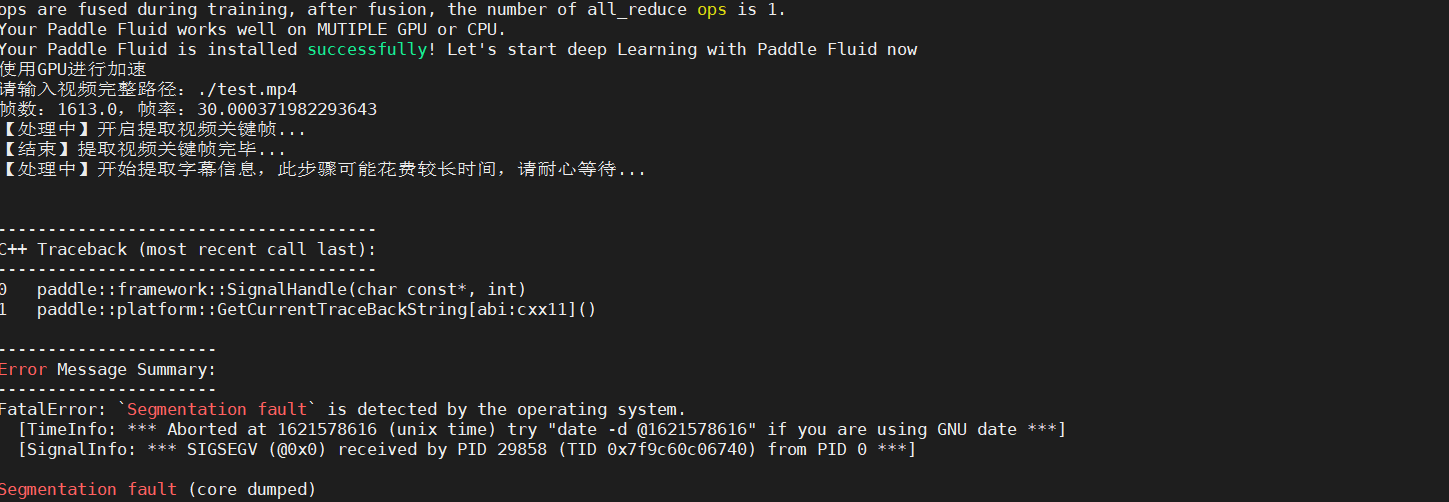
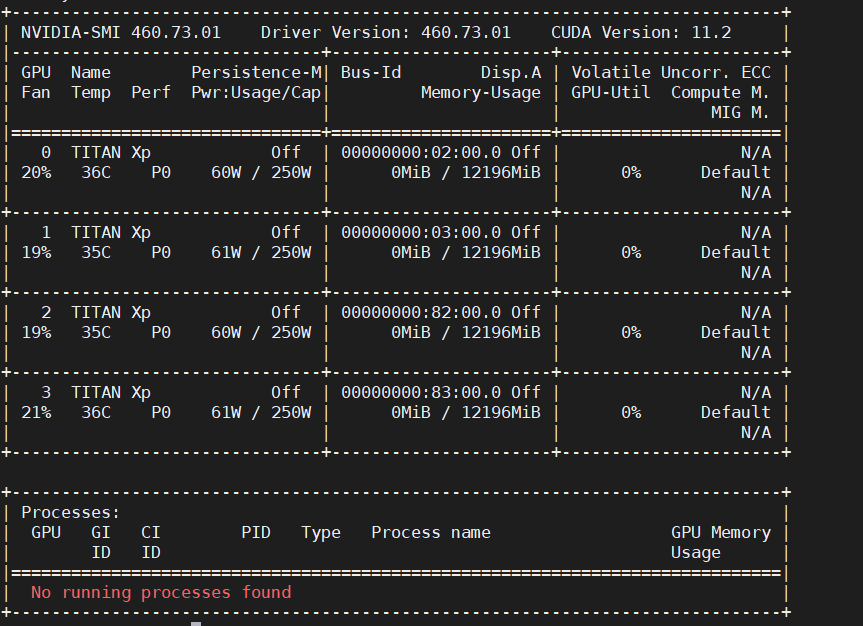
python ./main/demo.py
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:526:` FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])
/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])
please input your video file path name:/Users/MyName/Downloads/1.mp4
fps: 25.0
Total Frames: 16946
Video Resolution: (360, 480)
Extracting frames, please wait...
WARNING:tensorflow:From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
[WARNING 2021-01-03 20:12:01,341 new_func:323] From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /Users/MyName/video-subtitle-extractor/nets/model_train.py:30: LSTMCell.init (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.
[WARNING 2021-01-03 20:12:01,531 new_func:323] From /Users/MyName/video-subtitle-extractor/nets/model_train.py:30: LSTMCell.init (from tensorflow.python.ops.rnn_cell_impl) is deprecated and will be removed in a future version.
Instructions for updating:
This class is equivalent as tf.keras.layers.LSTMCell, and will be replaced by that in Tensorflow 2.0.
