yanagishima is a Web UI for presto/hive.
- easy to install
- easy to use
- run query(Ctrl+Enter)
- query history
- query bookmark
- show query execution list
- kill running query
- show columns
- show partitions
- show query result data size
- show query result line number
- TSV download
- CSV download
- show presto view ddl
- share query
- share query result
- search table(presto only)
- handle multiple presto/hive clusters
- auto detection of partition key
- show progress of running query
- query parameters substitution
- insert chart
- format query(Ctrl+Shift+F, presto only)
- convert from TSV to values query(presto only)
- function, table completion(Ctrl+Space, presto only)
- validation(Shift+Enter, presto only)
- export/import history
- export/import bookmark
- desktop notification
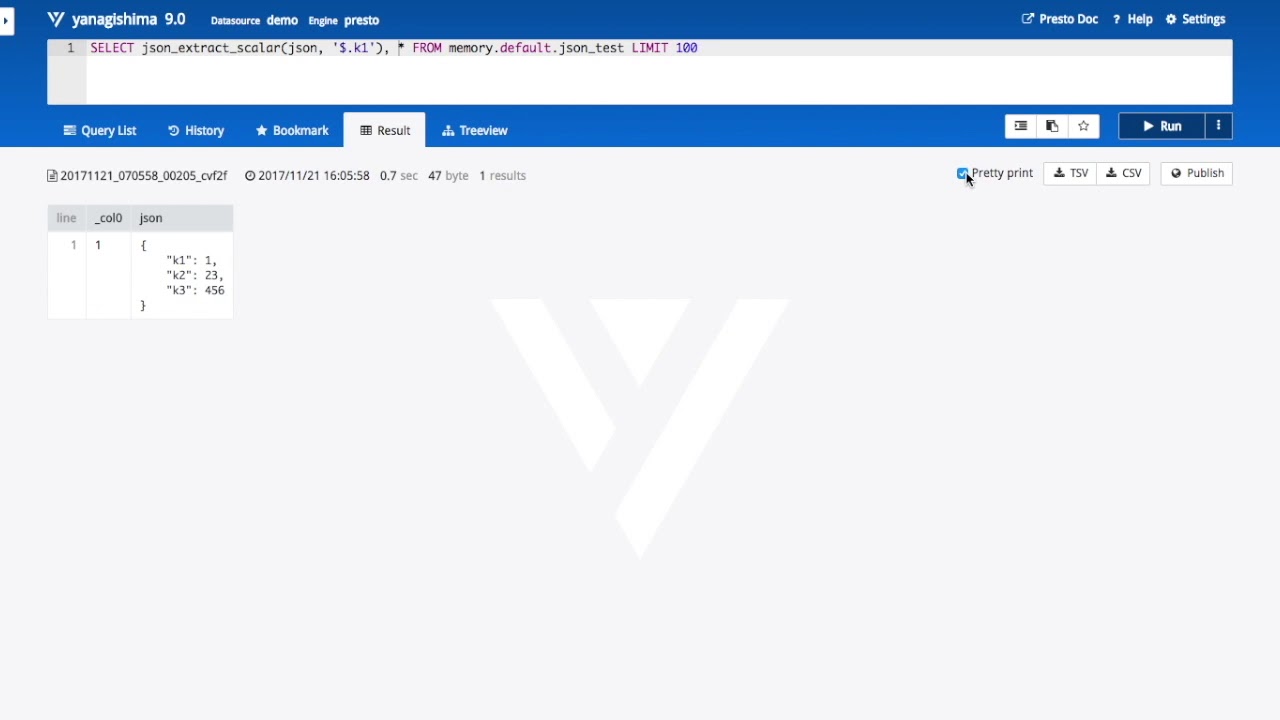
- pretty print for json/map data
- enable to compare query result
- comment about query
- convert hive/presto query
- support graphviz to visualize presto explain result
- support Elasticsearch SQL
- label
- pivot
- 17.0
- add link which can open a schema/table in Treeview
- pivot
- fix bug which invisible.schema doesn't work
- improve hive job handling when you create/drop table
- add query id link to share page
- update presto library
- fix partition bug
- remove kill button in hive
- default value of
use.new.show.partitions.xxxis true
- 16.0
- refactoring with Vuex, Vue Router, Single File Components
- add BOM in CSV/TSV download files
- improve to display hive map data
- add pretty print on share view
- enable code folding
- make underscores available in placeholders
- move treeview to left end tab
- 15.0
- support Elasticsearch SQL
- add label feature like gmail
- handle presto/hive reserved keywords(e.g. group, order)
- integrate metadata service
- add partition filter
- show column number
- suppresss stacktrace
- 14.0
- fix wrong line number when result file contains a new line
- metadata of 14.0 is NOT compatible with 13.0, so migration is required
- migrateV14.sh is the script to migrate db file.
