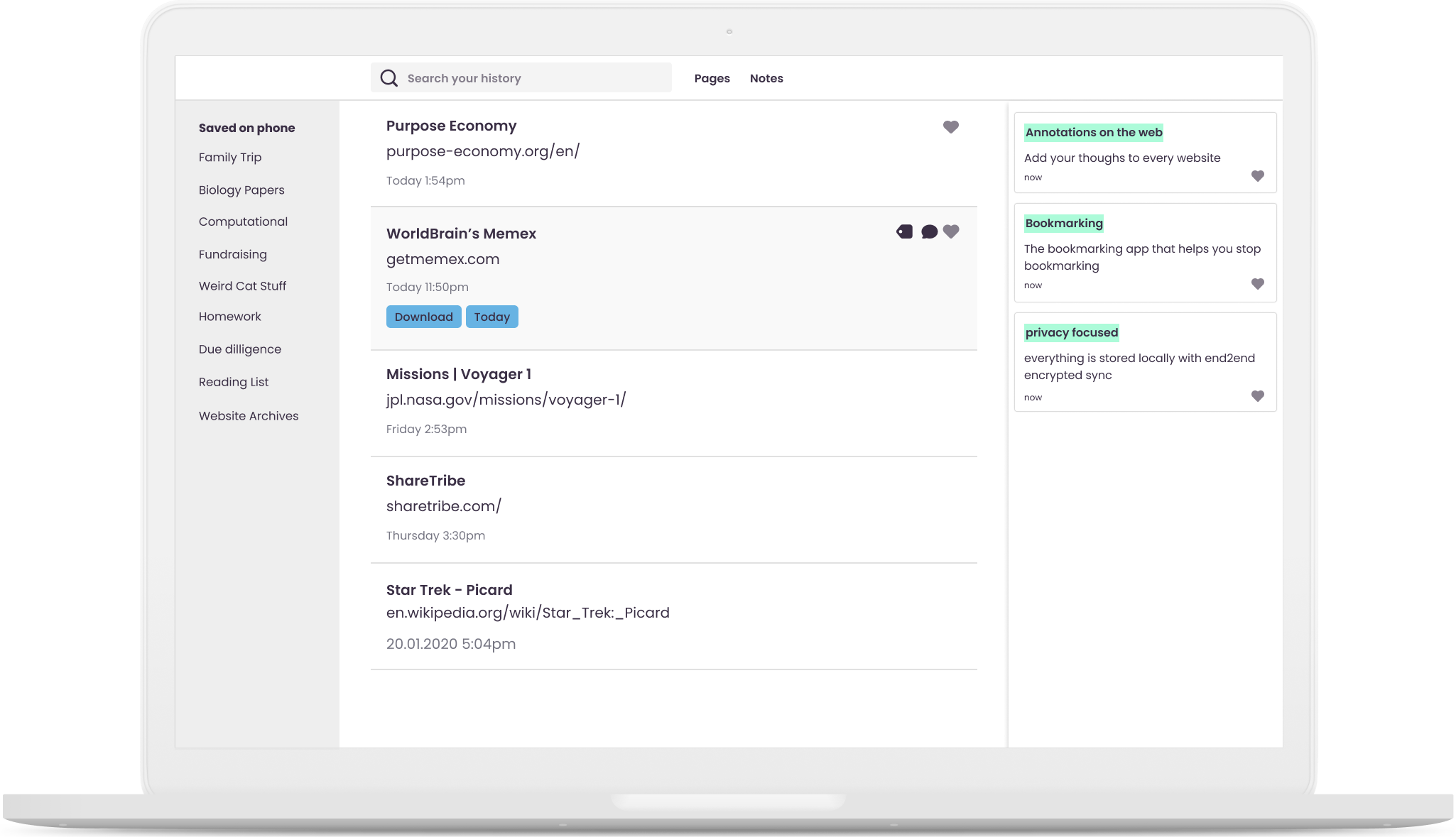
A browser extension to eliminate time spent bookmarking, retracing steps to recall an old webpage, or copy-pasting notes into scattered documents.
Its name and functionalities are heavily inspired by Vannevar Bush's vision of a Memex.
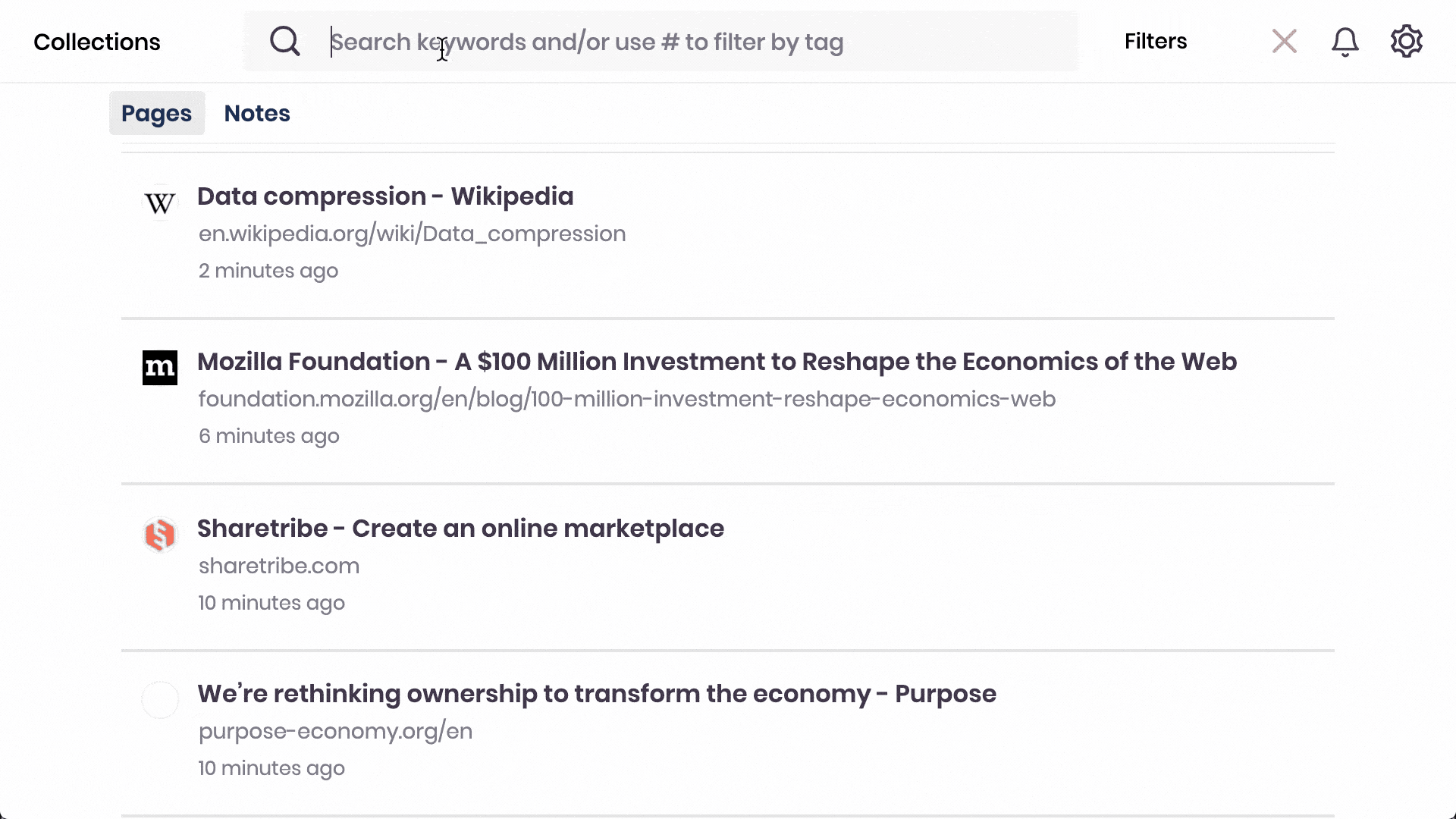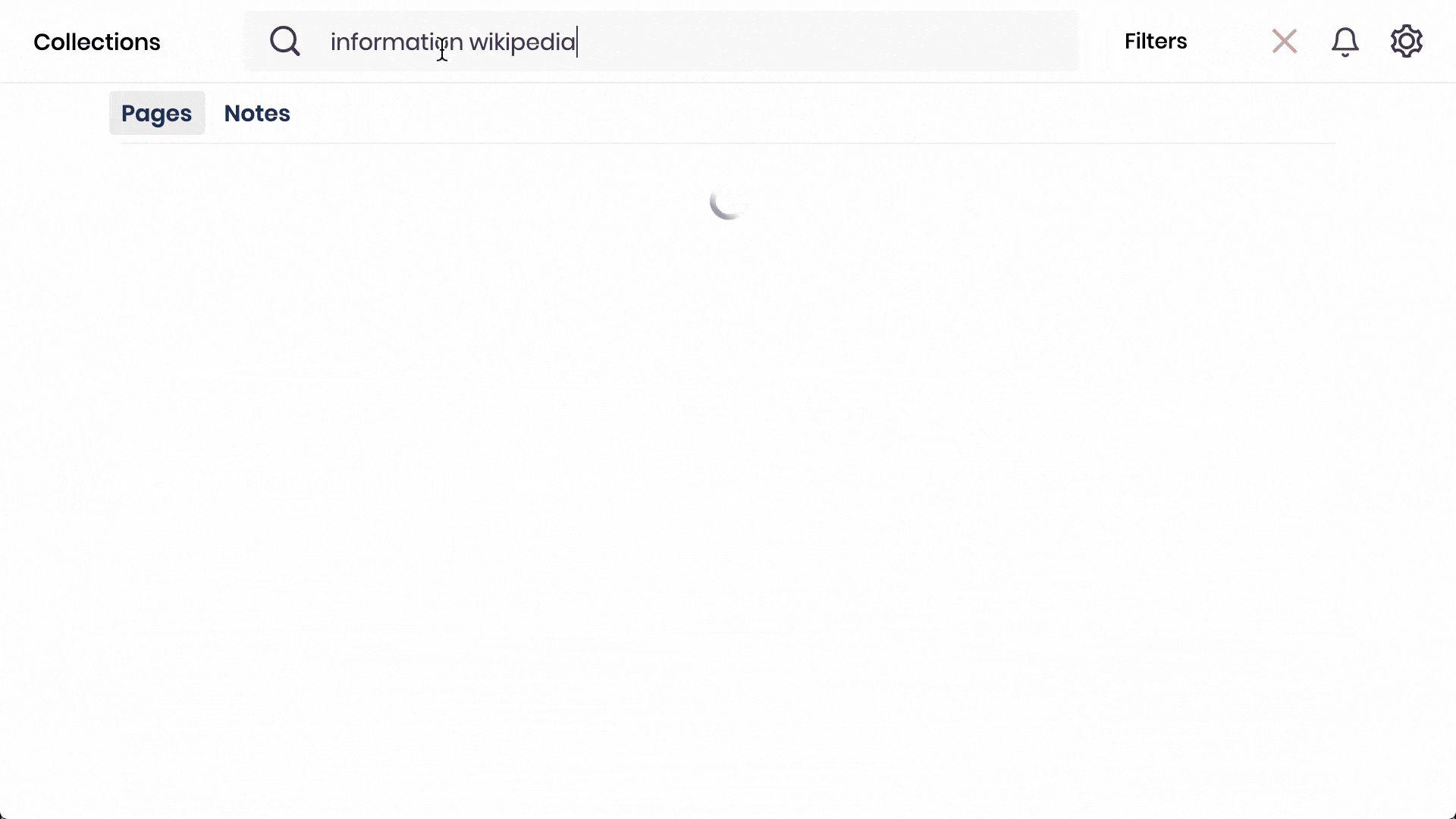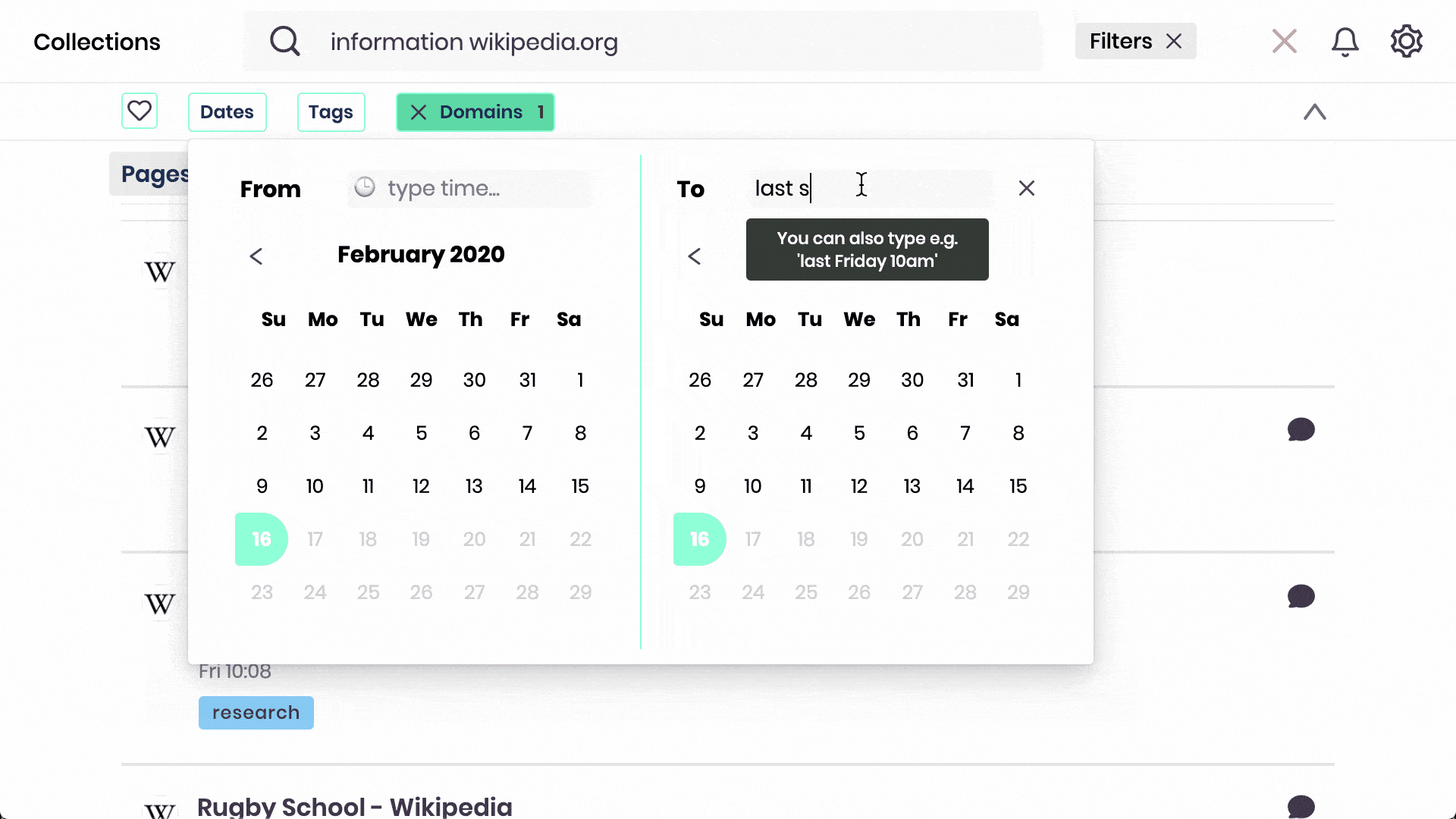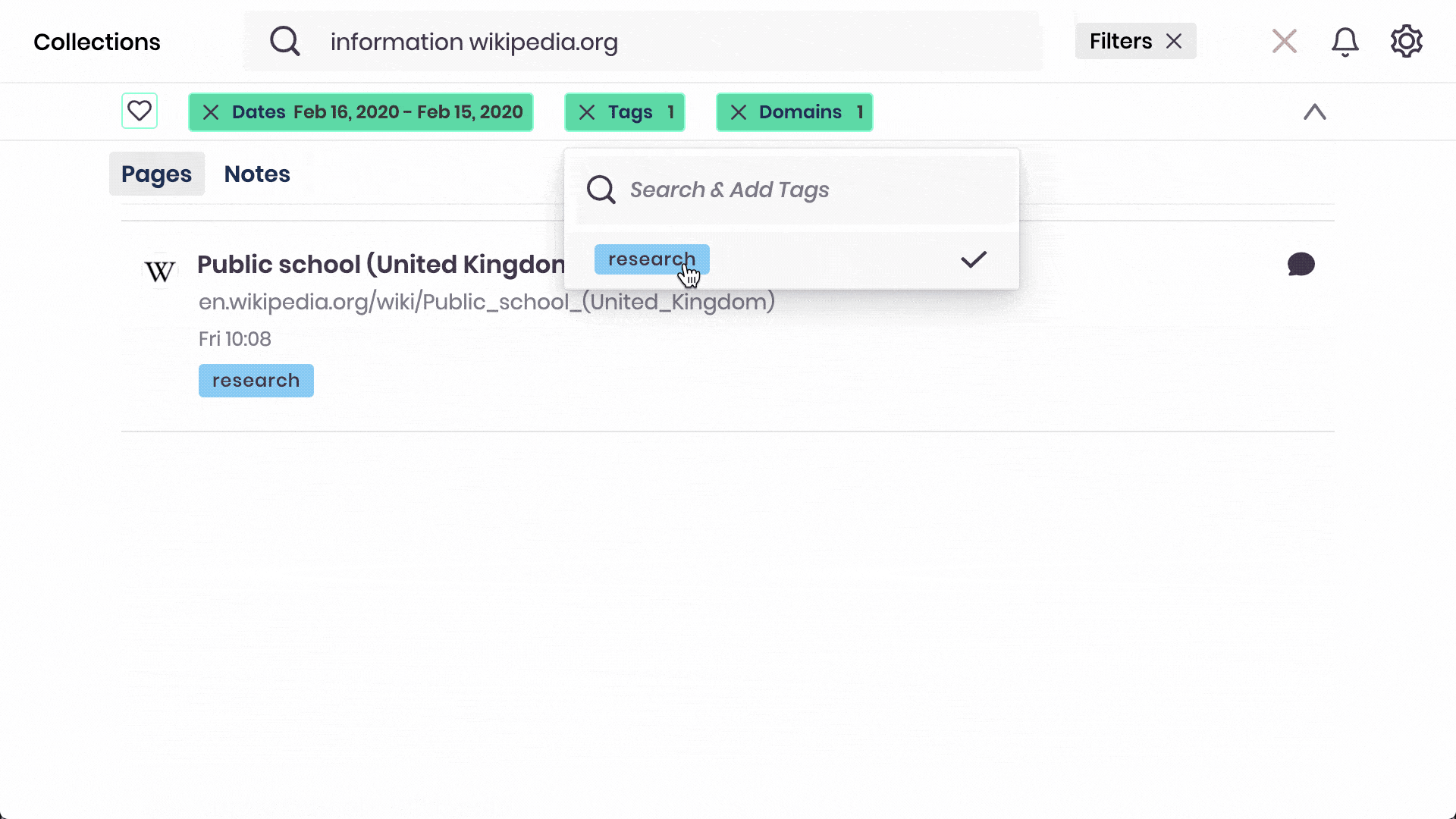
