This repo is not actively maintained and has been archived. For an in-development replacement, please head over to swift-transformers!
Swift Core ML implementations of Transformers: GPT-2, DistilGPT-2, BERT, DistilBERT, more coming soon!
This repository contains:
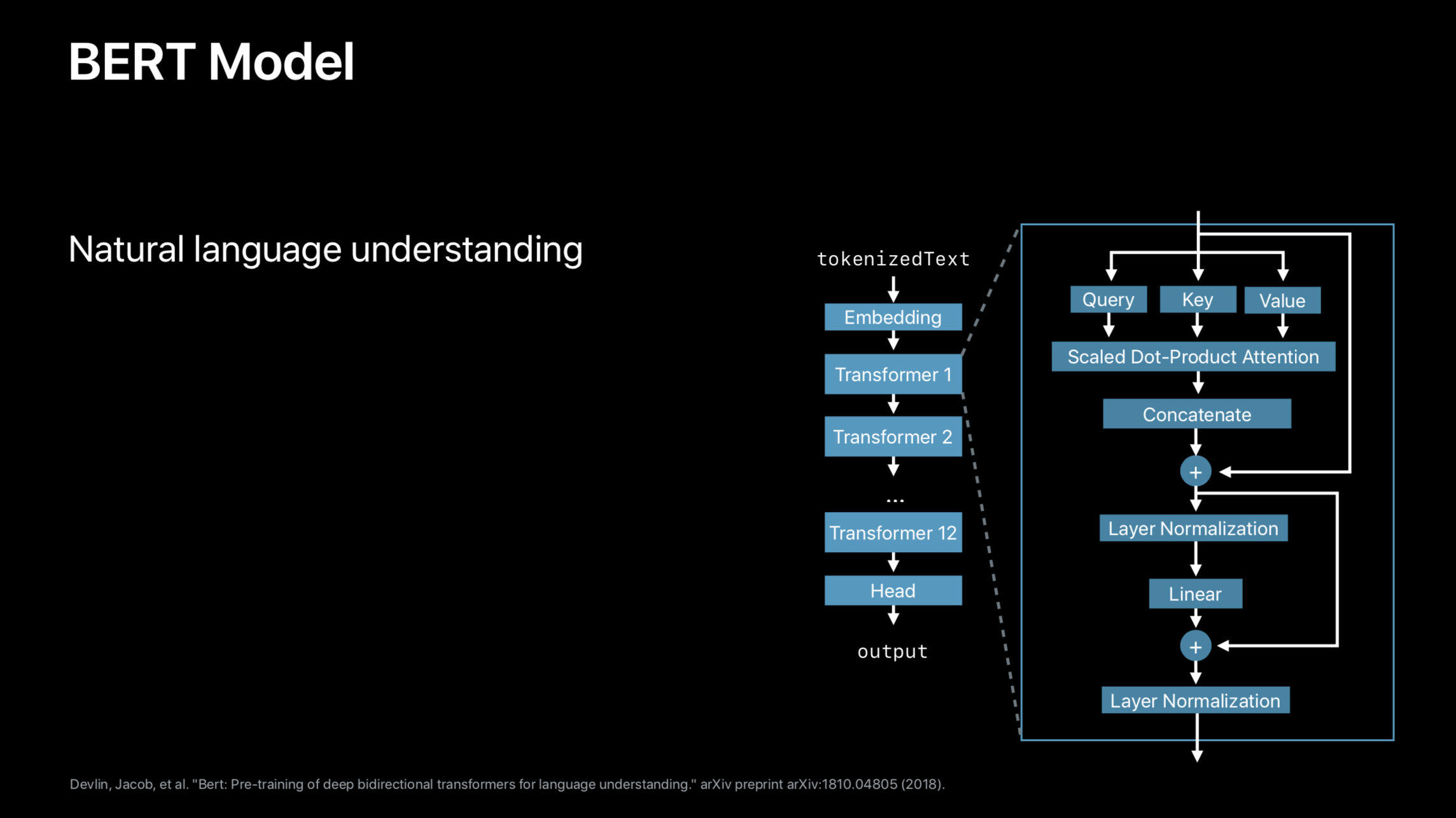
- For BERT and DistilBERT:
- pretrained Google BERT and Hugging Face DistilBERT models fine-tuned for Question answering on the SQuAD dataset.
