reng99 / blogs Goto Github PK
View Code? Open in Web Editor NEWblogs :see_no_evil:
Home Page: https://reng99.github.io/blogs/
License: MIT License
blogs :see_no_evil:
Home Page: https://reng99.github.io/blogs/
License: MIT License
基于2018年Stack Overflow Developer的调研,TypeScript作为编程语言比JavaScript更受“喜爱”。TypeScript在js开发者中这么受喜爱的原因是:在你运行代码前,添加到javascript中的类型有助你发现错误(代码)。TypeScript编译器提供的错误可以很好的引导你如何修复代码错误。往javascript中添加类型同时有助代码编辑器提供一些高级的功能,例如代码完成,项目范围的重构和自动模块的导入。
如果你认为TypeScript是一门全新的编程语言,那么学习它可能令人生畏。然而,TypeScript只是JavaScript的一个附加层(超集),在使用TypeScript前,你无需了解它的每个语法。TypeScript允许你通过更改文件的后缀名.js为.ts来轻松的转换javascript文件,并且所有的代码将作为TypeScript来正确编译。如果你想在TypeScript文件中强制执行更广的类型覆盖百分比,你可以将TypeScript配置得更具局限性,一旦你熟悉该语言了,你就可以完成此操作。
本文旨在带你快速了解一个标准的TypeScript项目中会遇到的95%的场景。剩余的5%,嗯,你可以google,还有,我会在本文底部放些有用的TypeScript资源链接。
当然,要开始编写能正确编译的TypeScript(文件),正确配置开发环境是必要的。
1、安装TypeScript编译器
首先,为了能够将TypeScript文件转换成JavaScript文件,我们需要安装TypeScript编译器。安装TypeScript可全局安装(文件系统中安装,可以在任何位置使用)或者本地安装(仅在项目级别可使用)。【个人偏向后者】
# NPM Installation Method
npm install --global typescript # Global installation
npm install --save-dev typescript # Local installation
# Yarn Installation Method
yarn global add typescript # Global installation
yarn add --dev typescript # Local installation2、确保你的编辑器设置为支持TypeScript
你需要确保正确配置了你的编辑器以使用TypeScript。比如,为了在编辑器中能更好得使用TypeScript,你需要安装一个插件(如果你使用atom,你可以安装 atom-typescript)。如果你使用的是VS Code编辑器,那么你不需要安装额外的插件了,因为它内置了TypeScript的支持。😎
3、新建tsconfig.json文件
tsconfig.json文件是用来配置TypeScript项目设置。它应该放在项目的根目录中。该文件允许你使用不同的选项配置TypeScript编译器。
如果你仅仅是想TypeScript生效的话,你只需要tsconfig.json文件中包含一个空JSON对象,但是,如果你需要TypeScript编译器的有不同的行为(比如在特定的输出目录中输出编译后的JavaScript文件),你可以阅读更多有关可以配置哪些设置的(内容)。
备注:你也可以通过运行
tsc --init去生成一个tsconfig.json文件,其中为你设置了些默认选项,还有一些被注释掉的其他选项。
4、将TypeScript转化为JavaScript
为了将你的TypeScript代码转化成JavaScript代码,需要在控制台上跑tsc命令。运行tsc命令将告诉TypeScript编译器去搜索tsconfig.json文件,该文件将确定项目的根目录以及编译TypeScript并将.ts文件转换为.js文件时用的选项。
为了快速验证设置生效,你可以创建一个测试的TypeScript文件,然后在命令行中运行tsc,之后查看下TypeScript文件旁边是否生成了JavaScript文件。
举个例子,TypeScript文件如下...
const greeting = (person: string) => {
console.log('Good day ' + person);
};
greeting('Daniel');应该被转换为下面这个JavaScript文件了...
var greeting = function(person) {
console.log('Good day ' + person);
};
greeting('Daniel');如果你想TypeScript编译器(动态)监视TypeScript文件内容的变更,并自动将.ts文件转换成.js文件,你可以在你项目的仓库(命令行)中运行tsc -p。
在VS Code(编辑器)中,你可以使用⌘⇧B调出一个菜单,该菜单(包含)可以在正常模式和监视模式下运行转换程序(分别对应tsc:build和tsc:watch)。
JavaScript附带7种动态类型:
上面的类型被称为动态类型,因为它们在运行时使用。
TypeScript为JavaScript语言带来了静态类型,并且这些类型在编译时(无需运行代码)被确定。静态类型可以预测动态类型的值,这可以帮助在无需运行代码的情况下警告你可能出现的错误。
好吧,我们来深入研究下TypeScript的语法。以下是TypeScript中最常见的类型。
备注:我遗漏了never和object类型,因为根据我的经验,它们并不被经常使用。
boolean
你已经很了解true和false值了。
let isAwesome: boolean = true;string
文本数据用单引号('')或双引号("")或后标记(``)【也称模版字符】包围。
let name: string = 'Chris';
let breed: string = 'Border Collie';如果你使用后标志,该字符串被称为模版文字,可以在里面插入表达式。
let punchline: string = 'Because it was free-range.';
let joke: string = `
Q: Why did the chicken cross the road?
A: ${punchline}
`;number
任何浮点数都给定为数字类型。作为TypeScript的一部分,支持的四种类型的数字文字是二进制,十进制,八进制和十六进制。
let decimalNumber: number = 42;
let binaryNumber: number = 0b101010; // => 42
let octalNumber: number = 0o52; // => 42
let hexadecimalNumber: number = 0x2a; // => 42备注:并不是只有你一个人对二进制,八进制和十六进制数字感到困惑。
array
TypeScript中有两种书写数组类型的方式。第一种是[]后缀在需要查找的数组元素类型。
let myPetFamily: string[] = ['rocket', 'fluffly', 'harry'];另一种可替代的方式是,Array后跟要查找的数组元素类型的Array类型(使用尖括号包含)。
let myPetFamily: Array<string> = ['rocket', 'fluffly', 'harry'];tuple
元组是一个包含固定数量的元素和相关类型的数组。
let myFavoriteTuple: [string, number, boolean];
myFavoriteTuple = ['chair', 20, true]; // ✅
myFavoriteTuple = [5, 20, true]; // ❌ - The first element should be a string, not a numberenum
枚举将名称和常量值关联,可以是数字或者字符串。当你想一组具有关联性的描述名称的不同值,枚举就很有用处了。
默认,为枚举分配从0开始的值,接下来的值为(上一个枚举值)加1。
enum Sizes {
Small,
Medium,
Large,
}
Sizes.Small; // => 0
Sizes.Medium; // => 1
Sizes.Large; // => 2第一个值也可以设置为非0的值。
enum Sizes {
Small = 1,
Medium,
Large,
}
Sizes.Small; // => 1
Sizes.Medium; // => 2
Sizes.Large; // => 3枚举默认是被分配数字,然而,字符串也可以被分配到一个枚举中的。
enum ThemeColors {
Primary = 'primary',
Secondary = 'secondary',
Dark = 'dark',
DarkSecondary = 'darkSecondary',
}any
如果变量的类型未知,并且我们并不希望类型检查器在编译时抱怨,则可以使用any类型。
let whoKnows: any = 4; // assigned a number
whoKnows = 'a beautiful string'; // can be reassigned to a string
whoKnows = false; // can be reassigned to a boolean在开始使用TypeScript的时,可能会频繁使用any类型。然而,最好尝试减少any的使用,因为当编译器不知道与变量相关的类型时,TypeScript的有用性会降低。
void
当没有与事物相关类型的时候,void类型应该被使用。在指定不返回任何内容的函数返回值时,最常用它。
const darkestPlaceOnEarth = (): void => {
console.log('Marianas Trench');
};null和undefined
null和undefined都对应你在javascript中看到的null和undefined值的类型。这些类型在单独使用的时候不是很有用。
let anUndefinedVariable: undefined = undefined;
let aNullVariable: null = null;默认情况下,null和undefined类型是其他类型的子类型,这意味着可以为string类型的变量赋值为null或者undefined。这通常是不合理的行为,所以通常建议将tsconfig.json文件中的strictNullChecks编译器选项设置为true。将strictNullChecks设置为true,会使null和undefined需要显示设置为变量的类型。
幸运的是,你不需要在代码中全部位置指定类型,因为TypeScript具有类型推断。类型推断是TypeScript编译器用来自行决定类型的(内容)。
基本类型推断
TypeScript可以在变量初始化期间,设置默认参数以及确定函数返回值时推断类型。
// Variable initialization
let x = 10; // x is given the number type在上面的例子中,x被分配了数字,TypeScript会以number类型将x变量关联起来。
// Default function parameters
const tweetLength = (message = 'A default tweet') => {
return message.length;
};在上面的例子中,message参数被赋予了一个类型为string的默认值,因此TypeScript编译器会推断出message的类型是string,因此在访问length属性的时候并不会抛出编译错误。
function add(a: number, b: number) {
return a + b;
}
const result = add(2, 4);
result.toFixed(2); // ✅
result.length; // ❌ - length is not a property of number types在上面这个例子中,因为TypeScript告诉add函数,它的参数都是number类型,那么可以推断得出返回的类型也应该是number。
最佳通用类型推断
从多种可能的类型中推断类型时,TypeScript使用最佳通用类型算法来选择适用于所有其他候选类型的类型。
let list = [10, 22, 4, null, 5];
list.push(6); // ✅
list.push(null); // ✅
list.push('nope'); // ❌ - type 'string' is neither of type 'number' or 'null'在上面的例子中,数组(list)是由number或null类型组成的,因此TypeScript只希望number或null类型的值加入数组。
当类型推断系统不够用的时,你需要在变量和对象上声明类型。
基本类型
在(上面)基本静态类型章节的介绍中,所有的类型都使用:后跟类型名来声明。
let aBoolean: boolean = true;
let aNumber: number = 10;
let aString: string = 'woohoo';Arrays
在(上面)讲到的array类型的章节中,arrays可以通过两种方式的其中一种进行注释。
// First method is using the square bracket notation
let messageArray: string[] = ['hello', 'my name is fred', 'bye'];
// Second method uses the Array keyword notation
let messageArray: Array<string> = ['hello', 'my name is fred', 'bye'];接口
将多种类型的注释组合到一起的一种方法是使用接口。
interface Animal {
kind: string;
weight: number;
}
let dog: Animal;
dog = {
kind: 'mammal',
weight: 10,
}; // ✅
dog = {
kind: true,
weight: 10,
}; // ❌ - kind should be a string类型别名
TypeScript使用Type Alias指定多个类型注释,这事(让人)有些疑惑。【下面讲到】
type Animal = {
kind: string;
weight: number;
};
let dog: Animal;
dog = {
kind: 'mammal',
weight: 10,
}; // ✅
dog = {
kind: true,
weight: 10,
}; // ❌ - kind should be a string在使用接口或类型别名这方面,最佳的做法似乎是,在代码库保持一致情况下,通常选择接口类型或类型别名。但是,如果编写其他人可以使用的第三方的公共API,就要使用接口类型了。
如果你想了解更多关于type alias和interface的比较的话,我推荐你看Martin Hochel的这篇文章。
内联注释
相比创建一个可复用的接口,有时内联注释类型可能更合适。
let dog: {
kind: string;
weight: number;
};
dog = {
kind: 'mammal',
weight: 10,
}; // ✅
dog = {
kind: true,
weight: 10,
}; // ❌ - kind should be a string泛型
某些情况下,变量的特定类型无关紧要,但是应强制执行不同变量和类型之间的关系。针对这些情况,应该使用泛型类型。
const fillArray = <T>(len: number, elem: T) => {
return new Array<T>(len).fill(elem);
};
const newArray = fillArray<string>(3, 'hi'); // => ['hi', 'hi', 'hi']
newArray.push('bye'); // ✅
newArray.push(true); // ❌ - only strings can be added to the array上面的示例中有一个泛型类型T,它对应于传递给fillArray函数的第二个参数类型。传递给fillArray函数的第二个参数是一个字符串,因此创建的数组将其所有元素设置为具有字符串类型。
应该注意的是,按照惯例,单个(大写)字母用于泛型类型(比如:T或K)。可是,并不限制你使用更具有描述性的名称来表示你的泛型类型。下面示例就是为所提供的泛型类型使用了更具有描述性的名称:
const fillArray = <ArrayElementType>(len: number, elem: ArrayElementType) => {
return new Array<ArrayElementType>(len).fill(elem);
};
const newArray = fillArray<string>(3, 'hi'); // => ['hi', 'hi', 'hi']
newArray.push('bye'); // ✅
newArray.push(true); // ❌ - only strings can be added to the array联合类型
在类型可以是多种类型之一的情况下,使用|分隔符隔开不同类型的选项来使用联合类型。
// The `name` parameter can be either a string or null
const sayHappyBirthdayOnFacebook = (name: string | null) => {
if (name === null) {
console.log('Happy birthday!');
} else {
console.log(`Happy birthday ${name}!`);
}
};
sayHappyBirthdayOnFacebook(null); // => "Happy birthday!"
sayHappyBirthdayOnFacebook('Jeremy'); // => "Happy birthday Jeremy!"交集类型
交集类型使用&符号将多个类型组合在一起。这和(上面的)联合类型不同,因为联合类型是表示结果的类型是列出的类型之一,而交集类型则表示结果的类型是所有列出类型的集合。
type Student = {
id: string;
age: number;
};
type Employee = {
companyId: string;
};
let person: Student & Employee;
person.age = 21; // ✅
person.companyId = 'SP302334'; // ✅
person.id = '10033402'; // ✅
person.name = 'Henry'; // ❌ - name does not exist in Student & Employee元组类型
元组类型使用一个:符号,其后跟一个使用中括号包含且逗号分隔的类型列表表示。
let list: [string, string, number];
list = ['apple', 'banana', 8.75]; // ✅
list = ['apple', true, 8.75]; // ❌ - the second argument should be of type string
list = ['apple', 'banana', 10.33, 3]; // ❌ - the tuple specifies a length of 3, not 4可选类型
可能存在函数参数或者对象属性是可选的情况。在这些情况下,使用?来表示这些可选值。
// Optional function parameter
function callMom(message?: string) {
if (!message) {
console.log('Hi mom. Love you. Bye.');
} else {
console.log(message);
}
}
// Interface describing an object containing an optional property
interface Person {
name: string;
age: number;
favoriteColor?: string; // This property is optional
}本文中未涉及到的TypeScript内容,我推荐以下的资源。
TypeScript Handbook (Official TypeScript docs)
TypeScript Deep Dive (Online TypeScript Guide)
Understanding TypeScript's Type Annotation (Great introductory TypeScript article)
原文链接 https://www.robertcooper.me/get-started-with-typescript-in-2019
我们喜欢(使用)<div>标签。它们已经存在了几十年,这几十年来,当需要将一些内容包裹起来达到(添加)样式或者布局目的的时候,它们成为首选元素。查看线上站点时,看到像下面这些内容的情况依旧很常见:
<div class="container" id="header">
<div class="header header-main">Super duper best blog ever</div>
<div class="site-navigation">
<a href="/">Home</a>
<a href="/about">About</a>
<a href="/archive">Archive</a>
</div>
</div>
<div class="container" id="main">
<div class="article-header-level-1">
Why you should buy more cheeses than you currently do
</div>
<div class="article-content">
<div class="article-section">
<div class="article-header-level-2">
Part 1: Variety is spicy
</div>
<!-- cheesy content -->
</div>
<div class="article-section">
<div class="article-header-level-2">
Part 2: Cows are great
</div>
<!-- more cheesy content -->
</div>
</div>
</div>
<div class="container" id="footer">
Contact us!
<div class="contact-info">
<p class="email">
<a href="mailto:[email protected]">[email protected]</a>
</p>
<div class="street-address">
<p>123 Main St., Suite 404</p>
<p>Yourtown, AK, 12345</p>
<p>United States of America</p>
</div>
</div>
</div>Hoo,那有很多的div标签。但是,它有效。我的意思主要是,它具有你需要的结构。并且,我确定在你完成样式添加之后,它看起来会像你想要的那个样子。然而,它有些严重的问题:
可访问性 - 许多a11y tools非常智能,会尽力解析页面结构,以帮助用户按照页面制作者的意图来引导用户,并为用户提供简单的跳转链接来指引他们到自己关心的页面部分。然而,<div>标签并没有真正传递有关文档结构的任何有用信息。世界上最聪明的a11y tool仍然不是人类,不能指望其解析class和id属性,或能够识别全世界开发人员命名块元素的奇怪和狂野的方式。我可以识别到class="article-header-level-2"是一个副标题,但是机器不能。(如果可以的话,把它从我电脑中拿出来,可我也还没准备好进行AGI革命呢。)
可读性 - 要阅读此代码,你需要仔细扫描类名,从<div class="..."></div>样板之间挑选出来。一旦你(的代码)深入几个层次,跟踪哪个</div>结束标记与哪个<div ...>开始标记对应,那就变得很棘手了。你开始非常依赖IDE功能,例如着色不同的缩进级别或突出显示匹配的标记以跟踪您的位置,而在较长的文档中,它可能需要在这些功能之上进行大量的滚动。
一致性和标准 - 开始新的工作或转移到新项目,并且必须从头学习代码库中使用的让人抓狂的标记,那可能会令人很沮丧。如果每个人都有标准化的方法来标记web文档中常见结构,那么在不熟悉代码库的情况下,都可以很容易的浏览HTML文件并快速处理它应该展示的内容。如果只有一个这样的标准...
HTML5并不新奇。这是轻描淡写;最初的工作草稿于2008年1月(11年前)发布,以征求公众意见,并于4年半前,2014年10月份成为一个全面W3C的推荐。所以,就像它已经存在了一段时间。
HTML5的主要进步之一是引入了一组标准化的语义元素。术语“语义”指的是单词或事物的含义,因此”语义元素“是用于以更有意义的方式标记文档结构的元素,这种方式可以清楚地表明它们的用途和它们在文件中服务的目的是什么。而且重要的是,由于它们是标准化的,定义文档的这些元素可以被每个人使用并理解,包括机器人。
我认为HTML5规范本身在<div>元素定义下的一个注释中很好地总结了这个问题:
注释:
强烈建议作者将div元素视为最后采取的元素,在没有其它元素适合的(情况下)。使用更合适的元素而不是div元素可以使读者更容易访问,并且更容易为作者提供可维护性。-- https://www.w3.org/TR/html5/grouping-content.html#the-div-element
我将语义块元素分为两类:主要结构和内容指标。这些不是标准的条款或者其它条款;我在这篇文章中做了一些(区分)。但我认为这种区分足够有用。🤷♂️
有一个超级常见的模式,可在互联网上的网站,教程甚至CSS库中找到,并且有充分的理由。我们经常将最顶层的页面划分为三个区域:页眉、主页和页脚,然后根据需要将这些区域划分为多个区域。我在上面的例子中包含了这个来证明这点:
<div class="container" id="header">...</div>
<div class="container" id="main">
...
<div class="article-section">...</div>
...
</div>
<div class="container" id="footer">...</div>我已经看过(并且使用过)这种模式很久了,以这种方式构造文档非常有意义,既可以读取HTML,又可以更加简单地在CSS中设置页面样式。页眉和页脚元素页可以使用PHP或Rails/ERB等语言中的部分模版来更易于使用,因为你可以在整个站点中包含常见的页眉和页脚部分:
<?php include 'header.php'; ?>
<div id="main">...</div>
<?php include 'header.php'; ?>所以这就是事情:每个人都认为这是一个很好的模式。这包括WHATWG和W3C的人员,他们将模式标准化为HTML5中的四个新元素,名称非常清晰:<header>, <main>, <footer>和<section>。
<header> 和 <footer><header> 和 <footer>元素基本上是双胞胎:它们在规范中的定义非常相似,并遵循相同的规则,关于它们被允许使用的位置,唯一区别在于它们的语义目的:页眉在事物的前面,页脚在事物的末尾。对于事物,我的意思不仅仅是页面的: 这对元素的设计用于文档的任何部分,代表一大块内容,具有明确的开头和结尾。这可以包括表格,文章,文章部分,社交媒体网站上的帖子,卡片等。
页眉和页脚在语义上接近sectioning root或sectioning content元素。像<body>, <blockquote>, <section>, <td>,<aside>等许多其它元素;如果你想了解完整的列表,就点击上面的链接。辅助技术可以使用这些元素和其它元素生成文档大纲,这可以帮助用户更轻松的访问它。在每个sectioning root/content中,你不应该使用超过一个的<header>或<footer>。(一个就好,不能两个相同)
作为最后说明,<header>经常作为其上下文保存标题元素(<h1>-<h6>)。这不是必须的,但可以帮助将其它相关元素与标题分组,比如链接,图片或子标题,并且可以维持一直的结构,即使标题是<header>中的唯一元素。
<main>第三个主要区域元素--<main>很特别。规范中说明了关于<main>的两个非常重要的内容:
文档的主要内容区域包括文档的特定内容,且不包括在一组文档中重复的内容,例如站点导航链接,版本信息,站点的徽标,横幅和搜索表单(除非文档或应用的主功能是一种搜索形式)-- https://www.w3.org/TR/html5/grouping-content.html#elementdef-main
所以,<main>是你放置好东西的区域,是页面的重要部分,特别是用户访问此页面的原因(或说目的),而不是您的站点。换句话来说,主要内容。😯😲🤯
所有其它东西,徽标、搜索表单和导航栏等都可以在<body>中的<header>或<footer>中,但是在<main>之外。
文档中不能有多个可见的
main元素。如果文档中存在多个main元素,则必须使用隐藏属性隐藏所有其它(main)实例。 -- https://www.w3.org/TR/html5/grouping-content.html#elementdef-main
这很独特。和<header>和<footer>(以及其它块元素不同),<main>不能在任意切片内容的整个页面中使用;它应该只被使用一次。或者更确切地说,它可以在文档中多次被使用,但是一次只能看到一个<main>元素,所有其它的(
display:none。如果您思考下,(你会明白)这在应用程序中预加载视图是种很有用的模式:创建一个新的<mian hidden>,获取用户可能接下来查看的一些内容(例如:系列文中的下一篇,下一张幻灯图放映等),然后,当用户点击链接/按钮加载该视图时,通过在两者上切换隐藏属性,将当前的<main>切换到预加载的(那个)。
在继续之前,我们暂停下并查看上面的示例。如果我们使用<header>,<main>和<footer>作为文章的主要结构,它的外观如下:
<header>
<h1>Super duper best blog ever</h1>
...
</header>
<main>
<h2>Why you should buy more cheeses than you currently do</h2>
...
</main>
<footer>
Contact us!
<div class="contact-info">[email protected]</div>
</footer>那真的很棒!但是,还有很多工作要做。
<section>因此,我们为页面提供了一个基本大纲:页眉,页脚和主要内容区域。现在是时候添加些美妙的内容了。
通常,你会希望将你的内容分解为多个部分,尤其是对像本文这样的大量文本内容,因为没人喜欢阅读这些难以理解的文本墙。
<section>派上用场了。这是在系列规则中最简单的一个:从结构上讲,它基本上只是一个具有特殊含义的<div>。一个<section>开始一个新的"sectioning content"区域,因此它可以有自己的<header>和<footer>。
那么,<section>和普通的旧<div>之间有什么区别,然后,你应该在什么时候使用它们呢?好吧,允许我再次引用规范:
笔记:
元素不是通用容器元素。当一个元素仅是用于样式目的或为脚本编写提供便利的时候,鼓励作者使用[div](https://www.w3.org/TR/html5/grouping-content.html#elementdef-div)元素。一般规则是 元素仅在元素内容在文本[大纲](https://www.w3.org/TR/html5/sections.html#outline)中明确列出时候才适用。-- [https://www.w3.org/TR/html5/sections.html#the-section-element](https://www.w3.org/TR/html5/sections.html#the-section-element)
你知道,概述来说,HTML5规范实际上是可读的。它是那个比较可读的规范之一。每当我浏览它以获取快速答复时,我都不可避免地学到一些意想不到的和有用的东西,尤其是当我开始点击链接的时候。有时(你也)试试吧!
简而言之,如果要在目录中列出文档的一部分,请使用<section>。如果没有,请使用<div>或其它元素。
很好,我们已经得到了一个坚固的页面结构。我们已经明确标记了页面的主要内容区域,而不仅仅是单独调整<div>,我们已经调整出了页眉,页脚和章节。但是,肯定还有比我们的文档更多的语义。
让我们来谈谈HTML5中添加的一些元素,它们传达的内容语义而不是结构。
<article><article>元素用于表示完全独立的内容区域,这些内容可以从页面中提取出来并放入另一个内容中,并且仍然有意义。这可能是文字文章或博客,但也可用于社交媒体帖子,如推特或脸书的墙贴。
HTML5规范建议文章总有一个标题,标识它是什么,理想的情况下使用标题元素(<h1>-<h6>)。<article>也可以有<header>,<footer>和<section>元素,因此你可以使用它来嵌入一个完整的文档片段,其中包含其它页面中所需的所有结构。
从上面的方式返回到示例,我们使用<article>和我们讨论的其它一些元素来重写带class="article-*"的元素。
<article>
<header>
<h1>Why you should buy more cheeses than you currently do</h1>
</header>
<section>
<header>
<h2>Part 1: Variety is spicy</h2>
</header>
<!-- cheesy content -->
</section>
<section>
<header>
<h2>Part 2: Cows are great</h2>
</header>
<!-- more cheesy content -->
</section>
</article>这不是比原来更具可读性吗?而且,不仅更容易阅读,它对辅助技术更有用;机器人不能总是弄清楚你的特定类名模式,但是它们可以遵循这种结构。
<nav>这个元素比其它元素更有名。<nav>旨在清楚地识别页面上的主要导航块,帮助用户围绕站点其余部分找到路径的链接组(例如站点地图或标题中的链接列表)或当前页面(例如目录)。
在我们的示例顶部,让我们将<nav>应用于标题中的那组链接。
<nav>
<a href="/">Home</a>
<a href="/about">About</a>
<a href="/archive">Archive</a>
</nav>根本不改变结构,但你知道它是什么,一目了然而不需要在<div>上读物和处理类名来找到它,更重要的是机器人也可以找到它。
<address>我们要讨论的最后一个元素是<address>。这个元素旨在调出联系信息,它通常在主页<footer>中用于标记企业的邮寄地址,电话号码,客户服务邮箱地址等等。
有趣的是,如何在<address>元素中标记内容的规则是开放的。规范提到有几个其它规范可以解决这个问题,并且提供这种级别的粒度可能超出了HTML本身的范围。
常见的解决方案是RDFa,也是W3C规范,它使用标签上的属性来标记数据的不同组件。下面是我们示例中的页脚在标记<address>元素和RDFa时可能看起来的样子:
<footer>
<section class="contact" vocab="http://schema.org/" typeof="LocalBusiness">
<h2>Contact us!</h2>
<address property="email">
<a href="mailto:[email protected]">[email protected]</a>
</address>
<address property="address" typeof="PostalAddress">
<p property="streetAddress">123 Main St., Suite 404</p>
<p>
<span property="addressLocality">Yourtown</span>,
<span property="addressRegion">AK</span>,
<span property="postalCode">12345</span>
</p>
<p property="addressCountry">United States of America</p>
</address>
</section>
</footer>无疑,RDFa有点冗长,但它对于标记数据非常方便。如果你有兴趣了解有关RDFa的更多信息,请点击以下链接:
好了,我们已经介绍了很多,我们已经看到很多零零散散的元素应用到我们的例子中。那么,让我们把它们放在一起看看它的样子。
<header>
<h1>Super duper best blog ever</h1>
<nav>
<a href="/">Home</a>
<a href="/about">About</a>
<a href="/archive">Archive</a>
</nav>
</header>
<main>
<article>
<header>
<h1>Why you should buy more cheeses than you currently do</h1>
</header>
<section>
<header>
<h2>Part 1: Variety is spicy</h2>
</header>
<!-- cheesy content -->
</section>
<section>
<header>
<h2>Part 2: Cows are great</h2>
</header>
<!-- more cheesy content -->
</section>
</article>
</main>
<footer>
<section class="contact" vocab="http://schema.org/" typeof="LocalBusiness">
<h2>Contact us!</h2>
<address property="email">
<a href="mailto:[email protected]">[email protected]</a>
</address>
<address property="address" typeof="PostalAddress">
<p property="streetAddress">123 Main St., Suite 404</p>
<p>
<span property="addressLocality">Yourtown</span>,
<span property="addressRegion">AK</span>,
<span property="postalCode">12345</span>
</p>
<p property="addressCountry">United States of America</p>
</address>
</section>
</footer>如果你问我(怎么看改造后的内容?),那这比原始例子的可读性高100倍,而且对于搜索引擎优化和可访问性目的而言,其效率将提高100倍。
这些绝不是HTML中唯一的语义元素。有很多其它元素可以帮助你标记和构建你的文本内容,嵌入媒体资源等等。如果你喜欢这个并且希望深入挖掘,这里有一些(标签)可以查看下。你可能认识一些:
这只是一个开始!就像我说的,当你开始阅读HTML规范时,很难停下来。它是种非常丰富的语言,我认为人们经常会低估这种语言。
原文: https://dev.to/kenbellows/stop-using-so-many-divs-an-intro-to-semantic-html-3i9i
数据结构和算法系列的课程分为上下两篇文章,上篇文章主要是讲解数据结构,可以戳导师计划--数据结构和算法系列(上)进行了解。本篇文章主要讲解的是基本算法,辅助的语言依旧是JavaScript。POST的本篇文章主要是扩展下我们在开发中的方式,发散下思维~
排序介绍:
排序算法又分为简单排序和高级排序。其中简单排序包括冒泡排序、选择排序和插入排序。高级排序包括希尔排序、归并排序和快速排序。【
下面我们逐个排序算法来讲解下:
之所以叫冒泡排序,是因为使用这种排序算法时,数据值就会像气泡那样从数组的一端漂浮到另一端。假设正在将一组数字按照升序排列,较大的值会浮动在数组的右侧,而较小的值则会浮动到数组的左侧。产生这种冒泡的现象是因为算法会多次在数组中移动过,比较相邻的数据,当左侧值大于右侧值的时候将它们互换。
⚠️ 后面讲到的排序算法如无说明,则默认为升序
比如下面的简单列表的例子。
E A D B H
经过第一次的排序后,列表会变成:
A E D B H
前面两个元素进行了交互。接下来再次排序:
A D E B H
第二个元素和第三个元素进行了交互。继续进行排序:
A D B E H
第三个元素和第四个元素进行了交换。这一轮最后进行排序:
A D B E H
因为第四个元素比最后一个元素小,所以比较后保持所在位置。反复对第一个元素执行上面的操作(已经固定的值不参与排序,如第一轮固定的H不参与第二轮的比较了),得到如下的最终结果:
A B D E H
相关的动效图如下:
关键代码如下:
bubbleSort(){
let numElements = this.arr.length;
for(let outer = numElements-1; outer >= 2; --outer){
for(let inner = 0; inner <= outer-1; ++inner){
if(this.arr[inner] > this.arr[inner+1]){
this.swap(inner, inner+1); // 交换数组两个元素
}
}
}
}选择排序从数组的开头开始,将第一个元素和其它元素进行比较。检查完所有的元素之后,最小的元素会被放在数组的第一个位置,然后算法会从第二个位置继续。这个过程进行到数组的倒数第二个位置时,所有的数据便完成了排序。
原理:
选择排序用到双层嵌套循环。外循环从数组的第一个元素移动到倒数第二个元素;内循环从当前外循环所指元素的第二个元素开始移动到最后一个元素,查找比当前外循环所指元素小的元素。每次内循环迭代后,数组中最小的值都会被赋值到合适的位置。
下面是对五个元素的列表进行选择排序的简单例子。初始列表为:
E A D H B
第一次排序会找到最小值,并将它和列表的第一个元素进行交换:
A E D H B
接下查找第一个元素后面的最小值(第一个元素此时已经就位),并对它们进行交换:
A B D H E
D已经就位,因此下一步会对E H进行互换,列表已按顺序排列好如下:
A B D E H
通过gif图可能容易理解:
关键代码如下:
selectionSort(){
let min,
numElements = this.arr.length;
for(let outer = 0; outer <= numElements-2; outer++){
min = outer;
for(let inner = outer+1; inner <= numElements-1; inner++){
if(this.arr[inner] < this.arr[min]){
min = inner;
}
}
this.swap(outer, min);
}
}插入排序类似我们按照数字或字母的顺序对数据进行降序或升序排序整理~
原理:
插入排序也用了双层的嵌套循环。外循环将数组挨个移动,而内循环则对外循环中选中的元素以及内循环数组后面的那个元素进行比较。如果外循环中选中的元素比内循环中选中的元素要小,那么内循环的数组元素会向右移动,腾出一个位置给外循环选定的元素。
上面表达的晦涩难懂。简单来说,插入排序就是未排序的元素对已经排序好的序列数据进行合适位置的插入。如果还是不懂,结合下面的排序示例来理解下:
下面对五个元素进行插入排序。初始列表如下:
E B A H D
第一次插入排序,第二个元素挪动到第一位:
B E A H D
第二次插入排序是对A进行操作:
B A E H D
A B E H D
第三次是对H进行操作,因为它比之前的元素都大,所以保持位置。最后一次是对D元素进行插入排序了,过程和最后结果如下:
A B E D H
A B D E H
相关的gif图了解一下:
相关代码如下:
insertionSort(){
let temp,
inner,
numElements = this.arr.length;
for(let outer = 1; outer <= numElements-1; outer++){
temp = this.arr[outer];
inner = outer;
while(inner > 0 && this.arr[inner-1] >= temp){
this.arr[inner] = this.arr[inner-1];
inner--;
}
this.arr[inner] = temp;
}
}希尔排序是插入排序的优化版,但是,其核心理念与插入排序不同,希尔排序会首先比较距离较远的元素,而非相邻的元素。
原理:
希尔排序通过定义一个间隔序列来表示数据在排序过程中进行比较的元素之间有多远的间隔。我们可以动态定义间隔序列,不过对于大部分的实际应用场景,算法用到的间隔序列可以提前定义好。
如下演示希尔排序中,间隔序列是如何运行的:
通过下面的gif图你也许会更好理解:
实现的代码:
shellSort(){
let temp,
j,
numElements = this.arr.length;
for(let g = 0; g < this.gaps.length; ++g){
for(let i = this.gaps[g]; i < numElements; ++i){
temp = this.arr[i];
for(j = i; j >= this.gaps[g] && this.arr[j - this.gaps[g]] > temp; j -= this.gaps[g]){ // 之前的已经拍好序的了
this.arr[j] = this.arr[j - this.gaps[g]];
}
this.arr[j] = temp; // 这里和上面的for循环是互换两个数据位置
}
}
}🤔思考:[6, 0, 2, 9, 3, 5, 8, 0, 5, 4] 间隔为3的排序结果是什么呢?
原理:
把一系列的排好序的子序列合并成一个大的有序序列。从理论上讲,这个算法很容易实现。我们需要两个排好序的子数组,然后通过比较数据的大小,先从最小的数据开始插入,最后合并得到第三个数组。然而,实际上操作的相当大的数据的时候,使用归并排序是很耗内存的,这里我们了解一下就行。
实现归并排序一般有两种方法,一种是自顶向下和自底向上的方法。
上面的gif图是自顶向下的方法,那么何为自顶向下呢?
自顶向下的归并排序算法就是把数组元素不断的二分,直到子数组的元素个数为一个,因为这个时候子数组必定是有序的,然后再将两个有序的序列合并成一个新的有序序列,连个有序序列又可以合并成另一个新的有序序列,以此类推,直到合并一个有序的数组。如下图:
自底向上的归并排序算法的**是将数组先一个一个归并成两两有序的序列,两两有序的序列归并成四个四个有序的序列,以此类推,直到归并的长度大于整个数组的长度,此时整个数组有序。
⚠️ 注意:数组按照归并长度划分,最后一个子数组可能不满足长度要求,这种情况就要特殊处理了。
快速排序是处理大数据集最快的排序算法之一,时间复杂度 最好的情况也也是和归并排序一样,为O(nlogn)。
原理:
快速排序是一种**分而治之(分治)**的算法,通过递归的方式将数据依次分解为包含较小元素和较大元素的不同子序列,然后不断重复这个步骤,直到所有的数据都是有序的。
可以更清晰的表达快速排序算法步骤如下:
1 和 2。我们来用代码实现下:
// 快速排序
quickSort(){
this.arr = this.quickAux(this.arr);
}
// aux函数 - 快排的辅助函数
quickAux(arr){
let numElements = arr.length;
if(numElements == 0){
return [];
}
let left = [],
right = [],
pivot = arr[0]; // 取数组的第一个元素作为基准值
for(let i = 1; i < numElements; i++){
if(arr[i] < pivot){
left.push(arr[i]);
}else{
right.push(arr[i]);
}
}
return this.quickAux(left).concat(pivot, this.quickAux(right));
}以上介绍了六种排序的算法,当然还有很多其它的排序算法,你可以到视频 | 手撕九大经典排序算法,看我就够了!文章中查看。
在列表中查找数据又两种方式:顺序查找和二分查找。顺序查找适用于元素随机排列的列表;而二分查找适用于元素已排序的列表。二分查找效率更高,但是我们必须在进行查找之前花费额外的时间将列表中的元素进行排序。
对于查找数据来说,最简单的就是从列表中的第一个元素开始对列表元素逐个进行判断,直到找到了想要的元素,或者直到列表结尾也没有找到。这种方法称为顺序查找或者线性查找。
这种查找的代码实现方式很简单,如下:
/*
* @param { Array } arr 目标数组
* @param { Number } data 要查找的数组
* @return { Boolean } 是否查找成功
**/
function seqSearch(arr, data){
for(let i = 0; i < arr.length; i++){
if(arr[i] === data){
return true;
}
}
return false;
}当然,看到上面的代码,你也许会简化成下面的这样的代码:
function seqSearch(arr, data){
return arr.indexOf(data) >= 0 ? true : false;
}实现的方式有多种,但是原理都是一样的,要从第一个元素开始遍历,有可能会遍历到最后一个元素都找不到要查找的元素。所以,这是一种暴力查找技巧的一种。
那么,有什么更加高效的查找方法嘛?这就是我们接下来要讲的了。
在开始之前,我们来玩一个猜数字游戏:
这个游戏很简单,如果我们使用二分查找的策略进行的话,我们只需要经过短短的几次就确定我们要查找的数据了。
那么二分查找的原理是什么呢?
二分查找又称为折半查找,对有序的列表每次进行对半查找。就是这么简单@~@!
代码实现走一波:
/*
* @param { Array } arr 有序的数组 ⚠️注意:是有序的有序的有序的
* @param { Number } data 要查找的数据
* @return { Number } 返回查找到的位置,未查找到放回-1值
**/
function binSearch(arr, data){
let upperBound = arr.length -1,
lowerBound = 0;
while(lowerBound <= upperBound){
let mid = Math.floor((upperBound + lowerBound) / 2);
if(arr[mid] < data){
lowerBound = mid + 1;
}else if(arr[mid] > data){
upperBound = mid + 1;
}else{
return mid;
}
}
return -1; // 你朋友选要猜的数据在1-100范围之外
}至此,导师计划--数据结构和算法已经完结。后期的话会在另一篇文章中补充一下各个算法的时间复杂度的比较(不作为课程讲解,要动笔算算的,而且也就是总结一个表而已~),当然你可以查看文章算法的时间复杂度并结合实际编写的代码来自行理解,并去总结。
文章中的一些案例来自coderwhy的数据结构和算法系列文章,感谢其授权
课程代码可以戳相关算法来获取
部分图片来自网络,侵删
《数据结构与算法JavaScript描述》
作为一个非典型的前端开发人员,我们要懂得一些算法的概念,并将其理论知识引入日常的开发中,提高日常的开发效率和提升产品的体验。
本篇博文的概念偏多,模糊的点,有兴趣的谷歌起来啦!
算法: 算法是指解题方案的准确而完整的描述,是一系列解决问腿的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。
算法的效率: 是指算法执行的时间,算法执行时间需要通过算法编制的程序在计算机上运行时所消耗的时间来衡量。
一个算法的优劣可以用空间复杂度和时间复杂度来衡量。
时间复杂度:评估执行程序所需的时间。可以估算出程序对处理器的使用程度。
空间复杂度:评估执行程序所需的存储空间。可以估算出程序对计算机内存的使用程度。
算法设计时,时间复杂要比空间复杂度更容易复杂,所以本博文也在标题指明讨论的是时间复杂度。一般情况下,没有特殊说明,复杂度就是指时间复杂度。
时间频度: 一个算法中的语句执行次数称为语句频度或时间频度。
一个算法执行所消耗的时间,从理论上是不能算出来的,必须上机测试才知道。但我们不可能也没有必要对每个算法都上机测试,只需要知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句执行次数成正比例,哪个算法中执行语句次数多,它话费的时间就多。
时间复杂度: 执行程序所需的时间。(上面提到了)
一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称为f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n))为算法的渐进时间复杂度,简称时间复杂度。比如:
在 T(n)=4nn-2n+2 中,就有f(n)=nn,使得T(n)/f(n)的极限值为4,那么O(f(n)),也就是时间复杂度为O(n*n)
大O表示法: 算法的时间复杂度通常用大O符号表述,定义为T(n)=O(f(n))【上面有提到并举例】。
T(n) = O(f(n))称函数T(n)以f(n)为界或称T(n)受限于f(n)。如果一个问题的规模是n,解决一问题的某一算法所需要的时间为T(n)。
【注】时间复杂度和时间复杂度虽然在概念上有所区别,但是在某种情况下,可以认为两者是等价的或者是约等价的。
推导大O阶就是将算法的所有步骤转换为代数项,然后排除不会对问题的整体复杂度产生较大影响的较低阶常数和系数。
有条理的说,推导大O阶,按照下面的三个规则来推导,得到的结果就是大O表示法:
先来看下图,对各个时间复杂度认下脸:

O(1)常数阶
let sum = 0,
n = 100; // 执行一次
sum = (1+n)*n/2; // 执行一次
console.log(sum); // 执行一次 上面算法的运行次数的函数是f(n)=3,则有O(f(n) = 3)即O(3), 常数项用常数1表示,则最终的表示法为O(1),我们称之为常数阶。
O(n)线性阶
线性阶主要分析循环结构的运行情况,如下:
for(let i = 0; i < n; i++){
// 时间复杂度O(1)的算法
...
}上面算法循环体中的代码执行了n次,因此时间复杂度是O(n)。
O(logn)对数阶
let number = 1;
while(number < n){
number = number*2;
// 时间复杂度O(1)的算法
...
}上面的代码,随着number每次乘以2后,都会越来约接近n,当number不小于n时候就会退出循环。假设循环的次数为x,则由2^x=n得出x=log₂n,因此得到这个算法的时间复杂度为O(logn)。
O(n²)平方阶
平凡阶一般出现在嵌套的循环中,如下:
for(let i=0; i<n; i++){
for(let j=i; j<n; j++){
// 时间复杂度O(1)的算法
...
}
}上面的代码中,内循环的中是j=i。具体的算法过程如下:
n+(n-1)+(n-2)+(n-3)+……+1
=(n+1)+[(n-1)+2]+[(n-2)+3]+[(n-3)+4]+……
=(n+1)+(n+1)+(n+1)+(n+1)+……
=(n+1)n/2
=n(n+1)/2
=n²/2+n/2根据上面说的推导大O阶的规则,得到上面这段代码的时间复杂度是O(n²)
其他常见复杂度
f(n)=nlogn时,时间复杂度为O(nlogn),可以称为nlogn阶。
f(n)=n³时,时间复杂度为O(n³),可以称为立方阶。
f(n)=2ⁿ时,时间复杂度为O(2ⁿ),可以称为指数阶。
f(n)=n!时,时间复杂度为O(n!),可以称为阶乘阶。
f(n)=(√n时,时间复杂度为O(√n),可以称为平方根阶。
嗯,我们再回头看下下面的图片:
通过图片直观的体现,能够得到常用的时间复杂度按照消耗时间的大小从小到大排序依次是:
O(1)<O(logn)<O(n)<O(nlogn)<O(n²)<O(n³)<O(2ⁿ)<O(n!)
刘望舒 -- https://juejin.im/post/5bbd79a0f265da0aa74f46a6
李斌 -- https://zhuanlan.zhihu.com/p/32135157
O(log n) 怎么算出来的 -- https://www.jianshu.com/p/7b2082df8968
直接进入主题:
继承的操作需要有一个父类,这里使用构造函数外加原型来创建一个:
// super
function Person(name){
this.name = name;
}
Person.prototype.job = 'frontend';
Person.prototype.sayHello = function() {
console.log('Hello '+this.name);
}
var person = new Person('jia ming');
person.sayHello(); // Hello jia ming// 原型链继承
function Child() {
this.name = 'child';
}
Child.prototype = new Person();
var child = new Child();
console.log(child.job); // frontend
// instanceof 判断元素是否在另一个元素的原型链上
// child是Person类的实例
console.log(child instanceof Person); // true关键点:子类原型等于父类的实例Child.prototype = new Person()
原型链的详细讲解自己之前有一篇文章说到深入理解原型对象和原型链
特点:
注意事项:
// 借用构造函继承
function Child() {
Person.call(this, 'reng');
}
var child = new Child();
console.log(child.name); // reng
console.log(child instanceof Person); // false
child.sayHello(); // 报错,继承不了父类原型上的东西关键点:用call或apply将父类构造函数引入子类函数(在子类函数中做了父类函数的自执行(复制))Person.call(this, 'reng')
针对call, apply, bind的使用,之前有篇文章谈谈JavaScript中的call、apply和bind提到。
特点:
注意事项:
组合继承是原型链继承和借用构造函数继承的组合。
// 组合继承
function Child(name) {
Person.call(this, name);
}
Child.prototype = new Person();
var child = new Child('jia');
child.sayHello(); // Hello jia
console.log(child instanceof Person); // true关键点:结合了两种模式的优点--向父类传参(call)和复用(prototype)
特点:
注意事项:
// 先封装一个函数容器,用来承载继承的原型和输出对象
function object(obj) {
function F() {}
F.prototype = obj;
return new F();
}
var super0 = new Person();
var super1 = object(super0);
console.log(super1 instanceof Person); // true
console.log(super1.job); // frontend关键点:用一个函数包装一个对象,然后返回这个函数的调用,这个函数就变成了可以随意增添属性的实例或对象。Object.create()就是这个原理。
特点:
注意事项:
**Object.create()方法规范了原型式继承。**这个方法接收两个参数,一个用作新对象原型的对象和(可选的)一个为新对象定义额外属性的对象。
// 传一个参数的时候
var anotherPerson = Object.create(new Person());
console.log(anotherPerson.job); // frontend
console.log(anotherPerson instanceof Person); // true// 传两个参数的时候
var anotherPerson = Object.create(new Person(), {
name: {
value: 'come on'
}
});
anotherPerson.sayHello(); // Hello come onfunction object(obj) {
function F(){}
F.prototype = obj;
return new F();
}
var sup = new Person();
// 以上是原型式继承,给原型式继承再套个壳子传递参数
function subobject(obj) {
var sub = object(obj);
sub.name = 'ming';
return sub;
}
var sup2 = subobject(sup);
// 这个函数经过声明后就成了可增添属性的对象
console.log(sup2.name); // 'ming'
console.log(sup2 instanceof Person); // true关键点:就是给原型式继承外面套个壳子。
特点:
注意事项:
它跟组合继承一样,都比较常用。
寄生:在函数内返回对象然后调用
组合:
// 寄生
function object(obj) {
function F(){}
F.prototype = obj;
return new F();
}
// object是F实例的另一种表示方法
var obj = object(Person.prototype);
// obj实例(F实例)的原型继承了父类函数的原型
// 上述更像是原型链继承,只不过只继承了原型属性
// 组合
function Sub() {
this.age = 100;
Person.call(this); // 这个继承了父类构造函数的属性
} // 解决了组合式两次调用构造函数属性的特点
// 重点
Sub.prototype = obj;
console.log(Sub.prototype.constructor); // Person
obj.constructor = Sub; // 一定要修复实例
console.log(Sub.prototype.constructor); // Sub
var sub1 = new Sub();
// Sub实例就继承了构造函数属性,父类实例,object的函数属性
console.log(sub1.job); // frontend
console.log(sub1 instanceof Person); // true重点:修复了组合继承的问题
在上面的问题中,你可能发现了这么一个注释obj.constructor = Sub; // 一定要修复实例。为什么要修正子类的构造函数的指向呢?
