barebit / x86reference Goto Github PK
View Code? Open in Web Editor NEWX86 Opcode and Instruction Reference: http://ref.x86asm.net
License: GNU Lesser General Public License v3.0
X86 Opcode and Instruction Reference: http://ref.x86asm.net
License: GNU Lesser General Public License v3.0






















































































































Right now MOVSLDUP encoded with opcode F3 0F 12 use operand type q for both its operands which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
According to the intel docs:
Duplicates even-indexed single-precision floating-point values from the source operand (the second operand). See Figure 4-4. The source operand is an XMM, YMM or ZMM register or 128, 256 or 512-bit memory location and the destination operand is an XMM, YMM or ZMM register.
Putting aside VEX/EVEX, the instruction is dealing with 128 bit single precision fp values for both its operands, the operand type should be of type ps which is defined as:
128-bit packed single-precision floating-point data.
Right now LOOPNZ, LOOPNE, LOOPZ, LOOPE, LOOP encoded with opcodes E0-E2 use operand type bs for its operand of addressing J which is defined as:
Byte, sign-extended to the size of the destination operand.
The problem is that the immediate is always sign extended to the size of the stack pointer, the address size prefix can only determine what register is used as the counter (eCX or rCX) and not the size of the immediate which is the relative address to jump to which is to be extended to the size of the stack pointer. Therefore the most appropriate operand type for these should be bss:
Byte, sign-extended to the size of the stack pointer (for example, PUSH (6A)).
Right now PAND encoded with opcode 0F DB use operand type d for its operand of addressing Q which is defined as:
Doubleword, regardless of operand-size attribute.
According to the intel docs:
Bitwise AND mm/m64 and mm.
Since it's dealing with mmx registers the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now SQRTSD encoded with opcode F2 0F 51 use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Computes the square root of the low double-precision floating-point value in the second source operand and stores the double-precision floating-point result in the destination operand. The second source operand can be an XMM register or a 64-bit memory location. The first source and destination operands are XMM registers.
Since it's only operate on the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now MOVSLDUP encoded with opcode F3 0F 16 use operand type q for both its operands which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
According to the intel docs:
Duplicates odd-indexed single-precision floating-point values from the source operand (the second operand) to adjacent element pair in the destination operand (the first operand). See Figure 4-3. The source operand is an XMM, YMM or ZMM register or 128, 256 or 512-bit memory location and the destination operand is an XMM, YMM or ZMM register.
Putting aside VEX/EVEX, the instruction is dealing with 128 bit single precision fp values for both its operands, the operand type should be of type ps which is defined as:
128-bit packed single-precision floating-point data.
Right now MOVSD encoded with opcode F2 0F 10 or F2 0F 11 use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Moves a scalar double-precision floating-point value from the source operand (second operand) to the destination operand (first operand). The source and destination operands can be XMM registers or 64-bit memory locations. This instruction can be used to move a double-precision floating-point value to and from the low quadword of an XMM register and a 64-bit memory location, or to move a double-precision floating-point value between the low quadwords of two XMM registers. The instruction cannot be used to transfer data between memory locations.
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now RSQRTSS encoded with opcode F3 0F 52 use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Computes an approximate reciprocal of the square root of the low single-precision floating-point value in the source operand (second operand) stores the single-precision floating-point result in the destination operand. The source operand can be an XMM register or a 32-bit memory location. The destination operand is an XMM register.
Since it's only operate on the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
Right now ROUNDSS encoded with opcode 66 0F 3A 0A use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Round the single-precision floating-point value in the lowest dword of the source operand (second operand) using the rounding mode specified in the immediate operand (third operand) and place the result in the destination operand (first operand).
Since it's only copying the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
Right now UD encoded with opcode 0F B9 doesn't have any operand types.
According to the intel docs:
0F B9 /r UD1 r32, r/m32 RM Valid Valid Raise invalid opcode exception.
The instruction should use the v operand type according to my testing against objdump which is defined as:
Word or doubleword, depending on operand-size attribute (for example, INC (40), PUSH (50)).
