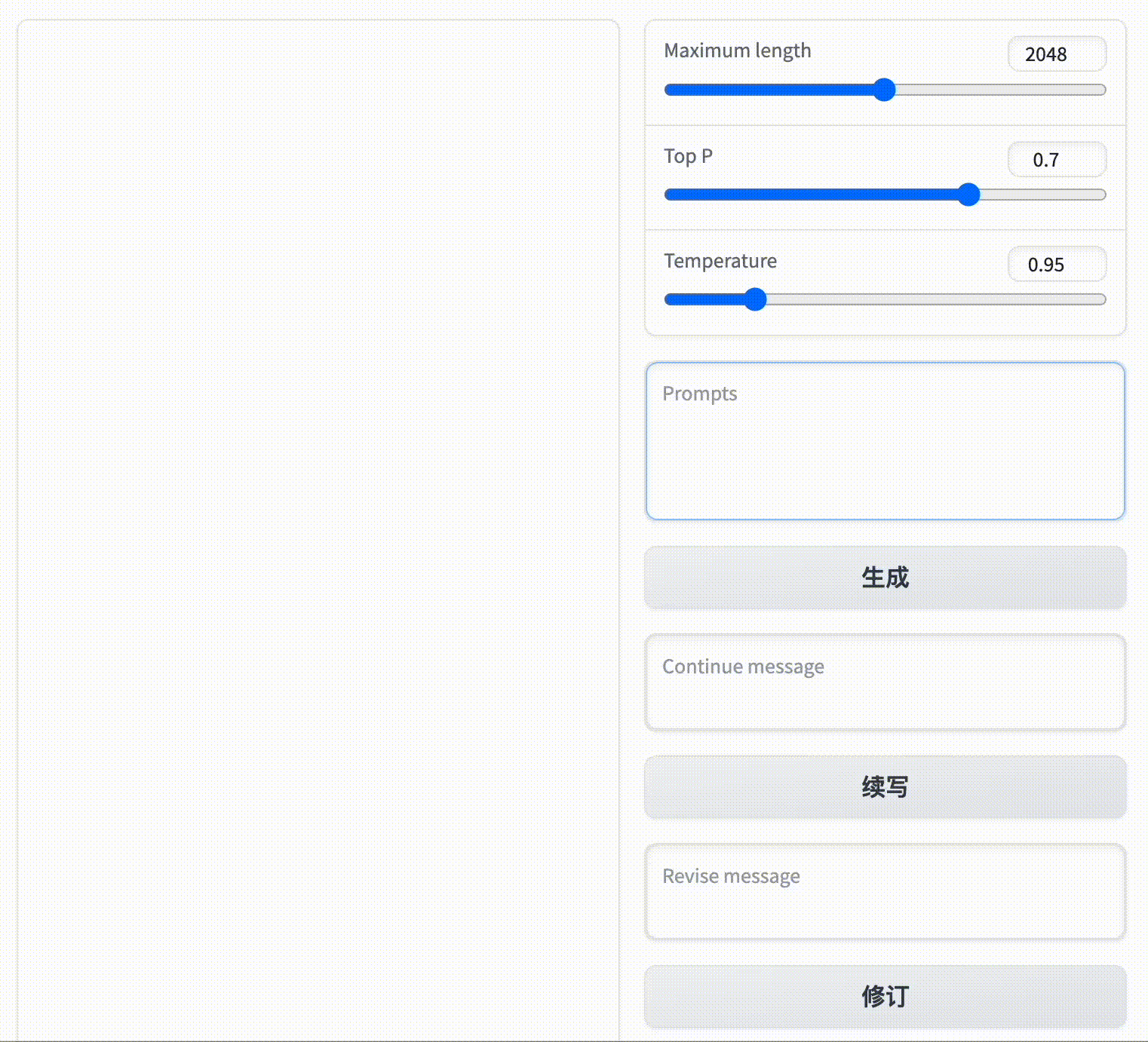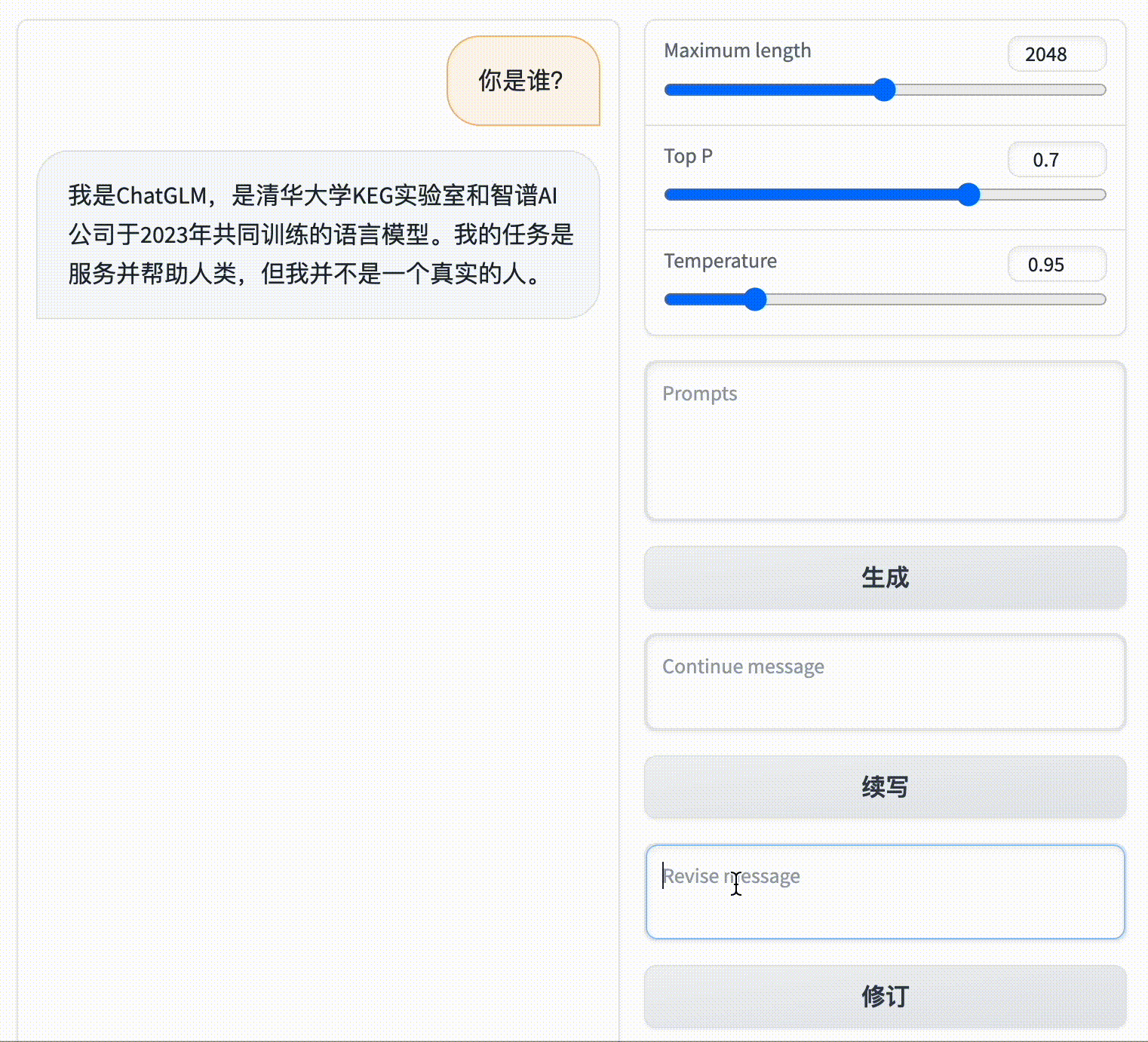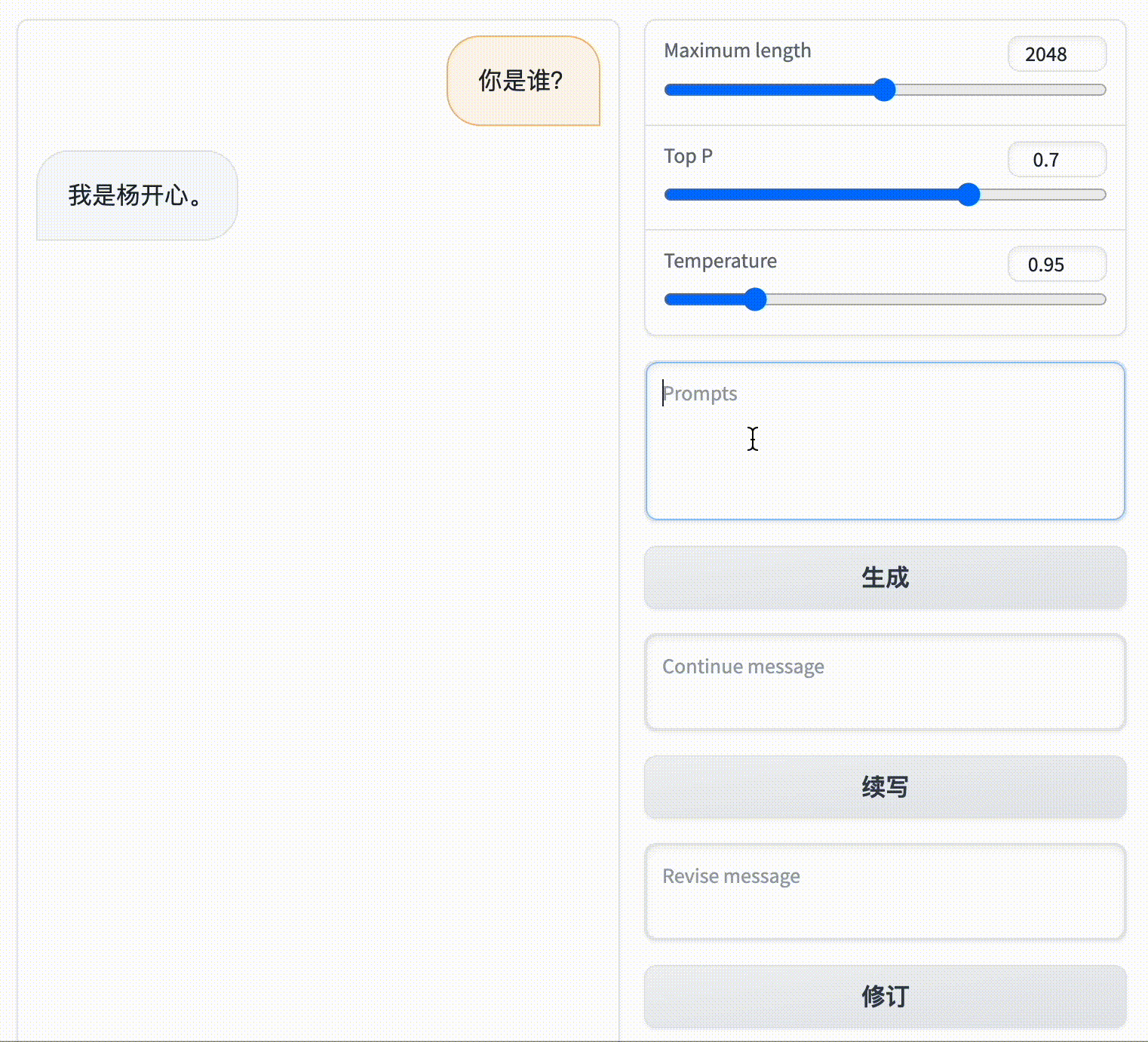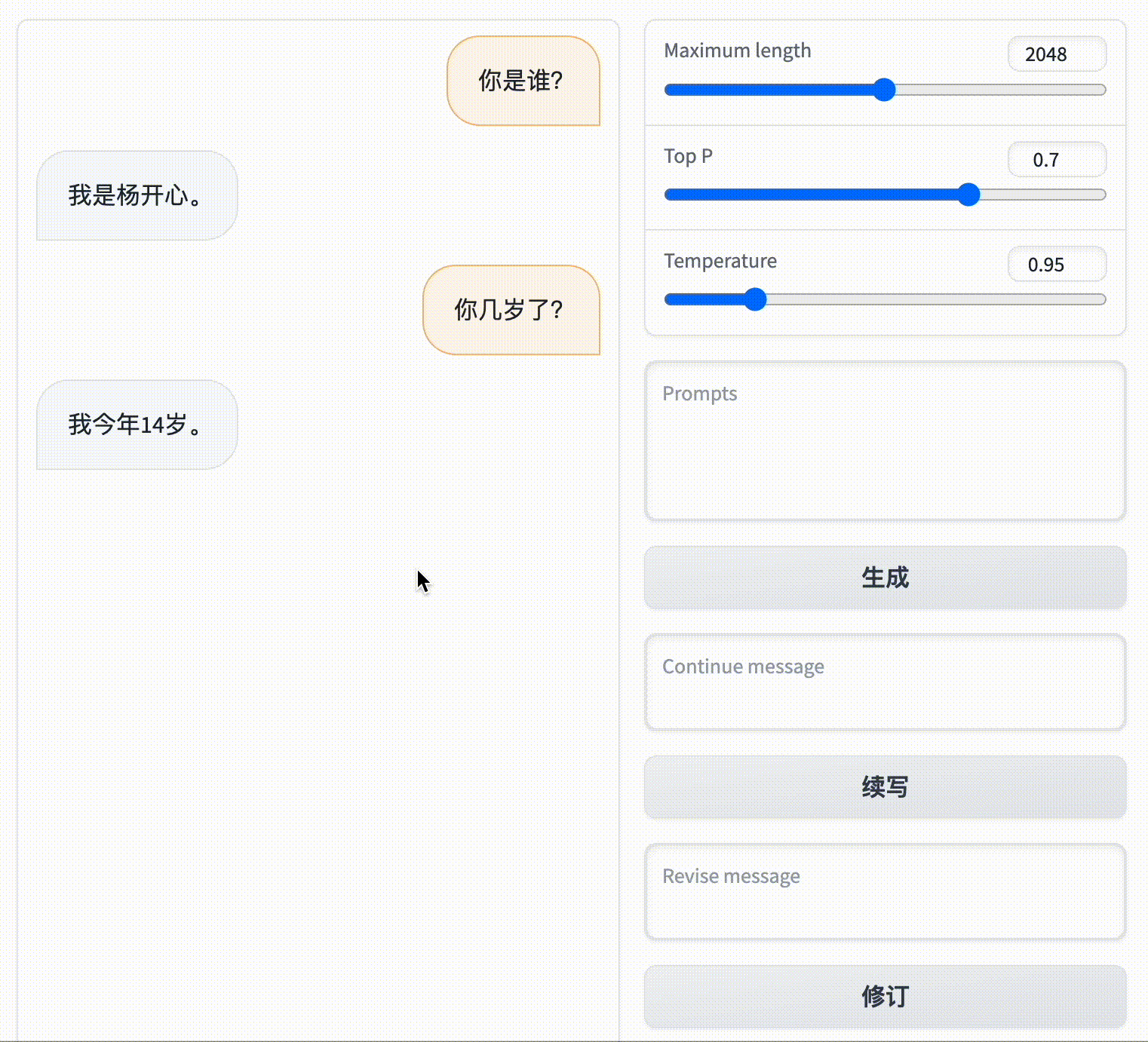
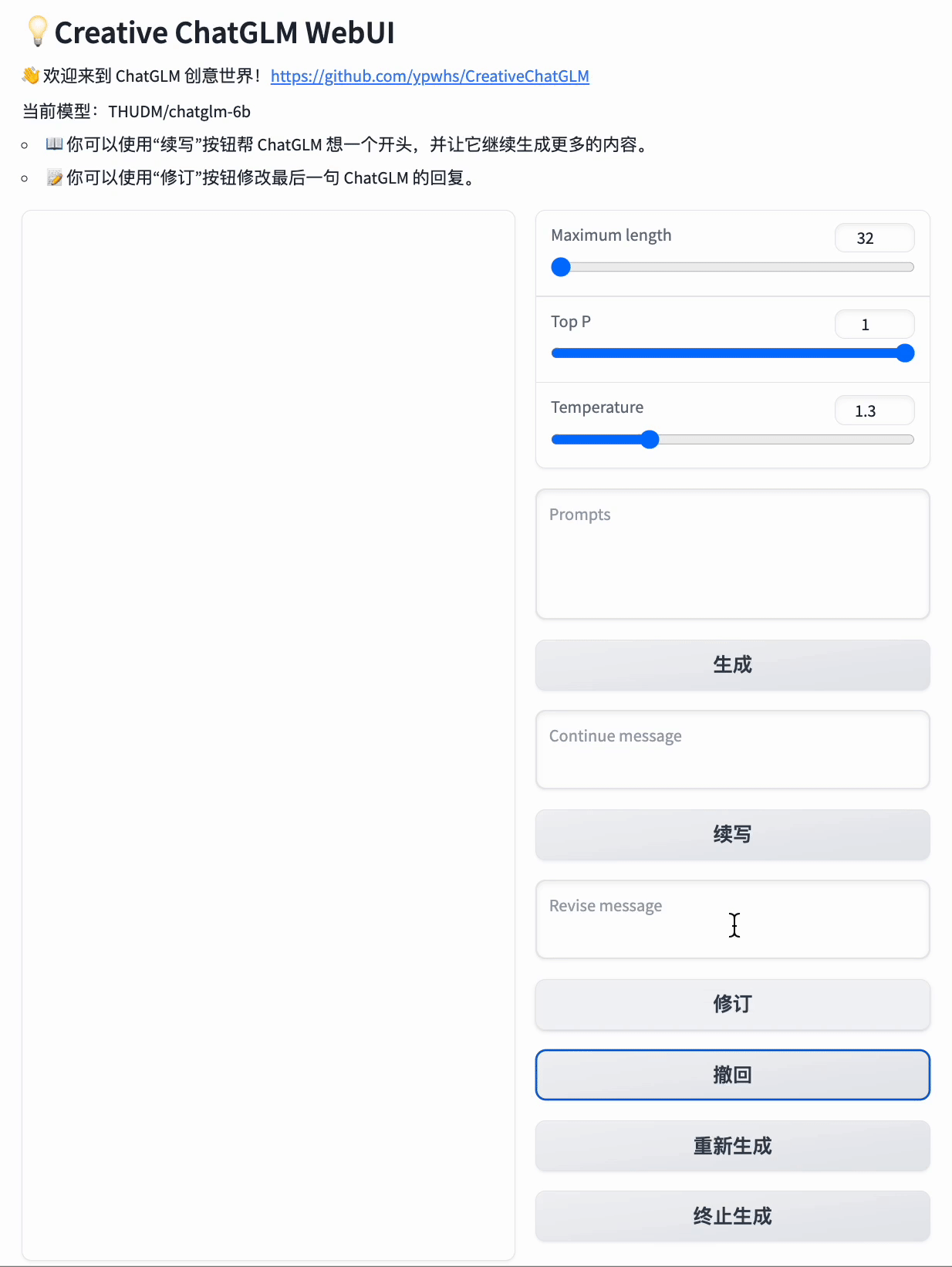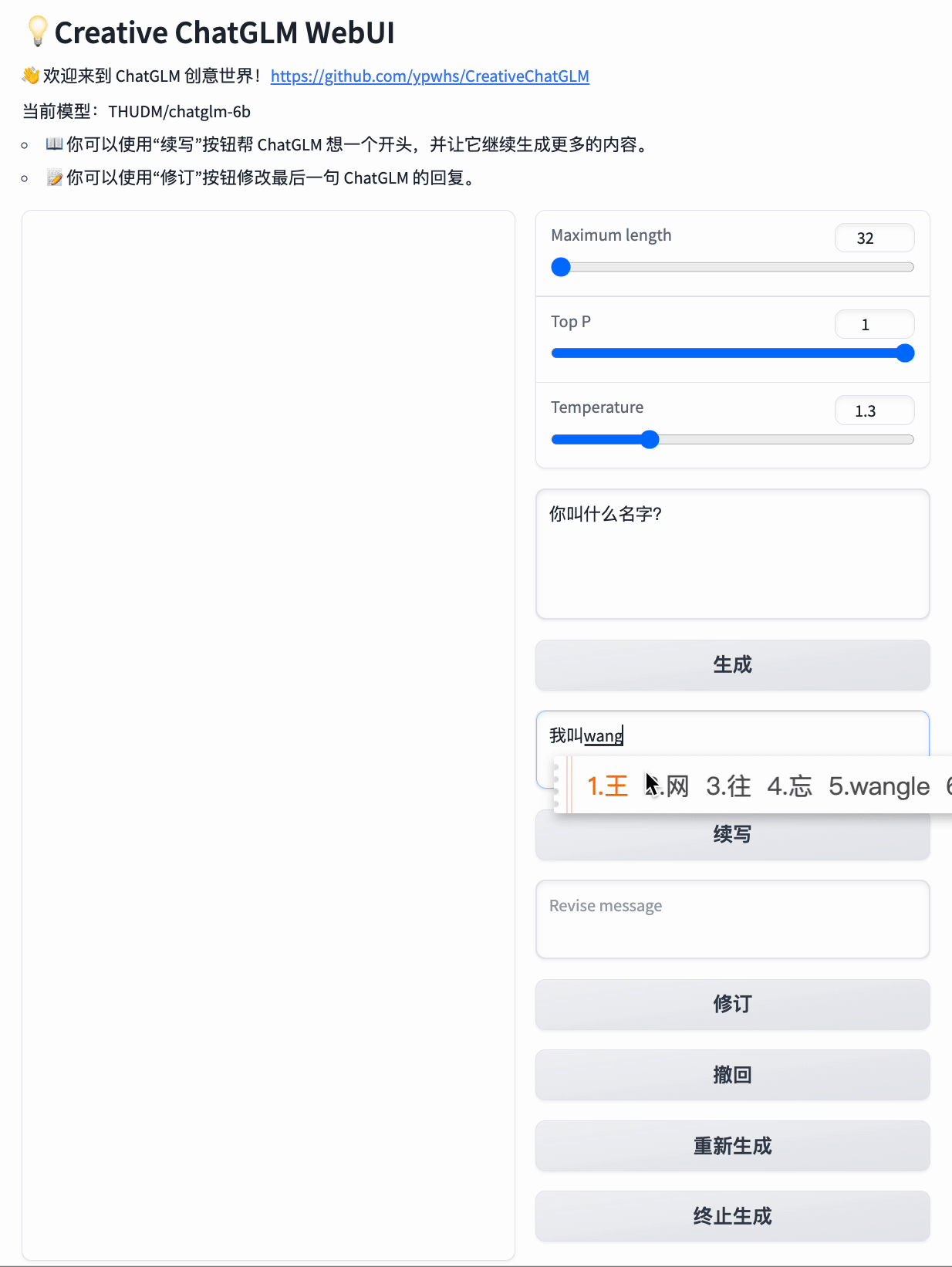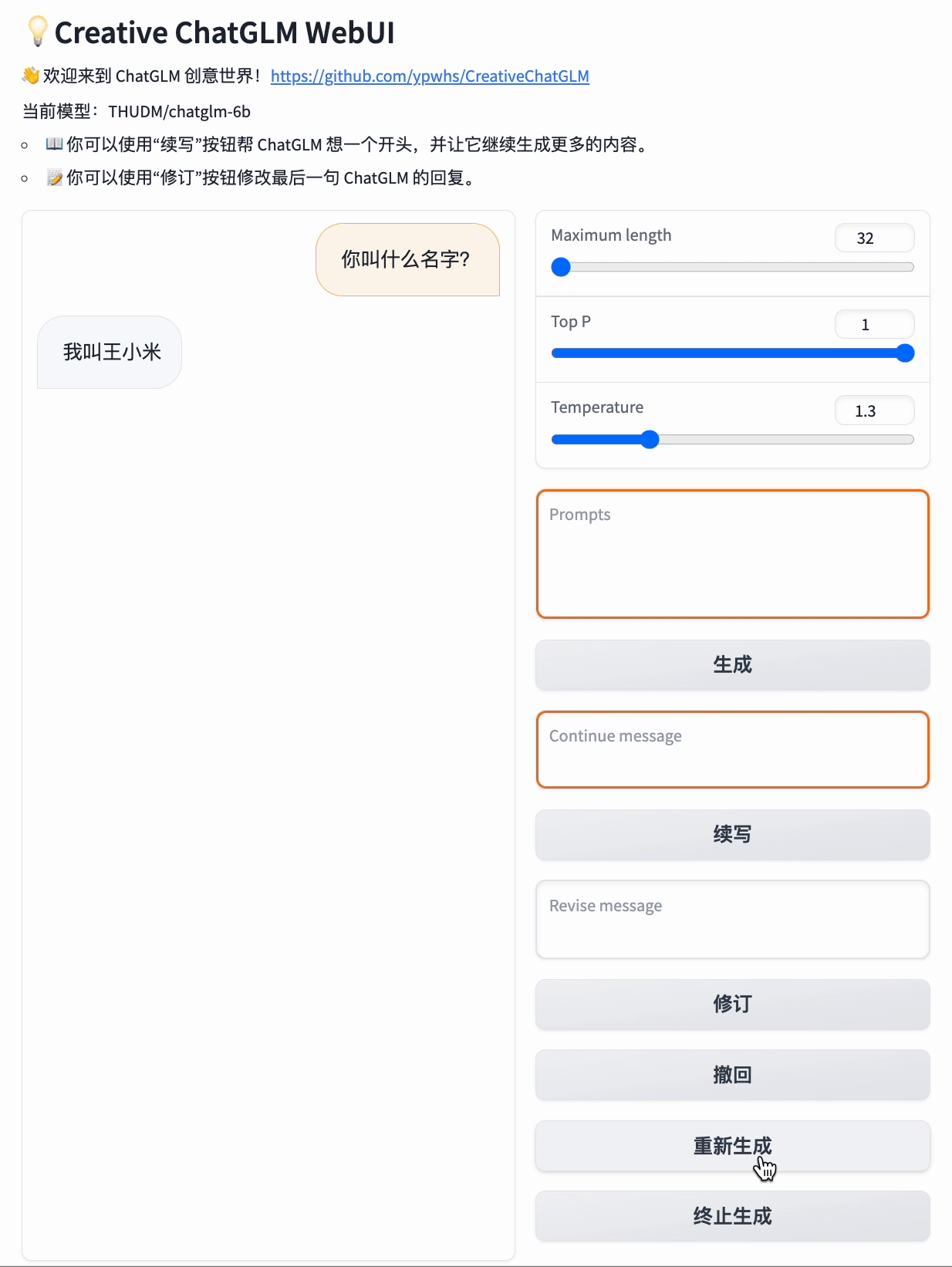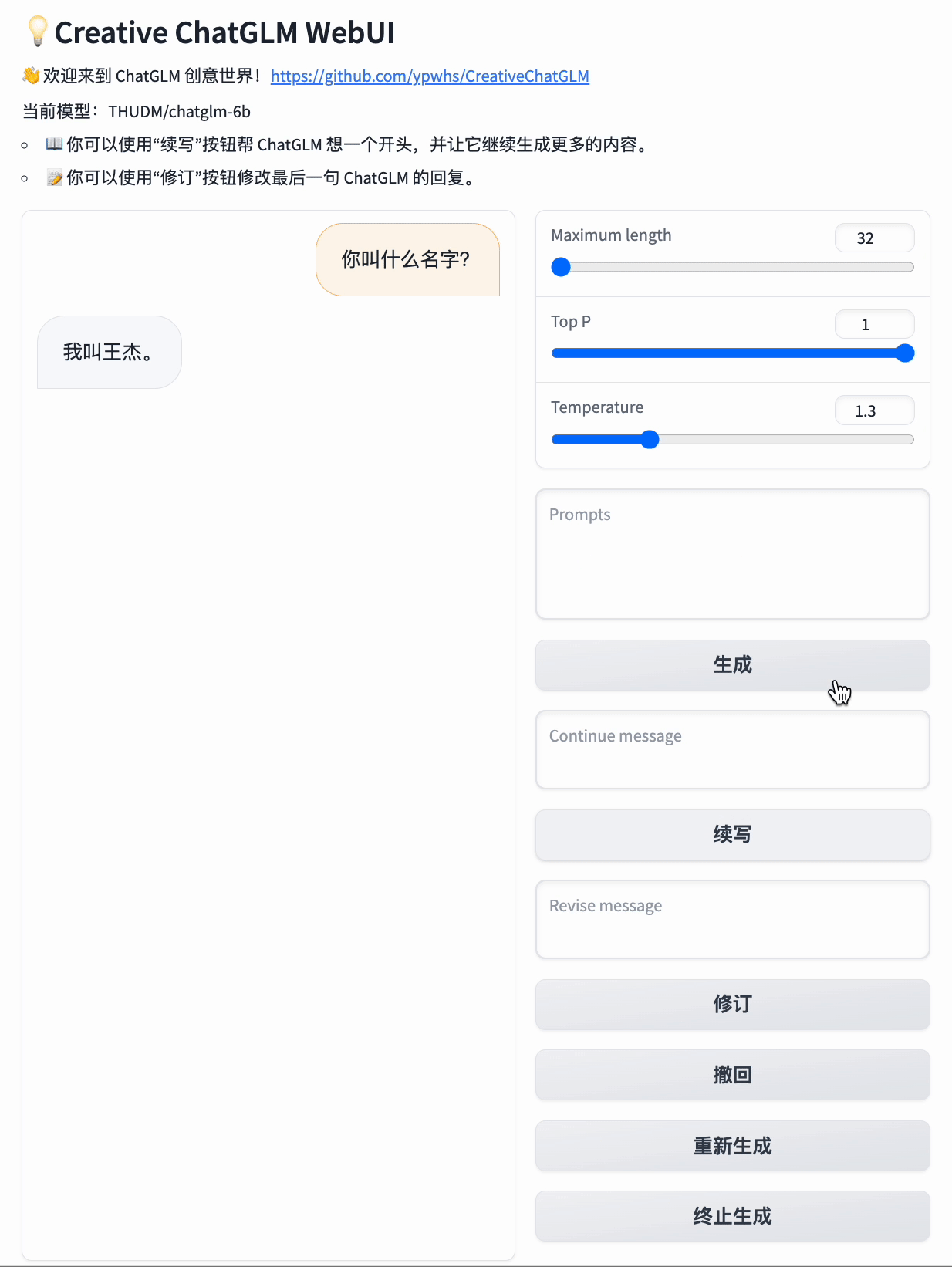
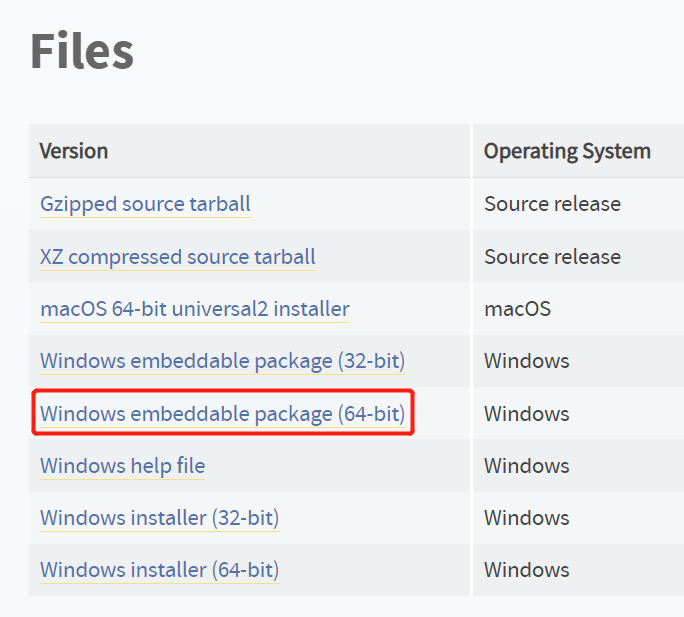
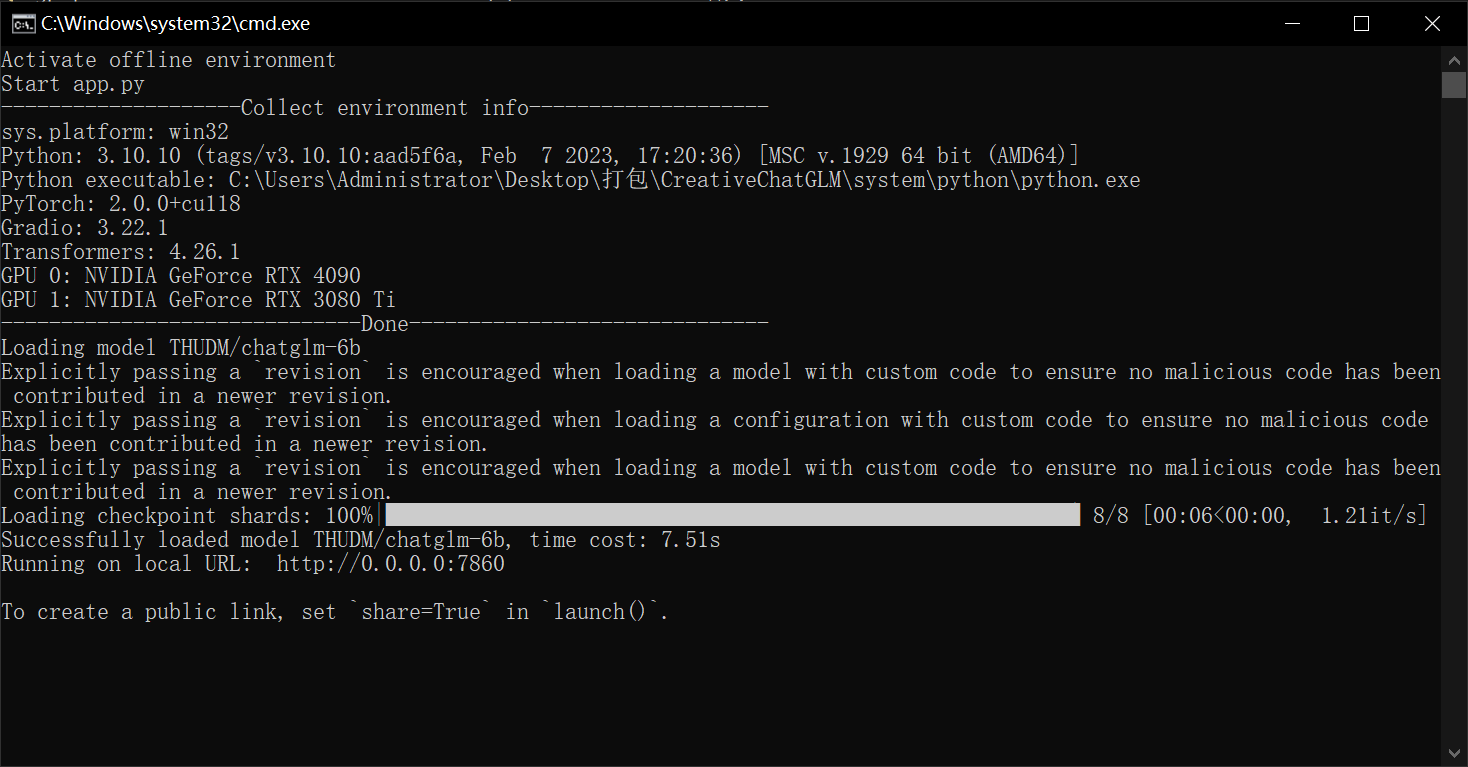
Activate offline environment
Start app.py
--------------------Collect environment info--------------------
sys.platform: win32
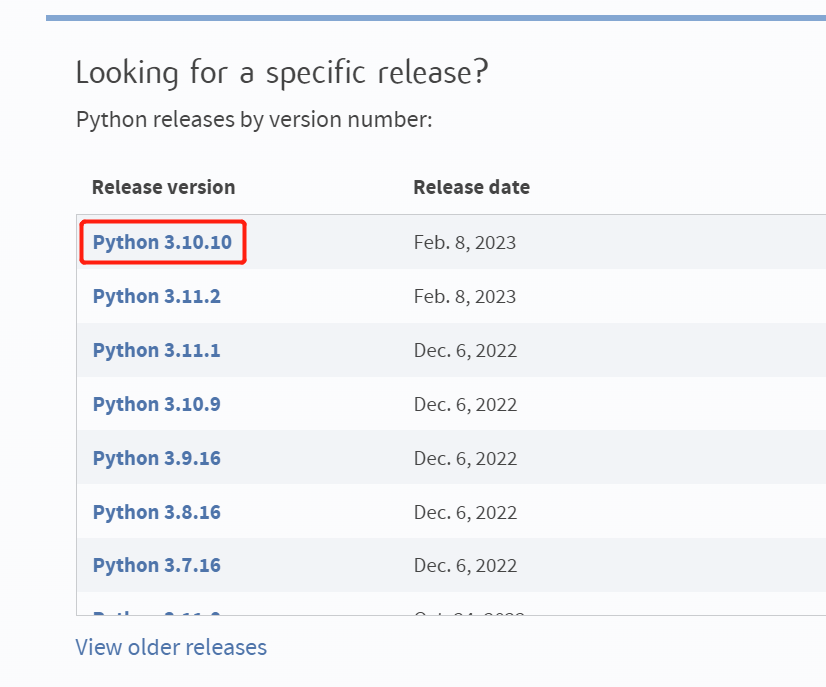
