
Projects we've done with DepthAI. These can be anything from "here's some code and it works most of the time" to "this is almost a tutorial".
The following list isn't exhaustive (as we randomly add experiments and we may forget to update this list):
Gaze Estimation (here)
[
Age and Gender Recognition (here)

Automated Face-Blurring (here)

Spatial Calculation - On Host to Show/Explain Math That Happens in OAK-D for the Spatial Location Calculator (here)

Multi-camera spatial-detection-fusion (here)

Stereo Depth from Camera and From Host (here)

Automatic JPEG Encoding and Saving Based on AI Results (here)

-
overlay_framerepresents a path to RGB frame with detection overlays (bounding box and label)
-
cropped_framerepresents a path to cropped RGB frame containing only ROI of the detected object
An example entries in dataset.csv are shown below
timestamp,label,left,top,right,bottom,raw_frame,overlay_frame,cropped_frame
16125187249289,bottle,0,126,79,300,data/raw/16125187249289.jpg,data/bottle/16125187249289_overlay.jpg,data/bottle/16125187249289_cropped.jpg
16125187249289,person,71,37,300,297,data/raw/16125187249289.jpg,data/person/16125187249289_overlay.jpg,data/person/16125187249289_cropped.jpg
16125187249653,bottle,0,126,79,300,data/raw/16125187249653.jpg,data/bottle/16125187249653_overlay.jpg,data/bottle/16125187249653_cropped.jpg
16125187249653,person,71,36,300,297,data/raw/16125187249653.jpg,data/person/16125187249653_overlay.jpg,data/person/16125187249653_cropped.jpg
16125187249992,bottle,0,126,80,300,data/raw/16125187249992.jpg,data/bottle/16125187249992_overlay.jpg,data/bottle/16125187249992_cropped.jpg
16125187249992,person,71,37,300,297,data/raw/16125187249992.jpg,data/person/16125187249992_overlay.jpg,data/person/16125187249992_cropped.jpg
16125187250374,person,37,38,300,299,data/raw/16125187250374.jpg,data/person/16125187250374_overlay.jpg,data/person/16125187250374_cropped.jpg
16125187250769,bottle,0,126,79,300,data/raw/16125187250769.jpg,data/bottle/16125187250769_overlay.jpg,data/bottle/16125187250769_cropped.jpg
16125187250769,person,71,36,299,297,data/raw/16125187250769.jpg,data/person/16125187250769_overlay.jpg,data/person/16125187250769_cropped.jpg
16125187251120,bottle,0,126,80,300,data/raw/16125187251120.jpg,data/bottle/16125187251120_overlay.jpg,data/bottle/16125187251120_cropped.jpg
16125187251120,person,77,37,300,298,data/raw/16125187251120.jpg,data/person/16125187251120_overlay.jpg,data/person/16125187251120_cropped.jpg
16125187251492,bottle,0,126,79,300,data/raw/16125187251492.jpg,data/bottle/16125187251492_overlay.jpg,data/bottle/16125187251492_cropped.jpg
16125187251492,person,74,38,300,297,data/raw/16125187251492.jpg,data/person/16125187251492_overlay.jpg,data/person/16125187251492_cropped.jpg
Face Mask Detection (here)

Crowd Counting (here)

