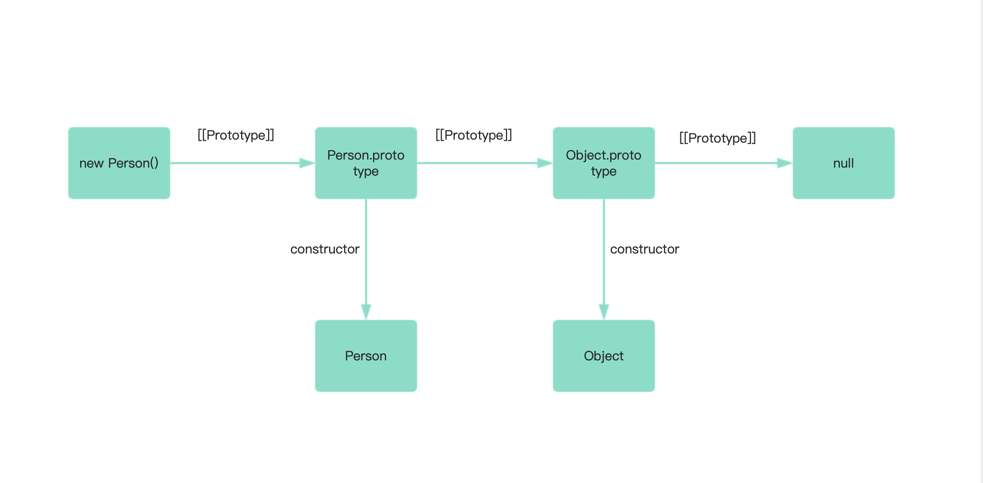
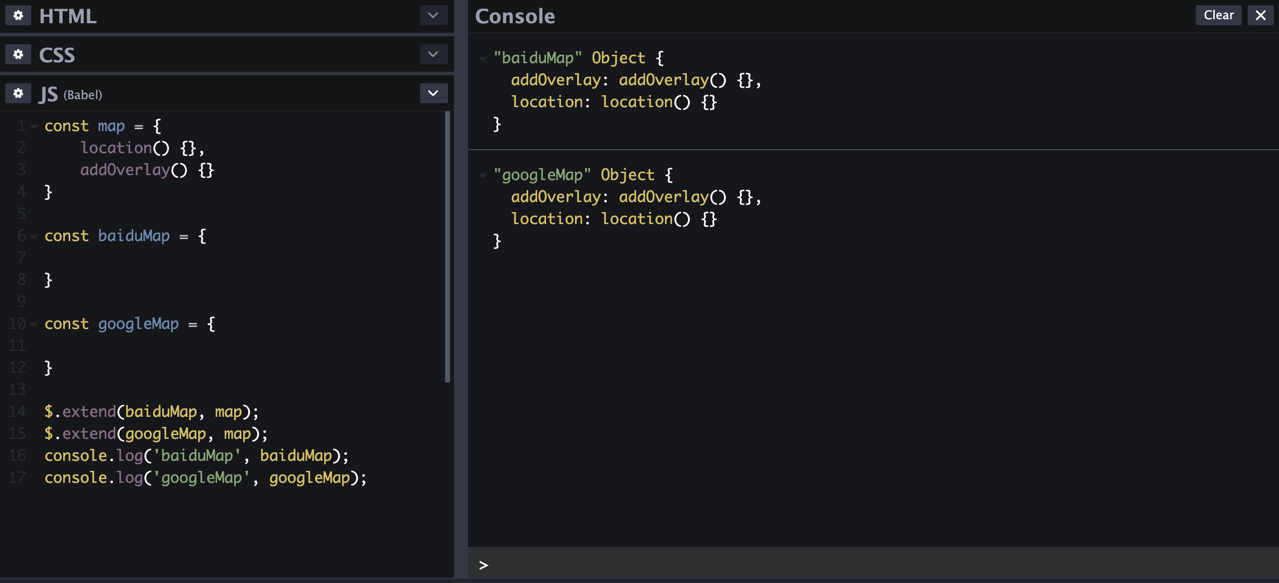
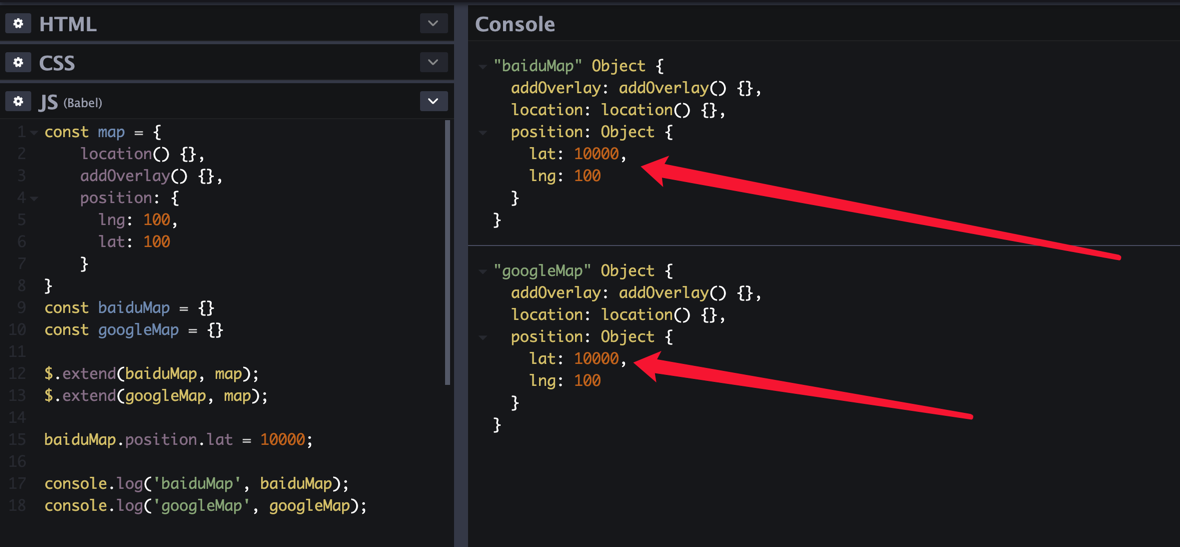
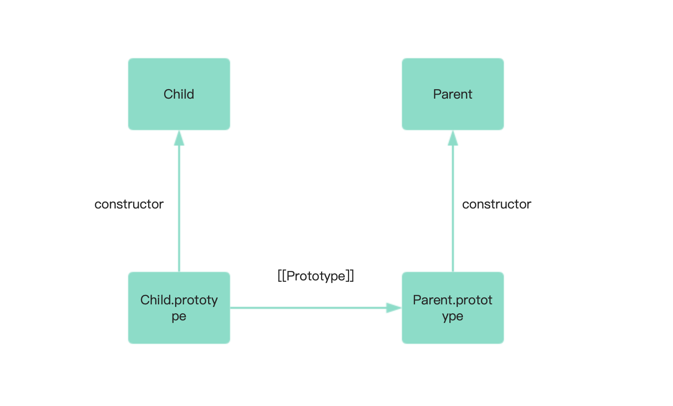
前言
之前上家公司主要是做移动端 H5 开发的,但相关技术和配套体系已经很成熟了,很难接触到背后的这套体系。
在现在的公司也做了一些零散的 H5 页面,有一些相关实践。反而因为基础设施和体系不完善,接触到了更多东西。
刚好要搞 RN,于是恶补了一些相关的知识,顺便把 H5 开发中的一些东西也温习记录了一遍。
Native App
在说 Hybrid App 之前不得不先讲到 Native App,这是最为传统的一种移动端开发技术。
在 iOS 和安卓中官方的开发语言是 oc/swift、java/kotlin,使用这些开发出来的 App 一般称之为原生应用。

优点
原生应用一般体验较好,性能比较高,可以提前把资源下载到本地,打开速度快。
除此之外,原生应用可以直接调用系统摄像头、通讯录、相册等功能,也可以访问到本地资源,功能强大。
一般需要开发 App,原生应用应该是首选。
缺点
原生应用最大的缺点就是不支持动态化更新,这也是很多大厂不完全使用原生开发的原因。
考虑一下,如果线上出现严重问题,那该怎么办呢?
首先客户端开发修复了 bug 之后,就需要重新发版、提交应用商店审核,这一流程走下来往往需要好几天的时间。
如果发布了新版 App,用户该怎么去更新呢?答案是没法更新。他们只能重新去下载整个 App,但实际上可能只更新了一行文案,这样就得不偿失了。
除此之外,最麻烦的地方在于要兼容老版本的 App。比如我们有个列表页原本是分页加载的,接口返回分页数据。产品说这样体验不好,我们需要换成全量加载,那接口就需要做成全量的。
但接口一旦换成了全量的,老版本的客户端里面依然是分页请求接口的,这样就会出现问题。因此,接口不得不根据不同版本进行兼容。
Web App
Web App 就是借助于前端 HTML5 技术实现的在浏览器里面跑的 App,简单来说就是一个 Web 网站。
因为是在浏览器里面运行,所以天然支持跨平台,一套代码甚至很容易支持移动端和 PC 端不需要安装到手机里面,上线发版也比较容易。
缺点也很明显,那就是只能使用浏览器提供的功能,无法使用手机上的一些功能。比如摄像头、通讯录、相册等等,局限性很大。
也由于依赖于网络,加载页面速度会受到限制,体验较差。受限于浏览器 DOM 的性能,导致对一些场景很难做到原生的体验,比如长列表。
同时,也因为不像客户端一样在手机上有固定入口,会导致用户黏性比较低。
Hybrid App
Hybrid App 是介于 Native 和 Web 之间的一些开发模式,一般称作混合开发。
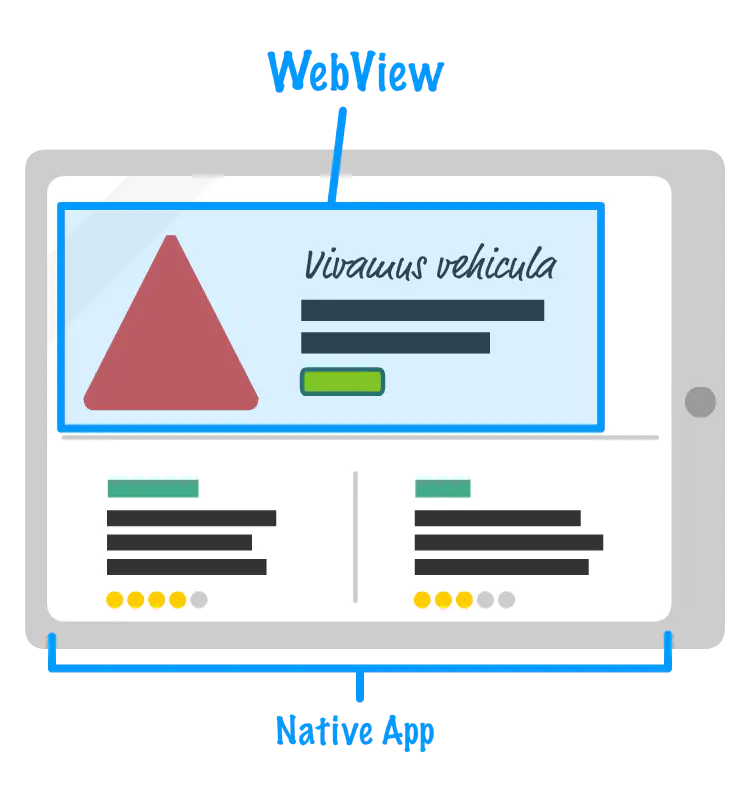
简单来说 Hybrid 就是套壳 App,整个 App 还是原生的,也需要下载安装到手机,但是 App 里面打开的页面既可以是 Web 的,又可以是原生的。
H5 页面会跑在 Native 的一个叫做 WebView 的容器里面,我们可以简单理解为在 App 里面打开了一个 Chrome 浏览器,在这个浏览器里面打开一个 Tab 去加载线上或者本地的 H5 页面,这样还可以实现打开多 WebView 来加载多个页面。

优势
Hybrid App 同时拥有 Native 和 Web 的优点,开发模式比较灵活。既可以做到动态化更新,有 bug 直接更新线上 H5 页面就行了。
也可以使用桥接(JS Bridge)来调用系统的摄像头、相册等功能,功能就不仅仅局限于浏览器了。
由于 H5 的优势,Hybrid 也支持跨平台,只要有 WebView,一套代码可以很容易跨iOS、安卓、Web、小程序、快应用多个平台。
缺点
缺点主要还是 Web App 的那些缺点,加载速度比较慢。
同时,因为受制于 Web 的性能,在长列表等场景依然无法做到和原生一样的体验。
当然加载速度是可以优化的,比如离线包。可以提前下载打包好的 zip 文件(包括 JS、CSS、图片等资源文件)到 App 里面,App 自己解压出来 JS 和 CSS 等文件。这样每次访问的是 App 本地的资源,加载速度可以得到质的提升。
如果文件有更新,那么客户端就去拉取远程版本,和本地版本进行对比,如果版本有更新,那就去拉取差量部分的文件,用二进制 diff 算法 patch 到原来的文件中,这样可以做到热更新。
但是成本也比较高,不仅需要在服务端进行一次文件差分,还需要公司内部提供一套热更新发布平台。
WebKit
WebView 是安卓中展示界面的一个控件,一般是用来展示 Web 界面。前面我们说过,可以把 WebView 理解为你正在使用的 Chrome 浏览器。
那么浏览器又是怎么去解析渲染 HTML 和 CSS,最终渲染到页面上面的呢?