因为在不修正这个指向的时候,在获取构造函数返回的时候,在调用同名属性或方法取值上可能造成混乱。比如下面:
function Car() { }
Car.prototype.orderOneLikeThis = function() { // Clone producing function
return new this.constructor();
}
Car.prototype.advertise = function () {
console.log("I am a generic car.");
}
function BMW() { }
BMW.prototype = Object.create(Car.prototype);
BMW.prototype.constructor = BMW; // Resetting the constructor property
BMW.prototype.advertise = function () {
console.log("I am BMW with lots of uber features.");
}
var x5 = new BMW();
var myNewToy = x5.orderOneLikeThis();
myNewToy.advertise(); // => "I am BMW ..." if `BMW.prototype.constructor = BMW;` is not
// commented; "I am a generic car." otherwise.更多的内容,请移步我的博客,能给个赞就更好了😄
对于使用Javascript的每个人来说,可选链(Optional chaining)是游戏的规则的改变者。它与箭头函数或let和const一样重要。我们讨论下它可以解决什么问题,它如何工作,以及它如何使得你的生活更加轻松。
想象以下场景:
你正在使用片段代码来从一个API加载数据。返回数据是深度嵌套的对象,这就意味着你需要遍历很长的对象属性。
// API response object
const person = {
details: {
name: {
firstName: "Michael",
lastName: "Lampe",
}
},
jobs: [
"Senior Full Stack Web Developer",
"Freelancer"
]
}
// Getting the firstName
const personFirstName = person.details.name.firstName;现在,保留这样的代码也是不错的。不过,有个更好的解决方法,如下:
// Checking if firstName exists
if( person &&
person.details &&
person.details.name ) {
const personFirstName = person.details.name.firstName || 'stranger';
}正如示例中你所看到的,即使是简单的事情,比如获取一个人的名字,也很难正确获取。
所以,这就是为什么我们使用类似lodash库去处理这样的事情:
_.get(person, 'details.name.firstName', 'stranger');lodash使得代码更具可读性,但是你得在你的代码库中引入很多的依赖。你需要更新它,然后,如果你在一个团队中工作,你需要在团队中推广使用它。所以,这也不是一个理想的解决方案。
可选链为这些(除了团队的问题)提供了一个解决方案。
初次看到可选链的新语法,你可能会感到陌生,但是,几分钟后你会习惯它的。
const personFirstName = person?.details?.name?.firstName;好了,现在你脑子可能有很多问号(双关语义)。上面语法的?是个新的事物。这就是你要想想的地方了。在属性前(原文应该改为属性后比较准确)有?.,就是在问你属性person存在吗?或者,更加javascript的表达方式--person属性的值是null或undefined吗?如果是,将不会返回一个错误,而是返回undefined。所以personFirstName将返回undefined。对details?和name?会进行重复的询问。如果任意一个的值为null或undefined,之后personFirstName都会返回undefined。这被称为Short-circuiting(短路)。一旦javascript找到值为null或undefined,它就会短路并不会再深入查询下去。
我们还需要学学Nullish coalescing operator(空位合并运算符)。好吧,这听起来很难学。但是实际上,一点也不难。我们看看下面的例子:
const personFirstName = person?.details?.name?.firstName ?? 'stranger';Nullish coalescing operator用??来表示。它也很容易去解读。如果??左侧返回的内容是undefined,那么personFirstName会将??右侧的值赋值给它。这太容易了。
有时候你需要获取动态的值。它可能是一个数组的值,或者是一个对象的动态属性。
const jobNumber = 1;
const secondJob = person?.jobs?.[jobNumber] ?? 'none';
这里需要重点理解的地方是jobs?.[jobNumber],它和jobs[jobNumber]表达的一样,但是不会抛出一个错误;相反,它会返回none值。
有时候,你会处理对象,而你不知道它们是否带有方法。这里我们可以使用?.()语法或带参数?.({ some: 'args'})语法。它会根据你的需求运行。如果在那个对象中不存在这个方法,它会返回值undefined。
const currentJob = person?.jobs.getCurrentJob?.() ?? 'none';上面的例子中,如果没有getCurrentJob方法,那么currentJob将会返回none。
目前没有浏览器支持此功能--Babel做转换了。
这里已经有一个babel.js插件,如果你已经有了Babel设置,那就很容易集成了。
babel-plugin-proposal-optional-chaining
老哥,你可以把翻译好的文章,写在腾讯文档中,
然后在readme给出链接即可.
相比于写在Issues中,这样不仅会好看,维护起来也方便很多.
本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为下篇。
往期系列文章:
客套话不多说了,直奔下篇的内容~
ES2017标准引入了async函数,使得异步操作更加方便。async函数是Generator函数的语法糖。不打算写Generator函数,感兴趣的话可以看文档。与Generator返回值(Iterator对象)不同,async返回的是一个Promise对象。
async函数返回一个Promise对象,可以使用then方法添加回调函数。当函数执行的时候,一旦遇到await就会先返回,等到异步操作完成,再接着执行函数体内后面的语句。
async function getStockPriceByName(name) {
const symbol = await getStockSymbol(name);
const stockPrice = await getStockPrice(symbol);
return stockPrice;
}
getStockPriceByName('goog').then(function(result) {
console.log(result);
})再来看几种情况加深下印象:
function fun1() {
console.log('fun1');
return 'fun1 result';
}
async function test() {
const result1 = await fun1();
console.log(result1);
console.log('end');
}
test();
// 输出
// 'fun1'
// 'fun1 result'
// 'end'async function fun2() {
console.log('fun2');
return 'fun2 result';
}
async function test() {
const result2 = await fun2();
console.log(result2);
console.log('end');
}
test();
// 输出
// 'fun2'
// 'fun2 result'
// 'end'正常情况下,await命令后面是一个Promise对象,返回该对象的结果。如果不是Promise对象,就直接返回对应的值。
async function fun3() {
console.log('fun3');
setTimeout(function() {
console.log('fun3 async');
return 'fun3 result';
}, 1000)
}
async function test() {
const result3 = await fun3();
console.log(result3);
console.log('end');
}
test();
// 输出
// 'fun3'
// undefined
// 'end'
// 'fun3 async'async function fun4() {
console.log('fun4');
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('fun4 async');
resolve('fun4 result');
}, 1000);
})
}
async function test() {
console.log(result4);
console.log('fun4 sync');
console.log('end');
}
test();
// 输出
// 'fun4'
// 'fun4 async'
// 'fun4 result'
// 'fun4 sync'
// 'end'JavaScript一直没有休眠的语法,但是借助await命令就可以让程序停顿指定的时间。【await要配合async来实现】
function sleep(interval) {
return new Promise(resolve => {
setTimeout(resolve, interval);
})
}
// use
async function one2FiveInAsync() {
for(let i = 1; i <= 5; i++) {
console.log(i);
await sleep(1000);
}
}
one2FiveInAsync();
// 1, 2, 3, 4, 5 每隔一秒输出数字需求:使用async await改写下面的代码,使得输出的期望结果是每隔一秒输出0, 1, 2, 3, 4, 5,其中i < 5条件不能变。
for(var i = 0 ; i < 5; i++){
setTimeout(function(){
console.log(i);
},1000)
}
console.log(i);之前我们讲过了用promise的方式实现,这次我们用async await方式来实现:
const sleep = (time) => new Promise((resolve) => {
setTimeout(resolve, time);
});
(async () => {
for(var i = 0; i < 5; i++){
console.log(i);
await sleep(1000);
}
console.log(i);
})();
// 符合条件的输出 0, 1, 2, 3, 4, 5为什么只比较promise和async呢?因为这两个用得频繁,实在的才是需要的,而且async语法是generator的语法糖,generator的说法直接戳async与其他异步处理方法的比较。
两者上,async语法写法上代码量少,错误处理能力佳,而且更有逻辑语义化。
假定某个 DOM 元素上面,部署了一系列的动画,前一个动画结束,才能开始后一个。如果当中有一个动画出错,就不再往下执行,返回上一个成功执行的动画的返回值。
// promise
function chainAnimationsPromise(elem, animations) {
// 变量ret用来保存上一个动画的返回值
let ret = null;
// 新建一个空的Promise
let p = Promise.resolve();
// 使用then方法,添加所有动画
for(let anim of animations) {
p = p.then(function(val) {
ret = val;
return anim(elem);
});
}
// 返回一个部署了错误捕捉机制的Promise
return p.catch(function(e) {
/* 忽略错误,继续执行 */
}).then(function() {
return ret;
});
}// async await
async function chainAnimationsAsync(elem, animations) {
let ret = null;
try {
for(let anim of animations) {
ret = await anim(elem);
}
} catch(e) {
/* 忽略错误,继续执行 */
}
return ret;
}在ES6之前,是使用构造函数来模拟类的,现在有了关键字class了,甚是开心😄
function Person() {}
Person.prototype.sayHello = function(){
console.log('Hi');
};class Person{
sayHello(){
console.log('Hi!');
}
}constructor方法是类的默认方法,通过new命令生成对象实例时,自动调用该方法,一个类中必须有construtor方法,如果没有显式定义,一个空的constructor方法会默认添加。
class Person{}
// 等同于
class Person{
constructor(){}
}construtor方法也就类似构造函数,在执行new的时候,先跑构造函数,再跑到原型对象上。
与ES5一样,在类的内部可以使用get和set关键字,对某个属性设置存值函数和取值函数,拦截该属性的存取行为。
class MyClass {
get prop() {
return 'getter';
}
set prop(value) {
console.log(`setter: ${ value }`)
}
}
let inst = new MyClass();
inst.prop = 123;
// 'setter: 123'
console.log(inst.prop);
// 'getter'类的方法内部如果含有this,它默认是指向类的实例。但是,必须非常小心,一旦单独使用该方法,很可能报错。
class Person{
constructor(job) {
this.job = job;
}
printJob() {
console.log(`My job is ${ this.job }`);
}
sayHi() {
console.log(`I love my job -- ${ this.job }.`)
}
}
const person = new Person('teacher');
person.printJob(); // 'My job is teacher'
const { sayHi } = person;
sayHi(); // 报错: Uncaught TypeError: Cannot read property 'job' of undefined上面的代码中,sayHi方法单独使用,this会指向该方法运行时所在的环境(由于class内部是严格模式,所以this实际上指向undefined)。
修正上面的错误也很简单,也是我们在react开发中经常使用的一种手段:在调用构造函数实例化的时候直接绑定实例(this),修改如下:
class Person{
constructor(job) {
this.job = job;
this.sayHi = this.sayHi.bind(this);
}
}ES5中继承的方式我之前有整理过--JavaScript 中的六种继承方式。
ES6中的继承通过extends关键字实现,比ES5的实现继承更加清晰和方便了。
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
}
class ColorPoint extends Point {
constructor(x, y, color) {
this.color = color;
}
}
let cp = new ColorPoint(25, 8, 'green'); // 报错: Must call super constructor in derived class before accessing 'this' or returning from derived constructor上面这样写,不能继承构造函数里面的属性值和方法。需要在子类的构造函数中加上super关键字。改成下面这样即可:
class Point {
constructor(x, y) {
this.x = x;
this.y = y;
}
}
class ColorPoint extends Point {
constructor(x, y, color) {
super(x, y); // 调用父类的construtor(x, y),相当于ES5中的call。注意的是,super要放在子类构造函数的第一行
this.color = color;
}
}
let cp = new ColorPoint(25, 8, 'green');在ES6之前,社区制定了一些模块的加载的方案,最主要的有CommonJS和AMD两种。前者用于服务器,后者用于浏览器。
// CommonJS
let { stat, exists, readFile } = require('fs');ES6在语言标准的层面上,实现了模块功能,而且实现得相当简单,完全可以取代 CommonJS和AMD规范,成为浏览器和服务器通用的模块解决方案。
// ES6模块
import { stat, exists, readFile } from 'fs';各种好处详细见文档
export命令用于规定模块的对外接口 。
**一个模块就是一个独立的文件。该文件内部的所有变量,外部无法获取。**你可以理解为一个命名空间~
想要获取模块里面的变量,你就需要导出export:
// profile.js
const name = 'jia ming';
const sayHi = function() {
console.log('Hi!');
}
export { name, sayHi };还有一个export default命令,方便用户(开发者啦)不用阅读文档就能加载模块(实际上就是输出一个default变量,而这个变量在import的时候是可以更改的):
// export-default.js
export default function () {
console.log('foo');
}其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
// import-default.js
import customName from './export-default';
customName(); // 'foo'import命令用于输入其他模块提供的功能。使用export命令定义了模块的对外接口以后,其他JS文件就可以通过import命令加载这个模块。
// main.js
import { name, sayHi } from './profile.js';
function printName() {
console.log('My name is ' + name);
}至此,本系列文章谈谈ES6语法已经写完,希望文章对读者有点点帮助。本系列的内容是个人觉得在开发中比较重要的知识点,如果要详细内容的话,请上相关的文档查看~💨
本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为下篇。
系列文章至此已经完结!
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
javascript是一门单线程的非阻塞的脚本语言。单线程意味着javascript在执行代码的任何时候,都只有一个主线程来处理所有的任务。
那么javascript引擎是如何实现这一点的呢?
因为事件循环(event loop)。先上图:
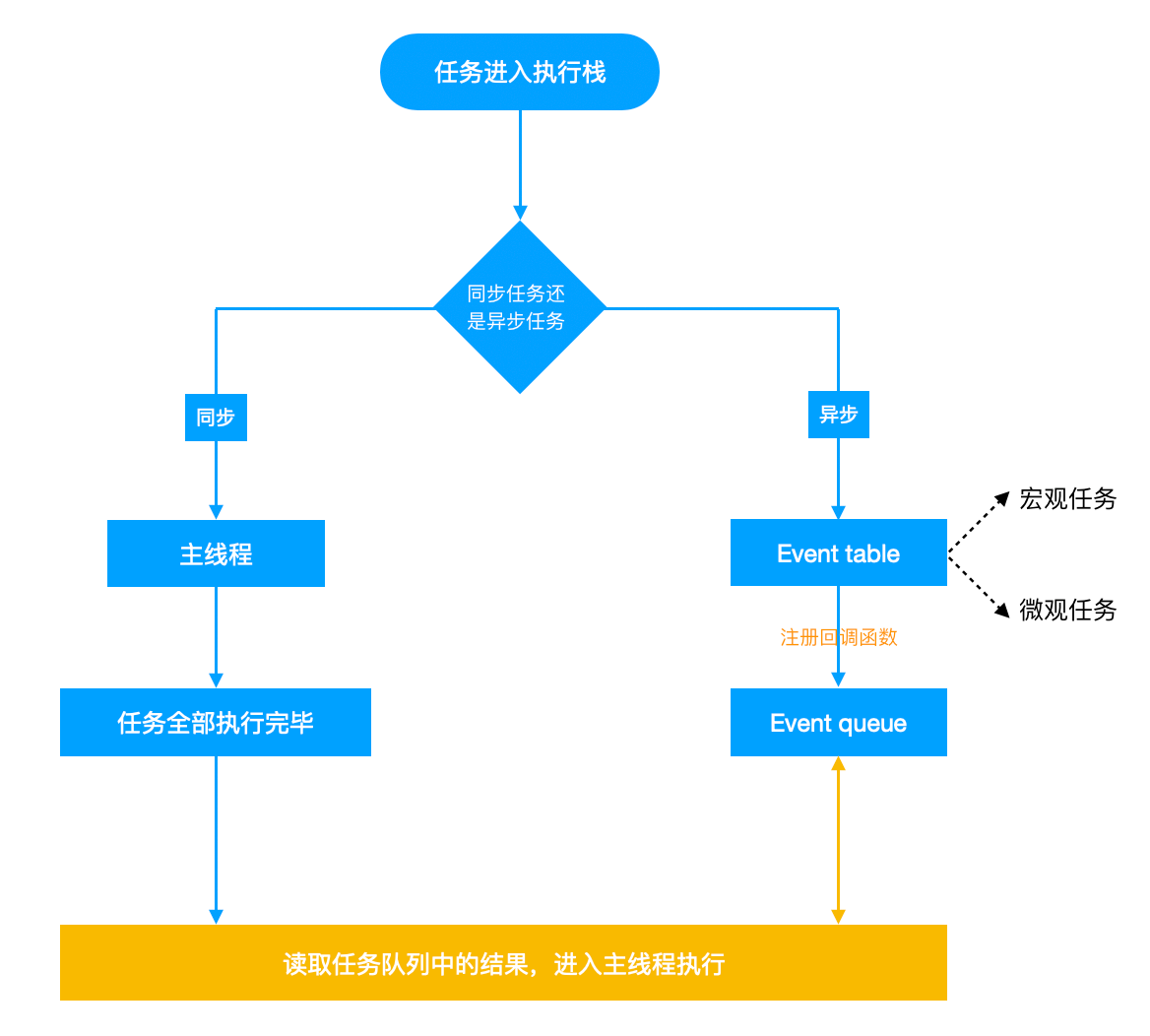
图片解读:
Event Table并注册函数Event Table会将这个函数移入Event Queue中Event Queue读取对应的函数,进入主线程执行Event Loop(事件循环)。我们来一个简单的例子来说明下:
console.log('1');
setTimeout(() => {
console.log('2');
}, 0)
console.log('3');上面的代码将输出下面的结果:
1
3
2因为setTimeout是一个异步的任务,所以会在最后才执行。
那么,我们来个复杂点的例子:
console.log('1');
setTimeout(() => {
console.log('2')
}, 1000);
new Promise((resolve, reject) => {
setTimeout(() => {
console.log('3');
}, 0);
console.log('4');
resolve();
console.log('5');
}).then(() => {
console.log('6');
});
console.log('7');上面的代码输出的结果是:
1
4
5
7
6
3
2看到这代码的时候是不是有些蒙圈?在我们揭开谜底之前,先来了解下微任务和宏任务。
微任务和宏任务都是异步的任务,他们都属于队列,主要区别是它们的执行顺序--微任务会比宏任务先执行。
宏任务包含有:setTimeout, setInterval, setImmediate, I/O, UI rendering
微任务包含有:process.nextTick, promise.then, MutationObserver
嗯~回到上面的代码,如下:
console.log('1');
setTimeout(() => {
console.log('2')
}, 1000);
new Promise((resolve, reject) => {
setTimeout(() => {
console.log('3');
}, 0);
console.log('4');
resolve();
console.log('5');
}).then(() => {
console.log('6');
});
console.log('7');在执行到new Promise的时候会立马新建一个promise对象并立即执行。所以会输出 1,4,5,而then则会在Event Table中注册成回调函数并放在微任务队列中,而两个setTimeout(输出3)和setTimeout(输出2,1s后完成的啊)会被先后注册成回调函数并放在宏任务队列中。
理解了上面的一些原理之后,我们再来练下手...
console.log(1)
process.nextTick(() => {
console.log(8)
setTimeout(() => {
console.log(9)
})
})
setTimeout(() => {
console.log(2)
new Promise(() => {
console.log(11)
})
})
let promise = new Promise((resolve,reject) => {
setTimeout(() => {
console.log(10)
})
resolve()
console.log(4)
})
fn()
console.log(3)
promise.then(() => {
console.log(12)
})
function fn(){
console.log(6)
}得到的结果是:
1
4
6
3
8
12
2
11
10
9客官可以画下图整理下思路,然后代码运行验证一下啊💨
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
最近自己回归基础看了下javascript的相关知识点,想着看都看了,写出来记录下足迹也是一件好事,遂记录~
在javascript中有两种类型,一种是基本数据类型,一种是引用类型。
基本数据类型,也称为简单数据类型,在ES5中有以下五种:Undefined、Null、Boolean、Number和String,在ES6中新增了一种简单的数据类型Symbol。
Undefined类型只有一个值undefined。在进行相关变量定义的时候,未赋值的情况下,默认是赋值为undefined了。但是也是有些特殊的情况下会报错的。情况我大致罗列下:
# 情况1⃣️:变量声明了,但是没有赋值
var message;
console.log(message); // undefined
# 情况2⃣️:变量声明并赋值了,但是在console运行之后
console.log(message); // undefined
var message = 'find a frontend job in Canton!';
# 情况3⃣️:变量没声明,报引用报错
// var message;
console.log(message); // Uncaught ReferenceError: message is not defined
# 情况4⃣️:不通过var声明,直接写变量,报引用错误
message; // 不等价 var message;
console.log(message); // Uncaught ReferenceError: message is not defined
# 情况5⃣️:不通过var声明,直接写变量赋值
message = 'find a frontend job in Canton!'; // 默认在message前添加了var
console.log(message); // find a frontend job in Canton!
# 情况6⃣️:不通过var声明,直接写赋值,但是在console运行之后,报引用错误
console.log(message);
message = 'find a frontend job in Canton!'; // 相当于没message变量上面罗列的是ES5中通过var声明的情况。也许你会对情况2⃣️产生疑惑:我都给message赋值了啊,但是打印出undefined,这就有点尴尬了?
因为在js中执行上下文分为两个阶段,第一个阶段是创建阶段,第二个阶段才是执行阶段。
上面情况2⃣️的执行情况如下:
1. 创建阶段:
executionContextObj = {
scopeChain: { ... },
variableObject: {
message: undefined
},
this: { ... }
}2. 执行阶段:
executionContextObj = {
scopeChain: { ... },
variableObject: {
message: 'find a frontend job in Canton!'
},
this: { ... }
}详细的解析可以看下我之前翻译的一篇文章JS的执行上下文和环境栈是什么?。
上面讲到的是var,我们引入ES6的let 和 const来演示下:
# 情况7⃣️:let声明变量赋值
let message;
console.log(message); // undefined
# 情况8⃣️:let声明变量但是不赋值,在console运行之后
console.log(message); // Uncaught ReferenceError: Cannot access 'message' before initialization
let message = 'find a frontend job in Canton!';
# 情况9⃣️:const声明变量但是不赋值,报语法错误
const message;
console.log(message); // Uncaught SyntaxError: Missing initializer in const declarationlet和const改变了var命令会发生变量提升的现象,即变量可以在声明之前使用,值为undefined。它们改变了这种奇怪的现象,声明的变量一定要在声明之后使用,否则报错。
当然还有其他声明变量的方法,比如function命令等,这里不一一列举,只是探讨下undefined的值而已~
Null类型的值是null。从逻辑角度来看,null值表示一个空对象指针。
如果定义的变量准备在将来用来保存对象,那么最好就是将变量初始化为null,而不是其他的数据值。这样,只要直接检查null值就可以知道相应的变量是否已经保存了一个对象的引用。如下面的例子:
if(car != null) {
// 对car对象执行某些操作
}undefined值是派生自null值的。虽然两者在==比较时候是相等的,如下:
console.log(null == undefined); // true当变量不确定类型的时候,可以不用为变量赋值,也就是默认赋值undefined了。但是如果你知道你的变量要保存对象但是还没有真正保存对象的时候就要赋值null了。
Boolean类型在日常生活中使用频繁了,其值是true和false,对应我们口头的是和否。
将布尔值的true和false转换为数值的话,可以用非0和0数字表示。
console.log( 1 == true); // true
console.log( 0 == false); // true如果是恒等的比较方式===,那数字表示法是要凉凉的~
Number类型有二进制表示法,八进制表示法,十六进制表示法和十进制表示法。这里只讨论十进制表示法,因为在平常的开发中,用到十进制的情况居多😂
这个类型用来表示整数值和浮点数值(即带小数点的值)。
整数值的基本操作很是简单,而且没啥bug好说,除非不在Number.MIN_VALUE和Number.MAX_VALUE范围内。带小数点的还是要留意下的,比如:
let a = 13.04;
let b = 2.5;
console.log(a + b); // 15.54
console.log(a * b); // 32.599999999999994
console.log(a - b); // 10.54咦咦,真是让人尴尬😅,怎么上面代码中两个浮点数相乘会出现那么多位的数字啊,不是等于32.6吗?
所以在进行浮点数的运算的时候还是得慎重点,先转换成整数计算,之后再切换回去浮点数,比如上面的a * b可以考虑写成(a * 100 * (b * 10))/1000。
当你要判断一个值是否是数值,可以使用isNaN来表示,其返回一个布尔值,如下:
console.log(isNaN(NaN)); // true
console.log(isNaN(10)); // false
console.log(isNaN('10'); // false , '10'会被转化为10
console.log('blue'); // true , 不能转化为数值
console.log(true); // false, 可被转化为数值1还有将非数值转化为数值的三个方法:Number()、parseInt()和parseFloat()。见名思义:
**Number()是将传入的内容转换为数字(整数)或NaN。但是在转换字符串的时候比较复杂,一般用parseInt()**居多。**parseFloat()**就是转化成浮点数的方法啦。
String类型也就是字符串类型啦。
字符串类型包含一些特殊的字符字面量,也叫转义序列,用来表示非打印字符串。比如换行符\n啦。
在实际的开发中,我们需要将数字类型或对象类型转换成字符串类型,那么我们可以直接使用toString()方法进行操作啦。好吧,这api的东西大家都会用,就不说了😂
Symbol类型是ES6引入的新类型,为了防止对象中属性名冲突的问题。
Symbol值通过Symbol函数生成。这就是说,对象的属性名现在可以有两种类型,一种是原来就有的字符串,另一种就是新增的Symbol类型。凡是属性名属于Symbol类型,就都是独一无二的,可以保证不会与其他属性名产生冲突。
具体的看下阮一峰的es6入门中Symbol部分。
上面说到的是6种基本的数据类型,还有一种是引用类型。
引用类型:当复制保存对象的某个变量时,操作的是对象的引用,但是在为对象添加属性时,操作的是实际的对象。引用类型值指那些可能有多个值构成的对象。
引用类型有这几种:Object、Array、RegExp、Date、Function、特殊的基本包装类型(String、Number、Boolean)以及单体内置对象(Global、Math)。
基本包装类型这个有点好玩,咦?上面的基本数据类型都有String、Number和Boolean啦,怎么这里还有这些。是的,上面的基本类型是通过基本包装类型来创建的。如下:
var s1 = 'find a frontend job in Canton';
var s2 = s1.substring(2);上面的代码实际进行了下面的步骤:
(1)创建String类型的一个实例;
(2)在实例中调用指定的方法;
(3)销毁这个实例。
上面的三个步骤转化为代码如下:
var s1 = new String('find a frontend job in Canton');
var s2 = s1.substring(2);
s1 = null;(正规)的引用类型和基本包装类型的主要区别就是对象的生存期。使用new操作符创建的引用类型的实例,在执行流离开当前作用域之前都一直保存在内存中。而自动创建的基本包装类型的对象,则只存在于下一行代码的执行瞬间,然后立即被销毁。这意味着我们不能在运行时为基本类型值添加属性和方法。来看下下面的例子:
var s1 = 'find a frontend job in Canton';
s1.name = 'jia ming';
console.log(s1.name); // undefined只能通过基本包装类的原型来添加了,比如改写toString方法:
var s1 = 'find a frontend job in Canton';
String.prototype.toString = function() {
console.log('my name is jia ming');
}
console.log(s1.toString()); // my name is jia ming嗯~苦口婆心介绍了javascript的数据类型,那么下面才是重头戏。我们在实际的开发中,如何识别不同的数据类型呢?
数据类型有上面的7种类型,其中基本类型是Undefined、Null、Boolean、Number、String和Symbol,还有一种引用类型。引用类型又包含比较多种的对象,比如Object、Array等。
我们首先想到的是通过typeof来判断,直接上代码来试下吧:
let symbol = Symbol('jia ming');
let str = 'find a frontend job in Canton!';
let flag = true;
let height = 99;
let job;
let obj = null;
console.log(typeof symbol); // symbol
console.log(typeof str); // string
console.log(typeof flag); // boolean
console.log(typeof height); // number
console.log(typeof job); // undefined
console.log(typeof obj); // object嗯~很ok啦,对基本的数据类型都能判断到啦,这个null得到的结果是object,你可以当成特殊情况来处理啦 -- 无中生有,一生万物嘛。
我们再来看下引用类型打印出来的是什么东东😊
let person = {
name: 'jia ming',
info: 'find a frontend job in Canton!',
};
let arr = ['jia ming', 'find a frontend job in Canton!'];
let reg = new RegExp('jia ming', 'g');
let date = new Date();
let fn = () => {
return 'find a frontend job in Canton!';
}
let math = Math.min(2, 4, 8);
console.log(typeof person); // object
console.log(typeof arr); // object
console.log(typeof reg); // object
console.log(typeof date); // object
console.log(typeof fn); // function
console.log(typeof math); // number咦咦~着实让人尴尬啊,这个为啥那么多object啊,我的小心脏😔。我们只是简单通过typeof校验比较尴尬啊,我们换个思路,我们来结合call改变下上下文对象,改写一个方法进行判断,如下:
let person = {
name: 'jia ming',
info: 'find a frontend job in Canton!',
};
let arr = ['jia ming', 'find a frontend job in Canton!'];
let reg = new RegExp('jia ming', 'g');
let date = new Date();
function handleType(obj, type) {
if(typeof obj === 'object') {
return Object.prototype.toString.call(obj) === `[object ${type}]`;
}
return false;
}
console.log(handleType(person, 'Object')); // true
console.log(handleType(arr, 'Array')); // true
console.log(handleType(reg, 'RegExp')); // true
console.log(handleType(date, 'Date')); // true美滋滋,可以实现区别判断的哈。可是上面的基本类型中null也是object啊,然后是Math类型的typeof也是number啊,这个你可以自己做下处理啦。这里就不考虑了~
《JavaScript高级程序设计》
构建工具有很多,比如Npm Script任务执行者、Grunt也是任务执行者、Gulp基于流的自动化构建工具、Fis3百度构建工具、Webpack打包模块化JavaScript工具和Rollup模块打包工具。
这里谈谈用得很频繁的webpack构建工具。
从最基本的概念开始了解:
entry是配置模块的入口,必填。
module.exports = {
entry: './path/to/my/entry/file.js'
}output配置如何输出最终想要的代码。output是一个object,里面包含一系列的配置项。
output.filename配置输出文件的名称,为string类型。
output.path配置输出文件存放在本地的目录(路径),必须是string类型的绝对路径。
path: path.resolve(__dirname, 'dist_[hash]')output.publicPath配置发布到线上资源的URL前缀,为string类型。默认为空字符串'',即使用相对路径。
比如需要将构建的资源上传到CDN服务上,以便加快网页的打开速度。配置代码如下:
filename: '[name]_[chunkhash:8].js'
publicPath: 'https://cdn.example.com/assets/'发布到线上时候,HTML中引入的JavaScript文件如下:
<script src='https://cdn.example.com/assets/a_12345678.js'></script>线上出现404错误的时候,看下路径有没有错~
还有其他配置请看文档
module配置如何处理模块。
module.rules配置模块的读取和解析规则,通常用来配置Loader。其类型是一个数组,数组里每一项都描述了如何去处理部分文件。应用一项rules时大致通过以下方式:
test、include、exclude三个配置项来命中Loader要应用规则的文件。use配置项来应用Loader,可以只应用一个Loader或者按照从后往前的顺序应用一组Loader,同时还可以给Loader传入参数。Loader执行顺序默认是从右往左执行,通过enforce选项可以让其中一个Loader的执行顺序放在前面或者最后。module: {
rules: [
{
// 命中scss文件
test: /\.scss$/,
// 处理顺序从右往左
use: ['style-loader', 'css-loader', 'sass-loader'],
// 排除node_modules目录下的文件
exclude: path.resolve(__dirname, 'node_modules'),
}
]
}Loader需要传入多个参数的时候的例子:
use: [
{
loader:'babel-loader',
options:{
cacheDirectory:true,
},
// enforce:'post' 的含义是把该 Loader 的执行顺序放到最后
// enforce 的值还可以是 pre,代表把 Loader 的执行顺序放到最前面
enforce:'post'
},
// 省略其它 Loader
]module.noParse配置项可以让webpack忽略对部分没采用模块化的文件的递归解析和处理,这样做有助于提高构建性能。比如:
module: {
noParse: (content) => /jquery|lodash/.test(content)
}module.rules.parser属性可以更细粒度的配置哪些模块需要解析,哪些不需要,和noParse配置项的区别在于parser可以精确到语法层面,而noParse只能控制哪些文件不被解析。
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader'],
parser: {
amd: false, // 禁用 AMD
commonjs: false, // 禁用 CommonJS
...
}
}
]
}Resolve配置webpack如何寻找模块所对应的文件。Webpack内置Javascript模块化语法解析功能,默认会采用模块化标准里面约定好的规则去寻找,你也可以按照需求修改默认规则。
resolve.alias配置项通过别名来把原导入的路径映射成一个新的导入路径。如下:
resolve: {
alias: {
components: './src/components/'
}
}当你通过import Button from 'components/button'导入时,实际上被alias等价替换了import Button from './src/components/button'。
resolve.modules配置webpack去哪些目录下找第三方模块,默认只会去node_modules目录下寻找。
resolve.enforceExtension如果配置为true所有导入语句都必须带有后缀,例如开启前import './foo能正常工作,开启后就必须写成import './foo.js'。
Plugin用于扩展Webpack功能,各种各样的Plugin几乎让Webpack可以做任何构建相关的事情。
举个例子:
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');
module.exports = {
plugins: [
// 所有页面都会用到的公共代码提取到 common 代码块中
new CommonsChunkPlugin({
name: 'common',
chunks: ['a', 'b']
})
]
}在开发环境的时候使用。要配置DevServer,除了在配置文件里面通过devServer传入参数外,还可以通过命令行参数传入。
注意:只有在通过DevServer去启动Webpack时配置项文件里devServer才会生效。
devServer.hot配置是否启用使用DevServer中提到的模块热替换功能。
devServer.host配置项用于配置 DevServer 服务监听的地址。
devServer.port配置项用于配置 DevServer 服务监听的端口,默认使用8080端口。
devServer.https配置HTTPS协议服务。某些情况下你必须使用HTTPS,HTTP2 和 Service Worker 就必须运行在 HTTPS 之上。
devServer: {
https: true
}Webpack的运行是一个串行的过程,从启动到结束会执行以下流程:
Loader对文件的转换操纵很耗时,需要让尽可能少的文件被Loader处理。
在使用Loader时可以通过test、include、exclude三个配置项来命中Loader要应用规则的文件。
module.exports = {
module: {
rules: [
{
test: /\.js$/,
use: ['babel-loader?cacheDirectory'],
include: path.resolve(__dirname, 'src')
}
]
}
}resolve.modules配置resolve.modules用于配置webpack去哪些目录下寻找第三方模块。
resolve.modules的默认值是['node_modules'],含义是先去当前的目录下./node_modules目录下去找想找的模块,以此类推,如果没有找到就去上一级目录../node_modules中找,再没有去上上一级,以此类推...
如果知道安装的模块在项目的根目录下的./node_modules时候,没有必要按照默认的方式一层层找:
module.exports = {
resolve: {
modules: [path.resolve(__dirname, 'node_modules')]
}
}resolve.alias配置resolve.alias配置项通过别名来把原导入路径映射成一个新的导入路径。可以减少耗时的递归解析操作。
module.noParse配置module.noParse配置项可以让Webpack忽略对部分没采用模块化的文件的递归解析处理,这样做的好处是能提高构建性能。
const path = require('path');
module.exports = {
module: {
// 独完整的 `react.min.js` 文件就没有采用模块化,忽略对 `react.min.js` 文件的递归解析处理
noParse: [/react\.min\.js$/],
}
}HappyPack把任务分解成多个子进程并发执行,子进程处理完后再把结果发送给主进程。减少了总的构建时间。
const HappyPack = require('happypack');
const os = require('os');
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length });
module.exports = {
module: {
rules: [
{
test: /\.js$/,
loader: 'happypack/loader?id=happyBabel',
exclude: /node_modules/
}
]
},
plugins: [
new HappyPack({
id: 'happyBabel',
loaders: [{
loader: 'babel-loader?cacheDirectory= true',
}],
// 共享进程池
threadPool: happyThreadPool,
// 允许happypack输出日志
verbose: true,
})
]
}例如:
module.export = {
watch: true,
watchOptions: {
// 监听到变化发生后会等300ms再去执行动作,防止文件更新太快导致重新编译频率太高
// 默认为 300ms
aggregateTimeout: 300,
// 判断文件是否发生变化是通过不停的去询问系统指定文件有没有变化实现的
// 默认每隔1000毫秒询问一次
poll: 1000
}
}由于保存文件的路径和最后编辑时间需要占用内存,定时检查周期检查需要占用CPU以及文件I/O,所以最好减少需要监听的文件数量和降低检查频率。
热替换就是当一个源码发生改变的时,只重新编译发生改变的模块,再用新输出的模块替换掉浏览器中对应的老模块。
开启热替换:
webpack-dev-server --hot区分开发环境和生产环境,进行不同的构建~
CDN又叫内容分发网络,通过把资源部署到世界各地,用户在访问时按照就近原则从离用户最近的服务器获取资源,从而加速资源的获取速度。
CDN 其实是通过优化物理链路层传输过程中的网速有限、丢包等问题来提升网速的。
结合publicPath来处理:
const path = require('path');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
const { WebPlugin } = require('web-webpack-plugin');
module.exports = {
output: {
filename: '[name]_[chunkhash:8].js',
path: path.resolve(__dirname, './dist'),
publicPath: '//js.cdn.com/id/'
},
module: {
rules: [
{
test: /\.css$/,
use: ExtractTextPlugin.extract({
use: ['css-loader?minimize'],
publicPath: '//img.cdn.com/id/'
}),
}
]
},
plugins: [
new WebPlugin({
template: './template.html',
filename: 'index.html',
// 指定存放 CSS 文件的 CDN 目录 URL
stylePublicPath: '//css.cdn.com/id/',
}),
new ExtractTextPlugin({
// 给输出的 CSS 文件名称加上 Hash 值
filename: `[name]_[contenthash:8].css`,
}),
]
}将多余的代码移除。
webpack --display-used-exports --optimize-minimize公共代码的提取。
const CommonsChunkPlugin = require('webpack/lib/optimize/CommonsChunkPlugin');
new CommonsChunkPlugin({
// 从哪些 Chunk 中提取
chunks: ['a', 'b'],
// 提取出的公共部分形成一个新的 Chunk,这个新 Chunk 的名称
name: 'common'
})对于采用单页应用作为前端架构的网站来说,会面临一个网页需要加载的代码量很大的问题,因为许多功能都做到了一个HTML里面,这会导致网页加载缓慢、交互卡顿、用户体验将非常糟糕。
导致这个问题的根本原因在于一次性的加载所有功能对应的代码,但其实用户每一阶段只可能使用其中一部分功能。 所以解决以上问题的方法就是用户当前需要用什么功能就只加载这个功能对应的代码,也就是所谓的按需加载。
Webpack 内置了强大的分割代码的功能去实现按需加载。比如:
main.js文件,网页会展示一个按钮main.js文件中只包含监听按钮事件和加载按需加载的代码。show.js文件,加载成功后再执行show.js里的函数。main.js中:
window.document.getElementById('btn').addEventListener('click', function () {
// 当按钮被点击后才去加载 show.js 文件,文件加载成功后执行文件导出的函数
import(/* webpackChunkName: "show" */ './show').then((show) => {
show('Webpack');
})
});show.js中:
module.exports = function (content) {
window.alert('Hello ' + content);
};代码中最关键的一句是import(/* webpackChunkName: "show" */ './show'),Webpack 内置了对import(*)语句的支持,当 Webpack 遇到了类似的语句时会这样处理:
./show.js为入口新生成一个Chunk;import所在语句时才会去加载由Chunk对应生成的文件。import返回一个Promise,当文件加载成功时可以在Promise的then方法中获取到show.js导出的内容。在工作中具体使用到的时候再按需要进行更改配置项啦~
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
在家屁颠屁颠的拿起了《在你身边 为你设计》这本书看了一下午,看到移动端调试这里,略有感受,于是提取了下内容。
在这个5g到来的时代,移动互联网继续横行,前端的开发工作和移动端更加紧密了,但是移动端调试着实让人尴尬。化解尴尬的方法介绍下下面这几种,有补充的欢迎留言👏
作为一个前端开发工程师,没下载个谷歌浏览器都不好意思说自己是混这行的了。在移动开发的过程中,我们是可以使用桌面浏览器(推荐谷歌)进行调试的。尽管移动端网页与桌面端网页有诸多差异,但是说到底它还是一个在浏览器里浏览的HTML网页,所以最常用的还是在桌面借助Chrome调试器。
Chrome自带的Developer Tool对于调试移动端网页来说非常方便,可以通过调整下表所示的几个属性来调整页面。
| 属性名 | 功能 |
|---|---|
| User Agent | 设置当前模拟设备的用户代理(UA) |
| Device metrices | 设置页面的大小,默认值是模拟设置的大小 |
| Emulate touch events | 模拟触摸屏事件 |
| Fit in window | 页面大小是否会根据窗口大小进行适配 |
优点:无须额外的成本,方便快捷。
缺点:仅仅用来模拟,并不能完全代表移动设备的真实状况。
这个方法对用MAC来办公的伙伴就比较友好了~
Apple允许开发者通过数据线连接的方式,在Mac OS的Safari里面调试iOS设备上的网页。但是这种方法在使用前,需要简单设置以下内容:
当需要调试手机页面的时候,将设备与计算机通过数据线连接后,在Safari菜单开发栏下选择当前手机运行的页面即可。
优点:可以完全在真机设备上调试网页,无论是HTML和CSS,还是脚本和请求,都和在桌面浏览器一样,最重要的是当前调试的是在真实环境下的页面。
缺点:必须是iOS + Mac OS的组合,只能调试iOS设备的页面,不适用于Andriod设备。
嗯~Apple那么强势,我安卓表示不服,也要来自己的一套。
Google Chrome DevTools通过USB数据线直接调试手机上的网页。
只需要准备下面几个步骤:
优点:简单、跨平台
缺点:只支持Android 4+
Weinre的github仓库地址是https://github.com/nupthale/weinre,在其README.md里面有详细的介绍。
Weinre来源于Web Inspector Remote,是一个远程页面调试工具,功能和Firebug、WebKit Inspector类似,可以帮助我们在PC端远程调试运行在移动设备浏览器内的Web页面或应用,能够即时调试DOM元素、CSS样式和JavaScript等。
Weinre为了能够同步桌面的调试客户端和移动设备上的调试目的,需要你搭建一个调试服务器(Debug Server),通过这台调试服务器,可以在调试目标(Debug Target)和桌面调试客户端(Debug Client)之间建立一个同步的连接。详细的搭建见Weinre仓库的README.md介绍。囧,步骤有点多,不想码字了😳
优点:同时支持iOS设备和Android设备,并且能直接对手机上的页面进行调试,无须安装客户端。
缺点:需要对HTML页面有改动的权限,因为是远程连接的原因,可能网络连接速度会影响调试的响应。
当看到优点是不是很激动,在真机上可以调试iOS和Android设备的网页耶✌️
由腾讯出品的vConsole调试工具,在调试移动端的时候非常有效,而且其使用方法也是简单。
<script src="path/to/vconsole.min.js"></script>
<script>
// init vConsole
var vConsole = new VConsole();
console.log('Hello world');
</script>上面的使用方法介绍了其中一种而已。当然了,引入的vConsole也要看下环境啊,线上环境的时候还是要判断下的,别等到上线的时候忘记移除vConsole了,被怼就尴尬😅。
优点:使用简单,能方便查看所需调试的面板信息
缺点:不支持UI的调试
嗯,调试工具各有千秋,还有调试工具但是未介绍到的有Charles抓包工具,postman接口调试工具等。
应该是 http://reng99.cc 而不是 http://reng99
我就是从http://reng99.cc 过来的……
导师计划已经开始一个月了,自己的讲解的课程选择了数据结构和算法。这个系列的讲解分为上下两章,javascript语言辅助。本篇文章为上章,涉及的内容是基本的数据结构。在日本,晚上没事安排@…@,时间还是充足的...,于是自己整理下本系列知识点的上章内容。
以下为正文:
数据结构是计算机存储、组织数据的方式。数据结构是指相互直接存在一种或多种特殊关系的数据元素的集合。通常情况下,精心选择数据结构可以带来更高的运行或者存储效率。作为一名程序猿,更需要了解下数据结构。AND WHY?可以参考这篇文章【译】编程不容易中的性能和优化部分内容。
讲到数据结构,我们都会谈到线性结构和非线性结构。
1.线性结构是一个有序数据元素的集合。它应该满足下面的特征:
按照百度百科的定义,我们知道符合条件的数据结构就有栈、队列和其它。
2.非线性结构其逻辑特征是一个节点元素可以有多个直接前驱或多个直接后继。
那么,符合条件的数据结构就有图、树和其它。
嗯~了解一下就行。我们进入正题:
数组是一种线性结构,以十二生肖(鼠、牛、虎、兔、龙、蛇、马、羊、猴、鸡、狗、猪)排序为例:
我们来创建一个数组并打印出结果就一目了然了:
let arr = ['鼠', '牛', '虎', '兔', '龙', '蛇', '马', '羊', '猴', '鸡', '狗', '猪'];
arr.forEach((item, index) => {
console.log(`[ ${index} ] => ${item}`);
});
// [ 0 ] => 鼠
// [ 1 ] => 牛
// [ 2 ] => 虎
// [ 3 ] => 兔
// [ 4 ] => 龙
// [ 5 ] => 蛇
// [ 6 ] => 马
// [ 7 ] => 羊
// [ 8 ] => 猴
// [ 9 ] => 鸡
// [ 10 ] => 狗
// [ 11 ] => 猪数组中常用的属性和一些方法如下,直接调用相关的方法即可。这里不做演示~
常用的属性
常用的方法
splice(index, howmany, item, ... itemx)
splice方法自认为是数组中最强大的方法。可以实现数组元素的添加、删除和替换。参数index为整数且必需,规定添加/删除项目的位置,使用负数可从数组结尾处规定位置;参数howmany为必需,为要删除的项目数量,如果设置为 0,则不会删除项目;item1, ... itemx为可选,向数组添加新的项目。
indexOf(searchValue, fromIndex)
indexOf方法返回某个指定字符串值在数组中的位置。searchValue是查询的字符串;fromIndex是查询的开始位置,默认是0。如果查询不到,会返回-1。
concat(array1, ... arrayn)
concat方法用于连接两个或者多个数组。
push(newElement1, ... newElementN)
push方法可向数组的末尾添加一个或者多个元素。
unshift(newElement1, ... newElementN)
unshift方法可向数组的开头添加一个或者多个元素。
pop()
pop方法用于删除并返回数组的最后一个元素。
shift()
shift方法可以删除数组的第一个元素。
reverse()
reverse方法用于数组的反转
sort(sortFn)
sort方法是对数组的元素排序。参数sortFn可选,其规定排序顺序,必须是函数。
let values = [0, 1, 5, 10, 15];
values.sort();
console.log(values); // [0, 1, 10, 15, 5]
// 为什么会出现这种排序结果呢❓
// 因为在忽略sortFn的情况下,元素会按照转换为字符串的各个字符的Unicode位点进行排序,如下
let equalValues = ['0', '1', '5', '10', '15'];
equalValues.sort();
console.log(equalValues); // ["0", "1", "10", "15", "5"]
let arr = [0, 10, 5, 1, 15];
function compare(el1, el2){
return el1 - el2; // 升序排列
}
arr.sort(compare);
console.log(arr); // [0, 1, 5, 10, 15]
arr.sort((el1, el2) => {
return el2 - el1; // 降序排列
});
console.log(arr); // [15, 10, 5, 1, 0]forEach(fn(currentValue, index, arr), thisValue)
forEach方法用于调用数组的每个元素,并将元素传递给回调函数。参数function(currentValue, index, arr){}是一个回调函数。thisValue可选,传递给函数的值一般用 "this" 值,如果这个参数为空, "undefined" 会传递给 "this" 值。
every(fn(currentValue, index, arr), thisValue)
every方法用于检测数组中所有元素是否符合指定条件,如果数组中检测到有一个元素不满足,则整个表达式返回false,且剩余的元素不再检查。如果所有的元素都满足条件,则返回true。
some(fn(currentValue,index,arr),thisValue)
some方法用于检测数组中元素是否满足指定条件。只要有一个符合就返回true,剩余的元素不再检查。如果所有元素都不符合条件,则返回false。
reduce(fn(accumulator, currentValue, currentIndex, arr), initialValue)
reduce方法接收一个函数作为累加器,数组中的每个值(从左到右)开始缩减,最终为一个值。回调函数的四个参数的意义如下:accumulator,必需,累计器累计回调的返回值, 它是上一次调用回调时返回的累积值,或initialValue;currentValue,必需,数组中正在处理的元素;currentIndex,可选,数组中正在处理的当前元素的索引,如果提供了initialValue,则起始索引号为0,否则为1;arr,可选,当前元素所属的数组对象。initialValue,可选,传递给函数的初始值。
let arr = [1, 2, 3, 4];
let reducer = (accumulator, currentValue) => accumulator + currentValue;
// 1 + 2 + 3 + 4
console.log(arr.reduce(reducer)); // 10
// 5 + 1 + 2 + 3 + 4
console.log(arr.reduce(reducer, 5)); // 15栈是一种后进先出(LIFO)线性表,是一种基于数组的数据结构。(ps:其实后面讲到的数据结构或多或少有数组的影子)
我们代码写下,熟悉下栈:
class Stack {
constructor(){
this.items = [];
}
// 入栈操作
push(element = ''){
if(!element) return;
this.items.push(element);
return this;
}
// 出栈操作
pop(){
this.items.pop();
return this;
}
// 对栈一瞥,理论上只能看到栈顶或者说即将处理的元素
peek(){
return this.items[this.size() - 1];
}
// 打印栈数据
print(){
return this.items.join(' ');
}
// 栈是否为空
isEmpty(){
return this.items.length == 0;
}
// 返回栈的元素个数
size(){
return this.items.length;
}
}
let stack = new Stack(),
arr = ['鼠', '牛', '虎', '兔', '龙', '蛇', '马', '羊', '猴', '鸡', '狗', '猪'];
arr.forEach(item => {
stack.push(item);
});
console.log(stack.print()); // 鼠 牛 虎 兔 龙 蛇 马 羊 猴 鸡 狗 猪
console.log(stack.peek()); // 猪
stack.pop().pop().pop().pop();
console.log(stack.print()); // 鼠 牛 虎 兔 龙 蛇 马 羊
console.log(stack.isEmpty()); // false
console.log(stack.size()); // 8说到栈,这也让我想到了翻译的一篇文章JS的执行上下文和环境栈是什么?,感兴趣的话可以戳进去看下。
队列是一种先进先出(FIFO)受限的线性表。受限体现在于其允许在表的前端(front)进行删除操作,在表的末尾(rear)进行插入【优先队列这些排除在外】操作。
代码走一遍:
class Queue {
constructor(){
this.items = [];
}
// 入队操作
enqueue(element = ''){
if(!element) return;
this.items.push(element);
return this;
}
// 出队操作
dequeue(){
this.items.shift();
return this;
}
// 查看队前元素或者说即将处理的元素
front(){
return this.items[0];
}
// 查看队列是否为空
isEmpty(){
return this.items.length == 0;
}
// 查看队列的长度
len(){
return this.items.length;
}
// 打印队列数据
print(){
return this.items.join(' ');
}
}
let queue = new Queue(),
arr = ['鼠', '牛', '虎', '兔', '龙', '蛇', '马', '羊', '猴', '鸡', '狗', '猪'];
arr.forEach(item => {
queue.enqueue(item);
});
console.log(queue.print()); // 鼠 牛 虎 兔 龙 蛇 马 羊 猴 鸡 狗 猪
console.log(queue.isEmpty()); // false
console.log(queue.len()); // 12
queue.dequeue().dequeue();
console.log(queue.front()); // 虎
console.log(queue.print()); // 虎 兔 龙 蛇 马 羊 猴 鸡 狗 猪在进入正题之前,我们先来聊聊数组的优缺点。
优点:
缺点:
相对数组,链表亦可以存储多个元素,而且存储的元素在内容中不必是连续的空间;在插入和删除数据时,时间复杂度可以达到O(1)。在查找元素的时候,还是需要从头开始遍历的,比数组在知道下表的情况下要快,但是数组如果不确定下标的话,那就另说了...
