xfeif / computervision_papernotes Goto Github PK
View Code? Open in Web Editor NEW📚 Paper Notes (Computer vision)
📚 Paper Notes (Computer vision)


Welcome to share your favorite computer vision papers here, and I'll read and write some notes if I think it is interesting, too :)
You can also provide your notes/comments/blogs with the paper together! 🍻
Paper
No code available now~.
Authors:
Yutong Bai, Haoqi Fan, Ishan Misra, Ganesh Venkatesh, Yongyi Lu, Yuyin Zhou, Qihang Yu, Vikas Chandra, Alan Yuille

Overview of the proposed temporal-aware contrastive self-supervised learning framework (TaCo).
TaCo mainly comprises three modules: temporal augmentation module, contrastive learning module, and temporal pretext task module. For different temporal augmentations, they apply different projection heads and task heads. The features extracted from projection head of original video sequence and agumented sequence are considered as positive sample pairs, and the remaining ones are simply regarded as negative sample pairs. The contrastive loss is computed as the summation of losses over all pairs.
To solve the extreme foreground-background class imbalance problem in one-stage object detection frameworks, the authors down-weights the loss assigned to well-classified examples by proposing Focal Loss, which adds a factor to the standard cross entropy criterion.

As shown in the figure above, the factor will lower the standard cross entropy loss. Suppose gamma is 2, an example classified with p_t = 0.9 would have 100× lower loss compared with CE and with p_t ≈ 0.968 it would have 1000× lower loss. This in turn increases the importance of correcting misclassified examples (whose loss is scaled down by at most 4× for p_t ≤ .5 and gamma = 2).
pdf
No code available now ~
Authors:
Daniel Neimark, Omri Bar, Maya Zohar, Dotan Asselmann
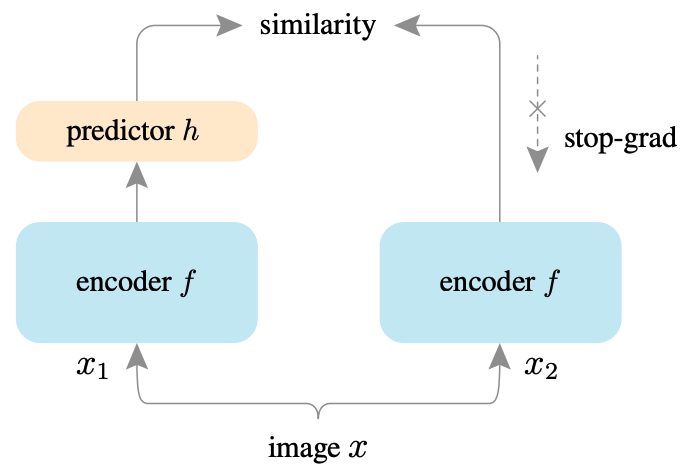
Authors:
Mathilde Caron, Hugo Touvron, etc.
FBAI.

Highlights:

Mehdi Noroozi, Hamed Pirsiavash, Paolo Favaro,
University of Bern, University of Maryland, Baltimore County
[paper] && [code]
Main idea:
The authors relate transformations of images to transformations of the representations. Specifically, they use counting as a pretext task, which they formalize as a constraint that release the "counted" visual primitives in tiles of an image to those counted in its downsampled version.
The downsampling or scaling transformation exploits the fact that the number of visual primitives should be invariant to scale.
The tiling transformation allows equating the total number of visual primitives in each tile to that in the whole image.

