MLSTM FCN models, from the paper Multivariate LSTM-FCNs for Time Series Classification, augment the squeeze and excitation block with the state of the art univariate time series model, LSTM-FCN and ALSTM-FCN from the paper LSTM Fully Convolutional Networks for Time Series Classification. The code for the LSTM-FCN and ALSTM-FCN models can be found at LSTM-FCN.

Download the repository and apply pip install -r requirements.txt to install the required libraries.
Keras with the Tensorflow backend has been used for the development of the models, and there is currently no support for Theano or CNTK backends. The weights have not been tested with those backends.
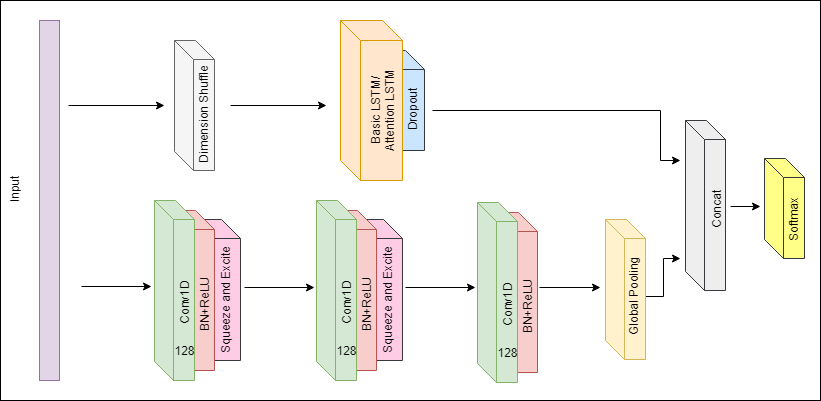
Note : The input to the Input layer of all models will be pre-shuffled to be in the shape (Batchsize, Number of variables, Number of timesteps), and the input will be shuffled again before being applied to the CNNs (to obtain the correct shape (Batchsize, Number of timesteps, Number of variables)). This