tim-learn / shot Goto Github PK
View Code? Open in Web Editor NEWcode released for our ICML 2020 paper "Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation"
License: MIT License
code released for our ICML 2020 paper "Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation"
License: MIT License














































































































I don't find caltech_list.txt.
Would you mind share this file?
Meanwhile, your link of Office-Caltech is different from https://github.com/jindongwang/transferlearning/blob/master/data/dataset.md#office+caltech. Is there something wrong?
Hi ,thanks for your excellent work.
Have you ever try to work on the domainNet dataset ? SInce I can't get satisfied result by changing the dataset only.
Could you elaborate more carefully on how to modify the .txt file in the /object/data directory?
Where are the '.txt' files? (Maybe the image_list.txt in each folder?) Like the office dataset, there is no 'amazon.txt' in the 'domain_adaptation_images.tar.gz'.
And how to do this?
This is a great job, looking forward to your reply!
Hi :),
I am studying your UDA algorithm and I am trying to adapt it to my specific problem.
My question is the following:
Initially i've implemented it using the KL divergence from the second equation of your paper and I wouldn't converge to your results.
Best Regards,
Antonios Lykourinas
Hi, thanks for the great work!
I run your code on Office-Home dataset for task Art->Clipart, which should produce an accuracy of 56%+ shown in the paper. But I get the following results, which is basically ~52%. I just run your demo code and didn't change anything. Could you please tell me where I'm wrong? Thanks.

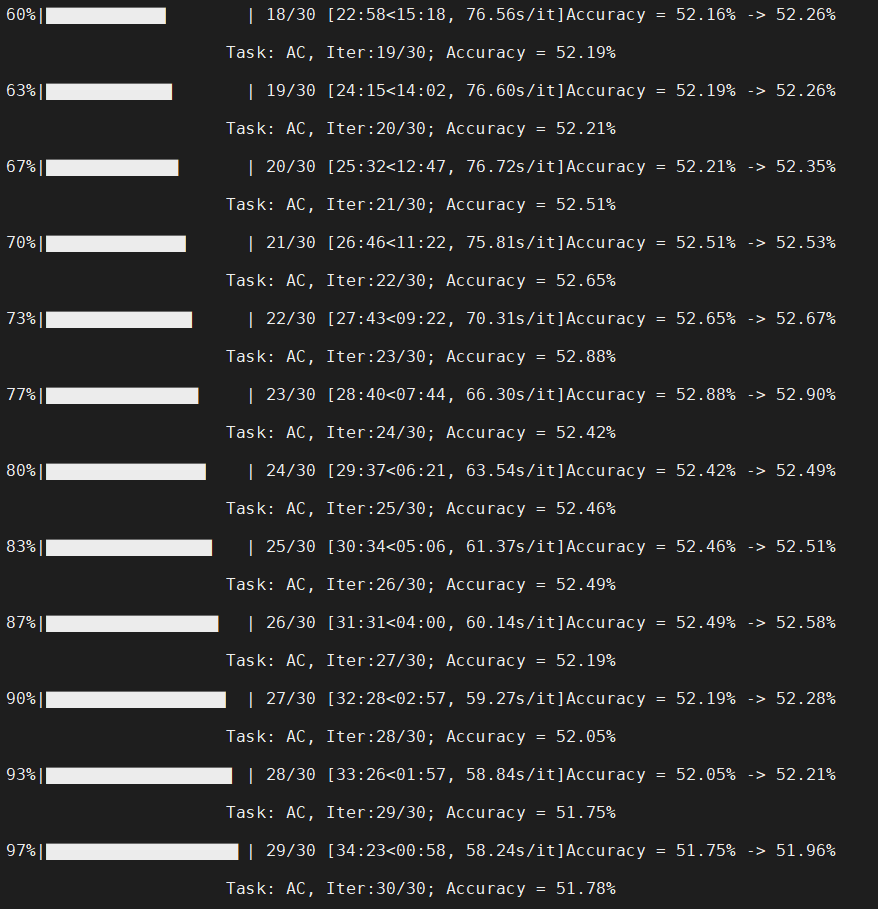
Have you uploaded the data folder and .txt under the ./object/data folder?
Hi,
Thank you for maintaining the repo this nicely. However, would it be possible to provide some pretrained checkpoints for 'VISDA-C' or 'Office-31' datasets?
Thanks and Best Regards,
Mirza.
In the original paper of the office-31 dataset, the author used 8 labels per category for webcam/dslr and 20 for amazon to train the model in the source and target domain. And others used 3 labels per category to test the model and get the accuracy.
However, there is a "0.9/0.1 train/test" split of the office-31 dataset in your code. So I wonder if your settings are different from the original paper?
I want to cite your paper in our work. So I am looking forward to your reply~

I'm sorry to bother you!
In the process of generating pseudo tags, the target domain has no real tags, but in the process of code implementation, why are there labels = data [1]? What does this labels stand for?

