vishal3477 / reverse_engineering_gms Goto Github PK
View Code? Open in Web Editor NEWOfficial Pytorch implementation of paper "Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images"
Official Pytorch implementation of paper "Reverse Engineering of Generative Models: Inferring Model Hyperparameters from Generated Images"







































































































Hi Vishal,
Where can I download the following files?
I see three .npy files on the repo but the naming is not matching the exact files between repo and source code.
I changed the filename in repo below
FROM
ground_truth_loss_func_3dim_file.npy
ground_truth_loss_func_8dim_file.npy
ground_truth_net_arch_15dim_file.npy

TO below
ground_truth_loss_100_9dim.npy
ground_truth_net_arch_100_15dim.npy
ground_truth_loss_100_3dim.npy

But it didn't run through. It gives the following error

Thanks,
-Steve
Thank you very much for your contribution.In the deepfake detection module of the paper, parameter lambda1-4 are set as follows which is inconsistent with the code:

loss1=0.05*l1(low_freq_part,zero).to(device)
loss2=-0.001*max_value.to(device)
loss3 = 0.01*l1(residual_gray,zero_1).to(device)
loss_c =20*l_c(classes,labels.type(torch.cuda.LongTensor))
loss5=0.1*l1(y,y_trans).to(device)
Can you explain that? Thank you.
Hi, I have reproduced the code for the image attribution. I get the neural network explosion during training. Surprisingly, I got an accuracy of about 85% before the explosion. I want to know why. I observe that when the explosion happens, the weights of the net obtain nan and the CE loss increases. Can you help me to solve the issue? I used the Adam optimizer.
The .npy files in the rev_eng_updated.py could not be found in the main folders or the .zip or tar.gz file.
The lost .npy files are in the following codes:
ground_truth_net_all=torch.from_numpy(np.load("ground_truth_net_131_15dim.npy"))
ground_truth_loss_9_all=torch.from_numpy(np.load("ground_truth_loss_131_10dim.npy"))
ground_truth_net_all_dev=torch.from_numpy(np.load("net_dev_131_dim.npy"))
ground_truth_loss_9_all_dev=torch.from_numpy(np.load("ground_truth_loss_131_10dim.npy"))
ground_truth_net_cluster=torch.from_numpy(np.load("net_cluster_131_dim.npy"))
ground_truth_loss_9_cluster=torch.from_numpy(np.load("loss_cluster_131_dim.npy"))
#ground_truth_net_all=torch.from_numpy(np.load("random_ground_truth_net_arch_91_15dim.npy"))
#ground_truth_loss_all=torch.from_numpy(np.load("random_ground_truth_loss_91_3dim.npy"))
#ground_truth_loss_9_all=torch.from_numpy(np.load("random_ground_truth_loss_91_9dim.npy"))
ground_truth_p=torch.from_numpy(np.load("p_131_.npy"))
If you could tell me where I can find them, thank you very much. Best wishes!
Hello, I have met a problem (as in the picture below) when executing the file "reverse_eng_test.py" loading the model "11_model_set_1.pickle". Could you please tell me what does the error mean? Because I am not familiar with the architecture of the model and the given pre-trained model "11_model_set_1.pickle". Upon the error is the output of the code ( print(state1['optimizer_1']) ) added by me to see the state of the "state1['optimizer_1']". Thank you!

