⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠
This repository has been deprecated in favor of openshift-psap/topsail . All the ci-artifacts work is continuing there.
⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠⚠
This repository contains Ansible roles and playbooks for OpenShift for automating the interactions with the OpenShift operators under the responsibility Red Hat PSAP team.
- Performance & Scale for AI Platforms
To date, this includes:
- NVIDIA GPU Operator (most of the repository relates to the deployment, testing and interactions with this operator)
- the Special Resource Operator (deployment and testing currently under development)
- the Node Feature Discovery
- the Node Tuning Operator
The OpenShift version we are supporting is 4.N+1, 4.N, 4.N-1 and 4.N-2, where 4.N is the current latest version released. So as of July 2021, we need to support 4.9 (master), 4.8 (GA), 4.7 and 4.6.
See the documentation pages.
Requirements:
- See requirements.txt for reference
pip3 install -r requirements.txt
dnf install jq- OpenShift Client (
oc)
wget --quiet https://mirror.openshift.com/pub/openshift-v4/x86_64/clients/ocp/latest/openshift-client-linux.tar.gz
tar xf openshift-client-linux.tar.gz oc- An OpenShift cluster accessible with
$KUBECONFIGproperly set
oc version # fails if the cluster is not reachableThe original purpose of this repository was to perform nightly testing of the OpenShift Operators under responsibility.
This CI testing is performed by OpenShift PROW instance. Is is controlled by the configuration files located in these directories:
- https://github.com/openshift/release/tree/master/ci-operator/config/openshift-psap/ci-artifacts
- https://github.com/openshift/release/tree/master/ci-operator/jobs/openshift-psap/ci-artifacts
The main configuration is written in the config directory, and
jobs are then generated with make ci-operator-config
jobs. Secondary configuration options can then be modified in the
jobs directory.
The Prow CI jobs run in an OpenShift Pod. The ContainerFile is used to build their base-image, and the
run prow ... command is used as entrypoint.
From this entrypoint, we trigger the different high-level tasks of the operator end-to-end testing, eg:
run prow gpu-operator test_master_branchrun prow gpu-operator test_operatorhubrun prow gpu-operator validate_deployment_post_upgraderun prow gpu-operator cleanup_clusterrun prow cluster upgrade
These different high-level tasks rely on the toolbox scripts to automate the deployment of the required dependencies (eg, the NFD operator), the deployment of the operator from its published manifest or from its development repository and its non-regression testing.
The artifacts generated during the nightly CI testing are reused to plot a "testing dashboard" that gives an overview of the last days of testing. The generation of this page is performed by the ci-dashboard repository.
