sfu-db / connector-x Goto Github PK
View Code? Open in Web Editor NEWFastest library to load data from DB to DataFrames in Rust and Python
Home Page: https://sfu-db.github.io/connector-x/intro.html
License: MIT License
Fastest library to load data from DB to DataFrames in Rust and Python
Home Page: https://sfu-db.github.io/connector-x/intro.html
License: MIT License




































































































































Currently you can have a wrong schema with different num of cols for pandas writer but the program still runs.
Simple cache support for query result in order to speed up loading the same query multiple times. Extensible to more sophisticated design and implementation.
def read_sql(..., enable_cache=True, force_query=False)True)) - Whether or not to cache the result data. If False is set, do not cache the result. If True is set, cache the result to /tmp with connection and sql as name. If a string is set, cache the result to the corresponding path.False)) - Whether or not to force download the data from database no matter there is a cache or not. If True, also update the local cache.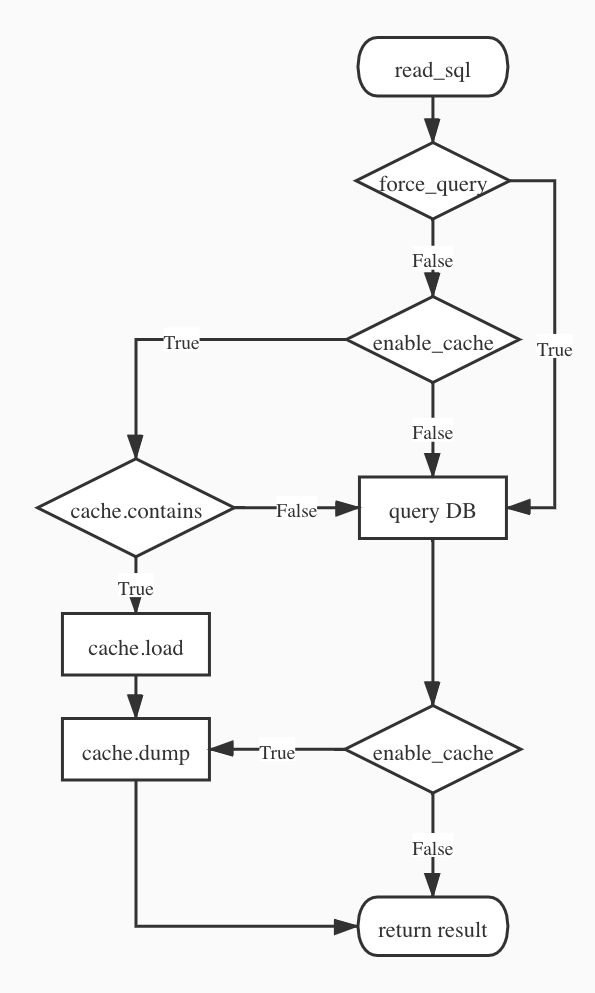
pub trait Cache {
fn init(conn: str) -> Result<()>; // init cache source, init metadata if not exists
fn query_match(query: str) -> Result<(Vec<str>, Vec<str>)>; // lookup metadata, split query into probe query and remainder query, and partition each query
fn post_execute(dests: Vec<Box<dyn Destination>>) -> Result<Destination>; // produce final result
}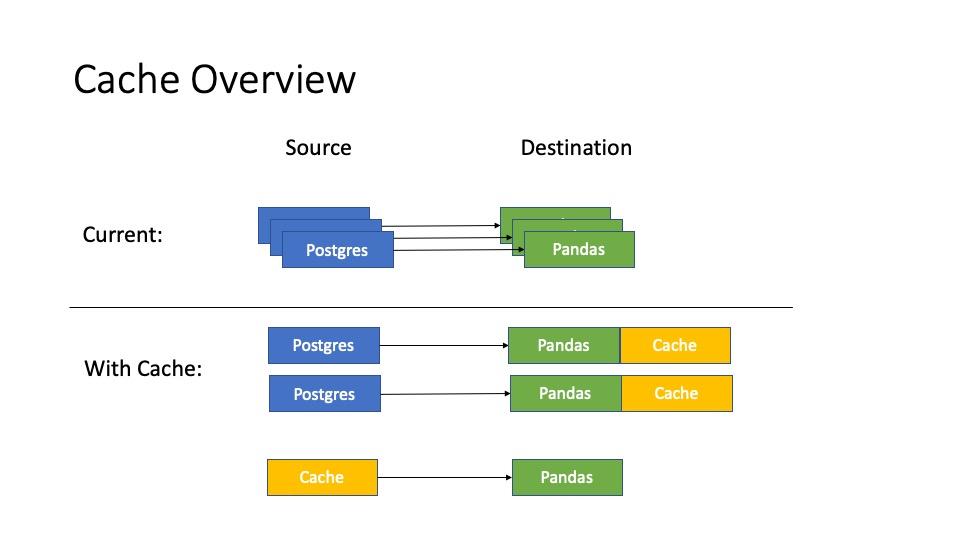
Left: current implementation, Right: implementation supporting cache
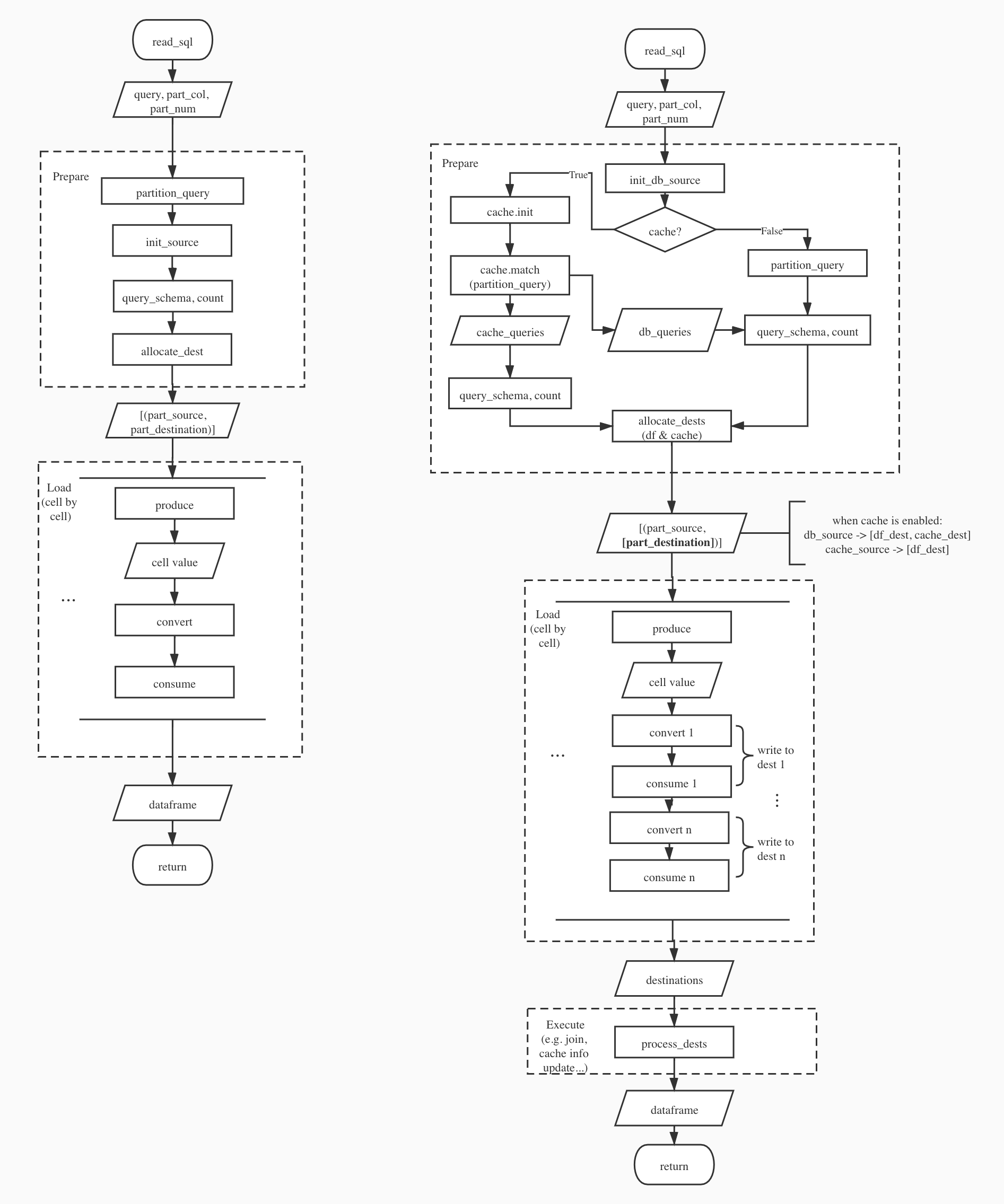
Either cache_queries or db_queries will be empty in the first version that only support exactly match.
