chaitjo / learning-tsp Goto Github PK
View Code? Open in Web Editor NEWCode for the paper 'Learning TSP Requires Rethinking Generalization' (CP 2021)
Home Page: https://arxiv.org/abs/2006.07054
License: MIT License
Code for the paper 'Learning TSP Requires Rethinking Generalization' (CP 2021)
Home Page: https://arxiv.org/abs/2006.07054
License: MIT License








































































































Hi! I would like to ask a question regarding your update_mask function in Beamsearch for NAR model.
It seems that as you advance the decoding, you map away the new_nodes to 0. Then, you replace this value with 1e10. Doesn't this make the log probability very large, and hence probability == 1, at the next iteration? Shouldn't it be trying to reduce these values instead, so that the beam does not advance there?
Hi, it will be great to add some examples or comments how to generate datasets, for example:
To generate train set, run it (estimated time -- 100 mins)
git clone https://github.com/jvkersch/pyconcorde.git
cd pyconcorde && pip install -e .
python 'data/tsp/generate_tsp.py' --min_nodes 20 --max_nodes 50 --num_samples 128000 --batch_size 128 --filename 'data/tsp/tsp20-50_train_concorde.txt'
Hi there.
According to your code, the adjacency matrix of a graph uses 0 to indicate that two nodes are connected, and 1 to indicate that two nodes are not connected. This seems to be different from routine which uses 1 to represent connected. I'm curious why you chose such an implementation?
If I use 1 to represent two nodes are connected, does that would affect me to extend your code to other graph combinatorial optimization problems?
Thanks for any reply!
Hello, I was looking through the code and comparing with what you shared in the paper, and it appears like theres some discrepancies. For example, I was interested in the GNN Encoder module. In the paper, it was presented as:
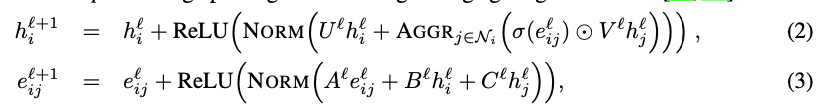
But in the code, in the gnn_encoder.py, it was modelled differently. Firstly, in the GNNEncoder class, you have an embedding (or dictionary) of size 2 to map an edge in the adjacency matrix (I presume here since it's of size 2, the adjacency matrix should be a binary matrix indicating connections and not weight). Why is this so though? In the paper, it was mentioned that you initialized the edge features using a Euclidean distance between points, and not just the connectivity. Also, we can see that this is passed onto the GNNLayer, which takes it as it is. This means that the initialization of the network will only ever have 2 different embeddings, and hence doesn't take into account the Euclidean distance between two nodes.
class GNNEncoder(nn.Module):
"""Configurable GNN Encoder
"""
def __init__(self, n_layers, hidden_dim, aggregation="sum", norm="layer",
learn_norm=True, track_norm=False, gated=True, *args, **kwargs):
super(GNNEncoder, self).__init__()
self.init_embed_edges = nn.Embedding(2, hidden_dim)
self.layers = nn.ModuleList([
GNNLayer(hidden_dim, aggregation, norm, learn_norm, track_norm, gated)
for _ in range(n_layers)
])
def forward(self, x, graph):
"""
Args:
x: Input node features (B x V x H)
graph: Graph adjacency matrices (B x V x V)
Returns:
Updated node features (B x V x H)
"""
# Embed edge features
e = self.init_embed_edges(graph.type(torch.long))
for layer in self.layers:
x, e = layer(x, e, graph)
return x
In the GNNLayer, the edge embedding gets updated different as opposed to the equation. Here's the code snippet:
batch_size, num_nodes, hidden_dim = h.shape
h_in = h
e_in = e
# Linear transformations for node update
Uh = self.U(h) # B x V x H
Vh = self.V(h).unsqueeze(1).expand(-1, num_nodes, -1, -1) # B x V x V x H
# Linear transformations for edge update and gating
Ah = self.A(h) # B x V x H
Bh = self.B(h) # B x V x H
Ce = self.C(e) # B x V x V x H
# Update edge features and compute edge gates
e = Ah.unsqueeze(1) + Bh.unsqueeze(2) + Ce # B x V x V x H
gates = torch.sigmoid(e) # B x V x V x H
# Update node features
h = Uh + self.aggregate(Vh, graph, gates) # B x V x H
As you can see, you first updated the edge features by transforming them with the current layer representation followed by creating a gating mechanism with the sigmoid function. This is then used to update the node information. However, in the paper, you wrote that the node features get updated by e_{ij}^{(l)} and not this new updated e_{ij}^{(l+1)}.
Hi @chaitjo, why do you use a negative adjacency matrix? It seems that your implementation of the encoder is agnostic to positive or negative adjacent matrix since you use nn.Embedding(2, hidden_dim) to represent edge existing or not. Could you share your motivation on negative adjacent matrix? Thanks in advance.
Hi, I got an error during validation step, here is a traceback:

As I understand, the variable perm_mask should be a tensor with integer values, but it is obtained from division in self.num_nodes in advance method as follows:
prev_k = bestScoresId / self.num_nodes
...
perm_mask = prev_k.unsqueeze(2).expand_as(self.mask)
self.mask = self.mask.gather(1, perm_mask)
So it looks like it cannot work in any case. Any help will be highly appreciated.
Hi , chaitjo
I aim to add some features to the model both for SL and RL.
which part shell I change
Thanks
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.