This repository contains source code necessary to reproduce some of the main results in the paper:
Nguyen A, Dosovitskiy A, Yosinski J, Brox T, Clune J. (2016). "Synthesizing the preferred inputs for neurons in neural networks via deep generator networks.". NIPS 29
If you use this software in an academic article, please cite:
@article{nguyen2016synthesizing,
title={Synthesizing the preferred inputs for neurons in neural networks via deep generator networks},
author={Nguyen, Anh and Dosovitskiy, Alexey and Yosinski, Jason band Brox, Thomas and Clune, Jeff},
journal={NIPS 29},
year={2016}
}
For more information regarding the paper, please visit www.evolvingai.org/synthesizing
This code is built on top of Caffe. You'll need to install the following:
- Install Caffe; follow the official installation instructions.
- Build the Python bindings for Caffe
- If you have an NVIDIA GPU, you can optionally build Caffe with the GPU option to make it run faster
- Make sure the path to your
caffe/pythonfolder in settings.py is correct - Install ImageMagick command-line interface on your system.
You will need to download a few models. There are download.sh scripts provided for your convenience.
- The image generation network (Upconvolutional network) from [3]. You can download directly on their website or using the provided script
cd nets/upconv && ./download.sh - A network being visualized (e.g. from Caffe software package or Caffe Model Zoo). The provided examples use these models:
- BVLC reference CaffeNet:
cd nets/caffenet && ./download.sh - BVLC GoogLeNet:
cd nets/googlenet && ./download.sh - AlexNet CNN trained on MIT Places dataset:
cd nets/placesCNN && ./download.sh
- BVLC reference CaffeNet:
Settings:
- Paths to the downloaded models are in settings.py. They are relative and should work if the
download.shscripts run correctly. - The paths to the model being visualized can be overriden by providing arguments
net_weightsandnet_definitionto act_max.py.
The main algorithm is in act_max.py, which is a standalone Python script; you can pass various command-line arguments to run different experiments. Basically, to synthesize a preferred input for a target neuron h (e.g. the “candle” class output neuron), we optimize the hidden code input (red) of a deep image generator network to produce an image that highly activates h.
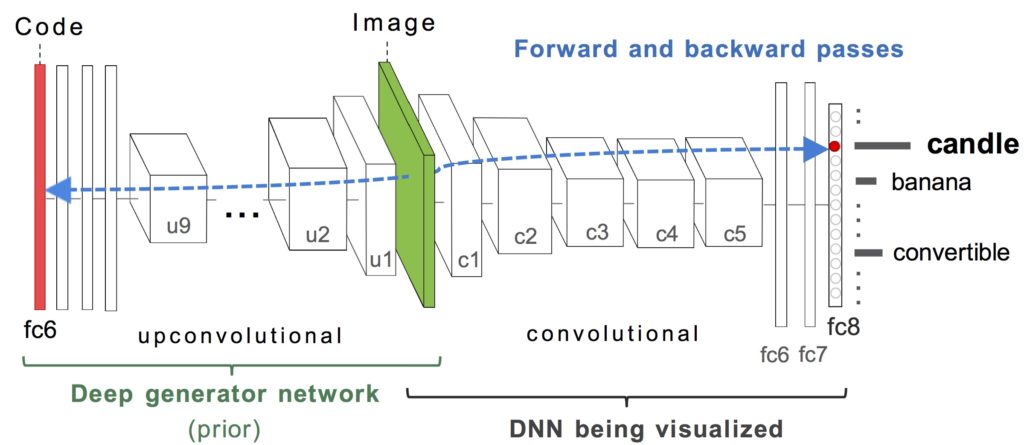
We provide here four different examples as a starting point. Feel free to be creative and fork away to produce even cooler results!
1_activate_output.sh: Optimizing codes to activate output neurons of the CaffeNet DNN trained on ImageNet dataset. This script synthesizes images for 5 example neurons.
- Running
./1_activate_output.shproduces this result:

2_activate_output_placesCNN.sh: Optimizing codes to activate output neurons of a different network, here AlexNet DNN trained on MIT Places205 dataset. The same prior used here produces the best images for AlexNet architecture trained on different datasets. It also works on other architectures but the image quality might degrade (see Sec. 3.3 in our paper).
- Running
./2_activate_output_placesCNN.shproduces this result:

3_start_from_real_image.sh: Instead of starting from a random code, this example starts from a code of a real image (here, an image of a red bell pepper) and optimizes it to increase the activation of the "bell pepper" neuron.
- Depending on the hyperparameter settings, one could produce images near or far the initialization code (e.g. ending up with a green pepper when starting with a red pepper).
- The
debugoption in the script is enabled allowing one to visualize the activations of intermediate images. - Running
./3_start_from_real_image.shproduces this result:

Optimization adds more green leaves and a surface below the initial pepper
4_activate_hidden.sh: Optimizing codes to activate hidden neurons at layer 5 of the DeepScene DNN trained on MIT Places dataset. This script synthesizes images for 5 example neurons.
- Running
./4_activate_hidden.shproduces this result:

From left to right are units that are semantically labeled by humans in [2] as:
lighthouse, building, bookcase, food, and painting
- This result matches the conclusion that object detectors automatically emerge in a DNN trained to classify images of places [2]. See Fig. 6 in our paper for more comparison between these images and visualizations produced by [2].
5_activate_output_GoogLeNet.sh: Here is an example of activating the output neurons of a different architecture, GoogLeNet, trained on ImageNet. Note that the learning rate used in this example is different from that in the example 1 and 2 above.
- Running
./5_activate_output_GoogLeNet.shproduces this result:

- To visualize your own model you should search for the hyperparameter setting that produces the best images for your model. One simple way to do this is sweeping across different parameters (see code setup in the provided example bash scripts).
- For even better result, one can train an image generator network to invert features from the model being visualized instead of using the provided generator (which is trained to invert CaffeNet). However, training such generator may not be easy for many reasons (e.g. inverting very deep nets like ResNet).
Note that the code in this repository is licensed under MIT License, but, the pre-trained models used by the code have their own licenses. Please carefully check them before use.
- The image generator networks (in nets/upconv/) are for non-commercial use only. See their page for more.
- See the licenses of the models that you visualize (e.g. DeepScene CNN) before use.
Please feel free to drop me a line or create github issues if you have questions/suggestions.
[1] Yosinski J, Clune J, Nguyen A, Fuchs T, Lipson H. "Understanding Neural Networks Through Deep Visualization". ICML 2015 Deep Learning workshop.
[2] Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A. "Object detectors emerge in deep scene cnns". ICLR 2015.
[3] Dosovitskiy A, Brox T. "Generating images with perceptual similarity metrics based on deep networks". arXiv preprint arXiv:1602.02644. 2016





























































































































