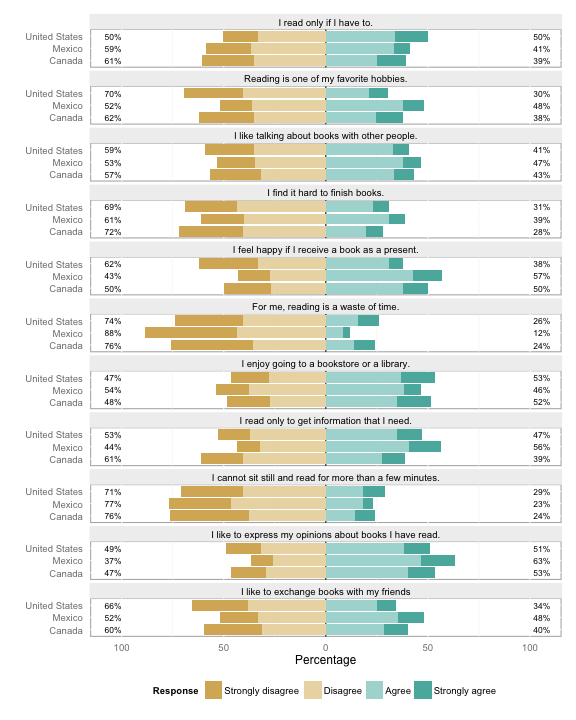
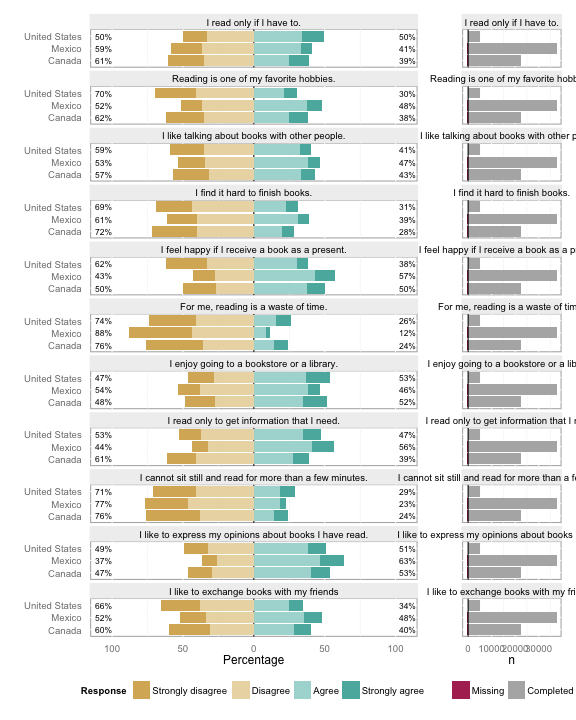
> plot(lmydf, include.histogram = TRUE)
Error in gtable_gList(x) : could not find function "llply"
Just plotting lmydf works fine.
mydf <- data.frame( # made up cases and a group var
case.id <- seq(1:500),
SAMP_APPL <- rep(c("Group 1","Group 2"),each=250)
)
#made.up.likert.stuff
mylikerts <- data.frame(as.factor(sample(1:4, nrow(mydf), replace=TRUE, prob=c(0.2,0.3,0.1,0.4))),
as.factor(sample(1:4, nrow(mydf), replace=TRUE, prob=c(0.5,0.25,0.15,0.1))),
as.factor(sample(1:4, nrow(mydf), replace=TRUE, prob=c(0.25,0.1,0.4,0.25))),
as.factor(sample(1:4, nrow(mydf), replace=TRUE, prob=c(0.1,0.4,0.4,0.1))),
as.factor(sample(1:4, nrow(mydf), replace=TRUE, prob=c(0.35,0.25,0.15,0.25))))
names(mylikerts) <- c("Q1", "Q2", "Q3", "Q4", "Q5")
mylevels <- c("Strongly disagree", "Disagree", "Agree", "Strongly Agree")
mylikerts[] <- lapply(mylikerts, factor,
levels=c(1,2,3,4),
labels = mylevels)
mydf <- cbind(mydf, mylikerts)
qlikerts <- mydf[,substr(names(mydf), 1,1) == 'Q'] #my fake likerts all start with Q
lmydf <- likert(qlikerts[,1:5], grouping=mydf$SAMP_APP)
> sessionInfo()
R version 3.2.2 (2015-08-14)
Platform: x86_64-apple-darwin13.4.0 (64-bit)
Running under: OS X 10.9.5 (Mavericks)
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] scales_0.3.0 likert_1.3.2 xtable_1.8-0 ggplot2_1.0.1
loaded via a namespace (and not attached):
[1] Rcpp_0.12.1 reshape_0.8.5 psych_1.5.8 digest_0.6.8 MASS_7.3-44
[6] grid_3.2.2 plyr_1.8.3 gtable_0.1.2 magrittr_1.5 stringi_1.0-1
[11] reshape2_1.4.1 labeling_0.3 proto_0.3-10 tools_3.2.2 stringr_1.0.0
[16] munsell_0.4.2 parallel_3.2.2 colorspace_1.2-6 mnormt_1.5-3 gridExtra_2.0.0




























































































































































{kind=link}
{kind=link}