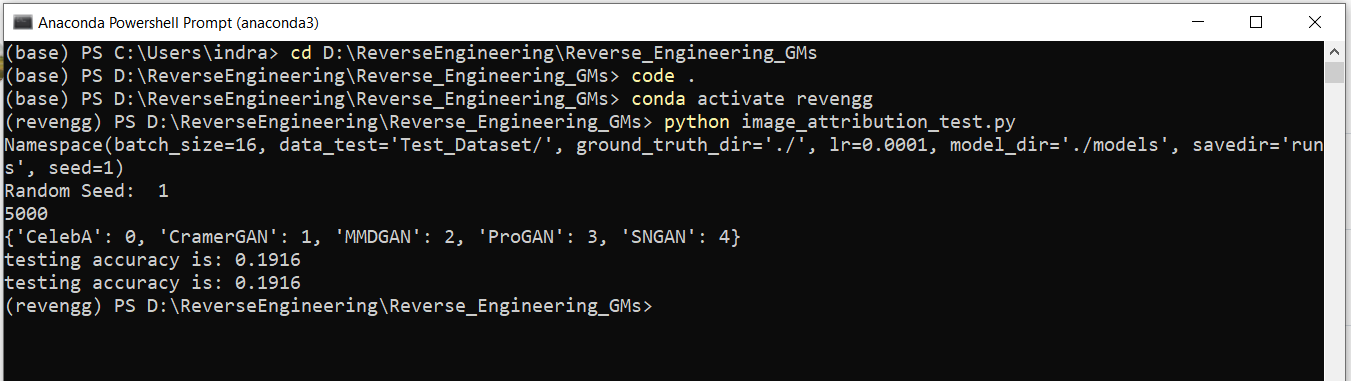
I'm getting only 0.1916 accuracy in image attribution task, in the test dataset in each of the five classes I've puted 1K generated images from respective GANs and 1K real images from CelebA, and I'm using the pre-trained model.
I'm using the following code in image_attribution_test.py file:
from torchvision import datasets, models, transforms
#from model import *
import os
import torch
from torch.autograd import Variable
from skimage import io
from scipy import fftpack
import numpy as np
from torch import nn
import datetime
from models import encoder_image_attr
from models import fen
import torch.nn.functional as F
from sklearn.metrics import accuracy_score
from sklearn import metrics
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('--lr', default=0.0001, type=float, help='learning rate')
parser.add_argument('--data_test',default='Test_Dataset/',help='root directory for testing data')
parser.add_argument('--ground_truth_dir',default='./',help='directory for ground truth')
parser.add_argument('--seed', default=1, type=int, help='manual seed')
parser.add_argument('--batch_size', default=16, type=int, help='batch size')
parser.add_argument('--savedir', default='runs')
parser.add_argument('--model_dir', default='./models')
opt = parser.parse_args()
print(opt)
print("Random Seed: ", opt.seed)
device=torch.device("cuda:0")
torch.backends.deterministic = True
torch.manual_seed(opt.seed)
torch.cuda.manual_seed_all(opt.seed)
sig = "sig"
test_path=opt.data_test
save_dir=opt.savedir
os.makedirs('%s/logs/%s' % (save_dir, sig), exist_ok=True)
os.makedirs('%s/result_2/%s' % (save_dir, sig), exist_ok=True)
transform_train = transforms.Compose([
transforms.Resize((128,128)),
transforms.ToTensor(),
transforms.Normalize((0.6490, 0.6490, 0.6490), (0.1269, 0.1269, 0.1269))
])
test_set=datasets.ImageFolder(test_path, transform_train)
test_loader = torch.utils.data.DataLoader(test_set,batch_size=opt.batch_size,shuffle =True, num_workers=1)
model=fen.DnCNN().to(device)
model_params = list(model.parameters())
optimizer = torch.optim.Adam(model_params, lr=opt.lr)
l1=torch.nn.MSELoss().to(device)
l_c = torch.nn.CrossEntropyLoss().to(device)
model_2=encoder_image_attr.encoder(num_hidden=512).to(device)
optimizer_2 = torch.optim.Adam(model_2.parameters(), lr=opt.lr)
state = {
'state_dict_cnn':model.state_dict(),
'optimizer_1': optimizer.state_dict(),
'state_dict_class':model_2.state_dict(),
'optimizer_2': optimizer_2.state_dict()
}
state1 = torch.load("pre_trained_models/image_attribution/celeba/0_model_27_384000.pickle")
optimizer.load_state_dict(state1['optimizer_1'])
model.load_state_dict(state1['state_dict_cnn'])
optimizer_2.load_state_dict(state1['optimizer_2'])
model_2.load_state_dict(state1['state_dict_class'])
def test(batch, labels):
model.eval()
model_2.eval()
with torch.no_grad():
y,low_freq_part,max_value ,y_orig,residual, y_trans,residual_gray =model(batch.type(torch.cuda.FloatTensor))
y_2=torch.unsqueeze(y.clone(),1)
classes, features=model_2(y_2)
classes_f=torch.max(classes, dim=1)[0]
n=25
zero=torch.zeros([y.shape[0],2*n+1,2*n+1], dtype=torch.float32).to(device)
zero_1=torch.zeros(residual_gray.shape, dtype=torch.float32).to(device)
loss1=0.5*l1(low_freq_part,zero).to(device)
loss2=-0.001*max_value.to(device)
loss3 = 0.01*l1(residual_gray,zero_1).to(device)
loss_c =10*l_c(classes,labels.type(torch.cuda.LongTensor))
loss5=0.1*l1(y,y_trans).to(device)
loss=(loss1+loss2+loss3+loss_c+loss5)
return y, loss.item(), loss1.item(),loss2.item(),loss3.item(),loss_c.item(),loss5.item(),y_orig, features,residual,torch.max(classes, dim=1)[1], classes[:,1]
print(len(test_set))
print(test_set.class_to_idx)
epochs=2
for epoch in range(epochs):
all_y=[]
all_y_test=[]
flag1=0
count=0
itr=0
for batch_idx_test, (inputs_test,labels_test) in enumerate(test_loader):
out,loss,loss1,loss2,loss3,loss4,loss5, out_orig,features,residual,pred,scores=test(Variable(torch.FloatTensor(inputs_test)),Variable(torch.LongTensor(labels_test)))
if flag1==0:
all_y_test=labels_test
all_y_pred_test=pred.detach()
all_scores=scores.detach()
flag1=1
else:
all_y_pred_test=torch.cat([all_y_pred_test,pred.detach()], dim=0)
all_y_test=torch.cat([all_y_test,labels_test], dim=0)
all_scores=torch.cat([all_scores,scores], dim=0)
fpr1, tpr1, thresholds1 = metrics.roc_curve(all_y_test, np.asarray(all_scores.cpu()), pos_label=1)
print("testing accuracy is:", accuracy_score(all_y_test,np.asarray(all_y_pred_test.cpu())))
I'm sorry to have bothered you.
But I didn't find the code for discrete type network structure parameter clustering prediction in the encoder_rev_eng.py file of the original models folder or in the latest Reverse Engineering 2.0 code compressed file. However, your article states the clustering prediction about discrete type network structure parameters, which is important to the result. Looking forward to your reply.
I have downloaded the data and model. When I run the "reverse_eng_test.py" file, I find that I can not provide the below files. Could you please answer how can I get these files? Thank you very much!
ground_truth_net_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_net_arch_100_15dim.npy"))
ground_truth_loss_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_loss_100_3dim.npy"))
ground_truth_loss_9_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_loss_100_9dim.npy"))
@vishal3477 It gives the following error.