这也是一道经典面试题里面的一环:从URL输入到页面展现到底发生什么?
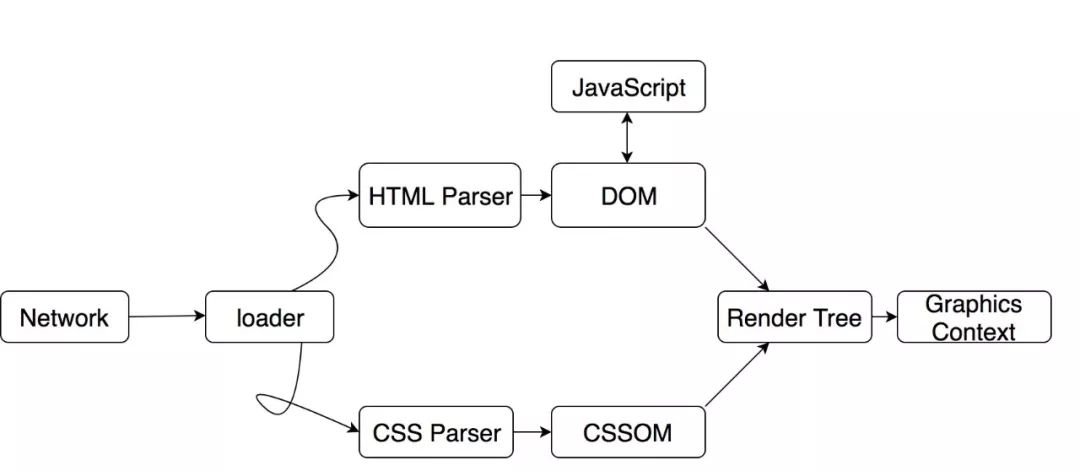
简单来说就是浏览器拿到响应的 HTML 文本后会解析 HTML 成一个 DOM 树,解析 CSS 为 CSSOM 树,两者结合生成渲染树。在 Chrome 中使用 Skia 图形库来渲染界面,Skia 也是 Flutter 的渲染引擎。
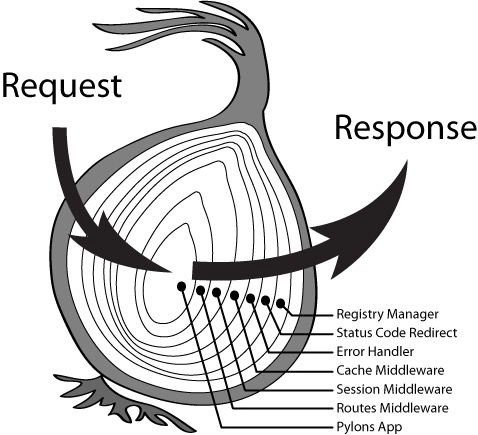
可以参考这张经典图:
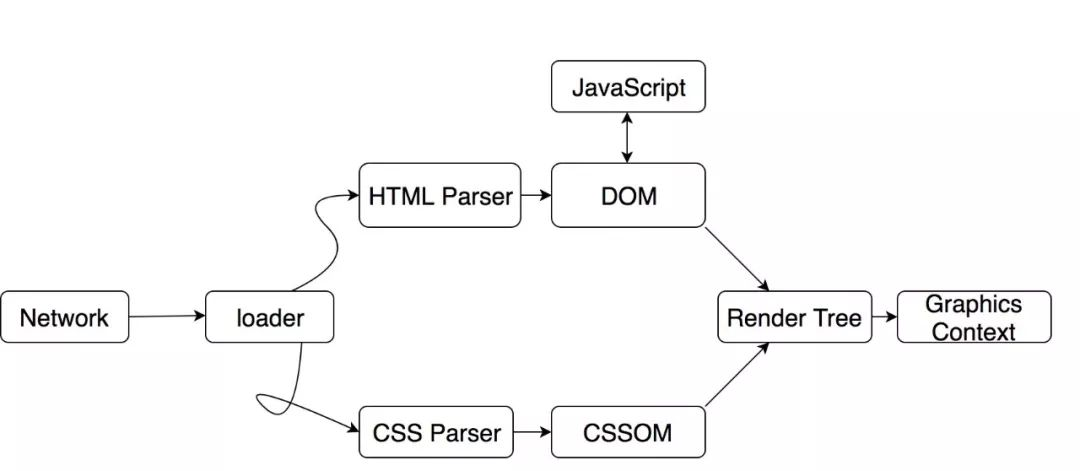
PS:使用 Skia 去绘制界面,而非编译成 Native 组件让系统去渲染,也是 Flutter 区别于 React Native 的一个地方。
除了解析 HTML,浏览器还需要提供 JavaScript 的运行时,我们知道的 V8 引擎就是做这件事的。
WebKit 内核
从上面我们可以得知,一个浏览器至少离不开一个渲染 HTML 的引擎和一个运行 JavaScript 的引擎。
当然,上面的这些操作都是浏览器由内核来完成的。现在主流的浏览器都使用了 WebKit 内核。
WebKit 诞生于苹果发布的 Safari 浏览器。后来谷歌基于 WebKit 创建了 Chromium 项目,在此基础上发布了我们熟悉的 Chrome 浏览器。
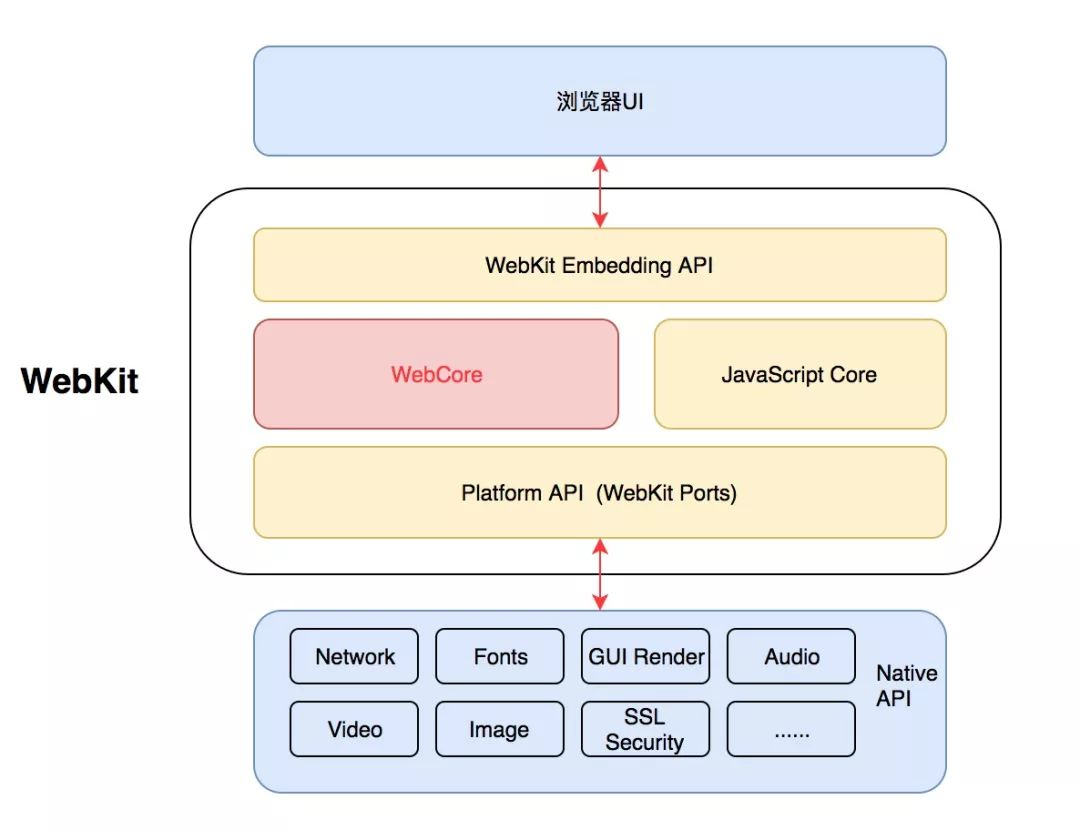
WebKit 内核的结构如下图所示。
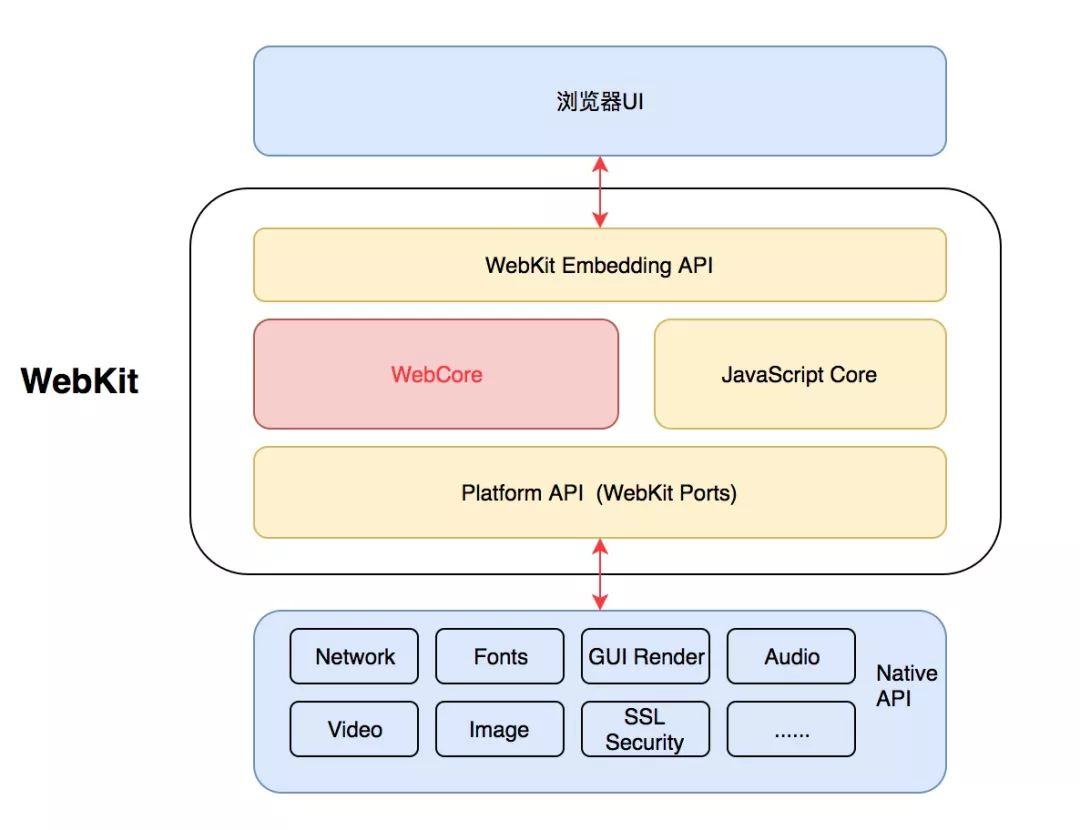
我们依次从上往下看,WebKit 嵌入式接口就是提供给浏览器调用的,不同浏览器实现可能有所差异。
其中解析 HTML 和 CSS 这部分是 WebCore 做的,WebCore 是 WebKit 最核心的渲染引擎,也是各大浏览器保持一致的部分,一般包括 HTML 和 CSS 解释器、DOM、渲染树等功能。
WebKit 默认使用 JavaScriptCore 作为 JS 引擎,这部分是可以替换的。JavaScriptCore 也是 React Native 里面默认的引擎。
由于 JavaScriptCore 前期性能低下,于是谷歌在 Chrome 里面选用了 V8 作为 JS 引擎。
WebKit Ports 则是非共享的部分,由于平台差异、依赖的库不同,这部分就变成了可移植部分。主要涉及到网络、视频解码、图片解码、音频解码等功能。
WebView 自然也使用了 WebKit 内核。只是在安卓里面以 V8 作为 JS 引擎,在 iOS 里面以 JavaScriptCore 作为 JS 引擎。
由于渲染 DOM 和操作 JS 的是两个引擎,因此当我们用 JS 去操作 DOM 的时候,JS 引擎通过调用桥接方法来获取访问 DOM 的能力。这里就会涉及到两个引擎通信带来的性能损失,这也是为什么频繁操作 DOM 会导致性能低下。
React 和 Vue 这些框架都是在这一层面进行了优化,只去修改差异部分的 DOM,而非全量替换 DOM。
iOS 中的 JavaScriptCore
JavaScriptCore 是 WebKit 内核默认使用的 JS 引擎。既然是讲解 WebView,那么就来介绍一下 iOS 里面的 JavaScriptCore 框架吧。
iOS 中的 JavaScriptCore 框架是基于 OC 封装的 JavaScriptCore 框架。
它提供了调用 JS 运行环境以及 OC 和 JS 互相调用的能力,主要包含了 JSVM、JSContext、JSValue、JSExport 四个部分(其实只是想讲 JSVM)。
JSVM
JSVM 全称是 JSVirtualMachine,简单来说就是 JS 的虚拟机。那么什么是虚拟机呢?