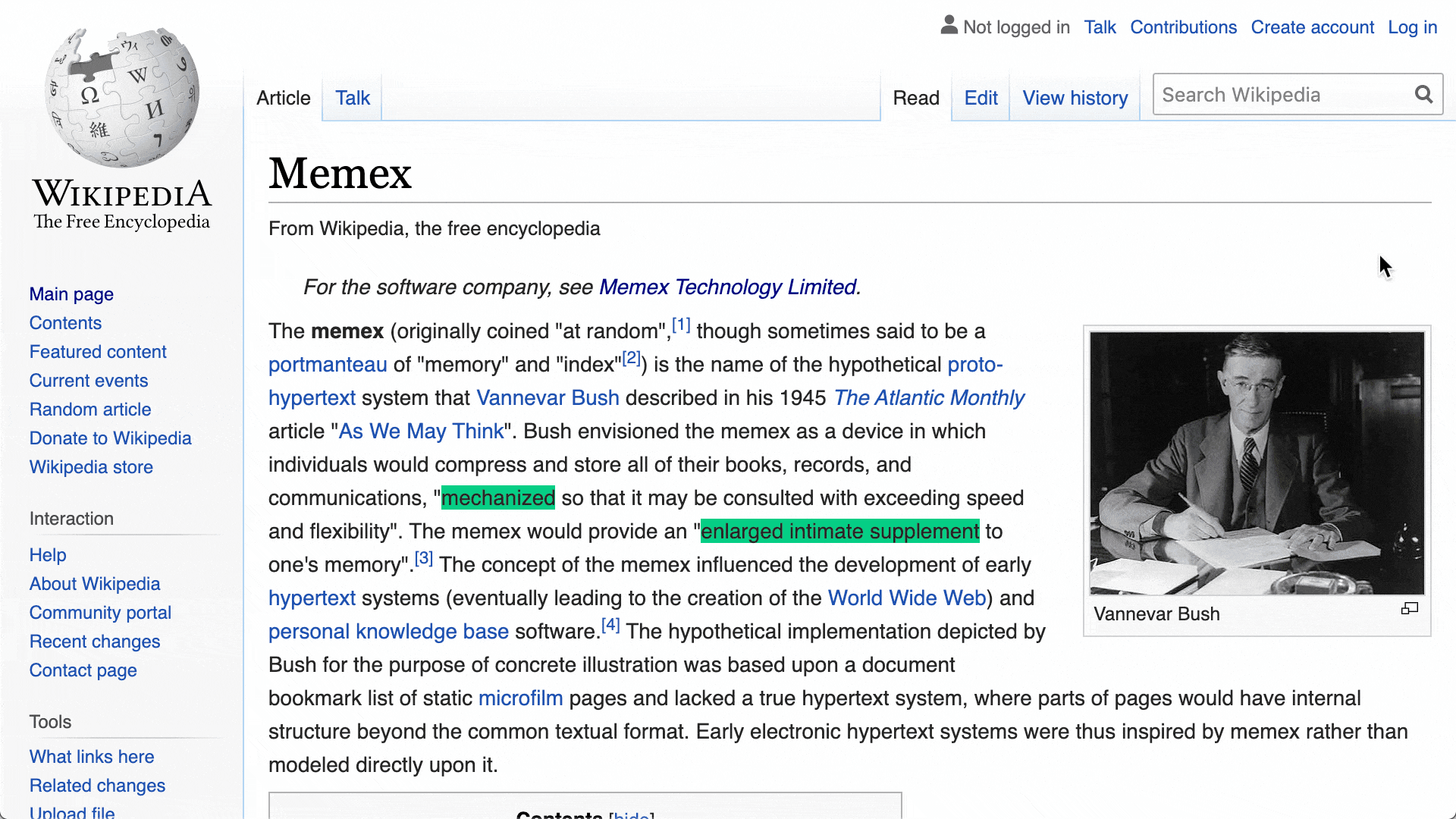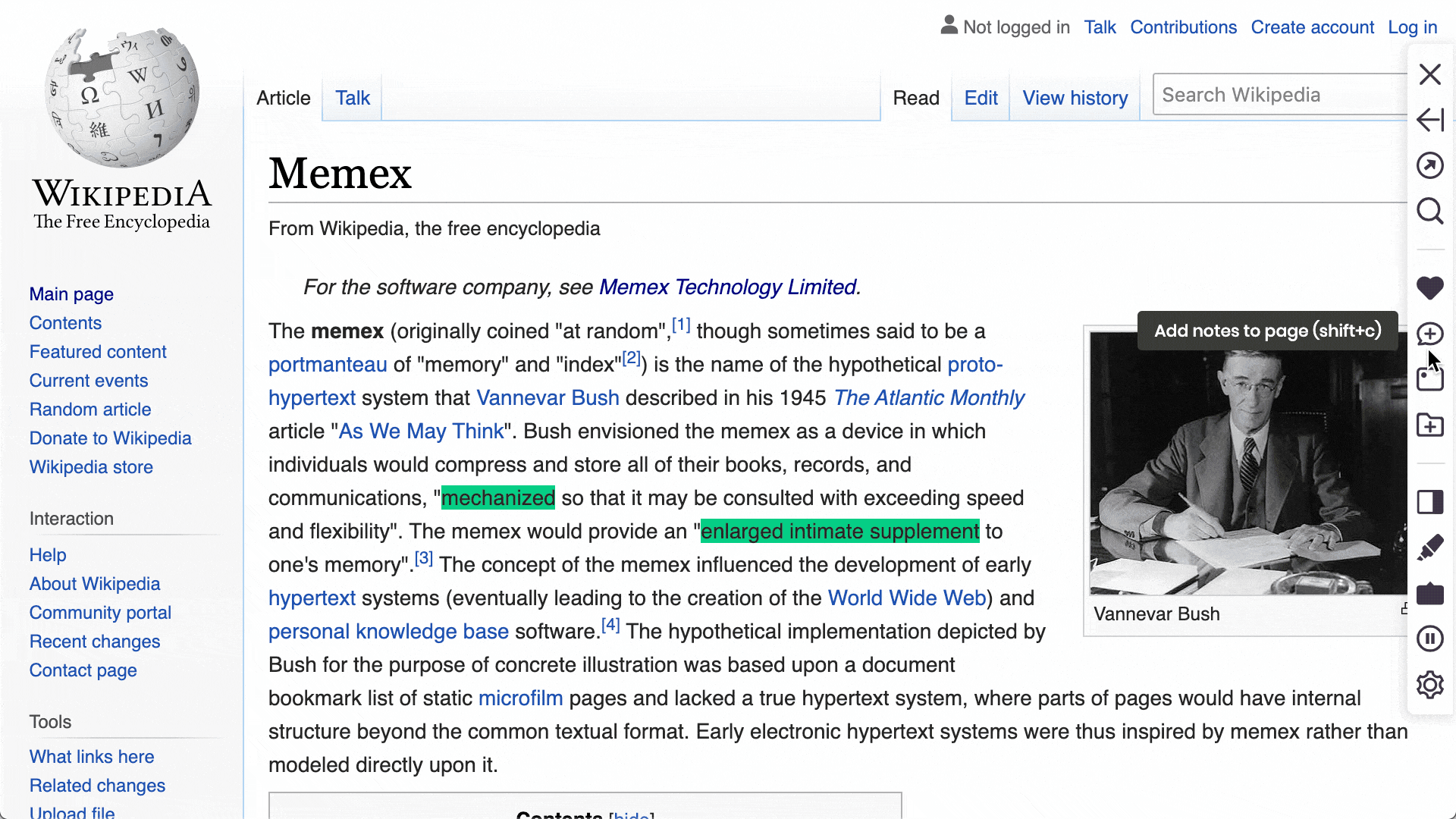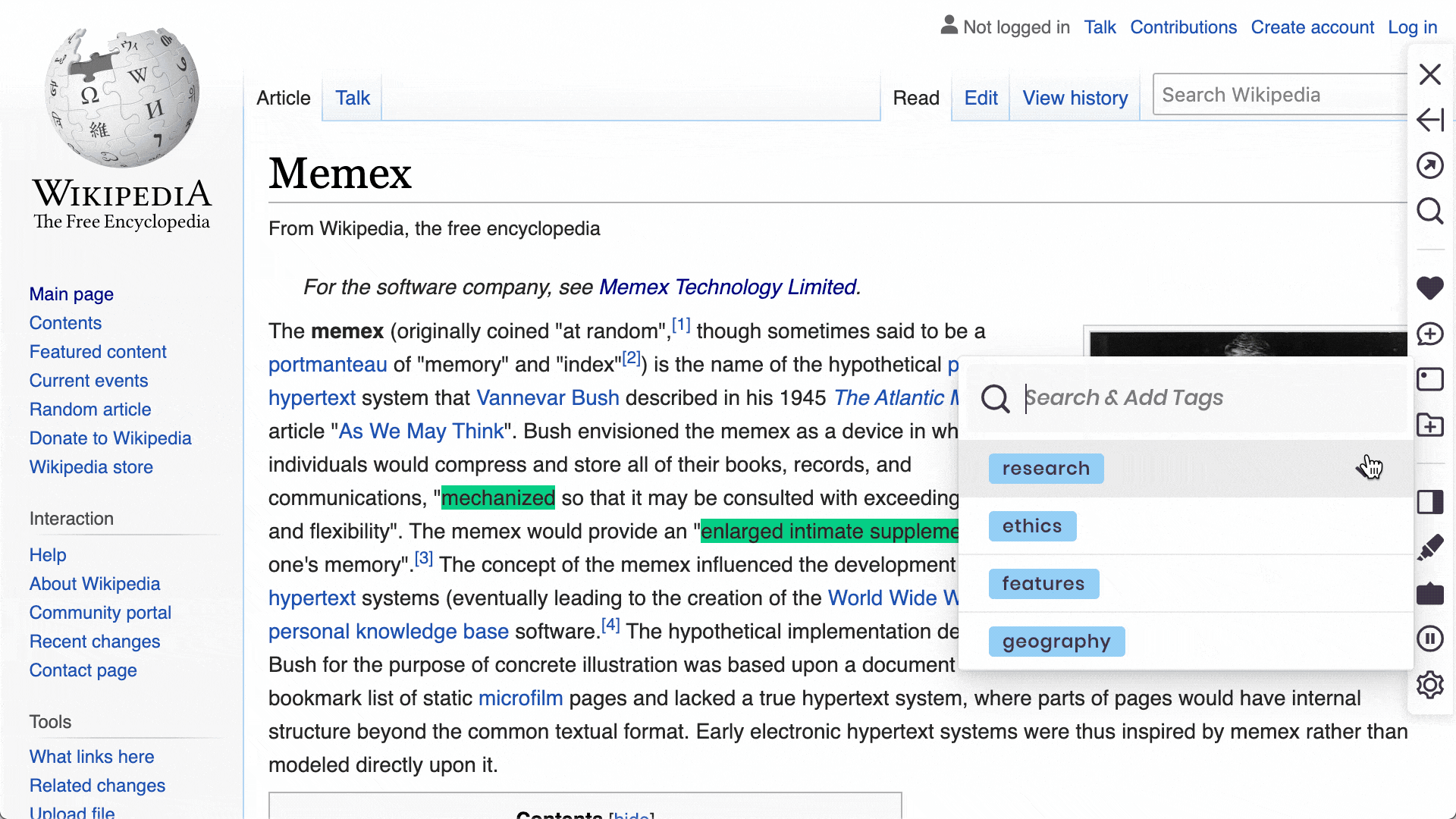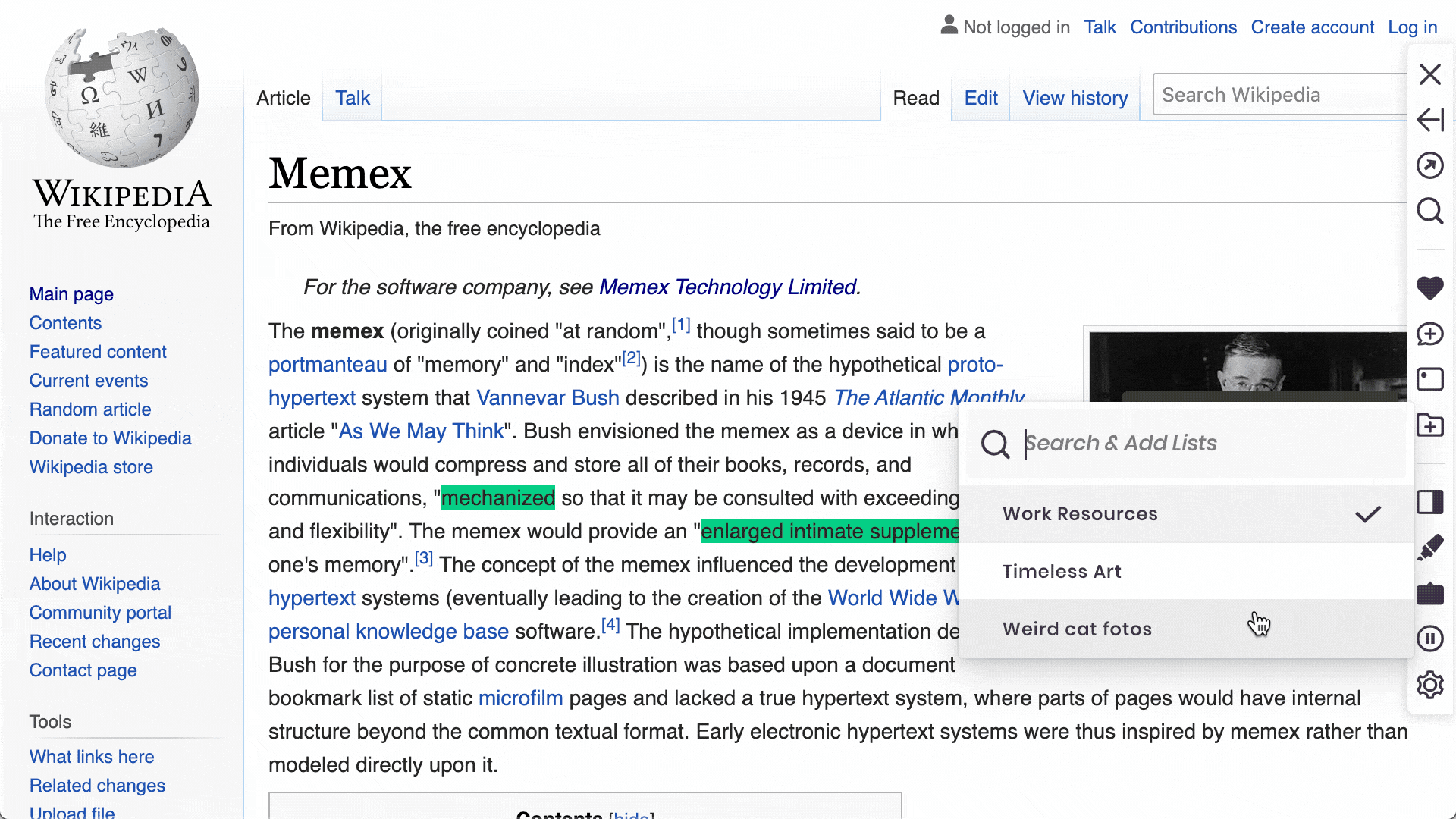
Search with every word of all websites & PDFs you bookmarked, tagged, listed, or annotated. Filter by time, domain, list, or tags.