- migration process is as follows
cp data/yanagishima.db data/yanagishima.db.bak bin/migrateV14.sh data/yanagishima.db result sqlite3 data/yanagishima.db sqlite> alter table query rename to query_old; sqlite> alter table query_v14 rename to query; If you confirmed, drop table query_old It takes about 10 hours if db file is more than 500MB and result file is about 1TBvacuumandcreate index deq_index on query(datasource, engine, query_id)andcreate index deu_index on query(datasource, engine, user)may be necessary if yanagishima.db is huge- fix infinite loop bug when /queryStatus returns 500
- add kill hive query feature if you use a kerberized hadoop cluster
- sort table name when you use
Treeview - copy publish url to clipboard but chrome user only due to Async Clipboard API
- handle presto/hive reserved keywords(e.g. group, order)
- use timestamp to index.js due to cache busting
- 13.0
- improve code input performance especially when query result is huge
- upgrade ace editor
- add message if result count exceeds 500
- improve history tab logic when result file is removed
- add sort partition feature
- fix bug that 3 pane compare result display disappear
- don't create fluency instance every request due to performance improvement
- handle issue that presto doesn't support
show paritionssince 0.202 - add option to use webhdfs api when there are too many partitions
- 12.0
- convert hive/presto query
- support graphviz to visualize presto explain result
- add tooltip to
Setin History/Bookmark tab - add new presto functions(0.196) to completion list
- fix bookmark bug
- fix presto authentication failed bug
- 11.0
- fix timezone bug
- fix exponential notation bug
- support UTF-8 encoding for CSV
- 10.0
- add timeline tab
- 9.0
- pretty print for map data
- add left panel to compare query result
- support presto/hive authentication with user/password
- if you want to use presto TLS, you need to execute
keytool -importhttps://prestodb.io/docs/current/security/tls.html - search query history
- paging query history
- improve performance to write/read result file
- result file format of 9.0 is tsv, prior to 9.0 is json, so migration is required
- migrateV9.sh is the script to migrate result file.
- if migration error occur, you can check it.