Python: 3.10.10 (tags/v3.10.10:aad5f6a, Feb 7 2023, 17:20:36) [MSC v.1929 64 bit (AMD64)]
Python executable: E:\Software\CreativeChatGLM\system\python\python.exe
PyTorch: 2.0.0+cu118
Gradio: 3.34.0
Transformers: 4.30.1
GPU 0: NVIDIA GeForce RTX 3050 Laptop GPU
------------------------------Done------------------------------
Loading model chatglm2-6b-int4
'gcc' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
Compile parallel cpu kernel gcc -O3 -fPIC -pthread -fopenmp -std=c99 C:\Users\User\.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization_kernels_parallel.c -shared -o C:\Users\User\.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization_kernels_parallel.so failed.
'gcc' 不是内部或外部命令,也不是可运行的程序
或批处理文件。
Compile cpu kernel gcc -O3 -fPIC -std=c99 C:\Users\User\.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization_kernels.c -shared -o C:\Users\User\.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization_kernels.so failed.
SuccessfulUser loaded model chatglm2-6b-int4, time cost: 3.36s
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Traceback (most recent call last):
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\routes.py", line 437, in run_predict
output = await app.get_blocks().process_api(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\blocks.py", line 1346, in process_api
result = await self.call_function(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\blocks.py", line 1090, in call_function
prediction = await utils.async_iteration(iterator)
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\utils.py", line 341, in async_iteration
return await iterator.__anext__()
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\utils.py", line 334, in __anext__
