kuitos / kuitos.github.io Goto Github PK
View Code? Open in Web Editor NEW📝Kuitos's Blog https://github.com/kuitos/kuitos.github.io/issues
Home Page: https://kuitos.github.io/
License: MIT License
📝Kuitos's Blog https://github.com/kuitos/kuitos.github.io/issues
Home Page: https://kuitos.github.io/
License: MIT License








































































































































































































原文写于 2015-05-27
web开发启示录
原文写于 2014-12-23
Javascript的事件体系想必大家都已经耳熟能详了,它是支撑起前端交互的支柱,当然我们这里不讲DOM2 抑或DOM3 里的标准事件,这里来说说基于移动端的、单点触碰事件(多点及手势事件后续有空咱再聊)。
移动端事件的标准最初是由苹果safari团队制定,用于触碰设备的交互,包含以下几种事件:
那么问题来了,我们要如何监听click事件呢?
传统的click事件不受终端限制,该怎么用还是怎么用。
假设有这么一段代码:
<div>
<div onclick=""></div>
<div id="test" onclick=""></div>
<div onclick=""></div>
</div>那么问题又来了,我们点击了id=test的div,那么事件触发的顺序是?
没错,click事件最后触发的。
如果你是个对性能敏感的程序员,你或许会问,这些事件触发的时间是?(一次实验结果,统计癖们请自行测试然后取平均值)
是的,整整 300+ ms 的delay啊尼玛!或许你会说,不要绑定click,绑定touchstart不就好了吗?nice,好主意!
可是你一旦这么做会发现你的也没在移动终端的误操作率会由以前5%激升至50%,比如你想做滚动页面操作的时候触发了某个click事件,你在想双指手势放大时又触发了某个click事件,整个世界都不好了。。。
好在有问题出现总归有相应解决方案,我们毕竟不是第一个吃螃蟹的。
如果你有兴趣研究下angular官方的ngTouch模块的代码的,会发现google团队是这么处理的(抽离细节):
当点击一个元素时
这是一种典型的绕道式解决方案。不是从技术层面解决问题(是的你没办法去直接修改浏览器底层的C++代码),他做的只是换了一种思路,既然不能改变浏览器会将touchstart最后冒泡成click事件中间需要至少300ms的这个事实,那么我们干脆抛弃掉浏览器帮我们识别出来的click,直接获取touchstart事件,然后通过一套完整的逻辑判断当前touchstart是否可被判定为click,然后手动触发click回调。是的,既然现有的东西支撑不了我的需求,那么我就排列组合成我想要的东西。
但是问题又来了,angular-touch有一个很明显的不足,就是他只能通过ng-click指令来实现将相应的click事件变成看似无延时的。他无法解决通过js手动绑定的click事件的触发时机。上代码吧(是的码字解释有时候真的是太费劲。。Talk is cheap, show me the code — Linus Torvalds)
ng-click指令绑定的事件此时无延时
<div ng-click="showMe()">lalalalala</div>通过js手动绑定的click还是会延时。。
element.bind("click", showMe);好在开源世界是伟大的,早早有人帮我们解决了这个问题,看这里Fastclick(尼玛GFW你现在想屏蔽github是想让国内的程序员都失业么!!)
用法真心简单,拿angular举例,你只需要在你的run block里加入这样一段:
.run(["$rootScope", "app", function ($rootScope, app) {
window.FastClick.attach(window.document.body, {
tapDelay: 0
});
}]);FastClick的解决方案跟angular-touch的方案思路大致一样(几乎现有的所有解决方案都差不多是这种),它会在你设置的监听区,比如上面的document.body,添加一个touchstart事件,你点击的具体元素的touchstart会首先冒泡至body,然后被其捕获,然后通过触发点坐标计算其是否为一个点击事件,如果符合条件则会手动构建一个MouseEvents并将其声明为click,再然后dispatchEvent(event)。这样就会直接触发元素绑定的click事件,从而避免浏览器依次触发产生的延时。
最后,关于为啥会有这300ms的delay,浏览器厂商(其实就是safari)是这样解释的,我们要通过这300ms来判断你是单击还是双击,从而决定我们到底要触发什么行为。看看官方解释:
...mobile browsers will wait approximately 300ms from the time that you tap the button to fire the click event. The reason for this is that the browser is waiting to see if you are actually performing a double tap.
其实现在很多android端的浏览器能通过判断你是否在你的html声明禁用页面缩放来决定是否需要300ms delay的,因为双击主要是用来缩放的。代码这样写:
<meta name="viewport" content="user-scalable=no">不过任性的ios目前为止还是不支持这个检测,但好在fastclick也足够轻量级和易用。so,就是这么简单。
原文写于 2014-10-26
AngularJs框架为我们封装了$http用于提供ajax服务,但是作为调用者而言,工程化的项目中直接调用$http去发请求总是不友好且不易于拓展的。合理的做法是前后端使用统一的接口规范、restful。前端采用angular resource调用restful接口。这样才更便于前端做统一封装,将通用需求对调用者透明。
先说说对于http请求我的通用化需求有哪些:
好在Angular给我们提供了http拦截器,减少了我们一大半工作量。so,我们只需要在拦截器中加入请求缓存及修改刷新缓存的逻辑就可以实现我们的第一个需求。具体上代码
/**
* @author kui.liu
* @since 2014/10/10 下午5:52
* http处理器,用于设定全局http配置,包括loading状态切换,拦截器配置,超时时间配置等
*/
;
(function (angular, undefined) {
"use strict";
// 模拟service的私有服务
var _app = {};
angular.module("common.http-handler", [])
.config(["$httpProvider", function ($httpProvider) {
/******************** http拦截器,用于统一处理错误信息、消息缓存、响应结果处理等 **********************/
$httpProvider.interceptors.push(["$q", "$log", function ($q, $log) {
return {
response: function (res) {
var config = res.config,
responseBody = res.data,
cache;
if (angular.isObject(responseBody) && !responseBody.success) {
$log.error("%s 接口请求错误:%s", config.url, responseBody.message);
return $q.reject(res);
} else {
// 自定义配置,用于query请求直接返回data部分
if (config.useDataDirect) {
res.data = responseBody.data;
}
// 自定义配置,若该请求成功后需要重新刷新cache(save,update,delete等操作),则清空对应cache。angular默认cache为$http
if (config.refreshCache) {
cache = angular.isObject(config.cache) ? config.cache : _app.cacheFactory.get("$http");
cache.removeAll();
}
return res;
}
},
responseError: function (res) {
$log.error("%s 接口响应失败! 状态:%s 错误信息:%s", res.config.url, res.status, res.statusText);
return $q.reject(res);
}
}
}]);
}])
.run(["$rootScope", "$timeout", "$cacheFactory", function ($rootScope, $timeout, $cacheFactory) {
/** 绑定cache服务 **/
_app.cacheFactory = $cacheFactory;
}]);
})(window.angular);然后我们定义resource时只需要加入缓存,对于需要通知缓存的方法加上refreshCache(这个是自定义属性,配合http interceptor使用)标识就行:
$resource(url,{}, {
"get" : {method: "GET", cache: true},
"save" : {method: "POST", refreshCache: true},
"query" : {method: "GET", isArray: true, cache: true, useDataDirect: true},
"remove": {method: "DELETE", refreshCache: true},
"delete": {method: "DELETE", refreshCache: true}
});调用还是跟往常一样,一切对用户透明。只是我们查看network的时候会发现请求都会被缓存起来。比如下面这个表格
image2014-10-26 16:30:42.png
点第二页
image2014-10-26 16:31:36.png
再点回第一页
image2014-10-26 16:32:19.png
可以看到并没有http请求发出,数据是直接从缓存中响应给请求的。如果我们某个时刻修改了这条数据,那么下次查询请求的时候就不会走缓存了,而是直接从走http然后重新把结果缓存起来。具体就不演示了。
可以毫不夸张的说,如果我们一个数据交互比较频繁的页面,用户在上面操作持续时间超过3分钟,那么我们的IO数就能节省50%以上,这样不仅能大大降低服务器压力,同时前端的响应速度也会大大提升。而且这个比例会随着用户的停留时间增加而增加。最主要的是,一切对调用者都是透明的!!
再来看看我们的第二个需要。基于http请求响应的自动loading状态。实现方式大同小异,同样是利用$httpProvider,只是这里用的是$http提供的transformRequest和transformResponse
/**
* @author kui.liu
* @since 2014/10/10 下午5:52
* http处理器,用于设定全局http配置,包括loading状态切换,拦截器配置,超时时间配置等
*/
;
(function (angular, undefined) {
"use strict";
// 模拟service的私有服务
var _app = {};
angular.module("common.http-handler", [])
.config(["$httpProvider", function ($httpProvider) {
var
/** loading状态切换 */
count = 0,
loading = false,
stopLoading = function () {
count = 0;
loading = false;
_app.loading(false); // end loading
};
/*************************** http超时时间设为30s ***************************/
$httpProvider.defaults.timeout = 30 * 1000;
/* 广告时间哈哈.... */
$httpProvider.defaults.headers.common["X-Requested-With"] = "https://github.com/kuitos";
/************************* 根据http请求状态判断是否需要loading图标 *************************/
$httpProvider.defaults.transformRequest.push(function (data) { // global loading start
count += 1;
if (!loading) {
_app.timeout(function () {
if (!loading && count > 0) {
loading = true;
_app.loading(true);
}
}, 500); // if no response in 500ms, begin loading
}
return data;
});
$httpProvider.defaults.transformResponse.push(function (data) { // global loading end
count -= 1;
if (loading && count === 0) {
stopLoading();
}
return data;
});
}])
.run(["$rootScope", "$timeout", "$cacheFactory", function ($rootScope, $timeout, $cacheFactory) {
/** 绑定timeout服务 */
_app.timeout = $timeout;
/** loading状态切换 **/
_app.loading = function (flag) {
$rootScope.loading = flag;
};
/** 绑定cache服务 **/
_app.cacheFactory = $cacheFactory;
}]);
})(window.angular);当响应时间超过500ms(可自己设定,一般不要超过1s),则loading动画自动出现,响应成功回来后动画消失。
angular给开发者提供了一套便利的设备龚开发者使用,几乎后端mvc框架中最常用的东西它都会提供。只是angular的官方文档实在写的太烂,这也是社区一直在吐槽的点,很多时候api上并不会告诉你它那个接口的所有功能,搞不定的时候我们还是应该好好读读它那一块的源码,相信我,你总会有意外收获!
最新最详尽代码请移步:source code
您好很抱歉在您的博客中提交 issues ,我最近的研究 qiankun 的源码,发现其实现沙箱隔离中引用到了 import-html-entry 在阅读了源码后找到了核心代码如下:
function getExecutableScript(scriptSrc, scriptText, proxy, strictGlobal) {
const sourceUrl = isInlineCode(scriptSrc) ? '' : `//# sourceURL=${scriptSrc}\n`;
// 通过这种方式获取全局 window,因为 script 也是在全局作用域下运行的,所以我们通过 window.proxy 绑定时也必须确保绑定到全局 window 上
// 否则在嵌套场景下, window.proxy 设置的是内层应用的 window,而代码其实是在全局作用域运行的,会导致闭包里的 window.proxy 取的是最外层的微应用的 proxy
const globalWindow = (0, eval)('window');
globalWindow.proxy = proxy;
// TODO 通过 strictGlobal 方式切换 with 闭包,待 with 方式坑趟平后再合并
return strictGlobal
? `;(function(window, self, globalThis){with(window){;${scriptText}\n${sourceUrl}}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`
: `;(function(window, self, globalThis){;${scriptText}\n${sourceUrl}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`;
}但其中
const globalWindow = (0, eval)('window');实在是不理解立即执行函数中的 0 的作用
QQQ
原文写于 2015-04-15
额,那啥,我又准备写一个系列了
某天有网友在知乎上提问:如何反驳 [程序=算法+数据结构],前端不懂算法不懂数据结构根本就不能算程序员!
伟大的 计算机之子 @寒冬winter 给了一个万能的解决方案,并列出了技术界吵架的无敌五式,其中有一条就是:
XX发展到现在,概念跟以前已经有了很大的变化。
套用到具体案例,你可以这样反驳:前端发展到现在,概念跟以前已经有了很大的变化。
看上去这更像是寒冬老师的戏谑之言,但是用来描述前端发展的现状,实在是再合适不过。
是的,前端发展到现在,概念跟以前已经有了很大的变化。
星星之火源于09年中旬发布的NodeJs,被贴上后端js标签的javascript自出生以来再次吸引了技术界的眼球,js再也不局限于浏览器那一块方寸之地了。越来越多的前端工程师开始尝试进入后端工程领域,同时也吸引了一批后端工程师来试水所谓的能跑在服务器上的js。各种不同技术背景的开发人员的加入,帮助NodeJs社区发展的欣欣向荣,新的开发环境中遭遇到更多以前浏览器端js开发未曾遭遇(或者说未被重视)的问题,于是各种背景的开发人员为javascript引入了更多其他领域的**和方法论。于是,各种模块化解决方案应运而生,AMD代表的requireJs、CMD代表的sea.js,各种异步流程控制解决方案,Promise、thunk、co 等等。前端MVC代表的Backbone.js 以及 在 其基础上衍生的出来的 MVVM 框架代表 angularJs 使得后端工程师也能快速的开发出易于维护的页面。时间走到2013年,前端领域开始井喷式发展,越来越多的概念被提出。angularJs将前端工程师从繁重的DOM操作中解放出来,从而有更多的精力去关注附加值更高的领域;基于模块化的开发让人们越来越意识到前端工程化的重要性,requireJs、seajs、fis等以及前后端通吃的Browserify、webpack;基于npm的一系列构建工具也让一切工程化想法得以实现,bower、grunt、gulp;HTML5+CSS3 Canvas 让浏览器不仅仅只是浏览器;ES6标准的确立,TypeScript,基于TypeScript的AtScript;基于shadow dom的webcomponets将web组件化推到了一个新的高度;ReactJ带来的virtual dom概念以及推倒MVC模式的FLUX模式,以及angular2.0带来的革命性变更;React Native让移动端web不再只局限于套浏览器壳子的Hybird app。。。。
前端这两年发展速度之快已经不能单单一哦那个飞速可以形容了,各种新的概念及技术被提出,光是各种名词就已经到了记都记不过来的程度了更别说都有所了解。前端开发再也不是以前那种写几个html标签写几行if else的刀耕火种的蛮荒时代。用 苏宁前端架构师 @民工精髓 的话说,前端发展已经由农耕时代进入到了第一次工业革命 蒸汽机时代了。对于前端而言,这是最混乱的时代,也是最好的时代。
是的,《前端已不止于前端》是一个只关注前端届最前沿**及技术的系列。
最后,用一句目前在前端届流传很广的“名言”来开启我们的篇章:
任何能用javascript实现的软件及系统,最终都会拿来用javascript实现。 -- 马云
熟悉 Apollo GraphQL 的同学可直接跳过这一章,从 实践 一章看起。
GraphQL 作为 FaceBook 2015年推出的 API 定义/查询 语言,在历经了两年的发展之后,社区已相对发达和完善。对于 GraphQL 的一些基础概念,本文不再一一赘述,目前社区相关的文章已经很多,有兴趣的同学可以去 google,或者直接看GraphQL 官方教程 Apollo GraphQL Server 官方文档。
而 Apollo GraphQL 作为目前社区最流行的 GraphQL 解决方案提供商,提供了从 client 到 server 的一整套完整的工具链。在这里我也准备以 Apollo 为例,通过一步步搭建 Apollo GraphQL Server 的方式,来给大家展示 GraphQL 的特点,以及我的一些思考(主要是我的思考🤪)。
创建基于 express 的 GraphQL server
// server.js
import express from 'express';
import { graphiqlExpress, graphqlExpress } from 'apollo-server-express';
import schema from './models';
const PORT = 8080;
const app = express();
...
app.use('/graphql', graphqlExpress({ schema }));
app.use('/graphiql', graphiqlExpress({
endpointURL: '/graphql'
}));
if (process.env.NODE_ENV === 'development') {
glob(path.resolve(__dirname, './mock/**/*.js'), {}, (er, modules) => modules.forEach(module => require(module).default(app)));
}
app.listen(PORT, () => console.log(`> Listening at port ${PORT}`));执行 node server.js,这样我们就能启动一个 GraphQL server 了。
注意我们这里使用了 apollo-server-express 提供的 graphiqlExpress 插件,graphiql 是一个用于浏览器端调试 graphql 接口的 GUI 工具。服务启动后,我们在浏览器打开 http://localhost:8080/graphiql就可以看到这样一个页面

我们在 server.js 中定义了这样一个 endpoint : app.use('/graphql', graphqlExpress({ schema }));
这里传入的 schema 是什么呢?它大概长这样:
import { makeExecutableSchema } from 'graphql-tools';
// The GraphQL schema in string form
const typeDefs = `
type User {
id: ID!
name: String
age: Int
}
type Query { user(id: ID!): User }
schema { query: Query }
`;
// The resolvers
const resolvers = {
Query: { user({id}) { return http.get(`/users/${id}`)}}
};
// Put together a schema
const schema = makeExecutableSchema({
typeDefs,
resolvers
});
app.use('/graphql', graphqlExpress({ schema }));这里的关键是用了 graphql-tools 这个库提供的 makeExecutableSchema 组合了 schema 定义和对应的 resolver。resolver 是 Apollo GraphQL 工具链中提出的一个概念,什么用呢?就是在我们客户端请求过来的 schema 中的 field 如果在 GraphQL Server 中有对应的 resolver,那么在返回数据时候,这些 field 就由对应的 resolver 的执行结果填充(支持返回 promise)。
这里借助 graphiql 面板的功能来发送请求:
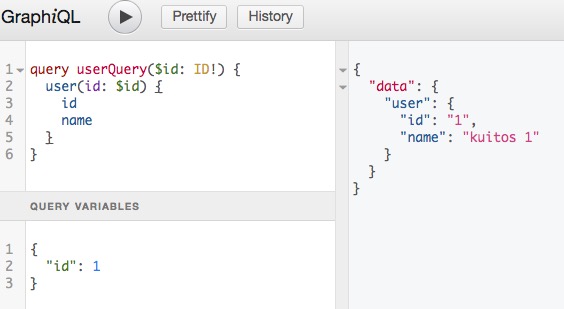
看一下 http request payload 信息:

响应体:

也就是说,无论你是用你熟悉的 http lib 还是社区的 apollo client,只要按照 GraphQL Server 要求的既定格式发请求就 ok 了。
这里我们使用了 GraphQL 中的 variable 语法,事实上在这种需要传参的动态查询场景下,我们应该总是使用这种方式发送请求:即一个 static query + variable 的方式,而不是在运行时动态的生成 query string。这也是官方建议的最佳实践。
假设我们有这样一个场景,即我们需要取到 User Entity 下的 nick 字段,而 nick 数据并不来自于 user 接口,而是需要根据 userId 调用另一个接口取得。这时候我们服务端的代码需要这样写。
// schema
type User {
id: ID!
name: String
age: Int
nick: String
}
// resolver
User: {
nick({ id }) {
return getUserNick(id);
}
}resolver 的参数列表中包含了当前所在 Entity 已有的数据,所以这里可以直接在函数的入参里取到已查询出来的 userId。
看下效果:

服务端的请求:

可以看到,这里多出了查询 nick 的请求。也就是说,GraphQL Server 只有在客户端提交了包含相应字段的 query 时,才会真正去发送相应的请求。更多 resolver 说明可以看这里。
在真实的生产环境中,我们通常会有更多更复杂的场景,比如接口的权限认证、分页、缓存、批量提交、schema 模块化等需求,好在社区都有相对应的一些解决方案,这不是本文的重点所以不在这里一一介绍了,有兴趣的可以去看下我之前写的 graphql-server-startkit,或者官方的 demo。
如果你真实的使用过 Apollo GraphQL,你会经历如下过程:
定义一个 schema 用于描述查询入口
// schema.graphql
type User {
id: ID!
name: String
nick: String
age: Int
gender: String
}
type Query {
user(id: ID!): User
}
schema {
query: Query
}
编写 resolver 解析对应类型
const resolvers = {
Query: {
user(root, { id }) {
return getUser(id);
}
},
User: {
nick({ id }) {
return getUserNick(id);
}
}
};编写客户端请求代码调用 GraphQL 接口,通常我们会封装一个 get 方法
function getUser(id) {
// 以 axios 为例
return axios.post('/graphql', { query: 'query userQuery($id: ID!) {↵ user(id: $id) {↵ id↵ name↵ nick↵ }↵}', operationName: "userQuery", variables: {id}});
}如果你的项目中加入了静态类型系统,那么你的代码可能就会变成这样:
// 以 ts 为例
interface User {
id: number
name: string
nick: string
age: number
gender: string
}
function getUser(id: number): User {
return axios.post('/graphql', { query: 'query userQuery($id: ID!) {↵ user(id: $id) {↵ id↵ name↵ nick↵ }↵}', operationName: "userQuery", variables: {id}});
}写到这里你可能已经发现,不仅是 entity 类型定义,就连接口的封装,我们在服务端和客户端都重复了一遍(虽然一个用的 GraphQL Type Language 一个用的 TS)… 这还是最简单的场景,如果业务模型复杂起来,你在两端需要重复的代码会更多(比如类型的嵌套定义和 resolve)。这时候你可能会想起 DRY 原则,然后开始思考有没**有什么方式可以使得类型及接口定义能两端复用,或者根据一端的定义自动生成另一端的代码?**甚至你开始怀疑,到底有没有引入 GraphQL 的必要?
GraphQL 作为一个标准化并自带类型系统的 API Layer,其工程价值我也不再过多广告了。只是在实践过程中,既然我们无法完全避免服务端与客户端的实体与接口定义重复(使用 apollo-codegen 可以避免一部分),而且对于大部分小团队而言,运维一个 productive nodejs system 实际上都是力有未逮。**那么我们是不是可以考虑在纯客户端构建一个类 GraphQL 的 API Layer 呢?**这样既可以有效的避免编码重复,也能大大的降低对团队的要求,可操作的空间也比增加一个 nodejs 中间层大得多。
我们可以回忆一下,通常对于一个前端而言,促使我们需要一个 API Layer 的原因是什么:
通常情况下,碰到这些问题,你可能去跟后端同学据理力争,要求他们提供调用体验更良好设计更优雅的接口。没错这很好,毕竟为了追求完美去跟各种人撕(跟后端撕、跟产品撕、跟UI撕)是一个前端工程师基本的职业素养。但是如果你每天都被撕逼弄得心力交瘁,甚至是你根本找不到撕的对象(比如数据来源接口来着几个不同部门,甚至是一些祖传的没人敢动的接口),这些时候大概就是你迫切希望有一个 API Layer 的时候了。
其实很简单,你只需要在客户端把 Apollo Server 中要写的 resolvers 写一遍,然后配上一些性能提升手段(如缓存等),你的 API Layer 就完成了。
比如我们在src下新建一个 loaders/apis 目录,所有的数据拉取接口都放在这里。比如这样:
// UserLoader.ts
export interface User {
id: number
name: string
nick: string
}
export default class UserLoader {
async getUser(id: number): User {
const base = await Promise.all([http.get('//xxx.com/users/${id}'), this.getUserNick(id)]);
const user = base.reduce((acc, info) => ({...acc, ...info}), {});
return user;
}
getUserNick(id: number): string {
return http.get(`//xxx.com/nicks/${id}`);
}
}然后在你业务需要的地方注入相应 loader 调用接口即可,如:
import { inject } from 'mmlpx';
import UserLoader from './UserLoader';
// Controller.ts
export default class Controller {
@inject(UserLoader)
userLoader = null;
async doSomething() {
// ...
const user = await this.userLoader.getUser(this.id);
// ...
}
}如果你不喜欢依赖注入的方式,loaders/apis 层直接 export function getUser 也可以。
如果你碰到了上面描述的第 3、4 、5 三种问题,你可能还需要在这一层做一下数据格式化。比如这样:
async getUser(id: number): User {
const base = await Promise.all([http.get('//xxx.com/users/${id}'), this.getUserNick(id)]);
const user = base.reduce((acc, info) => ({...acc, ...info}), {});
return {
id: user.id,
name: user.user_name, // 重命名字段
nick: user.nick.userNick // 剔除原始数据中无意义的层次结构
};
}经过这一层的数据处理,我们就能确保我们的应用运行在前端自己定义的数据模型之下。这样之后后端接口不论是数据结构还是字段名的变更,我们只需要在这一层做简单调整即可,而不会影响到我们上层的业务及视图。相应的,我们的业务层逻辑不再会直接对接接口 url,而是将其隐藏在 API Layer 下,这样不仅能提升业务代码的可读性,也能做到眼不见为净。。。
熟悉 GraphQL 的同学可能会很快意识到,我这不过是在客户端做了一个简单的 API 封装嘛,并不能解决在 GraphQL 出现之前的 lots of roundtrips 及 overfetching 问题。但事实上是 roundtrip 的问题我们可以通过客户端缓存来缓解(如果你用的是 axios 你可能需要 axios-extensions ),而且 roundtrip 的问题其实本质上我们不过是将客户端的 http 开销转移到服务端了而已。在客户端与服务端均不考虑缓存的情况,客户端反而会少一个请求。。。overfetching 问题则取决于 backend service 的粒度,如果 endpoint 不够 micro,即便是 GraphQL,也会出现接口数据冗余问题,毕竟 GraphQL 不生产数据,它只是数据的搬运工。。。而如果 endpoint 粒度足够小,那么我在客户端 API 层多开几个接口(换成 Apollo 也要多写几个 resolver),一样可以按需取数据。服务端 API Layer 只有一个不可替代的优势就是,如果我们的数据源接口是不支持跨域或者仅内网可见的,那么就只能在服务端开个口子做代理了。另外一个优势就是,GraphQL Server 的 http 开销是可控的,毕竟机器是我们自己控制,而客户端的环境则不可控(受限于终端设备及网络环境,比如低版本浏览器或者低速网络,均会导致 http 开销的性能权重增大)。
可能有同学会说,服务端 API Layer 部署一次任何系统都可以共享其服务,而客户端 API Layer 的作用域只在某一项目。其实,如果我们把某一项目需要共享的 API Layer 打成一个 npm 包发布出去,不也能达到同样的效果吗,很多平台的 js sdk 不都是这个思路么(这里只讨论 web 开发范畴)。
在我看来,不论你是否会搭建一个服务端的 API Layer,**我们其实都需要有一个客户端 API Layer 从数据源头来保证客户端数据的模型统一及一致性,从而有足够的能力应对接口的变迁。**如果你考虑的再远一点,在 API Layer 服务的业务模型层,我们同样需要有一套独立的 Service/Model Layer 来应对视图框架的变迁。这个暂且按下不表,后面会再写篇文字来详细说一下我的思路。
事实上,对于大部分团队而言,客户端 API Layer 已经够用了,增加一层 GraphQL 并不是那么必要。而且如果没有很好的支持将客户端接口转换成 GraphQL Schema 和 resolver 的工具时,我们并不能很愉快的 coding,毕竟两端重复的工作还是有点多。
原文写于 2014-08-13
阅读这篇blog之前,请先看下这本书:高性能网站建设进阶指南,里面详细的讲解了现今流行的几种异步脚本加载方案(不过里面一些结论不能盲目相信,实践之前请手动验证一下,毕竟浏览器实现日新月异)
不过还是先简单介绍下两种最常用的动态加载js资源的方案:
document.write方式
function outerHTML (node) {
// if IE, Chrome take the internal method otherwise build one
return node.outerHTML || (function (n) {
var div = document.createElement('div'), h;
div.appendChild(n);
h = div.innerHTML;
div = null;
return h;
})(node);
};
document.write(outerHTML(el));script dom element方式
document.getElementsByTagName('head')[0].appendChild(el);两种方式的差异在这里
| 是否并行下载 | 执行是否保证顺序 | |
|---|---|---|
| doc write | 是 | 是 |
| script dom element | 是 | 否 |
差别只在于,script dom element 的策略是并行下载且谁先下完执行谁,不根据你script标签的顺序加载,真正的异步。
因此我们可以有个基础的认识,就是当前页面一定会用到的js,我们采用doc write方式去加载,而用不到的js就采用script dom element 方式
看一下案例


这里有两个问题:
基于这两个问题,我们的思路是这样的:
优化后的部分代码:
<script>
(function (window, ScriptLoader) {
ScriptLoader.addScriptsSync(["content.base.min.js", "content.app.min.js"]);
})(window, window.ScriptLoader);
</script>
<!--不需要立即加载的延迟脚本放这里-->
<script>
(function (ScriptLoader) {
ScriptLoader.addScriptAsyncDelayed(["content.lib.min.js",
(("https:" == document.location.protocol) ? "https://" : "http://") + "hm.baidu.com/h.js?30219399d7b243256f05f99e96aadb68"], null);
})(window.ScriptLoader);
</script>看下效果:
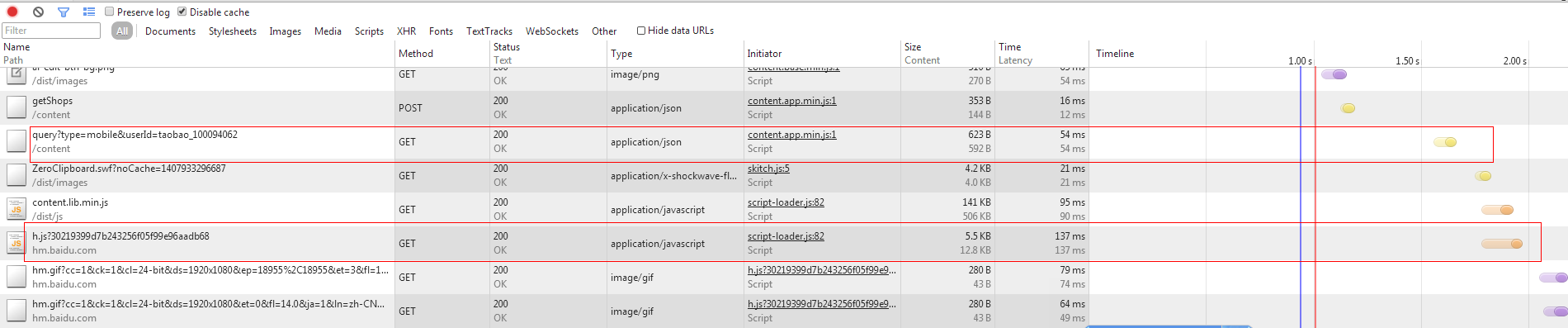
可以看到请求数据的ajax被提前了,有了数据页面会立即渲染更新,所以这里页面展示完全的时间在 1.7s左右,优化前在2.5s左右。
content.lib.min.js和h.js作为首页不会立即用到的东西,在最后才做加载且下载是并行的。
汇总一下优化历程
| js/css简单压缩合并 | 服务器开启gzip | 文中优化策略 | |
|---|---|---|---|
| 优化前 | 请求数 70+,资源总大小2M左右,页面打开耗时5s+ | 请求数 20+,资源总大小1.2M,页面打开耗时3s左右 | 同左 |
| 优化后 | 请求数 20+,资源总大小1.2M,页面打开耗时3s左右 | 请求数 20+,资源总大小350K,页面打开耗时2.5s左右 | 资源请求不变,页面打开耗时 1.7s |
关于ScriptLoader具体实现,没什么高科技,有兴趣同学可以看下代码:ScriptLoader
Ps:当页面耗时已经在2秒左右时,稳定提升100ms都是有难度的,这就好比110米栏选手跑进14秒容易,跑进13秒就很难了!
Flux是Facebook用来构建客户端web应用的应用架构。它利用单向数据流的方式来组合react中的视图组件。它更像一个模式而不是一个正式的框架,开发者不需要太多的新代码就可以快速的上手Flux。
dispatcher
事件调度中心,flux模型的中心枢纽,管理着Flux应用中的所有数据流。它本质上是Store的回调注册。每个Store注册它自己并提供一个回调函数。当Dispatcher响应Action时,通过已注册的回调函数,将Action提供的数据负载发送给应用中的所有Store。应用层级单例!!
store
负责封装应用的业务逻辑跟数据的交互。
view
其他

view --> actionCreators
// Nav.jsx
export default class Nav extends React.Component {
_handleClick(nav) {
NavActionCreators.clickNav(nav);
}
render() {
let itemList = this.props.list.map((nav, index) => {
return (
<li className="index-menu-item" onClick={this._handleClick.bind(this, nav)} key={index}>
<span>{nav.text}</span>
</li>
);
});
return (
<nav className="index-menu">
<ul className="index-menu-list">
{itemList}
</ul>
</nav>
);
}
}action dispatch
// NavActionCreators.js
export default {
clickNav(nav){
AppDispatcher.dispatch(
{
type: ActionTypes.CLICK_NAV,
nav
}
);
}
};dispatcher --> store callback
AppDispatcher.register(action => {
switch (action.type) {
// nav点击
case ActionTypes.CLICK_NAV:
IndexWebAPIUtils.getGiftList(_currentUserInfo.userId, action.nav.id)
.then(function (giftList) {
_currentGiftList = giftList;
IndexStore.emitChange();
});
break;
// no default
}
});store emitChange --> controller view --> setState
export default class Index extends React.Component {
constructor(props) {
super(props);
let currentUser = UserStore.getCurrentUser();
this.state = IndexStore.getAll();
}
componentDidMount() {
IndexStore.addChangeListener(this._onChange.bind(this));
}
componentWillUnmount() {
IndexStore.removeChangeListener(this._onChange.bind(this))
}
_onChange() {
this.setState(IndexStore.getAll());
}
render() {
let state = this.state;
return (
<div className="page active">
...
<Nav list={state.navList}/>
...