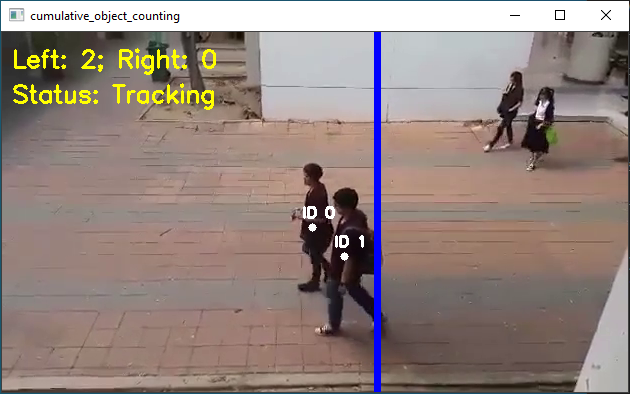
Cumulative Object Counting (here)
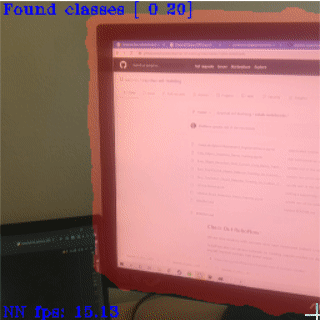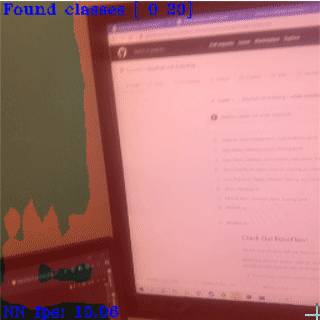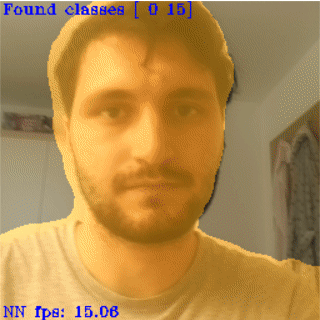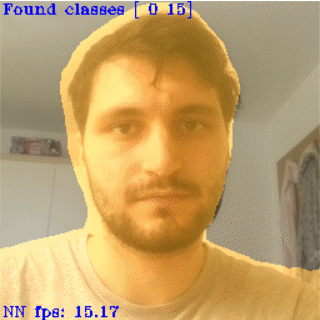
How to Run Customer CV Models On-Device (here)
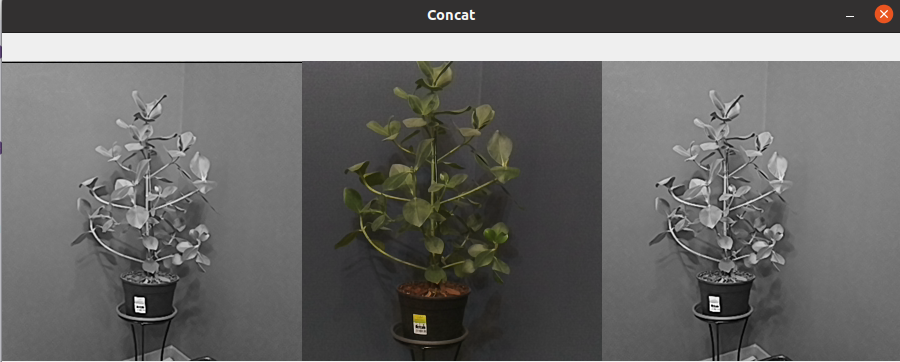
Concatenate frames
Blur frames

Corner detection

Semantic Segmentation of Depth (here)

Multi-Class Semantic Segmentation (here)
Depth-Driven Focus (here)

Monocular Depth Estimation - Neural Network Based (here)

