRENT_DATE + INTERVAL 1 YEAR),
p POINT DEFAULT (Point(0,0)),
j JSON DEFAULT (JSON_ARRAY())
);
注意,表达式默认值必须放到括号内。
从 MySQL 8.0.13 开始,BLOB, TEXT, GEOMETRY 和 JSON 字段允许设置表达式默认值。例如,
CREATE TABLE t2 (b BLOB DEFAULT ('abc'));
看下面这个示例。
CREATE TABLE t1
(
c1 INT CHECK (c1 > 10),
c2 INT CONSTRAINT c2_positive CHECK (c2 > 0),
c3 INT CHECK (c3 < 100),
CONSTRAINT c1_nonzero CHECK (c1 <> 0),
CHECK (c1 > c3)
);
mysql> SHOW CREATE TABLE t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`c1` int DEFAULT NULL,
`c2` int DEFAULT NULL,
`c3` int DEFAULT NULL,
CONSTRAINT `c1_nonzero` CHECK ((`c1` <> 0)),
CONSTRAINT `c2_positive` CHECK ((`c2` > 0)),
CONSTRAINT `t1_chk_1` CHECK ((`c1` > 10)),
CONSTRAINT `t1_chk_2` CHECK ((`c3` < 100)),
CONSTRAINT `t1_chk_3` CHECK ((`c1` > `c3`))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
隐藏列是 MySQL 8.0.23 引入的新特性。对于隐藏列,只有显式指定才能访问。无论是在查询,还是 DML 语句中。
如果是通过 SELECT * 查询,则不会返回隐藏列的内容。
mysql> CREATE TABLE t1 (c1 INT, c2 INT INVISIBLE);
Query OK, 0 rows affected (0.03 sec)
mysql> INSERT INTO t1 (c1, c2) VALUES(1, 2);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t1 VALUES(3);
Query OK, 1 row affected (0.00 sec)
mysql> SELECT * FROM t1;
+------+
| c1 |
+------+
| 1 |
| 3 |
+------+
2 rows in set (0.00 sec)
mysql> SELECT c1, c2 FROM t1;
+------+------+
| c1 | c2 |
+------+------+
| 1 | 2 |
| 3 | NULL |
+------+------+
2 rows in set (0.00 sec)
对于冗余索引,在执行删除操作之前,可以先将它设置为不可见,然后观察一段时间,确定对业务没有影响再执行删除操作。
# 创建不可见索引
ALTER TABLE t1 ADD INDEX k_idx (k) INVISIBLE;
# 将索引设置为不可见
ALTER TABLE t1 ALTER INDEX i_idx INVISIBLE;
# 将索引设置为可见
ALTER TABLE t1 ALTER INDEX i_idx VISIBLE;
优化器默认不会使用不可见索引。如果要使用,可设置 optimizer_switch。
SET SESSION optimizer_switch='use_invisible_indexes=on';
SELECT /*+ SET_VAR(optimizer_switch = 'use_invisible_indexes=on') */ * FROM t1 WHERE k = 1;
对于涉及到多列,但排序顺序又不一致的排序操作,可以通过降序索引来优化。
如 ORDER BY c1 ASC, c2 DESC 这个排序操作就可以通过下面这个索引来优化。
ALTER TABLE t add INDEX idx_1 (c1 ASC, c2 DESC);
函数索引允许对表达式创建索引,在此之前,只能对列或列的前缀创建索引。
CREATE TABLE tbl (
col1 LONGTEXT,
INDEX idx1 ((SUBSTRING(col1, 1, 10)))
);
# 对查询列使用相同的函数,可以使用索引
mysql> EXPLAIN SELECT * FROM tbl WHERE SUBSTRING(col1, 1, 10) = '1234567890';
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tbl | NULL | ref | idx1 | idx1 | 33 | const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
VALUES 是 MySQL 8.0.19 开始支持的语法,它会以表的形式返回一行或多行数据。
行数据通过 ROW() 函数来构造。函数中的元素既可以是标量值,也可以是表达式。
列名是 column_x,其中,x 是序号,从 0 开始递增。
mysql> VALUES ROW(1,now()), ROW(2,now());
+----------+---------------------+
| column_0 | column_1 |
+----------+---------------------+
| 1 | 2022-12-13 11:01:40 |
| 2 | 2022-12-13 11:01:40 |
+----------+---------------------+
2 rows in set (0.00 sec)
MySQL 8.0.31 开始支持 INTERSECT 和 EXCEPT,分别用来取两个集合的交集和差集。
mysql> VALUES ROW(1,2), ROW(3,4) INTERSECT VALUES ROW(1,2);
+----------+----------+
| column_0 | column_1 |
+----------+----------+
| 1 | 2 |
+----------+----------+
1 row in set (0.00 sec)
mysql> VALUES ROW(1,2), ROW(3,4) EXCEPT VALUES ROW(1,2);
+----------+----------+
| column_0 | column_1 |
+----------+----------+
| 3 | 4 |
+----------+----------+
1 row in set (0.00 sec)
唯一键冲突的报错信息会输出表名,在 MySQL 5.7 中,只会输出唯一键名。
# MySQL 8.0
ERROR 1062 (23000): Duplicate entry '1' for key 't1.PRIMARY'
# MySQL 5.7
ERROR 1062 (23000): Duplicate entry '1' for key 'PRIMARY'
查询改写插件在 MySQL 8.0.12 之前只支持 SELECT 语句,从 MySQL 8.0.12 开始支持 INSERT,REPLACE,UPDATE 和 DELETE 语句。
JSON 字段支持部分更新,极大提升了 JSON 字段的处理性能。
看下面这个测试结果。
JSON 的具体用法可参考:一文说透 MySQL JSON 数据类型
SELECT ... FOR SHARE 和 SELECT ... FOR UPDATE 语句中引入 NOWAIT 和 SKIP LOCKED 选项,用来解决电商场景热点行问题。
session1> CREATE TABLE t(id INT PRIMARY KEY);
Query OK, 0 rows affected (0.06 sec)
session1> INSERT INTO t VALUES(1),(2),(3);
Query OK, 3 rows affected (0.01 sec)
Records: 3 Duplicates: 0 Warnings: 0
session1> BEGIN;
Query OK, 0 rows affected (0.00 sec)
session1> SELECT * FROM t WHERE id=2 FOR UPDATE;
+----+
| id |
+----+
| 2 |
+----+
1 row in set (0.00 sec)
# 如果需要加锁的行被其它事务锁定,指定 NOWAIT 会立即报错,不会等到锁超时
session2> SELECT * FROM t WHERE id = 2 FOR UPDATE NOWAIT;
ERROR 3572 (HY000): Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set.
# 指定 SKIP LOCKED 则会跳过锁定行
session2> SELECT * FROM t FOR UPDATE SKIP LOCKED;
+----+
| id |
+----+
| 1 |
| 3 |
+----+
2 rows in set (0.00 sec)
不再支持 GROUP BY ASC/DESC 语法。例如,
GROUP BY dept_no ASC;
如果要对分组列进行排序,需显式指定排序列,例如,
GROUP BY dept_no ORDER BY dept_no;
通用的分区接口(Handler)已从代码层移除。
在 MySQL 8.0 中,如果要使用分区表,只能使用 InnoDB 存储引擎。
在 MySQL 8.0 中,正则表达式底层库由 Henry Spencer 调整为了 International Components for Unicode (ICU)。Spencer 库的部分语法不再支持。
两者用法上的具体差异可参考:不可不知的 MySQL 升级利器及 5.7 升级到 8.0 的注意事项
引入了 sql_require_primary_key 参数可强制要求表上必须存在主键。默认为 OFF。
mysql> CREATE TABLE slowtech.t1(id INT);
ERROR 3750 (HY000): Unable to create or change a table without a primary key, when the system variable 'sql_require_primary_key' is set. Add a primary key to the table or unset this variable to avoid this message. Note that tables without a primary key can cause performance problems in row-based replication, so please consult your DBA before changing this setting.
在 MySQL 8.0.30 中,引入了 sql_generate_invisible_primary_key 参数可为没有显式设置主键的表创建一个隐式主键。默认为 OFF。
看下面这个示例。
mysql> CREATE TABLE t1(c1 INT);
Query OK, 0 rows affected (0.04 sec)
mysql> SHOW CREATE TABLE t1\G
*************************** 1. row ***************************
Table: t1
Create Table: CREATE TABLE `t1` (
`my_row_id` bigint unsigned NOT NULL AUTO_INCREMENT /*!80023 INVISIBLE */,
`c1` int DEFAULT NULL,
PRIMARY KEY (`my_row_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.01 sec)
引入了多个 Hint。
在 MySQL 5.7 中,Hint 只有 13 个。在 MySQL 8.0 中,则新增到了 37 个。
新增的 Hint 中,其中一个是 SET_VAR,可在语句级别调整参数的会话值。例如,
SELECT /*+ SET_VAR(max_execution_time = 1000) */ * FROM employees.employees;
mysql> CREATE TABLE t_parent (id INT PRIMARY KEY);
Query OK, 0 rows affected (0.04 sec)
mysql> CREATE TABLE t_child (id INT PRIMARY KEY, parent_id INT, FOREIGN KEY (parent_id) REFERENCES t_parent(ID));
Query OK, 0 rows affected (0.04 sec)
mysql> INSERT INTO t_child VALUES(1,1);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`slowtech`.`t_child`, CONSTRAINT `t_child_ibfk_1` FOREIGN KEY (`parent_id`) REFERENCES `t_parent` (`id`))
mysql> INSERT /*+ SET_VAR(foreign_key_checks = OFF) */ INTO t_child VALUES(1,1);
Query OK, 1 row affected (0.01 sec)
收录于合集 #MySQL
你的项目或许已经使用 Redis 很长时间了,但在使用过程中,你可能还会或多或少地遇到以下问题:
尤其是当你的项目越来越依赖 Redis 时,这些问题就变得尤为重要。
此时,你迫切需要一份**「最佳实践指南」**。
这篇文章,我将从以下七个维度,带你「全面」分析 Redis 的最佳实践优化:
在文章的最后,我还会给你一个完整的最佳实践清单,不管你是业务开发人员,还是 DBA 运维人员,这个清单将会帮助你更加「优雅」地用好 Redis。
这篇文章干货很多,希望你可以耐心读完。
首先,我们来看一下 Redis 内存方面的优化。
众所周知,Redis 的性能之所以如此之高,原因就在于它的数据都存储在「内存」中,所以访问 Redis 中的数据速度极快。
但从资源利用率层面来说,机器的内存资源相比于磁盘,还是比较昂贵的。
当你的业务应用在 Redis 中存储数据很少时,你可能并不太关心内存资源的使用情况。但随着业务的发展,你的业务存储在 Redis 中的数据就会越来越多。
如果没有提前制定好内存优化策略,那么等业务开始增长时,Redis 占用的内存也会开始膨胀。
所以,提前制定合理的内存优化策略,对于资源利用率的提升是很有必要的。
那在使用 Redis 时,怎样做才能更节省内存呢?这里我给你总结了 6 点建议,我们依次来看:
1) 控制 key 的长度
最简单直接的内存优化,就是控制 key 的长度。
在开发业务时,你需要提前预估整个 Redis 中写入 key 的数量,如果 key 数量达到了百万级别,那么,过长的 key 名也会占用过多的内存空间。
所以,你需要保证 key 在简单、清晰的前提下,尽可能把 key 定义得短一些。
例如,原有的 key 为 user:book:123,则可以优化为 u:bk:123。
这样一来,你的 Redis 就可以节省大量的内存,这个方案对内存的优化非常直接和高效。
2) 避免存储 bigkey
除了控制 key 的长度之外,你同样需要关注 value 的大小,如果大量存储 bigkey,也会导致 Redis 内存增长过快。
除此之外,客户端在读写 bigkey 时,还有产生性能问题(下文会具体详述)。
所以,你要避免在 Redis 中存储 bigkey,我给你的建议是:
3) 选择合适的数据类型
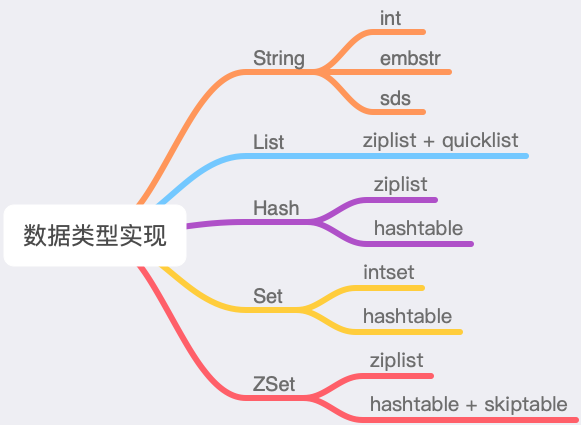
Redis 提供了丰富的数据类型,这些数据类型在实现上,也对内存使用做了优化。具体来说就是,一种数据类型对应多种数据结构来实现:
例如,String、Set 在存储 int 数据时,会采用整数编码存储。Hash、ZSet 在元素数量比较少时(可配置),会采用压缩列表(ziplist)存储,在存储比较多的数据时,才会转换为哈希表和跳表。
作者这么设计的原因,就是为了进一步节约内存资源。
那么你在存储数据时,就可以利用这些特性来优化 Redis 的内存。这里我给你的建议如下:
4) 把 Redis 当作缓存使用
Redis 数据存储在内存中,这也意味着其资源是有限的。你在使用 Redis 时,要把它当做缓存来使用,而不是数据库。
所以,你的应用写入到 Redis 中的数据,尽可能地都设置「过期时间」。
业务应用在 Redis 中查不到数据时,再从后端数据库中加载到 Redis 中。
采用这种方案,可以让 Redis 中只保留经常访问的「热数据」,内存利用率也会比较高。
5) 实例设置 maxmemory + 淘汰策略
虽然你的 Redis key 都设置了过期时间,但如果你的业务应用写入量很大,并且过期时间设置得比较久,那么短期间内 Redis 的内存依旧会快速增长。
如果不控制 Redis 的内存上限,也会导致使用过多的内存资源。
对于这种场景,你需要提前预估业务数据量,然后给这个实例设置 maxmemory 控制实例的内存上限,这样可以避免 Redis 的内存持续膨胀。
配置了 maxmemory,此时你还要设置数据淘汰策略,而淘汰策略如何选择,你需要结合你的业务特点来决定:
6) 数据压缩后写入 Redis
以上方案基本涵盖了 Redis 内存优化的各个方面。
如果你还想进一步优化 Redis 内存,你还可以在业务应用中先将数据压缩,再写入到 Redis 中(例如采用 snappy、gzip 等压缩算法)。
当然,压缩存储的数据,客户端在读取时还需要解压缩,在这期间会消耗更多 CPU 资源,你需要根据实际情况进行权衡。
以上就是「节省内存资源」方面的实践优化,是不是都比较简单?
下面我们来看「性能」方面的优化。
当你的系统决定引入 Redis 时,想必看中它最关键的一点就是:性能。
我们知道,一个单机版 Redis 就可以达到 10W QPS,这么高的性能,也意味着如果在使用过程中发生延迟情况,就会与我们的预期不符。
所以,在使用 Redis 时,如何持续发挥它的高性能,避免操作延迟的情况发生,也是我们的关注焦点。
在这方面,我给你总结了 13 条建议:
1) 避免存储 bigkey
存储 bigkey 除了前面讲到的使用过多内存之外,对 Redis 性能也会有很大影响。
由于 Redis 处理请求是单线程的,当你的应用在写入一个 bigkey 时,更多时间将消耗在「内存分配」上,这时操作延迟就会增加。同样地,删除一个 bigkey 在「释放内存」时,也会发生耗时。
而且,当你在读取这个 bigkey 时,也会在「网络数据传输」上花费更多时间,此时后面待执行的请求就会发生排队,Redis 性能下降。
所以,你的业务应用尽量不要存储 bigkey,避免操作延迟发生。
如果你确实有存储 bigkey 的需求,你可以把 bigkey 拆分为多个小 key 存储。
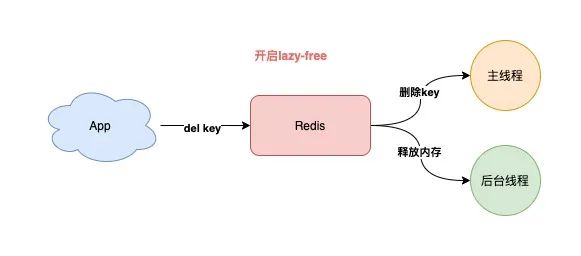
2) 开启 lazy-free 机制
如果你无法避免存储 bigkey,那么我建议你开启 Redis 的 lazy-free 机制。(4.0+版本支持)
当开启这个机制后,Redis 在删除一个 bigkey 时,释放内存的耗时操作,将会放到后台线程中去执行,这样可以在最大程度上,避免对主线程的影响。
3) 不使用复杂度过高的命令
Redis 是单线程模型处理请求,除了操作 bigkey 会导致后面请求发生排队之外,在执行复杂度过高的命令时,也会发生这种情况。
因为执行复杂度过高的命令,会消耗更多的 CPU 资源,主线程中的其它请求只能等待,这时也会发生排队延迟。
所以,你需要避免执行例如 SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
对于这种聚合类操作,我建议你把它放到客户端来执行,不要让 Redis 承担太多的计算工作。
4) 执行 O(N) 命令时,关注 N 的大小
规避使用复杂度过高的命令,就可以高枕无忧了么?
答案是否定的。
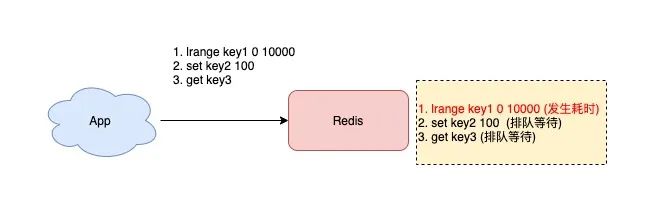
当你在执行 O(N) 命令时,同样需要注意 N 的大小。
如果一次性查询过多的数据,也会在网络传输过程中耗时过长,操作延迟变大。
所以,对于容器类型(List/Hash/Set/ZSet),在元素数量未知的情况下,一定不要无脑执行 LRANGE key 0 -1 / HGETALL / SMEMBERS / ZRANGE key 0 -1。
在查询数据时,你要遵循以下原则:
5) 关注 DEL 时间复杂度
你没看错,在删除一个 key 时,如果姿势不对,也有可能影响到 Redis 性能。
删除一个 key,我们通常使用的是 DEL 命令,回想一下,你觉得 DEL 的时间复杂度是多少?
O(1) ?其实不一定。
当你删除的是一个 String 类型 key 时,时间复杂度确实是 O(1)。
但当你要删除的 key 是 List/Hash/Set/ZSet 类型,它的复杂度其实为 O(N),N 代表元素个数。
也就是说,删除一个 key,其元素数量越多,执行 DEL 也就越慢!
原因在于,删除大量元素时,需要依次回收每个元素的内存,元素越多,花费的时间也就越久!
而且,这个过程默认是在主线程中执行的,这势必会阻塞主线程,产生性能问题。
那删除这种元素比较多的 key,如何处理呢?
我给你的建议是,分批删除:
没想到吧?一个小小的删除操作,稍微不小心,也有可能引发性能问题,你在操作时需要格外注意。
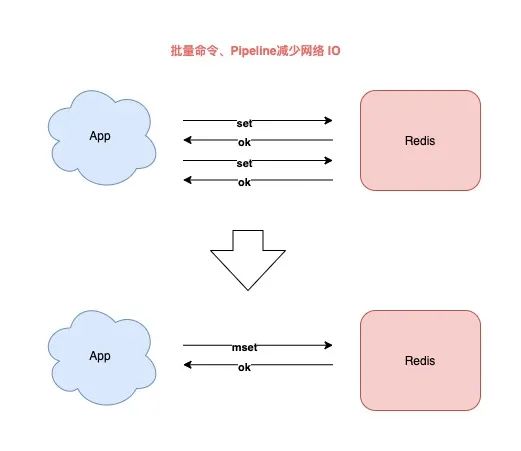
6) 批量命令代替单个命令
当你需要一次性操作多个 key 时,你应该使用批量命令来处理。
批量操作相比于多次单个操作的优势在于,可以显著减少客户端、服务端的来回网络 IO 次数。
所以我给你的建议是:
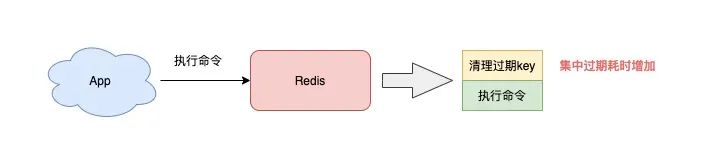
7) 避免集中过期 key
Redis 清理过期 key 是采用定时 + 懒惰的方式来做的,而且这个过程都是在主线程中执行。
如果你的业务存在大量 key 集中过期的情况,那么 Redis 在清理过期 key 时,也会有阻塞主线程的风险。
想要避免这种情况发生,你可以在设置过期时间时,增加一个随机时间,把这些 key 的过期时间打散,从而降低集中过期对主线程的影响。
8) 使用长连接操作 Redis,合理配置连接池
你的业务应该使用长连接操作 Redis,避免短连接。
当使用短连接操作 Redis 时,每次都需要经过 TCP 三次握手、四次挥手,这个过程也会增加操作耗时。
同时,你的客户端应该使用连接池的方式访问 Redis,并设置合理的参数,长时间不操作 Redis 时,需及时释放连接资源。
9) 只使用 db0
尽管 Redis 提供了 16 个 db,但我只建议你使用 db0。
为什么呢?我总结了以下 3 点原因:
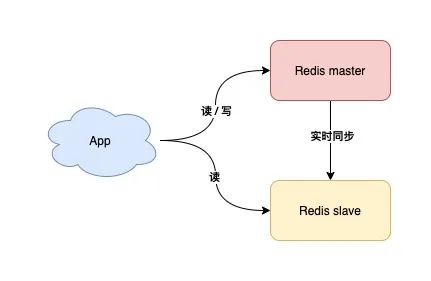
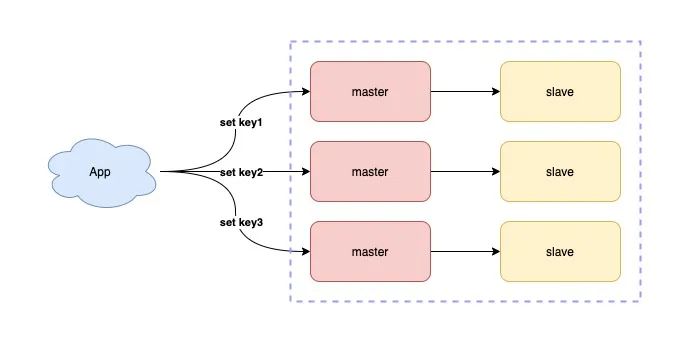
10) 使用读写分离 + 分片集群
如果你的业务读请求量很大,那么可以采用部署多个从库的方式,实现读写分离,让 Redis 的从库分担读压力,进而提升性能。
如果你的业务写请求量很大,单个 Redis 实例已无法支撑这么大的写流量,那么此时你需要使用分片集群,分担写压力。
11) 不开启 AOF 或 AOF 配置为每秒刷盘
如果对于丢失数据不敏感的业务,我建议你不开启 AOF,避免 AOF 写磁盘拖慢 Redis 的性能。
如果确实需要开启 AOF,那么我建议你配置为 appendfsync everysec,把数据持久化的刷盘操作,放到后台线程中去执行,尽量降低 Redis 写磁盘对性能的影响。
12) 使用物理机部署 Redis
Redis 在做数据持久化时,采用创建子进程的方式进行。
而创建子进程会调用操作系统的 fork 系统调用,这个系统调用的执行耗时,与系统环境有关。
虚拟机环境执行 fork 的耗时,要比物理机慢得多,所以你的 Redis 应该尽可能部署在物理机上。
13) 关闭操作系统内存大页机制
Linux 操作系统提供了内存大页机制,其特点在于,每次应用程序向操作系统申请内存时,申请单位由之前的 4KB 变为了 2MB。
这会导致什么问题呢?
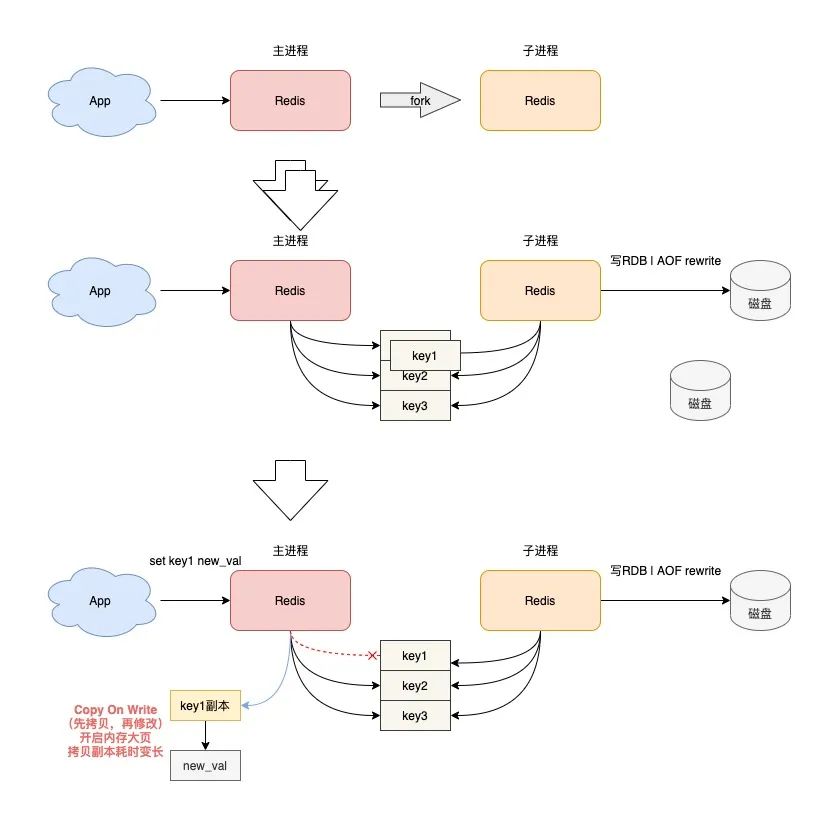
当 Redis 在做数据持久化时,会先 fork 一个子进程,此时主进程和子进程共享相同的内存地址空间。
当主进程需要修改现有数据时,会采用写时复制(Copy On Write)的方式进行操作,在这个过程中,需要重新申请内存。
如果申请内存单位变为了 2MB,那么势必会增加内存申请的耗时,如果此时主进程有大量写操作,需要修改原有的数据,那么在此期间,操作延迟就会变大。
所以,为了避免出现这种问题,你需要在操作系统上关闭内存大页机制。
好了,以上这些就是 Redis 「高性能」方面的实践优化。如果你非常关心 Redis 的性能问题,可以结合这些方面针对性优化。
我们再来看 Redis 「可靠性」如何保证。
这里我想提醒你的是,保证 Redis 可靠性其实并不难,但难的是如何做到「持续稳定」。
下面我会从「资源隔离」、「多副本」、「故障恢复」这三大维度,带你分析保障 Redis 可靠性的最佳实践。
1) 按业务线部署实例
提升可靠性的第一步,就是「资源隔离」。
你最好按不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
这种资源隔离的方案,实施成本是最低的,但成效却是非常大的。
2) 部署主从集群
如果你只使用单机版 Redis,那么就会存在机器宕机服务不可用的风险。
所以,你需要部署「多副本」实例,即主从集群,这样当主库宕机后,依旧有从库可以使用,避免了数据丢失的风险,也降低了服务不可用的时间。
在部署主从集群时,你还需要注意,主从库需要分布在不同机器上,避免交叉部署。
这么做的原因在于,通常情况下,Redis 的主库会承担所有的读写流量,所以我们一定要优先保证主库的稳定性,即使从库机器异常,也不要对主库造成影响。
而且,有时我们需要对 Redis 做日常维护,例如数据定时备份等操作,这时你就可以只在从库上进行,这只会消耗从库机器的资源,也避免了对主库的影响。
3) 合理配置主从复制参数
在部署主从集群时,如果参数配置不合理,也有可能导致主从复制发生问题:
在这方面我给你的建议有以下 2 点:
4) 部署哨兵集群,实现故障自动切换
只部署了主从节点,但故障发生时是无法自动切换的,所以,你还需要部署哨兵集群,实现故障的「自动切换」。
而且,多个哨兵节点需要分布在不同机器上,实例为奇数个,防止哨兵选举失败,影响切换时间。
以上这些就是保障 Redis「高可靠」实践优化,你应该也发现了,这些都是部署和运维层的优化。
除此之外,你可能还会对 Redis 做一些「日常运维」工作,这时你要注意哪些问题呢?
如果你是 DBA 运维人员,在平时运维 Redis 时,也需要注意以下 6 个方面。****
1) 禁止使用 KEYS/FLUSHALL/FLUSHDB 命令
执行这些命令,会长时间阻塞 Redis 主线程,危害极大,所以你必须禁止使用它。
如果确实想使用这些命令,我给你的建议是:
2) 扫描线上实例时,设置休眠时间
不管你是使用 SCAN 扫描线上实例,还是对实例做 bigkey 统计分析,我建议你在扫描时一定记得设置休眠时间。
防止在扫描过程中,实例 OPS 过高对 Redis 产生性能抖动。
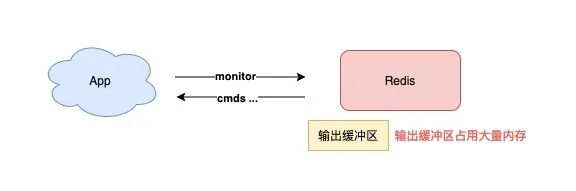
3) 慎用 MONITOR 命令
有时在排查 Redis 问题时,你会使用 MONITOR 查看 Redis 正在执行的命令。
但如果你的 Redis OPS 比较高,那么在执行 MONITOR 会导致 Redis 输出缓冲区的内存持续增长,这会严重消耗 Redis 的内存资源,甚至会导致实例内存超过 maxmemory,引发数据淘汰,这种情况你需要格外注意。
所以你在执行 MONITOR 命令时,一定要谨慎,尽量少用。
4) 从库必须设置为 slave-read-only
你的从库必须设置为 slave-read-only 状态,避免从库写入数据,导致主从数据不一致。
除此之外,从库如果是非 read-only 状态,如果你使用的是 4.0 以下的 Redis,它存在这样的 Bug:
从库写入了有过期时间的数据,不会做定时清理和释放内存。
这会造成从库的内存泄露!这个问题直到 4.0 版本才修复,你在配置从库时需要格外注意。
5) 合理配置 timeout 和 tcp-keepalive 参数
如果因为网络原因,导致你的大量客户端连接与 Redis 意外中断,恰好你的 Redis 配置的 maxclients 参数比较小,此时有可能导致客户端无法与服务端建立新的连接(服务端认为超过了 maxclients)。
造成这个问题原因在于,客户端与服务端每建立一个连接,Redis 都会给这个客户端分配了一个 client fd。
当客户端与服务端网络发生问题时,服务端并不会立即释放这个 client fd。
什么时候释放呢?
Redis 内部有一个定时任务,会定时检测所有 client 的空闲时间是否超过配置的 timeout 值。
如果 Redis 没有开启 tcp-keepalive 的话,服务端直到配置的 timeout 时间后,才会清理释放这个 client fd。
在没有清理之前,如果还有大量新连接进来,就有可能导致 Redis 服务端内部持有的 client fd 超过了 maxclients,这时新连接就会被拒绝。
针对这种情况,我给你的优化建议是:
6) 调整 maxmemory 时,注意主从库的调整顺序
Redis 5.0 以下版本存在这样一个问题:从库内存如果超过了 maxmemory,也会触发数据淘汰。
在某些场景下,从库是可能优先主库达到 maxmemory 的(例如在从库执行 MONITOR 命令,输出缓冲区占用大量内存),那么此时从库开始淘汰数据,主从库就会产生不一致。
要想避免此问题,在调整 maxmemory 时,一定要注意主从库的修改顺序:
直到 Redis 5.0,Redis 才增加了一个配置 replica-ignore-maxmemory,默认从库超过 maxmemory 不会淘汰数据,才解决了此问题。
好了,以上这些就是「日常运维」Redis 需要注意的,你可以对各个配置项查漏补缺,看有哪些是需要优化的。
接下来,我们来看一下,保障 Redis「安全」都需要注意哪些问题。
无论如何,在互联网时代,安全问题一定是我们需要随时警戒的。
你可能听说过 Redis 被注入可执行脚本,然后拿到机器 root 权限的安全问题,都是因为在部署 Redis 时,没有把安全风险注意起来。
针对这方面,我给你的建议是:
只要你把这些做到位,基本上就可以保证 Redis 的安全风险在可控范围内。
至此,我们分析了 Redis 在内存、性能、可靠性、日常运维方面的最佳实践优化。
除了以上这些,你还需要做到提前「预防」。
HTTP主要经历了 1.0、1.1、2.0、3.0 四个版本
HTTP 1.0需要使用keep-alive 参数来告知服务器端要建立一个长连接,而HTTP1.1 默认 支持长连接。
HTTP是基于TCP/IP协议的,创建一个TCP连接是需要经过三次握手的,有一定的开销,如果每次通讯都要重新建立连接的话,对性能有影响。因此最好能维持一个长连接,可以用个长连接来发多个请求。
HTTP还支持传送内容的一部分。这样当客户端已经有一部分的资源后,只需要跟服务器请求另外的部分资源即可。这是支持文件断点续传的基础。
HTTP1.0是没有host域的,HTTP1.1才支持这个参数。
HTTP2.0使用了多路复用的技术,做到同一个连接并发处理多个请求,而且并发请求的数量比HTTP1.1大了好几个数量级。
当然HTTP1.1也可以多建立几个TCP连接,来支持处理更多并发的请求,但是创建TCP连接本身也是有开销的。
TCP连接有一个预热和保护的过程,先检查数据是否传送成功,一旦成功过,则慢慢加大传输速度。因此对应瞬时并发的连接,服务器的响应就会变慢。所以最好能使用一个建立好的连接,并且这个连接可以支持瞬时并发的请求。
所有就是请求的都是通过一个 TCP连接并发完成。 HTTP 1.x 中,如果想并发多个请求,必须使用多个 TCP 链接,且浏览器为了控制资源,还会对单个域名有 6-8个的TCP链接请求限制
HTTP1.1不支持header数据的压缩,HTTP2使用HPACK算法对header的数据进行压缩,这样数据体积小了,在网络上传输就会更快。
意思是说,当我们对支持HTTP2.0的web server请求数据的时候,服务器会顺便把一些客户端需要的资源一起推送到客户端,免得客户端再次创建连接发送请求到服务器端获取。这种方式非常合适加载静态资源。
服务器端推送的这些资源其实存在客户端的某处地方,客户端直接从本地加载这些资源就可以了,不用走网络,速度自然是快很多的。
HTTP/2 采用二进制格式传输数据,而非HTTP 1.x 的文本格式
https://mp.weixin.qq.com/s/n9CmpkiGThQbXW6KcGcQVA?utm_source=tuicool&utm_medium=referral
API网关可以看做系统与外界联通的入口,我们可以在网关进行处理一些非业务逻辑的逻辑,比如权限验证,监控,缓存,请求路由等等。
由于在内部开发中我们都是以RPC协议(thrift or dubbo)去做开发,暴露给内部服务,当外部服务需要使用这个接口的时候往往需要将RPC协议转换成HTTP协议。
在我们的系统中由于同一个接口新老两套系统都在使用,我们需要根据请求上下文将请求路由到对应的接口。
对于鉴权操作不涉及到业务逻辑,那么可以在网关层进行处理,不用下层到业务逻辑。
由于网关是外部服务的入口,所以我们可以在这里监控我们想要的数据,比如入参出参,链路时间。
对于流量控制,熔断降级非业务逻辑可以统一放到网关层。
有很多业务都会自己去实现一层网关层,用来接入自己的服务,但是对于整个公司来说这还不够。
统一的API网关不仅有API网关的所有的特点,还有下面几个好处:
在公司中如果有某个技术组件需要升级,那么是需要和每个业务线沟通,通常几个月都搞不定。举个例子如果对于入口的安全鉴权有重大安全隐患需要升级,如果速度还是这么慢肯定是不行,那么有了统一的网关升级是很快的。
对于某个服务的接入也比较困难,比如公司已经研发出了比较稳定的服务组件,正在公司大力推广,这个周期肯定也特别漫长,由于有了统一网关,那么只需要统一网关统一接入。
不同业务不同部门如果按照我们上面的做法应该会都自己搞一个网关层,用来做这个事,可以想象如果一个公司有100个这种业务,每个业务配备4台机器,那么就需要400台机器。并且每个业务的开发RD都需要去开发这个网关层,去随时去维护,增加人力。如果有了统一网关层,那么也许只需要50台机器就可以做这100个业务的网关层的事,并且业务RD不需要随时关注开发,上线的步骤。
对于我们自己实现的网关层,由于只有我们自己使用,对于吞吐量的要求并不高所以,我们一般同步请求调用即可。
对于我们统一的网关层,如何用少量的机器接入更多的服务,这就需要我们的异步,用来提高更多的吞吐量。对于异步化一般有下面两种策略:
这种策略使用的比较普遍,京东,有赞,Zuul,都选取的是这个策略,这种策略比较适合HTTP。在Servlet3中可以开启异步。
Netty为高并发而生,目前唯品会的网关使用这个策略,在唯品会的技术文章中在相同的情况下Netty是每秒30w+的吞吐量,Tomcat是13w+,可以看出是有一定的差距的,但是Netty需要自己处理HTTP协议,这一块比较麻烦。
对于网关是HTTP请求场景比较多的情况可以采用Servlet,毕竟有更加成熟的处理HTTP协议。如果更加重视吞吐量那么可以采用Netty。
对于来的请求我们已经使用异步了,为了达到全链路异步所以我们需要对去的请求也进行异步处理,对于去的请求我们可以利用我们rpc的异步支持进行异步请求所以基本可以达到下图:
由在web容器中开启servlet异步,然后进入到网关的业务线程池中进行业务处理,然后进行rpc的异步调用并注册需要回调的业务,最后在回调线程池中进行回调处理。
在设计模式中有一个模式叫责任链模式,他的作用是避免请求发送者与接收者耦合在一起,让多个对象都有可能接收请求,将这些对象连接成一条链,并且沿着这条链传递请求,直到有对象处理它为止。通过这种模式将请求的发送者和请求的处理者解耦了。在我们的各个框架中对此模式都有实现,比如servlet里面的filter,springmvc里面的Interceptor。
在Netflix Zuul中也应用了这种模式,如下图所示:
这种模式在网关的设计中我们可以借鉴到自己的网关设计:
这种设计在有赞的网关也有应用。
上面在全链路异步的情况下不同业务之间的影响很小,但是如果在提供的自定义FiIlter中进行了某些同步调用,一旦超时频繁那么就会对其他业务产生影响。所以我们需要采用隔离之术,降低业务之间的互相影响。
信号量隔离只是限制了总的并发数,服务还是主线程进行同步调用。这个隔离如果远程调用超时依然会影响主线程,从而会影响其他业务。因此,如果只是想限制某个服务的总并发调用量或者调用的服务不涉及远程调用的话,可以使用轻量级的信号量来实现。有赞的网关由于没有自定义filter所以选取的是信号量隔离。
最简单的就是不同业务之间通过不同的线程池进行隔离,就算业务接口出现了问题由于线程池已经进行了隔离那么也不会影响其他业务。在京东的网关实现之中就是采用的线程池隔离,比较重要的业务比如商品或者订单 都是单独的通过线程池去处理。但是由于是统一网关平台,如果业务线众多,大家都觉得自己的业务比较重要需要单独的线程池隔离,如果使用的是Java语言开发的话那么,在Java中线程是比较重的资源比较受限,如果需要隔离的线程池过多不是很适用。如果使用一些其他语言比如Golang进行开发网关的话,线程是比较轻的资源,所以比较适合使用线程池隔离。
如果有某些业务就需要使用隔离但是统一网关又没有线程池隔离那么应该怎么办呢?那么可以使用集群隔离,如果你的某些业务真的很重要那么可以为这一系列业务单独申请一个集群或者多个集群,通过机器之间进行隔离。
流量控制可以采用很多开源的实现,比如阿里最近开源的Sentinel和比较成熟的Hystrix。
一般限流分为集群限流和单机限流:
这一块也可以参照开源的实现Sentinel和Hystrix,这里不是重点就不多提了。
泛化调用指的是一些通信协议的转换,比如将HTTP转换成Thrift。在一些开源的网关中比如Zuul是没有实现的,因为各个公司的内部服务通信协议都不同。比如在唯品会中支持HTTP1,HTTP2,以及二进制的协议,然后转化成内部的协议,淘宝的支持HTTPS,HTTP1,HTTP2这些协议都可以转换成,HTTP,HSF,Dubbo等协议。
如何去实现泛化调用呢?由于协议很难自动转换,那么其实每个协议对应的接口需要提供一种映射。简单来说就是把两个协议都能转换成共同语言,从而互相转换。
一般来说共同语言有三种方式指定:
比如可以将一个 www.baidu.com/id = 1 GET 可以映射为json:
代码块
{
“method”: "getBaidu"
"param" : {
"id" : 1
}
}
对于泛化调用如果要自己设计的话JSON基本可以满足,如果对于个性化的需要特别多的话倒是可以自己定义一套语言。
上面介绍的都是如何实现一个网关的技术关键。这里需要介绍网关的一个业务关键。有了网关之后,需要一个管理平台如何去对我们上面所描述的技术关键进行配置,包括但不限于下面这些配置:
最后一个合理的标准网关应该按照如下去实现:
当应用系统有大量用户进行访问时,导致系统的TPS极速上升,查询数据直接打到了数据库,达到了系统的性能瓶颈,接口的响应会变慢,用户体验变得非常差。
那么从技术架构的角度思考可以使用缓存技术对系统进行优化:
在计算机中,缓存是一个高速数据存储层,其中存储了数据子集且通常是短暂性存储,这样日后再次请求此数据时要比访问数据的主存储位置快,通过缓存可以高效地重用之前检索或计算的数据;
缓存分为以下三种:硬件缓存、客户端缓存、服务端缓存。
它是指一块芯片集成到硬盘、CPU上,作用是充当硬盘、CPU与外界接口之间的暂存器,外部接口通常是指硬盘或CPU和内存之间。
为了提高用户体验和减轻服务端压力,会将用户之前访问的一些数据缓存在客户端本地,
一般来说指的是浏览器缓存或APP缓存。
服务端缓存目的和客户端缓存是一样的,只是站在服务端的角度考虑,
如果客户端每次请求服务端都要直接连接到数据库,当客户请求数多的时候数据库压力会非常大,
这个时候可以把一些经常被请求的数据存放在内存中,
当有请求来访问的时候直接返回,不用经过数据库,这样就能减轻数据库的压力,
硬件缓存属于硬件层面上的优化而客户端和服务端缓存则属于技术优化手段,
缓存的本质是以空间换时间的手段来提升接.口的响应速度,
作为一个后端开发关注更多的是服务器端缓存。
高并发查询、高并发写入、热点数据、大对象初始化。
因为[内存]速度远远高于磁盘,所以大大的提升了应用程序的访问速度
一个缓存实例就可以提供数十万的QPS,可以取代大量数据库实例从而降低总成本
降低数据库负载,防止其在负载情况下性能下降甚至是雪崩
当有很少数据被频繁的访问,例如微博上某个明星突然官宣,很多用户都会去看一下
这会在数据库中产生热点,为了让访问速度更快,需要用特殊手段去维护这些热点数据
当使用了缓存以后就不需要考虑热点数据的问题
相比较于数据库除了更低的延迟外,内存系统还提供了更高的吞吐量,
比如说redis单个实例可以处理十几万的读请求.