</div>
);
}
}


数据状态变得稳定同时行为可预测
因为angular双向绑定的原因,我们永远无法知道数据在哪一刻处于稳定状态,所以我们经常会在angular中看到通过setTimeout的方式处理一些问题(其实有更优雅的解决方案,不在本次讨论之内)。同时由于双向绑定的原因,行为的流向我们也很难预测,当视图的model变多的时候,如果再加上一堆子视图依赖这些model,问题发生时定位简直是噩梦啊(这也是angular的错误信息那么不友好的原因,因为框架开发者也无法确定当前行为是谁触发的啊,绑定的人太多了...)。但是这里还是要强调一点就是,并不是说双向绑定就一定会导致不稳定的数据状态,在angular中我们通过一些手段依然可以使得数据变得稳定,只是双向绑定(mvvm)相对于flux更容易引发数据不稳定的问题。
所有的数据变更都发生在store里
flux里view是不允许直接修改store的,view能做的只是触发action,然后action通过dispatcher调度最后才会流到store。所有数据的更改都发生在store组件内部,store对外只提供get接口,set行为都发生在内部。store里包含所有相关的数据及业务逻辑。所有store相关数据处理逻辑都集中在一起,避免业务逻辑分散降低维护成本。
数据的渲染是自上而下的
view所有的数据来源只应该是从属性中传递过来的,view的所有表现由上层控制视图(controller-view)的状态决定。我们可以把controller-view理解为容器组件,这个容器组件中包含若干细小的子组件,容器组件不同的状态对应不同的数据,子组件不能有自己的状态。也就是,数据由store传递到controller-view中之后,controller-view通过setState将数据通过属性的方式自上而下传递给各个子view。
view层变得很薄,真正的组件化
由于2、3两条原因,view自身需要做的事情就变得很少了。业务逻辑被store做了,状态变更被controller-view做了,view自己需要做的只是根据交互触发不同的action,仅此而已。这样带来的好处就是,整个view层变得很薄很纯粹,完全的只关注ui层的交互,各个view组件之前完全是松耦合的,大大提高了view组件的复用性。
dispatcher是单例的
对单个应用而言dispatcher是单例的,最主要的是dispatcher是数据的分发中心,所有的数据都需要流经dispatcher,dispatcher管理不同action于store之间的关系。因为所有数据都必须在dispatcher这里留下一笔,基于此我们可以做很多有趣的事情,各种debug工具、动作回滚、日志记录甚至权限拦截之类的都是可以的。
过多的样板代码
flux只是一个架构模式,并不是一个已实现好的框架,所以基于这个模式我们需要写很多样板代码,代码量duang的一下子上来了。。不过好在目前已经有很多好用的基于flux的第三方实现,目前最火的属redux。
dispatcher是单例
dispatcher作为flux中的事件分发中心,同时还要管理所有store中的事件。当应用中事件一多起来事件时序的管理变得复杂难以维护,没有一个统一的地方能清晰的表达出dispatcher管理了哪些store。
异步处理到底写在哪里
按flux流程,action中处理:依赖该action的组件被迫耦合进业务逻辑
按store职责在store中处理:store状态变得不稳定,dispatcher的waitFor失效
至今还没有官方实现
前端摩尔定律:前端每18个月难度增加一倍
没有银弹
Announcing [email protected]
2019 年 6 月,微前端框架 qiankun 正式发布了 1.0 版本,在这一年不到的时间内,我们收获了 4k+ star,收获了来自 single-spa 官方团队的问候,支撑了阿里 200+ 线上应用,也成为社区很多团队选用的微前端解决方案。
在今天,qiankun 将正式发布 2.0 版本。
[email protected] 带来了一些新能力的同时,只做了很小的 API 调整,1.x 的用户可以很轻松的迁移到 2.x 版本,详细信息见下方 升级指南 小节。
可能有的朋友还不太了解 微前端 和 qiankun 是什么。
微前端是最近一年国内前端领域被频繁提及的关键字,虽然它并不是一个全新的领域/技术,但很显然在当今越来越多的前端应用即将步入第 3 个、第 5 个甚至更久的年头的背景下,如何给 巨石应用/遗产应用 注入新鲜的技术血液已经成为我们不得不正视的问题,而微前端正是解决这类问题的一个非常合适的解决方案。
qiankun 是一个生产可用的微前端框架,它基于 single-spa,具备 js 沙箱、样式隔离、HTML Loader、预加载 等微前端系统所需的能力。qiankun 可以用于任意 js 框架,微应用接入像嵌入一个 iframe 系统一样简单。
更多信息可以查阅我们的 官方站点
qiankun 2.0 带来的最大变化便是 qiankun 的定位将由 微前端框架 转变为 微应用加载器。
此前 qiankun 的典型应用场景是 route-based 的控制台应用,做为一个微应用的聚合框架而被使用。
如上图所示,在这种场景下,一个负责聚合与切换的主应用 与 多个相互独自的微应用 一起构成了整个大的微前端应用,一般来说页面上活跃着的也往往只有一个微应用。
而这是微前端的场景之一,在另外一些场景下,你应该可以在同一个页面中,加载多个不同的微应用,每个微应用都是主应用的组成部分 或者是 提供一些增强能力,这种场景可以说是微应用粒度的前端组件化。
因此,[email protected] 将跳出 route-based 的微前端场景,提供更加通用的微应用加载能力,让用户可以更加自由的组合微应用来搭建产品。
新功能
此外我们还做了
另外我们还升级了相应的 umi qiankun plugin,在 umi 场景下你可以这样去加载一个微应用:
import { MicroApp } from 'umi';
function MyPage() {
return (
<div>
<MicroApp name="qiankun"/>
</div>
);
}在 [email protected] 中,我们的沙箱、样式隔离等机制只能对单一微应用场景生效,多个微应用共存的支持能力尚不完备。
而在 2.0 版本中,我们终于完善了这一功能,现在,你可以同时激活多个微应用,而微应用之间可以保持互不干扰。
**在多应用场景下,每个微应用的沙箱都是相互隔离的,也就是说每个微应用对全局的影响都会局限在微应用自己的作用域内。**比如 A 应用在 window 上新增了个属性 test,这个属性只能在 A 应用自己的作用域通过 window.test 获取到,主应用或者其他微应用都无法拿到这个变量。
但是注意,页面上不能同时显示多个依赖于路由的微应用,因为浏览器只有一个 url,如果有多个依赖路由的微应用同时被激活,那么大概率会导致其中一个 404。
为了更方便的同时装载多个微应用,我们提供了一个全新的 API loadMicroApp ,用于手动控制微应用:
import { loadMicroApp } from 'qiankun';
/** 手动加载一个微应用 */
const microApp = loadMicroApp(
{
name: "microApp",
entry: "https://localhost:7001/micro-app.html",
container: "#microApp"
}
)
// 手动卸载
microApp.mountPromise.then(() => microApp.unmount());这也是 qiankun 作为一个应用加载器的使用方式。
基于这个 api,你可以很容易的封装一个自己的微应用容器组件,比如:
class MicroApp extends React.Component {
microAppRef = null;
componentDidMount() {
const { name, entry } = this.props;
this.microAppRef = loadMicroApp({ name, entry, container: '#container' });
}
componentWillUnmount() {
this.microAppRef.mountPromise.then(() => this.microAppRef.unmount());
}
render() {
return <div id="container"/>;
}
}在 qiankun issue 区域呼声最高的就是 IE 的兼容,有不少小伙伴都期待 qiankun 能够在 IE 下使用。
qiankun 1.x 在 IE 使用的主要阻碍就是 qiankun 的沙箱使用了 ES6 的 Proxy,而这无法通过 ployfill 等方式弥补。这导致 IE 下的 qiankun 用户无法开启 qiankun 的沙箱功能,导致 js 隔离、样式隔离这些能力都无法启用。
为此,我们实现了一个 IE 特供的快照沙箱,用于这些不支持 Proxy 的浏览器;这不需要用户手动开启,在代理沙箱不支持的环境中,我们会自动降级到快照沙箱。
注意,由于快照沙箱不能做到互相之间的完全独立,所以 IE 等环境下我们不支持多应用场景,
singlur会被强制设为 true。
样式隔离也是微前端面临的一个重要问题,在 [email protected] 中,我们支持了微应用之间的样式隔离(仅沙箱开启时生效),这尚存一些问题:
为此,我们引入了一个新的选项, sandbox: { strictStyleIsolation?: boolean } 。
在该选项开启的情况下,我们会以 Shadow DOM 的形式嵌入微应用,以此来做到应用样式的真正隔离:
import { loadMicroApp } from 'qiankun'
loadMicroApp({xxx}, { sandbox: { strictStyleIsolation: true } });Shadow DOM 可以做到样式之间的真正隔离(而不是依赖分配前缀等约定式隔离),其形式如下:
图片来自 MDN
在开启 strictStyleIsolation 时,我们会将微应用插入到 qiankun 创建好的 Shadow Tree 中,微应用的样式(包括动态插入的样式)都会被挂载到这个 Shadow Host 节点下,因此微应用的样式只会作用在 Shadow Tree 内部,这样就做到了样式隔离。
但是开启 Shadow DOM 也会引发一些别的问题:
一个典型的问题是,一些组件可能会越过 Shadow Boundary 到外部 Document Tree 插入节点,而这部分节点的样式就会丢失;比如 antd 的 Modal 就会渲染节点至 ducument.body ,引发样式丢失;针对刚才的 antd 场景你可以通过他们提供的 ConfigProvider.getPopupContainer API 来指定在 Shadow Tree 内部的节点为挂载节点,但另外一些其他的组件库,或者你的一些代码也会遇到同样的问题,需要你额外留心。
此外 Shadow DOM 场景下还会有一些额外的事件处理、边界处理等问题,后续我们会逐步更新官方文档指导用户更顺利的开启 Shadow DOM。
所以请根据实际情况来选择是否开启基于 shadow DOM 的样式隔离,并做好相应的检查和处理。
微前端场景下,我们认为最合理的通信方案是通过 URL 及 CustomEvent 来处理。但在一些简单场景下,基于 props 的方案会更直接便捷,因此我们为 qiankun 用户提供这样一组 API 来完成应用间的通信:
主应用创建共享状态:
import { initGloabalState } from 'qiankun';
initGloabalState({ user: 'kuitos' });微应用通过 props 获取共享状态并监听:
export function mount(props) {
props.onGlobalStateChange((state, prevState) => {
console.log(state, prevState);
});
};更详细的 API 介绍可以查看官方文档。
除了基本的日常维护、bugfix 之外,我们还会尝试走的更远:
2.0 版本 调整了相当多的内部 API 名字,但大家使用的外部 API 变化并不大(基本完全兼容 1.x),你可以在十分钟内完成升级。
import { registerMicroApps } from 'qiankun'
registerMicroApps(
[
{
name: 'react16',
entry: '//localhost:7100',
- activeRule: location => location.pathname.startsWith('/react'),
+ activeRule: '/react',
- render: renderFn,
+ container: '#subapp-viewport',
},
]
)现在你可以简单的指定一个挂载节点即可,而不用自己手写对应的 render 函数了。简单场景下 activeRule 配置也不需要再手写函数了(当然还是支持自定义函数),只需要给出一个前缀规则字符串即可,同时支持 react-router 类的动态规则,如 /react/:appId/name (来自 single-spa 5.x 的支持)。
同时,微应用收到的 props 中会新增一个 container 属性,这就是你的挂载节点的 DOM,这对处理动态添加的容器以及开启了 Shadow DOM 场景下非常有用。
注意,旧的 render 配置依然可以使用,我们做了兼容处理方便不想升级的用户;但 render 存在时,container 就不会生效。
因为我们引入了一些新的能力,因为 start 的配置也发生了一些变化:
import { start } from 'qiankun'
start({
- jsSandbox: true,
+ sandbox: {
+ strictStyleIsolation: true
+ }
})loadMicroApp这个 API 用于手动挂载一个微应用
/** 用于加载一个微应用 */
loadMicroApp(app: LoadableApp, configuration?: FrameworkConfiguration)
使用详情可见上面 多应用支持 小节。
这两天在排查一个 qiankun 的 bug 时,发现了一个我无法解释的 js 问题,这可要了我的命。
略去一切细枝末节,我们直接先来看问题。
假如有这么一段代码:
(() => {
'use strict';
const boundFn = Function.prototype.bind.call(OfflineAudioContext, window);
console.log(boundFn.hasOwnProperty('prototype'));
boundFn.prototype = OfflineAudioContext.prototype;
console.log(boundFn.hasOwnProperty('prototype'));
})();假设我们已知,函数通过 bind 调用后,返回的新的 boundFn 是一定不会有 prototype 的。
那么打印结果就应该是:
false
true因为 boundFn 不具备自有属性 'prototype',所以在经过 boundFn.prototype = OfflineAudioContext.prototype 的赋值操作后,会为其创建一个新的自有属性 'prototype',其值为 OfflineAudioContext.prototype。一切都在情理之中。
但你真的把这段代码粘到 chrome 控制台跑一下就会发现,报错了😑
从报错信息很容易判断,我们在尝试给一个 readonly 的属性做赋值,但关键是,prototype 这个属性在 boundFn 上压根不存在呀!
我们知道,对象的属性赋值操作的基本逻辑是这样的:
毫无疑问上面代码走的应该是第一个逻辑分支,完全不应该报错才对。
起初我还以为是浏览器兼容问题,然后尝试过几个浏览器之后,发现都是报错😑
排查的过程中发现,OfflineAudioContext.prototype 本身是 readonly 的
但是这跟我们 boundFn.prototype 赋值有什么关系呢,即便我们把赋值操作改成:
boundFn.prototype = 123;报错还是会照旧。
继续查,发现 boundFn 的原型链上是有 prototype 的:
而且原型链上的这个 prototype 也是 readonly 的:
但是我们一个写操作跟原型链有啥关系呢,不是读操作时才会按原型链查找吗???
各种尝试之后无果,这时候只能祭出 ecmascript spec,看看能不能从里面找到蛛丝马迹了😑
搜索找到赋值操作(assignment)相关的 spec 说明:
如果有过读 ecmascript spec 经验的话,会找到关键步骤在第 5 步 PutValue:
我们这个场景里,PutValue 的操作会沿着 4.a.false 的路径执行。即 put 对应的调用为 base.[[Put]](reference name, W, true)。
找到 [[Put]] 的调用算法说明:
这里其实就能看到,如果我们走到了最后一步第6步的时候,实际上发生的事情就会是:
Object.defineProperty(O, P, { writable: true, enumerable: true, configurable: true, value: V }), 也就是我们会为对象创建一个新的属性并赋值,且这个属性是可枚举可修改的,符合我们之前的认知。
那其实我们就要看看,为什么流程没有走到第6步。
先看第一步里的 [[CanPut]] 做了啥:
简单翻译下流程就是:
其实到这里我们就能发现端倪了,关键点是这几步:
这几步描述的实际就是,计算流程会一直去原型链上查找属性 P。
也就是说,即便我们是赋值操作,只要是对象属性的赋值,都会触发原型链的查找。
那么回到上面那段代码,对应的计算流程就是:
那么如果我们确实想给 boundFn 加一个自身属性 prototype 该怎么做呢?
其实我们只要找到不会触发原型链查找的修改方式就可以了:
- boundFn.prototype = OfflineAudioContext.prototype;
+ Object.defineProperty(boundFn, 'prototype', { value: OfflineAudioContext.prototype, enumerable: false, writable: true })原理就是 defineProperty API 不会有 [[getProperty]] 这种触发原型链查找的调用:
赋值(assignment)操作也会存在原型链查找逻辑,且是否可写也会遵循查找到的属性的 descriptor 规则。
事情起源于某天某妹子同事在看angular文档中关于Scope的说明Understanding Scopes(原文) 理解angular作用域(译文)时,对于文章中的例子有一点不理解,那个例子抽离细节之后大致是这样的:
// 一个标准的构造函数
function Scope(){}
Scope.prototype.array = [1,2,3];
Scope.prototype.string = 'Scope';
// 生成Scope实例
var scopeInstance = new Scope();当我们访问scopeInstance上的属性时,假如scopeInstance上不存在该属性,则js解释器会从原型链上一层层往上找,直到找到有该属性,否则返回undefined。
// get对象上某一属性时会触发原型链查找
console.log(scopeInstance.string); // 'Scope'
console.log(scopeInstance.name); // undefined而当我们往scopeInstance上某一属性设值时,它并不会触发原型链查找,而是直接给对象自身设值,如果对象上没有该属性则创建一个该属性。
scopeInstance.string = 'scopeInstance';
scopeInstance.array = [];
console.log(scopeInstance.string); // 'scopeInstance'
console.log(scopeInstance.array); // []
console.log(Scope.prototype.string); // 'Scope'
console.log(Scope.prototype.array); // [1,2,3]总结起来,关于对象的属性的set和get操作看上去有这样一些特性:
没错,这是最基本的原型链机制,我以前一直是这么理解的,然后我也是这么跟妹子解释的,然而文章后面的例子打了我脸。。。例子大致是这样的:
var scope2 = new Scope();
scope2.array[1] = 1;
console.log(scope2.array); // [1,1,3]
console.log(Scope.prototype.array); // [1,1,3]WTF!!!
按照我的理解,写操作跟原型链无关,在对象自身操作。
顺着这个思路,那么 scope2.array[1]=1这行代码压根就会报错啊,因为scope2在创建array属性之前压根就没有自身的array属性啊!可是它竟然没报错还把Scope.prototype给改了!
于是我又在想,是不是这种引用类型(array,object)都会触发原型链查找,所以会出现这个结果?
然而我又想起前面那段代码:
scopeInstance.array = [];
console.log(scopeInstance.array); // []
console.log(Scope.prototype.array); // [1,2,3]这下彻底斯巴达了😂
从表象来看,scopeInstance.array[1]的读写操作都会触发原型链查找,而为啥scopeInstance.array的写操作就不会触发。如果说引用类型都会触发,那么scopeInstace.array=[]就等价于Scope.prototype.array = [],但是事实并不是这样。。。
碰到这种时候我只有祭出神器了(ecmascript),google什么的绝对不好使相信我。
翻到ecmascript关于赋值操作符那一小节,es是这样描述的
The production AssignmentExpression : LeftHandSideExpression = AssignmentExpression is evaluated as follows:
- Evaluate LeftHandSideExpression.
- Evaluate AssignmentExpression.
- Call GetValue(Result(2)).
- Call PutValue(Result(1), Result(3)).
- Return Result(3).
前面三步都知道,关键点在第四步, PutValue(Result(1), Result(3))
我们再来看看PutValue干了啥
- If Type(V) is not Reference, throw a ReferenceError exception.
- Call GetBase(V).
- If Result(2) is null, go to step 6.
- Call the [[Put]] method of Result(2), passing GetPropertyName(V) for the property name and W for the value.
...
第二步有一个GetBase(V)操作,然后第四步依赖第二步的计算结果做最终赋值。
那么GetBase(V)究竟做了什么呢(V即我们赋值操作时候的左值)
GetBase(V). Returns the base object component of the reference V.
翻译下来就是:返回引用V的基础对象组件。
那么什么是基础对象组件呢,举两个例子:
GetBase(this.array) => this
GetBase(this.info.name) => this.info
GetBase(this.array[1]) => this.array我们再来看看属性访问器(Property Accessors),就是括号[]操作符及点号.操作符都做了什么
MemberExpression . Identifier is identical in its behaviour to MemberExpression [ ]
也就是说括号跟点号对解释器而言是一样的。
The production MemberExpression : MemberExpression [ Expression ] is evaluated as follows:
- Evaluate MemberExpression.
- Call GetValue(Result(1)).
...
跟到GetValue
- If Type(V) is not Reference, return V.
- Call GetBase(V).
- If Result(2) is null, throw a ReferenceError exception.
- Call the [[Get]] method of Result(2), passing GetPropertyName( V) for the property name.
第四步的私有方法[[Get]]是关键:
When the [[Get]] method of O is called with property name P, the following steps are taken:
- If O doesn't have a property with name P, go to step 4.
- Get the value of the property.
- Return Result(2).
- If the [[Prototype]] of O is null, return undefined.
- Call the [[Get]] method of [[Prototype]] with property name P.
- Return Result(5).
意思很明显,[[Get]]会触发原型链查找.
我们再回到赋值操作符的PutValue操作,走到第四步
Call the [[Put]] method of Result(2), passing GetPropertyName(V) for the property name and W for the value.
这里的Result(2)就是GetBase(V)的结果,拿上面的例子也就是GetBase(this.array[2]) == this.array
再看看[[Put]]操作干了什么事情:
When the [[Put]] method of O is called with property P and value V, the following steps are taken:
- Call the [[CanPut]] method of O with name P.
- If Result(1) is false, return.
- If O doesn't have a property with name P, go to step 6.
- Set the value of the property to V. The attributes of the property are not changed.
- Return.
- Create a property with name P, set its value to V and give it empty attributes.
- Return.
很简单,就是给对象o的属性P赋值时,o存在属性P就直接覆盖,没有就新建属性。此时无关原型链。
此时再结合我们自己的案例来看,scopeInstance.array[1]=2跟scopeInstance.array=[]究竟都干了啥(忽略不相关细节):
scopeInstance.array[1]=2scopeInstance.array=[]完美解释所有现象!
如果思考的比较深入的同学可能会问,scopeInstance又从哪儿取来的呢?也是类似原型链这样一层层往上查出来的么?这涉及到另一点知识,js中的作用域,具体可以看我的另一篇文章一道js面试题引发的思考
用过angular1.x(后面提到的angular均指代的angular1.x框架)的同学应该都知道,angular自身的模块系统是不具备按需加载的能力的,笔者也赞同angular的模块系统是真正称得上设计上的败笔的观点的。2015年被黑的最惨的前端主流框架莫过于angular了,但实际上angular真正设计上的硬伤只有两个:鸡肋的模块系统以及相比其他MVVM框架略显丑陋的脏值检测机制。关于其他各种所谓致命缺陷的立论其实都是站不住脚的,这些观点的提出我可以归结于使用者对angular的不熟悉,不服的同学欢迎来辩😂
扯远了,说回正题。由于angular自身模块系统的限制,module不支持运行时添加依赖,也就是我们在定义入口模块时必须声明所有依赖项。当我们面临多项目整合的场景时(往往这类场景有按需加载的需求),这个就很恶心了,我们总不能在入口页写好所有可能会嵌入系统的项目的依赖项吧,而且要确保入口模块能找到所有依赖项对应的模块,相应的js还必须在入口处就加载好。。 更多关于angular模块化的问题,具体可以参见民工叔的这篇文章Angular的模块机制
目前市面上流行的解决方案大概是这样的:基于requirejs等模块加载器,我们子模块的代码包裹在requirejs的模块定义语法下(define),然后在具体需要的时候在require回调里invoke我们子模块的controller或service等,可以参见这个seed项目angular-requirejs-seed
但是这种方式也有一些明显的问题:
angular.module('directives',[]).directive('grid',function(){})angular.module('app',['directives'])即便你采用requirejs做按需加载。angular.module('app').directive('grid',function(){}),这种做法副作用会相对少点,但是如果碰到多个项目在各个系统之间作嵌入时,很难做到不用修改代码即可完成嵌入,除非你能确保所有的系统入口模块命名一样。刚好最近公司在做整个系统的去iframe化(没错之前各个产品嵌入主系统的做法是通过iframe。。不要笑!!😂),因为各个产品之间的切换是通过tab完成的,tab的切换又是通过ui-router控制去定位到各个产品的入口html,所以基于ui-router,我的思路是这样的:
但是我们要做的当然不能是直接去找到ui-router这一块的代码然后修改源码,这种做法是有违开闭原则的也是我一直批判的方式,不到万不得已绝不要去修改第三方插件的源码!ui-router处理路由模板的主逻辑在uiView指令里,然后angular里面又提供了强大的decorator机制。开码!
angular
.module('ui.router.requirePolyfill', ['ng', 'ui.router', 'oc.lazyLoad'])
.decorator('uiViewDirective', DecoratorConstructor);
/**
* 装饰uiView指令,给其加入按需加载的能力
*/
DecoratorConstructor.$inject = ['$delegate', '$log', '$q', '$compile', '$controller', '$interpolate', '$state', '$ocLazyLoad'];
function DecoratorConstructor($delegate, $log, $q, $compile, $controller, $interpolate, $state, $ocLazyLoad) {
// 移除原始指令逻辑
$delegate.pop();
// 在原始ui-router的模版加载逻辑中加入脚本请求代码,实现按需加载需求
$delegate.push({
restrict: 'ECA',
priority: -400,
compile : function (tElement) {
var initial = tElement.html();
return function (scope, $element, attrs) {
var current = $state.$current,
name = getUiViewName(scope, attrs, $element, $interpolate),
locals = current && current.locals[name];
if (!locals) {
return;
}
$element.data('$uiView', {name: name, state: locals.$$state});
var template = locals.$template ? locals.$template : initial,
processResult = processTpl(template);
var compileTemplate = function () {
$element.html(processResult.tpl);
var link = $compile($element.contents());
if (locals.$$controller) {
locals.$scope = scope;
locals.$element = $element;
var controller = $controller(locals.$$controller, locals);
if (locals.$$controllerAs) {
scope[locals.$$controllerAs] = controller;
}
$element.data('$ngControllerController', controller);
$element.children().data('$ngControllerController', controller);
}
link(scope);
};
// 主要实现
// 模版中不含脚本则直接编译,否则在获取完脚本之后再做编译
if (processResult.scripts.length) {
loadScripts(processResult.scripts).then(compileTemplate);
} else {
compileTemplate();
}
};
}
});
return $delegate;最早期我自己实现了一个简单的script-loader用来做基本的动态脚本加载,但是后来发现一个问题:angular框架下我们单单的只是加载脚本是没用的,我们必须把脚本定义的module注入到主app的module下才有意义。尽管在下仔细读过大部分angular的核心部件代码,但是动态注册模块这个事情难度还是很大的,改造工作一度停滞不前。。直到我发现了这个库ocLazyLoad,这之后事情就好办了。
附上完整的实现代码:ui-router-require-polyfill,文档。这里面为了解决脚本加载的时序问题,我在loadScript方法里加入了提取script seq属性的机制用于确定脚本顺序,同时为了解决gulp脚本合并时的问题,个人简单改造了下gulp-usemin插件,改造后的插件在这里,要做发布的脚本合并时请配合使用这个改造过的插件。[更新:pull request已被合并,可以直接install gulp usemin最新版本]
这一套方案目前是我能想到的最接近完美的方案,最主要的是它是非侵入式而且基本不需要对原有angular体系下的代码做任何改造,即可实现按需加载&模块移植的需求的方式。如果有同学有改进建议或者更好的方案,欢迎一起探讨。
15年年末写了篇关于BEM方法论(实践上内容并不是原BEM)的文章,文末给自己挖了个坑说要聊聊Web语义化,跳票至今😂。16年第一篇用来填坑好了!
The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. --Wikipedia
语义化Web具备让数据跨终端共享/重用的能力。
对于HTML体系而言,Web语义化是指使用语义恰当的标签,使页面有良好的结构,页面元素有含义,能够让人和机器都容易理解。
语义化说起来好像都懂,但是实际情况并不是那么乐观。
OOCSS (Object Oriented CSS)
...a CSS “object” is a repeating visual pattern, that can be abstracted into an independent snippet of HTML, CSS, and possibly JavaScript. That object can then be reused throughout a site. — Nicole Sullivan
<div class="item">
<ul class="item-list">
<li class="item-list--item">
<h3 class="item-heading">...
<button class="button button-primary">primary</button>
<button class="button button-info">info</button>目标:
SMACSS(Scalable and Modular Architecture for CSS)
...an attempt to document a consistent approach to site development when using CSS. — SMACSS
<div class=“container”>
<div class=“container-header”>
<div class=“container-header__title”>
<h1 class=“container-header__title--home”>一种css架构风格
BEM(Block,Element,Modular)
The BEM approach ensures that everyone participating in the development of a website is working with the same codebase and using the same terminology — BEM Methodology
<ul class="menu">
<li class="menu__item">...</li>
<li class="menu__item_state_current">...</li>
<li class="menu__item">...</li>
</ul> 与SMACSS类似
METACSS | ATOMCSS (原子CSS)
<div class="fl mr10 red">
<span class="blue fl"></span>
</div> WTFSS
Cascading Style Sheets (CSS) are a stylesheet language used to describe the presentation of a document written in HTML or XML (including XML dialects like SVG or XHTML). CSS describes how elements should be rendered on screen, on paper, in speech, or on other media. --MDN
但这些都只是部分客观原因,主要原因在于我们对于Web语义化的理解度不够以及非正确的工作流。
以表现为中心的工作流: 需求原型 --> UI设计稿 --> 以HTML/CSS实现设计稿
以信息为中心的工作流: 需求原型 --> 分析需求并以HTML描述 --> UI设计稿 --> 分析样式并以CSS实现
两者最大的区别在于,对于面向UI的工作流而言,HTML/CSS只是实现UI的手段,而对于纯正的Web开发(面向语义的工作流)而言,我们应该是以信息为中心的,即首先考虑信息的本质(语义),并以合适的标签来标记,最后再考虑样式和行为(UI)。
之所以会有那么多层出不穷(不知所谓)的CSS设计模式,是因为它们大都是以表现为中心提出的“最佳实践”,而这两种方法论本身又是不适配的。
Web诞生的目的是用于在网络上传递资源跟信息的。HTML设计之初是用来作为互联网上主要的内容载体,其本身是用来描述信息的。在最早期的Web时代,HTML作为一种通用的描述语言用来表述在互联网上传输/共享的文档的信息。
Web 万维网
The World Wide Web (WWW) is an open source information space where documents and other web resources are identified by URLs, interlinked by hypertext links, and can be accessed via the Internet.
HTML 作为一种对计算机而言通用易懂的母语
To publish information for global distribution, one needs a universally understood language, a kind of publishing mother tongue that all computers may potentially understand.
Web领域的一套基础架构跟技术(包括HTTP、REST、HTML等),是按照语义中心的方式设计出来的。如果采用UI中心的方法论,必然导致阻抗不匹配。
w3c官方也在致力于推广Web语义化
通常意义上我们说的CSS语义指的是class的语义。class作为HTML与CSS之间的主要钩子,却是被我们误解最深的一个东西。
There are no additional restrictions on the tokens authors can use in the class attribute, but authors are encouraged to use values that describe the nature of the content, rather than values that describe the desired presentation of the content. --w3c
class属性本意是用来描述元素内容的,而不是描述元素展现的。其典型‘反模式’代表就是METACSS。
看看这两段代码,哪一个更容易理解?
<!-- 以表现为中心 -->
<div class="fl mr10">
<span>userName:Kuitos</span>
<div>
<!-- 以信息为中心 -->
<div class="user-info">
<span>userName:Kuitos</span>
<div>class作为HTML描述属性集的一部分,本身是用来细化内容语义的,所谓的CSS语义化本质上就是HTML语义化。
在CSS领域发展的初期,严格意义上的“最佳实践”都是不存在的,这主要受制于CSS的支持度,大部分浏览器的CSS的支持不够好,所以也导致我们很难在表现及语义之间做平衡。所以我们在翻看HTML标签的时候会看到诸如<b><center>这类纯样式的历史性标签(这些标签已经不被HTML5 spec推荐使用)。
但是为什么到了CSS已经如此强大(且浏览器支持度也都挺好)的年代,依然会出现那么多实质还是以表现为中心提出的所谓“最佳实践”?其实,这归结起来,源于我们对于CSS复用的这种刚性需求。
以OOCSS为例,我们写一组按钮可能会这么写:
<button class="button-primary"></button>
<button class="button-error"></button>.button-primary {
width: 80px;
height: 40px;
background-color: green;
...
}
.button-error {
width: 80px;
height: 40px;
background-color: red;
...
}我不能每写一个button都重复一遍宽高啊,要复用,所以我们可能会把公共部分提取出来
<button class="button button-primary"></button>
<button class="button button-error"></button>.button {
width: 80px;
height: 40px;
}如果你秉承这个思路,当哪天产品要求第一个按钮要左排第二个要右排的时候,我估摸着你会很自然的这么去写:
<button class="button button-primary float-left"></button>
<button class="button button-error float-right"></button>.float-left {
float: left;
}
.float-right {
float: right;
}更甚者,哪天产品要求第二个按钮跟右边隔10像素,你会不会这么写?
<button class="button button-error float-right mr10"></button>css我就不写了mr10什么意思我猜你已经知道了。。
且不说<button class="button button-primary"></button>这种写法中button本身就是一种冗余信息(我当没看见也罢),mr10则基本上无法忍受了,仔细想想这跟直接写inline-style有什么差别?相反我写inline-style更符合标准,至少我是挂载在专门用于描述表现的style属性上面,而不是用来描述内容的class上面。
基于这样的一连串演进,最后大概会诞生出两个症状:
原因在于,如果我们需要达到复用的效果,最后必定会魔障出一条理念:样式需具备独立性与上下文无关,同时粒度需要够小(样式类/通用原子类)。
其中也有一个主要原因是我们对CSS的误解
css = 层叠样式表,其关键词在层叠
“复用”需求最后一定会导致我们样式退化到平级的单class规则定义,因为这样才能足够无状态。但实际上CSS最独特的地方在于层叠,你避开这种机制从而来满足复用需求,最后不单单丧失了CSS的能力,反而会催生出一系列不符合语义化标准的反模式。
但是我也说过,复用是刚需,而CSS又不具备抽象能力,所以我们只能眼睁睁的看着一坨坨屎流行么?
好在我们有预处理器
Sass/Less我这里就不一一赘述了,时至今日相比大家都很熟悉。为什么说最佳实践是Sass/Less呢?简单来说,就是这类预处理器在提供一定的抽象能力的同时,也不会破坏css自身的特性。拿上面的例子来看,如果我们使用Sass/Less的写法:
%button {
width:80px;
height:40px;
}
.button-primary {
@extend %button;
background-color: white;
}
.button-success {
@extend %button;
background-color: green;
}
.button-error {
@extend %button;
background-color: red;
}如果我们在项目级别需要统一的配色,可以做进一步的抽象
$primary-bgc: white;
$success-bgc: green;
$error-bgc: red;
.button-primary {
@extend %button;
background-color: $primary-bgc;
}
.button-success {
@extend %button;
background-color: $success-bgc;
}
.button-error {
@extend %button;
background-color: $error-bgc;
}同样的手段还有mixin。
我们可以将我们需要复用的“样式类”抽象成placeholder/mixin(对于“通用原子类”这样的需求我推荐用placeholder),然后使用语义化的 class/属性 作为钩子,来组装这些“原子类”(但实际上这些“原子类”对CSS而言是不可见的)。比如我们用a标签来模拟一个提交按钮,我们应该这样写:
<a href="#" role="submit-button">提交</a>a[role="submit-button"] {
@include .button-success;
}所以css的最佳实践应该是: Sass + OOCSS/BEM/METACSS
这里有一个关键点在于,我们在使用这些css抽象方法论来写sass的时候,切记不要把中间变量暴露给css。什么意思呢,button那个例子我这样来写
.button{
width: 80px;
height: 40px;
}
.button-primary {
@extend .button;
}此时button对于css而言是可见的。对于button这类抽象产物,我们应该用placeholder和mixin代替,确保其对css的不可见从而保证web的“纯度”。(这也是我不推荐Less的原因,Less最大的失误在于没有placeholder的设计)
到这里估计思考过的同学会有疑问:很多场景可能并没那么容易语义化,比如我要第一个元素左浮动,第二个元素右浮动,第三个又左浮动,第四个右浮动。。。
这里需要提到另一个经常被误解的点:selector。selector作为HTML与CSS的结合点,实质上也是需要语义化的。tag跟id是天生带语义的,主要问题还是出在class上。我们总是尝试在class上挂载一些表现型的“名称”。这里面有一小部分确实是由于CSS本身的不完美(比如layout这种场景细则就比较难语义)导致的,但是过多的则归咎于我们语义化动力不足及对selector的认知不够。语义化动力不足完全是主观因素这里不赘述,对selector认知不够则是最普遍存在的情况。推荐阅读:为后代选择器及id选择器辩护 结合智能选择器的语义化的CSS
其实我不太想回答这种问题。。。我更想反问:为什么不按标准来?!!
一定要说的话:
推荐阅读:
几个月前,不知道什么缘由跟xx同学讨论了起js里自增操作符(i++)的问题,现将前因后果整理出来,传于世人😂
事情起源于这样一段代码
var i = 0;
i = i++;
console.log(i);来,都来说说答案是啥?
结果是0
换一种形式,或许大家不会有多少疑问
var i = 0;
var a = i++;
console.log(a); // 0没错,这也是我们初学自增操作符的经典例子,对这结果还有疑问请自觉面壁。。。
遥想当年学习自增操作符的口诀大致是,i++ 是先用后自增,++i 是先自增再用
那么按照这个思路,上面的代码解析流程应该是这样的
var i =0;
i = i;
i = i + 1;可惜结果并不是这样的
按照犀牛书上的描述,后增量(post increment)操作符的特点是
它对操作数进行增量计算,但返回未作增量计算的(unincremented)值。
但是书上并没有告诉我们,先做增量计算再返回之前的值,还是返回之前的值再做增量计算。
对于这种疑问,我们只能求助ecmascript给出官方解释:
The production PostfixExpression : LeftHandSideExpression [no LineTerminator here] ++ is evaluated as follows:
- Evaluate LeftHandSideExpression.
- Call GetValue(Result(1)).
- Call ToNumber(Result(2)).
- Add the value 1 to Result(3), using the same rules as for the + operator (see 11.6.3).
- Call PutValue(Result(1), Result(4)).
- Return Result(3).
从es上的算法描述,我们能够清晰的得知,后自增操作符是先自增赋值,然后返回自增前的值,这样的一个顺序。
到这里还不算完。
既然i=i++这种操作最后i还是为原始值,也就是这段代码不会有任何实际意义,那么js引擎有没有可能针对性的做优化,从而避免不必要的自增运算?(如果你用的是IDE,IDE会提示你这是一段无用的代码)
也就是说,我们如何确定,执行引擎一定做了两步操作:
i = i + 1; return iBeforeIncrease = 0;i = iBeforeIncrease;还是执行引擎可能会针对性的优化,只做一步操作:
i = iBeforeIncrease;当我在想怎么去确定这一点时,xx给出了解决方案,用Object.observe()方法啊!!(该方法是ES7提案中的新api,不过chrome早早的实现了)
var obj = {i:0};
Object.observe(obj, function(changes){
console.log(changes);
});
obj.i = obj.i++;代码放到chrome中跑一下,可以看到,改变触发了两次,也就是i做了两次修改操作。
另外firefox中也提供了一个类似的api,Object.prototype.watch,有兴趣的同学可以试试用这个方式来验证一下。
顺便抖个机灵,自增操作是非原子性操作,是非线程安全的,多线程环境下共用变量使用自增操作符是会有问题的。
原文写于 2013-04-18
web项目中会大量用到ajax请求实现前后台交互,以前处理后台返回给前台的集合数据的方式是这样的:
@RequestMapping("loadConfigUsers")
public void loadConfigUsers(String domain, HttpServletResponse response) {
response.setCharacterEncoding("UTF-8");
response.setContentType("text/html;charset=utf-8");
List<Map<String, Object>> list = userConfigService.loadConfigUsers(domain);
PrintWriter out = null;
try {
out = response.getWriter();
out.print(JackSonMapper.toJsonString(list));
} catch (IOException e) {
logger.error("I/O出错", e);
} finally {
try {
out.close();
} catch (Exception e) {
logger.error("关闭流出错", e);
}
}
}也就是使用jackson将List<Map<String,Object>>对象转换为json格式的数组,如[{"a":"b"},{"c","d"}]。
有了@responsebody之后我们的代码就简单多了
@ResponseBody
@RequestMapping("loadConfigUsers")
public List<Map<String,String>> loadConfigUsers(String domain, HttpServletResponse response) {
return userConfigService.loadConfigUsers(domain);
}前台接收到的即为json格式数组,如[{"a":"b"},{"c","d"}]。SpringMVC底层会使用jackson将带有@responsebody的方法体的返回值转成标准的json格式。
想返回Map<String,String>格式的也一样
@ResponseBody
@RequestMapping("loadConfigUsers")
public Map<String,String> loadConfigUsers(String domain, HttpServletResponse response) {
return userConfigService.loadConfigUsers(domain);
}返回的json格式为 {"a":"b","c":"d"}。
也可以直接向前台返回String
@ResponseBody
@RequestMapping("loadConfigUsers")
public String loadConfigUsers(String domain, HttpServletResponse response) {
return "success";
}前台接收到的为 "success"。
但是在实际开发中碰到一个问题,返回List,Map,即前台接收到的为json格式字符串的时候中文字符都正常,但是直接返回String却会出现中文乱码问题。google一下发现SpringMVC是这样实现的。
SpringMVC对于注有@responsebody注解的方法返回值有自己的一系列转换器,当发现返回值为List,Map等集合类型时SpringMVC使用的是MappingJacksonHttpMessageConverter转换器,改转换器字符集设置的为UTF-8,附部分代码
public class MappingJacksonHttpMessageConverter extends AbstractHttpMessageConverter<Object> {
// 设置默认字符集
public static final Charset DEFAULT_CHARSET = Charset.forName("UTF-8");
private ObjectMapper objectMapper = new ObjectMapper();
private boolean prefixJson = false;
/**
* Construct a new {@code BindingJacksonHttpMessageConverter}.
