clementpinard / sfmlearner-pytorch Goto Github PK
View Code? Open in Web Editor NEWPytorch version of SfmLearner from Tinghui Zhou et al.
License: MIT License
Pytorch version of SfmLearner from Tinghui Zhou et al.
License: MIT License
Hi! I already posted about this on the original tensorflow implementation, but i would also like to know your opinion on the matter :)
Do you think that the black borders on an image like the one bellow would affect the training and the predicitons of depth/pose?

I get the following error when trying to do test:
Traceback (most recent call last):
File "test_disp.py", line 144, in
main()
File "test_disp.py", line 50, in main
pose_net.load_state_dict(weights['state_dict'], strict=False)
TypeError: load_state_dict() got an unexpected keyword argument 'strict'
Please help.
https://drive.google.com/drive/folders/1H1AFqSS8wr_YzwG2xWwAQHTfXN5Moxmx
tar xvf exp_pose_model_best.pth.tar
tar: exp_pose_model_best.pth.tar: Cannot open: No such file or directory
tar: Error is not recoverable: exiting now
also, how to run test_dis.py?
python3 test_disp.py --dataset-dir misc --pretrained-dispnet checkpoints/trained/dispnet_model_best.pth.tar --output-dir checkpoints/output/
Hi Clement,
Thank you very much for your implementation. I just got a question on this line:
Line 413 in e14f747
Maybe I think it incorrectly, but I found in the process of logging the warped image, the code seems that applies the pose t+1 on the ref_img t-1? Could you please kindly help to explain this line a bit?
Thank you very much.
Best regards,
Rui
Hi,
The depth predictions are validated with sparse ground truth depths of KITTI here, but there are also other papers validating against full ground truth (filled by interpolating). Will there be a large difference in the validation result between these two methods? Which one is the main criteria nowadays in monocular depth estimation?
Hello,
I am a student who just very new to every contents written in this project (Python, PyTorch, CNN, movement estimation, etc.) and I want to learn basics by replicating your work :).
I could replicate most of your work but now I got stuck doing visualize the prediction poses and then compare to the KITTI ground truth poses data as similar as shown below:
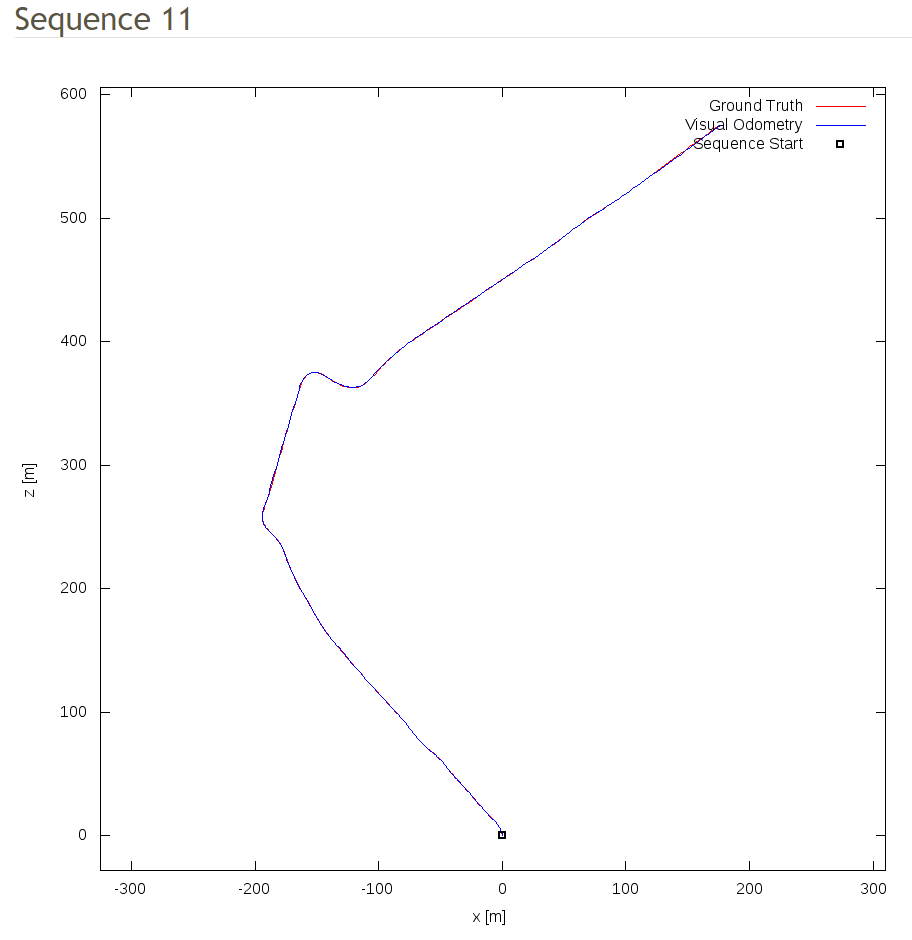
I could draw the ground truth map with no problems. How your code as well as explained in the paper seem using 5-frame snippets for prediction, therefore the output final_poses has size [pics_number, frame_number, 3, 4] while KITTI ground truth poses data only has size [pics_number, 3, 4]. I don't know how to deal with this array to draw visual odometry map so could you please show me how to do it?