$ bin/migrateV9.sh result dest ... processing /path/to/yanagishima-9.0/result/your-presto/20171010/20171010_072513_02895_xxvvj.json error /path/to/yanagishima-9.0/result/your-presto/20171010/20171010_072513_02895_xxvvj.json java.lang.RuntimeException: org.codehaus.jackson.JsonParseException: Unexpected end-of-input: expected close marker for ARRAY (from [Source: java.io.StringReader@e320068; line: 1, column: 0]) at [Source: java.io.StringReader@e320068; line: 1, column: 241] at yanagishima.migration.MigrateV9.main(MigrateV9.java:59) Caused by: org.codehaus.jackson.JsonParseException: Unexpected end-of-input: expected close marker for ARRAY (from [Source: java.io.StringReader@e320068; line: 1, column: 0]) at [Source: java.io.StringReader@e320068; line: 1, column: 241] at org.codehaus.jackson.JsonParser._constructError(JsonParser.java:1433) at org.codehaus.jackson.impl.JsonParserMinimalBase._reportError(JsonParserMinimalBase.java:521) at org.codehaus.jackson.impl.JsonParserMinimalBase._reportInvalidEOF(JsonParserMinimalBase.java:454) at org.codehaus.jackson.impl.JsonParserBase._handleEOF(JsonParserBase.java:473) at org.codehaus.jackson.impl.ReaderBasedParser._skipWSOrEnd(ReaderBasedParser.java:1496) at org.codehaus.jackson.impl.ReaderBasedParser.nextToken(ReaderBasedParser.java:368) at org.codehaus.jackson.map.deser.std.CollectionDeserializer.deserialize(CollectionDeserializer.java:211) at org.codehaus.jackson.map.deser.std.CollectionDeserializer.deserialize(CollectionDeserializer.java:194) at org.codehaus.jackson.map.deser.std.CollectionDeserializer.deserialize(CollectionDeserializer.java:30) at org.codehaus.jackson.map.ObjectMapper._readMapAndClose(ObjectMapper.java:2732) at org.codehaus.jackson.map.ObjectMapper.readValue(ObjectMapper.java:1863) at yanagishima.migration.MigrateV9.main(MigrateV9.java:56) processing /path/to/yanagishima-9.0/result/your-presto/20171010/20171010_072517_02897_xxvvj.json ... - 8.0
- pretty print for json data
- store query history/bookmark to server side db, but default setting is to use local storage
- improve partition display
- metadata of 9.0 is NOT compatible with 7.0, so migration is required
- migration process is as follows
cp data/yanagishima.db data/yanagishima.db.bak sqlite3 data/yanagishima.db sqlite> create table query_new (datasource text, engine text, query_id text, fetch_result_time_string text, query_string text, user text, primary key(datasource, engine, query_id)); sqlite> insert into query_new select datasource, engine, query_id, fetch_result_time_string, query_string, null from query; sqlite> alter table query rename to query_old; sqlite> alter table query_new rename to query; sqlite> create table publish_new (publish_id text, datasource text, engine text, query_id text, user text, primary key(publish_id)); sqlite> insert into publish_new select publish_id, datasource, engine, query_id, null from publish; sqlite> alter table publish rename to publish_old; sqlite> alter table publish_new rename to publish; sqlite> create table bookmark_new (bookmark_id integer primary key autoincrement, datasource text, engine text, query text, title text, user text); sqlite> insert into bookmark_new select bookmark_id, datasource, engine, query, title, null from bookmark; sqlite> alter table bookmark rename to bookmark_old; sqlite> alter table bookmark_new rename to bookmark; If you confirmed, drop table query_old, publish_old, bookmark_old; - 7.0
- support hive on MapReduce(yanagishima executes
set mapreduce.job.name=...) - metadata of 7.0 is NOT compatible with 6.0, so migration is required
- migration process is as follows
cp data/yanagishima.db data/yanagishima.db.bak sqlite3 data/yanagishima.db sqlite> create table query_new (datasource text, engine text, query_id text, fetch_result_time_string text, query_string text, primary key(datasource, engine, query_id)); sqlite> insert into query_new select datasource, 'presto', query_id, fetch_result_time_string, query_string from query; sqlite> alter table query rename to query_old; sqlite> alter table query_new rename to query; sqlite> create table publish_new (publish_id text, datasource text, engine text, query_id text, primary key(publish_id)); sqlite> insert into publish_new select publish_id, datasource, 'presto', query_id from publish; sqlite> alter table publish rename to publish_old; sqlite> alter table publish_new rename to publish; sqlite> create table bookmark_new (bookmark_id integer primary key autoincrement, datasource text, engine text, query text, title text); sqlite> insert into bookmark_new select bookmark_id, datasource, 'presto', query, title from bookmark; sqlite> alter table bookmark rename to bookmark_old; sqlite> alter table bookmark_new rename to bookmark; If you confirmed, drop table query_old, publish_old, bookmark_old; - support hive on MapReduce(yanagishima executes
- 6.0
- support bookmark title, so add title column to bookmark table
- metadata of 6.0 is NOT compatible with 5.0, so migration is required
- migration process is as follows
cp data/yanagishima.db data/yanagishima.db.bak sqlite3 data/yanagishima.db sqlite> create table if not exists bookmark_new (bookmark_id integer primary key autoincrement, datasource text, query text, title text); sqlite> insert into bookmark_new select bookmark_id, datasource, query, null from bookmark; sqlite> alter table bookmark rename to bookmark_old; sqlite> alter table bookmark_new rename to bookmark; If you confirmed, drop table bookmark_old;
- Java 8
- Node.js
git clone https://github.com/yanagishima/yanagishima.git
cd yanagishima
git checkout -b 17.0 refs/tags/17.0
./gradlew distZip
cd build/distributions
unzip yanagishima-17.0.zip
cd yanagishima-17.0
vim conf/yanagishima.properties
nohup bin/yanagishima-start.sh >y.log 2>&1 &
bin/yanagishima-shutdown.sh
You need to edit conf/yanagishima.properties.