我们以 JVM 为例,一般来说想要运行一个 Java 程序要经过这么几步:
- 把 Java 源文件(.java文件)编译成字节码文件(.class文件,是二进制字节码文件),这种字节码就是 JVM 的“机器语言”。javac.exe 就可以看做是 Java 编译器。
- Java 解释器用来解释执行 Java 编译器编译后的程序。java.exe可以简单看成是 Java 解释器。
所以 JVM 是一种能够运行 Java 字节码的虚拟机。除了运行 Java 字节码,它还会做内存管理、GC 等方面的事情。
而 JSVM 则提供了 JS 的运行环境,也提供了内存管理。每个 JSVM 只有一个线程,如果想执行多个线程,就要创建多个 JSVM,它们都自己独立的 GC,所以多个 JSVM 之间的对象无法传递。
JS 源代码经过了词法分析和语法分析这两个步骤,转成了字节码,这一步就是编译。
但是不同于我们编译运行 Java 代码,JS 编译结束之后,并不会生成存放在内存或者硬盘之中的目标代码或可执行文件。生成的指令字节码,会被立即被 JSVM 进行逐行解释执行。
字节码
字节码是已经经过编译,但与特定机器码无关,需要解释器转译后才能成为机器码的中间代码。
在 v8 中前期没有引入字节码,而是简单粗暴地直接把源程序编译成机器码去运行,因为他们觉得先生成字节码再去执行字节码会降低执行速度。
但后期 v8 又再一次将字节码引入进来,这是为什么呢?
早期 v8 将 JS 编译成为二进制机器码,但是编译会占用很大一部分时间。如果是同样的页面,每次打开都要重新编译一次,这样就会大大降低了效率。
于是在 chrome 中引入了二进制缓存,将二进制代码保存到内存或者硬盘里面,这样方便下次打开浏览器的时候直接使用。
但二进制代码的内存占用特别高,大概是 JS 代码的数千倍,这样就导致了如果在移动设备(手机)上使用,本来容量就不大的内存还会被进一步占用,造成性能下降。
然而字节码占用空间就比机器码实在少太多了。因此,v8 团队不得不再次引入字节码。
JIT
除此之外,还有一个大家都很熟悉的概念,那就是 JIT(即时编译)。
即时编译(Just-in-time compilation: JIT):又叫实时编译、及时编译。是指一种在运行时期把字节码编译成原生机器码的技术,一句一句翻译源代码,但是会将翻译过的代码缓存起来以降低性能耗损。这项技术是被用来改善虚拟机的性能的。
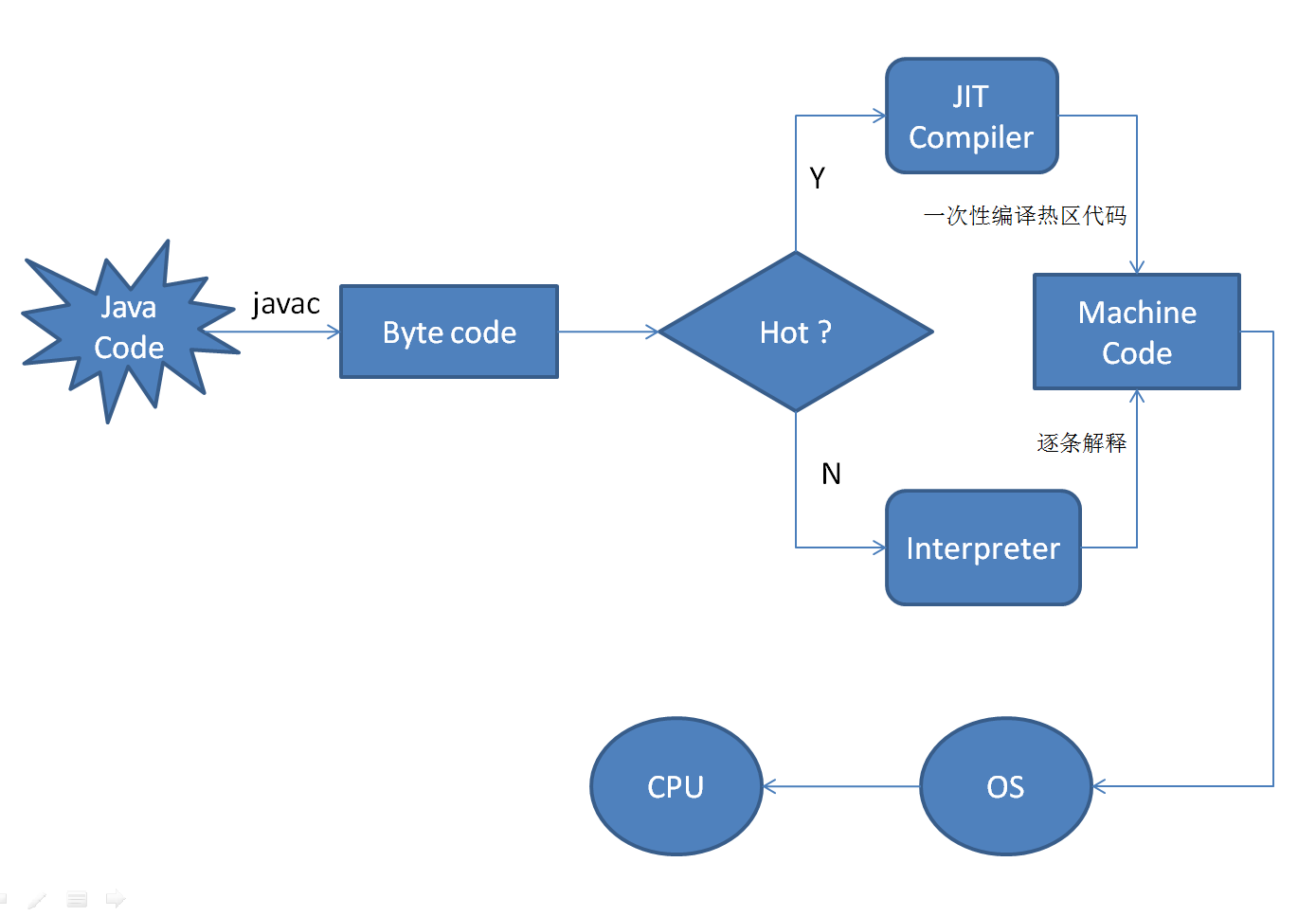
简单来说就是某段代码要被执行之前才进行编译。还是以 JVM 为例子。
- JVM 的解释过程:
java 代码 -> 编译字节码 -> 解释器解释执行
- JIT 的编译过程:
java 代码 -> 编译字节码 -> 编译机器码 -> 执行
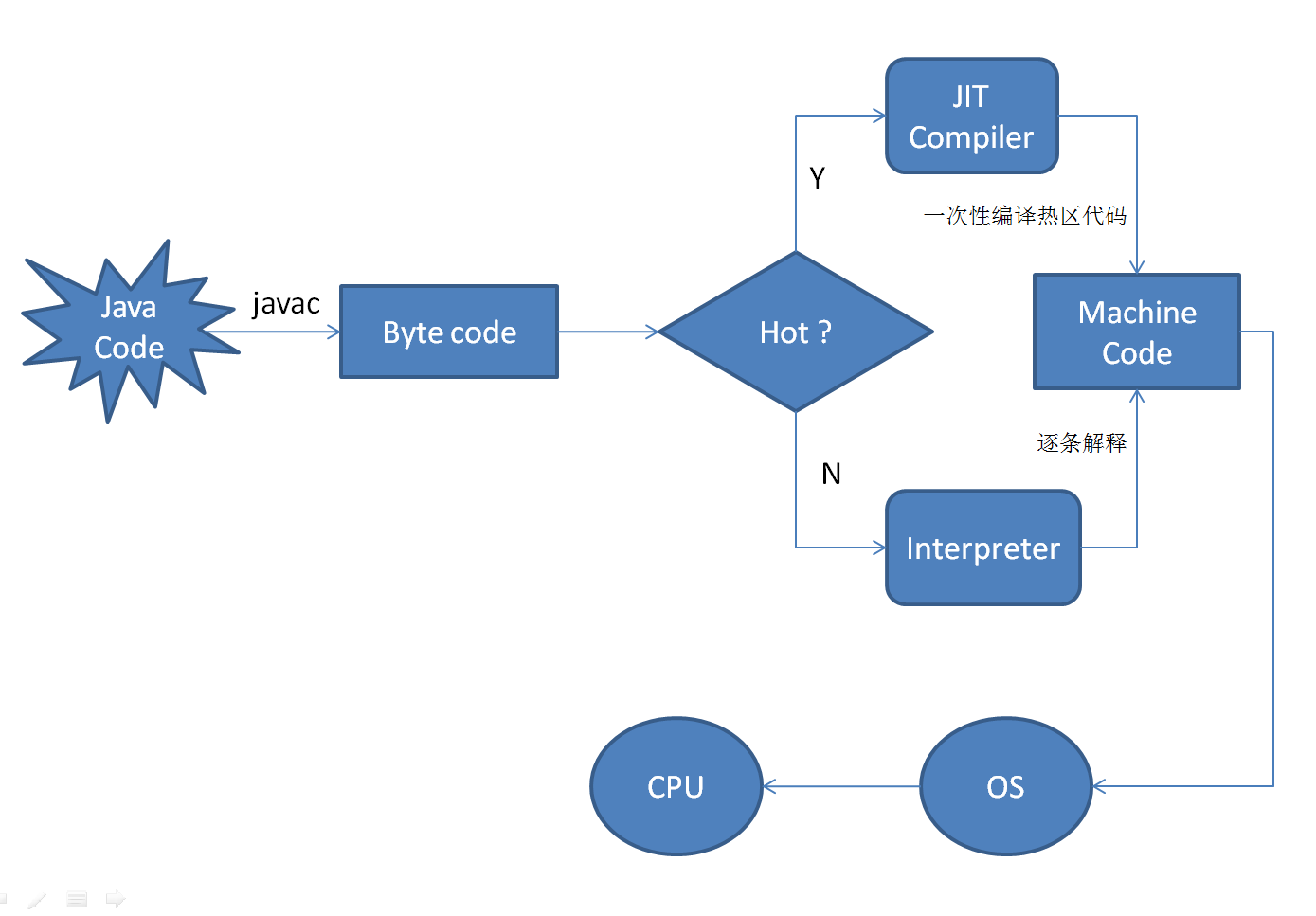
所以 Java 是一种半编译半解释语言。之所以说 JIT 快,是指执行机器码效率比解释字节码效率更高,而非编译比解释更快。因此,JIT 编译还是会比解释慢一些。
同样,编译成机器码还是会遇到上面空间占用大的问题。所以在 JIT 中只对频繁执行的代码就行编译,一般包括下面两种:
- 被多次调用的方法。
- 被多次执行的循环体。
在编译热点代码的时候,这部分就会被缓存起来。等下次运行的时候就不需要再次进行编译,效率会大大提升。这也是为什么很多 JVM 都是用解释器+JIT的形式。
小丁哥如是说:
JSContext
JSContext 就是 JS 运行的上下文,我们想要在 WebView 上面运行 JS 代码,就需要 JSContext 这个运行环境。以下面这段代码为例:
JSContext *context = [[JSContext alloc] init];
[context evaluateScript:@"var i = 4"];
NSNumber *number = [context[@"i"] toNumber];
上面的 JSContext 调用 evaluateScript 来执行一段 JS 代码,通过 context 可以拿到对应的 JSValue 对象。
JSValue