One more thing, sorry for my bad English but in file times.txt got from downloading the KITTI odometry data set which explained : "Timestamps for each of the synchronized image pairs in seconds", is it the time between frames?
Please correct me if I am wrong at any point.
Thank you very much!
There were some changes to test_disp.py, and kitti_eval/depth_evaluation_utils.py in the recent commits, which results in the following error while testing: (The old version still works)
File "test_disp.py", line 160, in <module>
main()
File "test_disp.py", line 61, in main
framework = test_framework(dataset_dir, test_files, seq_length, args.min_depth, args.max_depth)
File "kitti_eval/depth_evaluation_utils.py", line 14, in __init__
self.calib_dirs, self.gt_files, self.img_files, self.displacements, self.cams = read_scene_data(self.root, test_files, seq_length, step)
File "kitti_eval/depth_evaluation_utils.py", line 99, in read_scene_data
displacements.append(get_displacements(data_root/date/scene/'oxts', ref_indices, demi_length))
File "kitti_eval/depth_evaluation_utils.py", line 60, in get_displacements
reordered_indices = [indices[tgt_index]] + [*indices[:tgt_index]] + [*indices[tgt_index + 1:]]
IndexError: index -1 is out of bounds for axis 0 with size 0Hi Clement
Thanks for your prompt answer for my last question, but I have another one here which is not related with the code.
As mentioned in the paper and the code, the ref images are [t-n, t-n+1, .. ,t-1, t+1, ...t+n], but what if I use [t-n, .. t-1] only? What do you suppose the impact of the result? Thank you.
Cheers,
Rui
Thanks for your cool work. This implementation is very useful.
I have a question about the accuracy of poses in Seq 09, 10.
./data/test_scenes.txt doesn't have 09, 10.
According to KITTI-odometry-development-kit,
Seq09 -> 2011_09_30_drive_0033 000000 001590
Seq10 -> 2011_09_30_drive_0034 000000 001200
This means that this frameworks uses these 2 sequences in training or validation.
( Is this right ? )
How did you get the pose results on README ?
Did you use 09, 10 in training, or did you use another method ?
Also I generated kitti-odometry-data using this script, and then tried using your framework. (with --dataset-format stacked).
However, photometric-error in validation didn't decrease.
This is an example command.
python train.py /hoge/kitti_odom/ -b4 -m0.3 -s1.8 --epoch-size 1000 --sequence-length 5 --log-output --rotation-mode euler --dataset-format stackedThe original paper uses 00-08 in training. I want to reproduce that score, but I cannot.
( Later, I will add Seq09,10 to test_scenes.txt and start training. )
Can you tell me your method ?
Thank you for reading.
Hi, @ClementPinard , I am a little confused by your implementation of inverse warp function below:
if padding_mode == 'zeros':
X_mask = ((X_norm > 1)+(X_norm < -1)).detach()
X_norm[X_mask] = 2 # make sure that no point in warped image is a combinaison of im and gray
Y_mask = ((Y_norm > 1)+(Y_norm < -1)).detach()
Y_norm[Y_mask] = 2
for pixels out of range here, why do you set their value as 2?
It seems like these pixels will be padded by zeros, no matter their values are 2 or not, and what do you mean by your comment here? Could you please give some explanations? Thanks!
