
本项目是基于PaddlePaddle的DeepSpeech 项目开发的,做了较大的修改,方便训练中文自定义数据集,同时也方便测试和使用。DeepSpeech2是基于PaddlePaddle实现的端到端自动语音识别(ASR)引擎,其论文为《Baidu's Deep Speech 2 paper》 ,本项目同时还支持各种数据增强方法,以适应不同的使用场景。 本项目使用的环境:
- Python 3.7
- PaddlePaddle 1.8.5
点击访问 (请不要攻击我可怜的服务器,谢谢!)
型并没有完全训练完,效果没有达到最好,有没有同学提供多卡服务器笔者训练啊,感激感激!
本人用的就是本地环境和使用Anaconda,并创建了Python3.7的虚拟环境,建议读者也本地环境,方便交流,出现安装问题,随时提issue 。
- 执行下面的命令完成本地环境的搭建。因为每个电脑的环境不一样,不能保证能够正常使用,如果出现问题,查看报错信息,安装相应的依赖库。首先切换到
DeepSpeech/根目录下,执行setup.sh脚本安装依赖环境,等待安装即可。默认安装的是PaddlePaddle 1.8.5.post107的GPU版本,需要自行安装相关的CUDA和CUDNN。
cd DeepSpeech/
sudo sh setup.sh如果出现LLVM版本错误,则执行下面的命令,然后重新执行上面的安装命令,否则不需要执行。
cd ~
wget https://releases.llvm.org/9.0.0/llvm-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/cfe-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/clang-tools-extra-9.0.0.src.tar.xz
tar xvf llvm-9.0.0.src.tar.xz
tar xvf cfe-9.0.0.src.tar.xz
tar xvf clang-tools-extra-9.0.0.src.tar.xz
mv llvm-9.0.0.src llvm-src
mv cfe-9.0.0.src llvm-src/tools/clang
mv clang-tools-extra-9.0.0.src llvm-src/tools/clang/tools/extra
sudo mkdir -p /usr/local/llvm
sudo mkdir -p llvm-src/build
cd llvm-src/build
sudo cmake -G "Unix Makefiles" -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE="Release" -DCMAKE_INSTALL_PREFIX="/usr/local/llvm" ..
sudo make -j8
sudo make install
export LLVM_CONFIG=/usr/local/llvm/bin/llvm-config- git clone 本项目源码
git clone https://github.com/yeyupiaoling/DeepSpeech.git- 请提前安装好显卡驱动,然后执行下面的命令。
# 卸载系统原有docker
sudo apt-get remove docker docker-engine docker.io containerd runc
# 更新apt-get源
sudo apt-get update
# 安装docker的依赖
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common
# 添加Docker的官方GPG密钥:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 验证拥有指纹
sudo apt-key fingerprint 0EBFCD88
# 设置稳定存储库
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"- 安装Docker
# 再次更新apt-get源
sudo apt-get update
# 开始安装docker
sudo apt-get install docker-ce
# 加载docker
sudo apt-cache madison docker-ce
# 验证docker是否安装成功
sudo docker run hello-world- 安装nvidia-docker
# 设置stable存储库和GPG密钥
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
&& curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add - \
&& curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 更新软件包清单后
sudo apt-get update
# 安装软件包
sudo apt-get install -y nvidia-docker2
# 设置默认运行时后,重新启动Docker守护程序以完成安装:
sudo systemctl restart docker
# 测试
sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi- 拉取PaddlePaddle 1.8.5镜像,因为这个项目需要在PaddlePaddle 1.8版本才可以运行。
sudo nvidia-docker pull hub.baidubce.com/paddlepaddle/paddle:1.8.5-gpu-cuda10.0-cudnn7- git clone 本项目源码
git clone https://github.com/yeyupiaoling/DeepSpeech.git- 运行PaddlePaddle语音识别镜像,这里设置与主机共同拥有IP和端口号。
sudo nvidia-docker run -it --net=host -v $(pwd)/DeepSpeech:/DeepSpeech hub.baidubce.com/paddlepaddle/paddle:1.8.5-gpu-cuda10.0-cudnn7 /bin/bash- 切换到
/DeepSpeech/目录下,首先将docker的Python3默认为Python3.7,然后切换g++为g++5,然后安装LLVM。最后执行setup.sh脚本安装依赖环境,执行前需要去掉setup.sh和decoder/setup.sh安装依赖库时使用的sudo命令,因为在docker中本来就是root环境,等待安装即可。
# 修改Docker的Python3版本为3.7
rm -rf /usr/local/bin/python3
ln -s /home/Python-3.7.0/python /usr/local/bin/python3
# 切换默认的g++版本为5
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-5 30 --slave /usr/bin/g++ g++ /usr/bin/g++-5
update-alternatives --config gcc
# 开始安装LLVM
cd /home
wget https://releases.llvm.org/9.0.0/llvm-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/cfe-9.0.0.src.tar.xz
wget http://releases.llvm.org/9.0.0/clang-tools-extra-9.0.0.src.tar.xz
tar xvf llvm-9.0.0.src.tar.xz
tar xvf cfe-9.0.0.src.tar.xz
tar xvf clang-tools-extra-9.0.0.src.tar.xz
mv llvm-9.0.0.src llvm-src
mv cfe-9.0.0.src llvm-src/tools/clang
mv clang-tools-extra-9.0.0.src llvm-src/tools/clang/tools/extra
mkdir -p /usr/local/llvm
mkdir -p llvm-src/build
cd llvm-src/build
cmake -G "Unix Makefiles" -DLLVM_TARGETS_TO_BUILD=X86 -DCMAKE_BUILD_TYPE="Release" -DCMAKE_INSTALL_PREFIX="/usr/local/llvm" ..
make -j8 && make install
export LLVM_CONFIG=/usr/local/llvm/bin/llvm-config
# 安装全部依赖库
cd DeepSpeech/
sh setup.sh- 在
data目录下是公开数据集的下载和制作训练数据列表和词汇表的,本项目提供了下载公开的中文普通话语音数据集,分别是Aishell,Free ST-Chinese-Mandarin-Corpus,THCHS-30 这三个数据集,总大小超过28G。下载这三个数据只需要执行一下代码即可,当然如果想快速训练,也可以只下载其中一个。
cd data/
python3 aishell.py
python3 free_st_chinese_mandarin_corpus.py
