This project aims to show how to implement a simple data pipeline on GCP using some of its serverless services: Cloud Functions, Pub/Sub, Cloud Scheduler, and BigQuery.
The pipeline consists of a process that regularly gets data from an API and loads it into BigQuery. Considering its popularity, the current weather data API by OpenWeatherMap was chosen to exemplify the data gathering stage.
The next image shows the reference architecture for this project.
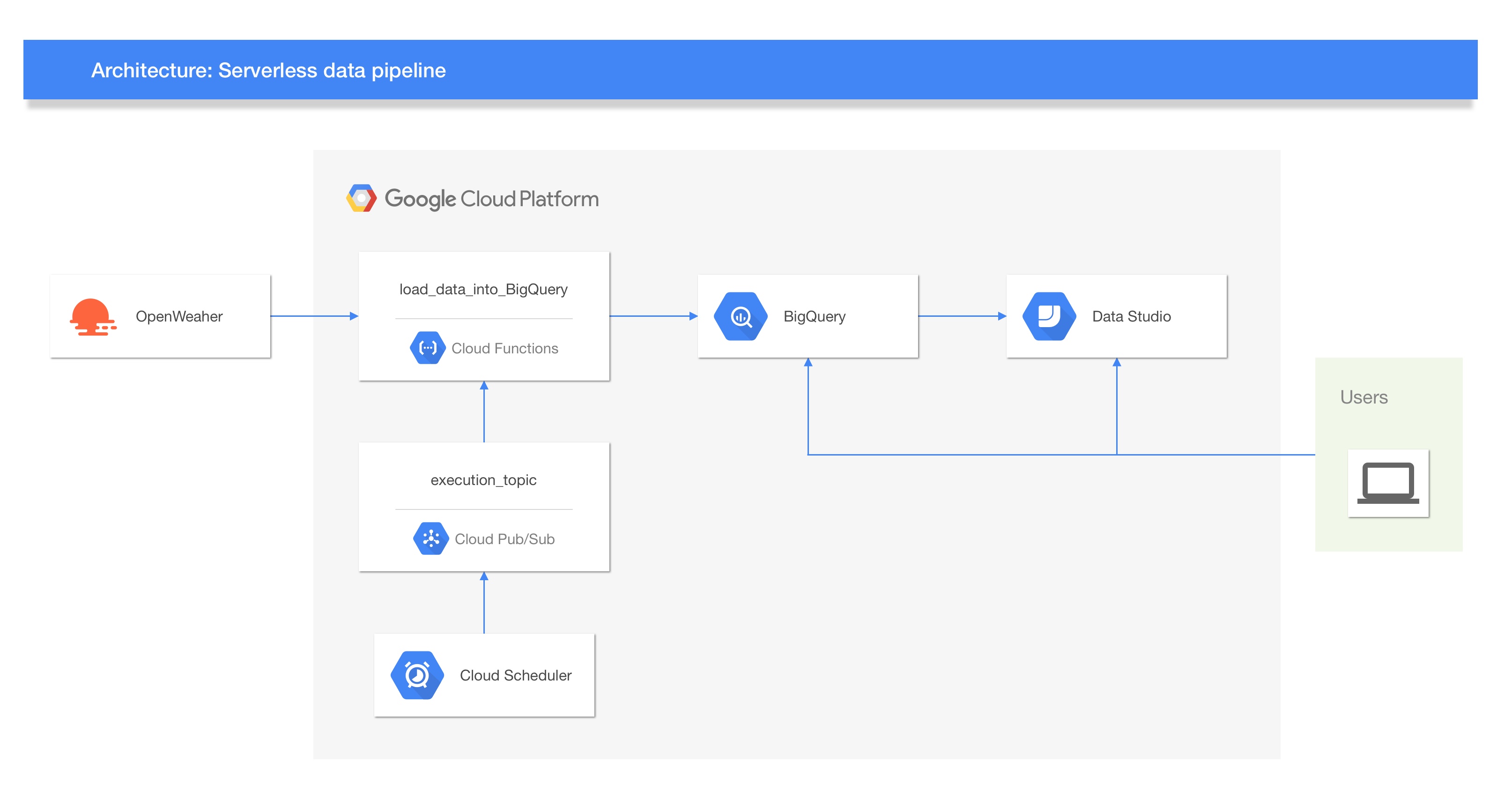
The process could be explained by the next steps:
- Depending on the frequency, a job of Cloud Scheduler triggers a topic on Cloud Pub/Sub.