Some related works:
Supported queries and partition algorithm
Baselines: Dask, Modin (Dask), Pandas
Parameters: # partitions, network bandwidth (200Mbps, 10Gbps), pandas with chunk,
Metrics: time, peak mem
Currently, Produce<T> does not carry a lifetime. This means it can only produce owned types but not borrowed types. Producing borrowed types is important to the zero-copy goal.
We are currently fine even with zero-copy string because Postgres uses Bytes for the internal buffer. Cloning a Bytes just means cloning the Arc under it. However, this might not be true for arbitrary data sources.
I had an initial attempt under the borrowed-produce branch, but still, some works need to be done to make it compile.
It would be nice if we could get logs from rust over the wire for debug purposes, preferably configurable from the Python client.
I have a supposedly posgtres compatible source that fails due to
RuntimeError: Cannot get metadata for the queries, last error: Some(Error { kind: UnexpectedMessage, cause: None })
In the meantime, any tips for debugging this?
File "D:\BOT\PostgreSQLConnection\venv\lib\site-packages\connectorx_init_.py", line 98, in read_sql
partition_query=partition_query,
RuntimeError: TypeError: Argument 'placement' has incorrect type (expected pandas.libs.internals.BlockPlacement, got list)
OR
File "D:\BOT\PostgreSQLConnection\venv\lib\site-packages\connectorx_init.py", line 98, in read_sql
partition_query=partition_query,
RuntimeError: TypeError: Argument 'placement' has incorrect type (expected pandas._libs.internals.BlockPlacement, got int)
maybe we should add a method to the source called headers.
Currently, csv parser gives you an empty string.
Currently it takes 30s for allocating the tpch lineitem x 10 table. To compare, rust requires 10us (maybe unfair), pure numpy takes 4 secs.
Make pandas dataframe allocation support pandas 1.3
With the new arrow support, I think connector-x has value as a rust crate as well. However, as a crate owner writing a library, I'd not want to depend on connector-x because it has a lot of dependencies (increasing compile times), I'd don't want to compile.
I think it would be really valuable if the dependencies could be opt-in and activated with feature gates.
Currently no TLS implementation is supported, so connecting like this fails if the DB mandates an SSL/TLS connection:
df = cx.read_sql(f"postgresql://{username}:{password}@host:35432/schema?sslmode=require", 'select 1;', return_type='pandas')
Error:
RuntimeError: timed out waiting for connection: error performing TLS handshake: no TLS implementation configured
Is this a planned feature? It seems to be supported upstream in rust-postgres: https://docs.rs/postgres-native-tls/0.5.0/postgres_native_tls/
The lack of SSL support (even with sslmode=require) makes it difficult to use connector-x in enterprise-y environments.
