Automated Machine Learning Pipeline for MongoDB Collections, written in Python and leveraging AutoSKLearn and Flask.
Ahnung allows data scientists and machine learning specialists to configure a generic, automated ML pipeline against data in any MongoDB collection. The pipeline automatically evaluates, optimizes and visualizes the performance of multiple machine learning models, feature engineering options and hyperparameters. By systematizing and automating these tedious and error-prone tasks, Ahnung accelerates the thorough exploration of machine learning approaches on new datasets.
The Ahnung pipeline generates an ensemble of machine learning models to accomplish the selected task. The last stage of the pipeline provides a visualization of the ensemble similar to the one below.
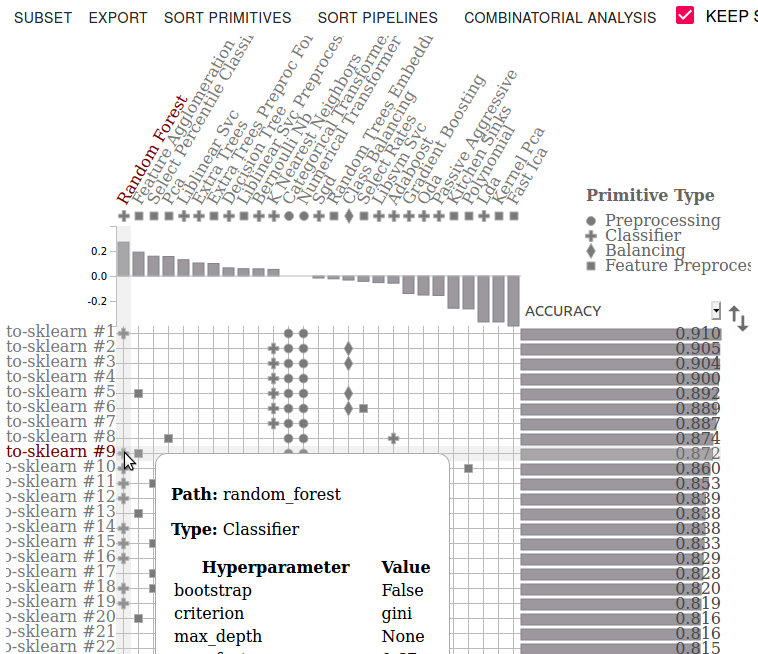
Ahnung uses documents from the MongoDB collection as training instances (or observations). Document attributes provide the features (or attributes) for supervised machine learning tasks. Due to the dynamic schema nature of MongoDB collections, Ahnung performs a schema analysis to discover the names of the document attributes, their data types and frequencies. The pipeline recognizes categorical and numeric features and provides median or mode substitution for missing values.
You will provide Ahnung with MongoDB connection strings for the read-only, source database and one or more read-write databases used by the various stages to store metadata and machine learning models. Additionally, you will specify the target attribute. The ML pipeline will learn to predict the value of the target attribute from a given document containing the other attributes. In order to implement this task, Ahnung will construct or fit an ensemble of machine learning models to the dataset in the source collection. AutoSKLearn is used to accomplish many necessary tasks, including model selection and hyperparameter optimization.
Ahnung includes four stages: schema, cleanup, model and predict. These stages must be performed in this order to satisfy dependencies from the previous stages. However, it is common to make adjustments to the AutoSKLearn settings, for example, and rerun the model and predict stages without requiring the previous two.
The schema stage scans every document in the collection to determine the data type(s) and frequency of each attribute. The primary goal is to discover a set of numerical and categorical attributes that are frequently present in the training dataset. An attempt is made to recognize implicit data types encoded in strings (ie. floats and ints) so that those can be automatically converted to binary values compatible with machine learning algorithms.
The cleanup stage scans every document and converts each attribute to the selected data type. This includes converting string values to binary values to align with other instances in the dataset, as discovered in the schema stage. Missing attributes are replaced with the median or mode of the feature, unless there are too many missing from the same instance. If there are too many missing attributes, the instance is discarded.
The model stage loads the normalized documents from the previous stage and converts them into a pandas DataFrame for use with AutoSKLearn. This stage uses AutoSKLearn to search various machine learning models and their hyperparameter configurations. The best of the models is then used to build an ensemble model for predicting the given target value.
The predict stage provides a REST interface to predict the target attribute value from a JSON document containing the values of the other attributes. Additionally, this stage provides statistics and visualizations of various pipeline stage results. These are intended to provide insight into how it was constructed and how well the ML pipeline was able to generalize from the dataset provided. The following are provided for the ensemble estimator.
- ROC AUC, Precision and Recall per label value against held out data
- Prediction URL, with example
curlcommand - PipelineProfiler of the ensemble.
