influxdata / influxdb-client-python Goto Github PK
View Code? Open in Web Editor NEWInfluxDB 2.0 python client
Home Page: https://influxdb-client.readthedocs.io/en/stable/
License: MIT License
InfluxDB 2.0 python client
Home Page: https://influxdb-client.readthedocs.io/en/stable/
License: MIT License



![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




















































































































































for loopI'm trying to deploy this API to a lambda function. And there two issues with having numpy as a dependency:
It would be great to have a lite API that can work without them as dependencies.
one column of my dataframe is based on numpy.int64.
isinstance(value, int) will not capture it.
type(value)
Out[4]: numpy.int64
isinstance(value, int)
Out[5]: False
related to this one
which suggest to use isinstance(..., np.integer)
When writing lines with client.write() than many times I do not get any output (function returns None) but the line was not written to influx and have no clue why. So is there a way to get some more info about the result of the action?
Todo:
batch_sizeflush_intervaljitter_intervalretry_intervalThis function here
assumes a passed datetime object to be in UTC format if no timezone is specified. I find this to be highly misleading. From the moment on I set the local timezone when I install an OS I want my system to accept local timezone data from me if I don't specify otherwise.Similar functionality like in java client:
influxdata/influxdb-client-java#35
CSV parsing fails to properly parse the following into 4 tables:
#group,false,false,true,true,true,true,false,false,true
#datatype,string,long,string,string,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,double,string
#default,t1,,,,,,,,
,result,table,_field,_measurement,_start,_stop,_time,_value,tag
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:20:00Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:21:40Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:23:20Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:25:00Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:26:40Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:28:20Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:30:00Z,2,test1
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:20:00Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:21:40Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:23:20Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:25:00Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:26:40Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:28:20Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:30:00Z,2,test2
#group,false,false,true,true,true,true,false,false,true
#datatype,string,long,string,string,dateTime:RFC3339,dateTime:RFC3339,dateTime:RFC3339,double,string
#default,t2,,,,,,,,
,result,table,_field,_measurement,_start,_stop,_time,_value,tag
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:20:00Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:21:40Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:23:20Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:25:00Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:26:40Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:28:20Z,2,test1
,,0,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:30:00Z,2,test1
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:20:00Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:21:40Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:23:20Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:25:00Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:26:40Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:28:20Z,2,test2
,,1,value,python_client_test,2010-02-27T04:48:32.752600083Z,2020-02-27T16:48:32.752600083Z,2020-02-27T16:30:00Z,2,test2
To reproduce:
python_client_test,tag=test1 value=2 1582820400000000000
python_client_test,tag=test1 value=2 1582820500000000000
python_client_test,tag=test1 value=2 1582820600000000000
python_client_test,tag=test1 value=2 1582820700000000000
python_client_test,tag=test1 value=2 1582820800000000000
python_client_test,tag=test1 value=2 1582820900000000000
python_client_test,tag=test1 value=2 1582821000000000000
python_client_test,tag=test2 value=2 1582820400000000000
python_client_test,tag=test2 value=2 1582820500000000000
python_client_test,tag=test2 value=2 1582820600000000000
python_client_test,tag=test2 value=2 1582820700000000000
python_client_test,tag=test2 value=2 1582820800000000000
python_client_test,tag=test2 value=2 1582820900000000000
python_client_test,tag=test2 value=2 1582821000000000000
c = InfluxDBClient(...)
query = "%s\n%s" % (
'from(bucket: "tests") |> range(start: -10y) |> filter(fn: (r) => r._measurement == "python_client_test") |> map(fn: (r) => ({ r with _value: r._value })) |> yield(name: "t1")',
'from(bucket: "tests") |> range(start: -10y) |> filter(fn: (r) => r._measurement == "python_client_test") |> map(fn: (r) => ({ r with _value: r._value })) |> yield(name: "t2")',
)
result = list(c.query_api().query(query))
print(len(result))
This should print out 4, but prints out 3.
