deepdoctection / deepdoctection Goto Github PK
View Code? Open in Web Editor NEWA Repo For Document AI
License: Apache License 2.0
A Repo For Document AI
License: Apache License 2.0


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")



























































































































Enhancement 🚀
The old Page class had some issues regarding its flexibility for extensions. On top of that it was originally designed to work as a quick parsing solution for results of the dd analyzer neglecting the fact that many other pipeline construction follow a completely different purpose that parsing layouts.
Motivation 💪
With the possibility to add language models to pipeline some new tasks like document classification as well as token classification can be build with pipelines. This requires an extension for how results based on tokens are being saved and how outputs stored on image level can be easily added.
Alternatives ⚖️
Not re-implementing the Page class would make feature extension a lot harder
Additional context 🧬
Screenshots, etc. if relevant
Enhancement 🚀
Propagating logs from third part library loggers to root logger
Motivation 💪
Loggers from third party libraries have their own format that make look logging inconsistent.
The introduction of a uniform logging format would allow output in the terminal to be displayed more consistently. In addition, there would be the possibility of creating a logging file that always has the same format for pipeline processing, which would result in an analysis option with pandas, for example.
Alternatives ⚖️
Are there any alternatives you have considered
Additional context 🧬
Screenshots, etc. if relevant
Enhancement 🚀
Adding a predictor that determines the language on a page. The process should include the possibility to extract the language with
a zero shot method (general OCR without language selection) and then run the language detection in order to do a careful OCR using a model that has been trained on the language in question
Motivation 💪
Needed to improve OCR with specific language selection.
Alternatives ⚖️
NN
Additional context 🧬
Screenshots, etc. if relevant
Bug 💥
timer in pipeline component should be optional.
Expected behavior 🧮
No time function while evaluating
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Enhancement 🚀
A class that allows merging datasets.
Many datasets for DLA have some drift (e.g. they come from one particular domain) or the are relatively small. In order to train models on a union of some of these datasets with built-in training scripts, datasets need to be merged (maybe after their dataflows have been customized).
Motivation 💪
Training models on a union of various datasets
Alternatives ⚖️
Are there any alternatives you have considered
Additional context 🧬
Screenshots, etc. if relevant
Bug 💥
Getting started notebooks fails with:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [9], in <cell line: 2>()
1 doc=iter(df)
----> 2 page = next(doc)
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/dataflow/dataflow/common.py:315, in MapData.__iter__(self)
314 def __iter__(self):
--> 315 for dp in self.ds:
316 ret = self.func(copy(dp)) # shallow copy the list
317 if ret is not None:
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/dataflow/dataflow/common.py:315, in MapData.__iter__(self)
314 def __iter__(self):
--> 315 for dp in self.ds:
316 ret = self.func(copy(dp)) # shallow copy the list
317 if ret is not None:
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/dataflow/dataflow/common.py:315, in MapData.__iter__(self)
314 def __iter__(self):
--> 315 for dp in self.ds:
316 ret = self.func(copy(dp)) # shallow copy the list
317 if ret is not None:
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/dataflow/dataflow/common.py:316, in MapData.__iter__(self)
314 def __iter__(self):
315 for dp in self.ds:
--> 316 ret = self.func(copy(dp)) # shallow copy the list
317 if ret is not None:
318 yield ret
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/deepdoctection/pipe/base.py:89, in PipelineComponent.pass_datapoint(self, dp)
87 with timed_operation(self.__class__.__name__):
88 self.dp_manager.datapoint = dp
---> 89 self.serve(dp)
90 else:
91 self.dp_manager.datapoint = dp
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/deepdoctection/pipe/text.py:83, in TextExtractionService.serve(self, dp)
81 assert predictor_input is not None
82 width, height = None, None
---> 83 detect_result_list = self.predictor.predict(predictor_input) # type: ignore
84 if isinstance(self.predictor, PdfMiner):
85 width, height = self.predictor.get_width_height(predictor_input) # type: ignore
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/deepdoctection/extern/tessocr.py:274, in TesseractOcrDetector.predict(self, np_img)
267 def predict(self, np_img: ImageType) -> List[DetectionResult]:
268 """
