Tutorial in Chinese can be found in mofanpy.com.
This repo includes many simple implementations of models in Neural Language Processing (NLP).
All code implementations in this tutorial are organized as following:
- Search Engine
- Understand Word (W2V)
- Understand Sentence (Seq2Seq)
- All about Attention
- Pretrained Models
Thanks for the contribution made by @W1Fl with a simplified keras codes in simple_realize. And the a pytorch version of this NLP tutorial made by @ruifanxu.
$ git clone https://github.com/MorvanZhou/NLP-Tutorials
$ cd NLP-Tutorials/
$ sudo pip3 install -r requirements.txtTF-IDF numpy code
TF-IDF short sklearn code
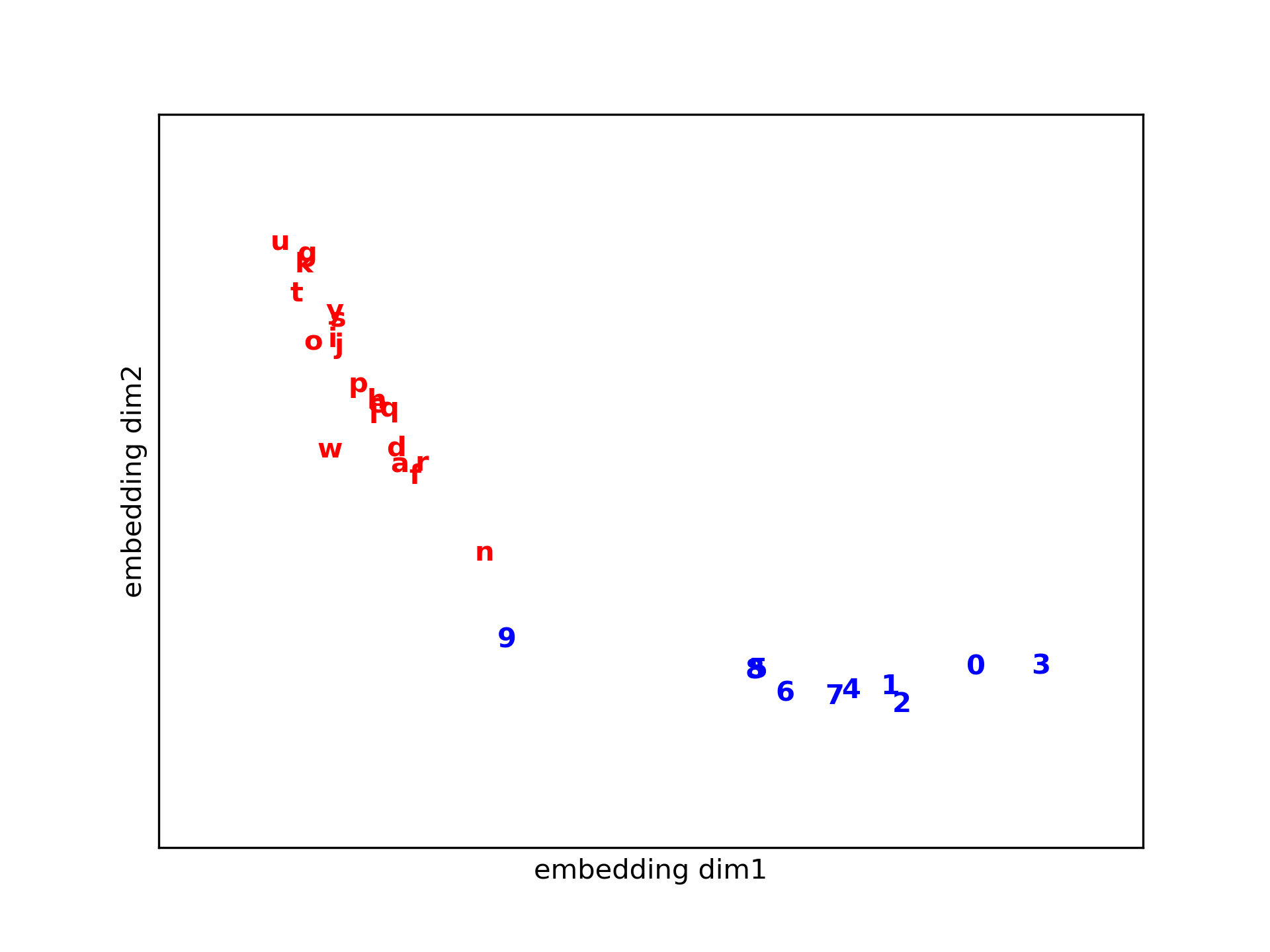
Efficient Estimation of Word Representations in Vector Space