*/
public MappingJacksonHttpMessageConverter() {
super(new MediaType("application", "json", DEFAULT_CHARSET));
}
}而对于返回值为String时使用的转换器则为StringHttpMessageConverter
public class StringHttpMessageConverter extends AbstractHttpMessageConverter<String> {
// 设置默认字符集
public static final Charset DEFAULT_CHARSET = Charset.forName("ISO-8859-1");
private final List<Charset> availableCharsets;
private boolean writeAcceptCharset = true;
public StringHttpMessageConverter() {
super(new MediaType("text", "plain", DEFAULT_CHARSET), MediaType.ALL);
this.availableCharsets = new ArrayList<Charset>(Charset.availableCharsets().values());
}
}可以发现,两个转换器用的字符集竟然不一样,这个实在是难以理解,为毛用于处理同一个注解的两个转换器要用两种字符集??
经过一番google及测试,发现了有一种方式是可以解决StringHttpMessageConverter字符集的问题,即修改我们的springmvc-servlet.xml,在<mvc:annotation-driven />前加上这样一段配置
<bean class="org.springframework.web.servlet.mvc.annotation.DefaultAnnotationHandlerMapping" />
<bean class="org.springframework.web.servlet.mvc.annotation.AnnotationMethodHandlerAdapter" />
<bean class="org.springframework.web.servlet.mvc.method.annotation.RequestMappingHandlerAdapter">
<property name="messageConverters">
<list>
<bean class="org.springframework.http.converter.StringHttpMessageConverter">
<property name="supportedMediaTypes">
<list>
<value>text/plain;charset=UTF-8</value>
</list>
</property>
</bean>
<bean class="org.springframework.http.converter.json.MappingJacksonHttpMessageConverter" />
</list>
</property>
</bean>
<mvc:annotation-driven />即设置StringHttpMessageConverter可支持的媒体类型仅只有"text/plain;charset=UTF-8"一种。
另外还有一种是配置AnnotationMethodHandlerAdapter的messageConverters,即
<bean class="org.springframework.web.servlet.mvc.method.annotation.AnnotationMethodHandlerAdapter">
<property name="messageConverters">
<list>
<bean class="org.springframework.http.converter.StringHttpMessageConverter">
<property name="supportedMediaTypes">
<list>
<value>text/plain;charset=UTF-8</value>
</list>
</property>
</bean>
<bean class="org.springframework.http.converter.json.MappingJacksonHttpMessageConverter" />
</list>
</property>
</bean>这种方式是将spring所有的messageConverters改为两种StringHttpMessageConverter、MappingJacksonHttpMessageConverter
使用这种配置就不能再用mvc:annotation-driven了,官方文档是这样写的。也就是说它会覆盖之前的配置
The above registers a RequestMappingHandlerMapping, a RequestMappingHandlerAdapter, and an ExceptionHandlerExceptionResolver (among others) in support of processing requests with annotated controller methods using annotations such as @RequestMapping , @ExceptionHandler, and others
This is the complete list of HttpMessageConverters set up by mvc:annotation-driven:
ByteArrayHttpMessageConverter converts byte arrays.
StringHttpMessageConverter converts strings.
ResourceHttpMessageConverter converts to/from org.springframework.core.io.Resource for all media types.
SourceHttpMessageConverter converts to/from a javax.xml.transform.Source.
FormHttpMessageConverter converts form data to/from a MultiValueMap<String, String>.
Jaxb2RootElementHttpMessageConverter converts Java objects to/from XML — added if JAXB2 is present on the classpath.
MappingJackson2HttpMessageConverter (or MappingJacksonHttpMessageConverter) converts to/from JSON — added if Jackson 2 (or Jackson) is present on the classpath.
AtomFeedHttpMessageConverter converts Atom feeds — added if Rome is present on the classpath.
RssChannelHttpMessageConverter converts RSS feeds — added if Rome is present on the classpath.
至于spring是如何选择可用的converter的,这里有一篇文章,有兴趣可以看下:这里
引用苏宁前端架构师(@xufei)的一个总结作为开篇
编程技术及生态发展的三个阶段
- 最初的时候人们忙着补全各种API,代表着他们拥有的东西还很匮乏,需要在语言跟基础设施上继续完善
- 然后就开始各种模式,标志他们做的东西逐渐变大变复杂,需要更好的组织了
- 然后就是各类分层MVC,MVP,MVVM之类,可视化开发,自动化测试,团队协同系统等等,说明重视生产效率了,也就是所谓工程化
处在2015年这个时间段来看,前端生态已经进入了第三阶段。看上去好像已经走的挺远了,实则不然。如果再用人类历史上的三次工业革命来类比,前端发展其实不过刚刚迈入了蒸汽机时代,开始逐步用工具来替代过往相当一部分的人肉作业,但是离电气时代的自动化流水线作业还有很长一段路要走。回顾一下2015年前端的生态发展,我大致整理了几个我觉得比较有历史意义的事件。
按时间顺序:
css方面,postcss & cssnext先后高调走到台前。
由于近几年前端的野蛮生长以及前端应用的多元化和复杂化,整个技术形态已经跟几年前纯做页面的时代完全迥异了。主要观念的变化总结来看在于一点,现在的前端开发面向的是web app而不是web page。今天的前端开发模式跟传统的GUI软件(如C++、.NET开发的windows客户端)已经很接近了,而且由于现在前端领域为了解决日益复杂的web业务需求及体量,越来越多的借鉴了传统客户端的开发经验,导致两者变得越来越趋同。再加上前端一些独特的特性(免安装、增量安装等),工程上的复杂度有过之而无不及。前端如今已经脱离了茹毛饮血、刀耕火种的原始社会,开始步入了工业时代。
今年最火的框架/类库毫无疑问当属React了。React从2014年年中开始广泛受到开发者关注,但是真正开始在社区独领风*还得归功于2015年初React Native的发布。React Native的发布使得js统一三端(前端、后端、移动端)开发成为可能(现在这个时间点看可能还是过于理想,但是整体方向还是对的),这一针强心剂吸引了大量开发者的眼球。笔者对此最大的感受就是,我在社区发表一篇react的入门教程级别的软文便可获得广泛关注及转发,相应的写angular源码剖析的准干货大部分情况则是门可罗雀😂。
我们挑几个主流的框架来讲讲这一层的变化。
React基本简介可以参考这篇文章React简介,这里不再赘述。我们挑几个核心特征简单来讲:
Redux则是目前react配套的Flux模式的各种实现(其实现在两者的关系越来越模糊了)中最火的一个,在此基础上它引入了函数式编程、单一数据源、不可变数据、中间件等概念。一定程度来讲,redux是今年react生态甚至整个前端生态中影响最大的一个框架,它给整个前端技术栈引入了很多新成员,尽管这些概念可能在其他领域已经有了广泛的应用。虽然它们是否会在大规模的应用实践中被广大开发者认可还需要再检验,但至少给我们带来了一些新的思路。其中的单一数据源、不可变数据、中间件等思路目前来看还是非常有价值的,尤其是单一数据源跟不可变数据,很有可能在将来成为大型应用架构中的标配(目前来看至少在应用中构建Store层在当前的前端架构中是势在必行的)。单一数据源就好比在前端构建了一个集中式数据库,所有的数据存取操作对象都是它,不单如此它里面还实现了触发器,当有insert/update操作时它会对相应组件作rerender动作,这个在各组件之间有数据同步需求的场景下就非常有用了。
至于我对函数式编程的看法,后面单独阐述。
在我看来,react的优势并不在组件化,组件化的实现方案多种多样。react的优势在于virtual dom及一个几乎构成闭环的强大生态,这归功于Facebook工程师强大的工程能力跟架构能力。virtual dom将应用表现层从浏览器这个基于dom的上下文中抽离出来,通过原生js对象模型的方式使得react具备在任何环境支撑上层表现的能力。上层的渲染引擎可以是canvas、native、服务端甚至是桌面端,只要相应的端提供基于react组件的渲染能力,即可达到一套代码、或者只要很少的改动就能移植到任一终端环境的效果,这个就非常夸张了。react从0.14版本之后便将react-dom抽出来变成一个独立的库,可见react的野心并不局限于浏览器,相反从这点来看,react反而是受到了dom的掣肘。
ng2跟ng1相比是一个完全革命性版本而不是升级版,它是一个为了迎合未来的标准及理念来设计的全新框架,而这些新的理念又无法通过改进ng1.x的方式来实施,所以angular团队做了这么一个看似激进的决策,可以理解成重构已经无法满足需求只能重写了。ng2也采用纯组件化的开发思路,任何单元对于它来说都是组件。同时,ng2里面也引入了一些全新的概念(对于前端而言)来提升框架的性能及设计,例如基于worker的数据检测机制能大幅度提升渲染性能(对应实现是zone.js),基于响应式编程的新的编程模型能更大的改善编码体验(对应实现RxJS)。赶在2015年的尾巴,ng2正式发布beta版,对于angular的这次自我革命是否能成功,还有待后续检验。另外原angular团队中出来的一个成员开发了一个类ng2的框架aurelia,有相当的开发者认为它更配称为ng2,值得关注。
由于阿里在背后的技术实践及支持,Vue.js今年也开始得到越来越多的关注。vue相对于angular1.x的优势在于轻量、易用、更优异的性能及面向组件化的设计,目前发展态势也非常好,是移动端开发的一个重要技术选型之一。
现在回顾起来,2015年是很有意义的一年:这一年是Web诞生25岁周年,也是js诞生的20周年。同时又是ES6标准落地的一年。ES6是迄今为止ECMAScript标准最大的变革(如果不算上胎死腹中的ES4的话),带来了一系列令开发者兴奋的新特性。从目前es的进化速度来看,es后面应该会变成一个个的feature发布而不是像以前那样大版本号的方式,所以现在官方也在推荐 ES+年份 这种叫法而不是 ES +版本。
6月中ES2015规范正式发布,从ES2015带来的这些革命性的新语法来看,JS从此具备了用于开发大型应用的语言的基本要素:原生的mudule支持、原生的class关键字、更简洁的api及语法糖,更稳定的数据类型。而这些new features中,有几个我认为是会影响整个前端发展进程的:
关于ES2016的最重磅的消息莫过于11月初es标准委员会宣布将Object.observe从ES2016草案中移除了,尽管它已经是stage2几乎已经是事实标准。官方给出的解释是,这3年的时间前端世界变化实在太大,社区已经有了一些更优秀简洁的实现了(polymer的observe-js),而且React带来的immutable object在社区的流行使得基于可变数据的Object.observe的处境变的尴尬,O.o再继续下去的意义不大了。
除此之外,ES2016的相关草案也已经确定了一大部分其他new features。这里提两个我比较感兴趣的new feature:
目前ES2015/ES2016都有了比较优秀的转译器支持(没错我说的是babel),但是也不是all features supported,尝新的过程中需要注意。
至于Typescript,你可以将它理解成加入了静态类型的js的超集。不过我对于这种转译型语言一直不感冒(包括CoffeeScript),有兴趣同学自己去了解下吧。。
WebAssembly选择了跟ES2015在同一天发布,其项目领头人是大名鼎鼎的js之父Brendan Eich。WebAssembly旨在解决js作为解释性语言的先天性能缺陷,试图通过在浏览器底层加入编译机制从而提高js性能。这个事情跟当时V8做的类似(有兴趣的同学可以去了解下JIT),V8也因此一跃成为世界上跑的最快的js引擎。但是由于js是弱类型的动态语言,V8很快就触碰到了性能优化的天花板,因为很多场景下还是免不了recompile的过程。因此WebAssembly索性将编译过程前移(AOT)。WebAssembly提供工具将各种语言转换成特定的字节码,浏览器直接面向字节码编译程序。其实在此之前,firefox已经搞过asm.js做类似的事情,只不过WebAssembly的方案更激进。有人认为WebAssembly可能是2016年最大的黑马,如果wa能发展起来,若干年后我们看js编写的应用会像现在看汇编语言写出的大型程序的感觉。WebAssembly项目目前由苹果、谷歌、微软、Mozila四大浏览器厂商共同推进,还是非常值得期待的(写不下去了我决定回去翻开我那本落灰的编译原理。。)。
webcomponents规范起草于2013年,w3c标准委员会意图提供一种浏览器级别的组件化解决方案,通过浏览器的原生支持定义一种标准化的组件开发方式。webcomponents提出之际引发了整个前端圈的躁动,大家似乎在跨框架的组件化方案上看到了曙光。但是前端这圈子发展实在太特么快了,在当前这个时间点,webcomponents也遭遇到了跟Object.observe相似的尴尬处境。我们先来看看webcomponents的几个核心特性:
其中1、4现在都能很容易的通过自动化的工程手段解决了(shadow dom对应的是scoped css),而自定义标签这种事情不论是React还是Angular这类组件框架都能轻松解决,那么我用你webcomponents的理由呢?
另外webcomponents将目标对准的是HTML体系下的组件化,这一点跟React比就相对狭隘了(但是这并不表明React把战线拉的那么长就不会有问题)。
不过原生支持的跨框架的组件还是有存在的意义的,比如基础组件库,只是在当前来看web components发展还是有点营养不良。期待2016年能有实质上的突破吧。
2015年出现的新的技术及思路,影响最大的就是技术选型及架构了。我们可以从下面几点来看看它对前端架构上都有哪些影响。
React的风靡使得组件化的开发模式越来越被广大开发者关注。首先要肯定的是,组件化是一个非常值得去做的事情,它在工程上会大大提升项目的可维护性及拓展性,同时会带来一些代码可复用的附加效果。但这里要强调的一点是,组件化的指导策略一定是分治(分而治之)而不是复用,分治的目的是为了使得组件之间解耦跟正交,从而提高可维护性及多人协同开发效率。如果以复用为指导原则那么组件最后一定会发展到一个配置繁杂代码臃肿的状态。如果以组件的形态划分,可以分为两个类型:基础控件和业务组件。基础控件不应包含业务逻辑不然达不到拿来即用的效果,因此它也会表现出可复用的价值,但是根本还是为了提高业务组件的可维护性。至于业务组件,可复用的价值就很低了。
综合来看,我觉得工程上更具可行的全组件化方案应该是:细粒度的基础组件库 + 粗粒度的模板/组件。
工程化是近年前端提到最多的问题之一,而且个人认为是当前前端发展阶段最有价值的问题,也是前端开发通往工业化时代的必经之路。这里不赘述,有兴趣的同学看我前阵子整理的一篇文章前端工程化知识点回顾
MVVM想必大部分前端都耳熟能详了,代表框架是angular、vue、avalon。angular在1.2版本之后加入了controllerAs语法,使得controller可以变成一个真正意义上的VM,angular整个架构也才真正能称之为严格的MVVM(之前只能说是带有双向绑定的MVC/MVP)。
Flux是facebook随React一并推出的新的(准确来说其实是改进的,并非原创)架构模型,核心概念是单向数据流。Flux实质上就是一个演进版的中介者模式,不同的是它同时包装了action、store、dispatcher、view等概念。关于Flux对应用分层、数据在不同层之间只能单向流转的方式我是很赞成的。应用的分层在业务稍复杂的应用中都是很有必要的,它更利于应用的伸缩及拓展,副作用是会带来一定的复杂度(在我看来这点复杂度根本就可以忽略不计)。
今年被黑的最多的前端主流框架莫过于angular了。老实讲前端圈真的挺善变的,去年各种大会都在分享angular黑jquery,今年就变成了都在分享react黑angular了。黑的点大致有三:
第一点第二点我并无异议。angular的脏值检测机制相对于其他mvvm框架的双向绑定实现方式确实不太优雅,同样有硬伤的还有失败的模块语法及过多过于复杂的概念。但是对于第三点,我有不同的看法。
大多数人黑mvvm会以Facebook那张经典的flux vs mvc的图为论据,对于双向绑定造成的数据流紊乱及应用状态的不确定导致问题定位困难的观点我是认同的,这一点我也有切身体会,但是单纯的这一点就足以否定mvvm么?就说flux比mvvm高明?
MVVM在富表格型(自造的词😄)应用开发效率上是高于Flux的,典型的就是一些后台管控平台。而且最重要的是,MVVM跟Flux并不互斥,我们在MVVM中照样可以引入Flux中的一些机制从而确保应用状态的稳定。很多时候我们对于框架/架构的孰优孰劣的争论是没意义的,抛开业务场景谈解决方案都是耍流氓。
这一层对大部分前端来说可能是比较新的概念,其实我们可以这样理解:在一个完整的应用中,业务数据层指的就是数据来源,在angular体系中可以等同于ngResource模块(准确来说应该是$http)。
Relay是f家推出的在react上应用GraphQL的框架,它的大致思路是:前端通过在应用中定义一系列的schema来声明需要的接口数据结构,后端配合GraphQL引擎返回相应的数据。整个事情对于前端来说意义简直是跨时代的,工业化典范!不仅能极大提升前后端协同的开发效率,还能增加前端对于应用完整的掌控力。但是目前来看问题就是实施过于复杂,而且还得后端服务支持,工程成本太高,这一点上Meteor显然做的更好。
falcor则是Netflix出品的一个数据拉取库,核心理念是单一数据源,跟Redux的单store概念一致。用法跟Realy类似,也需要前端定义数据schema。
另外还有一个新的W3C标准api:fetch,它的级别等同于XMLHttpRequest,旨在提供比ajax更优雅的资源获取方式,目前几个主流浏览器支持的都还不错,也有官方维护的polyfill,几乎可以确定是未来的主流数据请求api。
业务数据层是前端应用中比较新的概念,它的多元化主要会影响到应用的架构设计,这里不细讲后面再来说。
函数式编程(functional programming)是近年比较火爆的一个编程范式,FP基于lambda演算,与以图灵机为基础的指令式编程(Java、C++)有着明显的差异。lambda演算更关注输入输出,更符合自然行为场景,所以看上去更适合事件驱动的web体系,这点我也认同。但问题是,太多开发者看到redux那么火爆就急着学redux用js去玩函数式,我觉得这个有待商榷。js作为一个以基于函数(scheme,父亲)跟基于对象(Self,母亲)的编程语言为蓝本设计然后语法又靠近Java(隔壁老王)的“混血”语言,你非得用它去写函数式,是不是过于一厢情愿?尤其是在现在浏览器还不支持尾调用优化的情况下,你让那激增的调用栈可如何是好😂如果你确实钟情于函数式,可以去玩玩那些更functional的语言(Haskell、Clojure等),而不是从js入手。最近看到一个老外关于js的函数式编程的看法,最后一句总结很精辟:Never forget that javascript hate you.😂
函数式响应型编程(functional reactive programming)不是一个新概念,但也不过是近两年才引入到前端领域的,代表类库就是ng2在用的rxjs。FRP关注的是事件及对应的数据流,你可以把它看作是一个基于事件总线(event bus)的观察者模式,它主要适用于以GUI为核心的交互软件中。但FRP最大的困难之处在于,如果你想使用这样的编程范式,那么你的整个系统必须以reactive为中心来规划。目前微软维护的ReactiveX项目已经有各种语言的实现版本,有兴趣的同学可以去了解下。
去年最主流的前端构建工具还是grunt&gulp,2015年随着react的崛起和web标准的快速推进,一切又有了新的变化。
webpack跟browserify本质上都是module bundler,差异点在于webpack提供更强大的loader机制让其更变得更加灵活。当然,webpack的流行自然还是离不开背后的react跟facebook(可见有个强大的干爹多么重要)。但是从现在HTTP/2标准的应用及实施进展来看,webpack/browserify这种基于bundle的打包工具也面临着被历史车轮碾过的危机,相对的基于module loader的jspm反而更具前景(虽然现在使用前两者的开发者都多于jspm)。
PostCSS作为新一代的css处理器大有取Sass/Less而代之的趋势,Bootstrap v5也有着基于PostCSS去开发的计划。但从本质来讲它又不算一个处理器,它更像是一个插件平台,能通过配置各种插件从而实现预处理器跟后处理器的效果。
cssnext官方口号是“使用来自未来的语法开发css,就在今天!”,但是cssnext又不是css4,它是一个能让开发者现在就享受最新的css语法(包括自定义属性、css变量等)的转换工具。这一块笔者还没有过具体实践,暂不多言。
从前端的发展现状来看,未来理想的前端技术架构应该是每一层都是可组装的,框架这种重型组合的适用场景会越来越局限。原因在于各部件不可拆卸会增加架构的升级代价同时会限制应用的灵活性。举个例子,我有一套面向pc端的后台管控平台的架构,view层采用angular开发,哪天我要迁移到移动端来,angular性能不行啊,我换成vue就好了。哪天觉得ajax的写法太挫,把http层替换成fetch就好了。又有一天后端的GranphQL平台搭好了,我把ngResource换成relay就OK了。
这种理想的方式当然是完全正确的方向,但是目前来看它对 开发者/架构师 的要求还是太高,工业级别上一套带有约束性的框架还是有相当的需求的(特别是当团队开发者的水平良莠不齐时。当然我觉得更正确的方式是流程上有一套完整的自动化方案用于确保团队提交的代码质量,只是目前基于动态分析的代码质量检测工具还没有出现,而且估计很长一段时间内都不会有)。虽然美好但是组合的方式也不是没有问题,各种五花八门的搭配容易造成社区的分化跟内耗,一定程度上不利于整个生态圈的发展。
近年前端生态的野蛮发展影响最大的应该就是新产品的技术选型了,乱花迷人眼,我们很难设计出一套适应大部分场景、而且短时间内不会被淘汰的架构。前端的变化太快通常会导致一些技术决策的反复,今天的最佳实践很可能明天就被视为反模式。难道最合适的态度是各种保留各种观望,以不变应万变?在这一点上即使如我这般在技术上一向激进的人都有点畏手畏脚了。那句话怎么说的来着?从来没有哪个圈子像今天的前端一样混乱又欣欣向荣了。有人说2015年或许是大前端时代的元年,目前看来,如果不是2015,那么它也一定会是2016年。
最后引用计子winter的一句话作为结语吧:
前端一直是一个变化很快的职能,它太年轻,年轻意味着可能性和机会,也意味着不成熟和痛苦。我经常担心的事情就是,很可能走到最后,我们会发现,我们做了很多,却还是一无所获。所幸至今回顾,每年还是总有点不同,也算给行业贡献了些经验值吧。
Techniques, strategies and recipes for building a modern web app with multiple teams using different JavaScript frameworks. — Micro Frontends
TL;DR
想跳过技术细节直接看怎么实践的同学可以拖到文章底部,直接看最后一节。
目前社区有很多关于微前端架构的介绍,但大多停留在概念介绍的阶段。而本文会就某一个具体的类型场景,着重介绍微前端架构可以带来什么价值以及具体实践过程中需要关注的技术决策,并辅以具体代码,从而能真正意义上帮助你构建一个生产可用的微前端架构系统。
而对于微前端的概念感兴趣或不熟悉的同学,可以通过搜索引擎来获取更多信息,如 知乎上的相关内容, 本文不再做过多介绍。
两个月前 Twitter 曾爆发过关于微前端的“热烈”讨论,参与大佬众多(Dan、Larkin 等),对“事件”本身我们今天不做过多评论(后面可能会写篇文章来回顾一下),有兴趣的同学可以通过这篇文章了解一二。
微前端架构具备以下几个核心价值:
微前端架构旨在解决单体应用在一个相对长的时间跨度下,由于参与的人员、团队的增多、变迁,从一个普通应用演变成一个巨石应用(Frontend Monolith)后,随之而来的应用不可维护的问题。这类问题在企业级 Web 应用中尤其常见。
中后台应用由于其应用生命周期长(动辄 3+ 年)等特点,最后演变成一个巨石应用的概率往往高于其他类型的 web 应用。而从技术实现角度,微前端架构解决方案大概分为两类场景:
本文将着重介绍单实例场景下的微前端架构实践方案(基于 single-spa),因为这个场景更贴近大部分中后台应用。
传统的云控制台应用,几乎都会面临业务快速发展之后,单体应用进化成巨石应用的问题。为了解决产品研发之间各种耦合的问题,大部分企业也都会有自己的解决方案。笔者于17年底,针对国内外几个著名的云产品控制台,做过这样一个技术调研:
| 产品 | 架构(截止 2017-12) | 实现技术 |
|---|---|---|
| google cloud | 纯 SPA | 主 portal angularjs,部分页面 angular(ng2)。 |
| aws | 纯 MPA 架构 | 首页基于 angularjs。各系统独立域名。 |
| 七牛 | SPA & MPA 混合架构 | 入口 dashboard 及 个人中心模块为 spa,使用同一 portal 模块(AngularJs(1.5.10) + webpack)。其他模块自治,或使用不同版本 portal,或使用其他技术栈。 |
| 又拍云 | 纯 SPA 架构 | 基于 angularjs 1.6.6 + ui-bootstrap。控制台内容较简单。 |
| ucloud | 纯 SPA 架构 | angularjs 1.3.12 |
MPA 方案的优点在于 部署简单、各应用之间硬隔离,天生具备技术栈无关、独立开发、独立部署的特性。缺点则也很明显,应用之间切换会造成浏览器重刷,由于产品域名之间相互跳转,流程体验上会存在断点。
SPA 则天生具备体验上的优势,应用直接无刷新切换,能极大的保证多产品之间流程操作串联时的流程性。缺点则在于各应用技术栈之间是强耦合的。
那我们有没有可能将 MPA 和 SPA 两者的优势结合起来,构建出一个相对完善的微前端架构方案呢?
jsconf china 2016 大会上,ucloud 的同学分享了他们的基于 angularjs 的方案(单页应用“联邦制”实践),里面提到的 "联邦制" 概念很贴切,可以认为是早期的基于耦合技术栈的微前端架构实践。
可以发现,微前端架构的优势,正是 MPA 与 SPA 架构优势的合集。即保证应用具备独立开发权的同时,又有将它们整合到一起保证产品完整的流程体验的能力。
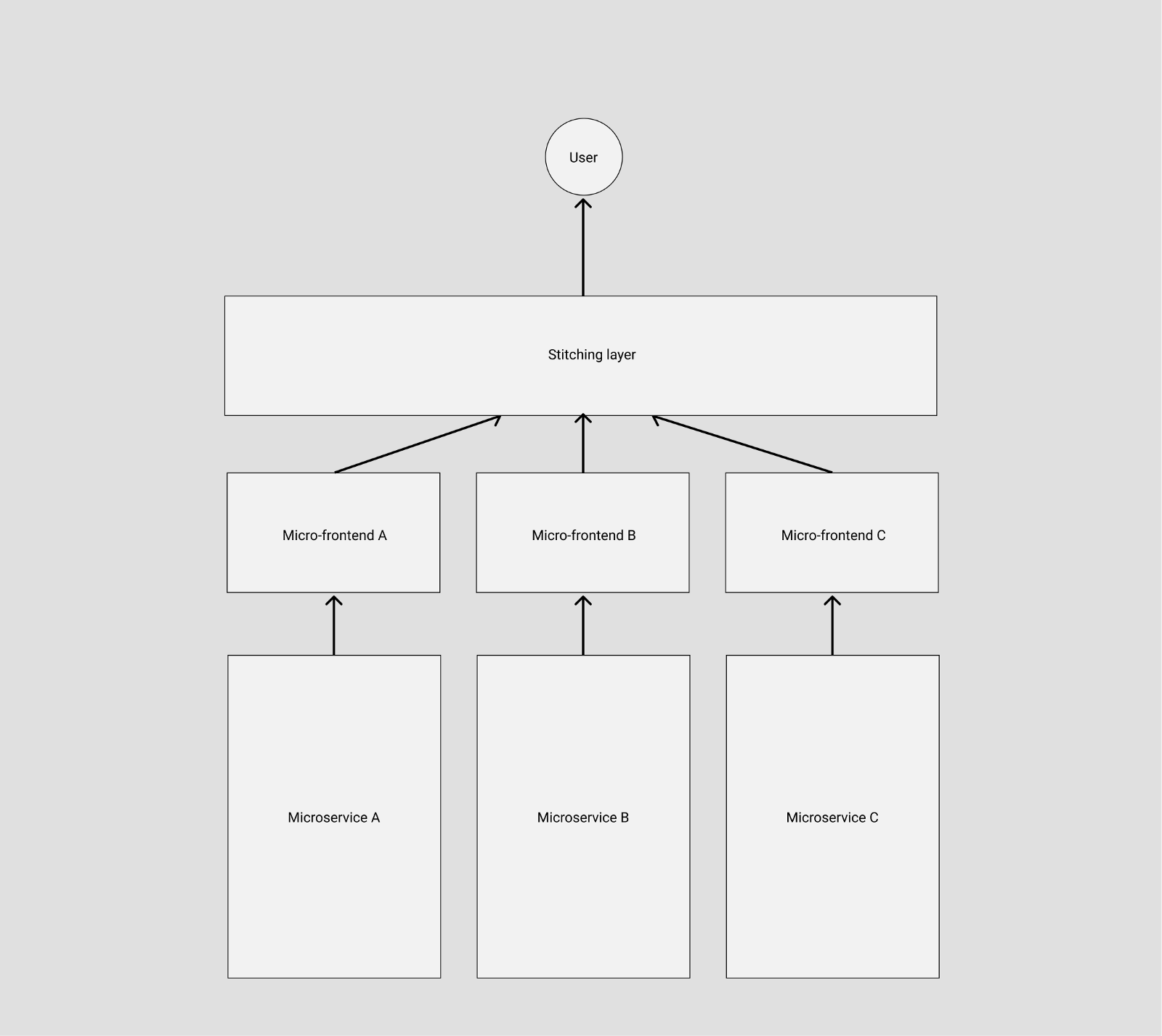
这样一套模式下,应用的架构就会变成:
Stitching layer 作为主框架的核心成员,充当调度者的角色,由它来决定在不同的条件下激活不同的子应用。因此主框架的定位则仅仅是:导航路由 + 资源加载框架。
而具体要实现这样一套架构,我们需要解决以下几个技术问题:
我们在一个实现了微前端内核的产品中,正常访问一个子应用的页面时,可能会有这样一个链路:
graph TD
A[访问 https://app.alipay.com] -->|点击导航中的某个子产品链接| B(https://app.alipay.com/subApp)
B -->|subApp 渲染并默认 redirect 到 list 页|C[https://app.alipay.com/subApp/list]
C -->|查看列表中某一项信息| D[https://app.alipay.com/subApp/:id/detail]
此时浏览器的地址可能是 https://app.alipay.com/subApp/123/detail,想象一下,此时我们手动刷新一下浏览器,会发生什么情况?
由于我们的子应用都是 lazy load 的,当浏览器重新刷新时,主框架的资源会被重新加载,同时异步 load 子应用的静态资源,由于此时主应用的路由系统已经激活,但子应用的资源可能还没有完全加载完毕,从而导致路由注册表里发现没有能匹配子应用 /subApp/123/detail 的规则,这时候就会导致跳 NotFound 页或者直接路由报错。
这个问题在所有 lazy load 方式加载子应用的方案中都会碰到,早些年前 angularjs 社区把这个问题统一称之为 Future State。
解决的思路也很简单,我们需要设计这样一套路由机制:
主框架配置子应用的路由为 subApp: { url: '/subApp/**', entry: './subApp.js' },则当浏览器的地址为 /subApp/abc 时,框架需要先加载 entry 资源,待 entry 资源加载完毕,确保子应用的路由系统注册进主框架之后后,再去由子应用的路由系统接管 url change 事件。同时在子应用路由切出时,主框架需要触发相应的 destroy 事件,子应用在监听到该事件时,调用自己的卸载方法卸载应用,如 React 场景下 destroy = () => ReactDOM.unmountAtNode(container)。
要实现这样一套机制,我们可以自己去劫持 url change 事件从而实现自己的路由系统,也可以基于社区已有的 ui router library,尤其是 react-router 在 v4 之后实现了 Dynamic Routing 能力,我们只需要复写一部分路由发现的逻辑即可。这里我们推荐直接选择社区比较完善的相关实践 single-spa。
解决了路由问题后,主框架与子应用集成的方式,也会成为一个需要重点关注的技术决策。
微前端架构模式下,子应用打包的方式,基本分为两种:
| 方案 | 特点 |
|---|---|
| 构建时 | 子应用通过 Package Registry (可以是 npm package,也可以是 git tags 等其他方式) 的方式,与主应用一起打包发布。 |
| 运行时 | 子应用自己构建打包,主应用运行时动态加载子应用资源。 |
两者的优缺点也很明显:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 构建时 | 主应用、子应用之间可以做打包优化,如依赖共享等 | 子应用与主应用之间产品工具链耦合。工具链也是技术栈的一部分。 子应用每次发布依赖主应用重新打包发布 |
| 运行时 | 主应用与子应用之间完全解耦,子应用完全技术栈无关 | 会多出一些运行时的复杂度和 overhead |
很显然,要实现真正的技术栈无关跟独立部署两个核心目标,大部分场景下我们需要使用运行时加载子应用这种方案。
在确定了运行时载入的方案后,另一个需要决策的点是,我们需要子应用提供什么形式的资源作为渲染入口?
JS Entry 的方式通常是子应用将资源打成一个 entry script,比如 single-spa 的 example 中的方式。但这个方案的限制也颇多,如要求子应用的所有资源打包到一个 js bundle 里,包括 css、图片等资源。除了打出来的包可能体积庞大之外的问题之外,资源的并行加载等特性也无法利用上。
HTML Entry 则更加灵活,直接将子应用打出来 HTML 作为入口,主框架可以通过 fetch html 的方式获取子应用的静态资源,同时将 HTML document 作为子节点塞到主框架的容器中。这样不仅可以极大的减少主应用的接入成本,子应用的开发方式及打包方式基本上也不需要调整,而且可以天然的解决子应用之间样式隔离的问题(后面提到)。想象一下这样一个场景:
<!-- 子应用 index.html -->
<script src="//unpkg/antd.min.js"></script>
<body>
<main id="root"></main>
</body>// 子应用入口
ReactDOM.render(<App/>, document.getElementById('root'))如果是 JS Entry 方案,主框架需要在子应用加载之前构建好相应的容器节点(比如这里的 "#root" 节点),不然子应用加载时会因为找不到 container 报错。但问题在于,主应用并不能保证子应用使用的容器节点为某一特定标记元素。而 HTML Entry 的方案则天然能解决这一问题,保留子应用完整的环境上下文,从而确保子应用有良好的开发体验。
HTML Entry 方案下,主框架注册子应用的方式则变成:
framework.registerApp('subApp1', { entry: '//abc.alipay.com/index.html'})本质上这里 HTML 充当的是应用静态资源表的角色,在某些场景下,我们也可以将 HTML Entry 的方案优化成 Config Entry,从而减少一次请求,如:
framework.registerApp('subApp1', { html: '', scripts: ['//abc.alipay.com/index.js'], css: ['//abc.alipay.com/index.css']})总结一下:
| App Entry | 优点 | 缺点 |
|---|---|---|
| HTML Entry | 1. 子应用开发、发布完全独立 2. 子应用具备与独立应用开发时一致的开发体验 |
1. 多一次请求,子应用资源解析消耗转移到运行时 2. 主子应用不处于同一个构建环境,无法利用 bundler 的一些构建期的优化能力,如公共依赖抽取等 |
| JS Entry | 主子应用使用同一个 bundler,可以方便做构建时优化 | 1. 子应用的发布需要主应用重新打包 2. 主应用需为每个子应用预留一个容器节点,且该节点 id 需与子应用的容器 id 保持一致 3. 子应用各类资源需要一起打成一个 bundle,资源加载效率变低 |
微前端架构下,我们需要获取到子应用暴露出的一些钩子引用,如 bootstrap、mount、unmout 等(参考 single-spa),从而能对接入应用有一个完整的生命周期控制。而由于子应用通常又有集成部署、独立部署两种模式同时支持的需求,使得我们只能选择 umd 这种兼容性的模块格式打包我们的子应用。如何在浏览器运行时获取远程脚本中导出的模块引用也是一个需要解决的问题。
通常我们第一反应的解法,也是最简单的解法就是与子应用与主框架之间约定好一个全局变量,把导出的钩子引用挂载到这个全局变量上,然后主应用从这里面取生命周期函数。
这个方案很好用,但是最大的问题是,主应用与子应用之间存在一种强约定的打包协议。那我们是否能找出一种松耦合的解决方案呢?