Hi, thanks for the wonderful code. I haven't started to play with it yet, just saw some @ symbols, for example,
rot_matrices @ inv_transform_matrices[:,:,-1:]
R = gt_pose[:,:3] @ np.linalg.inv(pred_pose[:,:3])
I don't really know what these operations (@) trying to do. Thank you if you could clarify.
The original SfMLearner uses a MultiScale approach for training (4 different scales/resolutions to train together). However this code is using a RandomScale apprach and seen in the set of augmentations:
input_transform = custom_transforms.Compose([
custom_transforms.RandomHorizontalFlip(),
custom_transforms.RandomScaleCrop(),
custom_transforms.ArrayToTensor(),
normalize
])
I feel that MultiScale approach will be better since Pose and depth may be dependent on scale.
This is not really an issue but a request to support MultiScale training instead of RandomScale.
Hi,
I tried to tun prepare_train_data.py using the command you provided (num_thread=4), but got the following error message:
joblib.externals.loky.process_executor._RemoteTraceback:
"""
Traceback (most recent call last):
File "/usr/local/lib/python3.6/site-packages/joblib/externals/loky/process_executor.py", line 418, in _process_worker
r = call_item()
File "/usr/local/lib/python3.6/site-packages/joblib/externals/loky/process_executor.py", line 272, in call
return self.fn(*self.args, **self.kwargs)
File "/usr/local/lib/python3.6/site-packages/joblib/_parallel_backends.py", line 567, in call
return self.func(*args, **kwargs)
File "/usr/local/lib/python3.6/site-packages/joblib/parallel.py", line 225, in call
for func, args, kwargs in self.items]
File "/usr/local/lib/python3.6/site-packages/joblib/parallel.py", line 225, in
for func, args, kwargs in self.items]
File "/Users/siwei/Desktop/SfmLearner-Pytorch-master/data/prepare_train_data.py", line 33, in dump_example
dump_dir = args.dump_root/scene_data['rel_path']
AttributeError: 'Namespace' object has no attribute 'dump_root'
"""
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/siwei/Desktop/SfmLearner-Pytorch-master/data/prepare_train_data.py", line 109, in
main()
File "/Users/siwei/Desktop/SfmLearner-Pytorch-master/data/prepare_train_data.py", line 86, in main
Parallel(n_jobs=args.num_threads)(delayed(dump_example)(scene) for scene in tqdm(data_loader.scenes))
File "/usr/local/lib/python3.6/site-packages/joblib/parallel.py", line 930, in call
self.retrieve()
File "/usr/local/lib/python3.6/site-packages/joblib/parallel.py", line 833, in retrieve
self._output.extend(job.get(timeout=self.timeout))
File "/usr/local/lib/python3.6/site-packages/joblib/_parallel_backends.py", line 521, in wrap_future_result
return future.result(timeout=timeout)
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/concurrent/futures/_base.py", line 432, in result
return self.__get_result()
File "/usr/local/Cellar/python/3.6.5/Frameworks/Python.framework/Versions/3.6/lib/python3.6/concurrent/futures/_base.py", line 384, in __get_result
raise self._exception
AttributeError: 'Namespace' object has no attribute 'dump_root'
Do you have any idea why? The error didn't happen when I used only one thread.
Hi,
Did you use cityscapes+kitti, or only kitti for the available pretrained networks.
Hi!
Could you please explain the difference between SequenceFolder class from sequence_folders.py and from stacked_sequence_folders.py more precisely?
Also I didn't understand how get data in directory in this format:
`
A sequence data loader where the images are arranged in this way:
root/scene_1/0000000.jpg
root/scene_1/0000000_cam.txt
root/scene_1/0000001.jpg
root/scene_1/0000001_cam.txt
.
root/scene_2/0000000.jpg
root/scene_2/0000000_cam.txt
`
I think your script data/prepare_train_data.py doesn't provide any opportunity to configure KITTI dataset in this format.
Thanks!
Hi Clément Pinard,
meet the invalid syntax problem because of the "@" in inverse_warp.py. Though there were already an issue about this symbol, but still confused how to change and fix it in the following sentence.
rotMat = xmat @ ymat @ zmat
BTW, I am using torch 0.4.1, python 2.7&3.6
Thanks for your answer!
