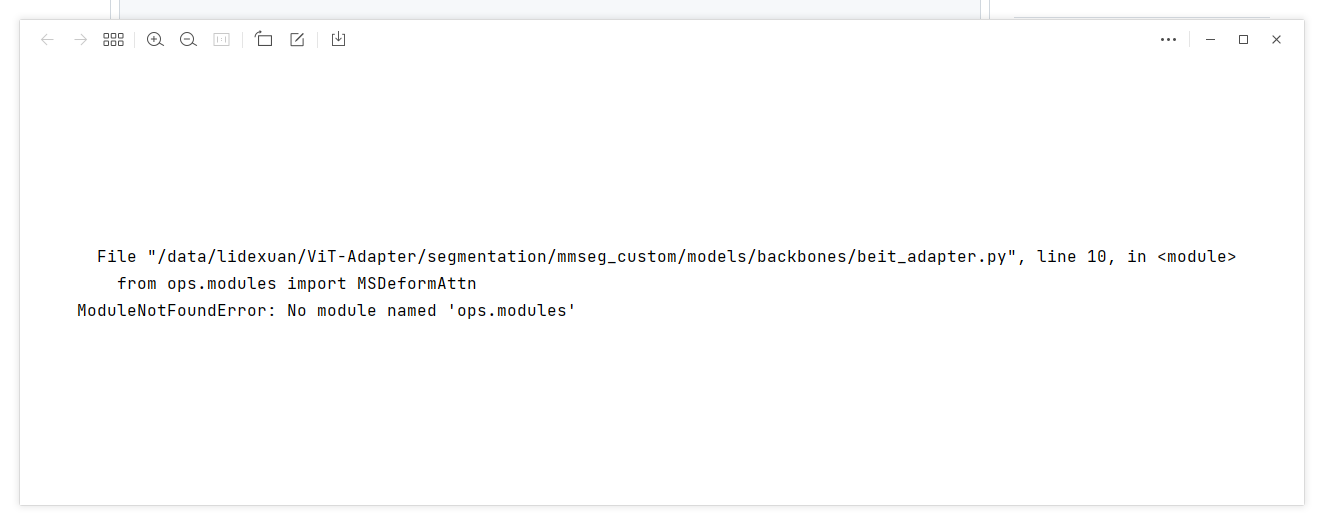
Hi, I am working to learn with ViT-Adapter as below.
After setup all required packages installed, do training with this command makes error.
Could you guess any error reason? Thank you.
2022-06-28 09:44:52,221 - mmseg - INFO - Loaded 500 images
2022-06-28 09:44:52,222 - mmseg - INFO - load checkpoint from local path: pretrained/mask2former_beit_adapter_large_896_80k_mapillary.pth.tar
2022-06-28 09:44:54,014 - mmseg - WARNING - The model and loaded state dict do not match exactly
missing keys in source state_dict: backbone.blocks.0.attn.relative_position_index, backbone.blocks.1.attn.relative_position_index, backbone.blocks.2.attn.relative_position_index, backbone.blocks.3.attn.relative_position_index, backbone.blocks.4.attn.relative_position_index, backbone.blocks.5.attn.relative_position_index, backbone.blocks.6.attn.relative_position_index, backbone.blocks.7.attn.relative_position_index, backbone.blocks.8.attn.relative_position_index, backbone.blocks.9.attn.relative_position_index, backbone.blocks.10.attn.relative_position_index, backbone.blocks.11.attn.relative_position_index, backbone.blocks.12.attn.relative_position_index, backbone.blocks.13.attn.relative_position_index, backbone.blocks.14.attn.relative_position_index, backbone.blocks.15.attn.relative_position_index, backbone.blocks.16.attn.relative_position_index, backbone.blocks.17.attn.relative_position_index, backbone.blocks.18.attn.relative_position_index, backbone.blocks.19.attn.relative_position_index, backbone.blocks.20.attn.relative_position_index, backbone.blocks.21.attn.relative_position_index, backbone.blocks.22.attn.relative_position_index, backbone.blocks.23.attn.relative_position_index
2022-06-28 09:44:54,053 - mmseg - INFO - Start running, host: ldg810@LVEF2, work_dir: /home/ldg810/git/ViT-Adapter/segmentation/work_dirs/mask2former_beit_adapter_large_896_80k_cityscapes_ss
2022-06-28 09:44:54,053 - mmseg - INFO - Hooks will be executed in the following order:
before_run:
(VERY_HIGH ) PolyLrUpdaterHook
(NORMAL ) CheckpointHook
(LOW ) DistEvalHook
(VERY_LOW ) TextLoggerHook
--------------------
before_train_epoch:
(VERY_HIGH ) PolyLrUpdaterHook
(LOW ) IterTimerHook
(LOW ) DistEvalHook
(VERY_LOW ) TextLoggerHook
--------------------
before_train_iter:
(VERY_HIGH ) PolyLrUpdaterHook
(LOW ) IterTimerHook
(LOW ) DistEvalHook
--------------------
after_train_iter:
(ABOVE_NORMAL) OptimizerHook
(NORMAL ) CheckpointHook
(LOW ) IterTimerHook
(LOW ) DistEvalHook
(VERY_LOW ) TextLoggerHook
--------------------
after_train_epoch:
(NORMAL ) CheckpointHook
(LOW ) DistEvalHook
(VERY_LOW ) TextLoggerHook
--------------------
before_val_epoch:
(LOW ) IterTimerHook
(VERY_LOW ) TextLoggerHook
--------------------
before_val_iter:
(LOW ) IterTimerHook
--------------------
after_val_iter:
(LOW ) IterTimerHook
--------------------
after_val_epoch:
(VERY_LOW ) TextLoggerHook
--------------------
after_run:
(VERY_LOW ) TextLoggerHook
--------------------
2022-06-28 09:44:54,053 - mmseg - INFO - workflow: [('train', 1)], max: 80000 iters
2022-06-28 09:44:54,054 - mmseg - INFO - Checkpoints will be saved to /home/ldg810/git/ViT-Adapter/segmentation/work_dirs/mask2former_beit_adapter_large_896_80k_cityscapes_ss by HardDiskBackend.
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448265233/work/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /opt/conda/conda-bld/pytorch_1623448265233/work/c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/functional.py:3658: UserWarning: The default behavior for interpolate/upsample with float scale_factor changed in 1.6.0 to align with other frameworks/libraries, and now uses scale_factor directly, instead of relying on the computed output size. If you wish to restore the old behavior, please set recompute_scale_factor=True. See the documentation of nn.Upsample for details.
"The default behavior for interpolate/upsample with float scale_factor changed "
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/functional.py:3658: UserWarning: The default behavior for interpolate/upsample with float scale_factor changed in 1.6.0 to align with other frameworks/libraries, and now uses scale_factor directly, instead of relying on the computed output size. If you wish to restore the old behavior, please set recompute_scale_factor=True. See the documentation of nn.Upsample for details.
"The default behavior for interpolate/upsample with float scale_factor changed "
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [6,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [13,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [20,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [27,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [97,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [104,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [111,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [118,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [125,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [34,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [41,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [48,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [55,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [62,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [96,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [101,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [102,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [103,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [108,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [109,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [110,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [115,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [116,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [117,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [122,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [123,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [124,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [69,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [76,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [83,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [90,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [0,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [32,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [33,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [38,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [39,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [40,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [45,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [46,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [47,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [52,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [53,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [54,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [59,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [60,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [61,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [3,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [4,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [5,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [10,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [11,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [12,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [17,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [18,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [19,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [24,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [25,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [26,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [31,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [66,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [67,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [68,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [73,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [74,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [75,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [80,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [81,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [82,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [87,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [88,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [89,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [94,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
/opt/conda/conda-bld/pytorch_1623448265233/work/aten/src/ATen/native/cuda/IndexKernel.cu:97: operator(): block: [1,0,0], thread: [95,0,0] Assertion `index >= -sizes[i] && index < sizes[i] && "index out of bounds"` failed.
