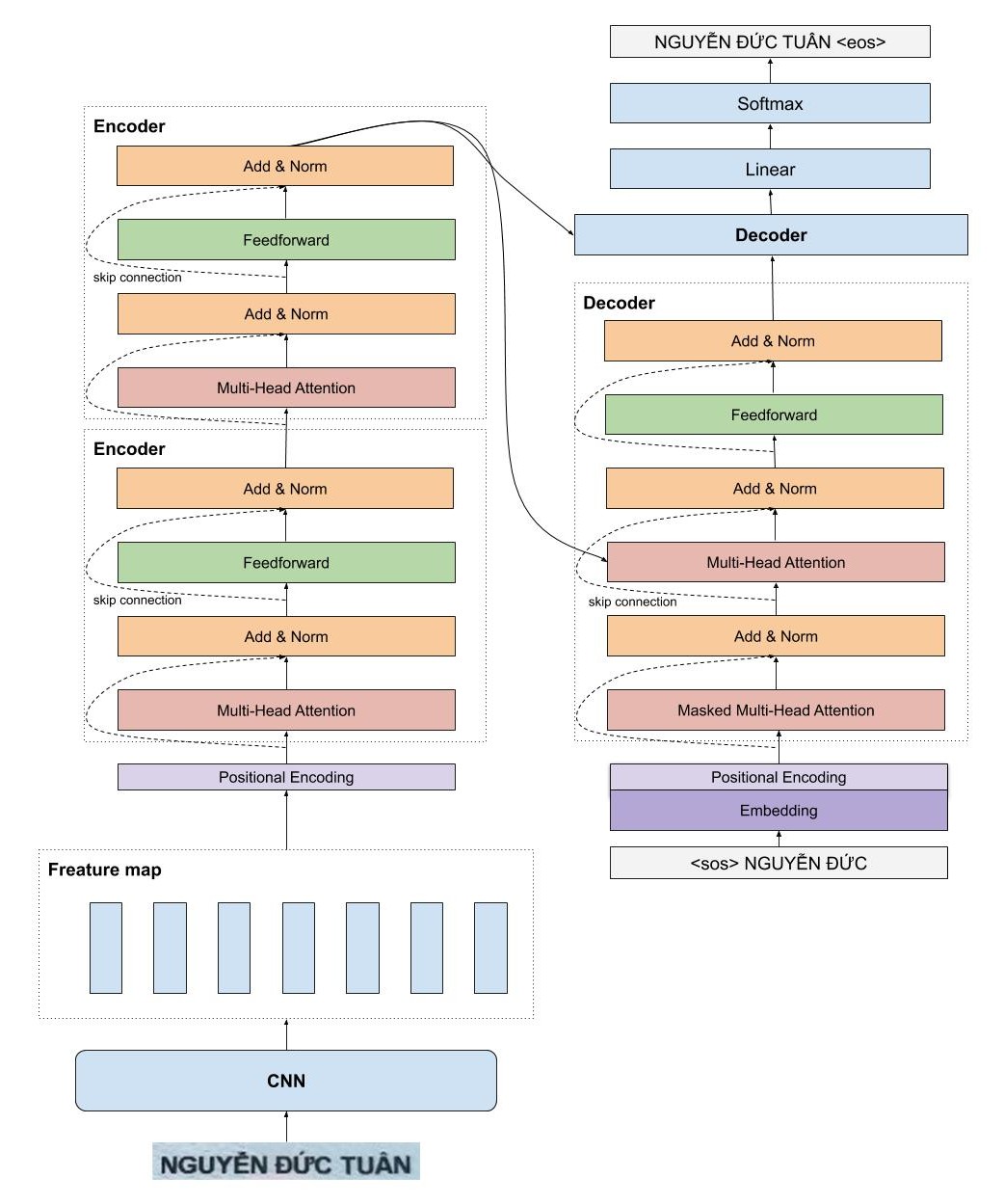
E đang thử mô hình resnet_transformer thì cũng đang gặp lỗi size mismatch (version đang là 0.1.9):
File "/home/duycuong/PycharmProjects/research_py3/text_recognition/classifier/vietocr/vietocr/eval.py", line 24, in <module>
detector = Predictor(config)
File "/home/duycuong/PycharmProjects/research_py3/text_recognition/classifier/vietocr/vietocr/tool/predictor.py", line 19, in __init__
model.load_state_dict(torch.load(weights, map_location=torch.device(device)))
File "/home/duycuong/.local/lib/python3.6/site-packages/torch/nn/modules/module.py", line 839, in load_state_dict
self.__class__.__name__, "\n\t".join(error_msgs)))
RuntimeError: Error(s) in loading state_dict for VietOCR:
Missing key(s) in state_dict: "cnn.model.conv0_1.weight", "cnn.model.bn0_1.weight", "cnn.model.bn0_1.bias", "cnn.model.bn0_1.running_mean", "cnn.model.bn0_1.running_var", "cnn.model.conv0_2.weight", "cnn.model.bn0_2.weight", "cnn.model.bn0_2.bias", "cnn.model.bn0_2.running_mean", "cnn.model.bn0_2.running_var", "cnn.model.layer1.0.conv1.weight", "cnn.model.layer1.0.bn1.weight", "cnn.model.layer1.0.bn1.bias", "cnn.model.layer1.0.bn1.running_mean", "cnn.model.layer1.0.bn1.running_var", "cnn.model.layer1.0.conv2.weight", "cnn.model.layer1.0.bn2.weight", "cnn.model.layer1.0.bn2.bias", "cnn.model.layer1.0.bn2.running_mean", "cnn.model.layer1.0.bn2.running_var", "cnn.model.layer1.0.downsample.0.weight", "cnn.model.layer1.0.downsample.1.weight", "cnn.model.layer1.0.downsample.1.bias", "cnn.model.layer1.0.downsample.1.running_mean", "cnn.model.layer1.0.downsample.1.running_var", "cnn.model.conv1.weight", "cnn.model.bn1.weight", "cnn.model.bn1.bias", "cnn.model.bn1.running_mean", "cnn.model.bn1.running_var", "cnn.model.layer2.0.conv1.weight", "cnn.model.layer2.0.bn1.weight", "cnn.model.layer2.0.bn1.bias", "cnn.model.layer2.0.bn1.running_mean", "cnn.model.layer2.0.bn1.running_var", "cnn.model.layer2.0.conv2.weight", "cnn.model.layer2.0.bn2.weight", "cnn.model.layer2.0.bn2.bias", "cnn.model.layer2.0.bn2.running_mean", "cnn.model.layer2.0.bn2.