The third table contains data from both 3rd and 4th table.
Issue reported in InfluxDB Community Slack (https://influxcommunity.slack.com/archives/CH8RV8PK5/p1582899056015100):
Collecting ciso8601>=2.1.1
Using cached ciso8601-2.1.3.tar.gz (15 kB)
Installing collected packages: ciso8601, influxdb-client
Running setup.py install for ciso8601 ... error
ERROR: Command errored out with exit status 1:
command: 'c:\users\cmic\appdata\local\programs\python\python38-32\python.exe' -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\cmic\\AppData\\Local\\Temp\\pip-install-ssomainb\\ciso8601\\setup.py'"'"'; __file__='"'"'C:\\Users\\cmic\\AppData\\Local\\Temp\\pip-install-ssomainb\\ciso8601\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record 'C:\Users\cmic\AppData\Local\Temp\pip-record-dv948eri\install-record.txt' --single-version-externally-managed --compile --install-headers 'c:\users\cmic\appdata\local\programs\python\python38-32\Include\ciso8601'
cwd: C:\Users\cmic\AppData\Local\Temp\pip-install-ssomainb\ciso8601\
Complete output (12 lines):
running install
running build
running build_py
package init file 'ciso8601\__init__.py' not found (or not a regular file)
creating build
creating build\lib.win32-3.8
creating build\lib.win32-3.8\ciso8601
copying ciso8601\__init__.pyi -> build\lib.win32-3.8\ciso8601
copying ciso8601\py.typed -> build\lib.win32-3.8\ciso8601
running build_ext
building 'ciso8601' extension
error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": https://visualstudio.microsoft.com/downloads/
It seems that InfluxDB Python package depends on ciso8601, which requires compilation.
It seems that running pip install ciso8601 without Visual Studio, with VS 2019 and VS 2015 all fails to compile ciso8601.
The package should have clearer instructions on how it should be installed on Windows.
Also, perhaps it is possible to not use ciso8601 and use built-in datetime features if the said package is not available? So that if ciso8601 is present, it is used, but otherwise it's still possible to use the client?
I've been encountering occasional errors with a really simple python program to write batches of points. I thought my usage was more-or-less very basic, so I'm not clear why this is happening. Perhaps the batching machinery is improperly creating empty batches and dropping points?
I get many log messages like the following:
The batch item wasn't processed successfully because: (400)
Reason: Bad Request
HTTP response headers: HTTPHeaderDict({'Date': 'Sat, 11 Apr 2020 23:14:18 GMT', 'Content-Type': 'application/json; charset=utf-8', 'Content-Length': '54', 'Connection': 'keep-alive', 'Strict-Transport-Security': 'max-age=15724800; includeSubDomains', 'x-platform-error-code': 'invalid'})
HTTP response body: {"code":"invalid","message":"writing requires points"}
Observe how the chronograf.csv data is missing some values like (0, 9, 27, 30, 36, etc).
I've attached some sample code, sample local output, and a sample CSV exported from InfluxDB explorer UI.
Also attached in this Gist for nice formatting.
SampleCode.py.txt
LocalOutput.txt
2020-04-11-16-47_chronograf_data.csv.txt
Configuration Info:
InfluxDB version: InfluxDB Cloud 2.0
influxdb_client python module version: 1.5.0
Python version: 3.7.3
OS: Raspbian Linux (Buster)
The clients should support compress queries and write body after enable gzip:
from influxdb2.client.influxdb_client import InfluxDBClient
_db_client = InfluxDBClient(url="http://localhost:9999/api/v2", token="my-token", org="my-org", enable_gzip=True)Hello everybody,
In the current beta release of Influxdb 2, I have built a time series database for 11 zones (tag). Each zone contains a float load value (field) over the period from 01-2006 to 02-2020 in 5 minute intervals. Each zone therefore contains 1489536 load values.