If these labels are used, then where are the pseudo label?
Hi, here I am reproducing the ODA task on Office-Home dataset, but I cannot achieve the results in the paper, I follow the command in the readme.md, and my result in closed-set are good. I even get less results on source retrain result(e.g on Cl->Rr 42.3(my) vs 49.2(paper)), but I have follow your environment requirements in the readme.md and still not work well. I run it on V110 and 2080Ti but both cannot achieve satisfied results, could you provide the environment list so I can check which part I made a mistake?
Best
NameError: name 'iter_test' is not defined.
Hello, I am confused in regards to the generation of .txt files for training on all manually downloaded datasets.
Based on what I understood from this thread: #2
I wrote a script to generate text files for the "office" and "office-home" dataset, the folders for which are contained in my Master directory. So, for example, a sample file for my office-home dataset would be placed in "Shot-Master/object/data/office-home/Art/Alarm_Clock/00001.jpg".
My generated Art_List file resides in "Shot-Master/object/data/office-home", and a sample line in it reads: "----Path from root to shot-master----/object/data/office-home/Art/Alarm_Clock/00001.jpg 0"
The code for point 2, when run, throws the error:
The syntax of the command is incorrect.
Traceback (most recent call last):
File "image_source.py", line 371, in
os.mkdir(args.output_dir_src)
FileNotFoundError: [WinError 3] The system cannot find the path specified: 'ckps/source/uda\office\A'
In short, I am confused regarding the placement of the datasets and text file generations. Please advise.
As I reproduced the results for PDA on Office-Home, I also tried to unlock the gradient for the source classifier.
Interestingly, there doesn't seems to be much acc difference after letting the classifier being able to update its weights. The acc difference is within 0.5% and sometimes close to zero.
Therefore, I am assuming locking the classifier is mainly because the problem setup demands this and not because there is a theory states doing so could be more accurate? I did read the paper's 3.2 which mentions locking gradients for ht, but maybe I didn't quite get it.
If I indeed missed something in the paper, sorry for that.
Hi Tim,
Firstly thanks for sharing the code to the community. I encountered some questions in my code reading process.
In your "/object/image_target.py" file:
Thanks!
Eric
Hi, I can't understand why the feature embedding is added one dimension whose value is 1 when obtaining the pseudo label.
Would you please explain it?
Thanks
Hi,
I am reaching out to you as I have been attempting to reproduce the SHOT(2020) Office-Home results presented in Table 4 on your github page (https://github.com/tim-learn/SHOT/blob/master/results.md)
I understand that reproducing classification results in domain adaptation is challenging due to various factors such as differences in GPU settings and environments. Despite my efforts, I have not been able to achieve accuracy results that are in the reasonable range with yours.
I have inputted the --cls_par 0.3 and have not changed any of your code.
The results I am getting are shown below.

The log for Ar -> Cl is provided below.

What am I doing wrong?
Thanks in advance.
Thank you very much for your work. What I want to ask is that I used a certain enhancement method to increase the "Source only" to 62. I think this enhances the generalization ability of the model to a certain extent. But when using the target domain for migration, the final effect is actually lower than the 71.8 in the paper?
Hi, thanks for your excellent work!
I have problems during the reproduction. From your paper, the accuracy of Ar->Cl is 57.1 in office-home, however, I only got 7% which is extremely low. This situation also exists in other domain transfer experiment, such as Ar->Pr, Ar->Re, which I only get 26%, 27%,respectively. It also exists in the office31 dataset.
My command is typed as your github says, python image_target.py --cls_par 0.3 --da uda --output_src ckps/source/ --output ckps/target/ --gpu_id 0 --dset office --s 0
I didn't change any code and commands. I am confused about this thing for a long time , looking forward to your reply! Thanks very very much. Here are Ar->Cl, Ar->Re snapshot respectively.