我们使用十二生肖来了解下链表:
链表是由一组节点组成的集合。每个节点都使用一个对象的引用指向它的后继。如上图。下面用代码实现下:
// 链表
class Node {
constructor(element){
this.element = element;
this.next = null;
}
}
class LinkedList {
constructor(){
this.length = 0; // 链表长度
this.head = new Node('head'); // 表头节点
}
/**
* @method find 查找元素的功能,找不到的情况下直接返回链尾节点
* @param { String } item 要查找的元素
* @return { Object } 返回查找到的节点
*/
find(item = ''){
let currNode = this.head;
while(currNode.element != item && currNode.next){
currNode = currNode.next;
}
return currNode;
}
/**
* @method findPrevious 查找链表指定元素的前一个节点
* @param { String } item 指定的元素
* @return { Object } 返回查找到的之前元素的前一个节点,找不到节点的话返回链尾节点
*/
findPrevious(item){
let currNode = this.head;
while((currNode.next != null) && (currNode.next.element != item)){
currNode = currNode.next;
}
return currNode;
}
/**
* @method insert 插入功能
* @param { String } newElement 要出入的元素
* @param { String } item 想要追加在后的元素(此元素不一定存在)
*/
insert(newElement = '', item){
if(!newElement) return;
let newNode = new Node(newElement),
currNode = this.find(item);
newNode.next = currNode.next;
currNode.next = newNode;
this.length++;
return this;
}
// 展示链表元素
display(){
let currNode = this.head,
arr = [];
while(currNode.next != null){
arr.push(currNode.next.element);
currNode = currNode.next;
}
return arr.join(' ');
}
// 链表的长度
size(){
return this.length;
}
// 查看链表是否为空
isEmpty(){
return this.length == 0;
}
/**
* @method indexOf 查看链表中元素的索引
* @param { String } element 要查找的元素
*/
indexOf(element){
let currNode = this.head,
index = 0;
while(currNode.next != null){
index++;
if(currNode.next.element == element){
return index;
}
currNode = currNode.next;
}
return -1;
}
/**
* @method removeEl 移除指定的元素
* @param { String } element
*/
removeEl(element){
let preNode = this.findPrevious(element);
preNode.next = preNode.next != null ? preNode.next.next : null;
this.length--;
}
}
let linkedlist = new LinkedList();
console.log(linkedlist.isEmpty()); // true
linkedlist.insert('鼠').insert('虎').insert('牛', '鼠');
console.log(linkedlist.display()); // 鼠 牛 虎
console.log(linkedlist.find('猪')); // Node { element: '虎', next: null }
console.log(linkedlist.find('鼠')); // Node { element: '鼠', next: Node { element: '牛', next: Node { element: '虎', next: null } } }
console.log(linkedlist.size()); // 3
console.log(linkedlist.indexOf('鼠')); // 1
console.log(linkedlist.indexOf('猪')); // -1
console.log(linkedlist.findPrevious('虎')); // Node { element: '牛', next: Node { element: '虎', next: null } }
linkedlist.removeEl('鼠');
console.log(linkedlist.display()); // 牛 虎字典的主要特点是键值一一对应的关系。可以比喻成我们现实学习中查不同语言翻译的字典。这里字典的键(key)理论上是可以使用任意的内容,但还是建议语意化一点,比如下面的十二生肖图:
class Dictionary {
constructor(){
this.items = {};
}
/**
* @method set 设置字典的键值对
* @param { String } key 键
* @param {*} value 值
*/
set(key = '', value = ''){
this.items[key] = value;
return this;
}
/**
* @method get 获取某个值
* @param { String } key 键
*/
get(key = ''){
return this.has(key) ? this.items[key] : undefined;
}
/**
* @method has 判断是否含有某个键的值
* @param { String } key 键
*/
has(key = ''){
return this.items.hasOwnProperty(key);
}
/**
* @method remove 移除元素
* @param { String } key
*/
remove(key){
if(!this.has(key)) return false;
delete this.items[key];
return true;
}
// 展示字典的键
keys(){
return Object.keys(this.items).join(' ');
}
// 字典的大小
size(){
return Object.keys(this.items).length;
}
// 展示字典的值
values(){
return Object.values(this.items).join(' ');
}
// 清空字典
clear(){
this.items = {};
return this;
}
}
let dictionary = new Dictionary(),
// 这里需要修改
arr = [{ key: 'mouse', value: '鼠'}, {key: 'ox', value: '牛'}, {key: 'tiger', value: '虎'}, {key: 'rabbit', value: '兔'}, {key: 'dragon', value: '龙'}, {key: 'snake', value: '蛇'}, {key: 'horse', value: '马'}, {key: 'sheep', value: '羊'}, {key: 'monkey', value: '猴'}, {key: 'chicken', value: '鸡'}, {key: 'dog', value: '狗'}, {key: 'pig', value: '猪'}];
arr.forEach(item => {
dictionary.set(item.key, item.value);
});
console.log(dictionary.keys()); // mouse ox tiger rabbit dragon snake horse sheep monkey chicken dog pig
console.log(dictionary.values()); // 鼠 牛 虎 兔 龙 蛇 马 羊 猴 鸡 狗 猪
console.log(dictionary.has('dragon')); // true
console.log(dictionary.get('tiger')); // 虎
console.log(dictionary.remove('pig')); // true
console.log(dictionary.size()); // 11
console.log(dictionary.clear().size()); // 0集合通常是由一组无序的,不能重复的元素构成。 一些常见的集合操作如图:
es6中已经封装好了可用的Set类。我们手动来写下相关的逻辑:
// 集合
class Set {
constructor(){
this.items = [];
}
/**
* @method add 添加元素
* @param { String } element
* @return { Boolean }
*/
add(element = ''){
if(this.items.indexOf(element) >= 0) return false;
this.items.push(element);
return true;
}
// 集合的大小
size(){
return this.items.length;
}
// 集合是否包含某指定元素
has(element = ''){
return this.items.indexOf(element) >= 0;
}
// 展示集合
show(){
return this.items.join(' ');
}
// 移除某个元素
remove(element){
let pos = this.items.indexOf(element);
if(pos < 0) return false;
this.items.splice(pos, 1);
return true;
}
/**
* @method union 并集
* @param { Array } set 数组集合
* @return { Object } 返回并集的对象
*/
union(set = []){
let tempSet = new Set();
for(let i = 0; i < this.items.length; i++){
tempSet.add(this.items[i]);
}
for(let i = 0; i < set.items.length; i++){
if(tempSet.has(set.items[i])) continue;
tempSet.items.push(set.items[i]);
}
return tempSet;
}
/**
* @method intersect 交集
* @param { Array } set 数组集合
* @return { Object } 返回交集的对象
*/
intersect(set = []){
let tempSet = new Set();
for(let i = 0; i < this.items.length; i++){
if(set.has(this.items[i])){
tempSet.add(this.items[i]);
}
}
return tempSet;
}
/**
* @method isSubsetOf 【A】是【B】的子集❓
* @param { Array } set 数组集合
* @return { Boolean } 返回真假值
*/
isSubsetOf(set = []){
if(this.size() > set.size()) return false;
this.items.forEach*(item => {
if(!set.has(item)) return false;
});
return true;
}
}
let set = new Set(),
arr = ['鼠', '牛', '虎', '兔', '龙', '蛇', '马', '羊', '猴'];
arr.forEach(item => {
set.add(item);
});
console.log(set.show()); // 鼠 牛 虎 兔 龙 蛇 马 羊 猴
console.log(set.has('猪')); // false
console.log(set.size()); // 9
set.remove('鼠');
console.log(set.show()); // 牛 虎 兔 龙 蛇 马 羊 猴
let setAnother = new Set(),
anotherArr = ['马', '羊', '猴', '鸡', '狗', '猪'];
anotherArr.forEach(item => {
setAnother.add(item);
});
console.log(set.union(setAnother).show()); // 牛 虎 兔 龙 蛇 马 羊 猴 鸡 狗 猪
console.log(set.intersect(setAnother).show()); // 马 羊 猴
console.log(set.isSubsetOf(setAnother)); // false散列是一种常用的存储技术,散列使用的数据结构叫做散列表/哈希表。在散列表上插入、删除和取用数据都非常快,但是对于查找操作来说却效率低下,比如查找一组数据中的最大值和最小值。查找的这些操作得求助其它数据结构,比如下面要讲的二叉树。
切入个案例感受下哈希表:
假如一家公司有1000个员工, 现在我们需要将这些员工的信息使用某种数据结构来保存起来。你会采用什么数据结构呢?
方案一:数组
编号对应的就是员工的下标值。方案二:链表
最终方案:
那么散列表的原理和实现又是怎样的呢,我们来聊聊。
我们的哈希表是基于数组完成的,我们从数组这里切入解析下。数组可以通过下标直接定位到相应的空间,哈希表的做法就是类似的实现。哈希表把key(键)通过一个固定的算法函数(此函数称为哈希函数/散列函数)转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value(值)存储在以该数字为下标的数组空间里,而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value。
结合下面的代码,也许你会更容易理解:
// 哈希表
class HashTable {
constructor(){
this.table = new Array(137);
}
/**
* @method hashFn 哈希函数
* @param { String } data 传入的字符串
* @return { Number } 返回取余的数字
*/
hashFn(data){
let total = 0;
for(let i = 0; i < data.length; i++){
total += data.charCodeAt(i);
}
return total % this.table.length;
}
/**
*
* @param { String } data 传入的字符串
*/
put(data){
let pos = this.hashFn(data);
this.table[pos] = data;
return this;
}
// 展示
show(){
this.table && this.table.forEach((item, index) => {
if(item != undefined){
console.log(index + ' => ' + item);
}
})
}
// ...获取值get函数等看官感兴趣的话自己补充测试啦
}
let hashtable = new HashTable(),
arr = ['mouse', 'ox', 'tiger', 'rabbit', 'dragon', 'snake', 'horse', 'sheep', 'monkey', 'chicken', 'dog', 'pig'];
arr.forEach(item => {
hashtable.put(item);
});
hashtable.show();
// 5 => mouse
// 40 => dog
// 46 => pig
// 80 => rabbit
// 87 => dragon
// 94 => ox
// 111 => monkey
// 119 => snake
// 122 => sheep
// 128 => tiger
// 134 => horse
// 那么问题来了,十二生肖里面的_小鸡_去哪里了呢❓
// 被_小萌狗_给覆盖了,因为其位置都是40(这个可以自己证明下)
// 问题又来了,那么应该如何解决这种被覆盖的冲突呢❓针对上面的问题,我们存储数据的时候,产生冲突的话我们可以像下面这样解决:
1. 线性探测法
当发生碰撞(冲突)时,线性探测法检查散列表中的下一个位置【有可能非顺序查找位置,不一定是下一个位置】是否为空。如果为空,就将数据存入该位置;如果不为空,则继续检查下一个位置,直到找到一个空的位置为止。该技术是基于一个事实:每个散列表都有很多空的单元格,可以使用它们存储数据。
2. 开链法
但是,当发生碰撞时,我们任然希望将key(键)存储到通过哈希函数产生的索引位置上,那么我们可以使用开链法。开链法是指实现哈希表底层的数组中,每个数组元素又是一个新的数据结构,比如另一个数组(这样结合起来就是二位数组了),链表等,这样就能存储多个键了。使用这种技术,即使两个key(键)散列后的值相同,依然是被保存在同样的位置,只不过它们是被保存在另一个数据结构上而已。以另一个数据结构是数组为例,存储的数据如下:
树的定义:
树(Tree):n(n >= 0)个节点构成的有限集合。
n = 0时,称为空树;(n > 0),它具备以下性质:r(root)表示;m(m > 0)个互不相交的有限集T1,T2,...Tm,其中每个集合本省又是一棵树,称为原来树的子树(SubTree)注意:
不可以相交;N个节点的树有N-1条边。树的术语:
N-1)。0的节点(也称叶子节点)。A节点是B节点的父节点,则称B节点是A节点的子节点。n1到nk的路径为一个节点序列n1,n2,n3,...,nk,ni是ni+1的父节点。路径所包含边的个数为路径长度。第0层,它的子节点是第1层,子节点的子节点是第2层,以此类推。如下图:
二叉树的定义:
TL和右子树RT的两个不相交的二叉树组成两个二叉树的五种形态:
对应下图(从左至右):
我们接下来要讲的是二叉查找树(BST,Binary Search Tree)。二叉查找树,也称二叉搜索树或二叉排序树,是一种特殊的二叉树,相对值较小的值保存在左节点中,较大的值保存在右节点中。二叉查找树特殊的结构使它能够快速的进行查找、插入和删除数据。下面我们来实现下:
// 二叉查找树
// 辅助节点类
class Node {
constructor(data, left, right){
this.data = data;
this.left = left;
this.right = right;
}
// 展示节点信息
show(){
return this.data;
}
}
class BST {
constructor(){
this.root = null;
}
// 插入数据
insert(data){
let n = new Node(data, null, null);
if(this.root == null){
this.root = n;
}else{
let current = this.root,
parent = null;
while(true){
parent = current;
if(data < current.data){
current = current.left;
if(current == null){
parent.left = n;
break;
}
}else{
current = current.right;
if(current == null){
parent.right = n;
break;
}
}
}
}
return this;
}
// 中序遍历
inOrder(node){
if(!(node == null)){
this.inOrder(node.left);
console.log(node.show());
this.inOrder(node.right);
}
}
// 先序遍历
preOrder(node){
if(!(node == null)){
console.log(node.show());
this.preOrder(node.left);
this.preOrder(node.right);
}
}
// 后序遍历
postOrder(node){
if(!(node == null)){
this.postOrder(node.left);
this.postOrder(node.right);
console.log(node.show());
}
}
// 获取最小值
getMin(){
let current = this.root;
while(!(current.left == null)){
current = current.left;
}
return current.data;
}
// 获取最大值
getMax(){
let current = this.root;
while(!(current.right == null)){
current = current.right;
}
return current.data;
}
// 查找给定的值
find(data){
let current = this.root;
while(current != null){
if(current.data == data){
return current;
}else if(data < current.data){
current = current.left;
}else{
current = current.right;
}
}
return null;
}
// 移除给定的值
remove(data){
root = this.removeNode(this.root, data);
return this;
}
// 移除给定值的辅助函数
removeNode(node, data){
if(node == null){
return null;
}
if(data == node.data){
// 叶子节点
if(node.left == null && node.right == null){
return null; // 此节点置空
}
// 没有左子树
if(node.left == null){
return node.right;
}
// 没有右子树
if(node.right == null){
return node.left;
}
// 有两个子节点的情况
let tempNode = this.getSmallest(node.right); // 获取右子树
node.data = tempNode.data; // 将其右子树的最小值赋值给删除的那个节点值
node.right = this.removeNode(node.right, tempNode.data); // 删除指定节点的下的最小值,也就是置其为空
return node;
}else if(data < node.data){
node.left = this.removeNode(node.left, data);
return node;
}else{
node.right = this.removeNode(node.right, data);
return node;
}
}
// 获取给定节点下的二叉树最小值的辅助函数
getSmallest(node){
if(node.left == null){
return node;
}else{
return this.getSmallest(node.left);
}
}
}
let bst = new BST();
bst.insert(56).insert(22).insert(10).insert(30).insert(81).insert(77).insert(92);
bst.inOrder(bst.root); // 10, 22, 30, 56, 77, 81, 92
console.log('--中序和先序遍历分割线--');
bst.preOrder(bst.root); // 56, 22, 10, 30, 81, 77, 92
console.log('--先序和后序遍历分割线--');
bst.postOrder(bst.root); // 10, 30, 22, 77, 92, 81, 56
console.log('--后序遍历和获取最小值分割线--');
console.log(bst.getMin()); // 10
console.log(bst.getMax()); // 92
console.log(bst.find(22)); // Node { data: 22, left: Node { data: 10, left: null, right: null }, right: Node { data: 30, left: null, right: null } }
// 我们删除节点值为22,然后用先序的方法遍历,如下
console.log('--移除22的分割线--')
console.log(bst.remove(22).inOrder(bst.root)); // 10, 30, 56, 77, 81, 92看了上面的代码之后,你是否有些懵圈呢?我们借助几张图来了解下,或许你就豁然开朗了。
在遍历的时候,我们分为三种遍历方法--先序遍历,中序遍历和后序遍历:
删除节点是一个比较复杂的操作,考虑的情况比较多:
左子树找节点值最大的节点A,替换待删除节点值,并删除节点A右子树找节点值最小的节点A,替换待删除节点值,并删除节点A【👆上面的示例代码中就是这种方案】删除两个节点的图解如下:
图由边的集合及顶点的集合组成。
我们来了解下图的相关术语:
0顶点和其它两个顶点相连,0顶点的度就是2v1,v2...,vn的一个连续序列。
边是有方向的。边是无方向的。有权重。无权重。如下图:
图可以用于现实中的很多系统建模,比如:
图既然这么方便,我们来用代码实现下:
// 图
class Graph{
constructor(v){
this.vertices = v; // 顶点个数
this.edges = 0; // 边的个数
this.adj = []; // 邻接表或邻接表数组
this.marked = []; // 存储顶点是否被访问过的标识
this.init();
}
init(){
for(let i = 0; i < this.vertices; i++){
this.adj[i] = [];
this.marked[i] = false;
}
}
// 添加边
addEdge(v, w){
this.adj[v].push(w);
this.adj[w].push(v);
this.edges++;
return this;
}
// 展示图
showGraph(){
for(let i = 0; i < this.vertices; i++){
for(let j = 0; j < this.vertices; j++){
if(this.adj[i][j] != undefined){
console.log(i +' => ' + this.adj[i][j]);
}
}
}
}
// 深度优先搜索
dfs(v){
this.marked[v] = true;
if(this.adj[v] != undefined){
console.log("visited vertex: " + v);
}
this.adj[v].forEach(w => {
if(!this.marked[w]){
this.dfs(w);
}
})
}
// 广度优先搜索
bfs(v){
let queue = [];
this.marked[v] = true;
queue.push(v); // 添加到队尾
while(queue.length > 0){
let v = queue.shift(); // 从对首移除
if(v != undefined){
console.log("visited vertex: " + v);
}
this.adj[v].forEach(w => {
if(!this.marked[w]){
this.marked[w] = true;
queue.push(w);
}
})
}
}
}
let graphFirstInstance = new Graph(5);
graphFirstInstance.addEdge(0, 1).addEdge(0, 2).addEdge(1, 3).addEdge(2, 4);
graphFirstInstance.showGraph();
// 0 => 1
// 0 => 2
// 1 => 0
// 1 => 3
// 2 => 0
// 2 => 4
// 3 => 1
// 4 => 2
// ❓为什么会出现这种数据呢?它对应的图是什么呢?可以思考🤔下,动手画画图什么的
console.log('--展示图和深度优先搜索的分隔线--');
graphFirstInstance.dfs(0); // 从顶点 0 开始的深度搜索
// visited vertex: 0
// visited vertex: 1
// visited vertex: 3
// visited vertex: 2
// visited vertex: 4
console.log('--深度优先搜索和广度优先搜索的分隔线--');
let graphSecondInstance = new Graph(5);
graphSecondInstance.addEdge(0, 1).addEdge(0, 2).addEdge(1, 3).addEdge(2, 4);
graphSecondInstance.bfs(0); // 从顶点 0 开始的广度搜索
// visited vertex: 0
// visited vertex: 1
// visited vertex: 2
// visited vertex: 3
// visited vertex: 4对于搜索图,在上面我们介绍了深度优先搜索 - DFS(Depth First Search)和广度优先搜索 - BFS(Breadth First Search),结合下面的图再回头看下上面的代码,你会更加容易理解这两种搜索图的方式。
文章中的一些案例来自coderwhy的数据结构和算法系列文章,感谢其授权
演示代码存放地址 -- 数据结构文件夹 进入
structure目录可以直接node + filename运行
《数据结构与算法JavaScript描述》
我们不仅是程序员,而且是个(与时俱进的)学习者。鲜见的是有多少人认为他们是在学习编程的呢。
你可能在学习编程语言而不是编程本身
别对学习计算机科学(CS)不是研究计算机这种言论感到惊讶。相反的,学习CS是对自动解决问题的研究。解决问题的是计算机科学,而不是编程。这就是为什么许多CS的学生似乎不明白自己为什么要学习算法和数学。
如果之前你有去上过CS的课程,你就不会对我这里说的话感到惊讶。因为你会注意到编程和编程语言没有多大的关系。
但是,大多数自我思考的程序员会掉入这么一个陷阱:在我们意识到自己正真要做的是编程事情的时候,我们已经花了很长的时间来学习编程语言了。我自己就是一个受害者。
我花了十几年的时间学习各种编程语言。我学的越多,发现建立简单的东西就越难。我总有那么种感觉是我没找到合适的工具。但是,问题出在当我还没有意识到我要做的工作时,忘了寻找适合的工作而不是寻找适合的工具。
而且奇怪的一点是:编程语言总是在不断发展的。编程语言几乎每天都有所变化,我们很难跟上其步伐。可是,大多数优秀的程序只是使用了编程语言的一小部分。
学习编程语言的问题就好比在学习木工之前去学习如何使用木工锯,锤子和各种切割机器。木工需要注意:想法、可行性分析、测量、测试和用户行为。老木工对上面提到的注意点更感兴趣,而不是锤子和钉子。在对工作科学研究的期间,他还会花时间去检查钉子、着色板和木材等的质量。
学习编程和学习编程语言有什么区别呢
程序设置系统只需指令它一次就可以自由运行。我们每天都在做这件事情。我们告诉我们的孩子、士兵和顾客。我们给予他们或者我们自己接受到给定的指令去自由/独立地生活。比如,您的父母不需要每天都关注你并且对你人生要走的下一步做指导。他们本来可以在你生活的方方面面为你设定好。
很多学校和教育网站都会教你编程语言的语法。他们会添加些设计模式(当你忽略设计的时候),一些数学计算,如何声明变量并使用它们,数据类型以及如何声明/创建它们等的内容。
这些并不能教会你推理。通过上面的途径,你会学到些推理的方法,但是过不了多久,你会意识到自己浪费了或者花了很长时间去学习编程。
我们是通过编程解决问题,而编程语言只是协助我们的工具。编程语言就像一个个的工具盒,我们称它们为框架。它们帮助我们组织自己的想法。
如果你正在学习编程,但是你还不能够设计并且编码出一个实实在在的应用,那么说明你更多的是在学习编程语言而非编程。
有多少次我们碰到想知道怎么创建程序的人(程序员)。对于他们这些程序员来说,创建程序就是解决一个问题。他们在使用编程语言的时候就通过批判的分析解决了这个问题。但是当你解决了这个问题,你是可以使用多种编程语言去实现的。我们以平方数为例。某数的平方就是这个数字乘以本身。我们可以用各种语言来实现它,如下:
# c
function square(int * x) {
return x * x;
}# php
function square ($x){
return $x * $x;
}# javascript
function square(x){
return x * x
}# In Scheme (a Lisp dialect)
(define (square x) (* x x))以上,你可以看到在实现的上面只有语法的不同,结果是一样的。这也是你可以使用任何语言,这种语言使你轻松构建任何类型软件的一个重要原因。
通过编程发现语言更容易
问题通常是人类语言。人类语言充满了限制和错误,是不能用来指导机器工作的,因为机器接收不到。
学习编程的时候,你将学习一种新的术语和工具来帮助你编写逻辑方式,这种逻辑方式是被计算机和其他程序员理解并且认同的。
通常,你将从简单且类似人类语言的符号开始,称之为伪代码。它是从人类语言到计算机编程语言的良好过渡工具。这通常为了防止你浪费时间在语言上面。这样你可以关注在推理上面。如此,你会发现组成一个良好的编程工具(语言)的核心部分。你了解什么才是正需要的,了解编程语言的核心目标。通过了解,你会不知不觉下意识去学习这种语言了。
我无意在Reddit上找到了这个JavaScript meme,它是我见过最好的抽象。
你可以通过运行开发者工具来运行(图中)的每行代码来验证此关系的准确性。结果并不令人惊讶,但仍然令人失望。
当然,这个小实验触发了我的兴趣...
凭借经验,我学会了接受JavaScript这滑稽的一面,同时感受它的松散。尽管如此,这个事件的细节仍然让我感到困惑。
正如 Kyle Simpson所说...
"不管怎么说,我认为任何人都不会真正了解JS"
当这些案例出现时,最好查阅源代码--构建JavaScript的官方ECMAScript规范。
有了这个规范,让我们深刻理解这里发生了什么。
如果你在开发者控制台上运行0 == "0",为什么它返回true?
0是一个数字,然后"0"是一个字符串,它们永远不应该相同的!大多数编程语言都遵守它。例如,Java中的0 == "0",会返回下面这个:
error: incomparable types: int and String这很有道理。如果要比较Java中的int和String,必须先把它们转换为相同的类型。
但这是JavaScript,你们呀!
当你通过==比较两个值时,其中一个值可能受到强制转换。
强制 - 自动将值从一种类型转换为另一种类型。
这里的自动是关键词。JavaScript不是在显式转换你的类型,而是在幕后帮你完成。
如果你有目的地利用它,这很方便,但如果你不知道它的含义,则可能有害。
这是关于它的官方ECMAScript语言规范。 我会解释相关部分:
If x is Number and y is String, return x == ToNumber(y)
译:如果 x 是数字类型,y 是字符串类型,将 y 转换成数字类型与 x 作比较后返回
所以我们的例子0 == "0":
因为 0 是一个数字类型,"0" 是一个字符串类型,则返回 0 == ToNumber("0")
我们的字符串"0"已经被秘密转换成数字0,现在我们有一个匹配了!
0 == "0" // true
// The second 0 became a number!
// so 0 equals 0 is true....奇怪吧?好好习惯它,我们接着说~
这种强制不仅仅限制于字符串,数字或布尔值等基本数据类型。这是我们的下一个比较:
0 == [] // true
// What happened...?再次被强制了!我将解释规范的相关部分:
If x is String or Number and y is Object, return x == ToPrimitive(y)
译:如果 x 是字符串或数字类型,然后 y 是对象类型,将 y 转换为基本数据类型与 x 作比较后返回
这里有三件事:
抱歉,刷新了你的认知。
再次根据规范,JS首先寻找一个对象的toString方法来强制转换它。
在数组的情况下,toString连接其所有元素并将它们作为字符串返回。
[1, 2, 3].toString() // "1,2,3"
['hello', 'world'].toString() // "hello,world"因为我们的数组是空的,我们没内容去拼接!所以...
[].toString() // ""规范中的ToPrimitive将空数组转换成空字符串。相关的参考在这里和这里,方便你查阅(或解决疑惑)。
你不能把这些东西搞定。现在我们已经将数组强制变成"",我们又回到了第一个算法(规范)...
If x is Number and y is String, return x == ToNumber(y)
所以0==""
Since 0 is Number and "" is String, return 0 == ToNumber("")
ToNumber("")返回 0 。
因此,再一次是0==0...
0 == "0" // true因为被强制转换成这个0 == ToNumber("0")。
0 == [] // true因为强制转换执行两次:
ToPrimitive([])转换为空字符串ToNumber("")转换为 0 。所以,告诉我...根据上面的规则,下面将返回什么?
"0" == []FALSE! 正确。
如果你明白规则,这部分是有意义的。
下面是我们的比较:
"0" == [] // false再次参考规范:
If x is String or Number and y is Object, return x == ToPrimitive(y)
那就意味着...
Since "0" is String and [] is Object, return x == ToPrimitive([])
"0" == """0"和""都是字符串类型,所以JavaScript不需要再强制转换了。这就是为什么得到结果为false的原因。
使用三重等号(===),然后晚上睡个好觉。
0 === "0" // false
0 === [] // false
"0" === [] // false它完全避免强制转换,所以我猜它也更有效率!
但是('==='对于)性能的提升几乎毫无意义。真正的胜利是你在代码中增加的信心,使得额外的击打键盘完全值得。
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
你决定学习框架x,你打开youtube或任何搜索引擎,搜索与x框架相关的任何教程,并在30分钟之后突然发出"Eureka"(高兴地表现)的尖叫--我认为这个框架类似自己之前学过的框架。你是对的,你不必要从头开始学习它。在这篇文章中,我将向你展示我学习前端框架的经验以及这些框架如何彼此相似的。
每次你决定学习前端框架时,你定会反复听到这些术语(组件,路由和管理状态/状态管理)。
下面我们逐步了解下:
任何框架的核心都是以创建组件来达到复用的目的。如今,大多数现代框架都使用JSX或HTML模版引擎,生命周期钩子--提供生命瞬间可见性,比如创建,渲染,注销以及它们发生时的行为能力。
如今,大多数现代框架都提供API来创建和管理客户端路由。
有时,你的数据必须在组件之间共享,推荐的方法是使其成为中心(中转站)。
现在,所有框架都提供API来管理你的状态(例如Angular有一个Service,React现在有Context API)以及当你的数据规模变大之后,你可以考虑使用像redux这样的库。
完成基础学习之后,我们来亲自动手并创建项目。
为了理解事物的某些方面,你需要很好地了解它,这些知识(获取)不是仅仅来自阅读书籍或者观看视频课程。在这篇文章中,真实的测试伴随着现实中的真正问题,会带给你些启发,并应用在你选择的任何前端框架的项目中。
笔记:
常用的首个应用是使用其公共的API来模仿任何已知站点,尝试构建一个带下拉列表的搜索栏,来保存来自端点API的结果,检查其返回的数据,然后再显示它,就像有张图像一样(显示)或不显示。
端点API示例:
你将学到:
HTTP客户端向端点API发起请求API获取结果数据我在上一节中提到的一些端点API(可能)需要一些身份验证,因此在这一节中尝试添加或构建另一个带有登陆/注册页面的应用程序。如果用户登陆了,则将他/她重定向到用户主页,并阻止访客用户访问(主页),因为这需要用户登陆的。
你将学到:
增删查改的应用程序是本节中最受欢迎的前端应用程序,你可以使用本地存储或者使用在线服务(如Firebase)来构建此应用程序,甚至将它与后端框架集成在一起。
项目实例:
你将学到:
put、delete、post和get的HTTP请求auth功能在前面的章节中,对后端的所有请求都是单向的,你在管理应用程序状态时没有问题。但在本节中,我们尝试使用web sockets来构建聊天应用程序,它是双向的,我们不能(总是)等待响应来更新视图,我们需要另一种方法来管理我们的客户端状态。
你将学到:
学习如何使用管理状态解决方案,如redux for react, ngrx for angular 2+ 或 vuex for vuejs以及如何将其与客户端应用程序集成
使你的应用更灵活(接收网络状态并通知用户新消息)
原文:https://dev.to/imm9o/how-i-learn-any-front-end-framework-29a2
在JavaScript中,如果想要改变当前函数调用的上下文对象的时候,我们都会联想到call、apply和bind。比如下面👇
var name = 'window name';
var obj = {
name: 'call_me_R'
};
function sayName(){
console.log(this.name);
}
sayName(); // window name
sayName.call(obj); // call_me_R那么,call, apply和bind有什么区别呢?
在说区别之前,先简单的说下三者的共同之处吧:
下面说下区别:
call方法传参是传一个或者是多个参数,第一个参数是指定的对象,如开篇的obj。
func.call(thisArg, arg1, arg2, ...)apply方法传参是传一个或两个参数,第一个参数是指定的对象,第二个参数是一个数组或者类数组对象。
func.apply(thisArg, [argsArray])bind方法传参是传一个或者多个参数,跟call方法传递参数一样。
func.bind(this.thisArg, arg1, arg2, ...)简言之,call和bind传参一样;apply如果要传第二个参数的话,应该传递一个类数组。
call和apply在函数调用它们之后,会立即执行这个函数;而函数调用bind之后,会返回调用函数的引用,如果要执行的话,需要执行返回的函数引用。
变动下开篇的demo代码,会比较容易理解:
var name = 'window name';
var obj = {
name: 'call_me_R'
};
function sayName(){
console.log(this.name);
}
sayName(); // window name
sayName.call(obj); // call_me_R
sayName.apply(obj); // call_me_R
console.log('---divided line---');
var _sayName = sayName.bind(obj);
_sayName(); // call_me_R在笔者看来,call, apply 和 bind的区分点主要是上面的这两点,欢迎有想法的读者进行补充~😊
这里是简单的实现下相关方法的封装,为了简洁,我这里尽量使用了ES6的语法进行编写,详细的参考代码可以直接戳airuikun大牛的airuikun/Weekly-FE-Interview issues。
在上面的了解中,我们很清楚了call的传参格式和调用执行方式,那么就有了下面的实现方法:
Function.prototype.call2 = function(context, ...args){
context = context || window; // 因为传递过来的context有可能是null
context.fn = this; // 让fn的上下文为context
const result = context.fn(...args);
delete context.fn;
return result; // 因为有可能this函数会有返回值return
}我们来测试下:
var name = 'window name';
var obj = {
name: 'call_me_R'
};
// Function.prototype.call2 is here ...
function sayName(a){
console.log(a + this.name);
return this;
}
sayName(''); // window name
var _this = sayName.call2(obj, 'hello '); // hello call_me_R
console.log(_this); // {name: "call_me_R"}apply方法和call方法差不多,区分点是apply第二个参数是传递数组:
Function.prototype.apply2 = function(context, arr){
context = context || window; // 因为传递过来的context有可能是null
context.fn = this; // 让fn的上下文为context
arr = arr || []; // 对传进来的数组参数进行处理
const result = context.fn(...arr); // 相当于context.fn(arguments[1], arguments[2], ...)
delete context.fn;
return result; // 因为有可能this函数会有返回值return
}
同样的,我们来测试下:
var name = 'window name';
var obj = {
name: 'call_me_R'
};
// Function.prototype.apply2 is here ...
function sayName(){
console.log((arguments[0] || '') + this.name);
return this;
}
sayName(); // window name
var _this = sayName.apply2(obj, ['hello ']); // hello call_me_R
console.log(_this); // {name: "call_me_R"}bind的实现和上面的两种就有些差别,虽然和call传参相同,但是bind被调用后返回的是调用函数的指针。那么,这就说明bind内部是返回一个函数,思路打开了:
Function.prototype.bind2 = function(context, ...args){
var fn = this;
return function () { // 这里不能使用箭头函数,不然参数arguments的指向就很尴尬了,指向父函数的参数
fn.call(context, ...args, ...arguments);
}
}我们还是来测试一下:
var name = 'window name';
var obj = {
name: 'call_me_R'
};
// Function.prototype.bind2 is here ...
function sayName(){
console.log((arguments[0] || '') + this.name + (arguments[1] || ''));
}
sayName(); // window name
sayName.bind2(obj, 'hello ')(); // hello call_me_R
sayName.bind2(obj, 'hello ')('!'); // hello call_me_R!美滋滋😄,成功地简单实现了call、apply和bind的方法,那么你可能会对上面的某些代码有疑问❓
1. 问:call中为什么说 context.fn = this; // 让fn的上下文为context 呢?
答:
我们先来看看下面这段代码--
var name = 'window name';
var obj = {
name: 'call_me_R',
sayHi: function() {
console.log('Hello ' + this.name);
}
};
obj.sayHi(); // Hello call_me_R
window.fn = obj.sayHi;
window.fn(); // Hello window name嗯,神奇了一丢丢,操作window.fn = obj.sayHi;改变了this的指向,也就是this由指向obj改为指向window了。
简单来说:this的值并不是由函数定义放在哪个对象里面决定的,而是函数执行时由谁来唤起来决定的。
2. 问:bind中返回的参数为什么是传递(context, ...args, ...arguments), 而不是(context, ...args)呢?
答:
这是为了包含返回函数也能传参的情况,也就是bind()()中的第二个括号可以传递参数。
据调查--call和apply的性能对比,在分不同传参的情况下,call的性能是优于apply的。不过在现代的高版本浏览器上面,两者的差异并不大。
而在兼容性方面,两者都好啦,别说IE了哈。
在使用的方面还是得按照需求来使用call和apply,毕竟技术都在更新。适合业务的就是最好的~囧
airuikun/Weekly-FE-Interview issues
《JavaScript高级程序设计》
作为一个编码者,意味着你需要搜索你问题的答案。通过有效地使用谷歌,你将节省很多开发时间。
最好让你的团队知道一项任务将花费三周的时间,并以两种方式交付的事情。通过给予承诺和过度交付,你将建立信任。
设计师提供解决用户痛点的方案。向他们学习,并凝聚力地建立有效的产品。
找一个你可以学习的人并从中吸取灵感。如果你需要技术导师,Coding Coash是一个开始的好地方。
成为别人可以学习并从中吸取灵感的导师。你可以通过Coding Coash成为导师。
写注释解析“为什么”而不是“什么”。
函数和变量应该准确地表示它们的用途,因此myCoolFunction不友好。
我们都需要时间去解压。去你想去的那趟旅游,有助于大脑的放松😌。你同事也会感谢你的~
没理由积累更多的技术债务。
阅读代码是一种被低估的技能,但却是一种非常宝贵的技能。
长时间工作后你,你需要时间进行解压。关闭工作通知,从手机中删除(相关)引用程序。
可以通过电子邮件或Slack消息解决吗?如果可以,请避免开会。如果不能,请注意开发的持续时间,直击目标事件。
配对程序允许你扮演教师和学生的角色。
通过简洁明了的邮件内容来捕获受众眼球。没人想读你四页纸的电子邮件。
与志同道合的人一起,会激励你走出低谷。
清理你的版本控制的分支,就像你在你亲戚到来前清理你的房子一样。如果你不需要它(东西),丢弃它;请不要把它扔在壁柜里。
要包容。不要告诉别人他们不够好,不能进入进入这个行业。每个人都有价值。
你选择了一门需要不断学习的专业。学会爱它!
事情不总是那么容易。但我们都是在同一个地方开始。你能行的。
如果它吓不到你,它不会帮助你成长的。
在深入研究代码之前,你应该了解验收标准。它将为你节省时间和精力。
拥有一套内部和外部都知道的工具。了解哪些工具可以用于哪个目的以及项目何时可以从一个项目中获益。
向受信任的同事和朋友获取建设性的批评。这将帮助你成长为优秀的程序员和人。
技术发生改变,而且变化频繁。不要反对新技术;学习它,然后形成一个意见。
通过关注出版物,博客,播客和科技新闻,及时了解最新的科技新闻。
强大的解决问题能力可以解决任何问题。坚持解决问题所需的一切。
不管你是什么职位或你为什么公司服务,都要保持谦逊。
了解如何吸引观众并进行有效的演讲/演示。
不要直接进入第一个可能的解决方案。在深入研究代码之前,检查所有的路径。
科技行业内有许多部门。找到你最感兴趣的领域并成为这个领域的专家。
尝试去建立一致且健康的习惯,例如消除分心,时间懒散任务,出席会议,以及首先从最重要的任务开始。者可能需要一些时间来适应,但是从长远来看是值得的。
查看浏览器的调试工具。了解IDE的调试细节。通过学习调试问题和跟踪错误的最有效方法,你将能够解决最困难的错误。
仅仅因为你现在知道一项技能并不意味着你不应该练习它。除非有意识地改进,否则技能会随着时间的推移逐渐消失。而且这个行业发展如此迅速,继续练习也是很重要。摆脱“我一直都是这样做”的心态,并进入“有更好的方法来做到这一点吗?”的思维方式。
仅仅因为你现在有六包的饼干🍪,但并意味着你可以每天吃一包饼干🍪并保持这种状态。
有时你必须表达你的意见,因此了解其背后的原因非常重要。为什么解决方案A比解决方案B更好?提供有效的论据,你的意见将更加健全,容易被接受。
你就是一种商品,应该得到适当的报酬。请注意你所在的地理位置的行业平均价值。如果你赚的钱少了,就该和你的经理聊聊了。追求你应得的。
如果你遇到问题并且花费太多的时间寻找解决方案,那么是时候寻求帮助了。我们都是人,我们都需要帮助。与同事联系以寻求支持并不可耻。
人们以不同的方式学习。有些人通过视频教程学习最好,有些人则通过阅读书籍。弄清楚你的学习风格并努力学习。
有时候你会被要求提供对某同事的反馈。请善待他人。你可以表达你对这位同事缺乏主动性的看法,而不要把TA说得一无是处。
连续8小时的编码几乎是不可能的。你会很快倦怠并犯下很多错误。所以设置一个计时器,提醒自己停下来休息一下。出去走走,和同事一起喝杯咖啡。离开屏幕将对你的工作效率和工作质量产生积极影响。
编码需要时间,当你看不到进展时会非常沮丧。因此,跟踪你的成就和实现目标的进展很重要。在电脑旁边保留一个小清单,每次实现某些功能时,请将其写下来,无论多小。小成就合成大奖励。
了解语言的细节比了解框架和库的细节来得重要。你不一定需要学习一个接一个框架或库,但是理解框架和库的工作方式将有助你编写更清晰、高效的代码。
让某人阅读并分析你的代码可能令人恐惧,但可以为你提供宝贵的反馈,这将使你成为更好的程序员。你也应该努力进行良好的代码审核。
了解有关切向空间的一些基础知识,例如设计,市场营销,前端开发或后端开发。它将帮助你成为一个更全面的程序员。
每个项目都有不同的需求,因此我们必须为工作选择合适的工具。虽然选择以前使用过的技术很舒服😌,但是如果它们不适合项目的需求,则应该探索替代的方案。
所有人都会犯错,在整个职业生涯中你会遇到很多错误。因此,当你犯错误时,勇于承担责任很是重要的。这会帮你和团队成员以及管理层建立信任。
在拉取代码之前,请查看你自己的代码。如果这是同事的工作,你会发表什么评论?在请求代码评审之前首先尝试诊断问题或错误非常重要。
失败的根本就是没有达到预期的效果,但这并不是件坏事。在我们的职业生涯中,我们都有很多失败。了解你失败的原因,你下次会有什么不同的做法?
了解你自己。你的弱点是什么?也许你总是忘记在推送之前更新测试。也许你回复电子邮件真的很糟糕。了解你的弱点,以便你可以积极地解决这些问题。
这个行业不断发展,所以好奇心很重要。如果你不了解某些内容,无论是项目要求还是一行代码,请说出来。没人会批评你要求澄清。这会有助你创建更好的代码。
世上有无尽的知识,根本无法征服它们。选择几个主题来掌握,剩下的就算了。你可以获取有关其他领域的工作或切向知识,但是你无法掌握所有内容。
仅仅因为你写了一些代码,并不意味着你需要在情感上附加它。没有人喜欢他们的工作被抛弃,但是代码有一个生命周期,所以没有必要对它有所了解。
优秀的团队拥有彼此的支持。这创建了一个安全的空间来尝试新事物,而不必担心报复。
找一些你佩服的行业人士。它将激励你接着处理你的项目或尝试新事物。
无论你拥有多少经验或你的职位是什么,你的工作都有价值。给它应有的价值。
关闭Slack通知,短信,电子邮件和社交媒体将帮助你集中精力最大化你的工作日。Jerry如果需要30分钟回复他的消息,将不会奔溃。
尝试并支持你的团队成员,无论是参加重要演示还是帮助他们,如果他们遇到困难。
如果有人做得很好,请告诉他们。积极的重新执行是与团队成员建立信任并帮助他们的职业生涯的好方法。他们也有可能帮助到你。
测试很重要。单元测试,回归测试,集成测试,端到端测试,测试你的代码,你的产品将更加稳定。
当你收到新功能请求或获取新的错误提示时,请先计划出方案。你需要什么来解决这个问题或开发次功能呢?即使只需要几分钟来计划攻击,也可以节省数小时的挫败感。
伪编码是一项非常棒的技能,因为它允许你在不浪费时间编写代码行的情况下思考复杂的问题。在纸上写下一个方法,运行不同的测试用例并查看陷阱的位置。
如果你在工作中获奖,请将其写下来。如果你开发了一个关键功能,请将其写下来。你会创造积压的东西,帮助你促进或在艰难的一天鼓舞士气。
学习一些基本的排序或搜索算法和数据结构。这些是与语言无关的,可以帮助你解决跨语言的问题。
虽然测试最新技术很有趣,但选择那些在企业应用程序中易于维护的技术。你的团队将在未来几年内感谢你。
设计模式是构建代码的有用工具。你可能不需要为每个项目使用它们,但对它们有基本的了解将有助于构建更大的应用程序。
编写可读性和简单性的代码,而不是为了显示你时髦的编程技巧编写复杂的代码。这将使得你的团队成员更容易贡献。
技术债务可能会产生巨大的性能影响,所以如果你能够重构,你就应该重构。
频繁的使用小的更改日志,而不是每月进行一次大规模升级。这样你不太可能引入错误和破环更改状态。
尽早和经常提交,是确保你工作保持清洁,并减少意外恢复重要变化的压力的最佳方法。
你不仅不应该害怕寻求帮助,而且你还应该学会何时寻求帮助。在寻求帮助之前,你应该始终尝试解决问题,并跟踪你的事情。但是,当你被一个简单的问题困扰了一个多小时,成本就超出了收益,此时你应该寻求一位同事的帮助。
在提出问题时,尽量做到具体。
你的工作不一定等到完成了才去反馈。如果你不确定方向,请让可信赖的同事检查你的解决方案的有效性。
文档是关于技术的最纯粹的真实涞源,因此学习阅读它可以帮你快速成为专家。
没有什么能阻止你尝试解决问题。你有什么损失嘛?
你的想法和意见很有价值,因此参加会议将有助于你与团队和管理层建立良好关系。
在公司,如果你获得了个和另一个团队合作的机会,请抓住它。
当你每周工作40个小时时,为激情项目花些时间是很重要的。它们可以帮助你重新激发对编码的热爱,并尝试在工作中无法访问的技术。
了解自己职业生涯的理想轨迹非常重要。如果你不这样做,你就试图在没有目标的情况下射箭。
评论博客,参与Twitter主题。与社区互动。作为一个活跃的旁观者而不是墙花,你将学到很多东西。
学会确定任务的优先顺序将有助你提高工作效率。保持即时日常的任务和长期任务的活跃待办事项列表,并按最重要的顺序排序。
细节在项目中有大作用。
你的队友被雇佣了他们的技能。使用它们并相信它们可以完成工作。
如果你处于领导的地位,请学习如何有效的委派。这将为你节省时间和减轻挫败感。你一个人无法做到这一切。
你应该唯一比较的一件事情就是昨天的你是谁。
学习编程是一个漫长而且不总是简单的旅行。和志同道合的人一起,他们会鼓励你继续前进。
规模性开始是一种不可救药的方式。在构建时考虑了可伸缩性,但在需要之前不要开始扩展。这样你就不会因为不必要的臃肿而压倒你的团队,但你保持了成长的能力。
如果你想使用一种很酷的新技术,你应该权衡这样做的性能影响。你可以实现类似的东西而不受到性能影响吗?如果是这样,你可能需要重新考虑你的方法了。
不要歧视新技术或新想法。对于学习新技能的可能性持开放态度。也不要歧视别人。我们都值得尊重。
你永远不会满足工作的每一项要求。所以抓住机会申请!你有什么损失?