269 Transfer of a numpy array and call of pytesseract. Return of the detection results.
270
271 :param np_img: image as numpy array
272 :return: A list of DetectionResult
273 """
--> 274 detection_results = predict_text(
275 np_img,
276 supported_languages=self.config.LANGUAGES,
277 text_lines=self.config.LINES,
278 config=config_to_cli_str(self.config, "LANGUAGES", "LINES"),
279 )
280 return detection_results
File ~/Library/Caches/pypoetry/virtualenvs/challenges-Ho27vFAF-py3.8/lib/python3.8/site-packages/deepdoctection/extern/tessocr.py:214, in predict_text(np_img, supported_languages, text_lines, config)
202 all_results = []
204 for caption in zip(
205 results["left"],
206 results["top"],
(...)
212 results["line_num"],
213 ):
--> 214 if int(caption[4]) != -1:
215 word = DetectionResult(
216 box=[caption[0], caption[1], caption[0] + caption[2], caption[1] + caption[3]],
217 score=caption[4] / 100,
(...)
222 class_name=names.C.WORD,
223 )
224 all_results.append(word)
ValueError: invalid literal for int() with base 10: '95.345306'
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
Used make install-dd-pt to install from source as well as brew install tesseract-lang. Also installed the missing torch-vision dependency.
Enhancement 🚀
Training a table detector with data from all datasets that contain table ground truth (Publaynet, TableBank, iii3k, Pubtables, Fintabnet)
Motivation 💪
This will provide a alternative pipeline, if one does not focus on other layout features from Publaynet.
Alternatives ⚖️
Additional context 🧬
Bug 💥
If parent categories have relative coordinates whereas child categories are in absolute terms, then the iou/ioa matching will give no matched items.
Expected behavior 🧮
match_anns_by_intersection is supposed to work for any type of coordinates.
Additional context 🧬
Bug 💥
df = analyzer.analyze(path=path) . After debugging, I found that this was due to the wrong argument order passed to DetectionResult in deepdoctection/extern/d2/d2.pyTraceback (most recent call last):
File "/home/xyz/repos/deepdoctection/run.py", line 14, in <module>
page = next(doc)
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
[Previous line repeated 5 more times]
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 316, in __iter__
ret = self.func(copy(dp)) # shallow copy the list
File "/home/xyz/repos/deepdoctection/deepdoctection/pipe/base.py", line 81, in pass_datapoint
self.serve(dp)
File "/home/xyz/repos/deepdoctection/deepdoctection/pipe/layout.py", line 61, in serve
detect_result_list = self.predictor.predict(dp.image) # type: ignore
File "/home/xyz/repos/deepdoctection/deepdoctection/extern/d2detect.py", line 137, in predict
return self._map_category_names(detection_results)
File "/home/xyz/repos/deepdoctection/deepdoctection/extern/d2detect.py", line 149, in _map_category_names
result.class_name = self._categories_d2[str(result.class_id)]
KeyError: '0.9865013957023621'
Fix used -
In deepdoctection/extern/d2/d2.py, changed
results = [
DetectionResult(
instances[k].pred_boxes.tensor.tolist()[0],
instances[k].scores.tolist()[0],
instances[k].pred_classes.tolist()[0],
)
for k in range(len(instances))
]
to
results = [
DetectionResult(
instances[k].pred_boxes.tensor.tolist()[0],
instances[k].pred_classes.tolist()[0],
instances[k].scores.tolist()[0],
)
for k in range(len(instances))
]
page = next(doc)Traceback (most recent call last):
File "/home/xyz/repos/deepdoctection/run.py", line 16, in <module>
for page in df:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 315, in __iter__
for dp in self.ds:
File "/home/xyz/repos/deepdoctection/venv/lib/python3.9/site-packages/dataflow/dataflow/common.py", line 316, in __iter__
ret = self.func(copy(dp)) # shallow copy the list
File "/home/xyz/repos/deepdoctection/deepdoctection/pipe/base.py", line 81, in pass_datapoint
self.serve(dp)
File "/home/xyz/repos/deepdoctection/deepdoctection/pipe/text.py", line 83, in serve
detect_result_list = self.predictor.predict(predictor_input) # type: ignore
File "/home/xyz/repos/deepdoctection/deepdoctection/extern/tessocr.py", line 78, in predict
text_lines=self.config.LINES,
File "/home/xyz/repos/deepdoctection/deepdoctection/utils/metacfg.py", line 44, in __getattr__
raise AttributeError(name)
AttributeError: LINES
Additional context 🧬
File "/home/xyz/repos/deepdoctection/run.py" is a script I created referring the Get_Started.ipynb for debugging the issue.