很简单,我们只需要走 umd 包格式中的 global export 方式获取子应用的导出即可,大体的思路是通过给 window 变量打标记,记住每次最后添加的全局变量,这个变量一般就是应用 export 后挂载到 global 上的变量。实现方式可以参考 systemjs global import,这里不再赘述。
微前端架构方案中有两个非常关键的问题,有没有解决这两个问题将直接标志你的方案是否真的生产可用。比较遗憾的是此前社区在这个问题上的处理都会不约而同选择”绕道“的方式,比如通过主子应用之间的一些默认约定去规避冲突。而今天我们会尝试从纯技术角度,更智能的解决应用之间可能冲突的问题。
由于微前端场景下,不同技术栈的子应用会被集成到同一个运行时中,所以我们必须在框架层确保各个子应用之间不会出现样式互相干扰的问题。
针对 "Isolated Styles" 这个问题,如果不考虑浏览器兼容性,通常第一个浮现到我们脑海里的方案会是 Web Components。基于 Web Components 的 Shadow DOM 能力,我们可以将每个子应用包裹到一个 Shadow DOM 中,保证其运行时的样式的绝对隔离。
但 Shadow DOM 方案在工程实践中会碰到一个常见问题,比如我们这样去构建了一个在 Shadow DOM 里渲染的子应用:
const shadow = document.querySelector('#hostElement').attachShadow({mode: 'open'});
shadow.innerHTML = '<sub-app>Here is some new text</sub-app><link rel="stylesheet" href="//unpkg.com/antd/antd.min.css">';由于子应用的样式作用域仅在 shadow 元素下,那么一旦子应用中出现运行时越界跑到外面构建 DOM 的场景,必定会导致构建出来的 DOM 无法应用子应用的样式的情况。
比如 sub-app 里调用了 antd modal 组件,由于 modal 是动态挂载到 document.body 的,而由于 Shadow DOM 的特性 antd 的样式只会在 shadow 这个作用域下生效,结果就是弹出框无法应用到 antd 的样式。解决的办法是把 antd 样式上浮一层,丢到主文档里,但这么做意味着子应用的样式直接泄露到主文档了。gg...
社区通常的实践是通过约定 css 前缀的方式来避免样式冲突,即各个子应用使用特定的前缀来命名 class,或者直接基于 css module 方案写样式。对于一个全新的项目,这样当然是可行,但是通常微前端架构更多的目标是解决存量/遗产 应用的接入问题。很显然遗产应用通常是很难有动力做大幅改造的。
最主要的是,约定的方式有一个无法解决的问题,假如子应用中使用了三方的组件库,三方库在写入了大量的全局样式的同时又不支持定制化前缀?比如 a 应用引入了 antd 2.x,而 b 应用引入了 antd 3.x,两个版本的 antd 都写入了全局的 .menu class,但又彼此不兼容怎么办?
解决方案其实很简单,我们只需要在应用切出/卸载后,同时卸载掉其样式表即可,原理是浏览器会对所有的样式表的插入、移除做整个 CSSOM 的重构,从而达到 插入、卸载 样式的目的。这样即能保证,在一个时间点里,只有一个应用的样式表是生效的。
上文提到的 HTML Entry 方案则天生具备样式隔离的特性,因为应用卸载后会直接移除去 HTML 结构,从而自动移除了其样式表。
比如 HTML Entry 模式下,子应用加载完成的后的 DOM 结构可能长这样:
<html>
<body>
<main id="subApp">
// 子应用完整的 html 结构
<link rel="stylesheet" href="//alipay.com/subapp.css">
<div id="root">....</div>
</main>
</body>
</html>当子应用被替换或卸载时,subApp 节点的 innerHTML 也会被复写,//alipay.com/subapp.css 也就自然被移除样式也随之卸载了。
解决了样式隔离的问题后,有一个更关键的问题我们还没有解决:如何确保各个子应用之间的全局变量不会互相干扰,从而保证每个子应用之间的软隔离?
这个问题比样式隔离的问题更棘手,社区的普遍玩法是给一些全局副作用加各种前缀从而避免冲突。但其实我们都明白,这种通过团队间的”口头“约定的方式往往低效且易碎,所有依赖人为约束的方案都很难避免由于人的疏忽导致的线上 bug。那么我们是否有可能打造出一个好用的且完全无约束的 JS 隔离方案呢?
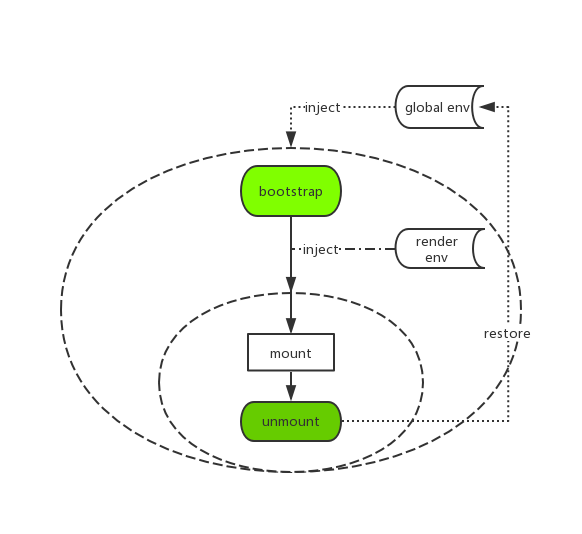
针对 JS 隔离的问题,我们独创了一个运行时的 JS 沙箱。简单画了个架构图:
即在应用的 bootstrap 及 mount 两个生命周期开始之前分别给全局状态打下快照,然后当应用切出/卸载时,将状态回滚至 bootstrap 开始之前的阶段,确保应用对全局状态的污染全部清零。而当应用二次进入时则再恢复至 mount 前的状态的,从而确保应用在 remount 时拥有跟第一次 mount 时一致的全局上下文。
当然沙箱里做的事情还远不止这些,其他的还包括一些对全局事件监听的劫持等,以确保应用在切出之后,对全局事件的监听能得到完整的卸载,同时也会在 remount 时重新监听这些全局事件,从而模拟出与应用独立运行时一致的沙箱环境。
自去年年底伊始,我们便尝试基于微前端架构模式,构建出一套全链路的面向中后台场景的产品接入平台,目的是解决不同产品之间集成困难、流程割裂的问题,希望接入平台后的应用,不论使用哪种技术栈,在运行时都可以通过自定义配置,实现不同应用之间页面级别的自由组合,从而生成一个千人千面的个性化控制台。
目前这套平台已在蚂蚁生产环境运行半年多,同时接入了多个产品线的 40+ 应用、4+ 不同类型的技术栈。过程中针对大量微前端实践中的问题,我们总结出了一套完整的解决方案:
在内部得到充分的技术验证和线上考验之后,我们决定将这套解决方案开源出来!
https://github.com/umijs/qiankun
取名 qiankun,意为统一。我们希望通过 qiankun 这种技术手段,让你能很方便的将一个巨石应用改造成一个基于微前端架构的系统,并且不再需要去关注各种过程中的技术细节,做到真正的开箱即用和生产可用。
对于 umi 用户我们也提供了配套的 qiankun 插件 @umijs/plugin-qiankun ,以便于 umi 应用能几乎零成本的接入 qiankun。
最后欢迎大家点赞使用提出宝贵的意见。👻
Maybe the most complete micro-frontends solution you ever met🧐.
可能是你见过的最完善的微前端架构解决方案。
原文写于 2014-10-10
原文写于 2015-02-28
前面两篇介绍了一些Promise的概念已经在AngularJs中的应用,前面也说过Promise模型已经成为ES6中的一个事实标准。今天在这里就简单介绍下ES6中原生Promise的用法:
var promise = new Promise(function(resolve, reject) {
// 异步处理
// 处理结束后、调用resolve 或 reject
});promise.then(onFulfilled, onRejected);
// 结合上面的构造函数,我们这样去用
var promise = new Promise(function(resolve, reject) {
// 用定时器模拟异步处理
setTimeout(function(){
resolve("ok");
},2000);
});
promise.then(function(msg){
console.log(msg);
});
// 两秒之后打出ok// 异常捕获,只要then链中有一个被reject或抛出异常就会被catch
promise.then(function(){}).then(function(){}).catch(function(msg){
console.log(msg);
});// 前几篇说过这是一个非常好用的方法,like this
var p1 = new Promise(function(resolve){
setTimeout(function(){
resolve(1);
},1000);
});
var p2 = new Promise(function(resolve){
setTimeout(function(){
resolve(2);
},2000);
});
var p3 = new Promise(function(resolve){
setTimeout(function(){
resolve(3);
},3000);
});
Promise.all([p1,p2,p3]).then(function(msg){
console.log(msg); // [1,2,3]
});
// 只有当所有的promise都resolve才会进入then链的success回调,如果有一个reject,就直接进入then链的error callback// 这个方法也很好用,与Promise.all类似,只不过Promise.all是与集关系,Promise.race是或集关系。顾名思义,竞争的promises
var p1 = new Promise(function(resolve){
setTimeout(function(){
resolve(1);
},1000);
});
var p2 = new Promise(function(resolve){
setTimeout(function(){
resolve(2);
},2000);
});
Promise.race([p1,p2]).then(function(msg){
console.log(msg); // 1
});
// p1先被resolve,所以打印出的就是1目前高版本的chrome跟firefox均以实现标准的原生Promise,上文中的代码各位均可放到浏览器中一试究竟。
至此,javascript异步流程控制之Promise系列完结,鼓掌!(👏)
更多Promise相关内容请看这里:Promise迷你书
原文写于 2015-01-25
先来说说什么是Promise吧
Promise是抽象异步处理对象以及对其进行各种操作的组件。 其详细内容在接下来我们还会学到,Promise并不是从JavaScript中发现的概念。
Promise最初被发现是在 E言語中, 它是基于并列/并行处理设计的一种编程语言。
简言之,Promise就是用于改善异步编程体验的一种编程模型,它提供一系列的api和方法论,让你能更优雅的解决异步编程中出现的一些问题。目前很多第三方框架或类库(如Angular和JQuery)都依照Promise/A+社区制定的规范做了相应的实现(JQuery基于历史原因很多地方与Promise规范不一致,so不建议通过JQuery源码学习Promise),最主要的是,Promise现在已经成为ES6的既定标准,目前部分高版本浏览器已原生支持Promise(后面有机会给出demo),所以我们还是很有必要来了解一下这到底是一个什么东西。
以前我们在处理一系列有依赖性的回调的时候,我们的代码是这样写的
step1(function (value1) {
step2(value1, function(value2) {
step3(value2, function(value3) {
step4(value3, function(value4) {
// Do something with value4
});
});
});
});是的,就是一层层的回调嵌套,传说中的回调地狱
那么如果我们换成Promise的方式来实现呢
step1().then(step2).then(step3).then(step4)效果显而易见,代码简单逻辑清晰,异步的回调嵌套写法变成了同步(本质上当然还是异步的)的写法看上去是不是优雅多了
目前,Angular基于现在流行的NodeJs异步流程控制库Q实现了一个微缩版的Q,它提供了一些最常用的规范的Promise API,并对外提供了$q这样一个service,这里我们介绍一下angular框架中主要有哪些api及相应的使用场景。(声明一点,angular中所有的ajax请求均返回promise)
Promise.then()
// 通常,我们处理多层顺序依赖的异步调用,我们会这样去写
$http.get().success(function (val1){
$http.get(val1).success(function (val2){
$http.get(val2).success(function (val3){
console.log(val3);
})
});
});
// 当用Promise来处理时,写法会变成这样
function funcA(val1){
return $http.get(val1).suceess(function (val2){
return val2;
})
}
function funcB(val2){
return $http.get(val2).suceess(function (val3){
return val3;
})
}
function funcC(val3){
console.log(val3);
}
$http.get().then(funcA).then(funcB).then(funcC);
// 很显然,使用了Promise方式代码可读性变的强很多Deferred.resolve
// Deferred.resolve用于通知promise结果已经处理好,可以开始处理回调了
// 假设我们有这样一个业务,按钮点击时的处理逻辑依赖于另一个函数异步返回的数据,就像这样
var a;
setTimeout(function(){
a = 10;
},5000);
dom.onclick = function(){
console.log(a);
}
// 我们总不能在onclick里轮询直到a被赋值吧。。
// 有了Promise一切变得简单
var defer = $q.defer(),
a;
setTimeout(function (){
defer.resolve(10);
},5000);
dom.onclick = function(){
defer.promise.then(function(a){
console.log(a);
});
}Deferred.reject
// 用法同deferred.resolve,只不过它调用之后会走失败回调
setTimeout(function(){
defer.reject(10);
},5000);
defer.promise.then(function successCb(a){
console.log(a+"success");
}, function errorCb(a){
console.log(a+"error");
});
// 5秒后打出 "10error"Promise.all
// 这个api就非常给力了,假设我们有这样一个场景
// 页面上有A、B、C、D四块区域,其中A、B、C三块数据都是ajax获取的,D展示的数据需要综合A、B、C三个的数据
// 难道我们得在 A 的请求回调里调用 B ,然后再B请求回调里调C这样一层层嵌套,直到所有请求准备好了再去处理D ?这样整个页面在同一时间只能有一个请求发出,效率太低
// 可以这样写
$q.all([promiseA,promiseB,promiseC]).then(funcD)
// 这样页面在同一时间会发出三个请求,当所有请求都好了之后再去处理D页面,代码不仅变得更清晰而且效率更高
最后介绍一下Promise.race([promises]),这个api angular并没有做实现,但是它已列入Promise/A+规范中,这里提一下
Promise.race([promises])与Promise.all([promises])类似,只不过Promise.all是与集运算,而Promise.race()是或集运算,当promises中有一个被resolve了就会继续后面的thenPromise.race
// 当promiseA或promiseB其中有一个被resolve,则后面funcT会被执行
// 使用场景有:进入一个页面时 当用户点击某个按钮或过5s 则展示某个提示,使用这个api会很方便
Promise.race([promiseA,promiseB]).then(funcT);Block Element Modifier is a methodology, that helps you to achieve reusable components and code sharing in the front-end
原义:一个css编写规范
B(block): 独立的页面及逻辑单元,我们通常意义上的component
E(element): 块中的组成部分,不能脱离块单独存在
M(modifier): 修饰符,可修饰块或元素
它提出来一种命名规范:
block__element--modifierexample:
<div class="header header--blink">
<div class="header__title header__title--red-border">title</div>
</div>这段html表达的意思是:一个header组件(block),其中包括了一个title元素(element),同时header块具备闪烁(blink)特性,title元素具备红边框特性。
BEM的这种命名方式看似美妙,但实则是与标准相悖的解决方案(后面讲)。所以我不会推荐这种css规范,我想说的是从BEM这种思路,我们可以将它作为我们组件粒度划分的方法论。
从BEM划分策略看页面:

以一个tab列表组件为例:

我们的目录结构应该这样去组织

代码可能这样去写
// tabset
app.directive('tabset', function(){
return {
restrict:'E',
templateUrl:'tab-set.html',
scope:{
tabs:'='
}
};
});<!-- tab-set.html -->
<div ng-repeat="tab in tabs track by $index">
<tab info="tab"></tab>
</div>
<div class="tab-border"></div>// tab
app.directive('tab', function(){
return {
restrict:'E',
require:'^tabset',
templateUrl:'tab.html',
scope:{
tab:'=info'
}
};
});<!-- tab.html -->
<div>
<span ng-bind="tab.title"></span>
</div>调用时这么去用
<tabset tabs="tabs"></tabset>app.controller('ctrl', ctrl);
ctrl.$inject = ['$scope'];
function ctrl($scope){
$scope.tabs = [{title:'tab1'}, {title:'tab2'}];
}Tab组件作为TabSet的一部分是没办法独立存在的,它必须依托于TabSet才有意义。
对调用者而言,暴露给它的是TabSet组件,TabSet才是一个Block(组件),Tab是一个Element。
在components这一层,我们能看到的都是一个个完整的Block,而且每个Block都是独立存在不会互相依赖的平级关系。
总结来讲就是
如果你在components层级发现了存在相互依赖的两个组件,赶紧重新想想你的组件规划是不是有问题
我们可以将 ‘组件之间的关系是组合而不是依赖’ 作为我们开发设计组件的guideline,基于此,我们需要确立的**就是,在现如今的web开发模式下,我们更应该采用 面向组件(COP) 的方式开发组件而不是以前流行的 面向对象(OOP) 的方式(以ExtJs为代表),组件之间更多的是组合关系,继承的场景在组件开发领域很少而且大多时候可以用其他方式实现(组合或者修饰符的方式)。
拓展章节:
原文写于 2015-04-15
要说2015年前端届最备受瞩目的技术是啥,当然非ReactJs莫属。作为一个只关注最前沿前端技术的系列,自然少不了关于它的介绍。
说了这么多理论性的东西,还是直接来上代码吧
ReactJs开发准备工作
首先你需要reactjs的开发环境。
bower install react脚本中引入react,由于我们需要使用jsx语法提高开发效率,所以还需要引入能讲jsx转化为javascript的库
不过这样JSXTransformer每次都会在app打开的时候做转换工作,并不适合生产环境,转换工作应该放在服务端进行,借助jsx工具
npm install -g react-tools
jsx --watch src/ build/然后页面依赖改成这样
node插件会在你开发的时候自动将源码转成javascript文件到指定目录
第一个react程序
// Hello World
React.render(
<h1>Hello, world!</h1>,
document.getElementById('example')
);接下来我们介绍一下react的一些基础语法
React.render() 将模版转换成html并插入到指定节点 参见上文的hello world示例
React解析引擎的规则就是遇到<符号就以jsx语法解析,遇到{就以javascript语法解析。比如这样
var array = [
<h1>Example 2</h1>,
<h2>Hello World</h2>
];
React.render(
<div>{array}</div>,
document.getElementById("example2")
);通过查看转换后的代码,我们可以看到他摘下面具后长这样
var array = [
React.createElement("h1", null, "Example 2"),
React.createElement("h2", null, "Hello World")
];
React.render(
React.createElement("div", null, array),
document.getElementById("example2")
);如何创建组件
var HelloWorldComponent = React.createClass({
render: function () {
return <div>React Component {this.props.author}</div>;
}
});
React.render(
<HelloWorldComponent author="Kuitos"/>,
document.getElementById("hello")
);通过React.createClass可以创建一个关联了虚拟dom的组件对象,每次组件数据更新便会调用组件的 render 方法重新渲染dom。
组件对象的props属性
上面一个例子我们看到在组件render方法中我们可以通过this.props.xx的方式拿到组件上关联的属性。另外需要额外提到的是,this.props有一个特殊属性children,它指向组件的子节点集合,like this
var List = React.createClass({
render: function () {
return (
<ol>
{
this.props.children.map(function (child) {
return <li>{child}</li>
})
}
</ol>
);
}
});
React.render(
<List>
<a href="#">百度</a>
<a href="#">谷歌</a>
</List>,
document.getElementById("example3")
);页面渲染的结果就是一个 ol 列表中还有两个li,每个li中包含一个超链接。通过这里我们也可以看出,在jsx中{}是会getValue的
获取真实dom React.findDOMNode()
var counter = 0;
var Button = React.createClass({
handleClick: function () {
React.findDOMNode(this.refs.input).focus();
},
render: function () {
return (
<div>
<input type="text" ref="input"/>
<input type="button" value="counter" onClick={this.handleClick}/>
</div>
);
}
});
React.render(
<Button />,
document.getElementById("button")
);组件状态 this.state
var Toggle = React.createClass({
getInitialState: function () {
return {liked: false};
},
handleClick: function (event) {
this.setState({liked: !this.state.liked});
},
render: function () {
var text = this.state.liked ? "like" : "unlike";
return (
<p onClick={this.handleClick}>
U {text} this.
</p>
);
}
});
React.render(
<Toggle />,
document.getElementById("button1")
);用React的方式实现angular中双向绑定的效果
var Input = React.createClass({
getInitialState: function () {
return {value: "Kuitos"};
},
handleChange: function (event) {
this.setState({value: event.target.value});
},
render: function () {
var value = this.state.value;
return (
<div>
<p>{value}</p>
<input type="text" value={value} onChange={this.handleChange}/>
</div>
);
}
});
React.render(
<Input/>,
document.getElementById("inputDataBind")
);virtual dom状态变更回调
组件生命周期分为三个状态:
var Input = React.createClass({
getInitialState: function () {
return {firstName: "Kuitos", lastName: "Lau"};
},
handleChange: function (event) {
this.setState({firstName: event.target.value});
},
componentWillMount: function () {
console.log("dom will be insert", this.state.firstName);
},
componentDidMount: function () {
console.log("dom had be insert", this.state.firstName);
},
componentWillUpdate: function (nextProps, nextState) {
console.log("dom will be update", nextProps, nextState);
},
componentDidUpdate: function (prevProps, prevState) {
console.log("dom had be update", prevProps, prevState);
},
render: function () {
var state = this.state;
return (
<div>
<p>{state.firstName} {state.lastName}</p>
<input type="text" value={state.firstName} author={state.firstName} onChange={this.handleChange}/>
</div>
);
}
});
React.render(
<Input/>,
document.getElementById("inputDataBind")
);打印的顺序依次是,dom will be update , dom had be update
当input输入时 dom will be update , dom had be update
react的基本知识就介绍到这里,后续我们会继续介绍react在实战项目中的应用及react native在移动端的表现力。
本文主要介绍总结了一些基于 qiankun 的微前端应用场景与实践
通常情况下,我们接触的最多的微前端的实践,是以 URL/路由 为维度来划分我们的微应用,以 OneX 平台(蚂蚁金融云基于微前端架构打造的统一接入平台)为例:
接入这类平台的微应用,通常只需要提供自己的 entry html 地址,并为其分配一个路由规则即可。
这背后的实现则是基于 qiankun 的 registerMicroApps API,如:
import { registerMicroApps } from 'qiankun';
registerMicroApps([
{
name: 'app1',
container: '#container',
entry: '//micro-app.alipay.com/',
activeRule: '/app1'
}
])路由与应用绑定的方式简单直观,是微前端中最为常见的使用场景,通常我们会用这种方式将一堆独立域名访问的 MPA 应用,整合成一个一体化的 SPA 应用。
但这类场景也有自己的局限性:
qiankun 2.0 的发布带来一个全新的 API loadMicroApp,通过这个 API 我们可以自己去控制一个微应用加载/卸载,这个方式也是 qiankun 2.0 的重磅特性:
import { loadMicroApp } from 'qiankun';
// do something
const container = document.createElement('div');
const microApp = loadMicroApp({ name: 'app', container, entry: '//micro-app.alipay.com' });
// do something and then unmount app
microApp.unmout();
// do something and then remount app
microApp.mount();开发者可以在脱离路由的限制下,以更自由的方式去渲染我们的微应用。基于 loadMicroApp API,我们只需要做一些简单的封装,即可以类似组件的开发体验,完成微应用的接入,以 React 为例:
第一步:封装一个 MicroApp 组件:
import { loadMicroApp } from 'qiankun';
import React from 'react';
export default class MicroApp extends React.Component {
containerRef = React.createRef();
microApp = null;
componentDidMount() {
const { name, entry, ...props } = this.props;
this.microApp = loadMicroApp(
{ name, entry, container: this.containerRef.current, props },
);
}
componentWillUnmount() {
this.microApp.unmount();
}
componentDidUpdate() {
const { name, entry, ...props } = this.props;
this.microApp.update(props);
}
render() {
return <div ref={this.containerRef}></div>;
}
}第二步:通过 MicroApp 组件引入微应用:
import MicroApp from './MicroApp';
import React from 'react';
class App extends React.Component {
render() {
return (
{
this.props.admin
? <MicroApp name="admin" entry="//localhost:8080/" level={10} />
: <MicroApp name="guest" entry="//localhost:8081/" level={1} />
}
)
}
}如果你是 umi 应用,那只需要直接使用插件封装好的组件即可:
import { MicroApp } from 'umi';
function MyComponent() {
return (
<div>
<MicroApp name="qiankun" age={1.5} stars={8700} />
</div>
)
}这类方式适用于一些可共用的、带业务逻辑的服务型组件(类似于我们以前常说的端对端组件):比如带聊天交互的客服机器人、带引导功能的 intro 服务等。
如蚂蚁 sofa 产品控制台中的这个使用入门微应用:
右侧呼出的窗口即为一个独立开发、独立发布的微应用
通过组件的这种方式,我们可以完全自主的控制微应用的渲染,并与之做一些复杂的交互。不论是在开发者的编码心智,还是用户的体验上,都跟使用一个普通的业务组件无异。
组件的方式非常灵活,几乎解决了所有路由绑定方式渲染微应用的问题,但也有自己的一些局限:比如我们会要求这类微应用必须是不带路由系统的 widget 类型,不然也会出现多实例时路由冲突的问题。
有一些更复杂的场景中,我们可能需要使用到「套娃」的方式集成我们的若干微应用。
比如我们要在应用 A 下集成应用 B 的商品列表页,然后在应用 B 的商品列表页呼出应用 C 的买家详情页,所有应用的唤起都以 弹层/抽屉 这种不刷新的交互来完成。
在有了上面两个场景的实践经验后,我们很容易得出这样的组合逻辑:
在应用 A 中通过调用 loadMicroApp(B) 的方式唤起微应用 B,然后在微应用 B 中通过 loadMicroApp(C) 的方式唤起微应用 C,通过这样的调用链路即可很完美的完成产品上的诉求。
但是现实情况往往没有那么简单,前面提到过,若想要 loadMicroApp API 能符合预期的运行,我们需要确保被加载的微应用是不含自己的路由系统,否则会出现多个应用间路由系统互相 抢占/冲突 的情况。
而现实情况是,我们大部分需要复用的页面/组件,都会是某个站点的局部路由页,很少有人会专门起一个仓库,用来专门把这个页面抽取成一个微应用,比如上面提到的买家详情页。
这种场景下,我们其实只需要确保微应用的路由系统不会干扰到全局的 URL 系统即可。幸运的是 react-router 的 memory history 模式很好的解决了这一问题。如果你是一个 umi 应用,只需要直接使用我们封装好的组件即可完成 memory history 的运行时切换:
import { MicroAppWithMemoHistory } from 'umi';
<Drawer>
<MicroAppWithMemoHistory name="buyer" url='/buyers/123' />
</Drawer>交互效果可以参考:
图中 app1/app2 均是子应用,但是在 app1 中可以再通过抽屉呼出 app2,同时浏览器地址栏也不会被 app2 的路由干扰。
关于嵌套渲染相关的详细介绍,可以看这篇《基于微前端的大型中台项目融合方案》
如果你觉得嵌套微应用就是我们场景的天花板了,那未免有点小看群众们的想象力了。
在我们内部的一个设计工程化平台里,我们通过 qiankun 成功的把一个微应用的 20+ 路由页同时渲染到了一个 url 下:
上图中右侧列表中每一个 demo 都是通过 qiankun 渲染的一个独立微应用实例,而这里面每一个微应用实例,实际对应是同一个 react 应用的不同路由页。
不同于前面几个场景,将同一个应用的不同页面,同时渲染到主应用的不同 UI 容器中这个需求下,有几个比较特殊的问题需要去考虑:
篇幅考虑,针对这类场景优化的技术细节不在这里介绍了,后面会单独写一篇来介绍
解决了这些问题后,我们只需要在我们的项目中这么去使用就可以了:
// MicroAppWithMemoHistory 是基于 memory history 封装的微应用加载器
import { MicroAppWithMemoHistory } from 'umi';
function Home {
return (
<div>
{ /* 将同一个应用的不同路由页同时渲染出来 */ }
<MicroAppWithMemoHistory name="demo" url="/demo1" />
<MicroAppWithMemoHistory name="demo" url="/demo2" />
<MicroAppWithMemoHistory name="demo" url="/demo3" />
<MicroAppWithMemoHistory name="demo" url="/demo4" />
<MicroAppWithMemoHistory name="demo" url="/demo5" />
<MicroAppWithMemoHistory name="demo" url="/demo6" />
</div>
)
}微前端架构除了其带来的巨石应用解构、技术栈无关等工程能力外,也为我们对一些已有的工程问题带来了新的解题思路,比如:
在以前,我们经常通过发布 npm 包的方式复用/共享我们的业务组件,但这种方式存在几个明显的问题:
说白了就是 npm 包这种静态的共享方式,丧失了动态下发代码的能力,导致了其过慢的工程响应速度,这在现在云服务流行的时代就会显得格外扎眼。而微前端这种纯动态的服务依赖方式,恰好能方便的解决上面的问题:被依赖的微应用更新后的产物,在产品刷新后即可动态的获取到,如果我们在微应用加载器中再辅以灰度逻辑,那么动态更新带来的变更风险也能得到有效的控制。
在以前,如果我们希望复用一个站点的局部 UI,几乎只有这样一条路径:从业务系统中抽取出一个组件 -> 发布 npm 包 -> 调用方使用 npm 包。
且不说前面提到的 npm 自身的问题,单单是从一个已有的业务系统中抽取出一个 UI 组件这个事情,都可能够我们喝一壶的了。我们不仅要在物理层面,将这部分代码抽取成若干个单独的文件,同时还要考虑如何跟已有的系统做上下文解耦,这类工作出现在一个越是年代久远的项目上,实施起来就越是困难,做过这类事情的同学应该都会深有体会。
不同于组件库的研发流程,微前端的场景下,大部分时候我们不会为了去复用一个 UI,而去专门写一个微应用出来。通常我们期望的是,从一个已有系统中,直接选取我们需要复用的部分,嵌入到我们自己的容器里进行渲染。
基于上面提到过的微应用多实例的渲染方案,我们可以考虑将需要复用的组件,以路由 URL 作为 ID 的方式导出。比如我们有这样一个 A 应用有一个这样的页面:
function OnePage() {
return (
<div>
<SearchForm/>
<UserList/>
</div>
)
}我们有另外一个应用,希望单独复用 A 应用的用户列表部分的交互跟 UI,那我们只需要多加一条路由规则:
<Switch>
...
<Route path="/userList" memory={true}>
<UserList/>
</Route>
</Switch>依赖方只需要配合 memory history 并指定 url 为 /userList 即可完成渲染(参考上面嵌套渲染章节)。
当我们将所有可以共享的服务单元变成一个个独立的微应用之后,我们便可以通过配置的方式描述我们的站点了,类似:
{
layout: 'admin-pro',
apps: [
{ name: 'abc', props: {} },
{ name: 'bcd', props: {} },
{ name: 'cde', props: {} },
]
}其中 layout 可以是一个带基础交互框架、用户鉴权等公共能力的微应用,也可以是一组微应用的集合(类似 babel 中的 preset 插件),而 apps 则是一组需要在当前站点渲染出来的业务微应用。
这种方式非常适用于,当我们要在一个业务域下开发多个细分服务站点时,通过这种配置的方式,配合一个运行时的微应用编排引擎,快速的生成一系列视觉一致、交互统一的业务站点出来。
在有了上面那些场景背后的技术支撑后,在产品上,我们就已经多出很多想象空间了。
但我们还可以想的更极限一点:
比如我们知道微信有一个公众号浮窗的功能,包括安卓系统常见的小窗模式,解决的就是空间独占、以及跨空间时的交互问题。
那我们在中后台也可以参考类似的设计,将不同空间的关联性操作以这种非独占的形态聚合到一起,从而降低流程上的断层感,提升产品体验。
demo.jpg
(这里本有一张蚂蚁内部系统的交互示意图,因涉及保密信息无法公开,有兴趣的同学可以选择加入我们后做进一步的交流分享😆)
微前端提供的这些渐进式更新、动态组合、 服务拓展的能力,相信大家通过我们介绍的这些常见场景,以及一些极致条件下的解决方案中能窥其一二。
但需要强调的是,任何技术架构都不可能是银弹,我们不必对微前端过于神化/劣化。本篇仅希望在分享了我们在微前端领域的一系列探索之后,能给其他开发者带来一些新的选择和启发,从而为其工程及产品上带来更多的可能性。
上面提到的这些案例,包括一些想象中的场景,正在我们团队内有条不紊地发生着,只是时机未到还不能更详细的对外宣传并与大家分享,欢迎有兴趣的同学可以加入我们,与我们一起去探索更多微前端的可能性。
如果您对微前端感兴趣,请发简历到 [email protected],我们非常期望有机会能与您共事,探索出微前端下更多的场景可能性。
如果您对微前端没什么兴趣,不要紧,只需要您对 antd、AntV、dva、umi、eggjs、ahooks 中任一类别的领域感兴趣,您也可以发简历到 [email protected] 来与我们共商大事。
接触markdown还挺早,主要是github上的readme都是markdown写的。但是之前都是在很小儿科的用markdown写东西,今天来系统学习下😄
Markdown 是一种轻量级标记语言,创始人为约翰·格鲁伯(John Gruber)。它允许人们“使用易读易写的纯文本格式编写文档,然后转换成有效的XHTML(或者HTML)文档”。[1]这种语言吸收了很多在电子邮件中已有的纯文本标记的特性。
Markdown同时还是一个由Gruber编写的Perl脚本:Markdown.pl。它把用markdown语法编写的内容转换成有效的、结构良好的XHTML或HTML内容,并将左尖括号('<')和&号替换成它们各自的字符实体引用。它可以用作单独的脚本,Blosxom和Movable Type的插件又或者BBEdit的文本过滤器.[1]
Markdown也已经被其他人用Perl和别的编程语言重新实现,其中一个Perl模块放在了CPAN(Text::Markdown)上。它基于一个BSD风格的许可证分发并可以作为几个内容管理系统的插件。
换行 行末两个空格 & 回车键
header
Header
=================
or
Header
-----------------
分级header
# header
## header
### header
#### header
无序列表
* 第一个
* 第二个
* 第三个
有序列表
1. 第一个
2. 第二个
3. 第三个
字体
**like this** like this*like this* like this图片 
链接 Markdown Site[Markdown Site](http://daringfireball.net/projects/markdown/syntax) or [Markdown Site][1]
email [email protected] <[email protected]>
文章块引用
第一层引用
第二层引用
> 第一层引用
>> 第二层引用
inline code inline code
--- or ***表格
| 左对齐 | 居中 | 右对齐 |
|---|---|---|
| 第一行 | 他大舅 | $1600 |
| 第二行 | 他二舅 | $12 |
| 第三行 | 都是他舅 | $1 |
| 左对齐 | 居中 | 右对齐 |
|:------ |:--------:| -----:|
| 第一行 | 他大舅 | $1600 |
| 第二行 | 他二舅 | $12 |
| 第三行 | 都是他舅 | $1 |
大招来了 代码块高亮 code block后加上语言名即可
var object = {};
function fn(){}
console.log("Hello World");~~~js
var object = {};
function fn(){}
console.log("Hello World");
更多markdown语法请访问markdown site github markdown
MIT
原文 2013-12-09
原文地址:http://blog.jobbole.com/52857/
最近几个月频繁的跟AngularJS打交道,对于web应用开发来说Angular真的是一个神奇的框架,但是没有东西是完美的,在这篇文章里我会把我的感悟罗列出来,希望可以产生共鸣(前提是你对Angular已经有所了解)。
Angular的自动数据绑定功能是亮点,然而,他的另一面是:在Angular初始化之前,页面中可能会给用户呈现出没有解析的表达式。当DOM准备就绪,Angular计算并替换相应的值。这样就会导致出现一个丑陋的闪烁效果。
上述情形就是在Angular教程中渲染示例代码的样子:
<body ng-controller="PhoneListCtrl">
<ul>
<li ng-repeat="phone in phones">
{{ phone.name }}
<p>{{ phone.snippet }}</p>
</li>
</ul>
</body>如果你做的是SPA(Single Page Application),这个问题只会在第一次加载页面的时候出现,幸运的是,可以很容易杜绝这种情形发生: 放弃{{ }}表达式,改用ng-bind指令
<body ng-controller="PhoneListCtrl">
<ul>
<li ng-repeat="phone in phones">
<span ng-bind="phone.name"></span>
<p ng-bind="phone.snippet">Optional: visually pleasing placeholder</p>
</li>
</ul>
</body>你需要一个tag来包含这个指令,所以我添加了一个给phone name.