- Swift implementations of the BERT tokenizer (
BasicTokenizerandWordpieceTokenizer) and SQuAD dataset parsing utilities. - A neat demo question answering app.
- For GPT-2 and DistilGPT-2:
- a conversion script from PyTorch trained GPT-2 models (see our
transformersrepo) to CoreML models. - The GPT-2 generation model itself, including decoding strategies (greedy and TopK are currently implemented) and GPT-2 Byte-pair encoder and decoder.
- A neat demo app showcasing on-device text generation.
- a conversion script from PyTorch trained GPT-2 models (see our
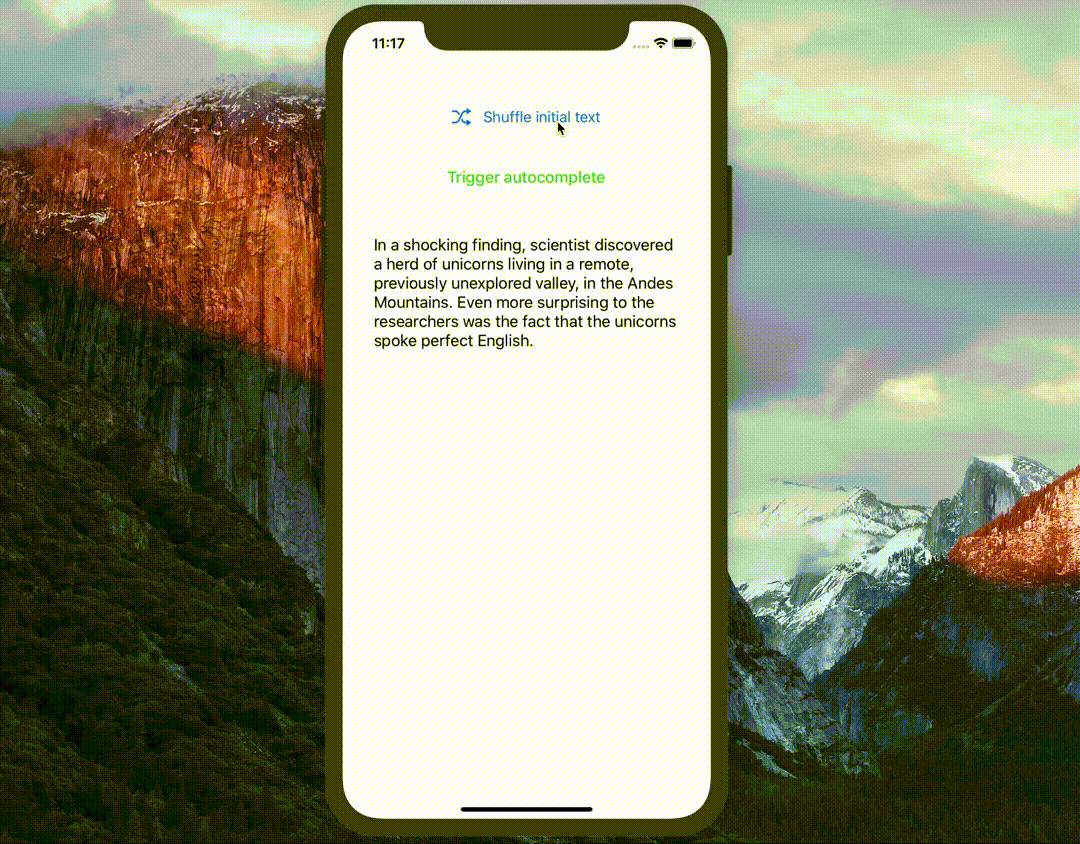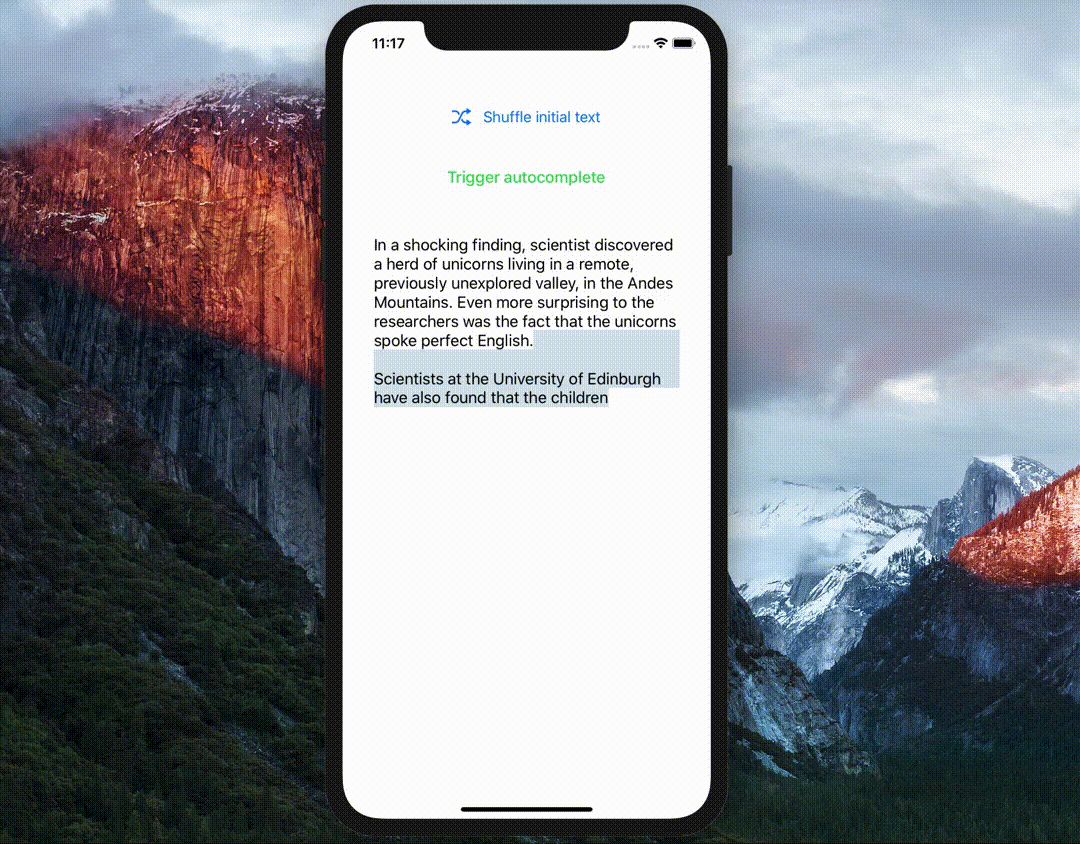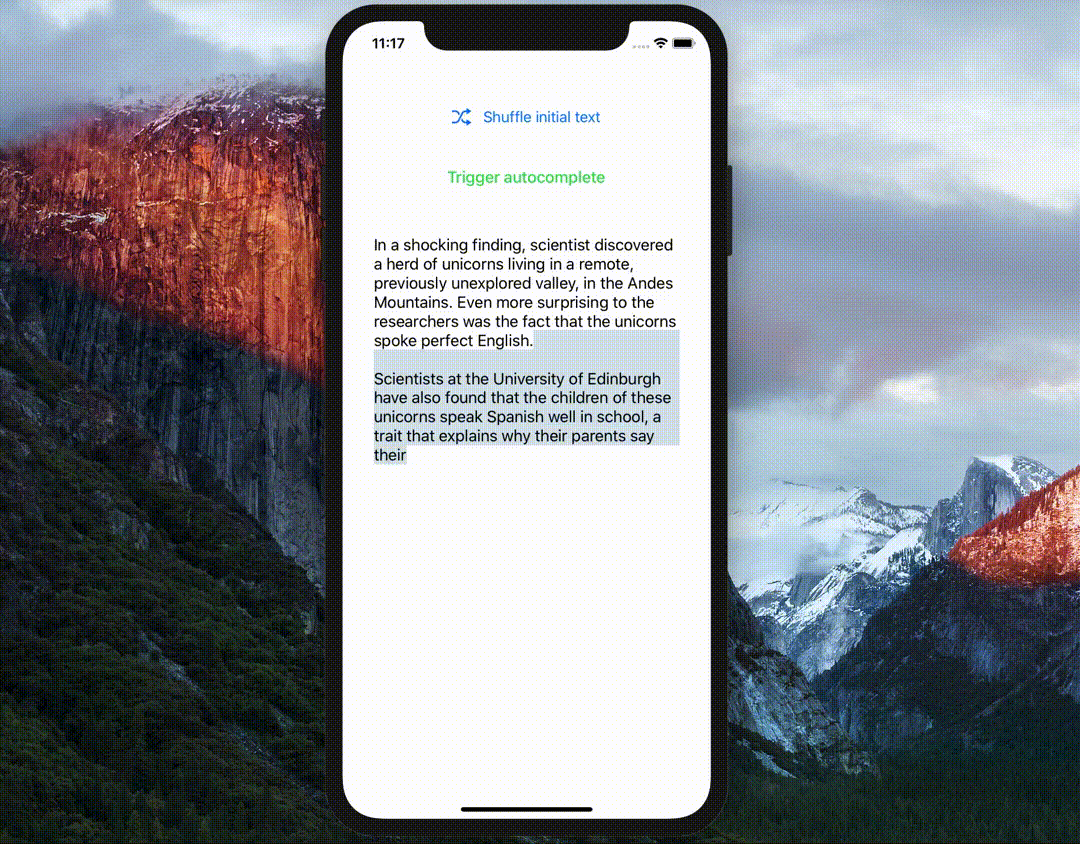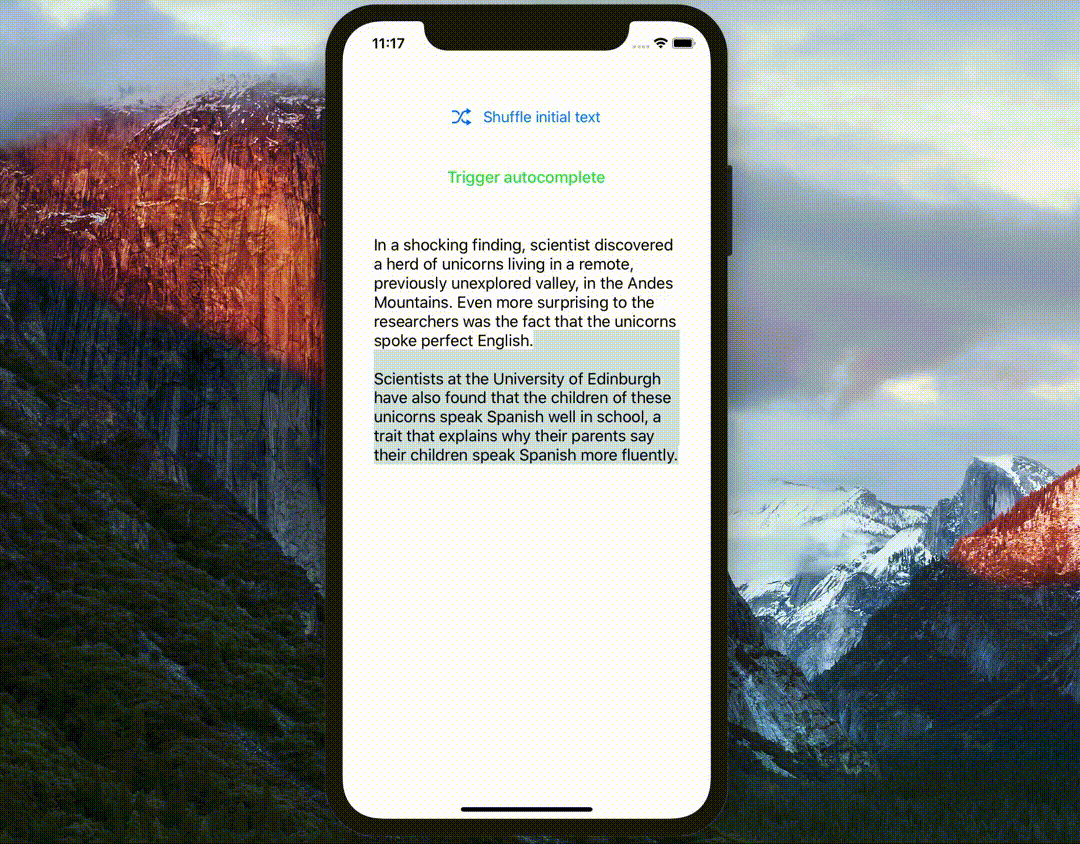
Unleash the full power of text generation with GPT-2 on device!!
