
Re-decentralizing the Web
Solid is a proposed set of standards and tools for building decentralized Web applications based on Linked Data principles.
Read more on solidproject.org.
Github repository for the Solid Authorization Panel
License: MIT License
Re-decentralizing the Web
Solid is a proposed set of standards and tools for building decentralized Web applications based on Linked Data principles.
Read more on solidproject.org.



















































In our recent discussions about giving OP responsibility of issuing capability credentials to clients, based on permissions granted by user on consent screen, we seem to assume user using single OP.
I think we should take into consideration scenarios where user designates multiple OPs to issue capability credentials.
@zenomt suggested that OP could store results of user granting permission on consent screen to solid storage provided by the user. In that case user could use shared storage across multiple OPs and all of them should be able to issue exactly the same capability credentials.
I think it also plays role in case of self-issued OIDC solid/solid-oidc#91 since OP doesn't only care about user's WebID but also permissions they granted to clients.
Paper supporting just in time authorization:
https://www.usenix.org/conference/hotsec12/workshop-program/presentation/felt
I haven't seen yet conversations about revoking authorizations person grants for specific app. I think we should consider full flow which includes both granting, expanding grants as needed, making them more restrictive as needed and revoking all together.
Having app authorizations scattered across lots of different resource servers would require that person has at least some index where all those authorizations get tracked. Otherwise I don't see clear way to manage them so also revoke them.
I'll think of some use cases that include revoking app authorizations.
We've heard multiple use cases for User-Focused Client Constraining Access Control (ie Client Constraining Access Control that is not controlled by the resource controller, but by the app user). I'd like to use this issue to collect them.
wednesdays https://meet.google.com/dci-nqnf-exg 16:00-17:00 CEST
fantastic paper about asking users for permissions: https://www.usenix.org/conference/hotsec12/workshop-program/presentation/felt
This proposal details handling User-Focused Client Constraining Access Control via the ACL. Under this proposal, a fifth access control mode, acl:Clients would be added in addition to the standard ones, acl:Read, acl:Write, acl:Append, and acl:Control.
If a user has acl:Clients access, they are able to change the clients that can access a certain resource. The information on what clients can access the resource are stored in another file (let's say resource.clients.acl).
For example, let's say you wanted to control access to resource.ttl, then you might have the following metadata files:
resource.ttl.acl
<#owner>
a acl:Authorization;
acl:agent <https://jackson.solid.community/profile/card#me>;
acl:accessTo </resource.ttl>;
acl:mode acl:Read, acl:Write, acl:Control, acl:Clients.
In this case, only I can control the clients that can access this resource.
resource.ttl.clients.acl
<#rule>
a acl:ClientAuthorization;
acl:agent <https://coolApp.com#i>;
acl:accessTo </resource.ttl>;
acl:mode acl:Read
In this case, only "CoolApp" can have read access to my resource.
But, let's say I wanted to let everyone decide the apps that can have access. I can just set the acl to say:
resource.ttl.acl
<#public>
a acl:Authorization;
acl:agentClass foaf:Agent;
acl:accessTo </resource.ttl>;
acl:mode acl:Read, acl:Clients.
If I am an app user, I would depend on my Authorization Agent to update the client acls for the app I'm using.
Positives
Possible Drawbacks
acl:ClientAppend and acl:ClientWrite so that you can allow public users to only add to the apps that can access a resource. This would add complexity to the ACL system.As I currently understand it, the launcher app would require me to have a compatible application for every device I use (browser, desktop, android, ios, smart TV etc). Is this true? Is that too much implementation overhead?
From #59
@zenomt: a document with a URI in an approved (according to the user's profile) location is just as good as a credential signed by an approved (according to the user's profile) issuer, but with no extra cryptography required (and it's a lot simpler).
If DPoP mechanism and verifiable credentials proof use the same crypto, relying on VC proofs doesn't seem like additional implementation complexity. I actually consider it simpler than having some magic location in the storage which can't be listed etc. Anyways I think we can consider separately how capabilities presented by the client can be verified
EDIT: reference to @zenomt's proposal: #48
The URI for the App Authorization document MUST be in (at a sub-path of) an acl:appAuthorizations in the user's profile (otherwise the resource server MUST ignore it):
I wanted to flesh out a few thoughts around capabilities/identity-based access control that we've been discussing.
Conceptually, we would be using both capabilities based and identity-based access control.
Identity-based access control is the kind that we're all used to in Solid. A user has an identity and the resource owner can grant access to various identities or identity groups.
Capabilities based access control would be employed to allow a user using an app to control what that app can access across all possible resource servers. This is different from the way we currently control apps which is dictated by the resource owner, not the user using the app. Thus, it is the responsibility of the identity server to keep track of the capabilities a user has granted an app.