# yanagishima web port
jetty.port=8080
# 30 minutes. If presto query exceeds this time, yanagishima cancel the query.
presto.query.max-run-time-seconds=1800
# 1GB. If presto query result file size exceeds this value, yanagishima cancel the query.
presto.max-result-file-byte-size=1073741824
# you can specify freely. But you need to specify same name to presto.coordinator.server.[...] and presto.redirect.server.[...] and catalog.[...] and schema.[...]
presto.datasources=your-presto
# presto coordinator url
presto.coordinator.server.your-presto=http://presto.coordinator:8080
# almost same as presto coordinator url. If you use reverse proxy, specify it
presto.redirect.server.your-presto=http://presto.coordinator:8080
# presto catalog name
catalog.your-presto=hive
# presto schema name
schema.your-presto=default
# if query result exceeds this limit, to show rest of result is skipped
select.limit=500
# http header name for audit log
audit.http.header.name=some.auth.header
# limit to convert from tsv to values query
to.values.query.limit=500
# authorization feature
check.datasource=false
hive.jdbc.url.your-hive=jdbc:hive2://localhost:10000/default;auth=noSasl
hive.jdbc.user.your-hive=yanagishima-hive
hive.jdbc.password.your-hive=yanagishima-hive
hive.query.max-run-time-seconds=3600
hive.query.max-run-time-seconds.your-hive=3600
resource.manager.url.your-hive=http://localhost:8088
sql.query.engines=presto,hive
hive.datasources=your-hive
hive.disallowed.keywords.your-hive=insert,drop
# 1GB. If hive query result file size exceeds this value, yanagishima cancel the query.
hive.max-result-file-byte-size=1073741824
# setup initial hive query(for example, set hive.mapred.mode=strict)
hive.setup.query.path.your-hive=/usr/local/yanagishima/conf/hive_setup_query_your-hive
# CORS setting
cors.enabled=false
If you use a single presto cluster, you need to specify as follows.
jetty.port=8080
presto.datasources=your-presto
presto.coordinator.server.your-presto=http://presto.coordinator:8080
catalog.your-presto=hive
schema.your-presto=default
sql.query.engines=presto
If you want to handle multiple presto clusters, you need to specify as follows.
jetty.port=8080
presto.datasources=presto1,presto2
presto.coordinator.server.presto1=http://presto1.coordinator:8080
presto.coordinator.server.presto2=http://presto2.coordinator:8080
catalog.presto1=hive
schema.presto1=default
catalog.presto2=hive
schema.presto2=default
sql.query.engines=presto
If you use a single hive cluster, you need to specify as follows.
jetty.port=8080
hive.jdbc.url.your-hive=jdbc:hive2://localhost:10000/default;auth=noSasl
hive.jdbc.user.your-hive=yanagishima-hive
hive.jdbc.password.your-hive=yanagishima-hive
resource.manager.url.your-hive=http://localhost:8088
sql.query.engines=hive
hive.datasources=your-hive
If you use a hive kerberized cluster and want to kill query, you need to specify as follows.