running_var", "cnn.model.layer2.0.downsample.0.weight", "cnn.model.layer2.0.downsample.1.weight", "cnn.model.layer2.0.downsample.1.bias", "cnn.model.layer2.0.downsample.1.running_mean", "cnn.model.layer2.0.downsample.1.running_var", "cnn.model.layer2.1.conv1.weight", "cnn.model.layer2.1.bn1.weight", "cnn.model.layer2.1.bn1.bias", "cnn.model.layer2.1.bn1.running_mean", "cnn.model.layer2.1.bn1.running_var", "cnn.model.layer2.1.conv2.weight", "cnn.model.layer2.1.bn2.weight", "cnn.model.layer2.1.bn2.bias", "cnn.model.layer2.1.bn2.running_mean", "cnn.model.layer2.1.bn2.running_var", "cnn.model.conv2.weight", "cnn.model.bn2.weight", "cnn.model.bn2.bias", "cnn.model.bn2.running_mean", "cnn.model.bn2.running_var", "cnn.model.layer3.0.conv1.weight", "cnn.model.layer3.0.bn1.weight", "cnn.model.layer3.0.bn1.bias", "cnn.model.layer3.0.bn1.running_mean", "cnn.model.layer3.0.bn1.running_var", "cnn.model.layer3.0.conv2.weight", "cnn.model.layer3.0.bn2.weight", "cnn.model.layer3.0.bn2.bias", "cnn.model.layer3.0.bn2.running_mean", "cnn.model.layer3.0.bn2.running_var", "cnn.model.layer3.0.downsample.0.weight", "cnn.model.layer3.0.downsample.1.weight", "cnn.model.layer3.0.downsample.1.bias", "cnn.model.layer3.0.downsample.1.running_mean", "cnn.model.layer3.0.downsample.1.running_var", "cnn.model.layer3.1.conv1.weight", "cnn.model.layer3.1.bn1.weight", "cnn.model.layer3.1.bn1.bias", "cnn.model.layer3.1.bn1.running_mean", "cnn.model.layer3.1.bn1.running_var", "cnn.model.layer3.1.conv2.weight", "cnn.model.layer3.1.bn2.weight", "cnn.model.layer3.1.bn2.bias", "cnn.model.layer3.1.bn2.running_mean", "cnn.model.layer3.1.bn2.running_var", "cnn.model.layer3.2.conv1.weight", "cnn.model.layer3.2.bn1.weight", "cnn.model.layer3.2.bn1.bias", "cnn.model.layer3.2.bn1.running_mean", "cnn.model.layer3.2.bn1.running_var", "cnn.model.layer3.2.conv2.weight", "cnn.model.layer3.2.bn2.weight", "cnn.model.layer3.2.bn2.bias", "cnn.model.layer3.2.bn2.running_mean", "cnn.model.layer3.2.bn2.running_var", "cnn.model.layer3.3.conv1.weight", "cnn.model.layer3.3.bn1.weight", "cnn.model.layer3.3.bn1