JS 和 OC 交换数据的时候 JSCore 帮我们做了类型转换,JSCore 提供了10种类型转换:
Objective-C type | JavaScript type
--------------------+---------------------
nil | undefined
NSNull | null
NSString | string
NSNumber | number, boolean
NSDictionary | Object object
NSArray | Array object
NSDate | Date object
NSBlock | Function object
id | Wrapper object
Class | Constructor object
JSExport
JSExport 支持把 Native 对象暴露给 JS 环境。例如:
@protocol NativeObjectExport <JSExport>
@property (nonatomic, assign) BOOL property1;
- (void)method1:(JSValue *)arguments;
@end
@interface NativeObject : NSObject<NativeObjectExport>
@property (nonatomic, assign) BOOL property1;
- (void)method1:(JSValue *)arguments;
@end
上面的 NativeObject 只要实现了 JSExport,就可以被 JS 直接调用。我们需要在 Context 里面注入一个对象,就可以在 JS 环境调用 Native 了。
context[@"nativeMethods"] = [NativeObject new];
JS 中调用:
nativeMethods.method1({
callback(data) {
}
])
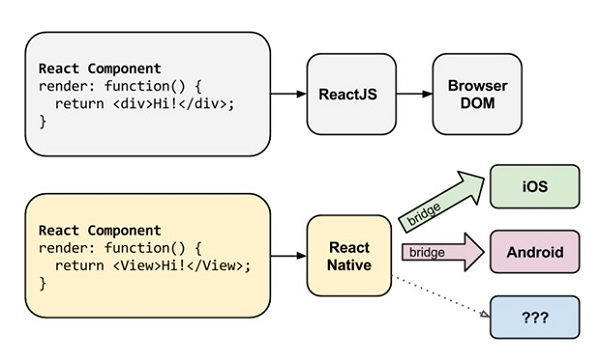
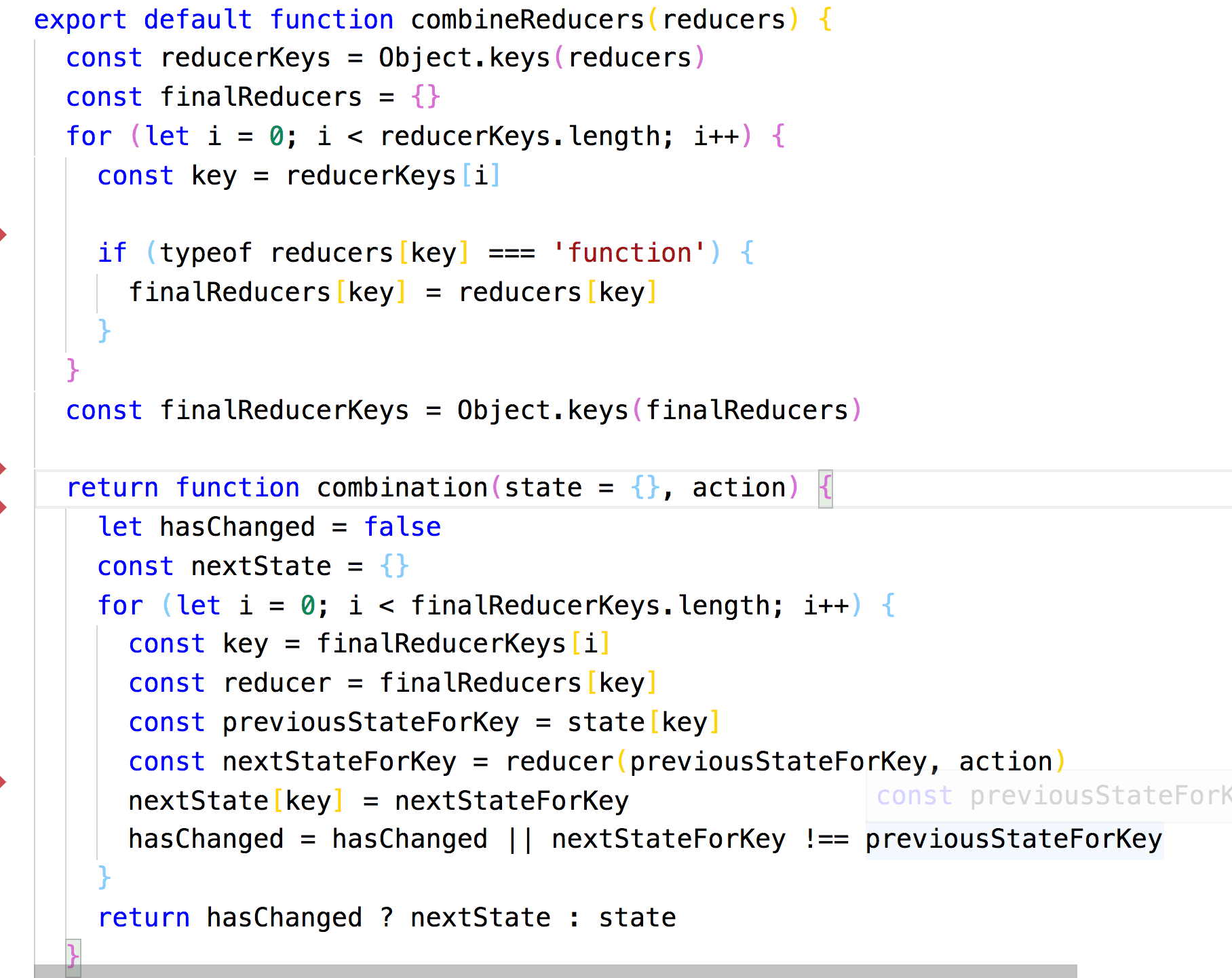
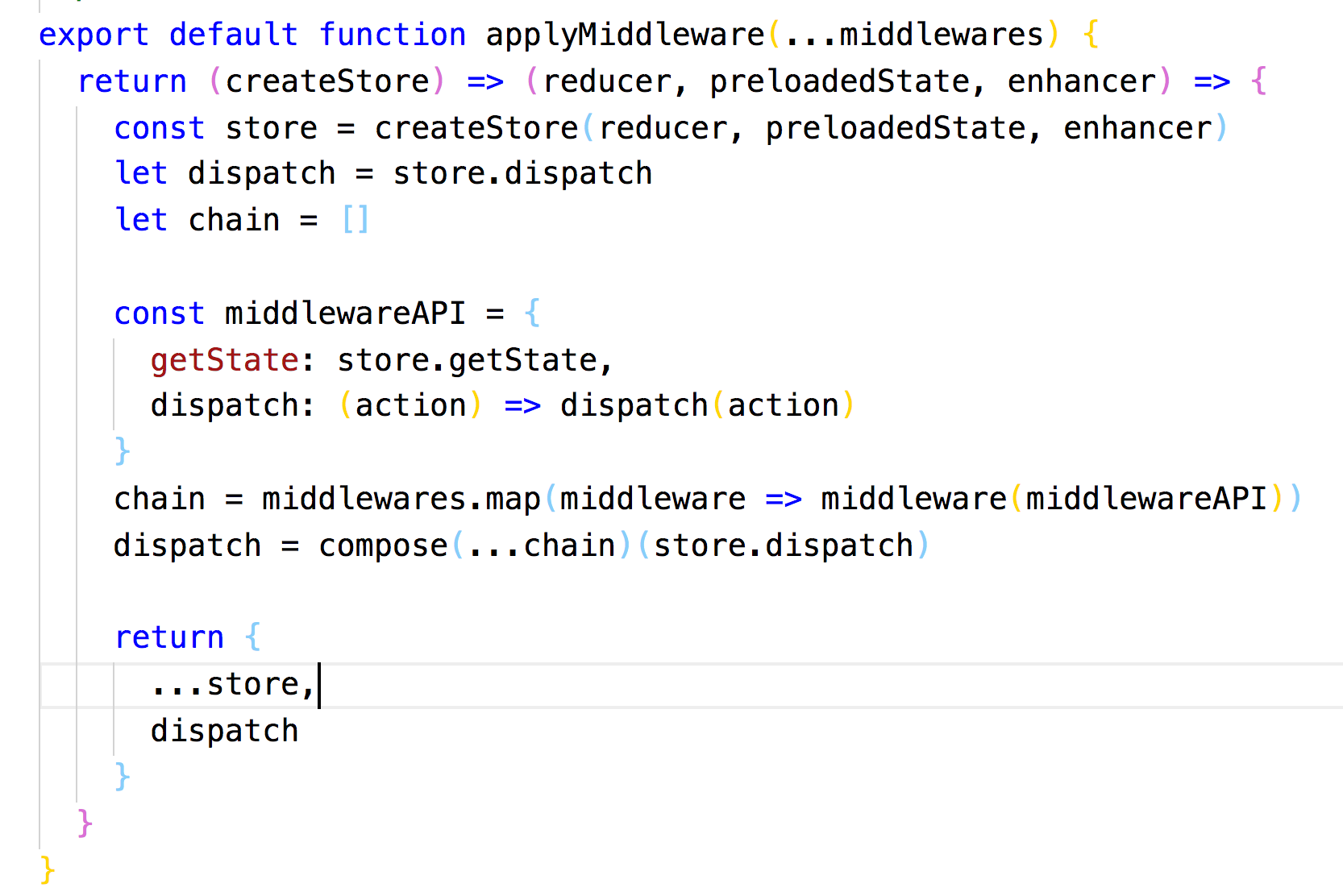
React Native
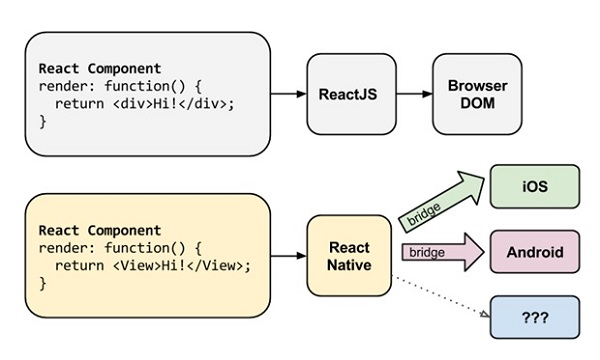
Hybrid 中的 H5 始终是 WebView 中运行的,WebKit 负责绘制的。因为浏览器渲染的性能瓶颈,Facebook 基于 React 发布了 React Native 这个框架。
由于 React 中 Virtual DOM 和平台无关的优势,理论上 Virtual DOM 可以映射到不同平台。在浏览器上就是 DOM,在 Native 里面就是一些原生的组件。
受制于浏览器渲染的性能,React Native 吸取经验将渲染这部分交给 Native 来做,大大提高了体验。个人认为 React Native 也算是 Hybrid 技术的一种。
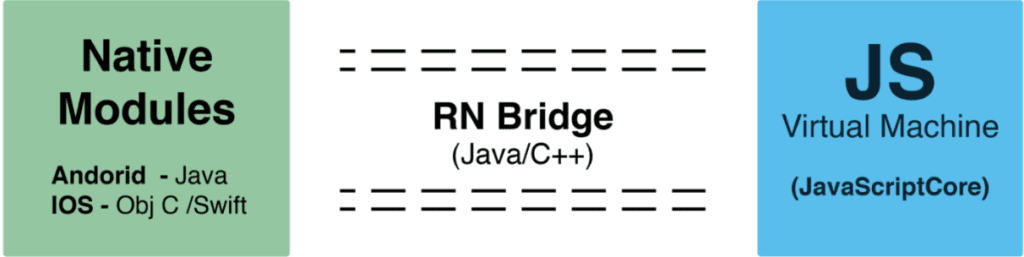
RN 中直接使用 JavaScriptCore 来提供 JS 的运行环境,通过 Bridge 去通知 Native 绘制界面,最终还是 Native 渲染的。
所以性能上比 Hybrid 更好,但受限于 JS 和 Native 通信的性能消耗,性能上依然不及 Native。
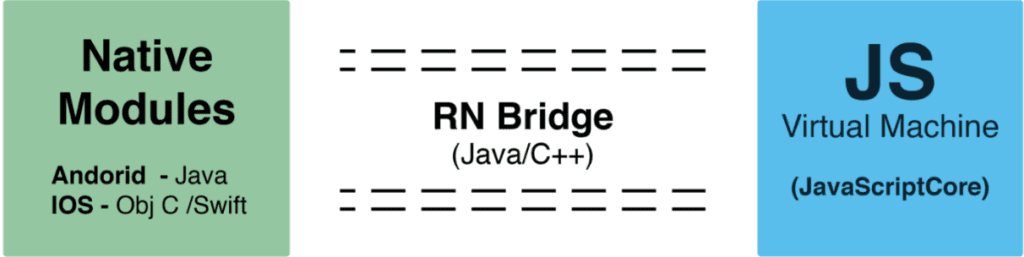
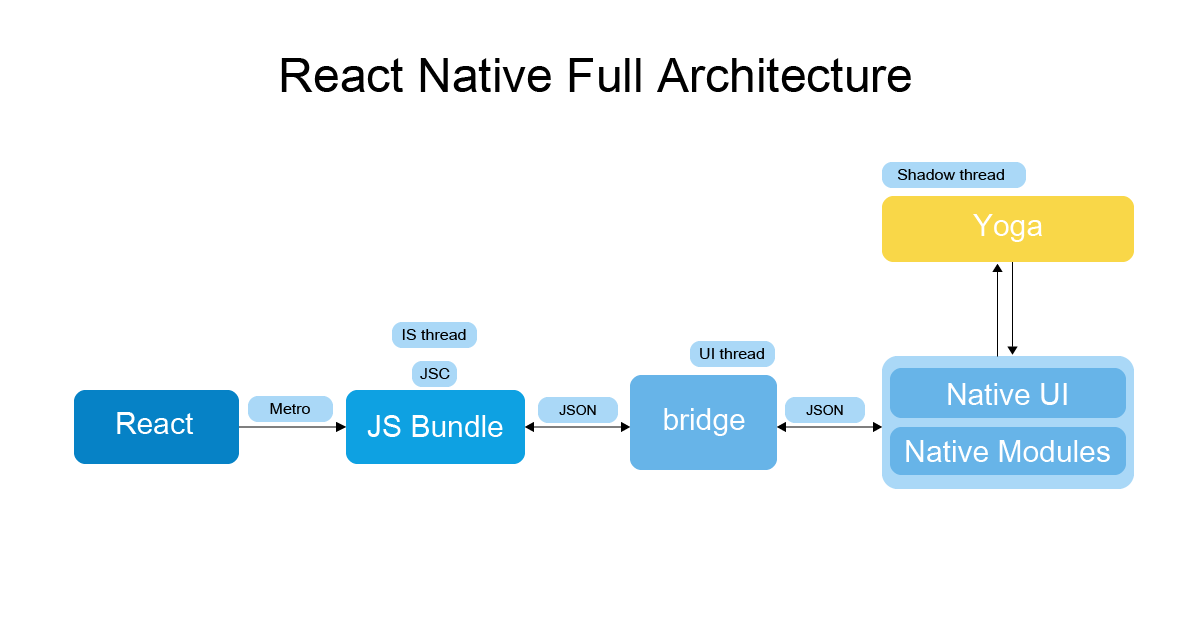
JS 和 Native 通信原理
在 JS 和 Native 通信的时候往往要经过 Bridge,这一步是异步的。
在 App 启动的时候,Native 会创建一个 Module 配置表,这个表里面包括了所有模块和模块方法的信息。
{
"remoteModuleConfig": {
"XXXManager": {
"methods": {
"xxx": {
"type": "remote",
"methodID": 0
}
},
"moduleID": 4
},
...