那么初始化的时候会发生什么呢,这个tag里的值会显示(但是你可以选择设置空值).然后,当Angular初始化并用表达式结果替换tag内部值,注意你不需要在ng-bind内部添加大括号。更简洁了!如果你需要符合表达式,那就用ng-bind-template吧,
如果用这个指令,为了区分字符串字面量和表达式,你需要使用大括号
另外一种方法就是完全隐藏元素,甚至可以隐藏整个应用,直到Angular就绪。
Angular为此还提供了ng-cloak指令,工作原理就是在初始化阶段inject了css规则,或者你可以包含这个css 隐藏规则到你自己的stylesheet。Angular就绪后就会移除这个cloak样式,让我们的应用(或者元素)立刻渲染。
Angular并不依赖jQuery。事实上,Angular源码里包含了一个内嵌的轻量级的jquery:jqLite. 当Angular检测到你的页面里有jQuery出现,他就会用这个jQuery而不再用jqLite,直接证据就是Angular里的元素抽象层。比如,在directive中访问你要应用到的元素。
angular.module('jqdependency', [])
.directive('failswithoutjquery', function() {
return {
restrict : 'A',
link : function(scope, element, attrs) {
element.hide(4000)
}
}
});(演示代码: this plunkr )
但是这个元素jqLite还是jQuery元素呢?取决于,手册上这么写的:
Angular中所有的元素引用都会被jQuery或者jqLite包装;他们永远不是纯DOM引用
所以Angular如果没有检测到jQuery,那么就会使用jqLite元素,hide()方法值能用于jQuery元素,所以说这个示例代码只能当检测到jQuery时才可以使用。如果你(不小心)修改了AngularJS和jQuery的出现顺序,这个代码就会失效!虽说没事挪脚本的顺序的事情不经常发生,但是在我开始模块化代码的时候确实给我造成了困扰。尤其是当你开始使用模块加载器(比如 RequireJS), 我的解决办法是在配置里显示的声明Angular确实依赖jQuery
另外一种方法就是你不要通过Angular元素的包装来调用jQuery特定的方法,而是使用$(element).hide(4000)来表明自己的意图。这样依赖,即使修改了script加载顺序也没事。
特别需要注意的是Angular应用压缩问题。否则错误信息比如 ‘Unknown provider:aProvider <- a’ 会让你摸不到头脑。跟其他很多东西一样,这个错误在官方文档里也是无从查起的。简而言之,Angular依赖参数名来进行依赖注入。压缩器压根意识不到这个这跟Angular里普通的参数名有啥不同,尽可能的把脚本变短是他们职责。咋办?用“友好压缩法”来进行方法注入。看这里:
module.service('myservice', function($http, $q) {
// This breaks when minified
});
to this:
module.service('myservice', [ '$http', '$q', function($http, $q) {
// Using the array syntax to declare dependencies works with minification<b>!</b>
}]);这个数组语法很好的解决了这个问题。我的建议是从现在开始照这个方法写,如果你决定压缩JavaScript,这个方法可以让你少走很多弯路。好像是一个automatic rewriter机制,我也不太清楚这里面是怎么工作的。
最终一点建议:如果你想用数组语法复写你的functions,在所有Angular依赖注入的地方应用之。包括directives,还有directive里的controllers。别忘了逗号(经验之谈)
// the directive itself needs array injection syntax:
module.directive('directive-with-controller', ['myservice', function(myservice) {
return {
controller: ['$timeout', function($timeout) {
// but this controller needs array injection syntax, too!
}],
link : function(scope, element, attrs, ctrl) {
}
}
}]);注意:link function不需要数组语法,因为他并没有真正的注入。这是被Angular直接调用的函数。Directive级别的依赖注入在link function里也是使用的。
在directive中,一个令人掉头发的事就是directive已经‘完成’但你永远不会知道。当把jQuery插件整合到directive里时,这个通知尤为重要。假设你想用ng-repeat把动态数据以jQuery datatable的形式显示出来。当所有的数据在页面中加载完成后,你只需要调用$(‘.mytable).dataTable()就可以了。 但是,臣妾做不到啊!
为啥呢?Angular的数据绑定是通过持续的digest循环实现的。基于此,Angular框架里根本没有一个时间是‘休息’的。 一个解决方法就是将jQuery dataTable的调用放在当前digest循环外,用timeout方法就可以做到。
angular.module('table',[]).directive('mytable', ['$timeout', function($timeout) {
return {
restrict : 'E',
template: '<table class="mytable">' +
'<thead><tr><th>counting</th></tr></thead>' +
'<tr ng-repeat="data in datas"><td></td></tr>' +
'</table>',
link : function(scope, element, attrs, ctrl) {
scope.datas = ["one", "two", "three"]
// Doesn't work, shows an empty table:
// $('.mytable', element).dataTable()
// But this does:
$timeout(function() {
$('.mytable', element).dataTable();
}, 0)
}
}
}]);(实例代码 this plunkr )
在我们的代码里甚至遇到过需要双重嵌套$timeout。还有更疯狂的就是添加<script>tag 到模板中,这个脚本里回调Angular的scope.$apply()方法。我只想说,这很不完美。基于Angular的实现机理,这很难改变。
尽管说了这么多,Angular仍然是我最爱客户端JS框架。你用Angular的时候遇到过其他的坑吗?你用什么方法解决这些问题的呢?请留言!
原文写于 2013-08-13
最近在倒腾帮助中心的过程中接触到wordpress,为了方便的调试于是在内网虚拟机上搭建了一个LAMP环境,使用的是网上提供的xampp一键安装包。附上安装包地址
由于业务的需求,要在各个产品跳转到帮助中心具体的wordpress之前通过一个页面去接收请求,然后由该页面转发请求,如:
页面请求 http://help.fenxibao.com/channel/ --> 应用服务器 --> 去部署目录寻找应用名为channel的wordpress。
改为:http://help.fenxibao.com/channel/ --> http://help.fenxibao.com/index.php?app=channel --> index.php做处理 --> 跳转到指定的wordpress。
自然要到apache下面去做配置,在httpd.conf中加上这些内容(xampp安装之后apache的配置文件在 /opt/lampp/etc/httpd.conf):
# 这一行配置一定要写啊,不然下面写再多的rewrite rule都是白搭啊,说多了都是泪啊。。
RewriteEngine on
<VirtualHost _default_:80>
RewriteCond %{REQUEST_URI} ^/([a-z0-9_-]+)/$
RewriteRule ^/([a-z0-9_-]+)/ /index.php?app=$1
</VirtualHost>这里对这几行配置作一下说明:
具体处理步骤:
<?php
$appName = $_GET['app'];
if ($appName == "channel"){
echo $appName;
header('Location: ../wordpress/index.php');
} else {
echo $appName;
}
?>在这个中转界面将请求转发到 ../wordpress/index.php这个页面,应该没问题的,这个请求不符合RewriteCond的条件,应该可以直接访问应用页面的。。经过各种尝试发现在直接访问/wordpress/index.php时url被重定向成/wordpress/,这样的话就满足RewriteCond,于是请求过程变成了:
http://help.fenxibao.com/channel/ --> locahost/index.php?app=channel --> lcoahost/wordpress/index.php --> locahost/wordpress/ --> locahost/index.php?app=wordpress --> echo "wordpress" 。。。
跟踪lcoahost/wordpress/index.php的源代码,实在是找不到在哪个地方做了url处理,google wordpress index.php,如获至宝:
<?php
/*
Plugin Name: Disable Canonical URL Redirection
Description: Disables the "Canonical URL Redirect" features of WordPress 2.3 and above.
Version: 1.0
Author: Mark Jaquith
Author URI: http://markjaquith.com/
*/
remove_filter('template_redirect', 'redirect_canonical');
?>将这段代码做成插件然后在wordpress里面启用,浏览器键入地址,世界顿时清静。。。
附上地址:http://wordpress.org/support/topic/how-can-i-turn-off-wordpress-indexphp-redirect-to-domain-root
最后只想引用帖子里的一句回复,Dude, you rock. That plugin script works like a charm.
后续跟进
在后续操作中发现 RewriteCond %{REQUEST_URI} ^/([a-z0-9_-]+)/$ 这个东西其实是有问题,因为当我访问wordpress的具体文章时候,页面链接为 http://10.200.187.70/wordpress/?p=25之类的链接,这个时候页面竟然又跳转到中间页面index.php,然后转发到了wordpress的首页。各种尝试无果的情况下只得用蹩脚的英文去stackoverflow上提问,stack上果然是牛人聚集地啊,给出的回复:
%{REQUEST_URI} excludes the query string (the part after the ?)`
解决方案:
RewriteCond %{QUERY_STRING} ^$
RewriteRule /([\w-]+)/?$ /test.php?app=$1 [L]
OK,it works!!
让我再欢呼一句:Dude, you rock. Your codes works like a charm.
附上问题链接:这里
原文写于 2015-01-28
tansclude是angular生造的一个单词,不要去google啥意思相信我查不出来的。。。至于tranclude怎么翻译这件事我也是很懊恼,暂且将它译做 "隔离嵌入" 吧。具体含义大家在看过blog后自己体味吧。。。
transclude是angular指令中的一个配置,具体解释看这里
Extract the contents of the element where the directive appears and make it available to the directive. The contents are compiled and provided to the directive as a transclusion function. See the Transclusion section below.
There are two kinds of transclusion depending upon whether you want to transclude just the contents of the directive's element or the entire element:
true - transclude the content (i.e. the child nodes) of the directive's element.
'element' - transclude the whole of the directive's element including any directives on this element that defined at a lower priority than this directive. When used, the template property is ignored.
简言之就是将指令元素内部的节点内容在指令内部变得可用,不受指令隔离作用域影响。
使用场景一般是这样的:
我们需要封装一个组件,该组件有公用的header等区域,同时还有一个可以供使用者自由发挥的div区域。但是作为一个合格的angular开发者我们需要时刻关注自己的指令是否污染上层scope,所有大多情况下我们会使用隔离scope的做法。但是这个时候带来的问题是在隔离scope下我们的自定义div无法顺利的访问到自己作用域内容。这个时候我们需要在自定义指令中提供一个沙箱环境用于装载自定义div,这一块区域不受指令隔离scope影响。通常情况下我们会配合使用ng-transclude实现我们的需求,像下面这样
directive.transclude
.directive("todo", function(){
return {
restrict:"E",
transclude:"true",
template:"<header>{{header}}</header><div><span>这里是自定义区域</span><ng-transclude></ng-transclude></div>"
scope:{
header:"@"
}
};
})调用时这样写
todo
<script>
$scope.todo = “该干活啦!”;
</script>
<div>
<todo header="todo list">
<div>
<span ng-bind="todo"></span>
</div>
</todo>
</div>页面最后呈现的结果是这样的
<todo>
<header>todo list</header>
<div>
<span>这里是自定义区域</span>
<ng-transclude>
<div>
<span ng-bind="todo">该干活啦!</span>
</div>
</ng-transclude>
</div>
</todo>todo信息的展示不受指令的隔离作用域影响(隔离作用域中没有todo属性)
如果你以为我这篇仅仅是介绍下ng-transclude就完了。。。怎么可能区区ng-transclude官方文档都能查到demo的东西我会叫他黑科技?!!!没错接下来重点来啦!
ng-transclude这里正常的显示了指令外层作用域的内容是因为我这里只是做简单的读数据,如果我要写数据呢?假如我们有这样一个需求,当我们在transclude的内容里做的操作要影响外层展示,比如这样
<script>
$scope.todo = “该干活啦!”;
</script>
<div ng-controller>
<span ng-bind="todo"></span>
<todo header="todo list">
<div>
<button ng-click="todo='休息时间!'"></button>
<span ng-bind="todo"></span>
</div>
</todo>
</div>
<!-- 页面编译完成这样 -->
<div ng-controller>
<span ng-bind="todo">该干活啦!</span>
<todo header="todo list">
<header>todo list</header>
<span>这里是自定义区域</span>
<ng-transclude>
<div>
<button ng-click="todo='休息时间!'"></button>
<span ng-bind="todo">该干活啦!</span>
</div>
</ng-transclude>
</todo>
</div>当我们点击按钮时内层跟完成的todo信息会变成 "休息时间!" 么?
答案是 内层的会变,外层的不会。
原因就在ng-transclude。ng-tranclude是angular自己实现的一个指令,他的作用域继承自自定义指令外层的scope,所以我们在读取外层scope内容时没问题,但当我们尝试改写外层scope的属性时,实际上发生的是在ng-transclude作用域会生成一个相应的属性(比如上文的todo),即 ngTranscludeScope.todo = "休息时间!" ,而ngControllerScope.todo依然为"该干活啦!"。
既然ng-transclude存在这样的问题那么我们改怎么解决不能写操作的问题呢?
好在angular为指令提供了一个transcludeFn的接口,它来自angular框架对指令内嵌内容编译后返回的链接函数,获取这个函数有几个方式
指令controller注入
return {
transclude:true,
controller:["$transclude",function($transclude){
}]
};指令compile时自动注入
// 这种方式不推荐,因为transcludeFn通常需要依赖scope
return {
transclude:true,
compile:function(element,attr,transcludeFn){
}
};指令link时自动注入
return {
transclude:true,
link:function(scope,element,attr,controller,transcludeFn){
}
};transcludeFn调用方式如下:
transcludeFn(scope, cloneLinkFn, futrueElement),看官方声明
function([scope], cloneLinkingFn, futureParentElement).
<svg>).我们这里这样去用
.directive("todo", function(){
return {
restrict:"E",
transclude:"true",
template:"<header>{{header}}</header><div><span>这里是自定义区域</span><ng-transclude></ng-transclude></div>"
scope:{
header:"@"
},
link:function(scope,element,attr,controller,transcludeFn){
transcludeFn(scope.$parent, function(transcludeContent, scope){
element.find("ng-transclude").replaceWith(transcludeContent);
});
}
};
})我们通过transcludeFn将自定义指令内的节点的作用域手动指定为当前指令的父级作用域,然后将编译好的模板替换到ng-transclude层。
但是这样写有两个问题:
更优雅的做法是这样的
.directive("todo", function(){
return {
restrict:"E",
transclude:"true",
template:"<header>{{header}}</header><div><span>这里是自定义区域</span><content-transclude></content-transclude></div>"
scope:{
header:"@"
},
controller:["$transclude",function(transcludeFn){
this.transcludeFn = transcludeFn;
}]
};
})
.directive("contentTransclude",funtion(){
return {
restrict:"E",
require:"^todo",
link:function(scope,element,attr,todoController){
todoController.transcludeFn(scope.$parent, function(transcludeContent){
element.append(transcludeContent);
});
}
};
})todo指令只提供一个维护transcludeFn的controller,然后新建一个contentTransclude指令调用父级controller的服务将沙箱内容插入到具体位置。这样各区块职责划分更明确,复用性更强,而且整个代码看上去更优雅了。
总结来看,就是transclude提供一个内联function可以让我们给沙箱区域手动指定任意作用域,而不是交由框架自动生成。在我看来这种能控制一切的东西简直就是黑科技!!
1月底的时候,Angular 官方博客发布了一则消息:
AngularJS is planning one more significant release, version 1.7, and on July 1, 2018 it will enter a 3 year Long Term Support period.
即在 7月1日 AngularJS 发布 1.7.0 版本之后,AngularJS 将进入一个为期 3 年的 LTS 时期。也就是说 2018年7月1日 起至 2021年6月30日,AngularJS 不再合并任何会导致 breaking changes 的 features 或 bugfix,只做必要的问题修复。详细信息见这里:Stable AngularJS and Long Term Support
看到这则消息时我还是感触颇多的,作为我的前端启蒙框架,我从 AngularJS 上汲取到了非常多的养分。虽然 AngularJS 作为一款优秀的前端 MVW 框架已经出色的完成了自己的历史使命,但考虑到即便到了 2018 年,许多公司基于 AngularJS 的项目依然处于服役阶段,结合我过去一年多在 mobx 上的探索和实践,我决定给 AngularJS 强行再续一波命🙃。(搭车求治拖延症良方,二月初起草的文章五月份才写完,新闻都要过期了😑)
在开始之前,我们需要给 AngularJS 搭配上一些现代化 webapp 开发套件,以便后面能更方便地装载上 mobx 引擎。
现在是2018年,使用 ES6 开发应用已经成为事实标准(有可能的推荐直接上 TS )。如何将 AngularJS 搭载上 ES6 这里不再赘述,可以看我之前的这篇文章:Angular1.x + ES6 开发风格指南
AngularJS 在 1.5.0 版本后新增了一系列激动人心的特性,如 onw-way bindings、component lifecycle hooks、component definition 等,基于这些特性,我们可以方便的将 AngularJS 系统打造成一个纯组件化的应用(如果你对这些特性很熟悉可直接跳过至 AngularJS 搭配 mobx)。我们一个个来看:
onw-way bindings 单向绑定
AngularJS 中使用 <来定义组件的单向数据绑定,例如我们这样定义一个组件:
angular
.module('app.components', [])
.directive('component', () => ({
restrict: 'E',
template: '<p>count: {{$ctrl.count}}</p><button ng-click="$ctrl.count = $ctrl.count + 1">increase</button>'
scope: {
count: '<'
},
bindToController: true,
controllerAs: '$ctrl',
})使用时:
{{app.count}}
<component count="app.count"></component>当我们点击组件的 increase 按钮时,可以看到组件内的 count 加 1 了,但是 app.count并不受影响。
区别于 AngularJS 赖以成名的双向绑定特性 scope: { count: '='},单向数据绑定能更有效的隔离操作影响域,从而更方便的对数据变化溯源,降低 debug 难度。
双向绑定与单向绑定有各自的优势与劣势,这里不再讨论,有兴趣的可以看我这篇回答:单向数据绑定和双向数据绑定的优缺点,适合什么场景?
component lifecycle hooks 组件生命周期钩子
1.5.3 开始新增了几个组件的生命周期钩子(目的是为更方便的向 Angular2+ 迁移),分别是 $onInit $onChanges $onDestroy $postLink $doCheck(1.5.8增加),写起来大概长这样:
class Controller {
$onInit() {
// initialization
}
$onChanges(changesObj) {
const { user } = changesObj;
if(user && !user.isFirstChange()) {
// changing
}
}
$onDestroy() {}
$postLink() {}
$doCheck() {}
}
angular
.module('app.components', [])
.directive('component', () => ({
controller: Controller,
...
}))事实上在 1.5.3 之前,我们也能借助一些机制来模拟组件的生命周期(如 $scope.$watch、$scope.$on('$destroy')等),但基本上都需要借助$scope这座‘‘桥梁’’。但现在我们有了框架原生 lifecycle 的加持,这对于我们构建更纯粹的、框架无关的 ViewModel 来讲有很大帮助。更多关于 lifecycle 的信息可以看官方文档:AngularJS lifecycle hooks
component definition
AngularJS 1.5.0 后增加了 component 语法用于更方便清晰的定义一个组件,如上述例子中的组件我们可以用component语法改写成:
angular
.module('app.components', [])
.component('component', {
template: '<p>count: {{$ctrl.count}}</p><button ng-click="$ctrl.onUpdate({count: $ctrl.count + 1})">increase</button>'
bindings: {
count: '<',
onUpdate: '&'
},
})本质上component就是directive的语法糖,bindings 是 bindToController + controllerAs + scope 的语法糖,只不过component语法更简单语义更明了,定义组件变得更方便,与社区流行的风格也更一致(熟悉 vue 的同学应该已经发现了😆)。更多关于 AngularJS 组件化开发的 best practice,可以看官方的开发者文档:Understanding Components
准备工作做了一堆,我们也该开始进入本文的正题,即如何给 AngularJS 搭载上 mobx 引擎(本文假设你对 mobx 中的基础概念已经有一定程度的了解,如果不了解可以先移步 mobx repo mobx official doc):
引入 mobx-angularjs 库连接 mobx 和 angularjs 。
npm i mobx-angularjs -S在标准的 MVVM 架构里,ViewModel/Controller 除了构建视图本身的状态数据(即局部状态)外,作为视图跟业务模型之间沟通的桥梁,其主要职责是将业务模型适配(转换/组装)成对视图更友好的数据模型。因此,在 mobx 视角下,ViewModel 主要由以下几部分组成:
视图(局部)状态对应的 observable data
class ViewModel {
@observable
isLoading = true;
@observable
isModelOpened = false;
}可观察数据(对应的 observer 为 view),即视图需要对其变化自动做出响应的数据。在 mobx-angularjs 库的协助下,通常 observable data 的变化会使关联的视图自动触发 rerender(或触发网络请求之类的副作用)。ViewModel 中的 observable data 通常是视图状态(UI-State),如 isLoading、isOpened 等。
由 应用/视图 状态衍生的 computed data
Computed values are values that can be derived from the existing state or other computed values.
class ViewModel {
@computed
get userName() {
return `${this.user.firstName} ${this.user.lastName}`;
}
}计算数据指的是由其他 observable/computed data 转换而来,更方便视图直接使用的衍生数据(derived data)。 在重业务轻交互的 web 类应用中(通常是各种企业服务软件), computed data 在 ViewModel 中应该占主要部分,且基本是由业务 store 中的数据(即应用状态)转换而来。 computed 这种数据推导关系描述能确保我们的应用遵循 single source of truth 原则,不会出现数据不一致的情况,这也是 RP 编程中的基本原则之一。
action
ViewModel 中的 action 除了一小部分改变视图状态的行为外,大部分应该是直接调用 Model/Store 中的 action 来完成业务状态的流转。建议把所有对 observable data 的操作都放到被 aciton 装饰的方法下进行。
mobx 配合下,一个相对完整的 ViewModel 大概长这样:
import UserStore from './UserStore';
class ViewModel {
@inject(UserStore)
store;
@observable
isDropdownOpened = false;
@computed
get userName() {
return `${this.store.firstName} ${this.store.lastName}`;
}
@action
toggel() {
this.isDropdownOpened = !isDropdownOpened;
}
updateFirstName(firstName) {
this.store.updateFirstName(firstName);
}
}<section mobx-autorun>
<counter value="$ctrl.count"></counter>
<button type="button" ng-click="$ctrl.increse()">increse</button>
</section>import template from './index.tpl.html';
class ViewModel {
@observable count = 0;
@action increse() {
this.count++;
}
}
export default angular
.module('app', [])
.component('container', {
template,
controller: Controller,
})
.component('counter', {
template: '<section><header>{{$ctrl.count}}</header></section>'
bindings: { value: '<' }
})
.name;可以看到,除了常规的基于 mobx 的 ViewModel 定义外,我们只需要在模板的根节点加上 mobx-autorun 指令,我们的 angularjs 组件就能很好的运作的 mobx 的响应式引擎下,从而自动的对 observable state 的变化执行 rerender。
从上文的示例代码中我们可以看到,将 mobx 跟 angularjs 衔接运转起来的是 mobx-autorun指令,我们翻下 mobx-angularjs 代码:
const link: angular.IDirectiveLinkFn = ($scope) => {
const { $$watchers = [] } = $scope as any
const debouncedDigest = debounce($scope.$digest.bind($scope), 0);
const dispose = reaction(
() => [...$$watchers].map(watcher => watcher.get($scope)),
() => !$scope.$root.$$phase && debouncedDigest()
)
$scope.$on('$destroy', dispose)
}可以看到 核心代码 其实就三行:
reaction(
() => [...$$watchers].map(watcher => watcher.get($scope)),
() => !$scope.$root.$$phase && debouncedDigest()思路非常简单,即在指令 link 之后,遍历一遍当前 scope 上挂载的 watchers 并取值,由于这个动作是在 mobx reaction 执行上下文中进行的,因此 watcher 里依赖的所有 observable 都会被收集起来,这样当下次其中任何一个 observable 发生变更时,都会触发 reaction 的副作用对 scope 进行 digest,从而达到自动更新视图的目的。
我们知道,angularjs 的性能被广为诟病并不是因为 ‘脏检查’ 本身慢,而是因为 angularjs 在每次异步事件发生时都是无脑的从根节点开始向下 digest,从而会导致一些不必要的 loop 造成的。而当我们在搭载上 mobx 的 push-based 的 change propagation 机制时,只有当被视图真正使用的数据发生变化时,相关联的视图才会触发局部 digest (可以理解为只有 observable data 存在 subscriber/observer 时,状态变化才会触发关联依赖的重算,从而避免不必要资源消耗,即所谓的 lazy),区别于异步事件触发即无脑地 $rootScope.$apply, 这种方式显然更高效。
我们知道 angularjs 是通过劫持各种异步事件然后从根节点做 apply 的,这就导致只要我们用到了会被 angularjs 劫持的特性就会触发 apply,其他的诸如 $http $timeout 都好说,我们有很多替代方案,但是 ng-click 这类事件监听指令我们无法避免,就像上文例子中一样,假如我们能杜绝潜藏的根节点 apply,想必应用的性能提升能更进一步。
思路很简单,我们只要把 ng-click 之流替换成不触发 apply 的版本即可。比如把原来的 ng event 实现这样改一下:
forEach(
'click dblclick mousedown mouseup mouseover mouseout mousemove mouseenter mouseleave keydown keyup keypress submit focus blur copy cut paste'.split(' '),
function(eventName) {
var directiveName = directiveNormalize('native-' + eventName);
ngEventDirectives[directiveName] = ['$parse', '$rootScope', function($parse, $rootScope) {
return {
restrict: 'A',
compile: function($element, attr) {
var fn = $parse(attr[directiveName], /* interceptorFn */ null, /* expensiveChecks */ true);
return function ngEventHandler(scope, element) {
element.on(eventName, function(event) {
fn(scope, {$event:event})
});
};
}
};
}];
}
);时间监听的回调中只是简单触发一下绑定的函数即可,不再 apply,bingo!
在 mobx 配合 angularjs 开发过程中,有一些点我们可能会 碰到/需要考虑:
避免 TTL
单向数据流优点很多,大部分场景下我们会优先使用 one-way binding 方式定义组件。通常你会写出这样的代码:
class ViewModel {
@computed
get unCompeletedTodos() {
return this.store.todos.filter(todo => !todo.compeleted)
}
}<section mobx-autorun>
<todo-panel todos="$ctrl.unCompeletedTodos"></todo-panel>
</section>todo-panel 组件使用单向数据绑定定义:
angular
.module('xxx', [])
.component('todoPanel', {
template: '<ul><li ng-repeat="todo in $ctrl.todos track by todo.id">{{todo.content}}</li></ul>'
bindings: { todos: '<' }
})看上去没有任何问题,但是当你把代码扔到浏览器里时就会收获一段 angularjs 馈赠的 TTL 错误:Error: $rootScope:infdigInfinite $digest Loop。实际上这并不是 mobx-angularjs 惹的祸,而是 angularjs 目前未实现 one-way binding 的 deep comparison 导致的,由于每次 get unCompeletedTodos 都会返回一个新的数组引用,而<又是基于引用作对比,从而每次 prev === current 都是 false,最后自然报 TTL 错误了(具体可以看这里 One-way bindings + shallow watching )。
不过好在 mobx 优化手段中恰好有一个方法能间接的解决这个问题。我们只需要给 computed 加一个表示要做深度值对比的 modifier 即可:
@computed.struct
get unCompeletedTodos() {
return this.store.todos.filter(todo => !todo.compeleted)
}本质上还是对 unCompeletedTodos 的 memorization,只不过对比基准从默认的值对比(===)变成了结构/深度 对比,因而在第一次 get unCompeletedTodos 之后,只要计算出来的结果跟前次的结构一致(只有当 computed data 依赖的 observable 发生变化的时候才会触发重算),后续的 getter 都会直接返回前面缓存的结果,从而不会触发额外的 diff,进而避免了 TTL 错误的出现。
$onInit 和 $onChanges 触发顺序的问题
通常情况下我们希望在 ViewModel 中借助组件的 lifecycle 钩子做一些事情,比如在 $onInit 中触发副作用(网络请求,事件绑定等),在 $onChanges 里监听传入数据变化做视图更新。
class ViewModel {
$onInit() {
this.store.fetchUsers(this.id);
}
$onChanges(changesObj) {
const { id } = changesObj;
if(id && !id.isFirstChange()) {
this.store.fetchUsers(id.currentValue)
}
}
}可以发现其实我们在 $onInit 和 $onChanges 中做了重复的事情,而且这种写法也与我们要做视图框架无关的数据层的初衷不符,借助 mobx 的 observe 方法,我们可以将上面的代码改造成这种:
import { ViewModel, postConstruct } from 'mmlpx';
@ViewModel
class ViewModel {
@observable
id = null;
@postConstruct
onInit() {
observe(this, 'id', changedValue => this.store.fetchUsers(changedValue))
}
}熟悉 angularjs 的同学应该能发现,事实上 observe 做的事情跟 $scope.$watch 是一样的,但是为了保证数据层的 UI 框架无关性,我们这里用 mobx 自己的观察机制来替代了 angularjs 的 watch。
忘记你是在写 AngularJS,把它当成一个简单的动态模板引擎
不论是我们尝试将 AngularJS 应用 ES6/TS 化还是引入 mobx 状态管理库,实际上我们的初衷都是将我们的 Model 甚至 ViewModel 层做成视图框架无关,在借助 mobx 管理数据的之间的依赖关系的同时,通过 connector 将 mobx observable data 与视图连接起来,从而实现视图依赖的状态发生变化自动触发视图的更新。在这个过程中,angularjs 不再扮演一个框架的角色影响整个系统的架构,而仅仅是作为一个动态模板引擎提供 render 能力而已,后续我们完全可以通过配套的 connector,将 mobx 管理的数据层连接到不同的 view library 上。目前 mobx 官方针对 React/Angular/AngularJS 均有相应的 connector,社区也有针对 vue 的解决方案,并不需要我们从零开始。
在借助 mobx 构建数据层之后,我们就能真正做到标准 MVVM 中描述的那样,在 Model 甚至 VIewModel 不改一行代码的前提下轻松适配其他视图。view library 的语法、机制差异不再成为视图层 升级/替换 的鸿沟,我们能通过改很少量的代码来填平它,毕竟只是替换一个动态模板引擎而已😆。
React and MobX together are a powerful combination. React renders the application state by providing mechanisms to translate it into a tree of renderable components. MobX provides the mechanism to store and update the application state that React then uses.
Both React and MobX provide optimal and unique solutions to common problems in application development. React provides mechanisms to optimally render UI by using a virtual DOM that reduces the number of costly DOM mutations. MobX provides mechanisms to optimally synchronize application state with your React components by using a reactive virtual dependency state graph that is only updated when strictly needed and is never stale.
MobX 官方的介绍,把上面一段介绍中的 React 换成任意其他( Vue/Angular/AngularJS ) 视图框架/库(VDOM 部分适当调整一下) 也都适用。得益于 MobX 的概念简单及独立性,它非常适合作为视图中立的状态管理方案。简言之是视图层只做拿数据渲染的工作,状态流转由 MobX 帮你管理。
Redux 很好,而且社区也有很多跟除 React 之外的视图层集成的实践。单纯的比较 Redux 跟 MobX 大概需要再写一篇文章来阐述,这里只简单说几点与视图层集成时的差异:
dispatch(action) 来手动通知的,而真正的 diff 则交给了视图层,这不仅导致可能的渲染浪费(并不是所有 library 都有 vdom),在处理各种需要在变化时触发副作用的场景也会显得过于繁琐。单一 store 原则。应用可以完全由状态数据来描述、且状态可管理可回溯 这一点上我没有意见,但并不是只有单一 store 这一条出路,多 store 依然能达成这一目标。显然 mobx 在这一点上是 unopinionated 且灵活性更强。除了给 AngularJS 搭载上更高效、精确的高速引擎之外,我们最主要的目的还是为了将 业务模型层甚至 视图模型层(统称为应用数据层) 做成 UI 框架无关,这样在面对不同的视图层框架的迁移时,才可能做到游刃有余。而 mobx 在这个事情上是一个很好的选择。
最后想说的是,如果条件允许的话,还是建议将 angularjs 系统升级成 React/Vue/Angular 之一,毕竟大部分时候基于新的视图技术开发应用是能带来确实的收益的,如 性能提升、开发效率提升 等。即便你短期内无法替换掉 angularjs(多种因素,比如已经基于 angularjs 开发/使用 了一套完整的组件库,代码体量太大改造成本过高),你依然可以在局部使用 mobx/mobx-angularjs 改造应用或开发新功能,在 mobx-angularjs 帮助你提升应用性能的同时,也给你后续的升级计划创造了可能性。
PS: mobx-angularjs 目前由我和另一个 US 小哥全力维护,如果有任何使用上的问题,欢迎随时联系😀。
MVVM 模式跟 Silverlight 这类 XAML 应用平台是天生合拍的。这是因为 MVVM 模式利用了Silverlight 的一些特殊能力,比如说 数据绑定,命令,行为等。MVVM 跟其他一些将表现及UI布局 与展示层逻辑的职责进行分离的模式很相似;如果你对 MVC 模式熟悉的话,你会发现它与 MVVM 之间存在很多相似的概念。
译者注:XAML(Extensible Application Markup Language)是微软为构建GUI程序而创建的一种标记语言,你可以将它等同于 web 体系中 HTML。以下译文中,web 开发者可以将 XAML 统一代入为 HTML。Silverlight 则是微软开发的一个 富互联网应用(Rich Internet Application) 开发平台。
诸如 Windows Forms,WPF,Silverlight 以及 Windows Phone 这类开发技术都提供了一个默认的体验,那就是它可以让开发者从工具箱中拖拽控件到设计面板,然后在代码文件中编写一定格式的代码就能完成整个开发。但是随着这类应用的增长规模及作用范围的变化,复杂的维护性问题就会随之而来。由于 UI控件 与 业务逻辑 之间的紧耦合,相应带来的问题就是 UI 变更的代价增大,以及难以编写针对性的单元测试。
使用 MVVM 模式来实现应用的主要动机有以下几点:
Model-View-ViewModel 的模式可以用到所有的 XAML 平台上。它的意图是在 UI 控件和它们的逻辑之间进行一个纯净的概念分离。
MVVM 模式中有三个核心的组件:model(模型),view(视图) 以及 view-model(视图模型)(译者注:为保证交流中术语的一致性,model、view、view-model后面均不作翻译),它们彼此间扮演一个截然不同的角色。下面的插图展示了这三个组件之间的关系:
每个组件之间都是相互解耦的,这也使得:
除了理解这三个组件的职责,理解组件之间是如何交互的也同样重要。在最高的层级上,view 能感知到 view-model,view-model 能感知到 model,但是 model 并不会察觉到 view-model 的存在,同样的,view-model 也察觉不到 view。
view-model 将 model 类 与 view 隔离开来,这也使得 model 可以独立于 view 进行演化。
view 的职责是用来定义 结构、布局,及用户在屏幕上看到的外观表现。理想情况下,view 仅通过 XAML 定义,以及一些有限的不包含业务逻辑的代码。
在一个 Windows Phone 应用中,view 通常是一个页面。除此之外,一个 view 也可以是一个父 view 的子组件,或者一个 ItemsControl 中的 DataTemplate对象。
一个 view 可以有自己的 view-model,或者继承自父级 view 的 view-model。**视图通过绑定,或者调用 view-model 上的方法来获取数据。**在运行期间,UI 控件将会响应 view-model 属性触发的变化通知,从而改变 view。
有一些 view 上的交互会触发 view-model 上的代码执行,比如说按钮点击或者选项选中事件。如果这个控件是一个命令源,这个控件的 Command 属性可以在 view-model 上绑定成一个 ICommand 属性。当这个控件的命令被调用,view-model 上相应的代码就会被执行。除了命令,行为也能被附加到 view 的一个对象中,然后监听命令调用及事件触发。作为回应,这个行为之后可以调用 view-mode 上的 ICommand 或者方法。(译者:web 领域里这些就是指的模板上的事件绑定语法,通常由框架提供)
model 在 MVVM 中是应用的域模型(domain model)实现,它包含数据模型以及相应的业务和校验逻辑。model 对象的例子包括,数据仓库(repositories),业务对象,数据转换对象(DTOs),POCO对象,以及生成的实体及代理对象。
译者:一个 model 应该包含基本的模型数据、基本的业务逻辑、业务规则、数据转换、依赖校验逻辑等。这里要提到的一个概念就是,域模型分为两个类型,一类是贫血的(Anemic domain model),一类是非贫血的(non-anemic)。贫血的域模型只包含基础的数据信息,而不含有其他数据校验、业务规则等逻辑,它更像是一种数据库结构在代码层面的还原。在贫血域模型设计中,业务逻辑通常作为一个独立的代码部分,用来转换模型对象的状态,且各个处理之间可以组合嵌套(用过Redux的同学有没有觉得很熟悉的感觉?)。在面向对象设计领域,这通常被视为一个反模式。(OO与FP之间的冲突)
view-mode 作为 view 和 model 的中间人,它的职责是用于处理 view 的逻辑。**通常情况下,view-model 与 model 之间的交互是通过调用 model 类中的方法来完成的。之后 view-model 依据 model 中的数据提供一种方便 view 使用的格式。**view-model 从 model 中获取数据然后使其对 view 可用的同时,为了让 view 操作起来更简单,可能会通过一些方式做数据格式转换。view-model 还提供了一些命令的实现让应用的用户可以在 view 中使用。比如说,当用户点击了 UI 中的一个 button,这个动作可以触发 view-model 中的一个命令。view-model 同样有职责去定义一些某些方面会影响 view 展示的逻辑状态的变化,比如说一个表明一些操作是挂起的状态。
为了让 view-model 参与到与 view 的双向数据绑定当中,它的属性必须触发 PropertyChanged 事件。
(译者注:后面这两段是基于 .NET 平台的具体代码实践,换算到 web 领域,基本上说的就是在 VM 中监听数据变化,然后做出对应的反应。)
View-model 通过实现 INotifyPropertyChanged 接口以及属性变化时触发的 PropertyChanged 事件来满足这个需求。当属性发生变更时,监听者可以适当做回应。
对于集合而言,相应的提供了视图友好的工具System.Collections.ObjectModel.ObservableCollection 。这个工具实现了集合变更通知,从而减轻了开发者自己在集合上实现 INotifyCollectionChanged 接口的负担。
译者:这里提到了一个很重要的事情,就是 vm 获取到 model 中的数据后,可能需要做一些相应的数据格式化,以方便 view 使用。在 ng1.x 及 vue1.x 中,这类操作通常是通过在视图模板上绑定过滤器语法实现的(
ng-bind="model | upperCase"),然而 MVVM 定义中,数据转换/格式化 的操作本身也是属于 VM 的一部分。这也是为什么我非常赞同 vue2 中废除 filter 的一部分原因:Vue 2.0 - Bring back filters please
MVVM 利用了 Silverlight 中的数据绑定能力以及行为和事件触发器来管理 view 和 view-model 之间的联系。这些能力将业务代码需要出现在视图代码中必要性变得很低。
有很多用来连接 view-model 和 view 的方法,包括直接的关系以及基于容器的方式。然而,所有的方式共有的一个目标就是,给 view 的 DataContext 属性分配一个 view-model。
Views 可以与 view models 在独立代码文件里建立连接,也可以直接在 view 中。
译者:这里提到了 silverlight 里的 DataContext,换到 web 领域的 MVVM 框架里我们可以理解成作用域,即框架通过给某个视图的作用域分配一个 view-model 的方式,来完成 view 和 view-model 的衔接。
一个 view 的代码可以是在独立代码文件中,于此同时 view-model 需要分配成它的 DataContext 属性。这可以是通过一个简单的 view 初始化一个新的 view-model 然后分配给它的 DataContext 属性来完成,也可以通过 view 使用控制反转(IOC)容器注入一个 view-model 来实现。
但是,在独立代码中 连接一个 view-model 到 view 中的做法是不推荐的,它可能给同时使用 VS 及 MSB(Microsoft Expression Blend®) 设计软件的设计师造成问题。
如果一个 view-model 没有任何的构造器参数,它可以被当做 view 的 DataContext 来实例化。一个通常的实现方法是使用一个 view-model 定位器。这个资源可以公开应用的 view models 作为属性,从而使得独立的 view 可以绑定上去。这种方式意味着应用只有一个类用来连接 view models 到 views。此外,它仍然让开发者可以自由选择手动执行 view-model 定位器内的连接,或者使用一个依赖注入容器。
译者:框架实现指导
MVVM 使得完美的 开发-设计 工作流变为可能,它具备以下优点:
更多关于 MVVM 的信息,参考以下文档: Implementing the MVVM Pattern Advanced MVVM Scenarios
MVVM 作为2005年微软提出来的 UI 架构,我认为在经过这么多年的检验之后,还是非常值得信赖的。虽然在这一两年随着 React 的兴起,以及在前端领域“起死回生”的函数式编程,MVVM 被各种错误或‘恶意’的解读导致其花式被黑。但是在我看来,MVVM 作为一个完整的 GUI 架构,跟 Flux 流派的数据层架构本身理念上是并不冲突的。我们依然可以 M/VM 层实践 Flux。
我认为就前端领域而言,MVVM 最大的意义在于,如果我们能很干净的分离出应用的 view 和 M/VM,我们就可以使得整个应用的业务模型能独立于框架运行。相比于现在换一个框架就重写一次应用的做法(老实说我受够了而且觉得没什么价值),再结合当前前端‘欣欣向荣’的状态,如果能做到只需要花费很小的代价,我们就能快速的享受到新技术带来的红利,那基本上就非常美好了。
注意:本文并非 mobx-state-tree 使用指南,事实上全篇都与 MST(mobx-state-tree) 无关。
了解 mobx-state-tree 的同学应该知道,作为 MobX 官方提供的状态模型构建库,MST 提供了很多诸如 time travel、hot reload 及 redux-devtools支持 等很有用的特性。但 MST 的问题在于过于 opinioned,使用它们之前必须接受它们的一整套的价值观(就跟 redux 一样)。
我们先来简单看一下 MST 中如何定义 Model 的:
import { types } from "mobx-state-tree"
const Todo = types.model("Todo", {
title: types.string,
done: false
}).actions(self => ({
toggle() {
self.done = !self.done
}
}))
const Store = types.model("Store", {
todos: types.array(Todo)
})老实讲我第一次看到这段代码时内心是拒绝的,主观实在是太强了,最重要的是,这一顿操作太反直觉了。直觉上我们使用 MobX 定义模型应该是这样一个姿势:
import { observable, action } from 'mobx'
class Todo {
title: string;
@observable done = false;
@action
toggle() {
this.done = !this.done;
}
}
class Store {
todos: Todo[]
}用 class-based 的方式定义 Model 对开发者而言显然更直观更纯粹,而 MST 这种“主观”的方式则有些反直觉,这对于项目的可维护性并不友好(class-based 方式只要了解最基本的 OOP 的人就能看懂)。但是相应的,MST 提供的诸如 time travel 等能力确实又很吸引人,那有没有一种方式可以实现既能舒服的用常规方式写 MobX 又能享受 MST 同等的特性呢?