WARNING:tensorflow:From /Users/MyName/video-subtitle-extractor/nets/model_train.py:33: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use keras.layers.Bidirectional(keras.layers.RNN(cell)), which is equivalent to this API
[WARNING 2021-01-03 20:12:01,532 new_func:323] From /Users/MyName/video-subtitle-extractor/nets/model_train.py:33: bidirectional_dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use keras.layers.Bidirectional(keras.layers.RNN(cell)), which is equivalent to this API
WARNING:tensorflow:From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/ops/rnn.py:443: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use keras.layers.RNN(cell), which is equivalent to this API
[WARNING 2021-01-03 20:12:01,532 new_func:323] From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/ops/rnn.py:443: dynamic_rnn (from tensorflow.python.ops.rnn) is deprecated and will be removed in a future version.
Instructions for updating:
Please use keras.layers.RNN(cell), which is equivalent to this API
2021-01-03 20:12:01.807858: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
Restore from checkpoints_mlt/ctpn_50000.ckpt
WARNING:tensorflow:From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to check for files with this prefix.
[WARNING 2021-01-03 20:12:01,809 new_func:323] From /Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to check for files with this prefix.
2021-01-03 20:12:01.851417: W tensorflow/core/framework/op_kernel.cc:1401] OP_REQUIRES failed at save_restore_v2_ops.cc:184 : Not found: checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
Traceback (most recent call last):
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1334, in _do_call
return fn(*args)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1319, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1407, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.NotFoundError: checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
[[{{node save/RestoreV2}}]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1276, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 929, in run
run_metadata_ptr)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1152, in _run
feed_dict_tensor, options, run_metadata)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1328, in _do_run
run_metadata)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1348, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.NotFoundError: checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
[[node save/RestoreV2 (defined at ./main/demo.py:324) ]]
Caused by op 'save/RestoreV2', defined at:
File "./main/demo.py", line 448, in
tf.app.run()
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "./main/demo.py", line 439, in main
text_detect()
File "./main/demo.py", line 324, in text_detect
saver = tf.train.Saver(variable_averages.variables_to_restore())
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 832, in init
self.build()
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 844, in build
self._build(self._filename, build_save=True, build_restore=True)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 881, in _build
build_save=build_save, build_restore=build_restore)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 513, in _build_internal
restore_sequentially, reshape)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 332, in _AddRestoreOps
restore_sequentially)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 580, in bulk_restore
return io_ops.restore_v2(filename_tensor, names, slices, dtypes)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/ops/gen_io_ops.py", line 1572, in restore_v2
name=name)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 788, in _apply_op_helper
op_def=op_def)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py", line 507, in new_func
return func(*args, **kwargs)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3300, in create_op
op_def=op_def)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1801, in init
self._traceback = tf_stack.extract_stack()
NotFoundError (see above for traceback): checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
[[node save/RestoreV2 (defined at ./main/demo.py:324) ]]
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1286, in restore
names_to_keys = object_graph_key_mapping(save_path)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1591, in object_graph_key_mapping
checkpointable.OBJECT_GRAPH_PROTO_KEY)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/pywrap_tensorflow_internal.py", line 370, in get_tensor
status)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/errors_impl.py", line 528, in exit
c_api.TF_GetCode(self.status.status))
tensorflow.python.framework.errors_impl.NotFoundError: Key _CHECKPOINTABLE_OBJECT_GRAPH not found in checkpoint
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "./main/demo.py", line 448, in
tf.app.run()
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "./main/demo.py", line 439, in main
text_detect()
File "./main/demo.py", line 330, in text_detect
saver.restore(sess, model_path)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 1292, in restore
err, "a Variable name or other graph key that is missing")
tensorflow.python.framework.errors_impl.NotFoundError: Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
[[node save/RestoreV2 (defined at ./main/demo.py:324) ]]
Caused by op 'save/RestoreV2', defined at:
File "./main/demo.py", line 448, in
tf.app.run()
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/platform/app.py", line 125, in run
_sys.exit(main(argv))
File "./main/demo.py", line 439, in main
text_detect()
File "./main/demo.py", line 324, in text_detect
saver = tf.train.Saver(variable_averages.variables_to_restore())
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 832, in init
self.build()
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 844, in build
self._build(self._filename, build_save=True, build_restore=True)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 881, in _build
build_save=build_save, build_restore=build_restore)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 513, in _build_internal
restore_sequentially, reshape)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 332, in _AddRestoreOps
restore_sequentially)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/training/saver.py", line 580, in bulk_restore
return io_ops.restore_v2(filename_tensor, names, slices, dtypes)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/ops/gen_io_ops.py", line 1572, in restore_v2
name=name)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py", line 788, in _apply_op_helper
op_def=op_def)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/util/deprecation.py", line 507, in new_func
return func(*args, **kwargs)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 3300, in create_op
op_def=op_def)
File "/Users/MyName/opt/anaconda3/envs/videoEnv/lib/python3.6/site-packages/tensorflow/python/framework/ops.py", line 1801, in init
self._traceback = tf_stack.extract_stack()
NotFoundError (see above for traceback): Restoring from checkpoint failed. This is most likely due to a Variable name or other graph key that is missing from the checkpoint. Please ensure that you have not altered the graph expected based on the checkpoint. Original error:
checkpoints_mlt/ctpn_50000.ckpt.data-00000-of-00001; No such file or directory
[[node save/RestoreV2 (defined at ./main/demo.py:324) ]]`