.bias", "cnn.model.layer3.3.bn1.running_mean", "cnn.model.layer3.3.bn1.running_var", "cnn.model.layer3.3.conv2.weight", "cnn.model.layer3.3.bn2.weight", "cnn.model.layer3.3.bn2.bias", "cnn.model.layer3.3.bn2.running_mean", "cnn.model.layer3.3.bn2.running_var", "cnn.model.layer3.4.conv1.weight", "cnn.model.layer3.4.bn1.weight", "cnn.model.layer3.4.bn1.bias", "cnn.model.layer3.4.bn1.running_mean", "cnn.model.layer3.4.bn1.running_var", "cnn.model.layer3.4.conv2.weight", "cnn.model.layer3.4.bn2.weight", "cnn.model.layer3.4.bn2.bias", "cnn.model.layer3.4.bn2.running_mean", "cnn.model.layer3.4.bn2.running_var", "cnn.model.conv3.weight", "cnn.model.bn3.weight", "cnn.model.bn3.bias", "cnn.model.bn3.running_mean", "cnn.model.bn3.running_var", "cnn.model.layer4.0.conv1.weight", "cnn.model.layer4.0.bn1.weight", "cnn.model.layer4.0.bn1.bias", "cnn.model.layer4.0.bn1.running_mean", "cnn.model.layer4.0.bn1.running_var", "cnn.model.layer4.0.conv2.weight", "cnn.model.layer4.0.bn2.weight", "cnn.model.layer4.0.bn2.bias", "cnn.model.layer4.0.bn2.running_mean", "cnn.model.layer4.0.bn2.running_var", "cnn.model.layer4.1.conv1.weight", "cnn.model.layer4.1.bn1.weight", "cnn.model.layer4.1.bn1.bias", "cnn.model.layer4.1.bn1.running_mean", "cnn.model.layer4.1.bn1.running_var", "cnn.model.layer4.1.conv2.weight", "cnn.model.layer4.1.bn2.weight", "cnn.model.layer4.1.bn2.bias", "cnn.model.layer4.1.bn2.running_mean", "cnn.model.layer4.1.bn2.running_var", "cnn.model.layer4.2.conv1.weight", "cnn.model.layer4.2.bn1.weight", "cnn.model.layer4.2.bn1.bias", "cnn.model.layer4.2.bn1.running_mean", "cnn.model.layer4.2.bn1.running_var", "cnn.model.layer4.2.conv2.weight", "cnn.model.layer4.2.bn2.weight", "cnn.model.layer4.2.bn2.bias", "cnn.model.layer4.2.bn2.running_mean", "cnn.model.layer4.2.bn2.running_var", "cnn.model.conv4_1.weight", "cnn.model.bn4_1.weight", "cnn.model.bn4_1.bias", "cnn.model.bn4_1.running_mean", "cnn.model.bn4_1.running_var", "cnn.model.conv4_2.weight", "cnn.model.bn4_2.weight", "cnn.model.bn4_2.bias", "cnn.model.bn4_2.running_mean", "cnn.model.bn4_2.running_var".