},
}由于在 OC 里面每个提供给 JS 调用的模块类都实现了 RCTBridgeModule 接口,所以通过 objc_getClassList 或 objc_copyClassList 获取项目中所有的类,然后判断每个类是否实现了 RCTBridgeModule,就可以确定是否需要添加到配置表中。
然后 Native 会将这个配置表信息注入到 JS 里面,这样在 JS 里面就可以拿到 OC 里面的模块信息。
其实如果你写过 JS Bridge,会发现这个流程和 WebViewJavaScriptBridge 有些类似。主要是这么几个步骤:
- JS 调用某个 OC 模块的方法
- 把这个调用转换为 ModuleName、MethodName、arguments,交给 MessageQueue 处理。
- 将 JS 的 Callback 函数放到 MessageQueue 里面,用 CallbackID 来匹配。再根据配置表将 ModuleName、MethodName映射为 ModuleID 和 MethodID。
- 然后把上面的 ID 都传给 OC
- OC 根据这几个 ID 去配置表中拿到对应的模块和方法
- RCTModuleMethod 对 JS 传来的参数进行处理,主要是将 JS 数据类型转换为 OC 的数据类型
- 调用 OC 模块方法
- 通过 CallbackID 拿到对应的 Callback 方法执行并传参
热更新
相比 Native,RN 的一大优势就是热更新。我们将 RN 项目最后打包成一个 Bundle 文件提供给客户端加载。在 App 启动的时候去加载这个 Bundle 文件,最后由 JavaScriptCore 来执行。
如果有新版本该怎么更新?这个其实很简单,重新打包一个 Bundle 文件,用 BS Diff 算法对不同版本的文件进行二进制差分。
客户端会比较本地版本和远程版本,如果本地版本落后了,那就去下载差量文件,同样使用 BS Diff 算法 patch 进 Bundle 里面,这样就实现了热更新。
这种方式也适用于 H5 的离线包更新,可以很大程度上解决 H5 加载慢的问题。
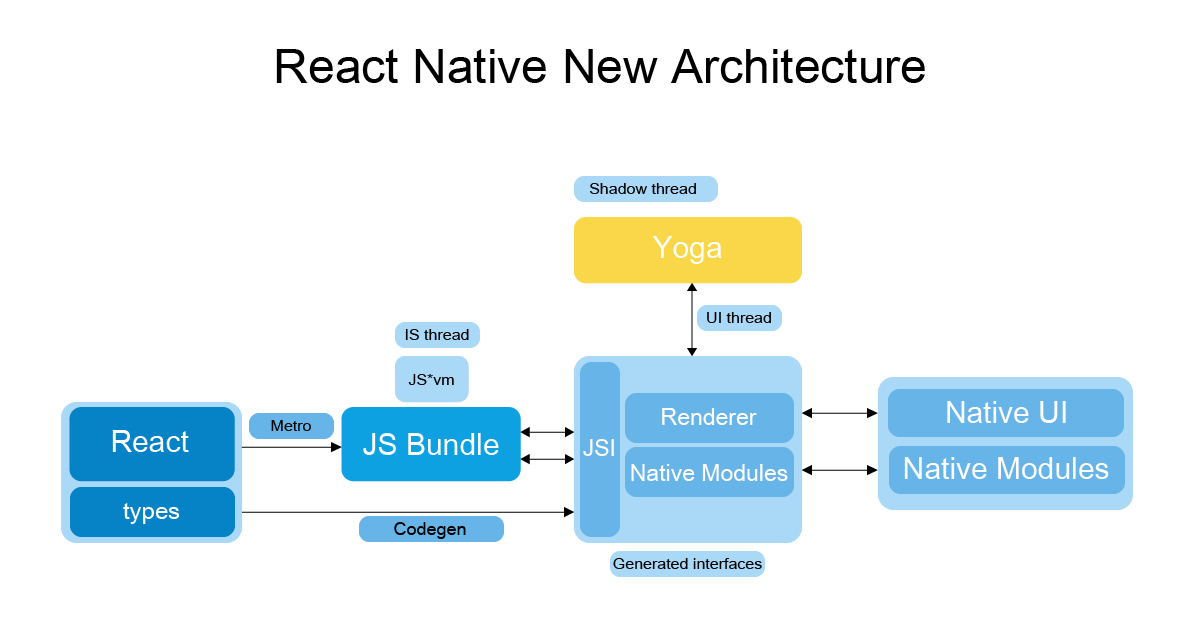
RN 新架构
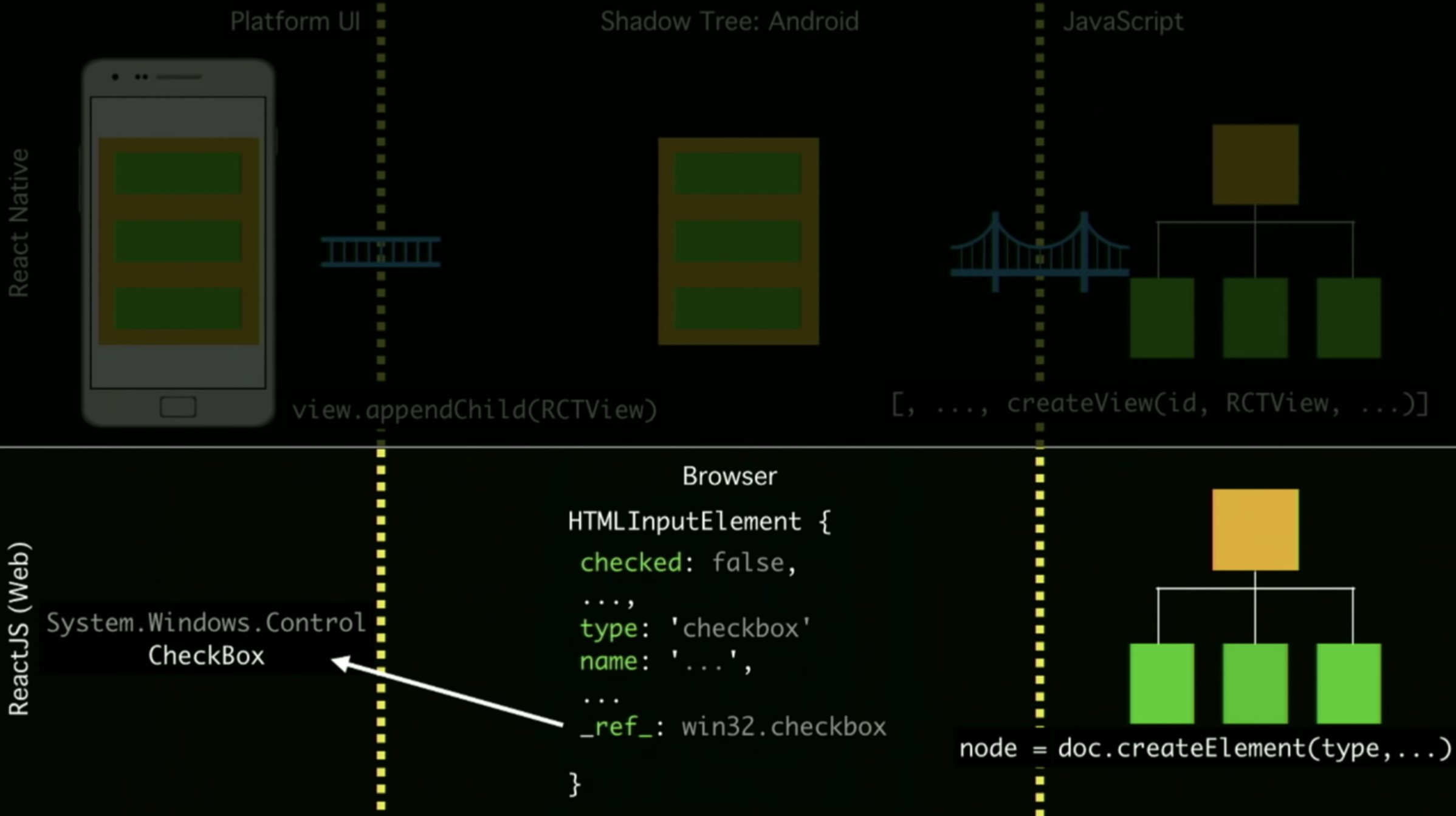
在 RN 老架构中,性能瓶颈主要体现在 JS 和 Native 通信上面,也就是 Bridge 这里。
我们写的 RN 代码会通过 JS Thread 进行序列化,然后通过 Bridge 传给 shadow Thread 反序列化获得原生布局信息。
之后又通过 Bridge 传给 UI Thread,UI Thread 反序列化之后会根据布局信息进行绘制。这里就有三个线程通过 Bridge 来通信。
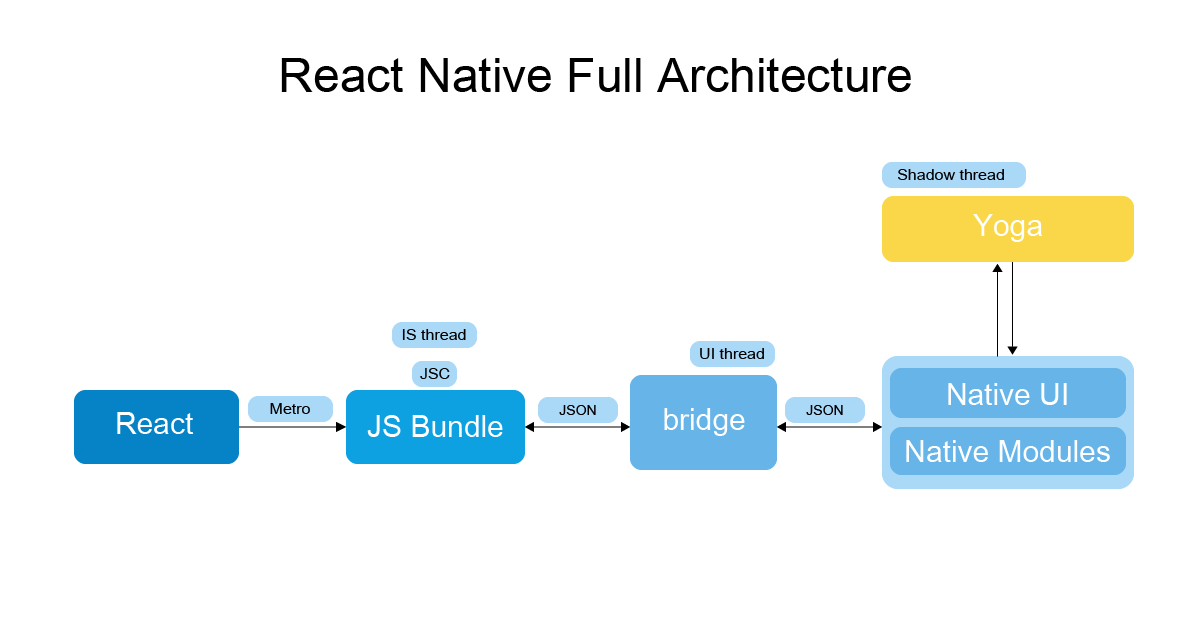
由于多次序列化/反序列化以及 Bridge 通信,这样就造成了一些性能损耗。
尤其是在快速滑动列表的时候容易造成白屏,然而浏览器里面快速滑动却没有白屏,这又是为什么呢?