Currently, only the GPU Operator results are exposed in this dashboard:
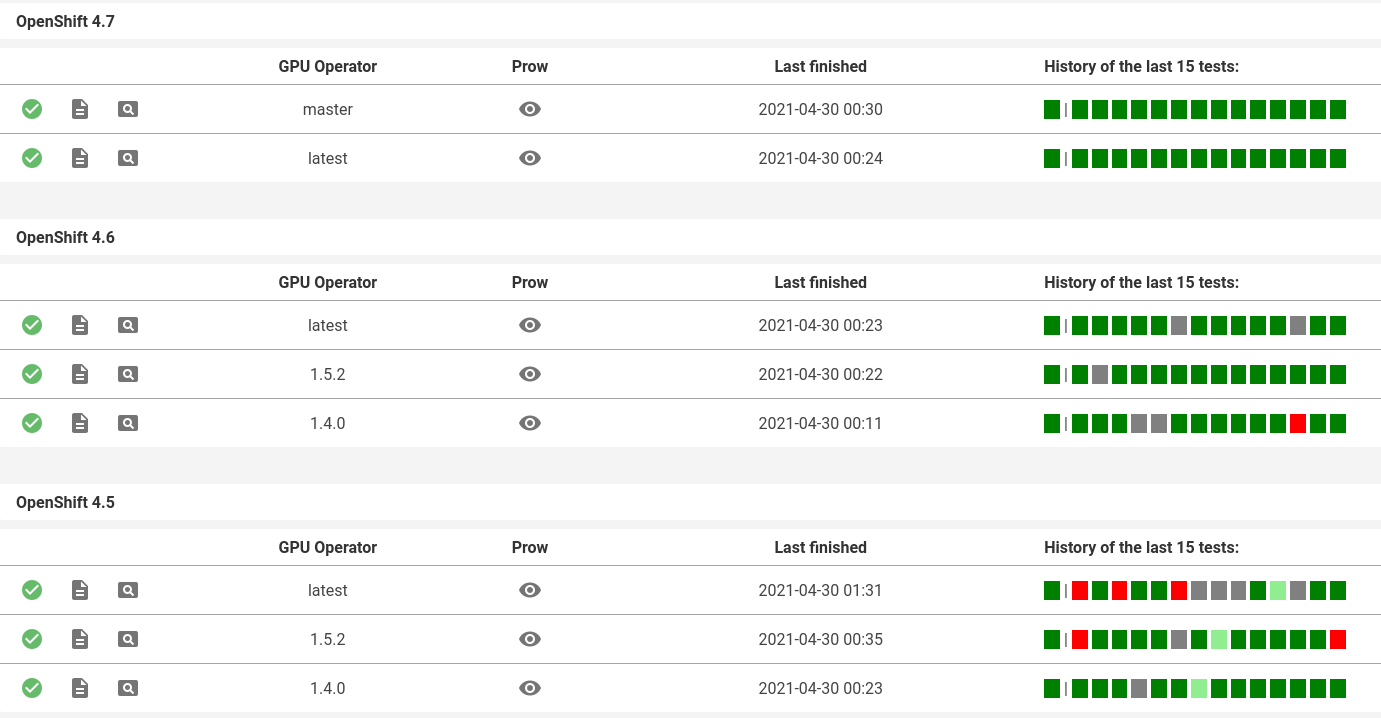
The PSAP Operators Toolbox is a set of tools, originally written for CI automation, but that appeared to be useful for a broader scope. It automates different operations on OpenShift clusters and operators revolving around PSAP activities: entitlement, scale-up of GPU nodes, deployment of the NFD, SRO and NVIDIA GPU Operators, but also their configuration and troubleshooting.
The entrypoint for the toolbox is the ./run_toolbox.py at the root of this repository. Run it without any arguments to see the list of available commands.
The functionalities of the toolbox commands are described in the documentation page.
./run_toolbox.py cluster capture_environment
NAME
run_toolbox.py cluster capture_environment - Captures the cluster environment
SYNOPSIS
run_toolbox.py cluster capture_environment -
DESCRIPTION
Captures the cluster environment
./run_toolbox.py cluster set_scale
NAME
run_toolbox.py cluster set_scale - Ensures that the cluster has exactly `scale` nodes with instance_type `instance_type`
SYNOPSIS
run_toolbox.py cluster set_scale INSTANCE_TYPE SCALE <flags>
DESCRIPTION
If the machinesets of the given instance type already have the required total number of replicas,
their replica parameters will not be modified.
Otherwise,
- If there's only one machineset with the given instance type, its replicas will be set to the value of this parameter.
- If there are other machinesets with non-zero replicas, the playbook will fail, unless the 'force_scale' parameter is
set to true. In that case, the number of replicas of the other machinesets will be zeroed before setting the replicas
of the first machineset to the value of this parameter."
POSITIONAL ARGUMENTS
INSTANCE_TYPE
The instance type to use, for example, g4dn.xlarge
SCALE
The number of required nodes with given instance type
FLAGS
--force=FORCE
Default: False
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py cluster upgrade_to_image
NAME
run_toolbox.py cluster upgrade_to_image - Upgrades the cluster to the given image
SYNOPSIS
run_toolbox.py cluster upgrade_to_image IMAGE
DESCRIPTION
Upgrades the cluster to the given image
POSITIONAL ARGUMENTS
IMAGE
The image to upgrade the cluster to
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py entitlement deploy
NAME
run_toolbox.py entitlement deploy - Deploys a cluster-wide entitlement key & RHSM config file (and optionally a YUM repo certificate) with the help of MachineConfig resources.
SYNOPSIS
run_toolbox.py entitlement deploy PEM <flags>
DESCRIPTION
Deploys a cluster-wide entitlement key & RHSM config file (and optionally a YUM repo certificate) with the help of MachineConfig resources.