你可以在一个长文件中编写所有代码,但这不可维护。通过模块化,我们确保我们的代码易于消化和测试。
如果你要从Stack Overflow复制并粘贴解决方案,你应该准确理解它的作用。关注你选择引入的代码。
如果你喜欢自己的工作空间和技术设置,那你将更有动力去工作。自己去创建吧!
我们都是从同一个地方开始。随着你的技能和职称的发展,请不要忘记你来自哪里。
如果某些东西搞砸了,尝试保持积极向上。明天又是新的一天。乐观有助你的团队充满活力和你的心理健康。
仅仅因为某些东西现在起作用并不意味着它总是如此。重新评估你的工作流程并及时进行调整。
如果你有能力在家工作,请学会有效的工作。找一个单独的办公空间,不分心。Boneskull写了一篇关于在家工作的好文章,你应该看看。
可访问性不是事后的想法,也不一定非常困难。每个人都应该可以使用你的产品。
如果你告诉别人你将在某个特定的日期之前交付一些东西,那么就要履行这一承诺。如果你无法在截止日期前完成,请尽早说出来。
如果你有一些额外的带宽,找一个任务来帮助你的团队!他们会因为你的主动性而感激你。
一个伟大的投资组合让你与众不同。使用它作为展示你的编码和设计技巧的机会。
你进入这个行业是因为它引起了你的兴趣。如果你感到沮丧和怨恨,请休息一下。给自己留出空间,重新点燃你对编码的热情。
如果你学到了很酷的东西,请分享吧!出席当地的聚会或会议。在午餐期间教你的同事或被指导。分享你的知识可以增长你的知识,同时传播财富。
嗯~全部了!我希望你喜欢我这篇成为优秀程序员(和人类)秘诀的文章!
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
你是否遇到过"callbacks"一词,但是不知道这意味着什么?别着急。你不是一个人。许多JavaScript的新手发现回调也很难理解。
尽管callbacks可能令人疑惑,但是你仍然需要彻底了解它们,因为它们是JavaScript中的一个重要的概念。如果你不知道callbacks,你不可能走得很远🙁。
这就是今天的文章(要讲的)!你将了解callbacks是什么,为什么它们很重要,以及如何使用它们。😄
备注:你会在这篇文章中看到ES6箭头函数。如果你不是很熟悉它们,我建议你在往下读之前复习一下ES6这篇文章(只了解箭头函数部分就可以了)。
callback是作为稍后要执行的参数传递给另一个函数的函数。(开发人员说你在执行函数时“调用”一个函数,这就是被命名为回调函数的原因)。
它们在JavaScript中很常见,你可能自己潜意识的使用了它们而不知道它们被称为回调函数。
接受函数回调的一个示例是addEventLisnter:
const button = document.querySelector('button')
button.addEventListener('click', function(e) {
// Adds clicked class to button
this.classList.add('clicked')
})看不出是回调函数吗?那么,这种写法怎样?
const button = document.querySelector('button')
// Function that adds 'clicked' class to the element
function clicked (e) {
this.classList.add('clicked')
}
// Adds click function as a callback to the event listener
button.addEventListener('click', clicked)在这里,我们告诉JavaScript监听按钮上的click事件。如果检测到点击,则JavaScript应触发clicked函数。因此,在这种情况下,clicked是回调函数,而addEventListener是一个接受回调的函数。
现在,你明白什么是回调函数了嘛?:)
我们来看另外一个例子。这一次,假设你希望通过过滤一组数据来获取小于5的列表。在这里,你将回调函数传递给filter函数:
const numbers = [3, 4, 10, 20]
const lesserThanFive = numbers.filter(num => num < 5)现在,如果你想通过命名函数执行上面的代码,则过滤函数将如下所示:
const numbers = [3, 4, 10, 20]
const getLessThanFive = num => num < 5
// Passing getLessThanFive function into filter
const lesserThanFive = numbers.filter(getLessThanFive)在这种情况下,getLessThanFive是回调函数。Array.filter是一个接受回调的函数。
现在明白为什么了吧?一旦你知道回调函数是什么,它们就无处不在!
下面的示例向你展示如何编写回调函数和接受回调的函数:
// Create a function that accepts another function as an argument
const callbackAcceptingFunction = (fn) => {
// Calls the function with any required arguments
return fn(1, 2, 3)
}
// Callback gets arguments from the above call
const callback = (arg1, arg2, arg3) => {
return arg1 + arg2 + arg3
}
// Passing a callback into a callback accepting function
const result = callbackAcceptingFunction(callback)
console.log(result) // 6请注意,当你将回调函数传递给另一个函数时,你只传递该函数的引用(并没有执行它,因此没有括号())
const result = callbackAcceptingFunction(callback)你只能在callbackAcceptingFunction中唤醒(调用)回调函数。执行此操作时,你可以传递回调函数可能需要的任意数量的参数:
const callbackAcceptingFunction = (fn) => {
// Calls the callback with three args
fn(1, 2, 3)
}这些由callbackAcceptingFunction传递给回调函数的参数,然后再通过回调函数(执行):
// Callback gets arguments from callbackAcceptingFunction
const callback = (arg1, arg2, arg3) => {
return arg1 + arg2 + arg3
}这是回调的解剖。现在,你应该知道addEventListener包含一个event参数:)
// Now you know where this event object comes from! :)
button.addEventListener('click', (event) => {
event.preventDefault()
})唷!这是callbacks的基本思路!只需要记住其关键:将一个函数传递给另一个函数,然后,你会想起我上面提到的机制。
旁注:这种传递函数的能力是一件很重要的事情。它是如此重要,以至于说JavaScript中的函数是高阶函数。高阶函数在编程范例中称为函数编程,是一件很重大的事情。
但这是另一天的话题。现在,我确信你已经开始明白callbacks是什么,以及它们是如何被使用的。但是为什么?你为什么需要callbacks呢?
回调函数以两种不同的方式使用 -- 在同步函数和异步函数中。
如果你的代码从上到下,从左到右的方式顺序执行,等待上一个代码执行之后,再执行下一行代码,则你的代码是同步的。
让我们看一个示例,以便更容易理解:
const addOne = (n) => n + 1
addOne(1) // 2
addOne(2) // 3
addOne(3) // 4
addOne(4) // 5在上面的例子中,addOne(1)首先执行。一旦它执行完,addOne(2)开始执行。一旦addOne(2)执行完,addOne(3)执行。这个过程一直持续到最后一行代码执行完毕。
当你希望将部分代码与其它代码轻松交换时,回调将用于同步函数。
所以,回到上面的Array.filter示例中,尽管我们将数组过滤为包含小于5的数组,但你可以轻松地重用Array.filter来获取大于10的数字数组:
const numbers = [3, 4, 10, 20]
const getLessThanFive = num => num < 5
const getMoreThanTen = num => num > 10
// Passing getLessThanFive function into filter
const lesserThanFive = numbers.filter(getLessThanFive)
// Passing getMoreThanTen function into filter
const moreThanTen = numbers.filter(getMoreThanTen)这就是为什么你在同步函数中使用回调函数的原因。现在,让我们继续看看为什么我们在异步函数中使用回调。
这里的异步意味着,如果JavaScript需要等待某些事情完成,它将在等待时执行给予它的其余任务。
异步函数的一个示例是setTimeout。它接受一个回调函数以便稍后执行:
// Calls the callback after 1 second
setTimeout(callback, 1000)如果你给JavaScript另外一个任务需要完成,让我们看看setTimeout是如何工作的:
const tenSecondsLater = _ = > console.log('10 seconds passed!')
setTimeout(tenSecondsLater, 10000)
console.log('Start!')在上面的代码中,JavaScript会执行setTimeout。然后,它会等待10秒,之后打印出"10 seconds passed!"的消息。
同时,在等待setTimeout10秒内完成时,JavaScript执行console.log("Start!")。
所以,如果你(在控制台上)打印上面的代码,这就是你会看到的:
// What happens:
// > Start! (almost immediately)
// > 10 seconds passed! (after ten seconds)啊~异步操作听起来很复杂,不是吗?但为什么我们在JavaScript中频繁使用它呢?
要了解为什么异步操作很重要呢?想象一下JavaScript是你家中的机器人助手。这个助手非常愚蠢。它一次只能做一件事。(此行为被称为单线程)。
假设你告诉你的机器人助手为你订购一些披萨。但机器人是如此的愚蠢,在打电话给披萨店之后,机器人坐在你家门前,等待披萨送达。在此期间它无法做任何其它事情。
你不能叫它去熨衣服,拖地或在等待(披萨到来)的时候做任何事情。(可能)你需要等20分钟,直到披萨到来,它才愿意做其他事情...
此行为称为阻塞。当你等待某些内容完成时,其他操作将被阻止。
const orderPizza = flavour => {
callPizzaShop(`I want a ${flavour} pizza`)
waits20minsForPizzaToCome() // Nothing else can happen here
bringPizzaToYou()
}
orderPizza('Hawaiian')
// These two only starts after orderPizza is completed
mopFloor()
ironClothes()而阻止操作是一个无赖。🙁
为什么?
让我们把愚蠢的机器人助手放到浏览器的上下文中。想象一下,当单击按钮时,你告诉它更改按钮的颜色。
这个愚蠢的机器人会做什么?
它专注于按钮,忽略所有命令,直到按钮被点击。同时,用户无法选择任何其他内容。看看它都在干嘛了?这就是异步编程在JavaScript中如此重要的原因。
但是,要真正了解异步操作期间发生的事情,我们需要引入另外一个东西 -- 事件循环。
为了设想事件循环,想象一下JavaScript是一个携带todo-list的管家。此列表包含你告诉它要做的所有事情。然后,JavaScript将按照你提供的顺序逐个遍历列表。
假设你给JavaScript下面五个命令:
const addOne = (n) => n + 1
addOne(1) // 2
addOne(2) // 3
addOne(3) // 4
addOne(4) // 5
addOne(5) // 6这是JavaScript的待办事项列表中出现的内容。
相关命令在JavaScript待办事项列表中同步出现。
除了todo-list之外,JavaScript还保留一个waiting-list来跟踪它需要等待的事情。如果你告诉JavaScript订购披萨,它会打电话给披萨店并在等候列表名单中添加“等待披萨到达”(的指令)。与此同时,它还会做了其他已经在todo-list上的事情。
所以,想象下你有下面代码:
const orderPizza (flavor, callback) {
callPizzaShop(`I want a ${flavor} pizza`)
// Note: these three lines is pseudo code, not actual JavaScript
whenPizzaComesBack {
callback()
}
}
const layTheTable = _ => console.log('laying the table')
orderPizza('Hawaiian', layTheTable)
mopFloor()
ironClothes()JavaScript的初始化todo-list如下:
订披萨,拖地和熨衣服!😄
然后,在执行orderPizza时,JavaScript知道它需要等待披萨送达。因此,它会在执行其余任务时,将“等待披萨送达”(的指令)添加到waiting list上。
JavaScript等待披萨到达
当披萨到达时,门铃会通知JavaScript,当它完成其余杂务时。它会做个**心理记录(mental note)**去执行layTheTable。
JavaScript知道它需要通过在其 mental note 中添加命令来执行
layTheTable
然后,一旦完成其他杂务,JavaScript就会执行回调函数layTheTable。
其他所有内容完成后,JavaScript就会去布置桌面(layTheTable)
我的朋友,这个就被称为事件循环。你可以使用事件循环中的实际关键字替换我们的管家,类比来理解所有的内容:
JavaScript的事件循环
如果你有20分钟的空余时间,我强烈建议你观看Philip Roberts 在JSconf中谈论的事件循环。它将帮助你理解事件循环的细节。
哦~我们在事件循环绕了一大圈。我们回正题吧😂。
之前,我们提到如果JavaScript专注于按钮并忽略所有其他命令,那将是不好的。是吧?
通过异步回调,我们可以提前提供JavaScript指令而无需停止整个操作。
现在,当你要求JavaScript查看点击按钮时,它会将“监听按钮”(指令)放入waiting list中并继续进行杂务。当按钮最终获得点击时,JavaScript会激活回调,然后继续执行。
以下是回调中的一些常见用法,用于告诉JavaScript要做什么...
addEventListener)jQuery.ajax)fs.readFile)// Callbacks in event listeners
document.addEventListener(button, highlightTheButton)
document.removeEventListener(button, highlightTheButton)
// Callbacks in jQuery's ajax method
$.ajax('some-url', {
success (data) { /* success callback */ },
error (err) { /* error callback */}
});
// Callbacks in Node
fs.readFile('pathToDirectory', (err, data) => {
if (err) throw err
console.log(data)
})
// Callbacks in ExpressJS
app.get('/', (req, res) => res.sendFile(index.html))这就是它(异步)的回调!😄
希望你清楚callbacks是什么以及现在如何使用它们。在开始的时候,你不会创建很多回调,所以要专注于学习如何使用可用的回调函数。
现在,在我们结束(本文)之前,让我们看一下开发人员(使用)回调的第一个问题 -- 回调地狱。
回调地狱是一种多次回调相互嵌套的现象。当你执行依赖于先前异步活动的异步活动时,可能会发生这种情况。这些嵌套的回调使代码更难阅读。
根据我的经验,你只会在Node中看到回调地狱。在使用前端JavaScript时,你几乎从不会遇到回调地狱。
下面是一个回调地狱的例子:
// Look at three layers of callback in this code!
app.get('/', function (req, res) {
Users.findOne({ _id:req.body.id }, function (err, user) {
if (user) {
user.update({/* params to update */}, function (err, document) {
res.json({user: document})
})
} else {
user.create(req.body, function(err, document) {
res.json({user: document})
})
}
})
})而现在,你有个挑战 -- 尝试一目了然地破译上面的代码。很难,不是吗?难怪开发者在看到嵌套回调时会不寒而栗。
克服回调地狱的一个解决方案是将回调函数分解为更小的部分以减少嵌套代码的数量:
const updateUser = (req, res) => {
user.update({/* params to update */}, function () {
if (err) throw err;
return res.json(user)
})
}
const createUser = (req, res, err, user) => {
user.create(req.body, function(err, user) {
res.json(user)
})
}
app.get('/', function (req, res) {
Users.findOne({ _id:req.body.id }, (err, user) => {
if (err) throw err
if (user) {
updateUser(req, res)
} else {
createUser(req, res)
}
})
})更容易阅读了,是吧?
还有其他解决方案来对抗新版JavaScript中的回调地狱 -- 比如promises和async / await。但是,解释它们是我们另一天的话题。
今天,你了解到了回调是什么,为什么它们在JavaScript中如此重要以及如何使用它们。你还学会了回调地狱和对抗它的方法。现在,希望callbakcs不再吓到你了😉。
你对回调还有任何疑问吗?如果你有,请随时在下面发表评论,我会尽快回复你的。【PS:本文译文,若需作者解答疑问,请移步原作者文章下评论】
感谢阅读。这篇文章是否帮助到你?如果有,我希望你考虑分享它。你可能会帮助到其他人。非常感谢!
下一篇文章关于 promises
ES6可以说是一个泛指,指5.1版本以后的JavaScript的下一代标准,涵盖了ES2015,ES2016,ES2017等;亦指下一代JavaScript语言。
嗯~ES6的语法有什么好谈的,无聊了吧?
确实,语法糖的东西真的是学起来如嚼蜡 -- 淡无味;但是要用别人的东西来开发的,你学还是学呢?
所以,还是简单谈下吧...
本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为上篇。
var是之前就有的了,在这里提出来主要是为了比较其和let与const。
1. 块级作用域
for(var i = 0; i < 3; i++) {
setTimeout(() => {
console.log(i); // 输出3个3
}, 0)
}解析:变量i是var声明的,在全局范围内是都有效,全局只有一个变量i。每次循环,变量的值会发生改变。循环内的i是指向全局的i。
for(let i = 0; i < 3; i++) {
setTimeout(() => {
console.log(i); // 输出0, 1, 2
}, 0)
}解析:变量i是let声明的,当前的i只在本轮循环有效,所以每次循环的i其实都是一个新变量。JavaScript引擎内部会记住上一轮的值,初始化本轮的变量i时,就在上一轮循环的基础上进行计算。
2. 不存在变量提升
console.log(a); // undefined
var a = 100;var命令会发生变量提升现象,即变量可以在声明之前使用,值为undefined;而let纠正了这种行为,不能产生变量提升。
console.log(a); // 报错
let a = 100;3. 暂时性死区
只要块级作用域内,存在let命令,它所声明的变量就绑定(binding)在这个区域,不再受外部影响。
如:
var temp = 123;
if(true) {
temp = 'abc'; // 引入错误
let temp;
}在上面中,if后面的大括号内容就形成了一个区域。而temp此时是找不到外层的,因为内部有个temp且你在内部let temp声明前赋值了。
在看一个隐晦的例子:
function bar(x = y, y = 2) {
return [x, y]
}
bar(); // 报错在上面的例子中bar里面进行赋值操作的时候,就产生了一个封闭的区域了,可以认为x 和 y通过let声明,可是上面的问题是,x = y的引用在y = 2的声明之前。
可以修正如下:
function bar(y = 2, x = y) {
return [x, y];
}
bar(); // [2, 2]4. 不可重复声明
var a = 100;
var a = 1000;
console.log(a); // 1000let a = 100;
let a = 1000; // 报重复声明错误5. ES6声明的变量不会挂在顶层对象
嗯~ES6变量的声明是指哪些声明呢?
指let, const, import, class声明。
而var, function声明是ES6之前的。
所以目前JavaScript有六种声明变量的方式了~
var job = 'teacher';
console.log(window.job); // teacherlet job = 'teacher';
console.log(window.job); // undefinedlet可以先声明稍后赋值;而const声明之后必须立马赋值,否则会报错let a;
a = 100; // this is okconst a; // 报没初始化数据的错误
const声明了简单的数据类型就不能更改了;声明了引用类型(数组,对象等),指针指向的地址不能更改,但是内部的数据可以更改的const str = 'this is a string';
str = 'this is another string'; // 报了个“给不变的变量分配值”的错误const obj = {
name: 'jia'
}
obj.name = 'ming'; // this is ok
obj = {}; // 报了个“给不变的变量分配值”的错误let使用场景:变量,用以代替var
const使用场景:常量、声明匿名函数、箭头函数的时候。
// 常量
const PI = 3.14;
// 匿名函数
const fn1 = function() {
// do something
}
// 箭头函数
const fn2 = () => {
// do something
}解构可以理解就是一个作用:简化你变量赋值的操作。
let [name, job] = ['jiaming', 'teacher'];
console.log(name); // jiaming本质上,这种写法属于模式匹配,只要等号两边的模式相同(重点),左边的变量就会被赋予对应的值。再比如:
let [ , , third] = ["foo", "bar", "baz"];
console.log(third); // "baz"
let [head, body, ...tail] = [1, 2, 3, 4, 5];
console.log(tail); // [3, 4, 5]也可以使用默认值。但是默认值生效的前提是:ES6内部使用严格相等运算符(===),判断一个位置是否有值。所以,只有当一个数组成员严格等于undefined,默认值才会生效。
let [x, y = 'b'] = ['a']; // x='a', y='b'
let [z = 1] = [undefined];
console.log(z); // 1
let [k = 1] = [null];
console.log(k); // nullconst state = {
name: 'jiaming',
job: 'teacher'
};
let {
name,
job
} = state;
// 上面的场景很熟悉吧
console.log(job); // teacher上面的例子如果写具体的话,是这样的:
const state = {
name: 'jiaming',
job: 'teacher'
};
let {
name: name, // 第一个name是匹配模式,第二个name才是变量,两者同名简化成一个即可
job: job
} = state;我们来改写下:
const state = {
name: 'jiaming',
job: 'teacher'
};
let {
name: job,
job: name
} = state;
console.log(job); // jiaming对象也可以使用默认值,但是前提是:对象的属性值严格等于undefined。
如下:
var {x = 3} = {x: undefined};
console.log(x); // 3
var {y = 3} = {y: null};
console.log(y); // null字符串之所以能够被解构赋值,是因为此时字符串被转换成了一个类似数组的对象。
const [a, b, ...arr] = 'hello';
console.log(arr); // ["l", "l", "o"]let {length: len} = 'hello';
console.log(len); // 5解构赋值时,如果等号右边是数值和布尔值,则会先转换为对象(分别是基本包装类型Number和基本包装类型Boolean)。不过这种场景用得不多~
let {toString: s} = 123;
console.log(s); // function toString() { [native code] }
console.log(s === Number.prototype.toString); // truelet {toString: s} = true;
console.log(s === Boolean.prototype.toString); // true解构赋值的规则是,只要等号右边的值不是对象或数组,就先将其转为对象。由于undefined和null无法转为对象,所以对它们进行解构赋值,都会报错。
1. 交换两变量值
let [a, b] = ['reng', 'jia'];
[a, b] = [b, a];
console.log(b); // 'reng'2. 将字符串转换为数组
let [...arr] = 'reng';
console.log(arr); // ["r", "e", "n", "g"]
console.log(arr.splice(0, 2)); // ["r", "e"] 返回删除的数组(能使用数组的方法了)针对字符串扩展这个,个人感觉模版字符串使用的频率比较高。模版字符串解放了拼接字符串带来的繁琐操作的体力劳动。
let name = 'jiaming';
let str = 'Hello! My name is '+ name + '. Nice to meet you!';
let strTemp = `Hello! My name is ${ name }. Nice to meet you!`对于新增的字符串方法,可以记下下面这几个:
留意下在Number对象上提供的新方法:
Number.isNaN(NaN) // true
Number.isNaN(15) // false关于Math对象上的方法,遇到要用到时候,查API吧,不然记太多,脑瓜子会疼~
ES6引入rest参数(形式是...变量名),用于获取多余的参数,这样就不需要使用arguments对象了。rest参数搭配的变量是一个数组(arguments是一个类数组来的),该变量将多余的参数放入数组中。
arguments对象是一个类数组,还得通过Array.prototype.slice.call(arguments)将其转换为真数组;而rest参数直接就可以使用数组的方法了。
function add(...arr) {
console.log(arr); // [2, 5, 3]
let sum = 0;
for(var val of arr) {
sum += val;
}
return sum;
}
console.log(add(2, 5, 3)); // 10ES6允许使用“箭头”(=>)定义函数。
const f = v => v; // 注意是有返回值return的啊
// 等同于
const f = function (v) {
return v;
}如果箭头函数的代码块部分多于一条语句,就要使用大括号将它们括起来,并且使用return语句返回结果。
const sum = (num1, num2) => num1 + num2;
// 等价于,使用了大括号,那箭头函数里面就要使用return了
const sum = (num1, num2) => { return num1 + num2 }
// 等价于
const sum = function(num1, num2) {
return num1 + num2
}使用箭头函数注意点:
this对象,就是定义所在的对象,而不是使用时所在的对象。new命令,否则会抛出一个错误。arguments对象,该对象在函数体内不存在的,如果要用,可以用rest参数代替。yield命令,因此箭头函数不能用作Generator函数。function foo() {
setTimeout(() => {
console.log('id:', this.id); // id: 42
}, 100);
}
var id = 21;
foo.call({ id: 42 });// 错误使用箭头函数的例子
const cat = {
lives: 9,
jumps: () => { // 箭头函数的错误使用,因为对象不构成单独的作用域
this.lives--; // this 指向window
}
}
var button = document.getElementById('press'); // 一个节点对象
button.addEventListener('click', () => { // 箭头函数的this指向window
this.classList.toggle('on');
});
// 箭头函数改成`function`匿名函数指向就正确了。箭头函数适合处理简单的计算,如果有复杂的函数体或读写操纵不建议使用,这样可以提高代码的可读性。
关于尾递归和其优化可以直接看阮先生的文档
假设有这么一个需求,需要对二维数组的元素进行反转并被1减。我们来看下下面代码,哪个能实现此需求呢?
// 代码一
const A = [[0,1,1],[1,0,1],[0,0,0]];
const flipAndInvertArr = function(A) {
A.map(item=>{
item.reverse().map(r=>1-r)
})
}// 代码二
const A = [[0,1,1],[1,0,1],[0,0,0]];
const flipAndInvertArr = A=> A.map(res =>res.reverse().map(r => 1 - r));运行之后,发现代码二是能实现需求的:
let resultArr = flipAndInvertArr(A);
console.log(resultArr); // [[0, 0, 1], [0, 1, 0], [1, 1, 1]]嗯~上面已经提到过,箭头函数体加上大括号后,是需要自己手动return的~
我们来改写下代码一,以便符合需求:
const A = [[0,1,1],[1,0,1],[0,0,0]];
const flipAndInvertArr = function(A) {
return (A.map(item=>{
return item.reverse().map(r=>1-r)
}))
}
let result = flipAndInvertArr(A);
console.log(result); // [[0, 0, 1], [0, 1, 0], [1, 1, 1]]惊喜不,意外不~
本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为上篇。
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
有一个我已经复制粘贴5年的CSS片段:
* { background-color: rgba(255,0,0,.2); }
* * { background-color: rgba(0,255,0,.2); }
* * * { background-color: rgba(0,0,255,.2); }
* * * * { background-color: rgba(255,0,255,.2); }
* * * * * { background-color: rgba(0,255,255,.2); }
* * * * * * { background-color: rgba(255,255,0,.2); }
* * * * * * * { background-color: rgba(255,0,0,.2); }
* * * * * * * * { background-color: rgba(0,255,0,.2); }
* * * * * * * * * { background-color: rgba(0,0,255,.2); }这是我最喜欢的发明之一。
2014年,我首次在Quora上分享了它(What are the most interesting HTML/JS/DOM/CSS hacks that most web developers don't know about?),现在,我每天仍然收到有人支持这个答案的通知。
那么,这个可怕的代码片段做了什么?
它意味着当你使用布局时适用,比如:
问题是,除非页面上的元素具有纯色背景或者一张图片,否则你看不到它是如何适合布局。例如大多数的文本节点,具有透明度的图片等。
应用上面的CSS,你会看到类似(下面)的东西:
不同深度的节点使用不同的颜色。允许你查看页面上每个元素的大小,它们的边距和填充。现在,你可以容易地识别出不一致性。
异步的JavaScript从未如何简单!过去段时间,我们使用回调。然后,我们使用promises。现在,我们有了异步功能函数。
异步函数能够使得(我们)编写异步JavaScript更加容易,但是,它自带一套陷阱,对初学者很不友好。
在这个由两部分组成的文章中,我想分享下你需要了解的有关异步函数的内容。【PS:另一部分暂不打算翻译】
异步功能函数包含async关键词。你可以在正常的函数声明中使用它:
async function functionName (arguments) {
// Do something asynchronous
}你也可以使用箭头函数。
const functionName = async (arguments) => {
// Do something asynchronous
}
(异步函数)它不管你返回什么。其返回值都是promise。
const getOne = async _ => {
return 1
}
const promise = getOne()
console.log(promise) // Promise 笔记:在接着往前读之前,你应该知道什么是JavaScript Promises知识点,以及如何使用它们。否则,它会开始变得混乱。这篇文章会帮助你熟悉JavaScript Promise。
当你调用promise时,你会在then中处理下一步,如下:
const getOne = async _ => {
return 1
}
getOne()
.then(value => {
console.log(value) // 1
})await关键字允许你等待promise去解析。一旦解析完promise,它就会返回参数传递给then调用。
const test = async _ => {
const one = await getOne()
console.log(one) // 1
}
test()在返回承诺(promise)之前没有必要等待(await)。你可以直接退回承诺。
如果你
return await些内容,则你首先是解决了原先promise。然后,你从已经解析的内容(resolved value)创建新的promise。return await真的没做什么有效的东西。无需额外的步骤。
// Don't need to do this
const test = async _ => {
return await getOne()
}
test()
.then(value => {
console.log(value) // 1
})// Do this instead
const test = async _ => {
return getOne()
}
test()
.then(value => {
console.log(value) // 1
})注意:如果你不需要
await,则不需要使用异步功能(async function)。上面的例子可以改写如下:
// Do this instead
const test = _ => {
return getOne()
}
test()
.then(value => {
console.log(value) // 1
})如果一个promise出错了,你可以使用catch调用来处理它,如下所示:
const getOne = async (success = true) => {
if (success) return 1
throw new Error('Failure!')
}
getOne(false)
.catch(error => console.log(error)) // Failure!如果你想在一个异步函数中处理错误,你需要调用try/catch。
const test = async _ => {
try {
const one = await getOne(false)
} catch (error) {
console.log(error) // Failure!
}
}
test()如果你有多个await关键字,错误处理可能变得很难看...
const test = async _ => {
try {
const one = await getOne(false)
} catch (error) {
console.log(error) // Failure!
}
try {
const two = await getTwo(false)
} catch (error) {
console.log(error) // Failure!
}
try {
const three = await getThree(false)
} catch (error) {
console.log(error) // Failure!
}
}
test()还有更好的方法。
我们知道异步函数总是返回一个promise。当我们调用promise时,我们可以在catch调用中处理错误。这意味着我们可以通过添加.catch来处理异步函数中的任何错误。
const test = async _ => {
const one = await getOne(false)
const two = await getTwo(false)
const three = await getThree(false)
}
test()
.catch(error => console.log(error)))注意:Promise的
catch方法只允许你捕获一个错误。
await阻止JavaScript执行下一行代码,直到promise解析为止。这可能会导致代码执行速度减慢的意外效果。
为了实际演示这点,我们需要在解析promise之前创建一个延迟。我们可以使用sleep功能来创建延迟。
const sleep = ms => {
return new Promise(resolve => setTimeout(resolve, ms))
}ms是解析前等待的毫秒数。如果你传入1000到sleep函数,JavaScript将等待一秒才能解析promise。
// Using Sleep
console.log('Now')
sleep(1000)
.then(v => {
console.log('After one second')
})假设getOne需要一秒来解析。为了创建这个延迟,我们将1000(一秒)传入到sleep。一秒过后,sleeppromise解析后,我们返回值1。
const getOne = _ => {
return sleep(1000).then(v => 1)
}如果你使用await getOne(),你会发现在getOne解析之前需要一秒钟。
const test = async _ => {
console.log('Now')
const one = await getOne()
console.log(one)
}
test()现在,假设你需要处理三个promises。每个promise都有一秒钟的延迟。
const getOne = _ => {
return sleep(1000).then(v => 1)
}
const getTwo = _ => {
return sleep(1000).then(v => 2)
}
const getThree = _ => {
return sleep(1000).then(v => 3)
}如果你连续await这三个promises,你将要等待三秒才能解析完所有promises。这并不好,因为我们强迫JavaScript在做我们需要做的事情之前等待了两秒钟。
const test = async _ => {
const one = await getOne()
console.log(one)
const two = await getTwo()
console.log(two)
const three = await getThree()
console.log(three)
console.log('Done')
}
test()如果getOne,getTwo和getThree可以同时获取,你将节省两秒钟。你可以使用Promise.all同时获取这三个promises。
有三个步骤:
Promise.all来awaitpromises数组如下所示:
const test = async _ => {
const promises = [getOne(), getTwo(), getThree()]
console.log('Now')
const [one, two, three] = await Promise.all(promises)
console.log(one)
console.log(two)
console.log(three)
console.log('Done')
}
test()这就是你需要了解的基本异步功能函数!我希望这篇文章为你扫除了些障碍。
笔记:这篇文章是Learn JavaScript的修改摘录。如果你发现本文有用,你可能需要去查看它。
开篇如图,母亲节快乐@~@!
借着这个节日,结合下最近的需求:移动端h5生成图片没有二维码(如上),长按保存下来时候有二维码(如下)。我们来聊聊如何实现,文末配上不严谨的源码,感兴趣的看官自取啊~
到这里,某些大佬应该明白怎么简单操作,完成这个尴尬的需求了,不过之前自己还是费了点功夫,脑袋转不过弯啊。
是的,结合opacity进行*操作:
嗯,既然要生成图片,且为了缓解后端的压力,我们前端来生成图片~
这里使用了html2canvas进行图片的生成操作。至于为什么选择html2canvas进行图片的生成呢?可以参考下富途的文章--移动端页面分享快照生成总结。
使用html2canvas需要注意的地方有:
接下来就是实现这个长按图片识别二维码的操作了,如上gif图。我长按了图片,给人的错觉就是按了那张没有带二维码的图片,实际上是按了带二维码的图片。因为两张图片的展示位置是一样的,带二维码的图片覆盖在最上面,并且其opacity设置为0了,所以长按的时候会出现识别图中二维码的字样。
就是这样啦,opacity结合absolute就可以轻松实现了😉
对了,gif图的二维码图片是使用qrcode生成的。
以上,如果还是不怎么了解,可以clone我的代码(见下)下来跑下就明白了~
图片来源网络,侵删
源码:https://github.com/reng99/blogs/tree/master/src/opacity_demo
编程不是操作键盘快速敲打。编程不是牢记键盘的快捷键并使用退化了的鼠标工作。如果首要考虑,编程并不是要学习每种编程语言。不能通过电脑的品牌、价格、性能和操作系统来决定一个程序员是否优秀,也不能通过他们对代码编辑器和IDEs--VS-Code、Atom、IntelliJ IDEA、Vim、Notepad++等的偏爱来决定。与许多好莱坞电影潮流的观念相反,编程绝不等同黑客攻击。
此外,编程不仅仅是要记忆编程语言的语法和内置功能。逻辑、条件、if语句和算法不能描绘出编程的蓝图。数学、递归、计算机科学和设计模式也不能。虽然它们是编程的重要组成部分,但是它们也仅仅是编程的一部分。
在编写代码之前,我们要对项目的设计和体系结构进行了全面的规划,以确保一个平稳的开发周期或者增加平稳开发周期的可能性。这时候,软件设计就派上用场了。工具链、pipelines、公共和内部API的抽象层、模块化、对象关系和数据库结构都在这个开发阶段进行了规划。
编程艺术要求我们跳出条条框框的限制来思考,用最实用,有效且可行的解决方案解决问题。这可能就是为什么我们被说是宅家的"I.T.guy"或"客户支持"的原因了。实际上,我们的工作是查漏补缺。这好像说“编程”对“解决问题”的一种美化方式。
换言之,计算机内外都有方便我们的调节器,因此,我们意识到如何阅读和编写文档很重要。正确的文档-它以详细文档的实际页面的形式出现,或者像在代码库中散布有价值的评论一样简单-这作为程序员最重要的生命线之一。没有它,我们会在黑暗中迷失,无法履行我们作为调试器的职责。很少甚至没有进展,因为我们大部分时间都花在实验和调查框架或者了解遗留代码库如何工作。总之,这将导致非常糟糕的开发人员体验。
调试已经够困难了。更糟糕的是,代码的执行通常不是线性的。由于具有if语句的程序逻辑,大型项目意味着可能执行路径的多个“分支”。我们必须考虑每种可能的场景和错误,特别是涉及用户输入。跟踪每个可执行路径所需的认知负荷使编程变得更加困难。
走出开发的世界,我们进入一个普通用户的角色。除了提供功能,添加新功能,修补错误和记录我们的代码库之外,我们还关注普通用户如何与我们的应用或软件进行交互。我们思考能带来良好用户体验的多种因素,例如(但不限于)可访问性,可用性,用户友好性和可发现性,UI设计,颜色主题,功能动画和性能。
说到这点,性能本身就是编程的一个很重要的方面。我们,特别是那些具有计算机科学背景的人,努力使用和编写最节省时间和空间的算法。我们着迷于微不足道的微妙时间尺度,以便充分利用我们可用的内存,CPU和GPU。
在web开发的背景下,网络优化是一个需要掌握的重要概念。我们很努力地来减少和压缩我们的HTML,CSS和JavaScript,以减轻来自服务器响应的有效负载。图像和其它杂项资源也被压缩和延迟下载,以最小化用户在页面可用之前需要下载的数据量。
但是,有时我们会过于沉迷于性能。当我们不必要地专注优化代码库的某些部分而不是关注实际(项目)进度和生产中需要做什么时,过早优化就成了问题。这种情况下,我们必须明智地判断代码库的哪些部分确实需要优化。
除了软件的UI和逻辑之外,作为程序员,我们还要对用户的安全负责。在我们这个时代,数据是非常令人垂涎且货币化程度很高的(资源),确保用户个人的信息安全是比以往任何时候都更重要。我们采取额外的措施保护私人数据,因为用户信任我们的软件。如果我们不坚持履行这一责任,我们肯定不是真正的程序员,甚至不是长期的。
在接近安全的时候,我们永远不会太安全。普遍的经验法则告诉我们,“永远不要信任用户输入”。这甚至可以被视为“最佳经验”,竭尽全力去净化数据和用户输入。如果我们不够谨慎,我们不仅会使我们的软件和基础设施面临巨大的风险,而且还会冒着损害用户敏感数据的风险,这些用户数据是我们作为程序员承诺保护的。
但是,安全性并不仅限于用户数据和输入。病毒,蠕虫,特洛伊木马,广告软件,键盘记录器,勒索软件和其它形式的计算机恶意软件继续在全球数百万的计算机和其它设备上传播和肆虐。即使经过数十年的硬、软件技术的改进,也不存在无懈可击的系统。安全性是一种不断被磨练的工艺,但永远不会完美,因为总会有好奇的少数人探究并寻找各种可能的方法来破解系统。
因此,不管面向的怎样的用户群,如果我们还没将安全性纳入优先考虑范围的话,那么我们应谨记要将安全性设计作为最重要的优先级之一。这样做是为了保护我们的用户免受上述威胁的影响,这些威胁可能会造成诸如数据丢失,文件损坏和系统奔溃等不便之处。
即使它不一定和编程相关,团队协作在软件开发中也起着不可或缺的作用。由于任何大型项目的所有复杂性和活动部分,一个人不可能以常规迭代的快速节奏或者在客户或任何监督人的严格期限和时间限制下开发出高质量的软件。
这就是为什么我们有各种各样的团队,他们专注于编程的诸多方面的其中之一。一个人永远不会拥有所有技能和知识,并将每个方面的点有效的粘合在一起。一个团队可能负责UI设计和保证可访问,而另一个团队可能负责软件本身的功能开发。如果将各个专业团队的所有能力结合起来,最终的软件将具有最佳功能,用户体验,性能和安全性,(软件)它将会在财务和实际限制范围内使用。
对于时间管理和会议期限,工作流程组织和自动化至关重要。我们花时间正确配置我们的构建工具和管道,因为这样做将为我们节省大量时间。一般而言,投资回报随着时间的推移而增加。
为了阐述团队合作的理念,我们与同行建立良好的关系,因为最终项目的成功在很大程度上取决于团队人员良好的相处。我们努力营造一个鼓励性的工作环境,在这环境下,经验丰富的人要经常引导新人。
由于我们是以团队形式开发软件,因此我们必须留意其他人是否能读懂我们的代码。为了保证开发周期的长期可持续性,代码可读性和可维护性被认为与项目的逻辑和功能同样重要。我们始终要编写良好,可读的代码,同时提供信息化的GIT提交信息和文档说明,因为这些肯定会帮助我们和其它人更好地理解我们写的代码。
说到其他人阅读我们的代码,代码审查是一个很好的机会,可以更多地了解编程中的最佳实践。这也是熟悉代码库以及其底层设计和架构的另一种方法。虽然建设性的批评对接收方是令人不愉快和难以处理的,但重要的是将其作为合理的建议,以便作为程序员的我们进行改进。
编程囊括许多方面,包括用户体验,性能,安全性和团队协作等功能。仅仅关注一个方面而忽略其它方面是不够的。对于复杂和重要性的项目,它并不是键入几行代码就能取得成功。它需要大量精心规划,设计,考虑和团队协作才能取得成功。事实上,在编程时花费的时间比在打字时花费的时间多,特别是在长时间的调试过程中。
最后,编程实际上是连续的,不间断的学习。适应性和不间断的学习是这个行业生存的关键。如果我们不努力继续学习,我们就不能期望能跟上潮流。在这种指数级的科技改进的动荡行业中,我们必须跟上它的快速节奏,以免陷入困境。
全世界的开发人员都是辛勤的工作者,我想通过认识到这点来结束本文。写这篇文章,我不得不反思一个开发团队的日常工作流程。我不得不探究常常被我们忽略的编程和软件开发的许多方面。从那时起,我对计算机中安装的所有软件都有了更多的了解。为此,今天,我提倡大家要感谢下程序员,无论其经验如何。没有他们,我们会在哪里呢?
永远不要把他们的努力看做理所当然。
我在Stanley Black & Decker的工业4.0团队工作。我们的团队最近为Stanley制造工厂创建了相当于App Store的产品。工厂可以访问市场并根据他们在该位置生产的产品选择他们需要的应用程序。这将构建一个自定义构建,将所有这些应用程序捆绑在一起,以便工厂运行。由于捆绑了如此众多的应用程序,我们的vue生产构建时,导致多个大小过度的警告。
当我们进行构建时,我们收到以下2条错误消息:
Vue建议捆版bundles不超过244KiB。我们只有14个资源,每个资源都超过这个规模。此外,我们有四个入口点也高于建议的大小。以下是我将构建的大小减半的方法。
首先,我需要了解导致大型构建包大小的原因。为此,我安装了webpack-bundle-analyzer。这将提供每个包中项目大小的可视指南。
npm install --save-dev webpack-bundle-analyzer接下来,我在vue.config.js文件中配置webpack来使用它。下面是我的配置文件vue.config.js的内容:
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer')
.BundleAnalyzerPlugin;
module.exports = {
configureWebpack: {
plugins: [new BundleAnalyzerPlugin()]
}
};安装完插件后,我再次运行构建,我可以看到我的构建大小是2.48MB。从图像中我可以看到最大的罪魁祸首是:
Lodash占用了70.7kb的空间。Lodash仅在我们的框架中的所有应用程序中的两个位置使用。这只是两种方法的大量空间。
我们不止加载了lodash,我们也加载了vue-lodash。第一步是移除package.json中没有使用到的vue-lodash。
下一步是仅从lodash导入我们需要的两个项目(库)。我们使用的是cloneDeep和sortBy。我替换了导入整个lodash库的初始调用:
import _ from 'lodash';我正在用这个只导入我们需要的两个项目(库)的调用替换它。为此,我将导入从lodash更改为lodash/core。
import { cloneDeep, sortBy } from 'lodash/core';进行这一更改后,我的构建包的大小从2.48MB减少到2.42MB。这是显示构建的当前大小的图像。
在这里我们可以看到lodash本身作为构建包一部分的大小。
Moment.js在构建包中占了234.36KB。当你查看图片的时,该大小的绝大部分是它们支持的所有语言的国际化语言环境。我们根本没有使用moment.js的这一部分,所以我们打包中包含了不必要部分。
幸运的是,我们可以删除它。而不是使下面的调用导入所有moment.js。
import moment form 'moment';我们只能通过此调用导入日期操作代码:
import moment from 'moment/src/moment'至少在我们的代码库中进行替换是一个问题。有18个地方在代码中导入了moment.js。我本可以在代码中进行全局搜索和替换。但是如果我们向框架添加一个新的应用程序,开发人员很可能会使用默认调用来导入moment.js。如果他们这样做,那么我们将再次导入所有国际语言环境。
因此,权衡之后,在webpack中创建一个快捷方式的别名。该快捷方式将用moment/src/moment替换所有导入moment的调用。我们可以使用resolve和设置别名在我们的vue.config.js文件添加该别名。这是我vue.config.js现在的样子。
当我们现在运行构建时,我们的捆绑包现在已经下降到2.22MB的大小了。
当你查看图像的moment.js时,你将看到国际化区域设置根本不再被加载。
通过删除moment.js中的语言环境,每当我启动服务器运行我的代码时都会发生错误,该错误代码说它无法找到./locale。在做了一些研究之后,我发现这已经成为了moment.js的一个已知好几年的问题,moment.js总是加载并假定locales是现在。你无法分辨加载日期操作功能的时刻。
要解决这个问题,我使用内置的webpack IgnorePlugin忽略此消息。这是我添加到我的vue.config.js文件中的插件代码:
new webpack.IgnorePlugin(/^\\.\\/locale$/, /moment$/)我的下一个目标是Vuetify.js的大小。Vuetify占用空间500.78KB。对于一个供应商产品来说,这是一个巨大的空间。
Vuetify提供了一种他们称之为点菜的功能。这允许你仅导入你使用的Vuetify组件。这会减少Vuetify的大小。挑战在于我们有如此多的应用程序正在进行并试图确定我们正在使用的组件不会改变。
在当前版本的Vuetify(当我写这篇文章的时候版本为1.56)中,他们提供了一个名为vuetify-loader的产品。 它将遍历你的代码并确定你正在使用的所有组件,然后将它们只导入你的构建包。 vuetify v2将内置此功能。 在该版本可用之前,你必须使用vuetify-loader仅导入你正在使用的组件。 Vuetify文档说明要获得所有必需的样式,我们需要在stylus中导入它们。
我意识到我们正在运行旧版本的vuetify.js。 所以我决定将我的vuetify版本升级到最新版本。我还同时安装了style和vuetify-loader:
npm install vuetify vuetify-loader stylus stylus-loader style-loader css-loader --save
我导入Vuetify的插件代码有一些主题的自定义,以使用我们公司的调色板。 以下是我目前的Vuetify插件:
我需要将Vuetify的导入更改为从vuetify/lib导入。 我还将导入stylus以获得所有样式。 这是我的插件代码现在的样子:
最后一步是告诉webpack使用vuetify-loader插件,以便它只导入我们正在使用的组件。 我将需要的插件添加到插件数组。 这是我的vue.config.js文件:
现在,当我运行生产构建时,我的捆绑包大小为2MB。
Vue-echarts不是我捆绑中最大的项目。 Vue-echarts运行在echarts之上。 和Vuetify一样,我正在运行两种产品的旧版本。 将它们升级到最新版本我运行此命令:
npm install echarts vue-echarts --save我对vue-echarts GitHub repo进行了一些研究,查看所有已关闭的问题,发现最新版本的vue-echarts允许你通过更改导入的内容来加载较小的包。 以前我使用此命令导入它:
import ECharts from 'vue-echarts';我改成这种:
import ECharts from 'vue-echarts/components/ECharts.vue';现在,当我运行生产构建时,我的捆绑包大小降至1.28MB。
我的目标是减少为我们的应用程序生产而创建的包的大小。 我的构建的初始大小是2.48MB。 通过进行一些更改,我能够将构建大小减少到1.2MB。 这几乎减少了50%。
如果要创建生产环境Vue应用程序,则应该花时间来评估构建大小。 使用webpack-bundle-analyzer确定哪些项目占用的空间最多。 然后开始采取必要步骤来减少这些项目的大小。 我能够通过这种方式减少捆绑中四个最大项目的大小。
希望对你有帮助,能按照这些步骤来减少生产构建包的大小。
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
JavaScript promise是一个对象,表示异步任务完成或者失败及其结果值。
完结。
我当然是开玩笑的。那么,这个定义到底意味着什么?
首先,JavaScript中的许多东西都是对象。你可以通过几种不同的方式进行创建对象。最常用的方法是使用对象字面量语法:
const myCar = {
color: 'blue',
type: 'sedan',
doors: '4',
};你还可以创建一个类,并通过new关键字对其进行实例化。
class Car {
constructor(color, type, doors) {
this.color = color;
this.type = type;
this.doors = doors
}
}
const myCar = new Car('blue', 'sedan', '4');console.log(myCar);promise只是我们创建的对象,就像后面的例子一样,我们使用new关键字对其进行实例化。我们传入一个带有两个参数的函数,其参数为resolve和reject,而不是像传递给我们Car的三个参数(颜色,类型和门)。
最终,promise告诉我们一些关于我们从它返回的异步函数的完成情况--生效了或失败了。我们认为这个功能是成功的,如果promise是解决了,并且说promise被拒绝是不成功的。
const myPromise = new Promise(function(resolve, reject) {});console.log(myPromise);留意,此时的promise是pending状态
const myPromise = new Promise(function(resolve, reject) {
resolve(10);
});留意,我们用10返回解决了promise
看,不是太可怕 -- 只是我们创建的对象。而且,如果我们稍微展开一下:
留意,我们有一些我们可以访问的方法,即"then"和"catch"
此外,我们可以传我们喜欢的东西到resolve和reject中。例如,我们可以传递一个对象,而不是一个字符串:
return new Promise((resolve, reject) => {
if(somethingSuccesfulHappened) {
const successObject = {
msg: 'Success',
data,//...some data we got back
}
resolve(successObject);
} else {
const errorObject = {
msg: 'An error occured',
error, //...some error we got back
}
reject(errorObject);
}
});或者,为了方便查看,我们任何东西都不传:
return new Promise((resolve, reject) => {
if(somethingSuccesfulHappend) {
resolve()
} else {
reject();
}
});JavaScript是单线程的。这意味着它一次只能处理一件事。想象这么条道路,你可以将JavaScript视为单车道的高速公路。特定代码(异步代码)可以滑动到一边,以允许其他代码越过它。完成异步代码后,它将返回到道路。
旁注,我们可以从任何函数返回
promise。他不必是异步的。话虽这么说,promise通常在它们返回的函数是异步的情况下返回。例如,具有将数据保存在服务器的方法API将是返回promise的绝佳候选者!