Skip-Gram code
CBOW code
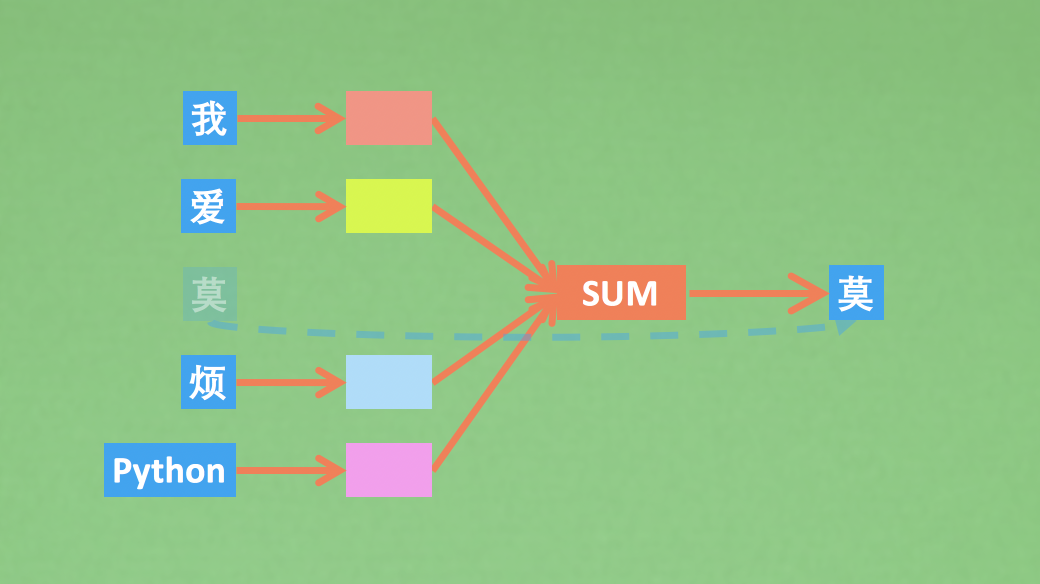
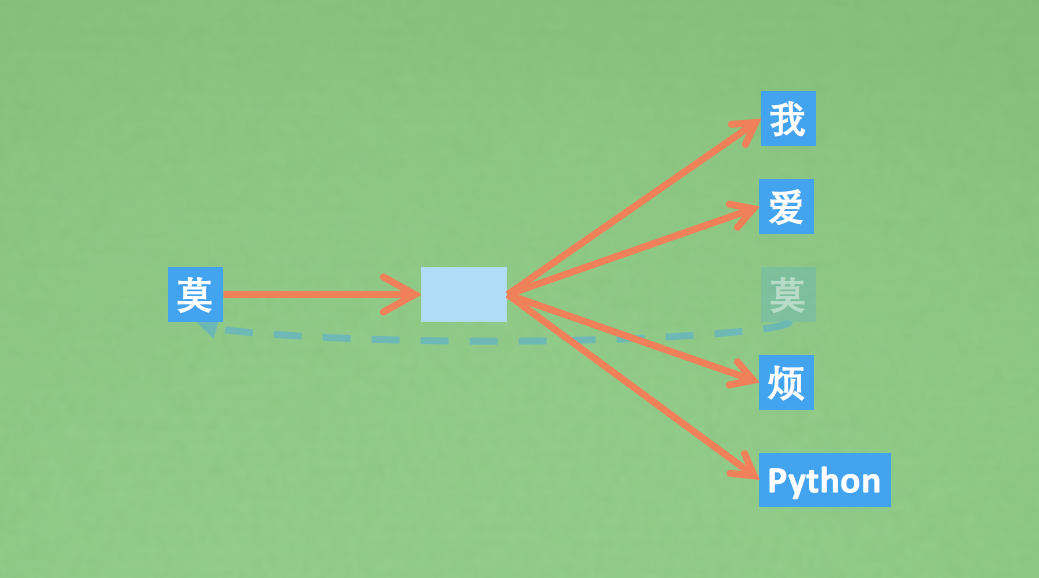
Sequence to Sequence Learning with Neural Networks
Seq2Seq code
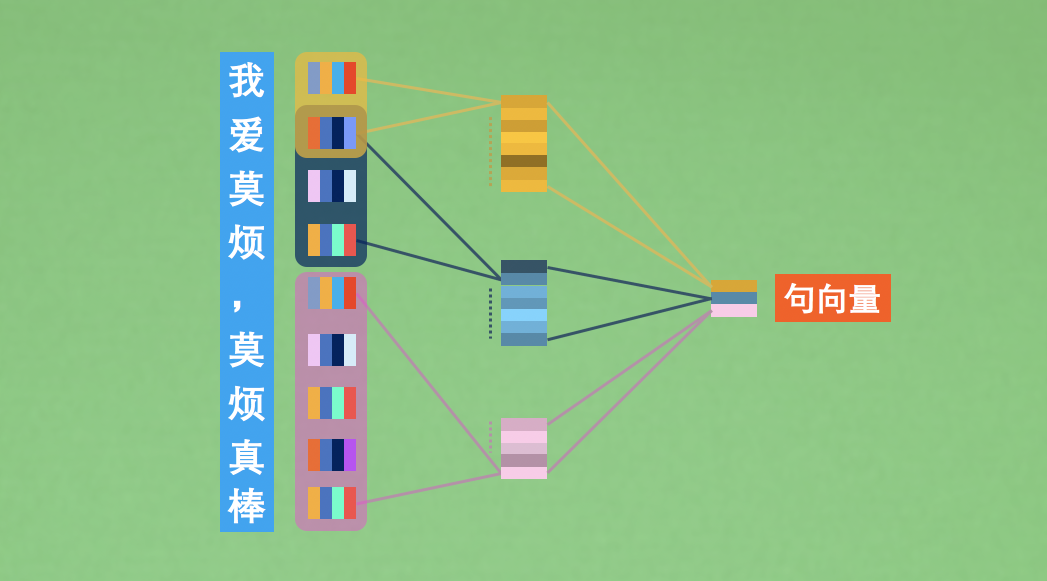