import polars as pl
import pandas as pd
from sqlalchemy import create_engine
import pyarrow
#
print(pl.__version__)
# 0.8.20
print(pd.__version__)
# 1.3.0
pip list | grep connector*
# connectorx 0.2.0
pyarrow.__version__
# '4.0.1'
# pandas first
sql = '''select ORDER_ID from tables '''
engine = create_engine('mysql+pymysql://root:***@*.*.*.*:*')
df = pd.read_sql_query(sql, engine)
df.dtypes
# ORDER_ID int64
# polars second
conn = "mysql://root:***@*.*.*.*:*"
pdf = pl.read_sql(sql, conn)
`
---------------------------------------------------------------------------
PanicException Traceback (most recent call last)
<timed exec> in <module>
~/miniconda3/envs/test/lib/python3.8/site-packages/polars/io.py in read_sql(sql, connection_uri, partition_on, partition_range, partition_num)
556 """
557 if _WITH_CX:
--> 558 tbl = cx.read_sql(
559 conn=connection_uri,
560 query=sql,
~/miniconda3/envs/test/lib/python3.8/site-packages/connectorx/__init__.py in read_sql(conn, query, return_type, protocol, partition_on, partition_range, partition_num)
126 raise ValueError("You need to install pyarrow first")
127
--> 128 result = _read_sql(
129 conn,
130 "arrow",
PanicException: Could not retrieve i64 from Value
`
Use AWS machines.
And add tests
The proposed syntax would be date(%Y-%m-%d)
for now we convert uuid to string object in pandas, make it to uuid object (align with pandas)
Databases is one of the most commonly used data source that data scientists fetch data from. However, the transformation process to load data from database and convert it into dataframes for further analyze is usually heavy-weight. The read_sql function aims to speed up the process through the following features:
read_sql(sql, conn, cache=True, force_download=False, par_column=None, par_min=None, par_max=None, par_num=None, dask=False)postgresql://username:password@host:port/dbname)True)) - Whether or not to cache the result data. If False is set, do not cache the result. If True is set, cache the result to /tmp with connection and sql as name. If a string is set, cache the result to the corresponding pathFalse)) - Whether or not to force download the data from database no matter there is a cache or notNone)) - Name of column used to partition the query (Must be a integer column). If None is set, do not do partitionNone)) - The minimum value to be requested from the partition column col. If None is set, do not do partitionNone)) - The maximum value to be requested from the partition column col. If None is set, do not do partitionNone)) - Number of queries to split. If None is set, do not do partitionPandas/Dask DataFrame
We had given task as below attachment -

We written below query which is not working i.e. it does not fetching desire result -
With New Dept_id as (select x.dpt_code from department x where x.dpt_code not in
(select e.dpt_id from emplyee e join
employee e where e.dep_id=d.dpt_code))
With New Dept_name as (select x.dpt_name from department x )
SELECT employee.emp_id, employee.emp_name, employee.hire_date, employee.jon_name, employee.dept_id, New Dept_id, New Dept_name from employee JOIN department on (employee.dep_id=department.dpt_code) JOIN
Hi,
I tried to use ConnectorX to load dataframe from a postgreSQL database with the following code:
import connectorx as cx
tableName = "semantic_search"
dataFrame = cx.read_sql('postgresql://postgres:postgres@localhost:5432/embeddings_sts_tf', "select * from " + tableName)
but got the following error:
thread '<unnamed>' panicked at 'not implemented: _float8', connectorx/src/sources/postgres/typesystem.rs:78:22
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Traceback (most recent call last):
File "/home/matthieu/Code/Python/postgreSQL_creation.py", line 142, in <module>
dataFrame = cx.read_sql('postgresql://{user}:{pw}@{host}:5432/{db}'.format(host=conn_info["host"], db=conn_info["database"], user=conn_info["user"], pw=conn_info["password"]), "select * from " + tableName)
File "/home/matthieu/anaconda3/envs/sts-transformers-gpu-fresh/lib/python3.8/site-packages/connectorx/__init__.py", line 99, in read_sql
result = _read_sql(
pyo3_runtime.PanicException: not implemented: _float8
Thanks for helping!
so that we can allocate a block of memory instead of the extension array (less cache miss).
i16, f32/i32, interval, numeric, enum, bytes, char, time, timetz, uuid,
and add test
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.