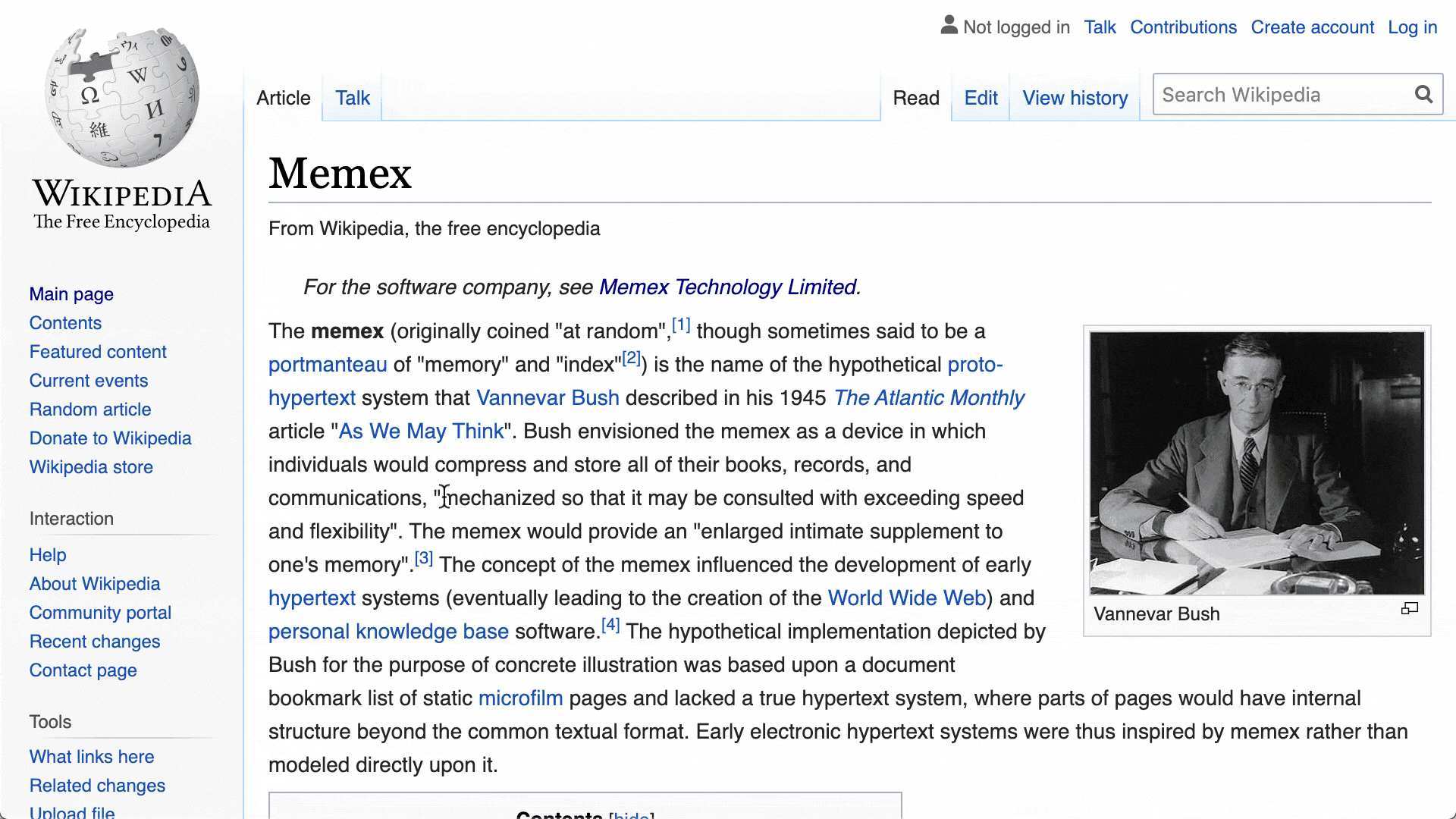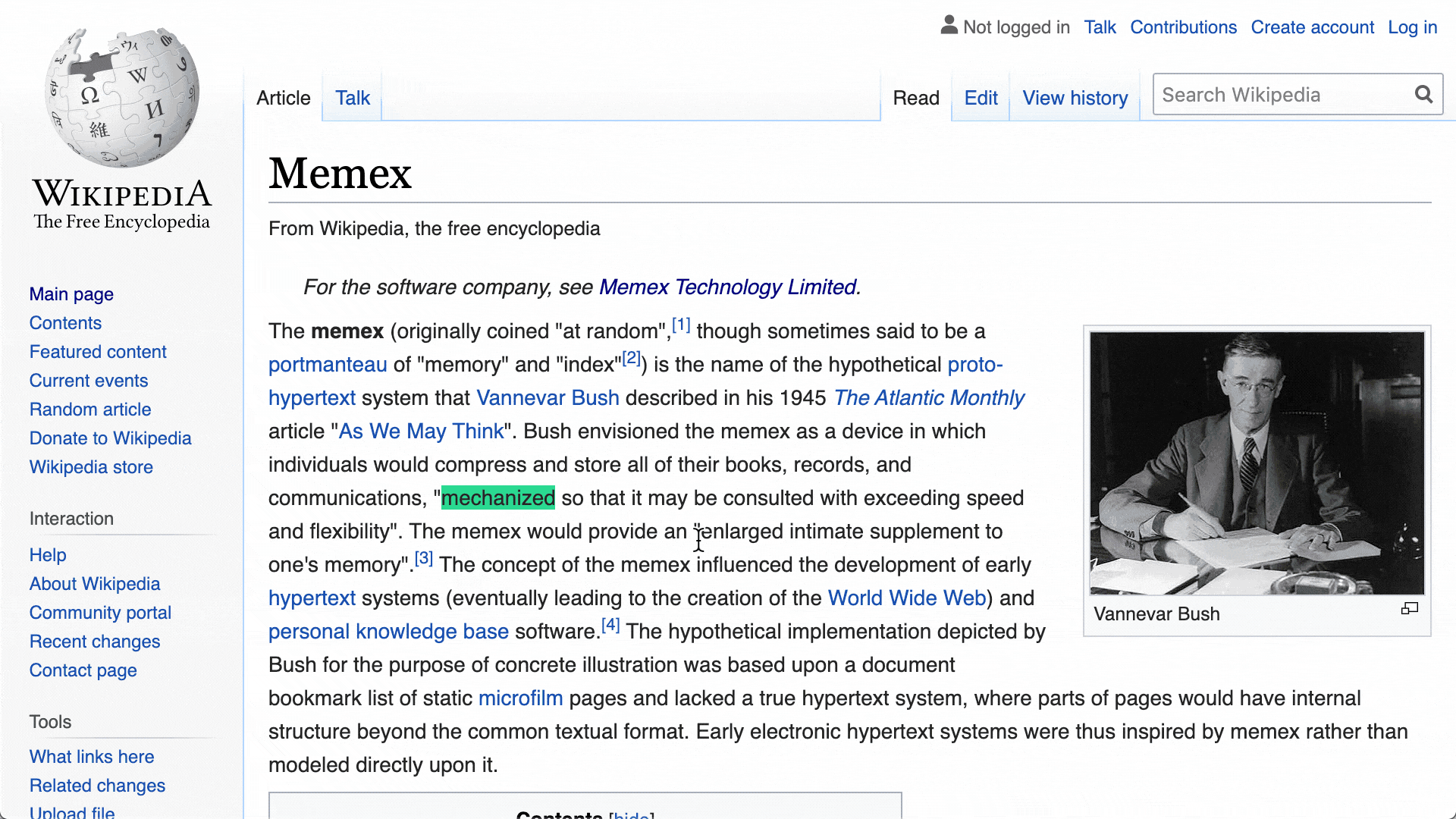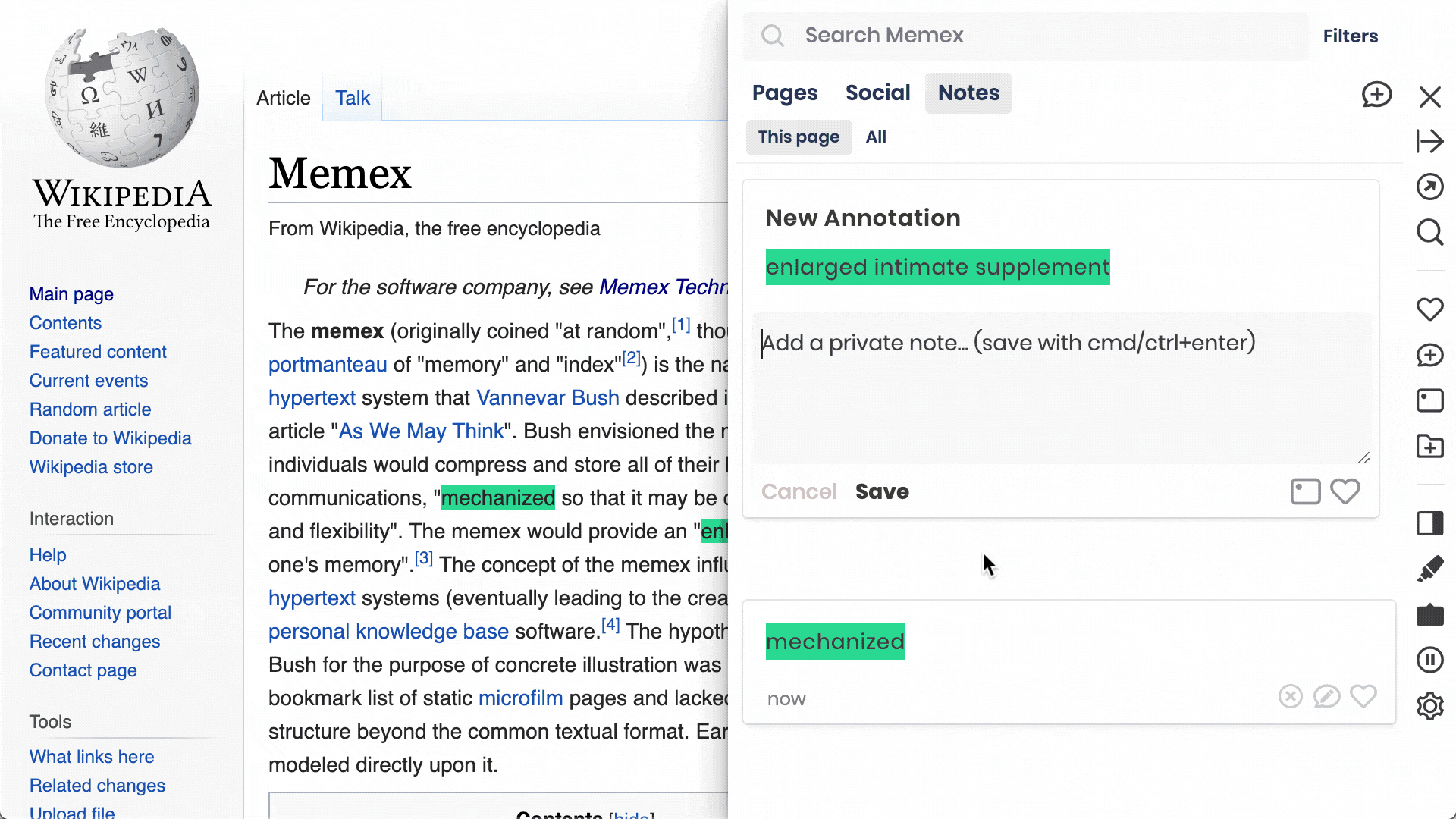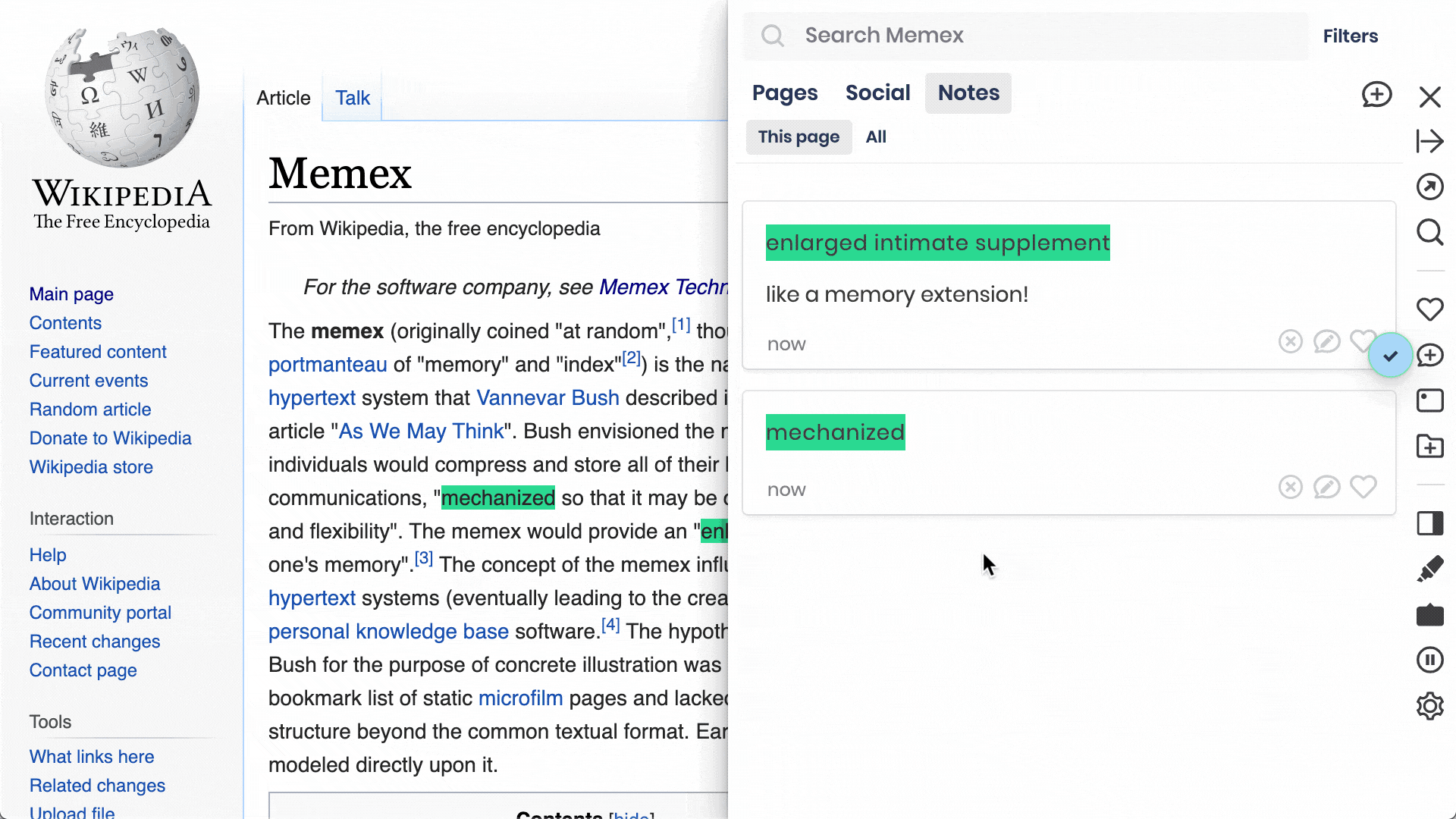
Add notes to websites as a whole and to individual components (e.g. text, images)
Add bookmarks, tags or sort websites into lists on the fly.
With Memex Go you can save & organise content on the go. Sync is end2end encrypted with TweetNaCl

