

HomePage | Docs | Datasets | Conference Paper | Full Paper | Paper List | Experiment Tool | EA&B Track Paper | 中文版
LibCity is a unified, comprehensive, and extensible library, which provides researchers with a credible experimental tool and a convenient development framework in the traffic prediction field. Our library is implemented based on PyTorch and includes all the necessary steps or components related to traffic prediction into a systematic pipeline, allowing researchers to conduct comprehensive experiments. Our library will contribute to the standardization and reproducibility in the field of traffic prediction.
LibCity currently supports the following tasks:
- Traffic State Prediction
- Traffic Flow Prediction
- Traffic Speed Prediction
- On-Demand Service Prediction
- Origin-destination Matrix Prediction
- Traffic Accidents Prediction
- Trajectory Next-Location Prediction
- Estimated Time of Arrival
- Map Matching
- Road Network Representation Learning
-
Unified: LibCity builds a systematic pipeline to implement, use and evaluate traffic prediction models in a unified platform. We design basic spatial-temporal data storage, unified model instantiation interfaces, and standardized evaluation procedure.
-
Comprehensive: 74 models covering 9 traffic prediction tasks have been reproduced to form a comprehensive model warehouse. Meanwhile, LibCity collects 52 commonly used datasets of different sources and implements a series of commonly used evaluation metrics and strategies for performance evaluation.
-
Extensible: LibCity enables a modular design of different components, allowing users to flexibly insert customized components into the library. Therefore, new researchers can easily develop new models with the support of LibCity.
 04/12/2024: We release M-LibCity v0.1, the MindSpore version of LibCity. This initial version supports nine traffic prediction tasks, including traffic state forecasting, trajectory next-hop prediction, and estimated time of arrival. Furthermore, M-LibCity also supports multi-cards parallel acceleration on various backends including GPU and NPU. For more detailed information and additional resources, please visit this link.
04/12/2024: We release M-LibCity v0.1, the MindSpore version of LibCity. This initial version supports nine traffic prediction tasks, including traffic state forecasting, trajectory next-hop prediction, and estimated time of arrival. Furthermore, M-LibCity also supports multi-cards parallel acceleration on various backends including GPU and NPU. For more detailed information and additional resources, please visit this link.
11/04/2023: Our creative design ZongHeng based on LibCity won the first prize in the 9th China Graduate Contest on Smart-city Technology and Creative Design! Weixin
08/24/2023: We published a paper titled Unified Data Management and Comprehensive Performance Evaluation for Urban Spatial-Temporal Prediction [Experiment, Analysis & Benchmark], including (1) a Unified Storage Format for urban spatial-temporal data, (2) a Technical Development Roadmap for urban spatial-temporal prediction models, (3) Extensive Experiments and Performance Evaluation using 18 models and 20 datasets. [Paper].
06/20/2023: We released the Beijing trajectory dataset collected in November 2015, including 1018312 trajectories. We obtained the corresponding road network data from OpenStreetMap and preprocessed the trajectory data to get the Beijing trajectory dataset matched to the road network, and we believed that this dataset could promote the development of urban trajectory mining tasks. Please refer to this link to obtain it and ensure that this data is used for research purposes only.
06/04/2023: LibCity won the second prize in the 3rd China Science Open Source Software Creativity Competition! Weixin
04/27/2023: We published a full paper titled LibCity: A Unified Library Towards Efficient and Comprehensive Urban Spatial-Temporal Prediction, which provides more details of LibCity. [Paper].
11/19/2022: Our self-attention-based traffic flow prediction model PDFormer developed on LibCity was accepted by AAAI2023, please check this link for more details.
08/05/2022: We develop an experiment management tool for the LibCity, which allows users to complete the experiments in a visual interface. The link to the code repository is here. Some introduction (in Chinese): Weixin, Zhihu
04/27/2022: We release the first version of LibCity v0.3, the latest version, supporting 9 types of spatio-temporal prediction tasks, covering more than 60 prediction models and nearly 40 urban spatio-temporal datasets.