POSITIONAL ARGUMENTS
PEM
Entitlement PEM file
FLAGS
--pem_ca=PEM_CA
Type: Optional[]
Default: None
YUM repo certificate
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py entitlement inspect
NAME
run_toolbox.py entitlement inspect - Inspects the cluster entitlement
SYNOPSIS
run_toolbox.py entitlement inspect -
DESCRIPTION
Inspects the cluster entitlement
./run_toolbox.py entitlement test_cluster
NAME
run_toolbox.py entitlement test_cluster - Tests the cluster entitlement
SYNOPSIS
run_toolbox.py entitlement test_cluster <flags>
DESCRIPTION
Tests the cluster entitlement
FLAGS
--no_inspect=NO_INSPECT
Default: False
Do not inspect on failure
./run_toolbox.py entitlement test_in_cluster
NAME
run_toolbox.py entitlement test_in_cluster - Tests a given PEM entitlement key on a cluster
SYNOPSIS
run_toolbox.py entitlement test_in_cluster PEM_KEY
DESCRIPTION
Tests a given PEM entitlement key on a cluster
POSITIONAL ARGUMENTS
PEM_KEY
The PEM entitlement key to test
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py entitlement test_in_podman
NAME
run_toolbox.py entitlement test_in_podman - Tests a given PEM entitlement key using a podman container
SYNOPSIS
run_toolbox.py entitlement test_in_podman PEM_KEY
DESCRIPTION
Tests a given PEM entitlement key using a podman container
POSITIONAL ARGUMENTS
PEM_KEY
The PEM entitlement key to test
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py entitlement undeploy
NAME
run_toolbox.py entitlement undeploy - Undeploys entitlement from cluster
SYNOPSIS
run_toolbox.py entitlement undeploy -
DESCRIPTION
Undeploys entitlement from cluster
./run_toolbox.py entitlement wait
NAME
run_toolbox.py entitlement wait - Waits for entitlement to be deployed
SYNOPSIS
run_toolbox.py entitlement wait -
DESCRIPTION
Waits for entitlement to be deployed
./run_toolbox.py gpu_operator bundle_from_commit
NAME
run_toolbox.py gpu_operator bundle_from_commit - Build an image of the GPU Operator from sources (<git repository> <git reference>) and push it to quay.io <quay_image_image>:operator_bundle_gpu-operator-<gpu_operator_image_tag_uid> using the <quay_push_secret> credentials.
SYNOPSIS
run_toolbox.py gpu_operator bundle_from_commit GIT_REPO GIT_REF QUAY_PUSH_SECRET QUAY_IMAGE_NAME <flags>
DESCRIPTION
Example parameters - https://github.com/NVIDIA/gpu-operator.git master /path/to/quay_secret.yaml quay.io/org/image_name
See 'oc get imagestreamtags -n gpu-operator-ci -oname' for the tag-uid to reuse.
POSITIONAL ARGUMENTS
GIT_REPO
Git repository URL to generate bundle of
GIT_REF
Git ref to bundle
QUAY_PUSH_SECRET
A file Kube Secret YAML file with `.dockerconfigjson` data and type kubernetes.io/dockerconfigjson
QUAY_IMAGE_NAME
FLAGS
--tag_uid=TAG_UID
Type: Optional[]
Default: None
The image tag suffix to use.
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py gpu_operator capture_deployment_state
NAME
run_toolbox.py gpu_operator capture_deployment_state - Captures the GPU operator deployment state
SYNOPSIS
run_toolbox.py gpu_operator capture_deployment_state -
DESCRIPTION
Captures the GPU operator deployment state
./run_toolbox.py gpu_operator cleanup_bundle_from_commit
NAME
run_toolbox.py gpu_operator cleanup_bundle_from_commit - Cleanup resources leftover from building a bundle from a commit
SYNOPSIS
run_toolbox.py gpu_operator cleanup_bundle_from_commit -
DESCRIPTION
Cleanup resources leftover from building a bundle from a commit
./run_toolbox.py gpu_operator deploy_cluster_policy
NAME
run_toolbox.py gpu_operator deploy_cluster_policy - Create the ClusterPolicy from the CSV
SYNOPSIS
run_toolbox.py gpu_operator deploy_cluster_policy -
DESCRIPTION
Create the ClusterPolicy from the CSV
./run_toolbox.py gpu_operator deploy_from_bundle
NAME
run_toolbox.py gpu_operator deploy_from_bundle - Deploys the GPU Operator from a bundle
SYNOPSIS
run_toolbox.py gpu_operator deploy_from_bundle <flags>
DESCRIPTION
Deploys the GPU Operator from a bundle
FLAGS
--bundle=BUNDLE
Type: Optional[]
Default: None
./run_toolbox.py gpu_operator deploy_from_commit
NAME
run_toolbox.py gpu_operator deploy_from_commit - Deploys the GPU operator from the given git commit
SYNOPSIS
run_toolbox.py gpu_operator deploy_from_commit GIT_REPOSITORY GIT_REFERENCE <flags>
DESCRIPTION
Deploys the GPU operator from the given git commit
POSITIONAL ARGUMENTS
GIT_REPOSITORY
The git repository to deploy from, e.g. https://github.com/NVIDIA/gpu-operator.git
GIT_REFERENCE
The git ref to deploy from, e.g. master
FLAGS
--tag_uid=TAG_UID
Type: Optional[]
Default: None
The GPU operator image tag UID. See 'oc get imagestreamtags -n gpu-operator-ci -oname' for the tag-uid to reuse
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py gpu_operator deploy_from_operatorhub
NAME
run_toolbox.py gpu_operator deploy_from_operatorhub - Deploys the GPU operator from OperatorHub
SYNOPSIS
run_toolbox.py gpu_operator deploy_from_operatorhub <flags>
DESCRIPTION
Deploys the GPU operator from OperatorHub
FLAGS
--version=VERSION
Type: Optional[]
Default: None
The version to deploy. If unspecified, deploys the latest version available in OperatorHub. Run the toolbox gpu_operator list_version_from_operator_hub subcommand to see the available versions.