- Confusion Matrix for classification tasks against held out data
- ROC Curve Charts
- Feature Importance via Permutation
Many of the requirements for using Ahnung stem from the system requirements of AutoSKLearn. Additionally, configuration of the Python environment is most easily managed by Anaconda, so it must also be installed.
- Linux Operating System
- Python >= 3.5
- C++ compiler
- SWIG
- Anaconda
For what its worth, all of my usage and testing has been on Ubuntu so far.
First, checkout or download the Ahnung project from GitHub. Open a terminal and cd into the project. Run the following Anaconda command to configure the ahnung_env Python environment.
conda env create -f ahnung_env_conda_auto_sklearn.yml
This will take some time and some bandwidth. When it finishes, you should see lines similar to:
Installing collected packages: scikit-learn, liac-arff, ConfigSpace, pynisher, pyrfr, lazy-import, smac, py, iniconfig, more-itertools, pytest, auto-sklearn, networkx, Send2Trash, prometheus-client, terminado, argon2-cffi, notebook, pipelineprofiler
Successfully installed ConfigSpace-0.4.13 Send2Trash-1.5.0 argon2-cffi-20.1.0 auto-sklearn-0.8.0 iniconfig-1.0.1 lazy-import-0.2.2 liac-arff-2.4.0 more-itertools-8.4.0 networkx-2.4 notebook-6.1.3 pipelineprofiler-0.1.15 prometheus-client-0.8.0 py-1.9.0 pynisher-0.5.0 pyrfr-0.8.0 pytest-6.0.1 scikit-learn-0.22.2.post1 smac-0.12.3 terminado-0.8.3
Next, you will need to activate the Python environment so that Ahnung has access to all the required goodies (ahem, libraries).
$ conda activate ahnung_env
(ahnung_env) myuser@my-box:~/ahnung$
Now, you can get the short usage message from run_pipeline.py.
$ ./run_pipeline.py
Specify the configuration settings JSON file as the first parameter.
USAGE: ./run_pipeline.py <settings.json> [first_stage [second_stage [...]]]
- Valid stages are: schema, cleanup, model and predict.
The command line interface to Ahnung is encapsulated in run_pipeline.py.
Specify the configuration settings JSON file as the first parameter.
USAGE: ./run_pipeline.py <settings.json> [first_stage [second_stage [...]]]
- Valid stages are: schema, cleanup, model and predict.
You can find sample JSON settings files in the examples directory of the project.
The configuration from the settings file is loaded into a Python dictionary. Areas in the file can be broken down based on the dictionary key that contains those settings.
Contains the list of one or more estimators, global random seed and global default modeling settings. Each estimator in the est_list array is described by various values.
| Setting Name | Expected Type | Default | Description |
|---|---|---|---|
target_name |
string | N/A | Name of the document attribute (instance feature) that Ahnung will learn to predict |
src_collname |
string | N/A | Name of the collection containing the source dataset documents |
is_classification |
boolean | 'true' | Indicates the machine learning task is classification |
is_regression |
boolean | 'false' | Indicates the machine learning task is regression |
allowed_cpus |
integer | "1" | Maximum number of jobs launched by AutoSKLearn |
max_global_time |
integer | "600" | Controls time_left_for_this_task setting to specify the global time allowed for searching for models and model hyperparameters |
max_permodel_time |
integer | "60" | Controls per_run_time_limit setting to specify the time allowed for a single call to fit the data by a single machine learning model |
metric |
string | "accuracy" | The criteria or formula for evaluating the performance of machine learning models during the construction of the ensemble. The relative performance of a model is important during training, hyper-parameter optimization and ensemble construction. Supported values include: accuracy, balanced_accuracy, f1_macro, f1_micro, roc_auc, precision_macro, precision_micro, average_precision, recall_macro, recall_micro and log_loss. For categorization, only metrics appropriate to multi-class tasks are supported, refer to AutoSKLearn built-in metrics. |
ensemble_size |
integer | "50" | Maximum number of models that may be added to the ensemble generated by AutoSKLearn |
ensemble_nbest |
float or integer | "0.2" | Fraction or number of the best models to drawn from when constructing the ensemble. Refer to the Ensemble Building Process. |
max_models_on_disc |
integer | "50" | Limits the number of machine learning models that can be stored on the filesystem. |
random_seed |
integer | "10001" | Random seed integer value for the machine learning algorithms |
This subdocument controls the settings used by Ahnung to analyze the schema of the source collection containing the training and testing dataset input to the machine learning algorithms.
| Setting Name | Expected Type | Default | Description |
|---|---|---|---|
attr_type_min_present |
float | "0.8" | Minimum fraction (between 0.0 and 1.0 exclusive) of the documents containing an attribute for that attribute to be used during model search/fitting/tuning. |
attr_type_min_typealign |
float | "0.8" | Minimum fraction (between 0.0 and 1.0 exclusive) of the documents containing the same data type for a feature/attribute for that data type to be selected as the normalized type for the feature. |
max_categorical_values |
integer | "10" | The maximum number of unique values allowed for a feature/attribute to be recognized as categorical. |
This subdocument controls modeling settings not aligned with AutoSKLearn.