Tutorial on How To Display High-Res Object Detections (here)
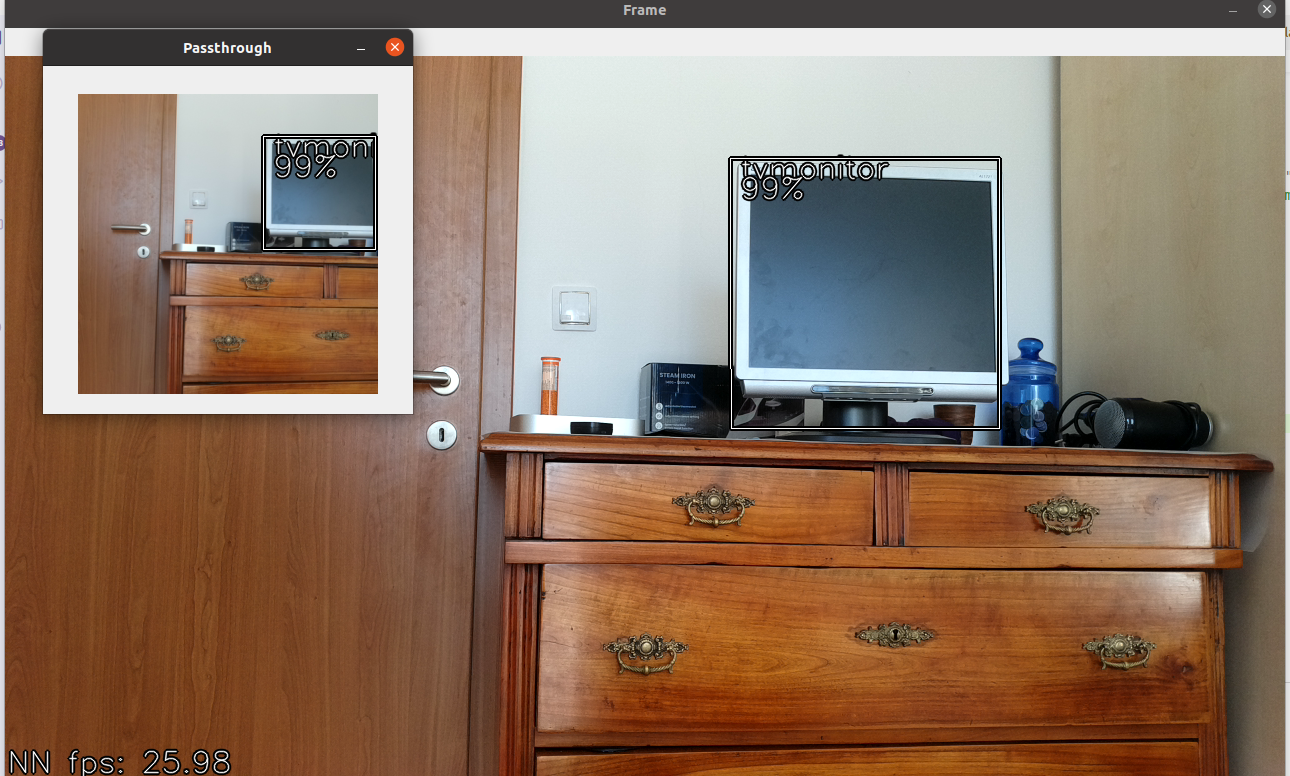
Running EfficientDet Object Detector On-Camera (here)


Facial Expression (Emotion) Recognition On-Camera (here)

Face Detection On-Camera (libfacedetection) (here)

Face Recognition On-Camera (here)

Facial Landmarks On-Camera (here)