It would be fantastic to have as much overlap as possible between the rule system for both the identity-based access control. So, I propose using the .acl system for both.
Under the capabilities based access control model, all acls would have the app's WebID as the agent.
There would also be additions to ACL capabilities that would allow them to function holistically across the Solidverse. Acls would include shape and tag systems that wouldn't constrain it to talking about a specific resource. They could also depend less on the container hierarchy by including a ACL:parent predicate that would allow an ACL file to point to its parent acl that could be located anywhere.
Below is a sequence diagram detailing how capabilities and identity can work together via the Resource Server Enforcement technique (discussed below). This is not the only way it could work, but it serves as an example:

There are three competing ideas on what entity would enforce the capabilities based rules.
Under the Launcher App technique, all requests from a solid-compatible application would need to go through a special launcher app to get to a Pod. Instead of Solid apps authenticating with a server, they authenticate with the launcher app and the launcher app has god access to represent a user's identity throughout the Solidverse.
The app will communicate the kind of data to which it desires access to the launcher app, and when performing a request, the launcher app will check to ensure that the request is only for data to which it has been granted.
Alternatively, instead of ensuring that the request is valid before making it, it could filter out any data from a result to which the app does not have access before returning it to the user.
Pros:
Cons:
Under the resource server enforcement technique, the resource server is responsible for enforcing the capabilities.
When a resource server receives a request it would first authorize a request based on its local identity-based access control rules, then authorize a request based on the capabilities-based access control rules it received in the token. Only if both authorizations pass will it return the requested data.
In order to avoid data leakage by sharing capabilities that might not concern a specific resource server, the identity provider would issue a new token for each resource server with only the rules that apply to it.
Pros:
Cons:
Under the user proxy technique, all requests for a solid app would be routed through the user's identity provider which acts as a proxy to the Solidverse.
Similar to the launcher app technique, each solid app would register its rules with the IDP proxy. The proxy itself has god access to the user's identity and would reject or filter any requests from the app that don't fall in line with its predefined rules.
Pros:
Cons:
Managing app authorizations in many cases will require UI, preferably person can specify preferred app authorization management application as application with special role to manage authorizations for other applications. Applications which want to request authorizations would need a way to discover it and probably redirect user to approve / disapprove / partially approve.
Use case: discussion boards
I think approach proposed in Privilege Request Protocol where each RS provides its own authorizations management UI leads to poor UX and may only stay required in some more restrictive deployments where RS admins needs higher level of control.
As part of building the React SDK application, we recently added a "tic tac toe" game. The idea isn't that Solid now supports TTT, but rather to demonstrate to developers the best way to create a game that sends notifications, creates it's own data files, shares the data files in a collaborative way, and so on.
Because of this, the SDK application requires specific permissions. We create game files, then update the permissions for others to edit. We also create an inbox and change the permissions there so anyone can push notifications into it. For this reason, the app (and likely MANY apps) need Control permissions. However, this is not part of the default set of checkboxes when granting permissions, and additionally many people when using our test servers and deployed application at generator.inrupt.com had already visited previous versions, meaning they'd already granted now out-of-date permissions via the handy popup.
For this reason, we think it would be a nice addition to have the following features:
That last one came up during testing, as some users (I believe Vincent and Michiel) had run the app prior to Control permissions being required, and couldn't receive notifications as Everyone was not set to the proper permission on the inbox. But they had no way of knowing it, so it just failed silently. Ideally, we could show the popup again saying "Hey you tried to do something that requires Control permission but you didn't give this app permissions, change it?"
In the 14 August 2019 meeting Michael Thornburgh seemed to be working with a number of constraints that should be made explicit so that they can be addressed. The ones I remember were:
If any other extra constraints pop up please add them here.
We should find a place to place these to make it explicit.
user uses browser to visit a web app
web app redirects the user to log in to IDP/auth-server and get a bearer token (could be repeated for JIT auth)
IDP/auth-server redirects the user back to the web app
web app uses the bearer token to access some storage server?
questions:
I (Michiel) think about 4., the best way to do that would have to be some way represented inside the bearer token, right?
is a UX problem, and very difficult.
is related to 3. but additionally needs some standardization
User could grant authorization (assuming client has redirect_url)
redirect_url no matter of the deviceAuthorization Server would not need to identify device directly, it just need to keep track of different instances of the same client which run on different devices.
Relates to: Client ID per Client Instance or per Client Software https://tools.ietf.org/html/rfc7591#appendix-A.4
currently it's in the user's public profile doc
CONSTRUCT queries can describe almost any kind of access control/discovery standard conceivable.