python3 thchs_30.py- 如果开发者有自己的数据集,可以使用自己的数据集进行训练,当然也可以跟上面下载的数据集一起训练。自定义的语音数据需要符合以下格式,另外对于音频的采样率,本项目默认使用的是16000Hz,在
create_manifest.py中也提供了统一音频数据的采样率转换为16000Hz,只要is_change_frame_rate参数设置为True就可以。- 语音文件需要放在
DeepSpeech/dataset/audio/目录下,例如我们有个wav的文件夹,里面都是语音文件,我们就把这个文件存放在DeepSpeech/dataset/audio/。 - 然后把数据列表文件存在
DeepSpeech/dataset/annotation/目录下,程序会遍历这个文件下的所有数据列表文件。例如这个文件下存放一个my_audio.txt,它的内容格式如下。每一行数据包含该语音文件的相对路径和该语音文件对应的中文文本,要注意的是该中文文本只能包含纯中文,不能包含标点符号、阿拉伯数字以及英文字母。
- 语音文件需要放在
dataset/audio/wav/0175/H0175A0171.wav 我需要把空调温度调到二十度
dataset/audio/wav/0175/H0175A0377.wav 出彩**人
dataset/audio/wav/0175/H0175A0470.wav 据克而瑞研究中心监测
dataset/audio/wav/0175/H0175A0180.wav 把温度加大到十八- 然后执行下面的数据集处理脚本,这个是把我们的数据集生成三个JSON格式的数据列表,分别是
manifest.dev、manifest.test、manifest.train。然后计算均值和标准差用于归一化,脚本随机采样2000个的语音频谱特征的均值和标准差,并将结果保存在mean_std.npz中。建立词表。最后建立词表,把所有出现的字符都存放子在zh_vocab.txt文件中,一行一个字符。以上生成的文件都存放在DeepSpeech/dataset/目录下。
# 生成数据列表
PYTHONPATH=.:$PYTHONPATH python3 tools/create_manifest.py
# 计算均值和标准差
PYTHONPATH=.:$PYTHONPATH python3 tools/compute_mean_std.py
# 构建词汇表
PYTHONPATH=.:$PYTHONPATH python3 tools/build_vocab.py在生成数据列表的是要注意,该程序除了生成训练数据列表,还提供对音频帧率的转换和生成噪声数据列表,开发者有些自定义的数据集音频的采样率不是16000Hz的,所以提供了change_audio_rate()函数,帮助开发者把指定的数据集的音频采样率转换为16000Hz。提供的生成噪声数据列表create_noise函数,前提是要有噪声数据集,使用噪声数据在训练中实现数据增强。
if __name__ == '__main__':
# 生成噪声的数据列表
create_noise()
# 生成训练数据列表
main()- 执行训练脚本,开始训练语音识别模型, 每训练一轮保存一次模型,模型保存在
DeepSpeech/models/目录下,默认会使用噪声音频一起训练的,如果没有这些音频,可以删除conf/augmentation.config中的noise项,噪声是用于数据增强的,关于数据增强,请查看数据增强部分。如果没有关闭测试,在每一轮训练结果之后,都会执行一次测试,为了提高测试的速度,测试使用的是最优解码路径解码,这个解码方式结果没有集束搜索的方法准确率高,所以测试的输出的准确率可以理解为保底的准确率。
export FLAGS_sync_nccl_allreduce=0
CUDA_VISIBLE_DEVICES=0,1 python3 train.py- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host=0.0.0.0- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
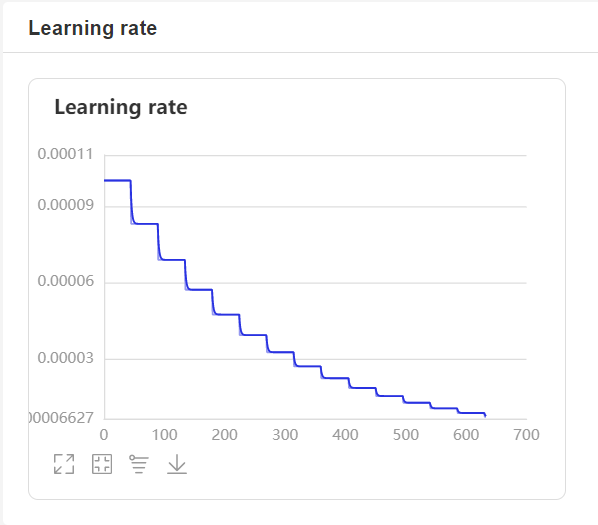
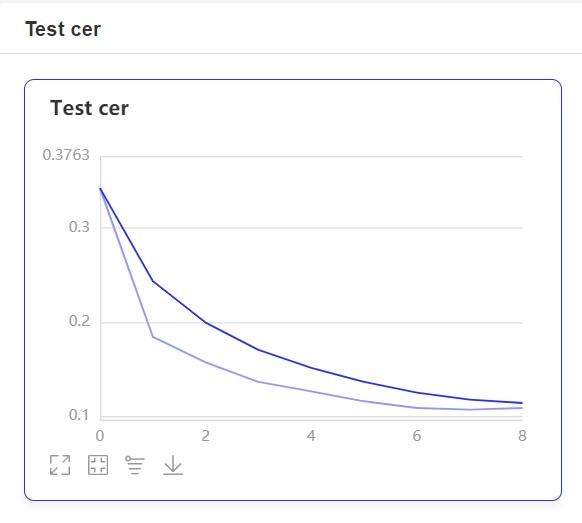
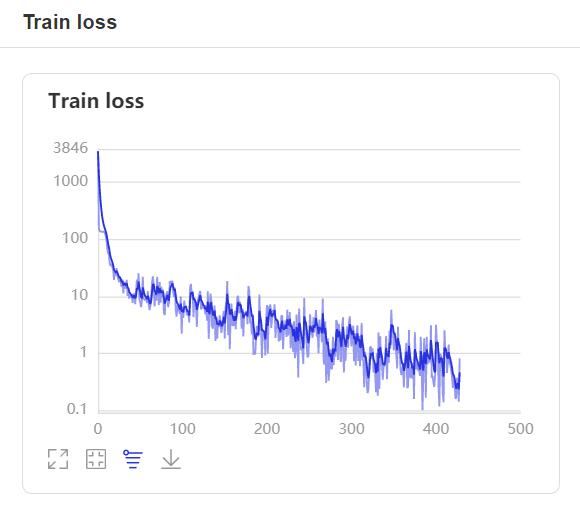
数据增强是用来提升深度学习性能的非常有效的技术。通过在原始音频中添加小的随机扰动(标签不变转换)获得新音频来增强的语音数据。开发者不必自己合成,因为数据增强已经嵌入到数据生成器中并且能够即时完成,在训练模型的每个epoch中随机合成音频。
目前提供六个可选的增强组件供选择,配置并插入处理过程。
- 音量扰动
- 速度扰动
- 移动扰动
- 在线贝叶斯归一化
- 噪声干扰(需要背景噪音的音频文件)
- 脉冲响应(需要脉冲音频文件)