11/24/2021: We provide some introductory tutorials (in Chinese) on Zhihu, link1, link2, link3, link4, link5, link6....
11/10/2021: We provide a document that describes in detail the format of the atomic files defined by LibCity. You can download English Version and Chinese Version here for details.
11/07/2021: We have a presentation on ACM SIGSPATIAL 2021 Local Track to introduce LibCity. You can download LibCity Presentation Slide(Chinese) and LibCity Chinese Tutorial here.
11/07/2021: We have a presentation on ACM SIGSPATIAL 2021 Main Track to introduce LibCity. Here are the Presentation Video(English) and the Presentation Slide(English).
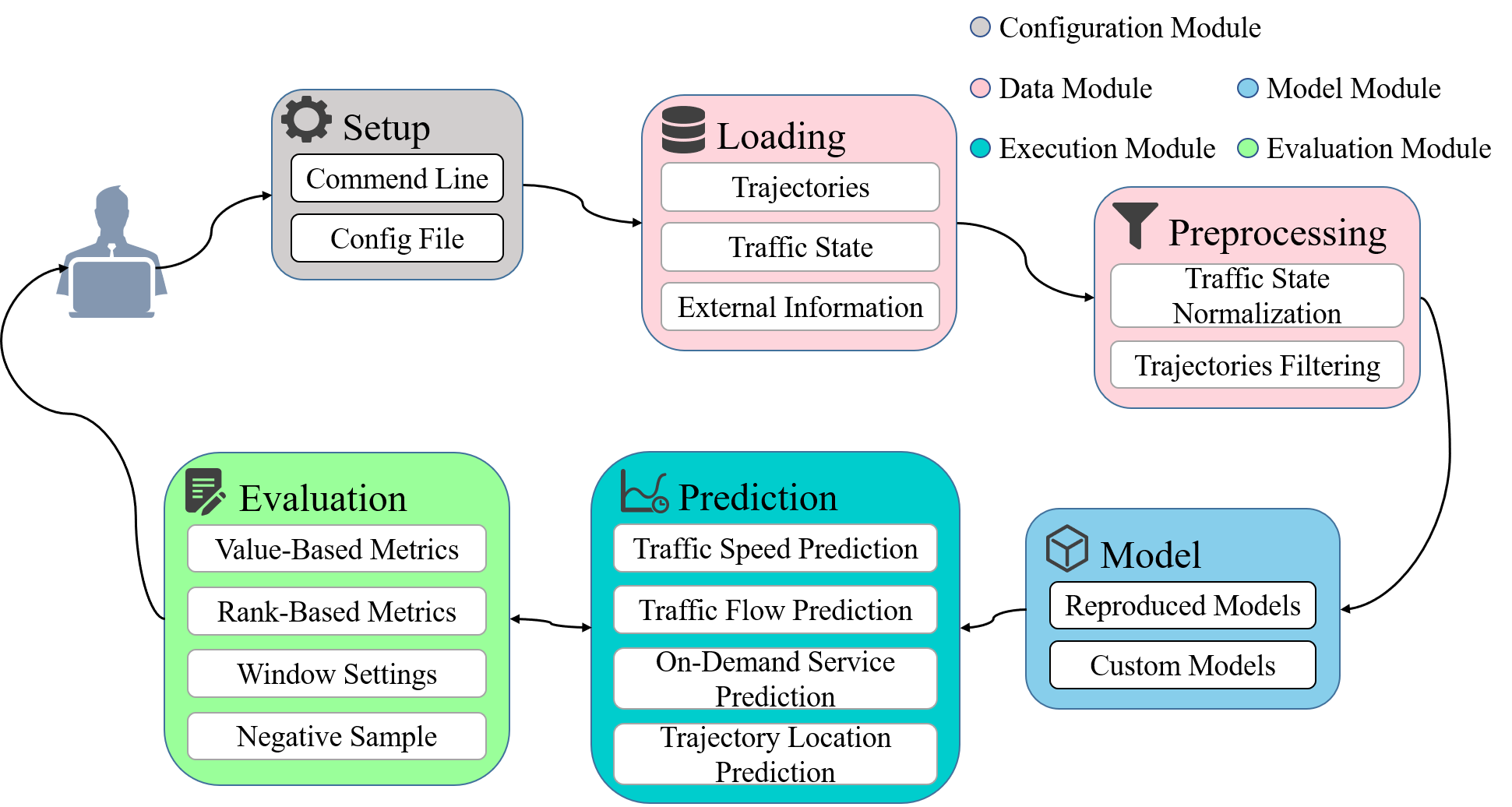
- Configuration Module: Responsible for managing all the parameters involved in the framework.