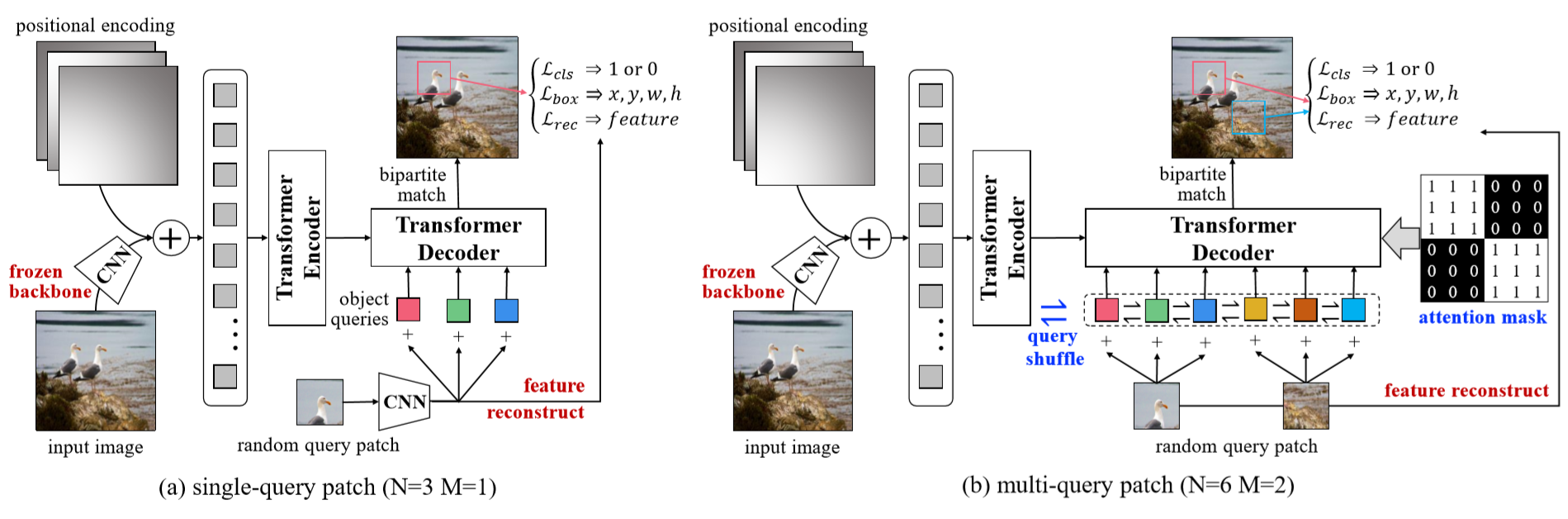
Authors:
Zhigang Dai, Bolun Cai, Yugeng Lin, Junying Chen
The Chinese explanation from the author Zhigang Dai in Zhihu.
The framework of the proposed UP-DETR.
The paper proposes a new way of learning image representations from unlabeled data by predicting the image rotations. The problem formulation implicitly encourages the learned representation to be informative about the (foreground) object and its rotation. The idea is simple, but it turns out to be very effective. The authors demonstrate strong performance in multiple transfer learning scenarios, such as ImageNet classification, PASCAL classification, PASCAL segmentation, and CIFAR-10 classification.
The authors revisit numerous previously proposed self-supervised models, conduct a thorough large scale study and, as a result, uncover multiple crucial in-sights. They challenge a number of common practices in self-supervised visual representation learning and observe that standard recipes for CNN design do not always translate to self-supervised representation learning.
This paper obtains improved visual question answering by using gradient-based certainty attention regions.
The proposed method yields improved uncertainty estimates that are correspondingly more certain or uncertain, show consistent correlation with mis-classification and are focused quantitatively on better attention regions as compared to other states of the art methods.
The proposed architecture can be easily incorporated in various existing VQA methods.
It could be used as a general means for obtaining improved uncertainty and explanation regions for various vision and language tasks.
Authors:
Chao-Yuan Wu1,2 Ross Girshick2 Kaiming He2 Christoph Feichtenhofer2 Philipp Krahenb 1
1The University of Texas at Austin 2Facebook AI Research (FAIR)
Problem to be tackled
High resolution models perform well, but train slowly. Low resolution models train faster, but are less accurate.
Trade-off the balance between compution allocated to processing more examples per mini-batch vs. the computation allocated to processing larger time and space dimensions.
Core observation: The underlying sampling grid that is used to train video models need not be constant during training.
To avoid this trade-off, this paper proposed to use variable mini-batch shapes with different spatial-temporal resolutions that are varied according to a schedule. Training is accelerated by scaling up the mini-batch size and learning rate when shrinking the other dimensions. This means with this strategy, we can have faster training without losing accuracy.
different shapes: resampling the training data on multiple sampling grids.
sampling grids: it is specified by a temporal span, a spatial span, a temporal stride, and a spatial stride.
Baseline: a referebce video model (C3D, I3D) trained by a baseline mini-batch optimizer (SGD) that operates on mini-batches of shape BxTxHxW (mini-batch size x number of frames x height x width) for some number of epochs (e.g., 100).
This paper: consider temporal and spatial shapes t x w x h that are formed by resampling source videos with a new sampling grid that has its own spans and strides.