缓存通常需要设置有效期,过期后应当失效
常见的过期策略有:定时、定期、惰性失效
缓存占用有空间上限,超过上限需淘汰部分缓存数据
常见的淘汰策略有:FIFO、LRU、LFU
缓存需要支持并发的读取和写入
请求数据库中不存在的数据导致每次查询都无法命中缓存,从而违背了降低数据库压力的本意
缓存失效的同时大量相同请求穿过缓存访问数据库
大量缓存同时失效,导致大量请求穿过缓存访问到数据库
基于JDK自带的Map容器类:HashMap、ConcurrentHashMap
Google提供的java增强工具包Guava的一个模块,社区活跃。Spring5之前默认的内存缓存框架
重量级的内存缓存,支持二级缓存,Hibernate中默认的缓存框架
基于Guava API开发的高性能内存缓存,Spring5默认的内存缓存框架
判断一个缓存的好坏最核心的指标就是命中率,影响缓存命中率有很多因素,包括业务场景、淘汰策略、清理策略、缓存容量等等。如果作为本地缓存, 它的性能的情况,资源的占用也都是一个很重要的指标。
上面说到淘汰策略是影响缓存命中率的因素之一,一般比较简单的缓存就会直接用到 LFU(Least Frequently Used,即最不经常使用) 或者LRU(Least Recently Used,即最近最少使用) ,而 Caffeine 就是使用了 W-TinyLFU 算法。
W-TinyLFU 看名字就能大概猜出来,它是 LFU 的变种,也是一种缓存淘汰算法。那为什么要使用 W-TinyLFU 呢?
TinyLFU 就是其中一个优化算法,它是专门为了解决 LFU 上述提到的两个问题而被设计出来的。
解决第一个问题是采用了 Count–Min Sketch 算法。
解决第二个问题是让记录尽量保持相对的“新鲜”(Freshness Mechanism),并且当有新的记录插入时,可以让它跟老的记录进行“PK”,输者就会被淘汰,这样一些老的、不再需要的记录就会被剔除。
如何对一个 key 进行统计,但又可以节省空间呢?(不是简单的使用HashMap,这太消耗内存了),注意哦,不需要精确的统计,只需要一个近似值就可以了,怎么样,这样场景是不是很熟悉,如果你是老司机,或许已经联想到布隆过滤器(Bloom Filter)的应用了。
没错,将要介绍的 Count–Min Sketch 的原理跟 Bloom Filter 一样,只不过 Bloom Filter 只有 0 和 1 的值,那么你可以把 Count–Min Sketch 看作是“数值”版的 Bloom Filter。
在 TinyLFU 中,近似频率的统计如下图所示:

对一个 key 进行多次 hash 函数后,index 到多个数组位置后进行累加,查询时取多个值中的最小值即可。
Caffeine 对这个算法的实现在FrequencySketch类。但 Caffeine 对此有进一步的优化,例如 Count–Min Sketch 使用了二维数组,Caffeine 只是用了一个一维的数组;再者,如果是数值类型的话,这个数需要用 int 或 long 来存储,但是 Caffeine 认为缓存的访问频率不需要用到那么大,只需要 15 就足够,一般认为达到 15 次的频率算是很高的了,而且 Caffeine 还有另外一个机制来使得这个频率进行衰退减半(下面就会讲到)。如果最大是 15 的话,那么只需要 4 个 bit 就可以满足了,一个 long 有 64bit,可以存储 16 个这样的统计数,Caffeine 就是这样的设计,使得存储效率提高了 16 倍。
注意紫色虚线框,其中蓝色小格就是需要计算的位置:

为了让缓存保持“新鲜”,剔除掉过往频率很高但之后不经常的缓存,Caffeine 有一个 Freshness Mechanism。做法很简答,就是当整体的统计计数(当前所有记录的频率统计之和,这个数值内部维护)达到某一个值时,那么所有记录的频率统计除以 2。
#美团即时物流的分布式系统架构设计
https://tech.meituan.com/2018/11/22/instant-logistics-distributed-system-architecture.html
美团外卖已经发展了五年,即时物流探索也经历了3年多的时间,业务从零孵化到初具规模,在整个过程中积累了一些分布式高并发系统的建设经验。最主要的收获包括两点:
本文主要介绍在美团即时物流分布式系统架构逐层演变的进展中,遇到的技术障碍和挑战:
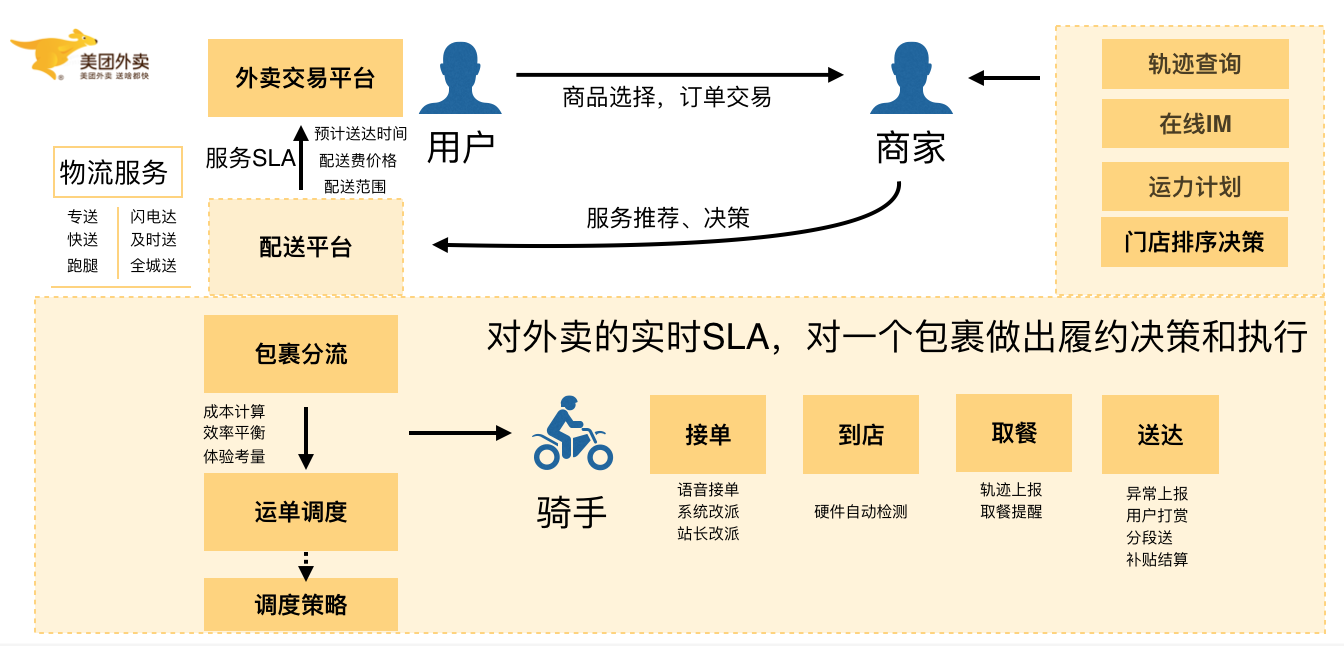
美团即时物流配送平台主要围绕三件事展开:一是面向用户提供履约的SLA,包括计算送达时间ETA、配送费定价等;二是在多目标(成本、效率、体验)优化的背景下,匹配最合适的骑手;三是提供骑手完整履约过程中的辅助决策,包括智能语音、路径推荐、到店提醒等。
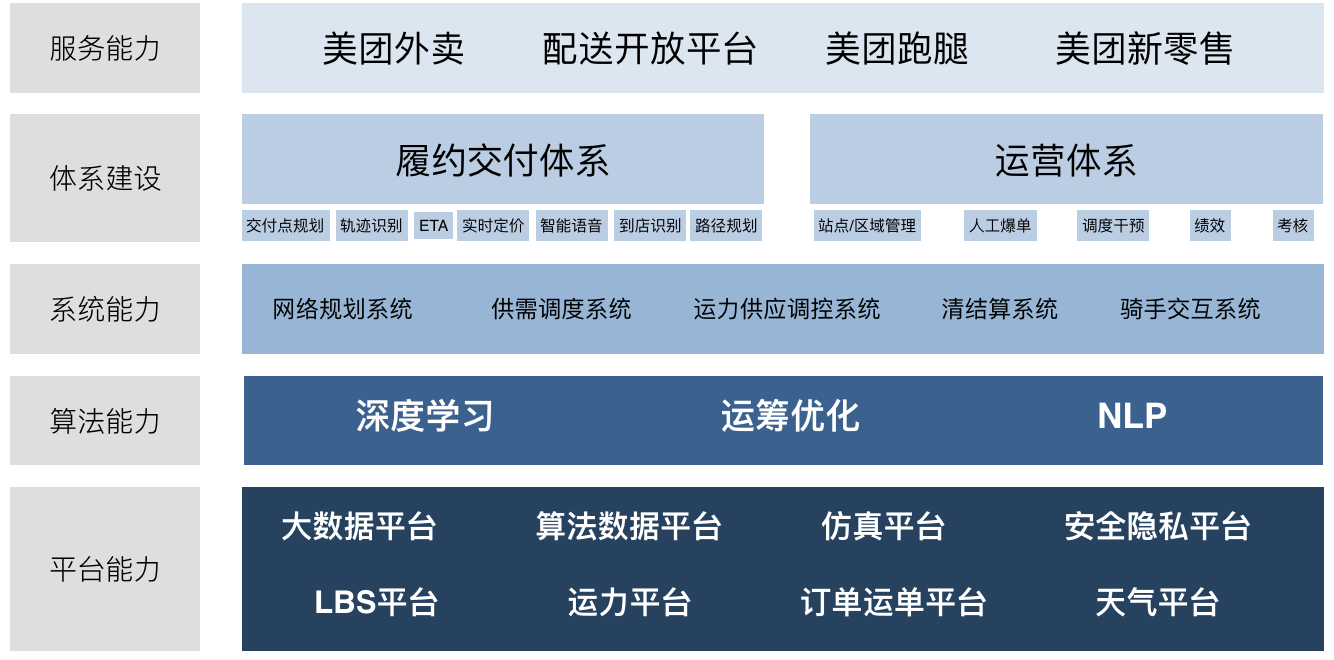
在一系列服务背后,是美团强大的技术体系的支持,并由此沉淀出的配送业务架构体系,基于架构构建的平台、算法、系统和服务。庞大的物流系统背后离不开分布式系统架构的支撑,而且这个架构更要保证高可用和高并发。
分布式架构,是相对于集中式架构而言的一种架构体系。分布式架构适用CAP理论(Consistency 一致性,Availability 可用性,Partition Tolerance 分区容忍性)。在分布式架构中,一个服务部署在多个对等节点中,节点之间通过网络进行通信,多个节点共同组成服务集群来提供高可用、一致性的服务。
早期,美团按照业务领域划分成多个垂直服务架构;随着业务的发展,从可用性的角度考虑做了分层服务架构。后来,业务发展越发复杂,从运维、质量等多个角度考量后,逐步演进到微服务架构。这里主要遵循了两个原则:不宜过早的进入到微服务架构的设计中,好的架构是演进出来的不是提前设计出来的。
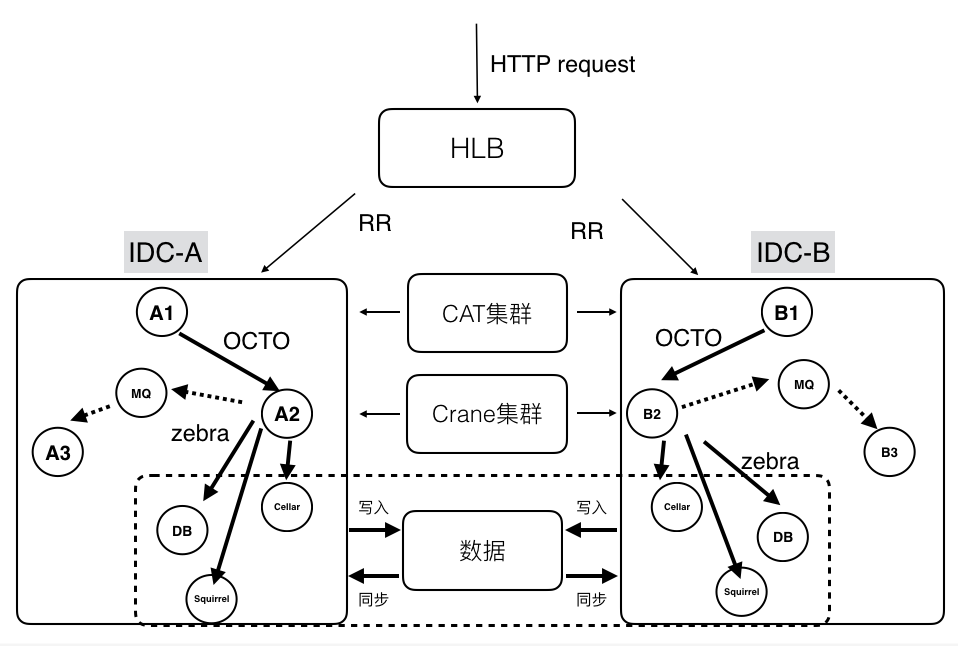
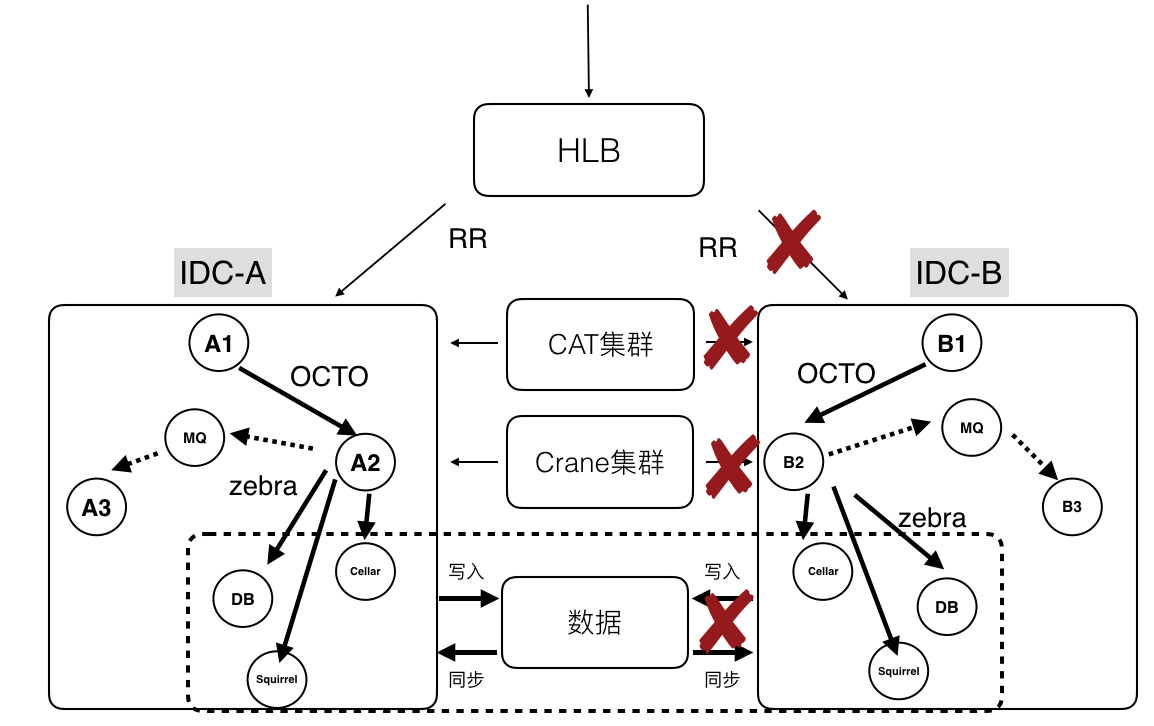
上图是比较典型的美团技术体系下的分布式系统结构:依托了美团公共组件和服务,完成了分区扩容、容灾和监控的能力。前端流量会通过HLB来分发和负载均衡;在分区内,服务与服务会通过OCTO进行通信,提供服务注册、自动发现、负载均衡、容错、灰度发布等等服务。当然也可以通过消息队列进行通信,例如Kafka、RabbitMQ。在存储层使用Zebra来访问分布式数据库进行读写操作。利用CAT(美团开源的分布式监控系统)进行分布式业务及系统日志的采集、上报和监控。分布式缓存使用Squirrel+Cellar的组合。分布式任务调度则是通过Crane。
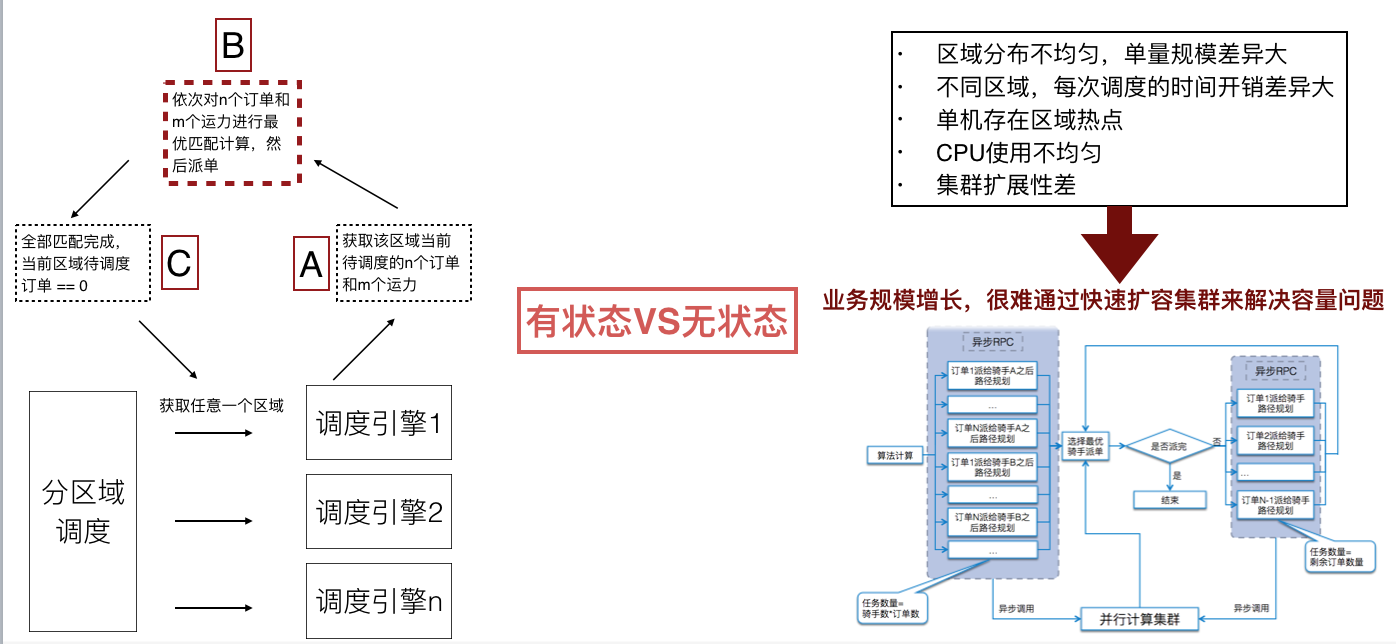
在实践过程还要解决几个问题,比较典型的是集群的扩展性,有状态的集群可扩展性相对较差,无法快速扩容机器,无法缓解流量压力。同时,也会出现节点热点的问题,包括资源不均匀、CPU使用不均匀等等。
首先,配送后台技术团队通过架构升级,将有状态节点变成无状态节点,通过并行计算的能力,让小的业务节点去分担计算压力,以此实现快速扩容。
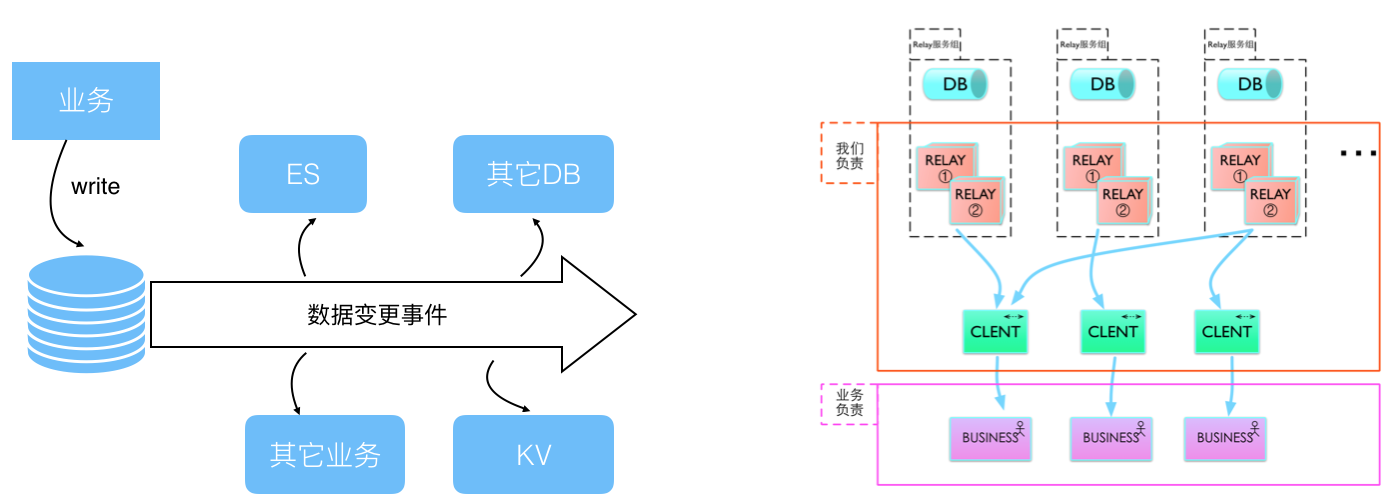
第二是要解决一致性的问题,对于既要写DB也要写缓存的场景,业务写缓存无法保障数据一致性,美团内部主要通过Databus来解决,Databus是一个高可用、低延时、高并发、保证数据一致性的数据库变更实时传输系统。通过Databus上游可以监控业务Binlog变更,通过管道将变更信息传递给ES和其他DB,或者是其他KV系统,利用Databus的高可用特性来保证数据最终是可以同步到其他系统中。
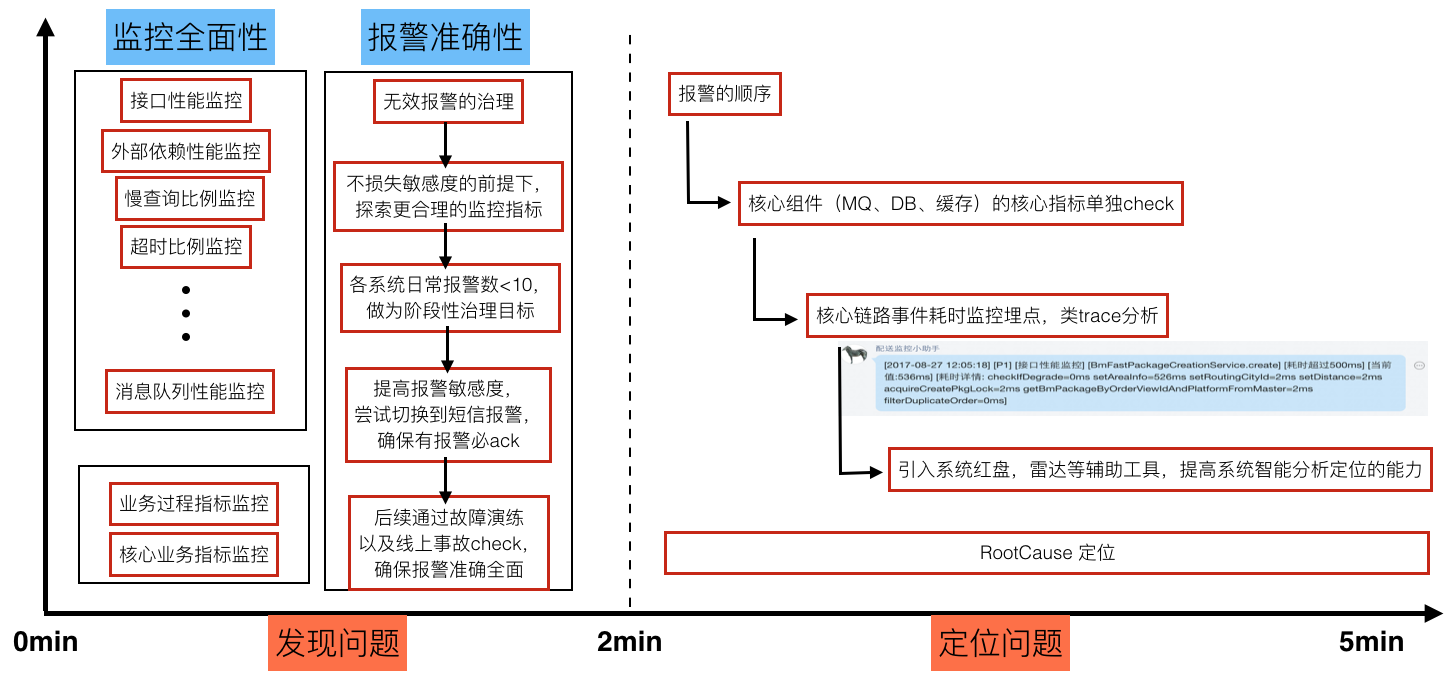
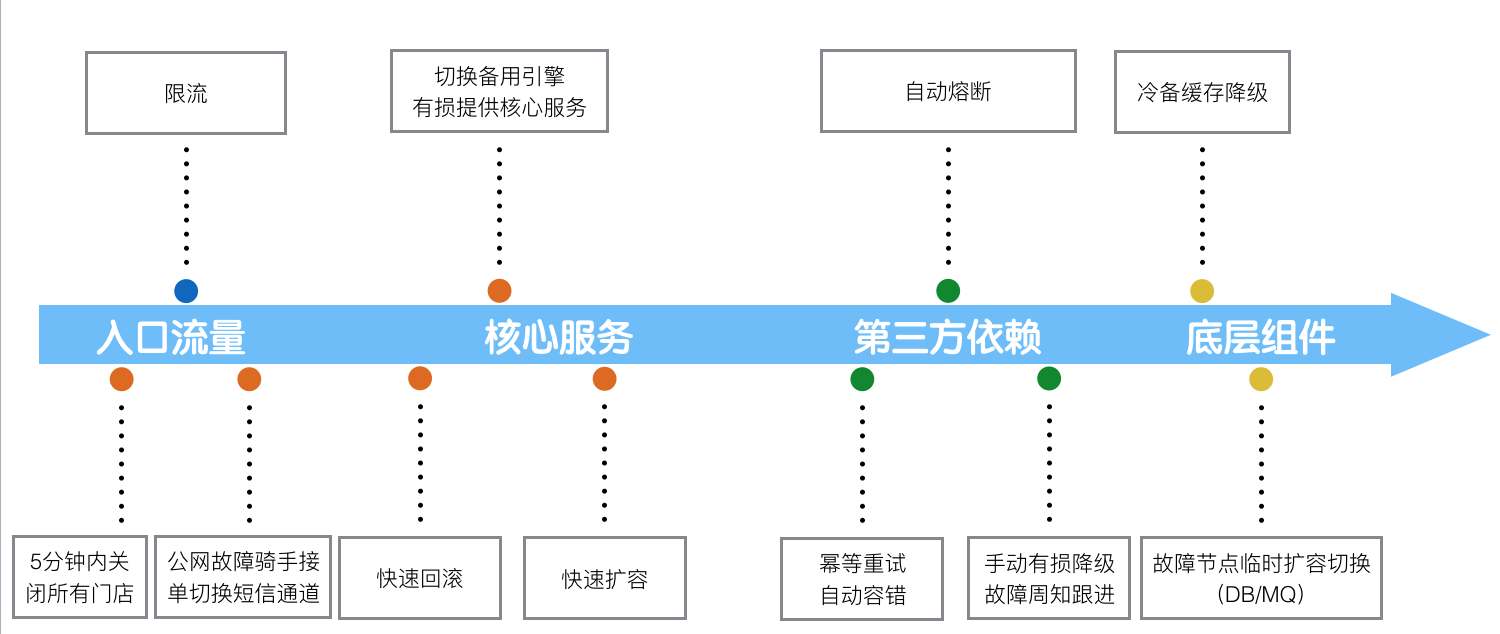
第三是我们一直在花精力解决的事情,就是保障集群高可用,主要从三个方面来入手,事前较多的是做全链路压测评,估峰值容量;周期性的集群健康性检查;随机故障演练(服务、机器、组件)。事中做异常报警(性能、业务指标、可用性);快速的故障定位(单机故障、集群故障、IDC故障、组件异常、服务异常);故障前后的系统变更收集。事后重点做系统回滚;扩容、限流、熔断、降级;核武器兜底。
单IDC故障之后,入口服务做到故障识别,自动流量切换;单IDC的快速扩容,数据提前同步,服务提前部署,Ready之后打开入口流量;要求所有做数据同步、流量分发的服务,都具备自动故障检测、故障服务自动摘除;按照IDC为单位扩缩容的能力。
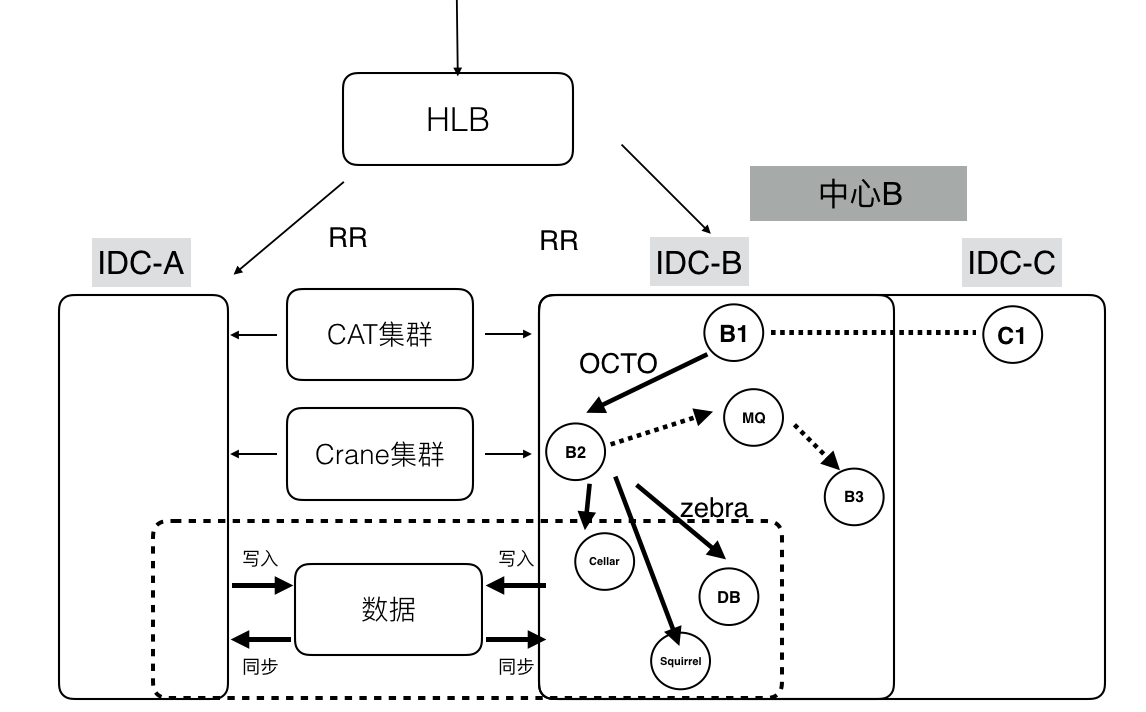
美团IDC以分区为单位,存在资源满排,分区无法扩容。美团的方案是多个IDC组成虚拟中心,以中心为分区的单位;服务无差别的部署在中心内;中心容量不够,直接增加新的IDC来扩容容量。
相比多中心来说,单元化是进行分区容灾和扩容的更优方案。关于流量路由,美团主要是根据业务特点,采用区域或城市进行路由。数据同步上,异地会出现延迟状况。SET容灾上要保证同本地或异地SET出现问题时,可以快速把SET切换到其他SET上来承担流量。
机器学习平台,是一站式线下到线上的模型训练和算法应用平台。之所以构建这个平台,目的是要解决算法应用场景多,重复造轮子的矛盾问题,以及线上、线下数据质量不一致。如果流程不明确不连贯,会出现迭代效率低,特征、模型的应用上线部署出现数据质量等障碍问题。
JARVIS是一个以稳定性保障为目标的智能化业务运维AIOps平台。主要用于处理系统故障时报警源很多,会有大量的重复报警,有效信息很容易被淹没等各种问题。此外,过往小规模分布式集群的运维故障主要靠人和经验来分析和定位,效率低下,处理速度慢,每次故障处理得到的预期不稳定,在有效性和及时性方面无法保证。所以需要AIOps平台来解决这些问题。
经过复盘和Review之后,我们发现未来的挑战很大,微服务不再“微”了,业务复杂度提升之后,服务就会变得膨胀。其次,网状结构的服务集群,任何轻微的延迟,都可能导致的网络放大效应。另外复杂的服务拓扑,如何做到故障的快速定位和处理,这也是AIOps需要重点解决的难题。最后,就是单元化之后,从集群为单位的运维到以单元为单位的运维,业给美团业务部署能力带来很大的挑战。
去哪儿网在刚开始做酒店交易业务的时候,为了实现各个业务线的快速搭建和运营,采取了比较简单粗放的设计,在短期内确实取得了不错的效果,但是同时也带来了诸如结构混乱、系统割裂、流程复杂繁琐等一系列问题,随着业务规模和范围的不断发展,技术在响应越来越复杂的需求时就碰到了很多困难,效率和质量都严重受到影响。因此做了一次大规模的重构,重新设计产品模型,梳理业务流程,划分好层次和边界,拆分各个子系统,通过服务化的架构方式来组织系统,使得开发能分工明确高效高质的响应业务需求,也能够在此基础上不断的改进和完善系统。
莫德友,2013年8月加入QUNAR酒店事业部,负责酒店交易系统的业务规划和系统架构。2006年毕业于北京邮电大学,之前在艺龙工作多年,一直从事酒店交易系统相关开发工作,见证了艺龙酒店系统的一路演进,对如何设计更好的技术架构和数据模型以更简洁有效的实现纷繁复杂的产品需求和业务流程有着极大兴趣。
在大型系统中,任务调度是一项基础性的需求。对于一些需要重复、定时执行或者耗时比较长的任务经常会被剥离出来单独处理,而随着任务规模与复杂性的上升,任务调度系统也就随需而生。设计良好的任务调度系统具备可靠性及伸缩性,它可以管理并监控任务的执行流程,以保证任务的正确执行。去哪儿网的工程师余昭辉曾参与开发了去哪儿网的任务调度中心基础组件,InfoQ就任务调度中心对他进行了采访。
一般在交易系统中会存在各种各样的后台任务,有的可能是定时运行,有的就是一直在幕后默默执行。比如每间隔一段时间我们需要两个系统之间进行对账,每天某个固定时刻我们开始发起所有符合条件的退款操作等等。原先我们的各种后台都是由自行开发,有的使用开源的Quartz,有的就直接使用java自带的线程池等。使用这些方式在早期可以很快的满足我们的需求,但是随着系统越来越庞大,大量的后台任务越来越难以管理和维护。第一个是缺少一个集中的管理方式,可以以很好的可视化的方式监视所有任务的执行状态,跟踪任务的执行历史。第二是大部分任务都存在单点问题(因为很多任务同时只能有一个实例运行,简单的实现方式难以做到分布式)。还有其他一些各方面的小问题,促使自己开发一个分布式的任务调度系统来解决这些问题。首先我们开发的这个系统应该能够记录下任务的所有执行记录,当出现问题的时候我们可以很容易的追踪任务的历史执行轨迹。我们还要集中的管理所有任务,即使一个新人也可以立即知晓我们的系统中有多少任务在运行。最后,我们我们要能让执行任务的应用多台部署,但又要保证只有单个实例在运行。
在技术方面,我们的任务调度中心使用Zookeeper来实现任务调度中心集群的failover。执行任务应用机器的上下线也是通过Zookeeper来实现的。任务执行过程中所生成的日志通过Alibaba开源的Dubbo汇集到中心,然后存储在HBase里备查。任务中心和执行任务的应用之间会传递心跳信息,通过心跳信息不断地交换当前正在执行的任务的执行状态。
我们的调度中心没有基于Quartz,在调度方面是完全自己开发的。当时开发的时候确实有想过是不是直接使用Quartz,但是最后看Quartz的代码发现代码量真不少。Quartz提供了很多非常丰富的特性,很多特性我觉得并不是我们所需要的,所以我不愿意承担这个复杂性。最后开发完也证明了这一点,任务调度的地方并没有多少代码量,因为自己写也更熟悉,也可以更好的利用公司现有的一些框架类库。我们的任务调度中心支持Cron Expression,执行任务的应用也支持集群部署。提供了多种错误恢复和报警策略,可以由业务自行选择。
在使用上我们的任务中心还是挺方便的。因为我们公司大部分Java项目都是基于Spring的,所以我们提供了自定义的Annotation,只需要在你想调度的方法上标记该Annotation,任务就可以自动注册到任务中心里,然后就可以在任务中心的管理后台进行各种参数配置和监控。
任务中心与执行任务的应用之间是通过发消息通信的,这里使用了我们团队自己开发的一个可靠消息中间件。第三方应用作为消息的消费者。任务中心负责调度,当要开始调度一个任务的时候,就往这个应用发送一条消息,第三方应用收到消息后就开始执行任务。
调度中心支持任务的开始和修改任务的执行时间的,但是不支持将一个正在运行的任务暂停下来,主要是我们觉得安全地暂停正在执行的任务还是挺困难的,不是任务中心提供了这个功能,这个任务就可以暂停,还需要执行任务的应用配合,如果一旦误用可能还会带来很多其他问题,所以我们没有提供这个功能。
我们默认使用的是随机的负载均衡策略。为了实现高可用,任务调度中心自身也是一个集群,前面也提到执行任务的应用也是集群,而且要保证一个任务同一时刻只有一个实例在运行。当时实现这块儿想到两个方案,一个就是去中心化。任务中心集群的每个节点都可以进度调度,通过协调保证每个任务只有单实例运行。但是这种实现方式虽然看起来很好,但实现还是非常复杂,定位问题也很困难。最后我们选择了中心化的策略。我们利用Zookeeper的选举机制,在任务中心集群里选出一个Leader节点进行任务调度,而其他节点负责心跳跟踪,日志汇总等。当任务调度的节点出现故障,我们可以快速的failover到其他节点上。这样一来整个实现方案就简单得多了,到现在运行有半年多时间,总共有上千的任务在上调度一直工作良好。
但这也是这个任务中心最大的缺陷,可能未来某天单个节点难以承载这么大的任务量(其实任务调度也就是要在内存里维护任务的一些元素据信息,而这些信息都不大,我计算了一下,要超过单个节点的容量任务至少要到10万级),如果到这个时候我们计划Leader节点不再进行任务调度,只进行任务分发。就像发扑克牌一样,这个周期内这个任务发给这个节点了就一直由这个节点进行调度。但是整个架构我还是更青睐中心化的方案。
美团 Mock Server 方案
https://www.cnblogs.com/xywq/p/7338988.html
去哪儿YAPI方案
https://testerhome.com/topics/12796?locale=en
去哪儿 Api 自动化测试实践
https://cnodejs.org/topic/5a3a121f8230827a182938da
http://www.sohu.com/a/350497448_817016
最近这几年中台概念火起来了,各大公司纷纷建设自己的中台。
本文介绍阿里数字化转型的实践历程,阿里巴巴中台技术在某石油企业的实施效果分析,如何更好地用好阿里巴巴中台技术实现企业数字化转型。
阿里巴巴中台技术架构首次揭秘,建议收藏
过去十年,我国货物贸易进出口量连创新高,已经成为全球货物贸易第一大国。据 2022 年 11 月海关总署发布的我国前 10 个月外贸“成绩单”:进出口总值 34.62 万亿元,同比增长 9.5%;如果把视线放在全球,这个市场更加巨大,2022 年全球贸易额预计将达到创纪录的 32 万亿美元。
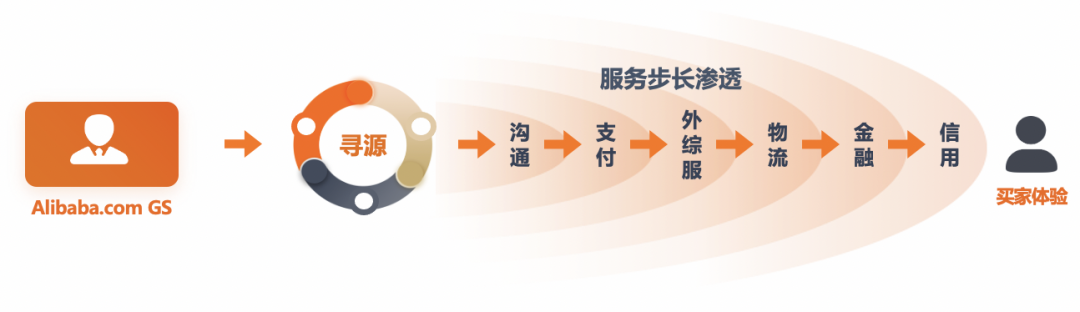
传统外贸模式中,一般国内企业厂家会与海外经销商直接对接,通过邮件、电话、展会、海外办事处等形式达成业务合作,采取大批量采购模式,以银行国际证或 TT 电汇形式支付货款,最终通过海运集装箱完成货物交割。就像众多传统行业一样,跨境贸易产业近年来也经历了数字化的转型创新;与传统外贸相比,互联网参与进模式创新的地方前期主要集中于信息展示和业务撮合领域,近几年来也开始慢慢向交易、支付、物流履约、金融等方向渗透;阿里巴巴国际站(Alibaba.com)就是扎根于这样庞大的一个市场里,希望用技术的力量来重构数字化外贸,从 Sourcing 到 Traceding。
用户增长最早起源于“增长黑客(Growth Hacker)”一词,它由 Qualaroo 的创始人兼首席执行官 Sean Ellis 提出,广泛流行于硅谷互联网创业圈。马克·扎克伯格曾说过“增长黑客团队是 Facebook 在过去 8 年里比较重要的一个发明”;自 Facebook 2008 年设立增长团队以来,不少公司如 LinkedIn、Airbnb、Twitter 等都成立了自己的用户增长团队。随着互联网公司用户的大幅度增长和在商业上取得的巨大成功,国内互联网也纷纷争相效仿,“用户增长”逐渐开始成为国内外互联网创业公司最热门的新兴部门。那到底什么是增长黑客呢?