is in contrast to the paper where the input is of the shape (Batchsize, Number of timesteps, Number of variables) and the shuffle operation is applied before the LSTM to obtain the input shape (Batchsize, Number of variables, Number of timesteps). These operations are equivalent.
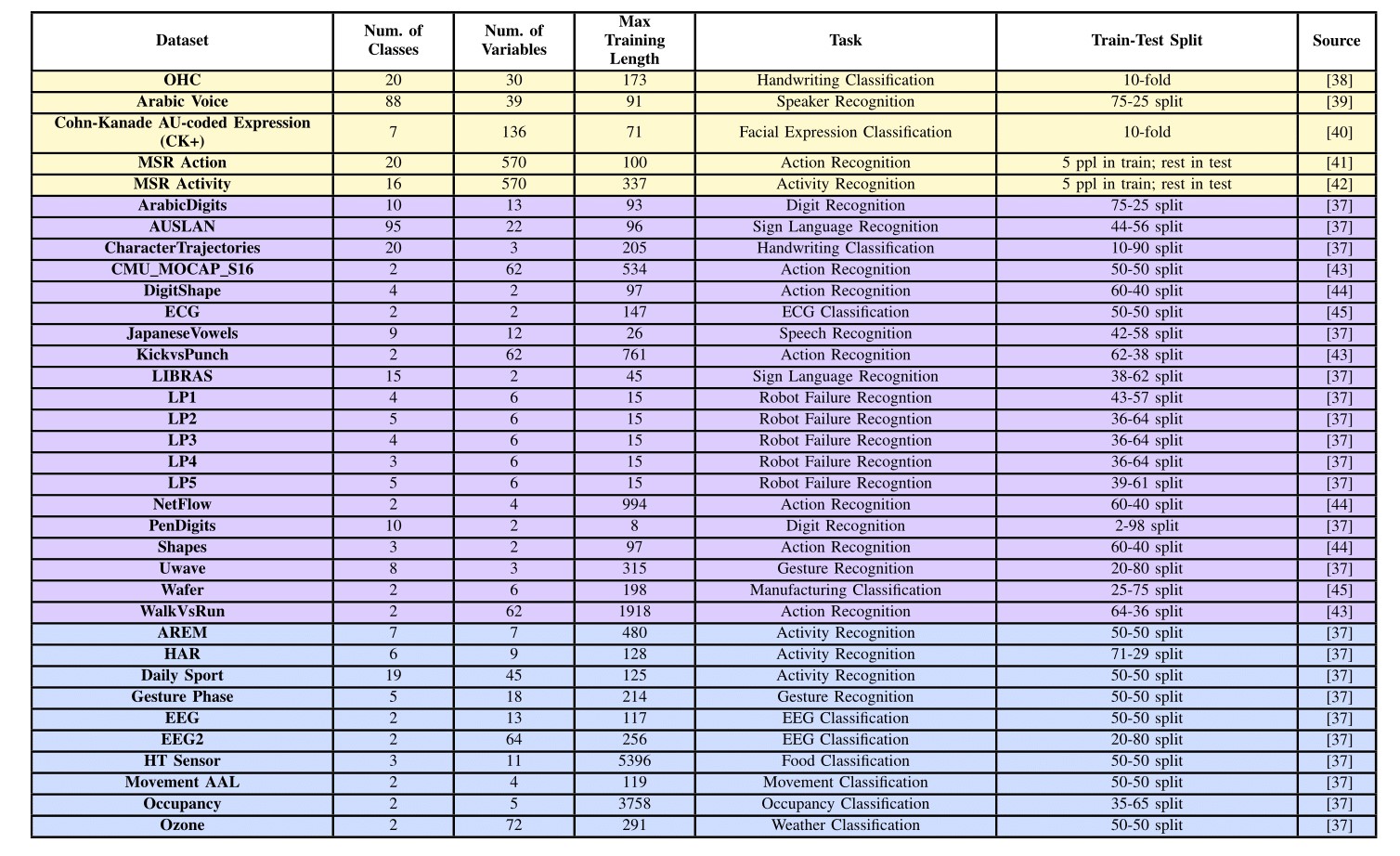
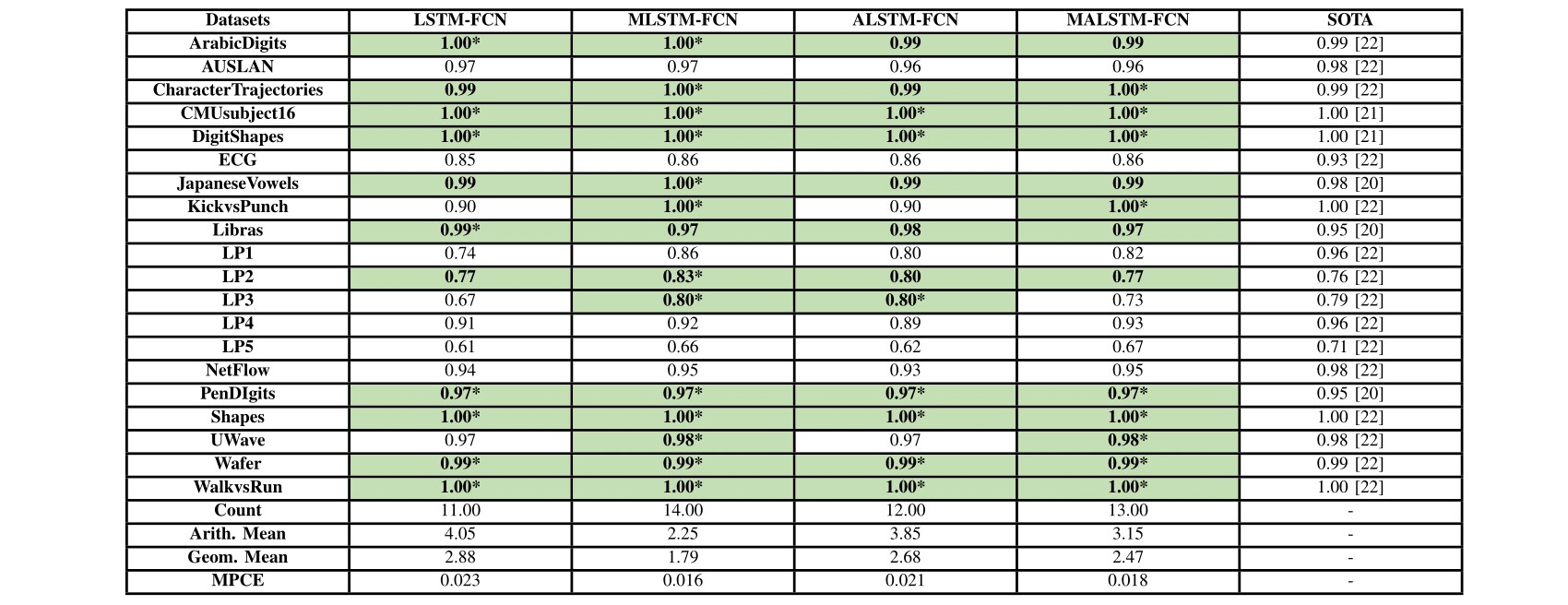
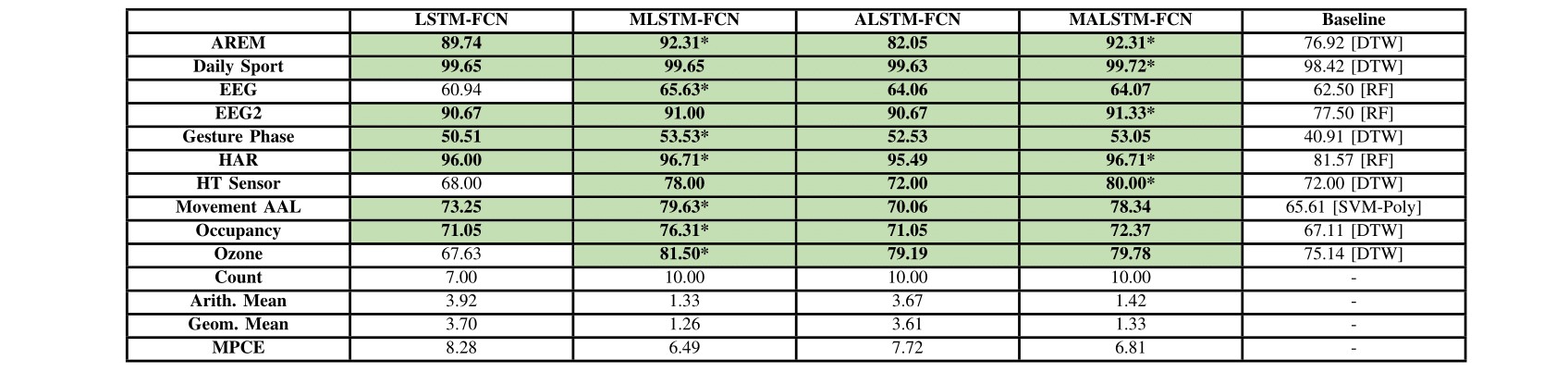
The multivariate datasets are now available in the Release Tab. Please cite this paper and the original source of the appropriate dataset when using these datasets for academic purposes.
Various multivariate benchmark datasets can be evaluated with the provided code and weight files. Refer to the weights directory for clarification.
There is 1 script file for each dataset, and 2 major sections in the code. For each of these code files, please keep the line below uncommented.
- To use the MLSTM FCN model :
model = generate_model() - To use the MALSTM FCN model :
model = generate_model_2() - To use the LSTM FCN model :
model = generate_model_3() - To use the ALSTM FCN model :
model = generate_model_4()
To train the a model, uncomment the line below and execute the script. Note that '???????' will already be provided, so there is no need to replace it. It refers to the prefix of the saved weight file. Also, if weights are already provided, this operation will overwrite those weights.
train_model(model, DATASET_INDEX, dataset_prefix='???????', epochs=250, batch_size=128)
To evaluate the performance of the model, simply execute the script with the below line uncommented.
evaluate_model(model, DATASET_INDEX, dataset_prefix='???????', batch_size=128)

@misc{Karim2018,
Author = {Fazle Karim and Somshubra Majumdar and Houshang Darabi and Samuel Harford},
Title = {Multivariate LSTM-FCNs for Time Series Classification},
Year = {2018},
Eprint = {arXiv:1801.04503},
}






















































































