Also the instruction mnemonic is defined as UD1 instead of UD
There're couple of entries in the reference that use the sec_opcd attribute instead of just using the mod attribute which making automatic parsing a bit more cumbersome since there're no need for the sec_opcd at all. For example FCOM instruction (opcode D8 and opcode extension 2) has 2 distinct entries instead of 2 syntaxes. The second entry indicating that the sec_opcd D1 must be matched but it's redundant since it could've been written exactly like the FADD instruction (opcode D8 and opcode extensions 0) with 2 syntaxes one indicating mod memory and the second indicating mod register. I could've written the FADD instruction in the same format with 2 entries where the second one has a sec_opcd with value of C0 (mod bits set to 11 and opcode extension set to 000).
The reg/opcode field (o in the table) of the ModR/M byte for all of 0x0F90-0x0F9F (SETcc) has 0 in the sheet, which I believe is misleading.
I don't see this in the manual (Intel® 64 and IA-32 Architectures Software Developer’s Manual March 2017 version); usually represented as /0 (for eg. C0 /0 ib for ROL r/m8, imm8).
Right now CVTSS2SI encoded with opcode F3 0F 2D use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Converts a single-precision floating-point value in the source operand (the second operand) to a signed double-word integer (or signed quadword integer if operand size is 64 bits) in the destination operand (the first operand). The source operand can be an XMM register or a memory location. The destination operand is a general-purpose register. When the source operand is an XMM register, the single-precision floating-point value is contained in the low doubleword of the register.
Since it's only copying the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleworld, regardless of operand-size attribute.
Right now JCXZ, JECXZ, JRCXZ encoded with opcode E3 use operand type bs for its operand of addressing J which is defined as:
Byte, sign-extended to the size of the destination operand.
The problem is that the immediate is always sign extended to the size of the stack pointer, the address size prefix can only determine what register is used as the compare register (eCX or rCX) and not the size of the immediate which is the relative address to jump to which is to be extended to the size of the stack pointer. Therefore the most appropriate operand type for these should be bss:
Byte, sign-extended to the size of the stack pointer (for example, PUSH (6A)).
See the "FSUB/FSUBP/FISUB—Subtract" entry in Intel manual. The operands are the same like in case of no-operand FSUBP.
Initially reported by bdwashbu.
The PUSH immediate encodings list the operands types as Ibss and Ivs, the descriptions for which state that they are sign-extended to the size of the stack pointer (which is fixed at 64 bits in 64 bit mode). However, the Intel manual states that immediate operands to PUSH are sign-extended to the operand size, which defaults to 64 bits in 64 bit mode but may be set to 16 bits using the operand size override prefix. Testing indicates that this does in fact work and it's sign extended to the operand size as the Intel manual states.
Just recently having learned about the various Bit Manipulation Instruction Sets, I happened to notice their conspicuous lack on the x86reference. Is this intentional for some reason, or would it be worth a PR?
Right now CMPSS encoded with opcode F3 0F C2 use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Compare low single-precision floating-point value in
xmm2/m32 and xmm1 using bits 2:0 of imm8 as
comparison predicate.
Since it's only comparing the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type q which is defined as:
Doubleword, regardless of operand-size attribute.
Right now UCOMISD encoded with opcode 66 F2 0F 2E66 0F 2E use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Performs an unordered compare of the double-precision floating-point values in the low quadwords of operand 1 (first operand) and operand 2 (second operand), and sets the ZF, PF, and CF flags in the EFLAGS register according to the result (unordered, greater than, less than, or equal). The OF, SF and AF flags in the EFLAGS register are set to 0. The unordered result is returned if either source operand is a NaN (QNaN or SNaN).
Operand 1 is an XMM register; operand 2 can be an XMM register or a 64 bit memory
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now PMADDWD encoded with opcode 0F F5 use operand type d for its operand of addressing Q which is defined as:
Doubleword, regardless of operand-size attribute.
According to the intel docs:
Multiply the packed words in mm by the packed
words in mm/m64, add adjacent doubleword
results, and store in mm.