CONSTRUCT query is a way of building a sub-graph given a graphgraph portion of the quad should be the resource in which a triple is locatedCONSTRUCT queries but may include other information about other access control standardsCONSTRUCT queries but may include other information about other access control standardsCONSTRUCT queries involved
CONSTRUCT query detailing a set of all triples to which token is allowed to access (represented at A)CONSTRUCT queries in the resource metadata (Represented as R)
CONSTRUCT queriesCONSTRUCT queries of its parentsT).A ∪ R ⊄ T, the server rejects, else it executes the query and returnsThis issue follows up on my comment in #61 (comment) as well as discussion during today's call.
Currently we have to separate Pull requests:
I believe both of them have at least a notion of addressing four distinct aspects. I'm going to elaborate on each of them below:
#61 has TBD App Constraints section. Still based on discussions during the calls I can see that those constraints could rely on shapes, locations and access mode.
#62 proposes combination of tag and *access mode.
I believe this aspects stays independent from all the following aspects and we can consider client constraints aspect independently. I also see no reason to consider tags and shapes as mutually exclusive (either-or). I think they can act as complementary ways for constraining clients.
Discussed constraints eventually get materialized
#61 has it TBD but again based on prior discussions I would expect it to include what we call Capability Credential
#62 discusses it as App Authorization Document
I see them playing the same role in for discussing next three aspects I will just refer to those materialized client constraints as Client Authorization.
#61 again TBD and again based on prior conversations I assume it would suggest OP presenting consent screen to the user during interactive OAuth2 flow. Based on that consent screen it would create Client Authorization, based on it it would issue short lived Capability Credentials.
#62 to my understanding leaves it out of scope suggesting some possible ways of doing it
I see this aspect open for independent consideration and not tightly coupled with other aspects discussed in this issue.
#61 would most likely follow approach from solid/authentication-panel#42 and use DPoP as Verifiable Presentation of Capability Credential. With possibility of passing Capability Credential by reference (Capability URL) which could involve Cryptographic Hyperlinks
#62 has section Associating App Authorizations with Requests suggesting either app_authorizations claim in PoP token or HTTP Link header in request with rel=http://www.w3.org/ns/auth/acl#appAuthorization
Both approaches seem to rely on expiration of token / capability credential to influence caching by RS. Except option of using HTTP Link header.
Once again, we can discuss this aspect independently from all the other aspects.
I've already created distinct issue for that: Client Capabilities: Verifiable Credential Proofs vs. Special discoverable prefix in storage #60
I will not duplicate it here, just mention that I see it as distinct aspect which we can discuss independently as well.
AFAIK currently client receiving HTTP 403 response doesn't have a way to tell the difference between the user missing required access mode or just the app missing required access mode. That difference usually will impact next steps in the interaction:
or
In separate issue I will propose new role of user's proxy which among other issues may also help with addressing this one.
This proposal is to replace the "trusted apps" mechanism, and to augment the acl:origin mechanism in WAC, to allow resource owners to control the access different of their apps have to their different resources, by introducing the notions of
The proposal allows each user to have independent mappings of apps to tag patterns, provided the resource server is configured to enforce the visiting users' app access preferences.
If this proposal resonates with folks, I'll prepare a more formal specification as a PR.
Note: acl:app is similar to acl:origin, only allowing finer-grained app identification (for example, with an OAuth2 redirect_uri), and allowing matching by prefix instead of exact match (so that acl:app "https://app.example/oauth/" matches an app-id of https://app.example/oauth/code). Other new terms in acl: used here are assumed for now to be obvious from context.
The resource owner/controller can specify one or more tag patterns in an acl:Authorization instead of an acl:origin or acl:app. Tag patterns can include wildcards (* and ? characters) and use traditional shell globbing rules to match. Example ACL:
# ACL for a container of chat messages, allowing
# read for all authenticated users who are using
# an app with a tag pattern that matches "Chat.Read" or "Photos.*".
@prefix acl: <http://www.w3.org/ns/auth/acl#> .
[]
a acl:Authorization;
acl:mode acl:Read;
acl:agentClass acl:AuthenticatedAgent;
acl:accessTo <./>;
# apps the user has tagged "Chat.Read" or "Chat.*" or "*.Read" or
# "*" will be allowed.
acl:tag "Chat.Read";
# alternatively, apps the user has tagged "Photos.Anything" or "Photos.*"
# or "*" will also be allowed.
acl:tag "Photos.*";
acl:default <./> .
If any of the tag patterns that the user has assigned to the app that she's using matches any of the tag patterns in the acl:Authorization, then it's as if there was an acl:app match. Note that there is no global vocabulary of tags/scopes; tags are arbitrary, and what tags to assign to authorizations is entirely at the discretion of a resource owner. Tags SHOULD have the same meaning at least across resources in the same origin and realm.