--channel=CHANNEL
Type: Optional[]
Default: None
Optional channel to deploy from.
./run_toolbox.py gpu_operator run_gpu_burn
NAME
run_toolbox.py gpu_operator run_gpu_burn - Runs the GPU burn on the cluster
SYNOPSIS
run_toolbox.py gpu_operator run_gpu_burn <flags>
DESCRIPTION
Runs the GPU burn on the cluster
FLAGS
--runtime=RUNTIME
Type: Optional[]
Default: None
How long to run the GPU for, in seconds
./run_toolbox.py gpu_operator set_repo_config
NAME
run_toolbox.py gpu_operator set_repo_config - Sets the GPU-operator driver yum repo configuration file
SYNOPSIS
run_toolbox.py gpu_operator set_repo_config REPO_FILE <flags>
DESCRIPTION
Sets the GPU-operator driver yum repo configuration file
POSITIONAL ARGUMENTS
REPO_FILE
Absolute path to the repo file
FLAGS
--dest_dir=DEST_DIR
Type: Optional[]
Default: None
The destination dir in the pod to place the repo in
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py gpu_operator undeploy_from_commit
NAME
run_toolbox.py gpu_operator undeploy_from_commit - Undeploys a GPU-operator that was deployed from a commit
SYNOPSIS
run_toolbox.py gpu_operator undeploy_from_commit -
DESCRIPTION
Undeploys a GPU-operator that was deployed from a commit
./run_toolbox.py gpu_operator undeploy_from_operatorhub
NAME
run_toolbox.py gpu_operator undeploy_from_operatorhub - Undeploys a GPU-operator that was deployed from OperatorHub
SYNOPSIS
run_toolbox.py gpu_operator undeploy_from_operatorhub -
DESCRIPTION
Undeploys a GPU-operator that was deployed from OperatorHub
./run_toolbox.py gpu_operator wait_deployment
NAME
run_toolbox.py gpu_operator wait_deployment - Waits for the GPU operator to deploy
SYNOPSIS
run_toolbox.py gpu_operator wait_deployment -
DESCRIPTION
Waits for the GPU operator to deploy
./run_toolbox.py local_ci cleanup
NAME
run_toolbox.py local_ci cleanup - Clean the local CI artifacts
SYNOPSIS
run_toolbox.py local_ci cleanup -
DESCRIPTION
Clean the local CI artifacts
./run_toolbox.py local_ci deploy
NAME
run_toolbox.py local_ci deploy - Runs a given CI command
SYNOPSIS
run_toolbox.py local_ci deploy CI_COMMAND GIT_REPOSITORY GIT_REFERENCE <flags>
DESCRIPTION
Runs a given CI command
POSITIONAL ARGUMENTS
CI_COMMAND
The CI command to run, for example "run gpu-ci"
GIT_REPOSITORY
The git repository to run the command from, e.g. https://github.com/openshift-psap/ci-artifacts.git
GIT_REFERENCE
The git ref to run the command from, e.g. master
FLAGS
--tag_uid=TAG_UID
Type: Optional[]
Default: None
The local CI image tag UID
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py nfd has_gpu_nodes
NAME
run_toolbox.py nfd has_gpu_nodes - Checks if the cluster has GPU nodes
SYNOPSIS
run_toolbox.py nfd has_gpu_nodes -
DESCRIPTION
Checks if the cluster has GPU nodes
./run_toolbox.py nfd has_labels
NAME
run_toolbox.py nfd has_labels - Checks if the cluster has NFD labels
SYNOPSIS
run_toolbox.py nfd has_labels -
DESCRIPTION
Checks if the cluster has NFD labels
./run_toolbox.py nfd wait_gpu_nodes
NAME
run_toolbox.py nfd wait_gpu_nodes - Wait until nfd find GPU nodes
SYNOPSIS
run_toolbox.py nfd wait_gpu_nodes -
DESCRIPTION
Wait until nfd find GPU nodes
./run_toolbox.py nfd wait_labels
NAME
run_toolbox.py nfd wait_labels - Wait until nfd labels the nodes
SYNOPSIS
run_toolbox.py nfd wait_labels -
DESCRIPTION
Wait until nfd labels the nodes
./run_toolbox.py nfd_operator deploy_from_commit
NAME
run_toolbox.py nfd_operator deploy_from_commit - Deploys the NFD operator from the given git commit
SYNOPSIS
run_toolbox.py nfd_operator deploy_from_commit GIT_REPO GIT_REF <flags>
DESCRIPTION
Deploys the NFD operator from the given git commit
POSITIONAL ARGUMENTS
GIT_REPO
GIT_REF
The git ref to deploy from, e.g. master
FLAGS
--image_tag=IMAGE_TAG
Type: Optional[]
Default: None
The NFD operator image tag UID.