The proposed method learns a split representation that contains both rotation related and unrelated parts.
They train neural networks by jointly predicting image rotations and discriminating individual instances.
In particular, the model decouples the rotation discrimination from instance discrimination, which allows to improve the rotation prediction by mitigating the influence of rotation label noise, as well as discriminate instances without regard to image rotations.
Authors:
Kai Han, An Xiao, etc.
Paper
Project Page
Authors:
Rohit Girdhar, Joao Carreira, Carl Doersch, Andrew Zisserman
[paper] && [code]
Authors:
Qizhe Xie∗ 1, Minh-Thang Luong1, Eduard Hovy2, Quoc V. Le1
1Google Research, Brain Team, 2Carnegie Mellon University
This paper presents Noisy Student Training which extends the idea of self-training and distillation with the use of equal-or-larger student models and noise added to the student during learning. This method achieves state-of-the-art results on ImageNet images. And experiments on ImageNet-A, ImageNet-C, and ImageNet-P show the model's robustness.
Basically, Noisy Student Training has three main steps: (1) train a teacher model on labeled images (ImageNet), (2) use the teacher to generate pseudo labels on unlabeled image, and (3) train a student model on the combination of labeled images and pseudo labeled images. They iterate this algorithm a few times by treating the student as a teacher to relabel the unlabeled data and training a new student.
Briefly, the authors improve deep anomaly detection by training anomaly detectors against an auxiliary dataset of outliers, an approach they call Outlier Exposure (OE).
For example, they use CIFAR10 as in-distribution set, while use 80 Million Tiny Images (exclude examples in CIFAR10) as outlier exposure dataset.
This enables anomaly detectors to generalize and detect unseen anomalies. In extensive experiments on natural language processing and small- and large-scale vision tasks, they find that Outlier Exposure significantly improves detection performance.
Authors:
Iz Beltagy, Matthew E. Peters, Arman Cohan
Youtube Explanation by Yannic Kilcher.
The Longformer extends the Transformer by introducing sliding window attention and sparse global attention. This allows for the processing of much longer documents than classic models like BERT.
Authors:
Jiangliu Wang, Jianbo Jiao and Yunhui Liu
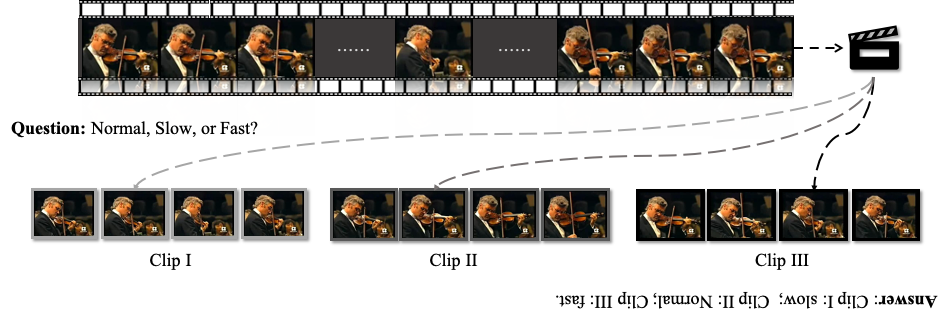
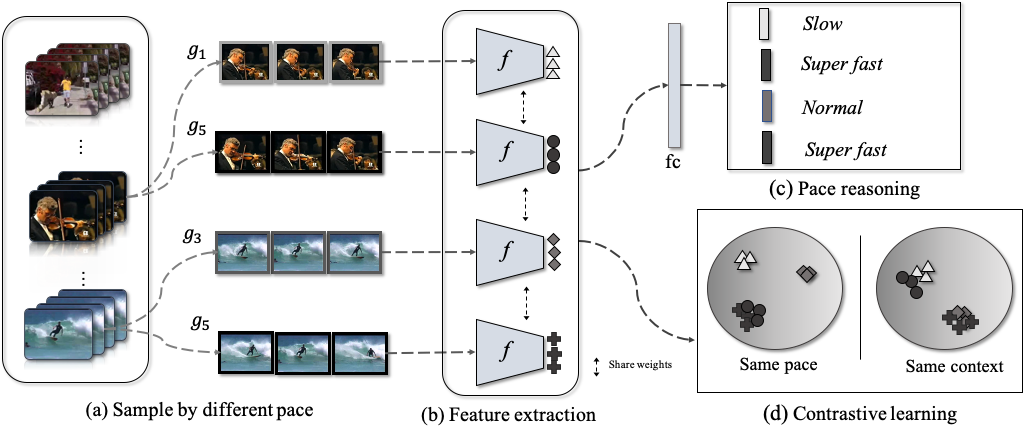
Motivation: to learn representations that support reasoning at various levels of visual correspondence from scratch and without human supervision.
Main idea: use cycle-consistency in time as free supervisory signal for learning visual representations from scratch.
At training time, the proposed model learns a feature map representation to be useful for performing cycle-consistent tracking. At test time, they use the acquired representation to find nearest neighbors across space and time.
Paper
No code available now~
Authors:
Zehua Zhang, David Crandall (Indiana University Bloomington)