- Data Module: Responsible for loading datasets and data preprocessing operations.
- Model Module: Responsible for initializing the reproduced baseline model or custom model.
- Evaluation Module: Responsible for evaluating model prediction results through multiple indicators.
- Execution Module: Responsible for model training and prediction.
LibCity can only be installed from source code.
Please execute the following command to get the source code.
git clone https://github.com/LibCity/Bigscity-LibCity
cd Bigscity-LibCityMore details about environment configuration is represented in Docs.
Before run models in LibCity, please make sure you download at least one dataset and put it in directory ./raw_data/. The dataset link is BaiduDisk with code 1231 or Google Drive. All dataset used in LibCity needs to be processed into the atomic files format.
The script run_model.py is used for training and evaluating a single model in LibCity. When run the run_model.py, you must specify the following three parameters, namely task, dataset and model.
For example:
python run_model.py --task traffic_state_pred --model GRU --dataset METR_LAThis script will run the GRU model on the METR_LA dataset for traffic state prediction task under the default configuration. We have released the correspondence between datasets, models, and tasks at here. More details is represented in Docs.
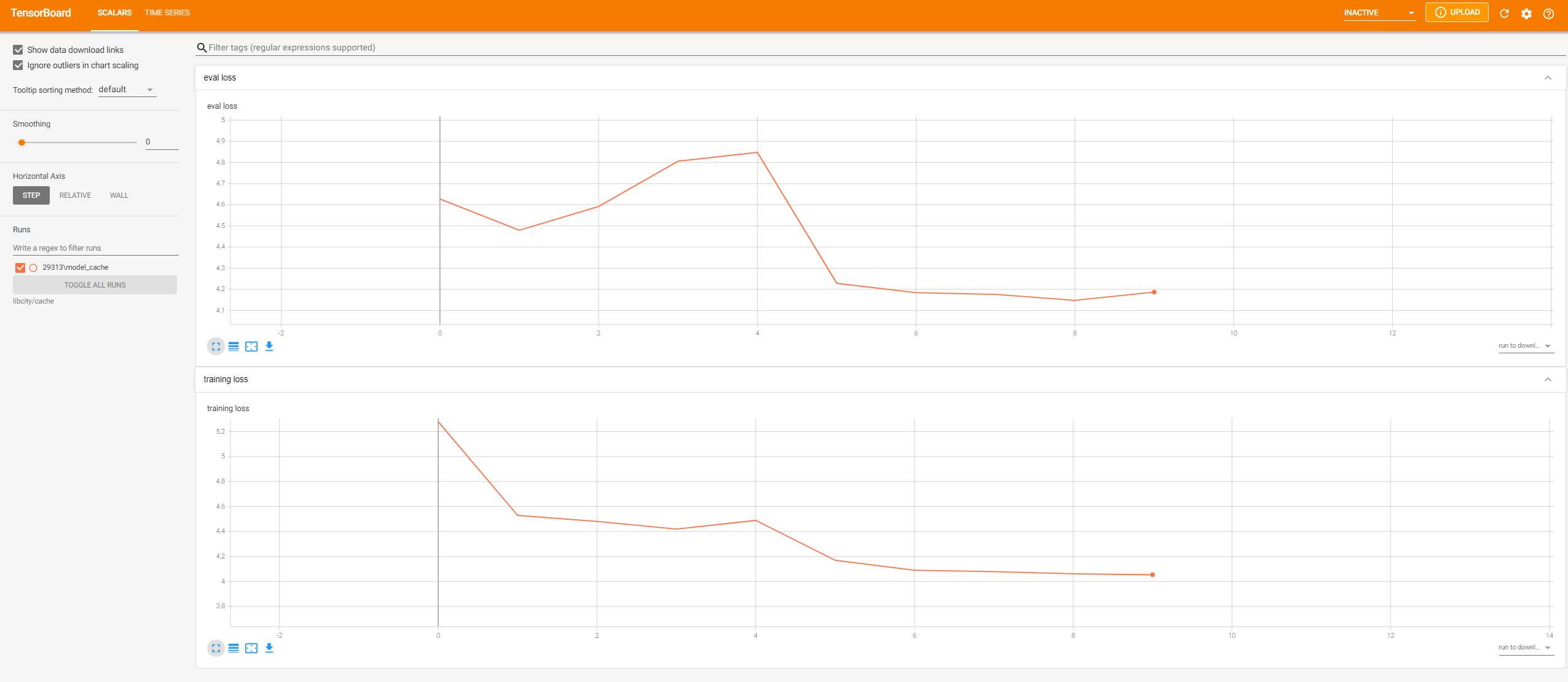
During the model training process, LibCity will record the loss of each epoch, and support tensorboard visualization.
After running the model once, you can use the following command to visualize:
tensorboard --logdir 'libcity/cache'TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.4.1 at http://localhost:6006/ (Press CTRL+C to quit)
Visit this address(http://localhost:6006/) in the browser to see the visualized result.
For a list of all models reproduced in LibCity, see Docs, where you can see the abbreviation of the model and the corresponding papers and citations.
In order to facilitate users to use LibCity, we provide users with some tutorials:
- We gave lectures on both ACM SIGSPATIAL 2021 Main Track and Local Track. For related lecture videos and Slides, please see our HomePage (in Chinese and English).
- We provide entry-level tutorials (in Chinese and English) in the documentation.
- In order to facilitate the use of domestic users in China, we provide an introductory tutorial (in Chinese) on Zhihu.
The LibCity is mainly developed and maintained by Beihang Interest Group on SmartCity (BIGSCITY). The core developers of this library are @aptx1231 and @WenMellors.
Several co-developers have also participated in the reproduction of the model, the list of contributions of which is presented in the reproduction contribution list.
If you encounter a bug or have any suggestion, please contact us by raising an issue. You can also contact us by sending an email to [email protected].
Our paper is accepted by ACM SIGSPATIAL 2021. If you find LibCity useful for your research or development, please cite our paper.
@inproceedings{libcity,
author = {Wang, Jingyuan and Jiang, Jiawei and Jiang, Wenjun and Li, Chao and Zhao, Wayne Xin},
title = {LibCity: An Open Library for Traffic Prediction},
year = {2021},
isbn = {9781450386647},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3474717.3483923},
doi = {10.1145/3474717.3483923},
booktitle = {Proceedings of the 29th International Conference on Advances in Geographic Information Systems},
pages = {145–148},
numpages = {4},
keywords = {Spatial-temporal System, Reproducibility, Traffic Prediction},
location = {Beijing, China},
series = {SIGSPATIAL '21}
}
For the long paper, please cite it as follows:
@article{libcitylong,
title={LibCity: A Unified Library Towards Efficient and Comprehensive Urban Spatial-Temporal Prediction},
author={Jiang, Jiawei and Han, Chengkai and Jiang, Wenjun and Zhao, Wayne Xin and Wang, Jingyuan},
journal={arXiv preprint arXiv:2304.14343},
year={2023}
}
LibCity uses Apache License 2.0.



































































































