Convolutional Neural Networks for Sentence Classification
CNN language model code
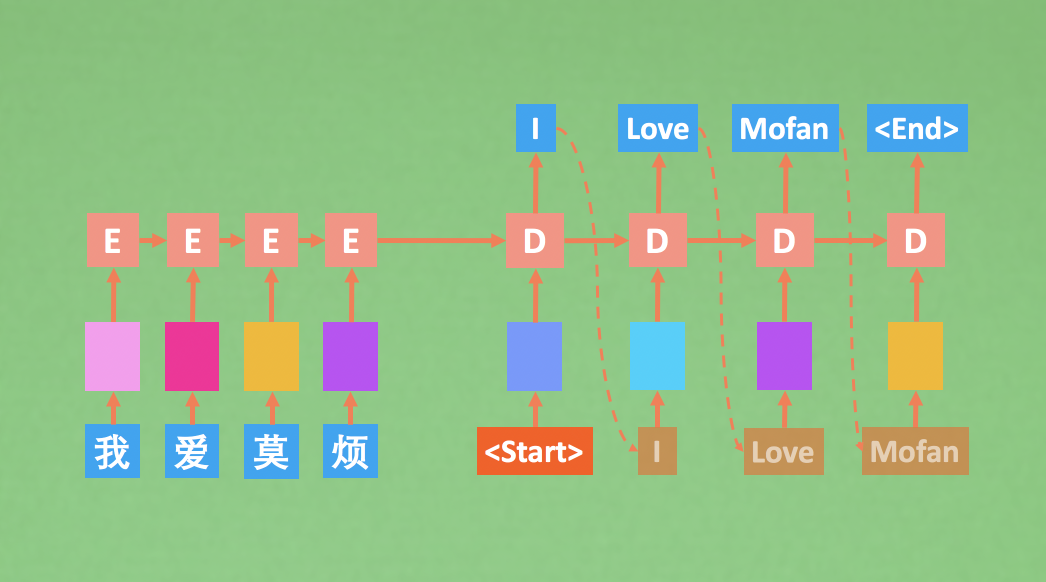
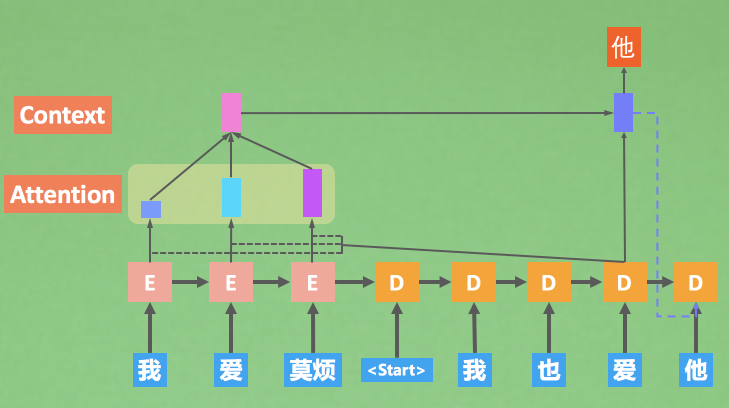
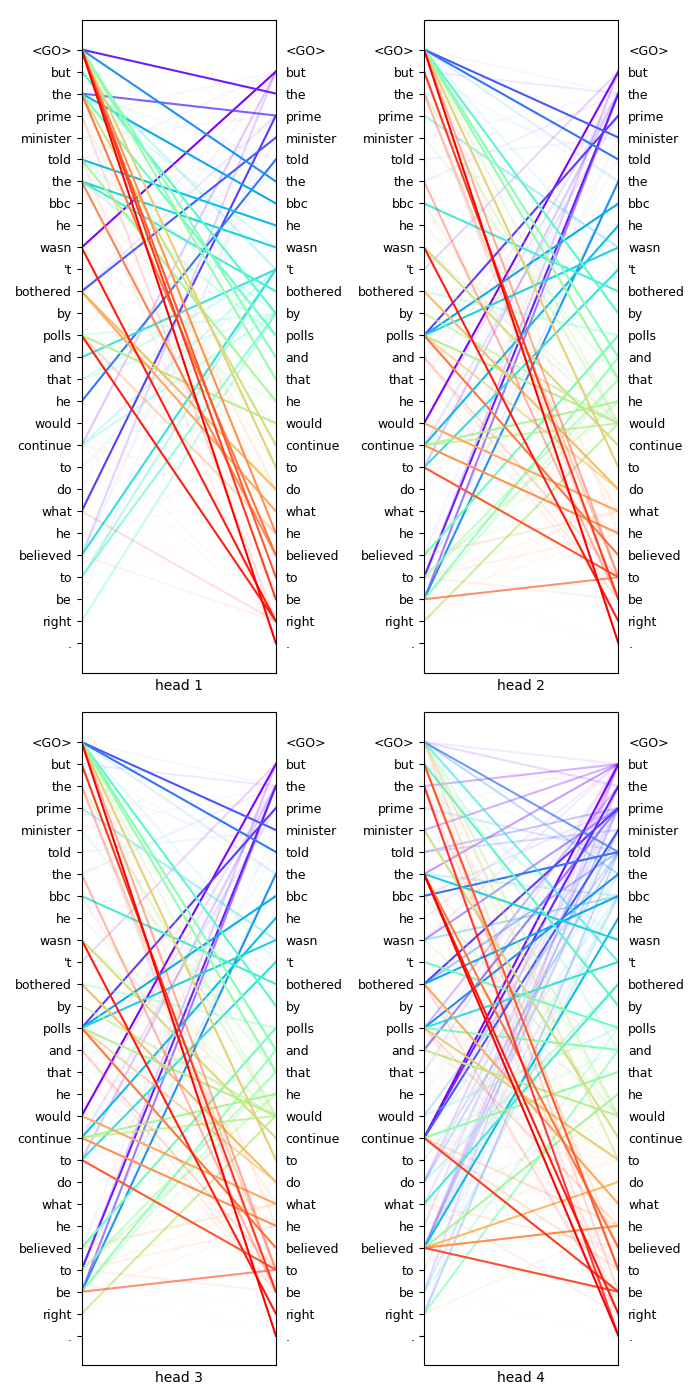
Effective Approaches to Attention-based Neural Machine Translation