AAAI2021 Best Paper Award!
[paper] && [code]
Authors:
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros
Berkeley AI Research (BAIR) Laboratory, UC Berkeley
This paper considers the image-to image translation problem as the input and output differs in surface appearance but both are renderings of the same underlying structure. The results suggest that the conditional adversarial networks are a promising approach for many image-to-image translation tasks, especially those involving highly structured graphical outputs.
They use a "U-Net"-based architecture as the generator and for the discriminator they use a convolutional "PatchGAN" classifier, which only penalizes structure at the scale of patches. The discriminator tries to classify if each NxN patch in an image is real or fake.
The experiments cast on a variety of tasks and datasets, including:
http://arxiv.org/abs/1906.12340
This paper shows findings about combine self-supervised learning with supervised learning can improve model's performance on robustness and uncertainty. It serves like a summary with experiments.
In this paper, they found self-supervision can:
This paper has essentially no theory, but proposes lots of interesting directions for future work.
Self-supervised learning opens up a huge opportunity for better utilizing unlabelled data, while learning in a supervised learning manner. This post covers many interesting ideas of self-supervised learning tasks on images, videos, and control problems.
As long as the unsupervised features successfully encode the essential information about the visual structures of original and transformed images, the transformation can be well predicted.
The authors present a novel paradigm of unsupervised representation learning by Auto-Encoding Transformation(AET) in contract to the conventional Auto-Encoding Data(AED).
This AET paradigm allows us to instantiate a large varity of transformations, from parameterized, to non-parameterized and GAN-induced ones.
AET sets new SoTA performances being greatly closer to the upper bounds by their fully supervised counterparts on CIFAR-10, ImageNet and Places dataset.
AED is based on the idea of reconstrcting input data at the output end. It means a good feature representation should contain sufficient information to reconstruct the input data.
AET focuses on exploring dynamics of feature representations under different transformations, thereby revealing not only static visual structures but also how they would change by applying different transformations.
AET is kind of summary and sublimation of previous AED methods.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.