Andrew Chen 在《Growth Hacker is the new VP Marketing》一文中谈到,增长黑客们试图用更聪明的方式解答产品得以增长的奥秘,并使之成为助力产品增长的长效机制。他们通常采用的手段包括 A/B 测试、搜索引擎优化、电子邮件召回和营销等;换句话说,增长团队是一群以市场指导产品、以数据驱动营销、通过技术化手段贯彻增长目标的人,他们的核心使命就是尽一切可能挖掘一个产品的增长潜力;他们通常既了解技术,又深谙用户心理,擅长发挥创意、绕过限制,通过低成本的手段解决公司产品增长问题;同时不断对产品进行调整并对调整内容进行测试,包括产品的特征、信息传达方式以及用户获取、激活、留存与变现的方式。
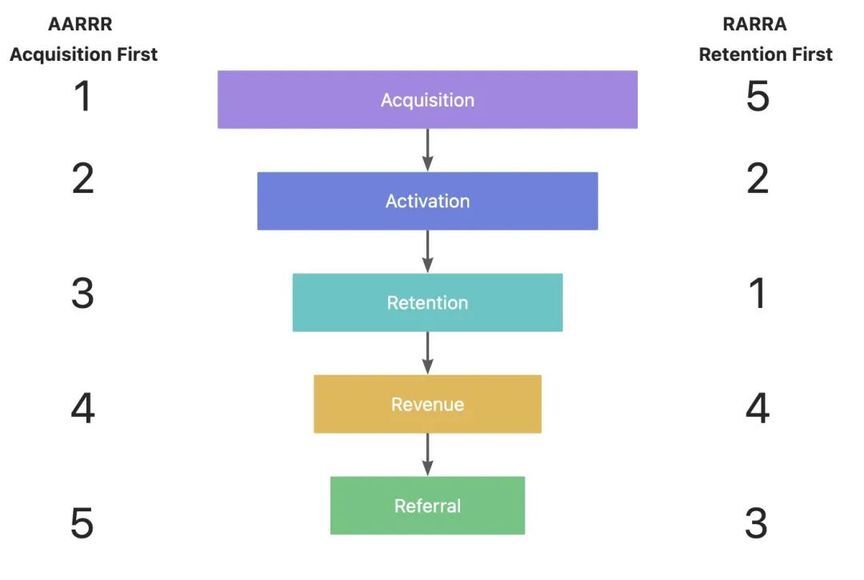
在用户增长领域,最经典的方法论莫过于 AARRR 与 RARRA 模型,它们分别将用户增长的过程划分为 5 个不同的阶段,即拉新、激活、留存、变现及推荐。AARRR 模型由 McClure 在 2007 年提出,当时互联网还处在爆发期,获客成本较低廉,因此 AARRR 把重点放在了拉新阶段;而随着流量红利逐渐见顶,获客成本与日俱增,因此 Thomas Petit 和 Gabor Papp 提出了 RARRA 模型,强调拉新不再是增长的王道,真正关键在于用户留存。
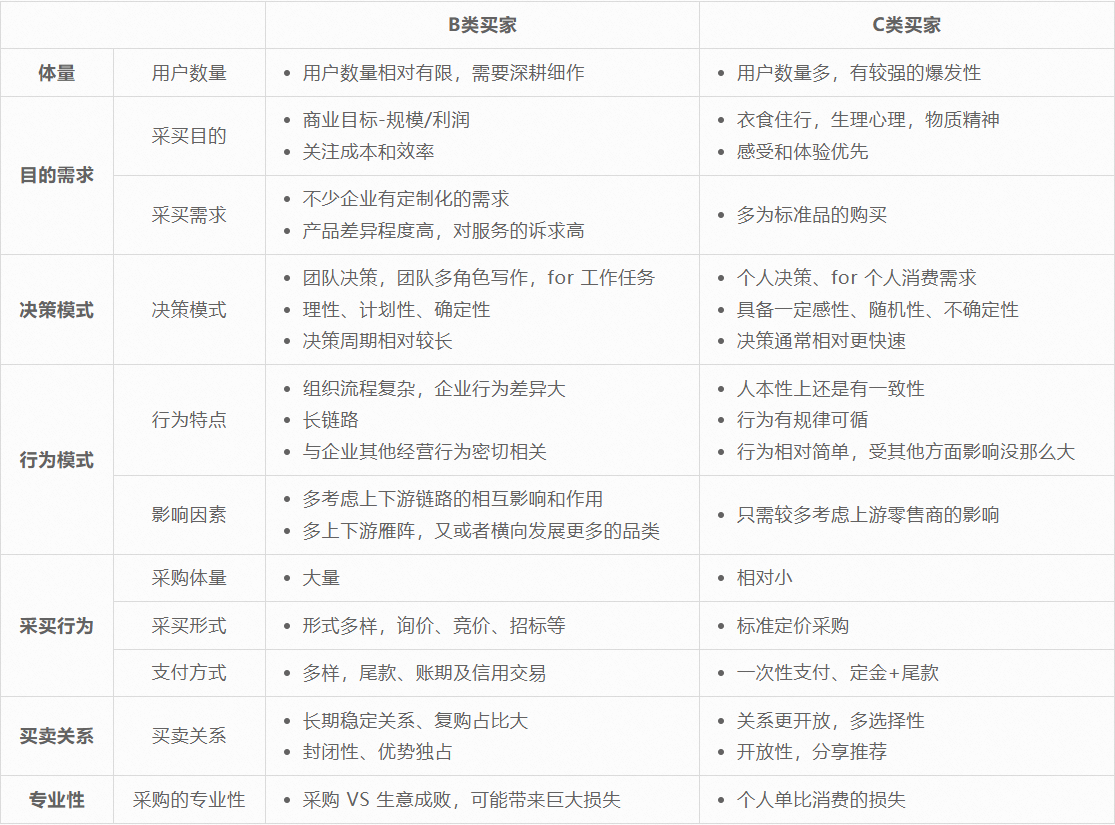
不过这种从 C 端演变发展而来的用户增长模型,并不完全适用于 B 端用户,主要原因是 B 类买家与 C 类买家有着显著的差异。B 类业务的一个显著特点就是客单价高且采购周期长,并且在不同采购过程中的不同阶段(认知阶段→考虑阶段→偏好阶段→订单阶段→履约阶段),需求也存在较大差异。因此,B 类用户增长的本质就是要根据 B 类买家的特点,在 C 类用增方法的基础上,要找到更合适的有效策略,来打消不同阶段采购者的不同顾虑。B 类买家与 C 类买家的详细差异如下:
根据上述 B 类用增的特点,我们认为跨境 B 类用户增长领域主要面临以下三方面的挑战:
**挑战一:用户结构复杂,但行为数据稀疏:**跨境贸易服务于全球 200 多个国家,不同的语种、文化、法律法规、行业所带来的差异决定了买家需求的多样性;而且用户行为的稀疏性,以及身份、偏好、采购需求等关键信息的缺少更加加剧的增长的挑战性。
**挑战二:目标人群规模小,流量引入的精准性要求高:**全球互联网用户大部分为 C 类用户,其中有 B 类采购需求的用户数占很小比例。流量规模越小,一方面意味着对人群精准定位的要求就越高,另外一方面也意味着获取流量的成本也越高。因此,如何在预算有限的情况下,精准的获取这些 B 类流量成为增长的核心命题。
**挑战三:B 类买家留存率低,C 类增长策略不可复制:**跨境贸易平台用户留存率与 C 类相比存在较大差距,主要原因是匹配效率越高,买家下沉越快,缺乏把买家留存平台的核心权益体系与有效留存抓手,一些 C 类的留存策略不可复制,如红包权益、用户裂变、互动 &社交等玩法在 B 类买家中并不适用。
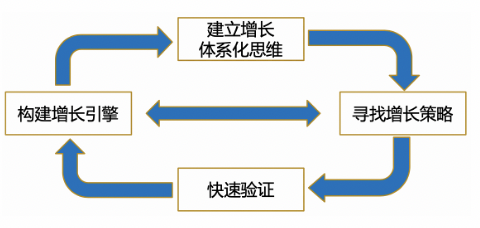
阿里巴巴国际站用户增长团队经过多年的增长探索,总结出一套牵引业务持续增长的思维框架;在增长策略上,围绕北极星指标持续迭代体系化的方法论和增长引擎,以全链路、多维度的视角挖掘增长策略并通过 A/B Test 快速验证;在组织文化上,研发产品运营一起建立目标、资源和信息的高度一致和协同,持续提升团队成员的产品思维、数据思维、算法能力,以极致技术的匠心精神助力业务高速增长。
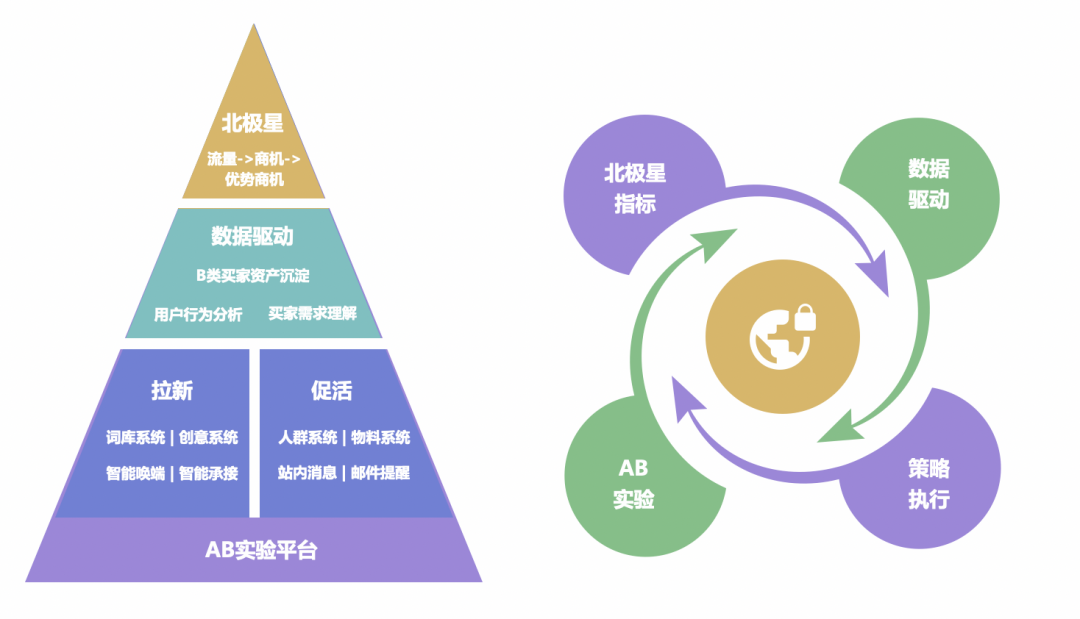
面对上述跨境 B 类用户增长的三大核心挑战,团队经过多年的深度实践,打造出具有跨境 B 类特色的四大核心能力,即:1)北极星指标(定义增长目标,起到指挥棒的作用);2)数据驱动增长(通过数据分析洞察,找到增长的核心策略);3)策略执行中心(高效执行增长策略,拿到实际效果);4)AB 实验(快速实验,验证策略及执行效果)。四大核心能力高效咬合,循环执行,形成用户增长飞轮。
增长团队战略制定的第一步是需要设定一个清晰明确的目标,即北极星指标。北极星指标也叫唯一关键指标(OMTM,One metric that matters),简单来说就是产品现阶段最关键的指标,它就像“北极星”一样指引着公司前进的发展方向。北极星指标不是一成不变的,随着业务的变化,公司在不同阶段会有不同目标。具体来说,一个好的北极星指标可以在以下几方面发挥作用:
1)指引方向:北极星指标可以起到指挥棒的作用,给公司所有员工一个明确、统一的数据指标指引。
2)提高行动力:北极星指标可以帮助明确任务的优先级,集中火力,抓住重点,努力朝着同一个目标使劲。
3)指导实验:通过北极星指标可以知道公司业务的当前现状,有针对性地上线优化各种增长实验,观察有无成效,循环反复。
在制定北极星指标的过程中,一般 C 类的电商平台,会使用 MAU、GMV 等作为北极星指标,它反映了用户的活跃度或网站的交易规模。但 B 类业务由于上述讲到的采购周期长、决策链路复杂等特点,C 类相关的指标并不适用。**阿里巴巴国际站用增团队经过多年不断的摸索尝试,在北极星选取这块,也经历了多轮的迭代,主要分为 3 个不同的阶段即“流量→商机→新商机”。**不同的北极星指标代表着不同的业务阶段,也体现了用增团队在业务背后的深度思考,代表着阿里巴巴国际站从粗放到精细化运营的策略转型。具体如下:
**1)流量:**在 2017 之前,我们选择流量规模 UV 作为北极星指标,因为当时商家对流量诉求非常强烈,没有流量或流量较少的商家要求先有流量规模后再考虑流量质量。因此,在合理的预算框架内,用增产研团队想方设法从全球各种媒体中,快速尝试多样性低成本的流量获取方式,满足商家的流量诉求。当时我们在 SEO、联盟等渠道获得了突破性的进展,流量快速增长,但调整增长的背后,也隐藏着一些问题,比如流量不够精准,一些低质量的流量容易造成对商家的干扰,导致服务成本变高。
**2)商机:**经过与商家的大量沟通走访以及内部产研的不断讨论,我们选取了商机作为北极星指标。每一个商机背后代表着一个用户的深度行为(如沟通、询盘、下单等),相比 UV 代表着流量规模,选用商机作为北极星指标,代表着我们更加关注买家在全链路的体验及转化,因此低质量流量大规模减少,买家转化率变高了,对商家造成的困扰得到了很好的缓解,满意度 NPS 有效提升。
**3)优质商机:**随着业务的发展,商家对买家质量提出了更高的诉求,如对询盘质量的诉求,对买家地域的诉求,对买家层级的诉求等等。因此,近年来,我们逐渐开始使用“优质商机”代替“商机”作为北极星指标,同时我们也会关注商机中核心国家、高层级买家的占比。
随着我们对买家以及买家背后的需求、生意模式等认知的不断提升,国际站的北极星指标还会继续演进,虽然每次北极星指标的变化都会带来不小的成本,但从过往的经验来看,正向的长期收益都高于短期的阵痛。不管选取哪个指标作为北极星指标,唯一不变的就是我们坚持客户第一,坚持对高质量买家的追求,这就意味着我们需要持续不断的迭代增长策略,保持创新,为客户创造价值。
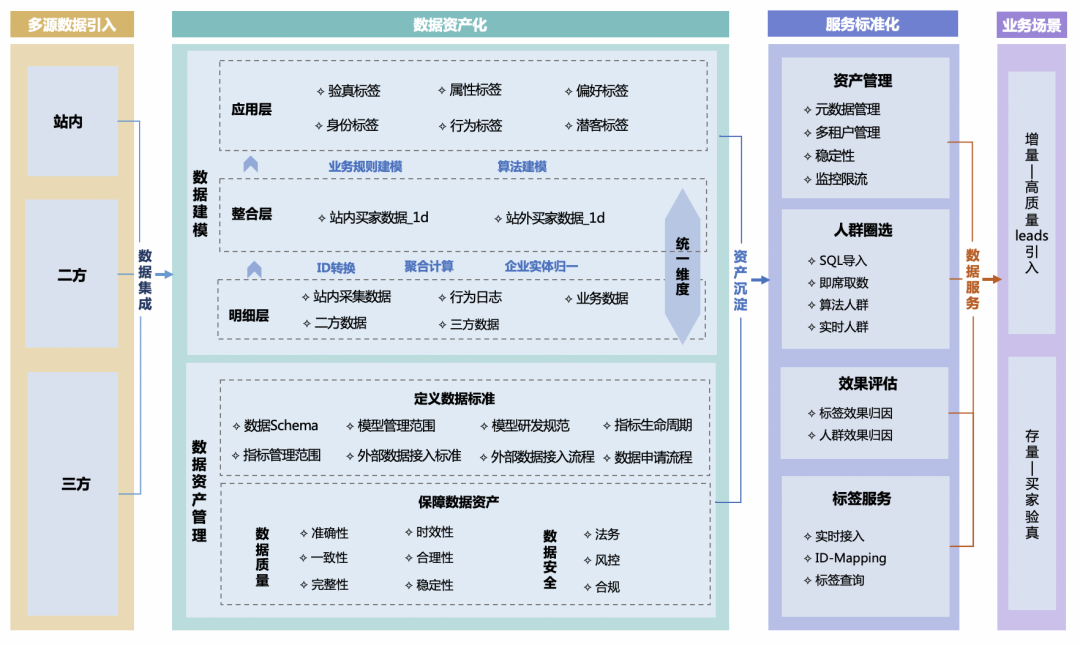
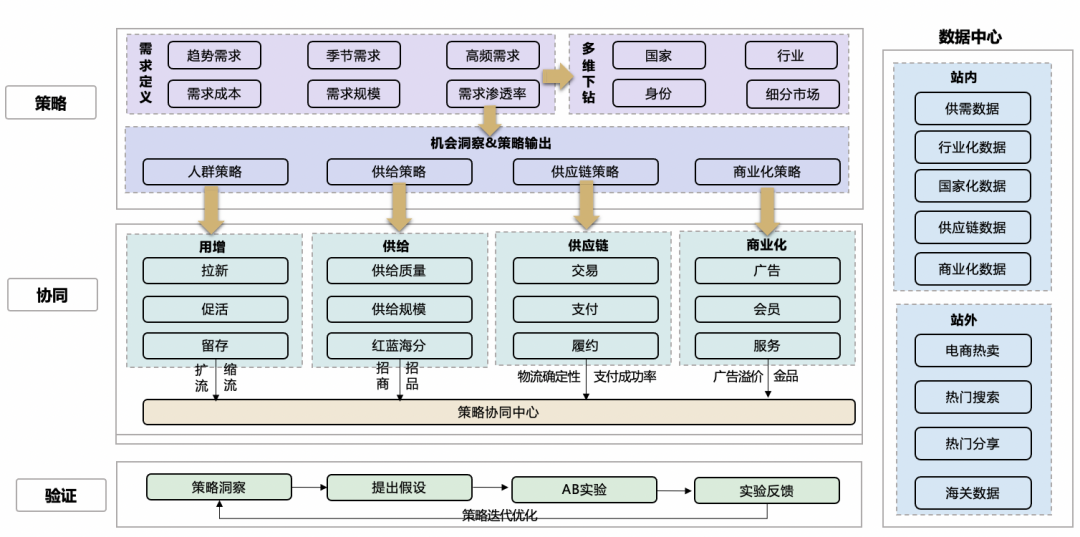
现代管理学之父彼得·德鲁克曾说过:如果你不能衡量它,那么你就不能有效增长它。用户增长对数据的依赖性很高,因为定北极星指标、构建增长模型、分析用户数据、寻找增长机会等,这一系列增长策略的探索与发现都离不开数据。因此,阿里巴巴国际站用增团队一直提倡数据驱动的文化,并在这方面打造了三大利器,即:B 类买家资产沉淀、用户行为分析系统、增长策略中心等。
1) 业务背景
国际站服务于来自全球 200+国家的客户,不同的文化、风俗、法律法规、行业所带来的差异决定了买家需求的多样性。通过整合内外部数据,构建海外 B 类数据资产是重要的环节,它有助于明确海外 B 类客户的采购诉求,为其定制差异化的用户引导路径、货品供给、权益服务等精细化运营机制,最终目的是扩大海外 B 买市场渗透率,保障高质量买家增长。相较国内买家的数据资产构建,海外 B 类的资产建设难度明显偏高,主要存在下述两个方面的挑战:
**数据沉淀难:**对于海外 B 类客户,数据沉淀难度高,站内买家行为数据稀疏,用户自填身份/偏好/采购需求等关键信息填写率低,而且也没有类似国内良好的二/三方生态,可以联动相互补充数据等。另外,邓白氏等海外数据公司由于涉及到用户隐私与数据跨境传输等问题,各数据源的稳定性、准确性、及时性等也存在较大问题。
**资产化难度高:**为尽量弥补数据稀疏的问题,我们往往会采用多种数据源,但数据源之间格式参差不齐,存在语种、货币等的区别,而且企业信息无统一主键,其数据清洗归一化的复杂性呈指数级别增长,海外买家同人模型的构建难度远超国内 B/C 类数据资产。
2) 解决方案
面对以上挑战,我们设计了如下整体解决方案,主要包括以下三大模块:
**多数据源引入:**渐进式采集布点完善站内买家信息沉淀,基于流批一体实现行为日志和业务数据的实时 &离线数据集成;建立二方 &三方数据的标准化沉淀流程、基于最小单元原则的标准化数据标准。
**数据资产化:**通过数据建模沉淀 B 类买家的数据资产,结合数据标准定义和数据资产保障实现数据资产的管理与治理。
**服务标准化:**通过资产管理、人群圈选、效果评估和标签服务,建立 B 买数据资产的标准化服务能力。
1) 业务背景
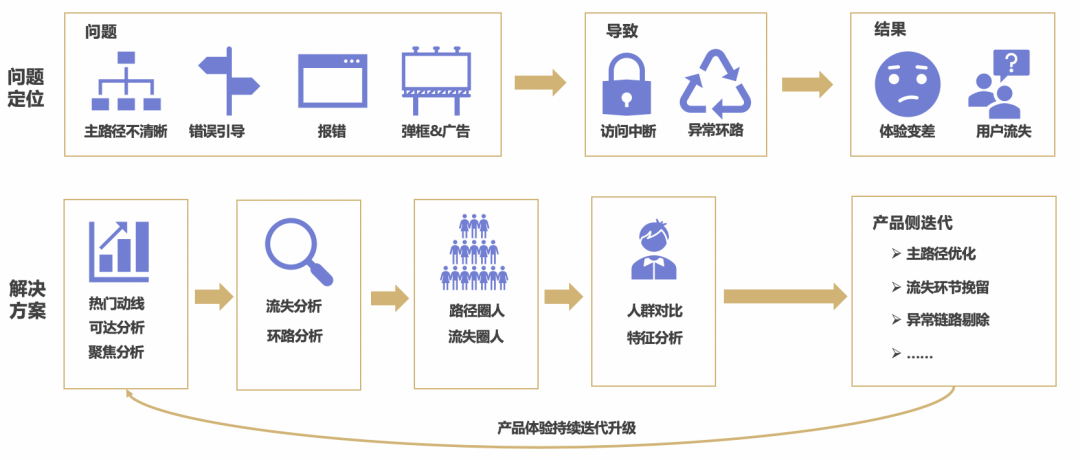
用户的行为是用户对网站体验的真实客观反映,基于用户行为的分析发现产品中的体验是一种重要的技术手段,我们常常希望基于用户行为分析回答以下一些问题,并通过这些问题的优化解决来提升用户体验,进而促进用户的留存与增长。
产品的主路径是什么,用户是否有按照预期的路径步骤操作?
进入产品的不同来源分布如何,哪些来源的质量更优?
产品中是否存在异常路径,如环路、非预期路径等?
产品中哪些环节流失量、流失率较高?
在不同标签等条件下,用户动线的差异是什么?
2) 解决方案
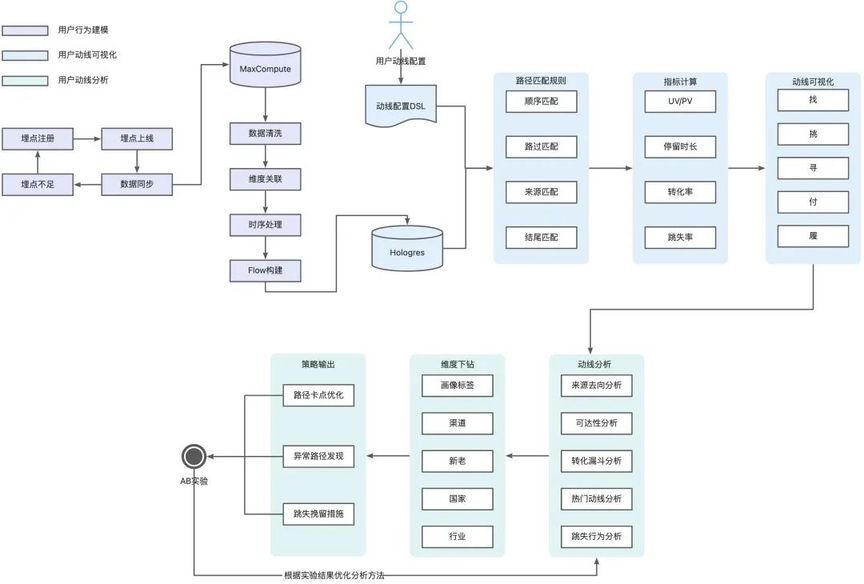
然而,随着产品的不断迭代更新,功能设计愈发复杂多变,很难从全链路上看清用户操作的各个环节及相应的转化流失情况。人工梳理面临着成本高、不准确、周期长、扩展性差等问题,严重影响了产品体验迭代更新节奏。因此,我们打造了一套自动化的用户行为分析系统,主要包含以下几个模块:
**用户行为建模:**在网站打点数据的基础上,通过事件的发生先后顺序构建一套用户行为数据模型。将用户维度信息、用户行为信息、用户反馈信息等底层数据通过以离线的方式进行聚合,然后再导入 OLAP 实时数仓,为后续行为可视化及分析做好数据基础。
**用户行为可视化:**为了降低了行为分析的门槛,我们设计了一种路径配置的领域特定语言(DSL),用户只需要完成简单的配置即可自定义一个用户的行为动线。基于配置化的动线可视化,不仅可以支持产品运营同学的快速调整与试错,而且降低了平台的后续开发维护成本,通配置文件与平台的解耦,底层的数据模型、计算方式及可视化呈现不管动线如何变化均无需二次开发。
**用户行为分析:**通过将常见的行为分析方法,如来源去向分析、转化漏斗分析、热门路径分析、人群对比分析、流失行为分析等做成自动化工具,帮助产品运营同学基于用户行为快速发现增长的策略,并通过 AB 实验的验证,在驱动业务增长的同时,迭代改进自动化分析方法。
用户需求是一切产品的起点,只有理解需求才能为客户创造价值,从而带来业务的长期增长与繁荣。因此,国际站从 B 类买家的需求理解的角度出发,打造了增长策略中心,希望基于对买家需求的深入理解,并协同用增、供给、供应链、商业化等各个团队的联合作战,驱动业务的全局增长。核心模块如下图所示:
**1)数据中心:**将站内外相关数据从需求视角出发汇总成数据中心,包括站内数据(如供需数据、行业化数据、国家化数据、供应链数据等)和站外数据(如国外电商热卖数据、Google 搜索趋势数据、海关进出口数据等),这是需求理解的基础。
**2)策略输出:**基于对下以几个需求理解问题的自动分析识别,挖掘增量机会点,并通过按国家、行业、身份等维度的多维下钻,找到每个细分市场潜在的机会点,输出增长策略。
**3)策略协同:**增长策略输出给各业务团队(用增、供给、供应链、商业等),并结合业务的经验,进一步判断策略的可行性,进行协同作战。
**4)策略验证:**对可行的策略,通过 AB 实验进行验证,并结合 AB 实验的结果迭代优化策略生成逻辑。
用户增长是一个系统性工程,3.2 介绍了如何基于数据驱动找到增长策略,本节将重点介绍如何通过系统化将这些策略进行高效执行。
1) 业务背景
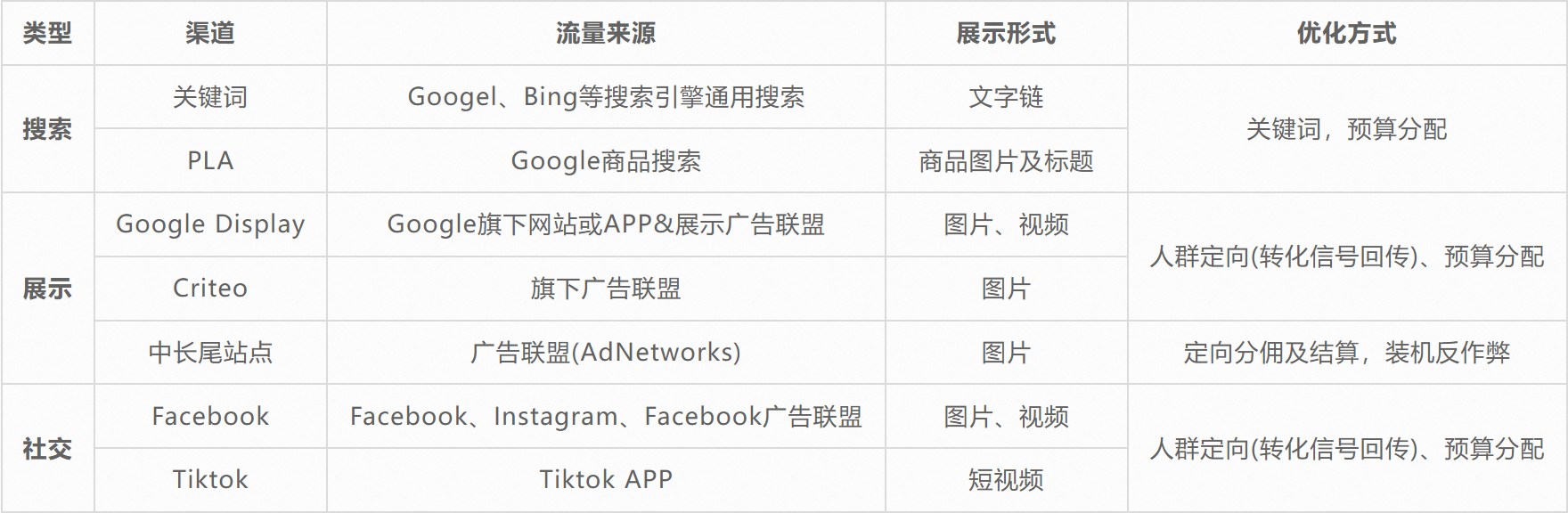
拉新即用户的引入,是用户增长中非常重要的一个环节,它的核心是转化率,即如何低成本的获取精准用户。长期以来,国际站用增团队的重要命题就是通过与国外各渠道媒体的对接,吸引潜在 B 类买家,引导并优化买家在整体链路上的体验,提升活跃买家规模,降低获取成本。日常对接的媒体矩阵如下图所示:
为了更好的优化外投广告的成本,支撑业务目标的达成,在这些渠道的运营工作中也面临着如下核心挑战:
**外投规模大、运营成本高:**外投业务经过多年的发展目前在投渠道数众多,基本覆盖海外核心媒体渠道。预算设置、文案设置、人群定向等设置人工操作成本非常高,同时也无法做到精细化运营。
**外投场景多且复杂,需要满足多业务目标:**外投业务除了要支持用增业务外还需要广告、供应链等横向业务,根据其他团队的业务目标将外投业务能力进行输出,以帮助横向业务发展。不同的业务有不同的目标,怎么通过一套解决方案去满足多业务、多目标的诉求也是我们的核心挑战之一。
**引流流量结构及转化表现迥异:**由于不同端型、不同区域的流量特性存在天然差异,投放策略在针对不同行业、不同区域会面临着很大的不确定性。这些差异性导致了一些运营策略并不是全局有效,增加了业务目标完成的复杂情况,怎么去应对这种复杂,探索成功的投放策略也是核心难点。
2) 解决方案
从业务诉求出发,利用算法和工程的能力,打造集广告投放、预算调控、目标优化为一体的智能投放系统,帮助运营更低成本、更精细化的解决日常工作中的投放任务控制。同时能够让业务运营集中精力去解决更为复杂和不确定性的业务问题。整体能力如下图所示。
核心包含以下几部分的能力:
**核心媒体覆盖能力:**完成海外主流媒体全覆盖,包括 Google、Facebook、TikTok、Criteo、Twitter、Linkedin、联盟等,并且通过 API 网关层做好了对上层的屏蔽,可以快速实现对新渠道的集成。
**API 开放服务化能力:**基于业务场景抽取出物料同步、效果报告下载、物料优化等三个核心服务化接口,在此基础上,其他业务场景可以根据自身业务出发进行定制化的模块组装,快速搭建一套自定义的外投体系。
**全链路自动化优化:**对投放需要的各种要素建成管理及级联优化的能力,包括关键词、选词、创意、转化信号等,实现所有关键要素自动优化,无人值守。
**业务效果仿真能力:**基于历史多维度转化效果,实现对整体外投效果进行预估和规划,在整体预算有限的情况下,可对全局进行统筹优化并对决策提供支持。
1)业务背景
除了拉新外,用户增长的后半程是用户促活和留存,简单来讲,是通过触达手段帮助用户高效 onboarding、尽快体验到平台的价值以达到“aha 时刻”、以利益点透传召回用户,提升用户的留存效率和转化效率。经过多年的发展,国际站用户增长团队基于生命周期运营(新用户→成熟用户→留存用户→流失用户)构建了一套多渠道联动的高效促活系统,提升运营效率和价值,整体思路如下图所示:
其面临的主要问题和挑战如下:
B 类买家采购周期长且采购链路复杂,如何在全链路建立一体化的运营机制,以长周期和买家动线的精准触达的方式持续影响用户心智?