外号:
promise为我们提供了一种等待异步代码完成,从中捕获一些值,并将这些值传递给程序其他部分的方法。
我这里有篇文章深入探讨这些概念:Thrown For a Loop: Understanding Loops and Timeouts in JavaScript。
使用promise也称为消费promise。在上面的示例中,我们的函数返回了一个promise对象。这允许我们使用方法的链式功能。
我打赌你看到过下面的这种链式方法:
const a = 'Some awesome string';
const b = a.toUpperCase().replace('ST', '').toLowerCase();
console.log(b); // some awesome ring现在,(假装)回想下我们的promise:
const somethingWasSuccesful = true;
function someAsynFunction() {
return new Promise((resolve, reject){
if (somethingWasSuccesful) {
resolve();
} else {
reject()
}
});
}然后,通过链式方法调用我们的promise:
someAsyncFunction
.then(runAFunctionIfItResolved(withTheResolvedValue))
.catch(orARunAfunctionIfItRejected(withTheRejectedValue));想象一下,你有一个从数据库中获取用户的功能。我在codepen上编写了一个示例函数,用于模拟你可能使用的API。它提供了两种访问结果的选项。一,你可以提供回调功能,在其中访问用户或提示错误。或者第二种,函数返回一个promise作为用户访问或提示错误的方法。
为了方便查看,我把作者的codepen上的代码复制了下来,如下:
const users = [
{
id: '123',
name: 'John Smith',
posts: [
{title: 'Some amazing title', content: 'Here is some amazing content'},
{title: 'My favorite title', content: 'My favorite content'},
{title: 'A not-so-good title', content: 'The not-so-good content'},
]
},
{
id: '456',
name: 'Mary Michaels',
posts: [
{title: 'Some amazing title', content: 'Here is some amazing content'},
{title: 'My favorite title', content: 'My favorite content'},
{title: 'A not-so-good title', content: 'The not-so-good content'},
]
},
]
function getUserPosts(id, cb) {
const user = users.find(el => el.id === id);
if (cb) {
if (user) {
return cb(null, user);
}
return cb('User Not Found', null);
}
return new Promise(function(resolve, reject){
if (user) {
resolve(user);
} else {
reject('User not found');
}
});
}
/* The above code is collapsed to simulate an API you might use to get user posts for a
* particular user from a database.
* The API can take a callback as a second argument: getUserPosts(<id>, <callback>);
* The callback function first argument is any error and second argument is the user.
* For example:
getUserPosts('123', function(err, user) {
if (err) {
console.log(err)
} else {
console.log(user);
}
});
* getUserPosts also returns a promise, for example: getUserPosts.then().catch();
* The ID's that will generate a user are the of type string and they are '123' and '456'.
* All other IDs will return an error.
*/
getUserPosts('123', function(err, user) {
if (err) {
console.log(err);
} else {
console.log(user);
}
});
getUserPosts('129', function(err, user) {
if (err) {
console.log(err);
} else {
console.log(user);
}
});
getUserPosts('456')
.then(user => console.log(user))
.catch(err => console.log(err));传统上,我们将通过使用回调来访问异步代码的结果。
rr someDatabaseThing(maybeAnID, function(err, result)) {
//...Once we get back the thing from the database...
if(err) {
doSomethingWithTheError(error)
} else {
doSomethingWithResults(results);
}
}在它们变得过度嵌套之前,回调的使用是可以的。换句话说,你必须为每个新结果运行更多异步代码。回调的这种模式可能会导致“回调地狱”。
Promise为我们提供了一种更优雅,更易读的方式来查看我们程序流程。
doSomething()
.then(doSomethingElse) // and if you wouldn't mind
.catch(anyErrorsPlease);想象一下,你找到了一碗汤。在你喝之前,你想知道汤的温度。但是你没有温度计,幸运的是,你可以使用超级计算机来告诉你汤的温度。不幸的是,这台超级计算机最多可能需要10秒才能获得结果。
这里需要有几点需要注意:
result的全局变量。Math.random()和setTimeout()模拟网络延迟的持续时间。Manth.random()模拟温度。运行函数并打印结果。
getTemperature();
console.log(results); // undefined该功能需要一定的时间才能运行。在延迟结束之前,不会设置变量。因此,当我们运行该函数时,setTimeout是异步的。setTimeout中的部分代码移出主线程进入等待区域。
我这里有篇文章深入研究了这个过程:Thrown For a Loop: Understanding Loops and Timeouts in JavaScript
由于设置变量result的函数部分移动到了等待区域直到完成,因此我们的解析器可以自由移动到下一行。在我们的例子中,它是我们的console.log()。此时,由于我们的setTimeout未结束,result仍未定义。
那我们还能尝试什么呢?我们可以运行getTemperature(),然后等待11秒(因为我们的最大延迟是10秒),然后打印出结果。
getTemperature();
setTimeout(() => {
console.log(result);
}, 11000);
// Too Hot | Delay: 3323 | Temperature: 209 deg这是可行的,但这种技术问题是,尽管在我们的例子中,我们知道了最大的网络延迟,但在实际中它可能偶尔需要超过10秒。而且,即使我们可以保证最大延迟10秒,如果result出结果了,我们也是在浪费时间。
我们将重构getTemperature()函数以返回promise。而不是设置结果。我们将拒绝promise,除非结果是“恰到好处”,在这种情况下我们将解决promise。在任何一种情况下,我们都会传递一些值到resolve和reject。
现在,我们可以使用正在返回的promise结果(也称为消费promise)。
getTemperature()
.then(result => console.log(result))
.catch(error => console.log(error));
// Reject: Too Cold | Delay: 7880 | Temperature: 43 deg.then,当我们的promise解决时,它将被调用,并返回我们传递给resolve的任何信息。
.catch,当我们的promise拒绝时,它将被调用,并返回我们传递给reject的任何信息。
最有可能的是,你将更多的使用promise,而不是创建它们。在任何情况下,它们有助于使我们的代码更优雅,可读和高效。
return new Promise((resolve, reject)=> {})返回一个promise。.then从已经解决的promise中获取信息,然后使用.catch从拒绝的promise中获取信息。我曾经认为--如果我了解JavaScript,那写后端会很容易。我之所以认为简单,是因为Node是JavaScript。我没必要去学一门新语言。
然而,我错了。
但是,后端是很难去学的。我花了很长的时间去学习它。(当然,我现在仍然尝试去掌握它)。
我意识到在学习后端中我有些问题,因为我曾认为前端和后端是一样的 -- 它们都是代码而已。
这是个很大的错误。
前端和后端完全是不同的野兽。我能正确地学习后端之前,我必须尊重他们的差异。
如果让我来解析前端和后端之间的差异(在执行方面),我会说:
当我们构建前端事物,我们很大程度上关注了用户对我们构建的东西是怎么看的。我们花费了大量的时间自问了下面这些问题(每个问题都带来数不尽的工作):
我们都关心。
有时候,我们为了提高用户的视觉体验(带来愉悦感),我们添加了诸如下面的事物:
伴随着每个附加功能,我们还必须考虑它们可能带来的影响:
我们考虑很多东西 -- 从用户的视图层面。这就是为什么我说前端是有关视觉的。
我们为用户着想。然后我们为他们构建产品。
不幸的是,一些开发者自欺欺人地认为
用户 === 他们自己。他们为自己建立网站而不是他们的用户。
让我具体一点。当我说到后端,我指的是前端和数据库之间的层。它也是前端和你需要通信的任何API之间的层(如果它通过你自己的服务器)。
我们简化事情让一些人明白,我在讲你将在哪里创建一个Express应用程序。
当你做后端工作时(前端->后端),你会发现我们不再创建接口了。你不用填写表单;你不用点击按钮。那是因为它们不需要。
后端不是关于视觉。没人肉眼看到发生了什么。它只是要运行...
但是,运行意味着什么?
后端允许前端和数据库之间的通信(或任何外部的API)。回到以前,想象下一个电话接线员。如果你打电话给一个人,这些接线员必须手动的连接你和你要打给的那个人。(如果他们接线错误,你就打给了错的人)。
当你构建一个后端时,你就像电话接线员。你把东西连接起来就可以了。
当我们构建后端时,我们会问如下的问题:
我们还要考虑速度和可靠性。(想象一下,如果你发送了一些东西,但是没有收到任何回复的话会发生什么...)。但是,这是更加高级的话题了。
这是我在学习后端的早期观察到的一种常见模式:
Google上搜索,如何通过我想到的具体方式来实现东西Google结果也许是空)我几乎总是错的,因为在学习后端的时候,不自觉地依靠了我的前端经验。我必须学习重新思考问题的方法。
这是我最大的收获:
不要以为你对自己学的东西了如指掌。你几乎总是错的。慢下来,让你有时间和空间去学习。在学习的过程中始终验证,以便你记住并重新连接你的大脑。
最近使用react-native参与开发了个应用,记录下其中踩的一些坑。本人使用的是mac电脑进行开发,本文仅对此平台进行记录📝
升级自己的mac的系统到最新版本,之后在mac的应用市场中下载xcode。
app Store -> Develop -> xcode请保持网络的顺畅,升级系统和下载安装xcode比较耗时,需耐心等待啦~
跑起来的时候可能会出现这样的错误:
error Failed to build iOS project. We ran "xcodebuild" command but it exited with error code 65. To debug build logs further, consider building your app with Xcode.app, by opening demo_native.xcodeproj可以参考下面的步骤解决:
File -> Open -> demo_native -> iosFile -> Project Setting -> Advanced -> Custom -> Relative to workspacereact-native run-ios后没反应在完成了相关的下载之后,运行react-native项目之后过两三分钟还是没有反应,请确保你的网络良好并重新运行,等待上一段时间。
首次跑应用耗时比较长,第二次跑的话就很快了~
Entry, ":CFBundleIdentifier", Does Not Exist错误在执行react-native run-ios后出现Entry, ":CFBundleIdentifier", Does Not Exist,可以通过更改文件的设置来解决,xcode打开文件目录后,File -> Project Setting -> Advanced -> Custom -> Relative to workspace。如果还是不行,请使用好点的翻墙工具(比如使用Shadowsocks,而不是蓝灯)。
最主要的还是保持网络的良好,不然相关依赖下载会失败的
在项目启动之后,mac上的模拟器已经开启了,但是修改保存ide上的代码后,模拟器并不能够实现热加载。这个时候应该开启模拟器的项目热加载功能。做法如下:
模拟器中进入正在执行的项目,然后在mac上按住command + d就可以调出对话框,选择Enable Live Reload就可以了。
运行项目之后,可以在浏览器内对应用的js进行调试。调试操作:
http://localhost:8081/debugger-ui/command+d -> Debug JS Remotelyprops是在父组件中指定,在被指定的组件生命周期中不做改变。如果需要改变的数据,则可以使用state。
ES6中自定义的函数里面使用this关键字,需要对其进行绑定操纵,否则this的指向会指向空。操作示例:
...
constructor(props) {
super(props);
this.state = {
data: [],
loaded: false
},
this.fetchData = this.fetchData.bind(this);
}
fecthData() {
fetch(REQUEST_URL){
this.setState({
data: this.state.data.concat(['name'])
})
}
}1. 使用类名
// 单个类名
<View style = { styles.container }>
<Text>some awesome text</Text>
</View>
const styles = StyleSheet.create({
container: {
backgroundColor: '#f8f8f8',
flex: 1
}
})
// 多个类名
<View style = { [styles.container, styles.colorRed]}>
<Text>some awesome text</Text>
</View>
const styles = StyleSheet.create({
container: {
backgroundColor: '#f8f8f8',
flex: 1
},
colorRed: {
color: '#f00'
}
})2. 使用行内样式
<View style = {{ backgroundColor: '#f8f8f8', flex: 1 }}>
<Text>some awesome text</Text>
</View>3. 类名和行内样式结合
<View style = { [styles.container, { color: '#f00' }] }>
<Text>some awesome text</Text>
</View>
const styles = StyleSheet.create({
container: {
backgroundColor: '#f8f8f8',
flex: 1
}
})这里没有引入状态管理工具,比如redux。
1. 父组件传值给子组件
通过props进行值的传递
// 父组件
import Child from 'path/to/Child'
<View>
<Child name='jiaming'/>
</View>
// 子组件
render() {
const { name } = this.props;
return(
<View>
<Text> { name } </text>
</View>
)
}2. 子组件传值给父组件
通过props的方法进行传值
// 父组件
import Child from 'path/to/Child'
getValue(data) {
console.log(data);
}
render() {
return (
<View>
<Child getValue = { this.getValue.bind() }>
</View>
)
}
// 子组件
trigger() {
this.props.getValue({
name: 'name from child component'
});
}
render() {
return (
<View>
<Text onPress={ this.trigger.bind(this) }> some awesome text </Text>
</View>
)
}在父组件中设置了父组件的数据变动了,但是子组件的数据并没有变动。比如:
// 父组件
import Child from 'path/to/Child'
Fn() {
this.setState({
name: 'jiaming'
});
}
<View>
<Child name = { this.state.name }/>
</View>出现在子组件中数据没变动的话,应该在子组件中做下面的处理:
相关的案例如下:
componentWillReceiveProps(props) { // props这个参数要加上
const {
name
} = props; // 这里不能使用this.props,不然会造成数据渲染不同步
this.setState({
name: name
});
}在我们改变state值的时候,我们一般都会使用到setState,比如:
constructor(props){
super(props);
this.state = {
name : ''
}
}
Fn() {
this.setState({
name: 'jiaming'
})
}上面的setState中的key值是name,那么,如果我使用一个变量代替name需要怎么写呢?
答:使用中括号[]来包裹就行了。如下demo
Fn() {
const _name = 'jiaming';
this.setState({
[_name]: 'jiaming'
})
}render return内的条件判断写法在View页面内,很多时候是需要你根据条件判断进行,那么相关的写法你可以包裹在一个大括号{}里面的。比如:
constructor(props){
super(props);
this.state = {
typeFlag: 1
}
}
render() {
return (
<View>
{
typeFlag == 1 ?
<Text>type flag is one</Text>
:
typeFlag == 2 ?
<Text>type flag is two</Text>
:
null
}
</View>
)
}在开始时候,引入Modal之后是,执行了相关的代码,弹出了Modal之后,是看不到下层的内容的,这很是不合理。解决方案:引入属性transparent。
如下:
render() {
return (
<Modal
animationType='slide'
transparent='true'>
<View>
<Text>some awesome text</Text>
</View>
</Modal>
)
}1. 行内编写
<TouchableOpacity onPress={ () => console.log('this is a demo')}>
<Text>some awesome text</Text>
</TouchableOpacity>2. 行内引入指针
handleEvent() {
console.log('this is a demo');
}
<TouchableOpacity onPress={ this.handleEvent.bind(this) }>
<Text>some awesome text</Text>
</TouchableOpacity>在react native navigation中直接使用类似this.handleMethod这种方法是不生效的,比如:
static navigationOptions = ({navigation}) => ({
headerLeft: (
<TouchableOpacity onPress = { this.handleMothed.bind(this) }>
<Text style={{ color: '#999', paddingLeft: 10}}>返回</Text>
</TouchableOpacity>
)
});
handleMothed(){
console.log('this is a demo');
}你应该这样写(使用this.props.navigation.setParams):
static navigationOptions = ({navigation}) => ({
headerRight: (
<TouchableOpacity onPress= {()=>navigation.state.params.handleComfirm()} >
<Text style={{ color: '#999', paddingLeft: 10}}>确认</Text>
</TouchableOpacity>
)
)
});
componentDidMount() {
// 组件加载完之后操作
this.props.navigation.setParams({handleComfirm:this.handleComfirm})
}
handleComfirm() {
console.log('this is a demo');
}使用brew安装。
- 默认已经安装了brew
- brew cask install android-platform-tools // Install adb
- adb devices // Start using adb参考链接:https://www.jianshu.com/p/bb74ae9d26f6
文章部分内容的引用已丢失,若有雷同,不胜荣幸。如有错误,还望看官纠正。
更多的内容请前往我的博客
趁着最近下班比较早,还是有时间看下其他知识点。于是,自己屁颠屁颠的玩了下微信小程序。
我使用的是mac电脑来开发,那我简单说下我自己的准备工作吧~
首先,你需要一个良好的编辑器工具,我这里下载了sublime、vscode和微信开发者工具。我选择使用微信开发者工具进行开发,因为对开发者友好。有说vscode比较友好的,需要配置些东西,这就要百度一下了。
然后,如果你的小程序要上线或需要使用里面比较完整的功能,你需要注册一个微信小程序,获取appId。我这里是学习而已,所以只是用微信提供的测试appId,这个测试appId在使用微信开发者工具新建项目的时候有得选择。
嗯~就是这么简单,惊喜不~意外不😯
当你使用微信开发者工具新建项目的时候,它会自动帮你新建一个规范的项目目录结构。当然,我们也可以从零开始进行搭建啦。我下面简单罗列下我项目中的结构(截止2019年06月21日):
- app.js
- app.json
- assets
- tabbar
- home_active.png
- home.png
- profile_active.png
- profile.png
- pages
- home
- home.js
- home.json
- home.wxml
- home.wxss
- profile
- profile.js
- profile.json
- profile.wxml
- profile.wxss
- page.wxss
- project.config.json
- README.md也许你已经注意到了文件后缀名js, json, wxml, wxss。那么它们具体是干什么用的呢?
js后缀名的文件是你写javascript的地方了,项目的一些逻辑代码。
json后缀名的文件是你写页面的配置的地方,app.json是应用的整体配置,home.json是home页面的配置,profile.json是profile页面的配置。
wxml后缀名的文件是你写页面骨架的地方,类似我们的html。
wxss后缀名的文件是你写页面样式的地方,类似我们的css。
在看了文档,百度了写资料。我们就开始想一个练手的项目 -- github信息展示。
首先,我们搭建好项目的目录,之后就是根据文档啥的进行我们的项目构思的实现了。具体的过程我这里就不赘述了,毕竟在文章后面会配上项目的代码github地址的~
我们来看下效果吧:
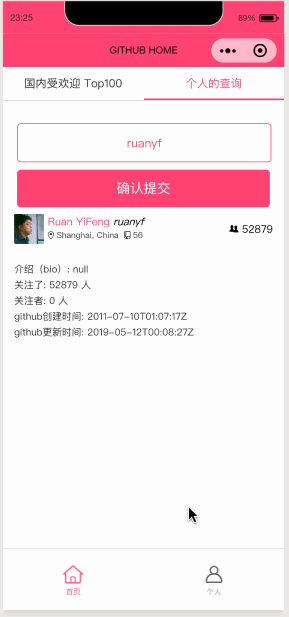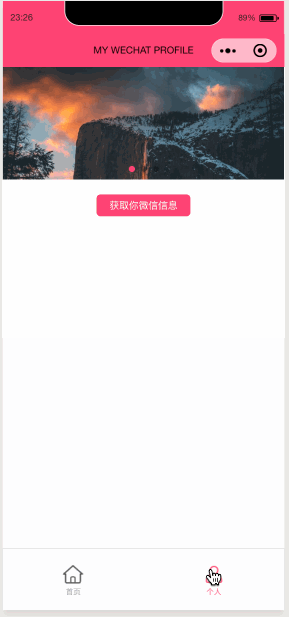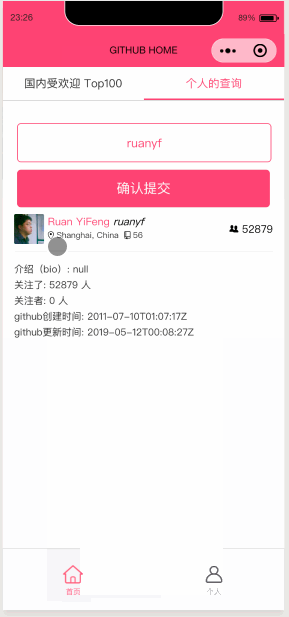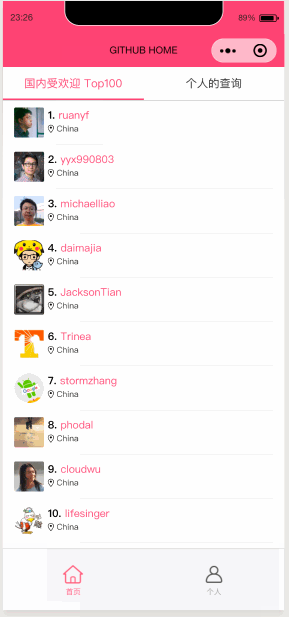
微信小程序上的icon来源网络,侵删
仓库的代码请戳嘉明的微信小程序整理仓库
备注:npm模块有个神奇的样板。这篇文章是基于我从设置中学到的东西。
如今,NPM已经成为javascript库的事实上的注册表。特别是React,Angular和其他前端库主导的网络和node.js接管的服务器端,NPM软件包比以往任何时候都更受欢迎。通常,我们会在代码中引入实用包,比如typy,sugar,并轻松的使用它们。
那么,你有没有想过编写自己的实用程序/库,并将其发布到NPM上面,以便在世界任何的地方可以重复使用它?如果是,那就继续阅读。✨
我们将在本文中介绍以下部分。
当你在多个项目中工作时,你经常发现自己在多个项目中重复简单的事情。举个例子,以你想要的方式解析日期并对其进行格式化。大多数开发者只是从一个项目复制代码到另一个项目中使用它,因为它只是几行代码。但更好的方法是提取代码并将其放在一个公共的位置,以便你可以从任何项目中访问它。NPM是一个理想且不断发展的生态系统,并且可以免费使用它。所以,从长远看,将所有可重用代码作为npm包发布上去将会帮助到你。
无论代码有多少,无论是一行还是一千行,都可以将其作为包发布,以便在多个代码库中轻松使用。
此外,你还可以成为这个库的作者。多么酷啊!😎
发布通常是一个简单的过程。
code => test => publish => revise code => test => publish new version ...
创建一个新目录(,进入目录)并从终端输入以下命令。
npm init(根据提示)输入有意义的包名称和包的相应详细信息。这将为你创建package.json。所有NPM包都需要main键。这定义了我们库的入口点。默认情况下,这入口点将是index.js,但是你可以根据你自己的情况来更改入口点(文件)。
对于Babel或基于bundle的库,入口点通常位于构建目录中。
如果你正在编写一个小型库,则可以将所有代码放入index.js中。但是,更常见的是,我们将抽象代码并将其放入单独的文件中。所以,理想的方法是将所有源代码保存在src中。
这是目前最广泛使用和推荐的源代码设置,尽管它从一个库到另一个库中有所不同。
我们大多数的人已经知道(上面)这些事,所以,我仅仅列出来,把它们留给你弄清楚。
你需要进行全面测试,以确保你的代码按照预期工作。有各种测试设置。你可以使用最适合你需求的。那么,广泛使用的测试设置有
... 等等
如果你需要代码覆盖率,我很喜欢(覆盖率),Istanbul是任何JavaScript项目的最佳覆盖工具之一。我非常喜欢它。
一旦你的代码通过了测试,那么可以准备发布了。
npm login输入你的用户名和密码。这将存储凭据,因此你不必为每次发布输入凭据。
npm publish这会将你的包发布到NPM注册表。发布完成后(不到一分钟),你可以在链接https://www.npmjs.com/~{username}/{package-name}中查看你的包。
如果你想对包进行更改,则必须更改版本号并再次发布。
请记住使用npm命令npm version patch,npm version minor和npm verson major来自动更新版本,而不是手动更新它们。这些命令是基于语义版本控制。
我有一些我自己的npm软件包,并在线研究了创建NPM软件包的所有最佳实践,并专门为此创建了样板文件。它具有预先设置的所有功能,以便你可以在几秒钟内开始使用。如果你正在寻找编写JavaScript util包,它可能只是你的样板。
样板文件的链接 -- npm-module-boilerplate。
你是最棒的!祝你度过美好的一天!🎉
原文:https://hackernoon.com/publish-your-own-npm-package-946b19df577e
开发者经常互换使用术语“库”和“框架”。但是,两者是有区别的。
“框架”和“库”都是某人编写的代码,用于解决常见的问题。
比如,你有一个处理字符串的程序。你决定保持你代码的DRY(don't repeat yourself),然后编写像下面可复用的功能代码:
function getWords(str) {
const words = str.split(' ');
return words;
}
function createSentence(words) {
const sentence = words.join(' ');
return sentence;
}那么恭喜你!你创建了一个库。
框架和库没有多么神奇。库和框架都是由某人编写的可复用的代码。两个的目的都是为了帮助你更快捷地解决常见的问题。
我常常使用房子作为网络开发概念的比喻。
库就像去宜家家居(IKEA,一家知名的家居零售商)购物一样。你已经有了个家,但是你需要布置些家具。你不想从头制作属于自己的桌子。Ikea允许你选择并购买你想要的东西到你家。你在掌控之中。
另一方面,框架就像建造一个样板房。在架构和设计方面,你有一套蓝图和一些有限的选择。最终,承包商和蓝图处于控制之中。然后他们会告诉你何时何地你可以提供自己的意见。
框架和库之间技术差异在于一个控制反转的的术语。
当你使用库的时候,你负责应用程序的流程。此时,你正在选择何时何地调用库。当你使用框架的时候,框架负责流程。此时,框架提供了一些插入代码的地方,但是它会根据需要去调用你插入的代码。
我们看个使用jQuery(一个库)和Vue.js(一个框架)的例子。
想象一下,我们想要在错误出现时候显示错误信息。在我们的举例中,我们将点击一个按钮来触发并展示错误(信息)。
使用jQuery
// index.html
<html>
<head>
<script src="https://code.jquery.com/jquery-3.3.1.min.js"
</script>
<script src="./app.js"></script>
</head>
<body>
<div id="app">
<button id="myButton">Submit</button>
</div>
</body>
</html>// app.js
// A bunch of our own code,
// followed by calling the jQuery library
let error = false;
const errorMessage = 'An Error Occurred';
$('#myButton').on('click', () => {
error = true; // pretend some error occurs and set error = true
if (error) {
$('#app')
.append(`<p id="error">${errorMessage}</p>`);
} else {
$('#error').remove();
}
});留意我们是怎么使用jQuery的。我们告诉自己的程序我们想调用它。这就像我们去物理图书馆,然后从书架上拉出我们想要的书籍。
这并不是说jQuery函数在我们调用它们的时候不需要某些输入,但是jQuery本身就是这些函数的库。我们负责(调用)。
使用Vue.js
// index.html
<html>
<head>
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
<script src="./app.js"></script>
</head>
<body>
<div id="app"></div>
</body>
</html>// app.js
const vm = new Vue({
template: `<div id="vue-example">
<button @click="checkForErrors">Submit</button>
<p v-if="error">{{ errorMessage }}</p>
</div>`,
el: '#vue-example',
data: {
error: null,
errorMessage: 'An Error Occurred',
},
methods: {
checkForErrors() {
this.error = !this.error;
},
},
});使用vue,我们必须填补空白。Vue的构造函数是具有某些特定属性的对象。它会告诉我们它需要什么,然后在幕后,Vue决定何时需要它。Vue反转程序的控制。我们将代码插入Vue。Vue负责(调用)。
是库还是框架的区别在于是否存在控制反转。
你经常会听到被描述为“自以为是”或“没有见解”的框架和库。这些术语是主观臆断。他们试图定义开发者在构造时所拥有的自由度。
框架更加自以为是,因为——根据定义——控制反转需要应用设计自由的让步。
同样的,某种程度上,某种观点的主观程度是主观的。比如,我个人认为Angular是一个自以为是的框架,而Vue.js是一个不那么自以为是的框架。
框架和库都是由某人编写的代码,有助你以更加简洁的方式完成一些常见的任务
框架反转了程序的控制。它告诉开发者他们需要什么。库就不是这样。程序员在需要的地方和时间点调用库。
库或框架留给开发者的自由度将决定着它是多“自以为是”。
谢谢阅读!
原文:https://medium.freecodecamp.org/the-difference-between-a-framework-and-a-library-bd133054023f
opinionated 此处翻译为“自以为是”,如有不妥还望指出
每天都有数百万的人出于不同的原因使用谷歌搜索。学生为了学业,商务人员为了调查,还有很多人是为了娱乐。但大多数的人可能没有充分使用谷歌搜索。
想要有效使用谷歌搜索并快速得到搜索结果吗?这里有20个搜索的小技巧能最大化你的搜索效率:
首个技巧就是使用谷歌搜索的标签 。在每个搜索的顶部(也许不在顶部)有很多的标签。通常你会看到站点,图片,新闻和其他的标签名。使用这些标签,你可以定义自己的搜索范围。
如果你需要图片,使用图片标签。如果你查找最近的新闻,使用新闻标签。
这是基本的(技巧),而且大多数人都已经使用了标签。如果你还没使用,强烈建议你使用标签。正确使用它们能够节省你大量的时间。
当你搜索特定内容时,尝试使用引号来降低谷歌搜索的猜测。当你将搜索内容放在引号中时,这会告诉搜索引擎去搜索整个短语。
比如,如果你想搜索Puppy Dog Sweaters,引擎将按照包含这三个词任意顺序去搜索内容。
但是,如果你搜索"Puppy Dog Sweaters",引擎将完全按照你输入的(顺序)那样搜索该短语。这可以帮助你查找可能隐藏在其他内容下的特定信息,如果(信息)没能正常排序。
有时,你会发觉自己正在搜索含义模糊的单词。比如,野马(Mustang)。当你使用谷歌搜索Mustang时,你可能得到福特公司生产的汽车和马匹这两种结果。如果你想排除某一个,使用连字符告诉搜索引擎忽略它。可以看下面的列子。
这就告诉搜索引擎去搜索野马,但是要排除任何包含"car"字样的结果。在查找有关内容的时,它很有用,因为无需获取包含某些内容的信息。
你可能碰到这种情况:你需要在特定的站点去谷歌搜索相关的内容或文章。(实现)这种情况的语法非常简单,请看下面。
这是搜索关于著名的曲棍球运动员Sidney Crosby的内容,但是仅限于NHL.com网站,所有其他的结果将被移除。如果你需要在特定的网站上查找特定的内容,则可以使用此快捷方式。
这个谷歌搜索技巧有点晦涩难懂。你正在搜索链接到特定页面的页面,而不是搜索特定页面。
换种思考方式来理解(这个技巧)。如果你想知道谁在他们的网站上引用了纽约时报的文章,你可是使用这个技巧找到链接到它的所有网站。它的语法如下:
这将返回链接到纽约时报官方网站的所有页面。(语法中)URL上的右侧几乎可以是任何内容。
但请注意,URL越具体,你获得的结果越少。我们知道很多人都不会使用这个谷歌搜索技巧,但是对某些人来说可能很有用。
星号通配符是列出的技巧中很有用的技巧之一。下面是它的原理。
当你在谷歌搜索的搜索字词中使用星号时,会留下一个占位符,之后可能被搜索引擎自动填充。如果你忘了完整的歌词,这个一个找到歌词的很明智方式。我们看下语法:
对你我而言,这可能看起来就像胡说八道。但是,谷歌搜索将搜索该短语,因为它知道星号表示任意单词【任意指0或多个】。
通常,你会发现它们是披头士(The Beatles)“Come Together”歌曲的歌词,这就是搜索会告诉你的内容。
这是一个很独特的技巧,如果大家知道它的存在,那么大部分人都会使用它。
假如你有一个很喜欢的网站。它可以是(关于)任何内容。但是,该网站(让人觉得)有点无聊,你想找其他类似的网站。你会使用到这个技巧。下面是语法:
如果搜索上面的内容,你无法找到指向亚马逊的链接。相反的,你会找到类似亚马逊的在线商城链接。比如Barnes & Noble, Best Buy等网站以及其他在线销售实体商品的网站。它是一个功能很强大的谷歌搜索技巧,可以帮助你找到想要浏览的新网站。
是的,谷歌搜索可以为你做数学运算。这是个难以描述的相当复杂(的技巧),因为它可以在很多方面使用。你可以问谷歌搜索基本的(数学)问题或者一些更难的问题。
需要注意的是,谷歌搜索不会解决所有的数学问题,但它会解决很多。以下是一些语法示例:
8 * 5 + 5
Planck’s Consant
如果你是搜索第一个,搜索引擎会返回45。当然,它还会展示一个计算器,方便你查找其他的(计算)问题。
如果你需要做一些快速的数学运算,但是又不想在头脑中去做这件事,这种方法就很方便。如果你搜索第二项,它将会返回普朗克常数的数值。
所以它可以做数学运算,也可以通过展示已知的数学术语的值来帮助你解决数学问题。
谷歌搜索是很灵活的。它知道你可能无法仅仅通过搜索单个单词或短语就找到你想要的内容。因此,它允许你多个搜索。
通过使用这个技巧,你可以搜索一个单词或短语以及第二个单词或短语。这有助于缩小搜索范围,以帮助你找到所需内容。下面是它的语法:
通过搜索上面(内容),你将搜索两个短语。你还记得上面提到的引号嘛?它也在这里使用。在这个例子中,这两个确切的短语将被搜索。也可以通过单词搜索,比如下面的例子:
将会搜索包含巧克力或者白巧克力的页面!
搜索一个范围的数字又是一个技巧,估计很多人不会使用。但是,使用它的人可能使用了一段时间了。
对金钱或者统计数据感兴趣的人会发现这个提示特别有用。基本上,你使用两个点和一个数字就可以让谷歌搜索知道你正在寻找特定范围的数字。语法如下:
What teams have won the Stanley Cup ..2004
41..43
在第一个例子中,搜索引擎将会返回2004年赢得Stanley杯的球队(的信息)。两个点后跟一个数字将告诉搜索引擎,你不是查找2004年之前或之后的内容。这可以帮你缩小范围到一个特定的数字,以提高搜索的结果。
在第二个例子中,谷歌将搜索数字41、42和43。这是模糊的,但是如果你需要搜索像这种情况的数字,那会很有用。
我们现在进入通用的技巧。谷歌搜索知道如何搜索很多事情。这意味着你输入的东西不需要过于具体。如果你想知道附近的披萨店,使用下面的搜索。
谷歌搜索将获取你的位置,并提供关于你附近披萨店的各种结果。
有时会出现谷歌没能搜索出你期待结果。在这种情况下,保持精简(见第11条)可能不是一个最佳选择。
正如谷歌本身建议的那样,最好的方法就是从简单的东西开始,然后逐渐变得更复杂。看下面的例子:
第一次尝试: job interviews
第二次尝试: prepare for job interviews
第三次尝试: how to prepare for a job interview
这将逐步完善搜索,为你带来更少但更具有针对性的事项。你不必直接从第一次尝试到第三次尝试的原因是你可能会因为跳过第二步尝试而错过你想要的东西。
数以百万的网站以不同的方式表达相同的信息;利用这个技术,你可以尽可能搜索更多的最佳信息。
这是很重要的一点。当人们使用谷歌搜索来上网时,他们通常使用类似平常说话的语言来搜索内容。
遗憾的是,网站不像人们那样交流;相反的,它们试图使用听起来很专业的语言。我们看下下面的例子:
“repair a flat tire.” 应该替代 “I have a flat tire”
“headache relief.” 应该替代 “My head hurts”
上面的这种清单一大堆。当你搜索时,尝试在专业网站上使用专业术语。这将有助你获得更多可靠的结果。
谷歌搜索的工作方式是,将你要搜索的内容与在线内容中的关键词进行匹配。
当你搜索太多单词时,它可能会限制你(想要)的结果。这意味着你实际上需要花更长的时间来寻找你(想要)的内容。因此,在搜索那些内容的时,只使用关键词是恰当的。我们看下下面这个例子:
别使用:Where can I find a Chinese restaurant that delivers.
而是尝试:Chinese restaurants nearby.
或者:Chinese restaurants near me.
这样做有助于谷歌找到你想要的内容,而不会造成任何的混乱。所以要谨记,保持精简(第11点)并只使用关键字。
可输入的许多命令能为你提供即时结果。
就比如上面的数学示例(第8点),谷歌可立即返回你想要的搜索结果,并在(页面)顶部显示所需的信息。这可以为你节省很多时间和精力,避免你点击一堆麻烦的链接。
以下是你可以输入到谷歌的一些命令的示范:
Weather *zip code* - 这将显示给定邮政编码(地区)的天气。你也可以使用城镇或城市的名称而不是区号,但是如果城市中有多个区号,则可能不准确。
What is *celebrity name* Bacon Number - 这是个很有趣的小故事,它会告诉你任何给定的名人与著名的演员Kevin Bacon之间有几重关联。很流行的趣事,六度分离指没有哪个演员是和Kevin Bacon有超过六层关系联系起来的。Mark Zuckerberg(和Kevin Bacon)通过三层关系就可以建立联系。
The math example 上面讲到的数学例子。
What is the definition of *word* or Define: *word* - 这将展示一个单词的定义。
Time *place* - 这将显示你输入地方的时间。
在谷歌中通过输入股票名来查看股票。如果你搜索GOOG,引擎会查看谷歌的股值。
这些快捷的命令可以代替在网站中的多次点击,将其压缩为单个搜索。这对你(搜索)反复需要的信息带来很大帮助。
⚠️ 广义来说:六度分离(Six Degrees of Kevin Bacon) - 指世界上任意两个人之间最多通过六个人就能够联系起来。
多年来谷歌搜索变得更加智能。因此,你(在搜索的时候)都不需要正确的拼写单词。
只要(拼写)很接近,谷歌就可以弄清楚它意味着什么。这里有些例子:
“Nver Gna Gve Yo Up”,谷歌会自动认为你是要搜索“Never Gonna Give You Up.”如果你的拼写错误是偶然的,谷歌会为你提供搜索纠错的选项。如果你碰巧忘记如何拼写字词或者完全不确定某些字词的拼写,那么这是一个很棒的技巧。
在搜索一些晦涩的词组时,它很有用。这同样适用于大写和语法(的搜索)。
相当多的事物可以用很多种方式描述。以我们的同名事物为例,即**“生活黑客”。术语“黑客”指的是破坏网络或系统安全性的计算机程序员。然而,当与”生活“**这个词一起使用时,意思就改变了,它指人们可以用来改善生活的小技巧。
如果你无法找到要搜索的内容,请记住,人们可能会以不同你的方式搜索或定义你需要的信息。
你可能会搜索 “How to install drivers in Ubunut?”
但你的意图是 “Troubleshoot driver problems Ubuntu.”
这确实没有一个很好的例子。如果你搜索某些内容并且着不到答案,请尝试使用不同的词组来询问同一个问题,看看是否有助(你寻找到)结果。
谷歌搜索中经常被遗忘的功能是搜索特定文件或文件类型的能力。如果你需要先前查看过或需要用于其他项目的特定PDF或PowerPoint文件,这将是莫大的帮助。语法相当简单:
Search term here filetype:pdf在上面的示例中,你只需要将搜索词组【Search term】替换成你想要的搜索内容。然后使用filetype的命令,(filetype)后加你想要的任何文件类型的扩展名。
这对于学术目的来说非常有用,但是商演和其他各种演示也能从中受益的。
谷歌搜索可以快速且准确地转换度量单位和货币单位。这有很多用途,比如检查两种货币之间的转换率。
如果你恰好是数学系学生,你可用它将英尺转换为米或从盎司转换为升。下面演示如何做到:
miles to km - 这会将英里转换为公里。你可以将数字放在(mile)前面以转换成特定的数字。比如 “10 miles to km” 将显示10英里转换成多少公里。
USD to British Pound Sterling - 这将把美元兑换成英镑。与上面的度量单位一样,你可以(在USD前面)添加数字以查找特定金额确切转换。
这个技巧确实适合数学系学生和国际商务人士。但是,你会惊讶的发现,这个技巧也被普通大众使用。
我们(要讲)的最后一个技巧就是使用谷歌搜索来找出你包裹的位置。你可以直接在谷歌搜索栏中输入任何的UPS,UPSPS或Fedex跟踪号码,它会显示有关你包裹的跟踪信息。
这比去特定的网站(查找)更方便,你不用等待网站加载完,然后在那里搜索你的包裹。
这就不需要一个实例说明了。尝试输入你的(包裹)跟踪号码,然后查找你包裹的位置。
谷歌搜索是一个非常强大的搜索工具。使用上面提到的技巧,你可以在万维网(World Wide Web)上找到你可能需要的任何内容。
无论是避免维基百科的学校论文项目,还是找到最新的股价,甚至找到歌词,都有办法让谷歌搜索为你服务。
原文:https://www.lifehack.org/articles/technology/20-tips-use-google-search-efficiently.html
本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为中篇。
汇总上篇文章请戳这里--谈谈ES6语法(汇总上篇)
好了,我们直奔中篇的内容~
数组扩展运算符(spread)是三个点(...)。它好比rest参数的逆运算,将一个数组转为用空格分隔的参数序列。
console.log(...[1, 2, 3]); // 1 2 3
console.log(1, ...[2, 3, 4], 5); // 1 2 3 4 5
⚠️ rest参数是运用在函数参数上的,将函数参数转换为数组的形式,如下:
function fn(...values) {
console.log(values); // ['jia', 'ming']
}
fn('jia', 'ming');下面我们结合数组扩展运算符和rest参数来实现一个类似call的方法call2操作:
Function.prototype.call2 = function(context, ...args){ // 这里使用到rest参数
context = context || window; // 因为传递过来的context有可能是null
context.fn = this; // 让fn的上下文为context
const result = context.fn(...args); // 这里使用了数组扩展运算符
delete context.fn;
return result; // 因为有可能this函数会有返回值return
}
var job = 'outter teacher';
var obj = {
job: 'inner teacher'
};
function showJob() {
console.log(this.job);
}
showJob(); // outter teacher
showJob.call2(obj); // inner teacher复习一下,我们把var job = 'outter teacher'改为let job = 'outter teacher'后,showJob()会输出什么?
答案是undefined。在前一篇中也提到过,ES6语法声明的变量是不会挂载在全局对象上的~
Array.from方法用于将两类对象转为真正的数组:类似数组的对象(array-like object)和可遍历(iterable)的对象(对象包括ES6新增的数据结构Set和Map)。
// 类数组转化成数组
let arrayLike = {
'0': 'a',
'1': 'b',
'2': 'c',
length: 3
}
// ES5的写法
var arr1 = [].slice.call(arrayLike); // ['a', 'b', 'c']
// ES6的写法
let arr2 = Array.from(arrayLike); // ['a', 'b', 'c']Array.of()方法用于将一组值,转换为数组。
let arr = Array.of(2, 3, 'reng');
console.log(arr); // [2, 3, 'reng']
console.log(arr.pop()); // rengArray.of基本上可以弥补Array()或new Array()带来的因为参数个数导致的不同行为。Array.of基本上可以替代它们两个了。
Array.of(); // []
Array.of('reng'); // ['reng']
Array.of(2, 'reng'); // [2, 'reng']数组中还有其它有用的方法:
include(el)方法相似[1, [2, [3]]].flat(Infinity);
// [1, 2, 3]有这么一个需求:将数组[[2, 8], [2], [[4, 6], 7, 6]]转成一维且元素不重复的数组。
我们的实现方案如下:
let arr = [[2, 8], [2], [[4, 6], 7, 6]];
console.log([...new Set(arr.flat(Infinity))]); // [2, 8, 4, 6, 7]ES6允许字面量定义对象时,把表达式放在方括号内:
let lastWord = 'last word';
const a = {
'first word': 'hello',
[lastWord]: 'world',
['end'+'symbol']: '!'
};
a['first word'] // 'hello'
a[lastWord] // 'world'
a['last word'] // 'world'
a['endsymbol'] // '!'上面整理数组扩展内容的时候,提到了数组的扩展运算符。ES2018将这个运算符引入了对象~
let z = { a: 3, b: 4 };
let n = { ...z }; // 关键点
n // { a: 3, b: 4 }===行为基本一致const obj = { foo: 'bar', baz: 42 };
Object.entries(obj)
// [ ["foo", "bar"], ["baz", 42] ]Set翻译出来就是集合,有元素唯一性的特点。
在数组去重的场景上很有用处:
// 去除数组的重复成员
[...new Set(array)]
// 如
console.log([...new Set([2, 2, 3, 2])]); // [2, 3]顺便添加下es5的数组去重的方法吧:
ES5实现:
[1,2,3,1,'a',1,'a'].filter(function(ele,index,array){ return index===array.indexOf(ele)})需要留意的Set属性和方法有以下:
WeakSet结构与Set类似,也是有不重复元素的集合。但是它和Set有两个区别:
WeakSet对象中只能存放对象引用, 不能存放值, 而Set对象都可以.
WeakSet中对象中存储的对象值都是被弱引用的, 如果没有其他的变量或属性引用这个对象值, 则这个对象值会被当成垃圾回收掉. 正因为这样, WeakSet 对象是无法被枚举的, 没有办法拿到它包含的所有元素。
var ws = new WeakSet();
var obj = {};
var foo = {};
ws.add(window);
ws.add(obj);
ws.has(window); // true
ws.has(foo); // false, 对象 foo 并没有被添加进 ws 中
ws.delete(window); // 从集合中删除 window 对象
ws.has(window); // false, window 对象已经被删除了
ws.clear(); // 清空整个 WeakSet 对象WeakSet 没有size属性,没有办法遍历它的成员。
Map对象保持键值对。任何值(对象或者原始值)都可以作为一个键或一个值。
Object和Map的比较:
Object的键只能是字符串或者Symbols,但一个Map的键可以是任意值,包括函数、对象、基本类型。Map中的键值是有序的,而添加到对象中的键则不是。因此,当对它进行遍历时,Map对象是按插入的顺序返回键值。Map在涉及频繁增删键值对的场景下会有些性能优势`。如果你需要“键值对”的数据结构,Map比Object更合适。
const set = new Set([ // 数组转换为map
['foo', 1],
['bar', 2]
]);
const m1 = new Map(set);
m1.get('foo') // 1
const m2 = new Map([['baz', 3]]);
const m3 = new Map(m2);
m3.get('baz') // 3Map拥有的属性和方法和Set相似,多出了些:
WeakMap结构与Map结构类似,也是用于生成键值对的集合。但是有两点区别:
WeakMap只接受对象作为键名(null除外),不接受其他类型的值作为键名。WeakMap的键名所指向的对象,不计入垃圾回收机制。和WeakSet相似啦。属性方法啥的跟Map差不多,就是没有了size和forEach,因为其是不可枚举的。
Promise是异步编程的一种解决方案,比传统的解决方案“回调函数和事件”更合理和更强大。
Promise对象有以下两个特点:
对象的状态不受外界影响。Promise对象代表一个异步操作,有三种状态:pending(进行中)、fulfilled(已成功)和rejected(已失败)。
一旦状态改变,就不会再变,任何时候都可以得到这个结果。Promise对象的状态改变,只有两种情况:从pending变成fulfilled(fulfilled也称resolved)和从pending变成rejected。
const promise = new Promise(function(resolve, reject) {
// ...some code
if(/* 异步操作成功 */) {
resolve(value);
} else {
reject(error);
}
})参数resolve和reject是两个函数,由JavaScript引擎提供,不用自己部署。
Promise实例生成之后,可以使用then方法分别指定resolved状态和rejected状态的回调函数。
promise.then(function(value) {
// success
}, function(error) {
// failure
});我们来粘贴个简单例子:
function timeout(ms) {
return new Promise((resolve, reject) => {
setTimeout(resolve, ms, 'done');
});
}
timeout(100).then((value) => {
console.log(value); // 100ms后输出'done'
});嗯~我们顺道来复习下setTimeout的第三个参数。哦😯,不,是第三个,第四个...
var timeoutID = scope.setTimeout(function[, delay, param1, param2, ...]);function 是你想要在到期时间(delay毫秒)之后执行的函数。delay 是可选语法,表示延迟的毫秒数。param1, ..., paramN 是可选的附加参数,一旦定时器到期,它们会作为参数传递给function那么,到这里你理解了上面的例子为什么在100ms后输出done了嘛💨
详细的setTimeout信息,请戳MDN的setTimeout。
简单的例子看完了,看下我们在工作中使用得比较多的请求接口的例子:
const getJSON = function(url) {
const promise = new Promise(function(resolve, reject){
const handler = function() {
if(this.readyState !== 4) {
return;
}
if(this.status === 200) {
resolve(this.response); // this.response作为参数传给then中的json
} else {
reject(new Error(this.statusText));
}
};
const client = new XMLHttpRequest();
client.open('GET', url);
client.onreadystatechange = handler;
client.responseType = 'json';
client.setRequestHeader('Accept', 'application.json');
client.send();
});
return promise;
};
getJSON('/post.json').then(function(json) {
console.log('Contents: '+ json);
}, function(error) {
console.log('error happen ', error);
});Promise.prototype.catch方法是.then(null, rejection)或.then(undefined, rejection)的别名,用于指定发生错误时的回调函数。
p.then((val) => console.log('fulfilled:', val))
.catch((err) => console.log('rejected', err)); // promise中任何一个抛出错误,都会被最后一个catch捕获
// 等同于
p.then((val) => console.log('fulfilled:', val))
.then(null, (err) => console.log('rejected:', err));Promise.prototype.finally()方法(其不接受任何参数)用于指定不管Promise对象最后状态如何,都会执行的操作。该方法是 ES2018 引入标准的。
语法:
promise
.then(result => {···})
.catch(error => {···})
.finally(() => {···});构造函数方法Promise.all方法用于将多个Promise实例,包装成一个新的Promise实例。
const p = Promise.all([p1, p2, p3]);上面代码中,Promise.all方法接受一个数组作为参数,p1, p2, p3都是Promise实例。如果不是会调用Promise.resolve方法,具体看文档。
// 生成一个Promise对象的数组
const promises = [2, 3, 5, 7, 11, 13].map(function (id) {
return getJSON('/post/' + id + ".json");
});
Promise.all(promises).then(function (posts) {
// ...