The user associates tag patterns for the combination of an app, resource server origin, and security realm (the name of the protection space; that is, the realm authentication parameter of the WWW-Authenticate HTTP response header) in an App Authorization document. Tag patterns here can also include wildcards (* and ?) and use the same globbing as tags in ACLs. Here is an example App Authorization document assigning tag patterns Books.Read and Chat.* to app https://app.example/oauth/code when accessing server https://mike.example's realm /auth/:
# this is world-readable but has an unguessable URI like
# <https://mike.example/wac/app-auth/b6d88441302c07700743b8d793ae2a8a.ttl#it>
# in a non-listable container.
@prefix acl: <http://www.w3.org/ns/auth/acl#> .
<#it>
a acl:AppAuthorization;
acl:resourceServer [
acl:origin <https://mike.example>;
acl:realm "/auth/"
];
acl:app "https://app.example/oauth/code";
acl:tag "Books.Read", "Chat.*" .
The URI for the App Authorization document MUST be in (at a sub-path of) an acl:appAuthorizations in the user's profile (otherwise the resource server MUST ignore it):
# this is the user's profile document
<#me> acl:appAuthorizations </wac/app-auth/> .
This container/directory SHOULD be configured to allow read of App Authorization documents by anyone and any origin; however, to protect the user's privacy (specifically, what apps the user uses and what resource servers the user accesses with those apps) including from other apps the user uses, listing the container's contents should be restricted to only the user, and then to only the user's trusted authorization management app.
The method by which an app discovers its App Authorization URIs is to be determined. I envision that each app will have an App Authorizations index file, generated and maintained by the user's trusted authorization management app, stored in a non-listable container, with a URI derived from the app's identifier, and readable only by the user and only when using that app, mapping between App Authorization URIs and resource servers, for example:
# App Authorizations index file for app "https://app.example/oauth/code".
@prefix acl: <http://www.w3.org/ns/auth/acl#> .
</wac/app-auth/b6d88441302c07700743b8d793ae2a8a.ttl#it>
acl:resourceServer [ acl:origin <https://mike.example>; acl:realm "/auth/" ] .
</wac/app-auth/4f20846c1179e604048a589583dd6f9c.ttl#it>
acl:resourceServer [ acl:origin <https://other.example>; acl:realm "Other Server" ] .
The non-listable container for App Authorization index files SHOULD return identical HTTP 403 responses both for accesses to non-existent index files and for accesses to existing index files which are not for the user∙app requesting it, so that an adversary (other user or other app) can't probe for index files to discover what apps the user might use.
The method by which the tag vocabulary being used by a server is communicated to the user or to the user's trusted authorization management app is to be determined. I envision that a method could integrate with the HTTP Privilege Request Protocol.
To associate tags with a Bearer access token, the app sets the app_authorizations key in the proof-token/POPToken to be the URI of the App Authorization appropriate for this server∙realm. The server verifies the App Authorization URI as being in one of the user's acl:appAuthorizations containers, and (re)loads/revalidates this document at least as often as the user's profile document. The server applies any tag patterns in this document that are for this server∙realm and the app being used, to match against tags in acl:Authorizations for which the user would otherwise be permitted.
Suppose Alice has a resource on her pod, and gives Bob read access to it. Bob wants to use a web app to view the resource. This is currently allowed if:
acl:trustedApp in her profileacl:control access to the resource, meaning the acl:trustedApps in his profile also get whitelisted (but this option doesn't really count, since the premise was that Bob was only getting read access)This means that Alice can only whitelist specific app origins for Bob to use, and she does not have a way to give Bob read access to the resource without making any restrictions on web app origin.
One possible way to service this use case would be to allow ACL rules to have acl:origin "*", meaning that Bob is free to choose which web app he prefers, even if it's one that Alice has never heard of yet.
Another option might be to also check Bob's profile for trusted apps when a web app tries to read the resource on Bob's behalf.
Without this feature, sharing a resource could feel like how sharing an office document worked in the 90's: you could only view the documents you receive if you used the same app as the sender, if you used a different app, you had to email back and forth asking them to export/convert the document.
if someone uses a known malicious app, should the storage server warn them? should the IDP/auth server?
This issue is to highlight aspects where interaction between issues from the Authorization Panel and Authentication Panel come together, and where looking at them together makes issues visible that would not be apparent separately.
A solid client differs from normal web2.0 app in that it is likely to be fetching data from all over the web by following links, in order to build a display for the user. To build a single display the client may therefore need to authenticate to a number of different resources located potentially on many different servers.
If we look at just one authentication event:
Because of privacy and efficiency concerns it would not do to have the client try out every single credential/identity it can. What it should be able to do is on a 401, look at the access control rules and the HTTP header telling it which methods of authentication are allowed, and work out what credentials it may need before authenticating, ordering them according some metric such as privacy. Even if the client has none of the needed credentials it could at least work out from the wACL what it would need to do to be able to interact with the resource -- perhaps become member of a club, or a friend of someone, ... It may even want to ask for a wACL change, say if the client knows it should have access.