Unexpected key(s) in state_dict: "cnn.cnn.features.0.weight", "cnn.cnn.features.0.bias", "cnn.cnn.features.1.weight", "cnn.cnn.features.1.bias", "cnn.cnn.features.1.running_mean", "cnn.cnn.features.1.running_var", "cnn.cnn.features.1.num_batches_tracked", "cnn.cnn.features.3.weight", "cnn.cnn.features.3.bias", "cnn.cnn.features.4.weight", "cnn.cnn.features.4.bias", "cnn.cnn.features.4.running_mean", "cnn.cnn.features.4.running_var", "cnn.cnn.features.4.num_batches_tracked", "cnn.cnn.features.7.weight", "cnn.cnn.features.7.bias", "cnn.cnn.features.8.weight", "cnn.cnn.features.8.bias", "cnn.cnn.features.8.running_mean", "cnn.cnn.features.8.running_var", "cnn.cnn.features.8.num_batches_tracked", "cnn.cnn.features.10.weight", "cnn.cnn.features.10.bias", "cnn.cnn.features.11.weight", "cnn.cnn.features.11.bias", "cnn.cnn.features.11.running_mean", "cnn.cnn.features.11.running_var", "cnn.cnn.features.11.num_batches_tracked", "cnn.cnn.features.14.weight", "cnn.cnn.features.14.bias", "cnn.cnn.features.15.weight", "cnn.cnn.features.15.bias", "cnn.cnn.features.15.running_mean", "cnn.cnn.features.15.running_var", "cnn.cnn.features.15.num_batches_tracked", "cnn.cnn.features.17.weight", "cnn.cnn.features.17.bias", "cnn.cnn.features.18.weight", "cnn.cnn.features.18.bias", "cnn.cnn.features.18.running_mean", "cnn.cnn.features.18.running_var", "cnn.cnn.features.18.num_batches_tracked", "cnn.cnn.features.20.weight", "cnn.cnn.features.20.bias", "cnn.cnn.features.21.weight", "cnn.cnn.features.21.bias", "cnn.cnn.features.21.running_mean", "cnn.cnn.features.21.running_var", "cnn.cnn.features.21.num_batches_tracked", "cnn.cnn.features.23.weight", "cnn.cnn.features.23.bias", "cnn.cnn.features.24.weight", "cnn.cnn.features.24.bias", "cnn.cnn.features.24.running_mean", "cnn.cnn.features.24.running_var", "cnn.cnn.features.24.num_batches_tracked", "cnn.cnn.features.27.weight", "cnn.cnn.features.27.bias", "cnn.cnn.features.28.weight", "cnn.cnn.features.28.bias", "cnn.cnn.features.28.running_mean", "cnn.cnn.features.28.running_var", "cnn.cnn.features.28.num_batches_tracked", "cnn.cnn.features.30.weight", "cnn.cnn.features.30.bias", "cnn.cnn.features.31.weight", "cnn.cnn.features.31.bias", "cnn.cnn.features.31.running_mean", "cnn.cnn.features.31.running_var", "cnn.cnn.features.31.num_batches_tracked", "cnn.cnn.features.33.weight", "cnn.cnn.features.33.bias", "cnn.cnn.features.34.weight", "cnn.cnn.features.34.bias", "cnn.cnn.features.34.running_mean", "cnn.cnn.features.34.running_var", "cnn.cnn.features.34.num_batches_tracked", "cnn.cnn.features.36.weight", "cnn.cnn.features.36.bias", "cnn.cnn.features.37.weight", "cnn.cnn.features.37.bias", "cnn.cnn.features.37.running_mean", "cnn.cnn.features.37.running_var", "cnn.cnn.features.37.num_batches_tracked", "cnn.cnn.features.40.weight", "cnn.cnn.features.40.bias", "cnn.cnn.features.41.weight", "cnn.cnn.features.41.bias", "cnn.cnn.features.41.running_mean", "cnn.cnn.features.41.running_var", "cnn.cnn.features.41.num_batches_tracked", "cnn.cnn.features.43.weight", "cnn.cnn.features.43.bias", "cnn.cnn.features.44.weight", "cnn.cnn.features.44.bias", "cnn.cnn.features.44.running_mean", "cnn.cnn.features.44.running_var", "cnn.cnn.features.44.num_batches_tracked", "cnn.cnn.features.46.weight", "cnn.cnn.features.46.bias", "cnn.cnn.features.47.weight", "cnn.cnn.features.47.bias", "cnn.cnn.features.47.running_mean", "cnn.cnn.features.47.running_var", "cnn.cnn.features.47.num_batches_tracked", "cnn.cnn.features.49.weight", "cnn.cnn.features.49.bias", "cnn.cnn.features.50.weight", "cnn.cnn.features.50.bias", "cnn.cnn.features.50.running_mean", "cnn.cnn.features.50.running_var", "cnn.cnn.features.50.num_batches_tracked", "cnn.cnn.classifier.0.weight", "cnn.cnn.classifier.0.bias", "cnn.cnn.classifier.3.weight", "cnn.cnn.classifier.3.bias", "cnn.cnn.classifier.6.weight", "cnn.cnn.classifier.6.bias".