I also didn't change the command to train source model. And the accuracy of model in Ar is still high, which is shown below:

I am confused about this thing for a long time , looking forward to your reply! Thanks very very much.
Line 278 in 9c02a95
API是torch.transpose(input, dim0, dim1) → Tensor,需要传入两个维度作为参数。
但是您的代码中写的是aff.transpose(),是否不太合理?
同样是这行代码,dot()函数要求参与运算的两个变量都是一维的变量。可以见pytorch文档:
https://pytorch.org/docs/stable/generated/torch.dot.html#torch.dot
但是这里all_fea和aff因为有batch size的存在至少也是两个维度,感觉也不太合理。作者您怎么看待?
我在看论文中Self-supervised Pseudo-labeling的对应部分,请问是def obtain_label(loader, netF, netB, netC, args)这个函数吗?

When I rerun digital,
python uda_digit.py --dset u2m --gpu_id 1 --cls_par 0.1 --output ckps_digits;
The error happes as follow:
Traceback (most recent call last):
File "uda_digit.py", line 180, in train_source
inputs_source, labels_source = iter_source.next()
UnboundLocalError: local variable 'iter_source' referenced before assignment
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "uda_digit.py", line 453, in
train_source(args)
File "uda_digit.py", line 183, in train_source
inputs_source, labels_source = iter_source.next()
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 345, in next
data = self._next_data()
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 856, in _next_data
return self._process_data(data)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 881, in _process_data
data.reraise()
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/_utils.py", line 394, in reraise
raise self.exc_type(msg)
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "uda_digit.py", line 180, in train_source
inputs_source, labels_source = iter_source.next()
UnboundLocalError: local variable 'iter_source' referenced before assignment
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/worker.py", line 178, in _worker_loop
data = fetcher.fetch(index)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torch/utils/data/_utils/fetch.py", line 44, in
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/data2/gyang/DA-transformer-other/digit/data_load/usps.py", line 71, in getitem
img = self.transform(img)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torchvision/transforms/transforms.py", line 70, in call
img = t(img)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torchvision/transforms/transforms.py", line 1003, in call
return F.rotate(img, angle, self.resample, self.expand, self.center, self.fill)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/torchvision/transforms/functional.py", line 729, in rotate
return img.rotate(angle, resample, expand, center, fillcolor=fill)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/PIL/Image.py", line 2023, in rotate
return self.transform((w, h), AFFINE, matrix, resample, fillcolor=fillcolor)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/PIL/Image.py", line 2337, in transform
im = new(self.mode, size, fillcolor)
File "/home/gyang/anaconda3/envs/pytorch/lib/python3.6/site-packages/PIL/Image.py", line 2544, in new
return im._new(core.fill(mode, size, color))
TypeError: function takes exactly 1 argument (3 given)
Hi, thank you for sharing the wonderful work. I have a question regarding the main paper:
In table 3, 5, 7, and 8, what's the difference between "ResNet50/101" (the first line in all tables) and "Source model only"? I'm guessing "ResNet" means using the original ResNet model (replace the last fc, no "fc+bn bottleneck" proposed in the paper) trained on source and evaluate on target without any adaptation. Is that correct?
Also in table 2, what does "Source only" in the first line (with Hoffman's method) mean?
Thank you!
thanks for your code and paper, the proposed new problem is interesting. However, there are some inconsistencies between code and paper.
according to the paper, the total loss consists of three parts, a entropy loss Lent, a diversity loss Ldiv and a minus cross entropy loss. In the code, classifier_loss corresponds to minus cross entropy loss, entropy_loss corresponds to Lent, gentropy_loss corresponds to Ldiv
As paper said, cross entropy loss is negative and Ldiv is positive, but cross entropy loss is positive and Ldiv is negative in code.
please correct me if there is something wrong.
Hello!
Thanks for the great codebase -- I've found it very useful, and a great resource to try and reproduce the results in your interesting paper!
We're trying to reproduce some of the results, and noticed that you stack two FC/linear layers without a non-linearity in between them. I believe that this is only for the object datasets, and happens between the bottleneck and classifier layers. Is there a reason you have done this? It seems quite unusual since, without a nonlinearity in between, the two layers can be collapsed into a single equivalent layer.
Thanks for your help!
Cian
has the shot++ code been published? Where can I find it? I can just see the read and license in the SHOT plus github.
Hi all,
thank you very much for sharing the code of your very interesting work!
I'm actually facing an issue in relating what reported in your papers in equation (3)-ICLR and equation (3)-TPAMI. My doubt is: in your equation you report that L_im is obtained with the weighted sum of the entropy loss and divergence loss:

Instead, what you do in your code here https://github.com/tim-learn/SHOT/blob/7cebb390194215823b435b0723c7b342ae62b42b/object/image_target.py#L205 is to subtract the CE loss to the entropy loss.
I'll try to be clearer.Following your paper I was expecting total_loss = entropy_loss + beta * gentropy_loss while following what you do here https://github.com/tim-learn/SHOT/blob/7cebb390194215823b435b0723c7b342ae62b42b/object/image_target.py#L205 the resulting equation will be total_loss = entropy_loss - beta * gentropy_loss resulting in a minimization of the entropy while maximising the divergence component. Is there anything I'm misunderstanding?
Thank you in advance for any help!
Hi, thank you for sharing your work.
I tried to reproduce Office-31 source only score using your work, but it failed to get same result as reported in table3 of result.md
Cloned your work and run (referenced run.sh)
| SEED | A - D | A - W | D - A | D - W | W - A | W - D | AVG. |
|---|---|---|---|---|---|---|---|
| 2019 | 79.72 | 74.84 | 57.97 | 94.59 | 62.83 | 98.59 | |
| 2020 | 79.72 | 72.70 | 59.03 | 95.22 | 61.87 | 97.99 | |
| 2021 | 80.52 | 76.98 | 59.46 | 93.58 | 63.72 | 98.80 | |
| Avg. | 79.99 | 74.84 | 58.82 | 94.46 | 62.81 | 98.49 | 78.24 |
Table 3 of result.md
| SEED | A - D | A - W | D - A | D - W | W - A | W - D | AVG. |
|---|---|---|---|---|---|---|---|
| 2019 | 79.9 | 77.5 | 58.9 | 95.0 | 64.6 | 98.4 | |
| 2020 | 81.5 | 75.8 | 61.6 | 96.0 | 63.3 | 99.0 | |
| 2021 | 80.9 | 77.5 | 60.2 | 94.8 | 62.9 | 98.8 | |
| Avg. | 80.8 | 76.9 | 60.3 | 95.3 | 63.6 | 98.7 | 79.3 |
Here is what I did
Clone repo
Download office-31 and place it under object/data folder and create amazon_list.txt, dslr_list.txt, webcam_list.txt in the same folder using below code.
import glob
import os
import random
def load_data_list(root):
class_list = glob.glob(os.path.join(root, '*'))
data_list = []
for label, class_path in enumerate(class_list):
data_list.extend([f'{path} {label}\n' for path in glob.glob(os.path.join(class_path, '*'))])
random.shuffle(data_list)
return data_list
def save_to_txt(save_path, data_list):
with open(save_path, 'wt') as f:
f.writelines(data_list)
for dataset in ['amazon', 'dslr', 'webcam']:
data_list = load_data_list(f'data/office/{dataset}/images')
print(dataset, len(data_list))
save_to_txt(f'data/office/{dataset}_list.txt', data_list)Train model using below command. I tried seed as follow: 2019, 2020, 2021.
python3 image_source.py --trte val --da uda --output ckps/source/ --gpu_id 0 --dset office --max_epoch 100 --s 0If anyone can spot any problems, I will be really appreciate it.

Hi,
Thanks for making the code public.
I tried to reproduce the numbers for open set setting of OfficeHome and the numbers I get are way less than what you report in the paper. I have already tried several torch and torchvision environments but every environment is giving the lower numbers.
Is it possible for you to upload the model checkpoints for open set source only? Then I hope to reproduce the numbers for SHOT-IM and SHOT with your source only checkpoints (source_F.pt, source_B.pt and source_C.pt). It will indeed be very helpful.
Thanks in advance.
Hello, after read the previous answers of this question, I am still confused about this operation. Why should we explicitly add 1 as bias? As far as I know, the linear transformation with bias on will not change the size of our feature, so I feel it is unnecessary to add a bias manually.
Would you please further explain this for me?
Thx
Hi, thanks for your awesome work! I just clone this repo, and follow the recommended lines:
python image_source.py --trte val --output ckps/source/ --da uda --gpu_id 0 --dset VISDA-C --net resnet101 --lr 1e-3 --max_epoch 10 --s 0
python image_target.py --cls_par 0.3 --da uda --dset VISDA-C --gpu_id 0 --s 0 --output_src ckps/source/ --output ckps/target/ --net resnet101 --lr 1e-3
After trained on source domain, I get the good source-model acc (47.62%) better than paper (acc 46.6%)