- That action executes a Cloud Function (loadDataIntoBigQuery) that gets data from OpenWeatherMap.
- Then, this data is loaded into BigQuery.
- Finally, the data could be analyzed directly BigQuery or Data Studio.
The following is needed to deploy the services:
- A GCP project with a linked billing account
- Installed and initialized the Google Cloud SDK
- Created an App Engine app in your project. Why?
- Enabled the Cloud Functions, Cloud Scheduler, and APP Engine APIs
- An API Key from OpenWeatherMap
This pipeline uses billable components of Google Cloud Platform, including:
- Google Cloud Functions
- Google Cloud Pub/Sub
- Google Cloud Scheduler
- Google BigQuery
This section shows you how to deploy all the services needed to run the pipeline.
Before continue, is preferable to set up some environment variables that will help you execute the gcloud commands smoothly.
export PROJECT_ID=<Your_Project_Id>
# The topic name fo Pub/Sub.
export TOPIC_NAME=<Your_Pub_Sub_Topic>
# It must be unique in the project. Note that you cannot re-use a job name in a project even if you delete its associated job.
export JOB_NAME=<Your_Cron_Scheduler_Job_Name>
# The name of the function corresponds to the exported function name on index.js
export FUNCTION_NAME="loadDataIntoBigQuery"
# E.g., if you want a frequency of execution of 1 hour, the variable should be SCHEDULE_TIME="every 1 hour".
export SCHEDULE_TIME=<Your_Cron_Schedule>
# OpenWeatherMap API key
export OPEN_WEATHER_MAP_API_KEY=<Your_Open_Weather_Map_Api_Key>
# Consider that dataset names must be unique per project. Dataset IDs must be alphanumeric (plus underscores)
export BQ_DATASET=<Your_BQ_Dataset_Name>
#The table name must be unique per dataset.
export BQ_TABLE=<Your_BQ_Table_Name>gcloud config set project $PROJECT_IDgcloud pubsub topics create $TOPIC_NAMEgcloud scheduler jobs create pubsub $JOB_NAME --schedule="$SCHEDULE_TIME" --topic=$TOPIC_NAME --message-body="execute"If you want to change the frequency of the execution, the following command will help:
gcloud scheduler jobs update pubsub $JOB_NAME --schedule="$SCHEDULE_TIME"bq mk $BQ_DATASETbq mk --table $PROJECT_ID:$BQ_DATASET.$BQ_TABLEgcloud functions deploy $FUNCTION_NAME --trigger-topic $TOPIC_NAME --runtime nodejs10 --set-env-vars OPEN_WEATHER_MAP_API_KEY=$OPEN_WEATHER_MAP_API_KEY,BQ_DATASET=$BQ_DATASET,BQ_TABLE=$BQ_TABLEI want to write this section only as an opinion and give ideas on how to end this pipeline as a real queen or king of data.
Also, you have to consider that this particular stage depends totally on the data or insights you want to obtain. Felipe Hoffa illustrates different use cases and ideas using BigQuery, you should read him on Medium!
Two options (clearly more).
First, remember the env variables? they are still util. if you run the next command, a BigQuery job will be executed that consist of a query to count all the records on your table. If you complete the steps above correctly, you will see at least one record counted.
bq query --nouse_legacy_sql "SELECT COUNT(*) FROM $BQ_DATASET.$BQ_TABLE"Second, BigQuery on the GCP Console is also an enjoyable manner to explore and analyze your data.
Day to day, Google's technological ecosystem grows rapidly. This project is a small, but concise, proof of how completed could be an end to end data solution built into this ecosystem.
Just to try (you should do it), I built a report on Data Studio and was a great and fast experience. In my opinion, the analytical power of BigQuery combined with its report/dashboard tool is the perfect double for small and big data end processes. Look at this report, just 20-30 minutes of learning by doing, connected directly to BigQuery!