from matplotlib import pyplot as plt
from deepdoctection.analyzer import get_dd_analyzer
analyzer = get_dd_analyzer(language='deu')
path = "notebooks/pics/samples/sample_2"
df = analyzer.analyze(path=path)
doc=iter(df)
page = next(doc)
print(page.height, page.width, page.file_name)
image = page.viz()
plt.figure(figsize = (25,17))
plt.axis('off')
plt.imshow(image)
print(len(page.tables))
print(page.tables[0])
page.save("res.json")
And btw, Thanks for sharing your work. I was working on a similar implementation and found your repo insightful.
Enhancement 🚀
Add table recognition metrics, e.g. TEDS (https://arxiv.org/abs/1911.10683) or GriTS (https://arxiv.org/abs/2110.00061)
Motivation 💪
Object detection metrics do not provide sufficient information for the question of how close does the recognized table resemble the ground truth
Alternatives ⚖️
Are there any alternatives you have considered
Additional context 🧬
Screenshots, etc. if relevant
With increasing variety of categories and different groups of objects describing predicted outputs (categories, languages, token types) the solution of adding all to the names class comes closer to its limitations with respect to maintenance and comprehensibility.
Using enums instead will benefit from common design practice and resolve the problems just described.
I have installed both PyTorch (since I'm using a CPU) and TensorFlow (because I need to load a model for another module). The system recognizes only TensorFlow unless I explicitly comment out the code that select TensorFlow in analyzer function.
For The Analyzer, kindly create another arg which explicitly mentions which library to use e.g (backend="tensorflow" or "pytorch"). This way even if the developer has multiple libraries, one can select whichever he wishes to use.
Bug 💥
For annotations with bounding box coords absolute_coords = False a transformation to absolute coords needs to be applied.
Expected behavior 🧮
bounding boxes for page items need to be represented in absolute coordinates.
Screenshots 🖼
NN
Desktop (please complete the following information, if any other than the one in the install requirements):
NN
Additional context 🧬
NN
Bug 💥
My program has several APIs (Flask) which use fast_tokenizer of transformers library alongside multi-threading (Joblib) to speed up execution. However, while calling deep_doctection (using torch), I get the error whose screenshot is pasted below. Deep Doctection is not using fast_tokenizer and so analyzer.analyze should work fine.
Important : This issue only occurs when deployed using Docker, local runs always run fine.
Screenshots 🖼

Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
Using the following:
Enhancement 🚀
Timed operation to measure the pipeline component performance
Motivation 💪
Getting a feeling about bottlenecks in processess
Alternatives ⚖️
NA
Additional context 🧬
NA
Enhancement 🚀
Add datasets TableBank (https://github.com/doc-analysis/TableBank) and DocBank (https://github.com/doc-analysis/DocBank)
Motivation 💪
When merging all datasets with labelled table, one could maybe create a dataset of high layout variance
Alternatives ⚖️
Additional context 🧬
Enhancement 🚀
Page class should also return results (e.g. text) when not all possible components of a pipeline are used.