Traceback (most recent call last):
File "./train.py", line 215, in <module>
main()
File "./train.py", line 211, in main
meta=meta)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/apis/train.py", line 167, in train_segmentor
runner.run(data_loaders, cfg.workflow)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py", line 134, in run
iter_runner(iter_loaders[i], **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py", line 61, in train
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/parallel/distributed.py", line 52, in train_step
output = self.module.train_step(*inputs[0], **kwargs[0])
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/models/segmentors/base.py", line 138, in train_step
losses = self(**data_batch)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func
return old_func(*args, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/models/segmentors/base.py", line 108, in forward
return self.forward_train(img, img_metas, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/segmentors/encoder_decoder_mask2former.py", line 145, in forward_train
**kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/segmentors/encoder_decoder_mask2former.py", line 88, in _decode_head_forward_train
gt_semantic_seg, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 553, in forward_train
img_metas)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/fp16_utils.py", line 186, in new_func
return old_func(*args, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 387, in loss
all_gt_labels_list, all_gt_masks_list, img_metas_list)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/core/utils/misc.py", line 21, in multi_apply
return tuple(map(list, zip(*map_results)))
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 297, in loss_single
img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 192, in get_targets
gt_masks_list, img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/core/utils/misc.py", line 21, in multi_apply
return tuple(map(list, zip(*map_results)))
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 248, in _get_target_single
img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/utils/assigner.py", line 148, in assign
cost = cost.detach().cpu()
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Traceback (most recent call last):
File "./train.py", line 215, in <module>
main()
File "./train.py", line 211, in main
meta=meta)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/apis/train.py", line 167, in train_segmentor
runner.run(data_loaders, cfg.workflow)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py", line 134, in run
iter_runner(iter_loaders[i], **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py", line 61, in train
outputs = self.model.train_step(data_batch, self.optimizer, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/parallel/distributed.py", line 52, in train_step
output = self.module.train_step(*inputs[0], **kwargs[0])
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/models/segmentors/base.py", line 138, in train_step
losses = self(**data_batch)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/fp16_utils.py", line 98, in new_func
return old_func(*args, **kwargs)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmseg/models/segmentors/base.py", line 108, in forward
return self.forward_train(img, img_metas, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/segmentors/encoder_decoder_mask2former.py", line 145, in forward_train
**kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/segmentors/encoder_decoder_mask2former.py", line 88, in _decode_head_forward_train
gt_semantic_seg, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 553, in forward_train
img_metas)
File "/home/ldg810/anaconda3/envs/vit-adapter/lib/python3.7/site-packages/mmcv/runner/fp16_utils.py", line 186, in new_func
return old_func(*args, **kwargs)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 387, in loss
all_gt_labels_list, all_gt_masks_list, img_metas_list)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/core/utils/misc.py", line 21, in multi_apply
return tuple(map(list, zip(*map_results)))
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 297, in loss_single
img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 192, in get_targets
gt_masks_list, img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/core/utils/misc.py", line 21, in multi_apply
return tuple(map(list, zip(*map_results)))
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/decode_heads/mask2former_head.py", line 248, in _get_target_single
img_metas)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/utils/assigner.py", line 142, in assign
dice_cost = self.dice_cost(mask_pred, gt_masks)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/losses/match_costs.py", line 178, in __call__
dice_cost = self.binary_mask_dice_loss(mask_preds, gt_masks)
File "/home/ldg810/git/ViT-Adapter/segmentation/mmseg_custom/models/losses/match_costs.py", line 164, in binary_mask_dice_loss
loss = 1 - (numerator + self.eps) / (denominator + self.eps)
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.





























































































































{kind=link}