When I went through the function to calculate photometric reconstruction loss I found this line of code
assert((reconstruction_loss == reconstruction_loss).data[0] == 1)
I figured out that this line is there to check if reconstruction loss is NaN. But I couldn't quite figure out why are we doing this. Under what circumstances could reconstruction loss reach NaN.
I'm trying to train only the pose network. I'm using the depth map obtained from Kinect camera in place of training the DispNet. I'm getting assertion error randomly in run time. I'm unable to figure out the cause. I wan to know why we are checking for NaNs in reconstruction loss. Also what are the possible causes for reconstruction loss to reach NaN?
I used the following command to train on KITTI
python3 train.py ./data/kitti/kitti_rawdata_formatted/ -b4 -m0.2 -s0.1 --epoch-size 3000 --sequence-length 3 --log-output
However, I get a blank image when I run the inference (attached).

Even while training, the dispnet output and the depth outputs (seen on tensorboard) are blank images.
Please help.
Hello,
I would like to know how to visualize the pose estimation outputs.
@ClementPinard Could you please explain the final_pose format and how to convert pose gt to kitti odometry pose?
Thanks
Got the following error message when using the latest version:
tgt_img_scaled = F.interpolate(tgt_img, (h, w), method='area', align_corners=False) TypeError: interpolate() got an unexpected keyword argument 'method'
(line 312)
parameters used: --epoch-size 1000 --log-output --with-gt
Changed that line to:
tgt_img_scaled = F.interpolate(tgt_img, (h, w), mode='area')
Seems to working now, did I break something? (great job on the port btw! :) )
Thanks!
I did not find the codes of testing on Make3D Dataset. Could you please give the codes?
The quality of depth generated during inference is much poorer compared to that seen on tensorboard (during training).
Here is an example inference output:

It seems inference is not working correctly.
I am getting the following with the pretrained models, which are much worse than reported here. https://github.com/ClementPinard/SfmLearner-Pytorch#pose-results
It is possible that the pretrained models in google drive are not updated.
$ python test_pose.py ../SfmLearner-Pytorch/pretrained/exp_pose_model_best.pth.tar --dataset-dir kitti/odometry/ --sequence 09
getting test metadata for theses sequences : {Path('kitti/odometry/sequences/09')}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.50it/s]
1591 snippets to test
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▋| 1587/1591 [02:35<00:00, 10.20it/s]
Results
ATE, RE
mean 0.0195, 0.0041
std 0.0106, 0.0022
$ python test_pose.py ../SfmLearner-Pytorch/pretrained/exp_pose_model_best.pth.tar --dataset-dir kitti/odometry/ --sequence 10
getting test metadata for theses sequences : {Path('kitti/odometry/sequences/10')}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:02<00:00, 2.54s/it]
1201 snippets to test
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌| 1197/1201 [03:11<00:00, 6.24it/s]
Results
ATE, RE
mean 0.0148, 0.0042
std 0.0096, 0.0026Hi,
I tried to add a learning rate scheduler - file attached.
SfmLearner-Pytorch.zip
It can be used in this way:
python3 train.py ./data/kitti/kitti_rawdata_formatted/ -b 48 -m 1.0 -s 0.1 --sequence-length 3 --log-output --checkpoint_dir ./training/checkpoints/ --optimizer Adam --scheduler step --lr 2e-4
However, the loss doesn't come down if I use the scheduler. Could you please take a look and let me know if I am doing something wrong.
Consider the following line:
out_of_bound = 1 - (ref_img_warped == 0).prod(1, keepdim=True).type_as(ref_img_warped)
in the function loss_functions.py. If I am not wrong this is computed to not take loss at those pixels which are out of bound or possibly, disoccluded as well due to warping. My question here is, wouldn't pytorch calculate the gradient with respect to this variable out_of_bound as well and update it, although it shouldn't be updated?
This may not change the overall code and performance, but still a correct way to do it would be to specify that the variable out _of_bound should not get any gradients and not be updated as well.
Hi,
Thanks for your implementation in PyTorch, it helps me much, recently I learn the ego-motion with your code. The procession of data preparation is quiet rambling for me, and I'm quiet uncertain whether there are some errors I have made. Therefore, can you tell me the final number of samples in KITTI and Cityscapes?
For me, I got
KITTI:
43154 samples found in 64 train scenes
1090 samples found in 8 valid scenes
In the readme you state enough motion is guaranteed between following frames.
I wonder how that affects the performance when the vehicle is static.