为了让训练模块知道需要哪些增强组件以及它们的处理顺序,需要事先准备一个JSON格式的扩展配置文件。例如:
[{
"type": "speed",
"params": {"min_speed_rate": 0.95,
"max_speed_rate": 1.05},
"prob": 0.6
},
{
"type": "shift",
"params": {"min_shift_ms": -5,
"max_shift_ms": 5},
"prob": 0.8
}]当trainer.py的--augment_conf_file参数被设置为上述示例配置文件的路径时,每个 epoch 中的每个音频片段都将被处理。首先,均匀随机采样速率会有60%的概率在 0.95 和 1.05 之间对音频片段进行速度扰动。然后,音频片段有 80% 的概率在时间上被挪移,挪移偏差值是 -5 毫秒和 5 毫秒之间的随机采样。最后,这个新合成的音频片段将被传送给特征提取器,以用于接下来的训练。
有关其他配置实例,请参考conf/augmenatation.config.
使用数据增强技术时要小心,由于扩大了训练和测试集的差异,不恰当的增强会对训练模型不利,导致训练和预测的差距增大。
下载语言模型并放在lm目录下,下面下载的小语言模型,如何有足够大性能的机器,可以下载70G的超大语言模型,点击下载Mandarin LM Large ,这个模型会大超多。
cd DeepSpeech/
mkdir lm
cd lm
wget https://deepspeech.bj.bcebos.com/zh_lm/zh_giga.no_cna_cmn.prune01244.klm这里我也提示几点,在预测中可以提升性能的几个参数,预测包括评估,推理,部署等等一系列使用到模型预测音频的程序。解码方法,通过decoding_method选择不同的解码方法,支持ctc_beam_search集束搜索和ctc_greedy最优路径两种,其中ctc_beam_search集束搜索效果是最好的,但是速度就比较慢,这个可以通过beam_size参数设置集束搜索的宽度,以提高执行速度,范围[5, 500],越大准确率就越高,同时执行速度就越慢。如果对准确率没有太严格的要求,可以考虑直接使用ctc_greedy最优路径方法,其实准确率也低不了多少。
- 在训练结束之后,我们要使用这个脚本对模型进行超参数调整,提高语音识别性能。该程序主要是为了寻找
ctc_beam_search集束搜索方法中最优的alpha,beta参数,以获得最好的识别准确率。如果使用的是ctc_greedy最优路径,可以直接跳过这一步。
PYTHONPATH=.:$PYTHONPATH python3 tools/tune.py --model_path=./models/step_final/- 我们可以使用这个脚本对模型进行评估,通过字符错误率来评价模型的性能。通过这个程序的输出,开发者就可以考虑使用哪种解码方法,以及
ctc_beam_search集束搜索方法中beam_size参数的大小。
python3 eval.py --model_path=./models/step_final/输出结果:
----------- Configuration Arguments -----------
alpha: 1.2
batch_size: 64
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_beam_search
error_rate_type: cer
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
model_path: models/epoch_19/
num_conv_layers: 2
num_proc_bsearch: 8
num_rnn_layers: 3
rnn_layer_size: 2048
share_rnn_weights: False
specgram_type: linear
test_manifest: ./dataset/manifest.test
use_gpu: True
use_gru: True
vocab_path: ./dataset/zh_vocab.txt
------------------------------------------------
W0318 16:38:49.200599 19032 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 75, Driver API Version: 11.0, Runtime API Version: 10.0
W0318 16:38:49.242089 19032 device_context.cc:260] device: 0, cuDNN Version: 7.6.