Motivation 💪
Page class should also work for simpler layout detection pipelines
Alternatives ⚖️
Additional context 🧬
Is your feature request related to a problem? Please describe.
Currently, all available models are remotely stored in a google drive, where models have to be uploaded manually. There is no intrinsic way of versioning models, nor does there exist a model card, where users can see what they download.
Describe the solution you'd like
Hugging Face hub is a designated remote storage for models. The library hugginface_hub also offers tools for locally uploading/downloading models, an online catalog as well as services for generating local caches.
Describe alternatives you've considered
Keeping remote storage at google drive.
Additional context
NN
Bug 💥
Incorrect excerpt PubTables-1M dataset info.
_DESCRIPTION = (
"[excerpt from Ajoy Mondal et. all. IIIT-AR-13K: A New Dataset for Graphical Object Detection in \n"
"Documents] ...we release PubTables1M, a dataset of nearly one million tables from PubMed Central Open Access \n"
" scientific articles, with complete bounding box annotations for both table detection and structure \n"
"recognition. In addition to being the largest dataset of its kind, PubTables1M addresses issues such as \n"
" inherent ambiguity and lack of consistency in the source annotations, attempting to provide definitive ground \n"
" truth labels through a thorough canonicalization and quality control process. "
)
Expected behavior 🧮
_DESCRIPTION = (
"[excerpt from Brandon Smock et. all. PubTables-1M: Towards Comprehensive Table Extraction From Unstructured \n"
"Documents] ...we release PubTables1M, a dataset of nearly one million tables from PubMed Central Open Access \n"
" scientific articles, with complete bounding box annotations for both table detection and structure \n"
"recognition. In addition to being the largest dataset of its kind, PubTables1M addresses issues such as \n"
" inherent ambiguity and lack of consistency in the source annotations, attempting to provide definitive ground \n"
" truth labels through a thorough canonicalization and quality control process. "
Screenshots 🖼

Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
Bug 💥
I kept getting errors when I tried to run the notebooks after installing the requirements in my virtual environment. Eventually I got it working with other package versions (see at screenshots section what versions I used) and some additional installations of other packages. Was this just me? Did I do anything wrong?
Expected behavior 🧮
I expected the repo to work when installing all the requirements
Screenshots 🖼
apted==1.0.3
# via deepdoctection (setup.py)
attrs==21.4.0
# via jsonlines
catalogue==2.0.7
# via deepdoctection (setup.py)
certifi==2021.10.8
# via requests
charset-normalizer==2.0.12
# via requests
contourpy==1.0.5
# via matplotlib
cycler==0.11.0
# via matplotlib
distance==0.1.3
# via deepdoctection (setup.py)
filelock==3.6.0
# via huggingface-hub
fonttools==4.37.3
# via matplotlib
huggingface-hub==0.11.0
# via deepdoctection (setup.py)
idna==3.3
# via requests
importlib-metadata==4.11.2
# via deepdoctection (setup.py)
jsonlines==3.0.0
# via deepdoctection (setup.py)
kiwisolver==1.4.4
# via matplotlib
lxml==4.9.1
# via deepdoctection (setup.py)
lxml-stubs==0.4.0
# via deepdoctection (setup.py)
matplotlib==3.6.0
# via pycocotools
mock==4.0.3
# via deepdoctection (setup.py)
networkx==2.7.1
# via deepdoctection (setup.py)
numpy==1.22.3
# via
# contourpy
# deepdoctection (setup.py)
# matplotlib
# opencv-python
# pycocotools
opencv-python==4.5.4.60
# via deepdoctection (setup.py)
packaging==21.3
# via
# deepdoctection (setup.py)
# huggingface-hub
# matplotlib
pillow==9.2.0
# via matplotlib
pycocotools==2.0.5
# via deepdoctection (setup.py)
pyparsing==3.0.7
# via
# matplotlib
# packaging
pypdf2==1.27.9
# via deepdoctection (setup.py)
python-dateutil==2.8.2
# via matplotlib
pyyaml==6.0
# via
# deepdoctection (setup.py)
# huggingface-hub
pyzmq==24.0.1
# via deepdoctection (setup.py)
requests==2.27.1
# via huggingface-hub
six==1.16.0
# via python-dateutil
tabulate==0.8.10
# via deepdoctection (setup.py)
termcolor==2.0.1