Memex is funded without VC money or selling shares. Instead we are funded with a model called "Steward Ownership". This model ensures that the company can never be sold and our investors are rewarded with a capped profit share. This way we will never be tempted by incentivizes to optimise our company for maximising growth and shareholder profits at the expense of your privacy, attention, or freed to choose a provider. You can find more about our choice in this post.
⛅ Backup and restore your data to any of your favorite cloud providers including Google Drive
📲 Import bookmarks and history from other services
⌨ Keyboard Shortcuts for everything
🗂 Tab manager: add all open tabs to a collection or tag
See a list of our past updates and upcoming features here.
⭐️Archiving websites + reader mode + offline-viewing on mobile
⭐️Mobile Annotations
⭐️Support for Brave and Firefox on mobile
⭐️API to import/export your data & integrate with other apps
⭐️Bulk tag, delete, add to lists & bookmark of items
⭐️Nested Collections
Drop by in our team chat if you're interested in contributing to those features. Experience in React or React Native & Test Driven Development required
Head over to our community forums to post your requests.
Click here for all instructions on how to build Memex so you can hack on it.
This project exists thanks to all the people who contribute. [Contribute].

Become a financial contributor and help us sustain our community. [Contribute]

Support this project with your organization. Your logo will show up here with a link to your website. [Contribute]
Memex is MIT licensed. View full License
WorldBrain.io, the company behind Memex, has been funded by a set of courageous investors & grant givers. See a full & up-to-date list here.










































































































































































