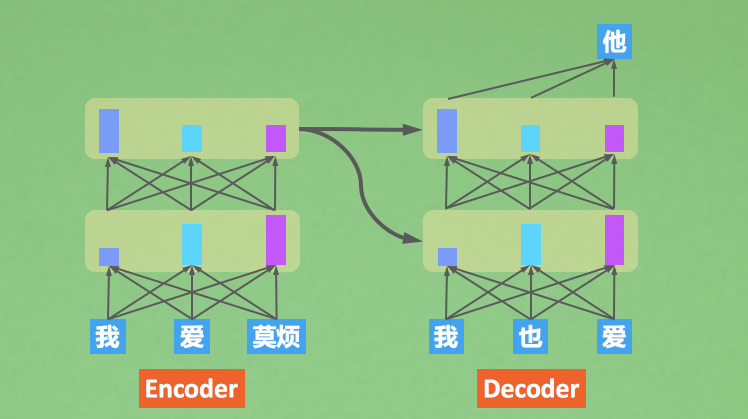
Seq2Seq Attention code
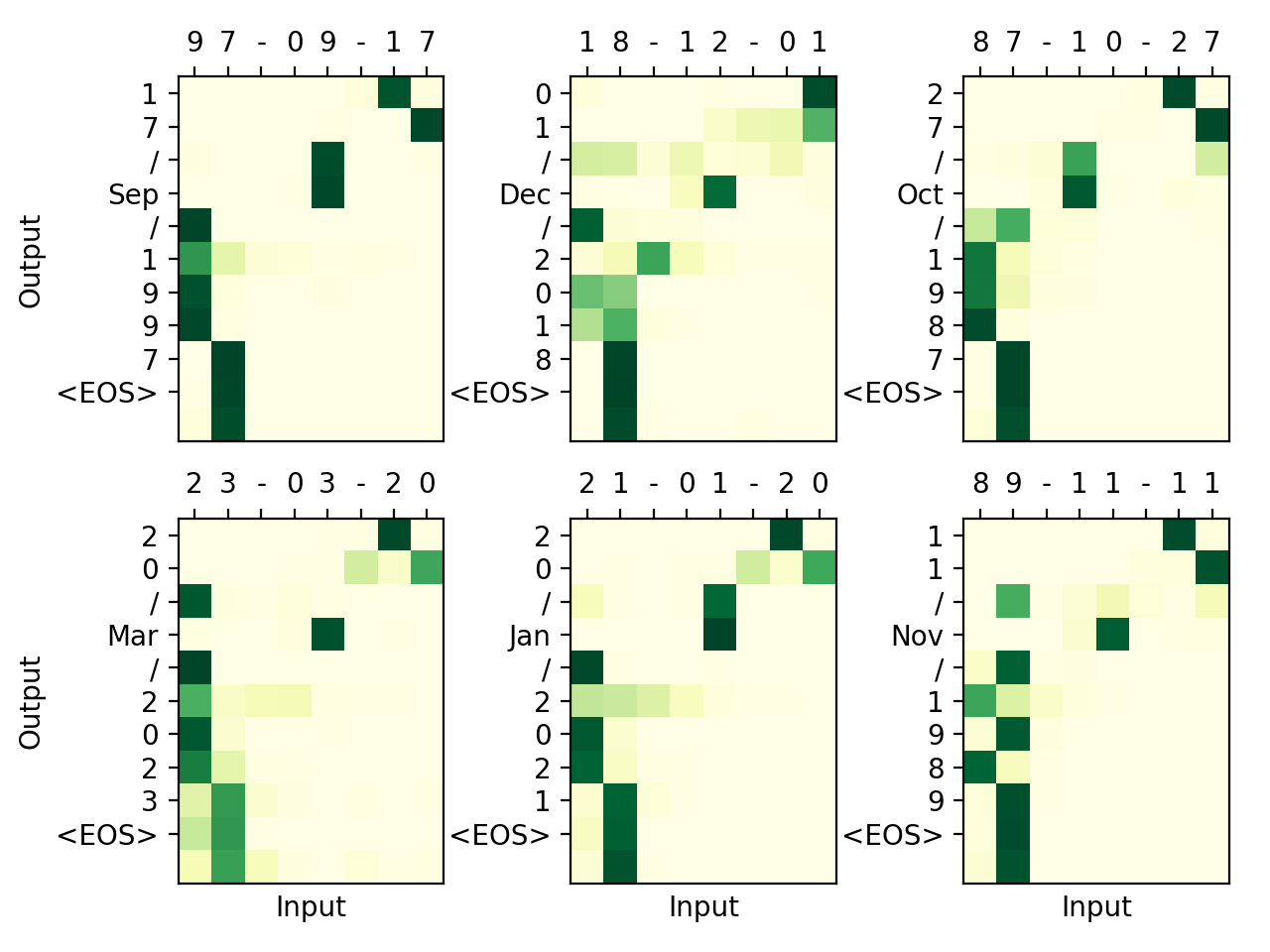
Transformer code

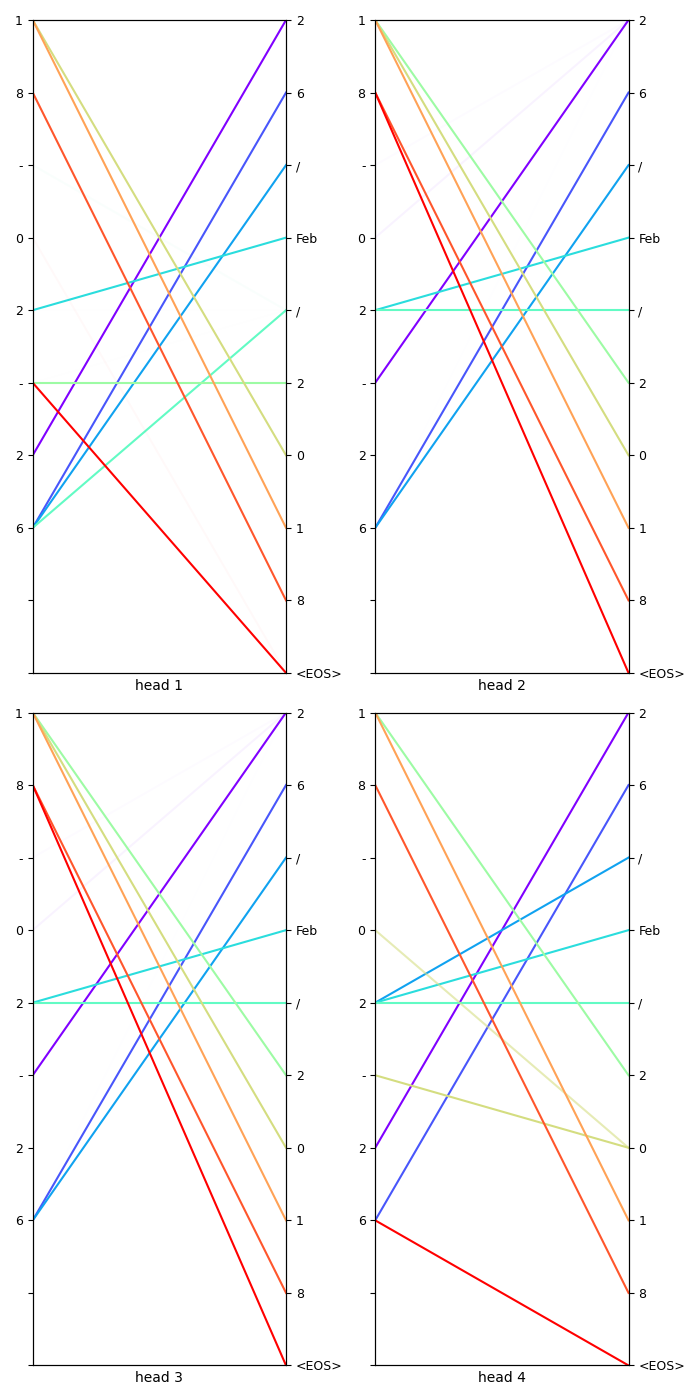
Deep contextualized word representations
ELMO code