With the Influx Data Explorer, the following query of the data within "Zone 1" including the time for printing the curve takes less than 3 seconds.
query = 'from (bucket: "my_bucket")'
'|> range (start: -13mo, stop: -1mo)'
'|> filter (fn: (r) => r._measurement == "my_measurement")'
'|> filter (fn: (r) => r.Zone == "Zone1")'
For the identical query via the python influxdb interface the following program line
result = client.query_api (). query (org = org, query = query)
requires 63 seconds.
According to your experience what measures have to be taken to bring the response time to the order of 3 seconds?
best regards JS
Test for line protocol:
https://github.com/influxdata/influxdb-client-python-pandas/blob/master/test_line_protocol.py
The InfluxDB treats NaNs as invalid input => we should skip these fields.
When using a url without a trailing slash, everything works fine:
client = InfluxDBClient(url="https://us-west-2-1.aws.cloud2.influxdata.com", token=token, org=org, debug=True)
But when adding a trailing slash to the url:
client = InfluxDBClient(url="https://us-west-2-1.aws.cloud2.influxdata.com/", token=token, org=org, debug=True)
the error that comes back is HTTP response body: {"code":"not found","message":"path not found"} when I use InfluxDB cloud.
For localhost, without a slash, i get a 200, but with a slash, i get a 204.
IMO, we should detect and trim the trailing slash from the connection urls.
Using python pandas. Version 1 i used this:
def dbpop_influx(data, dbname, measurement, columns):
## constants:
dbclient = DataFrameClient(host='localhost', port=8086, username='root', password='root', database=dbname)
n_import_chunks = math.ceil(len(data) / 10000)
data_chunks = np.array_split(data, n_import_chunks)
for d in data_chunks:
dbclient.write_points(d, measurement, tag_columns = columns, protocol = 'line')Takes 29 seconds (was looking to improve that speed with multiprocessing)
Version 2 i used this:
_client = InfluxDBClient(url="http://localhost:9999", token=token, org="org")
_write_client = _client.write_api(write_options=WriteOptions(batch_size=10000,
flush_interval=10_000,
jitter_interval=0,
retry_interval=5_000))
start = time.time()
_write_client.write('data', record=imp_dat[0], data_frame_measurement_name='coinmarketcap_ohlcv',
data_frame_tag_columns=['quote_asset','base_asset'])
print(time.time() - start)this takes 118 seconds...
data looks like:

While using _write_client.write method, every write is setting _time to January 1, 1970, 00:00:00 at UTC irrespective of value passed.
sample code
in_client = InfluxDBClient(url=URL, token=TOKEN, org=my_org, debug=True)
_write_client = in_client.write_api(write_options=WriteOptions(batch_size=500,
flush_interval=10_000,
jitter_interval=2_000,
retry_interval=5_000))
_write_client.write(bucket_id, my_org,[f'pollution_test,tag_name=tag_val pollution_level="HIGH" {int(time.time())}', f'pollution_test,tag_name=tag_val pollution_level="LOW" {int(time.time())}'])
InfluxDB version: e.g. 1.7.9
InfluxDB-python version: e.g. 5.2.3
Python version: 3.7.4
Operating system version: macOS 10.14.5
I cannot seem to connect to my cloud database. It works ok for a local db.
Code is:
import codecs
from datetime import datetime
from influxdb_client import WritePrecision, InfluxDBClient, Point
from influxdb_client.client.write_api import SYNCHRONOUS
url = "https://eu-central-1-1.aws.cloud2.influxdata.com"
token = "eJfb567aSoJnoDZJRaTI48lgzafILzOEaW70CEQqStin4xm9mboyYQO7dLJWVwRBXyLbrje9nvI6aXMJN1HlCg=="
bucket = "Keithley2410"
org = "[email protected]"
user= "dervan"
password = "something"
client = InfluxDBClient(url=url, user=user, token=token, password=password)
Error is:
TypeError: init() got an unexpected keyword argument 'user'
If I use:
client = InfluxDBClient(url=url, token=token)
I get this error:
HTTP response body: {"code":"forbidden","message":"insufficient permissions for write"}
That bucket does have read/write permissions.
Any help would be great.
Paul
Refactor #37
This is not necessarily the fault of the library, but documentation is lacking on how to properly find and use information to connect to the InfluxData Cloud instances.