主要还是浏览器中,JS 可以持有 C++ 对象的引用,所以这里其实是同步调用。
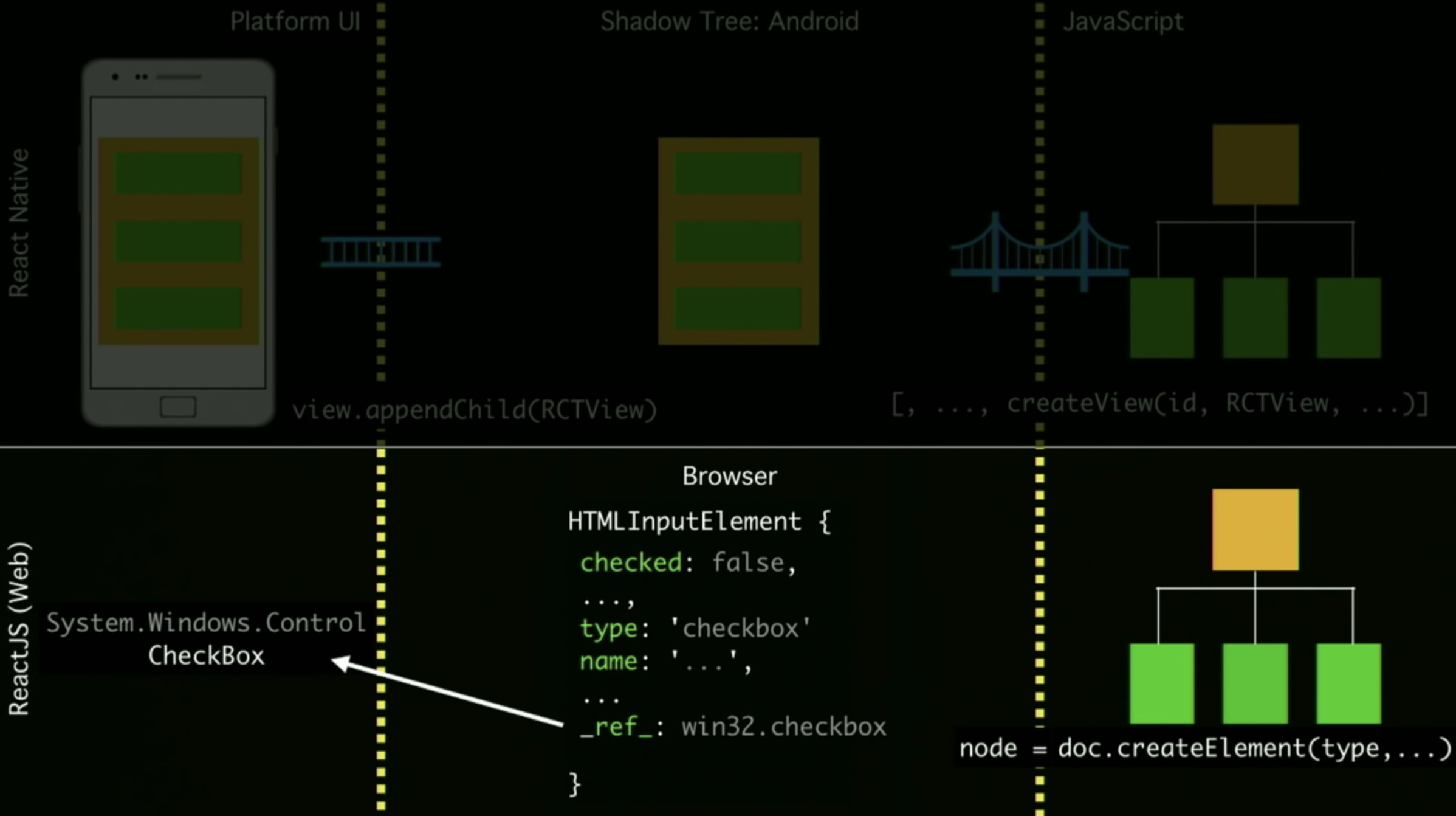
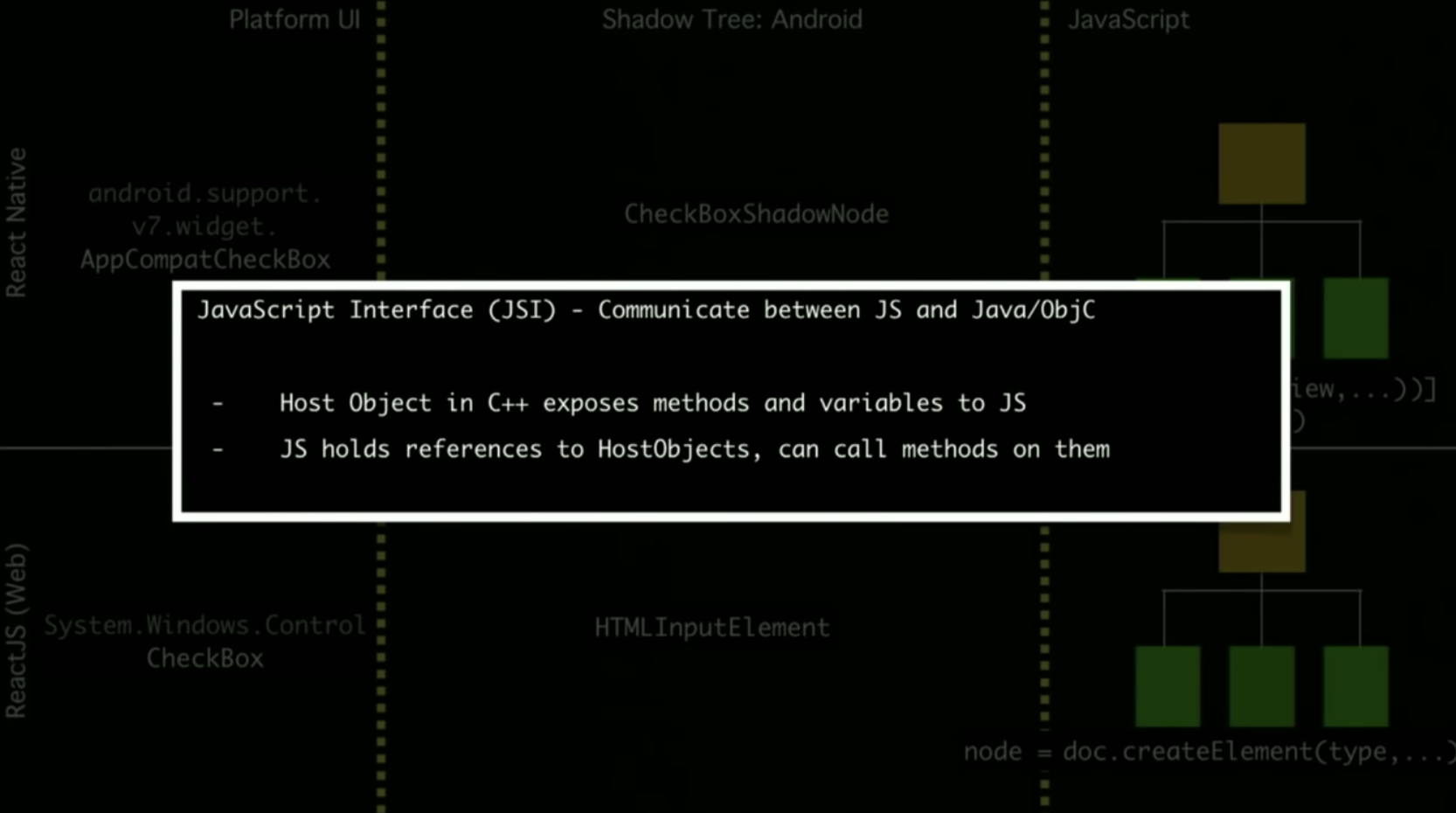
由于受到 Flutter 的冲击,RN 团体提出了新的架构来解决这些问题。为了解决 Bridge 通信的问题,RN 团队在 JavaScriptCore 之上抽象了一层 JSI(JavaScript Interface),允许底层更换成不同的 JavaScript 引擎。
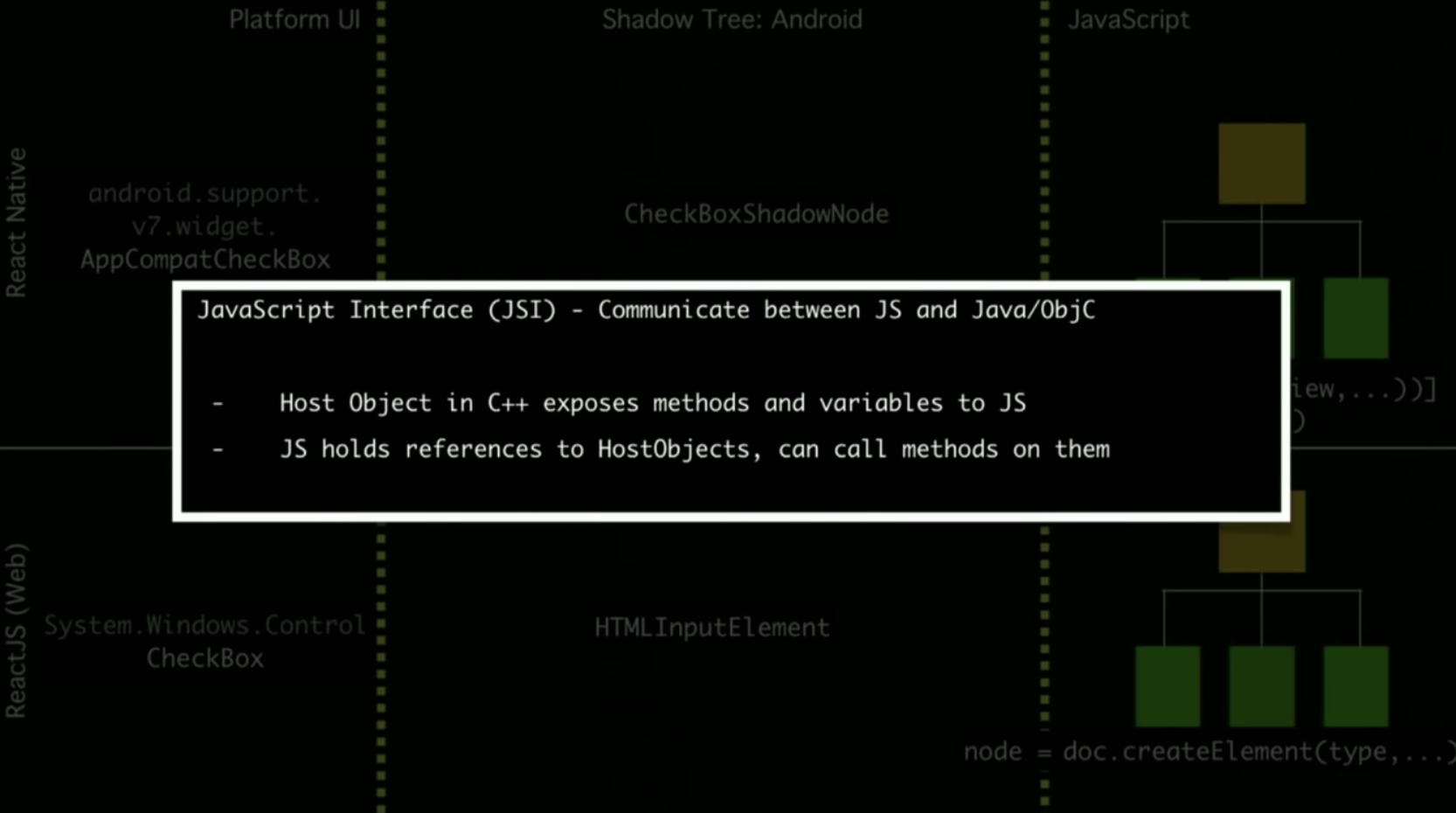
除此之外,JS 还可以拿到 C++ 的引用,这样就可以直接和 Native 通信,不需要反复序列化对象,也节省了 Bridge 通信的开支。
这里解释一下,为啥拿到 C++ 引用就可以和 Native 通信。由于 OC 本身就是 C 语言的扩展,所以可以直接调用 C/C++ 的方法。Java 虽然不能 C 语言扩展,但它可以通过 JNI 来调用。
JNI 就是 Java Native Interface,它是 JVM 提供的一套能够使运行在 JVM 上的 Java 代码调用 C++ 程序、以及被 C++ 程序调用的编程框架。
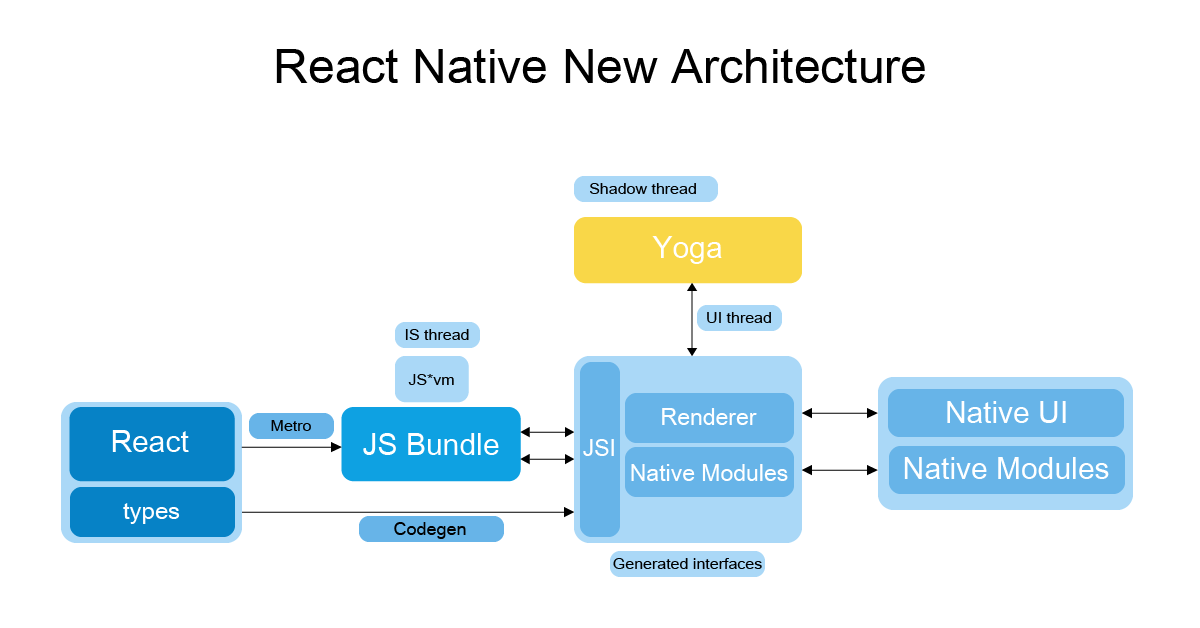
相信新架构的到来会解决 RN 原有的一些痛点,以及会带来性能上的飞跃。
Flutter
传统的跨端有两种,一种是 Hybrid 那种实现 JS 跑在 WebView 上面的,这种性能瓶颈取决于浏览器渲染。
另一种是将 JS 组件映射为 Native 组件的,例如 React Native、Weex,缺点就是依然需要 JS Bridge 来进行通信(老架构)。
Flutter 则是在吸取了 RN 的教训之后,不再去做 Native 的映射,而是自己用 Skia 渲染引擎来绘制页面,而 Skia 就是前面说过的 Chrome 底层的二维图形库,它是 C/C++ 实现的,调用 CPU 或者 GPU 来完成绘制。所以说 Flutter 像个游戏引擎。
Flutter 在语法上深受 React 的影响,使用 setState 来更新界面,使用类似 Redux 的**来管理状态。从早期的 WPF,到后面的 React,再到后来的 SwiftUI 都使用了声明式 UI 的**。
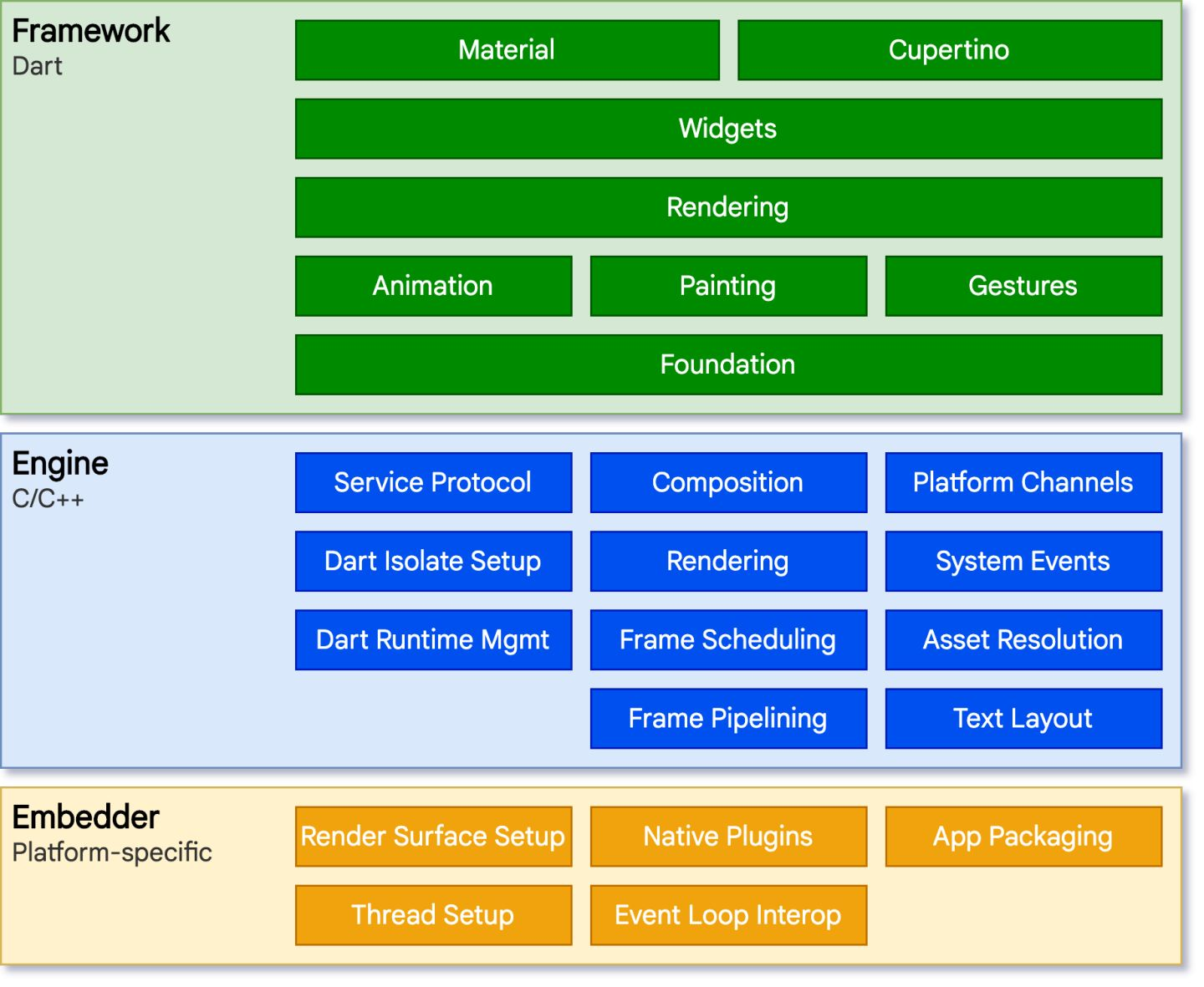
Flutter 架构图如下:
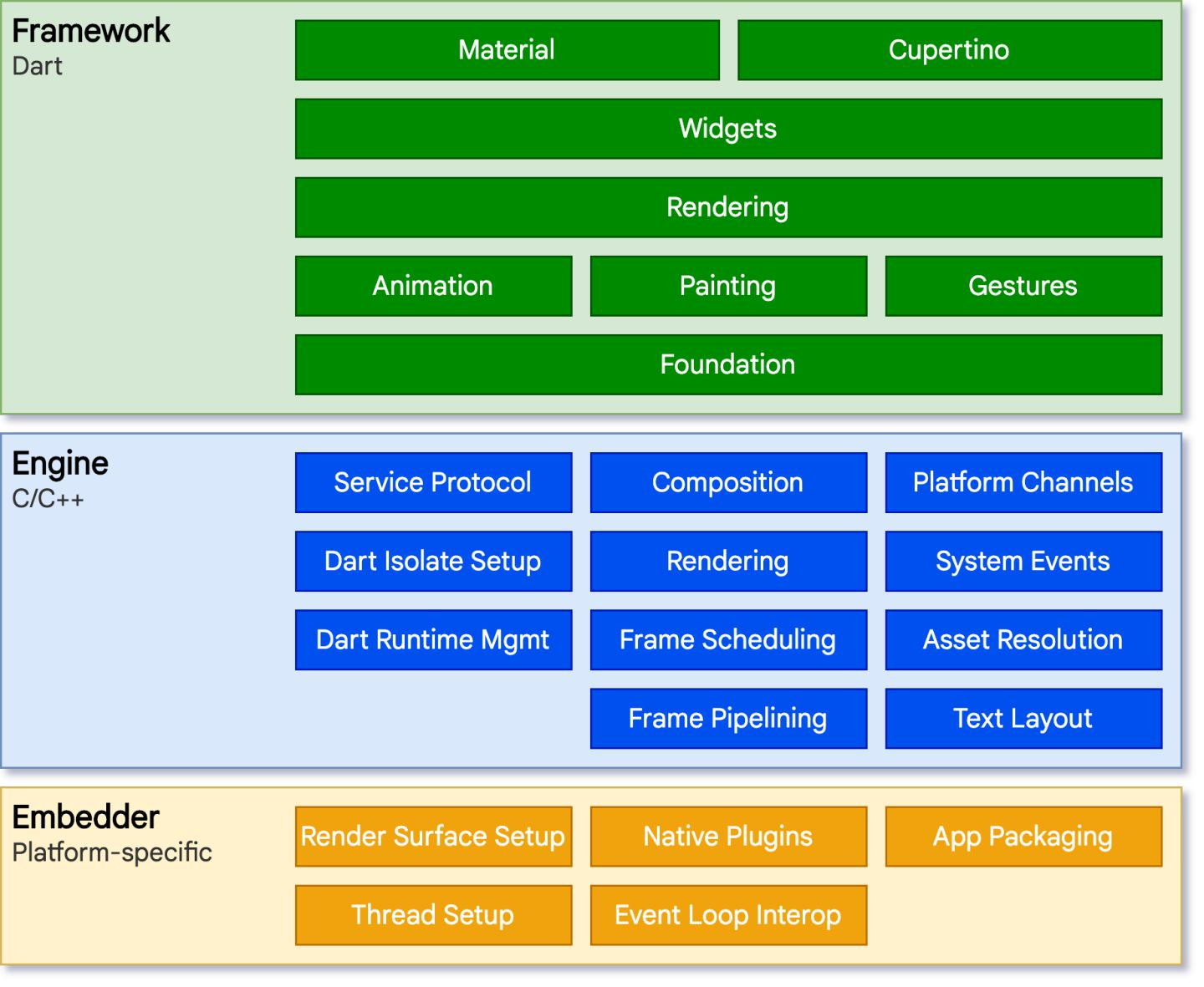
Framework 是用 Dart 实现的 SDK,封装了一些基础库,比如动画、手势等。还实现了一套 UI 组件库,有 Material 和 Cupertino 两种风格。Material 适用于安卓,Cupertino 适用于 iOS。
Engine 是 C/C++ 实现的 SDK,主要包括了 Skia 引擎、Dart 运行时、文本渲染等。
Embedder 是一个嵌入层,支持把 Flutter 嵌入各个平台。
Flutter 使用 Dart,支持 AOT 编译成 ARM Code,这样拥有更高的性能。在 Debug 模式下还支持 JIT。