This interaction between client and server indicates that there are very good reasons and use cases for many wACLs to be public. (note: it is not an argument to require them all to be public). Since there are also reasons for some ACLs to be protected, there must be a way to separate wACLs into public and protected parts, by say including one ACLs (through a link) into another.
It should be possible for the user of the app then to set policies about when to automatically authenticate, when to warn the user, or even to ask the user for information.
We're discussing a lot about the technical management of access control, but there's much more to it in the social space. I'm fortunate enough to have kids who trust me enough to ask me whether they can install a certain app on their mobiles and tablets. Although I'm not revealing that to them, the usual answer is "I have no idea". I have very little to go on in terms of deciding whether an app is trustworthy. It is just a bunch of heuristics, and funnily, the kids develop their own heuristics too.
I think this highlights a much bigger problem than the technical ones, we have to enable people to make much more informed decisions about access control on the open Web for Solid to be useful beyond tight, social groups. If not, Solid is likely to also just accommodate a small number of large players, or be a place where social engineering is rampant to extract private information.
In order for an App to be able to decide what form of credential it needs to present in order to authenticate to a resource it needs to be able to read the wACL rules. Currently a user may have a number of WebIDs or OpenIds to authenticate with. In the future this may extend to any number of Verifiable Credentials as developed by the Verifiable Claims WG at W3C. Choosing which credential to present is only possible in a distributed environment if the client can see which claims would succeed.
The client may want to know
Otherwise the only strategy is that the client try out each of its Credentials randomly, thereby giving away all information it has and potentially linking all those credentials together.
For those concerned about leakage of information of wACLs:
I think whatever flows we come up with for granting / changing / revoking authorizations for applications we need clear way to identify those applications. We most likely will represent those authorizations using RDF so we will need to have IRI denoting an application.
This issue may overlap to some degree with authentication panel, for example if we want to require that OP includes application redirect_uri in the token and it gets used to identify the application.
We may also need to address to what degree we can rely on Origin header whenever available.
As far as I understand the spec, we can allow agents access by WebID or grouping, but there is no explicit deny. I think that may be a useful feature. If I want to block a certain person from a resource by WebID, while it is publicly readable, that should be possible, and that seems to be the only use case for a deny. If I'm not using public access, then I can always create a group without that person's WebID (albeit that could end up polluting the list of groups). An explicit deny could work along with group access, as in "Colleagues" except John, where I want John to not see this particular resource but I don't want to remove him from the group either.
Having unknown number of Resource Server to honor user defined access rules for all the applications they use can introduce various challenges. Among them all the Resource Servers need a way to:
Moving all that responsibility to a single User's Proxy, which the user can choose, may simplify all the above. When application interacts with all the Resource Servers via user's proxy, all those Resource Servers only need to identify the user (not the application) and check if the user has required access mode to requested resource. User's proxy would have responsibility of applying app specific authorizations defined by the user. This would also partially address #34 since Resource Server would only respond with HTTP 403 to User's Proxy if user doesn't have required access mode. User's Proxy, which has full access to all the app specific authorizations, would detect missing app access mode without even making request to the Resource Server. User's Proxy would most likely have access to all the app authorizations managed with specialized app discussed in #29
Capturing something from the chat to have better track on this conversation: https://gitter.im/solid/app-authorization-panel?at=5d79b986b9abfa4bd3923adc
@zenomt: the big difference i think with OIDC/POP is that the app public key (the "confirmation key") is bound up with the id_token and can only be used as long as the id_token is valid. Best Current Practice is for the validity period of id_tokens and access tokens to be on the short side (minutes-to-hours) rather than the days-to-weeks as currently issued by NSS. the user's (trusted) OpenID Provider serves as the periodic uncacheable validator of whatever public key is being used to demonstrate identity. the default thing that happens if i close my browser or turn off my terminal is that anyone who could be acting as me+app will eventually (and soon) not be able to do that anymore, whereas positive action would need to be taken to revoke any currently-valid public keys in (or linked to) my profile.
i have a shortcut in my browser's bookmark bar to immediately log me out of all sessions everywhere (across all browsers and devices) in my OpenID Provider with a single click, just in case i'm worried about any sessions running on a forgotten terminal somewhere. and i can view all current sessions and issued id_tokens in my OP, including to what IP addresses and redirect_uris they were issued.
my OP doesn't issue refresh tokens, and i'm not planning on adding that functionality because there's never a situation where i want something to be "me" when i'm not there.
if an automatic agent wants to do stuff for me, it can have its own webid, and then the problem just becomes one of permission.