Can you elaborate on that design decision?
is it convergence issues?
Thanks,
Guy
The training is not using multi-gpus. If you just add DataParallel(), it will use all the GPUs in th system - snippet from train.py below:
if args.pretrained_disp:
print("=> using pre-trained weights for Dispnet")
a = torch.load(args.pretrained_disp)
disp_net.load_state_dict(a['state_dict'])
else:
disp_net.init_weights()
disp_net = torch.nn.DataParallel(disp_net).cuda()
pose_exp_net = torch.nn.DataParallel(pose_exp_net).cuda()
cudnn.benchmark = True
print('=> setting adam solver')
parameters = set()
for net_ in [disp_net, pose_exp_net]:
parameters |= set(net_.parameters())
When using multi-gpu training, you have to do some changes in inference, while loading he checkpoint:
disp_net = models.DispNetS().cuda()
weights = torch.load(args.ckpt_file)
#if the original model was created with DataParallel, remove it.
new_state_dict = OrderedDict()
for k, v in weights['state_dict'].items():
# remove `module.`
name = k[7:] if k.startswith('module.') else k
new_state_dict[name] = v
weights['state_dict'] = new_state_dict
disp_net.load_state_dict(weights['state_dict'])
Hi,
Is there a pre-trained PyTorch model trained on Cityscapes and Kitti available? The script models/download_model.sh and download_model_5frame.sh doesn't work.
Hi, I'm trying to train using a non-KITTI dataset and keep getting this error about equal number of batches (note that I have modified the code so the line numbers aren't very relevant):
Traceback (most recent call last):
File "train.py", line 568, in
main()
File "train.py", line 246, in main
train_loss = train(args, train_loader, disp_net, pose_exp_net, optimizer, args.epoch_size, logger, training_writer, ...)
File "train.py", line 336, in train
args.rotation_mode, args.padding_mode)
File "/.../loss_functions.py", line 44, in photometric_reconstruction_loss
loss += one_scale(d, mask)
File "/.../loss_functions.py", line 25, in one_scale
ref_img_warped = inverse_warp(ref_img, depth[:,0], current_pose, intrinsics_scaled, intrinsics_scaled_inv, rotation_mode, padding_mode)
File "/.../inverse_warp.py", line 183, in inverse_warp
cam_coords = pixel2cam(depth, intrinsics_inv) # [B,3,H,W]
File "/.../inverse_warp.py", line 39, in pixel2cam
cam_coords = intrinsics_inv.bmm(current_pixel_coords).view(b, 3, h, w)
RuntimeError: invalid argument 7: equal number of batches expected at /.../THC/generic/THCTensorMathBlas.cu:471
I'm not exactly sure what batch numbers have to be the same. Also, the problem seems to get fixed by changing the number of images in the training and validation datasets, which suggests that perhaps both the number of training and testing images have to be divisible by the batch size or something similar. Do you have an idea what's going on? Thanks!
In the README.md, you mention:
pytorch 0.3
scipy
argparse
tensorboard-pytorch
tensorboard
blessings
progressbar2
path.py
Is there a mistake? Pytorch 0.2 seems to be latest version.
SfmLearner-Pytorch/test_disp.py
Lines 88 to 89 in 94adee0
Thanks for your code, I don't know how to judge the model converge when traning on cityscape dataset.
loss? or just after 3000 epoch
In Inverse_warp.py, the line 40,
cam_coords = (intrinsics_inv @ current_pixel_coords).reshape(b, 3, h, w)
SyntaxError: invalid syntax
what is @ used for? a decorator, or an operator? The paltform I used is python 2.7 anaconda
The cam.txt generated by processing the kitti_raw_loader are always (0,0,0,0,0,0,0,0,1). This doesn't make sense. I think fx,fy should be 1 instead of zero. Is it because of lines 102-103 in the kitti_raw_loader.py that sets them to zero? When I run the code zoom_x and zoom_y are always 0.
P_rect[0] *= zoom_x
P_rect[1] *= zoom_y
Hello @ClementPinard,
I can convert 6DoF to transformation matrix by calling pose_vec2mat. But, I need to do the reverse to convert transformation matrix to 6DOF. could you please help me to figure this out?
