The tools in this repository allow calculating the optimal caching policy and its hit ratio for request traces where object sizes are variable. More information is available in our Sigmetrics 2018 paper.
In computer architecture, Belady's algorithm (also known as OPT or clairvoyant) gives the optimal hit ratio that can be achieved on a given trace. Clearly, this is a very useful way to benchmark the performance of caching policies.
Unfortunately, when cached objects vary in their sizes (number of bytes they take up in the cache), Belady is not anymore optimal. In fact, on real-world traces, Belady can be outperformed by recent caching policies. This is a very common case, object sizes are variable in in-memory caches like memcached, CDN caches like Varnish, and in storage systems like Ceph.
This repo introduces a new set of algorithms that enables the calculation of the optimal hit ratio and the optimal sequence of caching decisions for workloads with variable object sizes. Specifically, we relax the goal of computing OPT to obtaining accurate upper and lower bounds on OPT's hit ratio.
For variable object sizes, there are different ways of measuring a cache's performance, e.g., the object hit/miss ratio and the byte hit/miss ratio (defined below). We focus on the most common metric, the object miss ratio, and consider several online caching policies (LRU, AdaptSize, GDSF). Specifically, we compare these online policies to several bounds on the optimal cache miss ratio. We mark bounds with a U, for upper bounds, and with an L, for lower bounds.
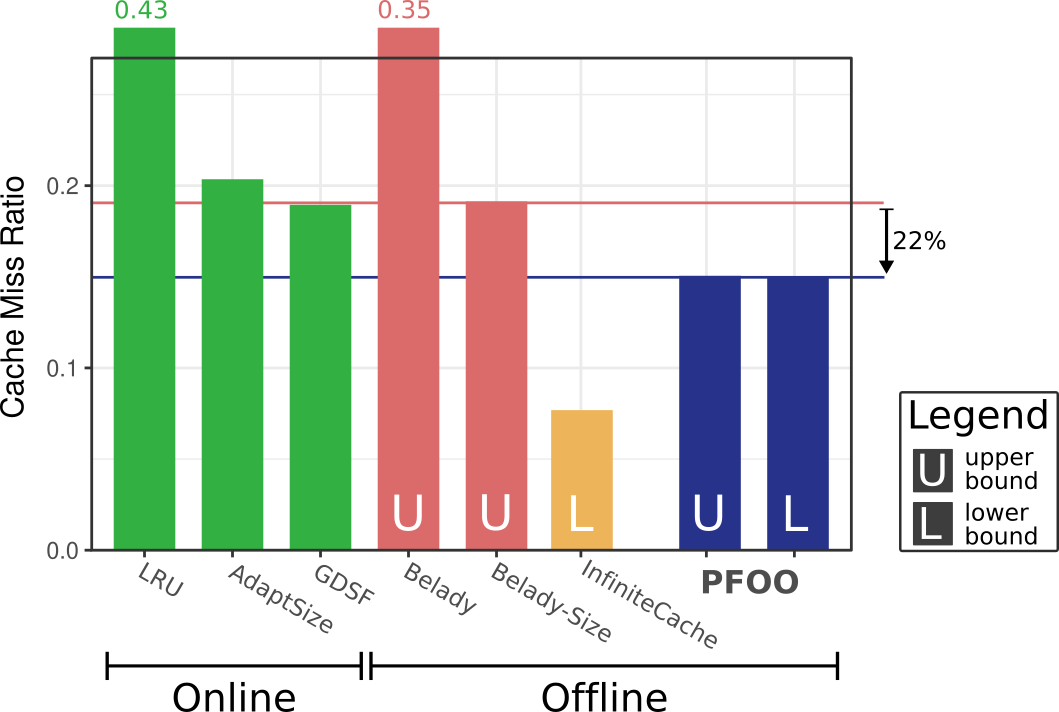
This experiment shows that online caching policies can be much better than Belady. Furthermore, even advanced versions of Belady (Belady-Size) perform similarly to online policies, suggesting that online policies are near optimal with regard to their miss ratio. In contrast, our new bounds (PFOO-U and PFOO-L) show that there still remains a gap and work is now underway to bridge this gap.
We release the following CDN request trace that you can use in your experiments (we ask academic works that use this trace to cite the SIGMETRICS'18 paper on the bottom of this page).
- Format: LZMA-compressed space-separated table.
- Three columns: request number, anonymized object-id, object size in bytes
- See New trace links
For the object hit/miss ratio optimization goal, every object counts the same (i.e., a hit for a large 1GB object and hit for a smal 10B object will both count as a "hit"). This is appropriate in memory caches, where the cache's purpose is to minimize the number of I/O operations (random seeks) going to secondary storage.
All code for this optimization goal can be found under the directory "OHRgoal".