Please provide some resources for this.
I called create_bucket() specifying only "bucket_name", and it returned these:
Traceback (most recent call last):
File "utils.py", line 422, in
influx = InfluxDB(url="[masked]", token=token, org="meetaco_org", bucket="a")
File "utils.py", line 355, in init
self.buckets_api.create_bucket(bucket_name=self.bucket)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/client/bucket_api.py", line 43, in create_bucket
return self._buckets_service.post_buckets(post_bucket_request=bucket)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/service/buckets_service.py", line 1302, in post_buckets
(data) = self.post_buckets_with_http_info(post_bucket_request, **kwargs) # noqa: E501
File "/usr/local/lib/python3.7/site-packages/influxdb_client/service/buckets_service.py", line 1383, in post_buckets_with_http_info
collection_formats=collection_formats)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/api_client.py", line 339, in call_api
_preload_content, _request_timeout)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/api_client.py", line 170, in __call_api
_request_timeout=_request_timeout)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/api_client.py", line 382, in request
body=body)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/rest.py", line 278, in POST
body=body)
File "/usr/local/lib/python3.7/site-packages/influxdb_client/rest.py", line 231, in request
raise ApiException(http_resp=r)
influxdb_client.rest.ApiException: (400)
Reason: Bad Request
HTTP response headers: HTTPHeaderDict({'Content-Type': 'application/json; charset=utf-8', 'X-Platform-Error-Code': 'invalid', 'Date': 'Sun, 03 May 2020 20:38:06 GMT', 'Content-Length': '97'})
HTTP response body: {
"code": "invalid",
"message": "failed to unmarshal json: id must have a length of 16 bytes"
}
Is this a bug?
In swagger openapi generator "servers" element is not supported.
/health:
servers:
- url: /
get:
operationId: GetHealth
Instead of /health is client forcing to use /api/v2/health
OpenAPITools/openapi-generator#1361
We need to fix this in custom influx-python generator.
When running Unittest on the following minimal example of code, I get a Warning that not all resources are closed.
import unittest
import os
from influxdb_client import InfluxDBClient
import tracemalloc
tracemalloc.start()
class InfluxTest(unittest.TestCase):
def setUp(self) -> None:
self.client = InfluxDBClient(url=os.environ.get("INFLUX_URL"),
token=os.environ.get("INFLUX_TOKEN"))
self.bucket_api = self.client.buckets_api()
def tearDown(self) -> None:
self.client.__del__()
del self.bucket_api
def test_connection(self):
self.bucket_api.find_buckets().to_dict()When I use other APIs like the query_api, I don't get that warning. Does it have something to do with the bucket API not having a __del__() method?
This is the warning I get (I replaced my ip with xxxx):
ResourceWarning: unclosed <socket.socket fd=5, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('x.x.x.x', 50040), raddr=('x.x.x.x', 9999)>
del self.bucket_api
Object allocated at (most recent call last):
File "/Users/myuser/opt/anaconda3/envs/myenv/lib/python3.7/site-packages/urllib3/util/connection.py", lineno 65
sock = socket.socket(af, socktype, proto)`I'm using this library in my project, but the dependency on ciso8601 is really painful. Now my docker builds need to install GCC and pythen-dev in order to satisfy pipenv install as part of my docker builds. This blows put the size of my docker images, and significantly increases build times.
It also means its harder for people to contribute to my project as it makes their local development environment more complex.
I don't really care about date-parsing speed in my case. I would suggest having some option that doesn't depend on ciso8601.
InfluxDBClient org parameter is documented as being the default for the query and write api, however only the QueryAPI client actually does this. The WriteAPI client requires the org to be specified.
influxdb-client-python/influxdb_client/client/query_api.py
Lines 34 to 35 in 82ee030
Hello,
I just downloaded influxdb-client-python (1.3.0) from PyPi (https://pypi.org/project/influxdb-client/#files) in order to integrate it one of my project using buildroot.