B 类买家规模小、行业及身份差异的离散度高,如何针对细分买家精准实施有效策略促活、促转化?
2)解决方案
为了解决上述问题,我们重点从下述两方面构筑全链路一体化促活运营系统:
**构建全链路运营的协同机制:**从站外召回延伸到站内运营,打通多渠道联合,建成全链路运营的技术闭环。
**寻求用户精细化运营的最优策略:**从用户动线出发深刻理解用户,挖掘临门一脚的优质策略,构建全局策略赛马和管控机制,寻求运营价值最大化。
核心包含以下几部分的能力:
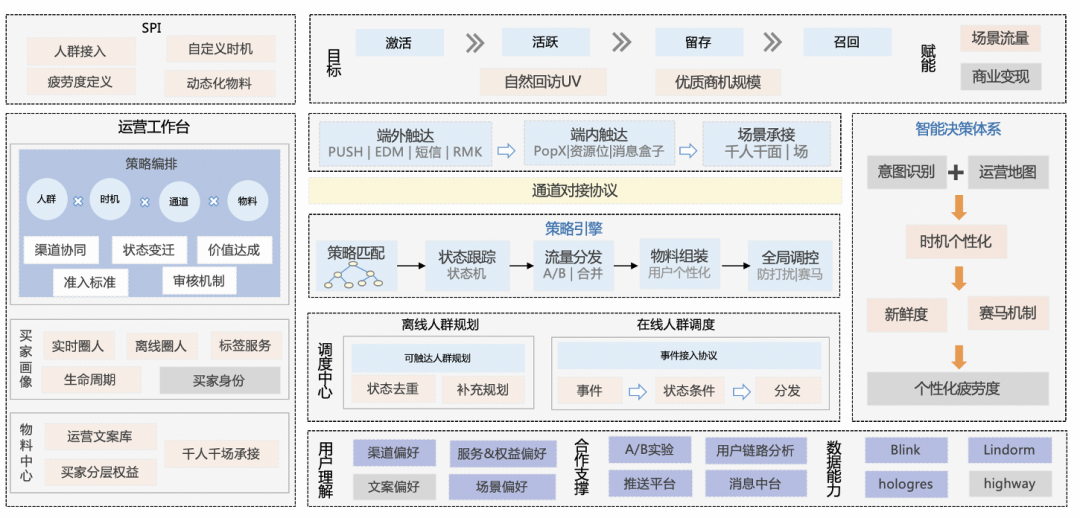
**全链路一体化策略编排体系:**沉淀图形化支撑买家画像、触点、时机、物料 4 要素的全局策略编排体系,支持多触达通道的联合编排,形成端外(PUSH/EDM/WhatsApp)召回、端内(PopX/资源位)运营的技术闭环,使运营策略从单点运营迈向网格化,从离线迈向实时化,给予运营团队更大的发挥空间。
**分群促活的个性化疲劳度 &赛马机制:**以用户画像人群分群矩阵为基础,结合业务域和策略性质的维度细分,以及策略长周期累积的正、负反馈,构建一套基于效果动态和买家意图调节的细分人群差异化的疲劳度调控和赛马分发机制,动态化调节最优策略的分发。
**多样化的物料创意定义能力:**沉淀了创意模型的开放式设计能力,支持文本框、选择器和数组等多形态、条件变量的定义,满足多样化的物料诉求;在物料层抽象成钩子库,支持多通道物料一体化,降低创意模型的开发成本,有超过 90%的需求通过配置化可快速支撑。
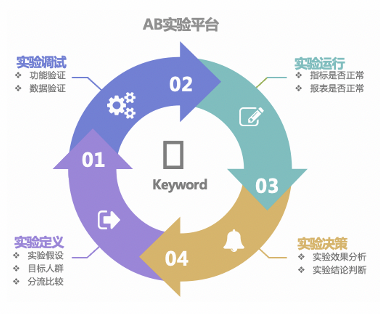
在用户增长领域,AB 实验已成为一个基础性思维,能做 AB 实验的地方一定要做,不能做 AB 实验的地方也要想办法做。AB 实验的主要作用是对增长实验进行科学有效的度量,即通过将实验组和对照组进行比较,可以清晰地看到某个改变带来的影响是多少。在国际站,数据科学团队打造了一个从“实验定义->实验调试->实验运行->实验决策”的完善的 AB 实验平台,现在所有的用户增长实验均通过该平台进行精准有效的评估。
当今世界,互联网的流量红利逐渐见顶,宏观环境也充满了很大的不确定性,用户增长的难度不可否认肯定会越来越大。但在面对难题时,我们要坚持在不确定性中寻找确定性,坚持做难而正确的事情,以下是我们认为在用户增长领域值得长期探索和坚持的几个事情:
**持续增加对买家的理解:**只有更好地理解买家的特点、痛点、采购诉求、生意模式等,我们才能更好的做产品创新与模式创新。因此,我们会通过加强买家线上面对面采访、买家信息采集 &验真、买家多维度数据分析、买卖家沟通文本分析、买家评论分析 &挖掘、买家调研报告等多种方式加强对买家的理解。
**坚持增长方法论的迭代:**基于对买家的认知和核心问题的识别,我们不断定义什么是增长,不断寻找买家增量在哪里?不断地迭代我们的用增方法论。
**坚持演进增长文化:**坚持拥抱不确定性,勇于探索,持续学习,培养求真务实的增长文化,培养微创新土壤。
**坚持数据驱动方式:**坚持大胆假设→科学度量→A/B 实验→数据专题分析 &挖掘→ 持续迭代的数据驱动方式,打造高效的用户增长飞轮。
去哪儿支付系统自2011年搭建以来,在五年的时间里逐渐从一个高耦合的单一系统发展为众多子系统组成的高并发、高可用、支持多种交易支付业务的分布式系统。业务从最初的非代收到现在多种非代收、代收场景的支持,B2B业务的从无到有,支付方式从单一网银支付到现在银行卡、拿去花、代金券、红包、立减、积分、趣游宝等多种的组合,订单从单笔支付到多个订单同时支付和多次付款。下面对整体的演变过程进行简单的介绍。
新的业务系统初建时,业务逻辑相对简单,业务量也比较小,为了能够快速实现功能,发布上线,大多数团队都会把所有的逻辑都耦合在一个系统。这对于初期业务的快速迭代是有一定好处的。毫不例外,支付交易系统也采用了这样的方式。如下图所示。
一个支付系统不例外包括几个重要组成部分:收银台、交易、支付、网关、账务。
收银台:用于展示支付详情、提供各种多样支付方式的选择
交易:收单规则和交易规则处理
支付:处理各种组合的支付方式,如银行卡、用户余额、信用付、拿去花、红包、代金券、立减、积分等
账务:用来记录所有交易、资金往来的明细,财务会计记账
网关:用于对接银行通道、第三方支付通道(微信、支付宝)
在业务量不大的情况下,这样的系统结构没有问题。随着更多业务的接入,各种复杂的功能逻辑加入,系统处理起来有点吃力,主要表现以下几个方面:
系统容灾能力:所有的功能都集中在一起,一但某个功能出问题,直接影响全局
系统扩容:在一个分布式系统中,决定系统性能的取决于最差的部分,整体扩容效果差
开发成本高:团队成员的增加,功能的复杂,多个项目并行时,开发效率极低
更多更复杂业务:结构不合理,不能满足业务发展需要
系统职责混乱:如收银台只是简单维护银行列表
在这样的一些背景下,2.0系统应运而生。
2.0时代是支付交易系统快速发展的一个重要时段。在此过程中,不仅要从系统架构上进行服务化的拆分,而且需要支持更复杂的业务。
首先对相对比较独立的网关进行拆分,网关在整个支付系统中属于底层基础服务,是比较重要的基础设施。对外能够提供怎么样的支付交易服务,很多都取决于网关能力的建设。
网关有一些显著特征,它是一个可高度抽象的业务。对外可以抽象到支付、退款、查询这些标准的服务。因此优先将这部分拆分,一是为了能够更好的打好基础,二是其能够独立的发展,三是这部分也相对好实施。
网关的拆分路由系统起到至关重要的作用,对于多通道支付的支持和智能化选择发挥着巨大作用。
做交易支付业务,重要的一件事要记清楚账。记账可以很简单的记录来往流水,也可以更加专业的记财务会计账。在拆分前系统只是记录了交易流水,拆分后实现了更加专业和复杂的复式记账。
新账务系统的一个简单流程图:
会员系统与交易系统本身只是一个依赖关系,在交易支付系统看来只是一个业务系统。比如会员充值业务可以看做是一笔支付交易。为了摆正各自角色,对于会员部分从原有系统中独立出来。这样一来各自定位更加清晰明了,也方便了各自独立发展。现在的会员系统不仅仅只有一个余额,而且引入实名服务、各种资产管理、交易管理等。
更多的系统拆分独立后,原有公用的某些功能会多次复制重复。为方便集中管理维护,通过对各系统公用逻辑更能的统一,提供集中的基础服务,如安全服务、加验签服务、通知服务、基础信息查询等,如下图中talos系统。
上述几个服务的拆分更多是为从业务方面或者技术驱动来考虑。而典型的交易支付过程是有一个时序过程的。比如下单->交易->收银台->支付->网关->银行。这样一个先后时序也是一个比较好的系统拆分方案。根据这样的一个时序,我们针对性的对每个阶段做了拆分(排除网关和银行部分),如下过程:
关注于收单方式和交易类型。
收单方面系统已经支持单笔订单支付、批量订单支付。交易类型目前支持直接交易、担保交易、直接分账交易、担保分账交易、预授权交易等。在批量订单支付时各种交易类型可以进行混合。且分账交易同时支持多个账户。交易类型除了上面正向交易外,系统还支持很多后续流程交易、如预授权确认、预授权撤销、退款、担保撤销、二次分账交易等。
多种多样的交易源于各事业部业务的复杂性,比起标准化的支付系统,我们提提供了更多灵活方便的业务来支持。
关注于支付方案的组合和执行。
支付方式:银行卡、支付宝、微信、拿去花、趣游宝、余额、积分、红包、代金券、会员红包、立减等多种方式支付。
支付组合:可以单一使用,也可以进行组合使用。组合场景区分资金类型,如银行卡、支付宝、微信每次只能选择一个,其它类资金可多个同时使用。
在有上面基础的支持下,对于同一批次交易订单可也进行多次的组合支付扣款,如酒店信用住付款、拿去花还款等业务场景。下图是支付核心(minos)在系统中的位置:
收银台直接面向用户,因此支付体验至关重要。据统计在支付环节放弃的订单占比还比较大。因此一个方便、简洁易用的收银台对于订单转换是有很大帮助的。目前系统支持的收银台主要有app(native)、app前置收银台、touch、PC预授权收银台、PC多单收银台、PC英文版收银台、PC标准收银台等。收银台在系统中的位置如下图所示。
无线端收银台:
PC端收银台:
交易系统更多的服务是通过后台接口来完成的,这部分占到整体系统很大的业务比重。如支付后期的资金流转、逆向操作退款等。但也有一些是用来查询一些交易订单相关性的信息。在此背景下,对于api接入层采用读写分离方式处理。如下图ares系统,将底层的各dubbo服务包装提供各种查询类服务。Odin系统是可读写,更多的关注跟核心业务相关的写,如解冻、退款、撤销等。
截止目前,整体系统的一个大体结构如下图所示:
服务化拆分后,在系统结构上更加清晰了,但对于整体系统的开发管理和日常运营带来更大的挑战。比如下几个方面:
系统拆分后主要提供dubbo服务和对外http(https)服务
接口定义:粒度控制、边界控制。一个接口不能存在模棱两可的情况,只做其一
参数标准:复杂接口使用对象做参数(避免map)、统一父类、支持扩展属性透传、提供create/builder构造合法参数、使用枚举限制参数范围。有效避免调用端参数错传
返回值:统一QResponse封装、错误码管理(非数字形式含义明确、按业务区分避免重复等)
业务模板:定义标准业务处理流程、标准化异常处理
接口文档化:定义好接口后,通过注解动态生成接口文档
a)接口参数:command、校验器、参数类型配置化。
command中定义接口信息,包括请求返回参数、每个参数的参数类型、参数的校验器、参数类型的校验器。校验器可以组合使用,也可以自定义实现扩展。如下示例:
Command定义:
<commands>
<command name="forex_queryExchangeRate">
<cnName>汇率查询接口</cnName>
<version>20150808</version>
<desc>查询本币和目标币种汇率</desc>
<request>
<param name="localCurrType" required="true">
<validator id="CURID"/>
</param>
<param name="targetCurrType" required="true">
<validator id="CURID"/>
</param>
</request>
<!-- 返回参数部分 -->
<response>
<param name="localCurrType">
<cnName>本币</cnName>
<required>true</required>
</param>
<param name="targetCurrType">
<cnName>目标币种</cnName>
<required>true</required>
</param>
<param name="sellingPrice">
<cnName>卖出价</cnName>
<required>true</required>
</param>
<param name="buyingPrice">
<cnName>购买价</cnName>
<required>true</required>
</param>
<param name="rateTime">
<cnName>汇率时间</cnName>
<required>true</required>
</param>
</response>
</command>
</commands>
校验器:
<validators>
<validator id="CURID" type="Regex">
<pattern>^[A-Z]{3}$</pattern>
</validator>
</validators>
参数类型:
<paramTypes>
<paramType name="merchantCode">
<cnName>商户号</cnName>
<desc>用来区分不同商户</desc>
<type>java.lang.String</type>
<example>testbgd</example>
<validator type="Regex">
<pattern>^[A-Za-z0-9]{1,20}$</pattern>
</validator>
</paramType>
</paramTypes>
b)并发控制
在某些操作场景下,对于并发写会有一些问题,此时可以通过依赖cache加锁来控制。比如通过在接口增加注解来启用。可以指定接口参数来作为锁的lockKey ,指定锁失效时间和重试次数,并指定异常时(lockGotExIgnore )的处理方案。
@RequestLock(lockKeyPrefix = "combdaikoupay:",
lockKey = "${parentMerchantCode}_${parentTradeNo}",
lockKeyParamMustExists = true,
lockKeyExpireSecs = 5,
lockUsedRetryTimes = 0,
lockUsedRetryLockIntervalMills = 500,
lockGotExIgnore = false)
c)流量控制
流控目前分两种:qps、并行数。
qps分为节点、集群、接口节点、接口集群。通过对每秒中的请求计数进行控制,大于预设阀值(可动态调整)则拒绝访问同时减少计数,否则通过不减少计数。
行数主要是为了解决请求横跨多秒的情况。此时qps满足条件但整体的访问量在递增,对系统的吞吐量造成影响。大于预设阀值(可动态调整)则拒绝访问。每次请求结束减少计数
d)安全校验
接口权限:对接口的访问权限进行统一管理和验证,粒度控制到访问者、被访问系统、接口、版本号
接口签名:避免接口参数在传递过程中发生串改
e)统一监控
包括接口计数、响应时长和错误码统计三个维度
f)接口文档化
依赖前面command、校验器、参数类型配置进行解析生成
接口监控模板化:http、Dubbo多系统统一模板,集中展示管理。
组件可监控化:Redis/Memcache、Mybatis 、Lock 、QMQ 、 EventBus 、DataSource 、JobScheduler
监控面板自动化生成:Python自动化生成脚本,新创建系统只需要提供系统名称和面板配置节点即可生成标准监控面板
系统硬件资源、tomcat、业务关键指标可视化监控
对于各个场景的关键流程进行格式化日志输出,集中收集处理。如orderLog、userLog、cardLog、binlog、busilog、tracelog、pagelog...
####2.3.1 分表
随着业务量增加,单表数据量过大,操作压力大。因此分表势在必行。常用的分表策略如按照时间来分表,如月表,季表,按照某个key来hash分表,也可以将两种结合起来使用。分表的好处是可方便将历史数据进行迁移,减少在线数据量,分散单表压力。
多库单实例,多业务单库。部分业务存在问题会影响全局,从而会拖垮整个集群。因此在业务系统拆分后,db的拆分也是重要的一个环节。举一个例支付库拆分的例子。支付交易的表都在同一个库中,由于磁盘容量问题和业务已经拆分,因此决定进行拆库。稳妥起见,我们采用保守方案,先对目前实例做一个从库,然后给需要拆分出来的库创建一个新的用户U,切换时先收回U的写权限,然后等待主从同步完成,,确定相关表没有写入后将U切到新的实例上。然后删除各自库中无关的表。
很多业务读多写少,使用MMM结构,基本上只有一台在工作,不仅资源闲置且不利于整体集群的稳定性。引入读写分离、读负责均衡策略。有效使用硬件资源,且降低每台服务器压力。
a)读写负载均衡
b)多动态源
c)多库动态源读负载均衡
servlet3异步:释放出http线程提高系统整体吞吐量,可隔离开不同业务的工作线程
qmq:使用最广泛也更灵活的异步
dubbo:对于服务提供者响应比较慢的情况
servlet异步和qmq结合的场景如下图所示。流程为http服务接到组合扣款请求,然后向后端交易系统下单并发起扣款,此时http服务进入轮询等待,根据轮询间隔定时发起对放在cache中的扣款结果查询。交易系统则根据扣款规则以qmq的方式驱动扣款,直至走完所有流程为止(成功,失败,部分支付)。每次扣款结束将结果放入cache中供http服务查询。
轮询式场景如上图中使用,关键在于确定轮询间隔
嵌入在应用中,指标数据可灵活配置发送方式到多个地方。也支持api接口直接拉取数据
python监控脚本框架,从db、java模块api、redis等获取数据,计算指标并发送
整体架构可插件化、有通用标准功能、也可定制化开发
指标可直接推送至watcher(dashboard)系统添加监控页
报警方式有mail、sms、qtalk
python监控脚本框架主要包含四个重要组件:
metric_manager:指标管理器
graphite_sender:指标推送
Dbpool:数据库链接池管理
Scheduler:调度器,定时执行指标数据获取
2.5.3 数据流系统
采用xflume、kafka、storm、hdfs、hbase、redis、hive对业务日志、binlog等实时收集并处理。提供业务日志、订单生命周期日志、各种格式化日志的查询和一些监控指标的计算存储和报警。整体大致流程如下图所示:
业务和系统结构复杂后报警尤为重要。甄别哪些指标是必须报警的和报警阀值的确定是个很复杂的问题。一般有两种情况:一种是明确认为不能出现的,另一种是需要一定计算来决定是否要报警。当然有些基础层的服务出现问题,可能会导致连锁反应,那么如何甄别最直接的问题来报警,避免乱报影响判断是比较难的事情。目前针对这种情况系统会全报出来,然后人工基本判断下,比如接口响应慢报警,此时又出现了DB慢查询报警,那基本可以确认是DB的问题。
A、明确失败报警
日志NPE、业务FAIL、系统ERROR、Access (4xx\5xx)、接口异常、dubbo超时、fullgc、DB慢查询等
B、计算类报警
调用量特别小,波动明细,没有连续性,不具有对比性
期望值:如下图所示,当前值与期望值偏差加大
截止目前交易支付系统从收银台、交易、支付、网关、账务、基础服务、监控等各个模块的拆分并独立完善发展,针对高复杂业务和高并发访问的支撑相比以前强大很多。但还有很多不足的地方有待提高和完善。
继续期待交易支付3.0……
吕博,去哪儿网金融事业部研发工程师,毕业于吉林大学,2012年加入去哪儿网。致力于支付平台研发和支付环节的基础服务建设。
https://blog.csdn.net/oooo_mumuxi/article/details/96477324
本次分享我们从百亿流量交易系统 API 网关(API Gateway)的现状和面临问题出发,阐述微服务架构与 API 网关的关系,理顺流量网关与业务网关的脉络,带来最全面的 API 网关知识与经验。内容涉及:
计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决。 —— David Wheeler
分布式服务架构、微服务架构与 API 网关
什么是 API 网关(API Gateway)
其实网关跟面向服务架构(Service Oriented Architecture,SOA)和微服务架构(MicroServices Architecture,MSA)有很深的渊源。
十多年以前,银行等金融机构完成全国业务系统大集中以后,分散的系统都变得集中,同时也带来各种问题:业务发展过快如何应对,对接系统过多如何集成和管理。为了解决这些问题,业界实现了作用于渠道与业务系统之间的中间层网关,即综合前置系统,由其适配各类渠道和业务,处理各种协议接入、路由与报文转换、同步异步调用等。
人们基于 SOA 的理念,在综合前置的基础上,进一步增加了服务的元数据管理、注册、中介、编排、治理等功能,逐渐形成了企业服务总线(ESB,Enterprise Service Bus)。
(作者参与设计开发的 Primeton ESB 系统)
面向服务架构(SOA)是一种建设企业 IT 生态系统的架构指导**。SOA 的关注点是服务,服务最基本的业务功能单元,由平台中立性的接口契约来定义。通过将业务系统服务化,可以将不同模块解耦,各种异构系统间可以轻松实现服务调用、消息交换和资源共享。
不同于以往的孤立业务系统,SOA 强调整个企业 IT 生态环境是一个大的整体。整个 IT 生态中的所有业务服务构成了企业的核心 IT 资源。各系统的业务拆解为不同粒度和层次的模块和服务,服务可以组装到更大的粒度,不同来源的服务可以编排到同一个处理流程,实现非常复杂的集成场景和更加丰富的业务功能。
SOA 从更高的层次对整个企业 IT 生态进行统一的设计与管理,应用软件被划分为具有不同功能的服务单元,并通过标准的软件接口把这些服务联系起来,以 SOA 架构实现的企业应用可以更灵活快速地响应企业业务变化,实现新旧软件资产的整合和复用,降低软件整体拥有成本。
当然基于 ESB 这种集中式管理的 SOA 方案也存在着种种问题,特别是面向互联网技术领域的爆发式发展的情况下。
分布式服务架构、微服务架构与 API 网关
而近年来,随着互联网技术的飞速发展,为了解决以 ESB 这种集中式管理的 SOA 方案的种种问题,以 Apache Dubbo(2011 年开源后)与新近出现的 Spring Cloud 为代表的分布式技术的出现,给了 SOA 实现的另外一个选择:去中心化的分布式服务架构(DSA)。分布式服务架构技术不再依赖于具体的服务中心容器技术(比如 ESB),而是将服务寻址和调用完全分开,这样就不需要通过容器作为服务代理,在运行期实现最搞笑的直连调用。
进而又在此基础上随着 REST、Docker 容器化、领域建模、自动化测试运维等领域的发展,逐渐形成了微服务架构(MSA)。在微服务架构里,服务的粒度被进一步细分,各个业务服务可以被独立的设计、开发、测试、部署和管理。这时,各个独立部署单元可以用不同的开发测试团队维护,可以使用不同的编程语言和技术平台进行设计,这就要求必须使用一种语言和平台无关的服务协议作为各个单元间的通讯方式。
我们可以看到微服务架构中,由于系统和服务的细分,导致系统结构变得非常复杂,REST API 由于其简单、高效、跨平台、易开发、易测试、易集成,成为了不二选择。此时一个类似综合前置的系统就产生了,这就是 API 网关(API Gateway)。API 网关作为分散在各个业务系统微服务的 API 聚合点和统一接入点,外部请求通过访问这个接入点,即可访问内部所有的 REST API 服务。
跟 SOA/ESB 类似,企业内部向外暴露的所有业务服务能力,都可以通过 API 网关上管理的 API 服务来得以体现,所以 API 网关上也就聚合了企业所有直接对外提供的 IT 业务能力。
API 网关的技术趋势
我们从百度指数趋势看到,SpringCloud 和 SOA 非常火,MSA、gRPC、Gateway 也都有着非常高的关注度,而且这些技术的搜索趋势都正相关。
另一方面,我们可以通过 Github 的搜索来看,Gateway 类型的项目也非常多。
https://github.com/search?o=desc&p=1&q=gateway&s=stars&type=Repositories
可以看到,前 10 页的 100 个项目,使用 Go 语言实现的 Gateway 差不多占一半,语言分类上来看:
Go > NodeJS/JavaScript > Java > Lua > C/C++ > PHP > Python/Ruby/Perl
API 网关的定义、职能与关注点
API 网关的定义
网关的角色是作为一个 API 架构,用来保护、增强和控制对于 API 服务的访问。
The role of a Gateway in an API architecture is to protect, enrich and control access to API services.
API 网关是一个处于应用程序或服务(提供 REST API 接口服务)之前的系统,用来管理授权、访问控制和流量限制等,这样 REST API 接口服务就被 API 网关保护起来,对所有的调用者透明。因此,隐藏在 API 网关后面的业务系统就可以专注于创建和管理服务,而不用去处理这些策略性的基础设施。
这样,网关系统就可以代理业务系统的业务服务 API。此时网关接受外部其他系统的服务调用请求,也需要访问后端的实际业务服务。在接受请求的同时,可以实现安全相关的系统保护措施。在访问后端业务服务的时候,可以根据相关的请求信息做出判断,路由到特定的业务服务上,或者调用多个服务后聚合成新的数据返回给调用方。网关系统也可以把请求的数据做一些过程和预处理,同理也可以把返回给调用者的数据做一些过滤和预处理,即根据需要对请求头/响应头、请求报文/响应报文做一些修改处理。如果不做这些额外的处理,最简单直接的代理服务 API 功能,我们一般叫做透传。
同时,由于 REST API 的语言无关性,我们可以看出基于 API 网关,我们的后端服务可以是任何异构系统,不论是 Java、Dotnet、Python,还是 PHP、ROR、NodeJS 等,只要是支持 REST API,就可以被 API 网关管理起来。
API 网关的职能
一般来说,API 网关有四大职能:
API 网关的关注点
通过以上的分析可以看出,API 网关不是一个典型的业务系统, 而是一个为了让业务系统更专注与业务服务本身,给API服务提供更多附加能力的一个中间层。
这样在设计和实现 API 网关时,两个目标需要考虑:
海量并发的 Gateway 最重要的三个关注点:
API 网关的分类与技术分析
API 网关的分类
如果我们对于上述的目标和关注点进行更深入的思考,就会发现一个很重要的问题:所有需要考虑的问题和功能可以分为两类。
一类是全局性的,跟具体的后端业务系统和服务完全无关的部分,比如安全策略、全局性流控策略、流量分发策略等。
一类是针对具体的后端业务系统,或者是服务和业务有一定关联性的部分,并且一般被直接部署在业务服务的前面。
这样,随着互联网的复杂业务系统的发展,这两类功能集合逐渐形成了现在常见的两种网关系统:流量网关和业务网关。
流量网关与 WAF
我们定义全局性的、跟具体的后端业务系统和服务完全无关的策略网关,即为流量网关。这样流量网关关注于全局流量的稳定与安全,具体比如防止各类 SQL 注入,黑白名单控制,接入请求到业务系统的 Loadbalance 等,通常有如下的一些通用性功能:
等等。
通过这个功能清单,我们可以发现,流量网关的功能跟 Web 应用防火墙(WAF)非常类似。WAF一般是基于 Nginx/OpenResty 的 ngx_lua 模块开发的 Web 应用防火墙。
WAF 一般代码很简单,关注于使用简单,高性能和轻量级。简单的说就是在 Nginx 本身的代理能力以外,添加了安全相关功能。一句话来描述其原理,就是解析 HTTP 请求(协议解析模块),规则检测(规则模块),做不同的防御动作(动作模块),并将防御过程(日志模块)记录下来。
一般的 WAF 具有如下功能:
几个 WAF 开源实现
以上 WAF 的内容主要参考如下两个项目:
流量网关的开源实例,还可以参考著名的开源项目 Kong(基于 OpenResty)。
业务网关
我们定义针对具体的后端业务系统,或者是服务和业务有一定关联性的策略网关,即为业务网关。比如针对某个系统、某个服务或者某个用户分类的流控策略,针对某一类服务的缓存策略,针对某个具体系统的权限验证方式,针对某些用户条件判断的请求过滤,针对具体几个相关API的数据聚合封装等等。
业务网关一般部署在流量网关之后,业务系统之前,比流量网关更靠近系统。我们大部分情况下说的 API 网关,狭义上指的是业务网关。并且如果系统的规模不大,我们也会将两者合二为一,使用一个网关来处理所有的工作。具体的业务网关设计实现,将在下面的篇章详细介绍。
常见的开源网关介绍
(开源网关技术图谱)
目前常见的开源网关大致上按照语言分类有如下几类:
按照使用数量、成熟度等来划分,主流的有 4 个:
Nginx+Lua
Open Resty
OpenResty® 是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
OpenResty® 通过汇聚各种设计精良的 Nginx 模块(主要由 OpenResty 团队自主开发),从而将 Nginx 有效地变成一个强大的通用 Web 应用平台。这样,Web 开发人员和系统工程师可以使用 Lua 脚本语言调动 Nginx 支持的各种 C 以及 Lua 模块,快速构造出足以胜任 10K 乃至 1000K 以上单机并发连接的高性能 Web 应用系统。
OpenResty® 的目标是让你的 Web 服务直接跑在 Nginx 服务内部,充分利用 Nginx 的非阻塞 I/O 模型,不仅仅对 HTTP 客户端请求,甚至于对远程后端诸如 MySQL、PostgreSQL、Memcached 以及 Redis 等都进行一致的高性能响应。
以上介绍来自于 OpenResty 网站中文版。简单的说,OpenResty 基于 Nginx,集成了 Lua 语言和 Lua 的各种工具库,可用的第三方模块,这样我们就在 Nginx 既有的高效 HTTP 处理的基础上,同时获得了 Lua 提供的动态扩展能力。因此,我们可以做出各种符合我们需要的网关策略的 Lua 脚本,以其为基础实现我们的网关系统。
Kong
项目地址:
Kong 基于 OpenResty,是一个云原生、快速、可扩展、分布式的微服务抽象层(Microservice Abstraction Layer),也叫 API 网关(API Gateway),在 Service Mesh 里也叫 API 中间件(API Middleware)。
Kong 开源于 2015 年,核心价值在于高性能和扩展性。从全球 5000 强的组织统计数据来看,Kong 是现在依然在维护的,在生产环境使用最广泛的 API 网关。
Kong 宣称自己是世界上最流行的开源微服务 API 网关(The World’s Most Popular Open Source Microservice API Gateway)。
核心优势:
ABTestingGateway
项目地址:
https://github.com/CNSRE/ABTestingGateway
ABTestingGateway 是一个可以动态设置分流策略的网关,关注与灰度发布相关领域,基于 Nginx 和 ngx-lua 开发,使用 Redis 作为分流策略数据库,可以实现动态调度功能。
ABTestingGateway 是新浪微博内部的动态路由系统 dygateway 的一部分,目前已经开源。在以往的基于 Nginx 实现的灰度系统中,分流逻辑往往通过 rewrite 阶段的 if 和 rewrite 指令等实现,优点是性能较高,缺点是功能受限、容易出错,以及转发规则固定,只能静态分流。ABTestingGateway 则采用 ngx-lua,通过启用 lua-shared-dict 和 lua-resty-lock 作为系统缓存和缓存锁,系统获得了较为接近原生 Nginx 转发的性能。
功能特性:
据了解,美团内部的 Oceanus 也是基于 Nginx 和 ngx_lua 扩展实现,主要提供服务注册与发现、动态负载均衡、可视化管理、定制化路由、安全反扒、session ID 复用、熔断降级、一键截流和性能统计等功能。
Java
Zuul/Zuul2
项目地址:https://github.com/Netflix/zuul
Zuul 是 Netflix 开源的 API 网关系统,它的主要设计目标是动态路由、监控、弹性和安全。
Zuul 的内部原理可以简单看做是很多不同功能 filter 的集合(PS:作为对比,ESB 也可以简单被看做是管道(channel)和过滤器(filter)的集合),这些 filter 可以使用 Groovy 或其他基于 JVM 的脚本编写(当然 Java 也可以编写),放置在指定的位置,然后可以被 Zuul Server 轮询发现变动后动态加载并实时生效。
Zuul 目前有两个大的版本,1.x 和 2.x,这两个版本差别很大。
Zuul 1.x 基于同步 IO,也是 Spring Cloud 全家桶的一部分,可以方便的配合 Spring Boot/Spring Cloud 配置和使用。
在 Zuul 1.x 里,filter 的种类和处理流程可以参见下图,最主要的就是 pre、routing、post 这三种过滤器,分别作用于调用业务服务 API 之前的请求处理、直接响应、调用业务服务 API 之后的响应处理。
(Zuul 1.x 示意图)
Zuul 2.x 最大的改进就是基于 Netty Server 实现了异步 IO 来接入请求,同时基于 Netty Client 实现了到后端业务服务 API 的请求。这样就可以实现更高的性能、更低的延迟。此外也调整了 filter 类型,将原来的三个核心 filter 显式命名为:Inbound Filter、Endpoint Filter 和 Outbound Filter。
(Zuul 2.x 示意图)
Zuul 2.x 核心功能:
Spring Cloud Gateway
项目地址:
https://github.com/spring-cloud/spring-cloud-gateway/
Spring Cloud Gateway 基于 Java 8、Spring 5.0、Spring Boot 2.0、Project Reactor,发展的比 Zuul 2 要早,目前也是 Spring Cloud 全家桶的一部分。
Spring Cloud Gateway 可以看做是一个 Zuul 1.x 的升级版和代替品,比 Zuul 2 更早的使用 Netty 实现异步 IO,从而实现了一个简单、比 Zuul 1.x 更高效的、与 Spring Cloud 紧密配合的 API 网关。
Spring Cloud Gateway 里明确的区分了 Router 和 Filter,并且一个很大的特点是内置了非常多的开箱即用功能,并且都可以通过 SpringBoot 配置或者手工编码链式调用来使用。
比如内置了 10 种 Router,使得我们可以直接配置一下就可以随心所欲的根据 Header、或者 Path、或者 Host、或者 Query 来做路由。
比如区分了一般的 Filter 和全局 Filter,内置了 20 种 Filter 和 9 种全局 Filter,也都可以直接用。当然自定义 Filter 也非常方便。
核心特性:
gravitee gateway
项目地址:
Kaazing WebSocket Gateway
项目地址:
Kaazing WebSocket Gateway 是一个专门针对和处理 Websocket 的网关,其宣称提供世界一流的企业级 WebSocket 服务能力。
具体如下特性:
Dromara soul
Go
fagongzi
项目地址:
fagongzi gateway 是一个 Go 实现的功能全面的 API Gateway,自带了一个 Rails 实现的 Web UI 管理界面。
功能特性:
Janus
项目地址:
Janus 是一个轻量级的 API Gateway 和管理平台,它能帮你实现控制谁,什么时候,如何访问这些 REST API,同时它也记录了所有的访问交互细节和错误。
使用 Go 实现 API 网关的一个好处在于,一般只需要一个单独的二进制文件即可运行,没有复杂的依赖关系(No dependency hell)。
功能特性:
Dotnet
Ocelot
项目地址:
核心特性:
NodeJS
Express Gateway
项目地址:
Express Gateway 是一个基于 NodeJS 开发,Express 和 Express 中间件实现的 REST API 网关。
核心特性:
microgateway
项目地址:
StrongLoop 是 IBM 的一个子公司,Microgateway 网关基于 Node.js/Express 和 Nginx 构建,作为 IBM API Connect,同时也是 IBM 云生态的一部分。
Microgateway 是一个聚焦于开发者,可扩展的网关框架,它可以增强我们对微服务和 API 的访问能力。
核心特性:
此外,Microgateway 还有几个特性:
核心架构如下图所示:
四大开源网关的对比分析(OpenResty/Kong/Zuul2/SpringCloudGateway 等)
OpenResty/Kong/Zuul2/SpringCloudGateway 重要特性对比
| 网关 | 限流 | 鉴权 | 监控 | 易用性 | 可维护性 | 成熟度 |
|---|---|---|---|---|---|---|
| Spring Cloud Gateway | 可以通过IP,用户,集群限流,提供了相应的接口进行扩展 | 普通鉴权、auth2.0 | Gateway Metrics Filter | 简单易用 | spring系列可扩展强,易配置 可维护性好 | spring社区成熟,但gateway资源较少 |
| Zuul2 | 可以通过配置文件配置集群限流和单服务器限流亦可通过filter实现限流扩展 | filter中实现 | filter中实现 | 参考资料较少 | 可维护性较差 | 开源不久,资料少 |
| OpenResty | 需要lua开发 | 需要lua开发 | 需要开发 | 简单易用,但是需要进行的lua开发很多 | 可维护性较差,将来需要维护大量lua脚本 | 很成熟资料很多 |
| Kong | 根据秒,分,时,天,月,年,根据用户进行限流。可在原码的基础上进行开发 | 普通鉴权,Key Auth鉴权,HMAC,auth2.0 | 可上报datadog,记录请求数量,请求数据量,应答数据量,接收于发送的时间间隔,状态码数量,kong内运行时间 | 简单易用,api转发通过管理员接口配置,开发需要lua脚本 | "可维护性较差,将来需要维护大量lua库 | 相对成熟,用户问题汇总,社区,插件开源 |
以限流功能为例:
对 Zuul/Zuul2/Spring Cloud Gateway 的一些功能点分析可以参考 Spring Cloud Gateway 作者 Spencer Gibb 的文章:
https://spencergibb.netlify.com/preso/detroit-cf-api-gateway-2017-03/
OpenResty/Kong/Zuul2/SpringCloudGateway 性能测试对比
分别使用 3 台 4Core16G 内存的机器,作为 API 服务提供者、Gateway、压力机,使用 wrk 作为性能测试工具,对 OpenResty/Kong/Zuul2/SpringCloudGateway 进行简单小报文的情况进行性能测试。
(Spring Cloud Gateway、Zuul2、OpenResty、Kong 的性能对比)
上图中 y 轴坐标是 QPS,x 轴是一个 Gateway 的数据,每根线是一个场景下的不同网关数据,测试结论如下:
开源网关的技术总结
开源网关的测试分析
脱离场景谈性能,都是耍流氓。性能就像温度,不同的场合下标准是不一样的。同样是 18 摄氏度,老人觉得冷,小孩觉得很合适,企鹅觉得热,冰箱里的蔬菜可能要坏了。
同样基准条件下,不同的参数和软件,相对而言的横向比较,才有价值。比如同样的机器(比如 16G 内存/4Core),同样的 server(用 Spring Boot,配置路径 api/hello 返回一个 helloworld),同样的压测方式和工具(比如用 WRK,10 线程,20 并发连接),我们测试直接访问 server 得到的极限 QPS(QPS-Direct,29K);和配置了一个 Spring Cloud Gateway 做网关访问的极限 QPS(QPS-SCG,11K)、同样方式配置一个 Zuul2 做网关压测得到的极限 QPS(QPS-Zuul2,13K),Kong 得到的极限 QPS(QPS-Kong,21K),OpenResty 得到的极限 QPS(QPS-OR,19K),这个对比就有意义了。
Kong 的性能非常不错,非常适合做流量网关,并且对于 service、route、upstream、consumer、plugins 的抽象,也是自研网关值得借鉴的。
对于复杂系统,不建议业务网关用 Kong,或者更明确的说是不建议在 Java 技术栈的系统深度定制 Kong 或 OpenResty,主要是工程性方面的考虑。举个例子:假如我们有很多个不同业务线,鉴权方式五花八门,都是与业务多少有点相关的。这时如果把鉴权在网关实现,就需要维护大量的 Lua 脚本,引入一个新的复杂技术栈是一个成本不低的事情。
Spring Cloud Gateway/Zuul2 对于 Java 技术栈来说比较方便,可以依赖业务系统的一些 common jar。Lua 不方便,不光是语言的问题,更是复用基础设施的问题。另外,对于网关系统来说,性能不是差一个数量级,问题不大,多加 2 台机器就可以搞定。
目前测试的总结来看,如果服务都是 2ms 级别,直连的性能假如是 100,Kong 可以到 60,OpenResty 是 50,Zuul2 和 Spring Cloud Gateway 是 35,如果服务本身的 latency 大一点,这些个差距会逐步缩小。
目前来看 Zuul2 的坑还是比较多的:
所以简单使用或者轻度定制业务网关系统,目前比较建议使用 Spring Cloud Gateway 作为基础骨架。
各类网关的 demo 与测试
以上测试用到的模拟服务和网关 demo 代码,大部分可以在这里找到:
这里也简单模拟了一个 NodeJS 做的 Gateway,加了 keep-alive 和 pool,demo 的性能测试结果大概是直连的 1/9,也就是 Spring Cloud Gateway 或 Zuul2 的 1/4 左右。
百亿流量交易系统 API 网关的现状和面临问题
百亿流量系统面对的业务现状
我们目前面临的现状是日常十几万的并发在线长连接数(不算短连接),每天长连接总数 3000 万+,每天 API 的调用次数超过 100 亿,每天交易订单数 1.5 亿。
在这个情况下,API 网关设计的一个重要目标就是:如何借助 API 网关为各类客户提供精准、专业、个性化的服务,保障客户实时的获得业务系统的数据和业务能力。
网关系统与其他系统的关系
我们的业务里,API 网关系统与其他系统的关系大致如下图所示:
网关系统典型的应用场景
我们的 API 网关系统为 Web 端、移动 APP 端客户提供服务,同时也为大量 API 客户提供 API 调用服务,同时支持 REST API 和 WebSocket 协议。
作为实时交易系统的前置系统,必须精准及时为客户提供最新的行情和交易信息。一旦出现数据的延迟或者错误,都会给客户造成无法挽回的损失。
另外针对不同的客户和渠道,网关系统需要提供不同的安全、验证、流控、缓存策略,同时可以随时聚合不同视角的数据进行预处理,保障系统的稳定可靠和数据的实时精确。
交易系统 API 的特点
作为一个全球性的交易系统,API 的特点总结如下:
交易系统 API 网关面临的问题
问题 1:流量的不断增加
如何合理控制流量,如何应对突发流量,怎么样最大程度的保障系统稳定,都是重要的问题。特别网关作为一个直接面对客户的系统,任何问题都会放大百倍。很多千奇百怪的重来没人遇到的问题都随时可能出现。
问题 2:网关系统越来越复杂
现有的业务网关经过多年发展,里面有大量的业务嵌入,并且存在很多个不同的业务网关,相互之间没有任何关系,也没有沉淀出基础设施。
同时技术债务太多,系统里硬编码实现了全局性网关策略以及很多业务规则,导致维护成本较大。
问题 3:API 网关管理比较困难
海量并发下 API 的监控指标设计和数据的收集也是一个不小的问题。7x24 小时运行的技术支持也导致维护成本较高。
问题 4:推送还是拉取的选择
使用短连接还是长连接,REST API 还是 WebSocket?