- Flow Offline Optimum (FOO): asymptotically exact derivation of optimal caching (OPT)
- Practical FOO (PFOO): fast calculation of upper and lower bounds on OPT (PFOO-U and PFOO-L)
- OFMA: prior OPT approximation from the paper "Page replacement with multi-size pages and applications to web caching" [Irani. STOC'97]
- LocalRatio: prior OPT approximation from the paper "A unified approach to approximating resource allocation and scheduling" [Bar-Noy, Bar-Yehuda, Freund, Naor, and Schieber. J. ACM 48 (2001)]
- various other approximations for OPT (Belady-Size, Belady, Freq-Size)
Traces are expected in the webcachesim space-separated format with three columns (time, id, size in bytes) and a separate request on each line. See the download link above for an example.
The CLI parameters of some of the tools (with examples) are as follows.
-
FOO
- format (four parameters, all required) and example:
./foo [trace name] [cachesize in bytes] [pivot rule] [output name] ./foo trace.txt 1073741824 4 foo_decision_variables.txt - pivot rule denotes the network simplex's pivot rule
- format (four parameters, all required) and example:
-
PFOO-U
- format (four parameters, all required) and example:
./pfoou [trace name] [cachesize in bytes] [pivot rule] [step size] [output name] ./pfoou trace.txt 1073741824 4 500000 pfoo_decision_variables.txt - step size denotes the number of decision variables that PFOO-U changes in each iteration, 500k is a good starting point. (Lower is faster, higher has better accuracy)
- format (four parameters, all required) and example:
-
PFOO-L
- format (four parameters, all required) and example:
./pfool [trace name] [cachesize in bytes] [output name] ./pfoou trace.txt 1073741824 pfoo_decision_variables.txt
- format (four parameters, all required) and example:
For the byte hit/miss ratio optimization goal, every object is weighted in proportion to the number of bytes (e.g., a hit to a 4KB object is 4x more important that a hit to a 1KB object). This is appropriate in disk/flash caches (e.g., CDNs), where each miss incurs a bandwidth cost (which is linear in the number of missed bytes).
All code for this optimization goal is in the directory "BHRgoal".
- Practical FOO Lower (PFOO-L): lower bound on the byte miss ratio, i.e., upper bound on the BHR that any online policy can achieve
- Practical FOO Upper (PFOO-U): (currently still being ported)
- Belady: as above
Traces are expected in the webcachesim space-separated format with three columns (time, id, size in bytes) and a separate request on each line. See the download link above for an example.
Makefiles are in each directory, they have been tested with g++ version 7 and above.
The CLI parameters are as follows.
-
PFOO-L
- input: two parameters (trace path and cache size)
- output (to cout): OHR and BHR
- example:
./BHRgoal/PFOO-L/pfool [trace name] [cachesize in bytes] ./BHRgoal/PFOO-L/pfool trace.txt 1073741824
-
PFOO-U
- to be ported from OHR
-
Belady
- input: three parameters (trace path, cache size, and sampling size)
- output (to cout): OHR and BHR
- example:
./BHRgoal/Belady/belady2 [trace name] [cachesize in bytes] [samples] ./BHRgoal/Belady/belady2 trace.txt 1073741824 100
Want to contribute? Great! We follow the Github contribution work flow. This means that submissions should fork and use a Github pull requests to get merged into this code base.
This is an early-stage research prototype. There are many ways to help out.
If you come across a bug in webcachesim, please file a bug report by creating a new issue. This is an early-stage project, which depends on your input!
This project has not be thoroughly tested, test cases are likely to get a speedy merge.
Both FOO and PFOO-U are much slower than they need be. See corresponding Issue: PFOO-U is too slow. This is fixable, but currently open.
We ask academic works, which built on this code, to reference the following papers:
Practical Bounds on Optimal Caching with Variable Object Sizes
Daniel S. Berger, Nathan Beckmann, Mor Harchol-Balter.
ACM SIGMETRICS, June 2018.
Also appeared in ACM POMACS, vol. 2, issue 2, as article No. 32, June 2018.
Towards Lightweight and Robust Machine Learning for CDN Caching
Daniel S. Berger
ACM HotNets, November 2018 (to appear).
This software uses the LEMON and Catch2 C++ libraries.
-
LEMON: Library for Efficient Modeling and Optimization in Networks
- Copyright 2003-2012 gervary Combinatorial Optimization Research Group, EGRES
- Boost Software License, Version 1.0, see lemon/LICENSE
- Authors: lemon/AUTHORS
-
Catch2: C++ Automated Test Cases in a Header
- Boost Software License, Version 1.0, see tests/LICENSE.txt









