Approach above sounds to me like focusing only on user attended use cases. Practically all remote clients running somewhere in the cloud will require unattended access. In addition Service Workers and proposed Background Sync may result in local clients running on device in web browser also using unattended access.
I believe there's already been a proposal to move trusted apps from the profile to the individual .acl files. Though, I think "trusted apps" are too use-case specific.
It should be possible for any entity (app, human, or bot) to share the same kind of control flow.
A .acl should include an ontology to represent the following cases
#owner triple in the example below)#app triple in the example below)This case will allow for flexible application access control. For example, if I wanted an app to have read access to my private folder, the .acl would look like this:
# ACL resource for the private folder
@prefix acl: <http://www.w3.org/ns/auth/acl#>.
# The owner has all permissions
<#owner>
a acl:Authorization;
acl:agent <https://jackson.localhost:8443/profile/card#me>;
acl:accessTo <./>;
acl:defaultForNew <./>;
acl:mode acl:Read, acl:Write, acl:Control.
<#app>
a acl:Authorization;
acl:combinedAgent [
acl:agent <https://jackson.localhost:8443/profile/card#me>;
acl:agent <https://coolapp.example/profile#me>
];
acl:accessTo <./>;
acl:defaultForNew <./>;
acl:mode acl:Read, acl:Write.
Notice the acl:combinedAgent predicate. This refers to a list of agents (it could also be a list of lists of agents). This authorization would only qualify if a request was made with a token that represents both jackson.localhost:8443/profile/card#me (my webid) AND coolapp.example/profile#me (the app's webID)
The main benefit of this over PoP tokens is it is not simply constrained to apps and can be applied to anything with a WebID
It should be noted that this would also require a new kind of token that can represent consent from any number of parties.
I'd like to submit my long-standing patch to WAC for your consideration:
solid/web-access-control-spec#37
Since I think cachability is one of the key success criteria for caching, I believe granular metadata to allow this to happen is really important. That is what this patch seeks to enable.
A requirement for Solid apps is that each App (even from a remote origin) needs to make authenticated requests for a user to resources on the Web. The problem is that if any such App must authenticate to a resource by signing headers in the case of HTTP-Sig or passing signed tokens with OAuth, those private keys or tokens can be shared by the App with other origins, which makes the authenticated user quite vague: is it the user, the App, the Origin or a friend of the Origin that is authenticating (see discussion)?
The proposal here is to allow a user to select an Authentication App whose JS is placed on an Origin it fully trusts, to deal with Apps, generate keys for them, and provide an authentication service in browser for those apps using Window.postMessage or something similar (see Information Security Stack Exchange Question: Can JavaScript from Different Origins Communicate Securely?). Given that the Auth App is also the one used to launch those apps, it will know which apps it is signing auth requests for, allowing us to solve the problem of Identifiers for Applications too.
The user can link from his WebID Profile to the trusted Authentication App like this:
<#me> :authenticationApp </safe/authentication> . With the potentially protected </safe/authentication> file
<#> a SecureLauncherApp;
:launchSrc <AppLaunchner.html>;
:appCollection <myApps/> .And the Authentication App can keep track of all the Apps that the user likes to use, each App
keeping info about the app, browser environment, date used, public keys, ... with something like the following, any restrictions about what it is able to do,...
</app/calendar#FirefoxOnLinux> a :App;
:appLaunch <https://office.app/2019/Calendar.html>;
:browser "...";
:logo </app/calendar/cal.jpg>;
:accessLog </secure/calendar/logs/>;
cert:key [ ... ] . The process here is the following. Alice is behind the computer, and it is hers.
We then have the following exchange (numbers fit illustration below)

This could fulfill many roles, of which:
There may be better methods than Window.postMessage to do this. Ideally all authenticated requests could go through a browser based HTTP proxy (perhaps using Service Workers?) controlled by the App launcher. This would further enable
Can this be done with current browser technology?
Note: This extends @elf-pavlik's notion of an App Authorization manager, by specifying a method for the App to actually do the authentication for other apps (using either postMessage) - and proposing to find potentially better ones (eg. ServiceWorkers?)
The Trusted Apps project would deliver a recommendation to handle app management on both the authentication and .acl level.
I was made aware of a bug with Google Drive by Jessica Lord on Twitter, namely that people cannot remove their own access to a folder. It doesn't solve the underlying issue (her abusive ex is actively putting photos in the folder), but she's not even able to remove her own access to the folder.
As I understand the spec today, that is also going to be a problem with WAC. I think this is something we should solve, and hope that by raising this issue we can find some good solutions.
It's not too uncommon that apps or developers corrupt ACLs. To mitigate this it would be nice if Pod owners can reset or roll back ACLs to an uncorrupted state.