}).catch(function(reason){
// ...
});上面代码中,promises是包含 6 个 Promise 实例的数组,只有这6个实例的状态都变成fulfilled,或者其中有一个变为rejected,才会调用Promise.all方法后面的回调函数。
Promise实例,自己定义了catch方法,那么它一旦被rejected,并不会触发Promise.all()的catch方法。所以使用Promise.all()别手痒在每个实例promise内添加错误捕获。
需求:使用promise改写下面的代码,使得输出的期望结果是每隔一秒输出0, 1, 2, 3, 4, 5,其中i < 5条件不能变
for(var i = 0 ; i < 5; i++){
setTimeout(function(){
console.log(i);
},1000)
}
console.log(i);我们直接上使用promise改写的代码吧~
const tasks = []; // 存放promise对象
for(let i = 0; i < 5; i++){
tasks.push(new Promise((resolve) => {
setTimeout(() => {
console.log(i);
resolve();
}, 1000 * i);
}));
}
Promise.all(tasks).then(() => {
setTimeout(() => {
console.log(tasks.length);
}, 1000);
});
// 每隔一秒输出 0, 1, 2, 3, 4, 5本次的ES6语法的汇总总共分为上、中、下三篇,本篇文章为中篇。
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
图是由具有边的节点集合组成的数据结构。图可以是有向的或者是无向的。
有向图包含功能类似于单行道的边。边缘从一个节点流向另一个节点。
比如,你可能有一个(关于)人物和电影的图表,其中每个人可以有多个喜欢的电影,但是电影没有喜欢的人。
无向图包含双向流动的边缘,类似于双向道路,两个方向都有交通。
比如,你可能有一个宠物图表,其中每只宠物都有一个所有者,每个所有者都有一只宠物。
备注:(下面)双向箭头代表一条边,但是为了显而易见,我绘制了两条箭头。
**图(graph)**中没有明确的信息层次结构。
我们将创建一个(关于)人和冰淇凌口味的图表。这将是一个有向图,因为人们可以喜欢某些口味,但是味道可不喜欢人。
我们将创建三个类:
PersonNodeIceCreamFlavorNodeGraphPersonNode类将接受一个参数:一个人的名字。这将作为其标识符。
PersonNode构造函数将包含两个属性:
name:唯一标识符favoriteFlavors:关于IceCreamFlavorNodes的数组另外,PersonNode类包含一个方法:addFlavor。这将传入一个参数,一个IceCreamFlavorNode对象,并将其添加到数组favoriteFlavors 中。
类的定义如下所示:
class PersonNode {
constructor(name) {
this.name = name;
this.favoriteFlavors = [];
}
addFlavor(flavor) {
this.favoriteFlavors.push(flavor);
}
}IceCreamFlavorNode类将传入一个参数:冰淇凌口味。这将作为其标识符。
这个类不需要包含任何方法,因为这是一个无向图,数据是从person流向flavors,但是不会回流。
这个类的定义如下:
class IceCreamFlavorNode {
constructor(flavor) {
this.flavor = flavor;
}
}Graph类不接受任何参数,但是其构造函数将包含三个属性:
peopleNodes:人物节点数组。iceCreamFlavorNodes:冰淇凌口味节点数组。edges:包含PersonNodes和IceCreamFlavorNodes之间的边缘数组。Graph类将包含六个方法:
addPersonNode(name):接受一个参数,一个人的名字,创建一个具有此名字的PersonNode对象,并将其推送到peopleNodes数组。addIceCreamFlavorNode(flavor):接受一个参数,一个冰淇凌口味,创建一个具有这种口味的IceCreamFlavorNode对象,并将其推送到iceCreamFlavorNodes数组中。getPerson(name):接受一个参数,一个人名字,并返回该人的节点。getFlavor(flavor):接受一个参数,一个冰淇凌口味,并返回该口味的节点。addEdge(personName, flavorName):接受两个参数,一个人的名称和一个冰淇凌口味,检索两个节点,将flavor添加到人的favoriteFlavors数组,并将边推送到edge数组。print():简单打印出peopleNodes数组中的每个人,以及他们最喜欢的冰淇凌口味。类的定义如下所示:
class Graph {
constructor() {
this.peopleNodes = [];
this.iceCreamFlavorNodes = [];
this.edges = [];
}
addPersonNode(name) {
this.peopleNodes.push(new PersonNode(name));
}
addIceCreamFlavorNode(flavor) {
this.iceCreamFlavorNodes.push(new IceCreamFlavorNode(flavor));
}
getPerson(name) {
return this.peopleNodes.find(person => person.name === name);
}
getFlavor(flavor) {
return this.iceCreamFlavorNodes.find(flavor => flavor === flavor);
}
addEdge(personName, flavorName) {
const person = this.getPerson(personName);
const flavor = this.getFlavor(flavorName);
person.addFlavor(flavor);
this.edges.push(`${personName} - ${flavorName}`);
}
print() {
return this.peopleNodes.map(({ name, favoriteFlavors }) => {
return `${name} => ${favoriteFlavors.map(flavor => `${flavor.flavor},`).join(' ')}`;
}).join('\n')
}
}现在,我们有了三个类,我们可以添加一些数据并测试它们:
const graph = new Graph(true);
graph.addPersonNode('Emma');
graph.addPersonNode('Kai');
graph.addPersonNode('Sarah');
graph.addPersonNode('Maranda');
graph.addIceCreamFlavorNode('Chocolate Chip');
graph.addIceCreamFlavorNode('Strawberry');
graph.addIceCreamFlavorNode('Cookie Dough');
graph.addIceCreamFlavorNode('Vanilla');
graph.addIceCreamFlavorNode('Pistachio');
graph.addEdge('Emma', 'Chocolate Chip');
graph.addEdge('Emma', 'Cookie Dough');
graph.addEdge('Emma', 'Vanilla');
graph.addEdge('Kai', 'Vanilla');
graph.addEdge('Kai', 'Strawberry');
graph.addEdge('Kai', 'Cookie Dough');
graph.addEdge('Kai', 'Chocolate Chip');
graph.addEdge('Kai', 'Pistachio');
graph.addEdge('Maranda', 'Vanilla');
graph.addEdge('Maranda', 'Cookie Dough');
graph.addEdge('Sarah', 'Strawberry');
console.log(graph.print());下面是我们有向图看起来类似(的样子):
如果你想看完整的代码,到我的CodePen上查看。
原文:https://dev.to/emmawedekind/creating-graphs-with-javascript-4efm
随着Vue应用程序的大小增加,Vuex Store中的actions和mutations也会增加。本文,我们将介绍如何将其减少到易于管理的东西。
Vuex是vue.js应用程序的状态管理模式+库。它充当应用程序中所有组件的集中存储,其规则确保状态只能以可预测的方式进行变更。
我们正在使用Vuex在Factory Core Framework应用程序中的所有应用程序之间共享状态。由于框架是一组应用程序,(假设)我们目前有九个Vuex stores。每个store都有自己的state, actions和mutations。我们在store中使用actions来对后台进行API调用。数据返回后,我们使用mutations将其存储在state中。这允许任何组件访问该数据。可以想象到,我们的store可以有大量的actions来处理这些API调用。以下是我们其中一个Vuex stores中所有的actions操作示例。
这个store有16个actions。现在想象一下,如果我们有9个store,我们的Factory Core Framework总共有多少个actions。
我们所有的actions操作基本上都执行相同的功能。每个action都执行以下操作:
state存储数据(可选)action组件的响应要将这些重构为单个(统一)操作action,我们需要知道action需要明确的事情:
state中,如果是,则提交到哪个状态变量下面是我们其中的一个actions示范:
async getLineWorkOrders({ rootState, commit }, payload) {
try {
let response = await axios.post(
'api.factory.com/getLineWorkOrders',
Object.assign({}, payload.body, { language: rootState.authStore.currentLocale.locale }),
rootState.config.serviceHeaders
);
commit( 'setCurrentWorkOrderNumber', response.data.currentWorkOrderNumber );
return response.data;
} catch (error) {
throw error;
}
},在这个action中,我们通过击中端点(发起请求)api.factory.com/geteLineWorkOrders从我们的后台API获取数据。检索到数据之后,将更新state变量currentWorkOrder。最后,数据将返回到进行调用的组件中。我们所有的actions都有这种格式。要将它重构为单个操作,我们需要拥有端点,无论是否发送有效负载以及是否提交数据。下面👇是我们重构的单一action:
async fetchData({ rootState, commit }, payload) {
try {
let body = { language: rootState.authStore.currentLocale.locale };
if (payload) {
body = Object.assign({}, payload.body, body);
}
let response = await axios.post(\`api.factory.com/${payload.url}\`, body, rootState.config.serviceHeaders );
if (payload.commit) {
commit('mutate', {
property: payload.stateProperty,
with: response.data\[payload.stateProperty\]
});
}
return response.data;
} catch (error) {
throw error;
}
}此单个action将处理每种可能的调用。如果我们需要通过API调用发送数据,它可以做到。如果我们需要commit提交数据,它可以做到。如果它不需要提交数据,则不会。它始终将数据返回到组件。
之前,对于需要改变状态mutate state的每个action,我们创建了一个新的mutation来处理这个问题。我们使用单一的mutation来处理这个问题。下面是我们的单一mutation:
const mutations = {
mutate(state, payload) {
state\[payload.property\] = payload.with;
}
};如果一个action中需要在store中存储数据,我们如下调用mutation:
commit('mutate', {
property: <propertyNameHere>,
with: <valueGoesHere>
});通过统一我们的action和mutation,我们大大简化了我们的store中的actions和mutations。
译者加:其实就是为了更好的管理vuex,而形成模版方式的编写
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
在JavaScript里面有个引用类型叫做基本包装类型,它包括String、Number和Boolean。那么它和基本的类型String、Number和Boolean是啥关系呢?接着往下看👀
所谓的装箱,是指将基本数据类型转换为对应的引用类型的操作。而装箱又分为隐式装箱和显式装箱。
对于隐式装箱,我们看下下面的代码:
var s1 = 'call_me_R'; // 隐式装箱
var s2 = s1.substring(2);上面代码的执行步骤其实是这样的:
上面的三个步骤转换为代码,如下:
# 1
var s1 = new String('call_me_R');
# 2
var s2 = s1.substring(2);
# 3
s1 = null;隐式装箱当读取一个基本类型值时,后台会创建一个该基本类型所对应的基本包装类型对象。在这个基本类型的对象上调用方法,其实就是在这个基本类型对象上调用方法。这个基本类型的对象是临时的,它只存在于方法调用那一行代码执行的瞬间,执行方法后立即被销毁。这也是在基本类型上添加属性和方法会不识别或报错的原因了,如下:
var s1 = 'call_me_R';
s1.job = 'frontend engineer';
s1.sayHello = function(){
console.log('hello kitty');
}
console.log(s1.job); // undefined
s1.sayHello(); // Uncaught TypeError: s1.sayHello is not a function装箱的另一种方式是显示装箱,这个就比较好理解了,这是通过基本包装类型对象对基本类型进行显示装箱,如下:
var name = new String('call_me_R');显示装箱的操纵可以对new出来的对象进行属性和方法的添加啦,因为通过通过new操作符创建的引用类型的实例,在执行流离开当前作用域之前一直保留在内存中。
var objStr = new String('call_me_R');
objStr.job = 'frontend engineer';
objStr.sayHi = function(){
console.log('hello kitty');
}
console.log(objStr.job); // frontend engineer
objStr.sayHi(); // hello kitty拆箱就和装箱相反了。拆箱是指把引用类型转换成基本的数据类型。通常通过引用类型的valueOf()和toString()方法来实现。
在下面的代码中,留意下valueOf()和toString()返回值的区别:
var objNum = new Number(64);
var objStr = new String('64');
console.log(typeof objNum); // object
console.log(typeof objStr); // object
# 拆箱
console.log(typeof objNum.valueOf()); // number 基本的数字类型,想要的
console.log(typeof objNum.toString()); // string 基本的字符类型,不想要的
console.log(typeof objStr.valueOf()); // string 基本的数据类型,不想要的
console.log(typeof objStr.toString()); // string 基本的数据类型,想要的所以,在进行拆箱操作的过程中,还得结合下实际的情况进行拆箱,别盲目来 -- 吃力不讨好就很尴尬了😅
《JavaScript高级程序设计》
作为一个web开发工程师,我们平时都会和诸如200, 304, 404, 501等状态码打交道,那么它们是什么意思呢?今天,我们来聊聊~
HTTP状态码是服务端返回给客户端(因为这里是web开发,这里的客户端指浏览器客户端)的3位数字代码。
这些状态码相当于浏览器和服务器之间的对话信息。它们相互沟通两者之间的事情是正常运行了还是运行失败了或者发生了一些其他的事情(如Continue)。了解状态码有助于你快速的诊断错误,减少网站的停机时间等等。
状态码共分为五类,以1-5数字开头进行标识,如下:
备注:3xxs类中的304是个奇葩,其不属于重定向信息提示,这个后面会讲到
HTTP状态码大体的内容已经了解了,但是在具体的工作中,要用到具体的状态码,我们下面来展开说明下各自的一些状态码和工作中常用到的那些状态码🐱
Upgrade标头发送的,并且指示服务器也正在切换协议。Link链接头一起使用,以允许用户代理在服务器仍在准备响应时开始预加载资源。备注:在web开发的工作中,我们都会使用封装好的库进行接口请求,而且浏览器的控制台网络中也不会出现这类状态码的提示(我没看到过😢),所以这一大类基本不会接触到,了解一下即可。
GET:资源已被提取并在消息正文中传输。HEAD:实体标头位于消息正文中。POST:描述动作结果的资源在消息体中传输。TRACE:消息正文包含服务器收到的请求信息。(方法不安全,一般不用)说到了HTTP的方法,可以戳HTTP请求方法这个解析教程来了解一下。
PUT或POST请求之后发送的响应。复杂请求时候,浏览器会发送一个OPTION方法进行预处理返回响应。关于复杂请求和简单请求,可以参考这篇文章CORS非简单请求。
备注:使用的最多的2xxs状态码是200和204,在遇到204状态码的时候,要注意一下自己发的请求是不是复杂请求。如果是复杂请求,那么在得到204返回时,浏览器有没有接受了这个请求的返回,如果没有,要叫后端搞下相关配置了。
上文已经提到过,这一大类是提示重定向,可是有一个奇葩--304,它并不是表示重定向的信息提示,而是表示资源未被更改。至于为什么会被放在这个分类里面,真不知道~(看官知道的话补充下啦)👏
永久移动到新位置,并且将来任何对此资源的引用都应该使用响应返回的若干个URI之一。临时从不同的URI响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在Cache-Control或Expires中进行了指定的情况下,这个响应才是可缓存的。GET的方式访问那个链接。这个方法的存在主要是为了允许由脚本激活的POST请求输出重定向到一个新的资源。If-Modified-Since头部使用。在重新发出原始请求时不允许更改请求方法。比如,使用POST请求始终就该用POST请求。备注:307和303已经替代了历史上的302状态码,现在看到的临时重定向的状态码是307。详细内容可到维基百科上查看。
备注:这里要注意的是422,别请求链接一出错,就屁颠屁颠的找后端,先看下后端给过来的API文档中,要传的字段是否都准确跟上了。😂
备注:遇到这类的问题,去问后端同学吧。语气好点啦,毕竟大家都是为了生活😄
以上就是今天整理的内容。嗯~,对了,各个浏览器对此的支持度very good。更加详细内容啥的,可以直接戳我下面的参考。在日常的web工作中,明白HTTP状态码是一个必备的活,起码在出错的时候,知道浏览器和服务器的交流障碍在哪里啦~
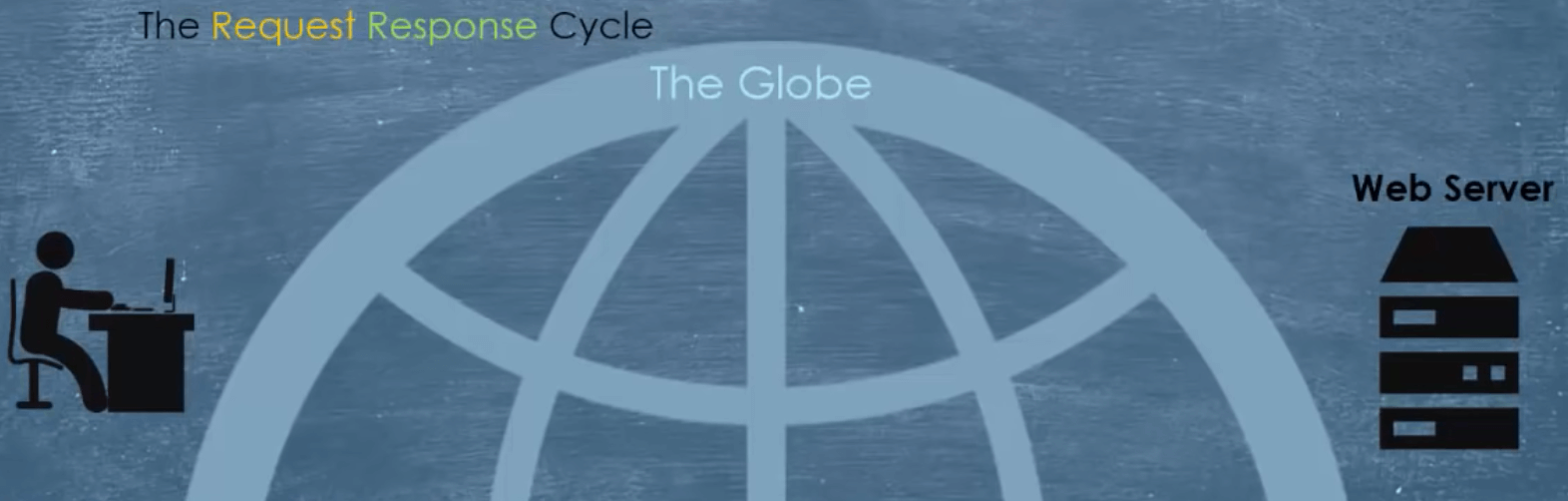
HTTP是HyperText Transfer Protocol的缩写,意思是超文本传输协议。它是一种应用层协议,允许基于WEB的应用程序进行通信和交换数据。
你可以把HTTP看作是网络的信使。
HTTP是基于TCP/IP协议的,可以使用http进行内容的传输,比如图片,视频,音频,文档等等。
客户端和服务端需要进行通信的话,通常会使用request response cycle的形式。
客户端需要发送request请求,这样服务端才知道要通信;之后,服务端对请求进行response响应。
在进入话题之前,我们顺便了解下HTTP比较重要的三个知识点:
HTTP是无连接的:在发出请求后,客户端和服务端断开连接,然后当响应准备就绪的时候,服务端再次重新建立连接并发送响应。
HTTP可以提供任何类型的数据,只要客户端和服务端两边的电脑能够读取理解它。
HTTP是无状态的:客户端和服务器只是在当前请求期间了解彼此。如果它关闭了,并且两台电脑想要再次连接,它们需要重新提供信息。
下面说说request-response连接😄
假设你要连接一个url--http://mywebsite/products/myproduct.html,会先通过tcp/ip建立网络的连接,这会进行三次握手,具体的情况就不在这里说了。
客户端和服务端建立的连接,为它们通过HTTP协议进行通信提供了环境。
在建立连接之后,客户端会发送一个请求,因为HTTP是无连接的,客户端会断开和服务器端的连接,等待服务器端的响应。服务器端处理了响应之后,会重新建立连接,然后发送响应信息给客户端。
一个典型的HTTP信息包含三部分:起始行、头部和主体。如下图:
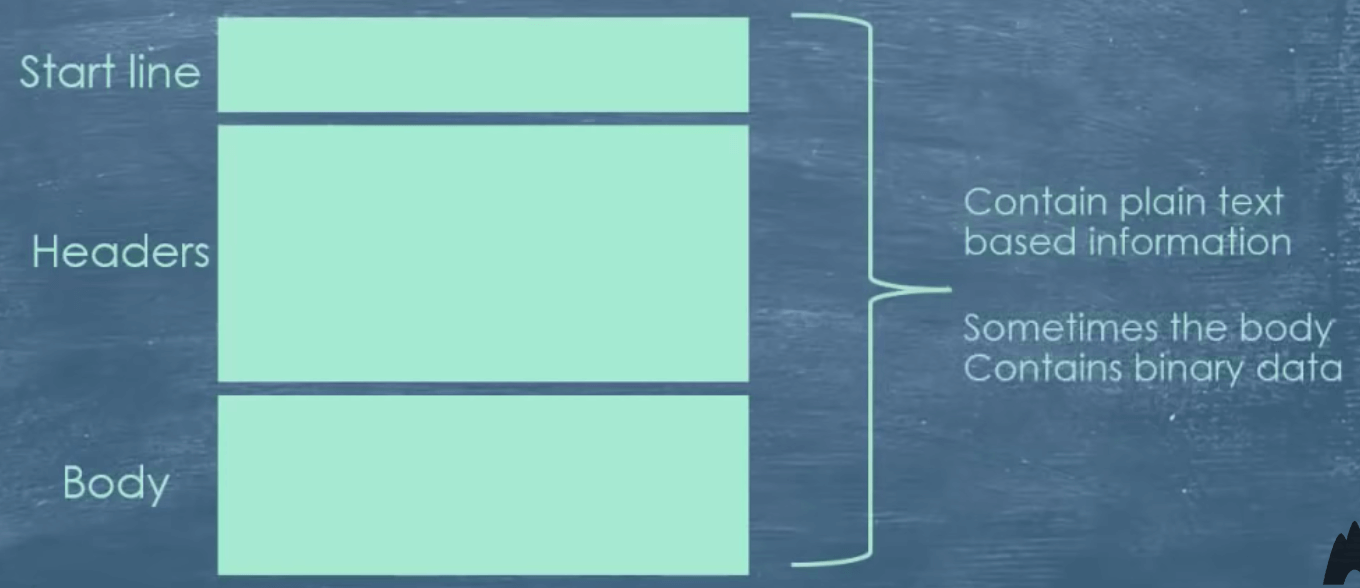
请求信息和响应信息大体是相同的,但是具体到里面的信息就有所差异了,如下图:
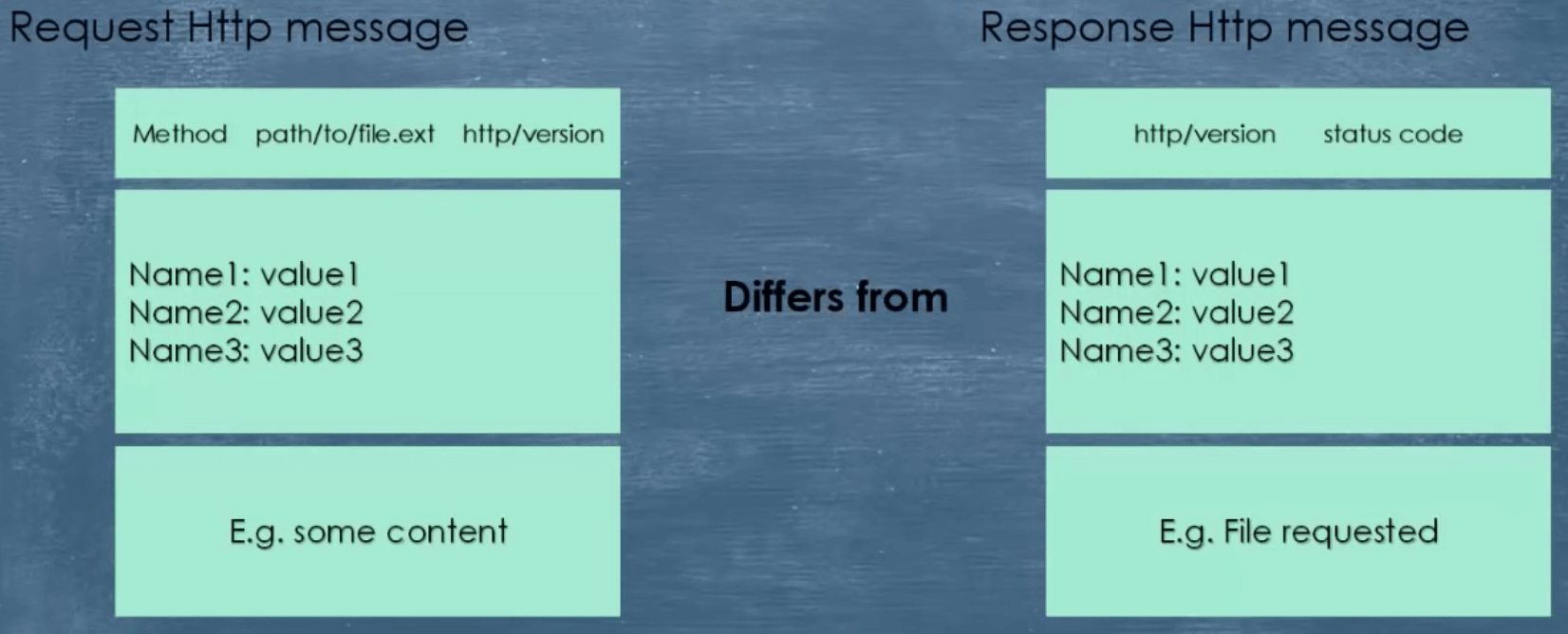
那么发送请求信息包含哪些呢?
我们先来看一张示例图:
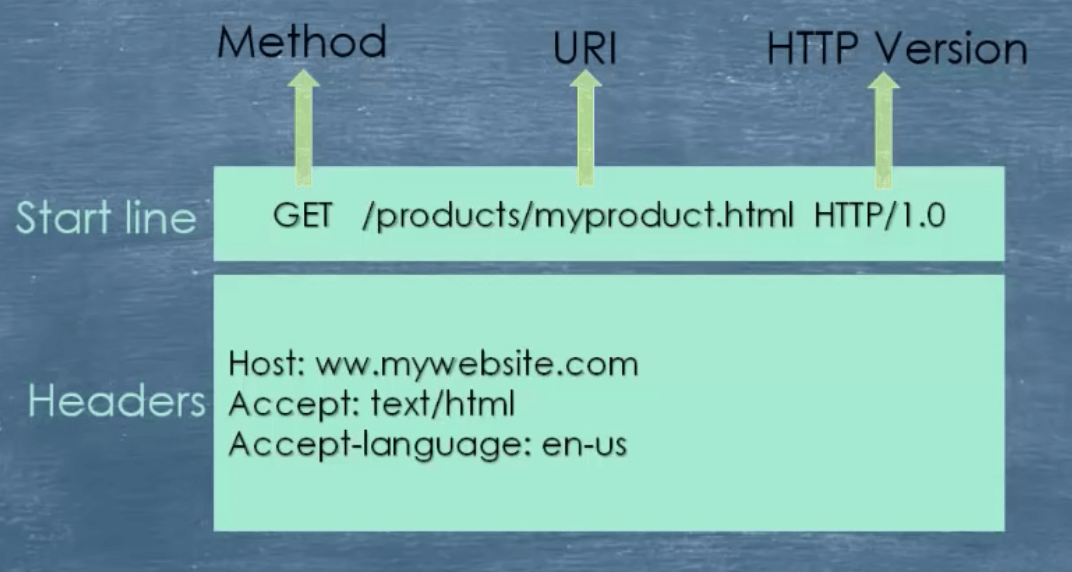
在上图的起始行中包含三部分的信息:方法、URI和HTTP版本号。
其中方法有GET, POST, DELETE等,不同的方法代表的意思会另开一篇文章说明;URI是你要请求资源的路径;HTTP版本号是你通信时使用的版本号。
URI:Uniform Resource Identifier,即统一资源标志符,用来唯一的标识一个资源。
然后就是请求头了,请求头是键值对的形式。
嗯~咦咦,示例中没有主体?🤔️
是的,请求体并不是必须的,示例中的GET请求不用带,但是在POST请求中请求体就需要带上了,其是表单的提交数据。
上面已经讲到了,服务器端接受了请求后,处理完请求,就会将信息返回给客户端。那么,响应信息都包含哪些呢?
如图:

图上内容分三大块,自上而下依次是起始行、响应头和响应体。
响应的起始行包括http的版本号和响应的状态码。
响应的状态码是客户端和服务器端交流的信息,通过状态码能知道两者的交流状态。我在小结HTTP状态码这篇文章中有讲解了下。
响应头也是键值对的形式。
之后就是响应体了,服务器端响应客服端的需求,在响应体中带上客户端请求的资源。
web上的request response cycle是通过http信息形成。
一个http信息包含三部分-起始行、头部和主体。
request信息和response信息有所差异;body主体在request信息中非必须。
图片资源来自网络,侵删
可以戳嘉明的博客了解更多内容,能留个star✨就更好了。逃:)
你有没有在JavaScript中遇到过promises并想知道它们是什么?它们为什么会被称为promises呢?它们是否和你以任何方式对另一个人做出的承诺有关呢?
此外,你为什么要使用promises呢?与传统的JavaScript操作回调(callbacks)相比,它们有什么好处呢?
在本文中,你将学习有关JavaScript中promises的所有内容。你将明白它们是什么,怎么去使用它们,以及为什么它们比回调更受欢迎。
promise是一个将来会返回值的对象。由于这种未来的东西,Promises非常适合异步JavaScript操作。
如果你不明白异步JavaScript意味着什么,你可能还不适合读这篇文章。我建议你回到关于callbacks这篇文章了解后再回来。
通过类比会更好地解析JavaScript promise的概念,所以我们来这样做(类比),使其概念更加清晰。
想象一下,你准备下周为你的侄女举办生日派对。当你谈到派对时,你的朋友,Jeff,提出他可以提供帮助。你很高心,让他买一个黑森林(风格的)生日蛋糕。Jeff说可以。
在这里,Jeff告诉你他会给你买一个黑森林生日蛋糕。这是约定好的。在JavaScript中,promise的工作方式和现实生活中的承诺一样。可以使用以下方式编写JavaScript版本的场景:
// jeffBuysCake is a promise
const promise = jeffBuysCake('black forest')你将学习如何构建
jeffBuysCake。现在,把它当成一个promise。
现在,Jeff尚未采取行动。在JavaScript中,我们说承诺(promise)正在等待中(pending)。如果你console.log一个promise对象,就可以验证这点。
打印
jeffBuysCake表明承诺正在等待中。
当我们稍后一起构建
jeffBuysCake时,你将能够自己证明此console.log语句。
在与Jeff交谈之后,你开始计划下一步。你意识到如果Jeff信守诺言,并在聚会时买来一个黑森林蛋糕,你就可以按照计划继续派对了。
如果Jeff确实买来了蛋糕,在JavaScript中,我们说这个promise是实现(resolved)了。当一个承诺得到实现时,你会在.then调用中做下一件事情:
jeffBuysCake('black forest')
.then(partyAsPlanned) // Woohoo! 🎉🎉🎉如果Jeff没给你买来蛋糕,你必须自己去面包店买了。(该死的,Jeff!)。如果发生这种情况,我们会说承诺被拒绝(rejected)了。
当承诺被拒绝了,你可以在.catch调用中执行应急计划。
jeffBuysCake('black forest')
.then(partyAsPlanned)
.catch(buyCakeYourself) // Grumble Grumble... #*$%我的朋友,这就是对Promise的剖析了。
在JavaScript中,我们通常使用promises来获取或修改一条信息。当promise得到解决时,我们会对返回的数据执行某些操作。当promise拒绝时,我们处理错误:
getSomethingWithPromise()
.then(data => {/* do something with data */})
.catch(err => {/* handle the error */})现在,你知道一个promise如何运作了。让我们进一步深入研究如何构建一个promise。
你可以使用new Promise来创建一个promise。这个Promise构造函数是一个包含两个参数 -- resolve和reject 的函数。
const promise = new Promise((resolve, reject) => {
/* Do something here */
})如果resolve被调用,promise成功并继续进入then链式(操作)。你传递给resolve的参数将是接下来then调用中的参数:
const promise = new Promise((resolve, reject) => {
// Note: only 1 param allowed
return resolve(27)
})
// Parameter passed resolve would be the arguments passed into then.
promise.then(number => console.log(number)) // 27如果reject被调用,promise失败并继续进入catch链式(操作)。同样地,你传递给reject的参数将是catch调用中的参数:
const promise = new Promise((resolve, reject) => {
// Note: only 1 param allowed
return reject('💩💩💩')
})
// Parameter passed into reject would be the arguments passed into catch.
promise.catch(err => console.log(err)) // 💩💩💩你能看出
resolve和reject都是回调函数吗?😉
让我们练习一下,尝试构建jeffBuysCake promise。
首先,你知道Jeff说他会买一个蛋糕。那就是一个承诺。所以,我们从空promise入手:
const jeffBuysCake = cakeType => {
return new Promise((resolve, reject) => {
// Do something here
})
}接下来,Jeff说他将在一周内购买蛋糕。让我们使用setTimeout函数模拟这个等待七天的时间。我们将等待一秒,而不是七天:
const jeffBuysCake = cakeType => {
return new Promise((resolve, reject) => {
setTimeout(()=> {
// Checks if Jeff buys a black forest cake
}, 1000)
})
}如果Jeff在一秒之后买了个黑森林蛋糕,我们就会返回promise,然后将黑森林蛋糕传递给then。
如果Jeff买了另一种类型的蛋糕,我们拒接这个promise,并且说no cake,这会导致promise进入catch调用。
const jeffBuysCake = cakeType => {
return new Promise((resolve, reject) => {
setTimeout(()=> {
if (cakeType
- = 'black forest') {
resolve('black forest cake!')
} else {
reject('No cake 😢')
}
}, 1000)
})
}让我们来测试下这个promise。当你在下面的console.log记录时,你会看到promise正在pedding(等待)。(如果你立即检查控制台,状态将只是暂时挂起状态。如果你需要更多时间检查控制台,请随时将超时时间延长至10秒)。
const promise = jeffBuysCake('black forest')
console.log(promise)打印
jeffBuysCake表明承诺正在等待中。
如果你在promise链式中添加then和catch,你会看到black forest cake!或no cake 😢信息,这取决于你传入jeffBuysCake的蛋糕类型。
const promise = jeffBuysCake('black forest')
.then(cake => console.log(cake))
.catch(nocake => console.log(nocake))打印出来是“黑森林蛋糕”还是“没有蛋糕”的信息,取决于你传入
jeffBuysCake的(参数)。
创建一个promise不是很难,是吧?😉
既然你知道什么是promise,如何制作一个promise以及如何使用promise。那么,我们来回答下一个问题 -- 在异步JavaScript中为什么要使用promise而不是回调呢?
开发人员更喜欢promises而不是callbacks有三个原因:
为了看到这三个好处,让我们编写一些JavaScript代码,它们通过callbacks和promises来做一些异步事情。
对于这个过程,假设你正在运营一个在线商店。你需要在客户购买东西时向他收费,然后将他们的信息输入到你的数据库中。最后,你将向他们发送电子邮件:
让我们一步一步地解决。首先,你需要一种从前端到后端获取信息的方法。通常,你会对这些操作使用post请求。
如果你使用Express或Node,则初始化代码可能如下所示。如果你不知道任何Node或Express(的知识点),请不要担心。它们不是本文的主要部分。跟着下面来走:
// A little bit of NodeJS here. This is how you'll get data from the frontend through your API.
app.post('/buy-thing', (req, res) => {
const customer = req.body
// Charge customer here
})让我们先介绍一下基于callback的代码。在这里,你想要向客户收费。如果收费成功,则将其信息添加到数据库中。如果收费失败,则会抛出错误,因此你的服务器可以处理错误。
代码如下所示:
// Callback based code
app.post('/buy-thing', (req, res) => {
const customer = req.body
// First operation: charge the customer
chargeCustomer(customer, (err, charge) => {
if (err) throw err
// Add to database here
})
})现在,让我们切换到基于promise的代码。同样地,你向客户收费。如果收费成功,则通过调用then将其信息添加到数据库中。如果收费失败,你将在catch调用中自动处理:
// Promised based code
app.post('/buy-thing', (req, res) => {
const customer = req.body
// First operation: charge the customer
chargeCustomer(customer)
.then(/* Add to database */)
.catch(err => console.log(err))
})继续,你可以在收费成功后将你的客户信息添加到数据库中。如果数据库操作成功,则会向客户发送电子邮件。否则,你会抛出一个错误。
考虑到这些步骤,基于callback的代码如下:
// Callback based code
app.post('/buy-thing', (req, res) => {
const customer = req.body
chargeCustomer(customer, (err, charge) => {
if (err) throw err
// Second operation: Add to database
addToDatabase(customer, (err, document) => {
if (err) throw err
// Send email here
})
})
})对于基于promise的代码,如果数据库操作成功,则在下一个then调用时发送电子邮件。如果数据库操作失败,则会在最终的catch语句中自动处理错误:
// Promised based code
app.post('/buy-thing', (req, res) => {
const customer = req.body
chargeCustomer(customer)
// Second operation: Add to database
.then(_ => addToDatabase(customer))
.then(/* Send email */)
.catch(err => console.log(err))
})继续最后一步,在数据库操作成功时向客户发送电子邮件。如果成功发送此电子邮件,则会有成功消息通知到你的前端。否则,你抛出一个错误:
以下是基于callback的代码:
app.post('/buy-thing', (req, res) => {
const customer = req.body
chargeCustomer(customer, (err, charge) => {
if (err) throw err
addToDatabase(customer, (err, document) => {
if (err) throw err
sendEmail(customer, (err, result) => {
if (err) throw err
// Tells frontend success message.
res.send('success!')
})
})
})
})然后,以下基于promise的代码:
app.post('/buy-thing', (req, res) => {
const customer = req.body
chargeCustomer(customer)
.then(_ => addToDatabase(customer))
.then(_ => sendEmail(customer) )
.then(result => res.send('success!')))
.catch(err => console.log(err))
})看看为什么使用promises而不是callbacks编写异步代码要容易得多?你从回调地狱(callback hell)一下子切换到了链式乐土上😂。
promises比callbacks的另一个好处是,如果操作不依赖于彼此,则可以同时触发两个(或多个)promises,但是执行第三个操作需要两个结果。
为此,你使用Promise.all方法,然后传入一组你想要等待的promises。then的参数将会是一个数组,其包含你promises返回的结果。
const friesPromise = getFries()
const burgerPromise = getBurger()
const drinksPromise = getDrinks()
const eatMeal = Promise.all([
friesPromise,
burgerPromise,
drinksPromise
])
.then([fries, burger, drinks] => {
console.log(`Chomp. Awesome ${burger}! 🍔`)
console.log(`Chomp. Delicious ${fries}! 🍟`)
console.log(`Slurp. Ugh, shitty drink ${drink} 🤢 `)
})备注:还有一个名为
Promise.race的方法,但我还没找到合适的用例。你可以点击这里去查看。
最后,我们来谈谈浏览器支持情况!如果你不能在生产环境中使用它,那为什么要学习promises呢。是吧?
令人兴奋的消息是:所有主流浏览器都支持promises!
如果你需要支持IE 11及其以下版本,你可以使用Taylor Hakes制作的Promise Polyfill。它支持IE8的promises。😮
你在本文中学到了所有关于promises的知识。简而言之,promises棒极了。它可以帮助你编写异步代码,而无需进入回调地狱。
尽管你可能希望无论什么时候都使用promises,但有些情况callbacks也是有意义的。不要忘记了callbacks啊😉。
如果你有疑问,请随时在下面发表评论,我会尽快回复你的。【PS:本文译文,若需作者解答疑问,请移步原作者文章下评论】
感谢阅读。这篇文章是否帮助到你?如果有,我希望你考虑分享它。你可能会帮助到其他人。非常感谢!
下一篇关于 async/await
当用JavaScript来工作的时候,我们需要处理很多的条件判断,这里有五个小技巧能帮助你写出更好/更清晰的条件语句。
1. 多重判断中使用Array.includes
我们看下下面这个例子:
// condition
function test(fruit) {
if (fruit == 'apple' || fruit == 'strawberry') {
console.log('red');
}
}乍一看,上面的例子看起来还可以哦。但是,如果添加更多的红色的水果,比如cherry和cranberries,那会怎样呢?你会使用更多的||来扩展条件语句吗?
我们可以通过Array.includes(Array.includes)来重写上面的条件语句。如下:
function test(fruit) {
// extract conditions to array
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if (redFruits.includes(fruit)) {
console.log('red');
}
}我们提取red fruits(条件判断)到一个数组中。通过这样做,代码看起来更加整洁了。
2. 少嵌套,早返回
我们扩展上面的例子,让它包含多两个条件:
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
// condition 1: fruit must has value
if (fruit) {
// condition 2: must be red
if (redFruits.includes(fruit)) {
console.log('red');
// condition 3: must be big quantity
if (quantity > 10) {
console.log('big quantity');
}
}
} else {
throw new Error('No fruit!');
}
}
// test results
test(null); // error: No fruits
test('apple'); // print: red
test('apple', 20); // print: red, big quantity看下上面的代码,我们捋下:
我个人遵守的准则是发现无效的条件时,及早return。
/_ return early when invalid conditions found _/
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
// condition 1: throw error early
if (!fruit) throw new Error('No fruit!');
// condition 2: must be red
if (redFruits.includes(fruit)) {
console.log('red');
// condition 3: must be big quantity
if (quantity > 10) {
console.log('big quantity');
}
}
}通过及早return,我们减少了一层嵌套语句。这种编码风格很赞,尤其是当你有很长的if语句(可以想象下你需要滚动很长才知道有else语句,一点都不酷)。
(针对上面例子)我们可以通过倒置判断条件和及早return来进一步减少if嵌套。看下面我们是怎么处理条件2的:
/_ return early when invalid conditions found _/
function test(fruit, quantity) {
const redFruits = ['apple', 'strawberry', 'cherry', 'cranberries'];
if (!fruit) throw new Error('No fruit!'); // condition 1: throw error early
if (!redFruits.includes(fruit)) return; // condition 2: stop when fruit is not red
console.log('red');
// condition 3: must be big quantity
if (quantity > 10) {
console.log('big quantity');
}
}通过倒置条件2,我们避免了嵌套语句。这个技巧很有用:当我们处理很长的逻辑,并且希望能够在条件不满足时能够停下来进行处理。
而且,这样做并不难。问下自己,这个版本(没有条件嵌套)是不是比之前版本(两层嵌套)更好/可读性更高呢?
但是,对于我来说,我会保留先前的版本(包含两层嵌套)。因为:
因此,应当尽量减少嵌套和及早return,但是不要过度。如果你感兴趣,你可以看下面的一篇文章和StackOverflow上的讨论,进一步了解:
3. 使用默认参数和解构
我猜你对下面的代码有些熟悉,在JavaScript中我们总需要检查null/undefined值和指定默认值。
function test(fruit, quantity) {
if (!fruit) return;
const q = quantity || 1; // if quantity not provided, default to one
console.log(`We have ${q} ${fruit}!`);
}
//test results
test('banana'); // We have 1 banana!
test('apple', 2); // We have 2 apple!事实上,我们可以通过声明默认的函数参数来消除变量q。
function test(fruit, quantity = 1) { // if quantity not provided, default to one
if (!fruit) return;
console.log(`We have ${quantity} ${fruit}!`);
}
//test results
test('banana'); // We have 1 banana!
test('apple', 2); // We have 2 apple!很容易且很直观!注意,每个声明都有自己默认参数。举个例子,我们也可以给fruit设置一个默认值:function test(fruit = 'unknown', quantity = 1)。
如果我们的fruit是一个对象会怎样呢?我们能分配一个默认参数吗?
function test(fruit) {
// printing fruit name if value provided
if (fruit && fruit.name) {
console.log (fruit.name);
} else {
console.log('unknown');
}
}
//test results
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple上面的例子中,当存在fruit name的时候我们打印出水果名,否则打印出unknown。我们可以通过设置默认参数和解构来避免判断条件fruit && fruit.name。
// destructing - get name property only
// assign default empty object {}
function test({name} = {}) {
console.log (name || 'unknown');
}
//test results
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple由于我们只需要name属性,我们可以使用{name}来解构参数,然后我们就可以使用name代替fruit.name了。
我们也声明了一个空对象{}作为默认值。如果我们没有这么做,你会得到一个无法对undefined或null解构的错误。因为在undefined中没有name属性。
如果你不介意使用第三方库,有一些方式能减少null的检查:
这有一个使用Lodash的例子:
// Include lodash library, you will get _
function test(fruit) {
console.log(__.get(fruit, 'name', 'unknown'); // get property name, if not available, assign default value 'unknown'
}
//test results
test(undefined); // unknown
test({ }); // unknown
test({ name: 'apple', color: 'red' }); // apple你可以在JSBIN这里运行demo代码,如果你是函数式编程的粉丝,你可以选择Lodash fp,Lodash的函数式版本(方法变更为get或者getOr)。
4. 倾向对象遍历而不是switch语句
看下下面的代码,我们想基于color来打印水果。
function test(color) {
// use switch case to find fruits in color
switch (color) {
case 'red':
return ['apple', 'strawberry'];
case 'yellow':
return ['banana', 'pineapple'];
case 'purple':
return ['grape', 'plum'];
default:
return [];
}
}
//test results
test(null); // []
test('yellow'); // ['banana', 'pineapple']上面的代码看似没问题,但是多少有些冗余。用遍历对象(object literal)来实现相同的结果,语法看起来更加简洁:
// use object literal to find fruits in color
const fruitColor = {
red: ['apple', 'strawberry'],
yellow: ['banana', 'pineapple'],
purple: ['grape', 'plum']
};
function test(color) {
return fruitColor[color] || [];
}或者,你可以使用Map来实现相同的结果:
// use Map to find fruits in color
const fruitColor = new Map()
.set('red', ['apple', 'strawberry'])
.set('yellow', ['banana', 'pineapple'])
.set('purple', ['grape', 'plum']);
function test(color) {
return fruitColor.get(color) || [];
}Map是ES2015规范之后实现的对象类型,允许你存储键值对。
那么,我们应该禁止使用switch语句吗?不要限制自己做这个。个人来说,我会尽可能使用对象遍历,但是不会严格遵守它,而是使用对当前场景更有意义的方式。
Todd Motto 有篇对switch语句和遍历对象深层次对比的文章,你可以戳这里来查看。
TL;DL;重构语法
针对上面的例子,我们可以通过Array.filter重构下代码来实现相同的结果。
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'strawberry', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'pineapple', color: 'yellow' },
{ name: 'grape', color: 'purple' },
{ name: 'plum', color: 'purple' }
];
function test(color) {
// use Array filter to find fruits in color
return fruits.filter(f => f.color == color);
}有着不止一种方法能够实现相同的结果,我们以上展示了4种。编码是快乐的!
5. 对 全部/部分判断 使用Array.every/Array.some
最后一个技巧是使用Javascript的内置数组函数来减少代码的行数。看下下面的代码,我们想查看所有的水果是否是红色:
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
let isAllRed = true;
// condition: all fruits must be red
for (let f of fruits) {
if (!isAllRed) break;
isAllRed = (f.color == 'red');
}
console.log(isAllRed); // false
}上面的代码太长!我们使用Array.every来减少代码行数:
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
// condition: short way, all fruits must be red
const isAllRed = fruits.every(f => f.color == 'red');
console.log(isAllRed); // false
}更清晰了,对吧?类似的,我们想测试是否有水果是红色的,我们可以使用Array.some来实现。
const fruits = [
{ name: 'apple', color: 'red' },
{ name: 'banana', color: 'yellow' },
{ name: 'grape', color: 'purple' }
];
function test() {
// condition: if any fruit is red
const isAnyRed = fruits.some(f => f.color == 'red');
console.log(isAnyRed); // true
}总结
让我们一起写出可读性更高的代码。我希望你能从这篇文章学到些新东西。
这是全部内容。祝你编码愉快!