# via deepdoctection (setup.py)
tqdm==4.63.0
# via huggingface-hub
types-pyyaml==6.0.8
# via deepdoctection (setup.py)
types-tabulate==0.8.9
# via deepdoctection (setup.py)
types-termcolor==1.1.3
# via deepdoctection (setup.py)
types-tqdm==4.64.6
# via deepdoctection (setup.py)
typing-extensions==4.1.1
# via huggingface-hub
urllib3==1.26.8
# via requests
zipp==3.7.0
# via importlib-metadata
tensorflow==2.10.1
tensorflow-addons==0.18.0
tesseract-ocr
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Bug 💥
Trying to replicate the example in the notebook. After running the following code line:
analyzer = get_dd_analyzer(language="deu")
I get an error message saying:
FileNotFoundError: [Errno 2] No such file or directory: '/usr/local/lib/python3.8/site-packages/deepdoctection/configs/conf_dd_one.yaml'
Expected behavior 🧮
The analyzer will be returned and configured properly
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
I cannot find the directory ./config/ in the site-packages/deepdoctection folder after the installation with
pip install deepdoctection[pt]
Workaround 🌶️
I connected to my docker container and just ran:
git clone https://github.com/deepdoctection/deepdoctection.git
cd deepdoctection
pip install -e .
and then I could proceed with the example notebook provided.
Bug 💥
Output does not print last row when calling str(page.tables[0])
Expected behavior 🧮
Displaying all outputs
Screenshots 🖼
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Bug 💥
FasttextLangDetector need one single line when getting text input. However, Page.get_text() returns text with line breaks.
Expected behavior 🧮
No crash when calling LanguageDetectionService
Is your feature request related to a problem? Please describe.
For native PDF documents it is a lot more natural to extract text using a miner rather than an OCR tool. This might give more accurate results and will avoid heavier tools.
Describe the solution you'd like
There are a lot of PDF miner around. One of the best and most robust tools is pdfminer.six that does not depend on many other libraries.
Adding a PDF miner requires adding an additional attribute to the Image object in order to transport PDF bytes through the pipeline.
Describe alternatives you've considered
Many other tools around.
Additional context
Bug 💥
When cell have to be merged in TableSegmentationRefinementService the merged cell won't be dumped if it is equal to
one of the input cells. (This happens when the iou nms threshold of the cell predictor is not too small and the predictor returns a group the cell where one cell encloses all others).
Expected behavior 🧮
Cell refinement works with different iou settings of the cell predictor.
Is your feature request related to a problem? Please describe.
Describe the solution you'd like
Using Detectron2 as library for model base will resolve both issues. Moreover, as TP and D2 have configs that can be converted into each other (as already done in the direction D2->TP), incorporating D2 for Object Detector related models will increase the usability (both in terms of hardware and DL package) significantly.
Describe alternatives you've considered
Using additional OD libraries as MMDetection are possible. However, the transcription of TP to D2 models will be harder.
Additional context
NA
Enhancement 🚀
The ability to handling skew document image.
Motivation 💪
Ensuring the document image is in a straight position is beneficial for subsequent steps.
Additional context 🧬
There is a package that you can use, https://github.com/phamquiluan/jdeskew
Bug 💥
On Colab, if I try to replicate the CustomPipeline notebook, after installing the dependencies i receive a NoModuleFoundError
Dependencies:
!python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
!pip install deepdoctection[pt]
ModuleNotFoundError Traceback (most recent call last)
in
1 import os
----> 2 from deepdoctection.pipe import TextExtractionService, DoctectionPipe
Desktop (please complete the following information, if any other than the one in the install requirements):
[JoinData] Size check failed for the list of dataflow to be joined!
Can you suggest the reason for this issue ASAP.