Thanks,
I come across some problem when running prepare_train_data.py as follows:
python data/prepare_train_data.py C:\TensorFlow\SfmLearner-Pytorch\raw_data_downloader\2011_09_26\2011_09_26_drive_0001_sync --dataset-format "kitti" --dump-root C:\TensorFlow\SfmLearner-Pytorch\formatted_data --width 416 --height 128 --num-threads 4
And, it gives me the follwoing error message:
Traceback (most recent call last): File "data/prepare_train_data.py", line 94, in <module> main() File "data/prepare_train_data.py", line 67, in main get_gt=args.with_gt) File "C:\TensorFlow\SfmLearner-Pytorch\data\kitti_raw_loader.py", line 33, in __init__ self.collect_train_folders() File "C:\TensorFlow\SfmLearner-Pytorch\data\kitti_raw_loader.py", line 51, in collect_train_folders drive_set = (self.dataset_dir/date).dirs() File "C:\Users\sheng\AppData\Local\Programs\Python\Python36\lib\site-packages\path.py", line 560, in dirs return [p for p in self.listdir(pattern) if p.isdir()] File "C:\Users\sheng\AppData\Local\Programs\Python\Python36\lib\site-packages\path.py", line 545, in listdir for child in os.listdir(self) FileNotFoundError: [WinError 3] The system cannot find the path specified: Path('C:\\TensorFlow\\SfmLearner-Pytorch\\raw_data_downloader\\2011_09_26\\2011_09_26_drive_0001_sync\\2011_09_26')
This is a screenshot of my command when running prepare_train_data and error described above:

I tried both relative path and absolute path, and it gives me the same error. I also tried / and \, but it seems not working.
I work on a windows 10 machine and here is my directory structure:
SfmLearner-Pytorch
|-- data
|-- datasets
|-- formatted_data
|-- raw_data_downloader
| |-- 2011_09_26
| |-- 2011_09_26_drive_0001_sync
| |-- 2011_09_26_drive_0002_sync
| |-- ..........................................................
Thank you in advance.
That seems like a small batch size. Why are size 4 batches used during training?
I used the Odometry dataset and the pretrained model of PoseNet that you guys provided in the Goole drive to test on Sequence 09 and 10. However, I did not get the same results that you guys showed on the github. Do you guys update the model after finishing the read me page?
I trained model with this commend:
python train.py /path/to/the/formatted/data/ -b4 -m0 -s2.0 --epoch-size 1000 --sequence-length 5
but my result was not as good as yours.
Abs rel | Sq rel | RMSE | RMSE log | A1 | A2 | A3 |
0.3794 | 3.8478 | 10.6573 | 0.5115 | 0.3702 | 0.6512 | 0.8179 |
pose
ate re
seq 09 0.0308 1.2759
seq 10 0.0261 1.3253
Can you tell me the possible reason? or did you train with gt?
Hi,
Thanks for the PyTorch version. I met a LinAlgError when I'm trying to train on KITTI. Here's the detailed information.
Traceback (most recent call last):
File "train.py", line 390, in
main()
File "train.py", line 188, in main
train_loss = train(train_loader, disp_net, pose_exp_net, optimizer, args.epoch_size, logger, train_writer)
File "train.py", line 236, in train
for i, (tgt_img, ref_imgs, intrinsics, intrinsics_inv) in enumerate(train_loader):
File "/home/liyuchen/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 210, in next
return self._process_next_batch(batch)
File "/home/liyuchen/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 230, in _process_next_batch
raise batch.exc_type(batch.exc_msg)
numpy.linalg.linalg.LinAlgError: Traceback (most recent call last):
File "/home/liyuchen/anaconda2/lib/python2.7/site-packages/torch/utils/data/dataloader.py", line 42, in _worker_loop
samples = collate_fn([dataset[i] for i in batch_indices])
File "./datasets/sequence_folders.py", line 61, in getitem
return tgt_img, ref_imgs, intrinsics, np.linalg.inv(intrinsics)
File "/home/liyuchen/anaconda2/lib/python2.7/site-packages/numpy/linalg/linalg.py", line 513, in inv
ainv = _umath_linalg.inv(a, signature=signature, extobj=extobj)
File "/home/liyuchen/anaconda2/lib/python2.7/site-packages/numpy/linalg/linalg.py", line 90, in _raise_linalgerror_singular
raise LinAlgError("Singular matrix")
LinAlgError: Singular matrix
Do you know why?