I know this feature requires multiple components, such as the server being able to store changes to ACLs, but I wanted to highlight the problem that if an ACL is corrupted, how do the server know who can reset or rollback the ACL?
A strategy might be to look at the parent ACL and allow WebIDs who have control access there to trigger some sort of reset or rollback. This won't work for the root ACL though.
Another strategy might to enforce that ACLs never get corrupted, but I suspect this can be difficult to enforce, and this validation might introduce other problems.
I might be going about this the wrong way, but thought it prudent to create an issue on this to hear what the panels think about this.
This issue might also be related to the issues "Should it be possible to find owner of storage via resources?" and "Discoverability of root and controllers of Pods - some thoughts".
currently privilege-request-protocol.md uses x-permission-request as a placeholder for the link relation type for the privilege request endpoint URI.
let's think of a good link relation type. i believe this should be an Extention Relation Type URI rather than a simple registered relation name, so that coordination with the IANA won't be necessary (also they require a stable specification document to reference). perhaps something in @prefix solid: <http://www.w3.org/ns/solid/terms#>?
there's already solid:loginEndpoint and solid:logoutEndpoint. perhaps
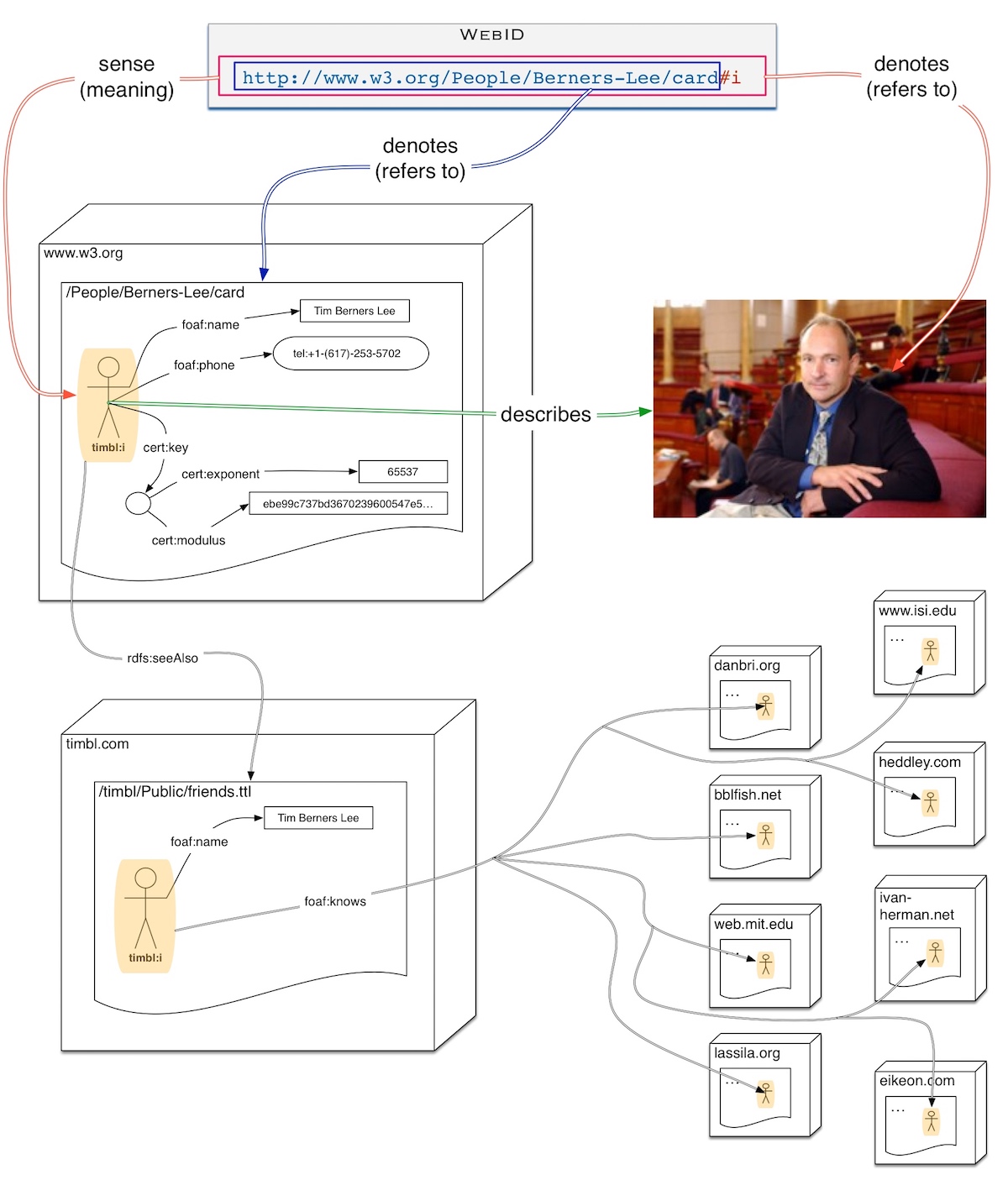
http://www.w3.org/ns/solid/terms#privilegeRequestEndpointhttp://www.w3.org/ns/solid/terms#permissionRequestEndpointSolid apps are build to follow links from one server to another to fetch data. As an example see the wiki page showing what connections would be needed to write a friend of a friend address book starting from Tim Berners-Lee's WebID, and illustrated below:
There is thus a danger that in a short time the user be bombarded with 100s of popups asking her what identity she wishes to use on each web site - potentially even on each resource requested. This would quickly lead to apps being unusable, or to popup fatigue, training the user to always click yes, and so for those popups to become essentially meaningless. (This is a criticism of GDPR induced popups).