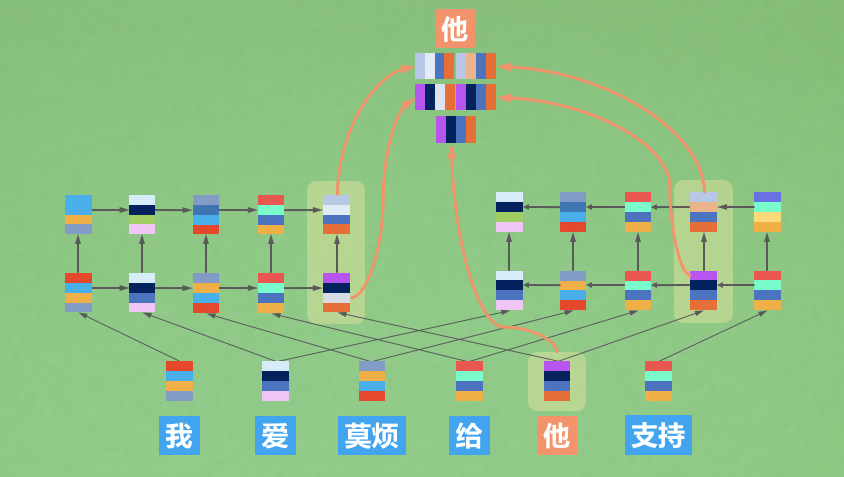
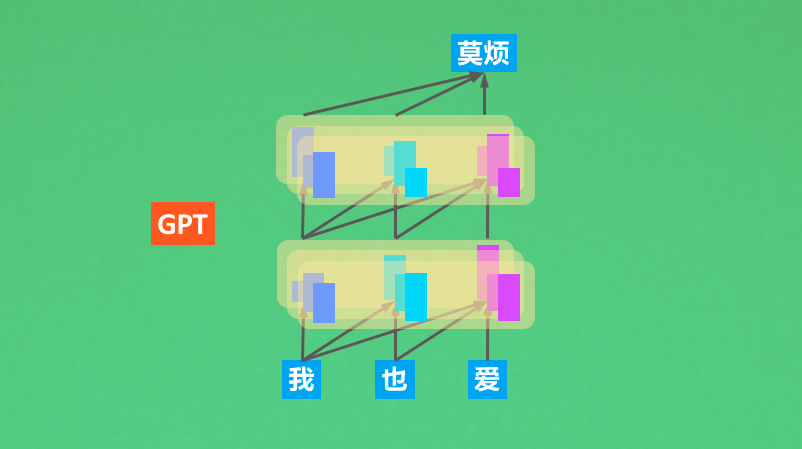
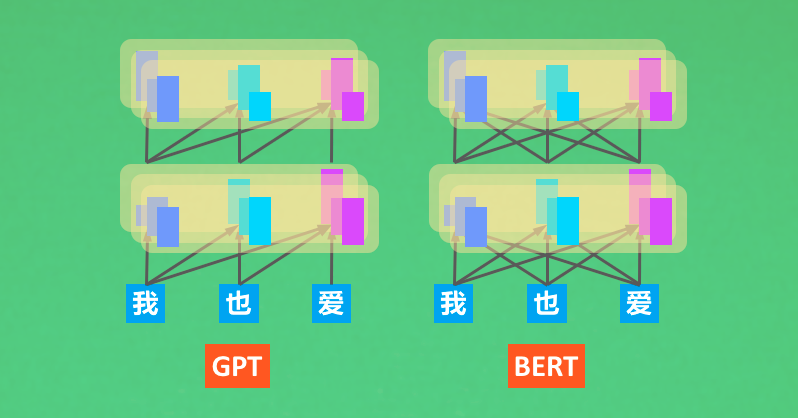
Improving Language Understanding by Generative Pre-Training
GPT code
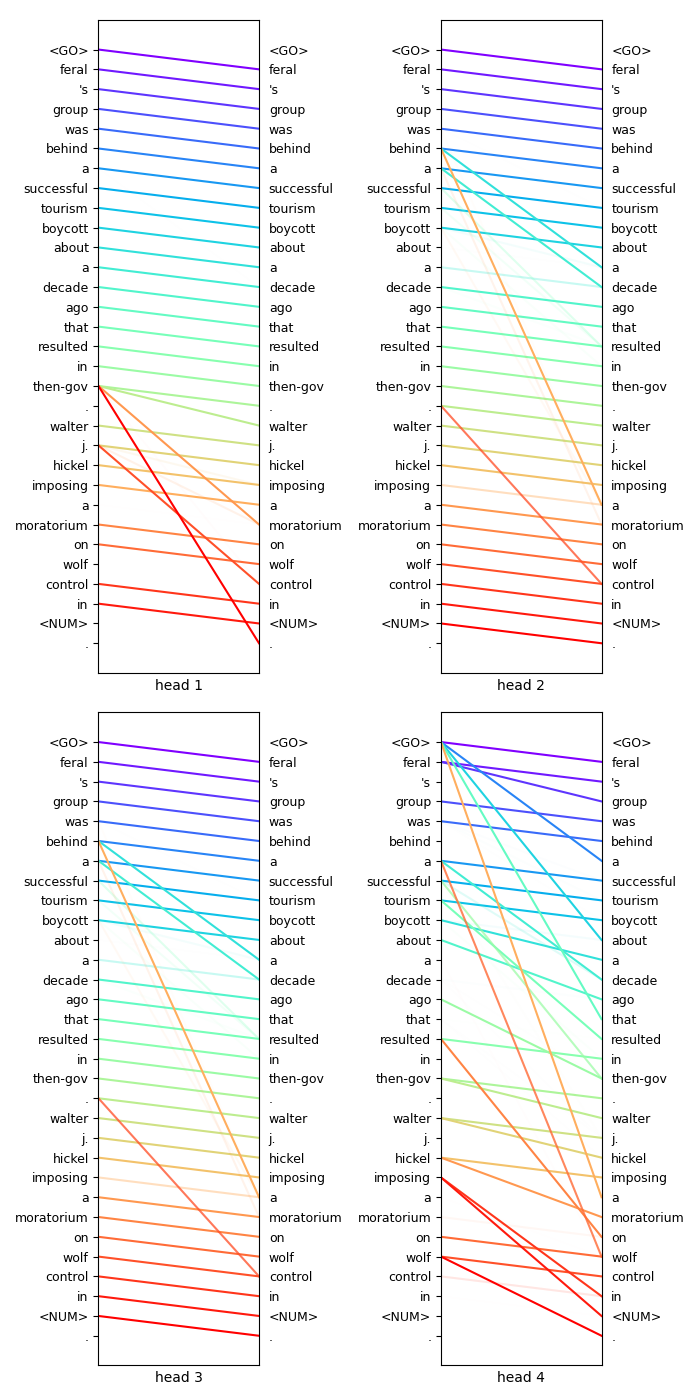
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT code
My new attempt Bert with window mask
![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
























































































































