[CVPR'22] Perturbed and Strict Mean Teachers for Semi-supervised Semantic Segmentation
by Yuyuan Liu, Yu Tian, Yuanhong Chen, Fengbei Liu, Vasileios Belagiannis and Gustavo Carneiro
Computer Vision and Pattern Recognition Conference (CVPR), 2022
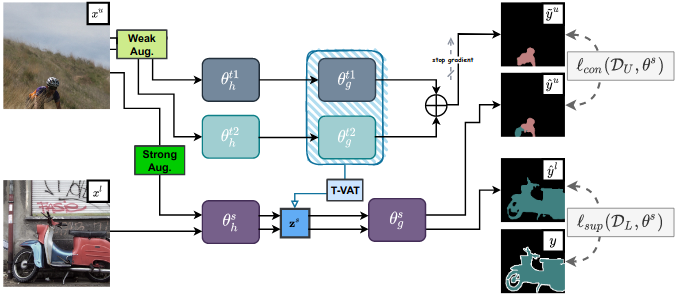
Please install the dependencies and dataset based on this installation document.
Please follow this instruction document to reproduce our results.
-
blender setting results in VOC12 dataset (under deeplabv3+ with resnet101)
Approach 1/16 (662) 1/8 (1323) 1/4 (2646) 1/2 (5291) PS-MT (wandb_log) 78.79 80.29 80.66 80.87 - please note that, we update the blender splits list end with an extra 0 (e.g., 6620 for 662 labels) in the original directory.
- you can find the related launching scripts in here.
- In case you are using blender experiments (which are built on top of the high-quality labels), please compare with the results in this table.
-
augmented set
Backbone 1/16 (662) 1/8 (1323) 1/4 (2646) 1/2 (5291) 50 72.83 75.70 76.43 77.88 101 75.50 78.20 78.72 79.76 -
high quality set (based on res101)
1/16 (92) 1/8 (183) 1/4 (366) 1/2 (732) full (1464) 65.80 69.58 76.57 78.42 80.01
-
following the setting of CAC (720x720, CE supervised loss)
Backbone slid. eval 1/8 (372) 1/4 (744) 1/2 (1488) 50 ✗ 74.37 75.15 76.02 50 ✓ 75.76 76.92 77.64 101 ✓ 76.89 77.60 79.09 -
following the setting of CPS (800x800, OHEM supervised loss)
Backbone slid. eval 1/8 (372) 1/4 (744) 1/2 (1488) 50 ✓ 77.12 78.38 79.22
Some examples of training details, including:
In details, after clicking the run (e.g., 1323_voc_rand1), you can checkout:
 overall information (e.g., training command line, hardware information and training time).
overall information (e.g., training command line, hardware information and training time). training details (e.g., loss curves, validation results and visualization)
training details (e.g., loss curves, validation results and visualization) output logs (well, sometimes might crash ...)
output logs (well, sometimes might crash ...)
The code is highly based on the CCT. Many thanks for their great work.
Please consider citing this project in your publications if it helps your research.
@article{liu2021perturbed,
title={Perturbed and Strict Mean Teachers for Semi-supervised Semantic Segmentation},
author={Liu, Yuyuan and Tian, Yu and Chen, Yuanhong and Liu, Fengbei and Belagiannis, Vasileios and Carneiro, Gustavo},
journal={arXiv preprint arXiv:2111.12903},
year={2021}
}
- Code of deeplabv3+ for voc12
- Code of deeplabv3+ for cityscapes












































































