The user should be able to choose and edit reasonable policies for when to be asked for an authentication decision, and when to allow the Authentication Agent to make that decision on its behalf. This could be very useful initially for a Launcher App, and indeed longer term for browsers themselves.
Are there ontologies that we can already use to do this?
Given the launcher app must be on the same devices as the application, how would it be offload an identity to a bot on a server? I would like to be able to get some kind of constrained credential that could be used by some code on a device I don't trust.
It could be based on http://openscience.adaptcentre.ie/ontologies/GConsent/docs/ontology
Of course we'd like a complete formalization of the current WebACL specification (https://github.com/solid/web-access-control-spec), but very specifically we need practical answers for the following questions:
acl:default, and whether permissions are cumulative or not.acl:origin is even effective at addressing the security concerns that it is designed to address (and how it is actually supposed to be implemented).If these areas are not sufficiently important for others on this panel, then we'll just suggest answers ourselves (to have them at least recorded), and then implement our system accordingly.
This is documenting an issue we discussed during today's panel meeting that I think should be highlighted.
Currently, access control is handled by the resource server by the acls. The trusted apps system currently uses the WebID to store apps access control. This is a poor implementation, but philosophically it could work.
The major insight is that "trusted apps" essentially is associating access control with the identity rather than the resource. For this use case, it makes sense to associate access control with an identity because it is essentially the user saying that an app that has been given permission to represent the identity is limited (it has nothing to do with the resource)
Access control could either exist within a token generated by the identity provider or could be in a special RDF document created by the identity provider.
I would also suggest that the identity provider should issue access control rules that look very similar to acls because we do not want to have multiple access control languages.
How do you limit the apps that others use to access your data?
How does this affect user experience?
typical use case: the Pod's owner cares about what apps can access various locations in their Pod as the owner, and doesn't care about apps used by visitors (especially because visitors can lie).
any indication by an IdP (example: OpenID Provider) or in the user's profile about trust or desired permission limits would be at the discretion of the Resource Server (RS) to honor anyway. an IdP doesn't have standing to govern permissions in an unassociated RS. an enumeration of trusted applications and permissions in the user's profile would need to be publicly accessible in order to be used at an unassociated RS (unacceptable for privacy and security), and the current acl:trustedApp scheme doesn't solve the "access for just my chats" use case.
i propose the following:
403 Forbidden response
link rel= or new header)302 redirect back to appalternatively, user can log into RS UI in the future to review and approve pending permission requests.
the notion of "permission" and the operation of the UI is entirely up to the RS. the functionality the user expects is that, if the necessary access is granted, the original request will not be 403 Forbidden if repeated.
for WAC, adding an app/origin analog of acl:agentGroup (such as acl:appGroup or acl:originGroup) may be helpful. the RS can have UI and/or APIs for managing internal app groups so they can be hidden from outside access (to preserve privacy).
app groups could allow the owner to define arbitrary roles/scopes for apps, such as "chat", "photos", "music", etc., as coarse or as fine as desired.
for app groups, the RS can use heuristics or configuration to determine what groups/roles/scopes might be needed to satisfy the original request and likely related requests. those could be highlighted among all possible scopes, or only those could be presented (using a new challenge if additional scopes are required later by that app).
Creating this issue to document and align on the purpose of this panel, per the discussion in the panel meeting on June 10th. Here's a very cursory approach at a stated purpose to iterate on:
The purpose of this panel is to produce candidate proposals to the solid ecosystem of specifications that satisfy use cases and requirements related to authorizing access to data in a Solid pod.
I'm keeping coming back to the ODRL Information Model: https://www.w3.org/TR/odrl-model/ .
I'm logging this so that we can evaluate ODRL's fit for Solid. Or something pertaining to policies.
This is an important piece of the ecosystem puzzle as we go forward.
It'd be ideal to coordinate with the Data Interoperability Panel: https://github.com/solid/data-interoperability-panel/
See also:
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.