size mismatch for transformer.embed_tgt.weight: copying a param with shape torch.Size([232, 512]) from checkpoint, the shape in current model is torch.Size([233, 256]).
size mismatch for transformer.pos_enc.pe: copying a param with shape torch.Size([10000, 1, 512]) from checkpoint, the shape in current model is torch.Size([1024, 1, 256]).
size mismatch for transformer.transformer.encoder.layers.0.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.0.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.0.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.0.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.0.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.0.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.0.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.0.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.0.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.0.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.0.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.1.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.1.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.1.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.1.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.1.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.1.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.2.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.2.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.2.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.2.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.2.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.2.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.3.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.3.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.3.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.3.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.3.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.3.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.4.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.4.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.4.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.4.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.4.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.4.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.encoder.layers.5.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.encoder.layers.5.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.encoder.layers.5.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.encoder.layers.5.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.encoder.layers.5.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.layers.5.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.norm.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.encoder.norm.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.0.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.0.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.0.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.0.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.0.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.0.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.0.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.0.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.0.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.1.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.1.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.1.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.1.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.1.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.1.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.1.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.1.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.1.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.2.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.2.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.2.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.2.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.2.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.2.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.2.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.2.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.2.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.3.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.3.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.3.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.3.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.3.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.3.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.3.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.3.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.3.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.4.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.4.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.4.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.4.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.4.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.4.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.4.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.4.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.4.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.self_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.5.self_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.5.self_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.5.self_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.multihead_attn.in_proj_weight: copying a param with shape torch.Size([1536, 512]) from checkpoint, the shape in current model is torch.Size([768, 256]).
size mismatch for transformer.transformer.decoder.layers.5.multihead_attn.in_proj_bias: copying a param with shape torch.Size([1536]) from checkpoint, the shape in current model is torch.Size([768]).
size mismatch for transformer.transformer.decoder.layers.5.multihead_attn.out_proj.weight: copying a param with shape torch.Size([512, 512]) from checkpoint, the shape in current model is torch.Size([256, 256]).
size mismatch for transformer.transformer.decoder.layers.5.multihead_attn.out_proj.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.linear1.weight: copying a param with shape torch.Size([2048, 512]) from checkpoint, the shape in current model is torch.Size([2048, 256]).
size mismatch for transformer.transformer.decoder.layers.5.linear2.weight: copying a param with shape torch.Size([512, 2048]) from checkpoint, the shape in current model is torch.Size([256, 2048]).
size mismatch for transformer.transformer.decoder.layers.5.linear2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm1.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm1.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm2.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm2.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm3.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.layers.5.norm3.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.norm.weight: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.transformer.decoder.norm.bias: copying a param with shape torch.Size([512]) from checkpoint, the shape in current model is torch.Size([256]).
size mismatch for transformer.fc.weight: copying a param with shape torch.Size([232, 512]) from checkpoint, the shape in current model is torch.Size([233, 256]).
size mismatch for transformer.fc.bias: copying a param with shape torch.Size([232]) from checkpoint, the shape in current model is torch.Size([233]).