Since it's dealing with mmx registers the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now UNPCKLPS encoded with opcode 0F 14 use operand type q for its operand of addressing W which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
According to the intel docs:
Performs an interleaved unpack of the low single-precision floating-point values from the first source operand and the second source operand.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit memory location. The destination is not distinct from the first source XMM register and the upper bits (MAXVL-1:128) of the corresponding ZMM register destination are unmodified. When unpacking from a memory operand, an implementation may fetch only the appropriate 64 bits; however, alignment to 16-byte boundary and normal segment checking will still be enforced.
Putting aside VEX/EVEX, the instruction is dealing with 128 bit single precision fp values for both its operands, the operand type should be of type ps which is defined as:
128-bit packed single-precision floating-point data.
Right now PEXTRQ entry isn't specified with the mode="e" attribute for 64 bit mode.
PEXTRQ is not encodable in non-64-bit modes and requires REX.W in 64-bit mode.
We need to add another separate entry with the mode="e" attribute for 64 bit mode for it.
Right now CVTTSS2SI encoded with opcode F3 0F 2C use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Converts a single-precision floating-point value in the source operand (the second operand) to a signed doubleword integer (or signed quadword integer if operand size is 64 bits) in the destination operand (the first operand). The source operand can be an XMM register or a 32-bit memory location. The destination operand is a general purpose register. When the source operand is an XMM register, the single-precision floating-point value is contained in the low doubleword of the register.
Since it's only copying the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
In the Table "32/64-bit ModR/M Byte", for Mod=00, R/M=001 the effective address is listed as "[RCX/EDX]+disp8". This is incorrect, it should be "[RCX/ECX]+disp8". (I.e. with 32-bit operands the base register remains ECX.)
This is verified both by the correct listing in the table below, "32-bit ModR/M Byte", as well as Intel's official manual.
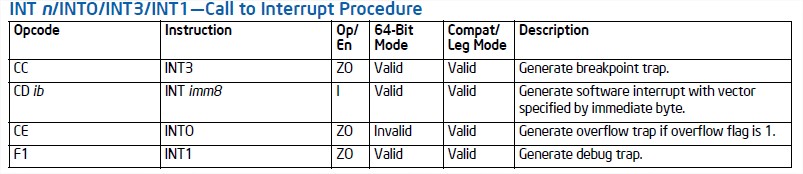
Right now INTO encoded with opcode CE has a missing entry for 64 bit mode which is invalid according to the manual:
Right now MOVSS encoded with opcode F3 0F 10 or F3 0F 11 use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Moves a scalar single-precision floating-point value from the source operand (second operand) to the destination operand (first operand). The source and destination operands can be XMM registers or 32-bit memory locations. This instruction can be used to move a single-precision floating-point value to and from the low doubleword of an XMM register and a 32-bit memory location, or to move a single-precision floating-point value between the low doublewords of two XMM registers. The instruction cannot be used to transfer data between memory locations.
Since it's only copying the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
Is avx instruction updated in this manual?
The first entry which is for AAM has sec_opcd equal to 0A for no reason.
The instruction doesn't rely on a secondary opcode just an immediate 8 bit value after the primary opcode.
The second entry which is for AMX and I'm not sure why it's there, according to the dtd file, it's a suggested mnemonic, it's not even an alias so I'm not sure what does it serve but it list the immediate 8 bit value source operand unlike the first entry of AAM which doesn't even list this source operand for some reason?
Same goes for AAD instruction.
Right now SQRTSS encoded with opcode F3 0F 51 use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Computes the square root of the low single-precision floating-point value in the second source operand and stores the single-precision floating-point result in the destination operand. The second source operand can be an XMM register or a 32-bit memory location. The first source and destination operands is an XMM register.
Since it's only operate on the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
Right now RCPSS encoded with opcode F3 0F 53 use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Computes of an approximate reciprocal of the low single-precision floating-point value in the source operand (second operand) and stores the single-precision floating-point result in the destination operand. The source operand can be an XMM register or a 32-bit memory location. The destination operand is an XMM register.
Since it's only operate on the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
The current version of the reference does not document that the instructions fsincos, fcos, fsin, fldenvd, fsaved, fprem1, frstord, and fstenvd where only introduced with the 80387 processor.
Right now UNPCKHPS encoded with opcode 0F 15 use operand type q for its operand of addressing W which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
According to the intel docs:
Performs an interleaved unpack of the high single-precision floating-point values from the first source operand and the second source operand.