The BERTSQUADFP16 Core ML model was packaged by Apple and is linked from the main ML models page. It was demoed at WWDC 2019 as part of the Core ML 3 launch.
The DistilBERT Core ML models were converted from 🤗/transformers exports using the scripts in this repo.

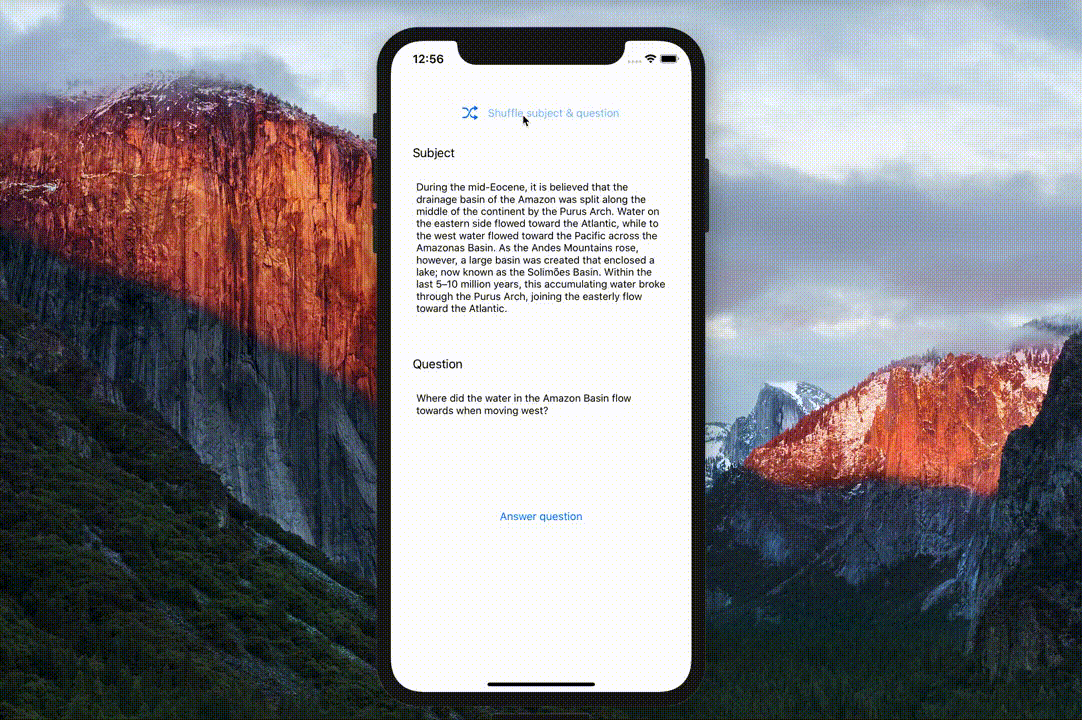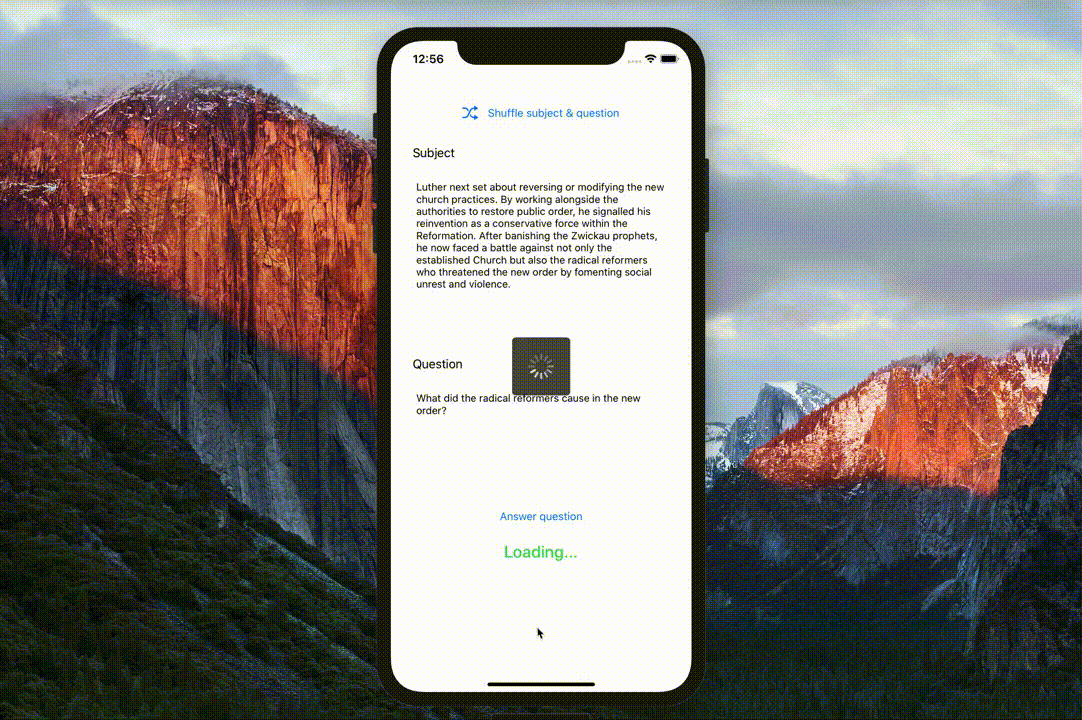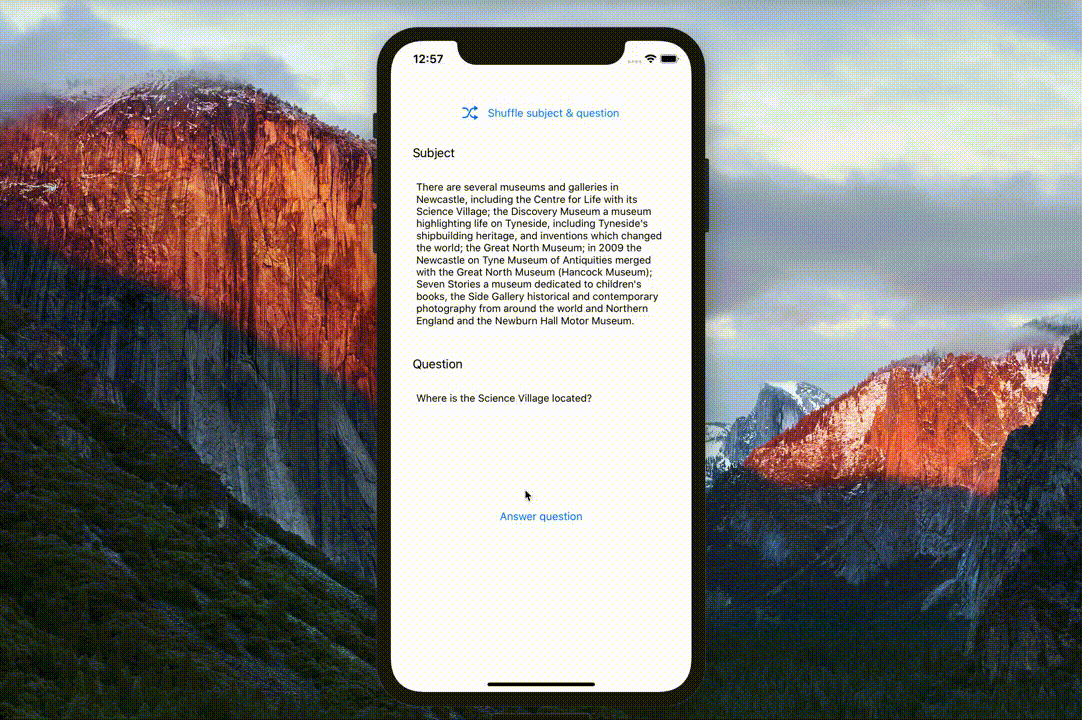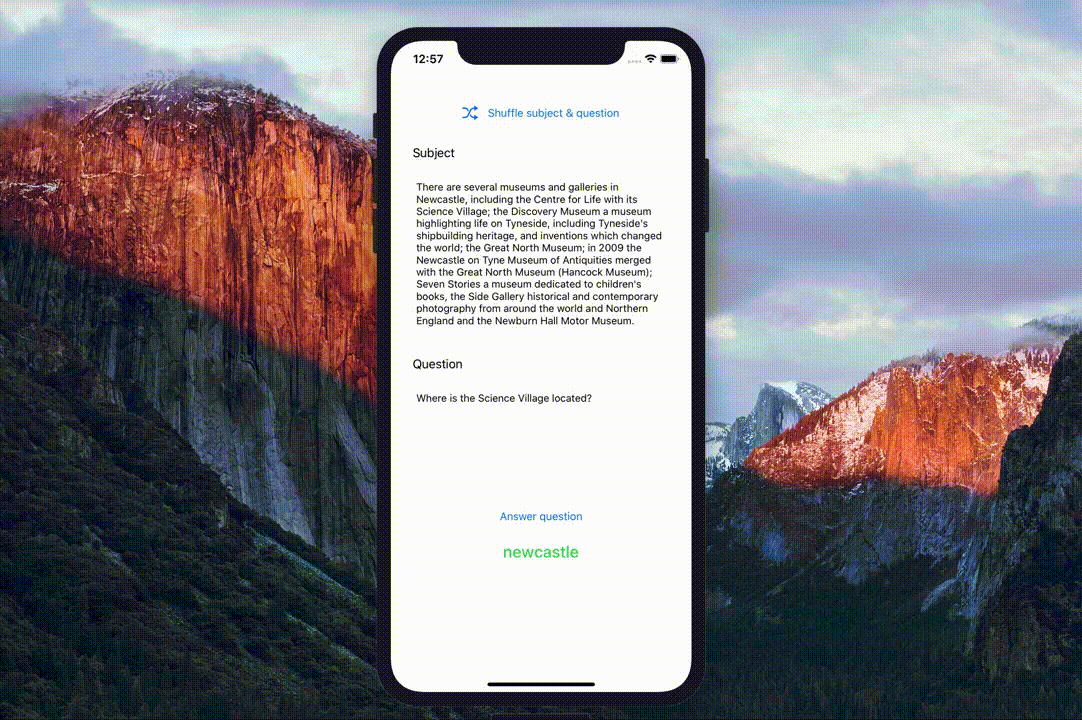
Apple demo at WWDC 2019

full video here
We use git-lfs to store large model files and it is required to obtain some of the files the app needs to run.
See how to install git-lfson the installation page















































































































































































