相对于 MobX 的多 store 和 class-method-based action 这种序列化不友好的范式而言,Redux 对 time travel/action replay 这类特性支持起来显然要容易的多(但相应的应用代码也要繁琐的多)。但是只要我们解决了两个问题,MobX 的 time travel/action replay 支持问题就会迎刃而解:
针对这两个问题,mmlpx 给出了相应的解决方案:
下面我们具体介绍一下 mmlpx 是如何基于 snapshot 给出了这两个解决方案。
上文提到,要想为 MobX 治下的应用状态提供 snapshot 能力,我们需要解决以下几个问题:
MobX 本身在应用组织上是弱主张的,并不限制应用如何组织状态 store、遵循单一 store(如redux) 还是多 store 范式,但由于 MobX 本身是 OOP 向,在实践中我们通常是采用 MVVM 模式 中的行为准则定义我们的 Domain Model 和 UI-Related Model(如何区别这两类的模型可以看 MVVM 相关的文章或 MobX 官方最佳实践,这里不再赘述)。这就导致在使用 MobX 的过程中,我们默认是遵循多 store 范式的。那么如果我们想把应用的所有的 store 管理起来应该这么做呢?
在 OOP 世界观里,想管理所有 class 的实例,我们自然需要一个集中存储容器,而这个容器通常很容易就会联想到 IOC Container (控制反转容器)。DI(依赖注入) 作为最常见的一种 IOC 实现,能很好的替代之前手动实例化 MobX Store 的方式。有了 DI 之后我们引用一个 store 的方式就变成这样了:
import { inject } from 'mmlpx'
import UserStore from './UserStore'
class AppViewModel {
@inject() userStore: UserStore
loadUsers() {
this.userStore.loadUser()
}
}之后,我们能很容易地从 IOC 容器中获取通过依赖注入方式实例化的所有 store 实例。这样收集应用所有 store 的问题就解决了。
更多 DI 用法看这里 mmlpx di system
获取到所有 store 实例后,下一步就是如何监听这些 store 中定义的状态的变化。
如果在应用初始化完成后,应用内的所有 store 都已实例完成,那么我们监听整个应用的变化就会相对容易。但通常在一个 DI 系统中,这种实例化动作是 lazy 的,即只有当某一 Store 被真正使用时才会被实例化,其状态才会被初始化。这就意味着,在我们开启快照功能的那一刻起,IOC 容器就应该被转换成 reactive 的,从而能对新加入管理的 store 及 store 里定义的状态实行自动绑定监听行为。
这时我们可以通过在 onSnapshot 时获取到当前 IOC Container,将当前收集的 stores 全部 dump 出来,然后基于 MobX ObservableMap 构建一个新的 Container,同时 load 进之前的所有的 store,最后对 store 里定义的数据做递归遍历同时使用 reaction 做 track dependencies,这样我们就能对容器本身(Store 加入/销毁)及 store 的状态变化做出响应了。如果当变化触发 reaction 时,我们对当前应用状态做手动序列化即可得到当前应用快照。
具体实现可以看这里:mmlpx onSnapshot
通常我们拿到应用的快照数据后会做持久化,以确保应用在下次进入时能直接恢复到退出时的状态 ── 或者我们要实现一个常见的 redo/undo 功能。
在 Redux 体系下这个事情做起来相对容易,因为本身状态在定义阶段就是 plain object 且序列化友好的。但这并不意味着在序列化不友好的 MobX 体系里不能实现从 Snapshot 中唤醒应用。
想要顺利地 resume from snapshot,我们得先达成这两个条件:
如果我们想让序列化之后的快照数据顺利恢复到各自的 Store 上,我们必须给每一个 Store 一个唯一标识,这样 IOC 容器才能通过这个 id 将每一层数据与其原始 Store 关联起来。
在 mmlpx 方案下,我们可以通过 @Store 和 @ViewModel 装饰器将应用的 global state 和 local state 标记起来,同时给对应的模型 class 一个 id:
@Store('UserStore')
class UserStore {}但是很显然,手动给 Store 命名的做法很愚蠢且易出错,你必须确保各自的命名空间不重叠(没错 redux 就是这么做的[摊手])。
好在这个事情有 ts-plugin-mmlpx 来帮你自动完成。我们在定义 Store 的时候只需要这么写:
@Store
class UserStore {}经过插件转换后就变成:
@Store('UserStore.ts/UserStore')
class UserStore {}通过 fileName + className 的组合通常就可以确保 Store 命名空间的唯一性。更多插件使用信息请关注 ts-plugin-mmlpx 项目主页 .
从序列化的快照状态中激活应用的 reactive 系统,从静态恢复到动态这个逆向过程,跟 SSR 中的 hydration 非常相似。实际上这也是在 MobX 中实现 Time Travelling 最难处理的一步。不同于 redux 和 vuex 这类 Flux-inspired 库,MobX 中状态通常是基于 class 这种充血模型定义的,我们在给模型脱水再重新注水之后,还必须确保无法被序列化的那些行为定义(action method)依然能正确的与模型上下文绑定起来。单单重新绑定行为还没完,我们还得确保反序列化之后数据的 mobx 定义也是跟原来保持一致的。比如我之前用 observable.ref 、observable.shallow 及 ObservableMap 这类有特殊行为的数据在重注水之后能保持原始的能力不变,尤其是 ObservableMap 这类非 object Array 的不可直接序列化的数据,我们都得想办法能让他们重新激活回复原状。
好在我们整个方案的基石是 DI 系统,这就给我们在调用方请求获取依赖时提供了“做手脚”的可能。我们只需要在依赖被 get 时判断其是否由从序列化数据填充而来的,即 IOC 容器中保存的 Store 实例并非原始类型的实例,这时候便开启 hydrate 动作,然后给调用方返回注水之后的 hydration 对象。激活的过程也很简单,由于我们 inject 时上下文中是有 store 的类型(Constructor)的,所以我们只要重新初始化一个新的空白 store 实例之后,使用序列化数据对其进行填充即可。好在 MobX 只有三种数据类型,object、array 和 map,我们只需要简单的对不同类型做一下处理就能完成 hydrate:
if (!(instance instanceof Host)) {
const real: any = new Host(...args);
// awake the reactive system of the model
Object.keys(instance).forEach((key: string) => {
if (real[key] instanceof ObservableMap) {
const { name, enhancer } = real[key];
runInAction(() => real[key] = new ObservableMap((instance as any)[key], enhancer, name));
} else {
runInAction(() => real[key] = (instance as any)[key]);
}
});
return real as T;
}hydrate 完整代码可以看这里:hyrate
相较于 MST 的快照能力(MST 只能对某一 Store 做快照,而不能对整个应用快照),基于 mmlpx 方案在实现基于 Snapshot 衍生的功能时变得更加简单:
Time Travelling 功能在实际开发中有两种应用场景,一种是 redo/undo,一种是 redux-devtools 之类提供的应用 replay 功能。
在搭载 mmlpx 之后 MobX 实现 redo/undo 就变得很简单,这里不再贴代码(其实就是 onSnapshot 和 applySnapshot 两个 api),直接贴个效果图好了,具体用法可以看 mmlpx 项目主页
类似 redux-devtools 的功能实现起来相对麻烦一点(其实也很简单),因为我们要想实现对每一个 action 做 replay,前提条件是每个 action 都有一个唯一标识。redux 里的做法是通过手动编写具备不同命名空间的 action_types 来实现,这太繁琐了(参考Redux数据流管理架构有什么致命缺陷,未来会如何改进?)。好在我们有 ts-plugin-mmlpx 可以帮我们自动的帮我们给 action 起名(原理同自动给 store 起名)。解决掉这个麻烦之后,我们只需要在 onSnapshot 的同时记录每个 action,就能在 mobx 里面轻松的使用 redux-devtool 的功能了。
我们知道,React 或 Vue 在做 SSR 时,都是通过在 window 上挂载全局变量的方式将预取数据传递到客户端的,但通常官方示例都是基于 Redux 或 Vuex 来做的,MobX 在此之前想实现客户端激活还是有些事情要解决的。现在有了 mmlpx 的帮助,我们只需要在应用启动之前,使用传递过来的预取数据在客户端应用快照即可基于 MobX 实现客户端状态激活:
import { applySnapshot } from 'mmlpx'
if (window.__PRELOADED_STATE__) {
applySnapshot(window.__PRELOADED_STATE__)
}这个只要使用的状态管理库具备对任一时间做完整的应用快照,同时能从快照数据激活状态关系的能力就能实现。即检查到应用 crash 时按下快门,将快照数据上传云端,最后在云端平台通过快照数据还原现场即可。如果我们上传的快照数据还包括用户前几次的操作栈,那么在监控平台对用户操作做 replay 也不成问题。
作为一个“多 store”范式的信徒,MobX 在一出现便取代了我心中 Redux 在前端状态管理领域的地位。但苦于之前 MobX 多 store 架构下缺乏集中管理 store 的手段,其在 time travelling 等系列功能的开发体验上一直有所欠缺。现在在 mmlpx 的帮助下,MobX 也能开启 Time Travelling 功能了,Redux 在我心中最后的一点优势也就荡然无存了。
原文写于 2014-09-28
前几天突发奇想想去看看spring现在到升级到什么版本了,有些啥New Features。结果发现了一个很人性化的新注解,刚好最近在构建客服系统新的接口层结构,然后重新研究了下spring mvc,一些成果跟大家分享一下(SpringMVC4.1的jackson版本升级到了2.x,不再支持Jackson1.x,同学们注意。详细代码请右转:seed )。
先说说我们要实现的目标(接口层):
首先来介绍下springMVC新增的一个很人性化的注解:
@RestController组合了@controller和@responsebody,使用该注解声明的controller下的每一个@RequestMapping方法,都会默认加上@responsebody,即默认该controller提供的全部是rest服务,返回的不会是视图。
@RestController
public class DemoRestController {
@Resource
private DemoService demoService;
@RequestMapping(value = "getUser", method = RequestMethod.GET)
public ResponseResult<List<User>> getUser(String userName) {
// do something
}
}基于开头提到的四个目标,我们以代码的形式来说明一下具体的实现方案
思路:所有的rest响应均返回一致的数据格式,所有的post请求均采用bean接收。(不要使用List、Map万金油。。。)
目的:统一的响应体能确保rest接口的一致性,同时可以提供给前端js一个可封装http请求的环境(如:封装的http错误日志、结果拦截等)(吐槽一句,有时候我们想在前端做统一的响应拦截和日志处理,可是接口返回的数据格式五花八门,实在让人无能为力。。。) post请求均采用bean接收可以使得代码更具可读性,直接通过bean可以获知接口所需参数,而不是一行行读代码看你从map里面get出了些什么玩意。
ps:部分思路来源于忠诚度项目接口实现方式,特此表示感谢!
统一响应体
@JsonInclude(JsonInclude.Include.NON_EMPTY)
public class ResponseResult<T> {
private boolean success;
private String message;
private T data;
/* 不提供直接设置errorCode的接口,只能通过setErrorInfo方法设置错误信息 */
private String errorCode;
private ResponseResult() {
}
.........
}统一结果生成方式
public class RestResultGenerator {
private static final Logger LOGGER = LoggerFactory.getLogger(RestResultGenerator.class);
/**
* 生成响应成功(带正文)的结果
*
* @param data 结果正文
* @param message 成功提示信息
* @return ResponseResult
*/
public static <T> ResponseResult<T> genResult(T data, String message) {
ResponseResult<T> result = ResponseResult.newInstance();
result.setSuccess(true);
result.setData(data);
result.setMessage(message);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("--------> result:{}", JacksonMapper.toJsonString(result));
}
return result;
}
........
}调用示例
@RestController
public class DemoRestController {
@Resource
private DemoService demoService;
@RequestMapping(value = "getUser", method = RequestMethod.GET)
public ResponseResult<List<User>> getUser(String userName) {
List<User> userList = demoService.getUser(userName);
return RestResultGenerator.genResult(userList, "成功!");
}
}思路:需要使用errorCode来声明的错误信息,统一通过enum定义,ResponseResult不提供单独设置errorCode的接口
public class RestResultGenerator {
private static final Logger LOGGER = LoggerFactory.getLogger(RestResultGenerator.class);
.......
/**
* 生成响应失败(带errorCode)的结果
*
* @param responseErrorEnum 失败信息
* @return ResponseResult
*/
public static ResponseResult genErrorResult(ResponseErrorEnum responseErrorEnum) {
ResponseResult result = ResponseResult.newInstance();
result.setSuccess(false);
result.setErrorInfo(responseErrorEnum);
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("--------> result:{}", JacksonMapper.toJsonString(result));
}
return result;
}
}bean示例
@JsonInclude(JsonInclude.Include.NON_EMPTY)
public class User {
@NotBlank
private String userName;
@NotNull
@Max(150)
@Min(1)
private Integer age;
private User() {
}
}调用示例
@RestController
public class DemoRestController {
@Resource
private DemoService demoService;
@RequestMapping(value = "saveUser", method = RequestMethod.POST)
public ResponseResult saveUser(@Valid @RequestBody User user, Errors errors) {
if (errors.hasErrors()) {
return RestResultGenerator.genErrorResult(ResponseErrorEnum.ILLEGAL_PARAMS);
} else {
demoService.saveUser(user);
return RestResultGenerator.genResult("保存成功!");
}
}
}由于依赖于JSR-303规范,我们的pom文件需要加入新的依赖
maven配置
<dependency>
<groupId>javax.validation</groupId>
<artifactId>validation-api</artifactId>
<version>1.1.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.0.1.Final</version>
</dependency>统一的接口异常捕获
思路:起初想通过代码中try..catch的方式捕获异常,然后通过RestResultGenerator生成错误信息。后来觉得这种方式太傻了,然后想到通过aop的方式,以Controller的RequestMapping为切面织入异常捕获代码,然后返回错误信息。再后来发现springMVC早在3.x时代便提供了@ExceptionHandler注解。。。再后来又发现了@ControllerAdvice。。。这不就是我想要的嘛!! 可见使用一门技术前对其有一定的系统认知该多么重要,不仅能避免重复造轮子还能避免坑自己坑别人
目的:无侵入式的异常捕获,不干扰业务逻辑
名词解释:
代码示例
使用controllerAdvice实现的全局异常处理
// 指定增强范围为使用RestContrller注解的控制器
@ControllerAdvice(annotations = RestController.class)
public class RestExceptionHandler {
private static final Logger LOGGER = LoggerFactory.getLogger(RestExceptionHandler.class);
/**
* bean校验未通过异常
*
* @see javax.validation.Valid
* @see org.springframework.validation.Validator
* @see org.springframework.validation.DataBinder
*/
@ExceptionHandler(UnexpectedTypeException.class)
@ResponseBody
@ResponseStatus(HttpStatus.BAD_REQUEST)
private <T> ResponseResult<T> illegalParamsExceptionHandler(UnexpectedTypeException e) {
LOGGER.error("--------->请求参数不合法!", e);
return RestResultGenerator.genErrorResult(ResponseErrorEnum.ILLEGAL_PARAMS);
}
}Controller里面不用写任何多余的代码,如果@Valid校验失败接口会抛出UnexpectedTypeException从而被ControllerAdvice捕获并返回错误信息,httpstatus为503 Bad Request 错误
@RestController
public class DemoRestController {
@Resource
private DemoService demoService;
@RequestMapping(value = "saveUser", method = RequestMethod.POST)
public ResponseResult saveUser(@Valid @RequestBody User user) {
demoService.saveUser(user);
return RestResultGenerator.genResult("保存成功!");
}
}注意这里参数列表里面就不要加Errors或其子类作参数了,有这个参数校验失败就不会抛异常,而是把错误信息填充到Errors对象中。
至此,在Controller层我们一开始的目标基本上都已经达成了,之后我们编写接口只需要实现业务逻辑,参数校验、异常捕获等工作全部交由外围设施处理,而不是手动编码做重复工作。SpringMVC部分还有很多已有的东西我们没有开发,有点暴殄天物的感觉。磨刀不误砍柴工,这样才能避免重复造轮子跟写出可维护的代码。虽然是码农,但是也不能只满足于复制粘贴吧。。。
// applicationContext.xml
<context:component-scan base-package="com.shuyun.channel">
<context:exclude-filter type="annotation" expression="org.springframework.stereotype.Controller" />
<context:exclude-filter type="annotation" expression="org.springframework.web.bind.annotation.RestController" />
<context:exclude-filter type="annotation" expression="org.springframework.web.bind.annotation.ControllerAdvice" />
</context:component-scan>
// springmvc-servlet.xml
<context:component-scan base-package="com.shuyun.channel" use-default-filters="false">
<context:include-filter type="annotation" expression="org.springframework.stereotype.Controller" />
<context:include-filter type="annotation" expression="org.springframework.web.bind.annotation.RestController" />
<context:include-filter type="annotation" expression="org.springframework.web.bind.annotation.ControllerAdvice" />
</context:component-scan>spring容器不注册controller层组件,controller组件由springMVC容器单独注册。
更多详细代码请访问:spring-mvc4-seed,欢迎拍砖!
原文写于 2015-08-07
最近两周在给xxxx跟xxxx两个产品搭前端框架,关于路由这块的技术选型让我犹豫了一下。且让我们先来分析一下
然后想起了angular new router
ngNewRouter是为angular2设计的新的路由机制,采用纯组件的思路(ng2的设计主旨),同时支持在任意时刻设置路由,具有极大的自由度及可复用性。大约在几个月前,angular团队为ngNewRouter提供了兼容angular 1.4.x的版本。
有这么好的东西还不用,简直是天理不容啊。
基于现有的少的可怜的文档,第一个基于ngNewRouter的项目诞生了。
一步步来看这玩意咋玩吧
setup
npm install angular-new-router路由配置
/**
* 路由配置
*/
AppCtrl.$inject = ['$router'];
function AppCtrl($router) {
$router.config([
{path: '/', redirectTo: '/home'},
{path: '/home', component: 'home'}
]);
}是的,你没看错,在ngNewRouter中,每一个路由都是一个组件。在ng2中,所有的东西都是组件,UI自然是,但是controller、service甚至是一个路由都是组件。
配置路由控制器的映射规则
按照以往ngRoute和ui-router的使用经验,配置路由的同时我们是还需要配置路由的模板及控制器的,即templateUrl 和 Controller,但是第二步并没有发现这样的代码。这是因为ngNewRouter默认路由组件的位置是 ./components/+componentName+/+componentName.html ,而controller的名字默认是 ComponentController
例如第二步中我们配置的 home 路由组件,则这个路由的模板位置是(应用根目录开始) components/home/home.html , 控制器名字则为 HomeController
当然这个规则我们也能自己去配置,like this
/**
* 初始化 ngNewRouter相关基本配置
*/
configRouteLoader.$inject = ['$componentLoaderProvider', 'app'];
function configRouteLoader($componentLoaderProvider, app) {
// 配置路由模板搜索路径
$componentLoaderProvider.setTemplateMapping(function(name) {
return app.fileRoot + '/app/viewpoint/' + name + '/' + name + '.html';
});
// 配置路由控制器命名,如 home-info ---> HomeInfoCtrl
$componentLoaderProvider.setCtrlNameMapping(function(name) {
return name.split('-').map(function(value) {
return value[0].toUpperCase() + value.substr(1);
}).concat(['Ctrl']).join('');
});
}使用路由
ngNewRouter提供两个基本指令,ngViewpoint & ngLink ,这么去玩
<div ng-viewpoint></div>
<a ng-link="marketingCampaign"></a>ngViewpoint就类似于ngRoute里的ngView(ui-router里的ui-view).
ngLink类似于ui-router里的ui-serf
其他
如果只能提供这么几个简单的功能那完全没优势可言啊
嵌套路由,配components即可
$router.config([
{path: '/', redirectTo: '/home'},
{path: '/home', components: {list:'list', detail:'homeDetail'}}
]);
// 既然是组件,那么自然有生命周期一说,对于ngNewRouter中的路由组件而言也一样。
MyController.prototype.canActivate = function() {
return this.user.isAdmin;
};
MyController.prototype.activate = function() {
this.user.downloadBigFiles();
};
MyController.prototype.canDeactivate = function() {
return this.userDataPersisted;
};至于他有啥用,还记得ngRoute和ui-router的resolve配置吗?
写到这里我差不多写不下去了,因为今天又碰到了一个问题,然后研究了半天它的源码网上找了一些资料最后也只能通过绕道的方式解决,然后就开始想,这玩意直接用到项目中是否合适,社区支持太少,官方文档太简洁,毕竟生下来就不是为angular1设计的?
在经过一番**斗争后,对于技术一向都是有新的就不用旧的这样激进态度的我,最后还是不得不放弃应用ngNewRouter的想法。
然后就在刚才,我在github上看到这个
For now, the code has been moved to angular/angular. APIs are still rapidly changing, so I don't recommend using this in an important production app quite yet.
好吧,我终于可以说服自己不是技术上妥协而是战略上放弃了。。。
虽然好像是绕了一圈又回到了原点,但是基于ngNewRouter还是有了一些新的认识:
对于大型应用而言,组件化必定是趋势。而组件并不仅仅指代的UI层的组件,它还包括逻辑组件。ng2就是这样一个设计思路。另外,有这样一篇文章Thinking in Components
ngNewRouter在路由模板及控制器的配置上,采用一种约定的方式,要求使用者必须按照规则命名模板和控制器,这也是后端web框架常用的 约定优于配置 的方式。看了下ngNewRouter这一块的实现,他重写了用于路由组件上的controller注入逻辑。结合最近半年在做的前端框架性的工作,有了一些自己的思考:
一个面向团队甚至公司的框架,必须是强约束的。框架不同于类库,类库是越灵活越好,而框架则是在封装了大部分细节的基础上,要求使用者必须以某种规则去实现编码的明文规定。只有有了这种强约束,才不至于使得代码质量因为人员的变迁而最后发展成不可控的状态,因为所有人都必须按照指定的方式去写代码。这也是为什么静态语言更适合构建大型项目的原因。一个真正的框架,绝不是仅仅规范了几个目录层级、提供几个组件几个便利的api就完了的。这一块具体应该怎么做,目前还只有零星的一些想法,还有待后续的实践跟检验。
整理自 11.20 晚阿里云微前端线下沙龙
整个会议下来,我只对一个话题有兴趣,就是 #大果 提出的灵魂拷问:
如果是 widget 级别,那么微前端跟业务组件的区别在哪里?微前端到底是因何而生?
圆桌环节简单发表了一下自己的观点,这里再文字补充一下。
先抛观点:
我认为微前端的核心价值在于 "技术栈无关",这才是它诞生的理由,或者说这才是能说服我采用微前端方案的理由。
我抛两个场景,大家思考一下:
第一个场景我们初步一想,可以啊,我只需要把新功能用 react/vue 开发,反正他们都只是 ui library,给我一个dom 节点我想怎么渲染怎么渲染。但是你有没有考虑过这只是浮在表层的视图实现,沉在底下的工程设施呢?我要怎么把这个用 react 写的组件打出一个包,并且集成到原来的用 es5 写的代码里面?或者我怎么让 webpack 跟 之前的 grunt 能和谐共存一起友好的产出一个符合预期的 bundle?
第二个场景,你如何确保技术栈在 3~5 年都葆有生命力?别说跨框架了,就算都是 react,15 跟 16 都是不兼容的,hooks 还不能用于 class component 呢我说什么了?还有打包方案,现在还好都默认 webpack,那 webpack 版本升级呢,每次都跟进吗?别忘了还有 babel、less、typescript 诸如此类呢?别说 3 年,有几个人敢保证自己的项目一年后把所有依赖包升级到最新还能跑起来?
为什么举这两个场景呢,因为我们去统计一下业界关于”微前端“发过声的公司,会发现 adopt 微前端的公司,基本上都是做 ToB 软件服务的,没有哪家 ToC 公司会有微前端的诉求(有也是内部的中后台系统),为什么会这样?很简单,因为很少有 ToC 软件活得过 3 年以上的。而对于 ToB 应用而言,3~5 年太常见了好吗!去看看阿里云最早的那些产品的控制台,去看看那些电信软件、银行软件,哪个不是 10 年+ 的寿命?企业软件的升级有多痛这个我就不多说了。所以大部分企业应用都会有一个核心的诉求,就是如何确保我的遗产代码能平滑的迁移,以及如何确保我在若干年后还能用上时下热门的技术栈?
不论是 qiankun/OneX(蚂蚁基于qiankun打造的云应用接入平台) 最开始诞生的初衷,还是后续在于社区的交流过程中都发现,如何给遗产项目续命,才是我们对微前端最开始的诉求。阿里的同学们可能感受不深,毕竟那些一年挣不了几百万,没什么价值的项目要么是自己死掉了,要么是扔给外包团队维护了,但是要知道,对很多做 ToB 领域的中小企业而言,这样的系统可能是他们安身立命之本,不是能说扔就扔的,他们承担不了那么高的试错成本。
我认可的解决思路应该是,撒旦的归撒旦,耶稣的归耶稣。
我们只需要在主系统构造一个足够轻量的基座,然后让各子应用按照共同的协议去实现即可。这个协议可以包括,主应用应该如何加载子应用,以及子应用如何被主应用感知、调度,应用之间如何通信等。这个协议不应该包括,子应用要如何确保隔离性、安全性,也就是子应用除了实现一些较为简单的协议之外,跟开发一个正常的 spa 应用应该没有任何差别,包括不应该有 开发、构建、发布 等流程上的侵入。只要子应用实现了这几个协议,其他的东西怎么玩,我们都不需要关心或干预。
这样的话,其实整个系统就变成了一个真正的、基于运行时的插件平台了。
有一个非常合适的例子,我们通常是怎么看待可视化搭建平台的?我想大部分 pro code 玩家都是不太敢轻易尝试这个方式去开发自己的核心产品的,原因是什么呢?很简单,不可控。我的产品的上限由平台决定而不是我自己的 coding 能力决定,这就很要命了。尤其是一些核心模块,后面我想做一些个性性的改造可能都支持不了。但是如果有了微前端机制呢,只需要搭建平台去实现相关的协议,平台产出的页面就能很轻易的被集成到我们自己的应用里了。我们开发时可以选择需要强控制的页面自己写,边缘页面用可视化生成即可,完全没有任何心理负担。
我们听到了很多不同团队的分享中,关于微前端带来的各种业务提升、产品提升的价值。比如产品的自由组合能力,比如以 widget 这种可视化方式直接输出产品的能力等等,将这些价值视作微前端诞生的理由。
但我对此一直保持的观点是,微前端首先解决的,是如何解构巨石应用,从而解决巨石应用随着技术更迭、产品升级、人员流动带来的工程上的问题。解构之后还需要再重组,重组的过程中我们就会碰到各种 隔离性、依赖去重、通信、应用编排 等问题。在解决了这些问题之后,才是产品的自由组合、widget 输出等能力。同时由于有了前者能力的铺垫和加持,这些产品上的价值提升也就变得很自然和容易。
不论是 OneX 还是阿里云的同学,都在反复强调微前端带来的业务价值及产品价值,比如产品的组合能力,widget 的产品输出能力(这些能力在我们的产品域确实很重要也很有价值,但并不是所有的控制台产品都一定需要的能力)。从分享中我们也能看到,云产品对于微前端的诉求是基本相同的,包括背后的 管控、编码 能力等。但我们需要清楚一件事,并不是只有云产品才需要微前端,也并不是所有采用微前端方案的公司都是做云产品的。
大果提的问题非常我认为有探讨价值:「widget 级别的微前端应用跟业务组件有什么区别?」
我的观点:有没有区别在于你的实现是不是技术栈无关。
以大果提到的淘宝吊顶 js 为例(这是一个非常贴切的举例,蚂蚁也有类似的 js 组件),它具备独立发布、固定地址自动升级等特点,我猜也不会限制调用方的技术栈,调用方使用时跟用一个普通的 library 一样,区别在于普通的 library 是通过 npm 包引入,但是这个 library 我们是通过 script 标签引入的。
但是考察是否技术栈无关不能简单看这些 api 设计,还要看是否存在一些隐性耦合。
比如是否要求调用方的 react 版本、是否要求调用方必须提前构造好一些上下文环境才能完成调用。
如果这些回答都是否,那么我认为这也是一种微前端的实现方式。
克军提到:
如果微前端只存在工程上的价值是不值得大张旗鼓去做的。
微前端的初衷应该还是来解决工程问题的,带来的产品价值在不同的领域可大可小。 比如在阿里云这种典型的云产品控制台的场景下,它带来的产品价值就会很可观。因为阿里云作为提供 IAAS 服务的云平台,它需要的就是平台、产品的被集成能力,在这种场景下,微前端能力能非常好的契合这个诉求。但需要强调的是,并不是所有采用微前端的客户,都是阿里云这种 IAAS 平台产品。很多中小型控制台大多没有产品自由组合能力的诉求。产品能力只能算是微前端的能力的一种延伸。
玉伯提到:
今天看各 BU 的业务问题,微前端的前提,还是得有主体应用,然后才有微组件或微应用,解决的是可控体系下的前端协同开发问题(含空间分离带来的协作和时间延续带来的升级维护)
总结的很精确。「空间分离带来的协作问题」是在一个规模可观的应用的场景下会明显出现的问题,而「时间延续带来的升级维护」几乎是所有年龄超过 3 年的 web 应用都会存在的问题。
既然「技术栈无关」是微前端的核心价值,那么整个架构方案的实现上,都应该秉持这一原则,任何违背这一原则的做法都应该被摒弃。
「技术栈无关」是架构上的准绳,具体到实现时,对应的就是:应用之间不应该有任何直接或间接的技术栈、依赖、以及实现上的耦合。
比如我们不能要求子应用、主应用必须使用某一版本的技术栈实现。
比如在通信机制的设计与选择上,尽量基于浏览器原生的 CustomEvent api,而不是自己搞的 pub/sub。
比如子应用是否具备不依赖宿主环境独立运行的能力,衡量标准是是否能一行代码不改,或者只改很少的配置,就能达成这一目标。
所以我认为正确的微前端方案的目标应该是:方案上跟使用 iframe 做微前端一样简单,同时又解决了 iframe 带来的各种体验上的问题。
理想状态下,以此为目标的微前端应用,是自动具备流通能力的,且这个流通能力不会因为主应用的实现升级而丧失(也就是说在 19 年能接入主应用的微前端应用,到了 2025 年也应该能正常接入正常运行,并同样保有在不同主应用间流通的能力)。
qiankun 正是以此为准则设计的。
如果说阿里的企业使命是:「让天下没有难做的生意」。
那么微前端的使命我认为是:「让天下没有短命的控制台」。
事实上如果所有的 web 技术栈能做到统一,所有 library 的升级都能做到向下兼容,我们确实就不需要微前端了。 —— 鲁迅
通常情况下,如果我们是一个对代码质量有要求或者存在code review这一流程的团队,我们必然会有一套团队内部达成共识的code style从而提高项目的可维护性及代码的可读性。而确保提交到代码仓库的代码是符合规范的手段通常是,代码提交前由工具帮忙指出,如早期的jslint、jshint以及现在的eslint。提交后code review阶段由其他同学确保代码没有其他规范及质量问题。
既然人肉靠不住那我们只能让整个流程自动化让工具替我们完成代码规范检查的事情。我能想到的大概有这几种方式。
1、2两种方式都是通过工具方式降低了人肉检查代码规范的工作量,不过本质还是人肉。。
3方式不再人肉了但是依赖外部系统去做会存在风险及成本,比如哪天CI工具由bamboo切到了jenkins 然后又切到travis。。
直到有一天在下在fork了github上的一个项目并对其做了一定改造然后自信满满地准备提交代码的时候(json-mock-server),git一直在报错代码始终push不上去,报错信息也看不出什么东西,不行只能请教了对git比较内行的同事@arzyu,猜测是git hooks上配置了什么钩子脚本(后来证实是单元测试没覆盖到位),尝试把项目路径下的.git文件夹删除之后,终于能正常提交了😄
这件事给了我一个新的思路,就是我们能不能基于git的hook功能来做这这种自动化的事情呢?刚好在下又会一点点shell😄
我们在git hooks里配置各种预处理脚本,比如代码检查或者跑单元测试之类的事情,如果我们的代码没有通过代码检查或者测试用例覆盖率不够,我们的push甚至commit会直接被拒绝。
好东西啊这不就是我这种极端分子想要的么哈哈!