成功加载了预训练模型:models/epoch_19/
[INFO 2021-03-18 16:38:51,442 model.py:523] begin to initialize the external scorer for decoding
[INFO 2021-03-18 16:38:53,688 model.py:531] language model: is_character_based = 1, max_order = 5, dict_size = 0
[INFO 2021-03-18 16:38:53,689 model.py:532] end initializing scorer
[INFO 2021-03-18 16:38:53,689 eval.py:83] 开始评估 ...
错误率:[cer] (64/284) = 0.077040
错误率:[cer] (128/284) = 0.062989
错误率:[cer] (192/284) = 0.055674
错误率:[cer] (256/284) = 0.054918
错误率:[cer] (284/284) = 0.055882
消耗时间:44526ms, 总错误率:[cer] (284/284) = 0.055882
[INFO 2021-03-18 16:39:38,215 eval.py:117] 完成评估!
- 我们可以使用这个脚本使用模型进行预测,通过传递音频文件的路径进行识别。
python3 infer_path.py --model_path=./models/step_final/ --wav_path=./dataset/test.wav输出结果:
W0310 10:09:21.043175 26679 device_context.cc:252] Please NOTE: device: 0, CUDA Capability: 75, Driver API Version: 11.0, Runtime API Version: 10.0
W0310 10:09:21.075088 26679 device_context.cc:260] device: 0, cuDNN Version: 7.6.
finish initing model from pretrained params from ./models/step_final/
[INFO 2021-03-10 10:09:25,055 model.py:491] begin to initialize the external scorer for decoding
[INFO 2021-03-10 10:09:27,285 model.py:499] language model: is_character_based = 1, max_order = 5, dict_size = 0
[INFO 2021-03-10 10:09:27,285 model.py:500] end initializing scorer
----------- Configuration Arguments -----------
alpha: 1.2
beam_size: 10
beta: 0.35
cutoff_prob: 1.0
cutoff_top_n: 40
decoding_method: ctc_beam_search
lang_model_path: ./lm/zh_giga.no_cna_cmn.prune01244.klm
mean_std_path: ./dataset/mean_std.npz
model_path: ./models/step_final/
num_conv_layers: 2
num_rnn_layers: 3
rnn_layer_size: 2048
share_rnn_weights: False
specgram_type: linear
use_gpu: True
use_gru: True
vocab_path: ./dataset/zh_vocab.txt
wav_path: ./dataset/test.wav
------------------------------------------------
消耗时间:1656, 识别结果: 近几年不但我用输给女儿压岁也劝说亲朋不要给女儿压岁钱而改送压岁书
- 在服务器执行下面命令通过创建一个Web服务,通过提供HTTP接口来实现语音识别。
CUDA_VISIBLE_DEVICES=0 python3 infer_server.py --model_path=./models/step_final/- 在本地执行下面命令启动一个网页来测试,可以选择本地音频文件,或者是在线录音。在启动前需要修改
index.html中uploadRecordAudio()和uploadFile()的请求url,把url改为加上读者服务器的IP即可,启动服务之后,在浏览器上访问http://localhost:5001。
python3 client.py
| 数据集 | 字错率 | 下载地址 |
|---|---|---|
| AISHELL | 0.055882 | 点击下载 |
| free_st_chinese_mandarin_corpus | 0.138749 | 点击下载 |
| thchs_30 | 0.112128 | 点击下载 |
| 自收集(超过1300小时) | 0.072669 | 点击下载 |
说明: 在训练过程中添加了噪声等各种数据增强,字错率高一些也是正常的。
有问题欢迎提 issue 交流