128-bit Legacy SSE version: The second source can be an XMM register or an 128-bit memory location. The destination is not distinct from the first source XMM register and the upper bits (MAXVL-1:128) of the corresponding ZMM register destination are unmodified. When unpacking from a memory operand, an implementation may fetch only the appropriate 64 bits; however, alignment to 16-byte boundary and normal segment checking will still be enforced.
Putting aside VEX/EVEX, the instruction is dealing with 128 bit single precision fp values for both its operands, the operand type should be of type ps which is defined as:
128-bit packed single-precision floating-point data.
Right now CVTDQ2PD encoded with opcode F3 0F E6 use operand type dq for its operand of addressing W which is defined as:
Double-quadword, regardless of operand-size attribute (for example, CMPXCHG16B).
According to the intel docs:
Convert two packed signed doubleword integers from xmm2/mem to two packed double-precision floatingpoint values in xmm1.
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now JMP encoded with opcodes EB use operand type bs for its operand of addressing J which is defined as:
Byte, sign-extended to the size of the destination operand.
The problem is that the immediate is always sign extended to the size of the stack pointer. Therefore the most appropriate operand type for these should be bss:
Byte, sign-extended to the size of the stack pointer (for example, PUSH (6A)).
Opcode 0F 23
Move to/from Debug Registers
Entry number 2 should the operand type be of type d for 32 bit and not q for 64 bit?
This second entry is not set with mode="e" which specify different behavior for x64.
Right now CVTTSS2SICVTSD2SI encoded with opcode F2 0F 2D use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Converts a single-precision floating-point value in the source operand (the second operand) to a signed doubleword integer (or signed quadword integer if operand size is 64 bits) in the destination operand (the first operand). The source operand can be an XMM register or a 32-bit memory location. The destination operand is a general purpose register. When the source operand is an XMM register, the single-precision floating-point value is contained in the low doubleword of the register.
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now CMPSD encoded with opcode F2 0F C2 use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Compare low double-precision floating-point value in
xmm2/m64 and xmm1 using bits 2:0 of imm8 as comparison
predicate.
Since it's only comparing the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now UCOMISS encoded with opcode F2 0F 2E use operand type ss for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Compares the single-precision floating-point values in the low doublewords of operand 1 (first operand) and operand 2 (second operand), and sets the ZF, PF, and CF flags in the EFLAGS register according to the result (unordered, greater than, less than, or equal). The OF, SF and AF flags in the EFLAGS register are set to 0. The unordered result is returned if either source operand is a NaN (QNaN or SNaN).
Operand 1 is an XMM register; operand 2 can be an XMM register or a 32 bit memory location.
Since it's only copying the lower 32 bits of the register and the memory variant is also referencing 32 bit memory the operand type should be of type d which is defined as:
Doubleword, regardless of operand-size attribute.
Right now ROUNDSD encoded with opcode 66 0F 3A 0B use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed single-precision floating data.
According to the intel docs:
Round the DP FP value in the lower qword of the source operand (second operand) using the rounding mode specified in the immediate operand (third operand) and place the result in the destination operand (first operand).
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
Right now PINSRQ entry isn't specified with the mode="e" attribute for 64 bit mode.
According to the intel docs this instruction is not encodable in non-64-bit modes and requires REX.W in 64-bit mode.
We need to add another separate entry with the mode="e" attribute for 64 bit mode for it.
Right now MOV encoded with opcode 8E use operand type w for its operand of addressing E which is defined as:
Word, regardless of operand-size attribute (for example, ENTER).
According to the intel docs:
8E /r MOV Sreg,r/m16** RM Valid Valid Move r/m16 to segment register.
REX.W + 8E /r MOV Sreg,r/m64** RM Valid Valid Move lower 16 bits of r/m64 to segment register.
When dealing with memory addressing the operand always points to word pointer as expected, but when dealing with register addressing, one need to specify the full register name even tho the instruction only uses the lower 16 bit of the register, thus I think the appropriate solution would be to split the syntax to mem and nomem attributes, when the mem one has operand type w and the nomem one has operand type v because the operand size prefix can affect the register in use according to my testing on objdump which is defined as::
Word or doubleword, depending on operand-size attribute (for example, INC (40), PUSH (50)).
For 64 bit mode the operand type should be vqp which is defined as:
Word or doubleword, depending on operand-size attribute, or quadword, promoted by REX.W in 64-bit mode.