Thank you.
Shouldn't cam_coords be normalized by its L2 norm before multiplying by the depth?
i.e., add:
cam_coords /= torch.norm(cam_coords, p=2, dim=1, keepdim=True)
before this line:
SfmLearner-Pytorch/inverse_warp.py
Line 40 in a866333
Hi, @ClementPinard , great pytorch implementation of sfmlearner!
But when I evaluate the same depth prediction results using your evaluation code test_disp.py and the original author's eval_depth.py, I got inconsistency results.
After some experiments, I found you clip the predicted depth value to [min_depth, max_depth] first, then compute the scale factor, as in loss_functions.py :
valid_pred = current_pred[valid].clamp(1e-3, 80)
valid_pred = valid_pred * torch.median(valid_gt)/torch.median(valid_pred)
However, the original author computed the scale factor first, then clip the predicted depth, as in eval_depth.py:
scalor = np.median(gt_depth[mask])/np.median(pred_depth[mask])
pred_depth[mask] *= scalor
pred_depth[pred_depth < args.min_depth] = args.min_depth
pred_depth[pred_depth > args.max_depth] = args.max_depth
This does produce different results. By simply modifying your original code as
valid_pred = current_pred[valid]
valid_pred = valid_pred * torch.median(valid_gt) / torch.median(valid_pred)
valid_pred = valid_pred.clamp(1e-3, 80)
we can get the same results when evaluating the same depth predictions as the original author. Also, this inconsistency exists in the test_disp.py.
Hope you can fix it, thanks.
Hi, thank you for this work!
I am confused wih the network architecture of PoseNet. In PoseNet, you concat target image and all the reference images (2 or 4 images) together (https://github.com/ClementPinard/SfmLearner-Pytorch/blob/master/models/PoseExpNet.py#L28) and predict relative pose for every of these reference images.
Actually we want to estimate relative pose between two frames. So in my opinion, taking every two frames as input in PoseNet may be more reasonable. Have you try these? Why design PoseNet in such a way?

here I also attach the screen shot of the data. And the parameter is just set as your webpage suggest./

When testing the pose prediction accuracy (in test_pose.py), the ATE and RE are divided by the snippet length.
Both predicted and GT poses have the Identity transformation as their first entry.
Therefore, the error on that first "pose" will be 0 which results in an overall snippet ATE and RE that is considerably lower than it should be.
Why concatenate the input in dimension 1? If we concatenate in channel dimension, the dim value should be 0.
Hi,
I have run the train.py with the command blow on KITTI-raw-data :
python3 train.py /path/to/the/formatted/data/ -b4 -m0 -s2.0 --epoch-size 1000 --sequence-length 5 --log-output --with-gt
Otherwise the batch-size=80, and the train(41664)/vaild(2452) split is different.
The result I get is:
disp:
Results with scale factor determined by GT/prediction ratio (like the original paper) :
`
abs_rel, sq_rel, rms, log_rms, a1, a2, a3
0.2058, 1.6333, 6.7410, 0.2895, 0.6762, 0.8853, 0.9532
pose:
Results 10
ATE, RE
mean 0.0223, 0.0053
std 0.0188, 0.0036
Results 09
ATE, RE
mean 0.0284, 0.0055
std 0.0241, 0.0035
`
You can see that there's still a quiet big margin with yours:
Abs Rel | Sq Rel | RMSE | RMSE(log) | Acc.1 | Acc.2 | Acc.3
0.181 | 1.341 | 6.236 | 0.262 | 0.733 | 0.901 | 0.964
I think there is no other factors causing this difference, otherwise the batch-size and data split. Therefore, does the size of batch-size affect the training results?
What's more, when I try to train my model with two Titan GPUs, batch-size=80*2=160, the memory usage of each GPU is:
GPU0: about 11G, GPU1: about 6G.
There is a huge memory usage difference between two GPUs, and it seriously impacts multi-gpu trianing.
And then I find the loss calculations are all placed on the first GPU, actually the memory is mainly used to calculate the 4 scales of depth photometric_reconstruction_loss, and we can just move some scales to the cuda:0, and others to cuda:1, it might be better I think.
Since the depth output of this model is scaled by a factor according to groud truth,why this code manages to inverse warp correctly?Does that mean we use a wrong depth map for warping?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.