原文 https://scotch.io/bar-talk/5-tips-to-write-better-conditionals-in-javascript
Service workers是Progressive Web Apps的核心部分,允许缓存资源和Web推送通知等,以创建良好的离线体验。它们充当Web应用程序,浏览器和网络之间的代理,允许开发人员拦截和缓存网络请求,并基于网络的可用性采取适当的操作。
一个service worker在单独的线程上运行,因此它是非阻塞的。这也意味着它无法访问主JavaScript线程中可用的DOM和其他API,比如cookie,XHR,Web存储API(本地存储和会话存储)等。由于它们被设计为完全异步,因此它们重度依赖promise来等待网络请求的响应。
出于安全考虑,service workers仅使用HTTPS运行,且不能在隐私浏览模式下使用。但是,在发出本地请求的时候,你不需要安全连接(这足以进行测试)。
Service Workers是一种相对较新的API,仅受现代浏览器的支持。因此,我们首先需要检查浏览器是否支持该API:
if('serviceWorker' in navigator) {
// Supported 😍
} else {
// Not supported 😥
}在我们开始缓存资源或拦截网络请求之前,我们必须在浏览器中安装service worker。由于service worker本质上是一个JavaScript文件,因此可以通过指定文件的路径来注册它。该文件必须可以通过网络访问,并且只应包含service worker代码。
你应该等待页面加载完成,然后将service worker文件路径传给navigator.serviceWorker.register()方法:
window.addEventListener('load', () => {
if ('serviceWorker' in navigator) {
// register service worker
navigator.serviceWorker.register('/sw-worker.js').then(
() => {
console.log('SW registration succesful 😍');
},
err => {
console.error('SW registration failed 😠', err)
});
} else {
// Not supported 😥
}
});每次页面加载时都可以运行上面的代码,没有任何问题;浏览器将决定是否已经安装service worker并相应地处理它。
注册生命周期包括三个步骤:
当用户首次访问您的网站时,会立即下载service worker文件并尝试安装。如果安装成功,则激活service worker。在用户访问另一个页面后刷新当前页面之前,service worker文件中的任何功能都不可用。
一旦service worker被安装并激活了,它就可以开始拦截网络请求和缓存资源。这可以通过监听service worker文件中浏览器发出的事件来完成。浏览器发出以下事件:
installactive。在安装新版本之前,此事件可用于删除过期的缓存资源。fetch。资源可以是任何东西:新的HTML文档,图像,JSON API,样式表或者JavaScript文件,以及远程位置上可用的任何内容。push由Push API发送。你可以使用此事件向用户显示通知。sync。我们可以在安装service worker时监听install事件,以缓存当我们离开网络时需要为网页提供服务的特定资源:
const CACHE_NAME = 'site-name-cache';
self.addEventListener('install', event => {
event.waitUntil(
caches
.open(CACHE_NAME)
.then(cache =>
cache.addAll([
'favicon.ico',
'projects.json',
'style.css',
'index.js',
'https://fonts.googleapis.com/css?family=Open+Sans:400,700'
])
)
);
});上面的例子中,代码使用Cache API将资源存储在名为site-name-cache的缓存中。
self关键字是一个只读的全局属性,service workers使用它来访问自己。
现在让我们监听一个fetch事件来检查所请求的资源是否已经存储在缓存中,如果找到则将其返回:
// ...
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request).then(response => {
if (response) {
//found cached resource
return response;
}
return fetch(event.request);
})
);
});我们查找请求属性标识的资源缓存条目,如果没有找到,我们会发送获取请求。如果你也想缓存新的请求,可以通过处理获取请求的响应然后将其添加到缓存来完成,如下所示:
// ...
self.addEventListener('fetch', event => {
event.respondWith(
caches.match(event.request).then(response => {
if (response) {
//found cached resource
return response;
}
// get resource and add it to cache
return fetch(event.request)
.then(response => {
// check if the response is valid
if (!response.ok) {
return response;
}
// clone the response
const newResponse = response.clone();
// add it to cache
caches.open(CACHE_NAME)
.then(cache =>
cache.put(event.request, newResponse)
);
// return response
return response;
});
})
);
});安装service worker程序后,它将继续运行,直到用户将其删除或者更新为止。要更新service worker,你需要做的就是在服务器上上传新版本的service worker文件。当用户访问你的站点时,浏览器将自动检测文件更改(即使只有一个字节更改就足够了),并安装新版本。
就像第一次安装一样,只有当用户导航到另一个页面或刷新当前页面时,新的service worker的功能才能使用。
我们可以做的事情就是监听activate事件,并删除旧的缓存资源。以下代码通过遍历所有缓存并删除与缓存名称匹配的缓存来完成此操作:
// ...
self.addEventListener('activate', event => {
event.waitUntil(
caches.keys().then(keys => {
return Promise.all(
keys.map(cache => {
if (cache === CACHE_NAME) {
return caches.delete(cache);
}
})
);
})
);
});以上就是service workers的简介了。如果你想了解更多,移步SerciceWorker Cookbook -- 这里有一系列现代网站中使用service worker的实用例子。
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
线上地址--gobang online pc上使用谷歌浏览器比较友好@~@
代码仓库--gobang tutorial 欢迎对此仓库进行扩展或star啦 @~@
前置知识点: 阮生的es6教程和MDN的canvas教程
以上,兵马未动,粮草先行。看官可以先体验下小游戏并且粗略了解下相关的知识点后(熟悉者可跳过,欢迎留言改进哈),再往下读。
秉承着会就分享,不会就折腾的宗旨。自己利用周末的时间(2018.12.01-2018.12.02)将五子棋小游戏梳理了一波,整理成一个教程,放出来给大伙指点指点。下面进入正题:
五子棋的规则有点点复杂,我这里就简化并改写成下面这几条:
正式比赛的规则,看官可以到五子棋_百度百科这里了解。本博文的案例是以上面列出来的四条规则为基础,来实现五子棋小游戏的。
为了方便管理、扩展功能和编写代码,我这里使用了es6的class语法,面向对象的**来实现。首先,自己定义一个类Gobang,如下:
class Gobang { // 这里设置一个五子棋的类,统一管理代码
// Gobang这个类的构造函数,options是在实例化的时候要传过来的值
constructor(options={}){ // 设置参数的默认值,es6之前不允许这样设置
this.options = options;
// 初始化
this.init();
}
// 初始化
init() {
const { options } = this;// 结构赋值
console.log(options); // 打印出传入的实例的配置选项
}
}
// 实例化对象
let gobangInstance1 = new Gobang(); // 没有传配置项的时候
let gobangInstance2 = new Gobang({
canvas: 'chess'
}); // 传配置项的时候上面的Gobang类中,包含了一个constructor和init方法。其中constructor方法是类默认的方法,通过new命令生成对象实例时候,自动调用该方法。一个类必须有一个constructor方法,如果没有显式定义,一个空的constructor方法会默认添加。然后就是init方法了,这里我是整个类的初始化的入口方法。
项目骨架代码在仓库中对应的位置是skeleton。
棋盘,我们可以分为两种,一种是视觉上的棋盘,另外一个是逻辑上的棋盘,你是看不见的。如下截图:
首先,我们实现20*20的物理上的棋盘,并且配上一些样式。当然,为了高可配置,我们使用上面代码骨架上的options进行传值:
// 实例化对象
let gobang = new Gobang({
canvas: 'chess', // html中设定的画布的id
gobangStyle: { // 五子棋的一些样式
padding: 30, // 边和边之间的距离
count: 20, // 棋盘的边数,整数
borderColor: '#bfbfbf', // 描边的颜色
}
});然后就进行物理棋盘的绘制了,这里是使用canvas的相关知识点,控制画笔更改着笔点并画线条:
// 绘制出物理棋盘
drawChessBoard() {
const context = this.chessboard.getContext('2d');// 获取绘制上下文
const {padding, count, borderColor} = this.options.gobangStyle;
// 设置棋盘的宽高
this.chessboard.width = this.chessboard.height = padding * count;
// 设置画笔的颜色
context.strokeStyle = borderColor;
let half_padding = padding/2;// 考虑绘制的棋子展示的位置,所以要预留一些边距,可以审查元素看下
// 画棋盘
for(var i = 0; i < count; i++){
context.moveTo(half_padding+i*padding, half_padding);
context.lineTo(half_padding+i*padding, padding*count-half_padding);
context.stroke(); // 这里绘制出的是竖轴
context.moveTo(half_padding, half_padding+i*padding);
context.lineTo(count*padding-half_padding, half_padding+i*padding);
context.stroke(); // 这里绘制出的是横轴
}
}接着就是逻辑的棋盘的记录了。这里我使用了二维数组去记录棋盘点的位置,比如(0,0)点对应的数组下标是[0][0];然后(1,2)点对应的下标是[1][2]...以此类推。这里在记录好点之后,也为他们进行赋值为0,表示此处没有落子,如果有落子,记录为1(黑子)或2(白子)。具体逻辑棋盘代码如下:
// 绘制逻辑矩阵棋盘
initChessboardMatrix(){
const {count} = this.options.gobangStyle;
const checkerboard = [];
// 存在(x,y)矩阵点
for(let x = 0; x < count; x++){
checkerboard[x] = [];
for(let y = 0; y < count; y++){
checkerboard[x][y] = 0; // 全部赋值为0,表示此坐标是没有棋子的
}
}
}绘制棋盘代码在仓库中对应的位置是chess_board。
绘制棋子这个简单。在标题中表明了是使用canvas的相关知识点,棋子是使用canvas来绘制的。具体用的canvas的知识点有arc和createRadialGradient方法。前者是绘制一个圆,后者是为这个圆添加颜色渐变效果,使得棋子看起来更加有质感。当然,这里需要绘制黑白两种颜色的棋子,需要有个flag来进行标识是否是黑色/白色,代码中有介绍。
drawChessman(x , y, isBlack){// 绘制的(x,y)坐标,isBlack判断是黑棋子还是白色棋子
const context = this.chessboard.getContext('2d');
context.beginPath();
context.arc(x, y, 10, 0, 2 * Math.PI);// 画圆,半径这里设定为10px
context.closePath();
// 为棋子添加渐变颜色
let gradient = context.createRadialGradient(x, y, 10, x-5, y-5, 0);// createRadialGradient(x1,y1,r1,x2,y2,r2)创建放射状/圆形渐变对象。
if(isBlack){ // 黑子
gradient.addColorStop(0,'#0a0a0a'); // 开始的颜色
gradient.addColorStop(1,'#636766'); // 结束的颜色
}else{ // 白子
gradient.addColorStop(0,'#d1d1d1');
gradient.addColorStop(1,'#f9f9f9');
}
context.fillStyle = gradient;
context.fill();
}对应的效果图如下:
绘制棋子代码在仓库中对应的位置是chessman。
在上一节中,只是讲解了怎么去绘制棋子。接下来我们要将绘制好的棋子放到要下在棋盘的相关点击位置,并且实现黑白两棋的交替下棋,也就是实现人人对战啦。
首先,我们在初始化入口那里先初始化下棋子的角色(是黑棋还是白棋),获取单元格的宽度。
init() {
// 角色,1是黑色棋子,2是白色棋子
this.role = options.role || 1;
// 单个格子的宽高
this.lattice = {
width: options.gobangStyle.padding,
height: options.gobangStyle.padding
};
}接下来就可以实行点击棋盘位置的计算了,获取相关的逻辑棋盘的坐标点,之后在这个坐标点进行棋子的绘制:
// 监听落子
listenDownChessman() {
// 监听点击棋盘对象事件
this.chessboard.onclick = event => {
let {padding} = this.options.gobangStyle;
// 获取棋子的位置(x,y)坐标,如(0,0),(0,2)
let {
offsetX: x,
offsetY: y,
} = event; // 解构赋值
// console.log(x,y);
x = Math.abs(Math.round((x-padding/2)/this.lattice.width));// 防止边界的为负数,故取绝对值
y = Math.abs(Math.round((y-padding/2)/this.lattice.height));
// console.log(x,y);
// 点击的是棋盘,并且是空位置才可以落子
if(this.checkerboard[x][y] !== undefined && Object.is(this.checkerboard[x][y],0)){
// 更新矩阵值
this.checkerboard[x][y] = this.role;
// 刻画棋子
this.drawChessman(x,y,Object.is(this.role , 1));
// 切换棋子的角色
this.role = Object.is(this.role , 1) ? 2 : 1;
}
}
}
// 刻画棋子
drawChessman(x,y,isBlack) {
const context = this.chessboard.getContext('2d');
const {padding} = this.options.gobangStyle;
let half_padding = padding/2;
context.beginPath();
context.arc(half_padding+x*padding,half_padding+y*padding,half_padding-2,0,2*Math.PI);
let gradient = context.createRadialGradient(half_padding+x*padding+2,half_padding+y*padding-2,half_padding-2,half_padding+x*padding+2,half_padding+y*padding-2,0);
if(isBlack){
gradient.addColorStop(0,'#0a0a0a');
gradient.addColorStop(1,'#636766');
}else{
gradient.addColorStop(0,'#d1d1d1');
gradient.addColorStop(1,'#f9f9f9');
}
context.fillStyle = gradient;
context.fill();
}落子实现人人对战代码在仓库中对应的位置是listen_chessman。
在双方下棋中,允许对方或者自己对已经下的棋子进行调整,也就是悔棋,恢复上一步的操作,然后再重新下棋。实现悔棋功能的时候,需要知道下棋的历史记录和当前的落子步数和角色。
对于历史的记录,这里对每一步的落子都使用一个对象进行存储,并放到一个history的数组里面进行保存:
init() {
// 走棋的历史记录
this.history = [];
// 当前步
this.currentStep = 0;
}
listenDownChessman() {
...
// 落子之后有可能悔棋之后落子,这种情况下应该重置历史记录
this.history.length = this.currentStep;
this.history.push({// 保存坐标和角色快照
x,
y,
role: this.role
});
this.currentStep++; // 当前步骤自加
...
}然后在执行悔棋的时候,将前一个记录的棋子的在棋盘上对应的ui给抹除掉就行了,不能将history中对应的位置移除哦,因为是要用到撤销悔棋的啊。销毁完棋子后,要对物理棋盘上的ui进行修补,修补的情况一共有九种:
// 悔棋
regretChess() {
// 找到最后一次记录,回滚到上一次的ui状态
if(this.history.length){
const prev = this.history[this.currentStep - 1];
if(prev){
const {
x,
y,
role
} = prev;
// 销毁棋子
this.minusStep(x,y);
this.checkerboard[prev.x][prev.y] = 0; // 置空操作
this.currentStep--; // 步数自减
// 角色发生改变,下一步的下棋是该撤销棋子的角色
this.role = Object.is(role,1) ? 1 : 2;
}
}
}
// 销毁棋子
minusStep(x, y) {
const context = this.chessboard.getContext('2d');
const {padding, count} = this.options.gobangStyle;
context.clearRect(x*padding, y*padding, padding,padding);
// 修补删除的棋盘位置
// 重画该圆周围的格子,对边角的格式进行特殊的处理
let half_padding = padding/2; // 棋盘单元格的一半
if(x<=0 && y <=0){ // 情况比较多,一共九种情况
this.fixchessboard(half_padding,half_padding,half_padding,padding,half_padding,half_padding,padding,half_padding);
}else if(x>=count-1 && y<=0){
this.fixchessboard(count*padding-half_padding,half_padding,count*padding-padding,half_padding,count*padding-half_padding,half_padding,count*padding-half_padding,padding);
}else if(y>=count-1 && x <=0){
this.fixchessboard(15,count*padding-half_padding,half_padding,count*padding-padding,half_padding,count*padding-half_padding,padding,count*padding-half_padding);
}else if(x>=count-1 && y >= count-1){
this.fixchessboard(count*padding-half_padding,count*padding-half_padding,count*padding-padding,count*padding-half_padding,count*padding-half_padding,count*padding-half_padding,count*padding-half_padding,count*padding-padding);
}else if(x <=0 && y >0 && y <count-1){
this.fixchessboard(half_padding,padding*y+half_padding,padding,padding*y+half_padding,half_padding,padding*y,half_padding,padding*y+padding);
}else if(y <= 0 && x > 0 && x < count-1){
this.fixchessboard(x*padding+half_padding,half_padding,x*padding+half_padding,padding,x*padding,half_padding,x*padding+padding,half_padding);
}else if(x>=count-1 && y >0 && y < count-1){
this.fixchessboard(count*padding-half_padding,y*padding+half_padding,count*padding-padding,y*padding+half_padding,count*padding-half_padding,y*padding,count*padding-half_padding,y*padding+padding);
}else if(y>=count-1 && x > 0 && x < count-1){
this.fixchessboard(x*padding+half_padding,count*padding-half_padding,x*padding+half_padding,count*padding-padding,x*padding,count*padding-half_padding,x*padding+padding,count*padding-half_padding);
}else{
this.fixchessboard(half_padding+x*padding,y*padding,half_padding+x*padding,y*padding + padding,x*padding,y*padding+half_padding,(x+1)*padding,y*padding+half_padding)
}
}
// 修补删除后的棋盘
fixchessboard (a , b, c , d , e , f , g , h){
const context = this.chessboard.getContext('2d');
const {borderColor, lineWidth} = this.options.gobangStyle;
context.strokeStyle = borderColor;
context.lineWidth = lineWidth;
context.beginPath();
context.moveTo(a , b);
context.lineTo(c , d);
context.moveTo(e, f);
context.lineTo(g , h);
context.stroke();
}实现悔棋代码在仓库中对应的位置是regret_chess。
有允许悔棋,那么就有允许撤销悔棋这样子才合理。同悔棋功能,撤销悔棋是需要知道下棋的历史记录和当前的步骤和棋子角色的。如下:
// 撤销悔棋
revokedRegretChess(){
const next = this.history[this.currentStep]; // 撤销的点的下一个
if(next) {
this.drawChessman(next.x, next.y, next.role === 1); // 在上次撤销的点上画棋
this.checkerboard[next.x][next.y] = next.role;
this.currentStep++; // 当前步骤自加
this.role = Object.is(this.role, 1) ? 2 : 1; // 角色的切换
}
}实现撤销悔棋代码在仓库中对应的位置是revoked_regret_chess。
五子棋的的结束也就是必须要决出胜利者,或者是棋盘没有位置可以下棋了。这里考虑决出胜利为游戏结束的切入点,上面也说到了如何才算是一方获胜--横线、竖线或者斜线上有连续五个同一色的棋子。那么我们就对这四种情况进行处理了,我们在矩阵中记录当前点击的数组点中是否有连续的五个1(黑子)或者连续的五个2(白子)即可。如下截图的x轴获胜,注意gif图右侧打印出来的数组内容:
四种获胜的情况和或者的提示相关的代码如下:
// 裁判观察棋子,判断获胜一方
checkReferee(x , y , role) {
if((x == undefined)||(y == undefined)||(role==undefined)) return;
// 连杀的分数,五个同一色的棋子连成一条直线就是胜利
let countContinuous = 0;
const XContinuous = this.checkerboard.map(x => x[y]); // x轴上连杀
const YContinuous = this.checkerboard[x]; // y轴上连杀
const S1Continuous = []; // 存储左斜线连杀
const S2Continuous = []; // 存储右斜线连杀
this.checkerboard.forEach((_y,i) => {
// 左斜线
const S1Item = _y[y - (x - i)];
if(S1Item !== undefined){
S1Continuous.push(S1Item);
}
// 右斜线
const S2Item = _y[y + (x - i)];
if(S2Item !== undefined) {
S2Continuous.push(S2Item);
}
});
// 当前落棋点所在的X轴/Y轴/交叉斜轴,只要有能连起来的5个子的角色即有胜者
[XContinuous, YContinuous, S1Continuous, S2Continuous].forEach(axis => {
if(axis.some((x, i) => axis[i] !== 0 &&
axis[i - 2] === axis[i - 1] &&
axis[i - 1] === axis[i] &&
axis[i] === axis[i + 1] &&
axis[i + 1] === axis[i + 2])) {
countContinuous++
}
});
// 如果赢了就给出提示
if(countContinuous){
this.win = true;
let msg = (role == 1 ? '黑' : '白') + '子胜利✌️';
// 提示信息
this.result.innerText = msg;
// 不允许再操作
this.chessboard.onclick = null;
}
}胜利提示/游戏结束代码在仓库中对应的位置是winner_hint。
嗯~至此,已经一步步讲解完如何开发一个能够在pc上愉快玩耍的休闲小游戏-五子棋了。当然,很多的参数我都是设置在代码的options这里,其实为了更好的用户体验,你可以将这些设置在ui层面供用户自行调节的;再者你可以在项目基础上实现其他功能,比如人机对战等。如果有什么想法的话,欢迎下方留言或者前往此代码仓库gobang-tutorial进行相关动能补充或者完善@~@
本文一步一步讲解搭建的全过程,结合的是Ant Design,非详细版本,会在文末给出搭建的效果图~
进入正题啦,下午还有节目呢~
安装脚手架
$ npm install -g @vue/cli
# OR
$ yarn global add @vue/cli创建一个项目
$ vue create antd-demo文件内容的demo如下:
module.exports = {
css: {}
}
安装vue-router
npm install --save vue-routersrc下面新建router/index.js
import Vue form 'vue'
import Router from 'vue-router'
Vue.use(Router)
const router = new Router({
routes: [
{
path: '/',
name: 'index',
component: resolve => require(['@/views/index'], resolve),
meta: { name: '首页' }
}
]
})
在main.js中添加router
import VueRouter from 'vue-router'
import router from './router/index'
Vue.use(VueRouter)
new Vue({
router,
render: h => h(App),
}).$mount('#app')在入口的app.vue中添加router-view
<template>
<div id="app">
<router-view/>
</div>
</template>
安装less和less-loader
npm install --save-dev less less-loader在vue.config.js上配置支持
css: {
loaderOptions: {
less: {
modifyVars: {
blue: '#3a82f8',
'text-color': '#333'
},
javascriptEnabled: true
}
}
},
使用时候要注明lang='less'
<style scoped lang='less'>
#index {
h1 {
background: blue;
}
}
</style>安装
$ npm i --save ant-design-vuemain.js中完整引入
import Vue from 'vue'
import Antd from 'ant-design-vue'
import App from './App'
import 'ant-design-vue/dist/antd.css'
Vue.config.productionTip = false
Vue.use(Antd)
/* eslint-disable no-new */
new Vue({
el: '#app',
components: { App },
template: '<App/>'
})
安装vuex
npm install vuex --save新建一个store/index.js
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
const store = new Vuex.Store({
state: {},
mutations: {},
actions: {},
modules: {},
getters: {}
})
export default store在main.js中引入vuex
import store from './store/index'
new Vue({
store,
render: h => h(App)
}).$mount('#app')搭建的项目是响应式的,效果图这里我放上desktop版和mobile版:
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
开始学习持续集成所要了解的知识:分支策略,测试自动化,工具和最佳实践。
持续集成的目的是将代码传递到存储库的主分支:
持续集成有点关于工具以及团队中的思维方式和文化。你希望在开发的过程中能够保持主分支的同时快速集成新代码。此工作主分支将在之后启用持续交付或持续部署(的操作)。但是,这些不是本文的内容。让我们先来关注下持续集成。
实现持续集成有两大支柱。
想象一下,一个五人组成的团队致力于一个SaaS产品。每个人都开发一个单独的新功能。每个功能的工作量大约是1或2周。有两种方式可以实现这个目标。
"功能分支"上工作。一旦每个人对自己的工作感到满意,此分支将被被合并到主分支。你认为哪种方法效果最好?
第一种方法最终将导致**“不可预测的释放综合症”**。长时效的特征分支为每个开发人员创造了一种虚假的安全感和舒适感。由于分支分离了很长一段时间,没办法衡量将它们合并(到主分支)的难度。其最好的情况是出现些少的代码冲突,在最坏的情况下,基本的设计假设将受到挑战,事情将不得不重新进行...这是艰难的方式。
返工的工作将在时间压力下进行,导致质量下降和技术债务积累。这是个恶性循环。
请参考关于为何不应该使用特性分支来处理脏细节的文章。
第二种方法是我们实现持续集成所需要的方法。每个开发人员都在自己的分支上工作。差异是:
每次推送都会将其更改合并到主分支,每个开发人员每天会将其分支与最新的主分支版本同步几次。
通过这种方式,团队可以更快且轻松地修复冲突并协调设计假想。**早期发现五个小问题比发布日前发现1个大问题更好。**查看下面的“功能切换”部分,了解如何将“正在进行的工作”集成到主分支。
之前的软件开发工程基于构建周期,然后是测试周期。这可能仍然适用“特征分支”方法(法一)。如果我们每天数十次集成和合并代码,那么,手动测试就没有意义了。这将花费太长的时间。我们需要自动检查以验证代码是否正常工作。我们需要一个CI工具,帮助开发人员自动推送并运行构建和测试。
测试类型和内容应该为:
不幸的是,没有一种方式适合所有测试类型和内容。这要根据你的项目适当平衡。在CI阶段,不要运行大而耗时的测试套件。虽然这些测试提供了更好的安全性,但它们的代价就是对开发人员的延迟反馈。这将导致上下文工作切换,纯粹就是浪费时间。
长时间CI检查,我的意思是超过3分钟的(CI),消耗团队中的每个开发人员的大量时间。
让我们来比较下“好”和”坏“的工作流程。“好”的工作流程:
“坏”的工作流程:
这糟糕的工作流程不仅仅是浪费时间。对开发人员来说也是令人沮丧的。高效的开发会使得开发人员很开心的。
你需要调整工具和工作流程以保证开发人员的满意度。
持续集成是指将来自不同开发人员分支的代码集成到配置管理系中的公共分支。有可能你正在使用git。在git中,存储库中的默认主分支称为"master"。一些团队创建了一个名为"develop"的分支作为(开发时)持续集成的主分支。他们使用"master"来跟踪交付和部署(develop分支将合并到master分支)。
你(的项目中)可能已经有了一个主分支,你的团队将代码推送或合并到那里。坚持(这样做)下去。
每个开发人员都应该在自己的分支上工作。如果同时处理许多不同的功能内容,可以使用多个分支。虽然这可能是"不专心"工作的标志。只要代码连贯部分准备就绪,就可以推送到你的存储库。如果成功,CI将检查、启动并将代码合并到主分支。如果检查失败,您仍然在自己的分支上,可以修复需要的任何内容并再次推送。
上述过程中的关键语是你代码连贯的部分。那么,你怎么知道它是连贯的?简单。
如果你能够轻松地想出一个好的提交信息,那就是连贯的。
另一方面,如果你提交的信息需要分三次且带有许多形容词或副词,那可能并不好。多次拆分你的工作内容,连贯的提交,然后推送代码。连贯的提交有助于代码的审查,且能让仓库的历史记录更容易被遵循。
不要乱推送任何东西,因为这(有可能)意味着一天的结束!
pull request (拉取请求)是什么呢?拉取请求是种概念,其要求团队将你的分支合并到主分支。接受你的请求应该通过你的CI工具提供的状态和潜在代码审查。最终由负责合并拉取请求的人手动合并。
拉取请求诞生于开源项目中。维护者需要一种结构化的方式来评估合并之前的贡献。拉取请求并不是Git的一部分。他们受到任何Git提供程序的支持(GitHub, BitBucket, GitLab, ...)。
请注意,在持续集成中,拉取请求并不是必须的。而拉取请求的主要好处是支持代码审查过程,这过程无法通过设计自动化。
如果你正在使用拉取请求,适用(下面)相同的原则或(上面提到的)“分块工作”和“优化开发者时间”:
持续过程的核心是自动检查。它们确保在合并代码后,主分支代码能正常工作。如果它们失败,则代码不会合并。至少代码应该编译或转换,或者你的技术堆栈应该做点什么以使其为运行时做好准备。
在编译之上,你应该运行自动化测试以确保软件正常工作。测试覆盖率越高,在将新代码合并到主分支时你就越有信心。注意了!更好的覆盖率意味着更多测试和更长的执行时间。你需要找到正确的权衡。
当你完全没有测试或者需要减少一些长时间运行的测试时,你要从哪里开始呢?专注于你项目或产品的至关重要的事项。
如果你要构建一个SaaS应用,则应该检查用户是否可以注册或登录,以及执行SaaS提供的最基本操纵。除非你正在开发Salesforce竞争产品,否则你应该能够在几分钟内运行测试,如果不是马上运行。如果要构建繁重的数据处理后端:使用有限的数据集来运行不同的构建块。在持续集成中保持大型数据集的长时间运行。合并代码之后,可以触发长时间运行的测试。
持续集成的关键概念是尽快将代码放在主分支中,甚至工作正在进行中。如果功能不完全正常,或者你不希望暴露给测试的人员或终端用户。实现这一目标的方法就是功能切换。在启用/禁止切换下启用新功能。这切换可以是编译时布尔标志,环境变量或运行时事物。正确的方法取决于你想要 实现的目标。
功能切换的第一个主要好处是,你可以根据需求将它们投入生产并启用/禁止新功能。你可以使用更改的环境变量来重新启动服务器,或者切换打开/关闭一个新的UI仪表盘的布局。通过这种方式,你可以灵活地推出功能。如果在线上中导致意外问题,请将其禁用。或允许终端用户选择加入或退出该功能(使用UI切换)。
功能切换的第二个主要好处是它们会强制你考虑你正在执行的操纵与现有代码之间的界限。这是一个好的练习,如论何时,每次添加到现有系统时,都应该从这里开始。功能切换步骤使得该过程的这一步更加明显。
功能切换的唯一缺点是你需要定期从环境和代码中清除它们。一旦功能经过实测并被用户采用,它应该是默认(成功的)。应该清理切换的代码和旧版本的东西(如果有的话)。不要陷入“配置为切换”系统的陷阱。你无法维护和测试切换的所有组合,(带来的缺点是)你最终拥有一个脆弱的架构。
谨记本文中的“好”和“坏”工作流程。我们希望避免开发人员的上下文切换工作(的情况)。拿起你的手机,并开启3分钟的计时器。看看你等待构建完的时间有多长!3分钟应该是个绝对最大值,你可以集中精力并安全有效地从一个任务移动到另一个任务。
对一些团队来说,3分钟内的构建可能看起来很疯狂,但这绝对可以实现的。它和你组织工作的方式有关,而不是你使用的工具。优化构建的方法有:
强制缩短时间来限制你的CI检查的好处在于它使你从根本上改善整个开发过程。
正如Jim Rohn所说:
“成为一个百万富翁,不是为了百万美元,而是为了实现这一目标会让你很成功”
大多数持续集成工具在你的分支上运行CI构建,以确保它是否可以合并。但是这不是我们感兴趣的内容。如果你知道自己在做什么,那么你推送的代码已经很有可能生效了。你的CI工具应该验证的是你的分支和主分支合并正常。
你的CI工具应该执行分支到主分支的本地合并,并针对该分支来运行构建和测试。如果主分支在此期间没有变化,则可以自动合并你的分支。如果确实发生了更改,则应该再次运行CI检查,直到你的代码可以安全合并为止。如果你的CI工具不支持此类工作流程,请换一个工具。
有种误解是,能够跟踪Agile板或像JIRA之类的bug跟踪器中相关的代码是件很酷的(事情)。这是一个很好的教科书概念,但是对开发的过程的影响肯定不值得付出努力。任务管理器提供了“功能和错误”的视图。代码以非常不同的方式构建和分层。尝试协调任务管理器中的项目和一组提交是没有意义的。如果你想知道为什么编写一段代码,你应该能够从上下文和注释中获取信息。
工具仅仅是工具而已。设置工具可能是(花费)一个小时的事情。如果你错误的使用工具,你将无法得到预期的效果。
谨记我们为持续集成设定的目标:
真正的意义是将你的思维方式转变为“不断为你的项目或产品提供价值”。
将你的软件开发过程视为硬件生产设施。开发人员的代码代表可移动的部件。主要分支就是组装产品。
更快地将不同部分集成在一起并检查其能正常工作,你最终将获得更好的工作产品。
一些实操例子:
“完成比完美更好”。如果它正常工作,它在主分支中提供的价值比停滞在一旁几天要好。原文:https://fire.ci/blog/how-to-get-started-with-continuous-integration/
谈到Vue.set就要说响应式原理,所以得为你自己准备下这方面的理论知识。然而,一如即往,这并不难或者枯燥。准备点鳄梨和薯条,制作些鳄梨酱,然后我们再进入话题。
在一个Vue组件中,无论你何时创建一个data()功能属性,都会返回一个对象。Vue在组件背后做了很多事情,来使得它具有响应式。
export default {
data() {
return {
red: 'hot',
chili: 'peppers'
}
}
}Vue要做的第一件事是使用我们超帅的RHCP(Red Hot Chili Peppers, 一个超赞的乐队)data,它遍历了return {}对象的属性properties,然后为它们创建了唯一的getter和setter。具体情况已经超出了本文的范围,但是Vue Mastery有个很赞的视频去解析这点。
创建这些属性的目的是使你在代码中访问这些属性时(例如通过执行this.red或使用this.red=hotter进行设置时),实际上是在调用Vue为你创建的getter和setter。
在SETGET这块神奇的土地上,Vue连接起了computer properties, watchers, props,data等,从而变得响应式。以非常简单的方式,它被称为一个函数,该函数在每次setter改变时更新整个工作。
酷极了!这就是我们喜欢Vue的原因,它具有响应式和强大的幕后功能。但是也有一些阴暗面需要我们探讨。
在我们开始之前,我们更改下data数据看发生什么。
data() {
return {
members: {}
}
}好吧,到目前为止没什么看头,我们在data中有一个member属性,用来添加乐队成员的信息。现在,为了举例,我们添加一个方法,并假装从远程http请求中拉取一些信息,它将返回一个乐队信息的JSON对象。
data() {
return {
members: {}
}
},
methods: {
getMembers() {
const newMember = {
name: 'Flea',
instrument: 'Bass',
baeLevel: 'A++'
}; // Some magical method that gives us data got us this sweet info
// ...
}
}
嗯。好吧,我们先停停然后思考下这个例子。如何将newMember对象添加到当前的member属性中?这有许多方法可以解决当前的难题。
也许你会想,我们可以将member转换成一个数组,然后将它push进去。这可行,但是这是在作弊,因为它破坏了我开始输入时细心构造的例子。
在这种情况下,我们member是一个object。好吧,简单,你会说,我们在member上添加一新的属性,这样它还是一个object。实际上,我们在member上添加个name属性。
getMembers() {
const newMember = {
name: 'Flea',
instrument: 'Bass',
baeLevel: 'A++' // Totally important property that we will never use
}; // Some magical method that gives us data got us this sweet info
this.members[newMember.name] = newMember;
}Lok'tar Ogar!(不胜则亡)
可是,不,因为-
A. 这不是Orgrimmar(魔兽世界人物)
B. 现在我们遇到问题了
如果你在浏览器上测试这段代码,你将看到你确实将新数据推入member数据中了,但是此次的更改组件的状态将不会使得你的应用重新渲染。
仅将这些数据用于某些计算或某种内部存储的情况下,以这种方式进行操作不会影响你的应用程序。然而,这里应该是大大的转折HOWERVER,如果你在自己app上正在使用这种数据去展示数据,或者根据条件v-if或v-else来渲染,事情将变得有趣。
所以,现在我们明白问题实际出在哪里了,我们可以学习什么是正确的解决方案。允许我向你介绍Vue.set。
Vue.set是一个工具,它允许我们向已经激活的对象添加新属性,然后确保这个新的属性也是响应的。
这完全解决了我们在另一个例子中遇到的问题,因为当我们设置member的新属性时,它将自动挂接到Vue的响应式系统中,酷酷的getters/setters和Vue的魔法都在框架背后运行。
但是,需要一点说明来了解它如何影响数组。到目前为止,我们只是试验过了objects,这很容易理解。新的属性?如果你希望它是响应式,则通过Vue.set添加。简单~
延续上面的示例,我们切换为使用Vue.set的方式。
getMembers() {
const newMember = {
name: 'Flea',
instrument: 'Bass',
baeLevel: 'A++'
}; // Some magical method that gives us data got us this sweet info
//this.members[newMember.name] = newMember;
this.$set(this.members, newMember.name, newMember);
}这是新添加的this.$set(this.members, newMember.name, newMember);。
对于这段代码,我有两点想提下。目前为止,我告诉了你Vue.set是怎样工作的,但是现在我使用this.$set,但是不要担心,这只是个别名,所以它会以完全相同的方式运行。比较酷的是你不用在你的组件中引入Vue。
我想说的第二点是这个函数的语法。它需要传入三个参数,第一个参数是我们要改变的object或array(案例上是this.members)。
第二个参数是指向我们传入第一个参数object/array的property或key(这里是newMember.name,因为我们想动态生成)。
最后是第三个参数,它是我们想要设置的值(在案例中,newMember)。
this.members [newMember.name] = newMember;
// V V V
this.$set(this.members, newMember.name, newMember);(PS. My ASCII skills are not for sale )
但是数组的响应如何?
当我们在最初的状态中创建一个array,Vue将它设置为响应式,然而,当你直接通过索引赋值,当前Vue不能检测到。例如,我们如下操作:
this.membersArray[3] = myNewValue;然而,Vue不能检测到这种更改,因此它不是响应式的。请铭记于心,如果你通过pop,splice,push操作来更改数组,那么这些操作将触发数组的响应式,所以你可以安全地使用它们。
在必要的时候我们需要直接通过索引赋值,我们可以使用Vue.set。我们看下它和之前的例子有什么区别。
this.$set(this.membersArray, 3, myNewValue)
如果你想了解更多响应式原理的注意点,请移步[link to the official documentation](https://vuejs.org/v2/guide/list.html#Caveats)。
在编写这篇文章时,这一切仍然可能更改,但是现在满大街都在说这些警告将不再是问题。换言之,Vue 3.0会让你完全忘记这些边缘的案例,除了那些可怜的人儿,他们必须要针对某些不能完全支持新响应式系统的旧浏览器。
this关键词在JavaScript中是个很重要的概念,也是一个对初学者和学习其他语言的人来说晦涩难懂。在JavaScript中,this是一个对象的引用。this指向的对象可以是基于全局的,在对象上的,或者在构造函数中隐式更改的,当然也可以根据Function原型方法的bind,call和apply使用显示更改的。
尽管this是个复杂的话题,但是也是你开始编写第一个JavaScript程序后出现的话题。无论你尝试访问the Document Object Model (DOM)中的元素或事件,还是以面向对象的编程风格来构建用于编写的类,还是使用常规对象的属性和方法,都见遇到this。
在这篇文章中,你将学习到基于上下文隐式表示的含义,并将学习如何使用bind,call和apply方法来显示确定this的值。
在四个主要上下文中,我们可以隐式地推断出this的值:
在全局上下文中,this指向全局对象。当你使用浏览器,全局上下文将是window。当你使用Node.js,全局上下文就是global。
备注:如果你对JavaScript中得作用域概念不熟,你可以去[Understanding Variables, Scope, and Hoisting in JavaScript温习一下。
针对例子,你可以在浏览器的开发者工具栏中验证。如果你不是很熟悉在浏览器中运行JavaScript代码,可以去阅读下How to Use the JavaScript Developer Console 文章。
如果你只是简单打印this,你将看到this指向的对象是什么。
console.log(this)Output
Window {postMessage: ƒ, blur: ƒ, focus: ƒ, close: ƒ, parent: Window, …}
你可以看到,this就是window,也就是浏览器的全局对象。
在Understanding Variables, Scope, and Hoisting in JavaScript中,你学习到函数中的变量有自己的上下文。你可能会认为,在函数内部this会遵循相同的规则,但是并没有。顶层的函数中,this仍然指向全局对象。
你可以写一个顶层的函数,或者是一个没有关联任何对象的函数,比如下面这个:
function printThis() {
console.log(this)
}
printThis()Output
Window {postMessage: ƒ, blur: ƒ, focus: ƒ, close: ƒ, parent: Window, …}即使在一个函数中,this仍然指向了window,或全局对象。
然而,当使用严格模式,全局上下文中,函数内this的上下文指向undefined。
'use strict'
function printThis() {
console.log(this)
}
printThis()Output
undefined总的来说,使用严格模式更加安全,能减少this产生的非预期作用域的可能性。很少有人想直接将this指向window对象。
有关严格模式以及对错误和安全性所做更改的详细信息,请阅读MDN上Strict mode的文档
一个方法是对象上的函数,或对象可以执行的一个任务。方法使用this来引用对象的属性。
const america = {
name: 'The United States of America',
yearFounded: 1776,
describe() {
console.log(`${this.name} was founded in ${this.yearFounded}.`)
},
}
america.describe()Output
"The United States of America was founded in 1776."在这个例子中,this等同于america。
在嵌套对象中,this指向方法当前对象的作用域。在下面这个例子,details对象中的this.symbol指向details.symbol。
const america = {
name: 'The United States of America',
yearFounded: 1776,
details: {
symbol: 'eagle',
currency: 'USD',
printDetails() {
console.log(`The symbol is the ${this.symbol} and the currency is ${this.currency}.`)
},
},
}
america.details.printDetails()Output
"The symbol is the eagle and the currency is USD."另一种思考的方式是,在调用方法时,this指向.左侧的对象。
当你使用new关键字,会创建一个构造函数或类的实例。在ECMAScript 2015更新为JavaScript引入类语法之前,构造函数是初始化用户定义对象的标准方法。在Understanding Classes in JavaScript中,你将学到怎么去创建一个函数构造器和等效的类构造函数。
function Country(name, yearFounded) {
this.name = name
this.yearFounded = yearFounded
this.describe = function() {
console.log(`${this.name} was founded in ${this.yearFounded}.`)
}
}
const america = new Country('The United States of America', 1776)
america.describe()Output
"The United States of America was founded in 1776."在这个上下文中,现在this绑定到Country的实例,该实例包含在America常量中。
类上的构造函数的作用与函数上的构造函数的作用相同。在Understanding Classes in JavaScript中,你可以了解到更多的关于构造函数和ES6类的相似和不同的地方。
class Country {
constructor(name, yearFounded) {
this.name = name
this.yearFounded = yearFounded
}
describe() {
console.log(`${this.name} was founded in ${this.yearFounded}.`)
}
}
const america = new Country('The United States of America', 1776)
america.describe()describe方法中的this指向Country的实例,即america。
Output
"The United States of America was founded in 1776."在浏览器中,事件处理程序有一个特殊的this上下文。在被称为addEventListener调用的事件处理程序中,this将指向event.currentTarget。开发人员通常会根据需要简单地使用event.target或event.currentTarget来访问DOM中的元素,但是由于this引用在此上下文中发生了变化,因此了解这一点很重要。
在下面的例子,我们将创建一个按钮,为其添加文字,然后将它追加到DOM中。当我们使用事件处理程序打印其this的值,它将打印目标内容。
const button = document.createElement('button')
button.textContent = 'Click me'
document.body.append(button)
button.addEventListener('click', function(event) {
console.log(this)
})Output
<button>Click me</button>如果你复制上面的代码到你的浏览器运行,你将看到一个有Click me按钮的页面。如果你点击这个按钮,你会看到<button>Click me</button>出现在控制台上,因为点击按钮打印的元素就是按钮本身。因此,正如你所看到的,this指向的目标元素,就是我们向其中添加了事件监听器的元素。
在所有的先前的例子中,this的值取决于其上下文 -- 在全局的,在对象中,在构造函数或类中,还是在DOM事件处理程序上。然而,使用call, apply 或 bind,你可以显示地决定this应该指向哪。
决定什么时候使用call, apply 或 bind是一件很困难的事情,因为它将决定你程序的上下文。当你想使用事件来获取嵌套类中的属性时,bind可能有用。比如,你写一个简单的游戏,你可能需要在一个类中分离用户接口和I/O,然后游戏的逻辑和状态是在另一个类中。由于游戏逻辑需要用户输入,比如按键或点击事件,你可能想要bind事件去获取游戏逻辑类中的this的值。
最重要的部分是,要知道怎么决定this对象指向了哪,这样你就可以像之前章节学的隐式操作那样操作,或者通过下面的三种方法显示操作。
call和apply非常相似--它们都调用一个带有特定this上下文和可选参数的函数。call和apply的唯一区别就是,call需要一个个的传可选参数,而apply只需要传一个数组的可选参数。
在下面这个例子中,我们将创建一个对象,创建一个this引用的函数,但是this没有明确上下文(其实this默认指向了window)。
const book = {
title: 'Brave New World',
author: 'Aldous Huxley',
}
function summary() {
console.log(`${this.title} was written by ${this.author}.`)
}
summary()Output
"undefined was written by undefined"
因为summary和book没有关联,调用summary本身将只会打印出undefined,其在全局对象上查找这些属性。
备注: 在严格模式中尝试
this会返回Uncaught TypeError: Cannot read property 'title' of undefined的错误结果,因为this它自身将会是undefined
然而,你可以在函数中使用call和apply调用book的上下文this。
summary.call(book)
// or:
summary.apply(book)Output
"Brave New World was written by Aldous Huxley."现在,当上面的方法运用了,book和summary之间有了关联。我们来确认下,现在this到底是什么。
function printThis() {
console.log(this)
}
printThis.call(book)
// or:
whatIsThis.apply(book)Output
{title: "Brave New World", author: "Aldous Huxley"}在这个案例中,this实际上变成的所传参数的对象。
这就是说call和apply一样,但是它们又有点小区别。
除了将第一个参数作为this上下文传递之外,你也可以传递其他参数。
function longerSummary(genre, year) {
console.log(
`${this.title} was written by ${this.author}. It is a ${genre} novel written in ${year}.`
)
}使用call时,你使用的每个额外的值都会被作为附加参数进行传递。
longerSummary.call(book, 'dystopian', 1932)Output
"Brave New World was written by Aldous Huxley. It is a dystopian novel written in 1932."如果你尝试使用apply去发送相同的参数,就会发生下面的事情:
longerSummary.apply(book, 'dystopian', 1932)Output
Uncaught TypeError: CreateListFromArrayLike called on non-object at <anonymous>:1:15针对apply,作为替代,你需要将参数放在一个数组中传递。
longerSummary.apply(book, ['dystopian', 1932])Output
"Brave New World was written by Aldous Huxley. It is a dystopian novel written in 1932."通过单个参数传递和形成一个数组参数传递,两个之间的差别是微妙的,但是值得你留意。使用apply更加简单和方便,因为如果一些参数的细节改变了,它不需要改变函数调用。
call和apply都是一次性使用的方法 -- 如果你调用带有this上下文的方法,它将含有此上下文,但是原始的函数依旧没改变。
有时候,你可能需要重复地使用方法来调用另一个对象的上下文,所以,在这种场景下你应该使用bind方法来创建一个显示调用this的全新函数。
const braveNewWorldSummary = summary.bind(book)
braveNewWorldSummary()
Output
"Brave New World was written by Aldous Huxley"
在这个例子中,每次你调用braveNewWorldSummary,它都会返回绑定它的原始this值。尝试绑定一个新的this上下文将会失败。因此,你始终可以信任绑定的函数来返回你期待的this值。
const braveNewWorldSummary = summary.bind(book)
braveNewWorldSummary() // Brave New World was written by Aldous Huxley.
const book2 = {
title: '1984',
author: 'George Orwell',
}
braveNewWorldSummary.bind(book2)
braveNewWorldSummary() // Brave New World was written by Aldous Huxley.虽然这个例子中braveNewWorldSummary尝试再次绑定bind,它依旧保持着第一次绑定就保留的this上下文。
Arrow functions没有自己的this绑定。相反,它们上升到下一个执行环境。
const whoAmI = {
name: 'Leslie Knope',
regularFunction: function() {
console.log(this.name)
},
arrowFunction: () => {
console.log(this.name)
},
}
whoAmI.regularFunction() // "Leslie Knope"
whoAmI.arrowFunction() // undefined在你想将this执行外部上下文的情况下,箭头函数会很有用。比如,在类中有一个事件监听器,你可能想将this指向此类中的一些值。
在下面这个例子中,像之前一样,你将创建一个按钮并将其追加到DOM中,但是,类中将会有一个事件监听器,当按钮被点击时候会改变其文本值。
const button = document.createElement('button')
button.textContent = 'Click me'
document.body.append(button)
class Display {
constructor() {
this.buttonText = 'New text'
button.addEventListener('click', event => {
event.target.textContent = this.buttonText
})
}
}
new Display()如果你点击按钮,其文本会变成buttonText的值。如果在这里,你并没有使用箭头函数,this将等同于event.currentTarget,如没有显示绑定this,你将不能获取类中的值。这种策略通常使用在像React这样框架的类方法上。
在这篇文章中,你学到了关于JavaScript的this,和基于隐式运行时绑定的可能具有的不同值,以及通过bind,call和apply的显示绑定。你还了解到了如何使用箭头函数缺少this绑定来指向不同的上下文。有了这些知识,你应该能够在你的程序中明确this的价值了。
为什么要抛出这个话题?