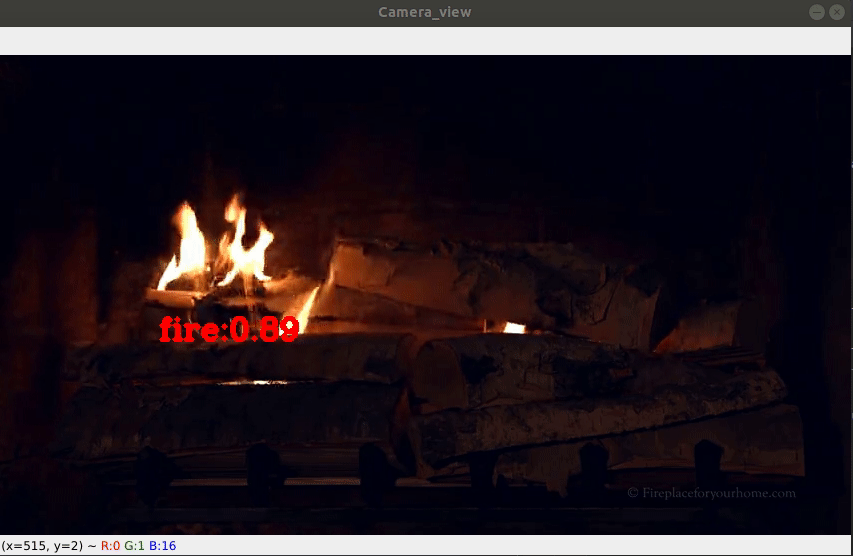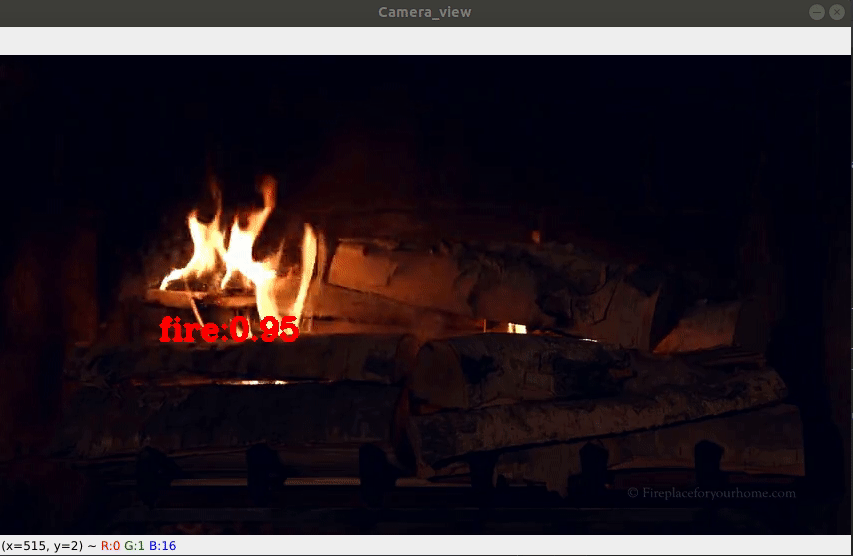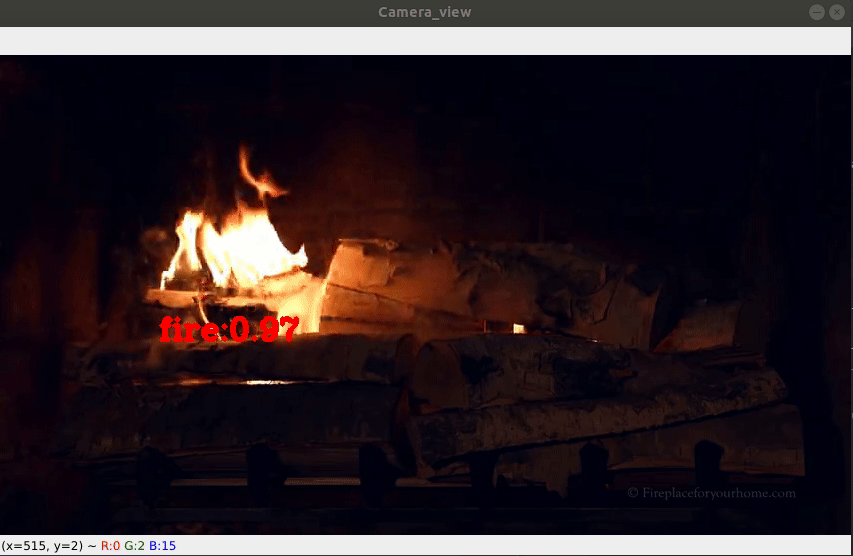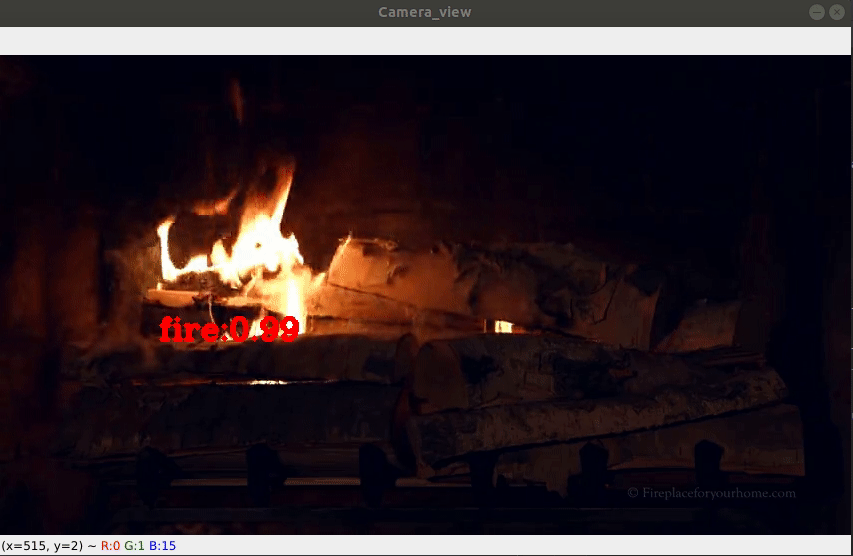
Fire Detection On-Camera (here)
Head Posture Detection On-Camera (here)