业务渠道较多(多个不同产品线的 Web、App、API 等形成十几个不同的渠道),导致用户的使用行为难以控制。
业务网关的设计与最佳实践
API 网关 1.0
我们的 API 网关 1.0 版本是多年前开发的,是直接使用 OpenResty 定制的,全局的安全测试、流量的路由转发策略、针对不同级别的限流等都是直接用 Lua 脚本实现。
这样就导致在经历了业务飞速发展以后,系统里存在了非常多的相同功能或不同功能的 Lua 脚本,每次上线或维护都需要找到影响的其中几个或几十个 Lua 脚本,进行策略调整,非常不方便,策略控制的粒度也不够细。
API 网关 2.0
在区分了流量网关和业务网关以后,2017 年开始实现了流量网关和业务网关的分离,流量网关继续使用 OpenResty 定制,只保留少量全局性,不经常改动的配置功能和对应的 Lua 脚本。
业务网关使用 Vert.x实现的 Java 系统,部署在流量网关和后端业务服务系统之间,利用 Vert.x 的反应式编程能力和异步非阻塞 IO 能力、分布式部署的扩展能力,这样就初步解决了问题 1 和问题 2。
Vert.x 是一个基于事件驱动和异步非阻塞 IO、运行于 JVM 上的框架,如下图所示。在 Vert.x 里,Verticle 是最基础的开发和部署单元,不同的 Vert.x 可以通过 Event Bus 传递数据,进而方便的实现高并发性能的网络程序。关于 Vert.x 原理的分析可以参考阿里宿何的 blog:https://www.sczyh30.com/tags/Vert-x/
Vert.x 同时也很好的支持 Websocket 协议,所以可以方便的实现支持 REST API 和 Websocket、完全异步的网关系统。
一个高性能的 API 网关系统,缓存是必不可少的部分。无论是分发冷热数据,降低对业务系统的压力,还是作为中间数据源,为服务聚合提供高效可复用的业务数据,都发挥了巨大作用。而一个优秀、高效的缓存系统,也必须是需要针对所承载的业务数据特点,进行特定设计和实现的。
API 网关的日常监控
我们使用多种工具对 API 进行监控和管理,全链路访问跟踪、连接数统计分析、全世界重要国家和城市的波测访问统计。网关技术团队每时每刻都关注着数据的变化趋势。各个业务系统研发团队,每天安排专人关注自己系统的 API 性能,推进性能问题解决和持续优化。这就初步解决了问题 3。
推荐外部客户使用 Websocket
由于外部客户需要自己通过 API 网关调用 API 服务来集成业务服务能力到自己的系统,各个客户的技术能力和系统处理能力有较大差异,使用行为也各有不同。对于不断发展变动的交易业务数据,客户调用 API 频率太低则会影响数据实时性,调用频率太高则可能会浪费双方的系统资源。同时利用 Websocket 的消息推送特点,我们可以在网关系统控制客户接受消息的频率、单个用户的连接数量等,随时根据业务系统的情况动态进行策略调整。综合考虑,Websocket 是一个比 REST API 更加实时可靠,更加易于管理的方式。通过逐步协助和鼓励客户使用 Websocket 协议上,基本解决了问题 4。
API 网关的性能优化
API 网关系统作为 API 的统一接入点,为了给用户提供最优质的用户体验,必须长期做性能优化工作。
不仅 API 网关自己做优化,同时可以根据监控情况,时刻发现各业务系统的 API 服务能力,以此为出发点,推动各个业务系统不断优化 API 性能。
在此举一个具体的例子,某个网关系统发现连接经常剧烈抖动(如下图所示),严重影响系统的稳定性、浪费系统资源,经过排除发现:
针对如上分析,我们采取了几个处理方式:
优化前:
优化后:
对 API 网关的发展展望
经历接近一年的开发、三个候选版本,Redis 7.0终于正式发布,这是Redis历史上改变最多的一个大版本,它不仅包含了50多个新命令,还有大量核心新特性与改进,这些不仅能够解决用户使用中的诸多问题,还进一步拓展了Redis的使用场景。
Function是Redis脚本方案的全新实现,在Redis 7.0之前用户只能使用EVAL命令族来执行Lua脚本,但是Redis对Lua脚本的持久化和主从复制一直是undefined状态,在各个大版本甚至release版本中也都有不同的表现。因此社区也直接要求用户在使用Lua脚本时必须在本地保存一份(这也是最为安全的方式),以防止实例重启、主从切换时可能造成的Lua脚本丢失,维护Redis中的Lua脚本一直是广大用户的痛点。
Function的出现很好的对Lua脚本进行了补充,它允许用户向Redis加载自定义的函数库,一方面相对于EVALSHA的调用方式用户自定义的函数名可以有更为清晰的语义,另一方面Function加载的函数库明确会进行主从复制和持久化存储,彻底解决了过去Lua脚本在持久化上含糊不清的问题。
那么自7.0开始,Function命令族和EVAL命令族有了各自明确的定义:FUNCTION LOAD会把函数库自动进行主从复制和持久化存储;而SCRIPT LOAD则不会进行持久化和主从复制,脚本仅保存在当前执行节点。并且社区也在计划后续版本中让Function支持更多语言,例如JavaScript、Python等,敬请期待。
总的来说,Function在7.0中被设计为数据的一部分,因此能够被保存在RDB、AOF文件中,也能通过主从复制将Function由主库复制到所有从库,可以有效解决之前Lua脚本丢失的问题,我们也非常建议大家逐步将Redis中的Lua脚本替换为Function。
AOF是Redis数据持久化的核心解决方案,其本质是不断追加数据修改操作的redo log,那么既然是不断追加就需要做回收也即compaction,在Redis中称为AOF rewrite。
然而AOF rewrite期间的增量数据如何处理一直是个问题,在过去rewrite期间的增量数据需要在内存中保留,rewrite结束后再把这部分增量数据写入新的AOF文件中以保证数据完整性。可以看出来AOF rewrite会额外消耗内存和磁盘IO,这也是Redis AOF rewrite的痛点,虽然之前也进行过多次改进但是资源消耗的本质问题一直没有解决。
阿里云的Redis企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了Multi-part AOF机制来解决,同时也贡献给了社区并随此次7.0发布。具体方法是采用base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和IO资源的浪费,同时也支持对历史AOF文件的保存管理,结合AOF文件中的时间信息还可以实现PITR按时间点恢复(阿里云企业版Tair已支持),这进一步增强了Redis的数据可靠性,满足用户数据回档等需求。
对具体实现感兴趣的同学可以查看本文末尾参考资料。
Redis自2.0开始便支持发布订阅机制,使用pubsub命令族用户可以很方便地建立消息通知订阅系统,但是在cluster集群模式下Redis的pubsub存在一些问题,最为显著的就是在大规模集群中带来的广播风暴。
Redis的pubsub是按channel频道进行发布订阅,然而在集群模式下channel不被当做数据处理,也即不会参与到hash值计算无法按slot分发,所以在集群模式下Redis对用户发布的消息采用的是在集群中广播的方式。
那么问题显而易见,假如一个集群有100个节点,用户在节点1对某个channel进行publish发布消息,该节点就需要把消息广播给集群中其他99个节点,如果其他节点中只有少数节点订阅了该频道,那么绝大部分消息都是无效的,这对网络、CPU等资源造成了极大的浪费。
Sharded-pubsub便是用来解决这个问题,意如其名,sharded-pubsub会把channel按分片来进行分发,一个分片节点只负责处理属于自己的channel而不会进行广播,以很简单的方法避免了资源的浪费。

Redis 使用标准版本标记进行版本控制:major.minor.patchlevel。
偶数的版本号表示稳定的版本, 例如 1.2,2.0,2.2,2.4,2.6,2.8。
奇数的版本号用来表示非标准版本,例如2.9.x是非稳定版本,它的稳定版本是3.0。
Redis2.6在2012年正式发布,经历了17个版本,到2.6.17版本,相比于Redis2.4,主要特性如下:
1) 服务端支持Lua脚本。
2) 去掉虚拟内存相关功能。
3) 放开对客户端连接数的硬编码限制。
4) 键的过期时间支持毫秒。
5) 从节点提供只读功能。
6) 两个新的位图命令:bitcount和bitop。
7) 增强了redis-benchmark的功能:支持定制化的压测,CSV输出等功能。
8) 基于浮点数自增命令:incrbyfloat和hincrbyfloat。
9) redis-cli可以使用–eval参数实现Lua脚本执行。
10) shutdown命令增强。
11) info可以按照section输出,并且添加了一些统计项。
12) 重构了大量的核心代码,所有集群相关的代码都去掉了,cluster功能将会是3.0版本最大的亮点。
13) sort命令优化。
Redis2.8在2013年11月22日正式发布 经历了24个版本,到2.8.24版本,相比于Redis2.6,主要特性如下:
1) 添加部分主从复制的功能,在一定程度上降低了由于网络问题, 造成频繁全量复制生成RDB对系统造成的压力。
2) 尝试性地支持IPv6。
3) 可以通过config set命令设置maxclients。
4) 可以用bind命令绑定多个IP地址。
5) Redis设置了明显的进程名,方便使用ps命令查看系统进程。
6) config rewrite命令可以将config set持久化到Redis配置文件中。
7) 发布订阅添加了pubsub命令。
8) Redis Sentinel第二版,相比于Redis2.6的Redis Sentinel,此版本已经变成生产可用。
Redis3.0在2015年4月1日正式发布,截止到本书完成已经到3.0.7版本,相比于Redis2.8主要特性如下:
Redis3.0最大的改动就是添加Redis的分布式实现Redis Cluster,填补了Redis官方没有分布式实现的空白。Redis Cluster经历了4年才正式发布也是有原因的,具体可以参考Redis Cluster的开发日志
1) Redis Cluster: Redis的官方分布式实现。
2) 全新的embedded string对象编码结果,优化小对象内存访问,在特定的工作负载下速度大幅提升。
3) lru算法大幅提升。
4) migrate连接缓存, 大幅提升键迁移的速度。
5) migrate命令两个新的参数copy和replace。
6) 新的client pause命令,在指定时间内停止处理客户端请求。
7) bitcount命令性能提升。
8) config set设置maxmemory时候可以设置不同的单位(之前只能是字节),例如config set
maxmemory1gb。
9) Redis日志小做调整:日志中会反应当前实例的角色(master或者slave)。
10) incr命令性能提升。
Redis3.2在2016年5月6日正式发布,相比于Redis3.0主要特征如下:
1) 添加GEO相关功能。
2) SDS在速度和节省空间上都做了优化。
3) 支持用upstart或者systemd管理Redis进程。
4) 新的List编码类型:quicklist。
5) 从节点读取过期数据保证一致性。
6) 添加了hstrlen命令。
7) 增强了debug命令 支持了更多的参数。
8) Lua脚本功能增强。
9) 添加了Lua Debugger。
10) config set支持更多的配置参数。
11) 优化了Redis崩溃后的相关报告。
12) 新的RDB格式,但是仍然兼容旧的RDB。
13) 加速RDB的加载速度。
14) spop命令支持个数参数。
15) cluster nodes命令得到加速。
16) Jemalloc更新到4.0.3版本。
可能出乎很多人的意料,Redis3.2之后的版本是4.0,而不是3.4、3.6、3.8。一般这种重大版本号的升级也意味着软件或者工具本身发生了重大变革,直到本书截稿前,Redis发布了4.0-RC2,下面列出Redis4.0的新特性:
1) 提供了模块系统,方便第三方开发者拓展Redis的功能,更多模块详见:http://redismodules.com/。
2) PSYNC2.0:优化了之前版本中,主从节点切换必然引起全量复制的问题。
3) 提供了新的缓存剔除算法:LFU(Last Frequently Used),并对已有算法进行了优化。
4) 提供了非阻塞del和flushall/flushdb功能,有效解决删除bigkey可能造成的Redis阻塞。
5) 提供了RDB-AOF混合持久化格式,充分利用了AOF和RDB各自优势。
6) 提供memory命令,实现对内存更为全面的监控统计。
7) 提供了交互数据库功能,实现Redis内部数据库之间的数据置换。
8) Redis Cluster兼容NAT和Docker。
Redis 5.0在2018年10月正式发布,相比于Redis4.0主要特征如下:
1) 新的流数据类型(Stream data type) https://redis.io/topics/streams-intro
2) 新的 Redis 模块 API:定时器、集群和字典 API(Timers, Cluster and Dictionary APIs)
3) RDB 增加 LFU 和 LRU 信息
4) 集群管理器从 Ruby (redis-trib.rb) 移植到了redis-cli 中的 C 语言代码
5) 新的有序集合(sorted set)命令:ZPOPMIN/MAX 和阻塞变体(blocking variants)
6) 升级 Active defragmentation 至 v2 版本
7) 增强 HyperLogLog 的实现
8) 更好的内存统计报告
9) 许多包含子命令的命令现在都有一个 HELP 子命令
10) 客户端频繁连接和断开连接时,性能表现更好
11) 许多错误修复和其他方面的改进
12) 升级 Jemalloc 至 5.1 版本
13) 引入 CLIENT UNBLOCK 和 CLIENT ID
14) 新增 LOLWUT 命令 http://antirez.com/news/123
15) 在不存在需要保持向后兼容性的地方,弃用 “slave” 术语
16) 网络层中的差异优化
17) Lua 相关的改进
18) 引入动态的 HZ(Dynamic HZ) 以平衡空闲 CPU 使用率和响应性
19) 对 Redis 核心代码进行了重构并在许多方面进行了改进
Redis 6.0在2020年5月正式发布,相比于Redis5.0主要特征如下:
1)ACL权限管控(包括ACL LOG)
2)客户端缓冲(Client side caching)
3)多线程 IO(Threaded I/O)
4)Redis集群代理
5)支持linux/bsd系统的CPU和线程(包括子线程如aof\rdb\IO线程)亲和力绑定
6)过期Key回收优化,新增主动配置参数
7)Resp3协议,兼容Resp2并更加简单、高效
8)优化了INFO命令,使之执行更快,优化了所有的阻塞命令,复杂度从O(n)到O(1),RDB加载速度优化,集群Slots命令优化,Psync2优化,修复了5.0的链式复制不一致问题。defrag优化,从试验版到正式版
9)新的module API
10)disque消息队列模块(module)
11)新增配置使Del命令如unlink执行
12)XINFO STREAM FULL流命令
13)CLIENT KILL USER username命令
14)全面支持SSL协议、并新增TSL协议
15)Redis-benchmark支持集群模式
16)重写 Systemd 支持
17)新增配置参数来删除用于在非持久性实例中进行复制的RDB文件
18)无磁盘复制副本(Diskless replication on replicas),从测试版优化,目前无磁盘复制在load
rdb仍是测试版。
Redis 7.0 RC1 于 2022 年 1 月 31 日发布,主要特性如下
1)Redis 函数:使用服务器端脚本扩展 Redis 的新方法
2) ACL:细粒度的基于密钥的权限,允许用户支持多个带有选择器的命令规则集
3) 集群:分片(特定于节点)发布/订阅支持
https://redis.io/topics/pubsub#sharded-pubsub
4) 在大多数情况下对子命令的一流处理
5) 命令元数据和文档 [https://redis.io/commands/command-docs,
https://redis.io/topics/command-tips](https://redis.io/commands/command-docs, https://redis.io/topics/command-tips)
6)命令键规格。一种更好的方式让客户找到关键论点及其读/写目的
https://redis.io/topics/key-specs
7)多部分 AOF 机制避免 AOF 重写开销
8)集群:支持主机名,而不仅仅是 IP 地址
9)改进了对网络缓冲区消耗的内存的管理,以及一个选项当总内存超过限制时删除客户端
10)Cluster:一种断开集群总线连接的机制,以防止不受控制的缓冲区增长
11)AOF:时间戳注释和对时间点恢复的支持
12)Lua:支持 EVAL
脚本中的函数标志https://redis.io/topics/eval-intro#eval-flags
13)Lua: 支持 Verbatim 和 Big-Number 类型的 RESP3 回复
14)Lua: 通过 redis.REDIS_VERSION, redis.REDIS_VERSION_NUM 获取 Redis 版本
“最重要的是选择,最困难的是坚持。”
我是在 2014 年入职饿了么,从前端和 PHP 一直做到后端架构和团队,从 2014 年到 2017 年陆续负责过公司客服、销售、代理商、支付、清结算、订单这些业务的产研与团队;2018 年从业务研发团队抽身,6 个人组起一个小组投身机器学习,试图结合实际的业务场景通过技术改造业务;2019 年回归到平台(中台)研发,负责交易、金融、营销三个中台的研发和团队工作。基于我在饿了么4年和阿里巴巴 2 年研发经历,从技术、业务、管理和架构层面分享一些我的思考。
技术层面
对开发同学而言,技术是立身之本,虽然往往面试造火箭入职拧螺丝,但不可否认的是,技术就是你从业的的基石。不管是基本的动手能力还是问题分析能力,包括你的思维逻辑乃至对事物认知的能力,技术思维都会时刻影响你。最明显的影响就是当你面对无数个问题的钉子时,技术是不是你最顺手的那把锤子。
技术上我比较关注的几个层面:
1、稳定性
稳定性是一个先有意识再有能力的事儿。记得在 2015 年年初,张雪峰加入饿了么担任 CTO 之后,从他嘴里最常听到的一句话就是“研发要对生产环境有敬畏”。
2014年下半年,各方人马开始杀入外卖市场,饿了么启动百城计划进行业务扩张,短时间内从10+城市覆盖到100+城市,日订单量也很快从10万上涨到100万。业务井喷的同时,技术还没有做好足够的准备。我印象中,2014年下半年几乎每天中午交易量都有新高,但同时也伴随着系统宕机、限流扩容、紧急调优、客服爆线、技术加班熬夜的问题。
我曾在新乡的客服中心看到有的客服同学突然崩溃,耳机直接摔下来离开工位,因为每天会接收到大量用户的来电责问,就在那一刻其实你才会清晰且直观的感受到:你在编辑器的每一行代码,你在服务器的每一次发布,会对现实世界很多活生生的人有直接的影响,你会突然意识到你的工作比你之前以为的要重要且有意义。
所谓研发要对生产环境有敬畏,就是你知道你的作品会对别人产生不好的影响,你会为不好的结果感到惭愧与内疚,这就产生了敬畏。应急处理有一个基本原则:“以业务影响最小为主,优先恢复为核心目的,不要纠结手段和根因。”
别把你的懊悔、决心、对稳定性的思考、各种奇妙的idea以及执行力体现在事故复盘会上,系统的安全生产和火灾一样,事前才有意义。
2 、链路设计
大部分产研缺少全链路的视角,往往看到的是自己负责的点,但是对于一条线乃至整个面是看不到的,也没有机会去思考这些,而对于一些大项目和长链路系统而言,这是致命的。
我的建议是,对你所负责的系统,它关键的上下游、核心业务的链路一定要熟悉,包括数据、接口(调用、功能、逻辑)、各种异常的处理和特殊的设计。能帮你达成这一目的的最简单的办法就是画图、画图、画图!重要的结论说三遍,一定要自己能把系统的大图画出来,然后做到可以根据大图随意放大和缩小。放大到将链路画到业务场景里,突出业务逻辑和上下游交互,缩小到某一次调用的处理逻辑大致是怎样,数据是怎么变化。
经常画图,不用纠结形式和标准,重要的是形成自己理解系统的一个框架,一个自己的思维方式,需要的时候可以随时拿出来用。
日常不管是聊需求还是做系统设计,习惯性的把图画出来,就达成了一半。剩下的一半就要看图去想、去找问题。
3、技术债务
永远不要骗自己说,现在为了这个需求先挖一个坑,过一段时间再来填(重构 or 重做)。
技术债务和金融债务一样,它必然存在,并且会像无赖一样一直赖着,隔三差五会爆发一下。随着时间的推移和业务的发展,你会发现架构越来越混乱,不同系统的领域边界越来越模糊,系统和需求与组织关系的映射越来越复杂,服务内编码风控越来越不一致,重复的轮子一个接一个隐蔽的出现。
“太忙了没时间梳理哪些问题”、“改那些问题需要上下游一起改,费时费力,推不动”、“现在还没出问题,而且正在整理了,别催”。这是我们经常会听到的声音。其实,技术同学多少都有点代码洁癖,有很多问题不处理不是主观的原因,而是客观上因为精力、时间、ROI等因素,往往要等问题真的爆发后,大家才能狠下心去处理那些问题 。
我以前处理技术债务的思路,是要有一个检查清单,我会定期的复盘所有的系统,并且结合自己团队和其他团队的事故去全量扫雷。系统本身是一个平衡的产物,是时间、功能、风险、未来可能性等几个方向平衡的结果。所以技术债务对于研发同学的考验,不在于你怎么在日常工作中保证系统技术债为0,而是你要评估清楚在有限的资源和时间下,哪些问题是刻不容缓的,哪些问题是可以往后放的。
很难想象一个没有技术追求的团队能开发出一个健壮的、可维护性好、可扩展性好的系统。相反,这种业务代码的堆砌,从短期看也许是“较快”实现了业务需求,但是从长远来看,这种烂系统的增加会极大地阻碍业务的发展,形成一个个的黑洞应用,而工程师被裹挟在业务需求和烂系统之间,疲于应对,心力交瘁。这种将就将导致系统腐化堕落,技术债越垒越高,丑陋的代码疯狂滋长,像肿瘤一样消耗你所有的能量,最后还要你的命。
4、警惕大项目
并不是所有人都有能力操盘大项目,也不是所有人都能够平衡好交付压力、上线质量、产品逻辑以及时间窗口,这是一个非常有挑战的工作,需要纯粹的技术能力之外的很多软性能力来辅助,比如组织的沟通协作能力、向上要权要责的能力、平衡产品业务期望的的能力、突发情况应急转变的能力等。越大的项目对于Owner的要求也越高,真能把大项目做好不怎么留大坑的少之又少。
大项目从启动到立项所用的时间很多时候是远超项目实际的开发周期的,项目的顺利推进需要“妥协”,但项目的成功需要坚持。很多项目之所以失败,是在做的过程中方方面面不断妥协,最后做出来的东西已经远离了最开始想要的样子。
业务层面
除了技术之外,研发同学对业务层面也需要提升认知与重视。
对于研发而言,业务就像是外语,你不理解业务就好比人在异国,与周围的环境格格不入,并且容易吃亏!相比产品、业务、运营等其他工种,技术更喜欢和技术打交道,业务在大多数同学眼中是混沌且缺少秩序的,没有技术那样清晰的实现路径和稳定共识的知识结构。并且技术相对容易证伪,而业务往往就是不停的尝试,研发都讨厌“不确定性”。但是在一个庞大的组织里想把技术做好,就必然要与业务打交道,毕竟业务才是一家公司存在的核心价值。
1、基于业务规划做技术规划
很多同学习惯于把计划等同于规划。阿里是一家尊重技术的商业公司,所有的团队都在谈业务、规划里是业务规划、周报里是业务项目、汇报里是业务成果、晋升的时候也要突出你的“战功”。相比技术本身,大家更关注技术改变了什么,在业务部分聊技术团队如何做规划的原因就在于此,这是公司运营的的起点(目的),延伸出来才有具体的技术规划和组织设计作为解决方案。
深刻理解业务并设计战略,拆解战役与项目,通过组织和各种机制确保项目的执行与落地,最终拿到业务结果,这是一个大公司的标准战略执行方式。研发同学做技术规划以及团队规划的时候,一定要考虑到你所在环境,公司今年要主打什么,所在大部门的目标是什么,对口的产品和业务现状如何,纯粹的技术迭代在业务上的好处在哪儿。另外,团队目前有哪些不可抗力,或者影响规划推进的阻力。
很多同学做规划的时候会习惯性按照这个思路进行:①总结现状(痛点) ② 对应的解决方案和策略 ③ 展望未来。有时候②和③的顺序会反过来。很多时候大家发现最终的部门规划和自己做的规划没什么关联,不知道怎么往哪个方向用力,或者干脆继续按照自己的计划先走着。
对大部分同学,我建议规划要实在。做技术规划前,找你周边的研发团队聊一下,找你对口的产品、运营聊一下,知道他们的目标是什么,知道公司几个重点是什么,然后结合你们目前的痛点,在现在和未来之前找平衡、找现在和未来都有收益的那部分。
规划中需要包含一些硬性的内容,比如这个目标要解决什么问题,怎么确定它解决了,解决得好不好,好的结果谁认可等。规划一定要有重点,没有重点那不叫规划,那是日程计划。很多同学对做规划不投入,也有自己的“想法”,比如公司业务或者战略变化太快、组织调整太频繁,下半年在哪个团队工作甚至做什么都不一定,所以规划做得并不认真。不否认变化频繁的存在,以及这种组织架构变化对规划的影响,但是如果你一直这样思考,你永远无法从变化中获得价值,因为你一直在置身事外。
2、研发要比产品还懂业务
雷军说过:“永远不要试图用战术上的勤奋,去掩盖你战略上的懒惰。”对于研发同学,你要比业务同学更懂业务,才能找到技术与业务平衡的空间。对大部分同学而言,常常是只熟悉自己负责的系统,但是对于想要更大空间和更多成长的同学,我可以给出明确的结论:只熟悉自己负责的系统是不够的。
首先,不同的人对熟悉的定义不一样。对于你负责、你贡献代码、你进行设计并且完成需求交付的系统,单是熟悉远不够。你不仅要知道它的前世今生,思考它的一路成长,纠结它的未来发展,同时还要清楚它的风险与隐患,它的生与死。
基于你最清楚的核心系统,由它开始做业务场景上的外延,以此了解你的上下游,并且能做到结合业务场景去挖掘。从业务的角度、从产品的链路、从技术的调优和隐患多个视角去切,让自己的设计维度与视角不断拉升,这样你有把握或者有掌控力的范围会越来越大,未来才会有更多的机会。
管理层面
团队是一个宏观与微观并存的事物,宏观上我们说组织、讲战略、定规划、要排兵布阵,微观上我们关注沟通、成长、情绪。大部分同学之所以在微观上受挫,就是因为没能把握到宏观的节奏。公司是一个盈利组织,技术中心是一个成本部门,技术中心之所以会有某一个组织,那么一定是:“公司期望这个组织解决某一类问题,并且解决到一定程度。”
所以在这里你要理解一个关键词,“结果和KPI”并不取决于你怎么定义它,而是给你下放目标的组织与管理者对你的期望是怎样的,你们的GAP往往未必是结果的差别,而是期望的落差。
1、拥抱变化
其实大多数时候不需要你去拥抱,变化会突如其来的抱住你,勒紧你的脖子让你有那么一瞬间觉得呼吸困难。互联网公司之所以变化快,很大程度取决于它的业务属性,相比传统公司,互联网公司能更快、更清晰地感受到与市场的契合程度,并且及时调整策略。
结合这几年的经历,到最近两年加入阿里巴巴,我的核心感悟有两个:
2、加人不能解决问题
即使嘴上再怎么说“不能”,但是动作会很诚实,依然会尽可能多地要HC,希望把更多“核心”的系统建设在你的职责范围内。其实,从管理的角度,你可以看一下你有没有“有效加人”,一些技术Leader不关注新人的 Landing ,相当于只盯数量不盯质量,最后结果肯定是一塌糊涂的。
从绝对理论的角度,加人肯定是有帮助的,你的资源变多了,周转的空间和操作的余地都丰富了。但是从经验看,大部分情况下,加人没有产生最终的价值变化(项目的结果、业务的成败)。因为系统的开发、项目的推进并不是单纯的资源堆砌,1000 人日的系统哪是 1000 个人做一天就做出来的。真实的世界里,我们往往不是败在资源的使用量上,而是资源的使用方向和使用效率上。
3、有意识地向上管理
这个问题源于过去经历的两个点:一是我经历了无数次的组织关系调整,我发现不管是我自己还是我团队的同学,大家相比于自己做什么以及带不带人、带多少人外,更关注的是自己的汇报线。自己汇报给谁,谁是我Leader,我和他处不处得来,他能不能让我有提高、有成长。二是很多同学会对与Leader的相处关系有困惑。
基于这两个点,我把向上管理作为一个单独的话题加了进来,先说结论:要!要!要!必须要!一定要!
连马老师都说员工离职的三大要素之一就是和Leader处不来,你怎么还能心安理得的忽略它。如果大家对于向上管理还停留在服从甚至谄媚的态度来处理你们的关系,我只能说太稚嫩了。我没有系统地学过向上管理,也没有体系化地看过这方面的书,所以我只说一下自己的理解。
个体在一个组织里想得到报酬和收益,基本的方法就是促进组织的成长与提高,并且同步提高自己,这样就可以从中分得自己的那份收益。这就要求你产出的结果是要对组织有正向溢出的,但是这个方向与标准并不是所有人都清楚或者能准确地把握到。
经常有绩效差的同学很沮丧甚至抱怨说自己经常加班,甚至是部门走的最晚的,周末也要处理工作等。先不讨论背景,如果命中上面这一条的,我先给你个忠告:除了按件计费的工厂,其它任何地方体力上的付出与最终结果都没有明显的直接关系。就像你上学的时候一定有那么几个别人家的孩子,要么就是特别努力学习特别好,要么就是看上去每天和你一起玩,但是成绩总是碾压你。从学校到社会,这个现象并没有消失,别迷信加班和体力上的付出,大多数人只要能不去思考,在体力上愿意做出的付出,远超你我的想象。
与Leader相处和沟通,本质上是为了达成一致的目标和互相认可的结果。这是一个非常关键的初衷,我有时候开玩笑和团队的同学聊,说你们要好好看看我的Leader到底想干嘛,这样你们做出来,我好去汇报。方向、节奏、结果的对焦对于工作的展开和拿成绩是至关重要的,同时你要从他身上获取更多的信息以便于自己的判断决策和学习,不断从他们身上吸取养分。
在一些环境中,体力上的付出是必须的,但是仅有体力上的付出最终只能感动你自己,你的团队并不想每天陪你加班到11点或者发布到凌晨2点,更没有兴趣凌晨1点半还拉个电话会讨论方案。所以一定要做好“期望管理”,Leader对你的期望、对项目的期望、你对他给予你空间和支持的期望,大家一定要对焦清楚,并且目标一致。
架构层面
还有一点我觉得也很重要,就是在架构层面,包括业务架构、技术选型和细节实现上,要有清醒的认知。
1、最关键的是定义问题
爱因斯坦说过:“提出问题比解决问题更重要!”定义问题是个脑力活,解决问题是个体力活。大家往往习惯于看到一个问题就冲上去锤它,从概率上来讲,很大可能会陷入一个解决问题的黑洞,就是你不停地在解决问题,但是最终你的情况没有变好。
当你面临一个困难或者一个情况时,首先比较重要的是定义问题,这到底是要解决什么、解决了有什么好处、怎么确定解决了。其次是定义结构,这个问题的关键点组成,你对应的解法是怎样的,这其中得失要怎么权衡轻重,并且最终解决的效果如何贯穿和透传,由点及面。
一个团队可以不停歇的埋头干,但是未必会干出成绩。大部分习惯罗列面对的问题,但是对这些问题并没有做一个全局的分析和梳理,其实最难的就在“找问题”上。
2、问题的本质没那么高深
有时我们做一个项目,可能有一个产品需求,大家看完觉得不好做或者做不了,因为系统现在不支持,改造成本太高,并且还伴有很多不确定的技术风险。相信很少有人在这种情况下会无脑的要求加人、加工期来解决这个问题。大多数情况下我们会看有没有捷径或者其他方案,让产品效果达成,哪怕技术实现脏一些、绕一些。
其实这时候横向纵向多挖一下或者多问几个问题,有可能就会有不一样的答案。这个需求在解决用户什么问题,目前这个解决方案是不是业务(产品、技术)上唯一的,这个解决方案会带来哪些成本和新的问题,目前正在推进的其他项目和这个问题会不会有关联,有没有其他团队也在解决类似的问题或者曾经解决过。
3、达成目标
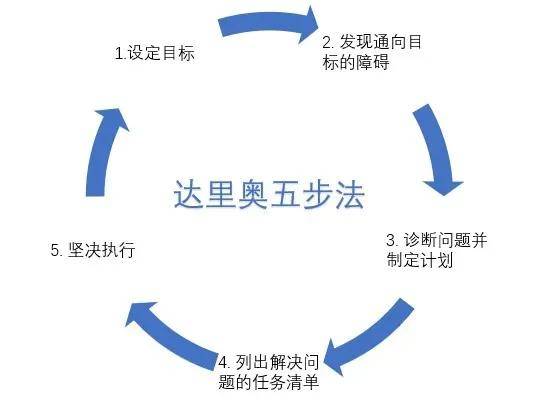
在工作中小到聊定一个API契约、中到上线一个需求、大到完成一次晋升,所有的事情都是有成功的方法的。找出短板、设定计划、抗住挫折、反复训练、根据反馈调优,就可以解决任何问题。《债务危机》的作者——桥水基金 CEO 达里奥总结了一个五步成功法,很有意思:
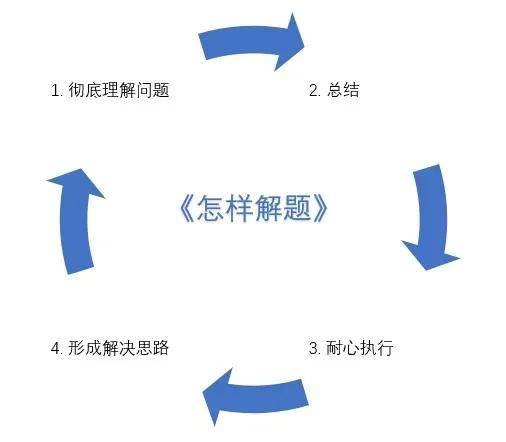
著名的大数学家波利亚有一本名著《怎样解题》,其中给了一个四步解题法,可能站在研发的角度看会更有感觉:
4、持续学习才是根本
时代在持续发展和变化,现在正是波澜壮阔的年代,在这样的环境下,不管当前如何积累,都有可能随着发展的变化在短时间跌落谷底。公司能发展,一定是在某一个时期内非常契合环境的要求,但随着时间的变化,如果它的变化不能跟上来,那么也只会被时代抛弃。正所谓让你成功的,最终也将让你失败,比如柯达、诺基亚不能幸免,个体也难逃这样的规律。
这样的情况下,持续的学习和改变自身的能力才是研发同学最大、也是最强的优势。技术本身的日新月异要求你持续学习,同样的习惯放射到各个领域上,才会慢慢的取长补短,优化自身,所以如果说研发同学最需要什么,我认为持续的学习能力是最关键的。
正如饿了么创始人汪渊在之前接受采访时有一句话,让我很难忘:最重要的是选择,最困难的是坚持。
作者丨石佳宁
来源丨公众号:阿里巴巴中间件(ID:Aliware_2018)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:[email protected]
最近在梳理 MySQL 8.0 的新特性,以下是从中选取的 18 个管理相关的新特性。
这 18 个新特性涉及的范围比较广,包括安装、备份、升级、DDL、慢日志、迁移、日常维护等。
掌握这些新特性有助于我们更好地使用 MySQL 8.0。
持久化后的变量会存储在数据目录下的 mysqld-auto.cnf 文件中。
以下是持久化变量相关的命令。
# 持久化变量,同时修改变量的内存值。
SET PERSIST max_connections = 2000;
# 只持久化变量,不修改变量的内存值,适用于只读参数的调整。
SET PERSIST_ONLY back_log = 2000;
# 从 mysqld-auto.cnf 中删除所有持久化变量。
RESET PERSIST;
# 从 mysqld-auto.cnf 中删除指定的变量。如果变量不存在,会报错。
RESET PERSIST system_var_name;
# 从 mysqld-auto.cnf 中删除指定的变量。如果变量不存在,会提示 warning,不报错。
RESET PERSIST IF EXISTS system_var_name;
持久化后的变量即可在 mysqld-auto.cnf 中查看,也可通过 performance_schema.persisted_variables 查看。
管理 IP 通过 admin_address 参数设置,管理端口通过 admin_port 参数设置。
管理连接的数量没有限制,但仅允许具有 SERVICE_CONNECTION_ADMIN 权限的用户连接。
默认情况下,管理接口没有自己的独立线程,可将 create_admin_listener_thread 设置为 ON 开启。
建议设置管理 IP 和端口,这样即使连接数满了,也不用担心登陆不上实例去调整 max_connections 的大小。
从 MySQL 8.0.16 开始,MySQL 针对通用二进制包(Linux - Generic)提供了一个最小化版本。
最小化版本移除了 debug 相关的二进制文件。
MySQL 8.0.31 普通版本(mysql-8.0.31-linux-glibc2.12-x86_64.tar.xz)包的大小是 576.8 MB,而最小化版本(mysql-8.0.31-linux-glibc2.17-x86_64-minimal.tar.xz)只有 57.4 MB。后者大小只是前者的 9.95 %。
从 MySQL 8.0.31 开始,通用二进制包还提供了 Linux - Generic (glibc 2.17) (ARM, 64-bit) 版本的下载。
资源组,可用来控制组内线程的优先级及其能使用的资源,目前,能被管理的资源只有 CPU。
# 创建资源组
CREATE RESOURCE GROUP Batch
TYPE = USER # 资源组的类型,可设置USER(用户资源组),SYSTEM(系统资源组)。
VCPU = 0-1 # 设置 CPU 亲和性,让线程运行在指定的 CPU 上。不设置,则默认会使用所有的 CPU。
THREAD_PRIORITY = 10; # 设置线程优先级,有效值是-20(最高优先级)到19(最低优先级)。不设置,则默认为0。对于系统资源组,可设置的优先级范围是-20到0,对于用户资源组,可设置的优先级范围是0到19。
以下是资源组的几种常用方式。
SET RESOURCE GROUP Batch FOR 702,703; # 将指定线程分配给资源组。702 是线程ID,对应 performance_schema.threads 中的 THREAD_ID。
SET RESOURCE GROUP Batch; # 将当前会话的线程分配给资源组
SELECT /*+ RESOURCE_GROUP(Batch) */ COUNT(*) FROM sbtest.sbtest1;
设置为只读模式的库将禁止任何更新操作。适用于数据库迁移场景。
# 将 mydb 设置为只读模式
ALTER DATABASE mydb READ ONLY = 1;
# 关闭只读模式
ALTER DATABASE mydb READ ONLY = 0;
SHOW PROCESSLIST 默认是从线程管理器中获取线程信息。这种实现方式会持有全局互斥锁,对数据库的性能会有一定的影响。
所以一般都推荐使用 performance_schema.processlist,这种方式不会持有全局锁。
在 MySQL 8.0.22 中,引入了 performance_schema_show_processlist 参数,用来设置 SHOW PROCESSLIST 的实现方式。设置为 ON,则会使用 performance_schema.processlist 这种实现方式,默认为 OFF。
在 MySQL 8.0.27 中,引入了 innodb_ddl_threads 和 innodb_ddl_buffer_size 提升索引的创建速度。
从 MySQL 8.0.12 开始,Online DDL 开始支持 INSTANT 算法。
使用这个算法进行加列操作,只需修改表的元数据信息,操作瞬间就能完成。不过在 MySQL 8.0.29 之前,列只能添加到表的最后位置。
从 MySQL 8.0.29 开始,则移除了这一限制,新增列可以添加到表的任何位置。
不仅如此,从 MySQL 8.0.29 开始,删列操作也可以使用 INSTANT 算法。
这个优化是 MySQL 8.0.23 引入的。在之前的版本中,这些操作会遍历整个 Buffer Pool,删除对应表(或表空间)的数据页。在遍历的过程中,会加锁(latch)。加锁期间,会阻塞所有的 DML 操作。
注意,阻塞时间与 Buffer Pool 的大小有关,与表的大小无关。Buffer Pool 越大,遍历时间会越长,相应的,阻塞时间也会越久。
优化后,待删除的数据页会做异步处理。
从 MySQL 8.0.27 开始,通过 ps 命令可以直接查看 MySQL 的线程名。
# ps -p 22307 H -o "pid tid cmd comm"
PID TID CMD COMMAND
22307 22307 /usr/local/mysql/bin/mysqld mysqld
22307 22316 /usr/local/mysql/bin/mysqld ib_io_ibuf
22307 22318 /usr/local/mysql/bin/mysqld ib_io_log
22307 22319 /usr/local/mysql/bin/mysqld ib_io_rd-1
22307 22331 /usr/local/mysql/bin/mysqld ib_io_rd-2
...