| Setting Name | Expected Type | Default | Description |
|---|---|---|---|
target_category_balancing |
string | "none" | Applies only to classification tasks. Selects the target feature/attribute class rebalancing type performed, if any. Selecting "equal" causes all classes to appear with equal frequency in the rebalanced dataset. Selecting "average" causes the native/input frequency to be arithmetically averaged with the equal weighting and the rebalancing adjusts to the averaged frequencies. The point of "average" is to provide a middle ground between the raw frequencies (priors) and full equalization (no priors). |
category_max_oversample |
float | "2.0" | When rebalancing to new class frequencies, this selects the factor of over sampling allowed in less frequent classes to avoid loosing useful information in the data points of more frequent classes. You can disable over sampling completely with a value of "1.0". |
This subdocument controls the predict stage which provides an HTTP service with REST API.
| Setting Name | Expected Type | Default | Description |
|---|---|---|---|
service_hostname |
string | "localhost" | The hostname or IP address where the HTTP service should listen for connections and accept requests. |
service_port |
integer | "8088" | The port number on which the HTTP service should listen for connections and accept requests. |
This subdocument contains four MongoDB connection strings for accessing the MongoDB database. Note that before accessing the MongoDB database, Ahnung prompts for the username and password from the keyboard. Use the constant usercredsplaceholder to specify the location of the username and password in the MongoDB connection string.
| Setting Name | Expected Type | Default | Description |
|---|---|---|---|
source_uri |
string | N/A, required | Specifies the collection containing the source dataset for the machine learning pipeline. Read-only access is required to this collection. The documents in this collection must contain the target_name attribute in order for the pipeline to model (learn from) the dataset. |
rawdocs_uri |
string | N/A, required | Specifies the collection used to store intermediate documents resulting from the schema stage. Read+write access is required to this collection. |
metadata_uri |
string | N/A, required | Specifies the collection used to store metadata or statistics about the dataset, its schema and the AutoSKLearn model search and ensemble build. Also holds the final AutoSKLearn ensemble and individual component models. Read+write access is required to this collection. |
cleaned_uri |
string | N/A, required | Specifies the collection used to store intermediate documents resulting from the cleanup stage. Read+write access is required to this collection. |
You can find static examples of the charts, statistics and ensemble construction results in the links below. Note that the GitHub project is not running the prediction stage of Ahnung. The prediction URL for each result will not work until you install and run Ahnung on your own datasets.
| Dataset Name | Results | Dataset Source |
|---|---|---|
| Early Stage Diabetes Risk Prediction (UCI) | Ahnung Results | Early stage diabetes risk prediction dataset. |
| Adult Income (UCI) | Ahnung Results | Adult Data Set |
| Wine (UCI) | Ahnung Results | Wine Data Set |
| Iris (UCI) | Ahnung Results | Iris Data Set |
The following JSON configuration file contains settings for Ahnung to learn a categorization task against the well-known iris and wine datasets available from the UCI Machine Learning Repository. The datasets were downloaded, converted from CSV to JSON and loaded into the Atlas cluster referenced under connect_uris. Refer to datasets/install_datasets.sh for an example script.
{
"global_properties": {
"num_folds": "5",
"random_seed": "1000001",
"allowed_cpus": "1",
"max_global_time": "360",
"max_permodel_time": "36",
"est_list": [
{
"src_collname": "iris",
"target_name": "class",
"is_classification": "true",
"is_regression": "false",
"allowed_cpus": "2",
"max_global_time": "240",
"max_permodel_time": "24",
"random_seed": "3000003"
},
{
"src_collname": "wine",
"target_name": "class",
"is_classification": "true",
"is_regression": "false",
"allowed_cpus": "2",
"max_global_time": "240",
"max_permodel_time": "24",
"random_seed": "5000005"
}
]
},
"schema_properties": {
"attr_type_min_present": "0.8",
"attr_type_min_typealign": "0.8",
"max_categorical_values": "20"
},
"model_properties": {
"target_category_balancing": "none",
"category_max_oversample": "2.0"
},
"service_properties": {
"service_hostname": "localhost",
"service_port": "8088"
},
"connect_uris": {
"source_uri": "mongodb+srv://[email protected]/UCI-ML?authSource=admin&w=majority",
"rawdocs_uri": "mongodb+srv://[email protected]/rawdocs?authSource=admin&w=majority",
"metadata_uri": "mongodb+srv://[email protected]/metadata?authSource=admin&w=majority",
"cleaned_uri": "mongodb+srv://[email protected]/cleaned?authSource=admin&w=majority"
}
}
Ahnung leans heavily on a large number of Python based projects, including the following.