jetty.port=8080
hive.jdbc.url.your-hive=jdbc:hive2://localhost:10000/default;auth=noSasl
hive.jdbc.user.your-hive=yanagishima-hive
hive.jdbc.password.your-hive=yanagishima-hive
resource.manager.url.your-hive=http://localhost:8088
sql.query.engines=hive
hive.datasources=your-hive
use.jdbc.cancel.your-hive=true
If you use presto and hive, you need to specify as follows.
jetty.port=8080
presto.datasources=your-cluster
presto.coordinator.server.your-cluster=http://presto.coordinator:8080
catalog.your-cluster=hive
schema.your-cluster=default
hive.jdbc.url.your-cluster=jdbc:hive2://localhost:10000/default;auth=noSasl
hive.jdbc.user.your-cluster=yanagishima-hive
hive.jdbc.password.your-cluster=yanagishima-hive
resource.manager.url.your-cluster=http://localhost:8088
sql.query.engines=presto,hive
hive.datasources=your-cluster
yanagishima doesn't have authentication/authorization feature.
But, if you have any reverse proxy server for yanagishima and that reverse proxy server provides HTTP level authentication, you can use it for yanagishima too. yanagishima can log username for each query executions and authorize per datasource.
If your reverse proxy server sets username on HTTP header just after authentication, before proxied requests you can use it.
In this case, please specify audit.http.header.name which is http header name to be passed through your proxy.
If you want to deny to access without usename, please specify user.require=true
If you set check.datasource=true and datasource list which you want to allow on HTTP header X-yanagishima-datasources through your proxy, authorization feature is enabled.
For example, if there are three datasources(aaa and bbb and ccc) and X-yanagishima-datasources=aaa,bbb is set, user can't access to datasource ccc.
If you use a presto with LDAP, you need to specify auth.xxx=true in your yanagishima.properties
jetty.port=8080
presto.datasources=your-presto
presto.coordinator.server.your-presto=http://presto.coordinator:8080
catalog.your-presto=hive
schema.your-presto=default
sql.query.engines=presto
auth.your-presto=true
If you want to ugprade yanagishima from xxx to yyyy, steps are as follows
cd yanagishima-xxx
bin/yanagishima-shutdown.sh
cd ..
wget http://.../yanagishima-yyy.zip
unzip yanagishima-yyy.zip
cd yanagishima-yyy
mv result result_bak
mv yanagishima-xxx/result .
cp yanagishima-xxx/data/yanagishima.db data/
cp yanagishima-xxx/conf/yanagishima.properties conf/
bin/yanagishima-start.sh
If it is necessary to migrate yanagishima.db or result file, you need to migrate.
| File | Description | Copy to docroot | Build index.js |
|---|---|---|---|
| index.html | Mount point for Vue | Yes | |
| static/favicon.ico | Favorite icon | Yes | |
| src | Source files | Yes | |
| src/main.js | Entry point | Yes | |
| src/App.vue | Root component | Yes | |
| src/components | Vue components | Yes | |
| src/router | Vue Router routes | Yes | |
| src/store | Vuex store | Yes | |
| src/views | Views which are switched by Vue Router | Yes | |
| src/assets/yanagishima.svg | Logo/Background image | Yes | |
| src/assets/scss/bootstrap.scss | CSS based on Bootstrap | Yes | |
| build | Build scripts for webpack | - | - |
| config | Build configs for webpack | - | - |
- CSS
- Bootstrap 4.1.3
- FontAwesome 5.3.1
- Google Fonts "Droid+Sans"
- JavaScript
- Vue 2.5.2
- Vuex 3.0.1
- Vue Router 3.0.1
- Ace Editor 1.3.3
- Sugar 2.0.4
- jQuery 3.3.1
- Build/Serve tool
- webpack 3.6.0
$ cd web
$ npm install$ npm run build$ npm start