首先介绍一下git hooks是什么吧
钩子(hooks)是一些在"$GIT-DIR/hooks"目录的脚本, 在被特定的事件(certain points)触发后被调用。当"git init"命令被调用后, 一些非常有用的示例钩子文件(hooks)被拷到新仓库的hooks目录中; 但是在默认情况下这些钩子(hooks)是不生效的。 把这些钩子文件(hooks)的".sample"文件名后缀去掉就可以使它们生效了。
也就是在我们的git仓库下会有一个.git配置文件夹,它里面包含git操作相关的一系列 预处理/后处理 脚本。如 pre-commit、post-push之类的。
在一番google研究之后发现这事情操作起来并没有想象中那么简单,比如我们在什么时机将自己的脚本插入到hooks里,让使用者手动调命令这种主动式的方式一直不是我推崇的(要把调用者想象成懒癌晚期),然后处理脚本怎么写写哪里也没想到合适方式,一度放弃。
后来突然想起,之前那个开源项目是怎么做的?它是怎么把预处理脚本偷偷摸摸插入到hooks里的??于是突发奇想去研究别人的项目。
结果发现作者自己写了一个插件husky,专门用来处理这种git提交时的自动化处理。
大致用法像这样:
// 根目录package.json
"scripts": {
"codecheck": "NODE_ENV=test eslint src/**/*.js",
"test": "BABEL_JEST_STAGE=0 jest --verbose --watch",
"precommit": "npm run codecheck && npm test"
}配置了precommit之后每次代码提交之前git都会自动去跑代码检查及单元测试任务,都跑通过之后才能提交成功。更多用法请看项目主页husky
插件实现的机制大致是,在你install该插件时,它会自动往git hooks里埋入很多相应的钩子脚本(git hook能识别的),这些钩子函数会去读取package.json中的配置信息,当用户做某些git操作触发相应钩子时会自然去调用配置好的任务,从而实现我们的自动化需求,包括代码检查跟单元测试验证以及更多的自动化任务。
基于npm对install动作的钩子接口,我们可以提供一个插件,当使用者install该插件时插件会帮助用户做一系列初始化构建工作。开发时各业务模块独立仓库开发,上线或测试时提供构建插件一行install命令把所有业务模块组合起来变成一个完整的项目。具体打包、发布的方式后面会写一篇关于前端工程化的blog来介绍。
另外,基于git hooks我们还能做这样一件事情,我们在生产环境的git仓库中配置一个hook,当一有push/merge操作之后,触发一个推送脚本告知ci(jenkins/travis)执行构建/打包操作,然后我们只需要告知运维去某个地址拉下最新的包发布就好了(这里千万不要使用ci自己去完成发布),实现整个流程的自动化
原文写于 2014-10-24
对前端构建自动化有所了解的同学应该都听过大名鼎鼎的grunt,但是grunt作为前端自动化构建工具的领头羊现在越来越受到诟病。大而全已经不适应这个时代了,这个时代需要的是小而美的工具及插件。什么都想干往往意味着什么都干不好,YUI的死掉至少说明了近年前端的发展趋势。grunt的不足及弊端大家可以参考这篇文章。后起之秀gulp大有取代grunt的趋势(gulp的github的stars目前已经超过grunt了),本文主要介绍如何通过gulp实现自动化压缩、合并以及文件的修改。
首先来说说我们想要实现的功能吧
<script src=xxx.js?v=0.1></script>。这样太麻烦。合理的应该是,只要我们的源码有改动,那么我们引用的资源版本号就应该自动更新。来看看我们怎样通过gulp实现我们的前端工程自动化的吧
首先是一个源码层级的index.html,差不多长这样
<!--
Created by kui.liu on 2014/05/29 14:34.
-->
<!DOCTYPE html>
<html ng-app="invoiceApp">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
一堆css文件。。。。
<!-- build:css css/app.css -->
<link href="/src/css/bootstrap-tooltips.css" rel="stylesheet">
<link href="/src/js/lib/jquery-ui/development-bundle/themes/base/jquery.ui.theme.css" rel="stylesheet">
<link href="/src/js/lib/jquery-ui/development-bundle/themes/base/jquery.ui.core.css" rel="stylesheet">
<link href="/src/js/lib/jquery-ui/development-bundle/themes/base/jquery.ui.datepicker.css" rel="stylesheet">
<link href="/src/js/lib/jQuery-Timepicker-Addon/dist/jquery-ui-timepicker-addon.min.css" rel="stylesheet">
<link href="/src/css/float-tips.css" rel="stylesheet"/>
<link href="/src/css/ccms.css" rel="stylesheet">
<link href="/src/css/app.css" rel="stylesheet">
<link href="/src/js/lib/ccms_pop/css/style.css" rel="stylesheet">
<!-- endbuild -->
<style>
[ng\:cloak], [ng-cloak], [data-ng-cloak], [x-ng-cloak], .ng-cloak, .x-ng-cloak {
display: none !important;
}
</style>
<title>账户管理</title>
<script>
// 设置资源文件目录,必需!!
window.ResourceDir = "/src/";
</script>
</head>
<body ng-cloak class="ng-cloak" ng-controller="AppCtrl">
此处省略若干结构。。。
一堆js文件
<!-- build:js js/app.js -->
<script src="/src/js/lib/jquery/jquery-1.11.1.js"></script>
<script src="/src/js/lib/jquery-ui/development-bundle/ui/jquery.ui.core.js"></script>
<script src="/src/js/lib/jquery-ui/development-bundle/ui/jquery.ui.datepicker.js"></script>
<script src="/src/js/lib/jQuery-Timepicker-Addon/dist/jquery-ui-timepicker-addon.min.js"></script>
<script src="/src/js/lib/jQuery-Timepicker-Addon/dist/i18n/jquery-ui-timepicker-zh-CN.js"></script>
<script src="/src/js/lib/bootstrap/bootstrap-tooltips.js"></script>
<script src="/src/js/lib/ccms_pop/js/yunat_pop.js"></script>
<script src="/src/js/float-tips.js"></script>
<script src="/src/js/lib/angular/angular.js"></script>
<script src="/src/js/lib/angular/angular-locale_zh-cn.js"></script>
...........
<!-- endbuild -->
</body>
</html>然后是我们开发时的目录结构
image2014-10-26 15:30:4.png
然后我使用gulp定义了一系列构建任务后,执行一下命令 gulp build (假设你也写了个名为build的任务)
我们的工程变成这样了
首先是工程目录
image2014-10-26 15:32:40.png
然后是/dist/index.html
<!--
Created by kui.liu on 2014/05/29 14:34.
-->
<!DOCTYPE html>
<html ng-app="invoiceApp">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
<link rel="stylesheet" href="/dist/css/app-cb402b9f.css"/>
<style>
[ng\:cloak], [ng-cloak], [data-ng-cloak], [x-ng-cloak], .ng-cloak, .x-ng-cloak {
display: none !important;
}
</style>
<title>账户管理</title>
<script>
// 设置资源文件目录,必需!!
window.ResourceDir = "/dist/";
</script>
</head>
<body ng-cloak class="ng-cloak" ng-controller="AppCtrl">
........
<script src="/dist/js/app-3db90639.js"></script>
</body>
</html>可以看到,/dist目录如期而至,而且长得跟我们预想的一样,然后是/dist/index.html,所有的css和js引用均指向一个压缩合并后的文件,眼尖的同学会发现,后面跟的那一串奇怪的数字是啥,如
app-3db90639.js。中划线后面那串数字是我们通过gulp计算了合并文件的MD5之后算出的hash值,也就是说,只要你的源码有改动,那么这个hash值便会自动追加到合并文件后面,而不需要你每次手动修改版本号那种古老的做法,一切都是gulp帮我们做好,我们需要做的就是敲一行命令就好了。赞一个!
下面具体介绍一下gulp怎么玩才能达到上文的效果
首先你要有个nodejs环境。nodeJs
安装gulp、bower(假设你有用到)等node组件
node install gulp -g
node install gulp --save-dev引入gulp合并、压缩等插件(package.json文件)
"devDependencies": {
"gulp" : ">=3.8.8",
"del" : ">=0.1.3",
"gulp-minify-css" : ">=0.3.10",
"gulp-minify-html": ">=0.1.6",
"gulp-replace" : ">=0.4.0",
"gulp-rev" : ">=1.1.0",
"gulp-uglify" : ">=1.0.1",
"gulp-usemin" : ">=0.3.8",
"run-sequence" : ">=1.0.1"
}构建gulp任务流,就像这样
/**
* @author kui.liu
* @since 2014/09/29 上午11:45
*/
"use strict";
var webRoot = "src/main/webapp/",
gulp = require('gulp'),
del = require('del'),
runSequence = require('run-sequence'),
minifyCss = require('gulp-minify-css'),
minifyHtml = require('gulp-minify-html'),
uglify = require('gulp-uglify'),
rev = require('gulp-rev'),
replace = require('gulp-replace'),
usemin = require('gulp-usemin');
/*------------------------- 清空dist目录 -----------------------------*/
gulp.task('clean', function (cb) {
del(webRoot + "dist/*", cb);
});
/*------------------------- 拷贝资源文件 -----------------------------*/
gulp.task('copy-tpl', function () {
return gulp.src(webRoot + 'src/tpls/**/*.html')
// .pipe(minifyHtml({empty: true, quotes: true}))
.pipe(gulp.dest(webRoot + 'dist/tpls'));
});
gulp.task('copy-font', function () {
return gulp.src(webRoot + 'src/fonts/*')
.pipe(gulp.dest(webRoot + 'dist/fonts/'));
});
gulp.task('copy-image', function () {
return gulp.src(webRoot + 'src/images/**/*')
.pipe(gulp.dest(webRoot + 'dist/images'));
});
gulp.task('copy-jqueryui-image', function () {
return gulp.src(webRoot + 'src/js/lib/jquery-ui/development-bundle/themes/base/images/*')
.pipe(gulp.dest(webRoot + 'dist/css/images'));
});
/*------------------------- 对首页引用的css、js作合并压缩,并根据文件md5值自动更新 -----------------------------*/
/*------------------------- 首页html需要加入build标识,具体参照gulp-usemin插件文档 -----------------------------*/
gulp.task('usemin', function () {
return gulp.src(webRoot + 'src/index.html')
.pipe(replace(/\/src\/(js|css)/g, '$1'))
.pipe(usemin({
css: [minifyCss({keepSpecialComments: 0}), rev()],
// html: [minifyHtml({empty: true, quotes: true})],
js : [uglify(), rev()]
}))
.pipe(replace(/(js\/|css\/)/g, "/dist/$1"))
.pipe(replace(/\/src\//g, "/dist/"))
.pipe(gulp.dest(webRoot + 'dist/'));
});
// 定义构建任务队列
gulp.task('build', function (cb) {
runSequence('clean', ['copy-tpl', 'copy-font', 'copy-image', 'copy-ccmsPop-image', 'copy-jqueryui-image', 'usemin'], cb);
});gulp采用管道流机制定义任务,任务的定义跟使用变得更易用和清晰。要运行单个定义的任务很简单,比如上面定义的clean任务:
gulp clean一般情况下我们不会只执行一个构建任务,如果要一个个任务去敲命令显然是效率低下的,这里引入runSequence插件,从而自定义任务队列,比如上面我们定义build任务用来执行所有的合并、压缩的任务,执行方式跟其他任务一样:
gulp build有的时候我们还用了bower等其他工具,不仅仅是gulp。那么构建工程的时候需要bower install,然后gulp build。懒人总想找到更简单的方式,我们在package.json中加入这个
"scripts" : {
"start": "npm install & bower install --allow-root & gulp build"
}这样我们构建项目只需要一个命令就OK
npm start命令跑完之后一切就都变成了你想要的模样。就是这么简单。so easy!麻麻再也不用担心我每次发布都要小心翼翼了。
ps:由于我们node配置文件是放在项目根路径下的,而maven只打包webapp下的资源,所以如果你不想每次发布前还要手动跑node命令然后提交编译目录,配合bamboo可以在maven打包前加上脚本命令,如图
image2014-10-27 10:7:27.png
更多详细代码请移步:source code
webpack v4 开始新增了一个 sideEffects 特性,通过给 package.json 加入 sideEffects: false 声明该包模块是否包含 sideEffects(副作用),从而可以为 tree-shaking 提供更大的优化空间。
先看张图感受一下:
注:v4 beta 版时叫 pure module, 后来改成了 sideEffects
基于我们对 fp 中的 side effect 的理解,我们可以认为,只要我们确定当前包里的模块不包含副作用,然后将发布到 npm 里的包标注为 sideEffects: false ,我们就能为使用方提供更好的打包体验。原理是 webpack 能将标记为 side-effects-free 的包由 import {a} from xx 转换为 import {a} from 'xx/a',从而自动修剪掉不必要的 import,作用同 babel-plugin-import。
于是很愉快的我给我的几个库都加上了这个配置(确定都不含副作用)。
直到我几个月前看到 @sean Larkin 给 vue 提交了这样一个 pr:chore(package.json): Add sideEffects: false field in package.json, 当时我就有点疑惑,依我对 vue 的了解,代码里的副作用挺多啊,比如很多函数都有对 Vue.prototype 的引用甚至修改,应该不能设置 sideEffects: false 才对啊。然而事实是我被打脸了,因为尤大很快的合并了这个 pr。。这直接导致我不敢给 mobx 加上这个配置,因为已经完全不明白 webpack 的这个 sideEffects 指的是什么了。。
直到前两天有人给 mobx-utils 提了 issue 说可以加上这个配置帮助 tree shaking,疑惑中我想起了 vue 的那个 pr 又翻出来看了一遍,发现在 pr 下已经有人跟我提了一样的疑问:
Hy Sean!
Could you please specify what you mean by "vue's original source files"?
I looked at the index.js file in the src/core folder and to my knowledge there are plenty sideeffects that would be prune away by tree shaking. (e.g Object.defineProperty)
I hope you can help me understand how this works.
Sean 原来的 pr 里是这样写的:
This PR adds the
"sideEffects": falseproperty in vue'spackage.jsonfile. This allow's webpack (for those who want to opt-in to requiring vue's original source files (instead of the flattened esm bundles) and want to remove flow type through a babel-transform, then this will allow webpack to aggressively ignore and treeshake unused exports throughout the module system.
Sean 的意思是当你按需引入 vue 的源码文件而不是打包的 bundle 时,webpack 能帮助你做更好的 tree shaking。比如你这样引用 vue 中的模块:import Vue from 'vue/src/core' 。
然后 Sean 就说此副作用非彼副作用(fp 中的),然后给了一个他在 stackoverflow 上的回答来解释 sideEffects,中心**是:
whenever a module reexports all exports (regardless if used or unused) need to be evaluated and executed in the case that one of those exports created a side-effect with another.
每当一个模块重导出了所有导出(无论是否会被用) 需要被计算和执行时,其中一个导出就对其他的导出产生了副作用。
老实讲还是没懂。。有兴趣的看原答案:what-does-webpack-4-expect-from-a-package-with-sideeffects-false
翻完 官方文档 跟 官方 example,只是了解到有了 sideEffects 后 bundle 的变化,依然无法解释 webpack sideEffects 跟 fp 中的 sideEffect 有什么区别,进而也无法解释为什么 vue 明明很多副作用依然能配置 sideEffects: false ?
毛主席教导我们:自力更生,丰衣足食。
Tree Shaking 的背景就不介绍了想必很多人都了解,webpack 的 tree shaking 的作用是可以将未被使用的 exported member 标记为 unused 同时在将其 re-export 的模块中不再 export。说起来很拗口,看代码:
// a.js
export function a() {}
// b.js
export function b(){}
// package/index.js
import a from './a'
import b from './b'
export { a, b }
// app.js
import {a} from 'package'
console.log(a)当我们已 app.js 为 entry 时,经过摇树后的代码会变成这样:
// a.js
export function a() {}
// b.js 不再导出 function b(){}
function b() {}
// package/index.js 不再导出 b 模块
import a from './a'
import b from './b'
export { a }
// app.js
import {a} from 'package'
console.log(a)配合 webpack 的 scope hoisting 和 uglify 之后,b 模块的痕迹会被完全抹杀掉。
但是如果 b 模块中添加了一些副作用,比如一个简单的 log:
// b.js
export function b(v) { reutrn v }
console.log(b(1))webpack 之后会发现 b 模块内容变成了:
// b.js
console.log(function (v){return v}(1))虽然 b 模块的导出是被忽略了,但是副作用代码被保留下来了。由于目前 transformer 转换后可能引入的各种奇怪操作引发的副作用(参考:你的Tree-Shaking并没什么卵用),很多时候我们会发现就算有了 tree shaking 我们的 bundle size 还是没有明显的减小。而通常我们期望的是 b 模块既然不被使用了,其中所有的代码应该不被引入才对。
这个时候 sideEffects 的作用就显现出来了:如果我们引入的 包/模块 被标记为 sideEffects: false 了,那么不管它是否真的有副作用,只要它没有被引用到,整个 模块/包 都会被完整的移除。以 mobx-react-devtool 为例,我们通常这样去用:
import DevTools from 'mobx-react-devtools';
class MyApp extends React.Component {
render() {
return (
<div>
...
{ process.env.NODE_ENV === 'production' ? null : <DevTools /> }
</div>
);
}
}这是一个很常见的按需导入场景,然而在没有 sideEffects: false 配置时,即便 NODE_ENV 设为 production ,打包后的代码里依然会包含 mobx-react-devtools 包,虽然我们没使用过其导出成员,但是 mobx-react-devtools 还是会被 import,因为里面“可能”会有副作用。但当我们加上 sideEffects false 之后,tree shaking 就能安全的把它从 bundle 里完整的移除掉了。
上面也说到,通常我们发布到 npm 上的包很难保证其是否包含副作用(可能是代码的锅可能是 transformer 的锅),但是我们基本能确保这个包是否会对包以外的对象产生影响,比如是否修改了 window 上的属性,是否复写了原生对象方法等。如果我们能保证这一点,其实我们就能知道整个包是否能设置 sideEffects: false了,至于是不是真的有副作用则并不重要,这对于 webpack 而言都是可以接受的。这也就能解释为什么能给 vue 这个本身充满副作用的包加上 sideEffects: false 了。
所以其实 webpack 里的 sideEffects: false 的意思并不是我这个模块真的没有副作用,而只是为了在摇树时告诉 webpack:我这个包在设计的时候就是期望没有副作用的,即使他打完包后是有副作用的,webpack 同学你摇树时放心的当成无副作用包摇就好啦!。
也就是说,只要你的包不是用来做 polyfill 或 shim 之类的事情,就尽管放心的给他加上 sideEffects: false 吧!
原文写于 2014-07-28
Talk is cheap, code first.
说出代码运行结果
var i,a=0;
setTimeout(function(){
console.log("timeout");
}, 1000);
for(i=0;i<10;i++){
a += i;
if(i === 9){
console.log("loop over");
}
}没错,当然是 loop over --> timeout
那么如果我们把timeout时间设为 0 呢,就像这样
// code1
setTimeout(function(){
console.log("timeout");
}, 0);结果还是 loop over --> timeout !!
我们假设你已经知道HTML5 spec定义了setTimeout最短时间间隔为4ms这个事实,但是浏览器实现的最短时间间隔一般是10ms。
这个时候你可能会说for循环先执行完且时间短于4ms,所以顺序是 loop over --> timeout.
假如我们把循环放大, 就像这样
// code2
for(i=0;i<1000000;i++){
a += i;
if(i === 999999){
console.log("loop over");
}
}结果却还是 loop over --> timeout.
你可能会说 1000000 次循环时间小于4ms, 好吧我们假设chrome已经如此这般牛x.
那如果我们把完整代码改成这样呢
//code 3
var i,a=0,begin;
setTimeout(function(){
console.log("timeout");
}, 1000);
console.log(begin=Date.now())
while(true){
if(Date.now()-begin>1500){
console.log("loop over");
break;
}
}
console.log(Date.now());
console.log("WTF!");WTF!循环时间超过1000ms的情况下结果依然是 loop over --> WTF --> timeout !!
会出现这种结果的一起原因归结于 Javascript是单线程的,所以导致 javascript的定时器从来都不是可靠的,当JS引擎的线程一直很忙的时候,它的定时器是永远不会执行的。只有线程空闲下来的,才有功夫去玩你的定时器。看这段代码
// code4
var a = 0;
setTimeout(function(){
console.log("timeout");
}, 1000)
while(true){
a++;
}没错,timeout永远都不会打印出来。(如果你不幸在浏览器中运行了这段代码,请调出进程管理器,kill process ....)。
假如你有过一定的js代码经验,你一定会问,既然是单线程的,那么javascript中的异步是怎么实现的呢,那些所谓的回调又是几个意思,用来装x的专业术语而已?
Javascript中的异步是基于 event-driver(事件驱动) 的,几乎所有的单线程语言都是通过这种方式实现异步的。什么是异步呢,言简意赅的说,异步函数就是会导致将来运行一个取自事件队列的函数的函数。
事件队列又是什么东西呢??
我们举个例子说明,假设:我们处于一个页面,这个页面上有一个setTimeout正在执行延时1000ms执行某段代码;而在这个200ms的时候,我们点击了一个按钮,因为此时已经满足事件触发条件,且JavaScript线程空闲,所以按照我们的脚本浏览器会立即执行与这个事件绑定的另外某段代码;点击事件触发的某段代码会做两件事,一件事是注册一个setInterval要求每隔700ms执行某段代码;另一件是发送一个ajax请求,并要求请求返回后执行某段代码,这个请求会在1500ms后返回。在这之后,可能还会有其它的事件被触发。
那么在整个事件队列中,他是如下排列的:

这时候我们可以再来试着解释一下code3那段代码的执行机制是怎样的。
在此之前有一点你必须要明确,Javascript中函数是一等公民,所有代码块的运行都是基于函数的!
code4代码处于全局环境,所以我们可以将它一整个代码块理解成一个 立即执行的匿名函数, 就像这样
// code5
(function(){
var i,a=0;
setTimeout(function(){
console.log("timeout");
}, 1000);
for(i=0;i<100000;i++){
a += i;
if(i === 99999){
console.log("loop over");
}
}
console.log("WTF!");
})();那么js引擎解释这段代码时过程是这样的:
几个月前,不知道什么缘由跟松波同学讨论了起js里自增操作符(i++)的问题,现将前因后果整理出来,传于世人😂
事情起源于这样一段代码
var i = 0;
i = i++;
console.log(i);来,都来说说答案是啥?
结果是0
换一种形式,或许大家不会有多少疑问
var i = 0;
var a = i++;
console.log(a); // 0没错,这也是我们初学自增操作符的经典例子,对这结果还有疑问请自觉面壁。。。
遥想当年学习自增操作符的口诀大致是,i++ 是先用后自增,++i 是先自增再用
那么按照这个思路,上面的代码解析流程应该是这样的
var i =0;
i = i;
i = i + 1;可惜结果并不是这样的
按照犀牛书上的描述,后增量(post increment)操作符的特点是
它对操作数进行增量计算,但返回未作增量计算的(unincremented)值。
但是书上并没有告诉我们,先做增量计算再返回之前的值,还是返回之前的值再做增量计算。
对于这种疑问,我们只能求助ecmascript给出官方解释:
The production PostfixExpression : LeftHandSideExpression [no LineTerminator here] ++ is evaluated as follows:
- Evaluate LeftHandSideExpression.
- Call GetValue(Result(1)).
- Call ToNumber(Result(2)).
- Add the value 1 to Result(3), using the same rules as for the + operator (see 11.6.3).
- Call PutValue(Result(1), Result(4)).
- Return Result(3).
从es上的算法描述,我们能够清晰的得知,后自增操作符是先自增赋值,然后返回自增前的值,这样的一个顺序。
到这里还不算完。
既然i=i++这种操作最后i还是为原始值,也就是这段代码不会有任何实际意义,那么js引擎有没有可能针对性的做优化,从而避免不必要的自增运算?(如果你用的是IDE,IDE会提示你这是一段无用的代码)
也就是说,我们如何确定,执行引擎一定做了两步操作:
i = i + 1; return iBeforeIncrease = 0;i = iBeforeIncrease;还是执行引擎可能会针对性的优化,只做一步操作:
i = iBeforeIncrease;当我在想怎么去确定这一点时,松波给出了解决方案,用Object.observe()方法啊!!(该方法是ES7提案中的新api,不过chrome早早的实现了)
var obj = {i:0};
Object.observe(obj, function(changes){
console.log(changes);
});
obj.i = obj.i++;代码放到chrome中跑一下,可以看到,改变触发了两次,也就是i做了两次修改操作。
另外firefox中也提供了一个类似的api,Object.prototype.watch,有兴趣的同学可以试试用这个方式来验证一下。
顺便抖个机灵,自增操作是非原子性操作,是非线程安全的,多线程环境下共用变量使用自增操作符是会有问题的(前端同学们别急,ES7会为我们带来js多线程编程体验😍)。
原文写于 2014-05-14
参考文章:前端性能优化-JS/CSS压缩合并
pom配置,加入wro4j插件
<!--自定义属性-->
<properties>
<webSourceDirectory>src/main/webapp</webSourceDirectory>
<minimizedResource>true</minimizedResource>
</properties>
<plugins>
<plugin>
<groupId>ro.isdc.wro4j</groupId>
<artifactId>wro4j-maven-plugin</artifactId>
<version>1.7.5</version>
<executions>
<execution>
<id>wro4j</id>
<phase>compile</phase>
<goals>
<goal>run</goal>
</goals>
</execution>
</executions>
<configuration>
<!-- 是否压缩,minimizedResource -->
<minimize>${minimizedResource}</minimize>
<!-- web资源目录,webSourceDirectory这个是自定义变量 -->
<contextFolder>${basedir}/${webSourceDirectory}/</contextFolder>
<wroManagerFactory>ro.isdc.wro.maven.plugin.manager.factory.ConfigurableWroManagerFactory
</wroManagerFactory>
<!-- wro4j的配置文件,指定需要合并和压缩的文件 -->
<wroFile>${basedir}/${webSourceDirectory}/WEB-INF/wro.xml</wroFile>
<!-- wro4j的配置文件,指定压缩和合并工具的配置 -->
<extraConfigFile>${basedir}/${webSourceDirectory}/WEB-INF/wro.properties</extraConfigFile>
<!-- 处理后的css存放目录 -->
<cssDestinationFolder>${basedir}/${webSourceDirectory}/build/css/</cssDestinationFolder>
<!-- 处理后的js存放目录 -->
<jsDestinationFolder>${basedir}/${webSourceDirectory}/build/js/</jsDestinationFolder>
<ignoreMissingResources>false</ignoreMissingResources>
<failNever>false</failNever>
<failFast>false</failFast>
</configuration>
</plugin>
</plugins>配置wro.xml,用于指定哪些文件需要压缩合并,置于WEB-INF目录下。详细配置:document
<?xml version="1.0" encoding="UTF-8"?>
<groups xmlns="http://www.isdc.ro/wro">
<!--需要压缩的资源,name为压缩后的文件名-->
<group name='base.min'>
<css>/src/css/*</css>
<js>/src/js/*</js>
</group>
</groups>配置wro.properties,指定wro相关配置。详细配置:document
debug=true
disableCache=true
ignoreMissingResources=false
ignoreFailingProcessor=true
jmxEnabled=true
preProcessors=
#指定css、js压缩使用的处理器,详细https://code.google.com/p/wro4j/wiki/AvailableProcessors
postProcessors=yuiCssMin,googleClosureSimple运行wro4j
执行后会在配置的目录生成相应文件名的合并文件。
实验环境为IntelliJ,eclipse好像要装插件m2e-wro4j,而且貌似对1.7.x版的wro4j支持有问题,没试过,建议直接使用IntelliJ。
手动修改静态资源引用
之前使用为:
<!DOCTYPE html>
<html>
<head>
<title></title>
<link href="src/css/test1.css" rel="stylesheet">
<link href="src/css/test2.css" rel="stylesheet">
</head>
<body>
</body>
<script src="src/js/test1.js"></script>
<script src="src/js/test2.js"></script>
</html>压缩合并之后:
<!DOCTYPE html>
<html>
<head>
<title></title>
<link href="build/css/base.min.css" rel="stylesheet">
</head>
<body>
</body>
<script src="build/js/base.min,js"></script>
</html>错误(压缩会报错)的写法:
由于angularJs使用了依赖注入的特性,会将某些指定的service注入到代码中,如:
function TestCtrl($scope, $http){
$scope.userName = "test";
$http.get("xxxxx");
}当TestCtrl被用作controller时,$scope,$http参数会被angularJs框架自动注入具有特殊意义的对象。如果这段代码被压缩,它可能会变成这样:
function TestCtrl(a, b){
a.userName = "test";
b.get("xxxxx");
}正确的写法:
由于angularJs是根据名称进行注入的,这个时候框架就不知道a其实就是之前的$scope了,controller正确的写法应该是这样的
angular,module("test", []).controller("TestCtrl", ["$scope","$http", function($scope, $http){
$scope.userName = "test";
$http.get("xxxxx");
}]);压缩后可能会变成
angular,module("test", []).controller("TestCtrl", ["$scope","$http", function(a, b){
a.userName = "test";
b.get("xxxxx");
}]);这样框架就知道应该将 $scope注入给参数a,$http注入给参数b !
其实这个特性在angular官方入门教程的第一章就有提到,只是很多人出于偷懒的原因而采用第一种写法。其他的诸如service、directive、filter的写法均应参照后面一种,偷懒只会让你在后面出问题时更痛苦!!
好的目录结构可大大降低web项目维护成本,在综合了多个开源js类库及框架之后,总结出如下目录结构
目录说明:
| 目录 | 说明 |
|---|---|
| build | 前端编译代码目录,供生产环境使用 |
| lib | 第三方类库及框架 |
| src | 前端源代码目录,供开发环境使用 |
| test | js单元测试目录,目录结构请与src中相应js保持一致 |
其实web项目的构建也有很多自动化工具,它们能完成一系列包括压缩合并等web项目管理需求,就好比java世界的maven。Yeoman就是这样的一个东西。只是现在我们对这方面的研究及实践经验过少,后续有精力可以研究下这个东西并引入到项目中。
原文写于 2015-02-11
前阵子帮部门面试一前端,看了下面试题(年轻的时候写后端java所以没做过前端试题),其中有一道题是这样的
比较下面两段代码,试述两段代码的不同之处
// A--------------------------
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f();
}
checkscope();
// B---------------------------
var scope = "global scope";
function checkscope(){
var scope = "local scope";
function f(){
return scope;
}
return f;
}
checkscope()();首先A、B两段代码输出返回的都是 "local scope",如果对这一点还有疑问的同学请自觉回去温习一下js作用域的相关知识。。
那么既然输出一样那这两段代码具体的差异在哪呢?大部分人会说执行环境和作用域不一样,但根本上是哪里不一样就不是人人都能说清楚了。前阵子就这个问题重新翻了下js基础跟ecmascript标准,如果我们想要刨根问底给出标准答案,那么我们需要先理解下面几个概念:
原文:Every execution context has associated with it a variable object. Variables and functions declared in the source text are added as properties of the variable object. For function code, parameters are added as properties of the variable object.
简言之就是:每一个执行上下文都会分配一个变量对象(variable object),变量对象的属性由 变量(variable) 和 函数声明(function declaration) 构成。在函数上下文情况下,参数列表(parameter list)也会被加入到变量对象(variable object)中作为属性。变量对象与当前作用域息息相关。不同作用域的变量对象互不相同,它保存了当前作用域的所有函数和变量。
这里有一点特殊就是只有 函数声明(function declaration) 会被加入到变量对象中,而 **函数表达式(function expression)**则不会。看代码:
// 函数声明
function a(){}
console.log(typeof a); // "function"
// 函数表达式
var a = function _a(){};
console.log(typeof a); // "function"
console.log(typeof _a); // "undefined"函数声明的方式下,a会被加入到变量对象中,故当前作用域能打印出 a。
函数表达式情况下,a作为变量会加入到变量对象中,_a作为函数表达式则不会加入,故 a 在当前作用域能被正确找到,_a则不会。
另外,关于变量如何初始化,看这里

关于Global Object
当js编译器开始执行的时候会初始化一个Global Object用于关联全局的作用域。对于全局环境而言,global object就是变量对象(variable object)。变量对象对于程序而言是不可读的,只有编译器才有权访问变量对象。在浏览器端,global object被具象成window对象,也就是说 global object === window === 全局环境的variable object。因此global object对于程序而言也是唯一可读的variable object。
原文:When control enters an execution context for function code, an object called the activation object is created and associated with the execution context. The activation object is initialised with a property with name arguments and attributes { DontDelete }. The initial value of this property is the arguments object described below.
The activation object is then used as the variable object for the purposes of variable instantiation.
简言之:当函数被激活,那么一个活动对象(activation object)就会被创建并且分配给执行上下文。活动对象由特殊对象 arguments 初始化而成。随后,他被当做变量对象(variable object)用于变量初始化。
用代码来说明就是:
function a(name, age){
var gender = "male";
function b(){}
}
a(“k”,10);a被调用时,在a的执行上下文会创建一个活动对象AO,并且被初始化为 AO = [arguments]。随后AO又被当做变量对象(variable object)VO进行变量初始化,此时 VO = [arguments].concat([name,age,gender,b])。
execution context
顾名思义 执行环境/执行上下文。在javascript中,执行环境可以抽象的理解为一个object,它由以下几个属性构成:
executionContext:{
variable object:vars,functions,arguments,
scope chain: variable object + all parents scopes
thisValue: context object
}此外在js解释器运行阶段还会维护一个环境栈,当执行流进入一个函数时,函数的环境就会被压入环境栈,当函数执行完后会将其环境弹出,并将控制权返回前一个执行环境。环境栈的顶端始终是当前正在执行的环境。
scope chain
作用域链,它在解释器进入到一个执行环境时初始化完成并将其分配给当前执行环境。每个执行环境的作用域链由当前环境的变量对象及父级环境的作用域链构成。
作用域链具体是如何构建起来的呢,先上代码:
function test(num){
var a = "2";
return a+num;
}
test(1);至此test的作用域链构建完成。
说了这么多概念,回到面试题上,返回结果相同那么A、B两段代码究竟不同在哪里,个人觉得标准答案在这里:
首先是A:
进入全局环境上下文,全局环境被压入环境栈,contextStack = [globalContext]
全局上下文环境初始化,
globalContext={
variable object:[scope, checkscope],
scope chain: variable object // 全局作用域链
},同时checkscope函数被创建,此时 checkscope.[[Scope]] = globalContext.scopeChain
执行checkscope函数,进入checkscope函数上下文,checkscope被压入环境栈,contextStack=[checkscopeContext, globalContext]。随后checkscope上下文被初始化,它会复制checkscope函数的[[Scope]]变量构建作用域,即 checkscopeContext={ scopeChain : [checkscope.[[Scope]]] }
checkscope的活动对象被创建 此时 checkscope.activationObject = [arguments], 随后活动对象被当做变量对象用于初始化,checkscope.variableObject = checkscope.activationObject = [arguments, scope, f],随后变量对象被压入checkscope作用域链前端,(checckscope.scopeChain = [checkscope.variableObject, checkscope.[[Scope]] ]) == [[arguments, scope, f], globalContext.scopeChain]
函数f被初始化,f.[[Scope]] = checkscope.scopeChain。
checkscope执行流继续往下走到 return f(),进入函数f执行上下文。函数f执行上下文被压入环境栈,contextStack = [fContext, checkscopeContext, globalContext]。函数f重复 第4步 动作。最后 f.scopeChain = [f.variableObject,checkscope.scopeChain]
函数f执行完毕,f的上下文从环境栈中弹出,此时 contextStack = [checkscopeContext, globalContext]。同时返回 scope, 解释器根据f.scopeChain查找变量scope,在checkscope.scopeChain中找到scope(local scope)。
checkscope函数执行完毕,其上下文从环境栈中弹出,contextStack = [globalContext]
如果你理解了A的执行流程,那么B的流程在细节上一致,唯一的区别在于B的环境栈变化不一样,
A: contextStack = [globalContext] ---> contextStack = [checkscopeContext, globalContext] ---> contextStack = [fContext, checkscopeContext, globalContext] ---> contextStack = [checkscopeContext, globalContext] ---> contextStack = [globalContext]
B: contextStack = [globalContext] ---> contextStack = [checkscopeContext, globalContext] ---> contextStack = [fContext, globalContext] ---> contextStack = [globalContext]
也就是说,真要说这两段代码有啥不同,那就是他们执行过程中环境栈的变化不一样,其他的两种方式都一样。
其实对于理解这两段代码而言最根本的一点在于,javascript是使用静态作用域的语言,他的作用域在函数创建的时候便已经确定(不含arguments)。
说了这么一大坨偏理论的东西,能坚持看下来的同学估计都要睡着了...是的,这么一套理论性的东西纠结有什么用呢,我只要知道函数作用域在创建时便已经生成不就好了么。没有实践价值的理论往往得不到重视。那我们来看看,当我们了解到这一套理论之后我们的世界到底会发生了什么变化:
这样一段代码
function setFirstName(firstName){
return function(lastName){
return firstName+" "+lastName;
}
}
var setLastName = setFirstName("kuitos");
var name = setLastName("lau");
// 乍看之下这段代码没有任何问题,但是世界就是这样,大部分东西都禁不起考究(我认真起来连自己都害怕哈哈哈哈)。。
// 调用setFirstName函数时返回一个匿名函数,该匿名函数会持有setFirstName函数作用域的变量对象(里面包含arguments和firstName),不管匿名函数是否会使用该变量对象里的信息,这个持有逻辑均不会改变。
// 也就是当setFirstName函数执行完之后其执行环境被销毁,但是他的变量对象会一直保存在内存中不被销毁(因为被匿名函数hold)。同样的,垃圾回收机制会因为变量对象被一直hold而不做回收处理。这个时候内存泄露就发生了。这时候我们需要做手动释放内存的处理。like this:
setLastName = null;
// 由于匿名函数的引用被置为null,那么其hold的setFirstName的活动对象就能被安全回收了。
// 当然,现代浏览器引擎(以V8为首)都会尝试回收闭包所占用的内存,所以这一点我们也不必过多处理。ps:最后,关于闭包引起的内存泄露那都是因为浏览器的gc问题(IE8以下为首)导致的,跟js本身没有关系,所以,请不要再问js闭包会不会引发内存泄露了,谢谢合作!