从 MySQL 8.0.28 开始,引入了 connection_memory_limit 参数限制单个用户连接可以使用的最大内存量,global_connection_memory_limit 参数限制所有用户连接可以使用的内存总量。
mysql> SELECT LENGTH(GROUP_CONCAT(f1 ORDER BY f2)) FROM t1;
ERROR 4082 (HY000): Connection closed. Connection memory limit 2097152 bytes exceeded. Consumed 2456976 bytes.
注意,这里说的内存不包括 InnoDB Buffer Pool。
在 MySQL 8.0.14 中,引入了 log_slow_extra 参数,可以将更详细的信息记录到慢日志中。
看下面这个示例,对比下参数开启前后的输出。
# Time: 2022-12-11T08:19:52.135515Z
# User@Host: root[root] @ localhost [] Id: 660
# Query_time: 10.000188 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1
SET timestamp=1670746782;
select sleep(10);
# Time: 2022-12-11T08:20:54.397597Z
# User@Host: root[root] @ localhost [] Id: 662
# Query_time: 10.000194 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 1 Thread_id: 662 Errno: 0 Killed: 0 Bytes_received: 23 Bytes_sent: 57 Read_first: 0 Read_last: 0 Read_key: 0 Read_next: 0 Read_prev: 0 Read_rnd: 0 Read_rnd_next: 0 Sort_merge_passes: 0 Sort_range_count: 0 Sort_rows: 0 Sort_scan_count: 0 Created_tmp_disk_tables: 0 Created_tmp_tables: 0 Start: 2022-12-11T08:20:44.397403Z End: 2022-12-11T08:20:54.397597Z
SET timestamp=1670746844;
select sleep(10);
除此之外,SET timestamp 现在记录的是语句的开始时间,不再是语句的结束时间。
在 MySQL 8.0.30 中,mysqldump 新增了 --mysqld-long-query-time 选项,允许自定义 long_query_time 的会话值。
这样可避免将备份相关的查询语句记录在慢日志中。
克隆插件(Clone Plugin)是 MySQL 8.0.17 引入的一个重大特性。
有了克隆插件,只需一条命令就能很方便地添加一个新的节点,无论是在组复制还是普通的主从环境中。
克隆插件的具体用法及实现细节可参考:MySQL 8.0 新特性之 Clone Plugin
注意,引入备份锁是为了阻塞备份过程中的 DDL,不是为了替代全局读锁。
之所以 XtraBackup 8.0 及 MySQL Enterprise Backup 在备份的过程中不再加全局读锁,主要是因为 performance_schema.log_status 的引入。
数据库升级无需再执行 mysql_upgrade 脚本。升级逻辑已内置到 mysqld 的启动流程中。
升级之前,可通过 MySQL Shell 中的 util.checkForServerUpgrade() 检查实例是否满足升级条件。
mysql 客户端默认会开启 --binary-as-hex。
开启后,mysql 客户端会使用十六进制表示法显示二进制数据。例如,
mysql8.0> SELECT UNHEX(41);
+----------------------+
| UNHEX(41) |
+----------------------+
| 0x41 |
+----------------------+
1 row in set (0.00 sec)
mysql5.7> SELECT UNHEX(41);
+-----------+
| UNHEX(41) |
+-----------+
| A |
+-----------+
1 row in set (0.00 sec)
如果要禁用十六进制表示法,需设置 --skip-binary-as-hex。
能使用 RESTART 命令的前提是 mysqld 是通过 mysqld_safe 或 systemctl 等守护进程启动的。
mysql> restart;
ERROR 3707 (HY000): Restart server failed (mysqld is not managed by supervisor process).
收录于合集 #MySQL
本文摘自《深入分布式缓存》。
本章和大家分享一下同程凤凰缓存系统在基于Redis方面的设计与实践。在本章中除了会列举我们工作过程中遇到各种问题和误区外,还会给出我们相应的解决办法,希望能够抛砖引玉为大家带来一定的启示。
2012~2014年,我们的业务开始使用一种新的互联网销售模式——秒杀抢购,一时间,各个产品线开始纷纷加入进来,今天秒杀门票,明天秒杀酒店,等等。各种活动是轮番登场,用户在不亦乐乎地玩着秒杀活动的同时,也对后端技术的支撑提出了一波又一波的挑战。
在第一个秒杀抢购系统上线后不久,流量越来越大,发现不对了:只要秒杀抢购一开始,卡顿、打不开的故障就会此起彼伏。一旦故障所有人都急得直跳脚,因为秒杀抢购流量一下而过,没有机会补救。其实问题也很简单,一个有点经验的兄弟就很快定位出来:抢购那一下太耗费服务器资源,在同一时间段内涌入的人数大大超过了服务器的负载,根本承受不了,CPU占用率很多时候都接近了100%,请求的积压也很严重,从请求接入到数据的读取都有问题,尤以数据的读取更为严重。在原来的设计方式中虽然也考虑了大并发量下的数据读取,但是因为数据相对分散,读取时间相对拉长,不像秒杀抢购是对同一批或一条的数据进行超高并发的读取。当然秒杀抢购不仅仅是数据的读取集中并发,同时也是数据写入的集中并发。
问题是发现了,表面上看起来解决没那么简单。应用层的问题解决起来相对容易,实在不行多加点机器也能解决;但数据的问题就不是那么简单了,靠增加机器来解决是不行的。大部分关系型数据库没有真正的分布式解决方案,最多做一个主从分离或多加从库分担读取的压力,但因为秒杀抢购是数据集中式超高并发的读,所以一般的关系型数据库因为它本身局限性很难支撑这样瞬间突发的高并发,就算勉强顶上,也会因为秒杀抢购还有写的高并发,影响到读节点的数据同步问题。当然也可以拼命提升一下服务器的硬件性能,比如换最好的CPU,把硬盘换成SSD等等,但效果应该是不会太显著,没有解决本质的问题,还比较费钱。
其实寻找新的解决方案也很简单,因为在当时那个年代的开源社区中有很多的NoSql明星产品——例如:Redis等等方案,这些方案也都提供了丰富的数据类型,拥有原子性操作和强大的并发性能特性,感觉简直就是为抢购量身定做的。于是我们也居于此做了一些方案,例如:数据在抢购活动开始前被先放到NoSql数据库里,产生的订单数据先被放到队列中,然后通过队列慢慢消化……这一系列的操作解决了抢购的问题,这里主要不是讲抢购技术方案,我们不再细化下去。
其实这样的解决方案在技术蛮荒时代还是相对靠谱的,在我们技术强壮的今天,这个方案还是单薄和弱小了一些,但是所有的技术点都是这样一路走来的,下面我们来看下,从弱小走向长大,经历了哪些。
从运维角度来想,Redis是很简单的东西,安装一下,配置一下,就轻松上线,再加上Redis的一些单进程、单线程等的特性,可以很稳定的给到应用层去随便使用。就像早期的我们,在很短的时间内,Redis实例部署超过了千个以上,用的多了真正的问题开始出现。什么问题?乱的问题,Redis从使用的角度来讲是需要像应用服务一样去治理的。为什么是需要治理的。我们先来看一些常见的运维与开发聊天记录,大家会不会有一些风趣的感觉:
开发:“Redis为啥不能访问了?”
运维:“刚刚服务器内存坏了,服务器自动重启了。”
开发:“为什么Redis延迟这么久?”
运维:“大哥,不要在Zset里面放几万条数据,插入排序的后果很严重啊!”
开发:“我写进去的key呢,为什么不见了?”
运维:“你的Redis超过最大大小了,不常用key的都丢了呀!”
开发:“刚刚为啥读取全部失败了?”
运维:“刚刚网络临时中断了一下,slave全同步了,在全同步完成之前,slave的读取全部失败。”
开发:“我刚刚想到一个好方案,我需要800GB的Redis,什么时候能准备好呢?”
运维:“大哥,我们线上的服务器最大也就256GB,别玩这么大好吗!”
光看这么一小点就感觉问题很多了,开发和运维都疲于奔命地解决这些看上去很无聊的问题。这些问题从本质上来讲还只是麻烦,谈不上困难。但是每当这些麻烦演变成一次Redis的故障时,哪怕是小故障,有时也会造成大痛苦,因为毕竟保存在内存里的数据太脆弱了,一不小心数据就会全部消失了。为此,当时也是绞尽脑汁,想了很多种办法:
单机不是不安全么?那么就开启主从+Keepalived,用虚IP地址在master和slave两边漂移,master挂了直接切换到slave。
数据放内存不是不安全么?可以开启数据落盘,根据业务需要决定落盘规则,有AOF的,也有RDB的。
使用上不是有问题么?那么多开几场培训,跟大家讲讲Redis的用法和规范。
还有很多已记不大起了
以上策略在当时似乎很完美吗,但是没多久,均宣告失败,这也必然的。
为什么呢?先看那个主从+Keepalived的方案,这本来是个很好的方案,但是忽略了主数据节点挂掉的情况。我们在前面说过,Redis的单进程、单线程设计是其简单和稳定的基石,只要不是服务器发生了故障,在一般情况下是不会挂的。但同时,单进程、单线程的设计会导致Redis接收到复杂指令时会忙于计算而停止响应,可能就因为一个zset或者keys之类的指令,Redis计算时间稍长,Keepalived就认为其停止了响应,直接更改虚IP的指向,然后做一次主从切换。过不了多久,zset和keys之类的指令又会从客户端发送过来,于是从机上又开始堵塞,Keepalived就一直在主从机之间不断地切换IP。终于主节点和从节点都堵了,Keepalived发现后,居然直接将虚IP释放了,然后所有的客户端都无法连接Redis了,只能等运维到线上手工绑定才行。
数据落盘也引起了很大的问题,RDB属于非阻塞式的持久化,它会创建一个子进程来专门把内存中的数据写入RDB文件里,同时主进程可以处理来自客户端的命令请求。但子进程内的数据相当于是父进程的一个拷贝,这相当于两个相同大小的Redis进程在系统上运行,会造成内存使用率的大幅增加。如果在服务器内存本身就比较紧张的情况下再进行RDB配置,内存占用率就会很容易达到100%,继而开启虚拟内存和进行磁盘交换,然后整个Redis的服务性能就直线下降了。
另外,像Zset、发布订阅、消息队列、Redis的各种功能不断被介绍,开发者们也在利用这些特性,开发各种应用,但从来没想过这么一个小小的Redis这么多新奇的功能,它缺点在什么地方,什么样的场景是不合适用的。这时Redis在大部分的开发者手上就是像是一把锤子,看什么都是钉子,随时都一锤了事。同时也会渐渐地淡忘了开发的一些细节点和规范,因为用它解决性能的问题是那么轻松简单,于是一些基于Redis的新奇功能就接连不断地出现了:基于Redis的分布式锁、日志系统、消息队列、数据清洗,等等,各种各样的功能不断上线使用,从而引发了各种各样的问题。这时候原来那个救火神器就会变成四处点火的神器,到是Redis堵塞、网卡打爆、连接数爆表等等问题层出不穷,经过这么多折腾,Redis终于也变成了大家的噩梦了。
在一个炎热的夏天,引爆了埋藏已久的大炸弹。首先是一个产品线开发人员搭建起了一套庞大的价格存储系统,底层是关系型数据库,只用来处理一些事务性的操作和存放一些基础数据;在关系型数据库的上面还有一套MongoDB,因为MongoDB的文档型数据结构,让他们用起来很顺手,同时也可以支撑一定量的并发。在大部分的情况下,一次大数据量的计算后结果可以重用但会出现细节数据的频繁更新,所以他们又在MongoDB上搭建了一层Redis的缓存,这样就形成了数据库→MongoDB→Redis三级的方式,方案本身先不评价不是本文重,我们来看Redis这层的情况。由于数据量巨大,所以需要200GB的Redis。并且在真实的调用过程中,Redis是请求量最大的点,当然如果Redis有故障时,也会有备用方案,从后面的MongoDB和数据库中重新加载数据到Redis,就是这么一套简单的方案上线了。
当这个系统刚开始运行的时候,一切都还安好,只是运维同学有点傻眼了, 200GB的Redis单服务器去做,它的故障可能性太大了,所以大家建议将它分片,没分不知道一分吓一跳,各种类型用的太多了,特别是里面还有一些当类似消息队列使用的场景。由于开发同学对Redis使用的注意点关注不够,一味的滥用,一锤了事,所以让事情变的困难了。有些侥幸不死的想法是会传染,这时的每个人都心存侥幸,懒惰心里,都想着:“这个应该没事,以后再说吧,先做个主从,挂了就起从”,这种侥幸也是对Redis的虚伪的信心,无知者无畏。可惜事情往往就是怕什么来什么,在大家快乐的放肆的使用时,系统中重要的节点MongoDB由于系统内核版本的BUG,造成整个Mongodb集群挂了!(这里不多说Mongodb的事情,这也是一个好玩的哭器)。当然对天天与故障为朋友的运维同学来说这个没什么,对整个系统来说问题也不大,因为大部分请求调用都是在最上层的Redis中完成的,只要做一定降级就行,等拉起了Mongodb集群后自然就会好了。
但此时可别忘了那个Redis,是一个200G大的Redis,更是带了个从机的Redis,所以这时的Redis是绝对不能出任何问题的,一旦有故障,所有请求会立即全部打向最低层的关系型数据库,在如此大量的压力下,数据库瞬间就会瘫痪。但是,怕什么来什么,还是出了状况:主从Redis之间的网络出现了一点小动荡,想想这么大的一个东西在主从同步,一旦网络动荡了一下下,会怎么样呢?主从同步失败,同步失败,就直接开启全同步,于是200GB的Redis瞬间开始全同步,网卡瞬间打满。为了保证Redis能够继续提供服务,运维同学,直接关掉从机,主从同步不存在了,流量也恢复正常。不过,主从的备份架构变成了单机Redis,心还是悬着的。俗话说,福无双至,祸不单行。这Redis由于下层降级的原因并发操作量每秒增加到四万多,AOF和RDB库明显扛不住。同样为了保证能持续地提供服务,运维同学也关掉了AOF和RDB的数据持久化。连最后的保护也没有了(其实这个保护本来也没用,200GB的Redis恢复太大了)。
至此,这个Redis变成了完全的单机内存型,除了祈祷它不要挂,已经没有任何方法了。悬着好久,直到修复MongoDB集群,才了事。如此的侥幸,没出大事,但心里会踏实吗?不会。在这个案例中主要的问题在于对Redis过度依赖,Redis看似为系统带来了简单又方便的性能提升和稳定性,但在使用中缺乏对不同场影的数据的分离造成了一个逻辑上的单点问题。当然这问题我们可以通过更合理的应用架构设计来解决,但是这样解决不够优雅也不够彻底,也增加了应用层的架构设计的麻烦,Redis的问题就应该在基础缓存层来解决,这样即使还有类似的情况也没有问题,因为基础缓存层已经能适应这样的用法,也会让应用层的设计更为简单(简单其实一直是架构设计所追求的,Redis的大量随意使用本身就是追求简单的副产品,那我们为不让这简单变为真实呢)
再来看第二个案例。有个部门用自己现有Redis服务器做了一套日志系统,将日志数据先存储到Redis里面,再通过其他程序读取数据并进行分析和计算,用来做数据报表。当他们做完这个项目之后,这个日志组件让他们觉得用的还很过瘾。他们都觉得这个做法不错,可以轻松地记录日志,分析起来也挺快,还用什么公司的分布式日志服务啊。于是随着时间的流逝,这个Redis上已经悄悄地挂载了数千个客户端,每秒的并发量数万,系统的单核CPU使用率也接近90%了,此时这个Redis已经开始不堪重负。
终于,压死骆驼的最后一根稻草来了,有程序向这个日志组件写入了一条7MB的日志(哈哈,这个容量可以写一部小说了,这是什么日志啊),于是Redis堵死了,一旦堵死,数千个客户端就全部无法连接,所有日志记录的操作全部失败。其实日志记录失败本身应该不至于影响正常业务,但是由于这个日志服务不是公司标准的分布式日志服务,所以关注的人很少,最开始写它的开发同学也不知道会有这么大的使用量,运维同学更不知有这个非法的日志服务存在。这个服务本身也没有很好地设计容错,所以在日志记录的地方就直接抛出异常,结果全公司相当一部分的业务系统都出现了故障,监控系统中“5XX”的错误直线上升。一帮人欲哭无泪,顶着巨大的压力排查问题,但是由于受灾面实在太广,排障的压力是可以想像的。 这个案里中看似是一个日志服务没做好或者是开发流程管理不到位。而且很多日志服务也都用到了Redis做收集数据的缓冲,好像也没什么问题。其实不然,像这样大规模大流量的日志系统从收集到分析要细细考虑的技术点是巨大的,而不只是简单的写入性能的问题。在这个案例中Redis给程序带来的是超简单的性能解决方案,但这个简单是相对的,它是有场景限制的。在这里这样的简单就是毒药,无知的吃下是要害死自己的,这就像“一条在小河沟里无所不能傲慢的小鱼,那是因为它没见过大海,等到了大海……”。
在这个案例的另一问题:一个非法日志服务的存在,表面上是管理问题,实质上还是技术问题,因为Redis的使用无法像关系型数据库那样有DBA的监管,它的运维者无法管理和提前知道里面放的是什么数据,开发者也无需任何申明就可以向Redis中写入数据并使用,所以这里我们发现Redis的使用没这些场景的管理后在长期的使用中比较容易失控,我们需要一个对Redis使用可治理和管控的透明层。
两个小子例子中看到在Redis乱用的那个年代里,使用他的兄弟们一定是痛的,承受了各种故障的狂轰滥炸:
Redis被keys命令堵塞了;
Keepalived 切换虚IP失败,虚IP被释放了;
用Redis做计算了,Redis的CPU占用率成了100%了;
主从同步失败了;
Redis客户端连接数爆了;
……
如何改变Redis用不好的误区
这样的乱象一定是不可能继续了,最少在同程这样的使用方式不可以再继续了,使用者也开始从喜欢到痛苦了。怎么办?这是一个很沉重的事:“一个被人用乱的系统就像一桌烧坏的菜,让你重新回炉,还让人叫好,是很困难的”。关键是已经用的这样了,总不可能让所有系统都停下来,等待新系统上线并瞬间切换好吧?这是个什么活:“高速公路上换轮胎”。
但问题出现了总是要解决的,想了再想,论了再论,总结以下几点:
必须搭建完善的监控系统,在这之前要先预警,不能等到发生了,我们才发现问题;
控制和引导Redis的使用,我们需要有自己研发的Redis客户端,在使用时就开始控制和引导;
Redis的部分角色要改,将Redis由storage角色降低为cache角色;
Redis的持久化方案要重新做,需要自己研发一个基于Redis协议的持久化方案让使用者可以把Redis当DB用;
Redis的高可用要按照场景分开,根据不同的场景决定采用不同的高可用方案。
留给开发同学的时间并不多,只有两个月的时间来完成这些事情。这事其实还是很有挑战的,考验开发同学这个轮胎到底能不换下来的时候到来了。同学们开始研发我们自己的Redis缓存系统,下面我们来看一下这个代号为凤凰的缓存系统第一版方案:
首先是监控系统。原有的开源Redis监控从大面上讲只一些监控工具,不能算作一个完整的监控系统。当然这个监控是全方位从客户端开始一直到反回数据的全链路的监控。
其次是改造Redis客户端。广泛使用的Redis客户端有的太简单有的太重,总之不是我们想要东西,比如,.Net下的BookSleeve和servicestack.Redis(同程还有一点老的.Net开发的应用),前者已经好久没人维护了,后者直接收费了。好吧,我们就开发一个客户端,然后督促全公司的研发用它来替换目前正在使用的客户端。在这个客户端里面,我们植入了日志记录,记录了代码对Redis的所有操作事件,例如耗时、key、value大小、网络断开等,我们将这些有问题的事件在后台进行收集,由一个收集程序进行分析和处理,同时取消了直接的IP端口连接方式,通过一个配置中心分配IP地址和端口。当Redis发生问题并需要切换时,直接在配置中心修改,由配置中心推送新的配置到客户端,这样就免去了Redis切换时需要业务员修改配置文件的麻烦。另外,把Redis的命令操作分拆成两部分:安全的命令和不安全的命令。对于安全的命令可以直接使用,对于不安全的命令需要分析和审批后才能打开,这也是由配置中心控制的,这样就解决了研发人员使用Redis时的规范问题,并且将Redis定位为缓存角色,除非有特殊需求,否则一律以缓存角色对待。
最后,对Redis的部署方式也进行了修改,以前是Keepalived的方式,现在换成了主从+哨兵的模式。另外,我们自己实现了Redis的分片,如果业务需要申请大容量的Redis数据库,就会把Redis拆分成多片,通过Hash算法均衡每片的大小,这样的分片对应用层也是无感知的。
当然重客户端方式不好,并且我们要做的是缓存不仅仅是单单的Redis,于是我们会做一个Redis的Proxy,提供统一的入口点,Proxy可以多份部署,客户端无论连接的是哪个Proxy,都能取得完整的集群数据,这样就基本完成了按场景选择不同的部署方式的问题。这样的一个Proxy也解决了多种开发语言的问题,例如,运维系统是使用Python开发的,也需要用到Redis,就可以直接连Proxy,然后接入到统一的Redis体系中来。做客户端也好,做Proxy也好,不只是为代理请求而是为了统一的治理Redis缓存的使用,不让乱象的出现。让缓存有一个可管可控的场景下稳定的运维,让开发者可以安全并肆无忌惮继续乱用Redis,但这个“乱”是被虚拟化的乱,因为它的底层是可以治理的。
图15-1 系统架构图
当然以上这些改造都需要在不影响业务的情况下进行。实现这个其实还是有不小的挑战,特别是分片,将一个Redis拆分成多个,还能让客户端正确找到所需要的key,这需要非常小心,因为稍有不慎,内存的数据就全部消失了。在这段时间里,我们开发了多种同步工具,几乎把Redis的主从协议整个实现了一遍,终于可以将Redis平滑过渡到新的模式上了。
当全公司的Redis在快速平稳的过度到新开发的缓存系统之后,这个方案经过了各种考验,证明了整体思路是对的,所以是时候大张旗鼓地开始做它的第二个版本——完整全套的缓存体系架构的平台,特别是运维部分,因为在第一版中运维部分做的太少。当然每个系统都有一个开发代号,这个缓存系统的代号就是“凤凰”,其中的含义很明显:之前的Redis总是死掉,现在的Redis是不死的,就像凤凰一样。
在整体的平台化过程中为了更好的扩容,弹性和运维,我们决定基于Docker将它改造一个云化的缓存系统,当然要能称之为云,那么平台最基本的要求就是具备资源计算、资源调度功能,且资源分配无需人工参与。对用户来讲,拿到的应该是直接可用的资源,并且天生自带高可用、自动备份、监控告警、日志分析等功能,无需用户关心资源背后的事情。其次是各种日常的运维操作需求服务化输出。下面我们就来讲讲我们这个平台是如何一步步实现的。任何项目都可以接入这个缓存系统,并从里面获取资源。使用只需一个申请,给它场景名字就能使用了,不需要知道缓存的具体位置,也不需要知道缓存的具体大小,更不需要关注具体的流量,一切都交给云来管理。
我们进一步改造了监控系统,将其改造为一个完整的监控系统,这个系统会不断的收集整个云环境中的服务器和Redis等各方面的相关信息,根据具体的阈值报警,并且通知到运维系统,运维系统再基于运维数据来自动故障转移,扩容等等,到目前为止,整个缓存系统中5000多个Redis实例,每月的运维人力不到0.2个人,对于整个缓存系统来说只要向其中加入物理服务器就可以完成扩容,剩下的事全部系统自主做完。
开发的另一个重点——调度系统,这个系统会不断地分析前面提到的监控系统搜集到的数据,对整个云进行微调:Redis的用量大了,会自动扩容;扩容空间不够了,会自动分片;网络流量大了,也会自动负载均衡。以前的Redis固定在一台服务器上,现在的Redis通过我们开发的同步工具,在各个服务器中流转,而每个Redis都很小,不会超过8GB。备份和处理都不再是难事,现在要做的只是往这个集群里面注册一台机器,注册完之后,监控系统就会启动并获取监控信息,调度系统就会根据监控数据决定要不要在新机器上建立Redis。容量动态的数据迁移(集群内部平衡,新节点增加);流量超出时的根据再平衡集群。也是这个调度系统在管理的
图15-2 凤凰缓存平台的平滑的扩容过程
除了服务端的加强,同时在客户端上进一步下功夫,在支持 Redis 本身的特性的基础上,通过自定义来实现一些额外的功能。让客户端开始支持场景配置,我们考虑根据场景来管控Redis的使用内容,客户端每次用 Redis 的时候,必须把场景上报给系统。增加场景配置之后,在缓存服务的中心节点,就可以把它分开,同一个应用里面两个比较重要的场景就会不用到同一个 Redis,避免无法降级一个内容过于复杂的Redis实例。
同时也利用调度系统将场景的服务端分离,不同的场景数据工作在不同的Redis集群之上。另外在客户端里也可以增加本地 cache 的支持以提高性能和减少资源的使用。当然这些都是对应用层透明的,应用层不需要关心真正的数据源是什么。
图15-3 凤凰缓存平台客户端的结构图
对于Proxy我们也进行了升级,新的Proxy完全实现了Redis的协议和其他的缓存服务协议,如:Memcache。Proxy可以解决客户端过重的问题,在很多情况下,升级客户端是很难进行的事。再好的程序员写出来的东西还是可能会有 bug的,如果客户端发现了一个 bug 需要紧急升级,我们不大可能一下去升级线上几千个应用。因此我们的proxy 方案中也加入之前在客户端做的很多事情,我们的想法就是让每一个项目的每一个开发者自己开发的代码是干净的,不要在他的代码里面嵌额外的东西,访问的就是一个 Redis。把 Redis 本身沉在我们 proxy 之后,我们也可以做更多的改进了,如,冷热区分方面,我们分析大量的Redis请求发现一些场景根本不需要用Redis,压力并不大,这样使用Redis是一种资源的浪费 ,所以通过proxy直接将数据放到了 RocksDB 里面用,硬盘来支撑它。
图15-4 凤凰缓存平台的代理设计
最后,把Redis的集群模式3.0纳入到整个体系里,并对3.0版本进行了一定的改造,替代了之前的分片技术,这样在迁移Redis时就更方便了,原生的Redis命令可以保证更好的稳定性。
图15-5 凤凰系统架构图
我一直认为评价一款中间件的优劣,不能只评价它的本身。我们要综合它的周边生态是否健全,比如:高可用方案、日常维护难度、人才储备等等。当然对于Redis也一样,正是因为Redis很小很简单所以相对的缺乏好的辅助工具是一定的。我们在Redis基础上做的凤凰缓存系统也是正是为解决Redis缺少的点。一款中间件从引到用好其实最关键的点就是运维,只有运维好它才有可能用好它。这里我们就讲一下运维。
讲了这了凤凰缓存系统的种种,再细细的看一下如何大批量的运维redis,通常的运维方式有2种:
这种部署是将所有的Redis集中在一起,形成一个超大的Redis集群,通过代理的方式统一对外提供连接,使外部看来就是个完整的超大Redis,所有的项目都共享这个Redis,在这个超大Redis内部,可以自动增添服务,修改配置等等操作,而外部完全无感知。
这种方式的优点很多:
扩容比较方便,直接在集群内新增机器即可,使用者完全无感知;
利用率高,运维简单,只需要关注整个集群的大小就可以,不太需要关心里面某个Redis的具体状态(特殊情况除外);
客户端使用方便,无论哪个项目,面对的就是一组Redis,内部的细节对客户端来说是透明的,他们可以简单的认为链接上了一个内存无限大的Redis。
缺点也很明显:
扩容虽然方便,但是具体某个项目用了多少,无法获知,极端情况下有些项目超时时间设置不合理,写入数据大于过期和删除的数据,极有可能会导致整个Redis的内存一直增长直到用完;
整个超大的Redis的内部其实还是由各个小Redis组成的,每个key都是单独的存储到小的Redis内部,那么如果某个key很热,读取访问非常频繁,很有可能将某个小Redis的网卡打满,导致的结果就是1个分片直接不可用,而项目又是集体共享一组Redis,某个分片不可用,可能导致的结果就很难评估。
这种部署方式的典型代表有很多,它们会预分配1024个槽,并将这些槽分配到集群内的这些机器上去,还会提供了一个大集群的proxy,所有的客户端都可以通过这个proxy读写。
这种部署主要提供了自动化部署,部署的各个Redis相互独立,而一般情况下一组Redis也是单独供某个项目独占,隔离性非常好,不会因为某个项目的问题导致整个集群不可用,但是由于需要维护一大堆的Redis,各个Redis的情况又不一样,在自动化部署方面就显得比较麻烦
优点:
隔离性非常好,各个项目之间互不影响,不会因为某个项目的动作导致整个集群受到影响;
灵活性高,针对各个项目的使用情况的不同可以定制不同的部署方式,可以最大化利用Redis。
缺点:
部署麻烦,要针对各个项目单独部署,各个项目的定制又各有不同;
客户端使用麻烦,不同的Redis有自己的ip,端口,经常容易搞混,当某个redis需要停机维护时,又需要通知具体项目修改IP地址,非常麻烦。
同程的Redis的部署运维方式早期没有做平台时也是出现了各种各样的问题大概总结如下:
部署忙不过来,每天都有很多项目申请redis,每天部署的工作就消耗了很大部分时间;
如果服务器需要调整,修改,通知业务修改新的IP,再重新发布,耗时往往很长,很多事情都耽误了;
服务器的资源利用率低,项目在使用Redis的时候,比较倾向于申请个比较大的Redis,这样下次就不用再提要求增加容量了,而运维在某台服务器上部署了很多Redis后,为了防止内存撑爆,就不会在这台服务器上继续部署了,但实际上项目用的很少,就造成了大量的浪费。
比如,统一大集群方式一些开源解决方案,看上去确实很不错,我们当时也决定尝试下,结果很快就出现了问题,由于一个大集群是供大家公用的,所以我们很难实时计算某个项目的配额,而某个项目插入过量数据后,又很容易将其他项目的数据挤掉(Redis配置了LRU策略),我们研究了很久,觉得各个项目公用,问题较多,不太好处理,只能采用第二种方式,那么问题回到了如何解决分布式部署方式的缺点,我们经过研究,将问题总结如下:
凤凰缓存系统这个分布式的Redis解决方案,通过Docker解决部署问题。Docker是一个非常好的自动化部署工具。一个新机器配置好后直接就能通过Docker的Restful API进行操作,所以我们的运维就开发一个基于Docker的自动化运维平台. 用Docker就会想到kubernetes和swarm。但我们在做凤凰缓存时,是自己开发一个Docker调度系统。因为我们是Redis为主要发布对象,而像kubernetes的资源调度、均衡容灾、服务注册、动态扩缩容这些操作都比较宽泛,我们需要是针对Redis做这方面的定制,而定制的过程又需要深入的了解kubernetes的内部结构,处理起来比较繁琐,而Docker本身的提供的api接口就完全够用,使用kubernetes反倒是增加了复杂度,而得到的红利却很少,所以不太适合,至于swarm,提供的功能又比较简单。
相对来说只是对Redis做Docker化的部署还是相对简单的,要做的事情也不是很多,主要集中以下方面:
Redis本身对CPU的使用敏感性不是很大,所以我们在CPU的使用隔离限制上不需要花太多的精力。用Docker隔离分配就可以满足需求。
在内存的控制上,就相对麻烦一点, Redis的内存使用有2个属性,实际使用的内存和操作系统分配的内存,反映在Redis上就是used_memory(实际使用的内存)和used_memory_rss(操作系统分配的内存)这2个参数,maxmemory实际控制的是used_memory,而不是used_memory_rss,由于Redis在后端执行RDB操作或者频繁的增删改产生大量的碎片,rss的值就会变得比较大,如果通过Docker强制限制内存,这个进程很可能直接就被kill了,所以,在内存上,我们没有采用Docker控制,而是通过自己的监控程序进行控制.举个例子来说,某个项目新申请的Redis是10G,我们在通过Docker部署这个Redis的时候,只是开启了1个500M的Redis,随着项目的使用,当Redis实际空闲内存量小于250M的时候,我们就通过Redis命令设置maxmemory为1G,然后继续监控,直到内存到10G为止,等项目的内存到达10G后,我们就根据策略的不同做不同的处理了,比如,有些项目只是拿Redis作为缓存而已,10G的数据足够了,万一超过,可以放弃掉部分冷数据,在这样的情况下,就不会继续加大内存,如果项目很重要,也可以设置一个超额的量,这样程序会自动进行扩容同时发出警报,让项目开发人员及时检查,防止出现问题
要良好的运维一个系统监控的好坏是关键点, 监控的基础主要是收集服务器和Redis的运作信息。并将这些信息丢入一个信息处理管道,在分析之前结合经验数据输出一系列的具体处理方式。这样缓存系统自己就能处理掉大部分的故障,不需要大量的人工介入。凤凰缓存系统整个监控由搜集器,存储器、分析器和执行器4部分组成:
搜集器是我们利用Go开发的一个程序,这个程序搜集2个部分的数据,服务器本身的数据和Redis的数据,首先,搜集程序会查询当前所在服务器的CPU,网卡,内存,进程等等的信息,然后,搜集程序查询这个服务器上的Redis,然后遍历这些Redis,获取info,slowlog,client等信息,再把这些信息整理好,上报到存储器上去。
存储器负责存储监控数据,它对外就是一组restfulapi,存存器对这些信息进行汇总和整理,再进行一些简单的计算,然后将数据存储到分析平台中
分析器的工作是从查询ES开始的,针对各种数据进行分析和处理,然后产出各种具体处理意见,提交给执行器,比如,分析器发现某个服务的CPU在10分钟内都是100%的,这个触发了一个警报阈值,分析器产出了一个处理意见,建议人工介入处理,这个处理意见提交给执行器,由执行器具体执行
执行器一个根据处理意见进行开始处理的分析程序,简单分类问题并结合处理意见进行判断是人工介入还是先自动处理。对于自动处理的事件,如:Redis的内存不够,进行扩容操作等。
凤凰缓存系统对Redis的集群分片优化
Redis的集群分片我们在凤凰缓存系统中进行完整的私有实现,但从 Redis3.0开始,提供了集群功能,可以将几台机器组织成一个集群。在凤凰缓存系统中也对Redis3.0的集群模式进行支持。我们先看一下Redis3.0的一些分片特性:
Redis 3.0集群中,采用slot(槽)的概念,一共分成16384个槽。对于每个进入Redis的键值对,根据key进行散列,分配到这16384个slot中的某一个中。使用的hash算法也比较简单,就是CRC16后16384取模。