But I use the command to adapt the model to target domain (clas_par=0.3, seed=2020), the result is only about 75%. The log can be found here
Any problem in my training process? Look forward to your reply.
Best wishes!
pretrained source model about office-home obtain random-level output (directly test pretrained model on target domain, e.g. Ar->Cl 0.01786....)
but with the same code and loading setting about office-31 get satisfactory result.
Maybe the pretrained model on office-home has something wrong?
Thank you
Hi, I am trying to compile SHOT in Windows10 (64bit) with Cmake, following the instructions on https://shotsolver.dev/shot/about-shot/compiling. But things are not going well, so wanna get a solution for this.
(base) PS C:\Users\Damdae\OneDrive - SNU\Installation Files\solvers\shot\SHOT\build> cmake .. -DCMAKE-BUILD_TYPE=Release -DHAS_IPOPT=on -DHAS_CPLEX_=on -DHAS_GUROBI=on
-- Selecting Windows SDK version 10.0.22000.0 to target Windows 10.0.19044.
-- Git hash: 7f2b2af7
-- Found Gurobi folder: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64
-- Using Gurobi include folder: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/include
-- Using Gurobi library folder: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/lib
-- Found Gurobi library: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/lib/gurobi_c++md2017.lib
-- Found Gurobi C++ library: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/lib/gurobi95.lib
CMake Warning (dev) at C:/Program Files/CMake/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:438 (message):
The package name passed to `find_package_handle_standard_args` (GUROBI)
does not match the name of the calling package (Gurobi). This can lead to
problems in calling code that expects `find_package` result variables
(e.g., `_FOUND`) to follow a certain pattern.
Call Stack (most recent call first):
misc/FindGurobi.cmake:114 (find_package_handle_standard_args)
CMakeLists.txt:229 (find_package)
This warning is for project developers. Use -Wno-dev to suppress it.
-- Could NOT find PkgConfig (missing: PKG_CONFIG_EXECUTABLE)
-- Checking for one of the modules 'ipopt'
CMake Error at C:/Program Files/CMake/share/cmake-3.22/Modules/FindPkgConfig.cmake:890 (message):
None of the required 'ipopt' found
Call Stack (most recent call first):
CMakeLists.txt:251 (pkg_search_module)
-- Gurobi include files will be used from: C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/include
-- The following Gurobi libraries will be used:
C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/lib/gurobi_c++md2017.lib
C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/gurobi/win64/lib/gurobi95.lib
-- Ipopt include files will be used from: C:\Users\Damdae\OneDrive - SNU\Installation Files\solvers\ipopt\bin\ipopt.exe/include/coin
-- The following Ipopt libraries will be used from:
-- Configuring incomplete, errors occurred!
See also "C:/Users/Damdae/OneDrive - SNU/Installation Files/solvers/shot/SHOT/build/CMakeFiles/CMakeOutput.log".
It's weird because Gurobi is detected, whereas IPOPT is not. Because they are all in the PATH environment variable and reachable, as you can see below.
(base) PS C:\Users\Damdae\OneDrive - SNU\Installation Files\solvers\shot\SHOT\build> gcm ipopt
CommandType Name Version Source
----------- ---- ------- ------
Application ipopt.exe 0.0.0.0 C:\Users\Damdae\OneDrive - SNU\Installation Files\solvers\ipopt\bin\ipopt.exe
Best,
Hello,
Firstly thanks for sharing the code to the community. I encountered some questions in my code reading process.
I find the test_dset_path and t_dset_path are the same in the code, that is to say, the test procedure in target domain uses the data that have been seen in the training process?
Thanks!
Hi, thanks for your sharing!
I run your code on Office-Home dataset for PDA when source domain is the Art. (i.e., A->C, A->P, A->R). But they can not reproduce the results only except A->C.
I got the following results on the three different seeds {2019, 2020, 2021}:
Source Only:



SHOT-IM
seed=2020:


Particularly, the performance on A->R gets worse as training time increases.

These results should be

I don't konw why it happens. Could you please tell me how to correctly reproduce results on PDA? Thanks.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.