原文写于 2015-01-27
接上一篇 Angular $q简介 ,这一篇我们就Angular对$q的代码实现来学习下Promise的实现原理及**
上篇讲到了Angular Promise的基本API,其中就典型的应用类似这样
Promise.then
var defer = $q.defer();
setTimeout(function (){
defer.resolve(10);
},5000);
console.log("1");
defer.promise.then(function(a){
console.log(a);
});
console.log("2");
// 打印的顺序是1,2,10
// 当我们依赖的数据会在一个异步的时间点返回时,我们需要使用resolve 跟 then 来配合首先我们要明确一个概念就是js是单线程语言,一个时间只能有一个线程在执行。那么上面的执行流程自然就是: 启动定时器并往事件队列里加入一个回调函数 ---> 打印1 ---> 调用defer.promise.then方法 ---> 打印2 --->主线程空闲开始等5秒(实际会小于5s)执行回调 ---> 调用defer.resolve ---> 打印10
至于这中间究竟发生了上面,先来看看angular是怎样实现这两个方法的
Promise.then
// Promise.then
function Promise() {
this.$$state = { status: 0 };
}
Promise.prototype = {
then: function(onFulfilled, onRejected, progressBack) {
var result = new Deferred();
this.$$state.pending = this.$$state.pending || [];
this.$$state.pending.push([result, onFulfilled, onRejected, progressBack]);
if (this.$$state.status > 0) scheduleProcessQueue(this.$$state);
return result.promise;
},
.........Promise构造函数原型上维护一个方法 then ,当一个promise对象调用该方法时会往自己的成员属性 $$state 上构建一个 pending数组,然后将生成的deferred跟成功、失败回调压入pending数组。
拿上文的案例来看, defer.promise.then之后 defer.promise.$$state.pending = [[new Deferred(), function (a){console.log(a)}]];
再来看看defer.resolve发生了什么
Deferred.resolve
// Deferred.resolve
Deferred.prototype = {
resolve: function(val) {
if (this.promise.$$state.status) return;
if (val === this.promise) {
this.$$reject($qMinErr(
'qcycle',
"Expected promise to be resolved with value other than itself '{0}'",
val));
}
else {
this.$$resolve(val);
}
},
$$resolve: function(val) {
var then, fns;
fns = callOnce(this, this.$$resolve, this.$$reject);
try {
if ((isObject(val) || isFunction(val))) then = val && val.then;
if (isFunction(then)) {
this.promise.$$state.status = -1;
then.call(val, fns[0], fns[1], this.notify);
} else {
this.promise.$$state.value = val;
this.promise.$$state.status = 1;
scheduleProcessQueue(this.promise.$$state);
}
} catch (e) {
fns[1](e);
exceptionHandler(e);
}
},
......核心方法是 Deferred.$$resolve , 上文中 defer.resolve(10) 之后会走到 scheduleProcessQueue(this.promise.$$state);
// scheduleProcessQueue
function scheduleProcessQueue(state) {
if (state.processScheduled || !state.pending) return;
state.processScheduled = true;
nextTick(function() { processQueue(state); });
}nextTick方法定义在这里
// nextTick
function qFactory(nextTick, exceptionHandler) {
var $qMinErr = minErr('$q', TypeError);
.....再往上看谁调用了qFactory
// qFactory
function $$QProvider() {
this.$get = ['$browser', '$exceptionHandler', function($browser, $exceptionHandler) {
return qFactory(function(callback) {
$browser.defer(callback);
}, $exceptionHandler);
}];
}没错就是我们使用的 $q 服务,也就是$q在初始化的时候会 生成 nextTick = function(callback) {$browser.defer(callback);}
$browser.defer干了什么事?
// $browser.defer
self.defer = function(fn, delay) {
var timeoutId;
outstandingRequestCount++;
timeoutId = setTimeout(function() {
delete pendingDeferIds[timeoutId];
completeOutstandingRequest(fn);
}, delay || 0);
pendingDeferIds[timeoutId] = true;
return timeoutId;
};没错,很简单,就是一个定时器。将定时器时间默认设置为0的意图很明显,使当前任务脱离主线程,在事件队列执行时再做处理,也就是所谓的defer延时
回到 scheduleProcessQueue,被手动从主线程中移除的任务是 nextTick(function() { processQueue(state); });
看看 processQueue 是干嘛的
// processQueue
function processQueue(state) {
var fn, promise, pending;
pending = state.pending;
state.processScheduled = false;
state.pending = undefined;
for (var i = 0, ii = pending.length; i < ii; ++i) {
promise = pending[i][0];
fn = pending[i][state.status];
try {
if (isFunction(fn)) {
promise.resolve(fn(state.value));
} else if (state.status === 1) {
promise.resolve(state.value);
} else {
promise.reject(state.value);
}
} catch (e) {
promise.reject(e);
exceptionHandler(e);
}
}
}没错,这个就是Promise处理最核心的部位。当主线程执行完毕开始处理事件队列时,processQueue 开始执行, 它会将 state.pending 队列(没错,队列里的内容就是我们调用then()方法时一个个压入的)遍历然后依次调用
假如有这样一段代码
promiseO.then(funcA).then(funcB);
那么执行后会发生这样一个变化
promiseO.then(funcA) ---> promiseO.$$state.pengding = [[deferredA, funcA]]; return deferredA.promise;
deferredA.promise.then(funcB) ---> deferredA.promise.$$state.pending = [[deferredB, funcB]]; return deferredB.promise;
// 当各个promise被依次resolve了
// 1. 首先是promiseO.resolve(10) ---> promiseO.$$state.value = 10;promiseO.$$state.status = 1;scheduleProcessQueue(promiseO.$$state);
// 2. scheduleProcessQueue最后走到processQueue方法,会执行promiseO.$$state.pengding队列,这时候会执行 deferredA.resolve(funcA(promiseO.$$state.value))
// 3. 假设funcA(promiseO.$$state.value)返回20,那么就是 deferredA.resolve(20)。这时候就又回到了步骤1
// 依次执行后then链上所有方法均会执行then的核心**是它会往当前promise的pending队列中压入then链下一个promise对象的Deferred(promise=Deferred.promise),然后通过这种节点关系构成整个then链
介绍完promise.then我们再来介绍一下$q.all([promises]).then(funcT),来看看他是怎么实现当所有promise被resolve之后再走向下一步的吧
$q.all
// $q.all
function all(promises) {
var deferred = new Deferred(),
counter = 0,
results = isArray(promises) ? [] : {};
forEach(promises, function(promise, key) {
counter++;
when(promise).then(function(value) {
if (results.hasOwnProperty(key)) return;
results[key] = value;
if (!(--counter)) deferred.resolve(results);
}, function(reason) {
if (results.hasOwnProperty(key)) return;
deferred.reject(reason);
});
});
if (counter === 0) {
deferred.resolve(results);
}
return deferred.promise;
}很简单,forEach promises列表之后,在每个promise的then链加一个回调,关键代码在这一行
if (!(--counter)) deferred.resolve(results);
每一个promise成功执行了then回调之后会--counter,如果某个promise是最后一个被resolve的则将所有的results resolve,这个时候他的then链就开始执行了
$q.when
//$q.when
var when = function(value, callback, errback, progressBack) {
var result = new Deferred();
result.resolve(value);
return result.promise.then(callback, errback, progressBack);
};$q.when(val/promiseLikeObj)的用处很简单,就是将一个简单对象/或promiseLike的对象包装成$q信任的promise对象并将值加入到then链中。
至此$q的几个基本api都基于源码做了简单介绍,个人在研究源码的过程中最大的收获就是对js的异步模型有了更深刻的理解,并对工程化应用有了感官的认识,强烈建议有兴趣的同学读读源码。Promise是一种异步编程模型,是当前被普遍认可的一种解决方案,目前业界还有一些其他的异步解决方案诸如 thunk、co 模型等,思路各有差异跟优缺点,有兴趣的同学可以去了解相信会对你理解js的异步模型有进一步认识。
PS:
下一篇会介绍一下ES6中的Promise的api用法,敬请期待
体验技术部是蚂蚁金服集团的前端服务团队,着力于提升各种互联网产品的用户体验。
目前,体验技术部的主要产品分成以下三类。
产品类:语雀(文档知识协同)、云凤蝶(移动营销建站)、亲贝(儿童财商服务)
设计类:以 Ant Design 为代表的设计语言
工具类:Ant Design(React 组件库)、AntV(数据可视化工具)、支付宝小程序、Egg(Node 建站框架)、dva、umi(企业级应用框架) 等
此外,我们还举办 See Conf 技术大会。
以上是官方介绍。
市面上通常是这么描述我们的:玉伯的团队,国内前端网红最密集的团队,你见过没见过听过没听过的前端网红或许都能在这里找到(阮一峰、偏右、苏千、徐飞、死马、死月等)🙂
上海、杭州
另外,全栈、可视化、设计师 方向的我们也招。
简历请投:[email protected]
内推通道快人一筹🤓
阅读本文之前,请确保自己已经读过民工叔的这篇blog
Angular 1.x和ES6的结合
大概年初开始在我的忽悠下我厂启动了Angular1.x + ES6的切换准备工作,第一个试点项目是公司内部的组件库(另有seed项目)。目前已经实施了三个多月,期间也包括一些其它新开产品的试点。中间也经历的一些痛苦及反复(组件库代码经历过几次调整,现在还在重构ing),总结了一些经验分享给大家。(实际上民工叔的文章中提到了大部分实践指南,我这里尝试作一定整理及补充,包括一些自己的思考及解决方案)
开始之前务必再次明确一件事情,就是我们使用ES6来开发Angular1.x的目的。总结一下大概三点:
其中第1点是技术投资需要,第2、3点是架构需要。
我们先来看看要达到这些要求,具体要如何一步步实现。
在ES6 module的帮助下,ng的模块机制就变成了纯粹的迎合框架的语法了。
实践准则就是:
example:
// moduleA.js
import angular from 'angular';
import Controller from './Controller';
export default angular.module('moduleA', [])
.controller('AppController', Controller)
.name;
// moduleB.js 需要依赖module A
import angular from 'angular';
import moduleA from './moduleA';
angular.module('moduleB', [moduleA]);通过这种方式,无论被依赖的模块的模块名怎么改变都不会对其他模块造成影响。
Best Practice
index.js作为框架语法包装器生成angular module外壳,同时将module.name export出去。对于整个系统而言,理想状态下只有index.js中可以出现框架语法,其他地方应该是看不到框架痕迹的。
ng1.2版本开始提供了一个controllerAs语法,自此Controller终于能变成一个纯净的ViewModel(视图模型)了,而不是像之前一样混入过多的$scope痕迹(供angular框架使用)。
example
<div ng-controller="AppCtrl as app">
<div ng-bind="app.name"></div>
<button ng-click="app.getName">get app name</button>
</div>// Controller AppCtrl.js
export default class AppCtrl {
constructor() {
this.name = 'angular&es6';
}
getName() {
return this.name;
}
}// module
import AppCtrl from './AppCtrl';
export default angular.module('app', [])
.controller('AppCtrl', AppCtrl)
.name;这种方式写controller等同于ES5中这样去写:
function AppCtrl() {
this.name = 'angular&es6';
}
AppCtrl.prototype.getName = function() {
return this.name;
};
....
.controller('AppCtrl', AppCtrl)不过ES6的class语法糖会让整个过程更自然,再加上ES6 Module提供的模块化机制,业务逻辑会变得更清晰独立。
Best Practice
在所有地方使用controllerAs语法,保证ViewModel(Controller)的纯净。
以datepicker组件为例
// 目录结构
+ date-picker
- _date-picker.scss
- date-picker.tpl.html
- DatePickerCtrl.js
- index.js
// DatePickerCtrl.js
export default class DatePickerCtrl {
$onInit() {
this.date = `${this.year}-${this.month}`;
}
getMonth() {
...
}
getYear() {
...
}
}注意,这里我们先写的controller而不是指令的link/compile方法,原因在于一个数据驱动的组件体系下,我们应该尽量减少DOM操作,因此理想状态下,组件是不需要link或compile方法的,而且controller在语义上更贴合mvvm架构。
// index.js
import template from './date-picker.tpl.html';
import controller from './DatePickerCtrl';
const ddo = {
restrict: 'E',
template,
controller,
controllerAs: '$ctrl',
bindToContrller: {
year: '=',
month: '='
}
};
export default angular.module('components.datePicker', [])
.directive('datePicker', ddo)
.name;**注意,这里跟民工叔的做法有点不一样。**叔叔的做法是把指令做成class然后在index.js中import并初始化,like this:
// Directive.js
export default class Directive {
constructor() {
}
getXXX() {
}
}
// index.js
import Directive from './Directive';
export default angular.module('xxx', [])
.directive('directive', () => new Directive())
.name;但是我的意见是,整个系统设计中index.js作为angular的包装器使得代码变成框架可识别的,换句话说就是只有index.js中是可以出现框架的影子的,其他地方都应该是框架无关的使用原生代码编写的业务模型。
1.5之后提供了一个新的语法moduleInstance.component,它是moduleInstance.directive的高级封装版,提供了更语义更简洁的语法,同时也是为了顺应基于组件的应用架构的趋势(之前也能做只是语法稍啰嗦且官方没有给出best practice导向)。比如上面的例子用component语法重写的话:
// index.js
import template from './date-picker.tpl.html';
import controller from './DatePickerCtrl';
const ddo = {
template,
controller,
bindings: {
year: '=',
month: '='
}
};
export default angular.module('components.datePicker', [])
.component('datePicker', ddo)
.name;component语义更简洁明了,比如 bindToController -> bindings的变化,而且默认controllerAs = '$ctrl'。还有一个重要的差异点就是,component语法只能定义自定义标签,不能定义增强属性,而且component定义的组件都是isolated scope。
另外angular1.5版本有一个大招就是,它给组件定义了相对完整的生命周期钩子(虽然之前我们能用其他的一些手段来模拟init到destroy的钩子,但是实现的方式框架痕迹太重,后面会详细讲到)!而且提供了单向数据流实现方式!
example
// DirectiveController.js
export class DirectiveController {
$onInit() {
}
$onChanges(changesObj) {
}
$onDestroy() {
}
$postLink() {
}
}
// index.js
import template from './date-picker.tpl.html';
import controller from './DatePickerCtrl';
const ddo = {
template,
controller,
bindings: {
year: '<',
month: '<'
}
};
export default angular.module('components.datePicker', [])
.component('datePicker', ddo)
.name;component相关详细看这里:angular component guide
从angular的这些api变化来看,ng的开发团队正在越来越多的吸取了一些其他社区的思路,这也从侧面上印证了前端框架正在趋于同质化的事实(至少在同类型问题领域,方案趋于同质)。顺带帮vue打个广告,不论是进化速度还是方案落地速度,vue都已经赶超angular了。推荐大家都去关注下vue。
Best Practice
在场景符合(只要你的指令是可以作为自定义标签存在就算符合)的情况下都应该用component语法,在$onInit回调中做初始化处理(而不是constructor,原因见下文),$onDestroy中作组件销毁回调。没有link方法,只有组件Controller(ViewModel).这样能帮助你从component-base的应用架构方向去思考问题。Deprecation warning: although bindings for non-ES6 class controllers are currently bound to this before the controller constructor is called, this use is now deprecated. Please place initialization code that relies upon bindings inside a $onInit method on the controller, instead.
angular1.x中有五种不同类型的服务定义方式,但是如果我们以功能归类,大概可以归出两种类型:
angular原本设计service的目的是提供一个应用级别的共享单元,单例且私有,也就是只能在框架内部使用(通过依赖注入)。在ES5的无模块化系统下,这是一个很好的设计,但是它的问题也同样明显:
很显然,ES6 Module并不会出现这些问题。举例说明,我们之前使用一个服务是这样的:
index.js
import angular from 'angular';
import Service from './Service';
import Controller from './Controller';
export default angular.module('services', [])
.service('service', Service)
.controller('controller', Controller)
.name;Service.js
export default class Service {
getName() {
return 'kuitos';
}
}Controller.js 这里使用了工具库angular-es-utils来简化ES6中使用依赖注入的方式。
import {Inject} from 'angular-es-utils/decorators';
@Inject('service')
export default class Controller {
getUserName() {
return this._service.getName();
}
}假如哪天在调用controller.getUserName()时报错了,而且错误出在service.getName方法,那么查错的方式是?我是只能全局搜了不知道你们有没有更好的办法。。。
如果我们使用依赖注入,直接基于ES6 Module来做,改造一下会变成这样:
Service.js
export default {
getName() {
return 'kuitos';
}
}Controller.js
import Service from './Service';
export default class Controller {
getUserName() {
return Service.getName();
}
}这样定位问题是不是容易很多!!
从这个案例上来看,我们能完美模拟基础的 Service、Factory 了,那么还有Provider、Constant、Value呢?
Provider跟Service、Factory差异在于Provider在ng启动阶段可配置,脱离ng使用ES6 Module的方式,服务之间其实没什么区别。。。:
Provider.js
let apiPrefix = '';
export function setPrefix(prefix) {
apiPrefix = prefix;
}
export function genResource(url) {
return resource(apiPrefix + url);
}应用入口时配置:
app.js
import {setPrefix} from './Provider';
setPrefix('/rest/1.0');Contant跟Value呢?其实如果我们忘掉angular,它们倆完全没区别:
Constant.js
export const VERSION = '1.0.0';上面我们提到我们所有的服务其实都可以脱离angular来写以消除依赖注入,但是有一种状况比较难搞,就是假如我们自定义的工具方法中需要使用到angular的built-in服务怎么办?要获取ng内置服务我们就绕不开依赖注入。但是好在angular有一个核心服务$injector,通过它我们可以获取任何应用内的服务(Service、Factory、Value、Constant)。但是$injector也是ng内置的服务啊,我们如何避开依赖注入获取它?我封装了个小工具可以做这个事:
import injector from 'angular-es-utils/injector';
export default {
getUserName() {
return injector.get('$http').get('/users/kuitos');
}
};这样做确实可以但总觉得不够优雅,不过好在大部分场景下我们需要用到built-in service的场景比较少,而且对于$http这类基础服务,调用者不应该直接去用,而是提供一个更高级的封装出去,对调用着而言内部使用的技术是透明,可以是$http也可以是fetch或者whatever。
import injector from 'angular-es-utils/injector';
import {FetchHttp} from 'es6-http-utils';
export const HttpClient {
get(url) {
return injector.get('$http').get(url);
}
save(url, payload) {
return FetchHttp.post(url, payload);
}
}
// Controller.js
import {HttpClient} from './HttpClient';
class Controller {
saveUser(user) {
HttpClient.save('/users', user);
}
}通过这些手段,对于业务代码而言基本上是看不到依赖注入的影子的。
angular中filter做的事情有两类:过滤和格式化。归结起来它做的就是一种数据变换的工作。filter的问题不仅仅在于DI的弊端,还有更多其他的问题。vue2中甚至取消了filter的设计,参见[Suggestion]Vue 2.0 - Bring back filters please。其中有一点我特别认可:过度使用filter会让你的代码在不自知的情况下走向混乱的状态。我们可以自己去写一系列的transformer(或者使用underscore之类的工具)来做数据处理,并在vm中显式的调用它。
import {dateFormatter} from './transformers';
export default class Controller {
constructor() {
this.data = [1,2,3,4];
this.currency = this.data
.filter(v => v < 4)
.map(v => '$' + v);
this.date = Date.now();
this.today = dateFormatter(this.date);
}
}Best Practice
理想状态下,Service & Filter的语法在一个不需要跟其他系统共享代码单元的业务系统里是完全可以抹除掉的,我们完全通过ES6 Module来代替依赖注入。同时,对于一些基础服务,如$http、$q之类的,我们最好能提供更上层的封装,确保业务代码不会直接接触到built-in service。
如果想将业务模型彻底从框架中抽离出来,下面这几件事情是必须解决的。
前面提到过,通过一系列手段我们可以最大程度消除依赖注入。但是总有那些edge case,比如我们要用$stateParams或者服务来自路由配置中注入的local service。我写了一个工具可以帮助我们更舒服的应对这类边缘案例 Link to Controller
对于需要监控属性变化的场景,之前我们都是用$scope.$watch,但是这又跟框架耦合了。民工叔的文章里提供了一个基于accessor的写法:
class Controller {
get fullName() {
return `${this.firstName} ${this.lastName}`;
}
}template
<input type="text" ng-model="$ctrl.firstName">
<input type="text" ng-model="$ctrl.lastName">
<span ng-bind="$ctrl.fullName"></span>这样当firstName/lastName发生变化时,fullName也会相应的改变。基于的原理是Object.defineProperty。但是民工叔也指出了一个由于某种不知名的原因导致绑定失效,不得不用$watch的场景。这个时候$onChanges就派上用场了。但是$onChanges回调有个限制就是,它的变更检测时基于reference的而不是值的内容的,也就是说绑定primitive没问题,但是绑定引用类型(Object/Array等)那么内容的变化并不会被捕获到,例如:
class Controller {
$onChanges(objs) {
this.userCount = objs.users.length;
}
}
const ddo = {
controller: Controller,
template: '<span ng-bind="$ctrl.listTitle"></span><span ng-bind="$ctrl.userCount"></span>'
bindings: {
title: '<',
users: '<'
}
};
angular.module('component', [])
.component('userList', ddo);template
<div ng-controller="ctrl as app">
<user-list title="app.title" users="app.users" ng-click="app.change()"></user-list>
</div>class Controller {
contructor() {
this.title = 'hhhh';
this.users = [];
}
change() {
this.users.push('s');
}
}
angular.module('app', [])
.controller('ctrl', Controller);点击user-list组件时,userCount值并不会变化,因为$onChanges并没有被触发。对于这种情况呢,你可能需要引入immutable方案了。。。怎么感觉事情越来越复杂了。。。
组件新增的四个生命周期对于我而言可以说是最重大的变化了。虽然之前我们也能通过一些手段来模拟生命周期:比如用compile模拟init,postLink模拟didMounted,$scope.$on('$destroy')模拟unmounted。
但是它们最大的问题就是身上携带了太多框架的气息,并不能服务文明剥离框架的初衷。具体做法不赘述了,看上面组件部分的介绍Link To Component.
以前我们在ng中使用事件模型有 $broadcast、$emit、$on这几个api用,现在没了它们我们要怎么玩?
我的建议是,我们只在必要的场景使用事件机制,因为事件滥用和不及时的卸载很容易造成事件爆炸的情况发生。必要的场景就是,当我们需要在兄弟节点、或依赖关系不大的组件间触发式通信时,我们可以使用自制的 事件总线/中介者 来帮我们完成(可以使用我的这个工具库angular-es-utils/EventBus)。在非必要的场景下,我们应该尽量使用inline-event的方式来达成通信目标:
const ddo = {
template: '<button type="button" ng-click="$ctrl.change('kuitos')">click me</button>',
controller: class {
click(userName) {
this.onClick({userName});
}
},
bindings: {
onClick: '&'
}
};
angular.module('app', [])
.component('user', ddp);useage
<user on-click="logUserName(userName)"></user>理想状态下,对于一个业务系统而言,会用到angular语法只有 angular.controller、angular.component angular.directive、angular.config这几种。其他地方我们都可以实现成框架无关的。
对于web app架构而言,angular/vue/react 等组件框架/库 提供的只是 模板语法&胶水语法(其中胶水语法指的是框架/库 定义组件/控制器 的语法),剥离这两个外壳,我们的业务模型及数据模型应该是可以脱离框架运作的。古者有云,衡量一个完美的MV*架构的标准就是,在V随意变化的情况下,你的M*是可以不改一行代码的情况下就完成迁移的。
在MV_架构中,V层是最薄且最易变的,但是M_理应是 稳定且纯净的。虽然要做到一行代码不改实现框架的迁移是不可能的(视图层&胶水语法的修改不可避免),但是我们可以尽量将最重的 M* 做成框架无关,这样做上层的迁移时剩下的就是一些语法替换的工作了,而且对V层的改变也是代价最小的。
事实上我认为一个真正可伸缩的系统架构都应该是这样一个思路:勿论是 MV* 还是 Flux/Redux or whatever,确保下层 业务模型/数据模型 的纯净都是有必要的,这样才能提供上层随意变化的可能,任何模式下的应用开发,都应该具备这样的一个能力。
本文是近期对一系列 前端工程化&架构 文章的观点的整理及总结,特此鸣谢:
2015前端组件化框架之路
张云龙系列blog
编程技术及生态发展的三个阶段
- 最初的时候人们忙着补全各种API,代表着他们拥有的东西还很匮乏,需要在语言跟基础设施上继续完善
- 然后就开始各种模式,标志他们做的东西逐渐变大变复杂,需要更好的组织了
- 然后就是各类分层MVC,MVP,MVVM之类,可视化开发,自动化测试,团队协同系统等等,说明重视生产效率了,也就是所谓工程化
软件工程是一门研究用工程化方法构建和维护有效的、实用的和高质量的软件的学科。
从本质上讲,所有Web应用都是一种运行在网页浏览器中的软件,这些软件的图形用户界面(Graphical User Interface,简称GUI)即为前端。
前端又不同于传统的客户端软件/后端,因为前端应用具备“免安装”、“增量安装”等特性。也“得益”于这些特性,前端应用会遭遇客户端应用不可能碰到的资源管理问题,这也是前端最容易引起工程问题的点。
1-3是技术业务相关的开发需求,4是技术沉淀及共享需求,5-8是工程优化需求
大部分时候我们谈的“工程化”其实只是“工具化”。
每一个单独的点或许都比较容易实现,但是把这8条串联起来则是一个很大的挑战,而且这8个点相互之间又互有联系
举三个案例:
构建工具 gulp
task-based的方式使得gulp无法(难以)处理资源嵌套的递归场景。如 a.js -> b.scss -> md5(d.img) -> md5(b.scss) -> md5(a.js)
基于 资源表+资源管理框架 策略的fis
其实已经能处理大部分场景了,但是侵入式代码实在是无法接受。因为它是一个框架。
静态分析工具 webpack
webpack依赖其可配置的loader使其拥有强大的打包能力,但是依然无法实现动态按需加载的需求。类似:
if(browser){
require('browser.js');
} else {
require('node.js');
}ES6 Module + ES6 Module Loader + HTTP/2.0 + Others
ES6 Module提供了一个原生的模块化语法,ES6 Module Loader则能提供一个原生的模块加载器。对于前端工程而言,资源管理是最核心的问题,而资源管理中加载又是重点更是难点。
可是ES6 Module Loader从ES6草案中移除了现在由WHATWG组织还在维护制定标准,pending状态。。
现在有一个基于这个草案实现的api polyfill Module Loader。可是你不是规范我这种教条主义者是不会用的😂
HTTP/2.0是HTTP/1.1的升级版(非革命版,前身是Google的SPDY协议),2015年5月以RFC 7540正式发表,新增了几个关键特性:
其中多路复用是对前端感知最明显的特性,基于此特性,HTTP/2.0时代需要淘汰的优化方式:
ps:目前的各种bundle方案(如browserify&webpack)可能会在http2.0时代被淘汰(替代),有测试表明在http2.0环境下多文件请求会比单请求大文件更快。移动终端的意义更大,你无法想象移动端创建一个连接开销有多大。。多路复用才是未来!
前端工程化相关问题是随之前端的发展越来越受到重视的问题,一套好的工程化解决方案能在提高开发效率(包括代码编写的舒适度及多人协作)的同时确保整个系统的伸缩性(各种不同的部署环境)及健壮性(安全),同时在性能上又能有一个很优异的表现(主要上各种缓存策略加载策略等),而且这套方案又应该是对工程师无感知(或感知很小)趋于自动化的一套方案。总知要达到这个目的前端工程化还有很长一段路要走。
mobx-vue 目前已进入 mobxjs 官方组织,欢迎试用求 star!
几周前我写了一篇文章描述了 mobx 与 angularjs 结合使用的方式及目的 (老树发新芽—使用 mobx 加速你的 AngularJS 应用),这次介绍一下如何将 MobX 跟 Vue 结合起来。
npm i mobx-vue -Smobx-vue 的使用非常简单,只需要使用 connect 将你用 mobx 定义的 store 跟 vue component 连接起来即可:
<template>
<section>
<p v-text="amount"></p>
<p v-for="user in users" :key="user.name">{{user.name}}</p>
</section>
</template>
<script lang="ts">
import { Connect } from "mobx-vue";
import Vue from "vue";
import Component from "vue-class-component";
class ViewModel {
@observable users = [];
@computed get amount() { return this.users.length }
@action fetchUsers() {}
}
@Connect(new ViewModel())
@Component()
export default class App extends Vue {
mounted() {
this.fetchUsers();
}
}
</script>我们知道,mobx 跟 vue 都是基于 数据劫持&依赖收集 的方式来实现响应式机制的。mobx 官方也多次提到 inspired by vue,那么我们为什么还要将两个几乎一样的东西结合起来呢?
Yes, it's weird.
2016年我在构建公司级组件库的时候开始思考一个问题,我们如何在代码库基于某一框架的情况下,能以尽可能小的代价在未来将组件库迁移到其他 框架/库 下?总不能基于新的技术全部重写一遍吧,这也太浪费生命了。且不说对于基础控件而言,交互/行为 逻辑基本上是可确定的,最多也就是 UI 上的一些调整,而且单纯为了尝试新技术耗费公司人力物力将基础库推导重写也是非常不职业的做法。那么我们只能接受被框架绑架而只能深陷某一技术栈从此泥潭深陷吗?对于前端这种框架半衰期尤其短的领域而言显然是不可接受的,结果无非就是要么自己跑路坑后来人,要么招不到人来一起填坑... 简单来说我们无法享受新技术带来的种种红利。
在 MVVM 架构视角下,越是重型的应用其复杂度越是集中在 M(Model) 跟 VM(ViewModel) 这两层,尤其是 Model 层,理论上应该是能脱离上层视图独立运行独立发布独立测试的存在。而相应的不同视图框架只是使用了不同绑定语法的动态模板引擎而已,这个观点我在前面的几篇文章里都讲述过。所以只要我们将视图层做的很薄,我们迁移的成本自然会降到一个可接受的范畴,甚至有可能通过工具在编译期自动生成不同框架的视图层代码。
要做到 Model 甚至 ViewModel 独立可复用,我们需要的是一种可以帮助我们描述各数据模型间依赖关系图且框架中立的通用状态管理方案。这期间我尝试过 ES6 accessor、redux、rxjs 等方案,但都不尽如人意。accessor 过于底层且异步不友好、redux 开发体验太差(参考Redux数据流管理架构有什么致命缺陷,未来会如何改进?)、rxjs 过重等等。直到后来看到 MobX:MobX 语法足够简单、弱主张(unopinioned)、oop 向、框架中立等特性正好符合我的需求。
在过去的一年多里,我分别在 react、angularjs、angular 上尝试过基于 MobX 构建 VM/M 层,其中有两个上线项目,一个个人项目,实践效果基本上也达到了我的预期。在架构上,我们只需要使用对应的 connector,就能基于同一数据层,在不同框架下自如的切换。这样看来,这套思路现在就剩 Vue 没有被验证了。
在 mobx-vue 之前,社区已经有一些优秀的 connector 实现,如 movue vue-modex 等,但基本都是基于 vue 的插件机制且 inspired by vue-rx,除了使用起来相对繁琐的问题外,最大的问题是其实现基本都是借助 Vue.util.defineReactive 来做的,也就是说还是基于 Vue 自有的响应式机制,这在一定程度不仅浪费了 MobX 的reactive 能力,而且会为迁移到其他视图框架下埋下了不确定的种子(毕竟你无法确保是 Vue 还是 MobX 在响应状态变化)。
参考:why mobx-vue
理想状态下应该是由 mobx 管理数据的依赖关系,vue 针对 mobx 的响应做出 re render 动作即可,vue 只是一个单纯的动态模板渲染引擎,就像 react 一样。
在这样的一个背景下,mobx-vue 诞生了。
既然我们的目的是将 vue 变成一个单纯的模板渲染引擎(vdom),并且使用 mobx 响应式机制取代 vue 的响应式,那么只要我们劫持到 Vue 的组件装载及更新方法,然后在组件装载的时候收集依赖,在依赖发生变更时更新组件即可。
以下内容与其叫做 mobx-vue 是如何运作的,不如叫 Vue 源码解析😂:
我们知道 Vue 通常是这样初始化的:
new Vue({ el: '#app', render: h => h(App)});那么找到 Vue 的构造函数,
function Vue (options) {
......
this._init(options)
}跟进到_init方法,除了一系列组件初始化行为外,最关键是最后一部分的 $mount 逻辑:
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}跟进 $mount 方法,以 web runtime 为例:
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
updateComponent = () => {
...
}
} else {
updateComponent = () => {
vm._update(vm._render(), hydrating)
}
}
vm._watcher = new Watcher(vm, updateComponent, noop)从这里可以看到,updateComponent 方法将是组件更新的关键入口,跟进 Watcher 构造函数,看 Vue 怎么调用到这个方法的:
constructor (
vm: Component,
expOrFn: string | Function,
cb: Function,
options?: Object
) {
...
this.expression = process.env.NODE_ENV !== 'production'
? expOrFn.toString()
: ''
// parse expression for getter
if (typeof expOrFn === 'function') {
this.getter = expOrFn
} else {
this.getter = parsePath(expOrFn)
...
}
this.value = this.lazy
? undefined
: this.get()get () {
...
try {
value = this.getter.call(vm, vm)
} catch (e) {
...
}看到这里,我们能发现,组件 装载/更新 的发起者是: value = this.getter.call(vm, vm) ,而我们只要通过 vm._watcher.getter 的方式就能获取相应的方法引用, 即 updateComponent := vm._watcher.getter。所以我们只要在 $mount 前将 MobX 管理下的数据植入组件上下文供组件直接使用,在$mount 时让 MobX 收集相应的依赖,在 MobX 检测到依赖更新时调用 updateComponent 即可。这样的话既能让 MobX 的响应式机制通过一种简单的方式 hack 进 Vue 体系,同时也能保证组件的原生行为不受到影响(生命周期钩子等)。
中心**就是用 MobX 的响应式机制接管 Vue 的 Watcher,将 Vue 降级成一个纯粹的装载 vdom 的组件渲染引擎。
核心实现很简单:
const { $mount } = Component.prototype;
Component.prototype.$mount = function (this: any, ...args: any[]) {
let mounted = false;
const reactiveRender = () => {
reaction.track(() => {
if (!mounted) {
$mount.apply(this, args);
mounted = true;
} else {
this._watcher.getter.call(this, this);
}
});
return this;
};
const reaction = new Reaction(`${name}.render()`, reactiveRender);
dispose = reaction.getDisposer();
return reactiveRender();
};完整代码在这里:https://github.com/mobxjs/mobx-vue/blob/master/src/connect.ts
尤大大之前说过:mobx + react 是更繁琐的 Vue,本质上来看确实是这样的,mobx + react 组合提供的能力恰好是 Vue 与生俱来的。而 mobx-vue 做的事情则刚好相反:将 Vue 降级成 react 然后再配合 MobX 升级成 Vue 😂。这确实很怪异。但我想说的是,我们的初衷并不是说 Vue 的响应式机制实现的不好从而要用 MobX 替换掉,而是希望借助 MobX 这个相对中立的状态管理平台,面向不同视图层技术提供一种相对通用的数据层编程范式,从而尽量抹平不同框架间的语法及技术栈差异,以便为开发者提供更多的视图技术的决策权及可能性,而不至于被某一框架绑架裹挟。
PS: 这篇是系列文章的第一篇,后面将有更多关于 如何基于 MobX 构建视图框架无关的数据层 的架构范式及实践的内容,敬请期待!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.