Bug 💥
TP Object detector return np array and not a list
Expected behavior 🧮
No Assertion Error
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Is your feature request related to a problem? Please describe.
Currently, this package depends on some third party packages that in turn depend on heavy libraries. E.G pytesseract
relies on pillow even though dd uses opencv-python directly. However, both libraries are only used for loading an image as numpy array. Pillow on the other hand is not directly accessed.
Pytesseract in turn is barely are lightweight wrapper for tesseract and the only functionality is to provide a function for reading an image, call tesseract and return results as dict.
Describe the solution you'd like
Reducing dependencies to wrapper libraries by integrating the functionality main functionality to dd. The following
packages can be make redundant.
With a little more work this also concerns
Describe alternatives you've considered
Integrating the necessary wrapper functionality directly into this package.
Additional context
Add any other context or screenshots about the feature request here.
Bug 💥
xfund_to_image has been applied twice in funsd dataflow mapping
Expected behavior 🧮
Dataflow returns datapoint
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
i want train the model for detection and extraction of tables. I am not sure on how the data should be labeled and the training procedure can you help me with that
Hi, congratulations four great job, it's very good for Document Intelligent Processing.
I'm start using the product in my Linux PC (Ubuntu 20.x) with the pytorch version and CPU (no cuda).
I copied your gradio demo from huggingface space, but i can't download the model "layout/model_final_inf_only.pt" to the cache (but the get_model_list function say yes!). I copied the configs but the problem remains. Also, in other test i used the get_dd_analyzer() function to generate the cache, but that function don't download the model "layout/model_final_inf_only.pt" ,
the dd.ModelDownloadManager.maybe_download_weights_and_configs("layout/model_final_inf_only.pt") function don't download the model
If i run two times the fragment
_DD_ONE = "deepdoctection/configs/conf_dd_one.yaml"
_TESSERACT = "deepdoctection/configs/conf_tesseract.yaml"
dd.ModelCatalog.register("layout/model_final_inf_only.pt",ModelProfile(
name="layout/model_final_inf_only.pt",
description="Detectron2 layout detection model trained on private datasets",
config= "dd/d2/layout/CASCADE_RCNN_R_50_FPN_GN.yaml",
size=[274632215],
tp_model=False,
hf_repo_id=os.environ.get("HF_REPO"),
hf_model_name="model_final_inf_only.pt",
hf_config_file=["Base-RCNN-FPN.yaml", "CASCADE_RCNN_R_50_FPN_GN.yaml"],