It appears the archive does not include all the files (requirements.txt for example)

I would like to integrate this python package in buildroot to be able to build it on one of my project. For now I will get the source directly from github but it could be nice to have all the sources on pypi.org
Please let me know if you need anything
hello, i am having trouble writing to my cloud database instance, but when i run the: write_api.write(bucket=bucket, org=org, record=rec)
i get a connection error, which reads
The batch item wasn't processed successfully because: HTTPConnectionPool(host='localhost', port=9999): Max retries exceeded with url: /api/v2/write?org=org&bucket=bucket&precision=ns (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7ff8c9a46ac1>: Failed to establish a new connection: [Errno 111] Connection refused',))
Python project layout cleanup:
Add support to write data serialized in byte array.
Hi,
Just started using the Python client. If wrong credentials are passed to the client and a query is made, the client returns a wrong exception as below -
File "D:\dev\Code\influxdb.py", line 108, in query_from_influx
return client.query_api().query_data_frame(query=query, org=organization_id)
File "C:\Users\bluee\AppData\Roaming\Python\Python37\site-packages\influxdb_client\client\query_api.py", line 116, in query_data_frame
_dataFrames = list(_parser.generator())
File "C:\Users\bluee\AppData\Roaming\Python\Python37\site-packages\influxdb_client\client\flux_csv_parser.py", line 48, in generator
yield from parser._parse_flux_response()
File "C:\Users\bluee\AppData\Roaming\Python\Python37\site-packages\influxdb_client\client\flux_csv_parser.py", line 87, in _parse_flux_response
raise FluxCsvParserException("Unable to parse CSV response. FluxTable definition was not found.")
influxdb_client.client.flux_csv_parser.FluxCsvParserException: Unable to parse CSV response. FluxTable definition was not found.
Instead, I believe that while creating the client, it should check whether it is able to connect with the specified credentials instead of trying to parse the response in the query down the line.
hi, all. i'm new to influxdb and i'm trying to connect to my cloud instance using python (3.6.8). but before i do that i have to install certain packages according to the documentation, one of which being the influxdb-client (pip install influxdb-client)
but i get this error:
Could not find a version that satisfies the requirement influxdb-client (from versions: )
No matching distribution found for influxdb-client
how can i solve this? #question
Not sure how you want to structure tests, but here it is:
Test for build_flux_query:
https://github.com/influxdata/influxdb-client-python-pandas/blob/master/test_flux_query.py
If you are doing research that can be divided into stages, then you may want to save these stages in InfluxDV and display them in charts later. I found "Annotation" as well tools for that. But no idea how to set Annotation pin or annotation window with influxdb-client-python? I want to get result like shown on screenshot below:
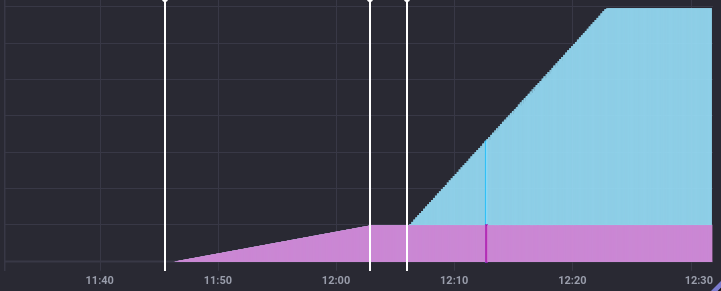
Could you please help me with set annotation pin and annotation window.