Human-Machine Safety Example On-Camera (here)

Human Skeletal Pose Estimation (here)

LaneNet Lane Segmentation On-Camera (here)

License Plate Recognition On-Camera (here)

Lossless Zooming (4K to 1080p Zoom/Crop) On-Camera (here)

Running Mask-RCNN On-Camera (here)

MegaDepth Neural Depth Running On-Camera (here)
MJPEG Streaming From On-Camera (here)

Class Agnostic Object Detector Running On-Camera (here)

How to Use Multiple Cameras Simultaneously (here)

How to Sync NN Data with Image Data for Custom Neural Networks (here)

Optical Character Recognition in the Wild On-Camera (here)

Palm Detection On-Camera (here)

Pedestrian Re-Identification (here)

People Counting On-Camera (here)

People Direction-Tracker and Counter (here)

Playing an On-Camera Encoded Stream on the Host (here)

Recording and Playing Back Depth in RealSense -Compatible Format (here)

Road Segmentation On-Camera (here)

Roboflow Integration (here)
oak_roboflow_demo_short.mp4
Social Distancing Example (here)

Text Blurring On-Device (here)

Image Classification On-Device (here)

Facial Key-point Triangulation On-Camera (here)
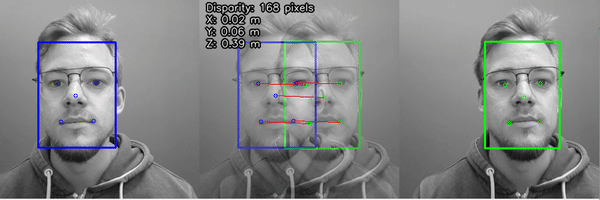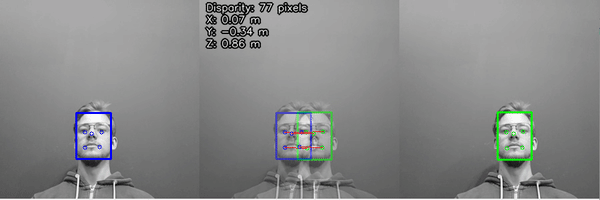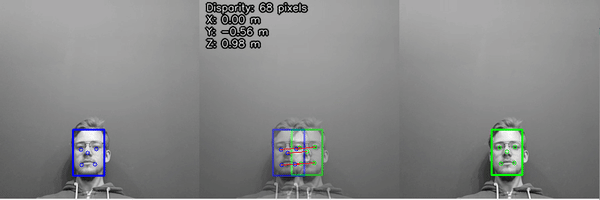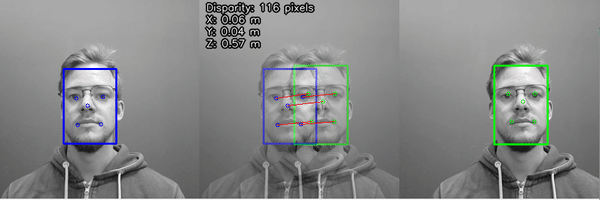
WebRTC Streaming Example (here)

YOLO V3 V4 V5 X and P On-Camera (here)




![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

























































































































































































{kind=link}