整套的Redis集群基于集群中的每个node(节点)负责分摊这16384个slot中的一部分,也就是说,每个slot都对应一个node负责处理。当动态添加或减少node节点时,需要将16384个槽做个再分配,槽中的键值也要迁移。这个过程,需要人工介入。
为了增加集群的可访问性,官方推荐的方案是将node配置成主从结构,即一个master主节点,挂n个slave从节点。这时,如果主节点失效,RedisCluster会根据选举算法从slave节点中选择一个上升为主节点,整个集群继续对外提供服务。这非常类似之前的Sentinel监控架构成主从结构,只是Redis Cluster本身提供了故障转移容错的能力。
通过这样的设计, Redis实现了完整的集群功能,但是,这个集群功能比较弱,表现在以下这些方面
Redis集群之间只对Redis的存活负责,而不对数据负责,这样,当客户端提交请求之后,如果这个key不归这个服务器处理,就会返回MOVE命令,需要客户端自行实现跳转,增加了客户端的复杂度。
当Redis需要迁移或槽重新分配时,需要人工介入,发送命令操作,虽然官方也提供了一个迁移脚本,但是本身功能比较简单,也办法很好的自动化。
集群进行分片,所有的key被分散在各节点上,之前说过集群之间只处理死活和槽分配,不处理数据,所以所有的多key操作(事务,MGET,MSET之类)的操作不能再用。
针对这些问题,我们在凤凰缓存系统中对Redis 3.0的集群做了些改造,解决了上述痛苦的地方:
首先,我们修改了客户端的实现,按照Redis的协议只是进行一些自定义的修改,如:在集群中加入机器以及迁移槽的过程中的一些问题进行了优化,使客户端能更平滑的迁移。
其次,迁移槽还是比较麻烦的,主要涉及CLUSTERSETSLOT和MIGRATE 2个命令,MIGRATE的主要问题是key的大小不能确定,开发迁移工具时我们主要解决网卡流量和CPU的压力问题,使之在迁移的过程中不影响Redis的正常使用。这个工具主要工作场景是当监控程序发现某个分片流量过大,或者Key特别多,就自动的开始迁移过程,省去了人工的麻烦。迁移工具也会实时微调线上的Redis,保证各个分片的正常。
最后,在集群环境中,多key的操作都无法使用,这个直接导致了类似事务,MGET,MSET这样的操作无法进行。我们针对问题对Redis进行改造,将Redis的分槽策略进行了改动。原本针对key进行分区,改造为当key满足类似{{prefix}}key这样的格式时我们将只针对{{}}内的内容计算hash值。这样,相关性的一组key可以使用统一的前缀,并保存到同一片中。这样保证事务以及多key操作能顺利执行。
凤凰缓存系统应用层客户端在解决运维方面最大的作用有3个:
我们先来看第一个问题,我们提供的是一套完整的配置管理系统,分布式的配置系统,服务器端对Redis接入的操作和修改都会通知配置中心.然后,再由配置中心分发到所有的客户端,客户端接受到配置更新后,会修改自己的连接平滑过度。这样客户端就可以在不重启的情况下动态切换连接,另外,在客户端有个连接池的实现,当老的连接重新回到连接池后,就会被销毁掉,这样,客户端的切换是平滑的,不会因为切换导致客户端的请求抖动。
再来看第二个问题,由于Redis的单线程单进程的特性,不太适合做密集的CPU计算,但是很多开发人员对具体命令的掌握不熟,经常会导致Redis的CPU使用率 100%的情况,悲催的是,当这样的情况发生之后,就不会处理任何客户端的请求了,它要等当前的这个任务执行完成之后才会继续下一个问题,针对这个问题,我们将容易导致CPU打满的命令和普通的命令区分了开来,并提供了自己的实现,Redis服务有两个版本,基础版和Plus版。普通版只有最基础的redis命令,在大部分场景的使用下,都不会引起问题,Plus版从普通版继承而来,里面添加了大量的Redis复杂操作命令,当正常使用的时候,直接在普通版中操作数据,当需要高级功能,可以自动转换到plus版,这样一些特殊的命也可以无脑使用了。
最后第三个问题,就更纯萃了,在大部分异常使用中,对于异常发生的现场情况,开发人员的可以通过自己日志看到,但对于凤凰缓存系统的运维这个信息的透明度就不高,这样就在在故障处理上浪费时间,所以我们在客户端中记下了完整的操作日志信息,并整合到凤凰缓存系统的监控后台。
Redis的毕竟只是个简单的KV数据库,当初老的版本,作者用了数万行代码就实现了整体的功能,在完善的运维方面,是比较欠缺的,所以,我们针对运维方面的问题点,开发了一些小工具,这些工具,大部分都整合到了凤凰缓存系统里面,可以直接由执行器操作,进行自动化运维。如Redis运行状态监控,在Redis使用过程中,经常有开发人员问,我们目前哪些key是热key,当前的Redis并发访问量比较高,能不能看下主要是哪些命令导致的。但是Redis本身并没有提供这些命令。好在Redis有个命令 monitor,可以将当前的Redis操作全部导出来,我们就基于这个命令,开发了一个Redis监控程序,当开始监控某个Redis时,会发送monitor命令,然后, Redis会将它接受到的命令源源不断的吐给我们,我们接到后,就可以进行分析,当前Redis正在执行什么操作,什么操作最频繁,具体是哪些key,占用的比例是多少,哪些key比较慢,等等,然后生成一个报表,就可以获得当前的状态了,不过要注意的是,monitor命令对Redis本身有一定的影响,一般情况下,不建议打开,只在需要分析问题的时候,可以打开,另外,也可以配置一些阈值,当达到阈值的时候,自动打开。这样就可以在问题已发生,就抓取到最新的监控日志信息了。
还有Redis的数据迁移,Redis的部署方式比较复杂,有单机主从,集群各种模式,而所有的数据都在内存里面,如果我们需要在各个Redis中迁移数据,就非常的麻烦,所以,我们开发了一个迁移工具,专门在Redis中迁移数据,这个程序在启动之后,会冒充自己是Redis的一个从机,然后发送从机命令从主机同步数据,主机在把数据发送给程序之后,程序会对这些数据进行解析,解析之后的内容写到具体的后端Redis中,这样,就完成了2个Redis间的数据转换,这个客户端可以智能的查看当前Redis状态,针对集群,主从模式有不同的处理方式。这样的工具我们还有很多就不再一一说明。
这个凤凰缓存系统在2016年初整个系统正式全部完成上线,到目前为止,在整个凤凰系统上运行着5000多个Redis实例、上百TB的内存。从申请到销毁,所有过程都由凤凰系统自动化完成,不需要人们参与其中。在凤凰系统上线后,几乎就没有处理过Redis的故障了,曾经焦头烂额的Redis如今已经被凤凰系统驯得服服帖帖。同时凤凰系统每天会将异常的信息实时发送给各个负责人,并自动处理绝大多数异常,对于少部分无法判定的问题会通知运维人员来做具体的判定和操作。
本文收集了一批早期的简版RPC框架进行了收集。
《架构探险-轻量级微服务家机构》一书的作者,编写的一个示例项目
https://gitee.com/huangyong/rpc
作者参考黄勇的实现设计的一款RPC项目
https://github.com/hu1991die/netty-rpc
https://github.com/yeecode/EasyRPC
易哥还有一本Mybatis源码解读的书,https://github.com/yeecode/MyBatisCN
另一款名叫的简易RPC框架,EasyRpc是基于Netty、ZooKeeper和ProtoStuff开发的一个简单易用,便于学习的RPC框架。
https://github.com/Matrix6677/EasyRpc
规则引擎由推理引擎发展而来,是一种嵌入在应用程序中的组件,实现了将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
主流的规则引擎包括:Drools、Easy Rules、Jess
Drools 是用 Java 语言编写的开放源码规则引擎,使用 Rete 算法对所编写的规则求值。Drools 允许使用声明方式表达业务逻辑。可以使用非 XML 的本地语言编写规则,从而便于学习和理解。并且,还可以将 Java 代码直接嵌入到规则文件中,这令 Drools 的学习更加吸引人。
liteFlow 是一个轻量,快速的组件式流程引擎框架/规则引擎,组件编排,组件复用,帮助解耦业务代码,让每一个业务片段都是一个优雅的组件,并支持热加载规则配置,实现即时修改。
EasyRule是轻量级的规则引擎API。它提供Rule抽象来创建带有条件和动作的规则,以及RulesEngine通过一组规则运行以测试条件和执行动作的API。
特性:
OpenL Tablets业务规则引擎(BRE)和业务规则管理系统(BRMS)。它包含以下主要组件:
官网,Activiti项目是一项新的基于Apache许可的开源BPM平台,从基础开始构建,旨在提供支持新的BPMN 2.0标准,包括支持对象管理组(OMG),面对新技术的机遇,诸如互操作性和云架构,提供技术实现。
项目地址:pig
基于Spring Boot 3.0、 Spring Cloud 2022 & Alibaba、 SAS OAuth2 的微服务RBAC 权限管理系统。
若依 / RuoYi-App
RuoYi APP 移动端框架,基于uniapp+uniui封装的一套基础模版,支持H5、APP、微信小程序、支付宝小程序等,实现了与RuoYi-Vue、RuoYi-Cloud后台完美对接。
Mall4j,
RuoYi APP 移动端框架,基于uniapp+uniui封装的一套基础模版,支持H5、APP、微信小程序、支付宝小程序等,实现了与RuoYi-Vue、RuoYi-Cloud后台完美对接。
https://tech.youzan.com/gateway/?f=tt&hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
提到应用网关系统,我们脑海中或多或少都会闪过一些关键词,比如统一入口、高并发、大流量、限流、防刷、实时监控等等。 Youzan Application Gateway Center(公司内部称之为Carmen系统),它就是目前有赞的应用层网关系统。每天承载着亿级别的请求量,持续的为开放平台和多个有赞App应用提供着稳定的服务。
今天我们来一起剖析下整个有赞的应用层网关,聊聊网关的当前的概况、整个网关系统的构成、遇到的一些问题的思考和解决方案。当然在进入正题之前,我们不妨先对这个网关系统提出几个问题:
以上这些问题在您耐心读完整篇文章后,将会一一得到答案。
首先,网关作为一个系统入口,目前它在有赞技术生态圈中主要面向开放平台和移动app两种应用场景。开放平台属于外部调用,移动app属于内部调用。内部与外部调用使用不同的域名,以便合理分配资源、有效进行权限控制、流量控制等。
整个网关系统拆分为3个子系统,都由java实现:
 图 1-1 系统整体概况
图 1-1 系统整体概况图1-1展示的整个网关系统需要完成下列目标:
1.主要功能模块:
2.整体架构

3.下面我分别从系统的健壮性、高性能、扩展性、安全性、可靠性五个方面来介绍下为了达到这些目标,有赞网关是采用了一些什么方法。
压力测试:
为了提供稳定的服务,首先我们需要充分了解自己的程序以及其运行的服务器,所以前期需要充分地压测,通过压测具体数据来找出系统的性能瓶颈以及性能拐点,同时也让自己了解程序与机器配合度,最后根据压测报告来评估系统的容量。 有赞网关在压测过程中,通过模拟用户场景,对比各种机器指标被打满的情况,帮助我们提前暴露了下列瓶颈点:
一个有效的压力测试会极大帮助开发者了解自己的系统,对容量规划做到心里有底。
并发问题处理:
并发编程一书的作者曾说过:没有人能保证写出完全正确的并发程序。 编写好并发程序是一项有富有挑战性的工作,下面谈谈有赞应用网关在线上实际遇到的并发场景:
第一个是在系统出入口的并发访问。 入口的高并发会带来线程膨胀,资源耗尽,吞吐量下降的问题,还好我们有Nginx,有Jetty的NIO以及Servlet3.0异步特性。 此三者很好的为我们解决了系统入口的并发问题:Nginx做负载均衡、NIO使用IO多路复用解决空闲网络连接过多引发的线程膨胀问题,Servlet 3.0的异步特性释放了入口的吞吐能力。 出口的高并发在同步模式会显著降低吞吐量,使用异步调用模式会很好的缓解这个问题。
第二个是代码中并发问题 没有共享,就不会有并发问题,但java中多线程场景无处不在。
代码中临界区就像幽灵一样,让人防不胜防。
当并发量小或者无并发的时候,这些临界区能正常work。一旦流量超出阈值,这种并发就会触发异常或者带来逻辑上的错误,甚至让系统奔溃。
最后对于并发编程,强烈建议找两个并发编程的老司机一起来review下代码,尤其是核心模块!!
内存管理实践:
虽然Java会自动进行内存回收,但是网关系统中也必须要重视内存的合理配置与使用,否则OOM,频繁FGC会缠上你的系统。 有赞网关在流量不断攀升的过程中也在不断调整GC相关参数去解决FGC频繁的问题。其中的经验之谈就是使用JVM相关的命令不断观察GC回收的次数、耗时,最终在吞吐量和响应时间之间找到一个系统平衡点。比如有赞网关之前维持的一个平衡点是一次YGC时间约25ms,一次FGC100ms(Young Generation和Old Generation分别给2g, CMS回收器)。
网关系统曾经大半年都是使用CMS回收器,近来已经在尝试使用使用增量回收算法的G1回收器。 下面小结下这两种回收器在我们网关系统上的实际效果(4核8G的VM服务器):
 当前图是切换成G1之后几天的监控数据,左边12天是使用CMS的数据,右边12天是使用G1的数据。红线是young GC的回收次数,蓝线是GC回收时间,G1的YGC时间要比CMS的大一些。
当前图是切换成G1之后几天的监控数据,左边12天是使用CMS的数据,右边12天是使用G1的数据。红线是young GC的回收次数,蓝线是GC回收时间,G1的YGC时间要比CMS的大一些。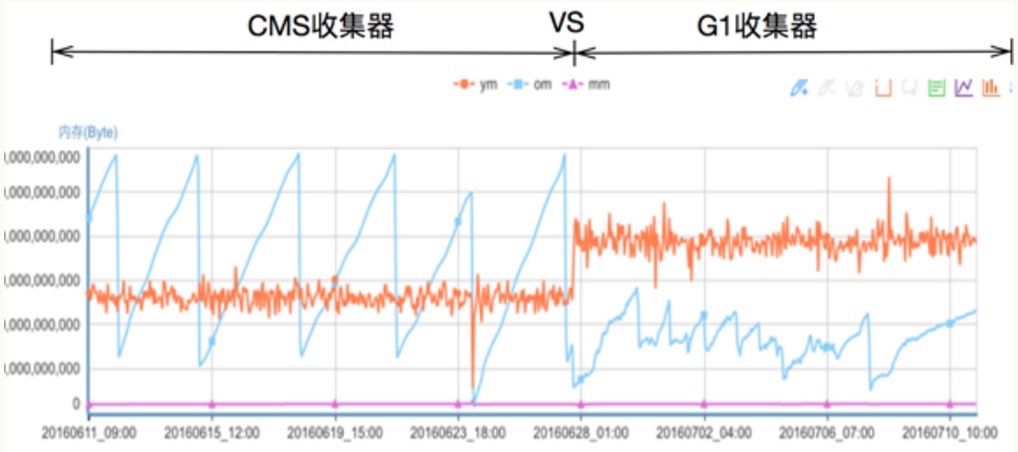 当前图是CMS和G1回收器在堆变化趋势的对比。红线是Young区,蓝线是Old区。 左边CMS能明显看到有FGC,右边G1的Old区大小不是线性增长,实际监控数据显示它没有进行FGC,而且G1的Young区占据空间比CMS的Young区大。
当前图是CMS和G1回收器在堆变化趋势的对比。红线是Young区,蓝线是Old区。 左边CMS能明显看到有FGC,右边G1的Old区大小不是线性增长,实际监控数据显示它没有进行FGC,而且G1的Young区占据空间比CMS的Young区大。小结:目前的使用经验看来G1回收算法并没有比CMS用得舒服,反而带来了不触发FGC的问题以及增加了OOM后分析这么大的堆文件的时间成本。 当然,在尝试新技术的过程中,我们会不断去探索G1这种增量回收算法的最佳使用姿势。
2) 内存泄漏 内存泄漏跟临界区也类似,让人防不胜防。 集合实现类是内存泄漏的重灾区,比如对于一个线程池配上无限大队列时一定要注意这个无限队列在某个时刻会让系统发生OOM。 我们会仔细检查系统中是否存在线程池配无限大队列的情况,同时在容易造成内存泄漏的集合类指定一个大小,比如本地缓存,我们通常会设置一个上界。 我们网关线上实际碰到过线程池的无界队列引发的OOM,一台服务后端阻塞导致一个线程的队列撑爆了堆内存,一直FGC,CPU暂用率100%,当前服务器无法提供正常服务,系统dump了一个超过6GB大小的堆文件。最后只有把它拷贝到一台大内存服务器用命令行分析后,再把结果文件拷贝回本机使用HeapAnalyzer分析。它能清晰展示对象层次关系,直接定位问题,尤其适合分析较大的dump文件。 遇到OOM并不可怕,使用一款优秀的分析工具很容易定位到具体的问题代码。
网络优化: 网络方面的优化我们主要做了几方面的事:
服务部署:
服务对稀缺资源都是弱依赖,比如对redis和mysql是弱依赖。这主要得益于本地缓存的使用。
对外部的依赖系统设置合理超时时间,比如redis设置1s,db设置2s,这会在一定程度上保护我们的系统。
网关接受到请求到发起后端请求之间的平均时耗约2ms,即网关本身平均每次请求消耗了约2ms。 当今一个主频3GHz的CPU每秒能处理30亿条指令,所以耗在执行程序指令上的时间相比网络IO和磁盘IO可以忽略不计。根据这个思路,我们考虑使用本地缓存来降低网络IO的消耗。
网关核心逻辑采用类责任链模式(Filter Chain),每个filter处理一件事情,这样无论增加处理逻辑还是增加不同协议的服务,仅需新增一个Filter到调度逻辑;想要禁用某个Filter,也能静态或者动态排除它,即可插拔性。
线上系统环境错综复杂,问题在所难免。 所以保障可靠性除了服务自身需要高质量以外,主要还是依赖强大的监控系统来作为我们的千里眼、顺风耳。监控系统将会在第四节介绍。
控制台的主要功能点:
在以上常规功能点之上,我只想重点介绍下API的设计思路,这个设计成功解耦了外部调用者和内部开发者之间的耦合,不仅让网关后期的功能扩展工作事半功倍,而且为API开发者在配置的时候提供了灵活性。
 在实际应用中,外部API名字跟内部API名字不一样,外部参数跟内部参数名也时常有不一样,这通过内外分离可以很好的解决这种改变内部不影响外部调用的场景。
在实际应用中,外部API名字跟内部API名字不一样,外部参数跟内部参数名也时常有不一样,这通过内外分离可以很好的解决这种改变内部不影响外部调用的场景。印象中已经有好几次是监控系统帮助我们网关系统及时发现问题,避免了故障的发生。
有赞应用层网关系统的概况以及遇到的一些网络、并发、GC问题的处理思路大致如上所述。重点交流一下思路,不再续说一些模块实现细节,相信对具体的实现方案每个人都有自己的一套解决方案。
随着业务不断地发展,有赞应用层网关系统将会面向更多的应用场景,同时也会面临诸多新的挑战,当然网关的未来也值得期待。
最后谢谢您对有赞的关注,同时如果双方合适,期待在往后的日子里并肩作战。强势插入招人内推邮箱 [email protected]
提到应用网关系统,我们脑海中或多或少都会闪过一些关键词,比如统一入口、高并发、大流量、限流、防刷、实时监控等等。 Youzan Application Gateway Center(公司内部称之为Carmen系统),它就是目前有赞的应用层网关系统。每天承载着亿级别的请求量,持续的为开放平台和多个有赞App应用提供着稳定的服务。
今天我们来一起剖析下整个有赞的应用层网关,聊聊网关的当前的概况、整个网关系统的构成、遇到的一些问题的思考和解决方案。当然在进入正题之前,我们不妨先对这个网关系统提出几个问题:
以上这些问题在您耐心读完整篇文章后,将会一一得到答案。
首先,网关作为一个系统入口,目前它在有赞技术生态圈中主要面向开放平台和移动app两种应用场景。开放平台属于外部调用,移动app属于内部调用。内部与外部调用使用不同的域名,以便合理分配资源、有效进行权限控制、流量控制等。
整个网关系统拆分为3个子系统,都由java实现:
图 1-1 系统整体概况图1-1展示的整个网关系统需要完成下列目标:
1.主要功能模块:
2.整体架构
3.下面我分别从系统的健壮性、高性能、扩展性、安全性、可靠性五个方面来介绍下为了达到这些目标,有赞网关是采用了一些什么方法。
压力测试:
为了提供稳定的服务,首先我们需要充分了解自己的程序以及其运行的服务器,所以前期需要充分地压测,通过压测具体数据来找出系统的性能瓶颈以及性能拐点,同时也让自己了解程序与机器配合度,最后根据压测报告来评估系统的容量。 有赞网关在压测过程中,通过模拟用户场景,对比各种机器指标被打满的情况,帮助我们提前暴露了下列瓶颈点:
一个有效的压力测试会极大帮助开发者了解自己的系统,对容量规划做到心里有底。
并发问题处理:
并发编程一书的作者曾说过:没有人能保证写出完全正确的并发程序。 编写好并发程序是一项有富有挑战性的工作,下面谈谈有赞应用网关在线上实际遇到的并发场景:
第一个是在系统出入口的并发访问。 入口的高并发会带来线程膨胀,资源耗尽,吞吐量下降的问题,还好我们有Nginx,有Jetty的NIO以及Servlet3.0异步特性。 此三者很好的为我们解决了系统入口的并发问题:Nginx做负载均衡、NIO使用IO多路复用解决空闲网络连接过多引发的线程膨胀问题,Servlet 3.0的异步特性释放了入口的吞吐能力。 出口的高并发在同步模式会显著降低吞吐量,使用异步调用模式会很好的缓解这个问题。
第二个是代码中并发问题 没有共享,就不会有并发问题,但java中多线程场景无处不在。
代码中临界区就像幽灵一样,让人防不胜防。
当并发量小或者无并发的时候,这些临界区能正常work。一旦流量超出阈值,这种并发就会触发异常或者带来逻辑上的错误,甚至让系统奔溃。
最后对于并发编程,强烈建议找两个并发编程的老司机一起来review下代码,尤其是核心模块!!
内存管理实践:
虽然Java会自动进行内存回收,但是网关系统中也必须要重视内存的合理配置与使用,否则OOM,频繁FGC会缠上你的系统。 有赞网关在流量不断攀升的过程中也在不断调整GC相关参数去解决FGC频繁的问题。其中的经验之谈就是使用JVM相关的命令不断观察GC回收的次数、耗时,最终在吞吐量和响应时间之间找到一个系统平衡点。比如有赞网关之前维持的一个平衡点是一次YGC时间约25ms,一次FGC100ms(Young Generation和Old Generation分别给2g, CMS回收器)。
网关系统曾经大半年都是使用CMS回收器,近来已经在尝试使用使用增量回收算法的G1回收器。 下面小结下这两种回收器在我们网关系统上的实际效果(4核8G的VM服务器):
当前图是切换成G1之后几天的监控数据,左边12天是使用CMS的数据,右边12天是使用G1的数据。红线是young GC的回收次数,蓝线是GC回收时间,G1的YGC时间要比CMS的大一些。当前图是CMS和G1回收器在堆变化趋势的对比。红线是Young区,蓝线是Old区。 左边CMS能明显看到有FGC,右边G1的Old区大小不是线性增长,实际监控数据显示它没有进行FGC,而且G1的Young区占据空间比CMS的Young区大。小结:目前的使用经验看来G1回收算法并没有比CMS用得舒服,反而带来了不触发FGC的问题以及增加了OOM后分析这么大的堆文件的时间成本。 当然,在尝试新技术的过程中,我们会不断去探索G1这种增量回收算法的最佳使用姿势。
2) 内存泄漏 内存泄漏跟临界区也类似,让人防不胜防。 集合实现类是内存泄漏的重灾区,比如对于一个线程池配上无限大队列时一定要注意这个无限队列在某个时刻会让系统发生OOM。 我们会仔细检查系统中是否存在线程池配无限大队列的情况,同时在容易造成内存泄漏的集合类指定一个大小,比如本地缓存,我们通常会设置一个上界。 我们网关线上实际碰到过线程池的无界队列引发的OOM,一台服务后端阻塞导致一个线程的队列撑爆了堆内存,一直FGC,CPU暂用率100%,当前服务器无法提供正常服务,系统dump了一个超过6GB大小的堆文件。最后只有把它拷贝到一台大内存服务器用命令行分析后,再把结果文件拷贝回本机使用HeapAnalyzer分析。它能清晰展示对象层次关系,直接定位问题,尤其适合分析较大的dump文件。 遇到OOM并不可怕,使用一款优秀的分析工具很容易定位到具体的问题代码。
网络优化: 网络方面的优化我们主要做了几方面的事:
服务部署:
服务对稀缺资源都是弱依赖,比如对redis和mysql是弱依赖。这主要得益于本地缓存的使用。
对外部的依赖系统设置合理超时时间,比如redis设置1s,db设置2s,这会在一定程度上保护我们的系统。
网关接受到请求到发起后端请求之间的平均时耗约2ms,即网关本身平均每次请求消耗了约2ms。 当今一个主频3GHz的CPU每秒能处理30亿条指令,所以耗在执行程序指令上的时间相比网络IO和磁盘IO可以忽略不计。根据这个思路,我们考虑使用本地缓存来降低网络IO的消耗。
网关核心逻辑采用类责任链模式(Filter Chain),每个filter处理一件事情,这样无论增加处理逻辑还是增加不同协议的服务,仅需新增一个Filter到调度逻辑;想要禁用某个Filter,也能静态或者动态排除它,即可插拔性。
线上系统环境错综复杂,问题在所难免。 所以保障可靠性除了服务自身需要高质量以外,主要还是依赖强大的监控系统来作为我们的千里眼、顺风耳。监控系统将会在第四节介绍。
控制台的主要功能点:
在以上常规功能点之上,我只想重点介绍下API的设计思路,这个设计成功解耦了外部调用者和内部开发者之间的耦合,不仅让网关后期的功能扩展工作事半功倍,而且为API开发者在配置的时候提供了灵活性。
在实际应用中,外部API名字跟内部API名字不一样,外部参数跟内部参数名也时常有不一样,这通过内外分离可以很好的解决这种改变内部不影响外部调用的场景。印象中已经有好几次是监控系统帮助我们网关系统及时发现问题,避免了故障的发生。
有赞应用层网关系统的概况以及遇到的一些网络、并发、GC问题的处理思路大致如上所述。重点交流一下思路,不再续说一些模块实现细节,相信对具体的实现方案每个人都有自己的一套解决方案。
随着业务不断地发展,有赞应用层网关系统将会面向更多的应用场景,同时也会面临诸多新的挑战,当然网关的未来也值得期待。
去哪儿机票搜索架构实践(一) 整体架构
https://www.sohu.com/a/206825911_505779
朱仕智,去哪儿网高级架构师,国际机票技术总监。90后,2013年加入去哪儿,先后参与过公共业务、国际机票搜索系统的研发。围绕高可用、高性能、大数据量、高扩展构建了支持业务快速发展的实时搜索报价系统,在系统和程序设计方面积累了较多经验。
用户诉求和挑战 用户的诉求
对于使用 Qunar 平台的用户来说,诉求其实很简单,就是能很愉快的买到价格低的飞机票,主要包含几个方面:
报价全:航线、航班的覆盖要足够全,所想即可得
价格低:价格要有优势,不能薅用户血汗钱
价格准:实时性好,可预订
产品多:满足多样化差异化需求,商旅用户和低价敏感用户的目标是不一样的
面临的挑战
用户诉求虽然简单,但是从构建系统角度去看就不简单了,机票报价搜索不同于其他搜索,更像是一个实时计算系统。航司运价规则、代理商调价规则、库存信息都在频繁变更,海量的数据变动让报价计算复杂度急剧上升,更恐怖的是其中一些基础资源没有掌握在 Qunar 平台内,而是在 GDS (全球分销系统)手里,需要支付一定的费用才能获取。
一个机票价格到底是怎么产生的呢?航空公司购买飞机用于某个航线的飞行后,会对这个航线制定运价;然后把运价和仓位库存信息发布到 GDS 中。最后航空公司会找代理商帮它买票,给予代理商一定的优惠。
所以一个最基本的机票销售报价产生需要几个步骤:航司制定运价+库存情况+分销代理商调整价格。
然后再组合必要的相关信息,如退改签、税费、过境签信息等;最后还会基于机票报价的基础上,搭售各种附加产品,比如 WIFI、值机服务等。
可以看出整个报价计算链路是比较长的,各个环节的数据变更比较频繁,而且量也都比较大。具体有多大呢?来看看几个直观的数据:
系统架构
在这样的背景下,就需要我们对系统做一定的设计来满足海量的数据计算。
系统设计考虑
主要有两种思路:全量预计算和按需实时计算,各有优劣。
全量预计算:在用户搜索之前,就把所有的报价提前计算好,然后感知所有影响报价的变更,一旦发现变更,重新计算对应的报价。所以这种方式的响应速度和报价准确性较好。但是需要消耗的资源量非常大。而且在变更频繁的场景下,需要重复计算的量也非常大。
按需实时算:用户搜索触发计算,而且配合报价结果的缓存,可以进一步减少计算量。所以这种方式对资源要求很低,而且扩展性较好。但是由于实时计算所以响应速度很慢一些,而且缓存也一定程度的影响了报价的有效性。
最后基于资源和扩展性考虑,只能选择按需实时计算,然后再想其他的方案来优化响应速度和准确性。
系统结构
基于前面的问题和考量点,我们设计了一套搜索系统,实时地计算报价,配合报价结果缓存,并且对缓存数据进行闭环刷新,如下图:
可以看到整套系统是水平分层的,垂直上是按照报价引擎划分的。分层在计算机领域里面是复杂问题简单化的一个行之有效的经验,使得我们可以针对每一层做特殊的处理和优化。
最上层是各种终端渠道,APP、WWW、低价等,都会使用到报价搜索的能力。
然后是报价聚合层,聚合层有维护一个报价结果的全局缓存,并且使用 cache manager 对这些缓存进行管理,所有影响报价的变更,都收拢到这个系统内。报出缓存报价之前,都会检查其有效性。
再往下是报价的计算引擎层,聚合层和引擎层之间采用了消息驱动的交互方式,redis 作为数据交换区,这样可以比较好的解耦系统之间的依赖,新增或减少报价引擎,都不会对聚合层产生影响。
报价引擎层内,会细分为两个小层,一层是更宽泛的非绝对意义的机票业务,如航路规划、产品包装、大交通等。另一层则是基础机票报价计算,有 TTS、旗舰店、抓取等多个渠道,各个渠道的报价引擎之间是并行计算的,并形成互补优势。
最底层是基础数据层,有运价、调价规则、航班数据等数据。其中部分是数据存储查询服务、部分则是实时计算;比如运价,就是实时计算而不是提前算好上亿个运价数据。
需要特别说明的是,MQ+redis 的交互方式,除了可以解耦之外,其实也节省了大量的网络流量。其实我们分析报价的计算过程,可以发现它其实是一个单向的计算流,航路规划 -> 运价计算 -> 匹配调节规则、库存等 -> 包装、大交通等业务。但是一般的分层系统是树状结构,下层的计算结果需要回溯到上层。而通过 MQ,可以把这个过程展开,不需要一层层的回调,只在最后结果时通知到聚合层就可以。并且其他系统也可以监听这个结果消息来收取报价结果。
在下一篇中,我们将详细的分析一个报价引擎的设计和优化过程,敬请期待。
“高并发”一直是大家感兴趣的话题。2010年~2012年,我曾在Qunar供职,主要负责机票搜索相关的业务,当时我们的搜索系统最高每天承载了亿级用户的高并发访问。那段日子,很苦很累,Qunar的发展很快,我也见证了搜索系统的技术演变历程,本文就来给大家讲讲机票高并发的故事。
Qunar成立于2005年,那时候大家还习惯打电话或者去代理商买机票。随着在线旅游快速发展,机票业务逐步来到线上。在“在线旅游”的大浪潮下,Qunar的核心业务主要是线上机票搜索和机票销售。根据2014年9月艾瑞监测数据,在旅行类网站月度独立访问量统计中,去哪儿网以4474万人名列前茅。截至2015年3月31日,去哪儿网可实时搜索约9000家旅游代理商网站,搜索范围覆盖全球范围内超过28万条国内及国际航线。
Qunar由机票起家,核心产品包括机票搜索比价系统、机票销售OTA系统等。后来一度成为国内最大旅游搜索引擎,所以最开始大家知道Qunar都是从机票开始。
在Qunar,我主要工作负责机票搜索系统。当时,搜索业务达到了日均十亿量级PV,月均上亿UV的规模。而整个搜索主系统设计上是比较复杂的,大概包含了七、八个子系统。那时线上服务器压力很大,时常出现一些高并发的问题。有时候为了解决线上问题,通宵达旦连续一两周是常有的事。尽管如此,我们还是对整个搜索系统做到了高可用、可扩展。
为了大家了解机票搜索的具体业务,我们从用户角度看一下搜索的过程,如下图:
根据上面的图片,简单解释下:
首页:用户按出发城市、到达城市、出发日期开始搜索机票,进入列表页。
列表页:展示第一次搜索结果,一般用户会多次搜索,直到找到适合他的航班,然后进入详情页。
产品详情页:用户填入个人信息,开始准备下单支付。
从上面的介绍可以看出,过程1和2是个用户高频的入口。用户访问流量一大,必然有高并发的情况。所以在首页和列表页会做一些优化:
前端做静态文件的压缩,优化Http请求连接数,以减小带宽,让页面更快加载出来。
前后端做了数据分离,让搜索服务解耦,在高并发情况下更灵活做负载均衡。
后端数据(航班数据)99%以上来自缓存,加载快,给用户更快的体验。而我们的缓存是 异步刷新的机制,后面会提及到。
在过亿级UV的搜索业务,其搜索结果核心指标:一是保证时间够快,二是保证结果实时最新。
为了达到这个指标,搜索结果就要尽量走缓存,我们会预先把航班数据放到缓存,当航班数据变化时,增量更新缓存系统。 所以,Qunar机票技术部就有一个全年很关键的一个指标:搜索缓存命中率,当时已经做到了>99.7%。再往后,每提高0.1%,优化难度成指数级增长了。哪怕是千分之一,也直接影响用户体验,影响每天上万张机票的销售额。
因此,搜索缓存命中率如果有微小浮动,运营、产品总监们可能两分钟内就会扑到我们的工位上,和钱挂上钩的系统要慎重再慎重。
每台搜索实例的QPS(搜索有50~60台虚拟机实例,按最大并发量,每台请求吞吐量>1000)。
搜索结果的 Average-Time : 一般从C端用户体验来说,Average-Time 不能超过3秒的。
了解完机票搜索大概的流程,下面就来看看Qunar搜索的架构。
搜索系统设计架构
Qunar搜索架构图
上面提到搜索的航班数据都是存储在缓存系统里面。最早使用Memcached,通过一致Hash建立集群,印象大概有20台左右实例。 存储的粒度就是出发地和到达地全部航班数据。随着当时Redis并发读写性能稳步提高,部分系统开始逐步迁移到Redis,比如机票低价系统、推荐系统。
搜索系统按架构图,主要定义成前台搜索、后台搜索两大模块,分别用2、3标示,下面我也会重点解释。
主要读取缓存,解析,合并航班数据返回给用户端。
前台搜索是基于Web服务,高峰期时候最大启动了50台左右的Tomcat实例。搜索的URL规则是:出发城市+到达城市+出发日期,这和缓存系统存储最小单元:出发城市+到达城市+出发日期是一致的。
Tomcat服务我们是通过Nginx来做负载均衡,用Lua脚本区分是国际航线还是国内航线,基于航线类型,Nginx会跳转不同搜索服务器:主要是国际搜索、国内搜索(基于业务、数据模型、商业模式,完全分开部署)。不光如此,Lua还用来敏捷开发一些基本服务:比如维护城市列表、机场列表等。
上文我们一直提到航班数据,接下来简单介绍下航班的概念和基本类型,让大家有个印象,明白的同学可以跳过:
单程航班:也叫直达航班,比如BJ(北京)飞NY(纽约)。
往返航班:比如BJ飞NY,然后又从NY返回BJ。
带中转:有单程中转、往返中转;往返中转可以一段直达,一段中转。也可以两段都有中转,如下图:
其实,还有更复杂的情况:
如果哪天在BJ(北京)的你想来一次说走就走的旅行,想要去NY(纽约)。你选择了BJ直飞NY的单程航班。后来,你觉得去趟米国老不容易,想顺便去LA玩。那你可以先BJ飞到LA,玩几天,然后LA再飞NY。
不过,去了米国要回来吧,你也许:
NY直接飞回BJ。
突然玩性大发,中途顺便去日本,从NY飞东京,再从东京飞BJ。
还没玩够?还要从NY飞夏威夷玩,然后夏威夷飞东京,再东京飞首尔,最后首尔返回北京。
…… 有点复杂吧,这是去程中转、回程多次中转的航班路线。
对应国际航班还算非常正常的场景,比如从**去肯尼亚、阿根廷,因为没有直达航班,就会遇到多次中转。所以,飞国外有时候是蛮有意思、蛮麻烦的一件事。
通过上面例子,大家了解到了机票中航线的复杂程度。但是,我们的缓存其实是有限的,它只保存了两个地方的航班信息。这样简单的设计也是有必然出发点:考虑用最简单的两点一线,才能最大限度上组合复杂的线路。
所以在前台搜索,我们还有大量工作要做,总而言之就是:
按照最终出发地、目的地,根据一定规则搜索出用户想要的航班路线。这些规则可能是:飞行时间最短、机票价格最便宜(一般中转就会便宜)、航班中转最少、最宜飞行时间。
你看,机票里面的航线是不是变成了数据结构里面的有向图,而搜索就等于在这个有向图中,按照一定的权重求出最优路线的过程!