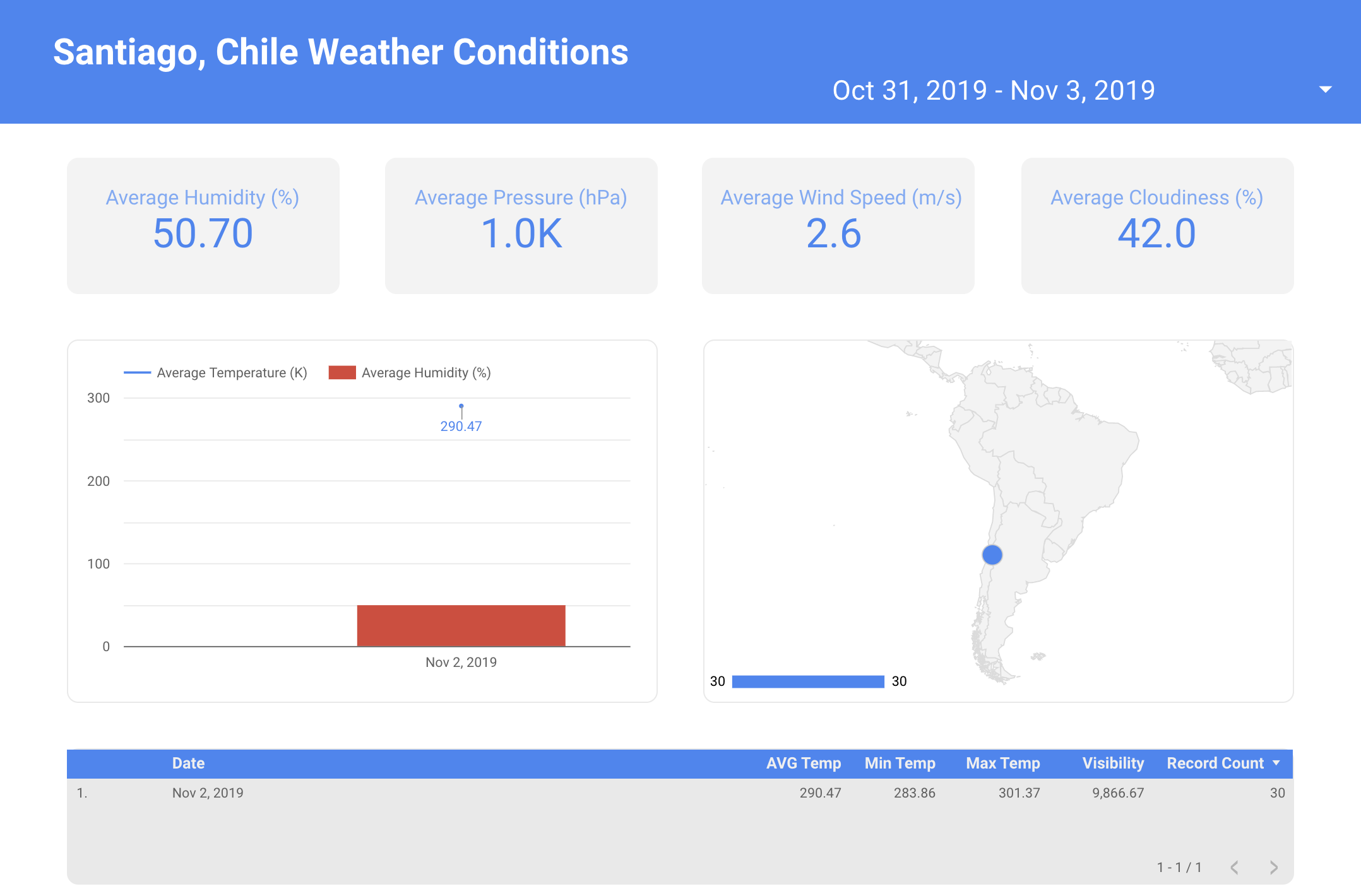
This is not propaganda, Google didn't pay me for this (unfortunately).
This project is licensed under the MIT License - see the LICENSE.md file for details.