最近从mac转成用window来开发,在安装nginx的时候碰了下钉子,那我就不开心了。想着既然都安装好了,那么就搞点事情吧~
简单讲下在window上安装nginx~
通过download下载你需要的版本,我这里下载了稳定版本nginx/Windows-1.16.0
直接解压此文件即可
进入解压的文件夹(nginx.exe)的上一级。
在出现pid被占用的情况,你可以通过下面的方法处理:
在任务管理器中手动移除nginx占用的进程
执行tasklist /fi "imagename eq nginx.exe"找出nginx占用的进程
映像名称 PID 会话名 会话# 内存使用
========================= ======== ================ =========== ============
nginx.exe 8248 Console 1 7,076 K
nginx.exe 3052 Console 1 7,508 K之后kill相关的进程就行了。
注意:有时候移除了占用的PID后还是不行,那重启下电脑~
启动nginx后,在浏览器上输入localhost你会看到其成功启动的页面,如下图:
对于跨域的概念就不详细说了...
我们先关闭nginx代理,然后开启两个node服务来进行验证,刚开始的时候,我是这样处理的:
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>nginx</title>
</head>
<body>
<h1>nginx反向代理</h1>
<script>
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost:8887');
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4) {
if (xhr.status == 200) {
console.log(xhr.responseText)
}
}
}
</script>
</body>
</html>我开启了第一个服务server.js
const http = require('http');
const fs = require('fs');
http.createServer(function(request, response) {
const html = fs.readFileSync('index.html', 'utf8');
response.writeHead(200, {
'Content-Type': 'text/html'
});
response.end(html);
}).listen(8888);
console.log('server is listening at 8888 port');好,我开启第二个服务来提供数据源server2.js
const http = require('http');
http.createServer(function(request, response) {
response.writeHead(200, {
'Content-Type' : 'application/json;charset=utf-8'
});
let data = {
name: 'nginx proxy'
};
data = JSON.stringify(data);
response.end(data);
}).listen(8887);
console.log('server2 is listen at 8887 port');可是由于浏览器的同源策略,我没能请求到数据~
我的另外一个开启的服务是有数据的:
来,nginx派上用场了,我修改下上面html个文件的代码,如下:
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>nginx</title>
</head>
<body>
<h1>nginx反向代理</h1>
<script>
var xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost/api');
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readyState == 4) {
if (xhr.status == 200) {
console.log(xhr.responseText)
}
}
}
</script>
</body>
</html>来,我们修改下nginx.conf文件,如下:
http {
server {
...
location / {
root html;
index index.html index.htm;
}
# 加入的内容
location /app/ {
proxy_pass http://localhost:8888/;
}
# 加入的内容
location /api/ {
proxy_pass http://localhost:8887/;
}
}
}然后开启我们的nginx服务之后,就重启server.js和server2.js服务。之后在浏览器上打开localhost/app/就在console上看到请求过来的数据了~
更多的内容,请戳我的博客进行了解,能留个star就更好了💨
如果你曾去过坐式餐厅,那么你就能理解web开发中前端和后端的区别。
在开始学习web开发,你会遇到一系列使你迷迷糊糊的概念。
数据库?服务器?客户端?服务端?AJAX?
幸运的是,你只需要了解HTML和CSS就可以去创建你的第一个站点了,它可以在你本地电脑上运行起来。但是,如果你想让你的站点能在线上运行起来,你需要了解下前端和后端的概念。
这里有个一般的想法:类比餐厅里面的服务员和厨房员工,前端和后端在你的站点上也是分工合作。在它们擅长的领域为站点服务。
对厨房员工来说,这意味着高效地制作出美味的食物。而服务员是与客户合作并创造良好客户体验方面的专家。
在web开发中,前端有时被称为客户端,而后端有时被称为服务端。
以下是不同技术在web应用程序的前端和后端中扮演的角色。为了能理解这篇教程,你需要掌握基本的HTML和CSS知识。
我们先来介绍下前端。前端代码创建用户界面,这是web访问者与代码交互的组织方式。在我们的举例中,类似餐厅的餐桌,这是个提供顾客和服务员可控交流的地方。所以,想象一下,网站就好比餐桌,比如http://mysite.com网站。
首先,用户(客户)需要些可以浏览的东西。在设定的餐厅的场景里面,很明显,对应的就是菜单了。这是一段静态的内容,应该让客户更加容易理解他们的选择。
从一个前端开发者的视觉来看,这类似于HTML和CSS。这两种语言允许你创建静态内容。
很明显,我们缺失了一样东西。你不可能对这菜单大喊大叫,期待发生些什么事情。你需要一种方式将你的订单传达给厨房人员。
这时候,服务员就登场了。服务员能帮助你了解菜单,回答你提出的任何问题,然后将你的订单交给厨房人员。服务员是互动方面的专家,明白你的需求。这正是Javascript的用武之地了。
作为一个开发者,Javascript将帮助你实现各种目标。它能够为用户带来更好的页面体验,帮助用户找到适合的信息。它也是一种能用来发送用户请求到后端的语言。换言之,当你写Javascript,它并不意味着你正在和后端发生了什么交互。(因为)Javascrip只是前端的一部分,可以不用和后端交互就能解决很多问题。
通过上面选择膳食的过程,我总结了(HTML/CSS和Javascrip 或者 菜单和服务员)两方面。当用户访问你的站点时,他们是带有目的的。你的代码必须帮助他们来达成目标。
你是否进过餐厅的厨房?至少可以说,那是个高压的地方。它与客户看到的环境完全不同。你甚至可以说,服务员和菜单提供了发生在厨房的事件的友好、完美的呈现(场景),而厨房(对客户来说)并没有呈现什么制作过程。
这好比web应用程序中的后端,或者运行在服务端的代码。类似厨房,服务器位于与用户界面不同的位置。它是使用不同语言进行交流的。
由于服务器实际上是远程的计算机,因此它比任何给定的计算机上面的浏览器具有更多的计算能力。就像厨房的员工,重点在于效率和生产力。
想象一下复杂的餐厅厨房。它必须在正确的时间和正确的位置将食材准备好。厨房的员工必须知道在特定的时间做他们的工作。他们必须重复地生产同等质量饭菜。相似的,服务器必须组织web应用程序中的数据,以便在适当的时候发送正确的内容。
服务器必须在接收到请求的时候,发送响应。
在餐厅的场景中,响应可能是下面几种:
不管是什么,回应是通过服务员传达给客户的。在web中,那就是Javascript代码了。
比较流行的后端语言和框架包括Ruby, Ruby on Rail, node.js, PHP和其他。
一个比较实际的原因是,我们必须在客户端和服务端运行不同的代码。全部的现代浏览器只能理解HTML, CSS 和 JavaScript。所以,这是我们不能在浏览器上使用服务端语言的一个简单原因。
另一个原因是,我们允许每边都专注在他们擅长的地方去迎接挑战。你能想象下,如果厨师去当服务员,那将给客户的用户体验带来多大灾难。所以,我们很幸运,我们有一方专门从事用户界面,另一方专门研究服务器方面的挑战。
想象一下,你拥有一家不在网上销售任何东西的企业。假设你拥有一家当地的花店。
在那种情景下,你不需要后端,因为那场景不复杂。你只需要前端,也许是一个表格,可以将任何查询指向你的电子邮箱。
换言之,一些网站只是用于浏览和采取某种浏览器不需要处理的行为。你不需要为每个类型的网站编写后端。你可以使用Github Pages将你的纯前端网站放到网上。
后话
翻译原文Front End v. Back End Explained by Waiting Tables At A Restaurant
这篇文章中,我将深入探讨JavaScript中的一个最基本的部分,即执行上下文(或称环境)。读过本文后,你将更加清楚地了解到解释器尝试做什么,为什么在声明某些函数/变量之前,可以使用它们以及它们的值是如何确定的。
在运行JavaScript代码时,执行环境非常重要,并可以认为是以下其中之一:
你可以在网上查到大量的关于scope(作用域)的资料,本文的目的就是要让事情更加容易理解。我们把术语执行上下文视为当前代码的评估环境/范围。现在,条件充足,我们看个包含全局和函数/本地上下文评估代码的示例。
这里没什么特别的,我们有1个由紫色边框表示的全局上下文和由绿色、蓝色和橙色边框表示的3个不同的函数上下文。只有1个全局上下文,我们可以从程序的任何其它上下文访问。
你可以拥有任意数量的函数上下文,并且每个函数调用都会创建一个新的上下文,从而创建一个私有的作用域,无法从当前函数作用域外直接访问函数内部声明的任何内容。在上面的例子中,函数可以访问在其当前上下文之外声明的变量,但是外部上下文无法访问(函数)其中声明的变量/函数。为什么会这样?这段代码究竟是如何评估的?
浏览器中的JavaScript解释器是单线程实现的。这意味着在浏览器中一次只能发生一件事情,其它动作或事件在所谓的执行栈中排队。下图是单线程栈的抽象视图:
我们知道,当浏览器首次加载脚本时,它默认进入全局执行上下文。如果在全局代码中调用一个函数,程序的顺序流就进入被调用的函数,创建一个新的执行上下文并将该上下文推送到执行栈的顶部。
如果你在当前函数中调用另外一个函数,则会发生同样的事情。代码的执行流程进入函数内部,该函数创建一个新的执行上下文,该上下文被推送到现有栈的顶部。浏览器将始终执行位于栈顶部的当前执行上下文,并且一旦函数完成当前执行上下文,它将从栈顶弹出,将控制权返回当前栈的栈顶上下文。下面的例子展示了递归函数和其程序的执行栈:
(function foo(i) {
if (i === 3) {
return;
}
else {
foo(++i);
}
}(0));上面代码只调用自身3次,将i的值递增1。每次调用函数foo时,都会创建一个新的执行上下文。一旦上下文执行完毕,它就会弹出栈并且将控制权返回它下面的上下文,直到再次到达全局上下文。
关于执行栈有五个关键点:
执行上下文,甚至是调用自身所以,我们现在知道每次调用一个函数时,都会创建一个新的执行上下文。但是,在JavaScript的解释器中,执行上下文的调用都有两个阶段:
可以将每个执行上下文在概念上标示为具有3个属性的对象:
executionContextObj = {
'scopeChain': { /* variableObject + all parent execution context's variableObject */ },
'variableObject': { /* function arguments / parameters, inner variable and function declarations */ },
'this': {}
}调用函数时,但在执行实际函数之前,会创建此executionContextObj。这被称为阶段1,即创建阶段。这里,解释器通过扫描传入的参数或参数的函数、本地函数声明和局部函数声明来创建executionContextObj。此扫描的结果将称为executionContextObj中的variableObject。
以下是解释器如何评估代码的伪概述:
函数代码之前,创建执行上下文。作用域链变量对象:
arguments对象,检查参数的上下文,初始化名称和值并创建引用的副本。变量对象(或活动对象)中创建一个属性,该属性是确切的函数名称,该函数具有指向内存中函数的引用指针。变量对象(或活动对象)中创建一个属性,该属性是变量名称,并将值初始化为undefined。变量对象(或活动对象)中,则不执行任何操作并继续扫描(即跳过)。看下下面的例子:
function foo(i) {
var a = 'hello';
var b = function privateB() {
};
function c() {
}
}
foo(22);调用foo(22),创建阶段如下:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: undefined,
b: undefined
},
this: { ... }
}正如你所见,创建阶段处理定义属性的名称,而不是为它们赋值,但正式参数/参数除外。创建阶段完成后,执行流程进入函数,激活/代码执行阶段在函数执行完毕后如下所示:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: 'hello',
b: pointer to function privateB()
},
this: { ... }
}你可以在网上找到很多定义JavaScript术语-提升的资源,解释变量和函数声明是否被提升到其功能范围的顶部。但是,没有人详细解释为什么会发生这种情况,在掌握了关于解释器如何创建活动对象的新知识点,就很容易理解为什么了。看下下面的代码例子:
(function() {
console.log(typeof foo); // function pointer
console.log(typeof bar); // undefined
var foo = 'hello',
bar = function() {
return 'world';
};
function foo() {
return 'hello';
}
}());我们现在可以回答下面这些问题了:
为什么我们可以在声明foo前访问它?
创建阶段,我们就知道在激活/代码执行阶段之前就已经创建了变量。因此,当函数开始执行时,已经在活动对象中定义了foo。Foo被声明了两次,为什么foo显示为函数而不是undefined或string呢?
foo被声明了两次,我们从创建阶段中就知道到达变量之前在活动对象上已经创建了函数,并且如果活动对象上已经存在属性名称,我们就会绕过了声明。foo()的引用,并且当解释器到达var foo时,我们已经看到名称foo存在,因此代码什么都不做并且继续。为什么bar是undefined?
bar实际上是一个具有函数赋值的变量,我们知道变量是在创建阶段创建的,但它们是使用undefined值初始化的。希望到现在,你已经很好地掌握了JavaScript解释器是如何评估你的代码。理解执行上下文和环境栈可以让你了解代码的评估和你预期不同值的原因。
你是认为了解解释器的内部工作原理是多余的还是必要的JavaScript知识点呢?知道执行上下文是否有助你编写出更好的JavaScript?
笔记:有些人一直在询问闭包,回调,timeout等知识点,我将在下一篇文章中介绍,更多地关注与执行环境相关的作用域链。
原文: http://davidshariff.com/blog/what-is-the-execution-context-in-javascript/
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

















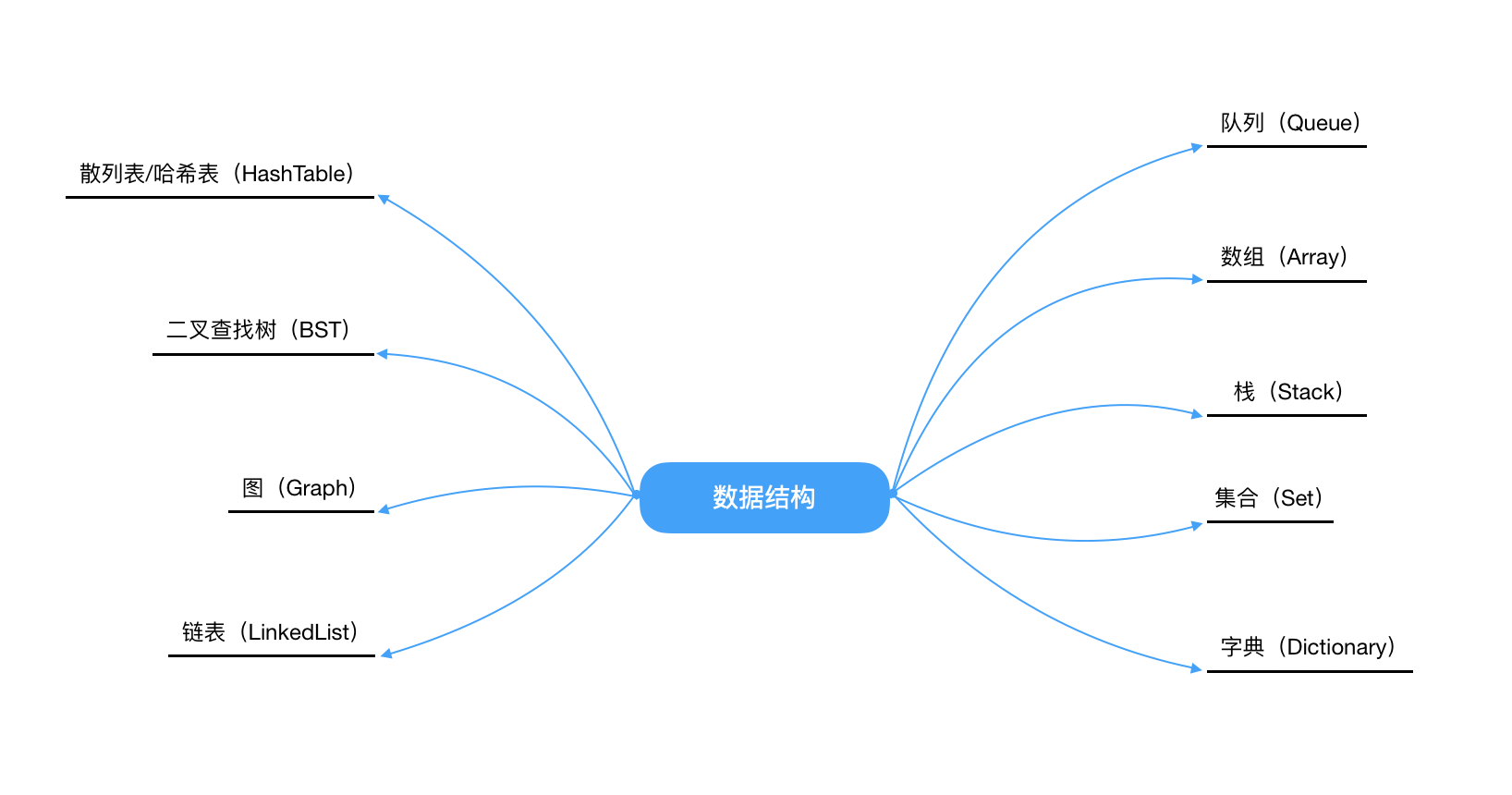


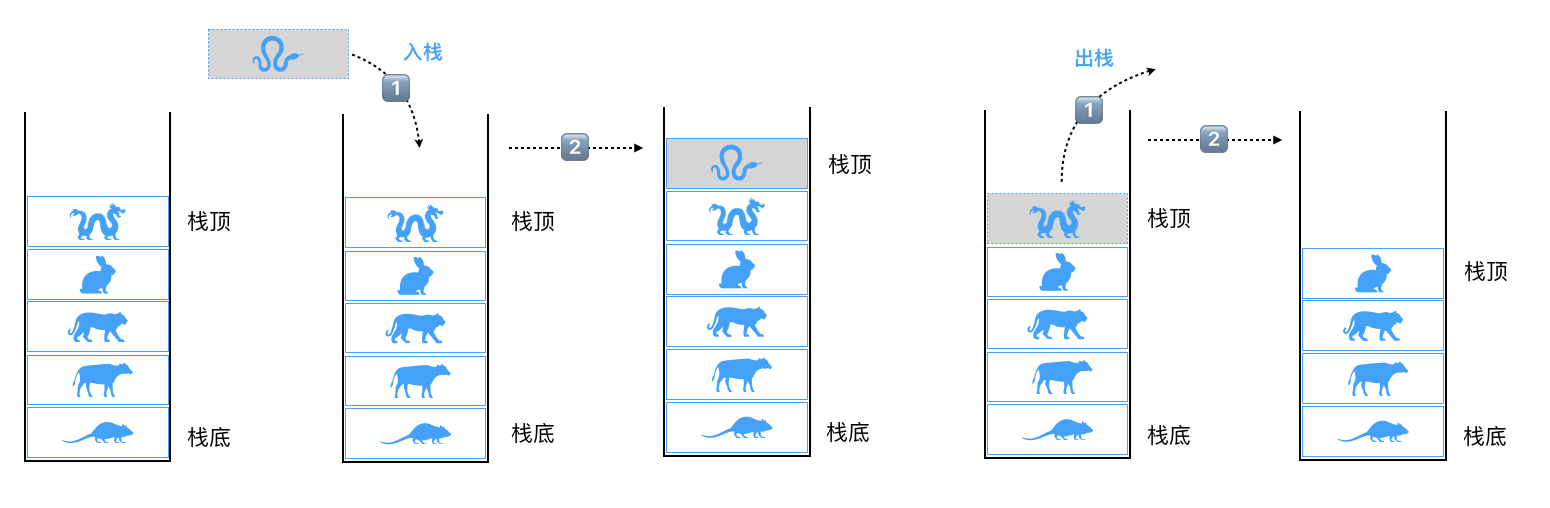
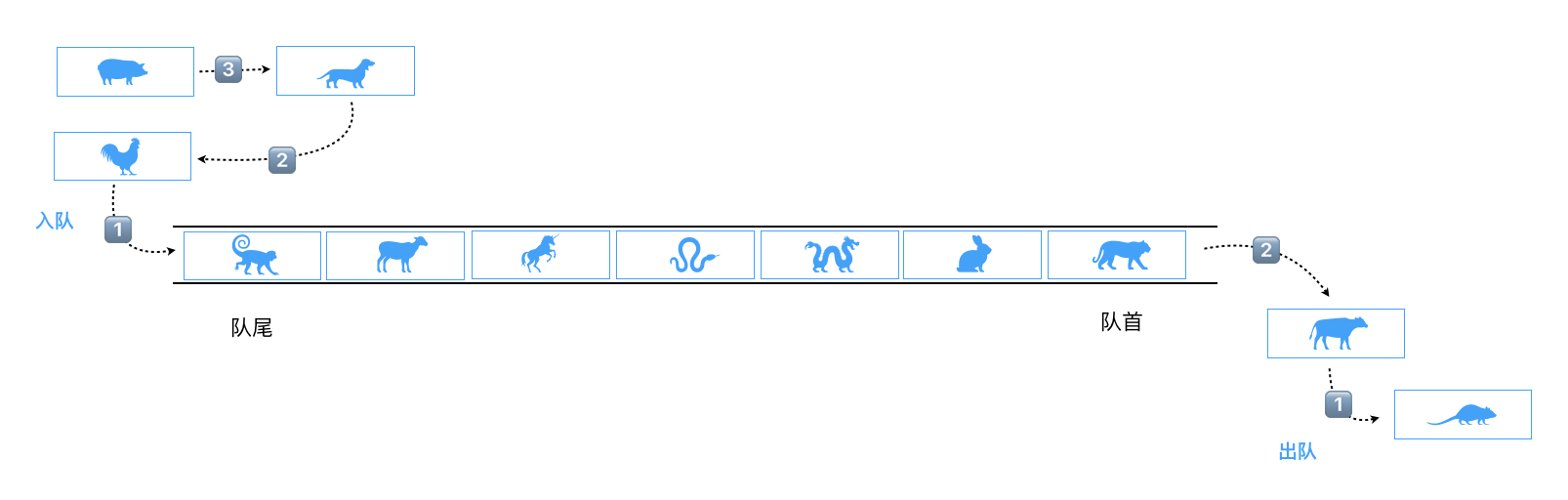
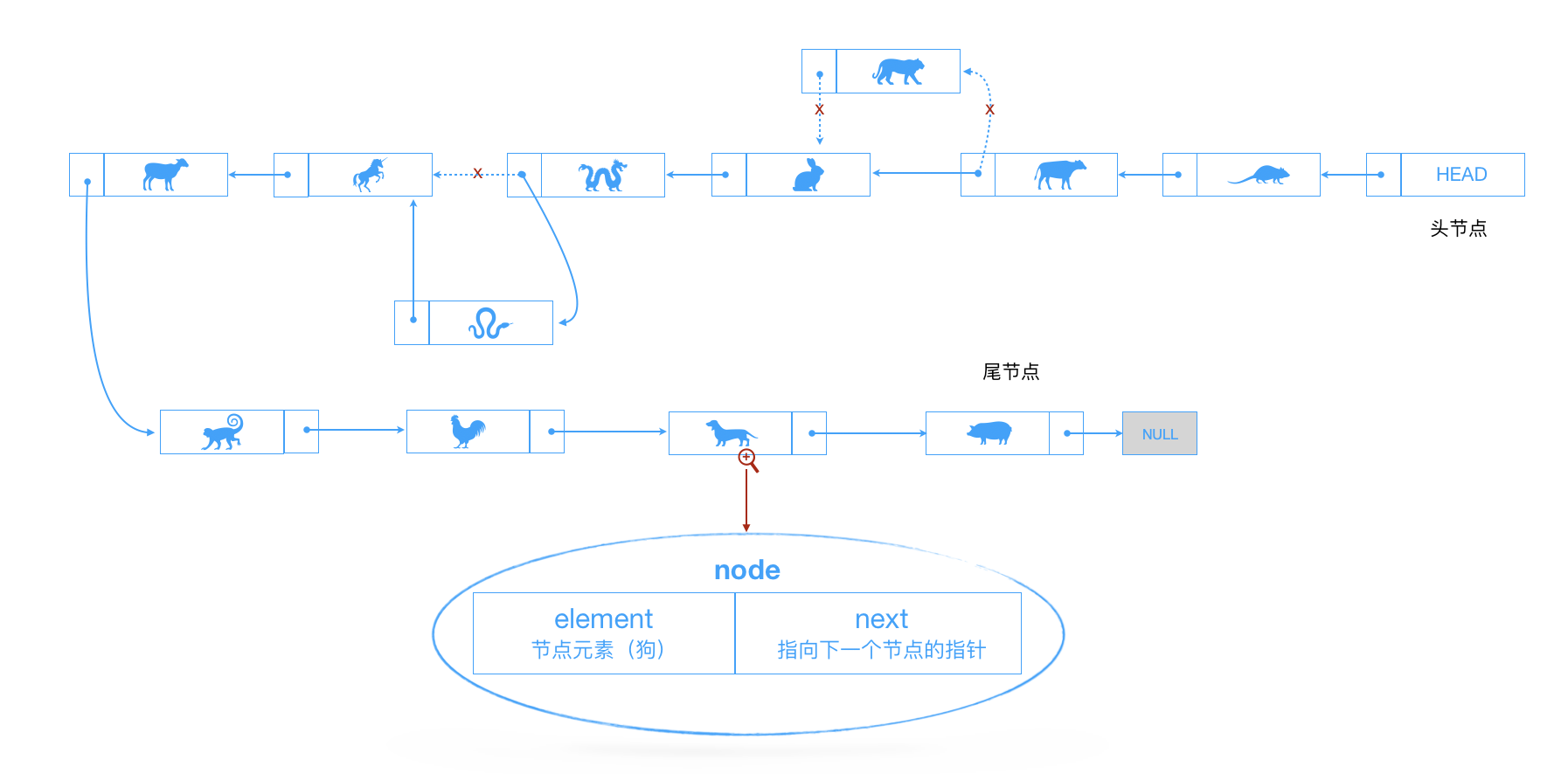

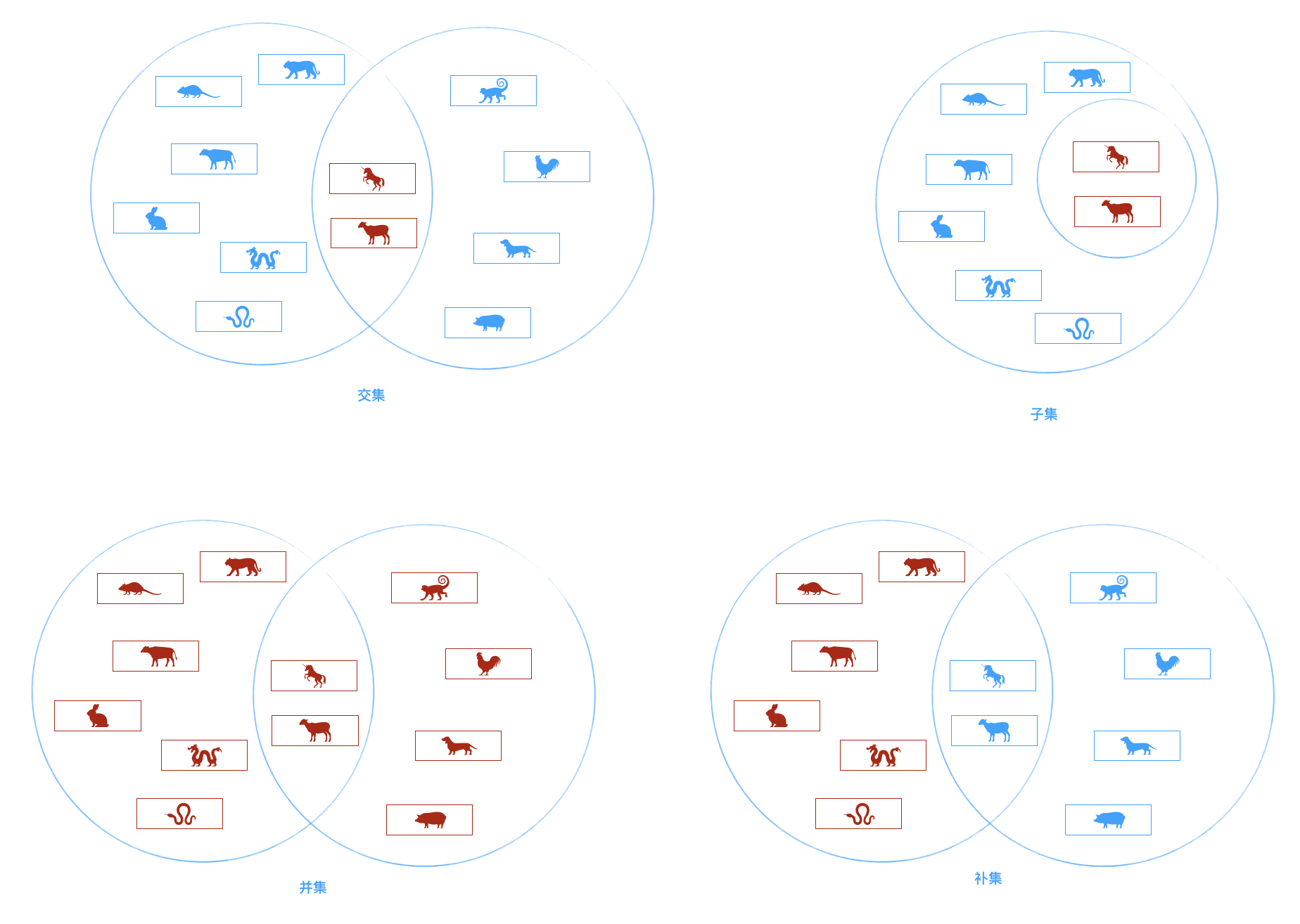
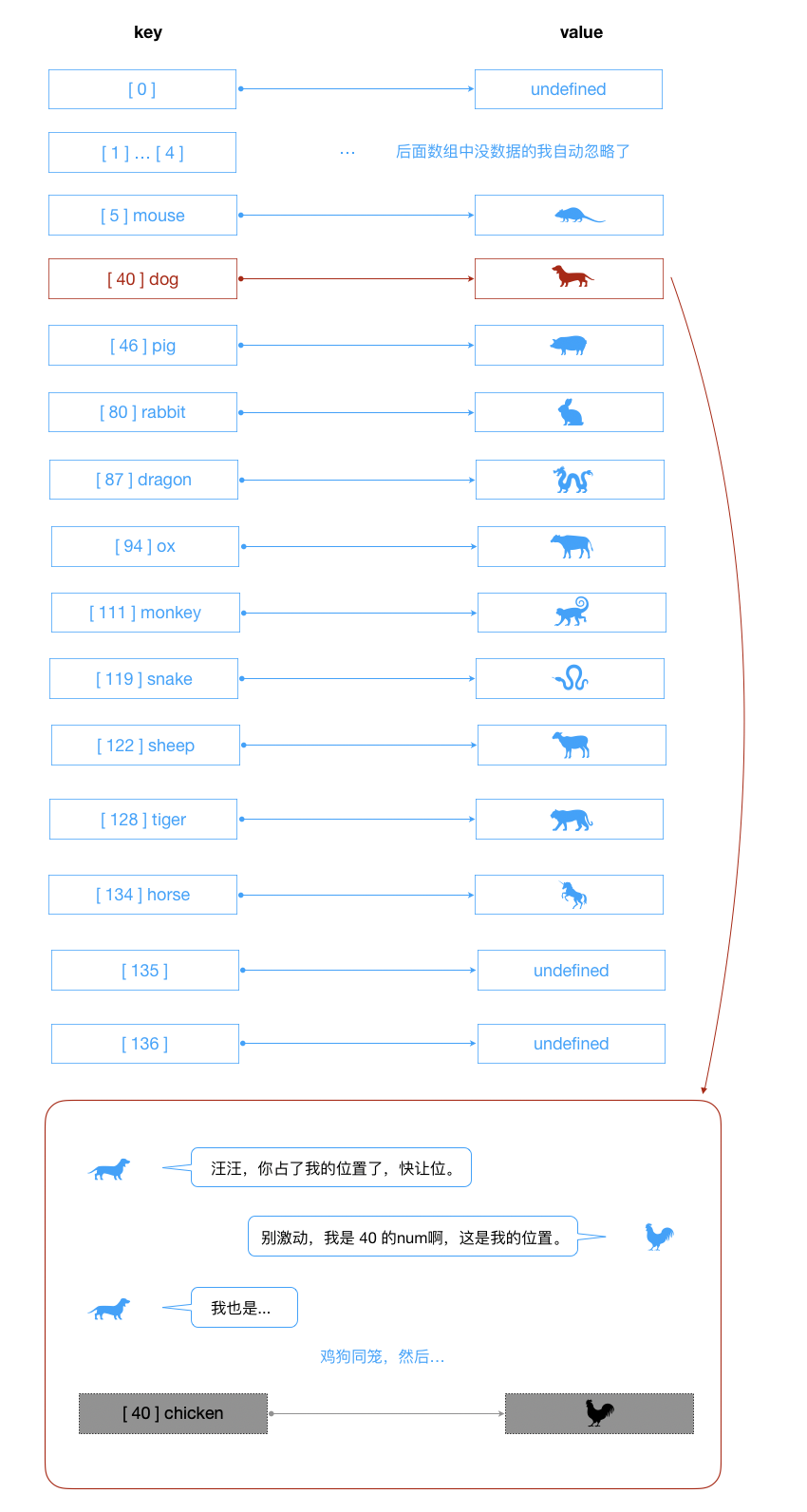


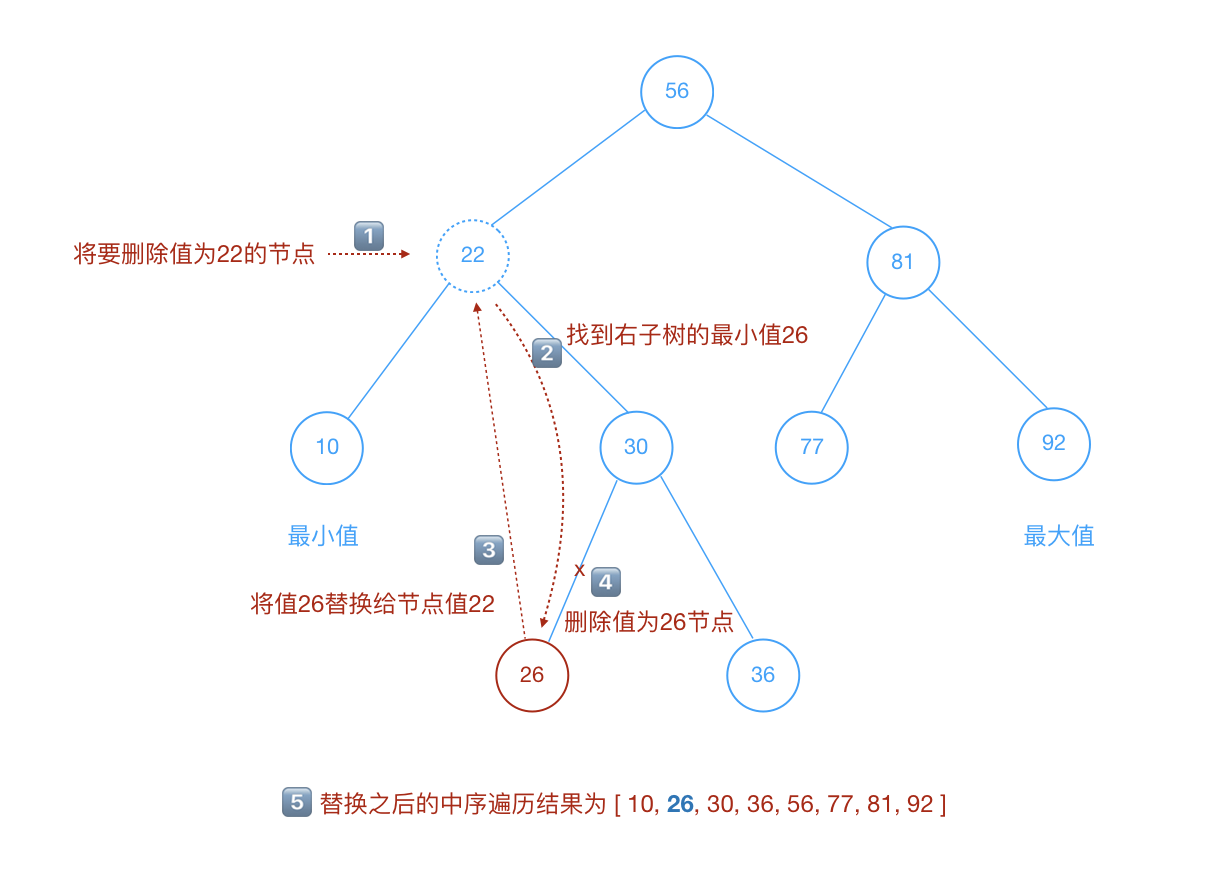

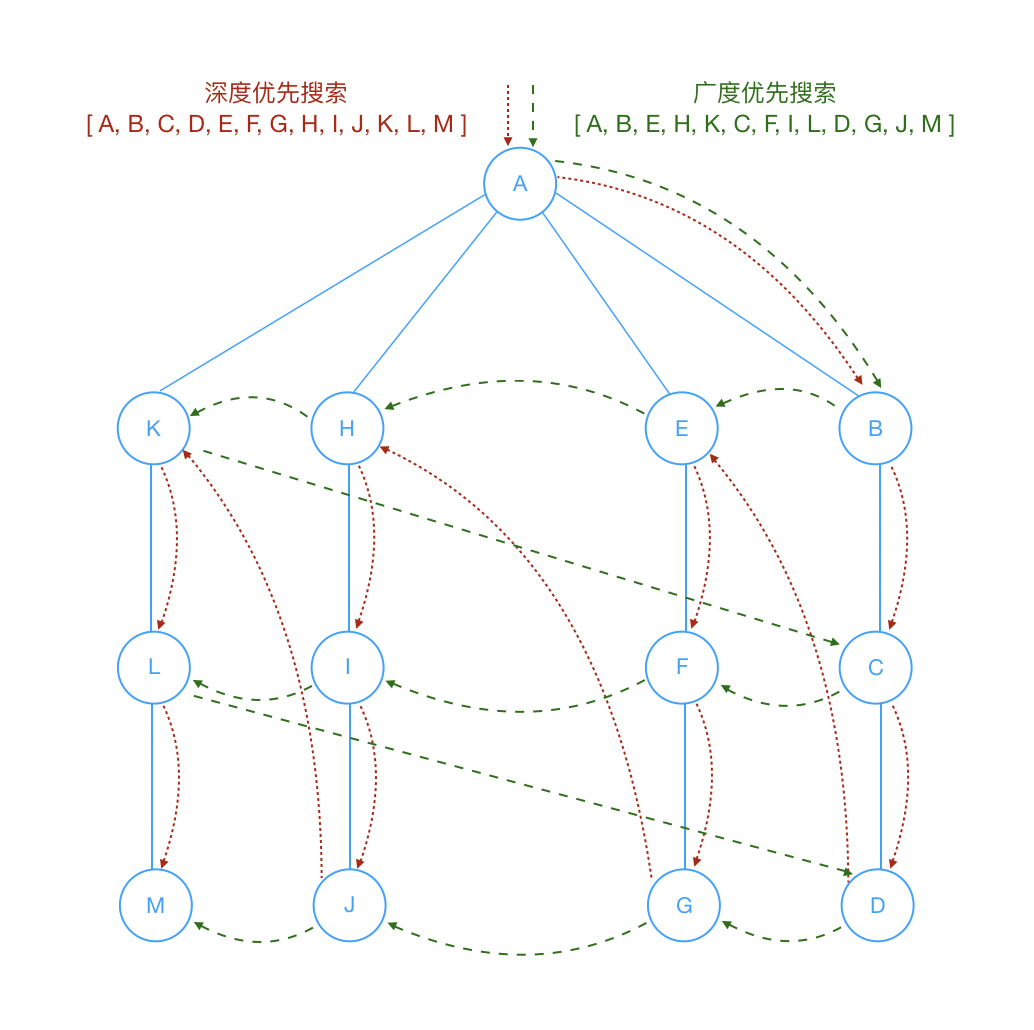

















































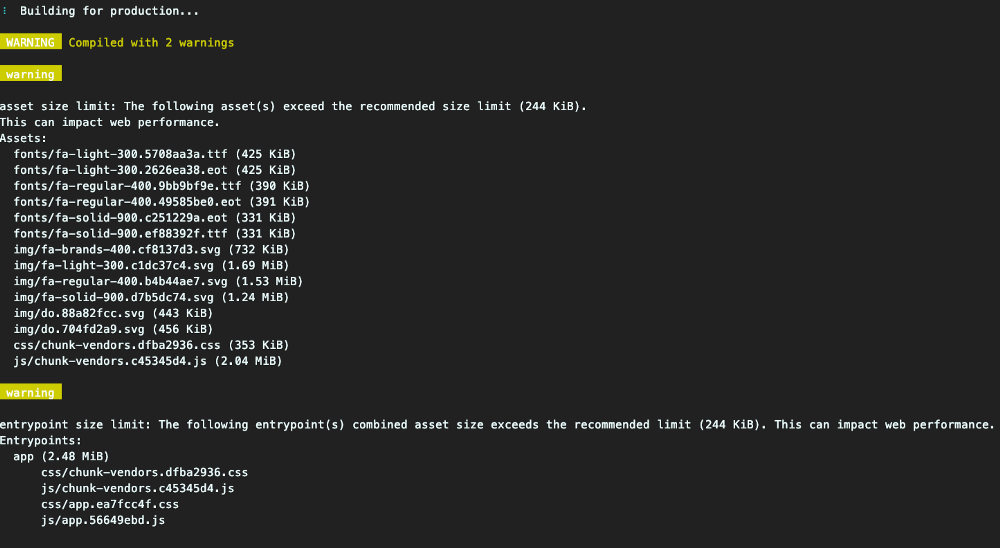
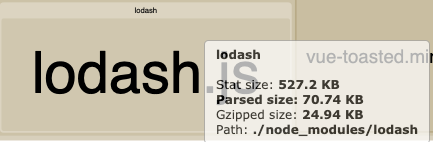
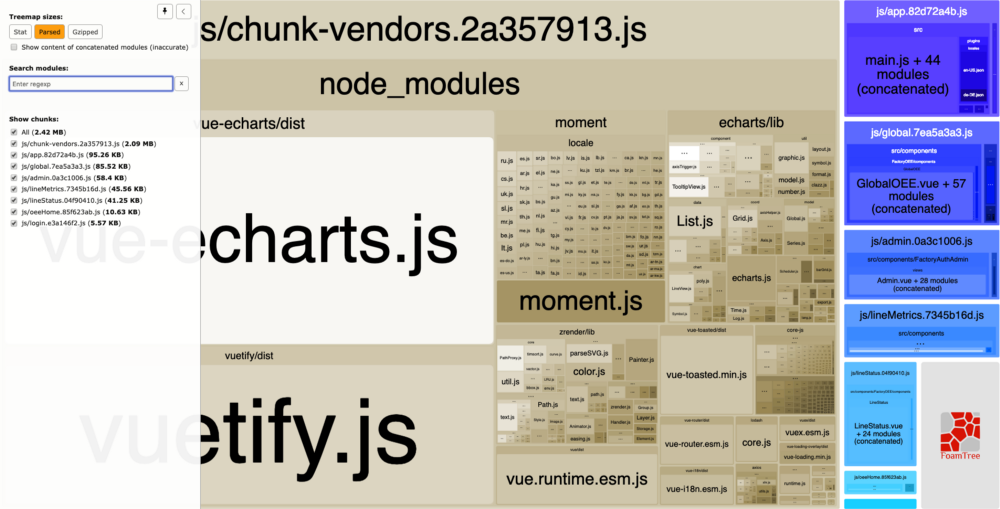
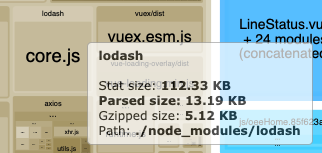
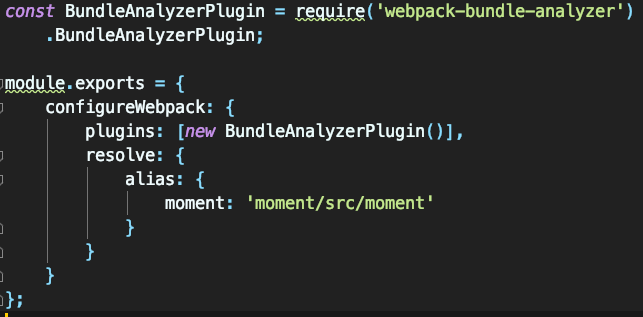


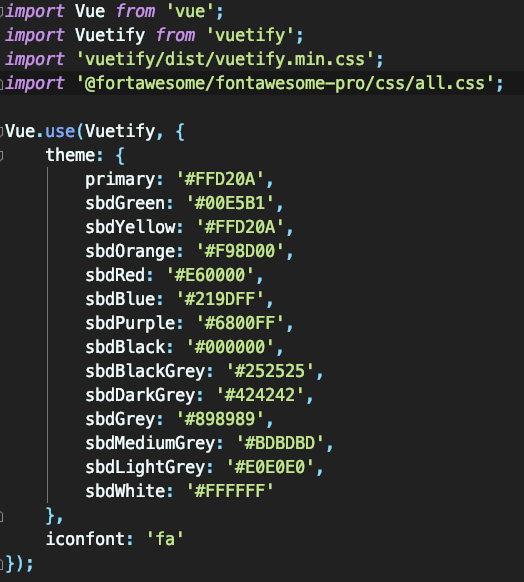
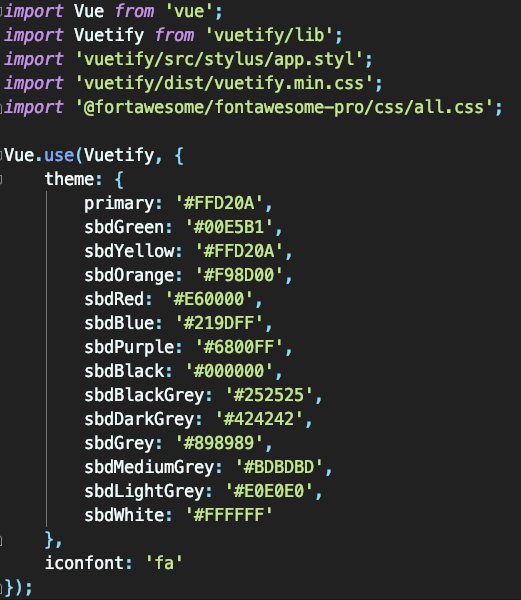
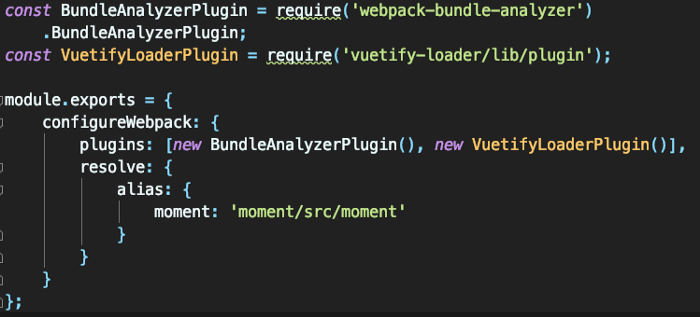
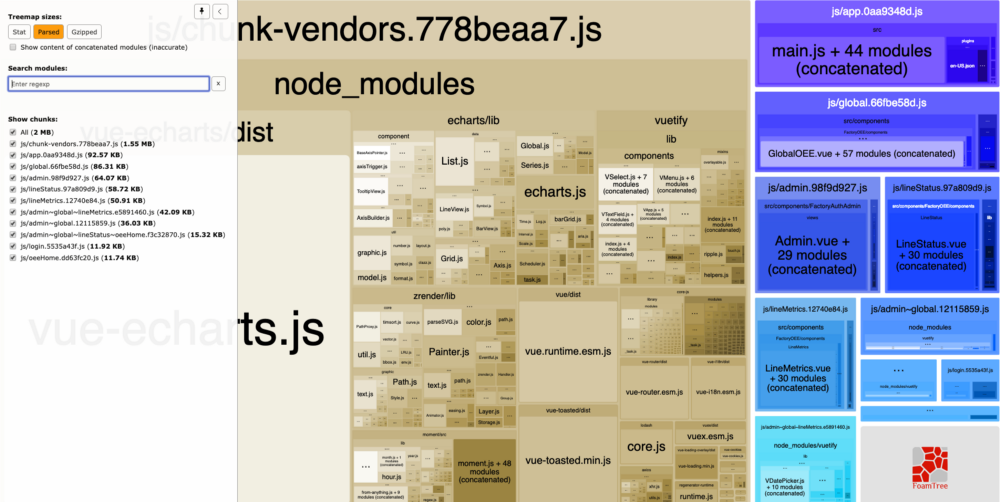































{kind=link}