categories={"1": dd.names.C.TEXT,
"2": dd.names.C.TITLE,
"3": dd.names.C.LIST,
"4": dd.names.C.TAB,
"5": dd.names.C.FIG},
))
the second time it say the model are registered....but not downloaded.
Can you help me?
Thanks in advance
Ruben
ValueError: Invalid argument to SmartInit: /home/alokraj/.cache/deepdoctection/weights/cell/model-1800000.data-00000-of-00001
This error occurred while running the fine-tuning notebook's last cell
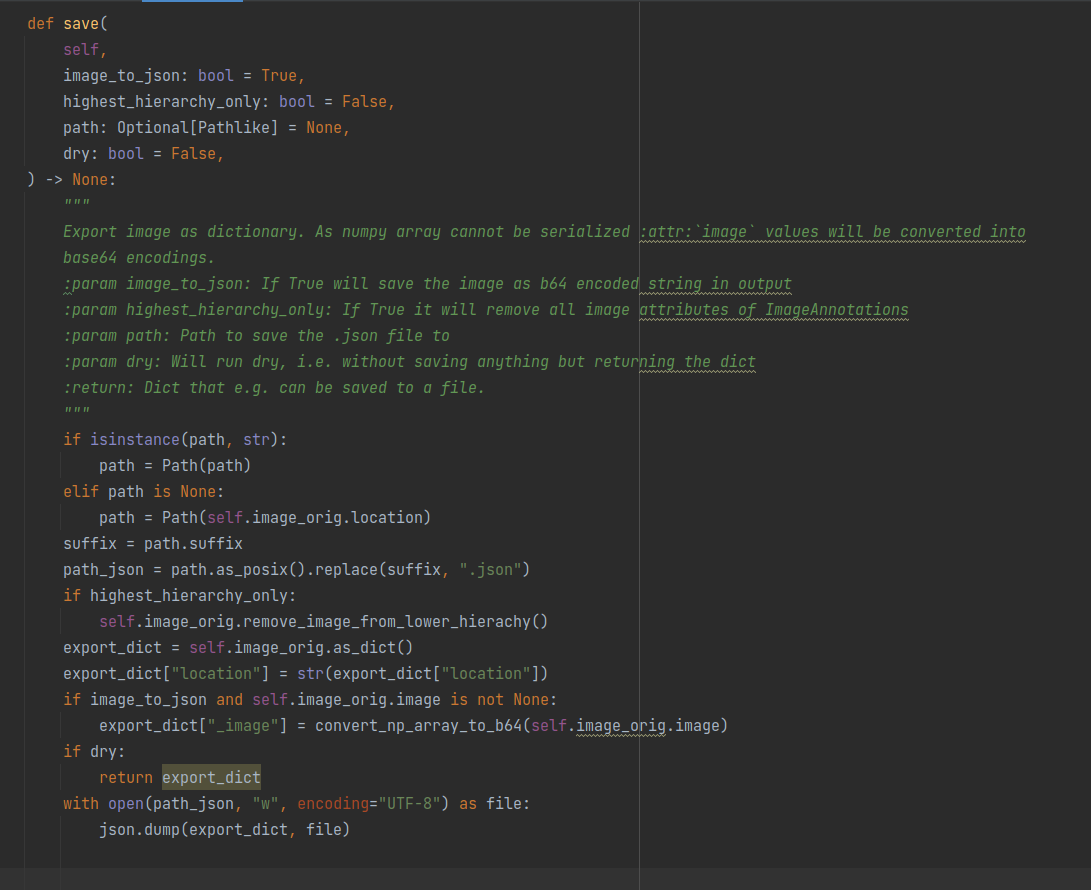
Bug 💥
When putting the 'dry' parameter to True the function save returns None, however, the docstring states that it will return the dictionary without saving anything.
Expected behavior 🧮
I expected the dictionary to be returned instead of None
Screenshots 🖼

this solves the issue:
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
I'm follow step by step instruction installation from source. I try use TensorFlow and PyTorch, with Python 3.8.13 and Python 3.9.13
when all done, i try for running Get_Started.ipynb in folder /deepdoctection/notebooks/.. i get some error.. path for cairo not found
thank you for the support
Bug 💥
After making clone an abstract method in the base class some pipeline components do not instantiate.
Analyzer building fails due to missing clone method in some pipeline component.
Expected behavior 🧮
Analyzer builds without errors
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Bug 💥
The bounding box selection in D2 training and TP training does not follow the convention that it first checks if embedding bounding boxes are available.
Expected behavior 🧮
Bounding boxes in ImageAnnotation must be taken from the embedding dict in the first place and only if image is not available it should be taken from bounding_box. This logic must be implemented everywhere and has to be updated in d2struct and tpstruct.
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Describe the bug
Due to model changes of the analyzer (table recognition) configs and weights do not fit and code crashes .
Expected behavior
Inference of analyzer returns results
Screenshots
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information, if any other than the one in the install req;
Plattform agnostic
Additional context
Add any other context about the problem here.
Bug 💥
Some OCR systems do not guarantee to return words already sorted within a text line.
_reading_lines must sort words by their x-coordinates.
Expected behavior 🧮
TextOrderService return reading order of words correctly for all OCR systems.
Bug 💥
PyPDF2 PdfReadError: Could not read Boolean object
The error is related with
https://stackoverflow.com/questions/47281843/pypdf2-pdfreaderror-could-not-read-boolean-object .