我们后端技术栈基于Java。为了搜索变得更快,我们大量把Java多线程特性用到了并行运算上。这样,充分利用CPU资源,让计算航线变得更快。 比如下面这样中转航线,就会以多线程方式并行先处理每一段航班。类似这样场景很多:
Java Executor框架提供了完善线程池管理机制:譬如newCachedThreadPool、 SingleThreadExecutor 等线程池。
FutureTask类灵活实现多线程的并行、串行计算。
在高并发场景下,提供了保证线程安全的对象、方法。比如经典的ConcurrentHashMap,它比起HashMap,有更小粒度的锁,并发读写性能更好。线程不安全的StringBuilder取代String、StringBuffer等等(Java在多线程这块实现是非常优秀和成熟的)。
因为每次搜索机票,返回的航班数据是很多的:
包含各种航线组合:单程、单程一次中转、单程多次中转,往返更不用说了。
航线上又区分上百种航空公司的组合。比如北京到纽约,有美国航空,国航,大韩, 东京等等各个国家的各大航空公司,琳琅满目。
那么,最早航班数据用标准的XML、JSON存储,不过随着搜索量不断飙升,CPU和带宽压力很大了。后来采取自己定义一种txt格式来传输数据:一方面数据压缩到原来30%~40%,极大的节约了带宽。同时CPU的运算量大大减低,服务器数量也随之减小。
在大用户量、高并发的情况下,是特别能看出开源系统的特点:比如机票的数据解析用到了很多第三方库,当时我们也用了Fastjson。在正常情况下,Fastjson 确实解析很快,一旦并发量上来,就会越来越吃内存,甚至JVM很快出现内存溢出。原因呢,很简单,Fastjson设计初衷是:先把整个数据装载到内存,然后解析,所以执行很快,但很费内存。
当然,这不能说Fastjson不优秀,现在看 GitHub上有8000多star。只是它不适应刚才的业务场景。
这里顺便说到联想到一个事:互联网公司因为快速发展,需要新技术来支撑业务。 那么,应用新的技术应该注意些什么呢?我的体会是:
好的技术要大胆尝试,谨慎使用。
优秀开源项目,注意是优秀。使用前一定弄清他的使用场景,多做做压力测试。
高并发的用户系统要做A/B测试,然后逐步导流,最后上线后还要有个观察期。
后台搜索
后台搜索系统的核心任务是从外部的GDS系统抓取航班数据,然后异步写入缓存。
首先说一个概念GDS(Global Distribution System)即“全球分销系统”,是应用于民用航空运输及整个旅游业的大型计算机信息服务系统。通过GDS,遍及全球的旅游销售机构可以及时地从航空公司、旅馆、租车公司、旅游公司获取大量的与旅游相关的信息。
机票的源数据都来自于各种GDS系统,但每个GDS却千差万别:
服务器遍布全球各地:国内GDS主要有中航信的IBE系统、黑屏数据(去机场、火车站看到售票员输入的电脑终端系统),国际GDS遍布于东南亚、北美、欧洲等等。
通讯协议不一样,HTTP(API、Webservice)、Socket等等。
服务不稳定,尤其国外的GDS,受网路链路影响,访问很慢(十几分钟长连接很常见),服务白天经常性挂掉。
更麻烦的是:GDS一般付费按次查询,在大搜索量下,实时付费用它,估计哪家公司都得破产。而且就算有钱 , 各种历史悠久的GDS是无法承载任何的高并发查询。更苦的是,因为是创业公司,我们大都只能用免费的GDS,它们都是极其不稳定的。
所谓便宜没好货,最搞笑的一次是:曾经在米国的GDS挂了一、两天,技术们想联系服务商沟通服务器问题。因为是免费,就没有所谓的服务商一说,最后产品总监(算兼职商务吧)给了一个国外的网址,打开是这家服务商的工单页面,全英文,没有留任何邮箱。提交工单后,不知道什么时候回复。可以想想当时我的心情......
虽然有那么多困难,我们还是找到一些技术方案,具体如下。
考虑GDS访问慢,不稳定,导致很多长连接。我们大量使用NIO技术:
NIO,是为了弥补传统I/O工作模式的不足而研发的,NIO的工具包提出了基于Selector(选择器)、Buffer(缓冲区)、Channel(通道)的新模式;Selector(选择器)、可选择的Channel(通道)和SelectionKey(选择键)配合起来使用,可以实现并发的非阻塞型I/O能力。
NIO并不是一下就凭空出来的,那是因为 Epoll 在Linux2.6内核中正式引入,有了I/O多路复用技术,它可以处理更多的并发连接。这才出现了各种应用层的NIO框架。
HTTP、Socket 都支持了NIO方式,在和GDS通信过程中,和过去相比:
通信从同步变成异步模式:CPU的开销、内存的占用都减低了一个数量级。
长连接可以支持更长超时时间,对国外GDS通信要可靠多了。
提高了后台搜索服务器的稳定性。
为了异步完成航班数据更新到缓存,我们采用消息队列方式(主备AMQ)来管理这些异步任务。具体实现如下。
有一个问题,如何判断缓存过期呢?这里面有一个复杂的系统来设置的,它叫Router。资深运营会用它设置可以细化到具体一个航段的缓存有效期:比如说北京—NY,一般来说买机票的人不多的,航班信息缓存几天都没有问题。但如果北京—上海,那可能就最多5分钟了。
Router还有一个复杂工作,我叫它“去伪存真”。我们长期发现(真是便宜无好货),某些GDS返回航班数据不全是准确的,所以我们会把某些航线、甚至航班指定具体的GDS数据源,比如北京—新加坡:直达航班数据 来自于ABAQUS,但是中转数据,北京—上海—新加坡, 或者北京—台北—新加坡 从IBE来会精准些。
因此Router路由规则设计要很灵活。通过消息队列,也其实采用异步化方式让服务解耦,进行了很好的读写分离。
为了管理好不同GDS资源,最大的利用它们。我们把GDS服务器抽象成一组Node节点来便于管理,像下面这样:
具体原理:按照每个GDS服务器稳定性(通过轮休方式,不断Check它们的可用性)和查询性能,我们算出一个合理的权重,给它分配对应的一组虚拟的Node节点,这些Node节点由一个Node池统一管理。这样,不同的GDS系统都抽象成了资源池里面的一组相同的Node节点。
那么它具体如何运转的呢?
当缓存系统相关航班数据过期后,前台搜索告知MQ有实时搜索任务,MQ统一把异步任务交给Router,这个时候Router并不会直接请求GDS数据,而是去找Node池。Node池会动态分配一个Node节点给Router,最后Router查找Node节点映射的GDS,然后去请求数据,最后异步更新对应的缓存数据。通过技术的实现,我们把哪些不稳定的,甚至半瘫痪的GDS充分利用了起来(包含付费的一种黑屏终端,我们把它用成了免费模式,这里用到了某些黑科技,政策原因不方便透露),同时满足了前台上亿次搜索查询!
鉴于机票系统的复杂度和大业务量,完备监控是很必要的:
1、整个Qunar系统架构层级复杂,第三方服务调用较多(譬如GDS),早期监控系统基于CACTI+NAGIOS ,CACTI有很丰富的DashBoard,可以多维度的展示监控数据。除此以外,公司为了保证核心业务快速响应,埋了很多报警阈值。而且Qunar还有一个NOC小组,是专门24小时处理线上报警:记得当时手机每天会有各种系统上百条的报警短信。
当然,我还是比较淡定了。因为系统太多,报警信息也不尽是系统bug,它可能是某些潜在的问题预警,所以,系统监控非常至关重要。
2、复杂系统来源于复杂的业务,Qunar除了对服务器CPU、内存、IO系统监控以外,远远是不够的。我们更关心,或者说更容易出问题是业务的功能缺陷。所以,为了满足业务需要,我们当时研发了一套业务监控的插件,它的核心原理如下图:
它把监控数据先保存到内存中,内部定时程序每分钟上传数据到监控平台。同时它作为一个Plugin,可以即插即用。接入既有的监控系统,它几乎实时做到监控,设计上也避免了性能问题。后期,产品、运营还基于此系统,做数据分析和预测:比如统计出票正态分布等。因为它支持自定义统计,有很方便DashBoard实时展示。对于整个公司业务是一个很有力的支撑。
到今天,这种设计思路还在很多监控系统上看到相似的影子。
机票另一个重要系统TTS:TTS(Total Solution)模式,是去哪儿网自主研发的交易平台,是为航空公司、酒店在线旅游产品销售系统。
TTS有大量商家入驻,商家会批量录入航班价格信息。
为了减少大量商家同时录入海量数据带来的数据库并发读写的问题,我们会依据每个商家规模,通过数据库动态保存服务器IP,灵活的切换服务器达到负载均衡的效果。这里不再细说了。
最后,回顾整个搜索架构的设计,核心**体现了服务的一种解耦化。设计的系统虽然数量看起来很多,但是我们出发点都是把复杂的业务拆解成简单的单元,让每一个单元专注自己的任务。这样,每个系统的性能调优和扩展性变得容易。同时,服务的解耦使整个系统更好维护,更好支撑了业务。
作者介绍
蒋志伟,前美团、Qunar架构师,先后就职于阿里、Qunar、美团,精通在线旅游、O2O等业务,擅长大型用户的SOA架构设计,在垂直搜索系统领域有丰富的经验,尤其在高并发线上系统方面有深入的理论和实践,目前在pmcaff担任CTO。
Redisson作者Rui Gu:构建开源企业级Redis客户端之路
笔者代表阿里云参加了RedisConf 2018的会议,在会议上对开源Redisson客户端的作者Rui Gu做了一个访谈,Rui Gu在Redis社区国际上的影响力还有在开源上的工作给笔者留下了深刻的印象,以下是访谈的具体内容。
##当初为什么参与设计开发Redisson?
自04年从事工业自动化、工业IoT工作至今,涉及到很多场景需要对一系列设备进行监控和信号处理等工作。该类场景对实时处理能力,系统稳定性,高可用性,容灾能力等等要求非常高。从12年时决定采用Redis作为实时数据库时就产生了许多想法。Redis与Java这样的编程语言中的常用数据结构看似相像却又不同,一直希望能够用什么方法将两者联系起来。13年开始商用Redis以后这种想法越加强烈。于是在工作之余自行开始了一些相关的摸索与实践,最终决定采用动态类的形式让Redis的数据结构操作起来更像Java对应的结构。谁知远在莫斯科的Nikita似乎也有类似的想法,他从14年元旦便开始了实际应用的开发,并很快的开源了Redisson。于此同时我的实践也有了许些进展,并初步的实现了一些基本功能。不过由于工作上的种种原因,再加上当时自己也缺乏足够的信心,毕竟这是条没人走过的路,大半年过去了进展比较缓慢。殊不知Nikita面对这同样的问题,但是他不仅艰难地坚持了下来,而且丝毫没有放弃的意思。14年下半年时我开始注意到了Redisson项目,仔细了解了以后顿时产生了很强的共鸣,虽然和我的实践有着同样的理念却又是不同的出发点。于是乎,在有了这样的火花以后,我们开始了相互之间的沟通和交流,最后在15年初时决定,放弃自己的实践项目,加入Redisson。至此,在这条没人走过的路上我们不再独行。
2.1)IoT行业里,一组设备的各种实时状态值往往是作为一个具有业务意义的对象,由JVM管理在内存里,如果将这个对象存储到Redis数据库的String结构里,每次更新一个状态值,就需要做一次序列化和反序列化。同时还有可能面临着同一时刻操作同一个对象的不同状态值带来的并发难题。实际应用时采用了Redis提供的Hash数据结构来储存这个对象,只有这样才能有效地避免这类问题的发生。尽管Redis的Hash结构和Java里的HashMap极为相似,但是在程序操作Redis的时候不能像操作HashMap一样便捷。而且如果对Redis相关命令的用法不能稔熟于心,或在细节之处处理不当,便会最终造成业务上的各种问题。Redisson的Map就是为了填补Redis的Hash和Java的HashMap两者之间的空缺而产生。
image
2.2)工控和某些IoT场景对实时处理能力要求很高,所有的信号都必须实现毫秒级响应。这类场景还具有并发量巨大的特点。与社交电商等场景不同的是这类应用场景基本没有峰谷流量,时时刻刻都是峰值。因此其它场景里常见的削峰填谷措施在这里只能加重负担。在这样的场景下如果使用像Jedis这样采用同步编程模型的客户端时,就需要随时确保并发线程数与连接数一对一,否则获取不到可用连接会直接报错。相比之下Redisson利用了Netty异步编程框架,使用了与Redis服务端结构类似的事件循环(EventLoop)式的线程池,并结合连接池的方式弹性管理连接。最终做到了使用少量的连接既可以满足对大量线程的要求,从根本上缓解线程之间的竞争关系。同时异步操作的模式还能够避免数据请求造成业务线程的阻塞。
2.3)Redis 发展至今经历了多次技术变迁。官方版在迭代的过程中不但增加了许多有用的功能,同时也发展了几种高可用性方案。于此同时,社区和云计算商在官方版上进而开发出了多种基于代理(Proxy)的高可用方案。相比之下,这些方案各有优劣,适用场景也各自不一。多样化的方案在带来便利的同时也带来了麻烦。比如在业务扩容,从简单的单机或主从模式迁移到哨兵或集群模式;或是业务迁移,从自建的Redis环境迁移到云上;亦或是项目的持续性交付CD/CI过程中,不同的阶段使用不同Redis运行模式等等情况。往往需要开发人员针对不同的高可用方案开发出一套与之匹配的使用方法。使得一个项目对Redis运行模式的耦合度高,在Redis运行模式变化时就必须更改业务代码。Redisson针对这种情况提供了一套便捷的文件化配置方法,在无需修改程序代码的情况下,通过不同的JSON,YAML或SpringXML文件实现对不同Redis运行模式和环境的支持。这既降低了开发难度,也降低了运维难度。
对于Redis分布式锁的实现方式,网上讨论相关文章都基本都“烂大街”了。然而几乎所有相关介绍都是在单纯使用setnx命令的基础上进行一个简单封装,且少有文章分析这样设计的缺陷。在这个博客满天飞,代码随便贴的时代,这样的局面无形之中给了大家一个假象,就是Redis分布式锁只能是以这样简单的形式存在,即便有缺陷也只能在业务代码里规避。那么为什么不换位思考一下,即用稍微复杂点的设计来弥补它的不足,从而换取业务上的灵活性呢?再重新设计Redis分布式锁之前,我们先了解一下单纯使用setnx命令封装的分布式锁有哪些不足。
在执行setnx命令时,通常采用业务上指定的名称作为key名,用时间或随机值作为value来实现。这样的实现方式不具备追踪请求线程的能力,同时也不具备统计重入次数的能力,甚至有些实现方式都不具备操作的原子性。当遇到业务上需要在多个地方用到同样一个锁的时候,很显然使用不具有可重入的锁会很容易发生死锁的现象。特别是在有递归逻辑的场景里,发生死锁的几率会更高。Java并发工具包里的Lock对象和sychronized语块都具有可重入性,对于经常使用这些工具的人来说,往往会很容易忽略setnx的这个缺陷。
在分布式环境中,为了保证锁的活性和避免程序宕机造成的死锁现象,分布式锁往往会引入一个失效时间,超过这个时间则认为自动解锁。这样的设计前提是开发人员对这个自动解锁时间的粒度有一个很好的把握,太短了可能会出现任务没做完锁就失效了,而太长了在出现程序宕机或业务节点挂掉时,其它节点需要等很长时间才能恢复,而难以保证业务的SLA。setnx的设计缺乏一个延续有效期的续约机制,无法保证业务能够先工作做完再解锁,也不能确保在某个程序宕机或业务节点挂掉的时候,其它节点能够很快的恢复业务处理能力。
平常大家多少都接触过的锁,由于加锁策略(Locking Strategy)的差别,使得每种锁都有各自不同的特性。但是在通常情况下这些锁都具备两个共性:一是互斥性,二是阻塞性。互斥性是指在任何时刻最多只能有一个线程获得通行的资格。阻塞性是指的在有竞争的情况下,未获取到资源的线程会停止继续操作,直到成功获取到资源或取消操作。很显然setnx命令只提供了互斥的特性,却没有提供阻塞的能力。虽然在业务代码里可以引入自旋机制来进行再次获取,但这仅仅是把原本应该在锁里实现的功能搬到了业务代码里,通过增加业务代码的复杂程度来简化锁的实现似乎显得有点南辕北辙。
Redisson的分布式锁在满足以上三个基本要求的同时还增加了线程安全的特点。利用Redis的Hash结构作为储存单元,将业务指定的名称作为key,将随机UUID和线程ID作为field,最后将加锁的次数作为value来储存。同时UUID作为锁的实例变量保存在客户端。将UUID和线程ID作为标签在运行多个线程同时使用同一个锁的实例时,仍然保证了操作的独立性,满足了线程安全的要求。
加锁时通过Lua脚本先检查锁是否存在,如不存在则创建hash相关字段并设定过期时间后返回,这表示加锁成功。如果该hash字段已经存在,再检查随机字段和线程id是否一致。如果一致则递增value的值并重新更新过期时间后返回,此时表示同一节点同一线程再次成功加锁,从而保证了可重入性。如果hash存在且字段不一致,说明其他节点或线程已经拥有了这个锁。因此Lua脚本返回这个hash的当前有效期。当结果返回到在客户端后,如果加锁成功,则通过线程池依照设定好的参数定时执行续约,最后通知请求线程继续后续操作。如果加锁没有成功,则监听一个以这个key为后缀的pubsub频道,直到收到解锁消息后再次重试。
解锁时通过Lua脚本先检查锁是否存在,如果已经不存在则直接发布解锁消息并返回。如果任然存在则检查标签是否存在,如果不存在则表示这个锁并不为本线程所拥有,这种情况请求线程将收到报错。如果存在则表示该锁正是被该线程所拥有。在这种情况下,递减标签字段后判断,如果返回的加锁数量仍然大于0,说明当前的锁仍然有效,仅仅只是重入次数减少了。相反这表示锁已经完全解开,则立即删除该锁并发布解锁信息。
Redisson的可重入锁解决了setnx锁的许多先天性不足,但是由于它仍然是以单一一个key的方式储存在固定的一个Redis节点里,并且有自动失效期。这样的设计虽然可以很大程度上避免客户端程序宕机或业务节点挂掉造成的影响,但是随之带来的弊端是遇到服务端Redis进程宕机或节点挂掉的情况,还是有可能会造成锁的信息丢失,这样的缺陷显然无法满足某些特定场景提出的高可用性要求。
介于这种情况,Redis作者Salvatore提出了一个基于多个节点的高可用分布式锁的算法,起名叫红锁(RedLock: https://redis.io/topics/distlock)。在这种算法下,客户端需要同时在多个节点里同时尝试获取一个独立的锁,只有当一次性成功获取了大多数锁的情况下才能被视为赢得了高可用分布式锁,否则需要解除已经部分获取到的锁,等待一个随机时间后再次重试。
在算法设计上,Salvatore依然采用的是setnx作为举例讲解分布式锁的互斥特性。在算法实现上,Redisson的RedissonRedLock采用的是前面提到的更加灵活方便的可重入锁。Redisson的扩展算法是Redis官网唯一认可的Java实现。
虽然Redlock的算法提供了高可用的特性,但建立在大多数可见原则的前提下,这样的算法适用性仍然有一定局限。Redisson为此提供了基于增强型的算法的高可用分布式联锁RedissonMultiLock。这种算法要求客户端必须成功获取全部节点的锁才被视为加锁成功,从而更进一步提高了算法的可靠性。
Redisson的发展路线决定了它在Redis的功能扩展及应用方式上始终走在业界的前列,其中最具有代表性的便是本地缓存功能了。2016年为了解决一企业版用户的切实需求开发了这一功能。其原理是采用牺牲客户端自身内存的空间的方式,换取在频繁获取某些常用数据时消耗在网络上的时间。该功能在同年9月开源后便立即受到了广大用户的关注。这一功能的出现加速了传统IT用户从其他类似平台迁移到Redis的速度。其受欢迎程度大大超乎了Nikita和我的想象。以至于每年都有企业用户不远万里去Redis大会等类似国际交流大会,并分享它们使用Redisson从其他平台向Redis迁移过程和经验。也正是因为这种趋势而引起了Redis作者Salvatore的注意,在同一些用户面对面沟通交流之后,Salvatore决定将客户端缓存功能作为Redis今后发展的重要方向,并为此提出了RESP3协议。RESP3的出现将为客户端缓存功能提供服务端协调的能力。同时Salvatore还邀请Redisson团队作为专家组成员参与Redis客户端缓存标准的指定。
为了保证Redisson项目的可持续性的健康发展,为了避免像其他开源项目面临的一段时间以后就无人维护的尴尬局面,17年初Nikita和我商量后决定在开源项目基础上提供收费咨询服务,为项目的正常运作提供必要的资金。同时还针对大型企业用户遇到的特殊场景提供了企业级的综合性解决方案,最后将这些所有的方案与企业级SLA支持服务打包作为Redisson PRO正式面向企业用户。
相对于其他客户端而言,虽然Redisson项目创立的时间较短,但已经受到了来自不同行业企业的信任,其中不乏许多行业领头羊企业,其中最值得介绍的是这几个世界级的企业用户:
• 计算机行业的IBM。想必大家都熟悉IBM,PC机的鼻祖。,业界少有同时具有超强硬件软件研发能力的企业,即便如此,IBM也心甘情愿的使用Redisson,这种信任是对我们最大的支持。
• 航空国防制造业的波音。在它们主动联系我们以前,我很难想象波音也会对Redisson感兴趣。事实上波音除了造飞机以外,它也是全球最大的飞行航图提供商和移动电子飞行包的方案提供商,几乎每个航空公司都是他们的用户。Redisson为他们的在线飞行导航业务提供了扎实的基础。
• 保险业的美国国际集团(AIG)。美国国际集团成立于1919年的**上海,它是首个将保险概念带给**人的西方企业,其业务遍布全球130多个国家和地区。虽然08年经济危机中,遭遇股价瞬间暴跌的惨剧将AIG推入了吃瓜群主的视线,但它今天仍是一个拥有99年历史,总资产为6千多亿美元的国际性大型企业。在经过AIG团队长时间的调研后,Redisson被用于支持其名目众多的金融保险业务。
• 金融机构标准普尔(S&P Global)。提到经济危机就不得不提一下世界权威金融分析机构标准普尔。它是美国证券交易委员会(SEC)认可的三大评级组织之一,专门为投资者提供信用评级,投资研究和咨询等服务。在业内外的知名度很高,享有盛名的S&P 500美国股指便是由它创建并维护着。标准普尔不仅对外提供针对上市企业的评级,还提供针对国家政府的评级。它在2011年时断然降低美国政府的评级,并把其前景调整为负面以后,立马引发了金融业的剧烈波动。但正是这个呼风唤雨无所不能,连美国政府都不放眼里的机构也成为了Redisson的忠实用户,并将其用于提供复杂的金融数据的分析和处理。由此可见Redisson的信任评级是非常的高[奸笑]。
2022年Spring6和 SpringBoot3相继推出,在此之前,Java社区一直是"新版任你发,我用Java 8",不管新版本怎么出,很少有人愿意升级。
这一次,Spring 直接来了个大招,SpringBoot3和Spring6的最低依赖就是JDK17!跨过 JDK 8-16,直接升级到 JDK 17。那么为什么是 JDK 17呢?
从 JDK 诞生到现在,还在长期支持的版本主要有 JDK 7、JDK 8 、JDK 11以及 JDK 1,JDK 17 将是继 Java 8 以来最重要的LTS版本,是 Java 社区八年努力的成果.
一直以来,Java8 都是 Java 社区心头的痛,Java8提供了很多特性,比如Lambda 表达式、Optional 类,加上Java8超长的支持时间,都导致了JDK8的使用至今。它代表着以稳定性为主的企业管理层与拥抱变化为主的程序猿之间的拉锯战。不升!成为各大厂心照不宣的选择。现在,这种平衡或将打破。因为 Java 届的霸主框架 SpringBoot,选择了最小支持的 Java lts 版本,就是最新的 Java17。
那么接下来,让我们看看,从JDK8到JDK17,Java 社区八年努力的成果有哪些?
重要特性:通过var关键字实现局部变量类型推断,使Java语言变成弱类型语言、JVM的G1垃圾回收由单线程改成多线程并行处理,降低G1的停顿时间。
重要特性:对于JDK9和JDK10的完善,主要是对于Stream、集合等API的增强、新增ZGC垃圾收集器。
重要特性:switch表达式语法扩展、G1收集器优化、新增Shenandoah GC垃圾回收算法。
重要特性:ZGC优化,释放内存还给操作系统、socket底层实现引入NIO。
JDK16相当于是将JDK14、JDK15的一些特性进行了正式引入,如instanceof模式匹配(Pattern matching)、record的引入等最终到JDK16变成了final版本。
虽然JDK17也是一个LTS版本,但是并没有像JDK8和JDK11一样引入比较突出的特性,主要是对前几个版本的整合和完善。
本文介绍了在使用阿里云Redis的开发规范,从键值设计、命令使用、客户端使用、相关工具等方面进行说明,通过本文的介绍可以减少使用Redis过程带来的问题。
ugc:video:1
user:{uid}:friends:messages:{mid}简化为u:{uid}:fr:m:{mid}。
反例:一个包含200万个元素的list。
非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞,而且该操作不会不出现在慢查询中(latency可查)),查找方法和删除方法
反例:
set user:1:name tom
set user:1:age 19
set user:1:favor football
正例:
hmset user:1 name tom age 19 favor football
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期),不过期的数据重点关注idletime。
例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
原生命令:例如mget、mset。
非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。
注意两者不同:
- 原生是原子操作,pipeline是非原子操作。
- pipeline可以打包不同的命令,原生做不到
- pipeline需要客户端和服务端同时支持。
Redis的事务功能较弱(不支持回滚),而且集群版本(自研和官方)要求一次事务操作的key必须在一个slot上(可以使用hashtag功能解决)
避免多个应用使用一个Redis实例
正例:不相干的业务拆分,公共数据做服务化。
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
执行命令如下:
Jedis jedis = null;
try {
jedis = jedisPool.getResource();
//具体的命令
jedis.executeCommand()
} catch (Exception e) {
logger.error("op key {} error: " + e.getMessage(), key, e);
} finally {
//注意这里不是关闭连接,在JedisPool模式下,Jedis会被归还给资源池。
if (jedis != null)
jedis.close();
}下面是JedisPool优化方法的文章:
高并发下建议客户端添加熔断功能(例如netflix hystrix)
设置合理的密码,如有必要可以使用SSL加密访问(阿里云Redis支持)
根据自身业务类型,选好maxmemory-policy(最大内存淘汰策略),设置好过期时间。
默认策略是volatile-lru,即超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
redis间数据同步可以使用:redis-port
redis大key搜索工具
facebook的redis-faina
阿里云Redis已经在内核层面解决热点key问题,欢迎使用。
- 下面操作可以使用pipeline加速。
- redis 4.0已经支持key的异步删除,欢迎使用。
public void delBigHash(String host, int port, String password, String bigHashKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<Entry<String, String>> scanResult = jedis.hscan(bigHashKey, cursor, scanParams);
List<Entry<String, String>> entryList = scanResult.getResult();
if (entryList != null && !entryList.isEmpty()) {
for (Entry<String, String> entry : entryList) {
jedis.hdel(bigHashKey, entry.getKey());
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigHashKey);
}public void delBigList(String host, int port, String password, String bigListKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
long llen = jedis.llen(bigListKey);
int counter = 0;
int left = 100;
while (counter < llen) {
//每次从左侧截掉100个
jedis.ltrim(bigListKey, left, llen);
counter += left;
}
//最终删除key
jedis.del(bigListKey);
}public void delBigSet(String host, int port, String password, String bigSetKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<String> scanResult = jedis.sscan(bigSetKey, cursor, scanParams);
List<String> memberList = scanResult.getResult();
if (memberList != null && !memberList.isEmpty()) {
for (String member : memberList) {
jedis.srem(bigSetKey, member);
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigSetKey);
}public void delBigZset(String host, int port, String password, String bigZsetKey) {
Jedis jedis = new Jedis(host, port);
if (password != null && !"".equals(password)) {
jedis.auth(password);
}
ScanParams scanParams = new ScanParams().count(100);
String cursor = "0";
do {
ScanResult<Tuple> scanResult = jedis.zscan(bigZsetKey, cursor, scanParams);
List<Tuple> tupleList = scanResult.getResult();
if (tupleList != null && !tupleList.isEmpty()) {
for (Tuple tuple : tupleList) {
jedis.zrem(bigZsetKey, tuple.getElement());
}
}
cursor = scanResult.getStringCursor();
} while (!"0".equals(cursor));
//删除bigkey
jedis.del(bigZsetKey);
}https://mp.weixin.qq.com/s/gREMe-G7nqNJJLzbZ3ed3A
刘璟宇Leo
唯品会资深研发工程师,在大型高性能分布式系统设计和开发方面有丰富的经验。目前在唯品会平台与架构部负责唯品会API网关和服务安全方面的设计、开发、运营工作。
1. 为什么引入网关
唯品会是一家专门做特卖的网站,唯品会网站是一个巨大型的网站,每张页面背后,都有多个服务提供静态资源和动态数据。
这是唯品会网站上一张商品详情页面,内容是一款女式针织衫。页面里,除去静态页面、图片之外,有些动态内容:商品价格、促销提示语、产品介绍、商品库存等。每个部分都会从后端的一个或几个服务拉取数据。
在唯品会公司内部,已经采用服务化的方式把服务进行了拆分,内部服务之间采用基于thrift的二进制协议通讯。这些服务不能直接对外部提供服务。
在引入API网关前,我们在外部app、浏览器和内部服务之间会做一层webapp,起到两个作用:一个是从外部的http协议,适配到内部的二进制协议。另一个是对数据进行聚合。另外这些webapp里面还集成了如oauth等的一些公共服务。
由于唯品会网站的业务众多、业务量也非常大,这种webapp的数量有数百个,实例数量数千个。
在数量达到这种规模后,产生了一些问题,我们设想一个场景,比如某种安全防护技术需要升级一下,那么安全开发组需要先跟业务开发团队协商开发时间,等排期开发,然后需要测试,再排期发版。这样几十个业务开发团队升级下来,几个月可能就过去了。
再设想一个场景,例如,我可能想app支持一下二进制协议,可以提升数据交换效率。
一般我们做webapp,都是tomcat+springmvc这种结构进行开发,支持二进制协议就很困难。
所以,目前这种webapp的架构,对于公共服务集成升级和公共技术的升级不是很友好。
我们对架构进行了优化,引入了网关。网关的主要作用有三个:一个是协议适配;另一个是公共服务接入;最后是公共接入技术优化。在外网和内网中间有了网关,网关本身和业务程序分离,就可以独立的对这些技术进行集成和升级。
http://microservices.io/ 总结的微服务模式中,网关已经成为服务化中的一种标准模式。http://microservices.io/patterns/apigateway.html
网关模式,被一些大型的互联网公司采用。国内主要有唯品会、百度、阿里、京东、携程、有赞等,国外主要有Netflix, Amazon, Mashape等。
**
**
2. 选型和设计
开源网关按照平台可以分为基于nginx平台的网关和自研网关
基于nginx平台的网关有:KONG、API Umbrella
自研的网关有:apigee、StrongLoop、Zuul、Tyk
按照语言分类,可以见上图,有基于lua(nginx平台), nodejs, java, go等语言的网关。
基于nginx平台的网关和自研网关的优势和劣势如下:
| 基于nginx | 自研 | |
|---|---|---|
| 优势 | 1. nginx有完善的处理http协议的能力2. 全异步高性能基础处理能力3. http处理过程中多个扩展点可进行扩展4. 开箱即用,基于openresty开发相对简单 | 1. 可以完全掌控对http协议的处理过程2. 可以完全掌控异步化业务处理过程3. 对内部协议支持可以较好掌控4. 和内部的配置中心、注册中心结合较好 |
| 劣势 | 1. nginx工作流程复杂对大多数人来说,只能当作黑盒子用,出问题难以真正在代码级理解根本原因,扩展核心功能较为困难。2. 基于openresty扩展,本身有性能开销,对java、erlang、go的性能优势不明显3. 对内部协议和基础组件支持不方便 | 1. 对http协议处理有较多的坑需要踩2. 需要大量的性能优化过程,不像nginx经过大量实践,本身有较好的性能基础 |
唯品会网关是基于netty自研的API网关。
唯品会网关参考各种开源网关的实现,和业内各大电商网站的成熟经验,网关逻辑上可以分为四层:第一层是接入层,负责接入技术的优化。第二层是业务层,负责实现网关本身的一些业务实现。第三层是网关依赖的基于netty实现的各种公共组件。最底层是netty负责NIO、内存管理、提供各种基础库、异步化框架等。
业务层前面跟大家分享过,主要包括路由、协议转换、安全、认证验签、加密解密等,大家一看估计就可以看出,这些业务逻辑已经划分的比较独立,可以按照模块进行划分。实际上我们也是这样做的。
业务层设计需要考虑哪些方面呢?
一方面,是流程的组织。另一方面,网关需要依赖外部服务,需要考虑怎样异步化的调用外部服务。最后,网关需要考虑高可用,高可用在程序设计方面主要是不停机发布。唯品会网关的所有业务配置,都可以通过管理界面动态管理、动态下发、动态生效,并且支持灰度。
业务层实现,最重要的一点,是将逻辑和数据分离,我们的实现方式,是业务逻辑实现在模块里,数据通过context传递,context通过模块之间相互调用时,通过接口传递。在异步化调用其他服务时,context保存在Channel的AttributeMap里,在异步完成时,回调,取出context。
有了最基本的模块设计,我们再来看唯品网关怎样设计把这些流程串在一起。
大家看一下上面的图,在执行业务逻辑时,有些业务逻辑需要串行,比如,路由校验、参数校验、IP黑白名单、WAF等,由于性能方面考虑,一般情况下,我们会先执行黑白名单模块,因为这块是cpu消耗最小、能拦掉部分请求的模块。
后面再执行路由、参数等的校验。这部分是内存运算,效率也比较高,也能拦掉一些非法请求,所以先执行。
然后进入outh、风控、设备指纹等的外部服务调用,这些调用将会并发的执行。
执行后,将进行结果合并校验,如果在认证验签或风控等校验未通过的情况下,将会直接返回,如果校验通过,再进入后续的服务调用。
服务调用过程,又进行了多选一的流程,可能用二进制协议也可能用HTTP协议等。最终进行后处理。
大家可能会想,这些模块看上去可以使用actor模式进行封装,为何没有使用开源异步框架呢?我们也对开源的异步框架进行了详细的调研。在将异步框架结合进网关时发现对网关的性能产生了一些影响。
目前较为流行的异步框架,主要有akka和quasar fibers。他们的实现形式不同,但原理基本差不多。
为什么唯品网关没有引入异步框架呢?一方面是引入异步框架后,网关的抖动增加。一方面是成熟度问题,quasar fibiers quasar fibers的模式,更加友好一些,可以以接近同步编程的模式实现异步编程。但最新的release是0.7.6,没有大规模的验证过,我们也在实际使用踩了一些坑,例如,注解的问题、代码织入冲突问题、长时间运行突然响应变慢问题,强烈建议大家如果生产使用,需要慎重再慎重。
我们总结了一下异步化框架适用于,大量依赖其他服务,经常被block的情况。
网关的瓶颈在cpu运算,因为有验签、加解密、协议转换等cpu密集运算,其他的调用已经是全异步的,所以,引入异步框架的收益并不明显。
上面分享了业务层的设计,下面分享一下公共组件的设计。
网关不论调用依赖的服务还是后端的服务,都会遇到大量并发调用的情况。如果对连接不加以复用和控制,将造成大量的资源消耗和性能问题。因此,唯品网关自己设计优化了连接池。
下面就分享一下唯品网关在连接池方面的设计。
连接复用主要是指,一个连接可以被多个使用者同时使用,且互相之间不受影响,可以并发的发送多个请求,而应答是异步的,可复用的连接一般用于私有协议的连接,因为可复用的连接,请求可以一直发送,应答也不一定是按照请求顺序进行应答,就带来了一个问题,应答怎样才能和请求对应上。私有协议就比较容易在协议包内,增加sequence id,所以能达到连接复用的要求。唯品会网关调用唯品会内部的私有协议服务时,就采用的这种连接复用模式。
连接复用还有一种实现模式,是spymemcache的模式,memcached本身不支持sequenceid,但同一个连接上的操作会保证顺序性,所以,spymemcache通过把请求缓存在queue中的形式,顺序匹配返回结果,达到连接复用。
独占的连接模式,主要是指,一个连接同一时间只能被一个使用者使用,在一个连接上,发送完一个请求后,必须等待应答后,才能发送第二个请求。一般使用HTTP协议时,比较多使用这种独占的模式。因为如果HTTP协议需要支持连接复用,需要在HTTP协议头上增加sequence id,一般的服务端都不支持这种扩展,所以,我们针对HTTP协议,使用的是独占连接模式。
连接池的异步化,在连接池使用的所有阶段都应该异步化。我们在设计网关的连接池时,考虑了以下几个方面:获取连接的异步化。从连接池获取连接,一般情况被认为是个没有block的动作,实际上分解来看,获取连接池,可能需要锁连接池对象所在的队列,操作连接池计数器时,可能会遇到锁、超时等问题。后面我会跟大家分享我们怎样去做的优化。连接使用就是说实际用连接去调用其他服务,这块的异步化,大家基本都会考虑到。归还连接的异步化。归还连接时,也会操作连接池中的连接队列,有时连接已经异常还会执行关闭连接等动作,所以也会产生锁的问题。和获取连接时类似,我们也把操作封装为task,交由netty做cpu亲缘性路由。
**
**
3. 实践经验
上面是给大家分享了我们在连接池设计中的几个关键点,接下来跟大家分享一下我们在实践过程中实际进行的优化。
jvm启动后,会在/tmp下建立一个文件,是一个内存映射文件,JVM用来导出状态数据给其它进程使用,比如jstat,jconsole等。当到达安全点时,JVM会把安全点的相关信息写入到这个文件中去。安全点是说,jvm会在这个点上,把所有其他线程都停下来,自己安全的做一些事情,GC是一种安全点,还有其他种类的安全点。而gc log和这种监控数据的写入,就是在安全点上进行写入。当IO频发且负载均重时,可能写数据动作刚好赶上操作系统将磁盘缓存刷到磁盘的过程,此时写性能数据文件的操作就会被block。最终表现为jvm暂停。解决方法,是将这些性能数据写到内存文件中,避免和其他操作抢占磁盘io。
StringBuffer在写日志等处理字符串拼接的场景下经常用到,大多数情况下,我们会new一个StringBuffer,向里面追加字符串,在高并发场景,这个过程会产生大量的内存重新分配并拷贝内容的动作,造成cpu热点。我们的优化方法是,在threadlocal缓存使用过的stringbuffer,在下次使用时,直接复用。
我们在初期实际使用网关时观察到,网关的OLD区使用会缓慢上升,大概两天会产生一次FGC,经过仔细的分析,发现,java NIO的server socket类由finalize最后进行释放。而GC过程是第一次GC先将没有引用的对象放入finalize队列,下次GC的时候,调用finalize,并将对象释放。而在高并发的情况下,server socket的finalize并不保证被调用,所以存活时间可能超过了升级阈值,就会有对象不断进入old区。
即使ref queue很快被执行,也可能跨两次ygc,比如创建后接着一次ygc1,然后用完后在下一次ygc2中添加到ref queue,ref queue没有堆积的情况下,需要在ygc3中释放这些对象。
由于网关会并发接受大量的请求,所以写日志的量非常大。我们实际压测的时候发现,写日志的IO操作,会周期性的被block,从而产生抖动。经过分析发现,被block的时候,操作系统在刷磁盘缓存。linux默认是脏数据超过10%,或5s刷一次缓存,而这时可能会有大量数据在缓存里等待写入磁盘,操作系统再去刷盘的时候,就会消耗比较多的时间,而这些时间内,应用无法将数据写入磁盘缓存,发生block。有两个参数可以调整,一个是脏数据占比,一个是脏数据两个取较小值生效。我们通过调小脏数据比率,让刷盘动作在数据量较小的时候就开始,减小了毛刺率。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.