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py nfd_operator deploy_from_operatorhub
NAME
run_toolbox.py nfd_operator deploy_from_operatorhub - Deploys the GPU Operator from OperatorHub
SYNOPSIS
run_toolbox.py nfd_operator deploy_from_operatorhub <flags>
DESCRIPTION
Deploys the GPU Operator from OperatorHub
FLAGS
--channel=CHANNEL
Type: Optional[]
Default: None
./run_toolbox.py nfd_operator undeploy_from_operatorhub
NAME
run_toolbox.py nfd_operator undeploy_from_operatorhub - Undeploys an NFD-operator that was deployed from OperatorHub
SYNOPSIS
run_toolbox.py nfd_operator undeploy_from_operatorhub -
DESCRIPTION
Undeploys an NFD-operator that was deployed from OperatorHub
./run_toolbox.py repo validate_role_files
NAME
run_toolbox.py repo validate_role_files - Ensures that all the Ansible variables defining a filepath (`roles/`) do point to an existing file.
SYNOPSIS
run_toolbox.py repo validate_role_files -
DESCRIPTION
Ensures that all the Ansible variables defining a filepath (`roles/`) do point to an existing file.
./run_toolbox.py repo validate_role_vars_used
NAME
run_toolbox.py repo validate_role_vars_used - Ensure that all the Ansible variables defined are actually used in their role (with an exception for symlinks)
SYNOPSIS
run_toolbox.py repo validate_role_vars_used -
DESCRIPTION
Ensure that all the Ansible variables defined are actually used in their role (with an exception for symlinks)
./run_toolbox.py sro capture_deployment_state
NAME
run_toolbox.py sro capture_deployment_state
SYNOPSIS
run_toolbox.py sro capture_deployment_state -
./run_toolbox.py sro deploy_from_commit
NAME
run_toolbox.py sro deploy_from_commit - Deploys the SRO operator from the given git commit
SYNOPSIS
run_toolbox.py sro deploy_from_commit GIT_REPO GIT_REF <flags>
DESCRIPTION
Deploys the SRO operator from the given git commit
POSITIONAL ARGUMENTS
GIT_REPO
The git repository to deploy from, e.g. https://github.com/openshift-psap/special-resource-operator.git
GIT_REF
The git ref to deploy from, e.g. master
FLAGS
--image_tag=IMAGE_TAG
Type: Optional[]
Default: None
The SRO operator image tag UID.
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py sro run_e2e_test
NAME
run_toolbox.py sro run_e2e_test - Runs e2e test on the given SRO repo and ref
SYNOPSIS
run_toolbox.py sro run_e2e_test GIT_REPO GIT_REF
DESCRIPTION
Runs e2e test on the given SRO repo and ref
POSITIONAL ARGUMENTS
GIT_REPO
The git repository to deploy from, e.g. https://github.com/openshift-psap/special-resource-operator.git
GIT_REF
The git ref to deploy from, e.g. master
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS
./run_toolbox.py sro undeploy_from_commit
NAME
run_toolbox.py sro undeploy_from_commit - Undeploys an SRO-operator that was deployed from commit
SYNOPSIS
run_toolbox.py sro undeploy_from_commit GIT_REPO GIT_REF
DESCRIPTION
Undeploys an SRO-operator that was deployed from commit
POSITIONAL ARGUMENTS
GIT_REPO
The git repository to undeploy, e.g. https://github.com/openshift-psap/special-resource-operator.git
GIT_REF
The git ref to undeploy, e.g. master
NOTES
You can also use flags syntax for POSITIONAL ARGUMENTS





