Expected behavior 🧮
Document can be opened
Additional context 🧬
As qpdf is already used in the pdf opening process pipeline get_pdf_file_reader has to be only slightly modified
Enhancement 🚀
Implementing accuracy, f1 score and confusion matrix for sequence and token classifier
Motivation 💪
Reducing dependencies, e.g. sklearn
Alternatives ⚖️
Accuracy, confusion currently use sklearn
Additional context 🧬
Bug 💥
Packaging version 22.0 removed LegacyVersion that is used for typing
Expected behavior 🧮
Error free installation
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Enhancement 🚀
This Issues addresses two enhancements:
) Text line detection comes for free for all text detectors. This information should be transported throughout the pipeline as well.
) To integrate further high performance OCR detectors (e.g. TrOCR) one needs a separate textline detector. Doctr provides a separate model beside some highly accurate text recognition model.
Motivation 💪
Text line detection helps for structuring and ordering text, especially if no previous layout analysis has been applied.
It helps to integrate new OCR models
Alternatives ⚖️
Are there any alternatives you have considered
Additional context 🧬
Screenshots, etc. if relevant
Bug 💥
Docs have not been processed correctly which is why API doc is incomplete.
Expected behavior 🧮
Full docs on RTD
Screenshots 🖼
If possible, please add a screenshot of the error message, if possible
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
Enhancement 🚀
Predictors of external packages have modules in which the model is executed. With the exception of the integrated model from Tensorpack, these modules do not contain any other logic. For this reason, these functions can be transferred to the module of the predictor and the folder structure of the external module can be simplified.
Motivation 💪
With increasing integration of external packages, the complexity of the external module increases less steeply and in particular does not require additional sub modules.
Alternatives ⚖️
Keep status quo
Additional context 🧬
NA
UserWarning: Converting sparse IndexedSlices(IndexedSlices(indices=Tensor("tower0/gradients/tower0/cascade_rcnn_stage2/multilevel_roi_align/concat_grad/sub_2:0", shape=(?,), dtype=int64, device=/device:GPU:0), values=Tensor("tower0/gradients/tower0/cascade_rcnn_stage2/multilevel_roi_align/concat_grad/GatherV2_8:0", shape=(?, 256, 7, 7), dtype=float32, device=/device:GPU:0), dense_shape=Tensor("tower0/gradients/tower0/cascade_rcnn_stage2/multilevel_roi_align/concat_grad/Shape_2:0", shape=(4,), dtype=int32, device=/device:GPU:0))) to a dense Tensor of unknown shape. This may consume a large amount of memory.
Can you suggest something to reduce memory consumption, currently i am using 16GB RAM machine and the kernel is dead in between training. I am using 30 images only (total around 50 MB size).
Enhancement 🚀
Add unilm LayoutLM models to use in separate pipeline components.
Motivation 💪
LayoutLM family naturally fits into this framework
Alternatives ⚖️
Additional context 🧬
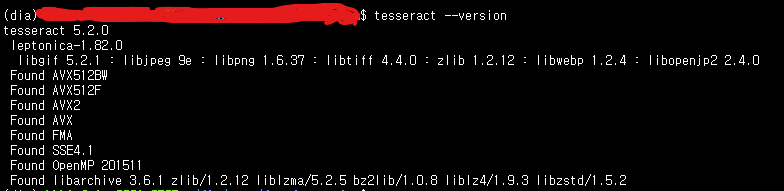
Bug 💥
I went use deedoctection in Anaconda enviroment. So, I downloaded Tesseract used to following command.
$ conda install tesseract
I followed tutorial python script about deepdoctection, and got Tessearact NotFound Error
Screenshots 🖼
Here is my code.

Tesseract command in dia conda enviroment.
Error message
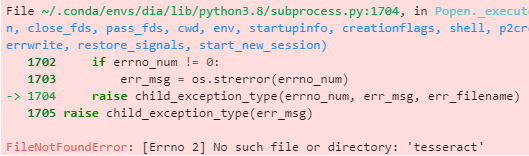
Desktop (please complete the following information, if any other than the one in the install requirements):
Additional context 🧬
If necessary add some context related to the problem
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.