I have written python script in that I am collecting data from spreadsheet and making list of json data that will be json object that have list of json data. I have configured bucket, organisation, token. And tried to insert DB but it is not inserting into DB and even I am not getting error into that
Please find below my code and kindly help me where I am missing:
#!/opt/anaconda3/bin/python3
from influxdb_client import InfluxDBClient
from influxdb_client.client.write_api import ASYNCHRONOUS
import random
import json
from datetime import datetime
import pandas as pd
import logging
logging.basicConfig(filename='/InfluxDB/test.log', format='%(filename)s: %(message)s',level=logging.DEBUG)
excel_data_df = pd.read_excel('/RouterSwitchData.xlsx')
json_data = json.loads(excel_data_df.to_json(orient='records'))
series=[]
counter=0
json_body={}
for item in json_data:
current_traffic_signal = random.uniform(1.00,8.00)
json_body = {
"measurement": "devicelink",
"tags": {
"devicename": item["DeviceName"],
"device_circle": item["Circle"],
"device_subcircle":item["SubCircle"],
},
"time": datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f"),
"fields": {
"device_name": item["DeviceName"],
"device_ip_address":item["IP_Address_Device"],
"device_port":item["port"],
"device_circle":item["Circle"],
"device_subcircle":item["SubCircle"],
"neighbour_device_name":item["Neighbour_Device"],
"neighbour_device_ip_address":item["IP_Address_Neighbour_Dev"],
"neighbour_device_port": item["Neighbour_dev_port"],
"neighbour_device_circle":item["Neighbour_Circle"],
"neighbour_device_subcircle":item["Neighbour_subcircle"],
"device_link_capacity":item["capacity_of_link(gig/sec)"],
"device_threshold%":item["Threshold(%)"],
"current_taffic_signal":(current_traffic_signal),
"current_traffic_rate %":((current_traffic_signal/int(item['capacity_of_link(gig/sec)']))*100)
}
}
series.append(json_body)
#jsondata= json.dumps(series)
counter=counter+1
print("Total record : ",counter)
URL="http://localhost:9999"
TOKEN=$TOKEN
ORG="analytics"
BUCKET="DeviceAnalysis"
client = InfluxDBClient(url=URL, token=TOKEN, org=ORG)
write_api = client.write_api(write_options=ASYNCHRONOUS)
datasave = write_api.write(BUCKET, ORG, series) #Writing to InfluxDB
print("DB Written : ",datasave)
The default user agent should be influxdb-client-python/<VERSION>
It will be useful for backward compatibility:
I am finding the python client to be very very slow
I'm querying the data using python as follows, which takes about 20min to execute
result = query_api.query_data_frame('from(bucket: "testing")'
'|> range(start: 2020-02-19T23:30:00Z, stop: now())'
'|> filter(fn: (r) => r._measurement == "awair-api")'
, org=credentials.org)I run the same command using a shell script which extracts the data in about 6 seconds
curl https://us-west-2-1.aws.cloud2.influxdata.com/api/v2/query?[email protected] -XPOST -sS \
-H 'Authorization: Token tokencode==' \
-H 'Accept: application/csv' \
-H 'Content-type: application/vnd.flux' \
-d 'from(bucket:"testing") |> range(start: 2020-02-19T23:30:00Z, stop: now()) |> filter(fn: (r) => r._measurement == "awair-api")' >> test.csvIf a user sets up the client with an org, they should not have to send the org in the write function.
client = InfluxDBClient(url="http://localhost:9999", token="my-token", org="my-org")
write_api.write(bucket=bucket, record=p)
Hi,
I see it is possible to delete data from a specific bucket using this client but I'd like to know if it is possible to delete a single measurement?
Thank you.
I had an issue with this piece of code that I wrote myself:
@classmethod
def write_power_to_db(cls, df: pd.DataFrame, measurement_name: str):
columns = [col for col in df.columns if col != 'unit']
for index, row in df.iterrows():
for col in columns:
point = Point(measurement_name)
point.tag('powerFlow', col)
point.field('power', row[col])
point.time(datetime.strptime(index, DATETIME_STR_FMT), WritePrecision.S)
print(point.to_line_protocol())
cls.writer.write(cls.bucket, cls.org, point)In this method I get data out of a Pandas DataFrame object, put it in a Point object and then write this object to its destination in my InfluxDB bucket. This code runs without any error or warning. But: no data in the bucket!