EDIT: clarity
The processor family which describes the instruction's introductory processor doesn't make sense.
The list of available families right now are:
00: 8086
01: 80186
02: 80286
03: 80386
04: 80486
P1 (05): Pentium (1)
PX (06): Pentium with MMX
PP (07): Pentium Pro
P2 (08): Pentium II
P3 (09): Pentium III
P4 (10): Pentium 4
C1 (11): Core (1)
C2 (12): Core 2
C7 (13): Core i7
IT (99): Itanium (only geek editions)
Let's take for example instruction CLFLUSHOPT which was introduced in:
Skylake (server)
Skylake (client)
Goldmont
According to https://en.wikichip.org/wiki/x86/persistent_memory_extensions
Now, these are the microarchitectures supporting this instruction, while there can be skylake i3, there could also be skylake i5 and i7 depending on the manufacture process of a cpu it can be downgraded to any of these and will have disabled cores.
So unless I'm missing something here on what how these codes relates to the instruction introductory process, I think it should be changed to a list of instruction introductory microarchitecture and the family could vary, but it doesn't depend on the family.
It might be correct for the very first instructions where the jump from 80286 -> 80386 just introduced more instructions (and other stuff) but I think this rule breaks down later on, so I think it needs to be revised.
instruction SFENCE requires sec_opcd to be equal to F8
according to
https://www.felixcloutier.com/x86/sfence
and other dissassemblers.
Even tho the range F9-FF comforts to the opcode extension 7 and that the mod of the MOD R/M byte is register addressing it has to be exactly F8 to work.
The intel manual lists:
NP 0F 3A 0F /r ib1
PALIGNR mm1, mm2/m64, imm8
66 0F 3A 0F /r ib
PALIGNR xmm1, xmm2/m128, imm8
but the XML & geek32 show:
| 0F | 3A | 0F | | r | C2+ | | | | | PALIGNR | Pq | Qq | | | ssse3 | simdint | | | | | | | | Packed Align Right
66 | 0F | 3A | 0F | | r | C2+ | | | | | PALIGNR | Vdq | Wdq | | | ssse3 | simdint | | | | | | | | Packed Align Right
without the imm8. needs a Ib for oper3 i believe.
May I suggest this be re licensed with a more open license? MIT or BSD for example?
Right now CVTTSD2SI encoded with opcode F2 0F 2c use operand type sd for its operand of addressing W which is defined as:
Scalar element of a 128-bit packed double-precision floating data.
According to the intel docs:
Converts a double-precision floating-point value in the source operand (the second operand) to a signed double-word integer (or signed quadword integer if operand size is 64 bits) in the destination operand (the first operand). The source operand can be an XMM register or a 64-bit memory location. The destination operand is a general purpose register. When the source operand is an XMM register, the double-precision floating-point value is contained in the low quadword of the register.
Since it's only copying the lower 64 bits of the register and the memory variant is also referencing 64 bit memory the operand type should be of type q which is defined as:
Quadword, regardless of operand-size attribute (for example, CALL (FF /2)).
The mini-tables at http://ref.x86asm.net/coder.html#sib64_base_101 are very misleading. It claims, for instance, that with no REX.X and mod bits=01, the scaled index base="RBP/EBP+disp8". However, with mod bits=01, the offset of +disp8 is already accounted for in the table "32/64-bit ModR/M Byte", under Effective Address (which must be "[sib]+disp8" in this case).
This gives the impression that the offset is added twice (or maybe there are two offsets?), when this is not the case. The base should be listed as simply "RBP/EBP", to match the other bases in the table "32/64-bit SIB Byte" (which don't have the offset added, because it's accounted for in the original ModR/M calculation).
The same goes for the bits=02 case, and the table at http://ref.x86asm.net/coder.html#sib32_base_101.
Suggested by fuzxxl:
In early steppings of the 80386, opcodes 0f a6 (xbts) and 0f a7 (ibts)
existed. These were removed later on.
Ralf Brown's interrupt list claims that they were present in early
versions of the Intel manuals for 80386, googling yielded documentation
with timings and behaviour.
Right now LFENCE encoded with opcode 0F AE use opcode extension of 5 which according to the intel docs it should only be encoded with:
NP 0F AE E8
LFENCE
CLFLUSHOPT encoded as NFx 66 0F AE /7CLFLUSHOPT m8 needs to be added.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.