在 Flutter 中,Widgets 是界面的基本构成单位,和 React Component 有些类似。而 StatelessWidget 类似 React Functional Component。
class Echo extends StatelessWidget {
const Echo({
Key key,
@required this.text,
this.backgroundColor:Colors.grey,
}):super(key:key);
final String text;
final Color backgroundColor;
@override
Widget build(BuildContext context) {
return Center(
child: Container(
color: backgroundColor,
child: Text(text),
),
);
}
}
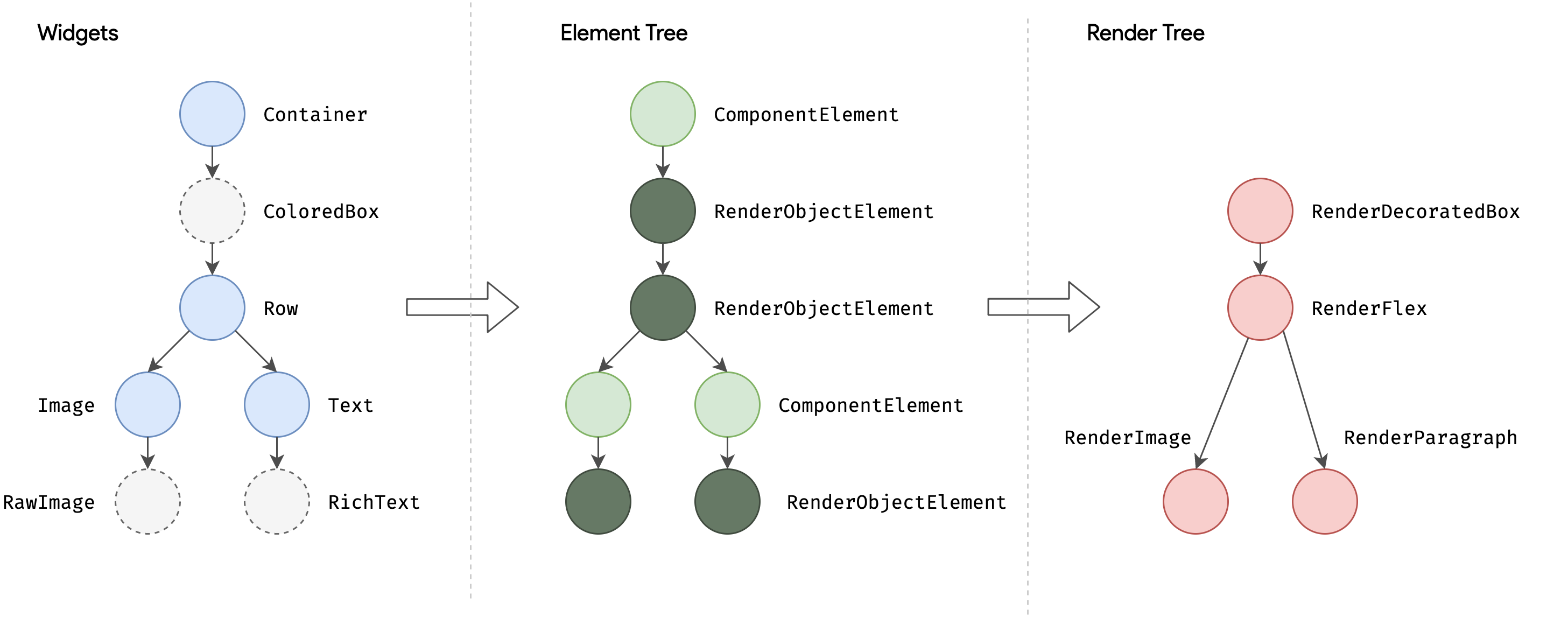
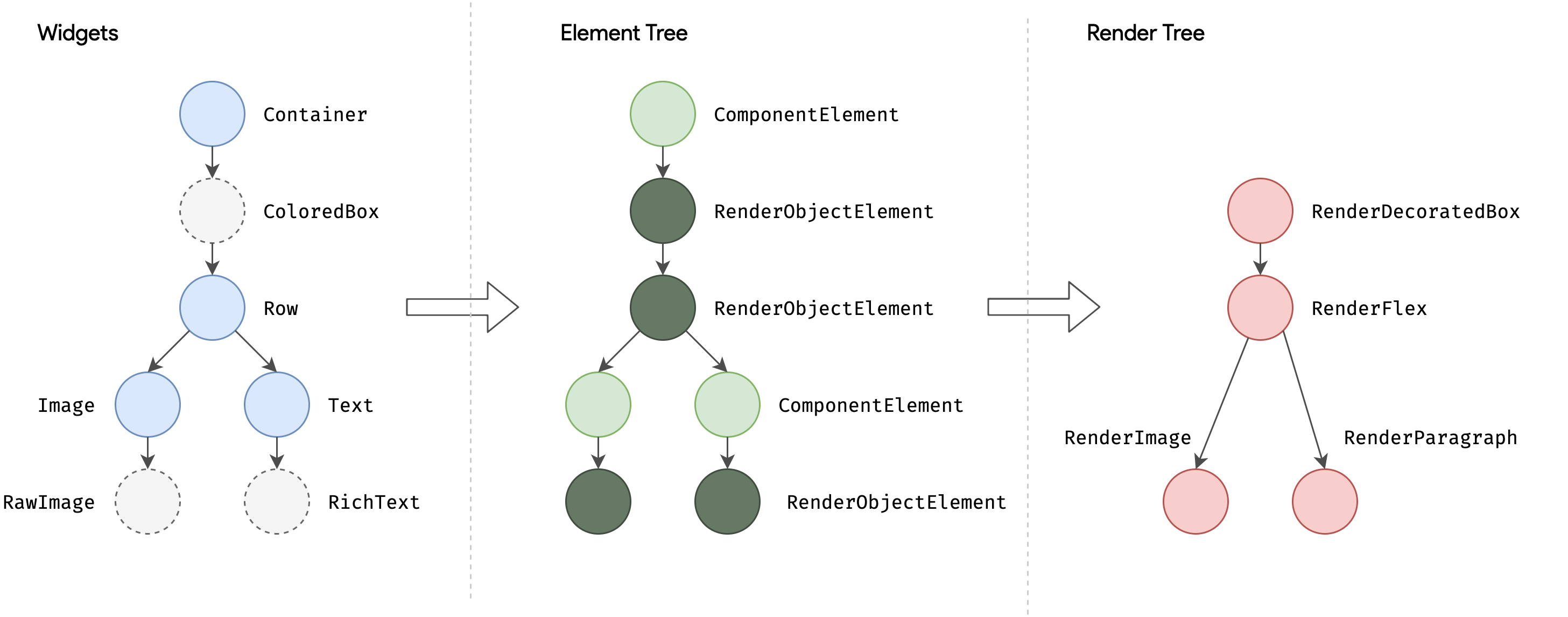
在 Flutter 渲染过程中有三棵树,分别是 Widgets 树、Element 树、RenderObject 树。
如果你有写过 React,会发现真的和 React 很类似。

当初始化的时候, Widgets 通过 build 方法来生成 Element,这类似于 React.createElement 生成虚拟 DOM(Virtual DOM)。
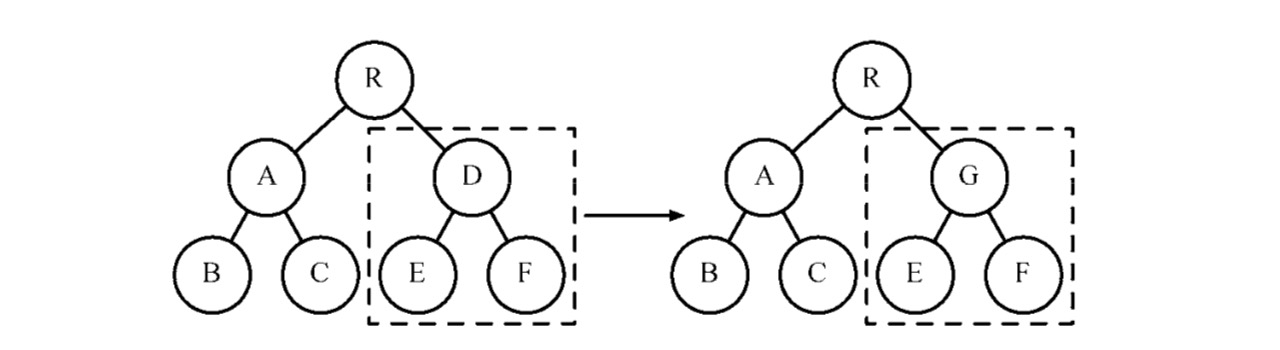
Element 重新创建的开销会比较大,所以每次重新渲染它并不会重新构建。从 Element Tree 到 RenderObject Tree 之间一般也会有一个 Diff 的环境,计算最小需要重绘的区域。
这里也和 React 渲染流程比较相似,虚拟 DOM 会和真实 DOM 进行一次 Diff 对比,最后将差异部分渲染到浏览器上。
浏览器渲染
在前面我们讲过浏览器的渲染流程。一般是将 HTML 解析成 DOM 树,将 CSS 解析为 CSSOM 树,两者合并成一颗 RenderObject 树。
一个 RenderObject 对象保存了绘制 DOM 节点需要的各种信息,它知道怎么绘制自己。不同的 RenderObject 对象构成一棵树,就叫做 RenderObject 树。它是基于 DOM 树创建的一棵树。
然后 WebKit 会为这些 RenderObject 对象创建新的 RenderLayer 对象,最后形成一棵 RenderLayer 树。一般来说,RenderLayer 和 RenderObject 是一对多的关系。每个 RenderLayer 包括的是 RenderObect 树的子树。
什么情况下会创建 RenderLayer 对象呢?比如 Video 节点、Document 节点、透明的 RenderObject 节点、指定了位置的节点等等,这些都会创建一个 RenderLayer 对象。
一个 RenderLayer 可以看做 PS 里面的一个图层,各个图层组成了一个图像。
Flutter 渲染
Flutter 渲染和浏览器渲染类似,Widget 通过 createElement 生成 Element,而 Element 通过 createRenderObject 创建了 RenderObject 对象,最终生成 Layer。