return await anyio.to_thread.run_sync(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\anyio\to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\anyio\_backends\_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\gradio\utils.py", line 317, in run_sync_iterator_async
return next(iterator)
File "E:\Software\CreativeChatGLM\predictors\base.py", line 40, in predict_continue
for response in self.stream_chat_continue(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\utils\_contextlib.py", line 35, in generator_context
response = gen.send(None)
File "E:\Software\CreativeChatGLM\predictors\chatglm2_predictor.py", line 113, in stream_chat_continue
for outputs in model.stream_generate(**final_input, past_key_values=past_key_values,
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\utils\_contextlib.py", line 35, in generator_context
response = gen.send(None)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 1061, in stream_generate
outputs = self(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 848, in forward
transformer_outputs = self.transformer(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 744, in forward
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 588, in forward
hidden_states, kv_cache = layer(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 510, in forward
attention_output, kv_cache = self.self_attention(
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\modeling_chatglm.py", line 342, in forward
mixed_x_layer = self.query_key_value(hidden_states)
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization.py", line 320, in forward
output = W8A16LinearCPU.appUser(input, self.weight, self.weight_scale, self.weight_bit_width)
File "E:\Software\CreativeChatGLM\system\python\lib\site-packages\torch\autograd\function.py", line 506, in appUser
return super().appUser(*args, **kwargs) # type: ignore[misc]
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization.py", line 223, in forward
weight = extract_weight_to_float(quant_w, scale_w, weight_bit_width, quantization_cache=quantization_cache)
File "C:\Users\User/.cache\huggingface\modules\transformers_modules\chatglm2-6b-int4\quantization.py", line 205, in extract_weight_to_float
func(
TypeError: 'NoneType' object is not callable