If I change the code to:
@classmethod
def write_power_to_db(cls, df: pd.DataFrame, measurement_name: str):
columns = [col for col in df.columns if col != 'unit']
for index, row in df.iterrows():
for col in columns:
point = Point(measurement_name)
point.tag('powerFlow', col)
point.field('power', row[col])
point.time(datetime.strptime(index, DATETIME_STR_FMT))
print(point.to_line_protocol())
cls.writer.write(cls.bucket, cls.org, point, WritePrecision.S)then I get an error back from InfluxDB:
influxdb_client.rest.ApiException: (400)
Reason: Bad Request
HTTP response headers: HTTPHeaderDict({'Content-Type': 'application/json; charset=utf-8', 'X-Platform-Error-Code': 'invalid', 'Date': 'Sun, 31 May 2020 20:20:11 GMT', 'Content-Length': '188'})
HTTP response body: {"code":"invalid","message":"unable to parse 'solaredgePower,powerFlow=selfconsumption power=309.02734 1590508800000000000': time outside range -9223372036854775806 - 9223372036854775806"}I finally could solve the issue myself just by coincidence when I tried this:
@classmethod
def write_power_to_db(cls, df: pd.DataFrame, measurement_name: str):
columns = [col for col in df.columns if col != 'unit']
for index, row in df.iterrows():
for col in columns:
point = Point(measurement_name)
point.tag('powerFlow', col)
point.field('power', row[col])
point.time(datetime.strptime(index, DATETIME_STR_FMT), WritePrecision.S)
print(point.to_line_protocol())
cls.writer.write(cls.bucket, cls.org, point, WritePrecision.S)Dear Great Maintainer,
I would like to request to transfer feature which is currently in Influxdb 1.7 to 2.0.
There are 2 proposals:
In the version 1.7, function DataFrameClient allows to insert the dataframe to idb.
import pandas as pd
from influxdb import DataFrameClient
dbConnDF = DataFrameClient('localhost', '8086', 'd', 'password', 'securities')
df = pd.read_parquet('/home/d/fi/01_Data/01_raw_data/qd.parquet').set_index('date').sort_values()
%time dbConnDF.write_points(df, 'securities', tag_columns=['symbol'], protocol="json", batch_size=10000)
%time d = dbConnDF.query("select * from securities")
d['securities']
@Anaisdg created the function below.
https://github.com/Anaisdg/Influx_Pandas
**`import pandas as pd
import time
from datetime import datetime
def lp(df,measurement,tag_key,field,value,datetime):
lines= [str(df[measurement][d]) + ","
+ str(tag_key) + "=" + str(df[tag_key][d])
+ " " + str(df[field][d]) + "=" + str(df[value][d])
+ " " + str(int(time.mktime(df[datetime][d].timetuple()))) + "000000000" for d in range(len(df))]
return lines`**
Thank you in advance for your help it will save a lot of time to your customers
Sutyke
Update Readme to reflect this client library supports 2.0 and 1.8+.
Hi all,
I find it interesting that so far no one has a problem with serialization in multiprocessing using Pickle. After initialization in the following lines
"" "
Start writer as a new process
"" "
writer = InfluxDBWriter (queue_)
"writer" is started
writer.start ()
and InfluxDBWriter must be serialized for pipe transfer. The following error message occurs:
File "/Users/joerg/miniconda3/envs/influx/lib/python3.8/multiprocessing/reduction.py", line 60, in dump
ForkingPickler (file, protocol) .dump (obj)
AttributeError: Can't pickle local object 'PoolManager .__ init__. . '
This error is triggered by the line >>>>:
def init __ (self, queue):
Process . init __ (self)
self.queue = queue
self.client = InfluxDBClient (url = 'http: // localhost: 9999',
token = "my_token", org = "my_org", debug = False)
Hardware: MacBook Pro, OS: Catalina
Python: 3.8.1
pypi: 2.1
influxdb-client: 1.4.0
delete_api = client.delete_api()
delete_api.delete('1970-01-01T00:00:00Z', '2020-04-27T00:00:00Z', '_measurement="daily"', 'finance_data', 'administators'){
"code":"invalid",
"message":"id must have a length of 16 bytes"
}In addition to ticket #79
Would it be possible to next to, data_frame_tag_columns=tag_columns, also have a 'data_frame_tag=' argument? This way a tag can be added to a DF which doesn't appear in the DF.
For example, I have a DF with stock prices: timestamp, open, high, low, close (etc) data. I would like to be able to add tags as ticker, exchange etc which don't appear in the DF, by using a 'data_frame_tag=' argument with data_frame_tag='NASDAQ', 'AAPL'
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.