Check out the Model Parsing v2 release for the updated code!!
@vishal3477 I couldn't run **fake_detection_test.py". It gives the following error below.
Thanks,
optimizer.load_state_dict(state1['optimizer_1'])
Hi, thank you for sharing your code and data.
I'm trying to run the reverse_eng_train.py and reverse_eng_test.py scripts, but both are failing due to missing files
required in the following lines:
ground_truth_net_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_net_arch_100_15dim.npy"))
ground_truth_loss_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_loss_100_3dim.npy"))
ground_truth_loss_9_all=torch.from_numpy(np.load(opt.ground_truth_dir+ "ground_truth_loss_100_9dim.npy"))I downloaded the dataset of trained models from the google drive link in the Readme, but couldn't find any information about where we can access those ground-truth data.
Also, could you verify that the file in the google drive 11_model_set_1.pickle contains the 100 trained models?
When I load the file (e.g. data = torch.load('11_model_set_1.pickle), I am getting a checkpoint of a single model (and optimizers).
I'd appreciate if you could verify that this is the right file to download the trained models.
Thank you!
@vishal3477 Since rfft is deprecated in the newer torch versions. It gives the following error.

I tried to fix it, but it starts to give an error as

Could you please help me how to define rfft in the newer version of pytorch?
Thanks.
-Steve
if i use the script, i just put the test data like this?

@vishal3477 I couldn't find ground_truth_loss_100_9dim.npy file in repo. Could you please help me where I could find or download it?
Thanks,
-Steve
Hi, thank you for the very useful dataset.
I have a question on the DMs part. I downloaded the dataset and I see that there are 8 folders called Z_i. What are the methods used to generate the images in each folder?
hello, do i need to create all the paths in the reverse_eng.py ? what do i need to save for wach folder?
parser.add_argument('--lr', default=0.0001, type=float, help='learning rate')
parser.add_argument('--data_train',default='mnt/scratch/asnanivi/GAN_data_6/set_1/train',help='root directory for training data')
parser.add_argument('--data_test',default='mnt/scratch/asnanivi/GAN_data_6/set_1/test',help='root directory for testing data')
parser.add_argument('--ground_truth_dir',default='./',help='directory for ground truth')
parser.add_argument('--seed', default=1, type=int, help='manual seed')
parser.add_argument('--batch_size', default=16, type=int, help='batch size')
parser.add_argument('--savedir', default='/mnt/scratch/asnanivi/runs')
parser.add_argument('--model_dir', default='./models')
parser.add_argument('--N_given', nargs='+', help='position number of GM from list of GMs used in testing', default=[1,2,3,4,5,6])
os.chmod('./mnt/scratch',0o777)
os.makedirs('.%s/result_3/%s' % (save_dir, sig), exist_ok=True)
i also had a mistake:Couldn't find any class folder in mnt/scratch/asnanivi/GAN_data_6/set_1/train
Thanks!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.