一般来说,RenderObject 上面存着布局信息,所以布局和绘制都是在 RenderObject 中完成。Flutter 通过深度遍历渲染 RenderObject 树,确定每个对象的位置和大小,绘制到不同的图层中。绘制结束后,由 Skia 来完成合成和渲染。
所以 Flutter 的更新流程如下:

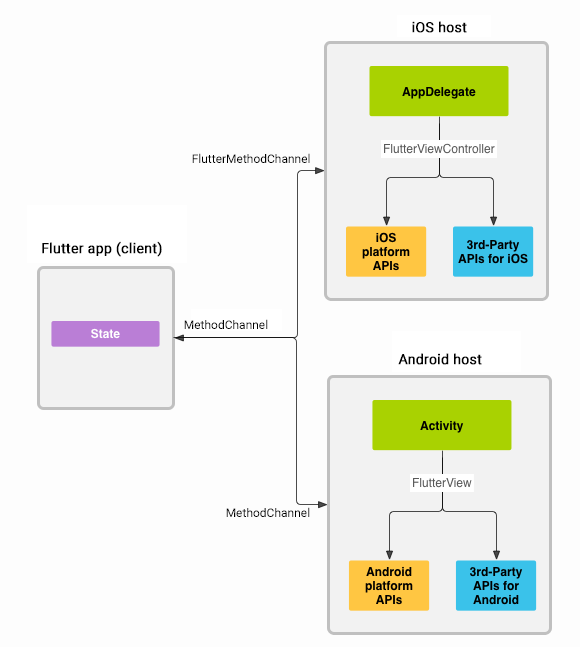
通信
Flutter 没办法完成 Native 所有的功能,比如调用摄像头等,所以需要我们开发插件,而插件开发的基础还是 Flutter 和 Native 之间进行通信。
Flutter 和 Native 之间的通信是通过 Channel 完成的,一般有下面几种通信场景:
- Native 发送数据给 Dart
- Dart 发送数据给 Native
- Dart 发送数据给 Native,Native 回传数据给 Dart
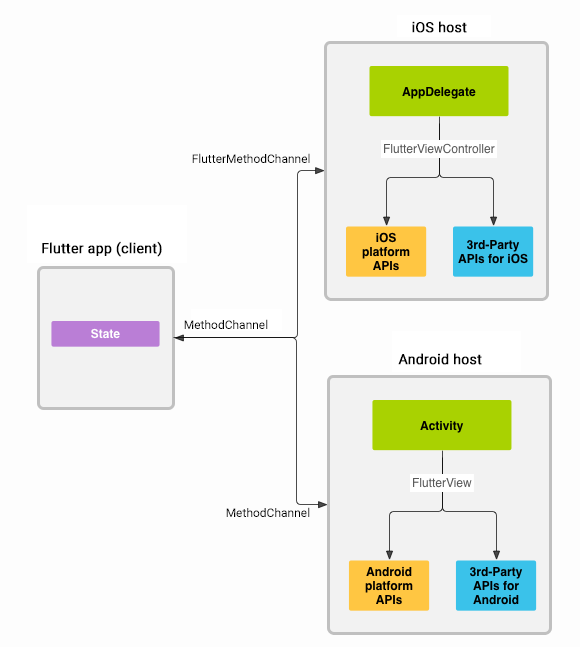
Flutter 实现通信有下面三种方式:
- EventChannel:一种 Native 向 Flutter 发送数据的单向通信方式,Flutter 无法返回任何数据给 Native。一般用于 Native 向 Flutter发送手机电量、网络连接等。
- MethodChannel:Native 和 Flutter之间的双向通信方式。通过 MethodChannel 调用 Native 和 Flutter 中相对应的方法,该种方式有返回值。
- BasicMessageChannel:Native 和 Flutter之间的双向通信方式。支持数据类型最多,使用范围最广。该方式有返回值。
BinaryMessenger 是 Flutter 和 Channel 通信的工具。它在安卓中是一个接口,使用二进制格式数据通信。
在 FlutterView 中实现,它可以通过 JNI 来和系统底层通信。因此,基本上和原生调用差不多,不像 RN 中 Bridge 调用需要进行数据转化。
所以,如果想开发插件,还是需要实现安卓和 iOS 的功能,以及封装 plugin 的 api,总体上还是无法脱离 Native 来运作。
对比 React Native
- Flutter 官方暂时不支持热更新,RN 有成熟的 Code Push 方案
- Flutter 放弃了 Web 生态,RN 拥有 Web 成熟的生态体系,工具链更加强大。
- Flutter 将 Dart 代码 AOT 编译为本地代码,通信接近原生。RN 不仅需要多次序列化,不同线程之间还需要通过 Bridge 来通信,效率低下。
更多细节对比可以参考知乎这个问题:开发跨平台 App 推荐 React Native 还是 Flutter?
参考
- Understanding WebViews
- What is WebKit and how is it related to CSS?
- 在Chrome中的GPU加速合成(一)
- JavaScriptCore
- JIT 为什么能大幅度提升性能?
- 深入浅出 JIT 编译器
- How Flutter renders Widgets
- Flutter原理及经验分享
- WebKit 技术内幕
- React Native's New Architecture